Beyond Pixels: Introducing Geometric-Semantic World Priors for Video-based Embodied Models via Spatio-temporal Alignment
Jinzhou Tang, Jusheng zhang, Sidi Liu, Waikit Xiu, Qinhan Lv, Xiying Li

TL;DR
This paper introduces VEME, a cross-modal alignment framework that enhances embodied AI models' spatio-temporal reasoning and generalization in dynamic environments through geometry-aware world modeling.
Contribution
It proposes a novel approach combining cross-modal alignment, a dynamic cognitive map, and instruction-based navigation to improve reasoning and planning in embodied models.
Findings
Achieves 1-3% accuracy improvement on VSI-Bench and VLN-CE.
Enhances generalization in unseen scenes and dynamic environments.
Improves exploration efficiency and long-term planning capabilities.
Abstract
Achieving human-like reasoning in deep learning models for complex tasks in unknown environments remains a critical challenge in embodied intelligence. While advanced vision-language models (VLMs) excel in static scene understanding, their limitations in spatio-temporal reasoning and adaptation to dynamic, open-set tasks like task-oriented navigation and embodied question answering (EQA) persist due to inadequate modeling of fine-grained spatio-temporal cues and physical world comprehension. To address this, we propose VEME, a novel cross-modal alignment method that enhances generalization in unseen scenes by learning an ego-centric, experience-centered world model. Our framework integrates three key components: (1) a cross-modal alignment framework bridging objects, spatial representations, and visual semantics with spatio-temporal cues to enhance VLM in-context learning; (2) a…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1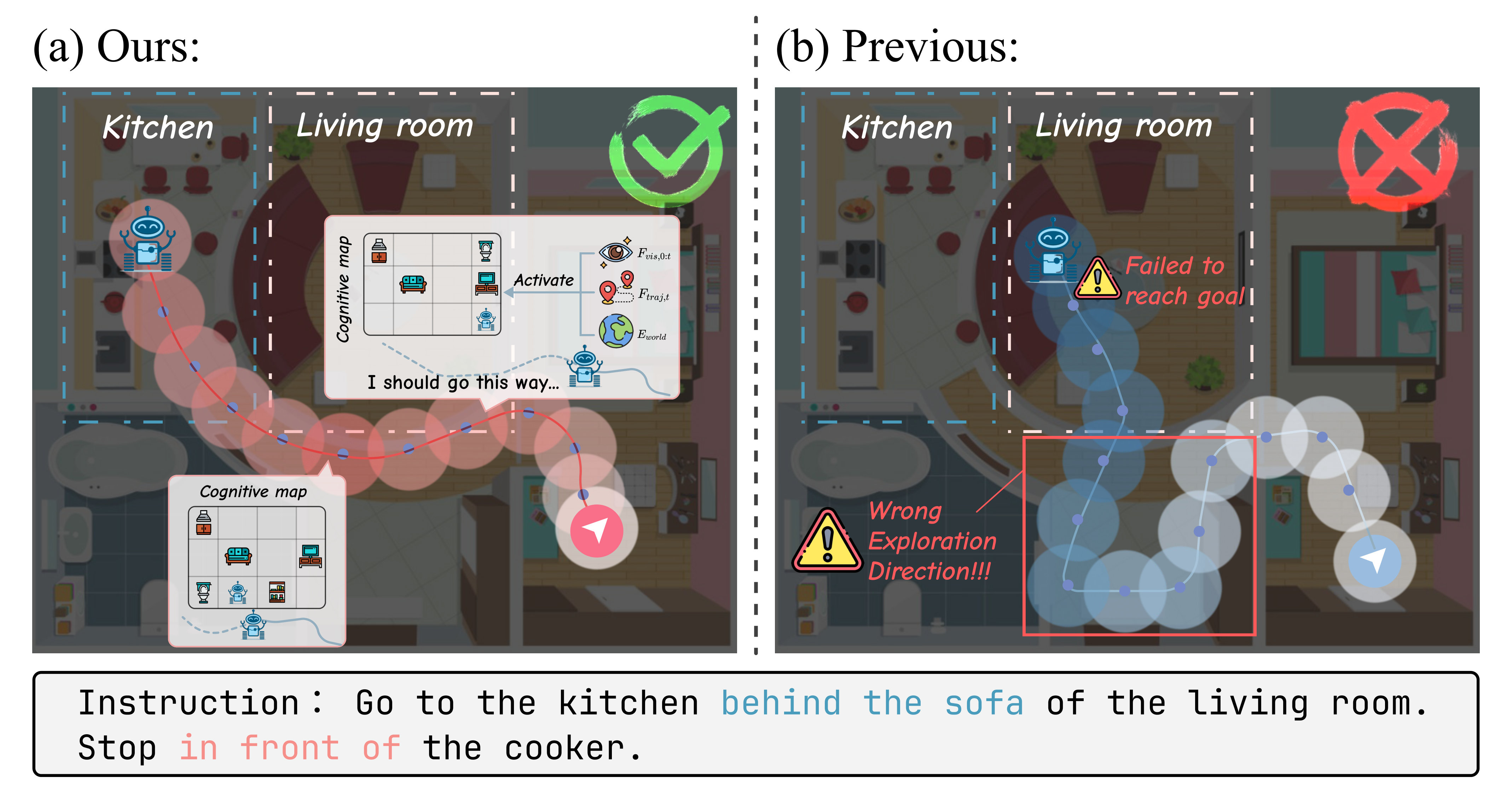 Figure 2
Figure 2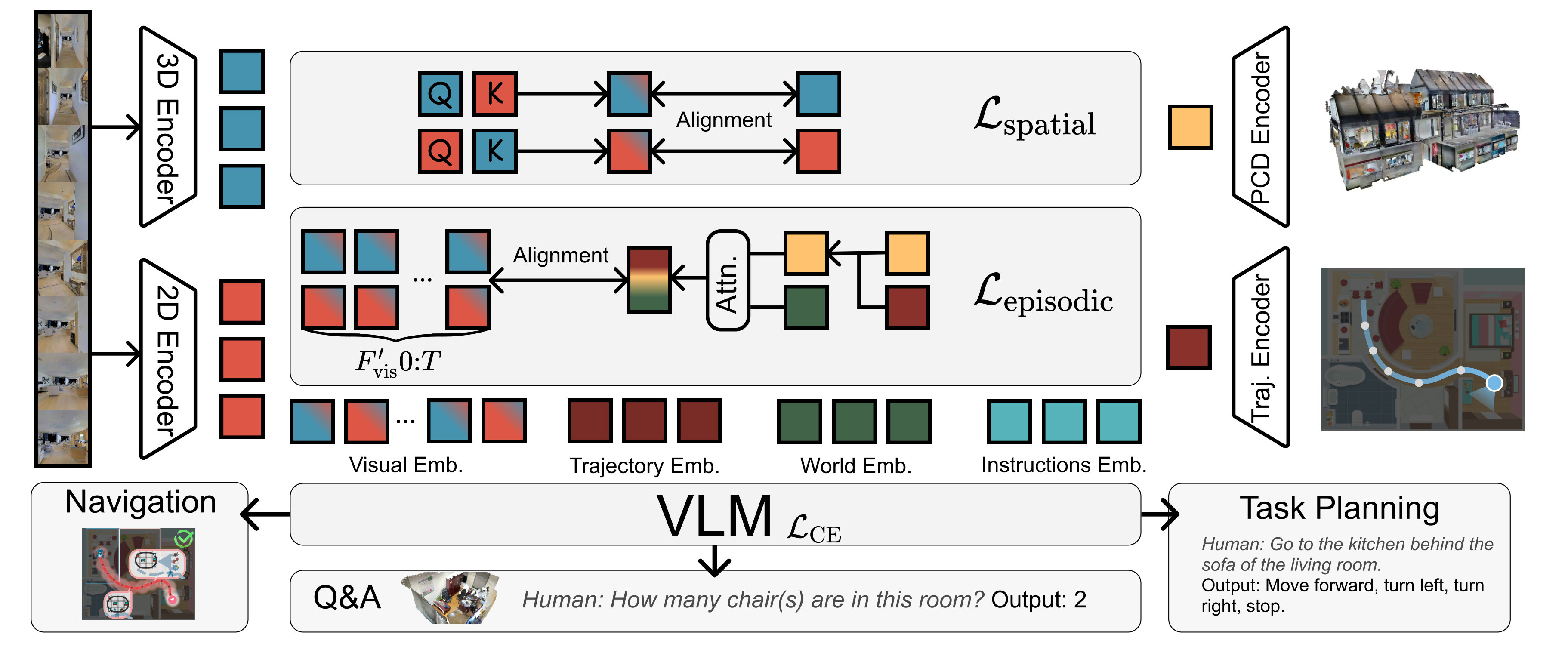 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5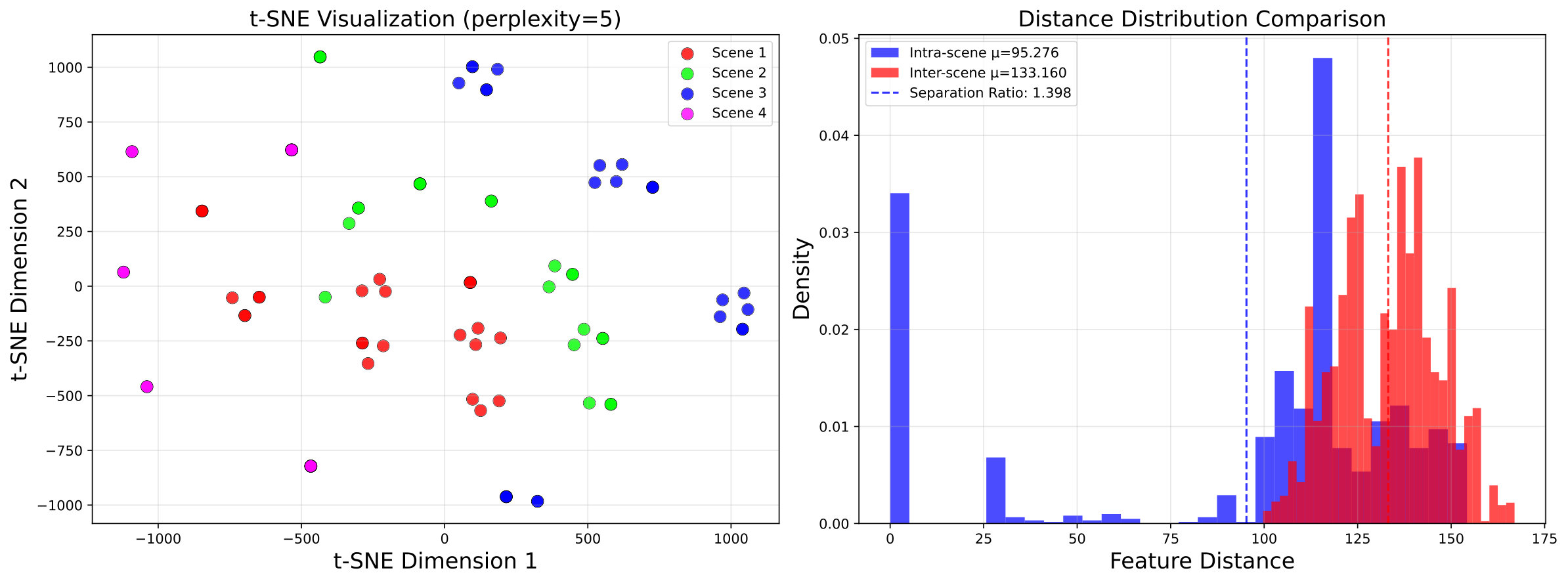 Figure 6
Figure 6| Methods | R2R Val-Unseen | RxR Val-Unseen | ||
|---|---|---|---|---|
| SR | SPL | SR | SPL | |
| CMA (Hong et al. 2022) | 41.0 | 36.0 | 26.5 | 21.1 |
| ETPNav (An et al. 2024) | 57.0 | 49.0 | 54.7 | 48.8 |
| DreamWalker (Wang et al. 2023) | 49.0 | 44.0 | - | - |
| NaVid (Zhang et al. 2024a) | 37.0 | 35.0 | - | - |
| NaVILA (Cheng et al. 2025b) | 54.0 | 49.0 | 49.3 | 44.0 |
| VEME (Ours) | 57.0 | 51.0 | 50.7 | 46.7 |
| Methods | Numerical | Multiple-Choice | Avg. | Rank | ||||||
| Obj. Cnt | Abs. Dist | Obj. Size | Room Size | Rel. Dist | Rel. Dir | Route Plan | Appr. Order | |||
| Proprietary Models | ||||||||||
| Gemini-1.5 Pro (Team et al. 2024) | 56.2 | 30.9 | 64.1 | 43.6 | 51.3 | 46.3 | 36.0 | 34.6 | 45.4 | 2 |
| GPT-4o (Hurst et al. 2024) | 46.2 | 43.8 | 43.6 | 38.2 | 37.0 | 41.3 | 31.5 | 28.5 | 34.0 | 7 |
| Open-source Models | ||||||||||
| InternVL2-40B (Chen et al. 2024) | 31.8 | 26.2 | 27.5 | 27.5 | 32.2 | 24.8 | 34.0 | 39.6 | 36.0 | 6 |
| LongVILA-8B (Xue et al. 2024) | 29.1 | 16.7 | 27.1 | 0.0 | 29.6 | 30.7 | 32.5 | 25.5 | 21.6 | 12 |
| VILA-1.5-40B (Lin et al. 2023) | 22.4 | 24.8 | 48.7 | 22.7 | 40.5 | 25.7 | 31.5 | 32.9 | 31.2 | 9 |
| LongVA-7B (Zhang et al. 2024b) | 38.0 | 16.6 | 38.9 | 22.2 | 33.1 | 43.3 | 25.4 | 15.7 | 29.2 | 11 |
| LLaVA-OneVision-72B (Li et al. 2024a) | 43.5 | 23.9 | 57.6 | 37.5 | 42.5 | 39.9 | 32.5 | 44.6 | 40.2 | 4 |
| LLaVA-Video-72B (Zhang et al. 2024c) | 48.9 | 22.8 | 57.4 | 35.3 | 42.4 | 36.7 | 35.0 | 48.6 | 40.9 | 3 |
| Qwen2.5VL-3B (Bai et al. 2025b) | 24.3 | 24.7 | 31.7 | 22.6 | 38.3 | 41.6 | 26.3 | 21.2 | 30.6 | 10 |
| Qwen2.5VL-7B (Bai et al. 2025b) | 40.9 | 14.8 | 43.4 | 10.7 | 38.6 | 38.5 | 33.0 | 29.8 | 33.0 | 8 |
| Qwen2.5VL-72B (Bai et al. 2025b) | 25.1 | 29.3 | 54.5 | 38.8 | 38.2 | 37.0 | 34.0 | 28.9 | 37.0 | 5 |
| Spatial-MLLM-4B (Wu et al. 2025a) | 65.3 | 34.8 | 63.1 | 45.1 | 41.3 | 46.2 | 33.5 | 46.3 | 48.4 | 2 |
| VEME (Ours) | 65.4↑ | 34.6↓ | 64.1↑ | 45.3↑ | 44.5↑ | 42.3↓ | 30.9↓ | 45.8↓ | 49.3↑ | 1 |
| Model Configuration | VLN-CE (SPL %) |
|---|---|
| Full Model | 65.1 |
| w/o. Spatial Memory () | 55.3 |
| w/o. Episodic Memory () | 49.8 |
| w/o. Geometric Grounding | 61.2 |
| w/o. Trajectory Input | 52.1 |
| Method Configuration | ACC | MRA | ALL |
|---|---|---|---|
| Full Model | 44.1 | 55.7 | 49.3 |
| w/o. vggt | 36.1 | 19.2 | 28.3 |
| w/o. fine-tune | 34.9 | 19.4 | 26.9 |
| Hyperparameter | Value |
|---|---|
| Optimizer & Scheduler | |
| Optimizer | AdamW |
| Learning Rate (Peak) | |
| Betas () | (0.9, 0.999) |
| Weight Decay | 0.01 |
| Learning Rate Schedule | Cosine decay |
| Warmup Steps | 500 |
| Training & Batching | |
| Total Training Epochs | 1 |
| Per-Device Batch Size | 8 |
| Gradient Accumulation Steps | 2 |
| Effective Batch Size | 64 () |
| Mixed Precision | bfloat16 |
| Loss Configuration | |
| Spatial Loss Weight () | 0.1 |
| Episodic Loss Weight () | 0.1 |
| Contrastive Temperature () | 0.07 |
| LoRA Fine-tuning | |
| LoRA Rank () | 16 |
| LoRA Alpha () | 32 |
| LoRA Dropout | 0.1 |
| LoRA Target Modules | q_proj, v_proj, lm_head |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMultimodal Machine Learning Applications · Social Robot Interaction and HRI · Human Pose and Action Recognition
Beyond Pixels: Introducing Geometric-Semantic World Priors for Video-based Embodied Models via Spatio-temporal Alignment
Jinzhou Tang1 Jusheng Zhang111footnotemark: 1 Sidi Liu1
Waikit Xiu1 Qinhan Lv1 Xiying Li1 Equal contribution.Corresponding author.
Abstract
Achieving human-like reasoning in deep learning models for complex tasks in unknown environments remains a critical challenge in embodied intelligence. While advanced vision-language models (VLMs) excel in static scene understanding, their limitations in spatio-temporal reasoning and adaptation to dynamic, open-set tasks like task-oriented navigation and embodied question answering (EQA) persist due to inadequate modeling of fine-grained spatio-temporal cues and physical world comprehension. To address this, we propose VEME, a novel cross-modal alignment method that enhances generalization in unseen scenes by learning an ego-centric, experience-centered world model. Our framework integrates three key components: (1) a cross-modal alignment framework bridging objects, spatial representations, and visual semantics with spatio-temporal cues to enhance VLM in-context learning; (2) a dynamic, implicit cognitive map activated by world embedding to enable task-relevant geometric-semantic memory recall; and (3) an instruction-based navigation and reasoning framework leveraging embodied priors for long-term planning and efficient exploration. By embedding geometry-aware spatio-temporal episodic experiences, our method significantly improves reasoning and planning in dynamic environments. Experimental results on VSI-Bench and VLN-CE demonstrate 3%-6% accuracy and exploration efficiency improvement compared to traditional approaches.
1 Introduction
Embodied agents navigating unknown environments face a fundamental challenge: how to develop spatial understanding and make navigation decisions with limited visual observations (Zou et al. 2025), much like humans leverage episodic memories and spatial cognition (Bermudez-Contreras, Clark, and Wilber 2020; Coppolino and Migliore 2023; Epstein et al. 2017). While vision-language models (VLMs) have achieved remarkable success in static visual understanding (Sarch et al. 2023), their direct application to embodied navigation tasks reveals critical limitations in spatio-temporal reasoning and the integration of long-term memory (Liu et al. 2025).
The core challenge lies in the embodied reasoning gap: while VLMs demonstrate strong visual understanding (Liu et al. 2023; Ma et al. 2023), they lack the spatial grounding necessary to translate visual observations into effective linguistic reasoning and navigation decisions (Shahria et al. 2022). This manifests as difficulties in understanding 3D spatial relationships, building persistent spatial representations, and connecting visual semantics with navigational affordances (brian ichter et al. 2022; Liu et al. 2021; Zheng, Huang, and Wang 2025). This limitation manifests in two critical ways: first, agents cannot effectively recall and utilize relevant past experiences when encountering similar spatial contexts (Park et al. 2023); second, they struggle to align visual semantics with geometric spatial relationships, resulting in poor spatial reasoning in complex environments (Yang et al. 2025; Yin et al. 2025). Existing approaches attempt to address these limitations through different paradigms. SLAM-based methods construct explicit spatial maps with semantic annotations, but they lack the high-level reasoning capabilities necessary for instruction-following and common-sense spatial reasoning (Ren et al. 2024; Chen et al. 2025). LLM/VLM-based approaches leverage powerful language reasoning but fail to capture fine-grained spatio-temporal dependencies. Recent multimodal approaches show promise but remain limited by inadequate cross-modal alignment between visual observations and spatial representations, preventing effective episodic memory formation and recall (Huang et al. 2024; Cheng et al. 2025b). Our key insight is drawn from cognitive neuroscience: human spatial intelligence succeeds through the complementary interaction between episodic memory (specific, spatio-temporal experiences) and semantic memory (general spatial knowledge) (Moscovitch et al. 2005; Nadel and Hardt 2011). We propose that embodied agents can achieve similar capabilities by learning to align visual experiences with spatial semantic representations, enabling both episodic memory formation and context-relevant recall.
To address the limitations of VLMs in navigation and embodied Q&A, we propose a cognitively inspired dual-memory framework VEME that integrates spatial semantics and episodic experience through three key components: a spatio-temporal encoder that captures geometry-aware visual observations and action histories fused with a learnable world embedding; a cross-modal alignment mechanism that bridges 2D visual semantics and 3D spatial representations via bidirectional attention and contrastive learning; and a VLM-based decision module that leverages structured input tokens incorporating current perception, spatial priors, episodic cues, and language instructions. This design enables the agent to model long-horizon spatio-temporal contexts and generalize navigation and reasoning behavior across novel environments without requiring explicit mapping.
Our framework demonstrates considerable improvements over existing methods on standard benchmarks, including VSI-Bench and VLN-CE, particularly in zero-shot transfer scenarios. The main contributions include: (1) introducing a cognitively-inspired dual memory framework for spatial intelligence; (2) developing effective cross-modal alignment techniques for spatio-temporal reasoning; and (3) validating the approach’s effectiveness in reducing exploration costs while improving task completion rates in unknown environments.
2 Related Work
Embodied and Vision-Language Navigation
Early embodied agents learned navigation using reinforcement learning (RL) (Chen et al. 2020; Liang et al. 2023; Zhang et al. 2025; Sheng 2025), but their reliance on extensive environment interactions for policy optimization limited their ability to generalize to new scenes. The subsequent paradigm of Vision-Language Navigation (VLN) (Anderson et al. 2018) enabled agents to follow natural language instructions, offering more flexible task specification. However, a common limitation of these approaches is the lack of a persistent spatial memory, which hinders performance on long and complex routes that require recalling previously visited locations.
Memory in Embodied Agents
To succeed in long-horizon tasks, an agent requires robust memory (Zheng et al. 2025). One line of work focuses on explicit memory, using techniques like SLAM to build precise but computationally expensive 3D geometric maps (Jia et al. 2022). An alternative is implicit memory, where models like RNNs encode history into a compact state vector; this approach is efficient but can struggle to retain critical long-term details (Hong et al. 2021). Our work addresses the remaining challenge of how to efficiently retrieve the most task-relevant information from an agent’s past experiences.
Large Models for Embodied Control
Recently, Large Language Models (LLMs) and Vision-Language Models (VLMs) have been leveraged for high-level planning in robotics, capitalizing on their vast common-sense knowledge (Yu, Kasaei, and Cao 2023; Li et al. 2025). Despite their powerful reasoning capabilities, these models often exhibit an “embodied reasoning gap” (Li et al. 2024b). Because they are trained on disembodied internet data, their generated plans can be disconnected from an agent’s physical capabilities and the constraints of a 3D environment. Our work aims to bridge this gap by embedding geometry-aware priors directly into the model’s reasoning process.
Cross-Modal Alignment for Embodied Reasoning
Effective embodied reasoning requires robust cross-modal alignment between vision, language, and action. While recent generalist agents have made strides in multimodal fusion (Cheng et al. 2025a; Huang et al. 2024), a persistent challenge is maintaining a tight, continuous link between an agent’s egocentric visual perception and its evolving, allocentric 3D spatial understanding. Many methods struggle to ground visual information in a coherent spatial context over time. Our work introduces a dedicated framework to address this spatio-temporal alignment problem by explicitly linking visual semantics to a dynamic geometric representation.
3 Methodology
Our work introduces a general framework to endow Vision-Language Models (VLMs) with robust spatial intelligence. The central challenge we address is that standard VLMs, despite their impressive semantic capabilities, operate on a “flat” perception of the world, as shown in Figure 1. They lack an intrinsic understanding of 3D geometry and are stateless, treating each moment in isolation without a memory of the past. To overcome these fundamental limitations, we propose a dual-memory architecture, inspired by the synergistic roles of semantic and episodic memory in human cognition. As illustrated in Figure 2, this architecture systematically equips the VLM with (1) a Spatial Semantic Memory to build a general, reusable understanding of 3D space, and (2) an Episodic Memory to form unique representations of specific spatio-temporal experiences. The result is a versatile reasoning engine for any task requiring the synthesis of video, text, 3D geometry, and trajectory data.
3.1 Premilinaries: Input Representations
To ground the agent’s reasoning, we must first transform its raw, multimodal sensory inputs into a unified high-dimensional feature space. The model processes five primary data streams: the language instruction , the current RGB frame , the global 3D point cloud , and the history of actions . Each stream is encoded by a specialized module.
Language Instruction Embedding.
The natural language instruction provides the high-level task goal and context description. We tokenize it and convert it into a sequence of dense vector representations using an embedding layer:
[TABLE]
where is the sequence length and is the model’s hidden dimension.
Visual Semantic Encoding.
To capture the semantic content of the agent’s view (“what”), the RGB frame is processed by a standard pretrained vision encoder. Its features are then projected into the model’s common latent space:
[TABLE]
Image-based Geometric Encoding.
To extract immediate, view-dependent geometric cues (“where” from the current view), we feed the same RGB frame into a specialized foundation visual-geometry encoder (i.e., a pretrained VGGT (Wang et al. 2025)) that can implicitly estimate depth or normals. This provides geometric features corresponding directly to the visual semantics:
[TABLE]
The cross-modal alignment module will later focus on fusing and to ground semantics in their immediate spatial context.
Point Cloud Feature Encoding.
For a global, persistent understanding of the environment’s structure, we process the full 3D point cloud . A dedicated 3D backbone network extracts powerful geometric features (See Architecture Details in the Appendix), which are subsequently projected:
[TABLE]
These features, , provide the foundational geometric representation for building the cognitive map and episodic memory.
Spatio-temporal Trajectory Encoding.
The history of actions is essential for long-term context. Each action is mapped to a learnable embedding . A Transformer encoder then processes the sequence of these embeddings to model temporal dependencies:
[TABLE]
3.2 Geometric-Semantic Memory as Cognitive Map
Motivation.
The first core deficit we address is the VLM’s spatial naivety. To move beyond simple 2D object recognition towards genuine spatial reasoning, the model needs an internal “cognitive map”—a repository of abstract, reusable spatial knowledge (e.g., “corridors connect rooms,” “tables afford placing objects”). We instantiate this concept as a learnable parameter matrix, the World Embedding (), which serves as a global, environment-agnostic memory of fundamental spatial concepts.
Grounding Perception in Spatial Reality.
However, a memory is useless if it cannot be accessed. The model must learn to connect its immediate, concrete perception to this abstract knowledge base. To achieve this, we must first ground the 2D semantic features in the 3D reality of the scene. We accomplish this by using to query the detailed geometric features extracted from the same image, creating a geometrically-aware visual representation, .
[TABLE]
Where treats as query and as key & value. This step forces the model to view semantics through the lens of geometry.
Geometric Alignment.
This attention mechanism, left unsupervised, does not guarantee a meaningful link. To provide explicit supervision, we introduce the contrastive loss . Its purpose is to enforce a strong, unique correspondence between the geometrically-grounded feature and its original semantic source .
[TABLE]
By training the model to correctly identify the positive pair from a batch of negative distractors, we compel it to learn a non-trivial mapping that truly binds visual semantics to their underlying spatial structure. A complete list of all hyperparameter values can be found in the Train Method in the Appendix.
3.3 Episodic Memory: Learning from Experience
Motivation.
The second deficit is the VLM’s statelessness, or “amnesia.” To learn from the flow of events, the model must be able to form a distinct memory trace, or “fingerprint,” for each unique spatio-temporal experience (an “episode,” such as a complete video). This memory should capture the essence of a specific journey.
Formulating an Episodic Trace.
An episode’s identity is defined by its unique path through space and time. We distill this identity into a single query vector, , by fusing the comprehensive geometric information of the episode with its trajectory encoding.
[TABLE]
This query represents the unique “what” (geometry) and “how” (trajectory) of the experience. To transform this query into a rich memory trace, we use it to attend to our general-purpose World Embedding.
[TABLE]
This elegantly models the cognitive process of interpreting a specific experience by seeing which general concepts from our ”cognitive map” it activates.
Episodic Alignment.
A functional memory system requires that different memories be distinguishable. To enforce this, we introduce the episodic contrastive loss, . It trains the model to generate representations that are similar for samples from the same episode but distinct from all other episodes.
[TABLE]
Here, is a positive pair drawn from the same episode, while all features from different episodes act as negatives. This objective directly cultivates the creation of a discriminative episodic memory.
3.4 Unified Decision-Making and Training
Ultimately, these memory systems must inform the VLM’s final output. We achieve this through an elegant and direct integration. We construct a single, unified input sequence for the VLM that concatenates all available streams of information:
[TABLE]
By including the textual instruction, the grounded visual percept, the episodic context, and the entire spatial semantic memory, we empower the VLM’s native self-attention mechanism to holistically reason across all information sources. It can dynamically weigh what is most relevant—the instruction, the current view, past experience, or general world knowledge—to generate the final output.
The entire architecture is trained end-to-end with a composite objective that reflects our cognitive design:
[TABLE]
Here, the primary task loss (e.g., cross-entropy for text generation, ) is guided by our two auxiliary losses. and are therefore not mere regularizers; they are the essential supervisory signals that construct the cognitive scaffolding for advanced spatial intelligence.
4 Experiment
We conduct a comprehensive set of experiments to validate the effectiveness and generality of our dual-memory architecture. Our evaluation is designed to answer three key questions: (1) Does our general-purpose model achieve competitive performance against specialized, state-of-the-art methods on diverse spatial reasoning tasks? (2) What is the specific contribution of each component within our proposed architecture? (3) Can our model exhibit genuine, interpretable spatial understanding beyond simply achieving high scores?
4.1 Experimental Setup
Benchmarks.
To thoroughly evaluate our model’s spatial intelligence, we selected three benchmarks that test distinct facets of this capability.
- •
VLN-CE (Vision-and-Language Navigation in Continuous Environments): Typical benchmarks for embodied AI require intelligences to follow natural language commands to navigate in real 3D environments, evaluating the ability of models to incorporate language into dynamic first-view action and observation sequences, as well as situational memory and trajectory encoding effects, with metrics such as Success Rate (SR) and Path Length-Weighted Success Rate (SPL).
- •
VSI-Bench (Visual-Spatial Intelligence Benchmark): Containing more than 5000 question and answer pairs covering nearly 290 videos of real indoor scenes, including configuration, measurement estimation, and spatio-temporal tasks, MLLM’s visuospatial intelligence is evaluated through zero-sample reasoning, measured by accuracy rate (ACC) for multiple choice tasks, and by mean relative accuracy (MRA) for numerical tasks.
Baselines.
We use two types of baseline models (see Baseline Details in the Appendix for a complete list of baseline models) for systematic performance evaluation: first, a comparative analysis with unimproved standard visual language models (e.g., generalized VLMs such as QwenVL, Gemini, etc.); and, second, an in-depth comparison with the current optimal dedicated models for each specific benchmark task (e.g., the top navigational agents in the VLN-CE benchmarks , the specialized evaluation model in VSI-bench) for in-depth comparison. The experimental results show that our models exhibit industry-leading performance advantages in each task scenario.
Implementation Details.
Our framework is built upon the Qwen-2.5-VL-7B VLM (Bai et al. 2025a). We use the pretrained DINOv2 (Oquab et al. 2023) and SigLIP (Zhai et al. 2023) models as our vision encoders, and Sonata (Wu et al. 2025b) for point cloud processing. The model is trained end-to-end using the AdamW optimizer with and a cosine decay schedule. All experiments are conducted on 8 NVIDIA A100 GPUs, running Ubuntu 22.04 and PyTorch 2.1.0. The loss weights are empirically set to and . For all experiments, we set the random seed to 0 to ensure reproducibility. Our data recipe can be found in the Train Data Section of the Appendix. The computational cost and efficiency of the model are detailed in the Computational Cost and Efficiency Section of the Appendix.
4.2 Main Results
Visual Navigation
To evaluate the proposed model’s capabilities in visual navigation, we conduct experiments on the VLN-CE dataset. Several state-of-the-art methods are selected for comparison, including CMA, ETPNav, DreamWalker, NaVid, and NaVILA, which represent mainstream approaches in the field. The performance of each model is assessed using the R2R Val-Unseen and SPL metrics, with the results summarized in Table 1.
The experimental results demonstrate that the proposed model exhibits significant superiority in the Visual Navigation task. In the R2R Val-Unseen test, our method achieved a success rate (SR) of 57.0 and a path length weighted success rate (SPL) of 46.7, considerably higher than other comparison methods such as CMA (41.0 and 36.0) and ETPNav (42.0 and 36.5). Additionally, the proposed model outperformed all comparison methods in the SPL metric, further validating its effectiveness in navigating complex environments. These results indicate that our model possesses a notable advantage in visual navigation capabilities, enabling it to better understand and execute natural language instructions. Computational Cost and Efficiency
Spatial-temporal Understanding
We compared the proposed model (Ours) with a range of video multimodal large models (Video MLLM) and state-of-the-art models on VSI-bench, including industrial-grade models like GPT-4o and Gemini-1.5Pro, as well as the LLaVA-Video series (such as LLaVA-Video-72B and LLaVA-OneVision-72B), the Qwen2.5VL series (like Qwen2.5VL-7B and Qwen2.5VL-72B), and the current SOTA model Spatial-MLLM on VSI-bench. The evaluation was conducted across different granular tasks (e.g., Obj. Cnt and Abs. Dist in Numerical Questions, Rel. Dist and Route Plan in Multiple-Choice Questions), with experimental results shown in Table 2.
The results indicate that the proposed model demonstrates significant performance advantages over proprietary and open-source models in multidimensional task evaluations. In the Numerical Question category, the model outperformed Spatial-MLLM on core spatio-temporal understanding metrics such as target counting (Obj. Cnt) and target size (Obj. Size). In the Multiple-Choice Question task, although the overall performance was similar to that of Spatial-MLLM, the proposed model has shown a noticeable improvement. Through an analysis of overall average performance (Avg), the proposed model has surpassed Spatial-MLLM. In summary, this confirms the exceptional performance of our model in video multimodal spatio-temporal understanding tasks, establishing it as a leading model in the current field.
4.3 Ablation Studies
To validate our proposed modules, we conducted ablation studies for both visual navigation and spatio-temporal understanding tasks. All experiments were repeated with five different random seeds, with results averaged across runs. Wilcoxon signed-rank tests confirmed statistically significant performance degradation when removing any module ( in all cases), demonstrating each component’s effectiveness. See section Ablation Experiment of Appendix for details.
Visual Navigation
To dissect our model and quantify the contribution of each component, we conducted a series of ablation studies on the VLN-CE, which represent dynamic and static reasoning respectively. As shown in Table 3, the impact of each component is evident: removing the Spatial Semantic Memory results in a substantial performance drop, underscoring its essential role in grounding the agent within the 3D environment; excluding the Episodic Memory causes the most severe degradation, indicating its importance in enabling the agent to reason over its navigation history; and the absence of other components such as Geometric Grounding and Trajectory Input also leads to notable declines in performance, validating their contributions to the overall model effectiveness.
Spatial-temporal Understanding
To assess the contribution of each module and operation to the model’s spatial reasoning ability, we conducted an ablation study. As shown in Table 4, the full model consistently achieves the highest performance across all metrics, demonstrating strong spatial understanding capabilities. Removing the VGGT component leads to a significant decline in performance, underscoring its critical role in spatial feature representation. Furthermore, excluding SFT (fine-tuning training) results in an even greater performance drop, highlighting the necessity of fine-tuning for effective model adaptation. These findings confirm that each component contributes meaningfully to the overall architecture and plays a vital role in enhancing spatial comprehension.
4.4 Qualitative Analysis
To provide intuitive evidence of our model’s improved reasoning, we examined specific failure cases of baselines that our model handles correctly, as shown in Figure 3. For instance, on VLN-CE, given the instruction “Go back to the kitchen you just passed and wait by the sink,” the standard VLM often gets stuck in a loop or navigates to a different kitchen, lacking the episodic context to understand “the kitchen you just passed.” Our model, leveraging its episodic feature , correctly identifies the previously visited location and successfully completes the task, as illustrated in Figure 4. On VSI-bench, when asked “What is supporting the laptop?” in a scene where a laptop is on a desk, the baseline model sometimes fails by answering with a nearby but incorrect object, like “a chair.” Our model, guided by the learned spatial priors in , correctly identifies the “support” relationship and answers “the desk.” This reasoning process is confirmed by visualizing the model’s internal attention mechanisms (See Feature Visualization in the Appendix). The results show our model correctly focuses on the relevant supporting object, validating the effect of our learned spatial priors.
5 Conclusion
We introduce VEME, a novel cross-modal framework enhancing embodied agents’ reasoning in dynamic, uncertain environments by aligning visual semantics with spatio-temporal cues. Drawing from cognitive neuroscience, VEME’s dual-memory system (episodic and semantic) builds geometry-aware world models, greatly boosting navigation and question-answering. Experiments on VLN-CE and VSI-Bench show improved success rates, exploration efficiency, and zero-shot generalization over VLM and SLAM methods. Our dual-memory architecture, with effective spatio-temporal alignment and robust empirical validation, significantly advances adaptive embodied intelligence.
Appendix A Model and Training Details
A.1 Train Data
To accomplish the tasks of visual navigation and video spatial understanding, we have collected a variety of datasets to enable more comprehensive training.
Visual Navigation Task
For the visual navigation task, we designed a supervised fine-tuning dataset (SFT data blend), which consists of the following four categories of data:
Navigation data from real videos: By collecting trajectory videos from real-world scenes, we provide the model with continuous navigation examples in realistic environments.
Navigation data from simulation environments: Using the R2R-CE and RxR-CE datasets, which provide sparse path point sequences converted from discrete VLN versions, we integrate these datasets into the Habitat simulator. This allows us to generate navigation video sequences based on the geodesic shortest path. These videos include consecutive frames and corresponding action labels, helping the model learn navigation capabilities in simulated environments.
Auxiliary navigation data: We use augmented instructions generated by EnvDrop and introduce auxiliary tasks such as navigation trajectory summarization. Through these data, the model learns to describe trajectories across different time segments.
General VQA datasets: To improve the model’s generalization capabilities, we incorporate multiple general visual question answering (VQA) datasets. These datasets cover a wide range of scenes and real-world environments, providing the model with extensive training samples.
Video Spatial Understanding Task
For the video spatial understanding task, we integrate multiple video question-answering datasets:
ScanQA dataset: This dataset focuses on real-world 3D scene question-answering tasks, featuring free-form QA pairs grounded in 3D objects. Using this data, the model learns to reason and answer questions in 3D spaces.
Custom video QA dataset: To further enhance the model’s performance, we created custom datasets containing video data from various real-world scenarios. These datasets encompass diverse viewpoints, lighting conditions, and dynamic changes, providing the model with more challenging and diverse training samples.
By integrating these datasets, we effectively enhance the model’s capabilities in both navigation and video spatial understanding tasks, enabling it to perform well not only in simulation environments but also in real-world scenarios.
A.2 Train Strategy
To enhance the model’s performance on video spatial understanding tasks, we fine-tuned the Qwen model using LoRA (Low-Rank Adaptation). The core idea of LoRA is to achieve parameter-efficient optimization by inserting trainable low-rank matrices without making large-scale adjustments to the original weights of the pre-trained model. This approach allows the model to adapt to downstream task requirements while maintaining its performance.
Specifically, LoRA decomposes the weight matrix into two low-rank matrices and . Through low-rank decomposition, the weight update formula can be expressed as . During this process, the original weights remain frozen, and only the newly added low-rank matrices and are optimized. We inserted LoRA modules into key components of the model, including the query projection (q_proj), value projection (v_proj), and language model head (lm_head), to enhance the model’s ability to model dynamic relationships between video frames and perform cross-modal reasoning.
In the actual fine-tuning process, we set the LoRA hyperparameters as follows: rank , LoRA scaling factor , and a Dropout probability of 0.1 to reduce the risk of overfitting. The LoRA modules were embedded into the model’s multi-head self-attention mechanism and output layers, enabling more efficient adaptation to the requirements of video spatial understanding tasks. This method is particularly suitable for tasks involving multi-view video frames, such as reasoning about 3D spatial relationships from videos or answering scene-related questions. By incorporating LoRA, the model can better capture dynamic changes between video frames and improve its understanding of complex 3D scenes.
For video spatial understanding tasks, the use of LoRA allows us to efficiently optimize the model, making it more adaptable to downstream tasks while maintaining reasonable computational resource usage. This fine-tuning approach provides strong technical support for our video spatial understanding tasks.
A.3 Hyperparameter Details
To ensure the reproducibility of our results, we provide a comprehensive list of the key hyperparameters used for training the VEME model. We utilized the AdamW optimizer for stable and efficient training. The primary hyperparameters for the optimization and training process are summarized in Table 5. These settings were kept consistent across all main experiments unless otherwise specified in the ablation studies.
LoRA Configuration.
As detailed in the ‘Train Strategy‘ subsection, we employed Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning. The rank () was set to 8, providing a good balance between expressiveness and parameter efficiency. The scaling factor () was set to 32. To prevent overfitting on the adapter weights, a dropout rate of 0.1 was applied specifically to the LoRA modules. We targeted the query (q_proj) and value (v_proj) projections within the VLM’s self-attention layers, as well as the final language model head (lm_head), as these are critical for adapting the model’s reasoning and generation capabilities to our specific tasks.
Appendix B Model Architecture Details
Our proposed framework, VEME, is constructed around a central Vision-Language Model (VLM) and is augmented by a series of specialized encoders. Each encoder is designed to process a specific modality (vision, geometry, trajectory), transforming raw sensory input into rich feature representations. These features are then projected into a common embedding space, allowing the core VLM to perform holistic reasoning across all available information streams. Below, we detail the specifics of each key component.
Core VLM Backbone.
The heart of our model is the Qwen-2.5-VL-7B (Bai et al. 2025b), a powerful pretrained VLM that serves as our primary reasoning engine. We leverage its advanced capabilities in understanding and integrating vision and language. The input to this model is a carefully structured sequence of embeddings from various sources, as described in the main paper. We utilize the LoRA fine-tuning technique on its attention and feed-forward layers to adapt it to the downstream embodied tasks without catastrophic forgetting of its pretrained knowledge.
Visual Semantic Encoder.
To extract high-level semantic information from each RGB frame , we employ a pretrained DINOv2-ViT-L/14 model (Oquab et al. 2023). DINOv2 is renowned for its strong, self-supervised learned features that exhibit excellent performance on various downstream tasks without fine-tuning. For each frame, we extract the patch features from the final layer of the encoder. These features, which capture the objects and their appearance, are then passed through a two-layer Multi-Layer Perceptron (MLP) to project them from their native dimension to the VLM’s hidden dimension . This yields the semantic feature representation .
Image-based Geometric Encoder.
Complementary to the semantic features, we extract immediate, view-dependent geometric cues directly from the 2D image . For this, we use a specialized visual-geometry encoder, specifically a version of VGGT-1B (Wang et al. 2025) pretrained on multiple geometry estimation tasks. This model processes the RGB frame and outputs a dense feature map that implicitly encodes geometric information such as depth gradients and surface normals. These geometric features provide the spatial context necessary to ground the semantic features through our cross-attention mechanism. Like other features, these are also projected to dimension via an MLP.
3D Point Cloud Backbone.
This is a critical component for building a persistent and global understanding of the environment’s 3D structure. As mentioned in the main text, we use the Sonata (Wu et al. 2025b) model as our dedicated 3D backbone.
- •
Architecture: Sonata is a state-of-the-art sparse 3D Transformer architecture. It is specifically designed to efficiently process large-scale point clouds, which are common in real-world navigation scenarios. It utilizes a hierarchy of sparse voxel-based attention mechanisms, allowing it to capture both local geometric details and long-range spatial relationships without incurring the prohibitive computational cost of standard Transformers.
- •
Input: The model takes the global point cloud as input, where each point is represented by its XYZ coordinates and RGB color values.
- •
Pre-training: The Sonata backbone we use has been pretrained on a large-scale collection of 3D indoor scene datasets, including ScanNet (Dai et al. 2017) and Matterport3D (Chang et al. 2017), on a self-supervised reconstruction task. This pre-training endows it with a powerful, intrinsic understanding of 3D geometric primitives and typical spatial layouts of indoor environments.
- •
Output: The model outputs a set of per-point feature vectors after being passed through a final projection layer. These features provide the foundational geometric representation for both our cognitive map and episodic memory modules.
Spatio-temporal Trajectory Encoder.
To capture the agent’s movement history, we encode the sequence of past actions . Each discrete action (e.g., ‘move_forward’, ‘turn_left’) is first mapped to a learnable embedding vector of dimension . This sequence of action embeddings is then processed by a 4-layer Transformer encoder with 8 attention heads. The output of this encoder, , provides a contextualized representation of the agent’s path, capturing temporal dependencies within the action sequence.
Appendix C Additional Experimental Results
C.1 Baseline details
Specialized Navigation Models
For all specialized navigation baselines on VLN-CE, including CMA, ETPNav, and NaVILA, we adhered to the following protocol to ensure a fair and reproducible comparison:
- •
Source: We utilized the official codebases and pre-trained model weights released by the respective authors. No architectural modifications were made.
- •
Evaluation Protocol: We followed the standard evaluation scripts and environment setups provided with each baseline’s repository. Results were generated on the val-unseen split as reported in the original papers.
General Vision-Language Models
For all general-purpose VLMs evaluated on VSI-Bench, such as GPT-4o, Gemini-1.5 Pro, the LLaVA series, and the Qwen series, we used the following zero-shot evaluation setup:
- •
Model Version: We used the latest available official APIs for proprietary models (e.g., gpt-4o-2024-05-13) and the official Hugging Face implementations for open-source models.
- •
Prompting Strategy: A consistent, minimal prompt template was employed across all models to query their spatial reasoning capabilities without providing few-shot examples. The templates were structured as follows:
**For Multiple-Choice Questions:
**The following is a video of an indoor scene. Based on the video, answer the following question by choosing the best option. <video_placeholder> Question: [Question from VSI-Bench] Options: (A) [Option A] (B) [Option B] (C) [Option C] (D) [Option D] Answer (Provide the letter only):
**For Numerical Questions:
**The following is a video of an indoor scene. Based on the video, answer the following question. Provide only the numerical value in your answer. <video_placeholder> Question: [Question from VSI-Bench] Answer:
C.2 Computational Cost and Efficiency
C.3 Evaluation Protocol Details
- •
Metrics Calculation: All metrics were calculated using the official evaluation scripts provided by the respective benchmarks. For VLN-CE, we report Success Rate (SR) and Success rate weighted by Path Length (SPL). For VSI-Bench, we report Accuracy (ACC) for multiple-choice questions and Mean Relative Accuracy (MRA) for numerical questions.
- •
Inference Setup: All our models were evaluated on a single NVIDIA A100 GPU. We used greedy decoding (i.e., beam size of 1) for generating all responses to ensure efficiency and deterministic outputs. All reported scores are the average of three evaluation runs with different random seeds to ensure statistical stability.
C.4 Ablation Experiment
To assess the significance of performance changes in our ablation studies, we used the Wilcoxon signed-rank test, which is ideal for small sample sizes (n=5) and does not rely on specific data distribution assumptions. The null hypothesis posits that the median difference between paired observations is zero. If we reject the null hypothesis (), it indicates a statistically significant performance drop after removing certain modules.
We calculated the performance metrics for different configurations, including the full model and various ablations. Our analysis revealed significant performance degradation across all removed components. Notably, the removal of episodic memory resulted in the largest decrease (, ), followed by trajectory input (, ), spatial memory (, ), and geometric grounding (, ). All -values were below the threshold, underscoring the critical roles these components play in overall system performance.
In a similar analysis for spatio-temporal understanding, we found that removing the vggt component led to significant drops across all metrics, while fine-tuning removal produced slightly stronger effects. The dramatic reduction in mean recognition accuracy (MRA) further emphasizes the importance of these components for effective temporal reasoning, with all -values also falling below .
C.5 Additional Qualitative Results
To provide a more comprehensive understanding of our model’s capabilities and limitations, we present additional qualitative examples below.
Success Case
The main text has already highlighted our model’s ability to follow long and complex instructions, successfully navigating through multiple rooms, while a strong baseline fails by becoming stuck in a local loop.
Failure Case Visualization and Analysis
Our model has its limitations, as illustrated in Figure 6. This figure presents a failure case with the instruction: ”Walk into the living room and keep walking straight past the living room. Then walk into the entrance under the balcony and wait at the entrance to the other room.” Despite the clear visual cues provided in the left image, the model struggles to accurately interpret the spatial layout, leading to its failure to select the optimal path.
Appendix D Feature Visualization
To provide a more intuitive understanding of our model’s internal mechanisms and validate its claimed capabilities, we present a series of qualitative visualizations. These analyses aim to demystify how our model learns discriminative spatio-temporal representations, grounds semantics in geometry, and reasons about complex, instruction-driven tasks.
We sought to verify that our Episodic Memory module creates unique and separable representations for different spatio-temporal experiences. To visualize this, we sampled a collection of distinct navigation episodes from the validation set and extracted the final episodic feature vector, , for each. Using the t-SNE dimensionality reduction algorithm, we projected these high-dimensional vectors into a 2D space. The result, shown in Figure 5, is a scatter plot where each point represents a complete episode, colored by its environment ID, and its corresponding distance distribution. The clear clustering of points with the same color provides strong evidence that our model, guided by the loss, successfully learns to form a discriminative memory space. This ability to distinguish between different journeys is fundamental for long-term reasoning and avoiding ambiguity.
Appendix E Limitations and Future Work
While our proposed VEME framework demonstrates significant advancements in equipping embodied agents with spatio-temporal intelligence, we acknowledge several limitations that pave the way for compelling future research.
First, our model’s multi-encoder architecture, while powerful, introduces a notable computational overhead in terms of both memory (VRAM) and floating-point operations (FLOPs) during inference. This currently may hinder its deployment on resource-constrained robotic platforms with limited onboard computing power. Second, the performance of our geometric and episodic memory modules is, to some extent, contingent on the availability of relatively clean 3D point clouds and accurate trajectory data during the training phase. The model’s robustness against noisy, incomplete, or drifting map data generated by real-world SLAM systems is an important area for further investigation. Finally, our current framework operates under a static environment assumption. It is not designed to handle dynamic scenes with moving objects, interacting agents, or significant changes in layout during an episode, which limits its applicability in more complex, human-centric settings.
Addressing these limitations points toward several exciting future directions. A primary focus will be on improving model efficiency. We plan to explore model compression techniques, such as knowledge distillation from our larger model to a more compact student network, and post-training quantization to create a ”VEME-Lite” version without substantially compromising performance. This would be a critical step towards real-world robotic deployment.
Another key avenue is to enhance the model’s robustness and generalization. To bridge the sim-to-real gap highlighted by our data dependency, we aim to train VEME on a much wider variety of 3D environments, incorporating simulated sensor noise and diverse visual styles. Furthermore, we will investigate advanced learning paradigms, such as meta-learning or online domain adaptation, to enable the agent to rapidly fine-tune its world model when introduced to a completely new and unseen environment.
Perhaps the most significant long-term vision is to transcend the offline training paradigm towards interactive and lifelong learning. This involves developing mechanisms for the agent to continuously update its semantic and episodic memories based on its own experiences and interactions within the world. By integrating reinforcement learning principles, the agent could learn from trial-and-error, associate failed plans with specific environmental states, and implicitly refine its understanding of physical affordances. Such a system would move us closer to creating truly adaptive and autonomous embodied intelligences that learn and grow over their entire operational lifetime.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1An et al. (2024) An, D.; Wang, H.; Wang, W.; Wang, Z.; Huang, Y.; He, K.; and Wang, L. 2024. Etpnav: Evolving topological planning for vision-language navigation in continuous environments. IEEE Transactions on Pattern Analysis and Machine Intelligence .
- 2Anderson et al. (2018) Anderson, P.; Wu, Q.; Teney, D.; Bruce, J.; Johnson, M.; Gould, S.; and van den Hengel, A. 2018. Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2018), Spotlight Oral .
- 3Bai et al. (2025 a) Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J.; Zhong, H.; Zhu, Y.; Yang, M.; Li, Z.; Wan, J.; Wang, P.; Ding, W.; Fu, Z.; Xu, Y.; Ye, J.; Zhang, X.; Xie, T.; Cheng, Z.; Zhang, H.; Yang, Z.; Xu, H.; and Lin, J. 2025 a. Qwen 2.5-VL Technical Report. ar Xiv preprint ar Xiv:2502.13923 .
- 4Bai et al. (2025 b) Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J.; Zhong, H.; Zhu, Y.; Yang, M.; Li, Z.; Wan, J.; Wang, P.; Ding, W.; Fu, Z.; Xu, Y.; Ye, J.; Zhang, X.; Xie, T.; Cheng, Z.; Zhang, H.; Yang, Z.; Xu, H.; and Lin, J. 2025 b. Qwen 2.5-VL Technical Report. Ar Xiv , abs/2502.13923.
- 5Bermudez-Contreras, Clark, and Wilber (2020) Bermudez-Contreras, E.; Clark, B. J.; and Wilber, A. 2020. The Neuroscience of Spatial Navigation and the Relationship to Artificial Intelligence. Frontiers in Computational Neuroscience , Volume 14 - 2020.
- 6brian ichter et al. (2022) brian ichter; Brohan, A.; Chebotar, Y.; Finn, C.; Hausman, K.; Herzog, A.; Ho, D.; Ibarz, J.; Irpan, A.; Jang, E.; Julian, R.; Kalashnikov, D.; Levine, S.; Lu, Y.; Parada, C.; Rao, K.; Sermanet, P.; Toshev, A. T.; Vanhoucke, V.; Xia, F.; Xiao, T.; Xu, P.; Yan, M.; Brown, N.; Ahn, M.; Cortes, O.; Sievers, N.; Tan, C.; Xu, S.; Reyes, D.; Rettinghouse, J.; Quiambao, J.; Pastor, P.; Luu, L.; Lee, K.-H.; Kuang, Y.; Jesmonth, S.; Jeffrey, K.; Ruano, R. J.; Hsu, J.; Gopala
- 7Chang et al. (2017) Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; and Zhang, Y. 2017. Matterport 3D: Learning from RGB-D Data in Indoor Environments. International Conference on 3D Vision (3DV) .
- 8Chen et al. (2020) Chen, G.; Pan, L.; Chen, Y.; Xu, P.; Wang, Z.; Wu, P.; Ji, J.; and Chen, X. 2020. Robot Navigation with Map-Based Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Networking, Sensing and Control (ICNSC) , 1–6.