Access Paths for Efficient Ordering with Large Language Models
Fuheng Zhao, Jiayue Chen, Yiming Pan, Tahseen Rabbani, Sohaib, Divyakant Agrawal, Amr El Abbadi, Paritosh Aggarwal, Anupam Datta, Dimitris Tsirogiannis

TL;DR
This paper introduces the LLM ORDER BY operator, explores its implementations, and develops a dynamic optimizer that improves sorting efficiency and accuracy in large language model systems.
Contribution
It proposes new semantic sorting algorithms, analyzes their performance, and presents a budget-aware optimizer for selecting optimal access paths in LLM-based sorting.
Findings
No single implementation is universally optimal across datasets.
A test-time scaling relationship exists between sorting cost and ordering quality.
The optimizer achieves ranking accuracy comparable or superior to static methods.
Abstract
In this work, we present the \texttt{LLM ORDER BY} semantic operator as a logical abstraction and conduct a systematic study of its physical implementations. First, we propose several improvements to existing semantic sorting algorithms and introduce a semantic-aware external merge sort algorithm. Our extensive evaluation reveals that no single implementation offers universal optimality on all datasets. From our evaluations, we observe a general test-time scaling relationship between sorting cost and the ordering quality for comparison-based algorithms. Building on these insights, we design a budget-aware optimizer that utilizes heuristic rules, LLM-as-Judge evaluation, and consensus aggregation to dynamically select the near-optimal access path for LLM ORDER BY. In our extensive evaluations, our optimizer consistently achieves ranking accuracy on par with or superior to the best static…
Click any figure to enlarge with its caption.
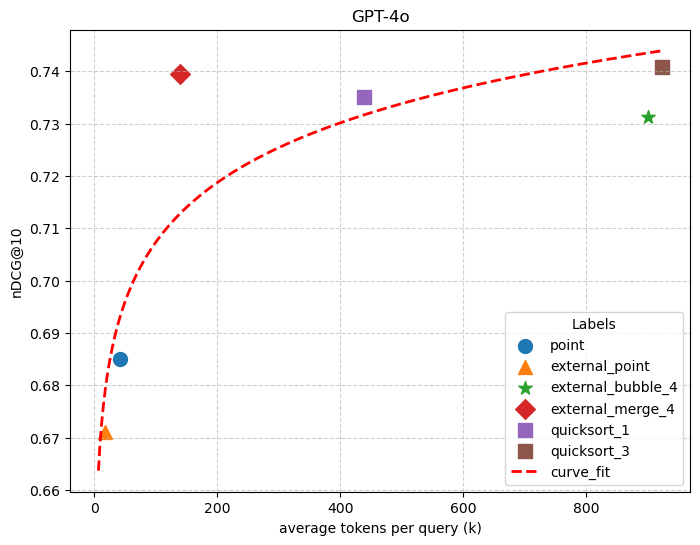 Figure 1
Figure 1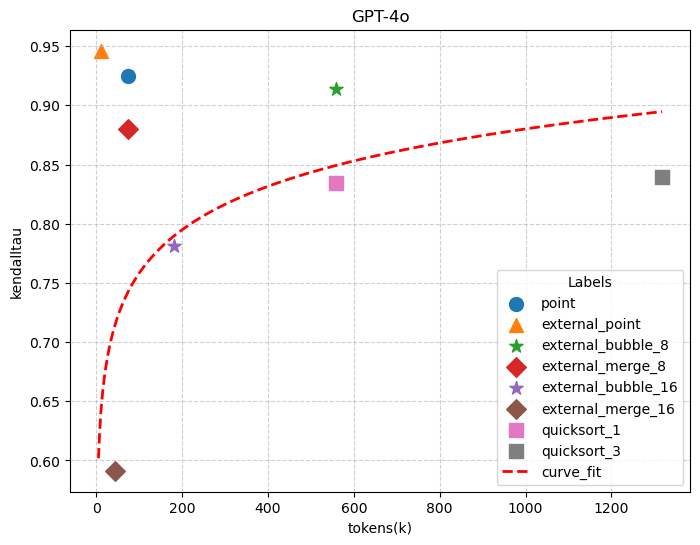 Figure 2
Figure 2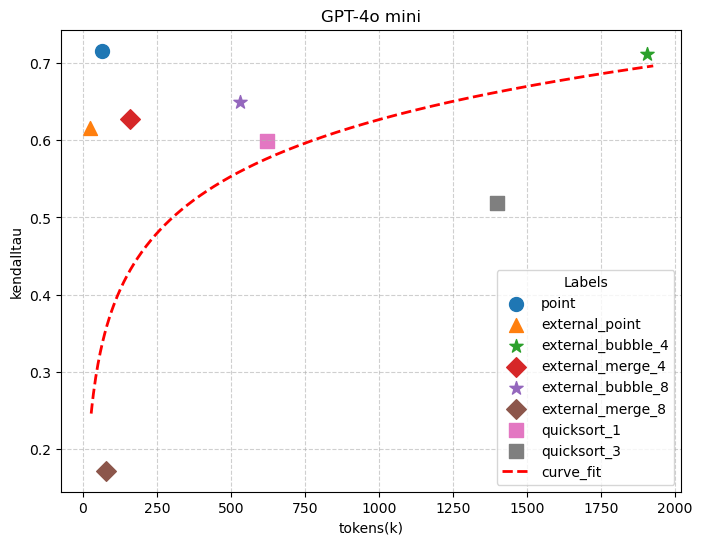 Figure 3
Figure 3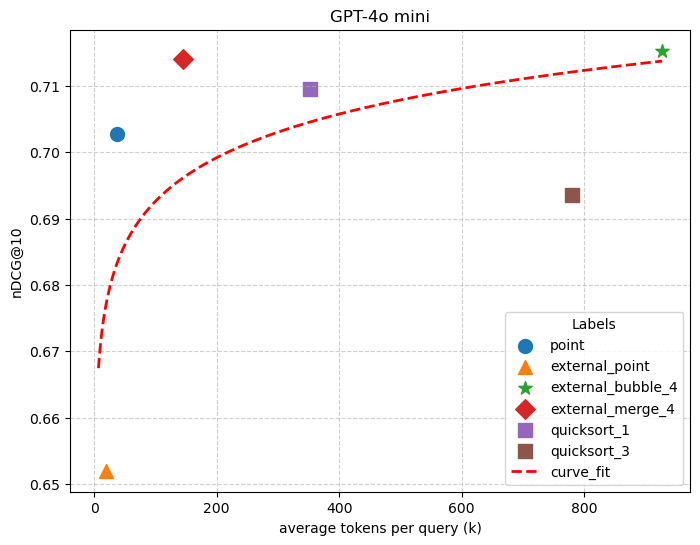 Figure 4
Figure 4| LLM Calls | ||
|---|---|---|
| Algorithm | Full Sort | Limit |
| Pointwise | ||
| Ext Pointwise | ||
| Quick Sort () | ||
| Ext Bubble | ||
| Ext Merge | ||
| Dataset | Model | Top-3 Best Standalone Algorithms | Best Optimizer | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1st Alg | Acc. | 2nd Alg | Acc. | 3rd Alg | Acc. | Judge | Self-Cons. | ||
| World | Llama-3.1-70B | point_search | 0.982 | point | 0.975 | ext_point_4_search | 0.969 | 0.982 | 0.982 |
| GPT-4.1 | point_search | 0.996 | point | 0.996 | ext_point_4_search | 0.995 | 0.996 | 0.996 | |
| Sembench | Llama-3.1-70B | ext_merge_4 | 0.919 | quick3 | 0.909 | quick | 0.909 | 0.919 | 0.921 |
| GPT-4.1 | ext_merge_4 | 0.921 | quick3 | 0.919 | quick | 0.919 | 0.924 | 0.924 | |
| DL20 | Llama-3.1-70B | ext_merge_4 | 0.690 | quick3 | 0.683 | quick | 0.682 | 0.694 | 0.690 |
| GPT-4.1 | ext_merge_4 | 0.719 | ext_bubble_4 | 0.717 | quick3 | 0.707 | 0.720 | 0.724 | |
| Model | Algorithm | Est($) | True($) | Diff($) |
|---|---|---|---|---|
| Llama-3.1-70B | point | 0.019 | 0.019 | 0.0001 |
| ext_point_4 | 0.008 | 0.009 | -0.0004 | |
| quick | 0.044 | 0.047 | -0.0036 | |
| quick_3 | 0.132 | 0.130 | 0.0017 | |
| ext_merge_4 | 0.033 | 0.031 | 0.0019 | |
| ext_bubble_4 | 0.077 | 0.077 | -0.0002 | |
| GPT-4.1 | point | 0.119 | 0.118 | 0.0013 |
| ext_point_4 | 0.057 | 0.057 | 0.0003 | |
| quick | 0.393 | 0.417 | -0.0241 | |
| quick_3 | 1.179 | 1.066 | 0.1131 | |
| ext_merge_4 | 0.311 | 0.293 | 0.0182 | |
| ext_bubble_4 | 0.673 | 0.644 | 0.0297 |
| Model | Samples | Borda | Judge |
|---|---|---|---|
| Llama-3.1-70B | 16 | 0.685 | 0.690 |
| 18 | 0.690 | 0.693 | |
| 20 | 0.690 | 0.694 | |
| GPT-4.1 | 16 | 0.716 | 0.722 |
| 18 | 0.719 | 0.721 | |
| 20 | 0.724 | 0.720 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNatural Language Processing Techniques · Topic Modeling · Machine Learning in Materials Science
\DeclareCaptionType
promptblock[Prompt Block] \DeclareCaptionTypequeryblock[Query Block]
Access Paths for Efficient Ordering with Large Language Models
Fuheng Zhao1, Jiayue Chen2, Yiming Pan3, Tahseen Rabbani2, Sohaib4
and
Divyakant Agrawal4, Amr El Abbadi4, Paritosh Aggarwal1, Anupam Datta1, Dimitris Tsirogiannis1
fuheng.zhao, paritosh.aggarwal, anupam.datta, [email protected]
jiayuechen, [email protected], [email protected], sohaib, divyagrawal, [email protected]
1Snowflake Inc. 2University of Chicago 3UC Los Angeles 4UC Santa Barbara
(2018)
Abstract.
In this work, we present the LLM ORDER BY semantic operator as a logical abstraction and conduct a systematic study of its physical implementations. First, we propose several improvements to existing semantic sorting algorithms and introduce a semantic-aware external merge sort algorithm. Our extensive evaluation reveals that no single implementation offers universal optimality on all datasets. From our evaluations, we observe a general test-time scaling relationship between sorting cost and the ordering quality for comparison-based algorithms. Building on these insights, we design a budget-aware optimizer that utilizes heuristic rules, LLM-as-Judge evaluation, and consensus aggregation to dynamically select the near-optimal access path for LLM ORDER BY. In our extensive evaluations, our optimizer consistently achieves ranking accuracy on par with or superior to the best static methods across all benchmarks. We believe that this work provides foundational insights into the principled optimization of semantic operators essential for building robust, large-scale LLM-powered analytic systems.
Semantic Operators, LLM Order By, Semantic Rank, AI Rank, Query Optimization
††copyright: acmlicensed††journalyear: 2018††doi: XXXXXXX.XXXXXXX††conference: Make sure to enter the correct conference title from your rights confirmation email; June 03–05, 2018; Woodstock, NY††submissionid: 123-A56-BU3††ccs: Information systems Data management systems
1. Introduction
Recent advances in large language models (LLMs) have facilitated complex data processing, such as automatically translating natural language questions into SQL queries (Zhao et al., 2024b; Floratou et al., 2024; Li et al., 2023; Gao et al., 2023; Gong et al., 2025), powering autonomous problem-solving agents (Zhuge et al., 2024; Shankar et al., 2024; Liu et al., 2025; Zhao et al., 2023; Sun et al., 2025a; Papadopoulos et al., 2025; Zhao et al., 2025; He et al., 2025), and introducing new declarative query languages with AI operators (Zeng and Yan, 2025; Zhao et al., 2024a; Satriani et al., 2025; Glenn et al., 2024; Aggarwal et al., 2025). Building LLM declarative interface through semantic operators has also attracted significant attention from industry, with systems such as BigQuery ML (Google Cloud, 2025), Snowflake AI SQL (Snowflake, Inc., 2025; Aggarwal et al., 2025), and Amazon Redshift’s user-defined functions (Amazon Web Services, 2024) providing support for these capabilities.
In this work, we focus on the implementation of one specific LLM/AI semantic operator: LLM ORDER BY, commonly used for sorting or ranking. Sorting is a fundamental operation in data processing and underpins a wide range of analytical and decision-making tasks. LLM ORDER BY enables ranking items based on semantic signals, user preferences, or task-specific criteria that are difficult to capture with traditional methods. For example, in information retrieval, it is common to use LLMs to re-rank retrieved documents or passages based on the user’s question or preferences (Zhu et al., 2023). In the context of relational data processing, LLMs can be leveraged to rank selected rows based on attributes that are not explicitly stored in the relational table, such as inferred sentiment or other factual information (Zhou et al., 2024; Zhao et al., 2024a). Let’s consider the following two concrete examples:
Example 1.0.
A User provides a query and, after an initial index filter (e.g., BM25 (Robertson et al., 2009)) on a large documents corpus, the user invokes the LLM ORDER BY operator to re-rank the retrieved subset. This approach allows the LLM to generate high quality ordered result based on a nuanced semantic understanding of the user’s query and preferences.
Example 1.0.
A company wants to rank customer feedback based on specific criteria, such as product dissatisfactory or satisfactory level, and to improve its product based on the feedback. Because ”dissatisfactory” or ”satisfactory” is a subjective attribute, the data analyst can invoke the LLM ORDER BY operator to rank the customer feedback based on this specific criteria, requiring the LLM to highlight the subtle and nuanced levels of customer sentiment. This capability enables the company to directly address the most critical product pain points or capitalize on successful features.
Given the importance of data ordering and ranking, researchers have explored a wide range of classical ideas in conjunction with LLMs. Prior works mainly study three classes of methods to implement sorting on top of LLMs: (i) pointwise sorting derives the value independently for each given key (e.g., passage relevance score, review sentiment score) (Drozdov et al., 2023; Sachan et al., 2022; Zhao et al., 2024a; Wang et al., 2025b), (ii) pairwise sorting compares two keys and then determines the relative order between them (Qin et al., 2023; Luo et al., 2024; Shah and Wainwright, 2018), and (iii) listwise sorting considers an entire set of keys simultaneously to produce a ranked order (Ma et al., 2023; Sun et al., 2023). There is no clear consensus on which approach is better. For example, Lotus (Patel et al., 2024), a recent LLM-powered data processing system, implements LLM-based ordering using a pairwise approach with quicksort. BigQuery ML implements LLM-based ordering using a pointwise method (Lao et al., 2025). Furthermore, on some benchmarks, researchers find listwise sorting often provide high accuracy (Ma et al., 2023; Pradeep et al., 2023), and on other benchmarks, researchers find that pairwise sorting provide higher accuracy (Qin et al., 2023).
Thus, in this paper, we aim to address the following question: Given a semantic LLM ORDER BY task and potentially a monetary budget, which algorithm should we use to maximize sorting accuracy? Before answering this question, we first wonder if there exists a universal optimal approach which achieves the best quality for all given tasks and datasets. To this end, we implemented existing approaches, proposed new LLM-based sorting algorithms, and conducted a systematic evaluation of different approaches within a unified experimental framework across different tasks. We observe that no algorithm outperforms the others across all tasks. In some cases, pointwise method (often criticized for its limited accuracy (Qin et al., 2023)) can, in fact, achieve strong accuracy in certain scenarios, while pairwise and listwise approaches excel in others. This highlights the importance of tailoring the ranking strategy to the task setting rather than relying on a one-size-fits-all solution. Moreover, this suggests that the LLM Access Path 111originating from classical data base systems (Selinger et al., 1979) for all semantic operators should be carefully selected based on query characteristics and the underlying model and data. Although this paper does not aim to optimize the selection of the access path for all operators, we present an optimizer that determines a highly accurate sorting approach for the LLM ORDER BY the operator.
After thoroughly examining the efficiency–effectiveness trade-offs in the initial evaluations, we conjecture a scaling relationship between compute cost and quality in semantic sorting, where increased computational consistently correlate with higher quality results. Building upon this insight, we propose two distinct optimizer configurations for the LLM ORDER BY operator: (i) an LLM-as-Judge optimizer that evaluates candidate quality, and (ii) a self-consistency optimizer that leverages aggregation to derive a robust consensus. The LLM-as-Judge approach leverages direct reasoning and reflection to maximize accuracy. The self-consistency optimization functions as a highly robust ensemble strategy, employing consensus aggregation to filter out anomalies and ensure superior stability on complex ranking tasks.
To conclude, our contributions can be summarized as follows:
- •
We propose several improvements to existing semantic sorting algorithms as well as a new semantic sorting algorithm which is an adaptation to the classical two-way merge sort algorithm (Selinger et al., 1979).
- •
With extensive performance and quality evaluations, we demonstrate that no single existing implementation is optimal for every semantic ordering task.
- •
Based on empirical data, we conjecture that LLM-based sorting obeys the test-time scaling law, which relates computational expenditure to output quality, forming a foundation for an intelligent optimizer.
- •
We design and implement a dynamic optimizer leveraging heuristics, LLM judgment, and consensus voting to maximize ranking quality within budget constraints.
- •
Our extensive experiments show that this adaptive approach outperforms single static algorithms across diverse benchmarks, successfully mitigating the performance volatility often associated with fixed strategies.
This paper is structured as follows: Section 2 provides background information on semantic sorting and establishes the notation. Section 3 reviews existing algorithms and introduces our proposed extensions, including the new semantic merge sort algorithm. Section 4 details our evaluation on two benchmarks, demonstrating that no single algorithm is universally optimal and quantifying the relationship between computational budget and accuracy. Section 5 introduces an optimizer that incorporates heuristic rules, LLM guidance, and consensus aggregation. Section 6 presents extensive experiments validating the effectiveness of our proposed optimizers. Finally, Section 7 concludes with a discussion of our findings.
2. Preliminary
The LLM ORDER BY semantic operator takes as input a list of data points along with a ranking criterion and produces an ordered list. These data points may represent diverse items, such as documents, reviews, or database rows, while the ranking criterion specifies the basis for ordering such as the relevance to a user question. Unlike traditional database settings, where the ordering attribute is explicitly stored in the table, LLM-based ordering relies on semantic judgments or inferred attributes. For example, ranking passages by relevance to a user query necessitates reasoning about semantic similarity between the query and the passage, where traditional SQL is confined to sorting by predefined attributes.
Previous LLM sorting algorithms are typically designed for passage or document ranking and are commonly categorized as pointwise, pairwise, or listwise. In this paper, we adopt a slightly different terminology. We refer to pointwise methods as value-based, pairwise methods as comparison-based, and further divide listwise methods into two variants: external value-based and external comparison-based. The intuition is that listwise methods can be viewed as batching multiple data points: either batching the derivation of values for multiple data points (external value-based) or batching the determination of the correct permutation (external comparison-based) for multiple data points. Value-based ordering methods are commonly implemented in current LLM-powered analytic systems (Zhao et al., 2024a; Wang et al., 2025b; Lao et al., 2025), typically excelling on benchmarks that test factual accuracy (e.g., ranking based on masked attributes of sports players’ height or celebrity’ birthday). On the other hand, systems like Lotus (Patel et al., 2024) employ comparison-based ordering for semantic ordering, achieving top-tier accuracy on sentence understanding tasks.
In our work, we focus on the semantic LLM ORDER BY operator and method of implementing the operator through standard generation APIs, treating the large language model as a semantic black box. In modern data infrastructures, models, whether proprietary or managed open-source, are predominantly exposed via high-level inference interfaces to abstract away the complexities of serving, hardware optimization, and security. Furthermore, emerging LLM-based analytical systems (Shankar et al., 2024; Liu et al., 2025; Trummer, 2025) increasingly rely on these standardized endpoints to ensure broad compatibility among different providers (e.g., OpenAI API (OpenAI, 2024b), Snowflake Cortex API (Snowflake, Inc., 2025), LiteLLM (BerriAI, 2025)). Also, the monetary cost of using these models can be calculated directly using the use of input and output tokens.
3. Methodology
In this section, we review existing semantic sorting algorithms (e.g., standard pointwise (Nogueira et al., 2020), quicksort (Patel et al., 2024), and external bubble sort (Sun et al., 2023)) and present our proposed optimizations: quick sort with majority voting, and semantic external merge sort.
3.1. Value-Based Ordering
In value-based ordering, the LLM assigns a value to each key, and the final ranking is obtained by sorting the keys according to these values. This approach is often the default implementation in many LLM-powered data systems (Zhao et al., 2024a; Alaparthi et al., 2025; Glenn et al., 2024; Lao et al., 2025). The value-based method requires LLM function calls where is the number of rows. Prompt Block 3.1 shows the template used to generate the relevance score for the passage ranking task.
To even further reduce the number of LLM function calls, a commonly used technique is to use the external pointwise approach, where keys are batched into a single prompt and the model returns a list of values (Cheng et al., 2023). With the external pointwise approach, the number of LLM function calls becomes . Also, the external pointwise method often leads to less monetary cost. This cost saving is achieved by sharing the instructional prefix across a batch of keys, rather than repeating it for each individual item. By amortizing the prompt’s token cost across items, the total number of billed input tokens is substantially reduced. Specifically, instead of evaluating a single key as shown in Prompt 3.1, this approach provides the LLM with a list of keys and tasks it with generating a corresponding list of values.
3.2. Comparison-Based Ordering
In comparison-based ordering, the LLM is asked to directly compare two or more keys and decide the ranking order. Instead of assigning independent values to each key, the model outputs a permutation of the input keys. Compared to value-based ordering, comparison-based methods are typically more expensive, as the number of comparisons can grow quadratically with the number of keys in the worst case. Typically, researchers have implemented quick sort and external bubble sort on top of the LLM comparators. In the case of external bubble sorting algorithm (Sun et al., 2023)222Also referred to as the Sliding Window Strategy, it sorts keys at a time and then advances by steps. It allows the model to repeatedly compare overlapping groups of keys (i.e., keys), so that items of higher rank gradually ’bubble up’ in successive windows.
In this subsection, we introduce two new comparison-based algorithms: (i) quick sort with majority voting to improve sorting quality compared to vanilla quick sort, and (ii) a semantic external merge sort inspired by the classical two-way external merge sort to reduce cost compared to external bubble sort. Later in the evaluations, we empirically demonstrate the effectiveness of these methods, showing that our quick sort variant leads to better accuracy than vanilla quick sort, and the external merge sort yields substantial cost savings while maintains high quality outputs.
As shown in Algorithm 1, LLM quick sort algorithm follows the classical divide-and-conquer strategy, and uses an LLM comparator (LLMSort) which takes in two keys and then determines the semantic order between these two keys. Prompt 3.2 shows the template used to generate the correct order between two passages. Unlike quick sort, which relies on a single comparison against the pivot to partition items, quick sort with majority votes aims to further improve the sorting robustness by validating the partition through majority voting. In this method, an item is compared not only with the pivot but also with a set of sampled ’peers’. The core intuition relies on transitivity: if a key is less than the pivot , it should logically be less than any item that is greater than . Items that achieve full consensus across all peer comparisons are partitioned immediately. Items with conflicting results are resolved iteratively; they wait until their peers are firmly classified into the Less () or Greater () sets, then a voting routine (Algorithm 2) determines their final placement. This ensures that high-confidence decisions anchor the partition structure before uncertain cases are resolved. Only when a deadlock occurs (i.e., no remaining unresolved items have fully classified peers), we trigger the voting routine on an unresolved item in order to resolve the cyclic dependencies.
To address the limitation of high running cost in the external bubble sort proposed in RankGPT (Sun et al., 2023), we propose a new semantic external merge sort approach inspired by the classical external merge sort approach (Knuth, 1997). As shown in Algorithm 3, our approach operates in two distinct phases. First, the Run Generation phase divides the input into runs of size , and each run is individually sorted using LLMSort with Prompt 3.2 to derive the LLM-sorted permutation. Second, the Merge Phase (Algorithm 4) iteratively merges two sorted runs into one sorted run. The two-way merge operation employs a sliding-window mechanism: it buffers keys ( keys from each sorted run) for the LLMSort to derive a partial ordering on this buffer. From this local ranking, we extract items and add them to the final output until the candidates from one of the input runs are exhausted within the current window. We must re-fill this buffer again before the next extraction. This is because we need to compare the unseen element from the exhausted run with the remaining items in the buffer to determine the total order. This process continues until one of the input runs is completely exhausted and the other input run is appended to the final output; hence, we obtain a merged sorted run.
3.3. Limit K
A common usage pattern is to combine the ORDER BY clause with LIMIT K, where the user wants to retrieve items from the sorted results. This pattern offers an additional opportunity to save the number of LLM invocations and costs. For example, the external bubble sorting algorithm (Sun et al., 2023), effectively finding the first sorted data points, reduces the number of calls to LLM from to . See Table 1 for the number of LLM function calls used in each algorithm in both full sort and LIMIT . Let’s assume the user wants to retrieve the first rows in descending order based on some criteria (e.g, retrieve the most relevant passages to the user question). In quick sort, after it separate rows into (lesser) and (greater) lists comparing each row to the pivot and validation samples, if contains more than rows, then only need to be sorted and can be discarded. This is also known as partial quick sort (Martínez, 2004). It can be seen as a quick select, which uses comparisons to find the partition with rows, and then apply quick sort on rows. For External Merge Sort (Algorithm 3 and Algorithm 4), it still performs the run generation phase (i.e., generating a sorted run with rows) and then perform 2-way merge. During the 2-way merge, if the merged list reaches items, then it can discard all the rest. As a result, having the LIMIT clause also reduces the number of invocations for external merge sort. For the first rounds, each run size will be less than , and each round requires function calls. Once the run size reaches , the behavior changes. For all subsequent rounds, we merge two runs of size but strictly cap the output at items (discarding the remaining ). As a result, the total number of items decrease by a factor of 2 for each round. Hence, the LLM function calls decrease from , to , to , etc. This is a gemoetric sequence which is upper bound by . The total LLM function calls can be approximated as .
4. Initial Evaluation
In this section, we evaluate our proposed algorithms alongside existing baselines on two different datasets. We report results in terms of both effectiveness (ranking quality) and cost (price), highlighting the trade-offs between value-based and comparison-based approaches. The main question we would like to answer in this section is that: Is there a single sorting algorithm that always gives the best ranking quality?
Datasets. The two dataset we used are:
- •
NBA: Contains 200 player names (OpenIntro, 2025) to be ordered by height. In the semantic order by task, the height is masked, requiring the sort operation to be performed based solely on the player names.
- •
DL19: TREC-DL19 is a widely used benchmark dataset in information retrieval literature (Craswell et al., 2020). The test sets contains 43 queries and 8.8 million passages. The goal is to rank the passages according to their relevance to each query.
4.1. Implementation and Metrics
In our experiments, all LLM models (Llama3.1-70b, Llama3.1-405b, and OpenAI GPT 4.1) are directly accessed through Snowflake Cortex REST API. For all experiments, we use the structured API and set the temperature to 0, which adopted greedy decoding to obtain the most deterministic outputs (OpenAI, 2024a). The input JSON schema was designed following the best practices of chain-of-thought prompting (Wei et al., 2022), as recommended in the OpenAI structured outputs guide (OpenAI, 2024b). All algorithms were implemented in Python. The pointwise (Liang et al., 2022) () and external pointwise () methods uses the rating scale prompt from (Zhuang et al., 2024); comparison based algorithms follow the prompt design in (Qin et al., 2023; Ma et al., 2023); and external comparison based algorithms utilize the listwise prompt from (Sun et al., 2023).
Notably, as we later demonstrate in this Section, the value-based approaches achieve high accuracy on strictly factual, non-reasoning tasks, such as estimating the heights of NBA players. Such high accuracy is achieved because these queries directly leverage the extensive world knowledge embedded within the models’ pre-training corpora (Morris et al., 2025; Noroozizadeh et al., 2025). To maximize the factual accuracy in these scenarios, we naturally augmented the value-based approaches with a web search tool, allowing the model to ground its values based on the web search information.
In evaluating sorted-ness on the NBA dataset, we adopt the well-established kendall’s tau metric (Kendall, 1938). It quantifies the correspondence between two rankings, with values near 1 indicating strong agreement and values near -1 indicating strong disagreement. In evaluating the sorted-ness on DL19, we adopt the standard nDCG@10 metric (Wang et al., 2013). In addition, we follow the conventions in DL19, in which the LLM Order By is applied on the top 100 passages retrieved by BM25 for each query (Robertson et al., 2009). We directly use the pyserini toolkit (Lin et al., 2021) for BM25 retrieval. Normalized discounted cumulative gain (nDCG) yields values from 0.0 to 1.0, where higher values indicate rankings that are closer to the ideal order.
4.2. Observations
NBA Player Height Ranking. The first row in Figure 1 reports Kendall’s tau score comparing predicted orderings with the ground truth. Overall, the value-based approach emerges as the top performing algorithm across three models. The pointwise method consistently achieves high accuracy across all models, whereas the performance of the external pointwise method is slightly lower. Furthermore, when equipped with web search capabilities, the pointwise approach can achieve near-perfect accuracy. However, we observed that web search results sometimes return conflicting information, typically due to discrepancies in how players’ heights are recorded (e.g., measured with versus without shoes). When evaluated with GPT 4.1, the pointwise and external pointwise methods achieve accuracies of 0.90 and 0.89, respectively. By integrating a web search tool, both approaches reach near-perfect accuracies of 0.97 and 0.96. A similar trend is observed with Llama3.1-70b, where augmenting the pointwise method with web search boosts its accuracy from a baseline of 0.89 up to 0.95. The success of the value-based method implies that for factual data, LLMs excel at directly inferring statistics they have memorized from their training corpora. In contrast, comparison-based approaches consistently underperform. Having the chain-of-thought reasoning steps in comparison based approaches does not close this gap, suggesting that the direct retrieval of internalized facts is more reliable than multi-step reasoning. Additionally, our proposed quick sort with majority voting consistently outperforms standard quick sort in accuracy across all three models, albeit at a higher cost. Our proposed semantic external Merge Sort algorithm achieves performance comparable to semantic external Bubble Sort, while significantly reducing the overall monetary costs.
DL19 Passage Ranking. The second row of Figure 1 reports the evaluation of different algorithms in DL19. The x-axis is the dollar cost and the y-axis is the mean across 43 queries (higher is better). For passage ranking tasks, comparison-based sorting algorithms excel. Our proposed semantic external merge sort and quick sort with majority voting consistently achieve the best mean . For example, using GPT 4.1, standard quick sort and external bubble sort achieve average scores of 0.727 and 0.728, respectively. In contrast, our quick sort with majority voting attains the best overall score of 0.735, while our external merge Sort achieves a competitive 0.722. These performance gains come with distinct cost trade-offs: the additional voting mechanism increases the cost of quick sort with majority voting by nearly 2.5 compared to the standard variant. Conversely, external merge sort maintains high accuracy while decreasing costs by 6 relative to external bubble Sort. The value based approach performs worse for passage ranking. When the task is not centered on deriving factual information, value-based approaches are less effective, as they lack the comparative reasoning needed to capture subtle relevance signals. This phenomenon has also been observed in many prior works (Ma et al., 2023; Pradeep et al., 2023).
Trade-off between Sorting Accuracy and Computation Through our initial observations, we find a consistent trade-off between accuracy and computational cost for reasoning tasks (e.g., DL19). In traditional relational Order By operator, different sorting algorithms are guaranteed to produce identical deterministic outputs. However, in the context of semantic Order By operations, algorithmic choice directly impacts output quality. As illustrated by the DL19 results in Figure 1, there is a clear relationship between sorting accuracy () and monetary price (derived from total token consumption). In most cases, these curves follow a log-linear trend indicative of diminishing returns: accuracy improves rapidly with modest initial increases in token usage, but quickly plateaus as costs continue to grow. Although there are isolated exceptions, such as the external pointwise method outperforming the standard pointwise approach on GPT-4.1, the overarching pattern dictates that higher computational expenditure generally yields improved sorting accuracy.
A universal best algorithm? Our results demonstrate that no single sorting algorithm is universally optimal across different domains. For instance, when ranking factual data such as NBA player heights, the pointwise approach excels and, with web search tools, it can reach nearly perfect accuracy. On the other hand, comparison-based approaches excel for reasoning-heavy tasks like DL19 passage relevance. To better understand this variance in reasoning tasks, we further analyzed the 43 individual user queries contained within the DL19 dataset.
Figure 2 demonstrate the accuracy distribution for each algorithm for the Llama 3.1-70b model. The star denotes the mean for each algorithm. The x-axis is the different algorithms and the y-axis is the . The sorting accuracy can change drastically by using different algorithm. The dashed line tracks the accuracy for the query with id 1113437. It demonstrates a case where both quick sort has better ranking quality than quick sort with majority vote and external merge sort has better ranking quality than external bubble sort, despite the fact that quick sort and external merge sort have lower mean than quick sort with majority vote and external buble sort. This highlights that, even within the same passage ranking benchmark, there is still no universally optimal algorithm across all queries. In a world where we know exactly which algorithm performs best for a given instance, we could leverage these specific strengths to maximize ranking effectiveness for every user query. The rightmost optimal algorithm in Figure 2 illustrates this scenario. It achieves a mean of 0.779, outperforming the best single algorithm, our proposed quick sort with majority vote with a mean of 0.735.
In summary, for factual datasets such as NBA player heights, the pointwise method with web search achieves the highest accuracy with minimal computational overhead on three models. For reasoning-heavy tasks, comparison-based algorithms exhibit a clear trade-off between accuracy and computational cost. Furthermore, a granular analysis of the 43 individual DL19 queries reveals that the optimal algorithmic choice varies significantly on a case-by-case basis. Because no single sorting algorithm is universally optimal, the most effective approach is to dynamically select the sorting strategy based on the specific query and the intrinsic characteristics of the data.
5. Optimizer Design
The challenges in designing an efficient optimizer for selecting the best physical implementation of LLM Order By operator are: i) understanding the sorting quality without ground truth labels. and ii) avoid exhaustively executing all potential algorithms on all data points. We look back at classical database query optimization literature (Wu et al., 2016; Gibbons and Matias, 1998; Chen et al., 2006). A recurring trend is the reliance on a subset of data samples or data summaries to inform algorithmic decision-making. Taking inspirations from the classical query optimizations, we build our optimizer by first sampling a subset of the data. Then, we can run several candidate algorithms in parallel, analyze the resulting performance (e.g., monetary cost and accuracy) metrics, and determine the near-optimal configuration.
5.1. Cost Estimation
Before diving into the design of our optimizer, we first establish a methodology for monetary cost estimation. Unlike traditional database queries where the result is always 100% accurate, AI SQL queries have inherent quality and cost trade-offs. Often times, the user wants to obtain a high quality result constrained by a cost budget. As a result, our optimizer needs to select the algorithms with respect to the user’s cost constraint.
Estimating the monetary cost for each algorithm with fixed parameters is relatively straightforward. In Table 1, we have written the number of LLM calls for each algorithm based on the number of input data points and algorithm parameters. After the sampling step, we run several algorithms in parallel and obtain their running costs. This empirical measurement is crucial, as it provides the actual running cost to calibrate the theoretical cost models. Specifically, we can directly scale the observed cost per LLM call across the different algorithms and input sizes to accurately project the total expenditure for the original datasets. By the law of large numbers, the higher sample ratio will lead to lower estimation error. In our experimental section, we show that a small sample size can already provide very accurate monetary cost estimation.
Example 5.0.
Assume the original dataset contains 100 data points and the user want to obtain a fully sorted list based on some criteria. The cost for running the pointwise sorting algorithm on the sample of size 20 is . Then our estimation on running the pointwise sorting algorithm over the entire dataset will be , since pointwise sort LLM calls scale linearly.
Example 5.0.
Assume the original dataset contains 100 data points and the user want to obtain a fully sorted list based on some criteria. The cost for running the external bubble sort algorithm with batch size of four on the sample of size 20 is . Then our estimation on running the external bubble sort algorithm with batch size of four over the entire dataset will be , since external bubble sort LLM calls scale quadratically.
5.2. Factual World Knowledge
In Section 4, we find that for ordering based on factual world knowledge tasks, LLMs (e.g., Llama 3.1 and OpenAI models) can directly recall factual data. The memorization of training corpora is an inherent characteristic of large language models and is essential for emergent reasoning abilities (Brown et al., 2021; Morris et al., 2025; Wang et al., 2025c). Consequently, the value-based methods achieve high accuracy with minimal cost. Furthermore, as we have demonstrated in Section 4, pairing the pointwise approach with web search capability can reach nearly perfect accuracy. In this configuration, the values derived by the web-augmented pointwise method act as both a direct, high-confidence probe of the model’s parametric memory and also grounded its results based on online sources.
Motivated by this observation, the challenge for ordering based on factual world knowledge becomes: Can we successfully identify whether the information needed to order the items is world knowledge? To address this question, we follow the methodology established in the field of membership inference in LLMs, and adopt the Inquiry Prompt from (Wen et al., 2024) as shown in Prompt 5.2, which has achieved high membership inference accuracy and relies only on the generation API. In the evaluations, we find that the Inquiry Prompt effectively distinguishes between world knowledge and unknown entities.
We run the inquiry on a sample of the input data and if the LLM identified this ranking task can be solved based on factual knowledge, the optimizer automatically uses pointwise with web search ranking strategy. if the LLM classifies the task as subjective or reasoning-dependent, the system safely falls back to the LLM-as-Judge or consensus aggregation approaches described later in this section. While the pointwise method is highly effective for factual sorting, its utility in broader semantic ordering is constrained by a lack of relative comparative context. By classifying the query upfront, we ensure this method is deployed specifically when the model can function as a reliable knowledge retriever.
5.3. Candidate Algorithms
The optimizer is tasked with dynamically selecting one algorithm to execute the LLM ORDER BY operation. The initial candidates include all value-based and comparison-based algorithms. We note that within our candidate pool, comparison-based algorithms: external bubble sort and external merge sort—introduce a functional dependency on the configured batch size and quick sort with majority voting takes in an int votes. While numerous valid configurations exist for these algorithms, constrained only by the model’s context window and budgets, it is computationally too expensive to empirically explore every configuration. Hence, we leverage our main insight derived from Section 4: higher computation generally leads to better accuracy. This finding implies that to maximize the performance potential (i.e., maximizing the computation) within a limited budget, we only need to explore the minimum viable batch size configuration for external comparison based algorithms and finding the maximum votes for quick sort, thereby ensuring the available budget is utilized toward the most promising algorithm candidate. To estimate the running price for each configuration, we perform a limited empirical sampling (monetary cost associated with a single LLM invocation) and then extrapolate the total cost by scaling the observed cost per unit of work. This scaling factor is shown in Table 1.
For all algorithms, we first execute them on a small sample subset. We then project these costs to the full dataset size according to Table 1, filtering out any methods where the estimated expense violates the user-specified budget. This candidate algorithm selection phase offers flexibility and generalizability. When a new semantic sorting algorithm is proposed, integrating it into the optimizer merely requires determining its cost function (the LLM function call complexity shown in Table 1) and its viable configuration that lead the maximum computation with in the budget (if applicable) to immediately include it in the competitive candidate pool.
The main challenge With a pool of strong candidate algorithms selected based on user-defined cost constraints, the remaining core task is to identify the best algorithm with respect to the quality of the ranking. Note that we always select a single algorithm from the candidate pool and run this algorithm over all data points once. To address the challenge of understanding the ranking quality, we introduce two distinct methodologies for measuring and evaluating the quality in the next two subsections.
5.4. LLM-as-Judge Optimizer
A common approach in evaluating complex tasks is the emergence of ”LLM-as-a-Judge”, where LLMs are employed as the evaluator. LLM-as-a-Judge approach has been adopted in many different domains (Gu et al., 2025). In the context of database, the researcher has used LLM-as-a-Judge to evaluate LLM powered natural language to SQL query translation (Zhao et al., 2023; Kim et al., 2024) and to evaluate LLM generated candidate query plans (Shankar et al., 2024; Ji et al., 2025). We explore if we can also leverage an LLM to determine the best algorithm for a sorting task. We run all candidate algorithms on the sampled data. The resulting list of output rankings, each tagged with a unique candidate identifier, is then compiled and presented. The LLM Judge is subsequently tasked with evaluating this aggregate output and identifying the candidate identifier corresponding to the optimally sorted result for the given input. The list-wise prompt 5.4 shows the template used to generate the LLM Judge decision, which include the task instruction, the sampled keys, and the execution results of candidate algorithms. This chain-of-thought (Zakhary et al., 2020) prompt is designed in accordance with industry-standard evaluation frameworks such as TruLens (56).
5.5. Self-Consistency Optimizer
To establish a highly robust and near-optimal sorting solution, we introduce the heuristic self-consistency optimizer. This approach adapts concepts from both collective voting literature (Saari, 2023; Heilman, 2022) and LLM self-consistency paradigms (Wang et al., 2023). Specifically, we treat the ranking order produced by all algorithms as a set of expressed preferences among the sorted order of items based on user defined criteria. To aggregate these diverse ’votes’ into a single, robust consensus ranking, we employ the Borda Count method (Emerson, 2013), mathematically assigning positional scores to calculate the final collective ranking order. To select the optimal heuristic algorithm, we first evaluate all candidate methods on a data sample. We construct a proxy ground truth by aggregating the rankings of all candidates using the Borda Count method. Next, we measure each candidate algorithm’s agreement with this proxy ranking. Finally, the system selects the algorithm that maximizes this proxy agreement—while strictly adhering to the computational budget—for full execution. While individual sorted runs may suffer from isolated reasoning errors or hallucinations, the aggregated consensus of multiple diverse runs is statistically far more likely to converge on the true semantic order. By selecting the candidate that best aligns with this consensus, we can effectively find the most reliable and robust algorithm for the specific dataset and task.
6. Experiments
We now present an evaluation of our proposed LLM-as-Judge and Self-Consistency optimizers (Section 5), building on top of value-based and comparison-based LLM sorting algorithms (Section 3). With systematic evaluation, we demonstrate that our proposed optimizer can achieve near-optimal accuracy through online evaluation.
6.1. Experimental Setup
Evaluation Datasets.
- (1)
2020 World Population (Prabhu, 2020): The query is to order these countries by their population. Populations are masked. 2. (2)
SembenchMovie Q9 (Lao et al., 2025): Originally designed to rank items for Ant-Man and the Wasp by positivity, we expanded this task to include 5 distinct queries corresponding to the top 5 most reviewed movies. For each query, we appended a DESC LIMIT 10 clause. 3. (3)
DL20 (Craswell et al., 2021): It contains 54 search queries associated with the 8.8 million passage corpus.
Evaluation Metrics. Similarly to the initial evaluation (Section 4), we use kendall’s tau to measure the accuracy of the sorted list in the 2020 world population, and use for SembenchMovie and DL20. On both metrics, higher value (closer to 1.0) indicates better sorting quality.
Ranking Solutions. In this section, we compare our proposed optimizer against a comprehensive set of single-algorithm solutions. For the value-based category, we include both external pointwise and standard pointwise algorithms. The pointwise method serves as a key approach as it is implemented in academic prototype and utilized by BigQuery for LLM-based semantic ranking (Lao et al., 2025; Zhao et al., 2024a). For instance, we employ the exact pointwise prompt utilized by BigQuery for the SembenchMovie dataset. For the comparison-based category, we evaluate standard quick sort (Qin et al., 2023) and external bubble sort (Sun et al., 2023), alongside with our proposed semantic ranking methods: quick sort with majority voting and external merge sort. We also note that Lotus (Patel et al., 2024) utilizes the quick sort method. The fundamental distinction between our proposed optimizer and these baselines is that: while single-algorithm solutions apply a static strategy regardless of the input, our optimizer dynamically selects the near-optimal algorithm at runtime.
Implementation Details. For all experiments in this section, we use Llama3.1-70b or GPT 4.1 models directly accessed using Snowflake Cortext API. The temperature is set to 0 to enable greedy decoding. Unless specified, the sample size for factual world data inquiry stage is fixed to five, and the sample size for running candidate algorithms is fixed to 20. In the LLM-as-Judge optimizer, the evaluation phase employs the identical backbone model used for the initial sorting. Utilizing the same model facilitates an internal reflection mechanism: the judge can seamlessly re-evaluate the candidate rankings for subtle errors and iteratively refine its assessments to maximize final accuracy. For the self-consistency optimizer, we measure candidate quality by comparing outputs to a derived aggregation through Borda Count. The quality is measured using Kendall’s for the World Population benchmark and for the remaining datasets, reflecting their distinct ranking objectives.
6.2. Optimizer Main Results
The main results of the evaluation are shown in Figure 3. The x-axis is the monetary costs and the y-axis is the ranking quality. In this set of experiments, we evaluate the optimizer under a sweep of monetary budgets tailored to each dataset-model pair: for DL20, we use budgets of 1, 3, 5, 7 for Llama-3.1-70B and 10, 20, 40, 80 for GPT-4.1; for Sembench Movie, we use 0.2, 0.4, 0.8, 1.6 for Llama-3.1-70B and 3, 6, 12, 24 for GPT-4.1; and for World Population, we use a single budget of 0.1 for Llama-3.1-70B and 1.0 for GPT-4.1. Across these settings, the optimizer is consistently competitive with the strongest standalone ranking algorithm, matching or out-performing the best single-algorithm performance.
World Population Benchmark. In the world population benchmark, our optimizer using the inquiry prompt (Prompt 5.2) successfully identified that the world population are factual information. Consequently, the optimizer automatically routed the query to the web-augmented pointwise method, achieving exceptionally high accuracies of 0.982 with Llama-3.1-70B and 0.996 with GPT-4.1. As detailed in Table 2, while the external pointwise method with web search ranks third and exhibits competitive accuracy, it remains less stable than the standard pointwise approach, which is align with our observations in Section 4 and prior literature (Cheng et al., 2023). Furthermore, these results demonstrate that for purely factual queries, comparison-based approaches not only demand a larger computational budget but also yield lower accuracy relative to value-based methods
Sembench Movie. The Sembench Movie dataset comprises five distinct queries based on most reviewed movies. During the initial inquiry phase, these queries are classified as subjective, non-factual data. Consequently, the optimizer bypassed the default method of pointwise with web serach. As illustrated in Figure 3, relying solely on the pointwise sorting algorithm, as currently adopted in the Sembench baseline (Lao et al., 2025), results in a significant degradation of ranking accuracy. For instance, on the Llama-3.1-70B model, the standard pointwise method achieves a score of 0.869 at a cost of 0.155; The self-consistency optimizer reaches an even higher accuracy of 0.921 at $0.157.
On both the Llama-3.1-70B and GPT-4.1 models, the optimizers correctly gravitate toward the high-accuracy regions dominated by comparison-based algorithms. Specifically, on the Llama-3.1 70b model, the self-consistency strategy (Opt(self-cons)) achieves of 0.921, effectively outperforming the best single algorithm baseline. Similarly, on the GPT 4.1 model, both the LLM-as-Judge and self-consistency strategies effectively navigate the candidate pool to select highly competitive algorithms and achieve of 0.924, maximizing accuracy while tightly managing the computational budget. However, we observe that our porposed optimizer score can occasionally decrease at higher budgets, demonstrating a non-monotonic relationship between cost and accuracy. While we generally observe a positive scaling relationship between computation and sorting accuracy across standlone algorithms, this trend is not absolute. In this dataset, higher-cost algorithms, such as quicksort with majority voting and external bubble sort, failed to outperform our proposed semantic external merge sort. Consequently, at higher budget tiers, the candidate pool expanded to include algorithms that were more expensive yet less effective, leading to suboptimal selections.
DL20. The DL20 benchmark comprises 54 queries. During the initial inquiry phase, GPT-4.1 classified 8 queries as factual, while Llama-3.1-70B classified none. This low recognition rate indicates that for the vast majority of these tasks, the models cannot rely on memorized ground truth, parametric knowledge, or web-augmented search to solve the ranking task. Hence, our proposed optimizer, for the vast majority of the queries, bypasses the pointwise shortcut and activates its dynamic evaluation protocols. It either employs an LLM-as-Judge approach to directly assess output quality, or utilizes a self-consistency strategy, measuring candidate outputs against a proxy ground truth constructed via Borda Count. As illustrated in Figure 3 (c) and (f), standard value-based approaches consistently underperform on the DL20 benchmark, validating our prior observation that these complex queries demand rigorous, comparison-based reasoning rather than simple parametric recall.
Zooming into the behavior of the LLM-as-Judge optimizer, we observe a distinct clustering effect: across both models, the judge consistently anchors to the external merge sort algorithm. This behavior reveals a critical insight: the judge correctly identifies external merge sort as the Pareto-optimal threshold, recognizing that the increased computation of more expensive algorithms fails to yield any meaningful gain in ranking quality. As shown in Table 2, external merge sort is the best performing standalone algorithm. Even when the monetary budget is significantly increased, the Judge declines to move toward ”higher-tier” candidates like external bubble sort or quick sort with majority voting. Through this process of internal self-reflection, the judge identifies that the performance of higher-cost candidates has effectively plateaued. Rather than blindly exhausting the budget, the optimizer reflects on the comparative quality of the traces and secures peak accuracies (0.694 on Llama-3.1-70B and 0.720 on GPT-4.1) by anchoring to the most efficient candidate, thereby avoiding unnecessary computational expenditure.
On the other hand, the Self-Consistency optimizer depends on the consensus of the entire candidate pool. It achieves robustness through cross-algorithm verification, aggregating all candidate rankings via Borda Count to construct a proxy ground truth. By focusing on the results shared by the majority of algorithms, this approach reduces the impact of errors made by any single candidate. As illustrated in Figure 3(f) on the GPT 4.1 model, this approach demonstrates particularly resilience for the complex DL20 queries. With the powerful GPT-4.1 model, the self-consistency optmizer successfully leverages this consensus to reach a peak accuracy of 0.724. This outperforms both the LLM-as-Judge (0.720) and the top standalone algorithm (0.719), demonstrating that a consensus-driven proxy can be more robust than a single model’s direct assessment when dealing with the high-complexity reasoning required for DL20.
To further comprehend the optimizer performance on the challenging DL20 benchmark, we analyze the accuracy distributions of the maximum budget presented in the box plots of Figure 4. LLM-as-a-Judge optimizer demonstrates remarkable stability across both models, maintaining a tight inter-quartile range. By utilizing self-reflection to anchor to the best candidate, the judge effectively ensures a consistently high performance floor. the Self-Consistency optimizer achieves impressive mean results; however, it displays a notably lower performance boundary on Llama-3.1-70B. With a weaker underlying model, the consensus becomes more susceptible to noise due to the inconsistent outputs across different algorithms; conversely, GPT-4.1 remains more stable. This suggests that the while aggregated consensus is a powerful tool for lifting average accuracy, it remains vulnerable to consensus noise. On particularly difficult queries where a majority of algorithms in the pool provide incorrect rankings, the Borda aggregation preserves these collective errors, dragging down the accuracy for the hardest tasks.
Summary. Based on evaluations across all three datasets, both optimizers consistently achieve a near-optimal Pareto frontier compared to standalone value-based and comparison-based methods. The optimizers offer a strategic trade-off between the accuracy and cost. The LLM-as-a-Judge based optimizer employs internal reflection to bypass the noise and inconsistent logic of complex sorting traces, whereas the self-consistency strategy draws from the collective signal of the candidate pool to push the accuracy ceiling. Our findings suggest a model-dependent selection strategy: more powerful and stable models benefit from the consensus-driven nature of self-consistency to maximize the accuracy, while for weaker or more volatile models, the judge-based approach is better for its ability to self-reflect and filter out algorithmic instability and maintain reliable performance floors. Furthermore, as detailed in Table 2, our proposed external merge sort and quick sort with majority voting consistently achieve the best results among the standalone algorithms, establishing a robust performance baseline for our optimization framework.
6.3. Cost Estimation
To ensure that the optimizer respects user-defined budget constraints, it is critical to accurately estimate the monetary cost of each candidate algorithm. Table 3 presents a comparison between our average cost estimations and the average actual costs incurred on DL20. Across both models, our cost model demonstrates high accuracy. For value-based algorithms, the estimation error is negligible. For comparison-based algorithms, the discrepancy also remains minimal, with the estimated cost consistently tracking the true cost within a small margin of error. We observe that the most notable variance occurs in quicksort with majority voting. The current cost formula treats the voting factor as a constant multiplier (), resulting in a slight overestimation. In practice, our implementation uses less amount of comparisons, because additional peer validation comparisons are bypassed if a partition size falls below the voting threshold . Consequently, the theoretical model acts as a conservative upper bound and the actual execution yields lower costs.
6.4. Sample Size Sensitivity
Table 4 indicates that performance is stable across the different sample ranges. Notably, we maintain a sample size greater than 10 to ensure sufficient ranking depth for the metric. While Llama-3.1 70B benefits from the judge’s self-reflection to filter unstable traces, GPT-4.1 scales effectively with Borda Count, achieving its peak at 20 samples. Overall, this robustness suggests that both optimization strategies successfully regularize against stochastic noise, making performance less sensitive to minor fluctuations.
7. Discussion
In this work, we presented the LLM ORDER BY semantic operator and systematically studied its physical implementations. We introduced several novel algorithmic designs to enhance existing semantic sorting methods, such as the external-merge semantic sort and quick sort with majority voting. Our evaluations reveal a clear pattern: external merge sort consistently provides high accuracy at a modest cost, and quicksort with majority voting achieves high accuracy at the expense of a significantly larger computational budget. Through a unified experimental framework across diverse sorting tasks, we demonstrated that no single access path is universally optimal. Instead, the effectiveness of an implementation is highly contingent on query characteristics and the underlying data, highlighting the necessity of adaptive access-path selection in practice. Furthermore, we empirically observed a test-time scaling phenomenon for the LLM Order By operator, where the sorting quality scales with the computational cost. This relationship provides a principled foundation for our optimizer’s heuristic rules, allowing for the dynamic selection of algorithms based on the available budget.
While existing systems often rely on static execution strategies for semantic Order By, these static approaches fail to adapt to different query tasks. To address this limitation, we introduce a dynamic optimizer that selects near-optimal physical implementations on the fly. Using heuristic rules, self-consistency aggregation, and LLM self-reflection, our approach successfully navigates the trade-off between accuracy and cost. This adaptive approach consistently achieves performance superior to or on par with the best fixed single-algorithm strategies, establishing a new standard for efficient LLM-based ranking. For instance, on the Sembench Movie dataset using GPT-4.1, our proposed external merge sort outperforms the default pointwise implementation in BigQuery ( vs. ), while our dynamic optimizer reaches a peak accuracy of . In future work, we plan to expand the capability of our optimizer to support other operators, such as semantic JOIN (Trummer, 2025; Sun et al., 2025b), Extract (Lin et al., 2025; Wang et al., 2025a), and Filter (Snowflake, Inc., 2025).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1P. Aggarwal, B. Chen, A. Datta, B. Han, B. Jiang, N. Jindal, Z. Li, A. Lin, P. Liskowski, J. Tayade, D. Tsirogiannis, N. Wiegand, and W. Zhao (2025) Cortex aisql: a production sql engine for unstructured data . External Links: 2511.07663 , Link Cited by: §1 .
- 2A. Alaparthi, P. Loh, and R. Marcus (2025) Scale LLM: a technique for scalable llm-augmented data systems . In Companion of the 2025 International Conference on Management of Data , pp. 11–14 . Cited by: §3.1 .
- 3Amazon Web Services (2024) Bringing generative ai to the data warehouse with amazon bedrock and amazon redshift . Note: AWS re:Post article; accessed: 2025-08-17 External Links: Link Cited by: §1 .
- 4Berri AI (2025) Lite LLM: python sdk and proxy server for calling 100+ llm apis . Note: Git Hub repository Accessed: 2025-11-28 External Links: Link Cited by: §2 .
- 5G. Brown, M. Bun, V. Feldman, A. Smith, and K. Talwar (2021) When is memorization of irrelevant training data necessary for high-accuracy learning? . In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , STOC ’21 , pp. 123–132 . External Links: Link , Document Cited by: §5.2 . · doi ↗
- 6Y. Chen, K. Yi, J. Zhang, and G. Li (2006) Two-level sampling for join size estimation . In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data , SIGMOD ’06 , Chicago, Illinois, USA , pp. 759–770 . External Links: Document Cited by: §5 . · doi ↗
- 7Z. Cheng, J. Kasai, and T. Yu (2023) Batch prompting: efficient inference with large language model apis . External Links: 2301.08721 , Link Cited by: §3.1 , §6.2 .
- 8N. Craswell, B. Mitra, E. Yilmaz, D. Campos, E. M. Voorhees, and I. Soboroff (2021) TREC deep learning track: reusable test collections in the large data regime . In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’21) , pp. 2369–2375 . External Links: Document , Link Cited by: item 3 . · doi ↗