Multi-Modal Convolutional Parameterisation Network for Guided Image Inverse Problems
Mikolaj Czerkawski, Priti Upadhyay, Christopher Davison, Robert Atkinson, Craig Michie, Ivan Andonovic, Malcolm Macdonald, Javier Cardona, Christos Tachtatzis

TL;DR
This paper introduces a new neural network method for solving image restoration tasks by combining information from multiple image types.
Contribution
The novel Multi-Modal Convolutional Parameterisation Network (MCPN) improves image inverse tasks by integrating shared and modality-specific networks.
Findings
MCPN outperforms single-mode networks in image inpainting and super-resolution tasks.
The proposed method effectively combines information from multiple image modalities.
Abstract
There are several image inverse tasks, such as inpainting or super-resolution, which can be solved using deep internal learning, a paradigm that involves employing deep neural networks to find a solution by learning from the sample itself rather than a dataset. For example, Deep Image Prior is a technique based on fitting a convolutional neural network to output the known parts of the image (such as non-inpainted regions or a low-resolution version of the image). However, this approach is not well adjusted for samples composed of multiple modalities. In some domains, such as satellite image processing, accommodating multi-modal representations could be beneficial or even essential. In this work, Multi-Modal Convolutional Parameterisation Network (MCPN) is proposed, where a convolutional neural network approximates shared information between multiple modes by combining a core shared…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1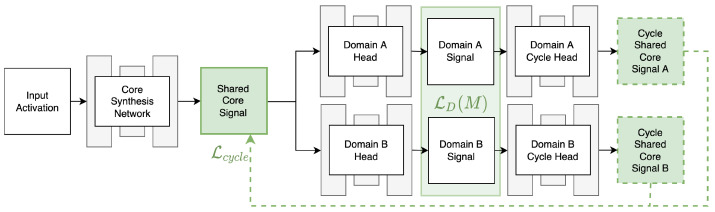 Figure 2
Figure 2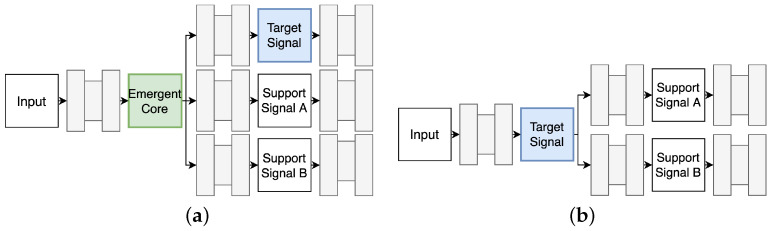 Figure 3
Figure 3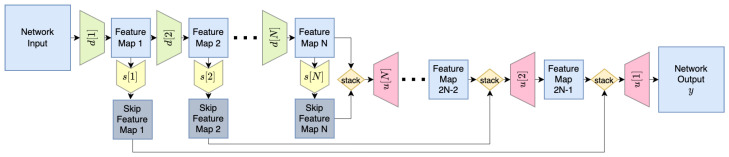 Figure 4
Figure 4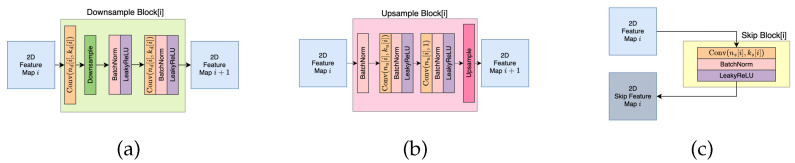 Figure 5
Figure 5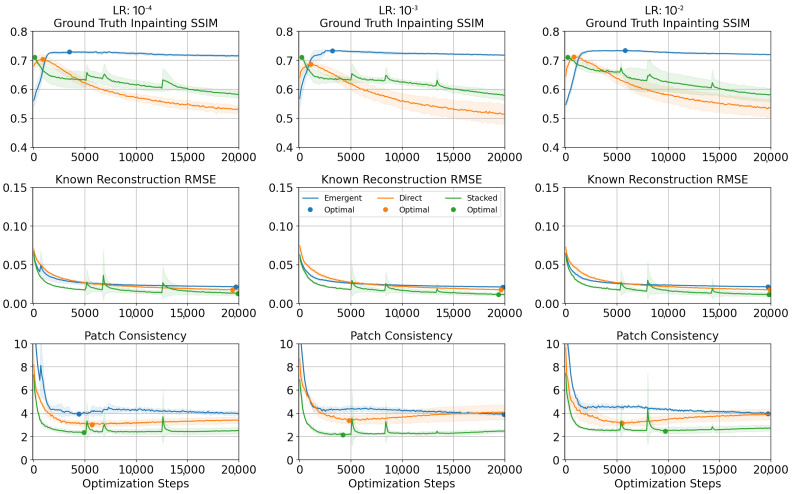 Figure 6
Figure 6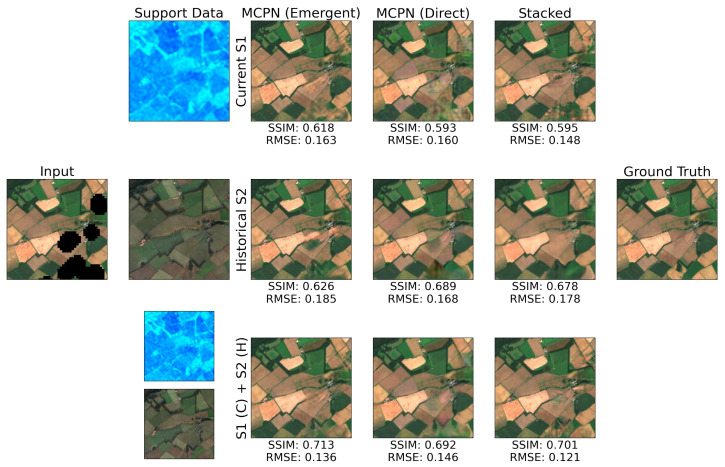 Figure 7
Figure 7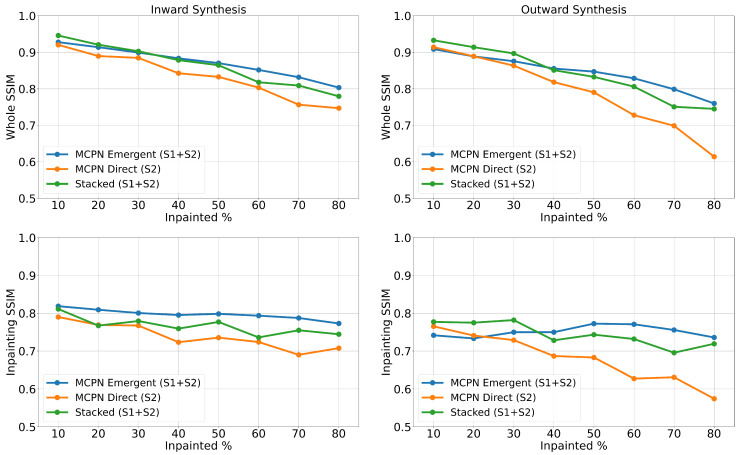 Figure 8
Figure 8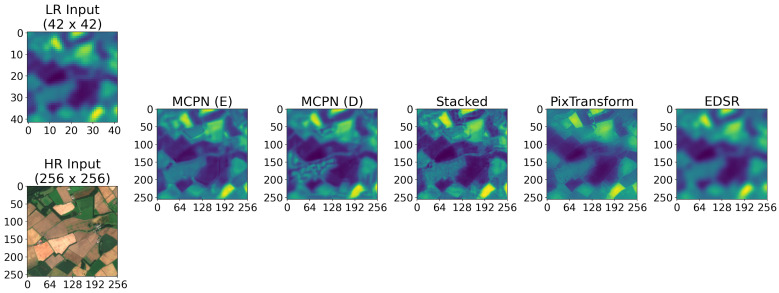 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11- —European Union Horizon 2020 Research and Innovation Programme
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Processing Techniques · Advanced Vision and Imaging · Image Processing Techniques and Applications
1. Introduction
The internal learning approach to computer vision is an alternate paradigm, where instead of learning to perform tasks based on an external set of samples, the information within the target image itself is used to solve image inverse problems such as inpainting or super-resolution. This has several benefits, but most importantly, it can reduce the effect of dataset bias and overfitting. Prior works have explored internal learning for image inverse problems [1,2], but tend to deal with single-modality data; most commonly, natural images. However, there are problems where synthesising data of spatially aligned images from multiple domains may be required. A prominent example of such a use case relates to the satellite image applications, where missing or corrupt regions in optical data can be imputed using the information from another source, such as Synthetic Aperture Radar (SAR) [3,4,5,6,7]. Similar challenges can be encountered in other domains, such as those involving image segmentation masks [8] or map-to-aerial pairs [8]. In these cases, internal learning techniques designed for a single domain are not architecturally optimised for handling multiple domains and may adapt poorly, yielding inferior performance. This motivates the technique proposed here, tailored for multi-modal image synthesis in an internal learning context.
Already mentioned above, satellite images are a good example of the potential application of multi-modal image synthesis techniques and several relevant use cases are presented in this work. The utility of satellite images for Earth observation can be significantly reduced when portions of data are missing, which is a relatively common occurrence, especially in the case of optical sensors [9]. The gaps in data can be a result of sensor malfunctions or inherent limitations, such as cloud occlusion or shadows [9]. As a consequence, there is a need for methods that can manipulate satellite images to make them usable for downstream processing. The majority of existing deep learning solutions involve training on an external dataset with the aim of generalising new samples [10,11]. In recent years, several methods based on the internal learning paradigm have been proposed for satellite image manipulation tasks [12,13,14,15,16]. In these cases, the existing information in the source image may be more important than external domain knowledge, and hence, internal learning can avoid issues associated with transferability between regions. The methods proposed in [12,13,14] apply a convolutional module that transforms one signal modality into another, hence requiring an equal number of support and synthesised samples. Alternative solutions are proposed in [15,16] that stack multi-domain images on top of each other, allowing for any quantities of support and synthesised images to be used and effectively treat them as a single representation. This may produce distorted output caused by interference between channels from disparate domains. Here, a method is proposed to alleviate these issues by learning a representation of spatially aligned signals of multiple diverging domains, capable of solving inverse tasks of inpainting and super-resolution. This is done in a fully internal learning regime (no requirement of pretraining on an external dataset) by parameterising individual domain images with a convolutional neural network architecture, hereby named Multi-modal Convolutional Parameterisation Network (MCPN). Two use case examples of MCPN are shown in Figure 1, demonstrating how information from two drastically different domains can be shared to facilitate synthesis.
To demonstrate the capabilities of the proposed framework in a wider range of domains, additional use cases for a multi-modal convolutional parameterisation network are explored. Specifically, it is demonstrated how the datasets of spatially aligned images used in pix2pix [8] can also be subject to image completion. This includes two datasets, where natural images are paired with segmentation masks, one dataset with pairs of optical satellite imagery and corresponding map representation from Google Maps, and finally, pairs of natural images taken day and night. As shown in Figure 1, simplified representations, such as segmentation masks can be used for creative purposes to manipulate images. The map abstraction from Google Maps can be used as a useful static guide for cleaning up real aerial footage, for example, when clouds are present. Finally, the night-to-day task is performed for evaluation purposes to represent two diverging natural image domains.
The remainder of the manuscript is organized as follows. The MCPN method is detailed in Section 2, including a description of hyperparameter configuration, learning rate adjustment for the internal optimization process, and methods for extracting converged weights. That is followed by the evaluation of the methods in Section 3, which primarily focuses on the processing of satellite images, including both inpainting and super-resolution, as well as the evaluation of other common multi-domain image datasets, with the aim to highlight the potential applicability of MCPN to other problems. The conclusions are drawn in Section 4.
2. Method Description
The MCPN consists of a single core network for producing a shared signal representation, as shown in Figure 2. The core synthesis network is responsible for producing a shared core signal from which all domain-specific signals can be derived. The derivation is carried out by domain-specific convolutional heads that transform the shared core signal to individual target domains. In effect, spatial information sharing between the domains is enforced by relying on the same shared core signal. Finally, a set of domain cycle heads is used to convert each domain target signal back to the shared core signal and promote consistency of inpaintings. This arrangement yields two loss terms optimised by the network, the domain-specific loss computed between the synthesised domain signals and the existing target reference, applied with an appropriate domain-specific mask M, and the cycle consistency loss computed as the difference between the shared core signal and the outputs of the cycle heads. Both losses , are computed as Mean Square Error (MSE) between the respective inputs.
The shared core signal is learned in an emergent fashion by backpropagating from the sum of individual domain-specific reconstruction losses and the cyclic terms . This variant of MCPN is referred to as Emergent Core MCPN and is further illustrated in Figure 3a. Another possibility is to use the synthesised signal of interest, such as an incomplete optical image, as the shared core representation, effectively dropping one of the domain-specific branches. Hence, is defined as a sum of a loss directly computed on the synthesised signal of interest at the output of the core network, plus the domain-specific losses, at the output of the head networks. This variant is referred to as Direct CoreMCPN, as shown in Figure 3b.
2.1. Framework Configuration
The capacities of the core network and the domain-specific heads determine how much information is contained in the shared core signal. As the capacity of the domain-specific heads decreases, the possible transforms between the shared core and individual output images are simpler. This capacity can be controlled by the number of layers, their width, and the activation functions applied to the networks. In this study, the core network is identical to the SkipNetwork employed in the Deep Image Prior [2] (illustrated in Figure 4) for the inpainting task with the configuration where = = [16, 32, 64, 128, 128, 128] (where and are the numbers of channels of the downsampling and upsampling submodules, respectively) and skip modules of four channels. The domain-specific networks are also composed of similar elements, but contain only two stages of [32, 32] channels, along with skip modules also with [32, 32]. Submodules are illustrated in Figure 5. For the Emergent variant, downsampling and upsampling operations are maintained as in the Deep Image Prior reference network. For the Direct variant, a stride of 1 is used for all layers, resulting in a preserved representation shape.
Further important factors influencing this dynamic are the size of the convolutional kernels in the domain-specific heads and the number of channels of the shared core representation. If the domain-specific kernels are set to the size of 1 × 1, then all pixels of the shared representations are processed independently, which forces the shared representation to contain a lot of information for every output pixel. If the kernel size is increased, then the local neighbourhood information is passed on to the head network, meaning that individual shared pixels do not have to contain full global context information. In this study, based on exploratory analysis, it has been found that a core representation with eight channels for the Emergent variant, and head kernel sizes of 3 × 3 provide an appropriate baseline configuration. For the Direct variant, the number of channels in the core representation is by definition equal to the number of channels in the target representation.
In the evaluation section, and for all resulting images, the configuration listed in Table 1 is used for MCPN, unless otherwise stated. Optimisation is carried out by employing an Adam optimiser with standard parameter values. The learning rate and the number of optimisation steps are determined based on the convergence discussion in Section 2.2. Furthermore, the main baseline, similar to [16], that accommodates multiple nodes by expanding output channels and stacking the multiple representations on top of each other (hence, it is referred to as ‘Stacked‘ throughout the paper) only uses the core network, without any heads, with the exact same topology as the core network of MCPN.
2.2. Convergence Detection
Comparing convolutional parameterisation architectures, the proposed MCPN variants, and the Stacked baseline [16], is challenging because they may require different learning rates to allow stable convergence and a different number of optimisation steps. Hence, setting the same learning rate and applying the same number of weight updates for all architectures may put some of the models at a disadvantage and bias the evaluation. To explore this effect, a set of experiments is carried out where the performance computed based on the known ground truth is traced for 20,000 optimisation steps. The two metrics used to measure the quality of a synthesized image with reference to a specific ground truth are Structural Similarity Index (SSIM) and Root Mean Square Error (RMSE), similar to the related work in [16] (furthermore, both whole image metrics and inpainting mask metrics are reported). There are other metrics that focus on perceptual quality assessment, such as FSIM [17], IW-SSIM [18], TReS [19], or UNIQUE [20]; however, here, the focus is on diverse domains (such as satellite images), which do not always prioritise the human subjective scoring, and hence, more agnostic metrics of RMSE and SSIM are employed similarly to the previous work on the topic [16].
In the seminal work on the Deep Image Prior [2], the output was produced using the weights obtained after applying a fixed number of optimiser steps, depending on the task. In the related work that adapts the method for satellite image inpainting [16], 4000 steps were used.
Another approach is to devise an adaptive strategy for detecting a suitable convergence state. One solution for an adaptive convergence detection is to measure the performance of the synthesis on the known, non-masked region and find a stopping criterion on that quantity, for example, RMSE between the source image and the network output in the non-masked region. However, in some scenarios, the reconstruction error of the known region could monotonically decrease or saturate without ever reaching a minimum, while the error in the inpainting could be increasing, thus yielding a poor solution.
Here, an alternative adaptive approach that takes into consideration the inpainted region is proposed. This is conducted by measuring the quality of inpainting as the similarity of texture patches between the inpainted and known region of the image, termed the patch consistency metric. The metric is computed as the Fréchet distance between the two distributions of low-level features of a pre-trained Inception network [21] in response to the inpainting region and the distribution of features from the known region, in a similar fashion to Single Image Fréchet Inception Distance (SIFID) [22]. The metric requires the computation of a feature map of the source image and a feature map of the image produced by the network. Patch representations of the known and inpainted regions can be obtained by applying the inpainting mask to the and its inverse to . Since the size of the feature maps is reduced in the layers of the Inception model, the mask M must also be reduced to apply it to the feature maps and . This is achieved by downsampling the mask M in the same manner as the features to obtain a downsampled feature mask . The feature mask equals 1.0 if and only if a given feature is affected by any pixel from the inpainting region. This way, the features extracted with the mask correspond to all features affected by the synthesised pixels, and the features extracted with the inverse mask filter out features that are only affected by the known region.
Figure 6 demonstrates how the values of the two adaptive convergence metrics and ground truth inpainting SSIM evolve over the optimisation process. The rows in order correspond to (i) ground truth inpainting SSIM, (ii) known reconstruction RMSE, and (iii) patch consistency. The three columns correspond to the tested learning rates of , , and . The traces have been obtained for four repeated runs of inpainting a single Sentinel-2 sample based on Sentinel-1 informing data. The analysis of the convergence detection methods is performed for the SAR-to-optical synthesis because it represents the most challenging scenario where the gap between domains is considerable. The inpainting mask used covers the whole image except for a border of 50 pixels around the image periphery.
The top row in Figure 6 contains the traces recording the value of the inpainting SSIM, which has been computed with reference to the ground truth. The maximum value of the trace indicates the top performance that could be achieved by each model, but extracting it requires knowledge of the ground truth not available in practice. The maximum values of inpainting SSIM tend to occur within the first 5000 steps for all three model types, regardless of the learning rate (with the exception of Emergent Core at learning rate). For the Stacked baseline (green line), this maximum value appears to be reached early in the process. This relates to the dynamics of Deep Image Prior convergence [2], where the low-frequency components are fit first before the fine detail. In effect, the low-frequency approximation at the beginning of the optimisation scores better than later solutions where high-frequency components are synthesised. The second and third rows contain the traces of the adaptive convergence detection metrics. The known region RMSE decreases monotonically (with occasional local spikes), and may be a poor choice for a proxy metric. In the third row, the patch consistency reaches minimum closer to the top performance states, but the two do not seem to align particularly well, for example, the minimum patch consistency is achieved long after the top performing SSIM for Direct and Stacked model variants.
As a supplement to Figure 6, Table 2 contains the average of extreme values of the inpainting SSIM, known region RMSE, and patch consistency for four repetitions. Furthermore, for each record, the table presents the mean and standard deviation of the number of optimisation steps after which the extreme value was reached. The Inpainting SSIM provides an indication of which learning rate results in the best performance for the tested sample. It is further apparent, that the minimised known region RMSE occurs very late in the training process and it is possible that it could keep converging further with more steps in the experiment. The patch consistency does reach a minimum value closer to the top performing Inpainting SSIM. Lastly, based on this result, the learning rate for each model has been selected, with for MCPN Emergent and for MCPN Direct and the Stacked baseline.
Using these learning rates, a broader experiment is conducted on the whole dataset of cloud-free images from Scotland (described in Section 3.1), with four repetitions on each sample, and with the same mask leaving out a 50-pixel border in the image. The average maximum inpainting SSIM that can be achieved is presented in the first column of Table 3, while the remaining columns contain the average inpainting SSIM obtained using the three convergence detection strategies (4000 steps, known region RMSE, and patch consistency). It appears that the Known Region RMSE method results in the top inpainting SSIM for the MCPN Emergent variant. This is likely to be caused by the optimisation dynamic that can be observed in the traces of Figure 6 (top row, blue lines), where the MCPN Emergent solution reaches a fairly stable plateau. This means that, on average, it may be more beneficial to train a bit longer to ensure all samples in the dataset can reach a stable plateau. The traces of the other two methods (top row, orange and green lines) do not exhibit this level of stability, as the Inpainting SSIM tends to decrease monotonically. This results in higher sensitivity in the number of optimisation steps and, in particular, the top inpainting SSIM is achieved early and consistently in fewer than 4000 steps. In contrast, the other convergence strategies prefer solutions after 4000 steps (as shown in Table 2) and they are likely to yield lower inpainting SSIM for MCPN Direct and Stacked baseline, as shown in Table 3.
Based on the above results, the rest of the experiments are conducted with the model-specific learning rates. To understand the intricacies of each synthesis method, results using all three convergence methods are obtained, and the optimal combination for each task is reported in the manuscript, while the complete records are presented in the Appendix A.
3. Evaluation
The proposed methods are evaluated on two common tasks related to remote sensing applications: (a) guided image inpainting and (b) guided super-resolution. Furthermore, to demonstrate their versatility, tests on image completion with other multi-modal image translation datasets are carried out.
3.1. Guided Satellite Image Inpainting
In this work, the inpainting capability of MCPN is evaluated on Sentinel-2 optical data (Figure 7). Although this data source is employed extensively in Earth observations, the presence of atmospheric phenomena such as clouds usually limits its potential. To inform the reconstruction of occluded regions, temporally proximate data from the Sentinel-1 can be used, which is less affected by atmospheric conditions. However, the domain shift between the optical and radar sensing modalities is large. As an alternative, historical optical data could be used to inform the synthesis process about the fine structure of the scene. This naturally relies on the assumption that the structure of the scene has not changed significantly compared to the historic data acquisition. The dataset used in [16] and created using a framework described in [23], contains pairs of temporally proximate Sentinel-1 and Sentinel-2 images for a period of 2 years and has been employed to evaluate MCPN. More specifically, the clear sky images from Scotland in the year 2020 are used as targets for the inpainting task, and the clear sky images from 2019 are averaged and used as the historical informing prior. The dataset also contains realistic masks (extracted from cloud masks for dates when clouds where present), which are applied to clear sky images to measure the quality of synthesised samples with a precise ground truth.
In the scope of this work, the main comparison made in the context of inpainting is between the conventional stacked variant used in [16] and the proposed MCPN variants (Emergent and Direct). While other recent works on satellite image inpainting have been published, such as [24,25], they do not address the same problem treated in this work, as they do not operate on multi-modal guidance data and do not solve the problem via internal learning. Furthermore, at the time of writing, the source code and weights have not been provided for these works. The image inpainting task is also currently researched in the general domain of computer vision [26,27,28]; however, these solutions are not appropriate for the same reason as they focus on a single RGB modality and are pre-trained on datasets that are not relevant for the satellite image domain.
Similar to the experiments in Section 2.2, where convergence dynamics were studied, all models are optimised for 20,000 steps in order to compare several convergence detection methods. The obtained peak SSIM performance for the inpainted region, not practically achievable without access to the ground truth, is shown in Table 4. Although this is infeasible, it provides an indication of the upper bound performance of each method.
For the challenging case where Sentinel-1 is the informing signal, the Emergent variant of MCPN offers higher inpainted SSIM, compared to the other two methods. It can be observed that the whole image SSIM is drastically lower for the Stacked compared to MCPN Emergent. This is primarily caused by the fact that the extracted images yielding the maximised SSIM for the inpainting region are often premature in the case of the Stacked approach and the MCPN direct. For the historical Sentinel-2 case, the Stacked method achieves the highest SSIM, which could be attributed to the less severe domain shift between the informing and synthesised signals. For the case of combined Sentinel-1 and Sentinel-2 informing sources, the Emergent variant results in a higher SSIM for both the inpainted region and the whole image. In terms of peak performance, the direct variant of MCPN is not as performant as the other methods, which could potentially be attributed to the bottleneck aspect of the architecture. However, as described in Section 3.2, this MCPN variant is beneficial for the image super-resolution task.
In practice, one of the convergence detection methods described in Section 2.2 must be employed; namely, a constant number of steps, patch consistency metric, or RMSE of the known pixels. It has been found that the optimisation dynamics of each synthesis method are quite different, and hence, different convergence detection techniques are appropriate. Based on the results contained and discussed in the Appendix A, the Known Region RMSE metric works best for the Emergent variant of MCPN, while the constant of 4000 steps is most beneficial for the Direct MCPN and the baseline Stacked approach. Hence, the performances resulting from these choices are contained in Table 5, indicating the quality of synthesis that can be realistically achieved.
The highest quality of inpainting (as well as reconstruction of the known region) is achieved by employing the Emergent MCPN framework for both current Sentinel-1 and historical Sentinel-2 images. Furthermore, consistent with the earlier results in [16], the introduction of historical data from the same modality brings significantly higher benefits compared to the current cross-modal Sentinel-1 representation. The domain shift between the informing and synthesised signals (as in the case of Sentinel-1) remains difficult to handle for the convolutional parameterisation models. However, the use of the MCPN scheme offers a significant improvement of inpainting quality, where the inpainting SSIM of MCPN Emergent and Direct are 0.638 and 0.601, compared to 0.576, achieved by the Stacked approach.
It is important to note that the results are expected to have a high standard deviation when compared to the global mean. The reason for this is that the difficulty of the individual image tasks varies greatly, depending on how large the masked area is and how predictable the missing content is. Naturally, for some tasks, some of the missing information is not feasible to recover when appropriate priors are absent from the informing signal. For that reason, the discussion so far has focused on the mean performance value. A potential alternative is to apply a correcting factor per sample (with a sample being a fixed image and a fixed mask shape) that accounts for its difficulty. For each sample, the mean and standard deviation of the metric value across methods indicate the difficulty of that specific inpainting task. Based on the resulting sample-specific mean and standard deviation, a z-score can be computed for each method, providing a scaled measure of the difference in performance with respect to all methods. By averaging the z-score value across all samples, a dataset-wide z-score is achieved that corrects for the varying levels of difficulty. The resulting values are shown in Table 6, where a value of +0.900 indicates that, on average, a given method results in a metric value of 0.900 standard deviations higher than the mean for that sample. Furthermore, each value is accompanied by an indicator mark that corresponds to the result of a Wilcoxon signed-rank test [29] of a hypothesis that a given metric distribution is a significant improvement (p = 0.05) with respect to the baseline Stacked approach.
The average z-score values confirm the earlier conclusions, where the Emergent Core leads to a significant performance boost for the Sentinel-1 data mode. For the historical Sentinel-2 mode, the Stacked approach appears to work best; however, for the data mode containing both Sentinel-1 and Sentinel-2, the Emergent Core MCPN exhibits a very high quality of inpainting compared to the other two methods.
To explore how the inpainting quality changes for different sizes of the synthesized region, a sweep of the mask size is conducted, where four clear-sky images from across the year are inpainted using a square mask with varying areas. Furthermore, both inward synthesis (where the synthesized region is fully surrounded by non-masked pixels) and outward synthesis (where the synthesized region is not surrounded by non-masked pixels) are explored by applying an inverse mask. The results of the sweep are shown in Figure 8, where the left column corresponds to inward synthesis, and the right column to outward synthesis. The two metrics of whole-image SSIM and inpainting SSIM are recorded for all three synthesis methods, each using the supporting data that provides the highest performance in Table 5 (S2 for MCPN Direct, and S1 + S2 for MCPN Emergent and Stacked).
The Emergent variant of MCPN (blue line) is leading significantly for all metrics if the inpainted region is 40% or more. The Direct variant of MCPN is outperformed by the Stacked method, which is consistent with the performance reported in Table 5 (0.692 Inpainting SSIM for MCPN Direct and 0.713 for Stacked).
3.2. Guided Satellite Image Super-Resolution
The multi-scale architectures can be readily adapted to perform a super-resolution task on the multi-modal representations. This can be achieved by employing a downsampling operation to the output of the target domain head and backpropagating gradients from a low-resolution source through it. Apart from this operation, the architecture of MCPN remains unchanged. Additional informing sources (such as the historical optical mean), inherently in high resolution, can be synthesised by the remaining domain heads along with the super-resolved image. This can help with producing structurally coherent upsampling. In all presented experimentation, the bilinear downsampling operation is selected. It is worth noting previous literature addressing a similar problem and commonly referring to it as guided super-resolution [30,31,32,33,34,35]. However, most of the previous works focus on the task of super-resolving a single-channel Depth image, based on a corresponding three-channel RGB image of higher resolution. This makes the application of many existing models to new problem settings difficult. Furthermore, MCPN constitutes a fully unsupervised framework, where no pretraining is carried out. This makes the PixTransform work introduced in [34] particularly appropriate as a baseline since it is also unsupervised. With minimal changes applied, to accommodate for three channels in the super-resolved image (rather than one, as in the depth image), it has been used for comparison in the conducted experiments. Furthermore, a common, externally-trained, baseline of EDSR [36] is tested as well (in this case, the low-resolution image is super-resolved without any guide image).
With this adjustment, all three synthesis methods are employed to upsample an inherently low-resolution source. Here, Band 9 Sentinel-2 with SWIR data, with a resolution of 60 metres, is super-resolved by using the current RGB bands (Bands 4, 3, and 2) with 10 m resolution as the informing signal. The results are shown in Figure 9, along with the two employed baselines of PixTransform [34] and EDSR [36]. In this case, the target upscaling factor is close to 6, and for EDSR, it is achieved by passing the image through the model with factor 2 followed by the model with factor 4. The result of these two consecutive EDSR passes yields an 8 times larger image, which is then interpolated down to 256 × 256 px resolution with a bilinear operation. Similarly, since the PixTransform tool requires the upscaling factor to be a whole integer, the image is first upsampled to 64 × 64 pixels and then supplied as the low-resolution source. In the case of MCPN, any upscaling factor can be achieved by substituting an appropriate downsampling operation into the process, making it more flexible than the compared baselines. Since a high-resolution ground truth for Band 9 of Sentinel-2 does not exist, it is challenging to compare these results beyond visual impression. The EDSR method results in a significant perceived blur while the convolutional parameterisation methods increase the fidelity of the image. The output of the Stacked baseline and the Emergent Core MCPN appears to contain more fine details propagated from the RGB image compared to the Direct Core MCPN. The PixTransform output appears to produce high-quality fine details compared to the other methods, but it also appears to yield reduced contrast in some parts of the image.
A quantitative evaluation approach is adopted here that relies on pairs of high-resolution images and their corresponding downsampled versions. The experiment has been conducted on 20 clear-sky RGB images from Scotland from the year 2020 with the supporting information of the historical average from the year 2019. In the process, each of the 20 images was subject to bilinear downsampling, which was subsequently used as the low-resolution input. The super-resolution performance achieved by each method is shown in Table 7, with the SSIM and RMSE values for three upscaling factors of 16, 8, and 4. Full results, for all convergence techniques and the ideal performance are included in Appendix A. It is shown that the MCPN Direct approach achieves superior performance for the task of super-resolution, consistently outperforming all other methods for all scaling factors. An example of the super-resolved outputs and a corresponding ground truth is shown in Figure 10, where MCPN Direct produces the highest quality output, especially for the larger factors, while MCPN Emergent introduces more artefacts to the super-resolved image since the correspondence between the two domain signals is not as constrained as in the case of the Direct Core variant. The PixTransform method appears to do well with reconstructing fine details in the scene (such as sharp region borders), but at the same time, it introduces a considerable color distortion, which ultimately leads to performance inferior to the MCPN Direct Core.
3.3. Guided Image Inpainting in Other Domains
The MCPN method can be applied to other tasks where spatially-aligned multi-modal data are available. Here, it is demonstrated how the same methods are used to perform image inpainting tasks on four common datasets that contain aligned multi-domain data: Facades, Maps, Night-to-Day, and CityScapes [8]. The task involves filling the square area in the middle of each image within a border of 50 pixels around the image periphery (this translates to about 37% of fill area for 256 × 256 px images).
The four datasets representing other types of tasks can be categorised into those containing a shallow descriptive guide, such as a segmentation mask (Facades, Maps, and CityScapes), and those containing a rich natural image guide (Night-to-Day). Depending on this aspect, a different convergence detection technique may be appropriate, and hence, the best performing one is applied on per-dataset and per-synthesis-method basis, as shown in Table 8 by indicating § as the 4000 steps technique, † as Known Region RMSE, and ‡ as Patch Consistency.
The results in Table 8 demonstrate that the MCPN variants can achieve superior performance to the Stacked baseline for all tasks (again, full results for all convergence detection methods and the ideal performance are included in Appendix A). For the datasets of Maps, Night-to-Day, and Cityscapes, the MCPN Emergent variant outperforms both other methods. For the task of inpainting Facade images based on a segmentation map, the Direct variant of MCPN exhibits higher performance than the Emergent variant. The Stacked baseline yields the lowest inpainting SSIM across all datasets, with the exception of the Night-to-Day, where it performs better than the Direct Core MCPN.
Some of the results for the above datasets are demonstrated in Figure 11. The tendency of the Stacked method to produce inpaintings inconsistent with the rest of the image is apparent, contributing to the highest errors associated with that technique. The Emergent Core MCPN produces higher structural distortions compared to the Direct Core MCPN.
4. Conclusions
The proposed method Multi-modal Convolutional Parameterisation Network (MCPN) demonstrates the capability of parameterising spatially aligned signals from multiple domains using convolutional neural network architectures. This capability enables an internal solution to several image inverse tasks, such as image completion or super-resolution. By definition, an MCPN model can readily be applied for any number of domains, and it has been shown that it can work with domain shifts as large as between image segmentation maps and corresponding natural images. The synthesis process takes in the order of several minutes on a single consumer-grade GPU and is fully unsupervised, requiring no external pretraining.
The Emergent Core variant of MCPN exhibits superior performance in the conducted experimentation for satellite image inpainting. This improvement is particularly significant for the difficult case of transferring information from the SAR source of Sentinel-1 to the optical image of Sentinel-2. Another use case for MCPN (including the direct Stacked approach) has been proposed, where an informing high-resolution image is used as a guide to super-resolve a spatially aligned low-resolution image. In this case, the MCPN Direct method exhibits the highest performance. This technique can potentially enable applications, where low-resolution remote sensing data sources are upsampled by transferring knowledge from other sensors to improve the fidelity of the observation. Finally, the evaluation contains results of image inpainting for other image datasets, where the MCPN methods provide a significant boost of the synthesis quality.
The established MCPN is a versatile tool that can facilitate internal learning of representations from disparate domains. The results indicate that this approach can significantly increase the quality of synthesis.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Gandelsman Y. Shocher A. Irani M. “Double-DIP”: Unsupervised Image Decomposition via Coupled Deep-Image-Priors Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Long Beach, CA, USA 15–20 June 2019110181102710.1109/CVPR.2019.01128 · doi ↗
- 2Ulyanov D. Vedaldi A. Lempitsky V. Deep Image Prior Int. J. Comput. Vis.20201281867188810.1007/s 11263-020-01303-4 · doi ↗
- 3Yokoya N. Grohnfeldt C. Chanussot J. Hyperspectral and Multispectral Data Fusion: A comparative review of the recent literature IEEE Geosci. Remote Sens. Mag.20175295610.1109/MGRS.2016.2637824 · doi ↗
- 4Shao Z. Cai J. Remote Sensing Image Fusion With Deep Convolutional Neural Network IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens.2018111656166910.1109/JSTARS.2018.2805923 · doi ↗
- 5Bermudez J.D. Happ P.N. Oliveira D.A. Feitosa R.Q. SAR to Optical Image Synthesis for Cloud Removal with Generative Adversarial Networks ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci.2018451110.5194/isprs-annals-IV-1-5-2018 · doi ↗
- 6Singh P. Komodakis N. Cloud-Gan: Cloud Removal for Sentinel-2 Imagery Using a Cyclic Consistent Generative Adversarial Networks Proceedings of the IGARSS 2018 IEEE International Geoscience and Remote Sensing Symposium Valencia, Spain 22–27 July 20181772177510.1109/IGARSS.2018.8519033 · doi ↗
- 7Meraner A. Ebel P. Zhu X.X. Schmitt M. Cloud removal in Sentinel-2 imagery using a deep residual neural network and SAR-optical data fusion ISPRS J. Photogramm. Remote Sens.202016633334610.1016/j.isprsjprs.2020.05.01332747852 PMC 7386944 · doi ↗ · pubmed ↗
- 8Isola P. Zhu J.Y. Zhou T. Efros A.A. Image-to-Image Translation with Conditional Adversarial Networks Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Honolulu, HI, USA 21–26 July 20175967597610.1109/CVPR.2017.632 · doi ↗