Automated news in practice: a cross-national ANT case study
Samuel Danzon-Chambaud, Julian Maitra, Samuel Danzon-Chambaud, Nathalie Pignard-Cheynel, Andrew Robotham, Samuel Danzon-Chambaud

TL;DR
This study explores how news organizations use automated news systems across different countries, highlighting changes and dependencies on technology.
Contribution
The paper introduces a cross-national ANT case study on automated news systems, revealing new implementations and dependencies.
Findings
Automated news systems incorporate alternate data sources like internal feeds and crowdsourced material.
Journalists use in-house tools and notification streams as new affordances for automated news.
Automated systems produce outputs beyond text, such as audio summaries for voice assistants.
Abstract
Background: This article provides a comprehensive picture of automated news’ usage—understood here as the auto-generation of journalistic text through software and algorithms, with no human intervention in-between except for the initial programming at 18 news organisations in Europe, North America and Australia, following a strategic sample inspired by Hallin and Mancini’s (2004) media system typology. Methods: To describe the many ways it is implemented, I rely on Actor-network theory (ANT) so as to distinguish situations where something more is added to automated news systems from those where initial intent is kept and where the software does what it is supposed to do. Semi-structured interviews with editorial staff, executives and technologists were conducted remotely and elements of a netnography were also carried out. Results: Overall, my findings show that the main…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
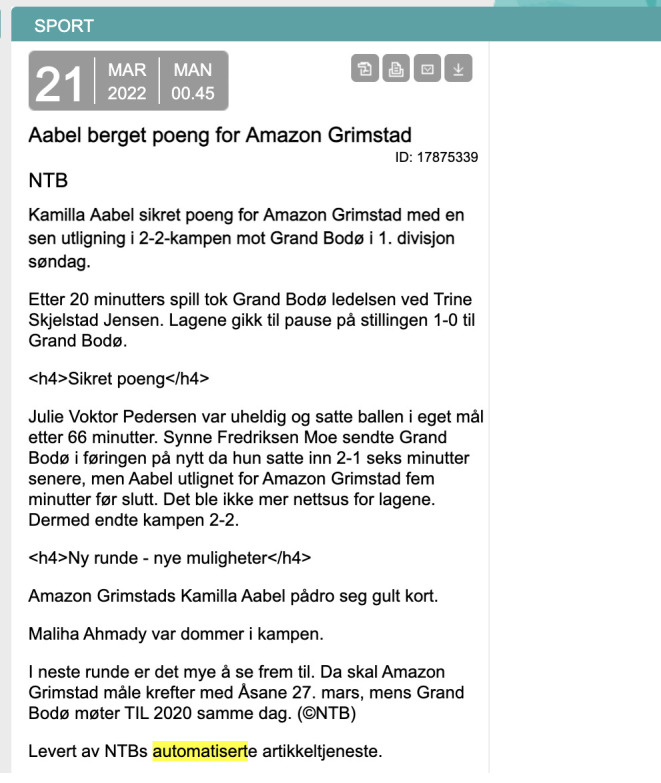 Figure 1
Figure 1 Figure 2
Figure 2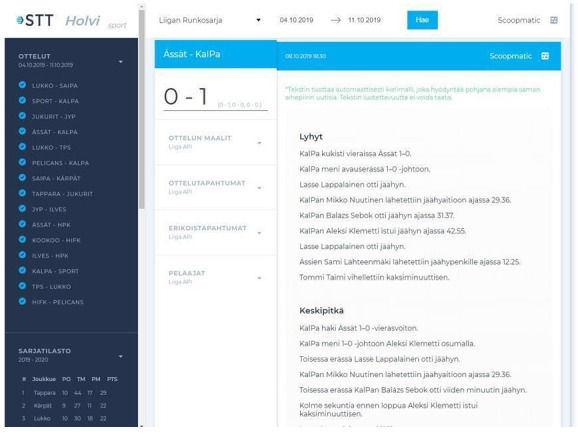 Figure 3
Figure 3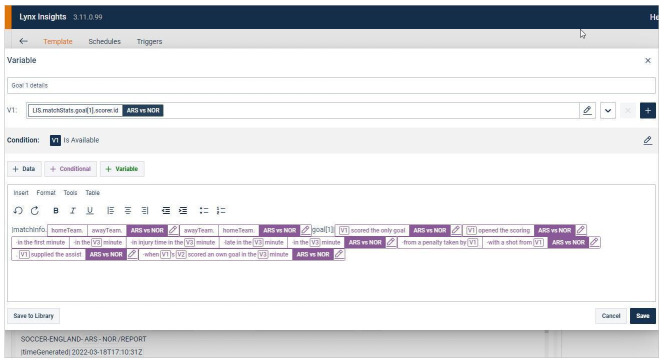 Figure 4
Figure 4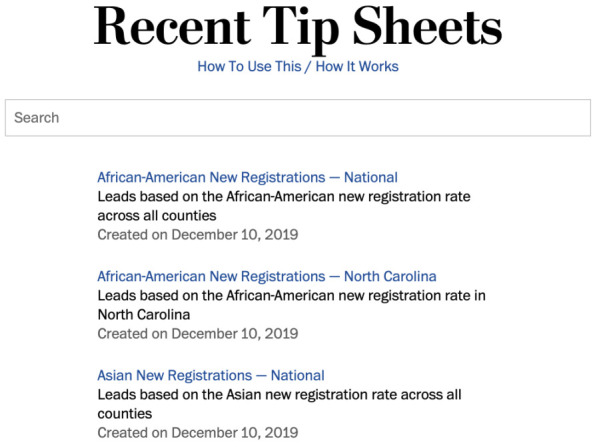 Figure 5
Figure 5| Media systems | News agencies | Newspapers | Public broadcasters |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| NORTH ATLANTIC | ||||
|---|---|---|---|---|
| News agencies | Newspapers | Public service broadcasters | ||
|
| Internal feed | – | – | ABC/BBC |
| Own data collection | Reuters | – | – | |
| Archives | – | – | – | |
| Crowdsourced material | – | – | ABC | |
| Social media feeds | Reuters | – | – | |
|
| In-house self-editing tool | Reuters | – | – |
| Notification stream | Reuters | – | BBC | |
| Automated backgrounders | Reuters | Washington Post | – | |
|
| NLG-to-audio | – | Washington Post | ABC |
| NORTH/CENTRAL | ||||
| News agencies | Newspapers | Public service broadcasters | ||
|
| Internal feed | – | – | – |
| Own data collection | – | – | – | |
| Archives | STT | – | – | |
| Crowdsourced material | – | Stuttgarter Zeitung | – | |
| Social media feeds | – | – | – | |
|
| In-house self-editing tool | – | – | – |
| Notification stream | – | – | – | |
| Automated backgrounders | – | – | – | |
|
| NLG-to-audio | – | – | – |
| MEDITERRANEAN | ||||
| News agencies | Newspapers | Public service broadcasters | ||
|
| Internal feed | – | – | – |
| Own data collection | AFP | – | – | |
| Archives | – | – | – | |
| Crowdsourced material | – | – | – | |
| Social media feeds | – | – | RTVE | |
|
| In-house self-editing tool | – | El Confidencial | – |
| Notification stream | – | – | – | |
| Automated backgrounders | – | – | – | |
|
| NLG-to-audio | – | – | – |
- —Horizon 2020 Framework Programme
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedia Studies and Communication · Social Media and Politics · Information Systems Theories and Implementation
Introduction
In recent years much attention has been given to automated news, a computer process generally understood as the auto-generation of journalistic text through software and algorithms, with no human intervention in-between except for the initial programming ( Carlson, 2015; Graefe, 2016). Automated news—which is also sometimes referred to as “automated journalism”, “algorithmic journalism” or “robot journalism”—relies on a basic utilisation of Natural Language Generation (i.e., NLG), a computer technique that has been used for several decades to generate text in areas like sports, finances and weather forecasting ( Dörr, 2016). In the case of automated news, NLG algorithms are used to fetch information on external or internal datasets, this in order to fill in the blanks left on pre-written text. This resembles a bit the game “Mad Libs” ( Diakopoulos, 2019), as programmers or editorial staff need to come up with templates that, on the one hand, include enough elements that can be predicted in advance and, on the other hand, can be connected to a big enough data flow.
Because of these limitations, only a small range of stories can be automated this way, for instance election results, financial news or sports summaries. Although there is little machine learning involved at the moment, this is becoming a growing area of interest: some machine learning applications of NLG production are already being advertised on the websites of companies that specialise in delivering automated content to business, media, and governmental organisations alike ( Narrativa, no date 1); the European Union-funded project EMBEDDIA is looking at including elements of machine learning in automated news generated using pre-written templates to make it less formulaic and nicer to read (see Leppänen, 2023; Rämö & Leppänen, 2021); and the Czech news agency ČTK has been experimenting with machine learning techniques to generate automated news templates, with the help of a research team at the University of West Bohemia ( Stefanikova, 2019).
Automated news started to be more discussed in the 2010s as The Los Angeles Times began covering homicides in an automated fashion ( Young & Hermida, 2015) and launched a tool to generate earthquake alerts ( Schwencke, 2014), while The Associated Press partnered with the firm Automated Insights to automate corporate earnings stories ( Colford, 2014). Proponents of automated news typically develop their technology in-house, outsource it to an external content provider or use third-party solutions that let journalists design their own automated stories. For instance, the Washington Post developed an in-house tool to produce short automated pieces during the 2016 Rio Olympics ( WashPost PR Blog, 2016a); Le Monde collaborated with the firm Syllabs to automatically cover the results of the 2015 regional elections in France ( Rédaction du Monde.fr, 2015); and the BBC subscribed to an online platform, Arria NLG Studio, that lets journalists template out their own automated stories using a type of No-code language that makes it accessible to editorial staff with little computing experience ( Molumby & Whitwell, 2019). As for its types of usage, automated news can be used to publish simultaneously at scale, as the Swiss media group Tamedia did with the generation of almost 40,000 hyperlocal stories to report on the outcome of a referendum ( Plattner & Orel, 2019), or serve as first drafts to assist journalists with their own writing, as this seems to be the case at Forbes and at the Wall Street Journal ( Willens, 2019; Zeisler & Schmidt, 2021).
In this article extracted from my PhD thesis ( Danzon-Chambaud, 2023) ^ 1 ^, I will provide a more complete picture of the use of automated news, using a cross-national multiple case study for this. To document the ways it is used and adapted across news organisations, I will rely on Actor-network theory (ANT) concepts to distinguish situations where something more is added to automated news systems—thus showing the overall direction that this new journalistic development is taking—from those where initial intent is kept and where it does what it is supposed to do. My sample for this research is made of 18 organisations based in 11 countries, which are representative of three media types (i.e., public service broadcasters, newspapers, news agencies); it follows a sampling strategy inspired by Hallin and Mancini’s (2004) media system typology as I looked at newsrooms that belong to the Mediterranean, North/Central and North Atlantic models. Due to COVID-19 limitations, I have made use of semi-structured interviews that were conducted remotely between September 2020 and April 2021, with email exchanges taking place up until 2022 to make sure content remained current and accurate. Elements of a netnography were also carried out as screenshots and online material were analysed in complement to these research interviews.
An ANT theoretical perspective
Before starting this inquiry, I will first explain the key ANT concepts used in this research. A fundamental aspect of ANT, which essentially revisits sociology using a “bottom-up” perspective, is that it takes into account a “rich bestiary of significant actors” ( Clark, 2020, p. 160)—or rather actants ( Blok, 2019; Crawford, 2005)—which involves human and non-human elements that can be as diverse as ( Michael, 2017a, p. 5) “mundane objects, exotic technologies, texts of all sorts, nonhuman environments and animals”. The term “actor-network” in itself speaks to the idea that every actor and all of its attributes—such as thinking, writing or loving for humans—are never entirely cut out from each other, thereby creating a “web of relations” that stretches “both within and beyond the body” and across which action is distributed ( Primo, 2019, p. 2; Law, 1992, p. 384). To better understand this, Law uses the following metaphor about himself (1992, pp. 383–384): “If you took away my computer, my colleagues, my office, my books, my desk, my telephone I wouldn't be a sociologist writing papers, delivering lectures, and producing "knowledge." I'd be something quite other—and the same is true for all of us.” As such, ANT is therefore well suited to studying change in practice ( Plesner, 2009); in the case of journalism, it helps account for all the “tools of the trade” (e.g., web searches, databases, smartphones) that make it as it is today, and can be used to document journalistic innovation, including automated news ( Primo, 2019, p. 2).
Another marker of ANT is the concept of translation: not to be confused with language translation, ANT’s translations rather speak to a phenomenon whereby heterogeneous entities ( Law, 1984) or actants come together to form an actor-network, thus potentially disengaging themselves from other structures they belong to ^ 2 ^. In his study depicting how a scallop species ( Pecten Maximus), local fishermen, the scientific community and a team of biologists engaged into forming an actor-network whose goal is to replenish scallops beds in the Saint-Brieuc bay, in France, Callon (1984) described how each of these entities translated their interests so that they pass through an obligatory point of passage—a common objective—which makes the network hold; in this case, it is the biologists’ novel research programme, who then become spokespersons for the group. As Callon ( ibid., p. 224) put it: “Translation is the mechanism by which the social and natural worlds progressively take form. The result is a situation in which certain entities control others.” That being said, for the actor-network to be able to last in time, successful enrolment, or ( ibid., p. 211) “the device by which a set of interrelated roles is defined and attributed to actors who accept them”, needs to be sustained, making it a structure where relational power is always up for negotiations ( Michael, 2017a). If robust enough, though, it may give rise to a macro actor that is able to restructure society as whole ( Cooren, 2009; Czarniawska, 2016).
In ANT, the process through which entities undergo translations and become stabilised enough to form an actor-network comes under terms like simplification, black-boxing or punctualisation ( Crawford, 2005; Michael, 2017a). Once firmly established, they become set structures passing on the same type of predictable output based on any given input, and are also able to act at distance ( Law, 1984). In ANT, stabilised actor-networks like these are known as immutable mobiles or inscriptions when they concern textual or graphical material ( Crawford, 2005; Hassard & Alcadipani, 2010; Latour, 2005; Michael, 2017b; Nikolova, 2008). Latour (2005), on his end, makes a distinction between two modes of acting: first, as intermediaries, where meaning is maintained and where outputs can be predicted by inputs; second, as mediators, where meaning is changed and where inputs are never a good predicator of outputs. Drawing on Callon (1990) and Latour (1992), Sayes (2014, p. 138) specifies that “an intermediary is a placeholder in the sense in which it merely does what anything else in its position would do”, whereas “a mediator is something more than this”: in the case of non-human elements, it is “seen as adding something to a chain of interaction or an association”. To explain these specifics, Latour gives the following example:
A properly functioning computer could be taken as a good case of a complicated intermediary while a banal conversation may become a terribly complex chain of mediators where passions, opinions, and attitudes bifurcate at every turn. But if it breaks down, a computer may turn into a horrendously complex mediator while a highly sophisticated panel during an academic conference may become a perfectly predictable and uneventful intermediary in rubber stamping a decision made elsewhere.( Latour, 2005, p. 39)
Latour (2005, p. 108) also suggests to consider that “ there exist translations between mediators that may generate traceable associations”: ANT researchers should then focus on establishing these connections in order to “follow the actors’ trails” ( Primo, 2019). As he expressed it:
To put it very simply: A good ANT account is a narrative or a description or a proposition where all the actors do something and don’t just sit there. Instead of simply transporting effects without transforming them, each of the points in the text may become a bifurcation, an event, or the origin of a new translation. As soon as actors are treated not as intermediaries but as mediators, they render the movement of the social visible to the reader.( Latour, 2005, p. 128)
Even though ANT has been recommended by Primo (2019) to study automated news, I found no use of it in a systematic literature review I conducted on automated news research ( Danzon-Chambaud, 2021a), which analysed 33 empirically-oriented scholarly articles published between 2005 and mid-2020. Although this review is by no means exhaustive as other publications on ANT and automated journalism may have very well fallen outside my search criteria ^ 3 ^, it is meanwhile representative of a research gap that needs to be further investigated. ANT certainly comes with its own limitations (see Ryfe, 2022), such as being too oblivious of any overarching social order and loosing track of the bigger picture (see Benson, 2017; Couldry, 2020), but it can meanwhile be used to give a “bottom-up” account of all the transformations that automated news is undergoing and—when used as mediators—point out to the overall direction that the “actor-network of automated journalism” is taking. My research questions (RQ) therefore go as follows:
RQ1. Using ANT’s lenses, what is the overall direction that automated news systems seem to be taking?
RQ2. What are the implications of these developments for journalistic professionalisation?
Methods
To answer these questions, I will follow a multiple case study design spanning across groups of countries, so as to have a diverse range of news organisations included in this research. According to Yin (1994), the rationale for case selection in multiple case studies is linked to the development of a rich theoretical framework, so that findings can be generalised to new cases. To reflect this, I have chosen a sampling strategy inspired by Hallin and Mancini’s (2004) media system typology so as to be able to ground this case study on their theoretical understanding of differentiation and de-differentiation ^ 4 ^ in Western news media. Hallin and Mancini—which has often been used as a guiding framework to draw strategic samples of news organisations that spread across groups countries (see Cornia et al., 2019; Cornia et al., 2020; Menke et al., 2018; Sehl et al., 2019; Sehl & Cornia, 2021; Sehl et al., 2021; Van den Bulck & Moe, 2018)—distinguish three types of media systems, based on their analysis of a set of dimensions that range from the structure of media markets to professionalisation and the role of State. These are: the “Mediterranean” or “Polarised Pluralist Model”, which includes countries such as France, Spain and Italy and is characterised, among others, by a low level of journalistic professionalisation—not dissimilar to political activism—and by strong connections with the State given delayed liberalisation in these countries (even if commercial influences have progressively grown in importance); the “North/Central European” or “Democratic Corporatist Model”, which concerns countries like the Nordics, Germany and Switzerland and where the media are considered social institutions that need to be protected by the State due to the pluralistic and consensus-based nature of these democracies, but still have a high degree of commercialisation and journalistic professionalisation; and the “North Atlantic'' or “Liberal Model”, which extends to countries like Canada, the United States and the United Kingdom, where commercialisation and journalistic professionalisation are relatively high and the role of the State moderated, even if sometimes commercial influences can circumscribe journalistic independence.
Following the logic of differentiation, Hallin and Mancini argued that the North Atlantic model of journalism sits the furthest away from social and political structures while the Mediterranean model presents strong ties between media and politics, which appear as two fields or sectors that often overlap. Finally, the North/Central European model is often situated somewhat in-between these two systems. They also observed that a process of de-differentation driven by market forces seems to be steering the Mediterranean and North/Central European models further away from socio-political influences to bring them closer to the types of commercial values found in the North Atlantic model, resulting in making these media systems more homogenous, even if differences in national political systems prevent them from being totally similar. That said, recent scholarship suggested that—even though Hallin and Mancini remains relevant to analyse media and political developments today—there is evidence that their existing models of journalism could also be converging towards a hybrid “Polarized Liberal” system, which started to be discussed in the wake of the 2016 presidential election in the United States and following Trump’s presidency ( Nechushtai, 2018).
As for choosing media types, I have decided to include news agencies, newspapers and public service media for the following reasons: first, the use of automated news at news agencies is well established, especially in Europe (see Fanta, 2017); second, it can be argued that newspapers are more likely to engage with this form of technology, as their business model that is under threat because of the digital turn forces them to be more innovative, as opposed for instance to commercial broadcasters that can still rely on stable advertising revenues and on other types of incomes ( Cornia et al., 2019); third, public service media can be considered leaders in providing “thorough” data journalism pieces to audiences (see Borges-Rey, 2016; De Maeyer et al., 2015), especially as data journalism experts are more likely to be hired at public service broadcasters in Germany ( Beiler et al., 2020) and as public service media in Australia developed their own in-house solutions ( de-Lima-Santos et al., 2021): this can let us posit that the kind of programming skills that is at use in data scraping activities can also be leveraged to set up automated news.
For this case study, I have relied on purposive sampling to select 18 news organisations, with each pair representing a different combination of media types and media systems (see Table 1). Due to COVID-19 limitations, semi-structured interviews with editorial staff, executives and technologists were conducted remotely between September 2020 and April 2021 (see Appendix A), with email exchanges taking place up until 2022 to make sure content remained current and accurate. To do this type of study, I obtained approval from my university’s research ethics committee. Among these interviewees were 8 BBC staffers that I could gain access to thanks to a secondment I did with my research program. Interviewees were contacted by email or via social media, a gatekeeper’s approval being sometimes needed ^ 5 ^. Their names were not divulged so that they could speak more freely, although it is most likely that their hierarchy knew that they were participating in this research project. Written informed consent was obtained from each of the participants, and they were given the opportunity to review some of their statements that dealt with potentially sensitive or unclear information, but not my own interpretation over what they shared. My exchanges were rather smooth, my interviewees generally knowing what I was asking about and not being caught off-guard (they were given an indication of what will be discussed, but were not handed the interview questions in advance). I asked for clarifications in follow-up emails when needed. Finally, sex and gender were not considered to be particularly relevant in this study: as such, interviewees were not asked to disclose their gender, but in a strictly binary sense it turned out that 23 of them were male and 5 were female, thus reflecting a gender gap that could be further investigated.
**Table 1.: News organisations studied based on media systems and media types
6 .**
To complement these interviews, I also analysed material published online (e.g., blog posts, trade publications, etc.) so as to have a better overview of the way automated journalism is implemented: these are linked to or referenced as such in my findings section; otherwise, information comes from statements collected over the course of my interviews. In addition, screenshots of automated news software or material that was found online or forwarded to me by research participants are also featured there: because these elements exclusively dealt with online collection, it is then appropriate to speak of a netnography, which is understood ( Kozinets, 2016) as a “specific approach to conducting ethnographic research that uses the archival and communications functions of contemporary Internet-based technologies such as mobile phones, tablets, and laptop computers” and can be made of textual, graphic, audio, photographic and audio-visual elements.
Last but not least, using ANT along with frameworks that are representative of any overarching social order (i.e., differentiation and de-differentiation theory) may be perceived as breaking one of its key tenets, which is to leave aside any preconceived ideas to follow the actors’ trails only. That being said, some of these frameworks can be seen as “companion concepts” that can be encountered at a later stage of analysis ( Winthereik, 2020); moreover, Couldry (2016, p. 5) stressed the importance of seeing ANT as “one important item in the media theorist’s toolkit that, like any tool, needs to be supplemented by others”.
Results
As described in my methodology, I will conduct here a cross-national multiple case study using Hallin and Mancini’s media system typology (2004) to strategically select news organisations—limiting myself to news agencies, newspapers and public service broadcasters—in order to reflect on their comprehension of differentiation and de-differentiation within the media industry. When analysing how automated news is implemented within these organisations, I will make use of ANT to distinguish two types of strategies: first, using automated news as intermediaries where initial intent is kept and where it does what it is supposed to do; second, using automated news as mediators when something more is added to existing practices, in this case additional meaningful translations where new human and non-human actants get involved, which shows the overall direction that it is taking, thus helping me answer my research questions.
Predictable uses as
intermediaries
First, based on some of the most prominent examples that are developed in the introduction, it can be said that automated news is used as intermediaries when private or public service datasets are being used as sources, when there is no journalistic involvement other than through the affordances already provided for by third-party tools and—for now—when text only is generated, sometimes with visualisations. Such an assemblage can be observed at news organisations outsourcing automated news to external content providers, like at the Associated Press, where teams collaborate with firms like Automated Insights and Data Skrive to come up with templates so that these companies can automate corporate earnings stories and sports recaps ^ 7 ^, based on private data (see Colford, 2014). Likewise, Italy’s news agency ANSA publishes weather forecasts that are sometimes generated using automation and data provided by a weather forecast company, but also national and regional accounts of the spread of COVID-19, using public data collected through Narrativa’s COVID-19 tracker initiative ^ 8 ^ and put together by the firm Applied XL ( Redazione ANSA, 2020; Narrativa, no date 2). As for Spain’s national public service broadcaster RTVE, it collaborated with Narrativa to run trials on less watched football competitions in Spain using private data and also prepared for generating stories on election results in small municipalities based on government data ( Corral, 2021). This is similar to what the French public radio broadcaster France Bleu and French newspapers belonging to the Belgian media group Rossel (e.g., La Voix du Nord, L’Union) have been doing during recent elections in France with automated news generated by the firms Syllabs (France Bleu) and LabSense (Rossel), based on governmental data. Besides, the Belgian newspapers group Sudpresse (owned by Rossel) and LabSense also collaborated on automating amateur football games in Belgium, sourcing data from a sports association.
Automated news used as intermediaries is also visible when it is designed internally. As such, Reuters’ data team has been developing automated news the usual way while setting up stories on sports, financial news and COVID-19, relying both on private and public data. This was also true of The Times’ automated journalism project on COVID-19 (see Danzon-Chambaud, 2021b), which was based on public data and programmed in-house. As for the Norwegian news agency NTB, it relied on a select few editorial developers with both a journalistic and technical background so as to be able to automate the same type of pandemic-related content as well as sports, election and financial news (see Figure 1), using private and public data for this.
An example of an automated football game recap that was generated at NTB.This figure has been reproduced from NTB with permission, under a CC-BY NC 4.0 license.
On their end, the data team at the newspaper Stuttgarter Zeitung programmed automated news to cover the 2021 German election at a municipal level with local governmental data, while a team of technologists at the Finnish public service broadcaster YLE developed automated summaries on sports and election results, using both private and public service data and helped by a journalist who can understand code. Moreover, YLE made its code for generating ice hockey recaps open source, following a Parliament's request to limit unfair competition in the Finnish media market: as a result, other organisations like Finland’s news agency STT used this code for their own ice hockey stories. Sometimes, an academic partner was also involved in the development of automated news, as in the Bavarian broadcaster Bayerischer Rundfunk’s collaboration with the Technical University of Munich to automate match reports for a basketball league in Germany ( Sebis Research News, 2021; Schneider & Köppen, 2021), which came in parallel with another project on COVID-19 (see Danzon-Chambaud, 2021b) and led to automating financial results as well ( Schneider, 2022). To do this, the team relied on public health sources for their COVID-19 project and on private data for sports and financial news. Lastly, after experimenting with their own solution to automate the Rio Summer Olympics, the 2016 presidential election in the United States and high school American football coverage ( WashPost PR Blog, 2016a; WashPost PR Blog, 2016b; WashPost PR Blog, 2017), the Washington Post’s engineering team joined forces with Northwestern University to develop a “computational political journalism R&D lab” ahead of the 2020 presidential elections ( Schmidt, 2019), this improving existing automated news models that draw on data collected by private brokers during election time.
Using automated news as intermediaries can also be found in the use of third-party self-editing tools that feature a form of No-code language, which allows editorial staff with little programming experience to design automated news on their own. This could be observed at the BBC, where the News Labs team used Arria NLG Studio to template out articles on A&E waiting times, tree planting and high street shopping, using public service datasets (see Danzon-Chambaud, 2021c). The Swiss newspaper group Tamedia used Wordsmith—Automated Insights’ own NLG technology that was made directly accessible to clients through a self-editing interface ( Mullin, 2015)—to draft out automated stories on referendums and election results in Switzerland ( Marchand, 2019; Plattner & Orel, 2019) and to provide a statistical roundup of the spread of COVID-19 (see Danzon-Chambaud, 2021b), using public service datasets. As for the Australian public service broadcaster ABC, it subscribed to a bot-building application, Chatfuel, to create a messenger bot (see Figure 2) that uses public service data to inform users on electoral results ( Archer, 2016; Elvery, 2016), but also to provide them with daily news summaries, weather forecasts and emergency alerts (see Ford & Hutchinson, 2019).
A daily news brief delivered by the Australian Broadcasting Corporation (ABC) through its conversational chatbot platform.This figure has been reproduced from ABC with permission, under a CC-BY NC 4.0 license.
Transformations as
mediators
In contrast to automated stories being used as intermediaries, mapping their roles as mediators requires carefully thinking about additional meaningful translations that new human and non-human actants could bring: this could be whenever these changes concern using sources other than private and public service data, deploying systems that are specifically built for journalists—other than through the affordances already provided for by third-party self-editing tools—and, lastly, generating outputs other than text. First, with regards to additional sources, a noticeable translation occurs as news organisations turn to their own internal feed, proceed to their own data collection or use archival material, thus avoiding the need to rely on third-party private or public service datasets. An example of this is the BBC’s and ABC’s efforts to connect their automated news system to an internal election results feed (see Danzon-Chambaud, 2021c for the BBC), which in the case of ABC is linked to the corporation’s own psephologist:
We're mostly looking at the data sources we use for broadcast to start with, or that are at that level. (...) The election one is coming from the Australian electoral commission or the State electoral commissions, but then it's going through our election expert's system, Antony Green. So it's being processed by his system and he's taking those raw figures and putting his knowledge of electoral systems over them to come up with predictions and things like that.(Manager, ABC, Australia)
In a few instances, news organisations collected data on their own in order to automate news text, as shown in AFP’s and Reuters’ statistical roundups on the spread of COVID-19, which were both automated using shared spreadsheets that were manually filled by journalists on the ground, even if at Reuters this system was also connected to open data sources. As for tapping into archival material, the Finnish news agency STT collaborated for a time with the University of Turku, in Southern Finland, to automate ice hockey recaps using machine learning models ( Kanerva et al., 2019) that were trained on STT’s own archives that dated back to the 1990s (see Figure 3). That being said, an executive at STT indicated that content generated this way did not meet the agency’s standards to be delivered to clients, but was accessible to them should they be interested in it:
The interface on which ice hockey stories were generated using machine learning models that were trained on STT’s internal archives, which covered games that were held since the 1990s.This figure has been reproduced from STT with permission, under a CC-BY NC 4.0 license.
It [STT’s archives] goes way back, but there wasn't enough reports for the AI because (...) it just wants all the data and more and more and more… And it wasn't enough for the AI to learn enough. And the second thing was that there was too much human… well, too much human in them. So there was, like, adjectives and things that weren't in the data that the machine was fed. (...) For example, in ice hockey there was, like, standings that weren't in the data that the machine was given. So we ended up using some manual work to go through, not all, but a lot of the stories.(Executive, STT, Finland)
Additional translations that related to source type were also visible in situations where crowdsourced material and social media feeds were used. The German newspaper Stuttgarter Zeitung relied on crowdsourced material to automate its air quality reports in the Stuttgart area, which were generated using AX Semantics’ self-editing tool and connected to open data sourced from a network of community sensors ( Plavec, 2017; Toporoff, 2017). In Australia, the ABC used opinion data collected through a polling exercise that is habitually done during election time so as to come with answers for its messenger bot ( Gee & Prior, 2018), an approach that was further extended to probe the public’s concerns on emergency preparedness. Social media feeds, on their end, were put to contribution using web scraping techniques, so as to be able to collect user-generated content and to conduct computational analysis on it. This was done, for instance, at the Spanish public service broadcaster RTVE, which partnered with the University Carlos III of Madrid to generate automated football stories that adopt a tone and voice that reflect users’ opinions ( del Rey García, 2020). “You can have the version for one team, for example: ‘It was a great success,’ the balanced news, and, on the other hand, (...) ‘they stole us the football match’”, said an executive at RTVE. Likewise, Reuters’ News Tracer acts as a “breaking news radar” while roaming on Twitter feeds to find relevant information, using advanced detection, classification and evaluation techniques for this; it then goes on to generate short automated text that is passed on to journalists for verification ( Emerging Technology from the arXiv, 2017; Liu et al., 2017).
Another area where additional translations are brought into force relates to automated news systems that are specifically built for journalists, other than through the affordances already provided for by third-party self-editing tools. These can be, first, internal software that comes with its own self-editing tool, features notification streams and provides access to auto-generated background information, as in Reuters’ Lynx Insight system where journalists can template out their own stories using a form of No-code language that resembles those of third-party tools (see Figure 4), receive Microsoft Teams notifications once stories generated this way or that the data team set up are ready and query this system as they look for automated news with background information on the subject that they are covering.
On Reuters’ Lynx Insight platform, journalists can template out their own automated stories using a form of No-code language that makes it accessible to news staff with little programming experience.This figure has been reproduced from Reuters with permission, under a CC-BY NC 4.0 license.
The online newspaper El Confidencial constitutes another example of the use of an internal self-editing tool, as the data team set up previews that help journalists visualise the automated story they are about to generate, instead of having to work right off computer scripts. “We prepared a web tool that they could use [that includes] the new text [created] with a different condition, and in real time they can see (...) how the final article will look like”, said a technologist at the online newspaper. In another example of the use of automated backgrounders, the engineering team at the Washington Post and Northwestern University teamed up to create a query system that lets journalists access automated background information on the 2020 presidential election in the United States (see Figure 5): this contained for instance indications on the number and ethnic distribution of new registered voters in a given county ( Diakopoulos et al., 2020; WashPost PR Blog, 2020a). As for automated notification streams, the BBC also relied on Slack notifications as part of combined workflow to cover the 2019 general election in the United Kingdom with automated news (see Danzon-Chambaud, 2021c).
At the Washington Post, a query system was set up in collaboration with Northwestern University so that reporters could access automated backgrounders that would help them cover the 2020 presidential election in the United States.This figure has been reproduced from [ Diakopoulos et al., 2020] with permission, under a CC-BY NC 4.0 license.
Finally, one last translation that could be observed has to do with generating output other than text, in this case NLG-to-audio content. This was visible in the Washington Post’s and ABC’s efforts to create stories of their own, and not just audio content suited to help with vision impairment. Automated audio stories generated this way could then be tailored to a listener’s location as in the Washington Post’s election updates that were inserted in the newspaper’s political podcasts ( WashPost PR Blog, 2020b) or be accessed via virtual assistants (e.g., Amazon’s Alexa) as in the ABC’s diffusion of emergency alert summaries that were created using its own NLG tool ( Collett, 2021; Collett, 2022).
In this section, I highlighted how automated news is being used at 18 news organisations that were selected based on Hallin and Mancini’s (2004) media system typology (i.e., North Atlantic, North/Central and Mediterranean models) and that featured different media types (i.e., news agencies, newspapers, public service broadcasters). Using ANT, I demonstrated that some of them used automated news as intermediaries, where initial intent is kept and where it does what it is supposed to do, while others considered it more as mediators while bringing in additional meaningful translations, which go as follows: first, enrolling alternate data sources while relying on a media organisation’s own internal feed, data collection or archives as a source or, else, on crowdsourced material or social media feeds; second, enticing journalists while putting them at the centre of interfaces that are designed internally like in-house self-editing tools, notification streams and/or search features to access automated backgrounders; and, third, enlisting vocal elements through generating NLG-to-audio content as an output. These translations, which are summarised in Table 2, will be further examined in the conclusion to see how they relate to differentiation and de-differentiation theory.
Table 2.: Automated news as mediators: areas with additional translations, per media system.
Conclusion
Using ANT’s lenses, considering automated news as mediator pointed out to new meaningful translations that are visible through the enrolment of alternate data sources (i.e., a media organisation’s own internal feed like the BBC’s and ABC’s election results feed, own data collection like Reuters’ and AFP’s manual input of COVID-19 statistics, or archives as in STT’s use of past sports reports to train machine learning models—as well as crowdsourced material like Stuttgarter Zeitung’s use of community sensor data or, else, social media feeds as in RTVE’s automated football stories that reflect readers’ own preferences), the enticement of journalists while putting them at the centre of interfaces that are designed internally like self-editing tools (e.g., Reuters, El Confidencial), notification streams (e.g., BBC, Reuters) and/or search features to access automated backgrounders (e.g., The Washington Post) and, finally, the enlistment of vocal elements as in NLG-to-audio output (e.g., ABC, The Washington Post). This makes the movement of what can be considered the “actor-network of automated journalism” discernible to the researcher’s eye and gives an indication as to where it is heading, thus answering RQ1.
All in all, this testifies of a growing journalistic professionalisation in the way automated news is being employed, as it is drifting away from political and commercial influences (i.e., public service data, data brokers, automated content providers and third-party self-editing tools) to become more under journalists’ control, but also in citizens’ hand (i.e., using crowdsourced material as a source). As shown in Table 2, North Atlantic media organisations (i.e., Reuters, The Washington Post, ABC, BBC) clearly lead the way in this process of differentiation, in accordance with Hallin and Mancini’s (2004) typology: as they write ( ibid., p. 80), “the Liberal Model is characterized by a high degree of differentiation of the media from other “other social bodies,” particularly those historically active in the political sphere”, which in this case also applies to techno-commercial influences. Hence, BBC’s and ABC’s use of internal feeds, Reuters’ own in-house self-editing tool and the Washington Post’s providing access to automated backgrounders—to name a few—all contribute to greater journalistic professionalisation by ensuring independence from all these forms of external influences.
That being said, a process of de-differentiation could also be at play in that compliance with platforms’ terms and conditions is generally needed to be able to connect to social media APIs (see van Dijck et al., 2018) and matching their technical standards is necessary to have automated audio stories featured on voice assistants (e.g., Amazon’s Alexa, Google Assistant). The question as to whether platforms or news organisations will act as spokespersons in this growing actor-network of automated journalism—and by extension RQ2—then remains open: should news media take on this role, for instance while developing their own self-editing solutions or relying on internal feeds, this could be interpreted as reinforcing the autonomy of the journalistic field, whereas—should they become too dependent on Big Tech companies for data acquisition and dissemination of automated news products—this may result in making the field even more porous to techno-commercial influences.
One limitation to this study has to do with a very much Western-centric selection of media organisations: at the time I reached out to interviewees, automated news was still a relatively new development that seemed to concern mostly news organisations based in the West, as well as some Asian newsrooms that could not efficiently research because of my own language limitations. This meant I could not document the use of automated news in certain regions, like South America or East Asia. That being said, a growing number of scholars are now looking into these areas, among which figure research on the way automated news is employed at the Czech news agency ČTK ( Moravec et al., 2020) and across South American news media ( García-Perdomo et al., 2022).
Another limitation relates to not being able to set in stone what remains essentially a field in flux, where new technical breakthroughs or ways of implementing automated journalism could be happening as I am writing these lines. For example, a couple of years ago, most NLG companies appeared to be external content providers only, in charge of creating automated news products in place of media companies, but then started offering self-editing tools as well, as in the case of Automated Insights (see Mullin, 2015). This fast-paced evolution of automated news products makes it difficult to analyse them based on development types (i.e., external content providers, in-house, third-party self-editing tools); however, this could be done once this is stabilised enough.
Other than this, possible research avenues include using ANT to determine whether, in the ongoing assemblage of an “automated journalism actor-network”, news organisations or platforms act as spokespersons, especially as it may turn into a macro actor able to restructure media production as a whole. To a certain extent, platforms can be seen as already gaining the upper hand as recent text summarisation efforts—which are somehow related to automated news—appear to be quite tailored to fitting social media content. Such an analysis would be essential in determining power relationships likely to shape future developments of automated news products.
Ethical approval
The Dublin City University Research Ethics Committee approved this study on the 25 ^th^ of February 2020, under the approval number: DCUREC/2020/032
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Archer L : Nine things we’ve learnt in one month on Facebook Messenger.[Medium], December 16,2016; (Accessed: 14 August 2022). Reference Source
- 2Blok A : Actor-network theory, actants.In: George Ritzer (ed.) The Blackwell Encyclopedia of Sociology. Hoboken, NJ: Wiley-Blackwell,2019. 10.1002/9781405165518.wbeosa 010.pub 2 · doi ↗
- 3Beiler M Irmer F Breda A : Data journalism at German newspapers and public broadcasters: a quantitative survey of structures, contents and perceptions. Journal Stud. 2020;21(11):1571–1589. 10.1080/1461670 X.2020.1772855 · doi ↗
- 4Benson R : From heterogeneity to differentiation: searching for a good explanation in a new descriptivist era.In: Pablo Boczkowski and C.W. Anderson (eds) Remaking the News: Essays on the Future of Journalism Scholarship in the Digital Age.Cambridge, MA: MIT Press,2017;27–46. 10.7551/mitpress/10648.003.0006 · doi ↗
- 5Borges-Rey E : Unravelling data journalism: a study of data journalism practice in British newsrooms. Journalism Practice. 2016;10(7):833–843. 10.1080/17512786.2016.1159921 · doi ↗
- 6Callon M : Some elements of a sociology of translation: domestication of the scallops and the fishermen of St Brieuc Bay. Sociol Rev. 1984;32(1_suppl):196–233. 10.1111/j.1467-954X.1984.tb 00113.x · doi ↗
- 7Callon M : Techno-economic networks and irreversibility.In: John Law (ed.) A Sociology of Monsters: Essays on Power, Technology and Domination.Abingdon-on-Thames: Routledge,1990;38(1suppl):132–161. 10.1111/j.1467-954X.1990.tb 03351.x · doi ↗
- 8Carlson M : The Robotic Reporter. Digital Journalism. 2015;3(3):416–431. 10.1080/21670811.2014.976412 · doi ↗