Cluster-Based Pairwise Contrastive Loss for Noise-Robust Speech Recognition
Geon Woo Lee, Hong Kook Kim

TL;DR
This paper introduces a new loss function for joint speech enhancement and recognition that improves performance in noisy environments.
Contribution
The novel cluster-based pairwise contrastive (CBPC) loss function enhances noise-robust speech recognition by leveraging linguistic information.
Findings
The CBPC loss function achieves lower word error rates than conventional joint training methods.
Speech quality scores improve with the proposed training approach compared to standalone and conventional models.
Combining CBPC with infoNCE loss reduces WER and boosts most speech quality metrics.
Abstract
This paper addresses a joint training approach applied to a pipeline comprising speech enhancement (SE) and automatic speech recognition (ASR) models, where an acoustic tokenizer is included in the pipeline to leverage the linguistic information from the ASR model to the SE model. The acoustic tokenizer takes the outputs of the ASR encoder and provides a pseudo-label through K-means clustering. To transfer the linguistic information, represented by pseudo-labels, from the acoustic tokenizer to the SE model, a cluster-based pairwise contrastive (CBPC) loss function is proposed, which is a self-supervised contrastive loss function, and combined with an information noise contrastive estimation (infoNCE) loss function. This combined loss function prevents the SE model from overfitting to outlier samples and represents the pronunciation variability in samples with the same pseudo-label. The…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1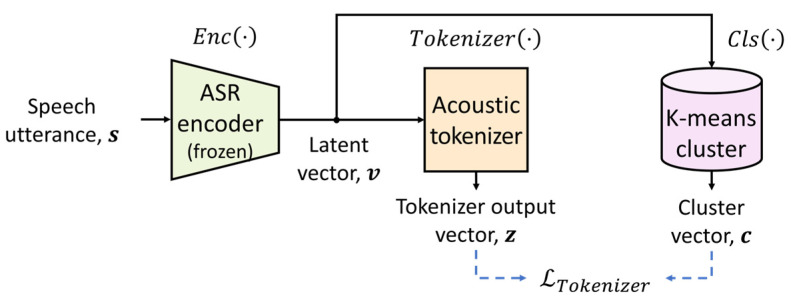 Figure 2
Figure 2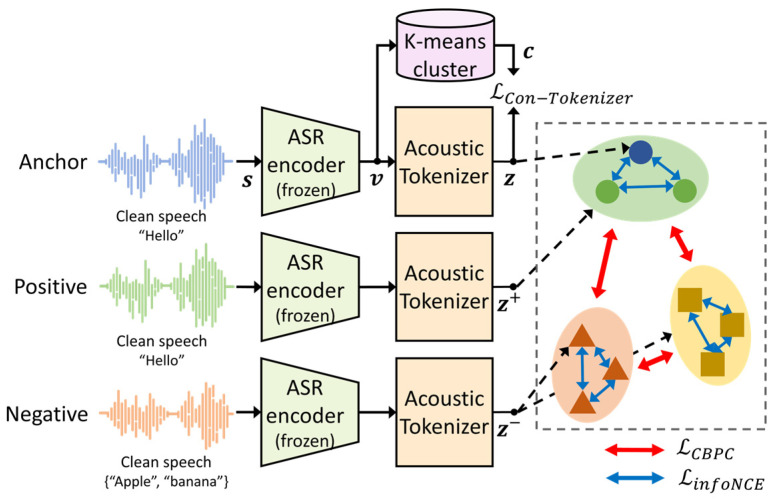 Figure 3
Figure 3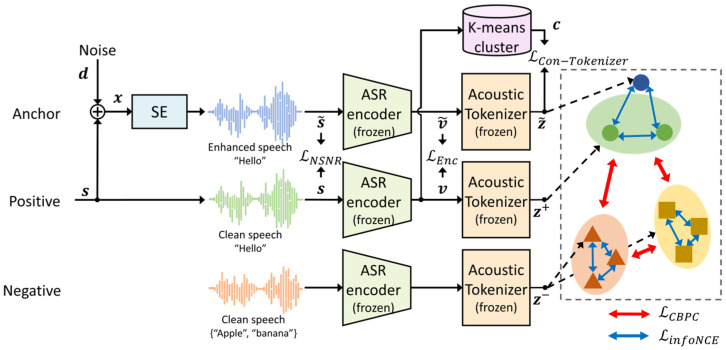 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Speech Recognition and Synthesis · Music and Audio Processing