Wage Sentiment Indices Derived from Survey Comments via Large Language Models
Taihei Sone

TL;DR
This paper introduces a novel Wage Sentiment Index derived from survey comments using Large Language Models, which effectively forecasts wage trends in Japan and outperforms existing models.
Contribution
It develops a new LLM-based sentiment index specifically for wages, extending previous sentiment frameworks and creating a scalable architecture for integrating diverse data sources.
Findings
WSI models outperform baseline approaches
LLM-based indices improve forecasting accuracy
Potential to enhance economic policy responsiveness
Abstract
The emergence of generative Artificial Intelligence (AI) has created new opportunities for economic text analysis. This study proposes a Wage Sentiment Index (WSI) constructed with Large Language Models (LLMs) to forecast wage dynamics in Japan. The analysis is based on the Economy Watchers Survey (EWS), a monthly survey conducted by the Cabinet Office of Japan that captures real-time economic assessments from workers in industries highly sensitive to business conditions. The WSI extends the framework of the Price Sentiment Index (PSI) used in prior studies, adapting it specifically to wage related sentiment. To ensure scalability and adaptability, a data architecture is also developed that enables integration of additional sources such as newspapers and social media. Experimental results demonstrate that WSI models based on LLMs significantly outperform both baseline approaches and…
Click any figure to enlarge with its caption.
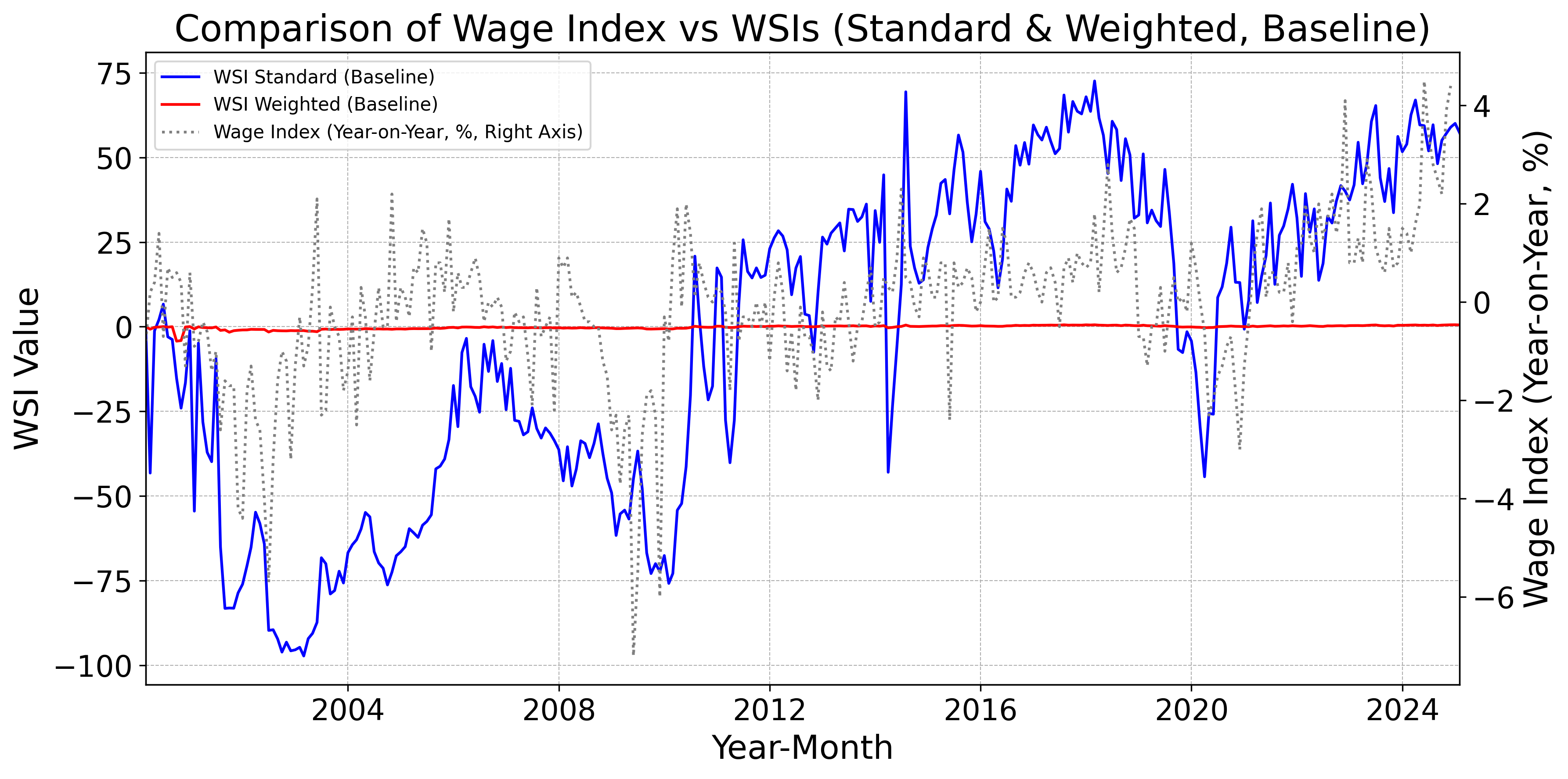 Figure 1
Figure 1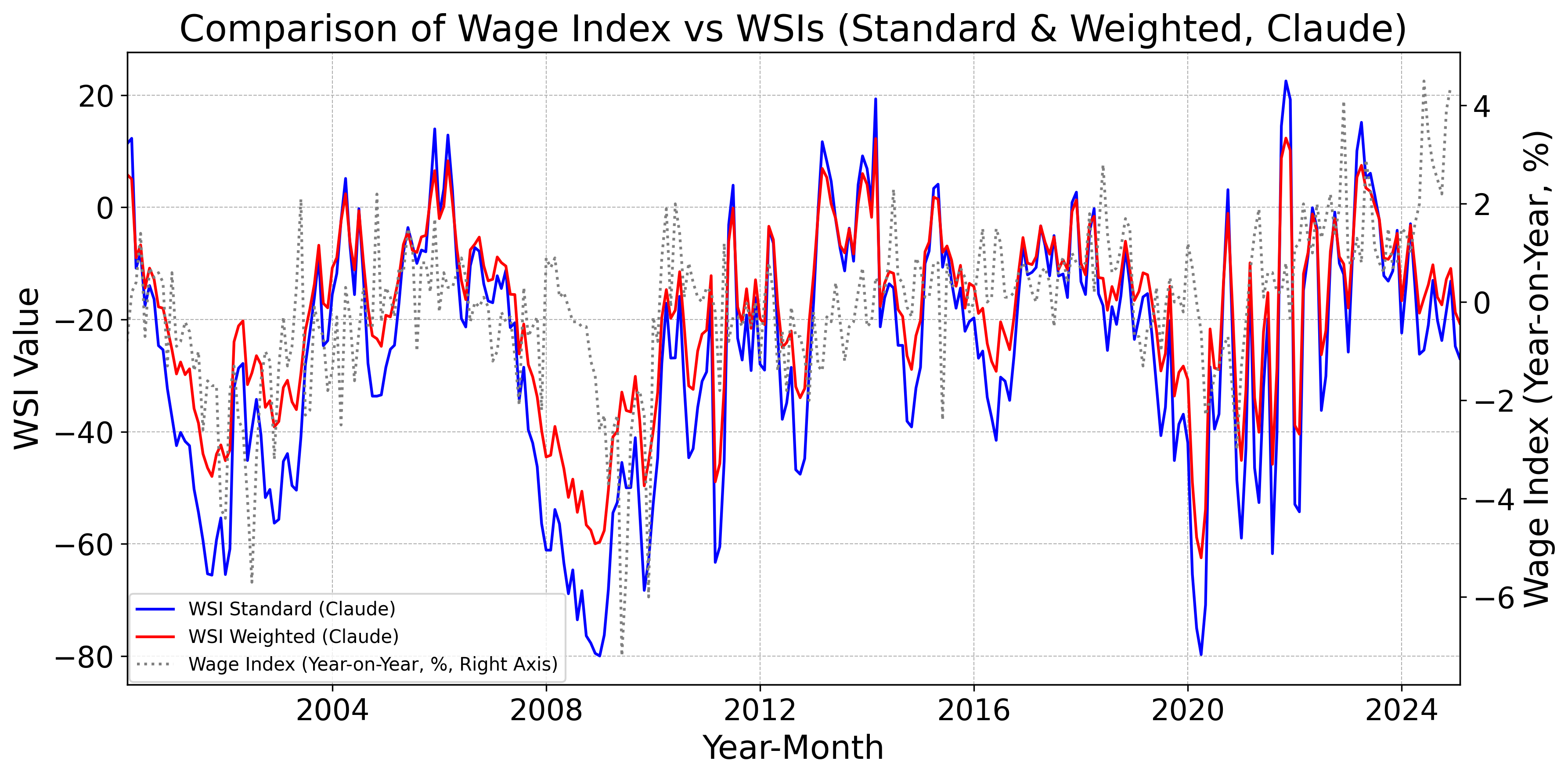 Figure 2
Figure 2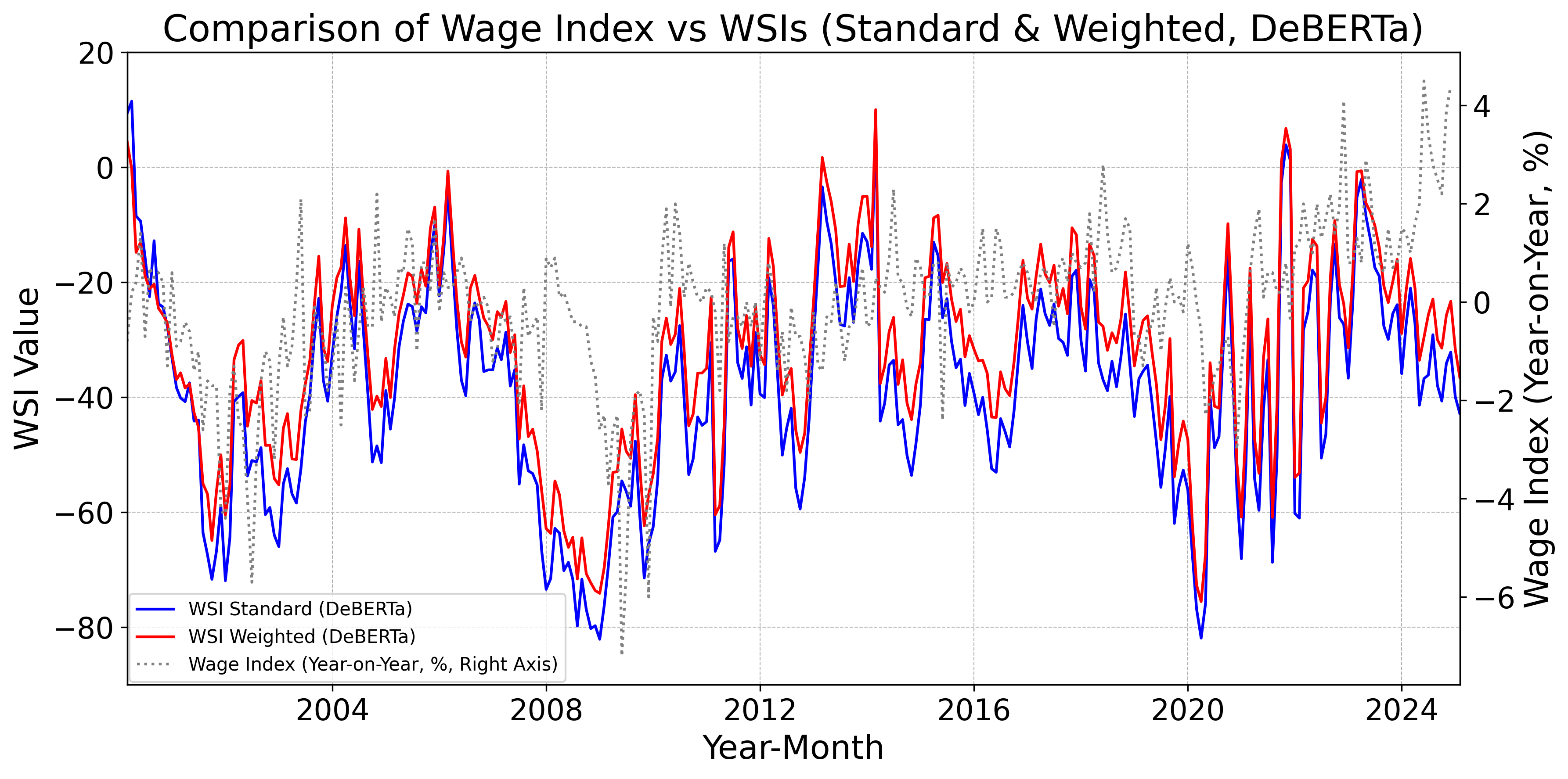 Figure 3
Figure 3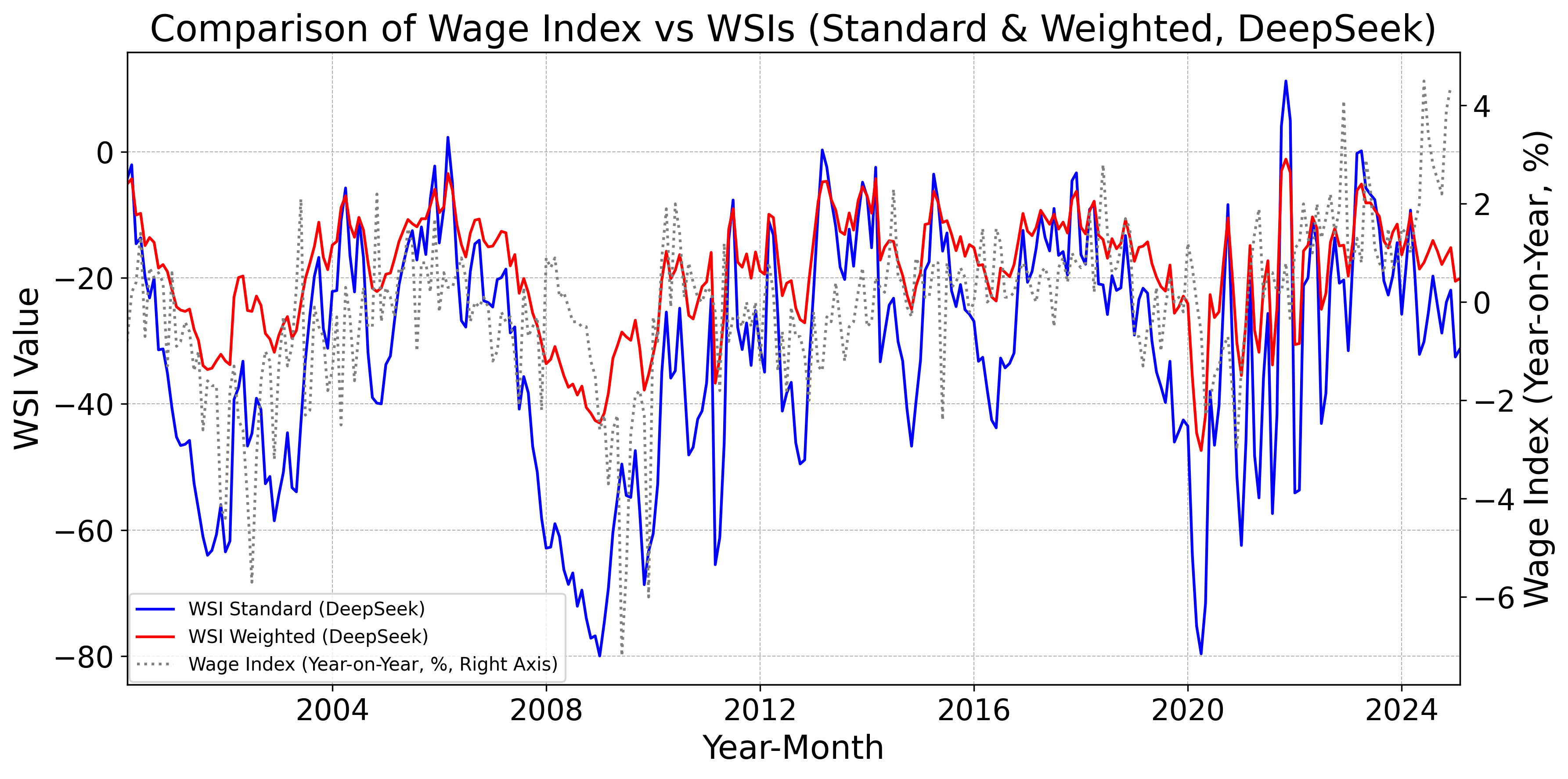 Figure 4
Figure 4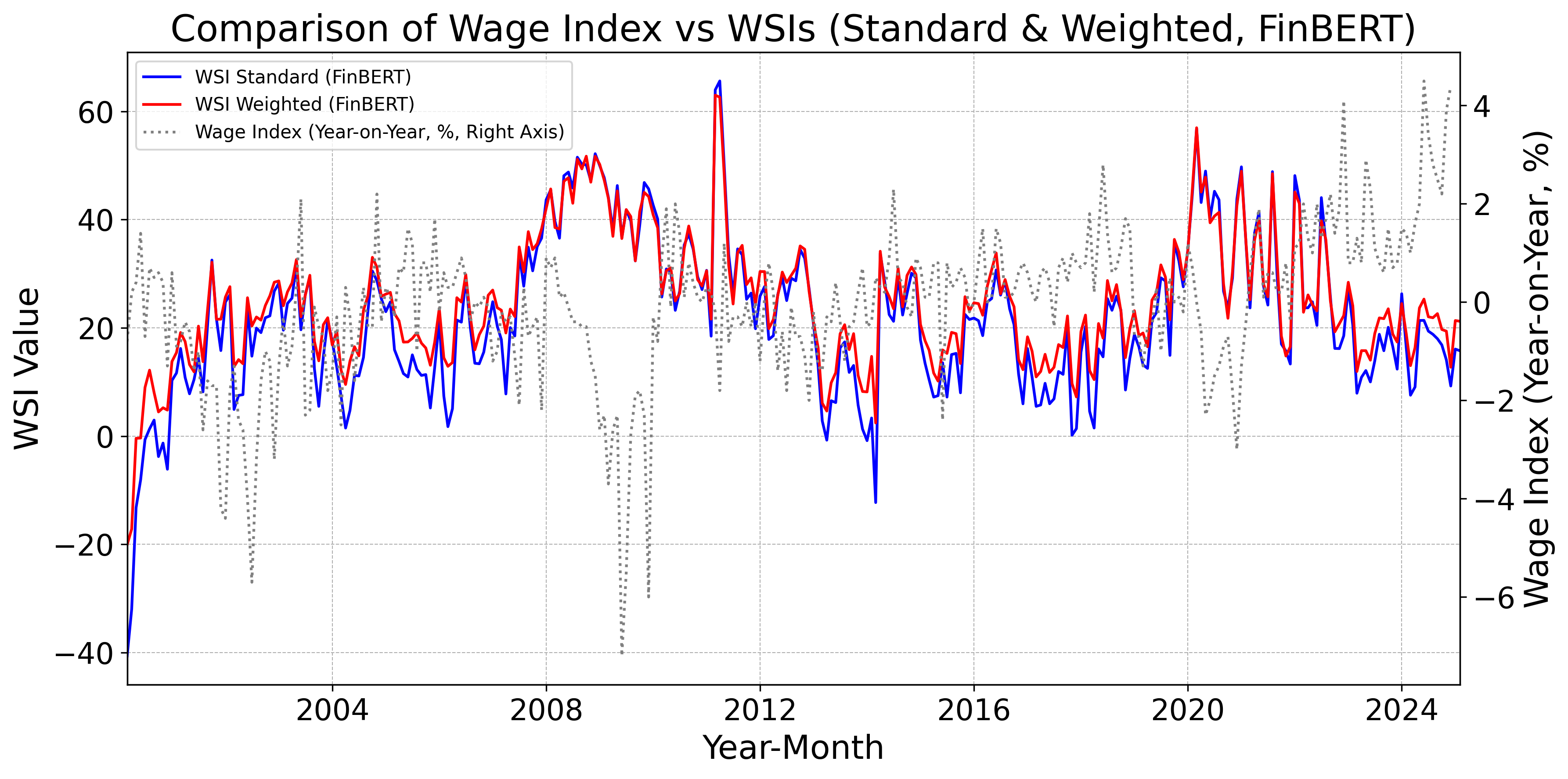 Figure 5
Figure 5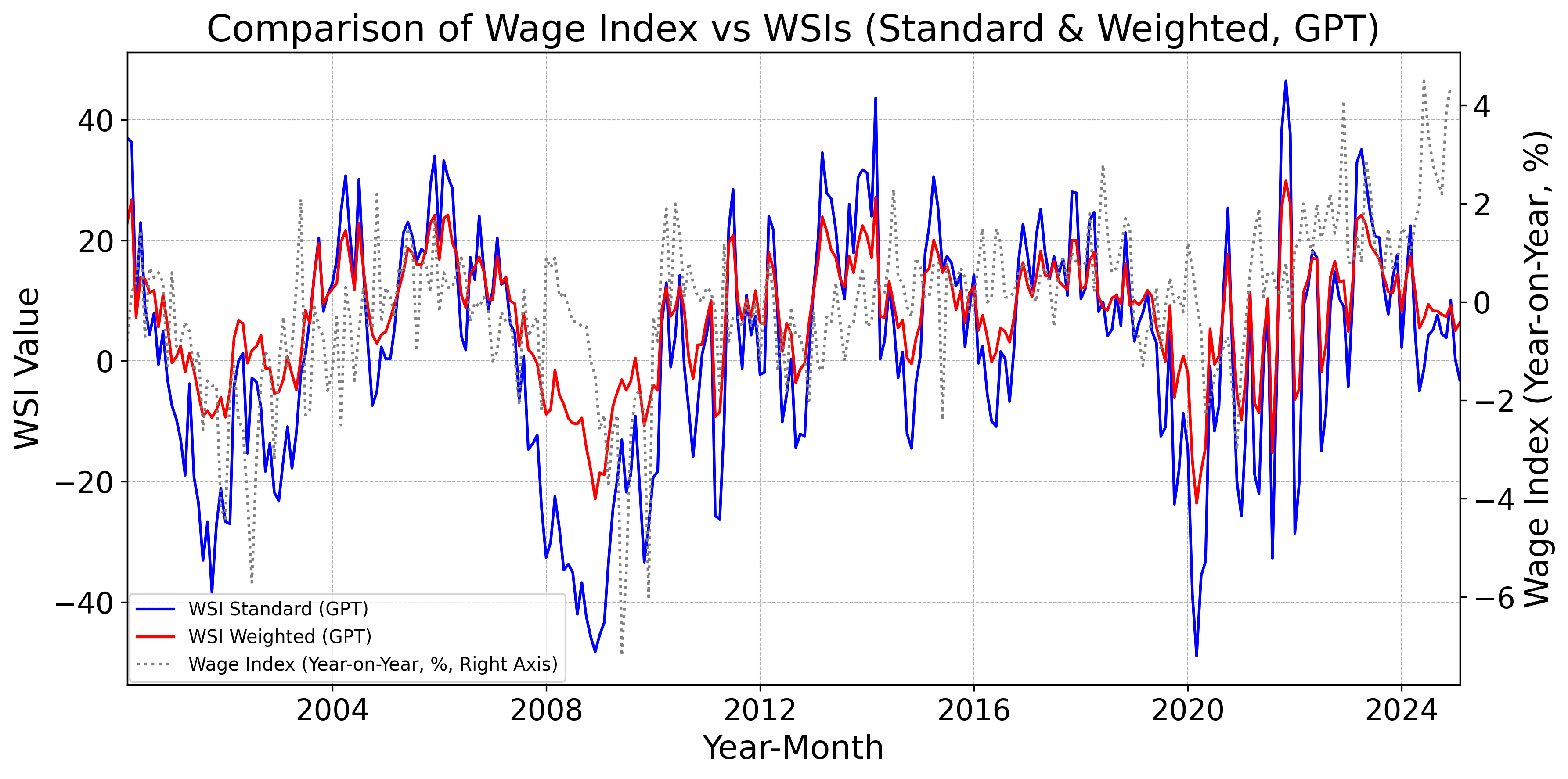 Figure 6
Figure 6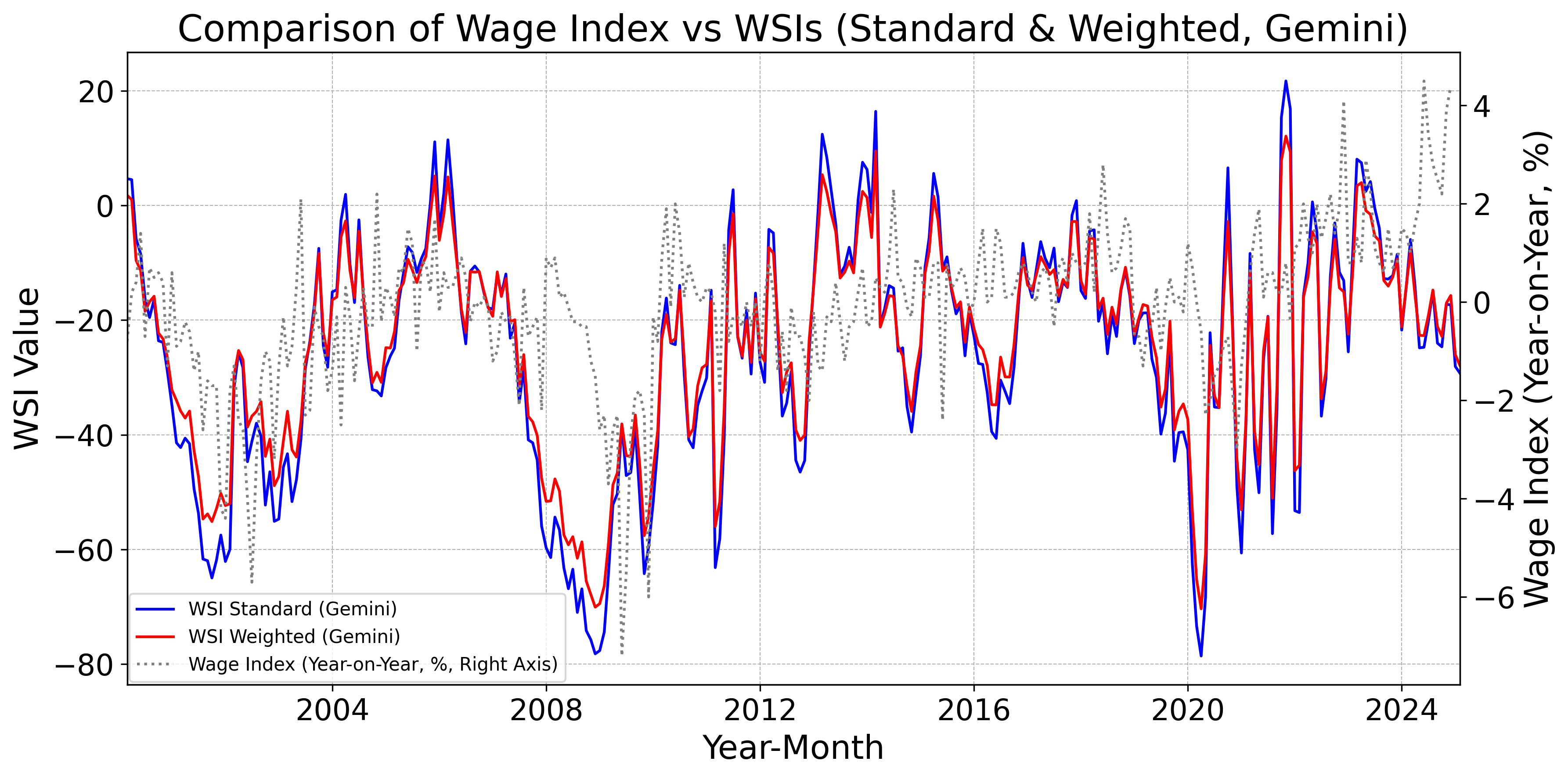 Figure 7
Figure 7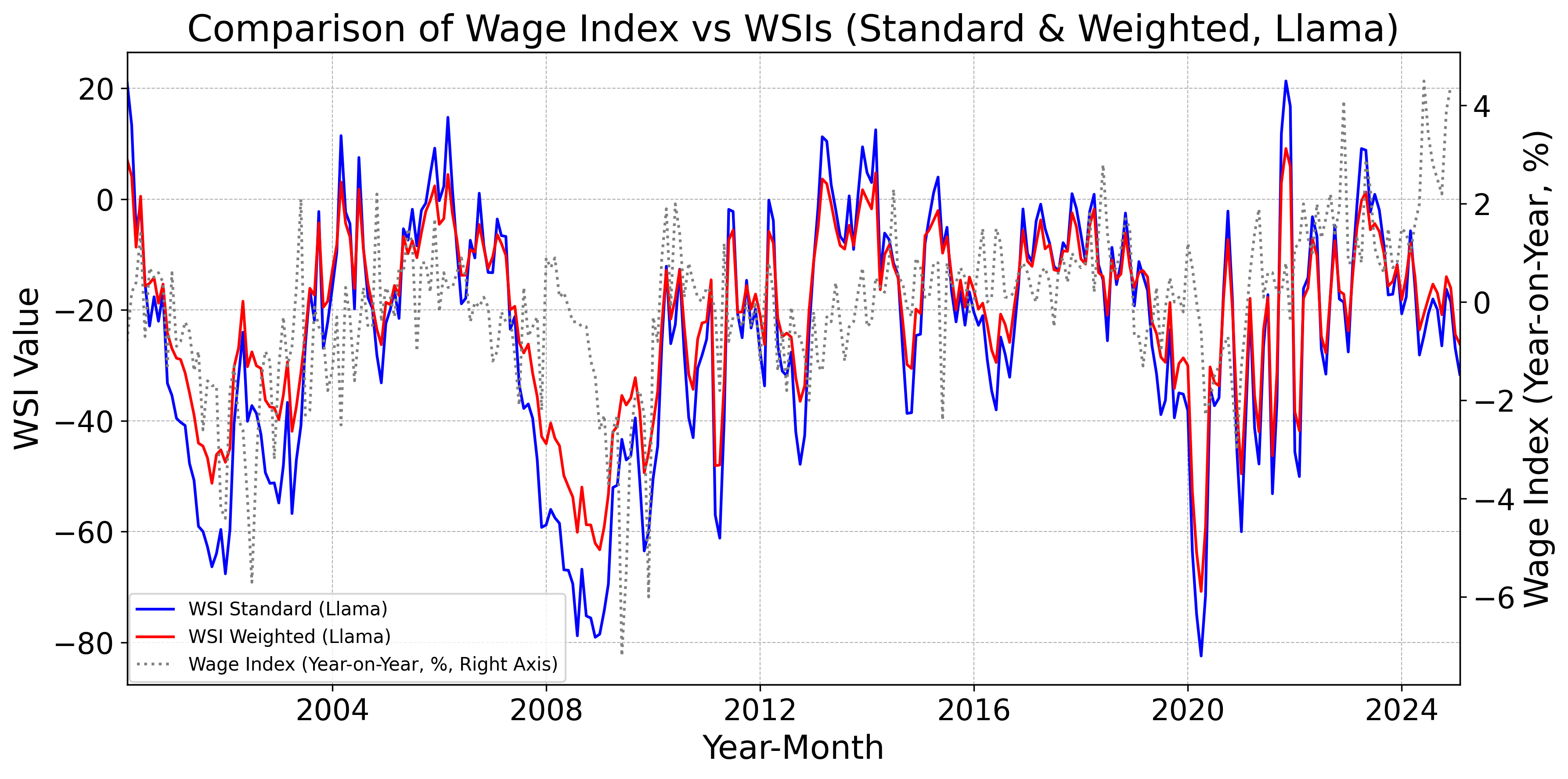 Figure 8
Figure 8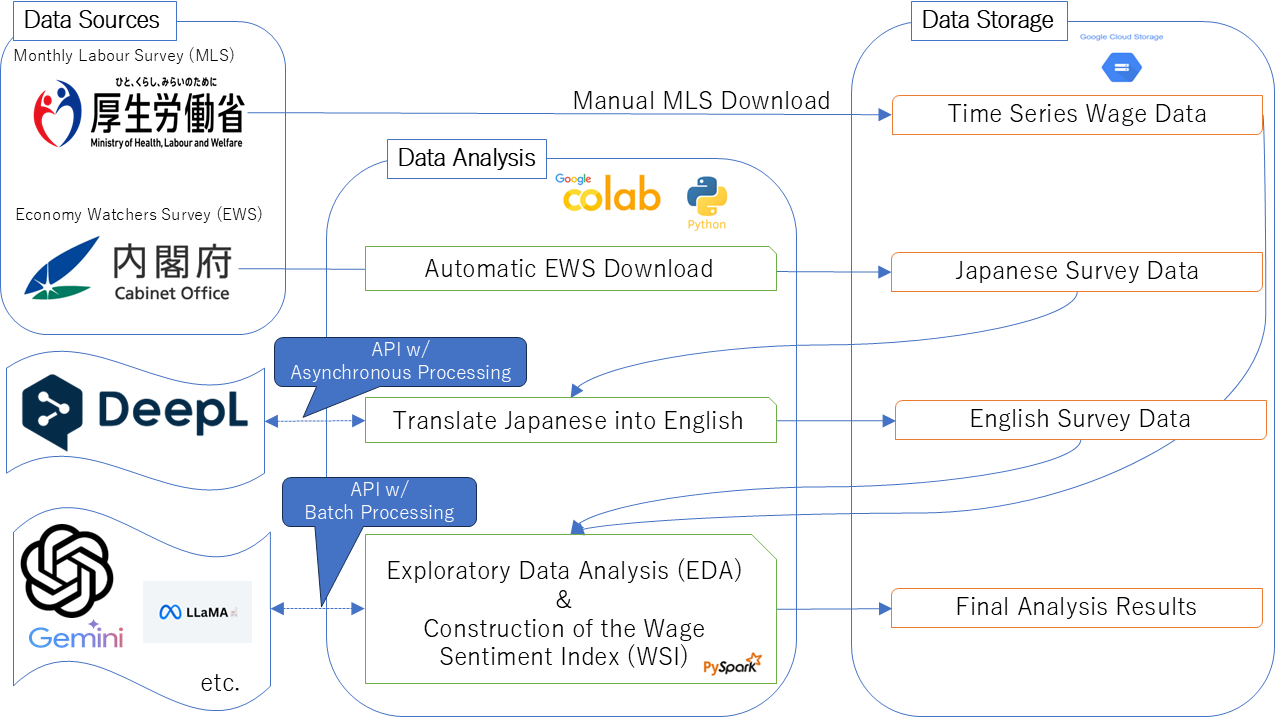 Figure 9
Figure 9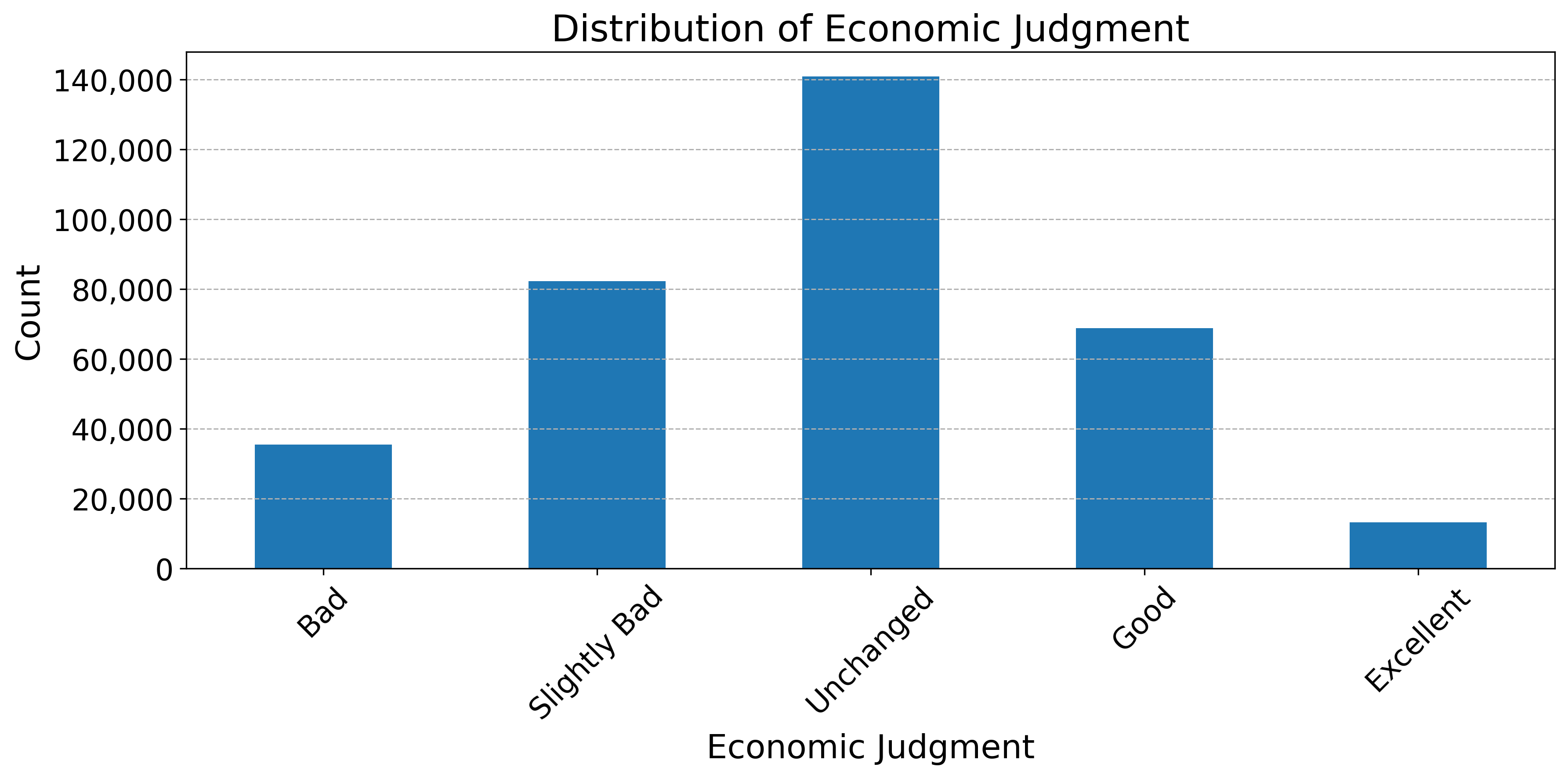 Figure 10
Figure 10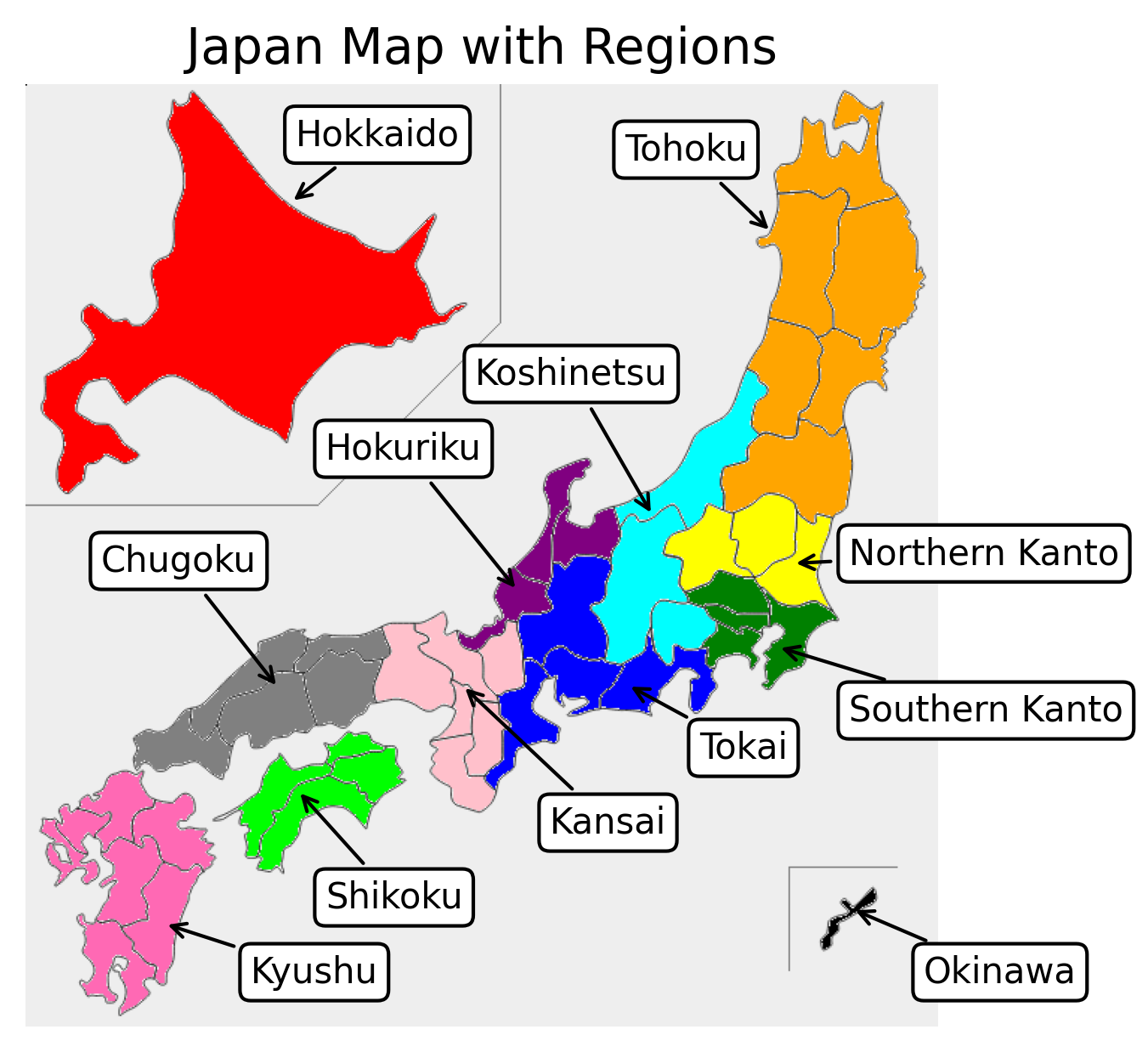 Figure 11
Figure 11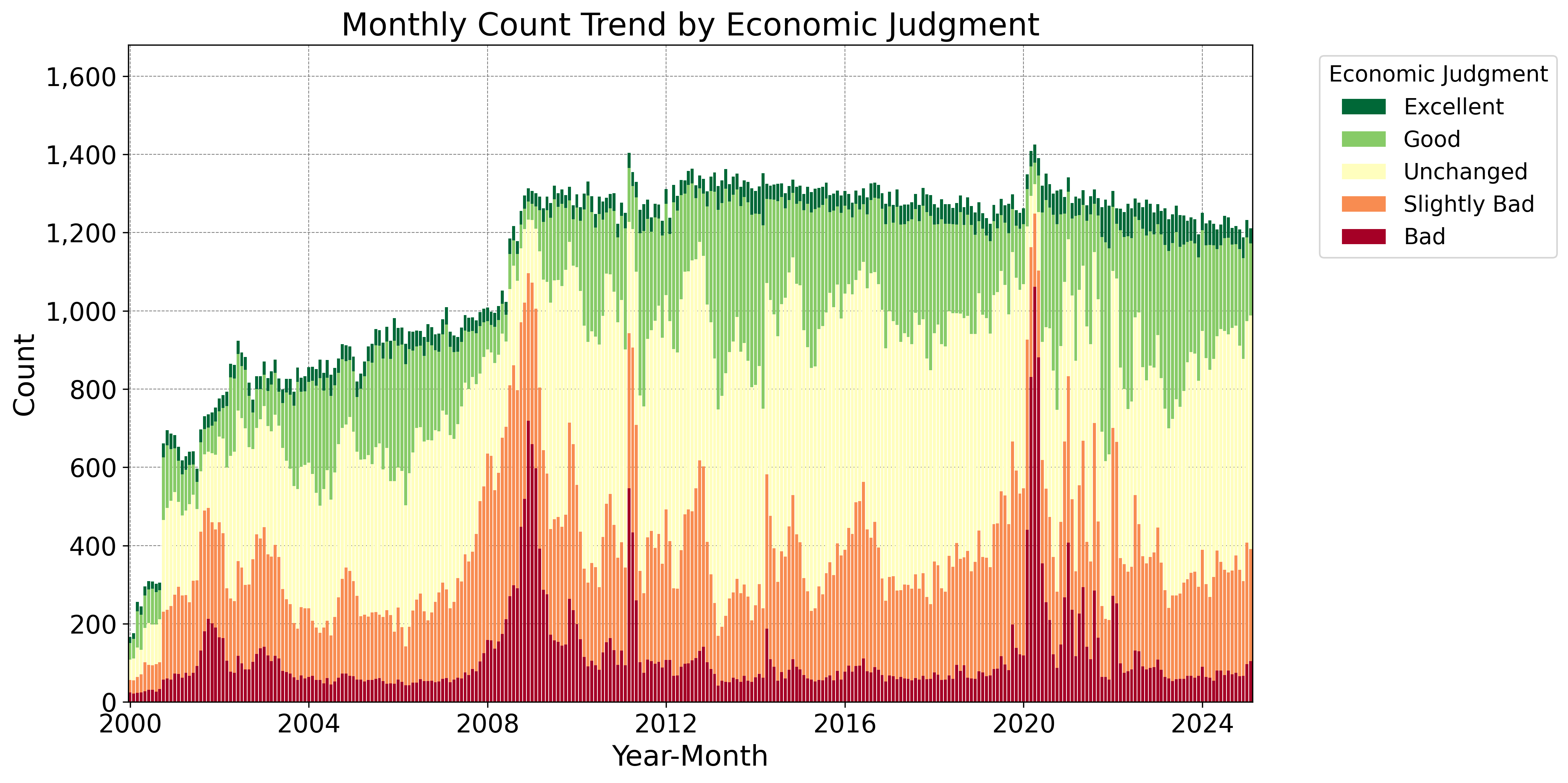 Figure 12
Figure 12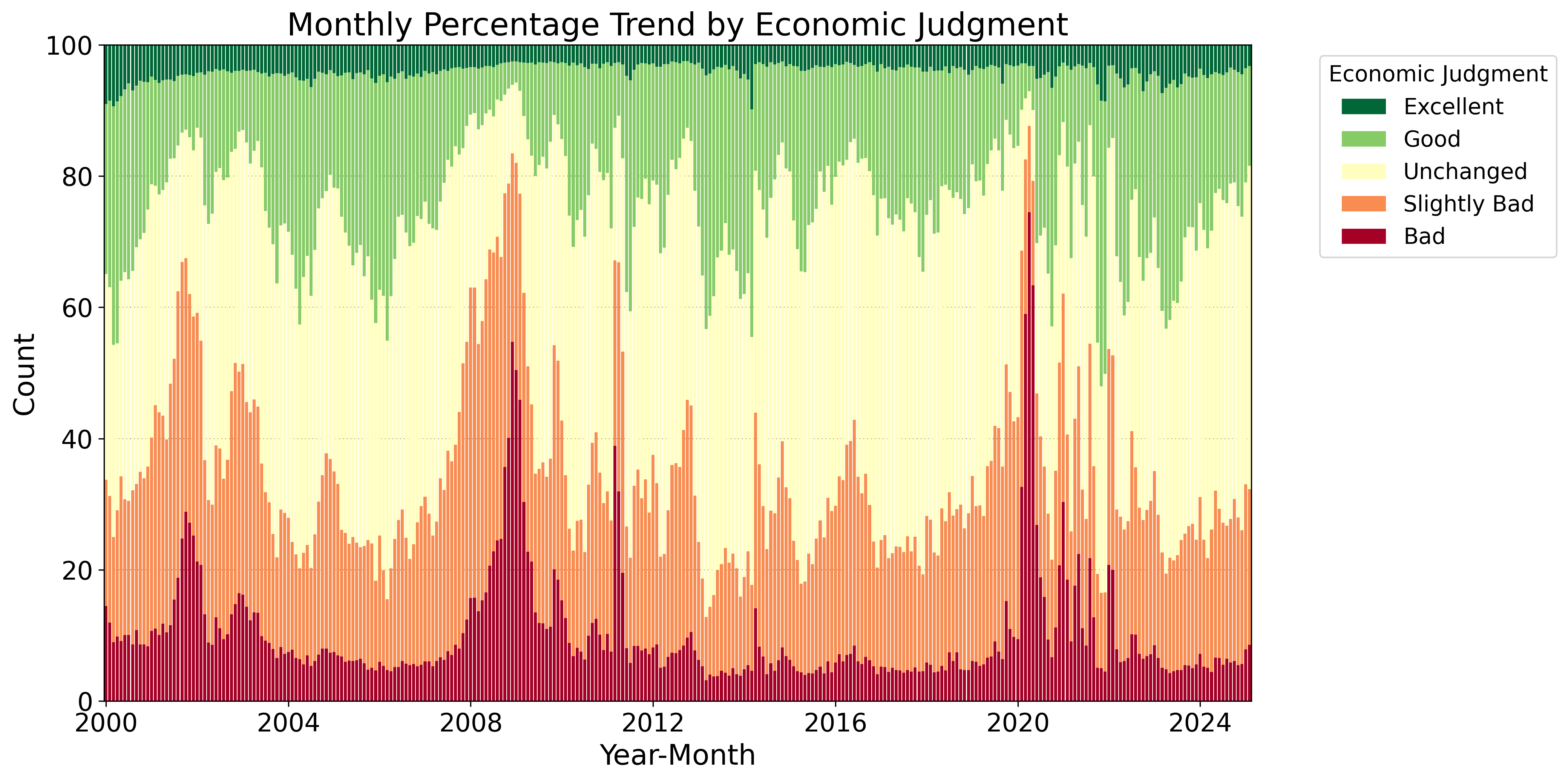 Figure 13
Figure 13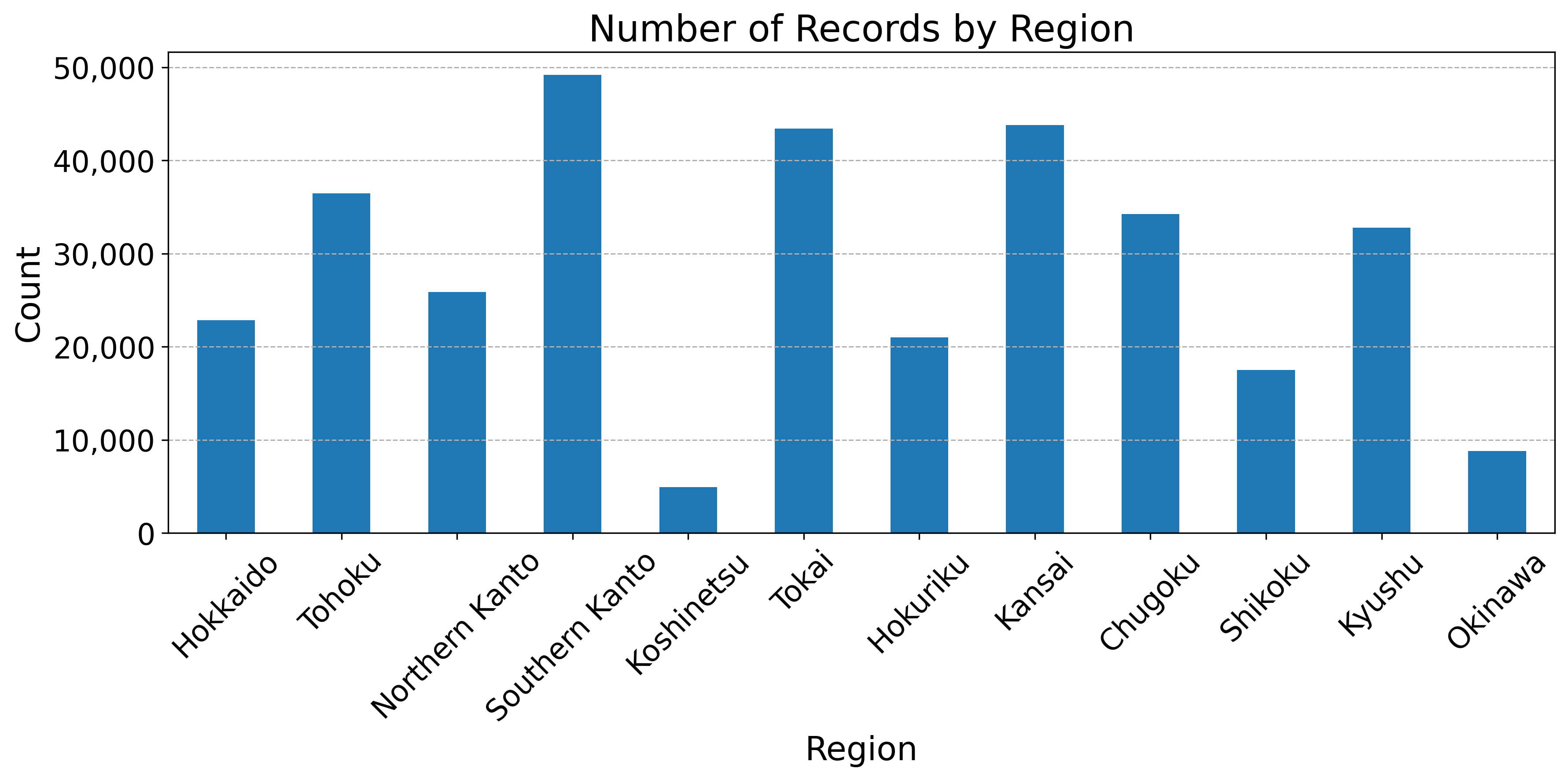 Figure 14
Figure 14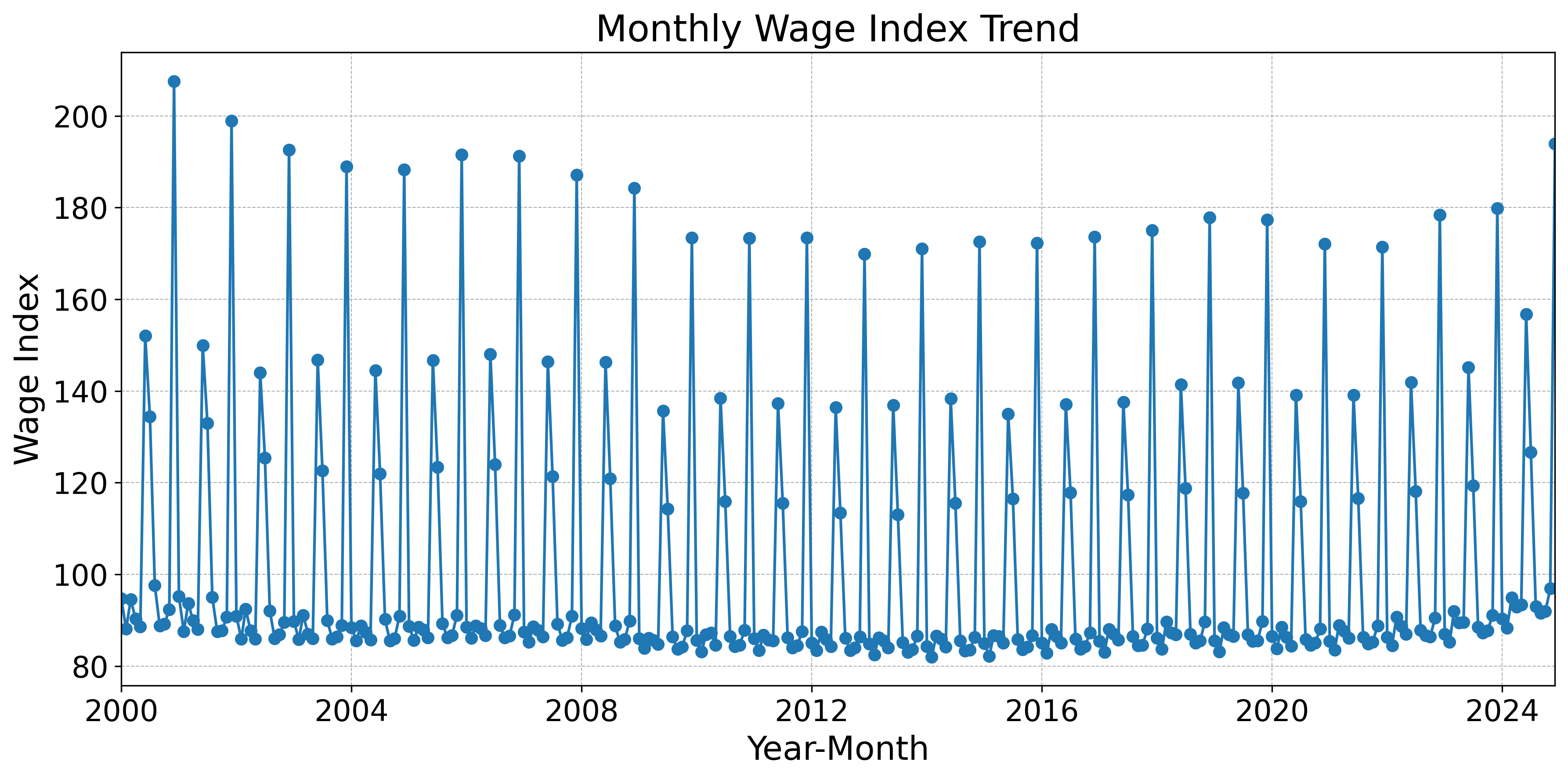 Figure 15
Figure 15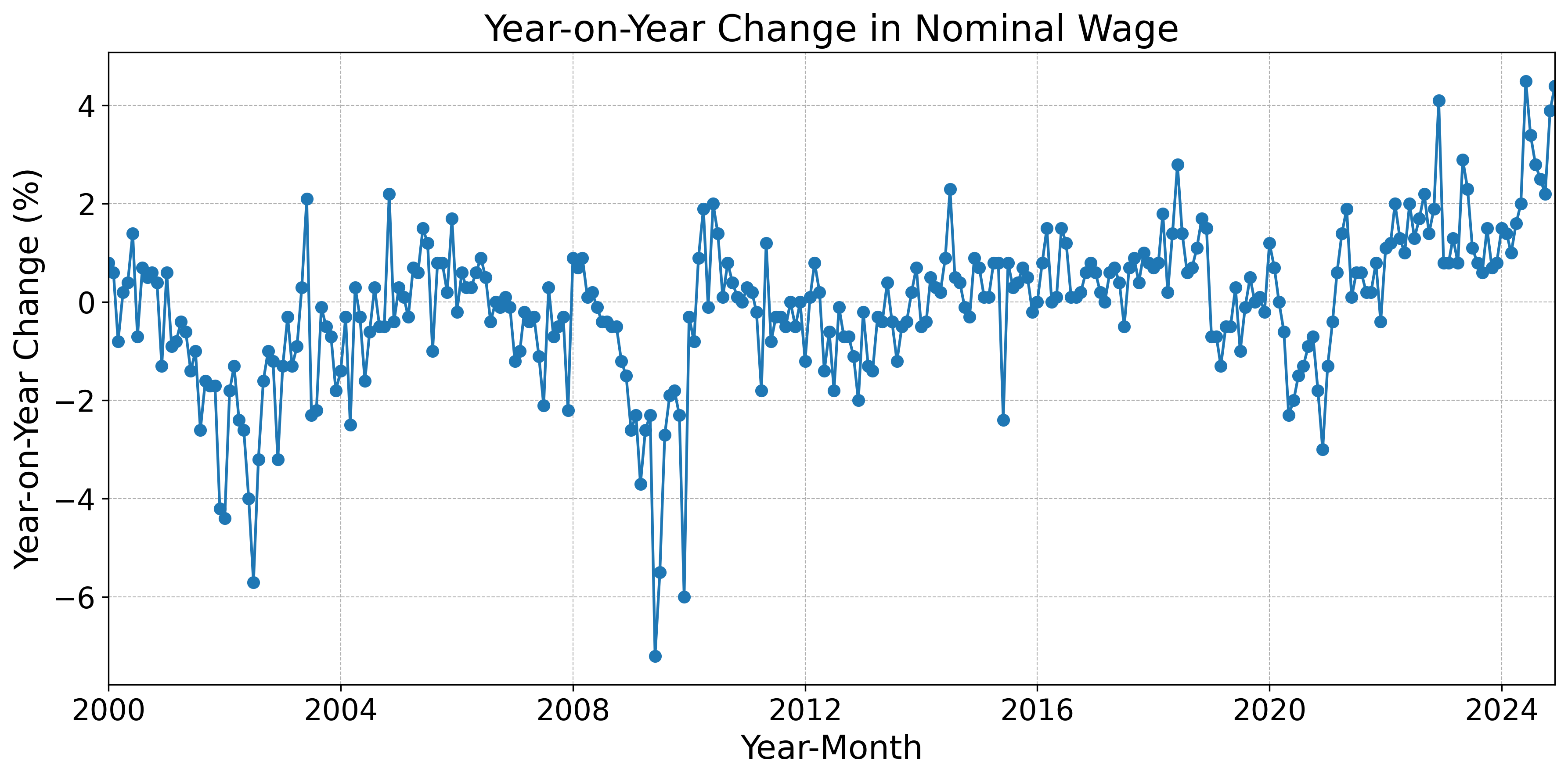 Figure 16
Figure 16| Baseline | FinBERT | DeBERTa | GPT |
| Baseline | FinBERT | DeBERTa | GPT |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputational and Text Analysis Methods · Stock Market Forecasting Methods · Sentiment Analysis and Opinion Mining
Wage Sentiment Indices Derived from Survey Comments via Large Language Models
Taihei Sone
Abstract
The emergence of generative Artificial Intelligence (AI) has created new opportunities for economic text analysis. This study proposes a Wage Sentiment Index (WSI) constructed with Large Language Models (LLMs) to forecast wage dynamics in Japan. The analysis is based on the Economy Watchers Survey (EWS), a monthly survey conducted by the Cabinet Office of Japan that captures real-time economic assessments from workers in industries highly sensitive to business conditions. The WSI extends the framework of the Price Sentiment Index (PSI) used in prior studies, adapting it specifically to wage-related sentiment. To ensure scalability and adaptability, a data architecture is also developed that enables integration of additional sources such as newspapers and social media. Experimental results demonstrate that WSI models based on LLMs significantly outperform both baseline approaches and pretrained models. These findings highlight the potential of LLM-driven sentiment indices to enhance the timeliness and effectiveness of economic policy design by governments and central banks.
I Introduction
Maintaining price stability and sustainable economic growth requires a deep understanding of labor market dynamics, particularly the trends in wages. Wages play a critical role in shaping consumer purchasing power, inflationary pressures, and broader economic activity. In recent years, substantial research has focused on using Large Language Models (LLMs) for analyzing economic data, with much of the emphasis placed on price forecasting. However, despite the importance of wages in economic planning and policy formation, studies on wage prediction through text mining have remained scarce. Traditional methods for wage analysis have relied on structured numerical data, such as employment statistics and industry-specific reports, which have often suffered from publication delays and limited predictive power. By contrast, unstructured textual data from surveys and public sentiment can offer timely and nuanced insights into evolving wage trends.
This study aims to fill this research gap by developing a “Wage Sentiment Index (WSI)” using text analysis on the Economy Watchers Survey (EWS) published by the Cabinet Office of Japan [1]. The WSI was constructed by applying the methodology used to develop the Price Sentiment Index (PSI), as presented in several previous studies [2, 3, 4, 5], to the context of wages. The EWS is a high-frequency, survey-based dataset that captures economic sentiment from various industry professionals and business owners. This study investigates the predictive capability of sentiment-derived indicators for forecasting nominal wages as reported in the Monthly Labour Survey (MLS) [6]. Textual data from the EWS, when analyzed using LLMs, were hypothesized to provide a reliable early indicator of wage movements, allowing policymakers and businesses to react more swiftly to labor market fluctuations. In addition, with a view to incorporating other text data, such as newspapers and social media, into the analysis in the future, a data architecture designed to achieve scalability was built.
The analysis indicated that LLMs showed a tendency to outperform baseline and pretrained models in predicting wage trends with the WSIs. In the future, the aim is to develop a data pipeline capable of automatically and rapidly collecting and processing diverse and large volumes of data to forecast various economic indicators, along with Artificial Intelligence (AI) agents responsible for managing and operating it. This is intended to contribute to the timely and appropriate policy formulation by governments and central banks.
The remainder of this paper is structured as follows. Section II reviews prior literature on text mining in economic analysis, particularly in price and wage forecasting. Section III describes the methodology, including data collection, classification models, and the construction of the WSI. Section IV discusses the data sources used in this study. Section V describes the data architecture constructed to ensure the scalability of the analysis in this study. Section VI verifies the usefulness of each WSI constructed using different models as a leading indicator of wage trends. Finally, Section VII summarizes the findings of this study and suggests avenues for future research.
II Related Literature
Wage prediction has been explored using Machine Learning (ML) and foundation models. In Saudi Arabia, multiple ML models, including Bayesian Gaussian Process regression, have significantly outperformed traditional linear regression [7]. Salary forecasts for data science professionals around the world have been examined using decision trees, random forests, and gradient boosting, highlighting the effectiveness of the decision trees [8]. In the United States, the use of foundation models to estimate wage disparities has shown a 15% improvement in wage prediction accuracy compared to standard econometric models [9]. It is evident that the application of ML and LLM has been advancing in the prediction of wage trends.
Sentiment analysis through text mining has played a crucial role in these labor market predictions. A Labor Market Conditions Index (LMCI) for China has been constructed using media sentiment, effectively tracking wage trends [10]. Social media sentiment analysis has been applied to gauge employment concerns in China, revealing regional sentiment variations [11]. Employee reviews from major tech firms have been analyzed using hybrid ML models to classify workplace satisfaction trends [12]. These approaches highlight the increasing importance of sentiment-driven analysis in labor market research.
Macroeconomic forecasting has also leveraged text mining extensively. Newspaper text analysis has improved Gross Domestic Product (GDP) and Consumer Price Index (CPI) forecasts [13]. Sentiment indices derived from millions of news articles have demonstrated predictive power in European GDP growth [14]. In Malaysia, ML-based sentiment analysis has been used to forecast investment trends [15].
Based on these previous studies, sentiment analysis using ML-based or LLM-based text mining appears to be effective for predicting trends in Japanese wages. As mentioned above, although such analysis is seen in other countries, it is rarely done in Japan. Therefore, this study will address this analysis.
In this case, previous research that has conducted a similar analysis on prices rather than wages can be used as a reference. The “Price Sentiment Index (PSI)” has been developed using a Naive Bayes classifier on the EWS data, demonstrating its role as a leading inflation indicator [2]. Further analysis has explored PSI’s relation to macroeconomic variables [3]. The introduction of multiple LLMs has improved inflation prediction accuracy [4], while refinements in LLM-based PSI models have identified shifts in inflation drivers from raw material costs to labor costs between 2022 and 2024 [5]. In these previous studies, price trends were predicted using PSI constructed using ML and LLMs, and this study aims to predict wage trends by constructing a WSI using a similar approach. In fact, it has been pointed out that there is an increasing need to extend these approaches to other economic indicators beyond the inflation rate, and this study will address the issues left unresolved by previous research [4]. Also, as the Bank of Japan, which is Japan’s central bank, places great importance on whether or not a virtuous cycle of prices and wages can be confirmed in its monetary policy management, there is a particularly high need to predict trends in wages among economic indicators other than prices.
Other uses of LLMs are also progressing, such as in the analysis of the stance of the central bank’s monetary policy. GPT-4 has been used to classify monetary policy stances with high accuracy [16]. Central Bank-specific LLMs (CB-LMs) have demonstrated superior performance in interpreting policy statements [17]. A fine-tuned large language model for central bank communications (CentralBankRoBERTa) have shown high accuracy in sentiment classification for monetary policy analysis [18]. While the analysis in these studies is mainly for private companies to predict the monetary policy of the central bank, the analysis in this study is for the central bank to predict the trends of private companies in order to formulate monetary policy. For this reason, these previous studies and this study are looking in opposite directions.
III Method
III-A How to Calculate the WSIs
The methodology consists of three steps. First, the EWS comments were classified into wage increase, wage decrease, and neutral wage categories using the baseline model, discriminative pretrained language models, and LLMs, with each comment assigned a probability of belonging to each category (see Subsection III-B for details of the baseline, pretrained, and LLM-based models)111When both the wage increase and wage decrease probabilities were zero, the comment was considered unrelated to wages and excluded from the WSIs calculation.. This classification provides a structured basis for text analysis, ensuring accurate capture of key wage sentiment indicators. Second, based on the classified comments, both the standard WSI and the weighted WSI were computed using the following formulas:
[TABLE]
[TABLE]
where
- •
, , and are the number of wage increase comments, wage decrease comments, neutral wage comments in each month , respectively.
- •
, , and indicate the probability that the -th comment in each month is related to a wage increase, a wage decrease, and a neutral wage, respectively.
- •
is the total number of comments in each month , which is equal to the sum of , , and 222Note that comments regarded as unrelated to wages were excluded..
These WSIs serve as a quantitative measure of wage sentiment, enabling comparisons across time periods and economic conditions. Finally, the time series of the WSIs were depicted, followed by a comparison with the nominal wage index (year-on-year) from the MLS to validate their predictive accuracy by means of Granger causality tests.
III-B How to Classify Comments When Calculating the WSIs
III-B1 Baseline Model
First, for each target month, all EWS records from at least two months prior were extracted, considering an approximate two-month lag between EWS reports and official wage statistics (MLS). The comments were transformed into a bag-of-words representation with standard preprocessing: lowercasing, stop word removal, and filtering to retain terms that appeared at least five times per month on average, in accordance with previous research [3]. Second, the Pearson correlation between each term’s monthly frequency and the wage growth index was computed, following previous research [3]. The top ten positively correlated terms and the top ten negatively correlated terms were then selected as positive words and negative words, respectively333When calculating the WSIs for a given month and for another month, the positive and negative words used for the calculation may differ, because the data period used to extract those words differs between the two cases. For example, when calculating the WSIs for December 2020, the positive and negative words are selected in advance using data up to October 2020, whereas when calculating the WSIs for December 2024, the positive and negative words are selected in advance using data up to October 2024. This makes it possible to calculate the WSIs while taking into account the dynamic changes in words related to wage trends.. Finally, the standard WSI and the weighted WSI for the month were calculated based on the occurrence frequency and occurrence ratio of those positive and negative words in the EWS comments for the month.
III-B2 Discriminative Pretrained Language Models
FinBERT and DeBERTaV3 were used to classify comments [19, 20]. These models were not fine-tuned; instead, the general-purpose versions were applied as they were.
III-B3 LLMs
GPT-3.5 Turbo, Claude 3.5 Sonnet, Gemini 1.5 Pro, Llama 3.3 70B444If an error occurred, Llama 3.1 8B was used instead [21]., and DeepSeek-V3-0324 were used to classify comments [22, 23, 24, 25, 26]. These models were not fine-tuned; instead, the general-purpose versions were applied as they were.
IV Data
IV-A The EWS
The EWS, published by the Cabinet Office of Japan, assesses economic conditions based on responses from business managers and employees [1]. It is conducted monthly and is timely, with results published about two weeks after the survey month. This dataset is valuable because it captures real-time sentiment from individuals who are directly involved in economic activities, providing a leading indicator of labor market trends. Data are available from January 2000. Since the EWS responses are mainly recorded in Japanese, the DeepL API was used to translate them into English for analysis [27].
Fig. 1 presents the distribution of judgments in the responses to the EWS from January 2000 to February 2025. The response “Unchanged” appears most frequently, while the persistent Japanese recession over the past several decades is reflected in a greater prevalence of “Slightly Bad” and “Bad” compared to “Excellent” and “Good.”
Fig. 2 shows the number of responses to the EWS by region from January 2000 to February 2025. This shows that there are particularly many responses from “Southern Kanto,” “Tokai,” and “Kansai,” which are areas with a high population density and are the economic centers of Japan. For the locations of each region, please refer to Fig. 3.
Fig. 7 shows the monthly series of the total number of responses to the EWS from January 2000 to February 2025, along with a breakdown of the number of responses for each judgment. An inspection of the figure indicates an increase in the total number of responses from 2000 to around 2008–2009. This likely reflects the impact of the amendment to Japan’s Statistics Act555Japan’s Statistics Act (Act No. 53 of 2007) was promulgated in 2007 and entered into force in 2009. The Act stipulates fundamental matters concerning official statistics compiled by administrative organs and related bodies. It classifies official statistics into two categories—fundamental statistics and general statistics—under which reporting by survey subjects is mandatory for the former but not for the latter. As the EWS is classified as general statistics under the Act, respondents are not legally obliged to report; nevertheless, in response to this legal revision, it appears that the survey population became motivated to respond as a precaution.. The breakdown of the responses shows that the composition ratio of “Slightly Bad” and “Bad” responses has remained relatively high, reflecting the decades-long recession in Japan. In particular, the composition ratio of these responses rose sharply in 2008 (the Lehman Shock) and in 2020 (the COVID-19 shock).
Fig. 7 is a graph in which the total number of responses in Fig. 7 is set to 100%. The interpretation of this graph is the same as that of Fig. 7.
IV-B The MLS
The MLS, published by the Ministry of Health, Labour and Welfare of Japan, tracks wage trends in Japan, but its publication lags by about two months [6]. Given this delay, leveraging the EWS for wage prediction offers practical advantages and allows for both immediate and retrospective analysis, making it possible to track evolving labor market conditions with a higher degree of accuracy. Data are available from January 1990. However, since the EWS data are available only from January 2000 onward as noted in Subsection IV-A, only MLS data from January 2000 onward are used in this study.
Fig. 7 shows the monthly series of the nominal wage index from January 2000 to December 2024. The series exhibits a cyclical pattern: wages typically rise in June and July, coinciding with summer bonus payments, and again in December, when winter bonuses are paid.
Fig. 7 shows the year-on-year change in nominal wages in Japan. The data period is from January 2000 to December 2024. The data show that, after hovering at a low level for several decades, nominal wages have been rising in recent years amid high inflation. Looking back, the negative year-on-year rate of change widened in the early 2000s—when the IT bubble burst and non-regular employment expanded—as well as in 2008 (the Lehman shock) and in 2020 (the COVID-19 shock).
V Data Architecture
In this study, a scalable data architecture was constructed to enable high-speed processing and accommodate future data expansion. The data architecture is presented in Fig. 8. The data sources consist of MLS and EWS, as described in Section IV. MLS has a relatively small data size and is compiled into a single xls file, which is manually uploaded to Google Cloud Storage. In contrast, EWS records the results of current evaluations and future outlook surveys for each month in separate CSV files666In this study, following the approach of [4], only the analysis results for survey responses related to current evaluations are presented.. Manually uploading approximately 600 files covering the past 25 years to Google Cloud Storage would be highly labor-intensive. To streamline this process, Python scripts are executed on Google Colab to automate the data upload.
Among the stored MLS and EWS datasets, MLS contains numerical series of past wage indices, whereas EWS consists of Japanese text reporting past economic confidence. To enhance the accuracy of analysis using discriminative pretrained language models and LLMs trained predominantly on English text, the EWS data are translated into English. Given the impracticality of manual translation, Python scripts executed on Google Colab leverage the DeepL API [27], with asynchronous processing implemented to expedite execution. The translated text is stored in Google Cloud Storage.
Subsequently, exploratory data analysis is conducted, and WSIs are constructed using the translated EWS data and the time series of year-on-year changes in nominal wages from MLS. For each model—whether a baseline model, a discriminative pretrained language model, or a LLM—the WSIs are constructed individually, and this procedure is performed for all models, with batch processing employed to minimize API latency, except for the baseline model.
Additionally, managing data frames with PySpark during the analysis process ensures scalability and supports a design capable of accommodating future data growth. The final analysis results are saved to Google Cloud Storage.
In this way, a data architecture capable of high-speed big data processing has been developed and is utilized for analysis.
VI Results & Discussions
In this chapter, the time series of the WSIs constructed using each model are plotted in Subsection VI-A, and their usefulness as leading indicators of wages is evaluated and compared using the Granger causality test in Subsection VI-B. The data period spans from March 2000 to February 2025777The earliest year and month at which both the EWS and the MLS are available is January 2000. However, in the baseline model, computing the WSI for a given month requires EWS and MLS data from at least two months earlier; consequently, the baseline model can compute the WSI no earlier than March 2000. For consistency, the other models also compute the WSI from March 2000 onward. See Subsubsection III-B1 for details..
VI-A WSI Time Series
Figs. 12–16 display, for the baseline model, FinBERT, DeBERTa, GPT, Claude, Gemini, Llama, and DeepSeek, the monthly standard and weighted WSIs alongside the year-on-year change in nominal wages. Fig. 12 indicates that the baseline WSIs deviate from the year-on-year change in nominal wages. By contrast, Figs. 12 and 12 show that the DeBERTa-based WSIs track the year-on-year change more closely than the FinBERT-based WSIs. Moreover, Figs. 12–16 demonstrate that WSIs constructed with LLMs tend to capture the year-on-year change accurately. Taken together, these findings suggest a clear hierarchy: pretrained models tend to outperform the baseline model as leading indicators of wages, and LLM-based WSIs in turn outperform those built with pretrained models.
VI-B Granger Causality Test
Tables VI-B and VI-B show the results of testing whether there is Granger causality between the standard WSI and the weighted WSI constructed using each model and the year-on-year change in nominal wages.
According to Table VI-B, the standard WSI constructed using LLMs is more useful as a leading indicator of wages than those constructed by the baseline model or by pretrained models. Specifically, when Granger causality tests are applied to the monthly series of the LLM-based standard WSI and the year-on-year change in nominal wages, statistical significance is observed at a greater number of lags. Notably, significance appears at short lags (1–3 months), which are important for policy operations, yielding results consistent with the design objective of compensating for the roughly two-month publication delay of the MLS relative to the EWS.
While Table VI-B yields results largely similar to those in Table VI-B, it differs in that the weighted WSI constructed with DeBERTa exhibits usefulness as a leading indicator of wages comparable to that of the weighted WSIs constructed with LLMs. Specifically, when Granger causality tests are applied to the monthly series of the DeBERTa-based weighted WSI and the year-on-year change in nominal wages, statistical significance is confirmed across a broad range of lags, mirroring the pattern observed when the tests are applied to the LLM-based weighted WSI and nominal wages. This likely reflects the fact that the weighted WSI is more continuous and fine-grained than the standard WSI, aligning well with DeBERTa’s capacity to capture subtle contextual nuances. By contrast, FinBERT’s class probabilities tend to be overly extreme toward positive or negative outcomes, and, whereas DeBERTa is trained on general-purpose text, FinBERT’s training data are skewed toward specialized financial documents; as a result, it is less able to accurately interpret EWS responses from the Japanese general public and, despite also being a pretrained model, fails to match DeBERTa’s performance.
In sum, constructing the WSI with LLMs can compensate for the approximately two-month publication lag of the MLS relative to the EWS; used as a leading indicator of wages, it can thereby support the policy operations of the government and the central bank. Moreover, employing a weighted WSI built with DeBERTa in place of LLMs would likely preserve its usefulness as a leading indicator of wages while reducing the budgetary burden by avoiding the API usage costs associated with LLMs.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Cabinet Office, Government of Japan, “Economy Watchers Survey,” https://www 5.cao.go.jp/keizai 3/watcher-e/index-e.html (English), https://www 5.cao.go.jp/keizai 3/watcher/watcher_menu.html (Japanese).
- 2[2] K. Otaka and K. Kan, “Economic analysis using machine learning - text mining of the Economy Watchers Survey,” Bank of Japan Working Paper Series , vol. 18, no. J-8, 2018, only available in Japanese. [Online]. Available: https://www.boj.or.jp/research/wps_rev/wps_2018/wp 18j 08.htm
- 3[3] J. Nakajima, H. Yamagata, T. Okuda, S. Katsuki, and T. Shinohara, “Extracting firms’ short-term inflation expectations from the Economy Watchers Survey using text analysis,” Bank of Japan Working Paper Series , vol. 21, no. E-12, 2021. [Online]. Available: https://www.boj.or.jp/en/research/wps_rev/wps_2021/wp 21e 12.htm
- 4[4] M. Suzuki and H. Sakaji, “Refined and segmented Price Sentiment Indices from survey comments,” in 2024 IEEE International Conference on Big Data (Big Data) . Los Alamitos, CA, USA: IEEE Computer Society, Dec. 2024, pp. 6642–6650. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/Big Data 62323.2024.10825585
- 5[5] K. Izawa, I. Kamei, N. Shibata, Y. Takahashi, and S. Yoneyama, “A new approach to textual analysis using large language models: application to the analysis of recent wage and price developments in Japan,” Bank of Japan Review Series , vol. 25, no. E-5, 2025. [Online]. Available: https://www.boj.or.jp/en/research/wps_rev/rev_2025/rev 25e 05.htm
- 6[6] Ministry of Health, Labour and Welfare of Japan, “Monthly Labour Survey,” https://www.mhlw.go.jp/english/database/db-l/monthly-labour.html (English), https://www.mhlw.go.jp/toukei/list/30-1.html (Japanese).
- 7[7] Y. T. Matbouli and S. M. Alghamdi, “Statistical machine learning regression models for salary prediction featuring economy wide activities and occupations,” Information , vol. 13, no. 10, 2022. [Online]. Available: https://www.mdpi.com/2078-2489/13/10/495
- 8[8] G. Zhalilova, A. Mamatkasymova, E. Zhusupova, and K. Zhalzhaeva, “Forecasting data science professionals’ salaries using machine learning methods based on real data,” AIP Conference Proceedings , vol. 3244, no. 1, p. 030034, 11 2024. [Online]. Available: https://doi.org/10.1063/5.0242445 · doi ↗