Multiple phenotype association tests based on sliced inverse regression
Wenyuan Sun, Kyongson Jon, Wensheng Zhu

TL;DR
This paper introduces a new statistical method for analyzing multiple traits and genetic variants, which is more efficient and accurate than existing approaches.
Contribution
A novel sliced inverse regression-based association test is proposed for joint analysis of multiple phenotypes and genetic variants.
Findings
The proposed SIR-based method outperforms existing methods in both low- and high-dimensional settings.
The method achieves higher efficiency and maintains correct type I error rates in genetic association studies.
Abstract
Joint analysis of multiple phenotypes in studies of biological systems such as Genome-Wide Association Studies is critical to revealing the functional interactions between various traits and genetic variants, but growth of data in dimensionality has become a very challenging problem in the widespread use of joint analysis. To handle the excessiveness of variables, we consider the sliced inverse regression (SIR) method. Specifically, we propose a novel SIR-based association test that is robust and powerful in testing the association between multiple predictors and multiple outcomes. We conduct simulation studies in both low- and high-dimensional settings with various numbers of Single-Nucleotide Polymorphisms and consider the correlation structure of traits. Simulation results show that the proposed method outperforms the existing methods. We also successfully apply our method to the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
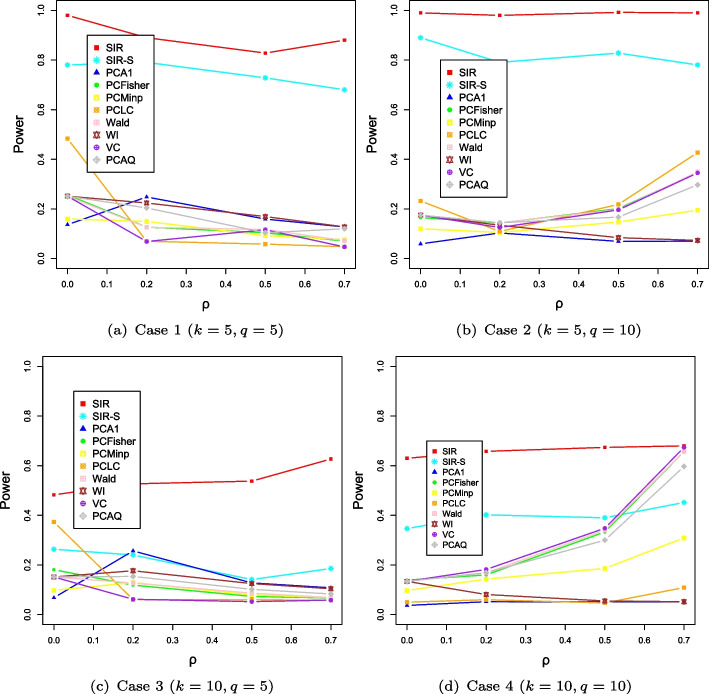 Figure 1
Figure 1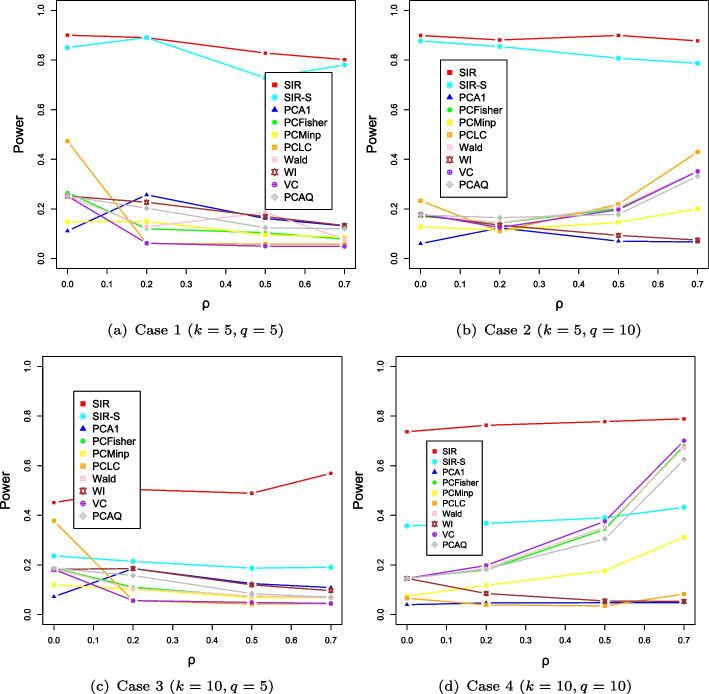 Figure 2
Figure 2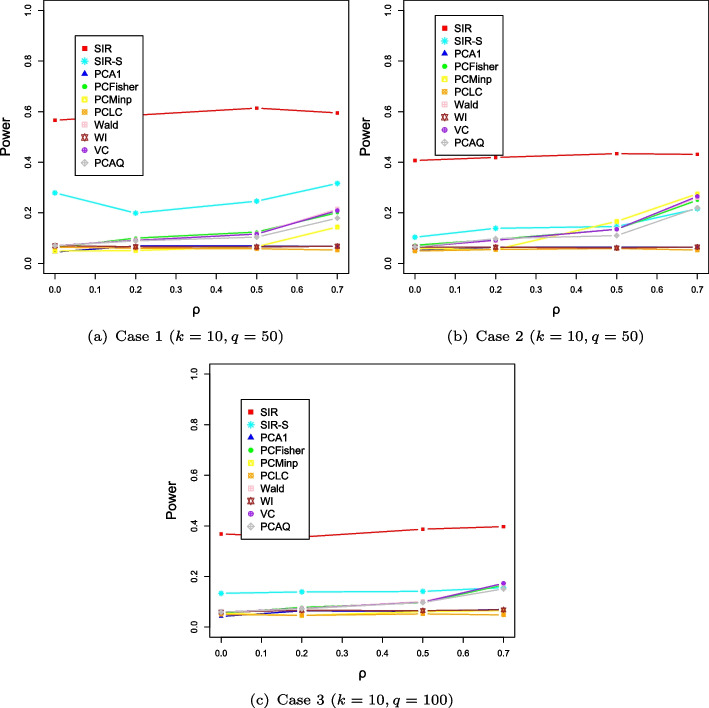 Figure 3
Figure 3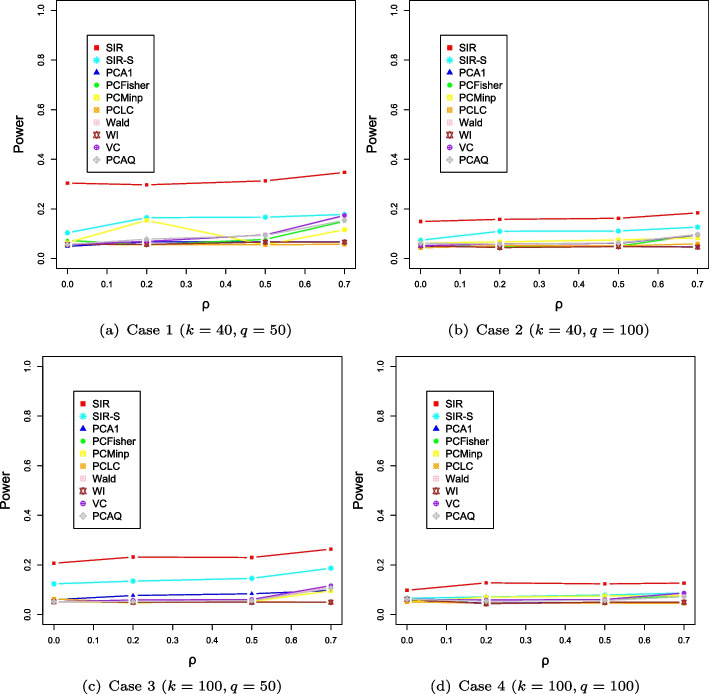 Figure 4
Figure 4- —http://dx.doi.org/10.13039/501100001809National Natural Science Foundation of China
- —National Key R&D Program of China
- —http://dx.doi.org/10.13039/100000002National Institutes of Health
- —http://dx.doi.org/10.13039/100000005U.S. Department of Defense
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGenetic Associations and Epidemiology · Gene expression and cancer classification · Genetic and phenotypic traits in livestock
Introduction
In recent biomedical research, Genome-Wide Association Studies (GWAS) often requires the simultaneous consideration of multiple phenotypes. It has been shown that jointly analyzing the multiple phenotypes together can increase statistical power to detect genetic variants [1, 2]. Introducing more information through the joint analysis will benefit revealing the complex relationship that may be undiscovered by the single phenotype analysis [3]. Meanwhile, the progressive improvements in data collection techniques have made it possible to measure more types of high-dimensional data on the same subject.
So far, the common strategies used to detect genetic associations in the joint analysis of multiple phenotypes can be roughly classified into several categories, such as regression model-based methods, nonparametric association methods, and p value correction methods. The regression model-based methods mainly exploit multivariate regression models [4–6], generalized estimating equations (GEEs), and mixed effects models [7–9]. As functional regression models perform well in most cases, Chui et al. [10] extended them to meta-analysis of pleiotropy traits, and Wang et al. [11] developed multivariate functional linear models and hypothesis testing procedure to test the association between multiple quantitative traits and multiple genetic variants in one genetic region. As a representative of the nonparametric association method, Zhang et al. [12] tested any hybrid of dichotomous, ordinal, and quantitative traits based on a generalization of Kendall’s tau. Zhu et al. [13] extend their method to accommodate covariates and proposed a nonparametric covariate-adjusted association test. Among the representative p value correction methods, one approach is Fisher’s combined method [14], which integrated the results from standard univariate analysis p value, and has been extended to dependent univariate test. Another approach called the minimum of the p value (Minp) method [15] has been applied to independent test studies to improve power when a SNP affects only a very small number of multiple phenotypes, but it is less powerful for denser signals. Sluis et al. [16] proposed the TATES method, which has good power in the presence of very few association signals but can lose its dominance otherwise.
Nevertheless, these methods focus only on the low-dimensional or moderate numbers of phenotypes. To this end, several dimension reduction methods, including principal component (PC) analysis, have been developed to reduce the high dimensionality of the phenotypes. Liu and Li [2] proposed the PC-based tests to take the high dimensional phenotypes into account and proved how to combine PCs together to achieve better power. But in fact, the PC-based tests consider only a single SNP, which makes it impossible to directly extend these tests to study the association between high dimensional phenotypes and multiple genotypes. Actually, with the development of next-generation sequencing technologies, recent GWAS usually collects high-dimensional SNPs and phenotypes. The implementation of association study often encounters other difficulties associated with the extremely high computational burden.
As another attempt to cope with the excessiveness of variables, Cook [17] introduced the idea of sufficient dimension reduction (SDR), which assumes that the response variable relates to only a few linear combinations of the many covariates. In this paper, we intend to reduce the dimension of the multivariate phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} without loss of information about the multiple genotypes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} based on the idea of SDR, where the dimension of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} could be large. To this end, we use the sliced inverse regression (SIR) proposed by Li [18] to seek the effective dimension-reduction (e.d.r) direction and propose a SIR-based testing method for genetic association with multiple phenotypes. Different from the principal component analysis, the motivation behind the SIR is to preserve regression information during carrying out dimension reduction of multivariate phenotype, so that the resulting variates capture important features of the regression relationship between the multivariate phenotypes and multiple phenotypes. The simulation studies illustrate that the type I error rates of our proposed tests are well-controlled and that the power is robust and powerful. We also apply the proposed SIR-based test to a real dataset, the Alzheimer’s Disease Neuroimaging Initiative (ADNI) dataset, and successively identify the new genetic variants.
Methods
SIR-based association test of multiple phenotypes
Data structure and linear regression
Suppose that data are collected from a population-based sequencing study with n independent individuals. For each individual, we observe q disease phenotypes and genotypes at k SNPs. Let the phenotype vector and genotype vector be \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}=(y_{1}, \dots , y_{q})^T$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}=(g_{1}, \dots , g_{k})^T$$\end{document} , respectively. Then, the observations of genotypes and trait measurements for n individuals are denoted as an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\times k$$\end{document} matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{G}} = (\varvec{g}_{1},\dots , \varvec{g}_{n})^{T}$$\end{document} and an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\times q$$\end{document} matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{Y}} = (\varvec{y}_{1}, \dots , \varvec{y}_{n})^{T}$$\end{document} , respectively. Here, notations of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}_{i}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}_{i}$$\end{document} refer to the instances of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} for i-th individual ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i=1,\dots ,n$$\end{document} ). In this study, the q could be large, so detecting disease-associated genetic variants with large q is very challenging. In addition, the effects of the correlation between phenotypes and the direction of genetic effects should be considered. For brevity, we focus on the most popular continuous phenotypes only and consider a multivariate linear regression model with large q.
To describe the relationship between the phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} and the genotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} , we propose the following linear model:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \varvec{y} ={\textbf{B}}^{T} \varvec{g} + \varvec{\varepsilon }, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{B}} = (\varvec{\beta }_{1}^T \dots , \varvec{\beta }_{k}^T)^{T}$$\end{document} is a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k \times q$$\end{document} matrix of the regression coefficients, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{j}=(\beta _{j1},\dots , \beta _{jq})$$\end{document} is a q-dimensional row vector of regression coefficients for the j-th SNP, which represents the effects of the j-th SNP on q phenotypes, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varepsilon }$$\end{document} is the q-dimensional error vector with zero mean and true covariance matrix, which is often unknown. Here, the intercepts are omitted with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} being properly centered. We can rewrite the above model in the following matrix form:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\textbf{Y}} = {\textbf{G}}{\textbf{B}}+ {\textbf{E}}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{E}}$$\end{document} = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\varvec{\varepsilon }_{1}, \dots , \varvec{\varepsilon }_{n})^T$$\end{document} is the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n \times q$$\end{document} error matrix with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varepsilon }_{i}$$\end{document} being the q-dimensional error vector for i-th individual.
Our primary interest lies in testing whether the genetic markers \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{g}}$$\end{document} are associated with the traits \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{y}}$$\end{document} . To address this problem, two strategies are commonly considered. Firstly, testing the effects of the j-th SNP on q phenotypes is equivalent to testing the null hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ H_{0}: \varvec{\beta }_j={\varvec{0}}$$\end{document} against the alternative hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_{1}$$\end{document} that at least one element of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_j$$\end{document} is not equal to zero. In this case, the Wald-type statistic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_1={\hat{\varvec{\beta }}}_j \left[ {\text {Cov}}({\hat{\varvec{\beta }}}_j)\right] ^{-1}{\hat{\varvec{\beta }}}_j^{T}$$\end{document} is adopted, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\varvec{\beta }}}_j$$\end{document} is the maximum likelihood estimator (MLE) of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_j$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}({\hat{\varvec{\beta }}}_j)$$\end{document} is its covariance matrix. The test statistic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_1$$\end{document} has q degrees of freedom. When q is large and heterogeneous effects exist, especially when a variant only affects a subset of traits, the test statistic may be less powerful due to the large degrees of freedom. Furthermore, conducting the association study with multiple tests often results in a significant loss of statistical power due to a large number of comparisons. The second strategy involves considering the association between all k SNPs and q phenotoypes, which is equivalent to testing the null hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ H_{0}: {\textbf{B}}_1={\varvec{0}}$$\end{document} . The Wald-type statistic can be rewritten as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_2=\hat{{\textbf{B}}}_1 \left[ {\text {Cov}}(\hat{{\textbf{B}}}_1)\right] ^{-1}\hat{{\textbf{B}}}_1^{T}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{{\textbf{B}}}_1$$\end{document} is the MLE of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{B}}_1=(\beta _{11}, \dots , \beta _{1q}, \beta _{21}, \dots , \beta _{2q}, \dots , \beta _{k1}, \dots , \beta _{kq})$$\end{document} . The test statistic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_2$$\end{document} has kq degrees of freedom and the implementation of the association study with high-dimensional phenotypes often encounters other difficulties concerning the extremely high computational burden. Since both \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_2$$\end{document} have their own disadvantages for large degrees of freedom, a common solution is to reduce the dimensionality of responses and/or predictors. In the following subsections, we present a SIR-based dimension reduction of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} and test procedures with reduced phenotypes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{y}}$$\end{document} .
SIR-based dimension reduction of \documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}$$\end{document}y
As the dimension of phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} is very large, it is highly desirable that interesting features of high-dimensional data are retrievable from low-dimensional projections. PCA is perhaps the most well-known method for reducing dimensionality. But since the procedure is carried out without using the predictor variable, certain interesting regression variables may be lost in the reduction process and hardly capture important features of the regression relationship between response variables and predictors. Another attempt to cope with the excessiveness of variables is the SDR approach, which assumes that only a few linear combinations of original variables are sufficient to reveal the information within them without changing their explanatory effect on the response variable. Identifying these linear combinations is the goal of dimension reduction. To this end, many authors have utilized the so-called sliced inverse regression (SIR) method proposed by [18], which focuses on the inverse regression method by reversing the relation between the response and predictor variables to benefit from the response variable being, usually, of lower dimension than predictor vector. Here, we adopt the SIR method to reduce the dimension of the multivariate response \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{y}}$$\end{document} without loss of information about the multiple genotypes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{g}}$$\end{document} .
To better understand the SIR method, we consider the following forward regression model:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \varvec{g}=f({\varvec{S}}_1^T\varvec{y}, {\varvec{S}}_2^T\varvec{y}, \dots , {\varvec{S}}_d^T\varvec{y}, \varvec{\epsilon }), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{S}}_1, \dots , {\varvec{S}}_d$$\end{document} are unknown e.d.r directions, d is the number of dimensions one want to achieve, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\epsilon }$$\end{document} is independent of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} , and f is an arbitrary unknown function on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbb {R}^{d+1}$$\end{document} . When the model (3) holds, the q-dimensional \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} can be projected onto the d-dimensional subspace with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d \ll q$$\end{document} , so that interesting features of the high-dimensional \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} are compressed by low-dimensional projections. If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} is statistically independent of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{S}}_m^T\varvec{y}, m=1,\dots ,d$$\end{document} , are given, it is sufficient to focus only on the d reduced variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{S}_m^T\varvec{y}$$\end{document} ’s for studying the relationship between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} . At this point, the column space of a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q\times d$$\end{document} matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{S}}=\left( {\varvec{S}}_1, \dots , {\varvec{S}}_d\right) $$\end{document} becomes a SDR subspace.
To reduce the dimension as much as possible, we are often interested in the SDR subspace with the smallest dimension. Under mild conditions [17, 19], the intersection of all SDR subspaces is still an SDR subspace, and the smallest SDR subspace is called the central subspace. For notational simplicity, in the following, we assume the central subspace to be estimated is spanned by a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q\times d_{0}$$\end{document} basis matrix, denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{S}}_0=\left( {\varvec{S}}_1, \dots , {\varvec{S}}_{d_0}\right) $$\end{document} . If we further assume that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} has been standardized to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{z}}$$\end{document} , under a linearity condition that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ E(\varvec{z}\mid {\textbf{S}}_0^T\varvec{z})$$\end{document} is linear in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ {\textbf{S}}_0^T\varvec{z} $$\end{document} , it is guaranteed that the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E(\varvec{z}\mid \varvec{g})$$\end{document} belong to the space spaned by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{S}_1, \dots , \varvec{S}_{d_0}$$\end{document} [18, 20]. Then, we can estimate the central subspace by applying a principal component analysis to the random vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E(\varvec{z}\mid \varvec{g})$$\end{document} , following the approach proposed by [18]. Equivalently, we can derive a basis of central subspace by solving
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathop {\arg \max }\limits _{{\textbf{S}}_0^T{\textbf{S}}_0={\textbf{I}}_{d_0}}\textrm{tr}\left( {\textbf{S}}_0^T{\text {Cov}}\left[ E(\varvec{z} \mid \varvec{g})\right] {\textbf{S}}_0\right) , \end{aligned}$$\end{document}the solution of which is formed by the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0$$\end{document} leading eigenvectors of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}\left[ E\left( \varvec{z} \mid \varvec{g}\right) \right] $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}\left[ E\left( \varvec{z} \mid \varvec{g}\right) \right] $$\end{document} = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E\left[ E\left( \varvec{z}\mid \varvec{g}\right) E\left( \varvec{z}\mid \varvec{g}\right) ^T\right] $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{tr}\left( \cdot \right) $$\end{document} represents the sum of the eigenvalues of the matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}[ E(\varvec{z} \mid \varvec{g})] $$\end{document} .
In this study, our concern is focused on testing the association between marker genes and multiple traits. However, under the null hypothesis, the traits and genes are independent. In this case, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}[ E(\varvec{z} \mid \varvec{g})]= E\left[ \left( E\left( \varvec{z}\mid \varvec{g}\right) - E\left[ E\left( \varvec{z}\mid \varvec{g}\right) \right] \right) \left( E\left( \varvec{z}\mid \varvec{g}\right) - E\left[ E\left( \varvec{z}\mid \varvec{g}\right) \right] \right) ^{T}\right] =0$$\end{document} , and the estimation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}\left[ E(\varvec{z} \mid \varvec{g})\right] $$\end{document} will be very small and close to 0 in actual situations, then it becomes challenging to directly apply the PCA on the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}\left[ E(\varvec{z} \mid \varvec{g})\right] $$\end{document} by following the SIR method suggested by [18]. Fortunately, we see the relation between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}\left[ E\left( \varvec{z} \mid \varvec{g}\right) \right] $$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ E[{\text {Cov}}(\varvec{z} \mid \varvec{g})]$$\end{document} as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} E\left[ {\text {Cov}}(\varvec{z} \mid \varvec{g})\right] ={\text {Cov}} (\varvec{z})-{\text {Cov}}\left[ E(\varvec{z} \mid \varvec{g})\right] =I-{\text {Cov}}\left[ E(\varvec{z} \mid \varvec{g})\right] . \end{aligned}$$\end{document}Alternatively, by applying the eigenvalue decomposition of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ E[{\text {Cov}}(\varvec{z} \mid \varvec{g})]$$\end{document} , we can determine the standardized e.d.r. directions which are the eigenvectors associated with the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0$$\end{document} smallest eigenvalues. This procedure equivalently derives a basis of central subspace by solving
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathop {\arg \min }\limits _{{\textbf{S}}_0^T{\textbf{S}}_0={\textbf{I}}_{d_0}}\textrm{tr}\left( {\textbf{S}}_0^T E\left[ {\text {Cov}}(\varvec{z} \mid \varvec{g})\right] {\textbf{S}}_0\right) , \end{aligned}$$\end{document}the solution of which is formed by the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0$$\end{document} leading eigenvectors of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E\left[ {\text {Cov}}(\varvec{z} \mid \varvec{g})\right] $$\end{document} .
In the following, we give a detailed estimation procedure utilizing the SIR scheme based on the observed data ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}_{i},\varvec{y}_{i}$$\end{document} ), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i = 1, \dots , n$$\end{document} :
- Standardize \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}_i$$\end{document} by an affine transformation to get \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{z}_i={\hat{\Sigma }}_{{\varvec{y y}}}^{-1 / 2}(\varvec{y_{i}}-\overline{\varvec{y}})$$\end{document} , ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i = 1, \dots , n$$\end{document} ), where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\Sigma }}_{\varvec{y y}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\overline{\varvec{y}}$$\end{document} are the sample covariance matrix and sample mean of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}_1,\dots , \varvec{y}_n$$\end{document} , respectively.
- Divide the range of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} into the H slices, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I_{1},\dots ,I_{H}$$\end{document} ; let the proportion of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}_{i}$$\end{document} ’s falling into the h-th slice be \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{p}}_{h}$$\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h=1, \dots , H$$\end{document} ), that is, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{p}}_{h}$$\end{document} = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(1 / n) \sum _{i=1}^{n} \delta _{h}\left( \varvec{g}_{i}\right) $$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{h}\left( \varvec{g}_{i}\right) $$\end{document} takes the value 0 or 1 depending on whether \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}_{i}$$\end{document} falls into the h-th slice \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I_{h}$$\end{document} or not.
- Within each slice, compute the sample covariance of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{z}_{i}$$\end{document} ’s, denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{v}}_h~(h=1, \dots , H)$$\end{document} , that is, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{v}}_h=\left( 1 / n {\hat{p}}_{h}\right) \sum _{\varvec{g}_{i} \in I_{h}} \varvec{z}_{i}\varvec{z}_{i}^T$$\end{document} .
- Conduct a (weighted) principal component analysis for the data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{v}}_h~ (h=1, \dots , H)$$\end{document} : firstly, form the weighted mean value \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{{\textbf{E}}}=\sum _{h=1}^{H} {\hat{p}}_{h} \hat{\varvec{v}}_h $$\end{document} ; next, find the eigenvalues and the eigenvectors for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{{\textbf{E}}}$$\end{document} .
- Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\varvec{\eta }}_{m}~(m=1,\dots , d_0)$$\end{document} be the m smallest eigenvectors. By transforming back to the original scale, output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{{\varvec{S}}}}_{m}=\hat{\varvec{\eta }}_{m} {\hat{\Sigma }}_{\varvec{yy}}^{-1 / 2}~(m=1,\dots , d_0)$$\end{document} which are in the e.d.r. space. When dividing the range of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} , the most natural choice is to divide it into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H=3^k$$\end{document} slices, considering the fact that each locus of the k SNPs takes values in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{0, 1, 2\}$$\end{document} . However, if the dimension of genotypes is very high, then such a straightforward implementation, while theoretically possible, is intractable in practice. This is because there will be many empty slices due to a massive number of slices and the limited sample size, making it impossible to calculate the covariance in those empty slices. For this reason, we adopt an alternative way of dividing the range of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} and grouping individuals, following the approach mentioned in [21]. Specifically, we first estimate the genetic relatedness matrix to measure genetic similarity among individuals and divide the range of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} in terms of that similarity. Next, we merge adjacent slices so that the number of individuals in each slice is not less than 5. Then, we calculate the conditional covariance of each slice according to the estimation procedure for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ E[{\text {Cov}}(\varvec{z} \mid \varvec{g})]$$\end{document} , which is described above.
SIR-based association test with reduced phenotypes
After estimating the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0$$\end{document} standardized e.d.r directions, the q-dimensional \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} can be projected onto the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0$$\end{document} -dimensional central subspace with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0 \ll q$$\end{document} . Then, the predictor variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} is related to only \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0$$\end{document} linear combinations, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{S}_1^T\varvec{y},\dots ,\varvec{S}_{d_0}^T\varvec{y}$$\end{document} , and it is sufficient to focus only on them. According to [17, 18], it is fair to say that one-component model ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0=1$$\end{document} ) has prevailed, therefore, for the sake of simplicity, only case of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0=1$$\end{document} is considered in this paper.
Consequently, the large dimensional phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}_i~(i=1,\dots ,n)$$\end{document} can be transformed into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{{y}}_{i}\in \mathbb {R}$$\end{document} without loss of information on the corresponding genotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}_i$$\end{document} . At this point, we can investigate the relationship between phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} and genotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} in the following form:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\tilde{{\varvec{Y}}}}= {\textbf{G}}{\tilde{\varvec{\beta }}} + {\tilde{{\varvec{E}}}}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{{\varvec{E}}}}$$\end{document} = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$({\tilde{\varvec{\varepsilon }}}_{1}, \dots , {\tilde{\varvec{\varepsilon }}}_{n})^T$$\end{document} is an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n \times 1$$\end{document} error vector with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\varvec{\varepsilon }}}_{i}$$\end{document} being the error term for i-th individual, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{{\varvec{Y}}}} = (\tilde{{y}}_{1}, \dots , \tilde{{y}}_{n})^{T}$$\end{document} is an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n\times 1$$\end{document} vector of the traits, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\varvec{\beta }}} $$\end{document} is a regression coefficient vector.
We aim to test whether the set of genetic markers is associated with phenotype after dimension reduction. This is equivalent to testing the null hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ H_{0}: {\tilde{\varvec{\beta }}}={\textbf{0}}$$\end{document} against the alternative hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_{1}$$\end{document} that at least one element of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\varvec{\beta }}}$$\end{document} is not equal to zero. In this case, Wald-type statistic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{T}=\left( \widehat{{\tilde{\varvec{\beta }}}}\right) ^{T} \left[ {\text {Cov}}(\widehat{{\tilde{\varvec{\beta }}}})\right] ^{-1}\left( \widehat{{\tilde{\varvec{\beta }}}}\right) $$\end{document} no longer follows the chi-square distribution under the null hypothesis, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\widehat{{\tilde{\varvec{\beta }}}}$$\end{document} is the MLE of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\varvec{\beta }}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Cov}}(\widehat{{\tilde{\varvec{\beta }}}})$$\end{document} is its covariance matrix. We use a permutation procedure to establish the null distribution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{T}$$\end{document} . The permutation is done by randomly assigning the genotypes while keeping the phenotypes for each individual. For each permuted data set, we use (7) to calculate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{T}$$\end{document} as we have done by using the original data set. We repeat this procedure 1000 times to generate the distribution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{T}$$\end{document} under the null hypothesis of no association between multiple genotypes and the phenotypes. This testing strategy, in the sense that it is about all coefficients, can be seen as a global test.
In addition to this, it is also possible to focus on the association of the single SNP after dimension reduction. To this end, we apply Bonferroni correction to adjust for multiple testing involving k markers, which is equivalent to testing the null hypothesis \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_{0}: \tilde{\beta }_k={\textbf{0}}$$\end{document} against \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_{a}: {\tilde{\beta }}_k\ne {\textbf{0}}$$\end{document} . The model for this case is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} {\tilde{y}}_i= g_{ik}{\tilde{\beta }}_k + {\tilde{\varvec{\varepsilon }}}_{i},~~i=1,\dots , n, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\beta }}_k$$\end{document} is a regression coefficient and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\varvec{\varepsilon }}}_{i}$$\end{document} is an error term for i-th individual. The test statistic \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{T}_k^2=\hat{{\tilde{\beta }}}_{k}^2/{\text {Var}}\left( \hat{{\tilde{\beta }}}_k\right) $$\end{document} also does not follow the chi-square distribution under the null hypothesis, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{{\tilde{\beta }}}_k$$\end{document} is the MLE of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tilde{\beta }}_k$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\text {Var}}(\hat{{\tilde{\beta }}}_k)$$\end{document} is its variance. To carry out the association test, we apply the permutation procedure to estimate the distribution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{T}_k$$\end{document} .
Simulation studies
We conduct a series of simulation studies to evaluate the numerical performance of the proposed association tests in comparison with eight other PC-based competing tests, such as PCA1, PCFisher, PCMinp, PCLC, Wald, WI, VC, and PCAQ [2]. In these PC-based tests, the PCA1 indicates using only the first principal component, the PCFisher can be viewed as a nonlinear combination of the PC p values, the PCMinp uses the minimum PC p value as a testing statistic, and other tests aim at constructing the linear or quadratic combinations of PCs weighted by the functions of eigenvalues.
We simulate the genotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}_{i}=(g_{i1}, \dots , g_{ik})^T$$\end{document} for the i-th individual at k SNPs, where the genotype of each SNP is sampled from a uniform distribution with a minor allele frequency (MAF=p) between 0.3 and 0.5 under the assumption of Hardy-Weinberg equilibrium. That is, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_{aa}=(1-p)^{2}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_{Aa} = 2p(1-p)$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p_{AA} =p^{2}$$\end{document} . The q-dimensional phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}_{i}$$\end{document} of the i-th individual is generated from the model (1), where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\varepsilon }_i$$\end{document} follows \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N({\textbf{0}},\Sigma )$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Sigma _{lm}=\rho ^{|l-m|}$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1\le l, m\le q$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} is the correlation coefficient between phenotypes. Note that the simulated data under the null hypothesis of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }={\textbf{0}}$$\end{document} can be used to calculate type I errors, whereas the data under the alternative hypothesis saying that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }$$\end{document} contains at least one nonzero element can be used to calculate powers for each method. Hereafter, this global test mentioned above is expressed as SIR in this study. Alternatively, based on the model (8), we can also perform the association test for each SNP separately, and adjust the test for all the SNPs through multiple testing procedure, named SIR-S.
In the simulation studies, we consider three scenarios: Scenario 1 is for the low-dimensional phenotype (q = 5 and 10) and low-dimensional genotype (k = 5 and 10); Scenario 2 is for the high-dimensional phenotype (q = 50 and 100) but low-dimensional genotype (k = 10); Scenario 3 is for both high-dimensional phenotype (q = 50 and 100) and genotype (k = 40 and 100). We set the nominal level of significance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha =0.05$$\end{document} . Since the PC-based methods focus on the association test of single marker, here we apply Bonferroni correction to adjust for multiple testing involving k markers. In each scenario, we increase the correlation coefficient of phenotype in a series of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} = 0, 0.2, 0.5, 0.7. For each scenario, we generate 100,000 and 1000 simulated data sets for type I error evaluation and for power calculation, respectively.
Scenario 1: low-dimensional phenotype and low-dimensional genotype
In this scenario, the dimension of phenotype is set to be q = 5 and 10, and the number of SNPs is set to be k = 5 and 10. We compare the power of each method in terms of the signal direction, signal strength, and the correlation structure among phenotypes. To this end, we consider different values of effect vector for each phenotype, specifically four cases for this scenario: Case 1 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=5$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=5$$\end{document} ; Case 2 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=5$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=10$$\end{document} ; Case 3 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=5$$\end{document} ; Case 4 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=10$$\end{document} . Here, we let most \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_j$$\end{document} ’s be zeros except for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}$$\end{document} being nonzeros. The effect vector of the third SNP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}$$\end{document} on each phenotype is positive, except for Case 4, where its direction is mixed. The value of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}$$\end{document} is given such that the fourth SNP is only associated with the second trait in all settings. The detailed setting of effect vectors is shown in Table 1.Table 1. Low-dimensional setting of effect vectors in Scenario 1Case 1k=5, q=5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=(1.10,1.10,1.10,1.10,1.10)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=(0.00,0.02,0.00,0.00,0.00)$$\end{document} Case 2k=5, q=10 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=(1.10,1.10,1.10,1.10,1.10,0.00,0.00,0.00,0.00,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=(0.00,0.02,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00)$$\end{document} Case 3k=10, q=5 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=(1.10,1.10,1.10,1.10,1.10)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=(0.00,0.02,0.00,0.00,0.00)$$\end{document} Case 4k=10, q=10 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=(1.10,-1.10,1.10,-1.10,1.10,0.00,0.00,0.00,0.00,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=(0.00,0.02,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$*$$\end{document} The default value of other effect vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\beta }_j}$$\end{document} ’s are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{0}}$$\end{document} Table 2. Empirical type I errors based on 100,000 replicates in Scenario 1nkq \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} SIRSIR-SPCA1PCFisherPCMinpPCLCWaldWI \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{VC}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{PCAQ}$$\end{document} 10005500.051330.051560.049810.046690.050110.049890.048900.047660.048870.047090.20.052840.050110.048240.048070.040780.048820.048000.048880.047400.049020.50.053670.048980.048560.048180.042190.049230.048910.049540.047880.049800.70.051050.049200.051090.048540.046790.049970.049670.051440.049620.05066 51000.055180.049270.048600.049660.054780.048410.049780.049880.049820.049740.20.053720.051450.049080.057010.049200.049080.049620.049350.050150.050160.50.048870.052190.054910.050310.049580.050880.048950.050110.050550.050670.70.052500.052960.048970.050280.048350.050130.048820.049840.049750.04578 10500.051970.057090.050430.048510.048460.048350.049650.049060.049040.050300.20.050650.052020.049980.050560.048890.054680.051030.049230.050200.051560.50.050910.053050.049910.050240.048560.049630.052030.047850.049120.049470.70.050260.052960.050160.049750.043830.048820.048160.049830.042370.04637 101000.054630.050970.492310.048120.049760.049750.049430.048410.044580.049470.20.049740.048690.050210.048540.050040.050020.049550.046850.048570.048570.50.051220.051240.052250.048740.049540.049660.047150.047930.048860.047890.70.050980.050140.048470.049940.047590.052070.048640.053050.049800.0426220005500.050350.051930.051090.049880.049270.050230.049870.046990.047880.049980.20.052540.050250.050240.049320.043660.049820.047690.047080.049030.040780.50.051730.050970.052040.048720.040180.048970.048290.049080.048740.050030.70.050180.051640.052080.049960.045790.047600.048870.050350.048780.0497851000.050870.055970.048450.057010.049200.048770.049500.049810.049780.047880.20.049750.053480.048310.051360.047980.050040.046980.049830.048270.045160.50.054290.056070.049850.048790.048760.051900.046230.046370.049830.047920.70.050520.053750.048120.049410.047910.050330.046820.047840.048130.04507 10500.053080.054690.050390.047930.049850.049550.049570.048750.047750.047780.20.052460.053250.048310.048390.049470.049760.050120.049750.043370.046420.50.051080.051980.050170.048840.047610.043830.048580.049530.044350.049360.70.050730.052060.049940.049650.048790.048980.048380.049620.043320.04642101000.051800.052490.049720.050890.050180.048860.049540.048740.046480.052600.20.054550.051670.048860.047870.049560.046320.049890.048470.048870.051050.50.052230.052280.049750.048970.045870.049580.050030.049960.049890.049880.70.050420.051750.048470.044340.049890.054110.048850.053050.048800.05062
From the results summarized in Table 2, it is apparent to see that the estimated type I error values of both SIR and SIR-S methods for different values of q, k, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} are very close to the true error level of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha =0.05$$\end{document} and the two methods have the well-controlled empirical type I error rates in most cases. For further comparisons, we also make the PC-based tests as additional baseline methods. Table 2 clearly shows that all the PC-based methods retain the empirical type I errors very well at the significance level in most cases. Notice that the type I error rate of the VC method has slightly conservative with the empirical type I error of 0.04237 when we set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=5$$\end{document} . Overall, the SIR and SIR-S methods can accurately control the empirical type I errors at the nominal level.
We further compare the empirical powers of the proposed tests with the existing PC-based methods. For each setup, we generate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=1000$$\end{document} and 2000 samples. The powers are calculated by the proportion of p values less than the significance level. We take the signal direction, signal strength, and the correlation structure among traits into account. Figures 1 and 2 show the powers of the ten comparative methods for different settings. We can see that the powers of the SIR and SIR-S methods are close to 1 and other PC-based methods are more powerless than the two methods in the case of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=5$$\end{document} . In a nutshell, with the same number of genotypes, if the dimension q is equal to 5, the powers of PC-based methods will decrease as the correlation coefficient increases, but if the dimension q is equal to 10, the power increases contrarily. However, the proposed methods still have much higher power than the other alternative methods. Different from the case of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=5$$\end{document} , we can see that the powers of the SIR and SIR-S methods decrease as the dimension of genotype k increases. The PCFisher, Wald, and VC have comparable performances to the proposed tests when the effect vectors are in a mixed direction for a strong phenotypic correlation. From Figs. 1 and 2, we know that both the SIR and SIR-S methods are sensitive to the direction of the signal. The increase in sample size has little effect on the power of all methods.Fig. 1. The evolution of power along with the varying correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} in the case of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=1000$$\end{document} Fig. 2. The evolution of power along with the varying correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} in case of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=2000$$\end{document}
Scenario 2: high-dimensional phenotype and low-dimensional genotype
To further show the performance of the proposed methods in the case of high-dimensional phenotype, we carry out additional simulations to compare our SIR and SIR-S methods with the other eight methods. Since Scenario 1 shows the sample size has little effect on the power for all methods, in this simulation, we only generate n=1000 individuals with different correlation structures of traits. The datasets are generated similarly to Scenario 1 except for the effect vectors. We consider three cases for this scenario: Case 1 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=50$$\end{document} ; Case 2 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=50$$\end{document} ; Case 3 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=100$$\end{document} . The effect vector of the third SNP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}$$\end{document} on the first five phenotypes is positive in Case 1 and Case 3, while the effect vectors in Case 2 have mixed directions. The setting of the different effect vectors is shown in Table 3. Table 4 summarizes the empirical type I errors of these methods for the association analysis. It is clear that all methods can control the empirical type I error well in most cases. Then, we compare the powers of our methods with the PC-based methods. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=50$$\end{document} , we have two cases and set the effects of the third SNP on the first five traits to be positive and mixed directions, respectively. In all cases, the fourth SNP is only associated with the second trait.Table 3. The setting of effect vectors in Scenario 2Case 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10,q=50$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=c(1.10,1.10,1.10,1.10,1.10,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=c(0.00,0.02,0.00,0.00,\dots ,0.00)$$\end{document} Case 2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10,q=50$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=c(1.10,-1.10,1.10,-1.10,1.10,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=c(0.00,0.02,0.00,0.00,\dots ,0.00)$$\end{document} Case 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=10,q=100$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=c(1.10,1.10,1.10,1.10,1.10,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=c(0.00,0.02,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$*$$\end{document} The default value of other effect vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\beta }_j}$$\end{document} ’s are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{0}}$$\end{document} Table 4. Empirical type I errors based on 100,000 replicates in Scenario 2k**q \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} SIRSIR-SPCA1PCFisherPCMinpPCLCWaldWIVCPCAQ10500.00.052150.051680.049620.051750.051830.053040.050540.053440.052140.050380.20.051670.052670.047820.045390.052640.050160.051630.049840.049930.050870.50.051020.051960.049350.050230.048630.051270.048460.048870.050620.050900.70.049850.052270.049350.047680.049960.050230.049630.047780.051230.05176101000.00.050150.051670.049160.052240.049850.048430.049080.052390.051050.051370.20.051030.050700.052620.051430.049980.047650.053250.050080.049640.056610.50.052340.051650.053050.048160.046230.043320.052330.051730.051410.051220.70.050040.052960.052030.049840.048430.047930.048780.050130.051270.05027
Simulation results for power comparisons are shown in Fig. 3. Figure 3 shows that the powers of our SIR and SIR-S methods decrease when the effect vectors are in mixed directions for the high-dimensional phenotypes. However, effect vectors in mixed directions do not affect the power of the PC-based methods. From these observations, we can see that our SIR and SIR-S methods are sensitive to the direction of effect vector for high-dimensional phenotypes. Clearly, the powers of all methods are affected by the dimensional increase of the phenotype to a certain degree. Compare to Scenario 1, the powers of both the SIR and SIR-S methods are somewhat decreased, but still, our methods outperform the competing methods in most cases.Fig. 3. The evolution of power along with the varying correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} in Scenario 2
Scenario 3: high-dimensional phenotype and high-dimensional genotype
We conduct additional simulations to compare the performance of our proposed tests with existing PC-based methods for both high-dimensional phenotype and genotype. From Scenario 2, we know that when effect vectors are in mixed directions, the powers of our proposed methods decrease in a high-dimensional phenotype setting. For a fair comparison with the PC-based methods, in this simulation, we consider the effect vector of the third SNP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}$$\end{document} on the first five phenotypes to be of mixed directions. Specifically, we consider high-dimensional phenotype and genotype with four cases: Case 1 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=40$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=50$$\end{document} ; Case 2 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=40$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=100$$\end{document} ; Case 3 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=100$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=50$$\end{document} ; Case 4 is for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=100$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$q=100$$\end{document} . Table 5 shows the setting of different effect vectors. The datasets are generated similarly to Scenario 1, but here the number of SNPs is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=40$$\end{document} or 100.Table 5. The setting of effect vectors in Scenario 3Case 1 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=40,q=50$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=c(1.10,-1.10,1.10,-1.10,1.10,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=c(0.00,0.02,0.00,0.00,\dots ,0.00)$$\end{document} Case 2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=40,q=100$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=c(1.10,-1.10,1.10,-1.10,1.10,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=c(0.00,0.02,0.00,0.00,\dots ,0.00)$$\end{document} Case 3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=100,q=50$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=c(1.10,-1.10,1.10,-1.10,1.10,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=c(0.00,0.02,0.00,0.00,\dots ,0.00)$$\end{document} Case 4 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k=100,q=100$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{3}=c(1.10,-1.10,1.10,-1.10,1.10,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_{4}=c(0.00,0.02,0.00,0.00,\dots ,0.00)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$*$$\end{document} The default value of other effect vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\beta }_j}$$\end{document} ’s are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{0}}$$\end{document} Table 6. Empirical type I errors based on 100,000 replicates in Scenario 3k**q \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} SIRSIR-SPCA1PCFisherPCMinpPCLCWaldWIVCPCAQ40500.00.049970.051420.050630.051890.049910.050290.049450.048790.048570.049970.20.048950.051490.051570.049940.048450.047720.050220.050150.051070.055410.50.050070.050570.050360.047340.050480.049510.050050.053020.052350.053260.70.049890.055030.050910.051960.049800.049790.050760.047800.049930.04892401000.00.051670.052770.054940.045560.049560.048600.049560.048590.048770.051960.20.047830.051670.047990.051470.050640.049580.049910.047030.049950.049860.50.051050.051980.048750.048890.049620.049380.048550.049740.049780.048840.70.052630.051350.049640.048790.050830.050450.049530.048200.049460.05278100500.00.052460.052050.048700.045690.048620.049740.046750.046870.047880.049670.20.050760.051300.048860.045680.047870.049870.048730.050440.046560.049680.50.050420.051780.049780.044670.048740.049560.044790.048700.048730.049940.70.052010.051610.048740.046760.049790.052130.046780.048350.046580.050161001000.00.049820.052160.050330.049840.049890.052250.048630.047820.046590.048930.20.049530.055730.051050.048820.049630.051950.049860.049830.046740.049420.50.050140.054360.050730.048360.051270.052850.049830.049760.047340.049710.70.049470.051740.049940.049030.049570.053160.051580.049940.046050.04996
Table 6 summarizes the simulation results for type I error estimates. It clearly shows that all methods can retain the empirical type I errors very well at the significance level.
Figure 4 presents the simulation results of power comparisons for all settings. The powers of our SIR and SIR-S methods are reduced as the dimensions of both genes and phenotypes increase. Nevertheless, the powers of the proposed methods are still slightly higher than the PC-based methods.Fig. 4. The evolution of power along with the varying correlation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} in Scenario 3
Scenario 4: simulation based on a real genotype data
In this section, we perform additional simulations to evaluate the performance of our SIR and SIR-S procedures on a more realistically simulated data, and compare with the other eight methods based on a real genotype data from the Genetic Analysis Workshop 17 (GAW17). The genotype data of 697 unrelated individuals are extracted from the sequence alignment files provided by the 1000 Genomes Project for their pilot3 study (http://www.1000genomes.org), in which we choose the TG gene as a candidate gene. The TG gene has 146 SNPs which encodes the thyroglobulin, one of the largest proteins in the human body, and mutation of the TG gene may cause hypothyroidism and autoimmune disorders [22].
In this simulation, the 100 dimensional phenotypes of the 697 individuals are generated from the model (1). To focus on the main points, six SNPs are selected as the causal variants. Specifically, the three SNPs, 20-th, 60-th, 100-th, are chosen to be far away and the others, 4-th, 6-th, 8-th, are chosen to be clustered. To consider the fact that the causal SNPs affect the disease in different directions, we set the effect vector of the each SNP \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_j$$\end{document} on the first five phenotypes to be of mixed directions, while the rest of them are set to be \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\textbf{0}}$$\end{document} . We generate 100,000 simulated data sets for type I error evaluation and 1000 data sets for power comparison.
Table 7 lists the empirical type I errors of the ten methods of the association analysis for TG gene at the nominal level of 0.05. From Table 7, it is apparent to see that all the methods control the empirical type I errors of the TG gene very well. Table 8 shows the power comparison results of the ten methods for different settings. It clearly shows that all methods are robust to the proportion of the causal variants, and the SIR and SIR-S methods provide more power than the other methods in most cases.Table 7. Empirical type I errors of the TG gene based on 100,000 replicates in Scenario 4 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} SIRSIR-SPCA1PCFisherPCMinpPCLCWaldWIVCPCAQ0.00.050010.051450.045100.044090.050400.052650.045510.048490.047760.051650.20.049980.051450.050170.047640.050440.046520.051350.052050.046570.055280.50.049850.050360.056480.048790.049660.051060.046670.055030.049860.056630.70.051130.049580.049890.047820.046610.051440.048760.055230.049750.05356Table 8Empirical powers of the TG gene based on 1000 replicates in Scenario 4 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\rho $$\end{document} SIRSIR-SPCA1PCFisherPCMinpPCLCWaldWIVCPCAQ0.00.3970.1610.2810.1950.1910.0740.0960.1040.1190.0960.20.3850.1670.0490.1170.1550.1210.1520.0550.1470.0990.50.3950.1580.0580.2920.2970.0550.2100.0620.2760.1650.70.4810.1720.0560.4410.3030.0820.4750.0510.4780.364
Application to the sequencing data from ADNI
We analyze the ADNI1 and ADNI2 datasets from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) study. The ADNI seeks to develop biomarkers of the disease and advance the understanding of AD (Alzheimer’s disease) pathophysiology, so as to improve diagnostic methods for early detection of AD and improve the clinical trial design. Additional goals are examining the rate of progress for both mild cognitive impairment and Alzheimer’s disease, as well as building a large repository of clinical and imaging data. ADNI is a study that assesses the effects of genetic variants on AD and various AD-related outcomes, including 3D brain imaging and cognitive measurements [23]. Proteolytic fragments of amyloid and post-translational modification of tau species in Cerebrospinal fluid (CSF) as well as cerebral amyloid deposition are important biomarkers for AD [24, 25].
A total of 800 subjects are included in the data, with 200 normal controls, 400 mild cognitive impairment (MCI), and 200 mild AD. We are interested in the association between genetic variants and five outcomes, including the hippocampus, entorhinal, amyloid beta (A \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _{42}$$\end{document} ), tau, and phosphorylated tau (ptau_181_) levels. It has been reported that the AOPE gene is related to AD and its associated outcomes [26]. Therefore, as in [27], SNP rs769449 in gene AOPE is selected in our study. We also include 15 SNPs around rs769449 in our study: 8 SNPs on the left of rs769449 and 7 SNPs on the right, respectively. The SNPs rs8106922, rs1160985, and rs394819 are located in an intronic region of gene TOMM40, while other SNPs rs1081101, rs405509, and rs769449 are in the gene APOE, and rs445925 in gene APOC1. In the preprocessing step, we exclude the subjects which missing outcomes and genetic variants. After quality control, a total of 453 subjects are available in our study.
We conduct an association study to identify genetic factors influencing the five outcomes. All the aforementioned methods are performed with the nominal level of significance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha =0.05$$\end{document} . Since the PC-based methods focus on the association test of a single marker, here we apply Bonferroni correction to adjust for multiple testing involving 16 markers ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _{\text {Bonferroni}}=0.05/16=0.0031$$\end{document} ). Four SNPs are detected by SIR method, including kgp8001324 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=2.3\times 10^{-2}$$\end{document} ), rs405509 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=5.3\times 10^{-3}$$\end{document} ), rs769449 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=1.1\times 10^{-3}$$\end{document} ), and rs445925 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=4.4\times 10^{-2}$$\end{document} ). Among them, two SNPs rs405509 and rs769449 are in the gene APOE, and rs445925 in the gene APOC1. Note that APOE and TOMM40 are well-known genes associated with AD [28]. In particular, the SNPs kgp8001324, rs405509, and rs769449 are detected by our SIR method and other comparative methods, justifying the effectiveness of the proposed method. Meanwhile, the SNP rs445925 in gene APOC1 can be detected only by the SIR method, and APOC1 gene is reported to be a genetic risk factor for dementia and cognitive impairment in the elderly and it has a significant impact on hippocampal volumes [29]. The p value of PCLC for detecting SNP kgp8001324 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=7.31\times 10^{-5}$$\end{document} ) is more significant than the SIR. As for SNP rs405509 in the gene APOE, the p value of PC5 is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$3\times 10^{-3}$$\end{document} similar to the SIR methods. The SNP rs769449 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=1.01\times 10^{-4}$$\end{document} ) in the gene APOE is also detected by PC5.Table 9. Comparison results of p value for detected SNPs by all methods using five traitsMethodNumber of detected SNPsSNPp value SIR4kgp80013242.30e−02rs4055095.30e−03rs7694491.10e−03rs4459254.40e−02PC11rs 81069223.00e−03PC54rs3948192.00e−03rs4055093.00e−03rs7694491.01e−04kgp213351033.00e−03 PCFisher2rs7694495.99e−04kgp213351035.03e−04PCLC1kgp80013247.31e−05PCMin1kgp21875748.11e−04VC1kgp80013242.00e−03WI1kgp21875744.01e−04Wald1kgp21875748.82e−04PCAQ1rs7694492.02e−04
The SNPs rs769449, rs405509, and kgp8001324 are detected by the SIR method as well as several comparative methods, which verifies the fact that these SNPs are associated with AD. In a nutshell, the SIR and PC5 methods, which detect four SNPs, perform better than other methods, but only the SIR method can detect one important SNP rs445925. In short, the SIR detects most SNPs across all cases, further confirming the advantages of the proposed method. We summarize a subset of the detected SNPs in Table 9.
Discussion
With the rapid development of next-generation sequence technologies, millions of SNPs and outcomes are usually collected in recent GWAS, and the high dimensionality of data has become a great challenge to statistical analysis. Furthermore, considering the complex correlations between multiple traits will be beneficial in revealing more latent information. In contrast to univariate analysis, multivariate analysis can exploit the correlations among phenotypes to improve power, in which a flexible framework is strongly essential for testing the association between multiple predictors and multiple outcomes.
In this paper, we proposed a novel SIR-based association test that enables the analysis of multiple traits while taking into account the similarity between one or more traits to facilitate information borrowing. First, this procedure could preserve important information about the original regression between responses \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} and predictors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} during carrying out the dimension reduction. To this end, we divided the range of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{g}$$\end{document} according to genotype similarity and estimated the genetic relatedness matrix to measure genetic similarity between individuals during dimension reduction of phenotype \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{y}$$\end{document} for the proposed method. Then, we assigned the individuals with similar genotypes to the same group, followed by conducting reduction steps, which significantly improved the computing speed. Second, several scenarios with low- and high-dimensional responses and genotypes were considered in our simulations. Our numerical studies illustrate that the powers of the SIR and SIR-S methods decrease as the genotype dimension k increases in low-dimensional phenotypes setting, where the PC-based methods exhibit comparable performances to our proposed method. In the high-dimensional phenotypes setting, we found that the direction of the effect vector has mixed direction, and the powers of proposed methods were reduced but with little effect on the PC-based methods. Finally, we conducted real-data analysis with five outcomes. Among several methods, the important SNP rs445925 in gene APOC1, which has a significant impact on hippocampal volumes, was detected only by our SIR-based method. Unlike the other methods, the SIR-based method also detected most SNPs across all cases. The analysis of ADNI data has shown that the proposed method can reveal biologically meaningful genetic markers with reasonable prediction accuracy and stability, providing suggestions for further clinical or epidemiological research. Through real-data analysis, we further confirmed that our method is more conducive to understanding the underlying genetic architecture in the multiple phenotype studies.
Note that our method cannot be applied to GWAS data in that the model (7) is not suitable to it. Although we can test each SNP one by one based on the model (8) to perform GWAS by adjusting for multiple testing theoretically, the procedure of SIR-based dimension reduction of phenotype needs to merge adjacent slices based on the genetic relatedness matrix which is estimated through the empirical correlation between two individuals. Therefore, it becomes increasingly challenging to guarantee gene similarity when there are more SNPs.
Conclusion
There are still some problems not be worked out, which will be investigated in our upcoming research. Here, we adopted the SIR-based method to estimate the central subspace, but other methods such as the sliced average variance estimation (SAVE) [30] and the directional regression (DR) [31] are also worth trying in the future. In addition, this paper only considered the case of one component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d_0 = 1$$\end{document} , but correlation analysis with multiple components can be similarly considered. We hope that the proposed methods can help in the search for genetic variants of complex diseases, and stimulate further interest and research in developing statistical methods for the analysis of next-generation sequence data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhu W Zhang H Why do we test multiple traits in genetic association studies?J Korean Stati Soc 200938111010.1016/j.jkss.2008.10.006PMC 271998519655045 · doi ↗ · pubmed ↗
- 2Liu Z Lin XA geometric perspective on the power of principal component association tests in multiple phenotype studies J Am Stat Assoc 20191145279759010.1080/01621459.2018.151336331564761 PMC 6764517 · doi ↗ · pubmed ↗
- 3Hilafu H Safo SE Haine L Sparse reduced-rank regression for integrating omics data BMC Bioinform 202021111710.1186/s 12859-020-03606-2PMC 733342132620072 · doi ↗ · pubmed ↗
- 4Maity A Sullivan PF Tzeng J-I Multivariate phenotype association analysis by marker-set kernel machine regression Genet Epidemiol 201236768669510.1002/gepi.2166322899176 PMC 3703860 · doi ↗ · pubmed ↗
- 5Broadaway KA Cutler DJ Duncan R Moore JL Ware EB Jhun MA Bielak LF Zhao W Smith JA Peyser PAA statistical approach for testing cross-phenotype effects of rare variants Am J Hum Genet 20169835254010.1016/j.ajhg.2016.01.01726942286 PMC 4800053 · doi ↗ · pubmed ↗
- 6Maier R Moser G Chen G-B Ripke S Absher D Agartz I Akil H Amin F Andreassen OA Anjorin A Joint analysis of psychiatric disorders increases accuracy of risk prediction for schizophrenia, bipolar disorder, and major depressive disorder Am J Hum Genet 20159622839410.1016/j.ajhg.2014.12.00625640677 PMC 4320268 · doi ↗ · pubmed ↗
- 7Lange C Silverman EK Xu X Weiss ST Laird NMA multivariate family-based association test using generalized estimating equations: FBAT-GEE Biostatistics 20034219520610.1093/biostatistics/4.2.19512925516 · doi ↗ · pubmed ↗
- 8Korte A Vilhjálmsson BJ Segura V Platt A Long Q Nordborg MA mixed-model approach for genome-wide association studies of correlated traits in structured populations Nat Genet 201244910667110.1038/ng.237622902788 PMC 3432668 · doi ↗ · pubmed ↗