Category-level Text-to-Image Retrieval Improved: Bridging the Domain Gap with Diffusion Models and Vision Encoders
Faizan Farooq Khan, Vladan Stojni\'c, Zakaria Laskar, Mohamed Elhoseiny, Giorgos Tolias

TL;DR
This paper presents a novel two-step method for category-level text-to-image retrieval that transforms text queries into visual representations using diffusion models, significantly improving retrieval accuracy over traditional VLM-based methods.
Contribution
It introduces a diffusion-based text-to-visual transformation and an aggregation network to enhance cross-modal retrieval performance, bridging the modality gap effectively.
Findings
Outperforms existing text-only retrieval methods
Consistently improves retrieval accuracy across datasets
Leverages diffusion models and vision encoders effectively
Abstract
This work explores text-to-image retrieval for queries that specify or describe a semantic category. While vision-and-language models (VLMs) like CLIP offer a straightforward open-vocabulary solution, they map text and images to distant regions in the representation space, limiting retrieval performance. To bridge this modality gap, we propose a two-step approach. First, we transform the text query into a visual query using a generative diffusion model. Then, we estimate image-to-image similarity with a vision model. Additionally, we introduce an aggregation network that combines multiple generated images into a single vector representation and fuses similarity scores across both query modalities. Our approach leverages advancements in vision encoders, VLMs, and text-to-image generation models. Extensive evaluations show that it consistently outperforms retrieval methods relying solely…
Click any figure to enlarge with its caption.
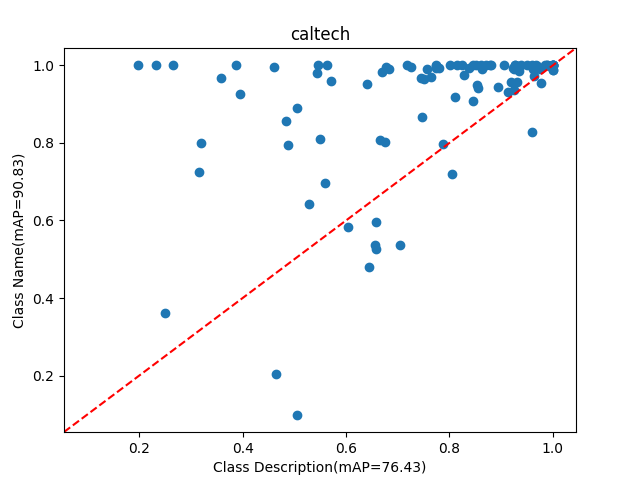 Figure 1
Figure 1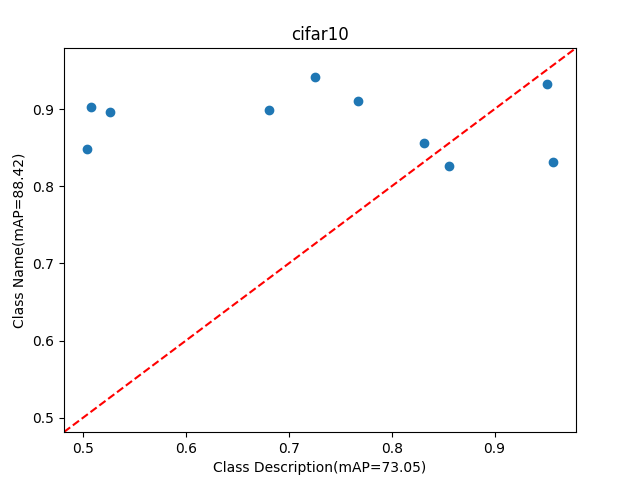 Figure 2
Figure 2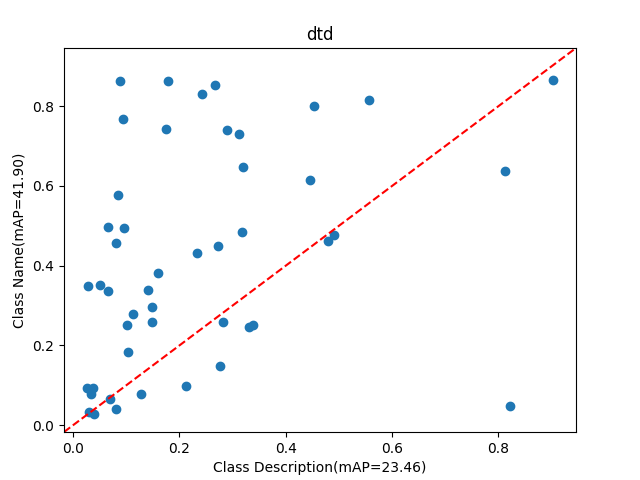 Figure 3
Figure 3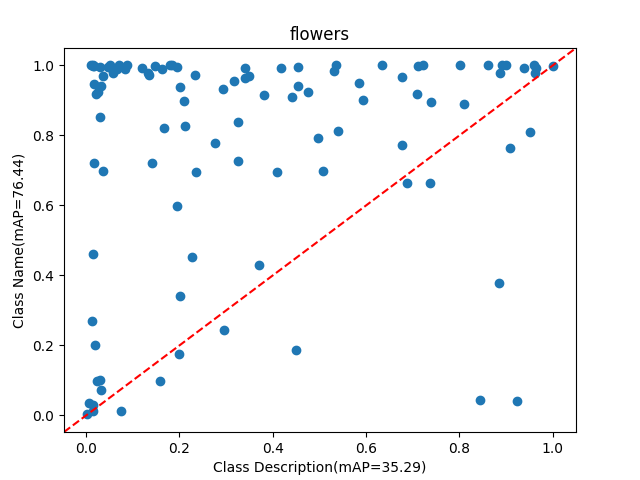 Figure 4
Figure 4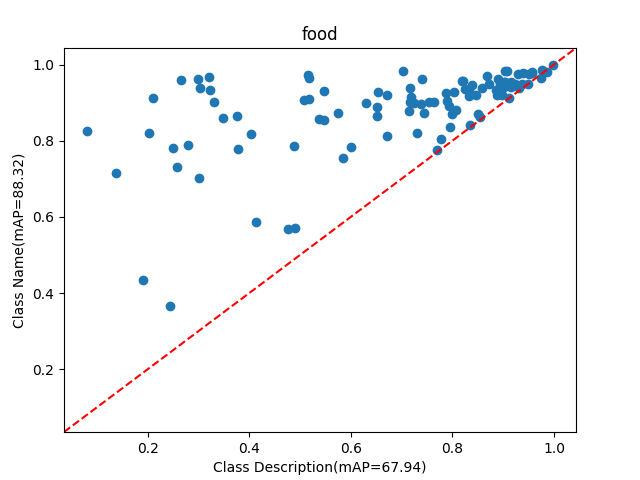 Figure 5
Figure 5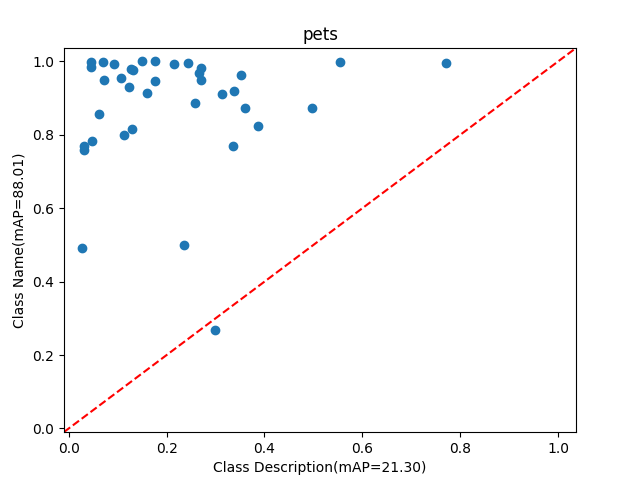 Figure 6
Figure 6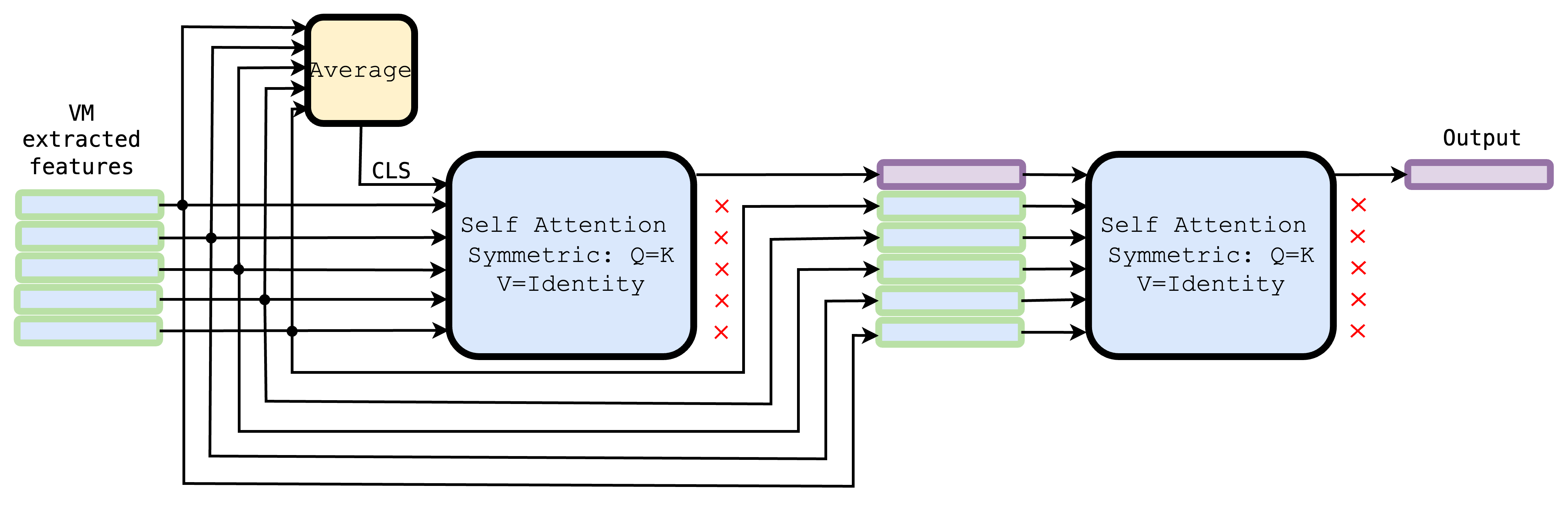 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40|
ImageNet |
DTD |
Stanford Cars |
SUN397 |
Food |
FGVC Aircraft |
Oxford Pets |
Caltech101 |
Flowers 102 |
UCF101 |
Kinetics-700 |
RESISC45 |
CIFAR-10 |
CIFAR-100 |
Places-365 |
Average |
|
| image-only (D) | 63.9 | 38.0 | 30.2 | 51.6 | 75.3 | 11.1 | 84.8 | 87.5 | 63.0 | 59.4 | 28.5 | 43.9 | 65.6 | 75.1 | 27.4 | 53.7 |
| query text - Class | ||||||||||||||||
| text-only (C) | 64.9 | 41.9 | 64.4 | 54.4 | 88.3 | 28.4 | 88.0 | 90.8 | 76.4 | 66.3 | 36.2 | 64.3 | 88.4 | 61.7 | 25.8 | 62.7 |
| image-only (C) | 32.1 | 25.2 | 35.8 | 37.4 | 62.3 | 14.3 | 47.0 | 73.8 | 42.6 | 46.7 | 14.9 | 42.2 | 78.8 | 51.6 | 17.0 | 41.4 |
| text (C)+image (C) | 51.3 | 36.5 | 53.1 | 50.7 | 82.2 | 21.8 | 73.7 | 85.3 | 67.6 | 59.3 | 26.7 | 58.1 | 89.7 | 65.6 | 23.7 | 56.4 |
| text(C)+image(D) | 73.2 | 43.9 | 37.0 | 56.9 | 80.9 | 15.6 | 87.9 | 91.3 | 72.8 | 65.0 | 33.4 | 57.2 | 87.0 | 82.1 | 30.6 | 61.0 |
| Tip-adapter (C,D) [Zhang et al.(2021)Zhang, Fang, Gao, Zhang, Li, Dai, Qiao, and Li] | 73.0 | 50.0 | 51.1 | 61.0 | 86.8 | 22.9 | 90.4 | 92.9 | 78.7 | 70.5 | 38.1 | 64.2 | 93.2 | 83.5 | 32.2 | 65.9 |
| Ours (C,D) | 73.8 | 50.1 | 67.1 | 62.4 | 90.7 | 29.0 | 91.0 | 93.0 | 79.6 | 72.5 | 40.8 | 66.6 | 90.4 | 80.3 | 31.9 | 67.9 |
| text-only (S) | 72.4 | 49.9 | 89.2 | 59.8 | 93.1 | 45.6 | 92.3 | 94.6 | 83.5 | 74.3 | 42.0 | 63.5 | 93.6 | 72.3 | 28.7 | 70.3 |
| image-only (S) | 38.7 | 31.6 | 56.4 | 41.9 | 65.5 | 17.4 | 61.7 | 79.4 | 56.3 | 51.9 | 22.4 | 51.2 | 80.1 | 60.5 | 20.7 | 49.0 |
| text (S)+image (S) | 60.1 | 42.0 | 76.1 | 55.0 | 85.9 | 32.2 | 82.1 | 89.8 | 78.0 | 65.2 | 33.2 | 60.6 | 90.5 | 72.9 | 27.5 | 63.4 |
| text(S)+image(D) | 70.8 | 46.7 | 49.6 | 57.9 | 82.6 | 23.6 | 89.0 | 92.5 | 77.9 | 67.6 | 34.9 | 57.8 | 91.1 | 84.3 | 31.3 | 63.8 |
| Tip-adapter (S,D) [Zhang et al.(2021)Zhang, Fang, Gao, Zhang, Li, Dai, Qiao, and Li] | 75.2 | 51.9 | 68.6 | 61.5 | 88.3 | 33.8 | 91.4 | 95.6 | 82.3 | 73.1 | 39.8 | 62.7 | 94.4 | 86.3 | 33.0 | 69.1 |
| Ours (S,D) | 77.4 | 54.6 | 88.2 | 64.4 | 92.9 | 44.1 | 92.9 | 95.5 | 84.0 | 77.1 | 44.0 | 65.1 | 94.0 | 85.4 | 33.3 | 72.9 |
| query text - Description-only | ||||||||||||||||
| text-only (C) | 34.4 | 23.5 | 8.5 | 38.1 | 67.9 | 12.6 | 21.3 | 76.4 | 35.3 | 48.0 | 18.5 | 42.4 | 73.0 | 42.3 | 16.2 | 37.2 |
| Ours (C,D) | 42.4 | 29.5 | 10.1 | 45.5 | 71.4 | 13.6 | 32.5 | 82.2 | 41.5 | 57.2 | 24.8 | 47.8 | 79.0 | 55.5 | 21.3 | 43.6 |
| text-only (S) | 46.3 | 32.7 | 12.3 | 42.5 | 79.8 | 14.3 | 37.1 | 80.0 | 43.5 | 53.4 | 26.8 | 47.5 | 75.3 | 57.4 | 20.3 | 44.6 |
| Ours (S,D) | 49.9 | 35.3 | 12.1 | 47.3 | 77.7 | 14.9 | 44.2 | 85.1 | 48.3 | 61.4 | 30.1 | 50.5 | 78.9 | 63.8 | 23.9 | 48.2 |
| query text - Description + Class | ||||||||||||||||
| text-only (C) | 65.5 | 47.0 | 66.2 | 53.6 | 90.5 | 30.9 | 85.2 | 93.4 | 80.4 | 66.6 | 31.4 | 54.6 | 94.4 | 70.0 | 24.5 | 63.6 |
| Ours (C,D) | 71.8 | 46.8 | 66.8 | 58.1 | 90.8 | 29.6 | 91.2 | 95.4 | 82.2 | 73.0 | 37.7 | 59.3 | 95.5 | 81.3 | 29.1 | 67.2 |
| text-only (S) | 73.1 | 51.4 | 88.5 | 57.4 | 93.6 | 48.3 | 93.5 | 95.6 | 87.9 | 73.5 | 40.3 | 59.7 | 95.4 | 77.5 | 28.7 | 70.9 |
| Ours (S,D) | 76.0 | 50.8 | 85.5 | 59.8 | 92.2 | 45.3 | 94.0 | 96.4 | 89.1 | 77.4 | 42.7 | 63.1 | 96.3 | 84.7 | 31.2 | 72.3 |
| SD query images only | |||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| mAP | 67.1 | 67.6 | 67.8 | 67.9 | 68.0 | 68.0 | 68.0 | 68.0 | 68.0 | 68.0 | |
| SD+SD-Turbo+Flux query images | |||||||||||
| 1+1+1 | 2+2+2 | 3+3+3 | 4+4+4 | 5+5+5 | |||||||
| mAP | 68.4 | 68.8 | 68.9 | 69.0 | 69.0 | ||||||
| Method | Average mAP |
|---|---|
| average aggregation | 61.0 |
| text baseline [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] | 62.6 |
| Ours Full | 68.0 |
| - w/o tuning | 63.2 |
| - w/o dual generator | 66.1 |
| - w/o dynamic negative mining | 67.1 |
| - w/o repeating input | 67.8 |
| Flickr-30k [Young et al.(2014)Young, Lai, Hodosh, and Hockenmaier] | ||||
| Variant | Method | R@1 | R@5 | R@10 |
| Clip-based | CLIP | 64.9 | 87.3 | 92.0 |
| DIVA [Wang et al.(2025)Wang, Sun, Zhang, Tang, Liu, and Wang] | 64.4 | 86.9 | 92.0 | |
| Ours(C,D) | 69.9 | 90.0 | 94.4 | |
| MetaCLIP-based | MetaCLIP | 73.4 | 92.3 | 95.8 |
| MODE-2 [Ma et al.(2024)Ma, Huang, Xie, Li, Zettlemoyer, Chang, Yih, and Xu] | 73.4 | 92.5 | 95.8 | |
| MODE-4 [Ma et al.(2024)Ma, Huang, Xie, Li, Zettlemoyer, Chang, Yih, and Xu] | 73.5 | 92.1 | 95.9 | |
| Ours(M,D) | 74.8 | 93.1 | 96.3 | |
| LLM-based | TIgER(LaVIT) [Qu et al.(2025)Qu, Li, Wang, Wang, Li, Nie, and Chua] | 68.8 | 82.9 | 86.4 |
| TIgER(SEED-LLaMA) [Qu et al.(2025)Qu, Li, Wang, Wang, Li, Nie, and Chua] | 71.7 | 91.8 | 95.4 | |
| Frozen [Pang et al.(2024)Pang, Xie, Man, and Wang] | 50.2 | 82.3 | 90.1 | |
|
ImageNet |
DTD |
Stanford Cars |
SUN397 |
Food |
FGVC Aircraft |
Oxford Pets |
Caltech101 |
Flowers 102 |
UCF101 |
Kinetics-700 |
RESISC45 |
CIFAR-10 |
CIFAR-100 |
Places-365 |
Average |
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| text-only(M) | 66.5 | 39.8 | 73.8 | 56.0 | 88.5 | 31.4 | 88.7 | 91.5 | 74.9 | 65.7 | 35.9 | 55.4 | 88.5 | 67.2 | 26.6 | 63.4 |
| image-only(M) | 34.9 | 20.9 | 35.7 | 35.1 | 58.6 | 15.7 | 52.0 | 74.3 | 35.1 | 46.3 | 18.6 | 33.4 | 74.8 | 48.9 | 16.7 | 40.1 |
| text(M) + image(M) | 54.1 | 32.4 | 54.7 | 50.2 | 81.5 | 22.4 | 75.4 | 87.4 | 62.0 | 61.8 | 30.4 | 53.0 | 88.5 | 64.3 | 23.7 | 56.1 |
| text(M) + image(D) | 69.9 | 46.0 | 57.2 | 57.2 | 83.7 | 23.9 | 89.0 | 91.8 | 76.9 | 65.6 | 34.3 | 54.7 | 79.0 | 81.7 | 30.3 | 62.7 |
| Ours | 74.2 | 48.5 | 74.1 | 63.2 | 90.3 | 33.7 | 91.5 | 94.3 | 79.3 | 71.9 | 40.3 | 59.2 | 90.2 | 83.0 | 32.2 | 68.4 |
| text-only(O) | 63.4 | 38.6 | 83.1 | 59.8 | 86.8 | 20.9 | 86.2 | 90.9 | 71.0 | 65.7 | 32.7 | 67.1 | 93.3 | 70.0 | 29.6 | 63.9 |
| image-only(O) | 41.0 | 31.2 | 52.6 | 45.7 | 66.1 | 13.9 | 58.2 | 79.9 | 50.1 | 50.8 | 21.4 | 51.2 | 82.2 | 53.9 | 22.8 | 48.1 |
| text(O)+image(O) | 56.1 | 39.8 | 70.4 | 56.2 | 80.6 | 19.3 | 75.6 | 87.6 | 65.3 | 61.2 | 29.9 | 62.3 | 92.1 | 66.8 | 28.4 | 59.4 |
| text(O)+image(D) | 70.3 | 46.3 | 50.7 | 59.5 | 82.9 | 16.3 | 88.2 | 92.7 | 73.8 | 66.7 | 34.6 | 62.8 | 94.5 | 84.9 | 32.3 | 63.8 |
| Ours | 70.8 | 45.0 | 82.2 | 63.4 | 89.0 | 23.0 | 89.2 | 93.1 | 74.9 | 69.8 | 36.9 | 67.8 | 94.5 | 80.0 | 32.7 | 67.5 |
| text-only(E) | 71.1 | 43.9 | 83.6 | 62.2 | 90.4 | 30.6 | 89.4 | 93.6 | 77.8 | 70.0 | 42.6 | 68.0 | 97.4 | 86.9 | 29.5 | 69.1 |
| image-only(E) | 39.8 | 24.7 | 50.5 | 41.4 | 65.7 | 14.9 | 60.2 | 78.6 | 55.9 | 50.0 | 23.5 | 43.4 | 81.6 | 69.3 | 19.6 | 47.9 |
| text(E)+image(E) | 55.9 | 32.5 | 66.9 | 52.7 | 83.1 | 20.9 | 78.1 | 87.4 | 71.1 | 60.5 | 32.9 | 57.7 | 88.8 | 79.8 | 25.7 | 59.6 |
| text(E)+image(D) | 69.8 | 44.9 | 45.8 | 57.8 | 81.9 | 17.0 | 87.9 | 91.9 | 73.7 | 65.6 | 34.2 | 58.5 | 91.4 | 85.4 | 31.1 | 62.4 |
| Ours | 75.9 | 51.2 | 82.4 | 65.0 | 91.3 | 31.2 | 90.7 | 94.6 | 79.9 | 73.1 | 43.0 | 68.5 | 95.3 | 89.8 | 33.5 | 71.0 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\addauthor
Faizan Farooq [email protected] \addauthorVladan Stojnić[email protected] \addauthorZakaria [email protected] \addauthorMohamed [email protected] \addauthorGiorgos [email protected] \addinstitution King Abdullah University of Science and Technology
Thuwal, Saudi Arabia
\addinstitution Visual Recognition Group
Faculty of Electrical Engineering
Czech Technical University in Prague
Category-level Text-to-Image Retrieval Improved
Category-level Text-to-Image Retrieval Improved: Bridging the Domain Gap with Diffusion Models and Vision Encoders
Abstract
This work explores text-to-image retrieval for queries that specify or describe a semantic category. While vision-and-language models (VLMs) like CLIP offer a straightforward open-vocabulary solution, they map text and images to distant regions in the representation space, limiting retrieval performance. To bridge this modality gap, we propose a two-step approach. First, we transform the text query into a visual query using a generative diffusion model. Then, we estimate image-to-image similarity with a vision model. Additionally, we introduce an aggregation network that combines multiple generated images into a single vector representation and fuses similarity scores across both query modalities. Our approach leverages advancements in vision encoders, VLMs, and text-to-image generation models. Extensive evaluations show that it consistently outperforms retrieval methods relying solely on text queries. Source code is available at: https://github.com/faixan-khan/cletir
1 Introduction
This work explores category-level image retrieval using a textual query that names or describes a semantic class, aiming to retrieve all images depicting objects of the specified class. This task is particularly crucial in open-world scenarios, where systems must handle arbitrary categories. It has practical applications in navigating large-scale digital image archives and visual datasets, such as computer vision training sets containing millions or billions of images. Moreover, such retrieval serves as a fundamental component in more complex computer vision pipelines [Udandarao et al.(2023)Udandarao, Gupta, and Albanie, Liu et al.(2023)Liu, Son, Yang, Liu, Gao, Lee, and Li, Stojnić et al.(2024)Stojnić, Kalantidis, and Tolias].
Despite its significance, category-level text-to-image retrieval has received limited attention in prior research. Existing approaches often rely on text-based image crawling from the web, followed by training an image classifier [Chatfield et al.(2015)Chatfield, Arandjelovic, Parkhi, and Zisserman], utilizing handcrafted representations [Chatfield and Zisserman(2012)] or early deep models [Chatfield et al.(2014)Chatfield, Simonyan, and Zisserman]. In contrast, more general text-to-image retrieval tasks have been more extensively studied [Huang et al.(2018)Huang, Wu, Song, and Wang, Chen et al.(2021)Chen, Hu, Wu, Jiang, and Wang, Faghri et al.(2017)Faghri, Fleet, Kiros, and Fidler, Li et al.(2019)Li, Zhang, Li, Li, and Fu, Chun et al.(2021)Chun, Oh, De Rezende, Kalantidis, and Larlus, Song and Soleymani(2019)], though they typically depend on domain-specific training and lack true open-vocabulary capabilities. The emergence of CLIP [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] revolutionized the field by enabling training-free, open-world retrieval [Ma et al.(2024)Ma, Huang, Xie, Li, Zettlemoyer, Chang, Yih, and Xu, Wang et al.(2025)Wang, Sun, Zhang, Tang, Liu, and Wang].
Building on advancements in vision-and-language models (VLMs) [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever, Li et al.(2022)Li, Li, Xiong, and Hoi, Jia et al.(2021)Jia, Yang, Xia, Chen, Parekh, Pham, Le, Sung, Li, and Duerig], we revisit category-level text-to-image retrieval. Leveraging VLMs makes this task straightforward, i.e., obtaining a text representation of the query and performing Euclidean search within the visual representations of database images. We evaluate this approach across multiple benchmarks. Despite their strong performance, VLMs exhibit a known modality gap, where text and image representations remain well-separated in the feature space [Liang et al.(2022)Liang, Zhang, Kwon, Yeung, and Zou, Schrodi et al.(2025)Schrodi, Hoffmann, Argus, Fischer, and Brox, Shi et al.(2023)Shi, Welle, Björkman, and Kragic]. Inspired by prior work [Zhang et al.(2023)Zhang, Hu, Li, Huang, Deng, Qiao, Gao, and Li, Wysoczanska et al.(2024)Wysoczanska, Siméoni, Ramamonjisoa, Bursuc, Trzcinski, and Pérez, Iscen et al.(2024)Iscen, Caron, Fathi, and Schmid] demonstrating the effectiveness of intra-modal operations over cross-modal ones, we propose bridging this gap by mapping text to images and subsequently performing image-to-image comparisons. To achieve this, we transform the text query into an image query using a text-to-image Generative Diffusion-based Model (GDM) [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer, Sauer et al.(2023)Sauer, Lorenz, Blattmann, and Rombach, Labs(2024)]. Instead of relying on the VLM’s vision encoder, we employ a foundational Vision Model (VM) for image-to-image similarity estimation. By properly fusing the multiple queries from both modalities, our approach achieves consistent improvements over the text-only baseline across fifteen benchmarks.
2 Related Work
In this section, we review the related work on text-to-image retrieval, the use of VLMs in visual recognition tasks, the synergy between VLMs and VMs for cross-modal recognition, and the use of image generation models as free training data generators.
Text-to-Image Retrieval is a cross-modal retrieval task aimed at finding images relevant to text descriptions such as captions. Traditional methods [Huang et al.(2018)Huang, Wu, Song, and Wang, Chen et al.(2021)Chen, Hu, Wu, Jiang, and Wang, Faghri et al.(2017)Faghri, Fleet, Kiros, and Fidler, Li et al.(2019)Li, Zhang, Li, Li, and Fu, Chun et al.(2021)Chun, Oh, De Rezende, Kalantidis, and Larlus, Song and Soleymani(2019)] rely on domain-specific training and lack open-vocabulary generalization. Some approaches improve model architectures [Huang et al.(2018)Huang, Wu, Song, and Wang, Chen et al.(2021)Chen, Hu, Wu, Jiang, and Wang, Li et al.(2019)Li, Zhang, Li, Li, and Fu], others propose new loss functions [Chun et al.(2021)Chun, Oh, De Rezende, Kalantidis, and Larlus, Faghri et al.(2017)Faghri, Fleet, Kiros, and Fidler], or design alternative embedding representations [Chun et al.(2021)Chun, Oh, De Rezende, Kalantidis, and Larlus, Song and Soleymani(2019)]. Category-level retrieval [Chatfield and Zisserman(2012), Chatfield et al.(2014)Chatfield, Simonyan, and Zisserman, Chatfield et al.(2015)Chatfield, Arandjelovic, Parkhi, and Zisserman, Vakhitov et al.(2016)Vakhitov, Kuzmin, and Lempitsky] is a special case where the query defines a category rather than a detailed caption. These works use Google Image Search to retrieve representative images and perform image-based retrieval. In contrast, we leverage modern foundation models for category-level retrieval.
VLMs for Image Recognition Tasks Vision-Language Models (VLMs)[Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever, Jia et al.(2021)Jia, Yang, Xia, Chen, Parekh, Pham, Le, Sung, Li, and Duerig, Cherti et al.(2023)Cherti, Beaumont, Wightman, Wortsman, Ilharco, Gordon, Schuhmann, Schmidt, and Jitsev, Zhai et al.(2023)Zhai, Mustafa, Kolesnikov, and Beyer], trained on large image-text datasets[Schuhmann et al.(2022)Schuhmann, Beaumont, Vencu, Gordon, Wightman, Cherti, Coombes, Katta, Mullis, Wortsman, Schramowski, Kundurthy, Crowson, Schmidt, Kaczmarczyk, and Jitsev, Byeon et al.(2022)Byeon, Park, Kim, Lee, Baek, and Kim, Xu et al.(2024)Xu, Xie, Tan, Huang, Howes, Sharma, Li, Ghosh, Zettlemoyer, and Feichtenhofer, Gadre et al.(2023)Gadre, Ilharco, Fang, Hayase, Smyrnis, Nguyen, Marten, Wortsman, Ghosh, Zhang, Orgad, Entezari, Daras, Pratt, Ramanujan, Bitton, Marathe, Mussmann, Vencu, Cherti, Krishna, Koh, Saukh, Ratner, Song, Hajishirzi, Farhadi, Beaumont, Oh, Dimakis, Jitsev, Carmon, Shankar, and Schmidt], achieve strong performance on various vision tasks. CLIP [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] and SigLIP [Zhai et al.(2023)Zhai, Mustafa, Kolesnikov, and Beyer] excel at zero-shot classification, further improved by methods like Tip-Adapter [Zhang et al.(2021)Zhang, Fang, Gao, Zhang, Li, Dai, Qiao, and Li], SuS-X [Udandarao et al.(2023)Udandarao, Gupta, and Albanie], and CaFO [Zhang et al.(2023)Zhang, Hu, Li, Huang, Deng, Qiao, Gao, and Li]. CoCa [Yu et al.(2022)Yu, Wang, Vasudevan, Yeung, Seyedhosseini, and Wu] and Florence [Yuan et al.(2021)Yuan, Chen, Chen, Codella, Dai, Gao, Hu, Huang, Li, Li, Liu, Liu, Liu, Lu, Shi, Wang, Wang, Xiao, Xiao, Yang, Zeng, Zhou, and Zhang] extend VLMs to video action recognition. Additionally, the advent of VLMs [Li et al.(2022)Li, Li, Xiong, and Hoi, Sun et al.(2024)Sun, Wang, Yu, Cui, Zhang, Zhang, and Wang, Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] opened the possibilities for performing text-to-image retrieval in the open-vocabulary setting without the necessity for domain-specific training. We take advantage of these capabilities and propose a way to utilize VLMs for category-level retrieval.
VLMs and VMs for Cross-modal Tasks Although VLMs perform well on cross-modal tasks, their embeddings are less effective for intra-modal tasks due to the modality gap [Liang et al.(2022)Liang, Zhang, Kwon, Yeung, and Zou, Shi et al.(2023)Shi, Welle, Björkman, and Kragic, Schrodi et al.(2025)Schrodi, Hoffmann, Argus, Fischer, and Brox]. To address this, several works incorporate Vision Models (VMs) for intra-modal components. CaFO [Zhang et al.(2023)Zhang, Hu, Li, Huang, Deng, Qiao, Gao, and Li] uses a self-supervised VM to boost few-shot classification. CLIP-DINOiser [Wysoczanska et al.(2024)Wysoczanska, Siméoni, Ramamonjisoa, Bursuc, Trzcinski, and Pérez], ProxyCLIP [Lan et al.(2024)Lan, Chen, Ke, Wang, Feng, and Zhang], LaVG [Kang and Cho(2024)], and LPOSS [Stojnić et al.(2025)Stojnić, Kalantidis, Matas, and Tolias] leverage DINO [Caron et al.(2021)Caron, Touvron, Misra, Jégou, Mairal, Bojanowski, and Joulin] for patch-level relationships, improving VLM-based semantic segmentation. Additionally, previous works like [Tong et al.(2024b)Tong, Liu, Zhai, Ma, LeCun, and Xie, Shen et al.(2024)Shen, Xiong, Zhao, Wu, Chen, Zhu, Liu, Xiao, Varadarajan, Bordes, Liu, Xu, Kim, Soran, Krishnamoorthi, Elhoseiny, and Chandra, Tong et al.(2024a)Tong, Brown, Wu, Woo, Iyer, Akula, Yang, Yang, Middepogu, Wang, Pan, Fergus, LeCun, and Xie] show VMs can enhance multi-modal LLMs. Inspired by this, we use DINOv2 [Oquab et al.(2023)Oquab, Darcet, Moutakanni, Vo, Szafraniec, Khalidov, Fernandez, Haziza, Massa, El-Nouby, Assran, Ballas, Galuba, Howes, Huang, Li, Misra, Rabbat, Sharma, Synnaeve, Xu, Jégou, Mairal, Labatut, Joulin, and Bojanowski] to extract embeddings for image-to-image retrieval.
Generative Models as Training Data Generators The emergence of realistic image generation models [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer, Saharia et al.(2022)Saharia, Chan, Saxena, Li, Whang, Denton, Ghasemipour, Lopes, Ayan, Salimans, Ho, Fleet, and Norouzi, Ramesh et al.(2021)Ramesh, Pavlov, Goh, Gray, Voss, Radford, Chen, and Sutskever] has prompted interest in their use for image recognition tasks. Sariyildiz et al. [Sariyildiz et al.(2023)Sariyildiz, Alahari, Larlus, and Kalantidis] show that models trained on synthetic ImageNet data transfer as well as those trained on real data. Azizi et al. [Azizi et al.(2023)Azizi, Kornblith, Saharia, Norouzi, and Fleet] further demonstrate improved performance when combining real and synthetic data. For segmentation, FreeMask [Yang et al.(2023)Yang, Xu, Kang, Shi, and Zhao] and DatasetDiffusion [Nguyen et al.(2023)Nguyen, Vu, Tran, and Nguyen] generate synthetic training images. Compared to these works, we investigate that if synthetic images can be used during inference for category-level image retrieval by using synthetic data to enrich the given text queries.
3 Preliminaries
Task Formulation We study category-level text-to-image retrieval, where the goal is to retrieve images based on category or class labels. Unlike image-to-image retrieval [Gordo and Larlus(2017), An et al.(2023)An, Deng, Yang, Li, Feng, Guo, Yang, and Liu, Ermolov et al.(2022)Ermolov, Mirvakhabova, Khrulkov, Sebe, and Oseledets], which retrieves images similar to a query image, this task retrieves images relevant to a query text. In contrast to instance-level retrieval [Chen et al.(2023)Chen, Liu, Wang, Bakker, Georgiou, Fieguth, Liu, and Lew], where relevance is based on depicting the same specific object, here it depends on belonging to the same semantic class. This cross-modal task takes a class name as input (e.g., “dog”) and retrieves all images depicting that category. We explore three query types: a class name, a class description, and both jointly.
VLM Vision-Language Models (VLMs)[Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever, Jia et al.(2021)Jia, Yang, Xia, Chen, Parekh, Pham, Le, Sung, Li, and Duerig, Li et al.(2022)Li, Li, Xiong, and Hoi] are well-suited for cross-modal tasks. These models consist of a textual encoder that maps text to its representation vector , and a vision encoder that maps image to its representation vector on a shared representation space. These models are trained on large image-caption datasets like WIT-400M[Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] and LAION [Schuhmann et al.(2022)Schuhmann, Beaumont, Vencu, Gordon, Wightman, Cherti, Coombes, Katta, Mullis, Wortsman, Schramowski, Kundurthy, Crowson, Schmidt, Kaczmarczyk, and Jitsev] via contrastive learning between and . We primarily use CLIP [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever], but also report results on EVA02-CLIP [Fang et al.(2023)Fang, Wang, Xie, Sun, Wu, Wang, Huang, Wang, and Cao], MetaCLIP [Xu et al.(2024)Xu, Xie, Tan, Huang, Howes, Sharma, Li, Ghosh, Zettlemoyer, and Feichtenhofer], SigLIP [Zhai et al.(2023)Zhai, Mustafa, Kolesnikov, and Beyer], and OpenCLIP [Ilharco et al.(2021)Ilharco, Wortsman, Wightman, Gordon, Carlini, Taori, Dave, Shankar, Namkoong, Miller, Hajishirzi, Farhadi, and Schmidt]. During test time, with the use of a VLM, the similarity between words and images is estimated straightforwardly.
GDM Generative Diffusion-based Models [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer, Saharia et al.(2022)Saharia, Chan, Saxena, Li, Whang, Denton, Ghasemipour, Lopes, Ayan, Salimans, Ho, Fleet, and Norouzi, Sauer et al.(2023)Sauer, Lorenz, Blattmann, and Rombach] are a class of large generative models that function on the principle of denoising diffusion to generate images. During inference, starting from a noisy input, the backward diffusion process is run to obtain a denoised image. The text-to-image GDMs use textual input conditioning to guide the generation process. Instead of starting from just a noisy input, the textual representation [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever, Vaswani et al.(2017)Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin] of text forms an additional input. This work primarily uses Stable Diffusion (SD)[Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer], Single-step Distilled Diffusion[Sauer et al.(2023)Sauer, Lorenz, Blattmann, and Rombach], and FLUX [Labs(2024)].
4 Method
Given text query , we describe the proposed approach enabling the similarity estimation between and each database (db) image . An overview is shown in Figure 1. The vanilla approach is to perform cross-modal retrieval via computing the text query to db image similarity via a VLM.
4.1 Generating Image Queries
Cross-modal retrieval suffers from the modality gap [Liang et al.(2022)Liang, Zhang, Kwon, Yeung, and Zou, Iscen et al.(2024)Iscen, Caron, Fathi, and Schmid] due to insufficient alignment between textual and visual representations in the pre-training stage. Lack of visual context in the form of query images hinders the application of standard intra-modal retrieval that is shown to be superior to cross-modal retrieval [Iscen et al.(2024)Iscen, Caron, Fathi, and Schmid]. We bridge this gap by generating image queries using a pre-trained text-to-image GDM. We use to prompt the diffusion model using a template ‘‘A photo of a ’’. We generate a set of visual queries per text query by varying the seed value to the diffusion model. Therefore, we are now given one text query and several image queries to perform the retrieval; the query is bi-modal, while the visual modality contains multiple queries. In our experiments, we explore the option of using multiple generative models [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer, Sauer et al.(2023)Sauer, Lorenz, Blattmann, and Rombach, Labs(2024)], both for training and testing, to capture complementary aspects of a class and to cancel each other’s mistakes.
4.2 Similarity Estimation
Cross-Modal Similarity The cross-modal similarity between image and text query is estimated with the use of a VLM via a simple dot product
Intra-modal Similarity Given the db image and generated images , the similarity between query and db image can be estimated indirectly through intra-modal similarity between and .
Instead of using the visual encoder of the VLM for this task, we assume access to the encoder of a Vision Model (VM) that maps images to a dimensional descriptor space. Estimating intra-modal similarity is the task VMs are originally optimized for, in contrast to VLMs, whose training objective only includes cross-modal terms and not intra-modal.
We obtain the db image representation and the representation for the generated query images given in set . We propose to first aggregate the representations and then compute the similarity to the db image. The aggregation is performed by the function . Then, is used to compute the intra-modal similarity between query and db image given by For there is no need for aggregation; we simply set .
Hybrid Similarity The hybrid similarity is a weighted combination of intra-modal and cross-modal similarities with . For extreme values 0 and 1, the similarity is equivalent to the cross-modal only or intra-modal only, respectively. We refer to those as text-only and image-only approaches, respectively, as well as hybrid when .
Aggregator architecture A baseline approach for is to perform average pooling, denoted by , which we evaluate in the experiments. Instead, we propose a learnable parametric model as the aggregator, whose parameters are learned directly from data.
The aggregator design relies on a sequence of simple self-attention layers that have distinctive differences from the standard practice. They use symmetric attention (query and key projections are the same), and value projections are identity functions. Additionally, the CLS token at the input of the first layer is not learnable and is set equal to the average pooling of all other input tokens. Those other input tokens are fed as input to all attention layers without any modification, with the CLS being the only one affected by the attention processing. An overview of the aggregator architecture is demonstrated in the supplementary material.
Concretely, the aggregator is a sequence of attention layers with the -th layer given by where is a linear transform applied independently per column, subscript indicates that this function is parametric with learnable parameters. Now, let be the input of the first layer, whose tokens (columns) are equal to for and . The last token can be seen as corresponding to the CLS token. The output of the first layer is , with tokens (columns) denoted by .
The input of the -th layer is formed by concatenating the inputs of the first layer and CLS output token of layer , i.e. . The same process is repeated across all layers. The final output vector of the aggregator is the CLS token of the last attention layer, i.e. . The learnable parameters of the aggregator are the parameters of all linear transforms, one per layer.
The proposed sequence of attention layers performs a more intuitive operation than standard attention or transformers, which include feed-forward layers and skip connections. By setting value projections to identity, the output representation space remains unchanged; i.e., the architecture performs only weighted mean operation with context-dependent weights. Thus, the final representation stays compatible with the db image’s representation space. Viewing attention layers as in-context mappings, we feed the same input tokens to all layers, iteratively transforming the CLS token in the context of the input vectors being aggregated.
4.3 Training: Aggregator and Modality Balance
The role of the aggregator function is to robustly aggregate the query representations such that relevant database images (positives) are ranked higher than irrelevant images (negatives). To learn the aggregator but also (VLM and VM are frozen), we generate a large synthetic training set. We prompt two GDMs, SD [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer] and FLUX [Labs(2024)], using category names from the OpenImages text corpus [Kuznetsova et al.(2020)Kuznetsova, Rom, Alldrin, Uijlings, Krasin, Pont-Tuset, Kamali, Popov, Malloci, Kolesnikov, Duerig, and Ferrari]. To simulate a zero-shot setup where we test on unseen classes, we remove classes from this corpus that match those of the benchmark datasets111We use CLIP to find the nearest neighbor of every class from the fifteen test benchmarks and remove all of them.. This process provides us with a training set of about 390k images with ten images per class per GDM, whose label is considered the class used as a prompt.
To construct a training batch, we sample classes, where each class name forms the text query, and then randomly sample generated images from this class to use as image queries () and as a positive (1). A negative image per class is chosen to be the hardest negative among the positives of other classes that are already sampled. The hardness is estimated using the hybrid similarity, taking into account the current status of the model. Contrastive loss is computed taking into account the hybrid similarity between query and positive image () and query and negative image () given by
[TABLE]
We set the parameter to be learnable and observe that back-propagation needs to be performed only through the intra-modal similarity term. This is due to the fact that the encoder models are frozen. We come up with the following empirical trick, which effectively increases the performance, and is motivated by the following two observations. We train with only synthetic images, but during testing, the similarity between real and synthetic images is computed. There is a discrepancy between the synthetic-to-real and the synthetic-to-synthetic image similarities, as shown in Figure 2. Therefore, we set the cross-modal similarity for positives to be fixed to 1 (the maximum similarity) as if we are dealing with perfect text-to-image similarity for the positives. The cross-modal similarity for negatives is properly estimated. Setting it to a fixed value would result in a trivial solution of , making the aggregator irrelevant.
5 Experiments
5.1 Experimental Setup
We perform experiments across 15 datasets: ImageNet [Russakovsky et al.(2015)Russakovsky, Deng, Su, Krause, Satheesh, Ma, Huang, Karpathy, Khosla, Bernstein, Berg, and Fei-Fei], Stanford Cars [Krause et al.(2013)Krause, Stark, Deng, and Fei-Fei], Describable Textures Dataset (DTD) [Cimpoi et al.(2014)Cimpoi, Maji, Kokkinos, Mohamed, and Vedaldi], Scene UNderstanding (SUN397) [Xiao et al.(2010)Xiao, Hays, Ehinger, Oliva, and Torralba], Food101 [Bossard et al.(2014)Bossard, Guillaumin, and Van Gool], FGVC Aircraft [Maji et al.(2013)Maji, Rahtu, Kannala, Blaschko, and Vedaldi], Oxford Pets [Parkhi et al.(2012)Parkhi, Vedaldi, Zisserman, and Jawahar], Caltech101 [Fei-Fei et al.(2004)Fei-Fei, Fergus, and Perona], Flowers 102 [Nilsback and Zisserman(2008)], UCF101 [Soomro et al.(2012)Soomro, Zamir, and Shah], Kinetics-700 [Carreira et al.(2019)Carreira, Noland, Hillier, and Zisserman], Remote Sensing Image Scene Classification (RESISC45) [Cheng et al.(2017)Cheng, Han, and Lu], CIFAR-10 [Krizhevsky(2009)], CIFAR-100 [Krizhevsky(2009)], and Places365 [Zhou et al.(2017)Zhou, Lapedriza, Khosla, Oliva, and Torralba]. For the two video datasets, we follow the same procedure as done in [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] by extracting the middle frame of the video. We report the scores using the official test sets as an image database for datasets that provide them, and for datasets that do not report an official split, we use the splits described in Zhou et al. [Zhou et al.(2022)Zhou, Yang, Loy, and Liu]. As there is no conventional split for RESISC45, we perform the retrieval using all images as the database.
We use CLIP [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] as a VLM with its visual and textual encoders as and , respectively. We use DINOv2 [Oquab et al.(2023)Oquab, Darcet, Moutakanni, Vo, Szafraniec, Khalidov, Fernandez, Haziza, Massa, El-Nouby, Assran, Ballas, Galuba, Howes, Huang, Li, Misra, Rabbat, Sharma, Synnaeve, Xu, Jégou, Mairal, Labatut, Joulin, and Bojanowski] as a VM and encoder . All the models are used with the ViT-L14 backbone [Dosovitskiy et al.(2021)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, Uszkoreit, and Houlsby]. Results for other backbones [Xu et al.(2024)Xu, Xie, Tan, Huang, Howes, Sharma, Li, Ghosh, Zettlemoyer, and Feichtenhofer, Sun et al.(2024)Sun, Wang, Yu, Cui, Zhang, Zhang, and Wang, Ilharco et al.(2021)Ilharco, Wortsman, Wightman, Gordon, Carlini, Taori, Dave, Shankar, Namkoong, Miller, Hajishirzi, Farhadi, and Schmidt] are reported in the supplementary.
To generate image queries for testing, we leverage Stable-Diffusion-Turbo [Sauer et al.(2023)Sauer, Lorenz, Blattmann, and Rombach] (SD-Turbo), Stable-Diffusion 2.1 [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer] (SD), FLUX [Labs(2024)]. The last two are the ones used for the training, too. We generate images per text query by changing the seed values per GDM. The training is performed for , while during testing, we use the aggregator for any number of input images since the attention architecture allows it. We use attention layers. Unless otherwise stated, we test with image queries from SD.
5.2 Results with Class Name as Query
We compare with the baseline approaches using text-only query (), image-only query () with five images, and text+image with equal modality importance (), which all use the average vector aggregator. We additionally compare it to the Tip-adapter [Zhang et al.(2021)Zhang, Fang, Gao, Zhang, Li, Dai, Qiao, and Li] similarity, which considers a text query and multiple image queries, even though it was proposed for zero-shot classification. We tune its hyperparameters based on grid search and performance evaluation for retrieval on our training set.
Table 1 summarizes results from two CLIP variants: original CLIP [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] and SigLIP [Zhai et al.(2023)Zhai, Mustafa, Kolesnikov, and Beyer]. The vanilla text-only approach is a strong starting point. Despite DINOv2 performing much better for the image-only baseline, the image queries solely are inferior to the text query, which better represents the “mode” of the class. Neither of the hybrid baselines manages to surpass the text-only approach. The proposed approach performs best and outperforms Tip-adapter [Zhang et al.(2021)Zhang, Fang, Gao, Zhang, Li, Dai, Qiao, and Li], which fails to beat the baseline for the stronger encoder, i.e. SigLIP.
To compare with the only previous approaches that perform category-level image retrieval, we evaluate on PASCAL VOC [Everingham et al.(2007)Everingham, Van Gool, Williams, Winn, and Zisserman] and compare with the reported numbers. The reproducibility of these methods is not as straightforward as they rely on crawling images from Google Image Search. Our proposed method achieves a Mean Precision of 96.1 at the top 100 ranks on the test split. This is higher than 92.1 [Chatfield et al.(2014)Chatfield, Simonyan, and Zisserman] achieved in prior work. Note that contributions in that line of research, such as the on-the-fly training of a binary classifier, are complementary to the methods explored in this work.
More and diverse generated image queries: We evaluate our approach with images from all generators rather than relying on a single one. As shown in Table 2, this leads to a clear performance boost, demonstrating that leveraging multiple generators can enhance the overall results. Performance using one generator saturates after , but after for 3 generators.
5.3 Results with Class Description as Query
Using only class description We introduce a novel task for image retrieval based on querying only by the category description. We consider a setup where users want to retrieve images of objects in a situation where they can not recall the exact name of the category but can describe the object’s looks or properties. To address this challenge, we establish a benchmark by prompting an LLM [OpenAI(2024)] with the class category . We prompt the LLM to generate coherent sentences describing the category without explicitly mentioning the category . The description for class “airplane” is, “a flying vehicle made of metal, equipped with wings is commonly used for air travel.” We create this benchmark for all fifteen datasets reported in section˜5.1 spanning fine-grained and coarse-grained tasks.
To generate image queries, we adopt a procedure similar to the one used for handling category-level image retrieval. However, rather than directly using the class label (which is unavailable in this setting), we instead utilize the generated description as the input to the GDM.
Using class name with description In this task, we combine the class label and its description as “ : ”. Image queries are generated as before. The input to GDM is the combined query of class label and the generated description ,i.e. “ : ”.
We then follow our approach to perform retrieval for both tasks. Using description only for retrieval is quite challenging as there is no mention of the class name. For example, the description for class “pink primrose” is, “the flower’s petals are a deep pink hue, with a bright yellow center.”. As shown in Table 1, our proposed method significantly improves performance across both tasks for CLIP [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] and SigLIP [Zhai et al.(2023)Zhai, Mustafa, Kolesnikov, and Beyer]. For description-only based retrieval, we improve the average performance over CLIP [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] by 6.4% and by 3.6% over SigLIP [Zhai et al.(2023)Zhai, Mustafa, Kolesnikov, and Beyer]. Adding the description to the class name enhances the text-only performance for both CLIP and SigLIP. However, our approach is still able to improve on both models. This highlights the effectiveness of the visual information generated by the GDM, which, when aggregated by our module, provides important contextual cues to enhance the retrieval process.
5.4 Ablation Study
Table˜3 shows the impact of different architectural and training choices on performance. Below, we detail the effects of each design choice. All variants use 5 SD query images.
** tuning ** Our approach, even without tuning (fixed at 0.5), outperforms CLIP [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever], unlike simple average aggregation, though the improvements are modest. However, with a properly tuned , we observe significant performance gains, highlighting the importance of balancing contributions from different modalities.
Dual Generator Our model is trained using a combination of SD [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer] and FLUX [Labs(2024)] to enhance diversity during training. To examine its impact, we compare it to a model trained exclusively with synthetic images from SD [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer]. Using two generators is clearly better.
Dynamic Negative Mining We dynamically mine the hardest negative within the batch in the standard approach and compare with mining once at the beginning of the training using the hybrid baseline method. Dynamic sampling provides a more adaptive selection of challenging negatives, leading to improved model robustness.
Repeating Attention Inputs In this experiment, the input to the second attention layer is the output of the first layer for all tokens instead of re-feeding the original input tokens. This results in a drop of 0.2% across fifteen benchmarks.
5.5 Analysis
Where do synthetic images help/harm? For better understanding, we visualize the distribution of the relevant features using t-SNE in Figure 3. The most common case of improvements is due to the different generators capturing different aspects of a class, which often works even if one of them is making mistakes. However, when image queries appear mostly near negatives, our approach can hurt the baseline.
Examples Table 4 highlights ImageNet classes with the largest performance gaps between our method and the text-only baseline. Performance drops often stem from GDM missing key visual cues—e.g., "hammer-shaped head" for hammerhead sharks—leading to confusion with similar-looking negatives. In contrast, our approach improves retrieval for visually similar classes like "pig" vs. "guinea pig" or "Prairie Grouse" vs. "Ruffed Grouse" by leveraging visual cues that help disambiguate where text alone falls short.
5.6 Results for Non-Class-Related Queries
While our work focuses on category-level image retrieval, we also show that our approach can enhance CLIP-like models for general retrieval where image captions form the text query. We compare our method against several works that improve or extend CLIP: DIVA [Wang et al.(2025)Wang, Sun, Zhang, Tang, Liu, and Wang] leverages generative feedback from text-to-image diffusion models to refine CLIP representations using only images; Mixture of Data Experts (MoDE) [Ma et al.(2024)Ma, Huang, Xie, Li, Zettlemoyer, Chang, Yih, and Xu] optimizes a system of CLIP data experts via clustering, with each expert trained on a specific data cluster to reduce sensitivity to false negatives. Both TIgER [Qu et al.(2025)Qu, Li, Wang, Wang, Li, Nie, and Chua] and FrozenLLM [Pang et al.(2024)Pang, Xie, Man, and Wang] explore the discriminative abilities of Multi-modal Large Language Models(MLLMs). TIgER [Qu et al.(2025)Qu, Li, Wang, Wang, Li, Nie, and Chua] introduces a generative retrieval method that operates in a training-free manner, and FrozenLLM [Pang et al.(2024)Pang, Xie, Man, and Wang] demonstrates that frozen transformer blocks from pre-trained language models can serve as effective visual encoders. We report the results in Table˜5. It can be seen that our model shows better improvements on both CLIP and MetaCLIP compared to previous works. We also perform better than baselines that utilize MLLMs for retrieval.
6 Conclusions
In this work, we revisit category-level text-to-image retrieval, expanding on the capabilities of VLMs. While VLMs serve as a robust starting point, we significantly advance beyond this by leveraging a diverse suite of foundational generative and representation models. By incorporating synthetic image generation via text prompts and specialized encoders for image-to-image similarity, we achieve substantial performance gains across a wide range of datasets. Our improvements enable better browsing of large image archives and research training sets.
7 Acknowledgement
This work was supported by the Junior Star GACR GM 21-28830M, the Czech Technical University in Prague grant No. SGS23/173/OHK3/3T/13, and by KAUST, under Award No. BAS/1/1685-01-01.
Supplementary Content for Category-level Text-to-Image Retrieval Improved: Bridging the Domain Gap with Diffusion Models and Vision Encoders:
This supplementary document includes the following
- •
Section A: We show the overview of the aggregator architecture.
- •
Section B: We compare the performance of our synthetic visual queries with “perfect” visual queries.
- •
Section C: We report further results for Description Based Retrieval and show examples where it outperforms class name-based retrieval.
- •
Section D: We report results on three more CLIP-based backbones.
- •
Section E: We show the robustness of our approach by analyzing the performance on ImageNet-C [Hendrycks and Dietterich(2019)].
- •
Section F: We present the top retrieved images across various categories, comparing two settings: one where the class name is provided and another where only the class description is used.
Appendix A Architecture
Figure 4 illustrates our proposed architecture for aggregating vision model (VM) extracted features using a symmetric self-attention mechanism. Given the visual features, we first prepend a CLS token(average of the inputs) and pass the sequence through a self-attention block where the query and key matrices are shared (Q=K) and the value is set to identity (V=Identity). This symmetric setup simplifies the attention computation while maintaining the ability to contextualize the CLS token.
Appendix B Real vs. Synthetic Queries
This experiment explores the potential performance improvement achievable by utilizing “perfect” visual queries instead of our synthetically generated ones from a GDM using the text queries . These perfect visual queries are sampled( for each query) from the training set of each benchmark dataset222We do not report the results on RESISC45 as we use the entire dataset as a database.. We employ these visual queries alongside text queries using our approach. Figure 5 illustrates that employing perfect visual queries enhances retrieval performance across all fourteen benchmarks by approximately 11.3% on average compared to the text-only baseline. Additionally, observing the same comparison with the image-only variant reveals a significant performance gap of 11.6% between SD-generated images and perfect image queries. This indicates the gap, seen through the lens of category-level retrieval, between real and generated images. This analysis shows that there is still scope left for improving GDM. As new approaches appear, we can easily plug our approach with new GDM to get closer and closer to the “perfect” visual queries.
Appendix C Description Based Retrieval
As reported in Subsection 5.3 of the main paper, generated descriptions do not contain the explicit mention of the class name. We ensure this by reviewing the generated descriptions. In Table˜6 and Table˜8, we visualize the images generated using the class descriptions, and it can be seen that the synthetic images can provide useful information.
C.1 Where Does Description Shine?
We analyze the performance of Class description retrieval by comparing it with Class name retrieval across six benchmarks. In certain cases, the Class description is more helpful than the Class name. We first compare the performance of the two approaches in Figure˜6 and then in Table˜6 we report the samples generated for classes where the Class description is more useful than the Class name. We also report more qualitative samples in Table˜8.
Appendix D Additional CLIP Backbones
In Table˜7, we report the results from three other CLIP backbones. MetaCLIP [Xu et al.(2024)Xu, Xie, Tan, Huang, Howes, Sharma, Li, Ghosh, Zettlemoyer, and Feichtenhofer], OpenCLIP [Ilharco et al.(2021)Ilharco, Wortsman, Wightman, Gordon, Carlini, Taori, Dave, Shankar, Namkoong, Miller, Hajishirzi, Farhadi, and Schmidt], and Eva-02 CLIP [Sun et al.(2024)Sun, Wang, Yu, Cui, Zhang, Zhang, and Wang]. Our method improves the average performance for all three backbones. This clearly proves that the inclusion of visual information outperforms text-only retrieval.
Appendix E Testing on Noisy Databases
In this section, we compare and analyze the robustness of our approach compared to the text-only baseline. We experiment on ImageNet-C [Hendrycks and Dietterich(2019)]. The ImageNet-C dataset is a benchmark for evaluating the robustness against common corruptions, such as noise, blur, weather effects, and digital distortions. It consists of various corruptions applied to the original ImageNet validation images at five severity levels. In Figure˜8, we show results for all five levels, starting from level one at the top and level five at the bottom. While both approaches exhibit a performance drop as corruption severity increases, our method demonstrates significantly greater robustness. At level 1 corruption, the text-only baseline performance drops by , whereas our approach shows a smaller drop of . As corruption severity escalates, the gap becomes more pronounced: at level 5, the text-only baseline experiences a drop, compared to a drop for our method. This trend shows the effectiveness of our approach in mitigating the impact of increasing corruption levels. This trend is visually compared in Figure˜7.
Appendix F Retrieved Examples for Class and Descriptions Based Retrieval
From Figure˜9 till Figure˜36, we present qualitative results for each dataset. For 10 randomly selected classes, we display the query class name, two images generated by SD [Rombach et al.(2022)Rombach, Blattmann, Lorenz, Esser, and Ommer] for that class, and the top 10 ranked database images sorted by similarity. Correct matches are highlighted in green, while incorrect ones are shown in red. For description-based retrieval, where the same classes are queried using only their textual descriptions (without the class name), we show the class descriptions, generated images from the description, and top-ranked database images.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[An et al.(2023)An, Deng, Yang, Li, Feng, Guo, Yang, and Liu] Xiang An, Jiankang Deng, Kaicheng Yang, Jaiwei Li, Ziyong Feng, Jia Guo, Jing Yang, and Tongliang Liu. Unicom: Universal and compact representation learning for image retrieval. In ICLR , 2023.
- 2[Azizi et al.(2023)Azizi, Kornblith, Saharia, Norouzi, and Fleet] Shekoofeh Azizi, Simon Kornblith, Chitwan Saharia, Mohammad Norouzi, and David J. Fleet. Synthetic data from diffusion models improves imagenet classification. TMLR , 2023.
- 3[Bossard et al.(2014)Bossard, Guillaumin, and Van Gool] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 – mining discriminative components with random forests. In ECCV , 2014.
- 4[Byeon et al.(2022)Byeon, Park, Kim, Lee, Baek, and Kim] Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim. Coyo-700m: Image-text pair dataset. https://github.com/kakaobrain/coyo-dataset , 2022.
- 5[Caron et al.(2021)Caron, Touvron, Misra, Jégou, Mairal, Bojanowski, and Joulin] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV , 2021.
- 6[Carreira et al.(2019)Carreira, Noland, Hillier, and Zisserman] Joao Carreira, Eric Noland, Chloe Hillier, and Andrew Zisserman. A short note on the kinetics-700 human action dataset. ar Xiv preprint ar Xiv:1907.06987 , 2019.
- 7[Chatfield and Zisserman(2012)] Ken Chatfield and Andrew Zisserman. VISOR: towards on-the-fly large-scale object category retrieval. In ACCV , 2012.
- 8[Chatfield et al.(2014)Chatfield, Simonyan, and Zisserman] Ken Chatfield, Karen Simonyan, and Andrew Zisserman. Efficient on-the-fly category retrieval using convnets and gpus. In ACCV , 2014.