LUT-Fuse: Towards Extremely Fast Infrared and Visible Image Fusion via Distillation to Learnable Look-Up Tables
Xunpeng Yi, Yibing Zhang, Xinyu Xiang, Qinglong Yan, Han Xu, Jiayi Ma

TL;DR
LUT-Fuse introduces a novel, extremely fast infrared and visible image fusion method using learnable lookup tables and distillation, achieving high speed and performance suitable for real-time applications on low-power devices.
Contribution
The paper presents a new LUT-based fusion model with a distillation strategy, significantly improving speed and efficiency over existing methods for multi-modal image fusion.
Findings
Requires less than one-tenth of the time of state-of-the-art algorithms
Achieves high operational speed on low-power devices
Demonstrates superior fusion performance and stability
Abstract
Current advanced research on infrared and visible image fusion primarily focuses on improving fusion performance, often neglecting the applicability on real-time fusion devices. In this paper, we propose a novel approach that towards extremely fast fusion via distillation to learnable lookup tables specifically designed for image fusion, termed as LUT-Fuse. Firstly, we develop a look-up table structure that utilizing low-order approximation encoding and high-level joint contextual scene encoding, which is well-suited for multi-modal fusion. Moreover, given the lack of ground truth in multi-modal image fusion, we naturally proposed the efficient LUT distillation strategy instead of traditional quantization LUT methods. By integrating the performance of the multi-modal fusion network (MM-Net) into the MM-LUT model, our method achieves significant breakthroughs in efficiency and…
Click any figure to enlarge with its caption.
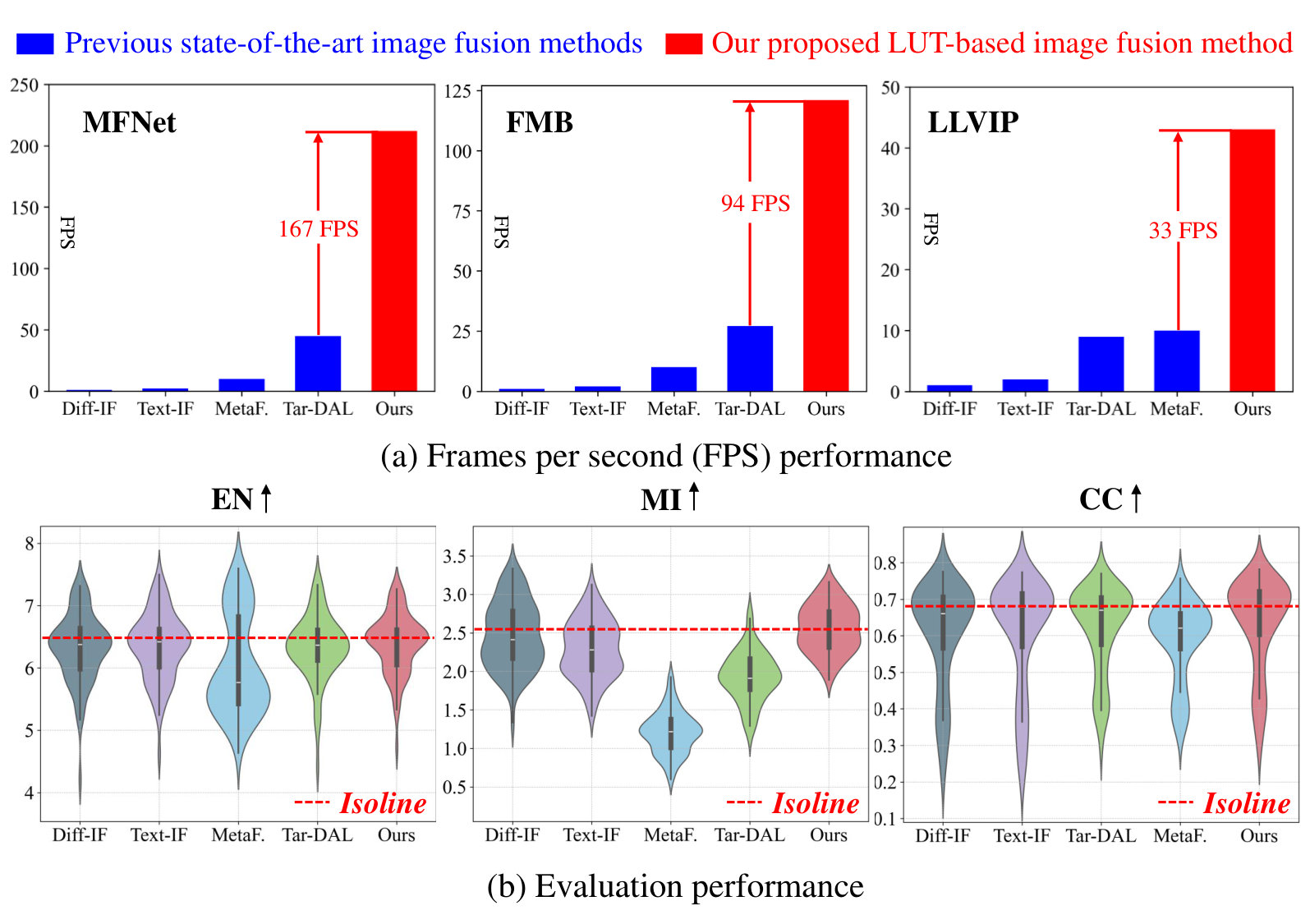 Figure 1
Figure 1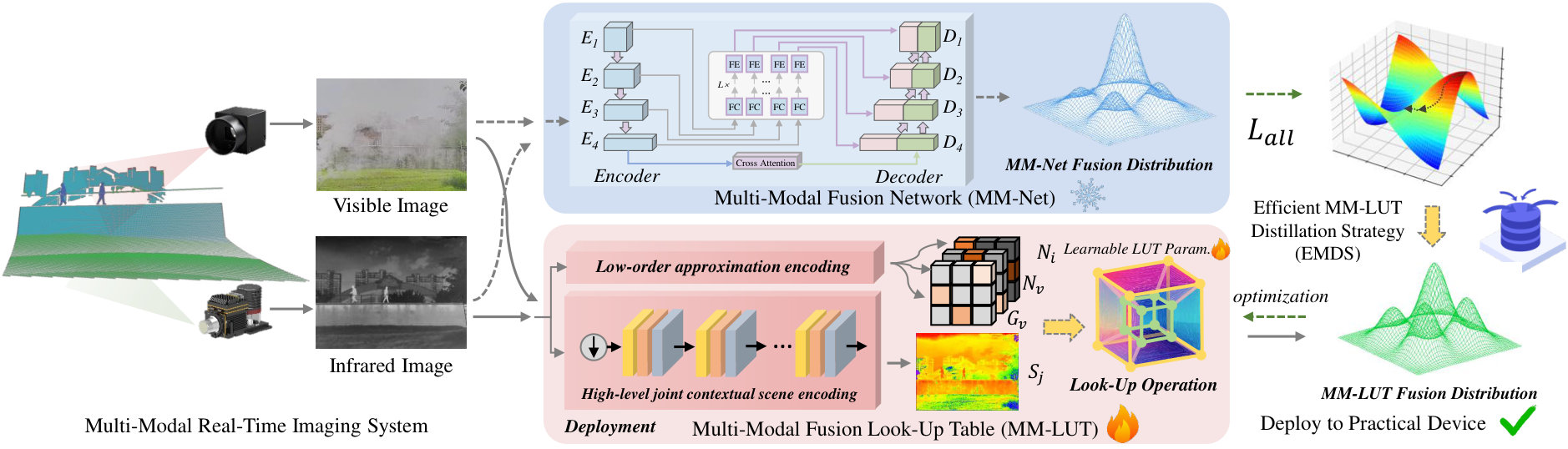 Figure 2
Figure 2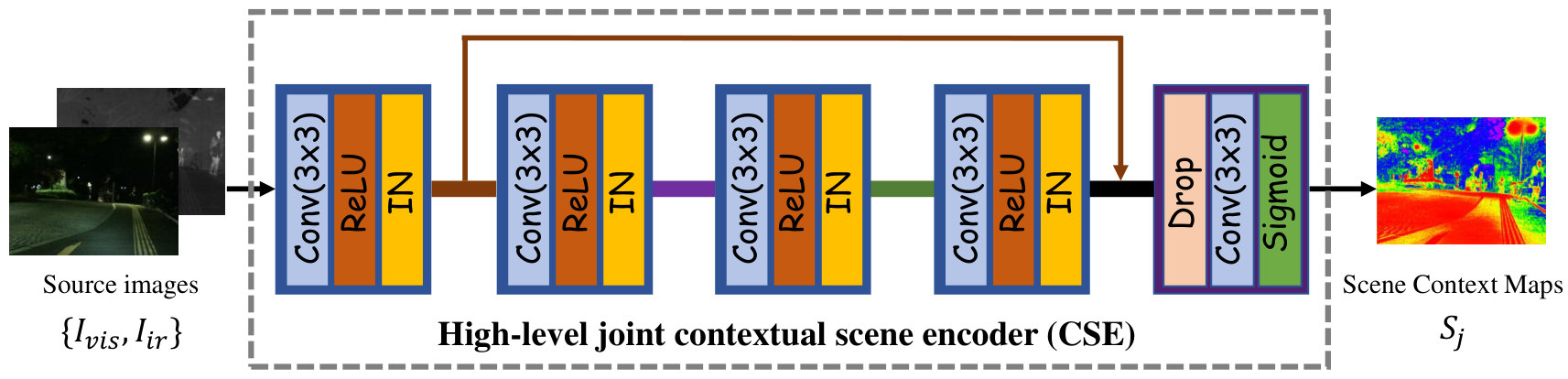 Figure 3
Figure 3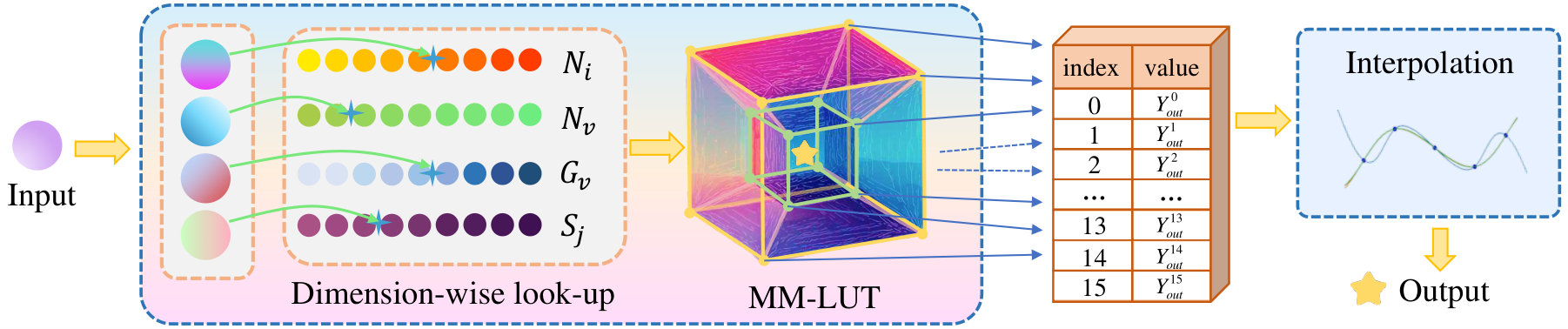 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9| Methods | MFNet Dataset | FMB Dataset | LLVIP Dataset | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MI | EN | CC | SSIM | MI | EN | CC | SSIM | MI | EN | CC | SSIM | ||||
| SDNet | 1.325 | 5.827 | 0.592 | 0.861 | 0.456 | 2.285 | 6.617 | 0.580 | 0.926 | 0.540 | 1.535 | 6.965 | 0.692 | 0.831 | 0.527 |
| U2Fusion | 1.426 | 5.185 | 0.618 | 0.650 | 0.349 | 1.983 | 6.410 | 0.579 | 0.987 | 0.556 | 1.329 | 6.807 | 0.715 | 0.839 | 0.483 |
| Tar-DAL | 1.942 | 6.337 | 0.623 | 0.838 | 0.452 | 2.190 | 6.472 | 0.540 | 0.897 | 0.415 | 1.953 | 7.411 | 0.696 | 0.790 | 0.388 |
| MetaFusion | 1.214 | 6.049 | 0.592 | 0.672 | 0.401 | 1.617 | 6.654 | 0.547 | 0.594 | 0.412 | 1.022 | 7.401 | 0.667 | 0.673 | 0.301 |
| LRRNet | 1.632 | 5.458 | 0.554 | 0.548 | 0.464 | 2.163 | 6.281 | 0.552 | 0.767 | 0.534 | 1.451 | 6.611 | 0.674 | 0.831 | 0.427 |
| Diff-IF | 2.432 | 6.323 | 0.611 | 0.891 | 0.688 | 2.745 | 6.623 | 0.507 | 0.963 | 0.639 | 2.185 | 7.455 | 0.702 | 0.904 | 0.598 |
| EMMA | 2.540 | 6.353 | 0.617 | 0.908 | 0.601 | 2.725 | 6.520 | 0.527 | 0.914 | 0.630 | 2.137 | 7.441 | 0.716 | 0.934 | 0.603 |
| CDDFuse | 2.172 | 6.309 | 0.610 | 0.973 | 0.626 | 2.710 | 6.651 | 0.557 | 0.988 | 0.657 | 2.305 | 7.495 | 0.711 | 0.927 | 0.618 |
| Text-IF | 2.346 | 6.381 | 0.614 | 0.941 | 0.683 | 2.645 | 6.503 | 0.528 | 0.932 | 0.651 | 1.905 | 7.536 | 0.704 | 0.910 | 0.651 |
| LUT-Fuse (ours) | 2.560 | 6.394 | 0.619 | 0.966 | 0.628 | 2.999 | 6.662 | 0.507 | 0.906 | 0.613 | 2.446 | 7.545 | 0.719 | 0.892 | 0.597 |
| LUT-Fuse (MM-Net) | 2.764 | 6.425 | 0.615 | 0.971 | 0.706 | 3.014 | 6.671 | 0.588 | 0.927 | 0.643 | 2.502 | 7.581 | 0.705 | 0.946 | 0.746 |
| Methods | Unlabel | Car | Person | Bike | Curve | Car Stop | Guard. | Cone | Bump | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|
| SDNet | 98.05 | 86.99 | 72.83 | 62.22 | 43.45 | 18.53 | 3.95 | 50.37 | 55.94 | 54.70 |
| U2Fusion | 97.94 | 85.81 | 71.28 | 62.62 | 37.16 | 31.56 | 7.05 | 44.10 | 53.84 | 54.59 |
| Tar-DAL | 97.97 | 85.85 | 70.88 | 61.95 | 38.87 | 28.83 | 6.40 | 43.85 | 45.08 | 53.30 |
| MetaFusion | 97.91 | 85.75 | 68.61 | 62.33 | 36.01 | 29.35 | 6.44 | 49.61 | 42.33 | 53.15 |
| LRRNet | 98.02 | 86.43 | 71.78 | 62.92 | 39.20 | 30.39 | 8.56 | 44.63 | 49.48 | 54.60 |
| Diff-IF | 97.94 | 84.63 | 71.55 | 61.90 | 41.74 | 18.83 | 4.81 | 50.07 | 47.42 | 53.21 |
| EMMA | 98.04 | 87.30 | 72.28 | 62.37 | 44.35 | 30.40 | 6.91 | 44.44 | 45.88 | 54.66 |
| CDDFuse | 98.05 | 86.33 | 72.32 | 61.34 | 41.94 | 21.37 | 3.20 | 49.15 | 48.08 | 53.53 |
| Text-IF | 98.02 | 86.31 | 72.45 | 62.57 | 43.11 | 30.54 | 3.30 | 51.51 | 50.12 | 55.32 |
| LUT-Fuse (ours) | 98.02 | 85.81 | 70.96 | 60.56 | 43.80 | 27.20 | 7.16 | 49.95 | 49.90 | 54.82 |
| LAE | CSE | EMDS | MI | EN | CC | SSIM | |
|---|---|---|---|---|---|---|---|
| ✓ | ✓ | 1.812 | 6.574 | 0.491 | 0.533 | 0.407 | |
| ✓ | ✓ | 1.747 | 6.445 | 0.508 | 0.553 | 0.404 | |
| ✓ | ✓ | 2.552 | 6.381 | 0.571 | 0.904 | 0.566 | |
| ✓ | ✓ | ✓ | 2.560 | 6.394 | 0.619 | 0.966 | 0.628 |
| Methods | Type | MI | EN | CC | SSIM | |
|---|---|---|---|---|---|---|
| Tar-DAL | quanti. | 1.236 | 4.995 | 0.408 | 0.476 | 0.306 |
| dist.(Ours) | 1.713 | 6.017 | 0.585 | 0.745 | 0.363 | |
| MetaFusion | quanti. | 1.127 | 5.355 | 0.468 | 0.559 | 0.354 |
| dist.(Ours) | 1.152 | 5.817 | 0.553 | 0.636 | 0.375 | |
| LRRNet | quanti. | 1.174 | 4.698 | 0.405 | 0.298 | 0.265 |
| dist.(Ours) | 1.542 | 5.301 | 0.547 | 0.473 | 0.401 | |
| Diff-IF | quanti. | 2.001 | 5.251 | 0.568 | 0.513 | 0.202 |
| dist.(Ours) | 2.251 | 6.313 | 0.602 | 0.817 | 0.625 | |
| EMMA | quanti. | 1.903 | 6.219 | 0.518 | 0.725 | 0.513 |
| dist.(Ours) | 2.374 | 6.275 | 0.593 | 0.815 | 0.552 | |
| CDDFuse | quanti. | 1.733 | 5.125 | 0.513 | 0.553 | 0.478 |
| dist.(Ours) | 2.087 | 6.128 | 0.595 | 0.857 | 0.568 |
| Methods | MFNet | FMB | LLVIP | Real Time |
|---|---|---|---|---|
| Time/ms | Time/ms | Time/ms | ||
| SDNet | 35.41 8.23 | 40.14 7.78 | 72.04 7.99 | |
| U2Fusion | 64.24 1.21 | 98.50 0.51 | 268.67 2.85 | ✗ |
| Tar-DAL | 21.83 0.34 | 36.08 0.36 | 102.93 1.07 | |
| MetaFusion | 96.51 1.20 | 97.43 1.80 | 98.19 2.34 | ✗ |
| LRRNet | 314.85 3.79 | 505.37 4.28 | 1357.12 5.50 | ✗ |
| Diff-IF | 1723.05 16.86 | 2818.82 24.52 | 8800.50 51.09 | ✗ |
| EMMA | 126.18 8.91 | 163.58 6.54 | 493.61 24.09 | ✗ |
| CDDFuse | 641.13 5.62 | 1045.06 10.47 | 2791.07 27.47 | ✗ |
| Text-IF | 522.38 2.55 | 826.96 10.28 | 2491.64 36.10 | ✗ |
| Ours | 4.70 0.70 | 8.20 1.80 | 23.20 0.90 | ✓ |
| Methods | 480P (640 480) | 720P (1280 720) | ||
|---|---|---|---|---|
| Time/ms | Real Time | Time/ms | Real Time | |
| SDNet | 126.50 2.86 | ✗ | 376.66 4.00 | ✗ |
| U2Fusion | 249.23 3.27 | ✗ | 778.42 45.33 | ✗ |
| Tar-DAL | 114.21 3.15 | ✗ | 389.34 40.08 | ✗ |
| MetaFusion | 484.41 4.32 | ✗ | 1542.38 27.04 | ✗ |
| LRRNet | 1368.37 9.59 | ✗ | 3988.30 99.85 | ✗ |
| Diff-IF | 8200.11 398.25 | ✗ | 29447.30 2372.92 | ✗ |
| EMMA | 459.61 17.14 | ✗ | 2127.95 43.99 | ✗ |
| CDDFuse | 2630.50 48.64 | ✗ | 8209.51 170.11 | ✗ |
| Text-IF | 2894.27 239.80 | ✗ | 7750.53 24.56 | ✗ |
| Ours | 18.23 1.62 | ✓ | 30.54 2.22 | ✓ |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image Fusion Techniques · Image Enhancement Techniques · Visual Attention and Saliency Detection
LUT-Fuse: Towards Extremely Fast Infrared and Visible Image Fusion via Distillation to Learnable Look-Up Tables
Xunpeng Yi1,∗, Yibing Zhang1,∗, Xinyu Xiang1, Qinglong Yan1, Han Xu2, Jiayi Ma1,†
1Electronic Information School, Wuhan University, Wuhan 430072, China
2School of Automation, Southeast University, Nanjing 210096, China
{yixunpeng, zhangyibing, xiangxinyu, qinglong_yan}@whu.edu.cn,
[email protected], [email protected]
Abstract
Current advanced research on infrared and visible image fusion primarily focuses on improving fusion performance, often neglecting the applicability on real-time fusion devices. In this paper, we propose a novel approach that towards extremely fast fusion via distillation to learnable lookup tables specifically designed for image fusion, termed as LUT-Fuse. Firstly, we develop a look-up table structure that utilizing low-order approximation encoding and high-level joint contextual scene encoding, which is well-suited for multi-modal fusion. Moreover, given the lack of ground truth in multi-modal image fusion, we naturally proposed the efficient LUT distillation strategy instead of traditional quantization LUT methods. By integrating the performance of the multi-modal fusion network (MM-Net) into the MM-LUT model, our method achieves significant breakthroughs in efficiency and performance. It typically requires less than one-tenth of the time compared to the current lightweight SOTA fusion algorithms, ensuring high operational speed across various scenarios, even in low-power mobile devices. Extensive experiments validate the superiority, reliability, and stability of our fusion approach. The code is available at https://github.com/zyb5/LUT-Fuse.
††footnotetext:
† Corresponding author.
∗ These authors contributed equally to this work.
1 Introduction
Image fusion represents a critical research area within the domain of digital image processing [10, 25, 37, 3, 19, 16]. Single-modal imaging systems are inherently limited in their ability to capture complete scene information, resulting in constrained information representation. In contrast, multi-modal imaging systems, by integrating complementary data sources, achieve more comprehensive scene characterization [28, 23, 11]. A prominent example of multi-modal image fusion is infrared and visible image fusion (IVIF). Visible images offer detailed reflection-based visual information, while infrared images provide thermal radiation information reflecting temperature variations in the scene [12, 13, 4]. This synergistic utilization of multiple modalities has significant applications across various fields, including industrial inspection systems, autonomous vehicle navigation, and military night vision technologies.
The application-specific requirements of multi-modal image fusion tasks necessitate the simultaneous achievement of high computational efficiency and superior fusion performance across diverse operational scenarios [30]. This dual requirement stems from two fundamental constraints: the computational limitations inherent in deployed devices and the downstream task performance demands of practical fusion applications. In recent years, there has been a surge in the development of advanced architectural frameworks, particularly Transformer-based [34, 27] and diffusion-based models [26, 35], specifically designed to improve fusion performance. These innovative approaches have achieved remarkable breakthroughs, consistently demonstrating superior performance across diverse application scenarios. However, a critical limitation in current research is that these studies predominantly focus on fusion performance metrics while significantly overlooking real-time processing considerations. Notably, the majority of these proposed methods fail to achieve real-time operational efficiency, even when implemented on state-of-the-art GPU hardware platforms. Even though some methods claim to achieve real-time operation, they primarily rely on the design of lightweight structures [30, 9, 31]. Moreover, their real-time operation scenarios are strictly limited, achieving only quasi-real-time performance in partial scenarios. Therefore, addressing real-time challenges in IVIF tasks has become an imperative research priority.
Look-up tables (LUTs) represent a widely adopted technology in data storage systems, enabling rapid retrieval of corresponding outputs through high-speed query mechanisms [14, 29]. This characteristic offers a promising solution for addressing computational efficiency challenges in image fusion tasks. Nevertheless, the direct transformation of fusion tasks into lookup-based operations faces two fundamental limitations: (1) The inherent absence of ground truth in fusion tasks prevents explicit deployment of LUT-based solutions. (2) Conventional quantization non-learnable approaches yield LUTs [6] with limited generalization capability and suboptimal fusion performance.
To address these issues, we propose a novel approach focusing on extremely fast fusion via distillation to learnable look-up tables designed for image fusion, termed as LUT-Fuse. Firstly, leveraging the low-order approximation and learnable scene relationships, we develop a comprehensive framework of MM-LUT, comprising zeroth-order and first-order components and the learnable scene context component, specifically designed to generate representative fusion look-up elements. Secondly, given the absence of ground truth in MMIF tasks, the proposed approach naturally incorporates fusion performance through an efficient MM-LUT distillation paradigm, effectively transferring the multi-modal fusion network (MM-Net) prior capabilities to MM-LUT. Also, the proposed LUT-Fuse employs the learnable MM-LUT designed for image fusion as the student model, enabling ultra-efficient fusion during inference. Consequently, LUT-Fuse successfully achieves a dual optimization, simultaneously delivering both real-time processing capability and superior fusion performance, as in Fig. 1.
Overall, our contributions can be summarized as follows:
- •
Towards extremely fast infrared and visible image fusion, we propose the learnable multi-modal fusion look-up tables, which contains low-order approximation encoding, and high-level joint contextual scene encoding as the look-up elements. These properties closely related to fusion can ensure the effectiveness of look-up tables.
- •
Given the inherent absence of ground truth in multi-modal image fusion tasks, we adopt the efficient MM-LUT distillation paradigm as a natural solution. This effectively transfers the superior fusion capabilities from the multi-modal fusion network to MM-LUT model. Through iterative optimization via gradient descent, MM-LUT is refined to achieve optimal fusion performance while maintaining extremely high efficiency.
- •
To the best of our knowledge, this is the first time that efficient distillation and learnable look-up tables have been used in multi-modal image fusion, achieving real-time performance even on low-power mobile devices. It requires only about one-tenth of the computational time of most lightweight fusion algorithms while maintaining competitive performance.
2 Related Work
2.1 Advanced Deep Learning-based Methods
Image fusion has made significant progress since the development of deep learning. In the initial developmental phase, auto-encoder-based architectures [7, 1] dominated the field, typically undergoing pre-training on extensive image datasets before implementing fusion through carefully crafted, manually designed strategies. Subsequently, end-to-end trainable fusion networks utilizing Convolutional Neural Networks are proposed [7, 22]. U2Fusion [24] implements densely connected network combined with lifelong learning mechanisms to accomplish unified image fusion across diverse scenarios. To further improve the performance, the Transformer-based and diffusion-based methods are introduced. CDDFuse [34] employs a Transformer-based architecture integrated with invertible neural network methodologies. Moreover, Diff-IF [26] accomplishes high-quality multi-modal image fusion by leveraging generative diffusion models. Furthermore, substantial advancements have been achieved in semantic-aware and degradation-robust image fusion methodologies, demonstrating superior fusion performance across various challenging scenarios. Text-IF [27] utilizes text-based modulation mechanisms, integrated with high-quality restored images, to accomplish degradation-aware fusion. Despite their impressive outcomes, these methods fail to satisfy the stringent real-time fusion demands required by most practical applications.
2.2 Real-Time Deep Learning-based Methods
Considering the efficiency limitations of computing platforms, some fusion methods for real-time operation have been proposed. However, the majority of these approaches rely primarily on the development of lightweight network to achieve their goals. In the early time, IFCNN [32] uses several stacked convolutional layers to achieve various image fusions and is one of the representative algorithms for high-speed fusion in deep learning. Subsequently, SDNet [30] achieves fast fusion through squeeze-and-decomposition and dual-branch lightweight convolutional layers. Similarly, Tar-DAL [9] utilizes concatenation operation and compact generator architectures to achieve fusion. Recently, APWNet [31] has employed lightweight-optimized convolutional layers as its core fusion architecture, complemented by task-specific guidance from downstream applications to enhance performance.
These lightweight methods exhibit quasi-real-time performance in limited scenarios but struggle to sustain consistent real-time efficacy across diverse environments. The evolution of imaging technologies has intensified demands for high-resolution image fusion, driving the development of universally adaptable real-time solutions.
3 Methodology
In this section, we initially present the comprehensive workflow of our proposed methodology, as illustrated in Fig. 2. Subsequently, we provide a detailed exposition of the developed learnable multi-modal fusion look-up table and efficient MM-LUT distillation. The section concludes with a thorough specification of loss functions.
3.1 Overall Structure
Leveraging the characteristics of infrared and visible image fusion tasks, we have developed an innovative multi-modal fusion look-up table (MM-LUT) architecture, which can integrate fusion capabilities from existing pre-trained multi-modal fusion networks (MM-Net). MM-LUT employs low-order approximation techniques and high-level contextual scene encoding to construct a comprehensive representation for look-up elements. Furthermore, it implements an optimization approach for MM-LUT, effectively replacing the conventional quantization approach. Given inherent absence of ground truth in MMIF, our MM-LUT distillation solution emerges as a particularly natural methodological choice, effectively addressing this fundamental limitation.
3.2 Multi-Modal Fusion Look-Up Table
MM-LUT architecture is systematically decomposed into two complementary components: low-order approximation and learnable higher-level joint contextual scene encoding, which collectively address diverse information aggregation requirements in multi-modal image fusion applications.
**Low-Order Approximation Encoding (LAE). ** Inspired by the approximation principles of Taylor expansion, we decompose multi-modal image fusion into distinct hierarchical levels, each corresponding to different orders of fusion operations. Given the inherent perceptual bias towards low-order signal variations, our method emphasizes the utilization of zeroth-order and first-order components.
In the infrared and visible image fusion task, infrared images primarily contribute zeroth-order information, specifically intensity, denoted as , which effectively represents salient thermal radiation objects. Visible images offer both comprehensive spectral intensity characteristics and detailed texture patterns. To optimize computational efficiency, we strategically approximate these low-order features as zeroth-order (intensity) and first-order (gradient) information components, denoted as and . is the first order derivative operator.
**High-Level Joint Contextual Scene Encoding (CSE). ** Although low-order information can be acquired with minimal computational overhead, it suffers from inherent representational limitations. To mitigate this constraint without compromising computing efficiency, we introduce a learnable high-level joint contextual scene encoder , expressed as:
[TABLE]
This adaptive encoding intelligently extracts look-up elements via optimized learning strategies, thereby enhancing performance. In detailed, it consists of five convolutional blocks with the kernel size of , as illustrated in Fig. 3.
**Multi-Modal Look-Up Operation. ** To optimize the efficiency of system integration, we have implemented a strategy that transforms large-scale computational tasks into look-up table operations, as in Fig. 4. Building upon the establishment of low-order approximation encoding and high-level joint contextual scene encoding, we further developed a LUT (towards , , and , ) for multi-modal image fusion:
[TABLE]
where denotes output fusion image. is the look-up operation in the MM-LUT.
They store the fusion mapping relationships in the form of a four-dimensional lattice, where each point position is determined by a quadruple . To be detailed, the quadruple is computed by the following equations:
[TABLE]
where is a hyper-parameter, denoting the max value of look-up elements divided by the setting bins. Subsequently, we applied the floor function to the positional parameters of this quadruple:
[TABLE]
where represents the floor function. Due to the discrete nature of LUT, cubic spline interpolation is required for processing. In other words, in the MM-LUT, the intermediate values between discrete points are obtained through interpolation from the surrounding points:
[TABLE]
[TABLE]
where , , , and are weighted parameters. . are four-dimensional lookup elements.
3.3 Efficient MM-LUT Distillation Strategy
Efficient Distillation. Different from the mainstream quantized LUT approaches employed for the acceleration, our MM-LUT incorporates trainable parameters to improve the performance. Given the absence of ground truth in multi-modal image fusion, we naturally propose leveraging distillation techniques to integrate fusion capabilities from the MM-Net .
Therefore, besides incorporating the trainable high-level joint contextual scene encoder to improve the performance, MM-LUT is also parameterized all internal components of the LUTs as learnable parameters, thereby circumventing the accuracy degradation and performance limitations inherent in quantization-based methods. In this way, the proposed collaborative distillation methods transform traditional quantization strategy into optimization strategy. It can be expressed as:
[TABLE]
where denotes the fusion network. represents the MM-LUT.
Optimizing MM-LUT Strategy. From this perspective, MM-LUT is conceptualized as learnable parameters that undergo optimization and refinement during the distillation. We have established a distillation loss function to regulate it, thereby enabling effective training of the MM-LUT:
[TABLE]
where denotes the step size for each update iteration. Considering the smoothness and monotonicity that LUTs should have, it is essential to incorporate constraints as regularization terms during the optimization to ensure stability. Ultimately, we get a compact and efficient MM-LUT that is readily deployable for extremely fast multi-modal fusion applications.
3.4 Loss Functions
The MM-Net serves as the foundation for achieving fundamental performance. We have employed the loss functions following the methodology outlined in [27], thereby ensuring state-of-the-art fusion outcomes.
Regarding the efficient fusion LUT distillation, we primarily employ three loss terms, including the intensity distillation loss, structural similarity distillation loss, and two LUT-specific regularization terms, namely smoothness regularization and monotonicity regularization.
Intensity Distillation Loss. To ensure that fusion outcomes of LUT-Fuse exhibit intensity values comparable to those of the advanced teacher network, we employ an intensity loss function as a constraint. It is defined as:
[TABLE]
Structural Similarity Distillation Loss. In order to enforce structural consistency between the fusion results of LUT-Fuse and the teacher network outputs, we apply structural similarity constraints, thereby enhancing both structural coherence and scene consistency in the fused results:
[TABLE]
Smooth Regularization. Non-smooth LUTs may induce abrupt fusion output variations between adjacent look-up indices, thereby compromising the robustness of the look-up table and potentially introducing artifacts in fusion outcomes. To address this issue, smoothness regularization incorporates an L2-norm regularization term to ensure local smoothness of the LUT elements. It can be expressed as:
[TABLE]
Monotonicity Regularization. Monotonic transformations preserve relative intensity consistency, thereby ensuring a more natural appearance in the fusion results. Furthermore, in practical training scenarios, the available data may not adequately cover the entire look-up space. Consequently, enforcing monotonicity enhances the generalization capability of the learned LUTs:
[TABLE]
Therefore, the overall loss functions for LUT-Fuse can be expressed as:
[TABLE]
where , , and are the hyper parameters.
4 Experiment
4.1 Implementation Details and Datasets
Implementation Details. For the LUT-Fuse consists MM-Net and MM-LUT, we first train the MM-Net as the same settings of [27]. MM-Net can adopt any advanced MMIF network. We utilize a novel fusion network, with details provided in the supplementary material. For MM-LUT, the learning rate is with the AdamW optimizer. And the batch size is set to 8. The source images are cropped to . The set of hyper-parameters is , , , and . The LUT-Fuse is trained for 500 epochs. Our training experiments were conducted on GeForce RTX 3090 GPU with PyTorch framework [15]. Considering practical deployment scenarios with power constraints, we evaluated performance on the GeForce RTX 4060 Ti and NVIDIA Jetson Orin NX edge platform to assess mobile deployment feasibility.
Datasets. To validate the effectiveness of our proposed LUT-Fuse, we conducted comprehensive evaluations on publicly available infrared and visible image fusion datasets, including MFNet [2], FMB [10], and LLVIP [5]. The MFNet, FMB, and LLVIP datasets feature resolutions of 640480, 800600, and 12801024, respectively. For our experiments, we utilized a total of 784 image pairs for training, while employing 150 images from MFNet, 100 from FMB, and 100 from LLVIP for testing purposes.
Metric. We employ the metrics including the mutual information (MI) [17], information entropy (EN) [18], correlation coefficient (CC), structural similarity index measure (SSIM) [20], and quality of gradient-based fusion () [12]. Higher values of MI, EN, CC, SSIM, and indicate higher quality of the fusion image.
SOTA Competitors. We compare LUT-Fuse with several state-of-the-art methods on multiple datasets. The methods for comparison include SDNet [30], U2Fusion [24], Tar-DAL [9], MetaFusion [33], LRRNet [8], Diff-IF[26], EMMA [36], CDDFuse [34], and Text-IF [27].
4.2 Qualitative Experiments
The qualitative results on multiple datasets are reported in Fig. 5. SDNet, U2Fusion, LRRNet poorly preserving thermal information and visible textures, could not obtain effective scene representation. Tar-DAL excels in infrared target object but fails in texture preservation, notably losing wheel details in the fourth row. CDDFuse, EMMA, and Text-IF achieve relatively good fusion results in most scenes, they fall behind LUT-Fuse in preserving human thermal radiation, as demonstrated in the first row. Overall, LUT-Fuse achieves remarkably competitive results in terms of highlighting thermal objects and clear visible texture while requiring only a fraction (around one-tenth) of the computational time compared to compared methods.
4.3 Quantitative Experiments
The quantitative results on multiple datasets are reported in Tab. 1. Our proposed LUT-Fuse demonstrates comprehensively optimal fusion performance compared with state-of-the-art fusion methods in terms of MFNet, FMB, and LLVIP datasets. In terms of MI and EN, it outperforms the comparative methods. In terms of CC, SSIM, and , it also gets competitive results. This demonstrates that LUT-Fuse maintains excellent quantitative performance while achieving exceptionally high computational speed.
4.4 Performance on High-Level Task
To verify the performance in downstream high-level vision tasks, we conduct semantic segmentation and object detection experiments on MFNet and LLVIP, respectively.
Semantic Segmentation. SegFormer [21] is adopted as the backbone in the semantic segmentation task. Qualitative and quantitative results are reported in Fig. 6 and Tab. 3. In Fig. 6, our method demonstrates optimal segmentation performance for both pedestrians and bicycles, while also showing highly competitive results in guardrail and car segmentation. In Tab. 3, our method achieves the second-best performance, with only a marginal gap compared to Text-IF. This demonstrates that our approach maintains excellent semantic preservation capabilities while requiring minimal computational overhead.
Object Detection. We employ YOLOv5111https://github.com/ultralytics/yolov5 as the object detection network and train it on the LLVIP dataset. Qualitative and quantitative experimental results are shown in Fig. 7 and Tab. 3. In Fig. 7, particularly in scenarios where other methods suffer from missed detections, our method shows superior detection performance. In Tab. 3, LUT-Fuse also exhibits comprehensively optimal semantic detection performance, demonstrating its robustness representation.
4.5 Ablation Experiments
To verify the effectiveness of the proposed module, we conduct ablation experiments on MFNet dataset. It includes the ablation of Low-order approximation encoding (LAE), high-level joint contextual scene encoding (CSE), and efficient MM-LUT distillation strategy (EMDS). Qualitative and quantitative results are presented in Fig. 8 and Tab. 4.
In Fig. 8, it reveals that the removal of any individual module significantly degrades the fusion performance, demonstrating the essential contribution of each component to the overall system functionality. Also, our full model achieves the best quantitative fusion metrics, as clearly demonstrated in Tab. 4.
4.6 Extended Experiments
Quantization vs. Distillation MM-LUT. Our proposed LUT-accelerated MMIF strategy demonstrates broad applicability across various fusion backbones. Although non-learnable quantization LUT methods, currently the mainstream approach [6], can do this to some extent by simulating input data and directly storing the network model output in LUTs. However, this strategy inevitably leads to reduced LUT precision and poor generalization capabilities. In contrast, our proposed learnable LUT framework leverages efficient LUT distillation to directly optimize the look-up table parameters, achieving superior performance. We conduct a series of experiments in SOTA methods. Both qualitative and quantitative results are presented in Fig. 9 and Tab. 5.
As indicated in residual maps of Fig. 9, our proposed distillation MM-LUT presents lower error compared to quantization solutions. In Tab. 5, our method achieves significant metric improvements across almost all experimental evaluations, demonstrating its better performance.
4.7 Running Time & Deployment Experiments
In practical applications, real-time performance is crucial for algorithm usability. The primary advantage of LUT-Fuse lies in its exceptional computational speed combined with competitive fusion quality. We validate this from two perspectives: PC and mobile/edge device platforms.
PC Platform. In the NVIDIA GeForce RTX 4060 Ti platform, as shown in Tab. 6, even methods specifically designed for real-time fusion can achieve only quasi-real-time performance in limited scenarios. This indicates that most existing methods struggle to meet real-time requirements even when deployed on high-performance computing platforms like GeForce RTX 4060 Ti with a power consumption of 165W, highlighting significant limitations in their practical applicability to real-world scenarios. Our proposed LUT-Fuse stands as the only method achieving real-time, and even super-real-time performance across all datasets.
Mobile Device Platform. In the NVIDIA Jetson Orin NX platform, as reported in Tab. 7, all comparative methods, including existing approaches specifically designed for real-time fusion, fail to achieve real-time performance on mobile processing devices. By contrast, our LUT-Fuse maintains real-time performance, which is the only one that can achieve this, demonstrating its adaptability to various practical applications. Compared with the current state-of-the-art lightweight methods (such as Tar-DAL in 720P), LUT-Fuse typically requires only about one-tenth of their computational time. Therefore, the ability to maintain real-time processing speeds on edge and mobile devices stands as a particularly distinctive feature of LUT-Fuse.
5 Conclusion
In this paper, we proposed a novel LUT framework towards extremely fast infrared and visible image fusion, termed as LUT-Fuse, which is the first application of LUTs in multi-modal image fusion to the best of our knowledge. It consists of a learnable LUT that is equipped with low-order approximation encoding and high-level joint contextual scene encoding, which is well-suited for multi-modal fusion. Given the lack of ground truth in MMIF, we naturally propose the efficient MM-LUT distillation strategy instead of traditional quantization LUT methods. It requires only around typically one-tenth of the time compared to current SOTA fusion algorithms, ensuring real-time performance even in low-power mobile devices. Extensive experiments validate the superiority, reliability, and stability of our proposed approach. In future research, our method shows strong potential for various fusion tasks, paving the way for advances in real-time image fusion.
Acknowledgments
This work was supported by NSFC (62276192).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Duffhauss et al. [2022] Fabian Duffhauss, Ngo Anh Vien, Hanna Ziesche, and Gerhard Neumann. Fusionvae: A deep hierarchical variational autoencoder for rgb image fusion. In European Conference on Computer Vision , pages 674–691. Springer, 2022.
- 2Ha et al. [2017] Qishen Ha, Kohei Watanabe, Takumi Karasawa, Yoshitaka Ushiku, and Tatsuya Harada. Mfnet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 5108–5115. IEEE, 2017.
- 3He et al. [2023] Chunming He, Kai Li, Guoxia Xu, Yulun Zhang, Runze Hu, Zhenhua Guo, and Xiu Li. Degradation-resistant unfolding network for heterogeneous image fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 12611–12621, 2023.
- 4Huang et al. [2022] Zhanbo Huang, Jinyuan Liu, Xin Fan, Risheng Liu, Wei Zhong, and Zhongxuan Luo. Reconet: Recurrent correction network for fast and efficient multi-modality image fusion. In Proceedings of the European Conference on Computer Vision (ECCV) , pages 539–555, 2022.
- 5Jia et al. [2021] Xinyu Jia, Chuang Zhu, Minzhen Li, Wenqi Tang, and Wenli Zhou. Llvip: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages 3496–3504, 2021.
- 6Jiang et al. [2023] Ting Jiang, Chuan Wang, Xinpeng Li, Ru Li, Haoqiang Fan, and Shuaicheng Liu. Meflut: Unsupervised 1d lookup tables for multi-exposure image fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 10542–10551, 2023.
- 7Li and Wu [2018] Hui Li and Xiao-Jun Wu. Densefuse: A fusion approach to infrared and visible images. IEEE Transactions on Image Processing , 28(5):2614–2623, 2018.
- 8Li et al. [2023] Hui Li, Tianyang Xu, Xiao-Jun Wu, Jiwen Lu, and Josef Kittler. Lrrnet: A novel representation learning guided fusion network for infrared and visible images. IEEE Transactions on Pattern Analysis and Machine Intelligence , 45(9):11040–11052, 2023.