Exploring Reasoning-Infused Text Embedding with Large Language Models for Zero-Shot Dense Retrieval
Yuxiang Liu, Tian Wang, Gourab Kundu, Tianyu Cao, Guang Cheng, Zhen Ge, Jianshu Chen, Qingjun Cui, and Trishul Chilimbi

TL;DR
This paper introduces RITE, a novel method that leverages reasoning capabilities of large language models to generate enriched text embeddings, significantly improving zero-shot dense retrieval performance on reasoning-intensive benchmarks.
Contribution
The paper proposes RITE, a new approach that infuses logical reasoning into text embeddings using generative LLMs, addressing limitations of existing embedding methods.
Findings
RITE outperforms existing methods on the BRIGHT benchmark.
Incorporating reasoning improves zero-shot retrieval accuracy.
RITE demonstrates robustness across diverse domains.
Abstract
Transformer-based models such as BERT and E5 have significantly advanced text embedding by capturing rich contextual representations. However, many complex real-world queries require sophisticated reasoning to retrieve relevant documents beyond surface-level lexical matching, where encoder-only retrievers often fall short. Decoder-only large language models (LLMs), known for their strong reasoning capabilities, offer a promising alternative. Despite this potential, existing LLM-based embedding methods primarily focus on contextual representation and do not fully exploit the reasoning strength of LLMs. To bridge this gap, we propose Reasoning-Infused Text Embedding (RITE), a simple but effective approach that integrates logical reasoning into the text embedding process using generative LLMs. RITE builds upon existing language model embedding techniques by generating intermediate…
Click any figure to enlarge with its caption.
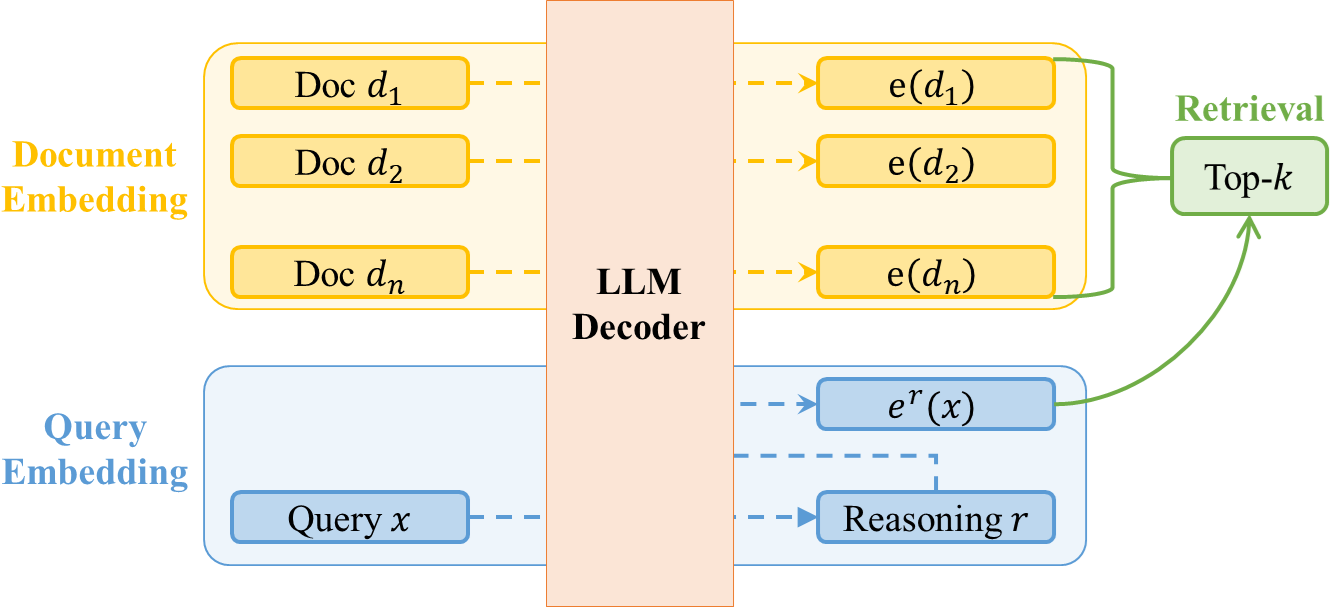 Figure 1
Figure 1| Backbones | Models | Bio. | Earth. | Econ. | Psy. | Rob. | Stack. | Sus. | Leet. | Pony | AoPS | TheoQ. | TheoT. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mistral 7B | Echo | 10.8 | 7.5 | 7.4 | 8.9 | 0.1 | 3.3 | 7.6 | 13.4 | 15.1 | 2.7 | 17.4 | 1.8 | 8.0 |
| RITE-Echo | 17.1 | 11.5 | 8.7 | 10.9 | 2.8 | 4.6 | 8.5 | 15.3 | 25.8 | 3.1 | 17.5 | 2.3 | 10.7 | |
| PR | 4.5 | 6.1 | 3.0 | 5.3 | 1.1 | 2.2 | 2.7 | 12.9 | 2.2 | 0.6 | 16.9 | 2.4 | 5.0 | |
| RITE-PR | 15.1 | 7.3 | 8.2 | 14.1 | 2.3 | 5.0 | 5.9 | 12.1 | 6.7 | 1.6 | 16.9 | 7.5 | 8.6 | |
| LLaMA 3 8B | Echo | 17.7 | 12.4 | 9.2 | 10.9 | 1.2 | 4.2 | 8.3 | 5.4 | 17.6 | 3.4 | 17.7 | 3.3 | 9.3 |
| RITE-Echo | 22.8 | 16.9 | 9.9 | 12.7 | 4.3 | 5.3 | 9.5 | 16.8 | 18.0 | 4.5 | 16.7 | 3.4 | 11.7 | |
| PR | 11.6 | 11.8 | 9.7 | 12.8 | 5.4 | 5.8 | 11.2 | 16.4 | 2.9 | 1.6 | 4.7 | 2.7 | 8.1 | |
| RITE-PR | 14.5 | 13.7 | 11.2 | 17.8 | 5.9 | 6.6 | 10.5 | 19.6 | 7.5 | 1.5 | 21.3 | 11.5 | 11.8 |
| Backbones | Models | Bio. | Earth. | Econ. | Psy. | Rob. | Stack. | Sus. | Leet. | Pony | AoPS | TheoQ. | TheoT. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mistral 7B | RITE-Echo | 17.1 | 11.5 | 8.7 | 10.9 | 2.8 | 4.6 | 8.5 | 15.3 | 25.8 | 3.1 | 17.5 | 2.3 |
| GT-Echo | 17.3 | 11.9 | 10.2 | 11.4 | 2.7 | 4.6 | 9.4 | - | - | 3.9 | 18.4 | 5.7 | |
| LLaMA 3 8B | RITE-Echo | 22.8 | 16.9 | 9.9 | 12.7 | 4.3 | 5.3 | 9.5 | 16.8 | 18.0 | 4.5 | 16.7 | 3.4 |
| GT-Echo | 24.7 | 19.1 | 11.1 | 16.6 | 5.1 | 5.4 | 12.3 | - | - | 5.4 | 18.1 | 8.4 |
| Backbones | Models | Bio. | Earth. | Econ. | Psy. | Rob. | Stack. | Sus. | Leet. | Pony | AoPS | TheoQ. | TheoT. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mistral 7B | RITE-PR | 15.1 | 7.3 | 8.2 | 14.1 | 2.3 | 5.0 | 5.9 | 12.1 | 6.7 | 1.6 | 16.9 | 7.5 |
| GT-PR | 10.0 | 9.9 | 10.7 | 15.1 | 2.8 | 4.1 | 9.5 | - | - | 2.7 | 18.6 | 29.0 | |
| LLaMA 3 8B | RITE-PR | 14.5 | 13.7 | 11.2 | 17.8 | 5.9 | 6.6 | 10.5 | 19.6 | 7.5 | 1.5 | 21.3 | 11.5 |
| GT-PR | 16.2 | 17.9 | 17.8 | 23.8 | 5.2 | 6.4 | 14.3 | - | - | 3.3 | 19.9 | 33.5 |
| Type | Text | nDCG@10 |
|---|---|---|
| Query | Do animals exhibit handedness (paw-ness?) preference? I have been observing my cat and found that when confronted with an unknown item, she will always use her front left paw to touch it. This has me wondering if animals exhibit handedness like humans do? (and do I have a left handed cat?) One note of importance is that with an unknown item, her approach is always identical, so possibly using the left paw means allowing a fast possible exit based on how she positions her body. This question is related to Are there dextral/sinistral higher animals?. However, I question the "paw-ness" as a consequence of how the cat is approaching new items (to be ready to flee), whereas the other question remarks about the high number of "right-pawed" dogs and questions the influence of people for this preference. | |
| Oracle | The question investigates if animals display limb preference, as observed in a cat favoring one paw. The document confirms that limb dominance is common across species, including mammals, birds, and invertebrates, thereby supporting the notion of widespread ‘paw-ness’ in animals. | 0.2372 |
| RITE | To answer your question, a more specific search query would be: "Do animals exhibit lateralized behavior or paw preference in performing tasks or interacting with objects?" Relevant documents should include: * Studies on animal cognition and behavior * Research on lateralization in non-human primates, birds, and other animals | 0.8503 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Advanced Graph Neural Networks · Information Retrieval and Search Behavior
\setcctype
by
Exploring Reasoning-Infused Text Embedding with Large Language Models for Zero-Shot Dense Retrieval
Yuxiang Liu
University of Illinois at Urbana-ChampaignUrbanaUSA
,
Tian Wang
AmazonPalo AltoUSA
,
Gourab Kundu
AmazonNew YorkUSA
,
Tianyu Cao
AmazonPalo AltoUSA
,
Guang Cheng
AmazonLos AngelesUSA
,
Zhen Ge
AmazonNew YorkUSA
,
Jianshu Chen
AmazonPalo AltoUSA
,
Qingjun Cui
AmazonPalo AltoUSA
and
Trishul Chilimbi
AmazonPalo AltoUSA
(2025)
Abstract.
Transformer-based models such as BERT and E5 have significantly advanced text embedding by capturing rich contextual representations. However, many complex real-world queries require sophisticated reasoning to retrieve relevant documents beyond surface-level lexical matching, where encoder-only retrievers often fall short. Decoder-only large language models (LLMs), known for their strong reasoning capabilities, offer a promising alternative. Despite this potential, existing LLM-based embedding methods primarily focus on contextual representation and do not fully exploit the reasoning strength of LLMs. To bridge this gap, we propose Reasoning-Infused Text Embedding (RITE), a simple but effective approach that integrates logical reasoning into the text embedding process using generative LLMs. RITE builds upon existing language model embedding techniques by generating intermediate reasoning texts in the token space before computing embeddings, thereby enriching representations with inferential depth. Experimental results on BRIGHT, a reasoning-intensive retrieval benchmark, demonstrate that RITE significantly enhances zero-shot retrieval performance across diverse domains, underscoring the effectiveness of incorporating reasoning into the embedding process.
Retrieval, Embedding, Language Model Embedding, LLMs
††journalyear: 2025††copyright: cc††conference: Proceedings of the 34th ACM International Conference on Information and Knowledge Management; November 10–14, 2025; Seoul, Republic of Korea††booktitle: Proceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM ’25), November 10–14, 2025, Seoul, Republic of Korea††doi: 10.1145/3746252.3760855††isbn: 979-8-4007-2040-6/2025/11††submissionid: csp3860††ccs: Information systems Language models
1. Introduction
Information retrieval is fundamental to numerous applications, including search (Kobayashi and Takeda, 2000), recommendation (Isinkaye et al., 2015), retrieval-augmented generation (Liu and Chang, 2025; Xu et al., 2024a), and question answering (Zhang et al., 2024b). Effective retrieval relies on accurately representing large-scale text corpora and efficiently mapping queries to relevant information, with text embeddings playing a crucial role in capturing semantic nuances (Patil et al., 2023; Jin et al., 2025).
Transformer-based encoders like BERT (Devlin et al., 2019) or E5 (Wang et al., 2022) significantly advance embedding by leveraging contextual representations to improve semantic understanding. However, real-world queries often require sophisticated reasoning, inference, and an understanding of implicit relationships beyond surface-level token similarity. Encoder-only retrievers, despite their success, frequently struggle with complex reasoning tasks (Xiao et al., 2024; Liu et al., 2023), necessitating additional components such as pre-retrieval query augmentation (Ma et al., 2023a; Wang et al., 2024b) or post-retrieval cross-document reasoning (Yu et al., 2023; Trivedi et al., 2023) to bridge the gap.
Meanwhile, Large language models (LLMs) (Jiang et al., 2023b; Achiam et al., 2023; Ji and Luo, 2025; Luo and Ji, 2025a; Yang et al., 2025, 2024; Luo and Ji, 2025b) exhibit strong reasoning capabilities that make them attractive for information retrieval (Xu et al., 2024b). Recent research has explored their use in text embeddings via direct extraction (Zhuang et al., 2024), distillation (Lee et al., 2024), or fine-tuning (Ma et al., 2023b; Wang et al., 2024a; BehnamGhader et al., 2024; Muennighoff et al., 2024). However, these approaches primarily focus on encoding contextual representations while underutilizing LLMs’ intrinsic reasoning abilities, which are crucial for interpreting complex queries (Xu et al., 2024c) and establishing deeper semantic relationships.
To address this gap, we propose Reasoning-Infused Text Embedding (RITE), a novel approach that seamlessly integrates reasoning into the embedding process using a single generative model. Unlike traditional methods that decouple reasoning and embedding across multiple components, RITE employs an LLM to directly perform reasoning in the token space before embedding extraction. This unified approach enables richer semantic representations, particularly in cases where complex understanding is required.
Building upon prior language model embedding techniques such as Echo (Springer et al., 2024) and PromptReps (Zhuang et al., 2024), RITE demonstrates substantial improvements in zero-shot retrieval performance when evaluated on BRIGHT (Su et al., 2024), a reasoning-intensive retrieval benchmark. Our results highlight the advantages of reasoning-infused embeddings, suggesting that integrating inferential depth into language model embeddings can significantly enhance retrieval capabilities. Furthermore, this work underscores the potential for future advancements through fine-tuning and optimization strategies, paving the way for more robust and intelligent retrieval systems.
2. Methodology
We propose Reasoning-Infused Text Embedding (RITE) to enhance zero-shot dense retrieval by incorporating reasoning into embedding using LLMs. RITE extends the capabilities of existing zero-shot embedding methods, Echo (Springer et al., 2024) and PromptReps (Zhuang et al., 2024), by involving an explicit reasoning step before embedding extraction.
2.1. Zero-Shot Language Model Embedding
Zero-shot dense retrieval leverages LLM-generated embeddings to retrieve relevant documents without training. We build upon two existing zero-shot embedding methods: Echo (Springer et al., 2024) and PromptReps (Zhuang et al., 2024), both of which serve as fundamental components of RITE.
Echo (Springer et al., 2024) addresses the inherent limitation of auto-regressive language models, which lack bidirectional contextual awareness in a single forward pass. Echo hypothesizes that repeating a text sequence enables the model to reinforce its understanding of the sentence structure, thereby improving representation quality. To operationalize this, Echo applies a self-repetition strategy and extracts the mean token representation of the second occurrence of an input text . The embedding is generated using the prompt111Note that ”query” in all prompts can be replaced with ”passage” when generating document embeddings.: Rewrite the query: , rewritten query: .
PromptReps (PR) (Zhuang et al., 2024) leverages the compressive power of LLMs by instructing them to summarize a query or document into a single-word representation. Inspired by prior work on constrained-text embeddings (Jiang et al., 2023a; Zhang et al., 2024a), PR generates an embedding by extracting the first output token from the prompt: Query: . Use one most important word to represent the query in a retrieval task. Make sure your word is in lowercase. The word is: “.
While Echo and PR generate high-quality embeddings, neither method explicitly incorporates reasoning, which is essential for complex queries requiring inference. To address this gap, RITE integrates an additional reasoning step, enriching query representations with deeper semantic and inferential understanding.
2.2. Reasoning-Infused Text Embedding (RITE)
While Echo and PR effectively generate semantic-rich embeddings, they do not explicitly integrate logical reasoning, which is crucial for handling complex queries requiring inference. RITE (Figure 1) extends these methods by injecting a reasoning step before embedding extraction, enriching query representations with inferential depth. RITE improves query embeddings by introducing a reasoning stage before embedding extraction. It consists of three key steps: (1) Reasoning Elicitation: Generate an inferentially enriched reasoning text from the query. (2) Embedding Extraction: Apply Echo or PR on the reasoning-infused query to obtain a final embedding. (3) Document Retrieval: Compute similarity between the query and document embeddings to retrieve the most relevant documents. A high-level overview of the RITE framework is illustrated in Figure 1.
2.2.1. Step 1: Eliciting Reasoning
Given a query , we first prompt the LLM to generate a reasoning text that provides additional contextual understanding, reformulation, or inferential expansion of the query. This is done using a reasoning-specific prompt , resulting in the generated reasoning text:
[TABLE]
We experiment with the following three reasoning prompts designed to elicit deeper query understanding, which encourage LLM to reformulate the query in a more retrieval-effective manner.
Prompt 1: Query: . After thinking step by step, provide a better search query for search engine to answer the given question.
Prompt 2: Query: . Think step by step to reason about what is the essential problem of this question, and what should be included in the relevant documents. Make your response concise.
Prompt 3: Query: . After thinking step by step, provide a better search query for search engine to answer the given question, and identify what should be included in the relevant documents. Make your response concise.
2.2.2. Step 2: Embedding Extraction
Once reasoning is generated, it is prepended to the original query before embedding. RITE extends Echo and PR to integrate the reasoning, resulting in two variants: (1) RITE-Echo: Applies the Echo repetition strategy to the reasoning-enriched query. (2) RITE-PR: Extracts a compressed reasoning-infused representation using the PR method.
These embedding strategies are formulated as follows: (1) RITE-Echo: [Reasoning text] Rewrite the query: , rewritten query: . (2) RITE-PR: Query: . [Reasoning text] Use one most important word to represent the query in a retrieval task. Make sure your word is in lowercase. The word is: “. By incorporating explicit reasoning, RITE ensures that the embeddings capture not only semantic similarity but also the underlying logical structure of the query.
2.2.3. Step 3: Document Retrieval
For each document in the corpus , an embedding is generated using either Echo or PR without reasoning augmentation. Retrieval is then performed by computing the cosine similarity between the reasoning-infused query embedding and the document embeddings:
[TABLE]
The top- documents with the highest similarity scores are retrieved as the most relevant results. By incorporating logical reasoning into the embedding process, RITE enables more robust retrieval of documents relevant to complex, inferential queries.
3. Experimental Setup
3.1. Datasets and Evaluation Metrics
To evaluate the effectiveness of Reasoning-Infused Text Embedding (RITE), we employ the BRIGHT benchmark (Su et al., 2024), a collection of 12 retrieval datasets spanning diverse domains such as biology, economics, psychology, robotics, and theoretical disciplines. These datasets are designed to assess retrieval models’ ability to handle complex queries requiring logical reasoning and inference.
We measure retrieval performance using Normalized Discounted Cumulative Gain at rank 10 (nDCG@10), a standard metric that captures both relevance ranking quality and retrieval effectiveness.
3.2. Implementation Details
We use Mistral 7B and LLaMA 3 8B, two open-source LLMs, as our backbone models. We employ their instruction-tuned variants and set the following hyperparameters for retrieval experiments: temperature to 0, frequency penalty to 0.3, limit the number of response choices to 1, and set maximum input lengths to 256 for passages and 128 for queries. The maximum generation tokens (for reasoning text) are selected from 256, 128, or 64, choosing the value that yields the best retrieval performance for each model.
For Echo, the embedding is derived from the last-layer hidden states before generating each token in the second occurrence of . While Springer et al. (2024) also considered using the last token representation, the mean token representation was found to be more effective in zero-shot scenarios, so we adopt it here. For PR, the embedding is taken from the last-layer hidden state before generating the first output token. Although Zhuang et al. (2024) also experimented with the average over multiple output tokens, we choose the first-token representation for simplicity and efficiency.
Similarly, for RITE-Echo, we extract the mean token representation of the second occurrence of as the embedding; for RITE-PR, we extract the hidden state corresponding to the first output token as the embedding, consistent with above.
4. Results
In this section, we analyze the performance of retrieval models across multiple domains using reasoning-infused embeddings. The evaluation considers the impact of reasoning-based infusion on retrieval effectiveness and further compares model-generated reasoning with oracle (human-crafted) reasoning.
4.1. Impact of Reasoning on Retrieval
To assess the effectiveness of reasoning-based embeddings, we compare RITE-enhanced methods (RITE-Echo and RITE-PR) against their respective baselines (Echo and PR) using the BRIGHT benchmark, as shown in Table 1.
For the Mistral 7B model, we observe a consistent performance boost with RITE-Echo, surpassing Echo across all categories. The most significant improvements include Biology (+58%), Economics (+18%), and Programming (Pony) (+71%). Similarly, RITE-PR shows substantial enhancements over PR, with notable gains in Psychology (+166%) and Biology (+236%). These findings indicate that reasoning-based embeddings lead to superior retrieval accuracy by enhancing the contextual understanding of queries, allowing for better alignment with relevant documents.
A similar pattern emerges for the LLaMA 3 8B model, where RITE-Echo improves retrieval effectiveness, particularly in Earth Sciences (+36%) and Robotics (+258%). Moreover, RITE-PR significantly enhances retrieval in Psychology (+39%) and TheoremQA (+353%). These results reinforce that reasoning-enriched embeddings benefit retrieval in both factual and theoretical domains by bridging the gap between query intent and document relevance.
Additionally, these improvements suggest that reasoning-infused embeddings enhance the model’s ability to handle complex and domain-specific queries. By incorporating reasoning, RITE-based approaches mitigate lexical mismatches and improve semantic coherence in retrieval tasks. This is particularly evident in knowledge-intensive disciplines such as Psychology and Mathematics, where conceptual depth plays a crucial role for effective search.
Overall, reasoning infusion substantially enhances retrieval effectiveness across different knowledge domains, making it a valuable approach for improving search relevance in diverse subject areas. Future advancements could explore fine-tuning reasoning methodologies to further optimize retrieval in specific disciplines.
4.2. Model-Generated vs. Oracle Reasoning
We also compare RITE embeddings generated from model-produced reasoning texts (RITE-Echo and RITE-PR) against embeddings using oracle (human-crafted) reasoning texts (GT-Echo and GT-PR).
The results in Tables 2 and 3, show that oracle reasoning consistently achieves superior retrieval performance. For instance, using the LLaMA 3 8B model, GT-Echo surpasses RITE-Echo in Earth Sciences (+13%) and TheoremQA (+8%). Similarly, GT-PR significantly outperforms RITE-PR in TheoremQA (+57%) and AoPS (+123%), highlighting the advantages of high-quality, human-authored reasoning texts in capturing domain-specific nuances.
However, RITE-generated reasoning performs competitively in some domains. In Biology and Stack Overflow, the differences between RITE and GT embeddings are minimal, indicating that automatic reasoning generation can approximate human-crafted explanations in specific contexts. This suggests that in fields where explicit domain knowledge is less critical, model-generated reasoning may serve as an efficient alternative to oracle reasoning.
Furthermore, the results indicate that the effectiveness of model-generated reasoning depends on the complexity of the subject matter. In fact-based and structured domains such as programming and biology, RITE performs comparably to human reasoning. Conversely, in abstract and mathematically rigorous areas such as TheoremQA and AoPS, oracle reasoning retains a distinct advantage due to its ability to leverage precise terminologies and formal structures.
These results suggest that while oracle reasoning remains the ideal, model-generated reasoning provides a feasible alternative that substantially enhances retrieval in zero-shot settings. A potential avenue for future work involves improving automatic reasoning techniques by integrating external knowledge bases or leveraging domain-specific language models to refine generated rationales. By doing so, model-generated reasoning could more effectively approximate human-level reasoning across a broader range of disciplines.
4.3. Case Study Analysis
We conducted case studies to explore how reasoning-enhanced embeddings influence retrieval effectiveness as an example in Table 4. In the Biology dataset, the RITE-generated reasoning significantly improves retrieval performance for queries related to lateralization in animals, achieving an nDCG@10 of 0.8503 compared to 0.2372 for the oracle reasoning. This improvement stems from the model’s ability to refine queries by emphasizing key biological concepts.
5. Conclusion
In this work, we introduced Reasoning-Infused Text Embedding (RITE), a novel approach that leverages the inherent reasoning capabilities of generative large language models (LLMs) to enhance zero-shot dense retrieval. Our experimental results on the BRIGHT benchmark, which spans diverse domains, demonstrate that RITE consistently surpasses traditional zero-shot embedding methods, such as Echo and PromptReps, by incorporating explicit reasoning into the embedding process.
Our findings highlight that the integration of reasoning significantly enhances retrieval, particularly in tasks requiring complex logical inference. The comparison between model-generated and oracle reasoning texts further underscores the efficacy of RITE, revealing that automatically generated reasoning closely approximates the performance of human-crafted explanations. This indicates that RITE can serve as a powerful tool for improving retrieval effectiveness in applications such as search engines, recommendation systems, and question-answering frameworks.
Additionally, the adaptability of RITE, which supports diverse prompt designs and LLM architectures, underscores its broad applicability across various retrieval scenarios. As generative models continue to advance, further fine-tuning and optimization of RITE have the potential to unlock even greater improvements in retrieval accuracy and computational efficiency. Future work will explore enhancements in prompt engineering, retrieval-specific LLM pretraining, and integration with hybrid retrieval paradigms to further refine and extend the capabilities of RITE.
6. GenAI Usage Disclosure
During our research, we used a GenAI tool solely for refining the language and improving the clarity of our writing. We did not use it for generating code or for drafting or composing the content of the paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. ar Xiv preprint ar Xiv:2303.08774 (2023).
- 3Behnam Ghader et al. (2024) Parishad Behnam Ghader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. 2024. Llm 2vec: Large language models are secretly powerful text encoders. ar Xiv preprint ar Xiv:2404.05961 (2024).
- 4Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , Jill Burstein, Christy Doran, and Thamar Solorio (Eds.). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186. · doi ↗
- 5Isinkaye et al. (2015) Folasade Olubusola Isinkaye, Yetunde O Folajimi, and Bolande Adefowoke Ojokoh. 2015. Recommendation systems: Principles, methods and evaluation. Egyptian informatics journal 16, 3 (2015), 261–273.
- 6Ji and Luo (2025) Cheng Ji and Huaiying Luo. 2025. Leveraging Large Language Model for Intelligent Log Processing and Autonomous Debugging in Cloud AI Platforms. In 2025 8th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE) . IEEE, 348–351.
- 7Jiang et al. (2023 b) Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023 b. Mistral 7B. ar Xiv preprint ar Xiv:2310.06825 (2023).
- 8Jiang et al. (2023 a) Ting Jiang, Shaohan Huang, Zhongzhi Luan, Deqing Wang, and Fuzhen Zhuang. 2023 a. Scaling sentence embeddings with large language models. ar Xiv preprint ar Xiv:2307.16645 (2023).