LLM-Driven Policy Diffusion: Enhancing Generalization in Offline Reinforcement Learning
Hanping Zhang, Yuhong Guo

TL;DR
This paper introduces LLMDPD, a novel offline reinforcement learning approach that uses large language models and trajectory prompts to improve generalization to new tasks, outperforming existing methods.
Contribution
The paper proposes a new method combining language and trajectory prompts with diffusion models to enhance offline RL generalization to unseen tasks.
Findings
LLMDPD outperforms state-of-the-art offline RL methods on unseen tasks.
Using language and trajectory prompts improves policy generalization.
The approach effectively leverages LLMs for task understanding in RL.
Abstract
Reinforcement Learning (RL) is known for its strong decision-making capabilities and has been widely applied in various real-world scenarios. However, with the increasing availability of offline datasets and the lack of well-designed online environments from human experts, the challenge of generalization in offline RL has become more prominent. Due to the limitations of offline data, RL agents trained solely on collected experiences often struggle to generalize to new tasks or environments. To address this challenge, we propose LLM-Driven Policy Diffusion (LLMDPD), a novel approach that enhances generalization in offline RL using task-specific prompts. Our method incorporates both text-based task descriptions and trajectory prompts to guide policy learning. We leverage a large language model (LLM) to process text-based prompts, utilizing its natural language understanding and extensive…
Click any figure to enlarge with its caption.
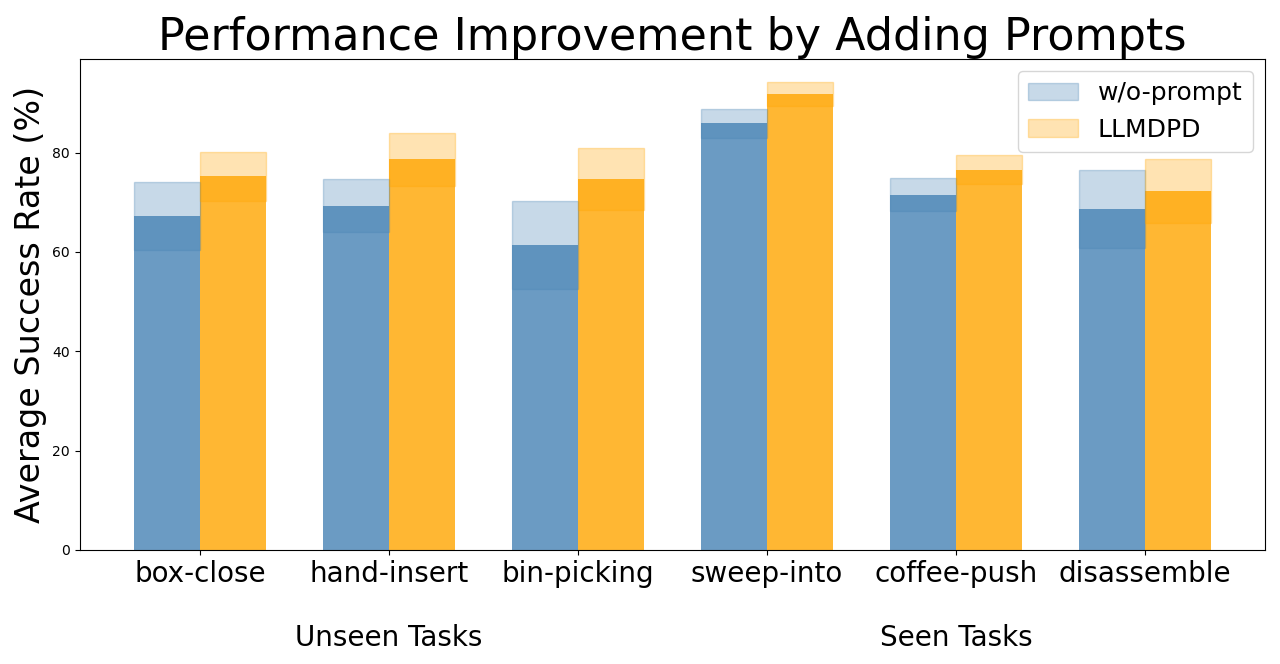 Figure 1
Figure 1 Figure 2
Figure 2| Type | Task | SAC | S4RL | RAD | MTDIFF | LLMDPD |
|---|---|---|---|---|---|---|
| Unseen | box-close | |||||
| hand-insert | ||||||
| bin-picking | ||||||
| Seen | sweep-into | |||||
| coffee-push | ||||||
| disassemble |
| Environment | PnF-Qgrad | SAORL | Diffusion-QL | OTTO | RD | ADS | LLMDPD |
|---|---|---|---|---|---|---|---|
| halfcheetah | |||||||
| hopper | |||||||
| walker2d | |||||||
| Average | 54.4 | 62.7 | 81.5 | 81.7 | 84.6 | 86.8 | 88.5 |
| Task | LLMDPD | LLMDPD-OLMo-1B | w/o-prompt | w/o- | w/o- | w/o-DP |
|---|---|---|---|---|---|---|
| box-close | ||||||
| hand-insert | ||||||
| bin-picking |
Peer Reviews
Decision·Submitted to ICLR 2026
- The paper is clear and well-structured in presenting the methodology and experiments. - The idea of using text embeddings from LLMs to provide prior knowledge for offline RL is novel and interesting.
- The paper does not provide a rigorous or unified definition of “generalization ability.” It mixes two types of generalization in Meta-RL and out-of-distribution generalization in offline RL. - The motivation for leveraging these combined modules (LLMs and Diffusion Policy) is not well justified. The paper seems to be a minor extension of Diffusion-QL with text embeddings and trajectory prompts. - This paper lacks a comprehensive comparison with existing methods in offline RL and Meta-RL. The b
1. The idea of leveraging large language models to encode task-level context for guiding offline policy learning is novel and inspiring, offering a promising direction for enhancing generalization in RL. 2. The paper is well-organized and clearly written, making it easy to follow the motivation, methodology, and experimental results.
1. The paper conflates two distinct forms of generalization: (i) out-of-distribution generalization within a single task, and (ii) generalization to unseen tasks. It remains unclear how LLMDPD addresses both types simultaneously, or whether improvements in one domain necessarily translate to the other. A clearer conceptual distinction and empirical validation of these two generalization aspects are needed. 2. The experimental setting is non-persuasive: a) The Meta-World experiments aim
* This paper introduces a conceptually clear and straightforward framework with relevant motivation. The paper writing is clear and easy to understand. * The experimental results show strong and solid advantage compared with multiple baselines, demonstrating the effectiveness of LLMDPD.
* The method is quite intuitive, and the novelty is quite marginal. Simply combining prompt encoders with policies can be quite common in this field (e.g., Prompt-DT). * Some of the evaluation tasks in the experiments are quite simple. Halfcheetah, hopper, and walker2d have relatively low dimensions in states and action spaces, making these tasks too simple to serve as a testbed to verify the effectiveness of such a proposed framework.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsReinforcement Learning in Robotics · Domain Adaptation and Few-Shot Learning · Multimodal Machine Learning Applications
LLM-Driven Policy Diffusion: Enhancing
Generalization in Offline Reinforcement Learning
Hanping Zhang, Yuhong Guo
Abstract
Reinforcement Learning (RL) is known for its strong decision-making capabilities and has been widely applied in various real-world scenarios. However, with the increasing availability of offline datasets and the lack of well-designed online environments from human experts, the challenge of generalization in offline RL has become more prominent. Due to the limitations of offline data, RL agents trained solely on collected experiences often struggle to generalize to new tasks or environments. To address this challenge, we propose LLM-Driven Policy Diffusion (LLMDPD), a novel approach that enhances generalization in offline RL using task-specific prompts. Our method incorporates both text-based task descriptions and trajectory prompts to guide policy learning. We leverage a large language model (LLM) to process text-based prompts, utilizing its natural language understanding and extensive knowledge base to provide rich task-relevant context. Simultaneously, we encode trajectory prompts using a transformer model, capturing structured behavioral patterns within the underlying transition dynamics. These prompts serve as conditional inputs to a context-aware policy-level diffusion model, enabling the RL agent to generalize effectively to unseen tasks. Our experimental results demonstrate that LLMDPD outperforms state-of-the-art offline RL methods on unseen tasks, highlighting its effectiveness in improving generalization and adaptability in diverse settings.
1 Introduction
Reinforcement Learning (RL) has emerged as a powerful paradigm for sequential decision-making and control, achieving remarkable success across a wide range of applications, from robotics (Tang et al., 2024) and autonomous driving (Lee et al., 2024) to finance (Liu et al., 2022) and healthcare (Yu et al., 2021). With the growing application of RL in real-world scenarios, the limitations of real-world RL environments have become increasingly evident—in many cases, access to either data or the environment is restricted. This highlights the importance of generalization in RL, which focuses on training RL agents on limited datasets or environments while ensuring their generalizability to unseen tasks or environments (Kirk et al., 2023), thereby reducing the need for extensive task-specific training and direct access to all possible environments. This not only enhances efficiency but also significantly reduces human effort in designing and collecting training data.
Generalization in RL however poses significant challenges, as it requires maximizing the performance of RL agents on unseen tasks or environments that were not covered in the training data. Prior research has identified several factors contributing to the generalization gap in deep RL agents, such as overfitting and memorization in deep neural networks, which can lead to poor adaptability (Arpit et al., 2017). To address these challenges, various methods have been explored, including data augmentation to enhance generalization to unseen states (Yarats et al., 2021; Raileanu et al., 2021; Zhang & Guo, 2021), generation of synthetic environments to increase training diversity (Wang et al., 2019; 2020), approaches to reduce discrepancies between different environments (Liu et al., 2020), and optimization strategies that account for environment variations (Raileanu & Fergus, 2021). However, in many real-world applications, direct access to online environments is often impractical. For example, in autonomous driving (Lee et al., 2024), training data is primarily collected from human drivers, resulting in large offline datasets rather than interactive online environments. This makes generalization in offline RL an especially important area of study. The goal is to train RL agents from offline data that can achieve strong performance while generalizing to unseen circumstances. Prior research has shown that generalization in offline RL is more challenging than in online RL (Mazoure et al., 2022; Mediratta et al., 2024), highlighting both its significance and inherent difficulties.
The main challenges of generalization in offline RL fall into two primary categories: (1) the generalization gap inherited from standard deep RL (Arpit et al., 2017), and (2) the lack of sufficient exploration data in offline RL training. Previous works have employed techniques such as data augmentation (Laskin et al., 2020; Sinha et al., 2022; Modhe et al., 2023) and adversarial training (Qiao & Yang, 2024) to address the generalization gap caused by overfitting. To improve training efficiency in offline RL—where arbitrary exploration like in online RL is not possible—researchers have sought to enhance data utilization (He et al., 2023) and mitigate the effects of out-of-distribution data, thereby improving generalization (Ma et al., 2024; Wang et al., 2024b). However, most prior work has primarily focused on reducing reliance on training data to enhance generalization. Few studies have leveraged readily available task-specific information such as text descriptions from offline data or incorporated easily collectible task-related data to enhance generalization.
In this work, we introduce LLM-Driven Policy Diffusion (LLMDPD), a novel approach to improving generalization in offline RL by leveraging task-specific prompts. We introduce two types of prompts: a text prompt, which is a textual description of the task or environment, and a trajectory prompt, which consists of a single trajectory collected from the target task or environment, both of which are easy and cheap to obtain. First, leveraging the capabilities of large language models (LLMs) in natural language processing (Qin et al., 2024) and knowledge distillation (Xu et al., 2024; Yang et al., 2024), we use a pre-trained LLM to process the text prompt, extracting useful insights from the task description while also drawing on the pre-collected knowledge embedded in the LLM. Second, we train a transformer model to process the trajectory prompt, capturing task-specific behavioral patterns from the transition dynamics of the prompt. Both prompts are encoded into latent embeddings, which serve as conditional inputs to support adaptive and context-aware policy training. We adopt policy diffusion as our policy function, which takes the state and the task-specific prompt embeddings as inputs and outputs a task-aware action distribution, enabling generalization to unseen tasks without fine-tuning. We evaluate LLMDPD on several benchmarks, and our experimental results show that LLMDPD outperforms state-of-the-art methods in offline RL generalization, demonstrating the effectiveness of our approach.
2 Related Works
Generalization in Offline RL
Generalization in RL focuses on addressing the generalization gap to enhance RL agent’s ability to perform well on unseen tasks or environments. Traditional generalization studies in RL primarily examine the generalizability of RL agents in online environments. However, with the increasing availability of large offline datasets and the lack of direct access to online environments in many real applications, present research has shifted toward a more challenging yet practical objective: improving generalization in offline RL. Mazoure et al. (2022) systematically analyzed the differences in generalization between online and offline RL, providing theoretical evidence that online RL algorithms struggle to generalize in offline settings. Mediratta et al. (2024) conducted experiments evaluating the generalization capabilities of widely used RL methods in both online and offline settings. Their results indicate that standard RL methods generalize more poorly in offline environments, reinforcing that generalization in offline RL is a more difficult problem. Laskin et al. (2020) and Sinha et al. (2022) introduced data augmentation schemes to enhance the generalization ability of offline RL agents. He et al. (2023) proposed the Multi-Task Diffusion Model (MTDIFF), which leverages knowledge from multi-task data to improve generalization in offline RL through shared information. Modhe et al. (2023) proposed an unseen state augmentation method to improve both generalization and value estimation for unseen states. Qiao & Yang (2024) introduced Soft Adversarial Offline Reinforcement Learning (SAORL), which imposes constraints on traditional adversarial examples, formulating a worst-case optimization problem to generate soft adversarial examples. Zhao et al. (2024) proposed Offline Trajectory Generalization through World Transformers for Offline Reinforcement Learning (OTTO), a method designed to learn state dynamics and reward functions, thereby enhancing generalization to unseen states. Ma et al. (2024) developed Representation Distinction (RD), a plugin method that improves offline RL generalization by detecting and preventing out-of-distribution state-action pairs. Similarly, Wang et al. (2024b) introduced Adversarial Data Splitting (ADS) to relax rigid out-of-distribution boundaries, ultimately improving generalization in offline RL.
Diffusion-based RL
Diffusion models have recently emerged as a powerful generative modeling approach for capturing complex data distributions, and their application to RL has gained traction. Diffuser (Janner et al., 2022) introduces the concept of using diffusion models to model trajectory distributions in offline RL. Several diffusion-based approaches have since extended this idea. Decision Diffuser (Ajay et al., 2022) conditions trajectory generation on high-level task information, such as rewards. PlanDiffuser (Sharan et al., 2024) integrates diffusion models with planning techniques to enhance precision in control tasks. MetaDiffuser (Ni et al., 2023) learns a contextual representation of tasks as conditional input to the diffusion model, enabling the generation of task-oriented trajectories. Similarly, Hierarchical Diffuser (Chen et al., 2024) decomposes long planning horizons into smaller segments, learning subgoals for each to improve planning efficiency. In addition to trajectory-based diffusion models, Wang et al. (2023) introduced Diffusion Policy to offline RL at the action level rather than the trajectory level, providing greater flexibility and more accurate transitions. Chi et al. (2023) further extended Diffusion Policy to broader RL scenarios, enabling effective policy learning for high-dimensional control tasks. Our proposed work is the first that exploits diffusion policy for generalization in offline RL.
Applications of LLM in RL
Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding, generating, and reasoning over text, making them powerful tools for a wide range of applications. Recently, many studies have started exploring the integration of LLMs into RL to enhance learning efficiency and decision-making. Sun et al. (2024) surveyed the application of LLMs in multi-agent RL frameworks, highlighting key advancements and future research directions. Cao et al. (2024) reviewed the existing literature on LLM-enhanced RL, summarizing advancements and challenges in the field. Du et al. (2023) introduced Exploring with LLMs (ELLM), a method that guides RL pretraining by generating prompted descriptions of the agent’s current state. Wang et al. (2024a) proposed LLM-Empowered State Representation (LESR), which leverages LLMs to generate task-relevant state representations, thereby improving the training efficiency of standard RL methods. More recently, Yan et al. (2025) treated LLMs as prior action distributions, integrating them into RL frameworks by using Bayesian inference methods to enhance the sample efficiency of traditional RL algorithms. Although LLMs have been applied across various domains of RL, their potential for improving generalization in RL remains largely unexplored. Our proposed work is the first to exploit the capacity of LLMs to enhance generalization in offline RL.
3 Method
Problem setting
In generalization learning for offline RL, we assume an offline dataset that contains data for seen tasks is given, where the training data for each task contains a collection of offline trajectory instances, paired with two additional prompts: a text prompt and a trajectory instance prompt . The text prompt provides a textual description for the corresponding task, while the trajectory prompt consists of a single trajectory collected from the given task using a behavior policy. Both prompts are easily collectible for either training or test tasks and can provide task-specific context information for the RL model, thereby supporting generalization to unseen tasks. Our goal is to learn an optimal policy from the offline dataset over multiple seen tasks such that it can generalize effectively to unseen tasks without fine-tuning, guided by the text and trajectory prompts from the target unseen tasks.
In this section, we present LLM-Driven Policy Diffusion (LLMDPD), a novel approach to enhancing generalization in offline RL. LLMDPD leverages both text and trajectory prompts for adaptive policy diffusion learning. We utilize a pre-trained large language model (LLM) and a parametric transformer as the embedding module to encode the text prompt and trajectory prompt, respectively. The resulting prompt embeddings capture task specific information and serve as conditional inputs for context-aware policy diffusion. We use diffusion Q-learning to jointly train the prompt embedding module and the policy diffusion module in an end-to-end manner, inducing prompt-based policy functions with enhanced adaptability and generalizability. The approach is elaborated below.
3.1 Prompt Embedding
3.1.1 LLM-Driven Text Prompt Embedding
The text prompt for each task consists a natural language description that provides explicit information for the corresponding task. It can be utilized to extract high-level semantic representations of the task, supporting subsequent learning.
To facilitate information extraction, we convert the text descriptions of the tasks into a structured format for expressing information of various components, including the task name, objective, constraints, and other specific attributes. An example of the structured text prompt is provided in Figure 1.
Next we utilize a pre-trained large language model (LLM), denoted as , to produce a latent prompt embedding from the structure text prompt . By harnessing LLMs’ ability to process natural language texts and leveraging knowledge distillation from their embedded prior knowledge, the latent prompt embedding is expected to encode rich task-relevant information. To enhance the efficiency of prompt interpretation, we also include a default brief instruction, e.g., “convert the following task description into a structured policy representation", to guide the LLM in processing the text prompt. Specifically, by using the structured text prompt together with the interpretation instruction as input, we obtain an embedding output by performing mean pooling to the token embeddings produced from the last hidden layer of the LLM, effectively capturing the overall context to ensure a comprehensive representation of the processed prompt. To enable adaptation to the subsequent policy learning task, we further introduce a multilayer perceptron (MLP) project head parameterized by on top of the LLM , refining the embedding output to a final embedding vector . This embedding process can be expressed using the following equation:
[TABLE]
Here the default interpretation instruction is omitted for simplicity. The parametric projection head can be trained end-to-end within the overall policy learning framework.
3.1.2 Transformer-Driven Trajectory Prompt Embedding
The trajectory instance prompt consists of a single trajectory collected from the corresponding task, represented as a sequence of state-action transitions, such as
[TABLE]
where and denote the state and action at timestep respectively, and denotes the length of the trajectory prompt. Unlike text prompts which explicitly provide task-specific descriptions, a trajectory prompt captures the transition dynamics and behavior patterns of the environment for the corresponding task. To generate informative embeddings from the trajectory prompts, we devise a parametric transformer as the encoder for the trajectory prompts, leveraging Transformer’s ability for capturing long-range dependencies in sequential data and supporting effective structural information extraction (Vaswani et al., 2017). Similar to text prompt embedding, we apply mean pooling over the transformer’s output and deploy a parametric MLP projection head on top of it. We use a function , parameterized by , to denote the overall trajectory prompt encoder that includes both the transformer and the MLP projection head. The final prompt embedding for a trajectory prompt can be produced from the encoder as follows:
[TABLE]
This transformer based encoder can be trained in an end-to-end manner through back-propagation within the policy learning framework, ensuring that the prompt embedding effectively supports the learning of a context-aware adaptive policy.
3.2 Context-Aware Conditional Policy Diffusion
To effectively leverage prompt embeddings that encode rich task-specific information to support generalizable policy learning from offline data, we propose to learn a context-aware conditional policy diffusion (CCPD) module as our policy function: , where denotes the parameters of the module. This function conditions the policy generation on task-specific contexts encoded by the text prompt embedding and trajectory prompt embedding .
The diffusion process of the CCPD module consists of two Markov Chain processes: a forward process and a reverse process. The forward process incrementally adds noise to an action sampled from offline data, transforming it into a Gaussian prior over diffusion steps. In the reverse process, starting from a Gaussian noise prior , the model progressively denoises the action at each timestep , conditioned on the given state and the corresponding prompt embeddings and . Specifically, at timestep , the next action in the sequential denoising process is generated from the following Gaussian distribution:
[TABLE]
Here, , and follows a predefined variance schedule (Ho et al., 2020); denotes a learned noise prediction network which estimates the added noise at each diffusion step, allowing the model to recover the clean action after timesteps. This CCPD module is trained together with the prompt embedding module on the offline data by minimizing a diffusion loss , defined as the mean squared error (MSE) between the true noise and the predicted noise:
[TABLE]
Given a trained policy diffusion module, the policy function is obtained by progressively denoising from a Gaussian prior, following the reverse diffusion process indicated by Eq.(4).
Incorporating Reward Maximization via Actor-Critic Policy Diffusion
Minimizing only the diffusion loss results in a behavior-cloned policy, which mimics the offline dataset without optimizing for rewards. To address this problem, we introduce a Q-function to estimate the expected cumulative reward. Specifically, we deploy the double Q-Learning strategy (Hasselt, 2010) that uses two Q-networks, and , to prevent Q-value overestimation, which are trained by minimizing the following Q-losses (Wang et al., 2023):
[TABLE]
where indicates the stopping-gradient network used for Q-value estimation, and denotes the reward observed in the trajectories of the offline dataset. The two Q-networks will converge to the same solution in the limit. We utilize the Q-values estimated by either one of the Q-networks ( or ) to guide the reverse policy diffusion process, generating actions that maximize the expected cumulative reward:
[TABLE]
To balance behavior cloning and reward maximization, the total training loss for the policy diffusion module is formulated as a weighted combination of and the negation of the reward objective :
[TABLE]
where is a hyperparameter controlling the trade-off between action denoising and reward-driven optimization. The policy diffusion module can be viewed as an actor and the Q-networks can be treated as critics. They can be simultaneously learned using the actor-critic learning strategy. The overall actor-critic diffusion training algorithm is illustrated in Algorithm 1. By combining policy diffusion with Q-learning, our LLMDPD model learns a generalizable and reward-maximizing policy, capable of adapting to unseen tasks under the guidance of task-aware prompts.
4 Experiments
To thoroughly evaluate the generalization performance of our LLMDPD method, we conducted experiments on the Meta-World dataset (Yu et al., 2020) and the D4RL dataset (Fu et al., 2020), both of which serve as benchmarks for evaluation an RL agent’s generalizability to unseen tasks.
4.1 Experiment on Meta-World
Environment
Meta-World (Yu et al., 2020) is a widely used benchmark designed for multi-task and meta-RL. It is implemented using the MuJoCo physics engine (Todorov et al., 2012), which provides a diverse set of near-realistic robotic manipulation tasks, such as picking, pushing, and reaching. A notable subvariant, Multi-Task 50 (MT50), consists of 50 robotic manipulation tasks well-suited for offline data collection, with each task accompanied by a detailed description. Among these 50 tasks, 45 are designated as training tasks, while the remaining 5 serve as unseen test tasks to evaluate an RL agent’s generalizability to novel tasks. With its pre-collected offline data and comprehensive task descriptions, Meta-World serves as an ideal testbed for our LLMDPD method.
Comparison Methods
We compare our LLMDPD method against four baselines on the Meta-World benchmark: SAC, S4RL, RAD, and MTDIFF. SAC (Haarnoja et al., 2018) is an off-policy actor-critic RL algorithm used to collect the offline dataset in Meta-World, serving as a fundamental baseline. RAD (Laskin et al., 2020) applies data augmentation in the state space, enhancing generalization, particularly for image-based observations. S4RL (Sinha et al., 2022) extends this idea by integrating advanced state-space augmentation techniques to improve generalization in offline RL. MTDIFF (He et al., 2023) is a diffusion-based multi-task RL method that facilitates implicit knowledge sharing across tasks, enabling better adaptation to unseen tasks.
Implementation Details
For offline data collection in Meta-World tasks, we follow the same criteria as (He et al., 2023), using SAC (Haarnoja et al., 2018) to pre-collect 40M timesteps of offline data. Our model adopts the same transformer architecture as MTDIFF (He et al., 2023) and learns policy diffusion based on the Diffusion-QL framework (Wang et al., 2023). We use the formal text descriptions from Meta-World (Yu et al., 2020) as text prompts and employ the same trained SAC agent to generate trajectory prompts. We primarily use Llama3-7B (Dubey et al., 2024) as our base LLM, with 3-layer MLP projection heads applied to both the LLM and transformer outputs. The RL agent is trained on three seen tasks: sweep-into, coffee-push, and disassemble, and its generalization performance is evaluated on three unseen tasks: box-close, hand-insert, and bin-picking.
Experimental Results
The experimental results for Meta-World tasks are presented in Table 1. We evaluate the generalization ability of our LLMDPD method on three unseen tasks while using its performance on seen tasks to evaluate its overall sample efficiency during training. The results show that LLMDPD significantly outperforms all other methods on the three unseen tasks. Notably, on the bin-picking task, LLMDPD achieves an 18.92 improvement in average success rate compared to the previous best method, MTDIFF. Similarly, it shows an improvement of 7.84 on box-close and 2.45 on hand-insert, demonstrating strong generalization capabilities, even when compared to state-of-the-art data augmentation methods.
On seen tasks, our LLMDPD method achieves strong results, outperforming all other methods on coffee-push and disassemble tasks. This demonstrates that LLMDPD not only exhibits strong generalization on unseen tasks but also efficiently learns from training on seen tasks. However, on the sweep-into task, our method falls slightly behind MTDIFF. This may be because text descriptions primarily enhance performance on complicated tasks, while offering limited gains on simpler tasks.
4.2 Experiment on D4RL
Environment
D4RL (Fu et al., 2020) is a benchmark dataset for offline RL, aiming to simulate real-world applications. Its locomotion suite, built on the MuJoCo physics engine (Todorov et al., 2012), includes pre-collected offline datasets at three expertise levels: medium-replay, medium, and medium-expert. D4RL is widely used to evaluate an offline RL agent’s generalization ability, as its datasets do not fully cover all possible state-action pairs. Among them, medium-replay consists of all samples collected during training until the policy reaches the medium level. Lacking a clean and optimal behavior policy, it is well-suited for evaluating an RL agent’s generalization capability.
Comparison Methods
We evaluate six comparison methods on the D4RL dataset: PnF-Qgrad, SAORL, Diffusion-QL, OTTO, ADS, and RD. PnF-Qgrad (Modhe et al., 2023) augments unseen states to fine-tune hyperparameters for existing offline RL methods, and we use its COMBO variant, referred to as PnF-Qgrad. SAORL (Qiao & Yang, 2024) enhances generalization by learning soft adversarial examples, while Diffusion-QL (Wang et al., 2023) trains a diffusion policy to maximize offline RL performance. OTTO (Zhao et al., 2024) leverages World Transformers to simulate high-reward trajectories for improved generalization, and we adopt its best variant, CQL+OTTO, referred to as OTTO. ADS (Wang et al., 2024b) splits data and generates adversarially hard examples to enhance generalization, and we use its best variant, MCQ+ADS, referred to as ADS. Finally, RD (Ma et al., 2024) improves generalization by differentiating in-sample and OOD state-action pairs, and we adopt its best variant, TD3-N-UNC+RD, referred to as RD. These methods provide a strong benchmark for evaluating our approach against state-of-the-art offline RL generalization techniques.
Implementation Details
We adopt the model architecture discussed in the previous section. The text prompt consists of task descriptions derived from the base MuJoCo environments (Todorov et al., 2012), along with detailed representations of action and state observations, the reward function, initial state, and termination conditions. The RL agent is trained on the pre-collected D4RL offline datasets of HalfCheetah, Hopper, and Walker2D at the medium-replay expertise level.
Experimental Results
The experimental results on the D4RL dataset are presented in Table 2. We evaluate the ability of the offline RL agent to generalize to unseen states and actions compared to the medium-replay offline datasets. The results show that LLMDPD achieves the highest overall performance based on average normalized scores. It also attains the best normalized scores in the Hopper and Walker2D environments, while in HalfCheetah, it performs comparably to the best method, ADS. These results demonstrate that LLMDPD not only generalizes to unseen tasks but also exhibits strong sample efficiency in training on offline datasets and adapting to unseen state observations not covered in the offline data.
4.3 Ablation Study
We conducted an ablation study on six variants of our model across three unseen tasks: (1) ‘LLMDPD’, our full model, which includes all components; (2) ‘LLMDPD-OLMo-1B’, which replaces the base LLM with OLMo-1B (Groeneveld et al., 2024) for processing text prompt embeddings; (3) ‘w/o-prompt’, which removes both text and trajectory prompts; (4) ‘w/o-’, which excludes only the text prompt; (5) ‘w/o-’, which excludes only the trajectory prompt; and (6) ‘w/o-DP’, which replaces the policy’s diffusion model with a standard trajectory-based diffusion model. This study systematically evaluates each component’s contribution to overall performance.
The results of the ablation study are presented in Table 3. The full model, ‘LLMDPD’, achieves the highest performance across all three tasks. Removing any component results in a performance drop, demonstrating the effectiveness of each part of our method. Replacing the base LLM with a smaller model in ‘LLMDPD-OLMo-1B’ leads to a decline in performance on all three tasks, indicating that larger models provide more detailed guidance to the policy by leveraging natural language processing and pre-collected knowledge. However, this variant still maintains strong generalization performance. Excluding both the text and trajectory prompts (‘w/o-prompt’) causes a significant performance drop, highlighting the importance of prompting in our method. The ‘w/o-prompt’ variant, which removes only the text prompt, results in an even more severe decline, particularly on hand-insert and bin-picking tasks. This suggests that without explicit textual guidance, the RL agent struggles to generalize to complex unseen tasks. Similarly, the ‘w/o-’ variant, which removes the trajectory prompt, exhibits degraded performance, demonstrating its role in helping the agent capture transition behaviors in unseen tasks. Additionally, ‘w/o-DP’, which replaces the policy diffusion model with a standard trajectory-based diffusion model, also experiences a significant performance drop. This demonstrates the importance of policy diffusion in reducing overfitting to seen offline data. Overall, the ablation results highlight the contribution of each component to LLMDPD’s performance, with prompts playing a particularly crucial role in achieving optimal generalization.
We provide a visualization of the performance improvement achieved by incorporating both text and trajectory prompts into our model, as shown in Figure 2. This figure illustrates the impact of prompts on the model’s performance across six tasks, with three unseen tasks (left) and three seen tasks (right). Across all tasks, the inclusion of prompts consistently enhances the average success rate, with the orange bars (LLMDPD) outperforming the blue bars (‘w/o-prompt’). Notably, incorporating prompts leads to a greater improvement in the three unseen tasks compared to the seen tasks, demonstrating better generalization performance beyond training on the existing offline dataset. Additionally, the inclusion of prompts slightly reduces the standard deviation, indicating more stable training on the offline dataset and improved consistency in performance. These findings suggest that prompt-driven learning not only boosts success rates but also contributes to more reliable and robust decision-making. Overall, these results highlight the crucial role of prompt-driven guidance in enhancing task understanding, execution, and generalization in offline RL.
5 Conclusion
In this work, we propose LLM-Driven Policy Diffusion (LLMDPD), a novel approach to enhancing generalization in offline RL through task-specific prompts. LLMDPD utilizes both easily collectible text-based task descriptions and single trajectory instances as prompts to guide policy learning. To provide rich task-relevant context, LLMDPD leverages LLMs to encode text-based prompts while using a transformer model to encode trajectory prompts. These prompts serve as conditional inputs to a context-aware policy diffusion module, enabling the RL agent to generalize effectively to unseen tasks. By integrating policy diffusion with Q-learning, LLMDPD employs an actor-critic diffusion algorithm to learn a generalizable, reward-maximizing policy. Experimental results on benchmark tasks show that LLMDPD outperforms state-of-the-art offline RL methods in terms of generalization, demonstrating its effectiveness in improving generalizability and adaptability.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ajay et al. (2022) Anurag Ajay, Yilun Du, Abhi Gupta, Joshua Tenenbaum, Tommi Jaakkola, and Pulkit Agrawal. Is conditional generative modeling all you need for decision-making? ar Xiv preprint ar Xiv:2211.15657 , 2022.
- 2Arpit et al. (2017) Devansh Arpit, Stanisław Jastrzębski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, et al. A closer look at memorization in deep networks. In International Conference on Machine Learning (ICML) , 2017.
- 3Cao et al. (2024) Yuji Cao, Huan Zhao, Yuheng Cheng, Ting Shu, Yue Chen, Guolong Liu, Gaoqi Liang, Junhua Zhao, Jinyue Yan, and Yun Li. Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods. IEEE Transactions on Neural Networks and Learning Systems , 2024.
- 4Chen et al. (2024) Chang Chen, Fei Deng, Kenji Kawaguchi, Caglar Gulcehre, and Sungjin Ahn. Simple hierarchical planning with diffusion. In The Twelfth International Conference on Learning Representations (ICLR) , 2024.
- 5Chi et al. (2023) Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research , pp. 02783649241273668, 2023.
- 6Du et al. (2023) Yuqing Du, Olivia Watkins, Zihan Wang, Cédric Colas, Trevor Darrell, Pieter Abbeel, Abhishek Gupta, and Jacob Andreas. Guiding pretraining in reinforcement learning with large language models. In International Conference on Machine Learning , 2023.
- 7Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. ar Xiv preprint ar Xiv:2407.21783 , 2024.
- 8Fu et al. (2020) Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D 4rl: Datasets for deep data-driven reinforcement learning. ar Xiv preprint ar Xiv:2004.07219 , 2020.