Circular metagenome-assembled genome of Candidatus Patescibacteria recovered from anaerobic digestion sludge
Riku Sakurai, Yasuhiro Fukuda, Chika Tada

TL;DR
Scientists reconstructed a circular genome of a candidate Patescibacteria species from a food waste treatment plant in Japan.
Contribution
The study presents a single-contig circular genome of Ca. Patescibacteria from anaerobic digestion sludge.
Findings
A circular genome of Ca. Patescibacteria was reconstructed from a food waste treatment plant.
The genome is small and lacks key biosynthetic pathways.
Taxonomic analysis placed the genome in the genus JAEZRQ01 (Ca. Parcubacteria).
Abstract
A single-contig, circular metagenome-assembled genome (cMAG) of Candidatus (Ca.) Patescibacteria was reconstructed from a mesophilic full-scale food waste treatment plant in Japan. The genome is of small size and lacks fundamental biosynthetic pathways. Taxonomic analysis using the Genome Taxonomy Database revealed that this cMAG belonged to the genus JAEZRQ01 (Ca. Parcubacteria).
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
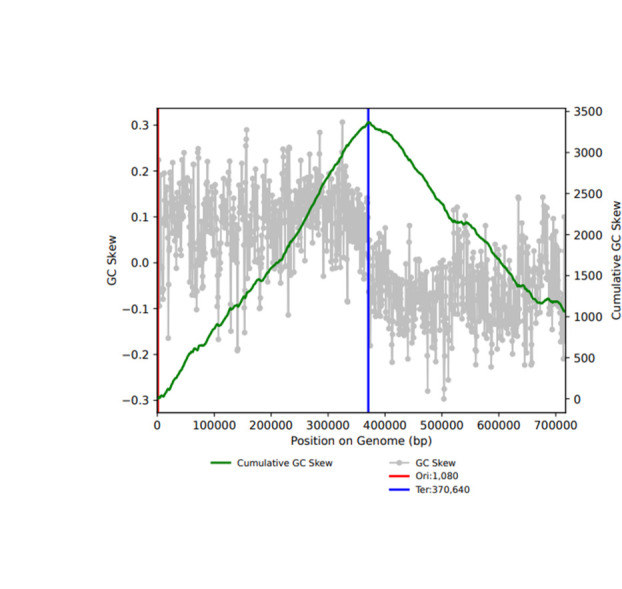 Fig 1
Fig 1- —Ministry of Education, Culture, Sports, Science and Technology (MEXT)
- —MEXT | Japan Society for the Promotion of Science (JSPS)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAstronomy and Astrophysical Research · Gamma-ray bursts and supernovae · History and Developments in Astronomy
ANNOUNCEMENT
A recent study revealed that Candidatus (Ca.) Patescibacteria functions in anaerobic digestion, interacting with methanogens (1). Understanding the role of Ca. Patescibacteria is crucial for maximizing the efficiency of methanogenesis.
Here, we present a circular metagenome-assembled genome (cMAG) of Ca. Patescibacteria, which was recovered from the sludge collected from a full-scale mesophilic food waste treatment plant in Tokyo, Japan, in 2022 (stored at −20°C until use). Genomic DNA was extracted using a FastDNA SPIN Kit for Soil (MP Biomedicals, USA). Sequencing was performed on PacBio Sequel IIe (Pacific Biosciences of California, USA) and DNBSEQ-G400 (MGI Tech, China) platforms, respectively. For PacBio sequencing, the quality of DNA extract was confirmed using the 5200 Fragment Analyzer System and Agilent HS Genomic DNA 50 kb Kit (Agilent Technologies, USA). The library was constructed using SMRTbell Express Template Prep Kit 2.0 (Pacific Biosciences of California). Sequencing polymerase was bound to SMRTbell libraries using Binding kit 2.2 (Pacific Biosciences of California). Adaptor sequences from PacBio raw sequencing data were trimmed using SMRT Link version 10.1.0.119528. The HiFi reads were generated by aligning the trimmed reads with an average quality of 20 or more using pancake with KSW2 (2–4), resulting in 157,984 reads (average: 6,957 bp). For DNBSEQ sequencing, the library was prepared by the MGIEasy FS DNA library prep set (MGI Tech, China), using the same DNA extract. The quality was confirmed using the Fragment Analyzer and dsDNA 915 Reagent Kit (Agilent Technologies). Circular DNA was constructed using a MGIEasy Circularization Kit. Subsequently, DNA nanoballs (DNBs) were constructed using a DNBSEQ-G400RS High-throughput Sequencing Kit (MGI Tech). 2 × 200 bp paired-end sequencing was performed on DNBSEQ-G400. Trimming of adaptor sequences and quality checks were performed using Trimmomatic v. 0.39. and Fastqc v. 0.11.9 (5), respectively.
Hybrid assembly was performed by metaSPAdes v. 3.10.1 (6), and the HiFi reads were assembled with hifiasm_meta v. 0.3.1 (7). Subsequently, quickmerge v. 0.3 (8) was utilized to merge them. Coverage was calculated by mapping DNBseq reads to the assembly using Bowtie2 v. 2.4.1 (9). Binning was performed using SemiBin2 v. 1.5.1 with built-in model “wastewater” (10). The resulting bin.765 was composed of one contig, with a completeness of 100% (0% contamination), and had one copy each of the 16S rRNA, 23S rRNA, and 5S rRNA gene as reported by MDMcleaner pipeline v. 0.8.7 (11). This MAG was curated by mapping DNBseq and HiFi reads and circularized by identifying the repeat region using Repeat Finder, in Geneious Prime 2023.2.1 (https://www.geneious.com). Default parameters were used for all software unless otherwise noted.
The recovered cMAG has a size of 717,294 bp, GC content of 41%, and 40× coverage. GC skew evaluation using gc_skew.py (https://github.com/christophertbrown/iRep) (12) revealed a well-defined pattern (13) (Fig. 1). Taxonomic analysis by GTDB-Tk v. 2.3.2 (14) indicates that this cMAG belongs to Ca. Patescibacteria (NCBI taxonomy: Ca. Parcubacteria). Annotation was performed by the Prokaryotic Genome Annotation Pipeline (15). The pathway analysis by GhostKOALA (16) suggested that de novo nucleotide synthesis, amino acid synthesis, and phospholipid synthesis pathways were incomplete, similar to other Ca. Patescibacteria species (17).
GC skew analysis. The diagram shows the GC skew (gray), cumulative GC skew (green line), Ori site (red line), and Ter site (blue line).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kuroda K, Yamamoto K, Nakai R, Hirakata Y, Kubota K, Nobu MK, Narihiro T. 2022. Symbiosis between Candidatus Patescibacteria and archaea discovered in wastewater-treating bioreactors. m Bio 13:e 0171122. doi:10.1128/mbio.01711-2236043790 PMC 9600506 · doi ↗ · pubmed ↗
- 2Li H. 2018. Minimap 2: pairwise alignment for nucleotide sequences. Bioinformatics 34:3094–3100. doi:10.1093/bioinformatics/bty 19129750242 PMC 6137996 · doi ↗ · pubmed ↗
- 3Suzuki H, Kasahara M. 2018. Introducing difference recurrence relations for faster semi-global alignment of long sequences. BMC Bioinformatics 19:45. doi:10.1186/s 12859-018-2014-829504909 PMC 5836832 · doi ↗ · pubmed ↗
- 4Pohjola JÅ, Syeda HT, Tanaka M, Winter K, Sau TW, Nott B, Ung TT, Mc Laughlin C, Seassau R, Myreen MO, Norrish M, Heiser G. 2023. “Pancake: verified systems programming made sweeter” Proceedings of the 12th Workshop on programming languages and operating systems, p 1–9Association for Computing Machinery, New York, USA. doi:10.1145/3623759.3624544 · doi ↗
- 5Babraham Bioinformatics. 2019 Fastqc a quality control tool for high throughput sequence data. https://www.bioinformatics.babraham.ac.uk/projects/fastqc.
- 6Nurk S, Meleshko D, Korobeynikov A, Pevzner PA. 2017. meta SP Ades: A new versatile Metagenomic assembler. Genome Res 27:824–834. doi:10.1101/gr.213959.11628298430 PMC 5411777 · doi ↗ · pubmed ↗
- 7Feng X, Cheng H, Portik D, Li H. 2022. Metagenome assembly of high-fidelity long reads with hifiasm-meta. Nat Methods 19:671–674. doi:10.1038/s 41592-022-01478-335534630 PMC 9343089 · doi ↗ · pubmed ↗
- 8Chakraborty M, Baldwin-Brown JG, Long AD, Emerson JJ. 2016. Contiguous and accurate de novo assembly of metazoan genomes with modest long read coverage. Nucleic Acids Res 44:e 147. doi:10.1093/nar/gkw 65427458204 PMC 5100563 · doi ↗ · pubmed ↗