Reflections on the Intermediate Data Structure (IDS)
George Alter

TL;DR
The paper discusses the Intermediate Data Structure (IDS), a flexible format for sharing life course data that uses unfamiliar data models to handle complex life histories.
Contribution
The paper highlights IDS's novel features like the Entity-Attribute-Value model and embedded metadata, which enable cross-domain data sharing.
Findings
IDS uses the Entity-Attribute-Value model to represent complex life histories.
Embedded metadata and the Chronicle file enhance IDS's flexibility and expandability.
IDS has parallels in other scientific fields, suggesting potential for future innovations.
Abstract
The Intermediate Data Structure (IDS) encourages sharing historical life course data by storing data in a common format. To encompass the complexity of life histories, IDS relies on data structures that are unfamiliar to most social scientists. This article examines four features of IDS that make it flexible and expandable: the Entity-Attribute-Value model, the relational database model, embedded metadata, and the Chronicle file. I also consider IDS from the perspective of current discussions about sharing data across scientific domains. We can find parallels to IDS in other fields that may lead to future innovations.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
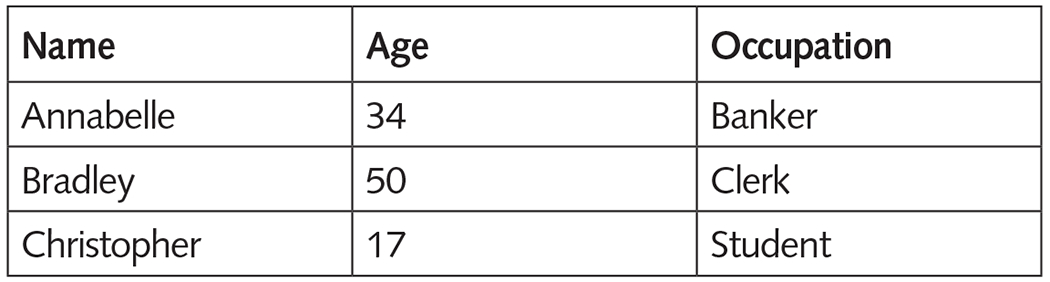 Figure 1
Figure 1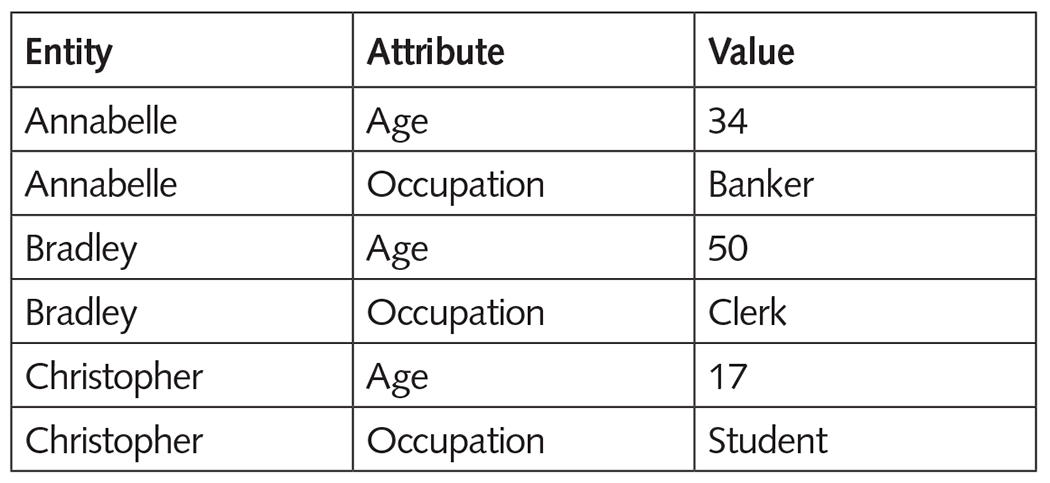 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Analysis and Archiving