TL;DR
SWIRL introduces a staged interleaved reinforcement learning workflow for multi-agent systems, improving stability and efficiency in mobile GUI control and other multi-agent tasks.
Contribution
It reformulates multi-agent reinforcement learning into sequential single-agent tasks, providing theoretical guarantees and demonstrating superior performance in GUI control and reasoning.
Findings
Outperforms existing methods on GUI benchmarks
Ensures stable training with theoretical safety bounds
Effective in multi-agent mathematical reasoning
Abstract
The rapid advancement of large vision language models (LVLMs) and agent systems has heightened interest in mobile GUI agents that can reliably translate natural language into interface operations. Existing single-agent approaches, however, remain limited by structural constraints. Although multi-agent systems naturally decouple different competencies, recent progress in multi-agent reinforcement learning (MARL) has often been hindered by inefficiency and remains incompatible with current LVLM architectures. To address these challenges, we introduce SWIRL, a staged workflow for interleaved reinforcement learning designed for multi-agent systems. SWIRL reformulates MARL into a sequence of single-agent reinforcement learning tasks, updating one agent at a time while keeping the others fixed. This formulation enables stable training and promotes efficient coordination across agents.…
Click any figure to enlarge with its caption.
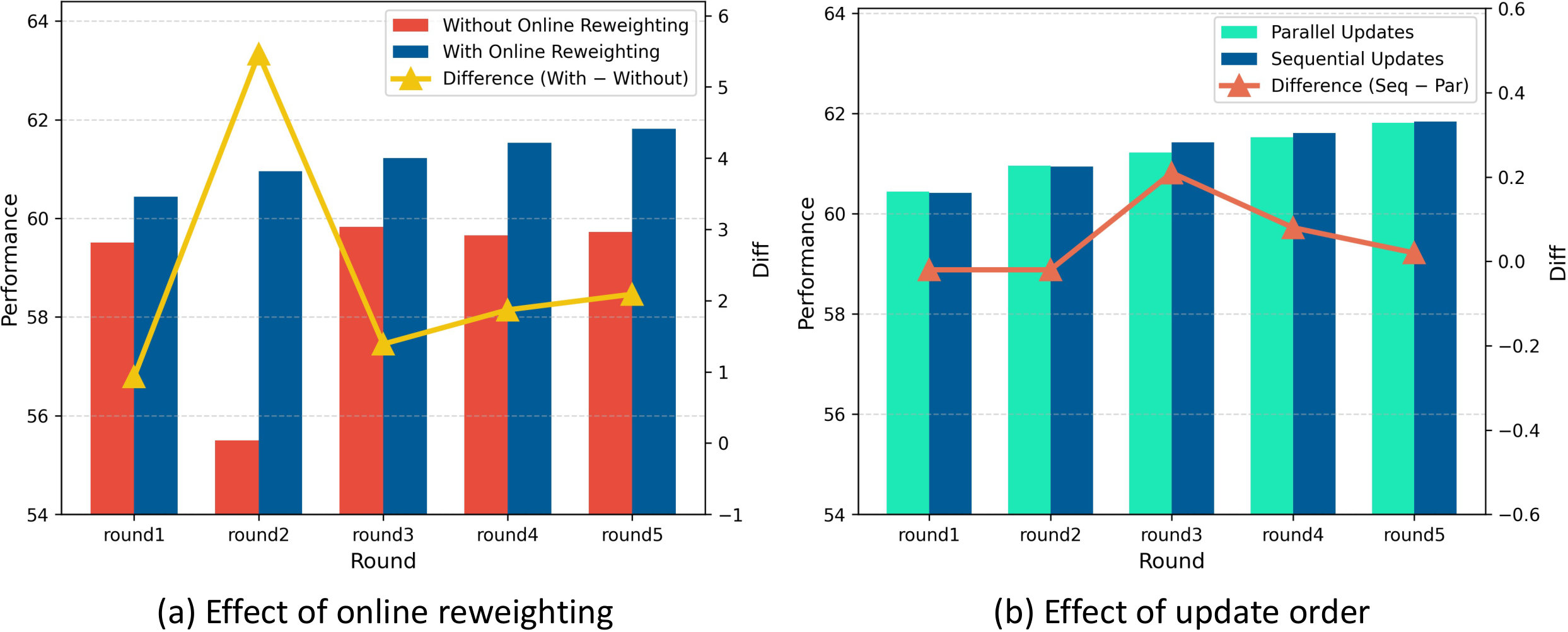 Figure 1
Figure 1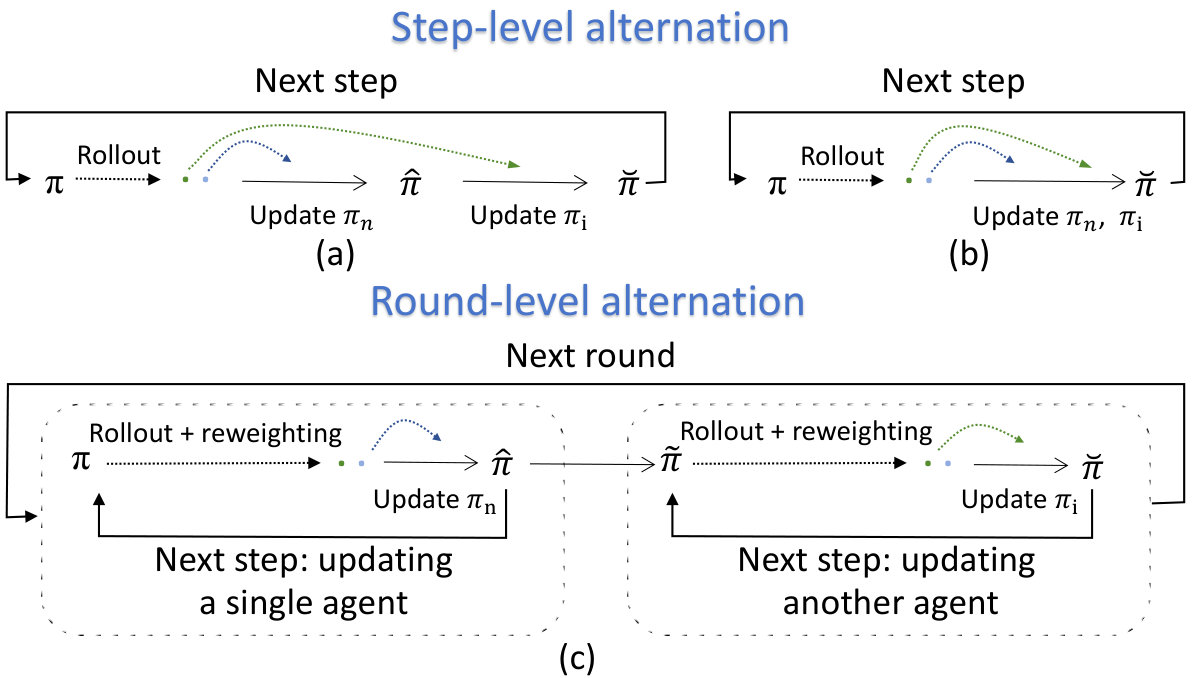 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7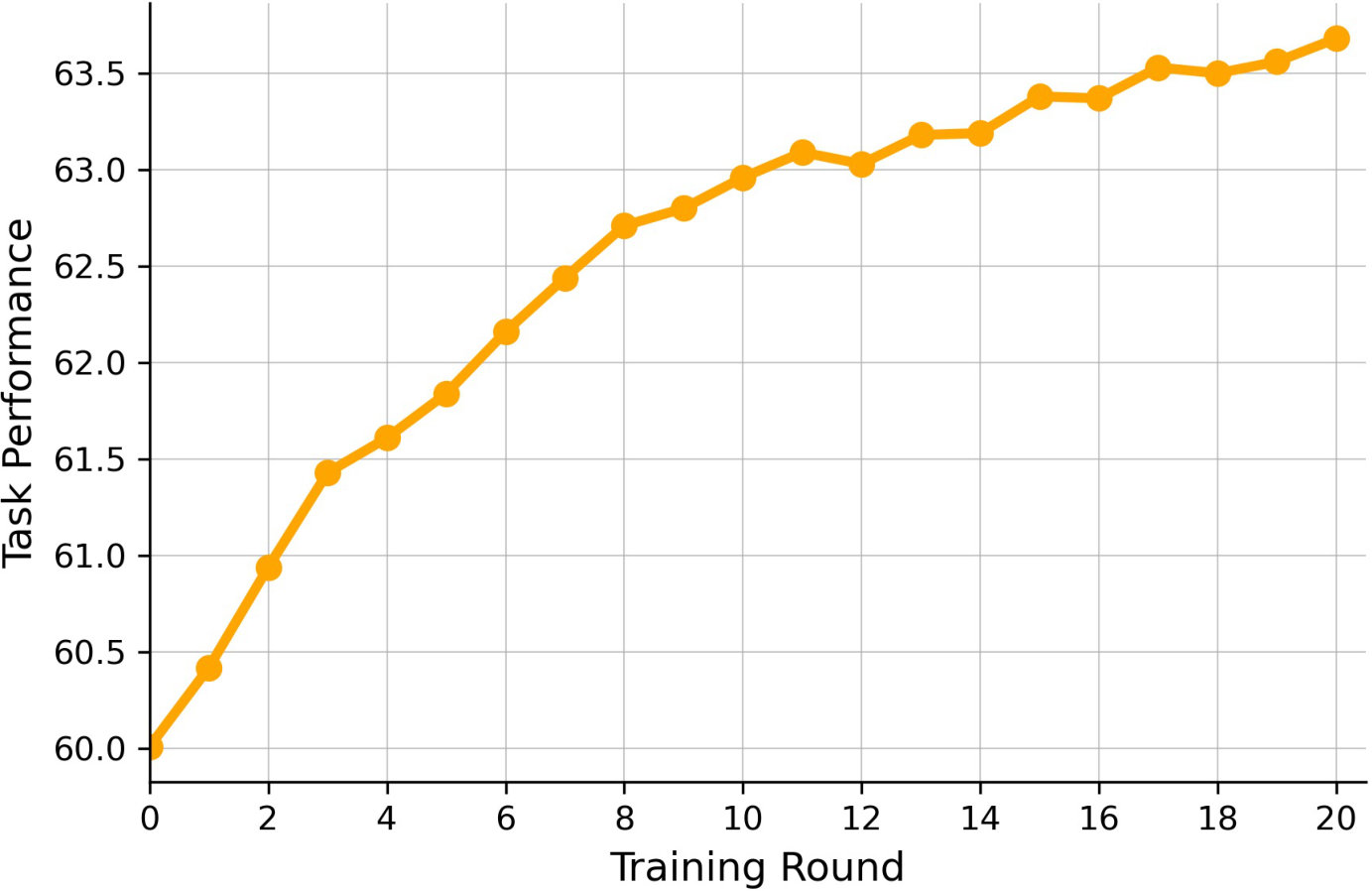 Figure 8
Figure 8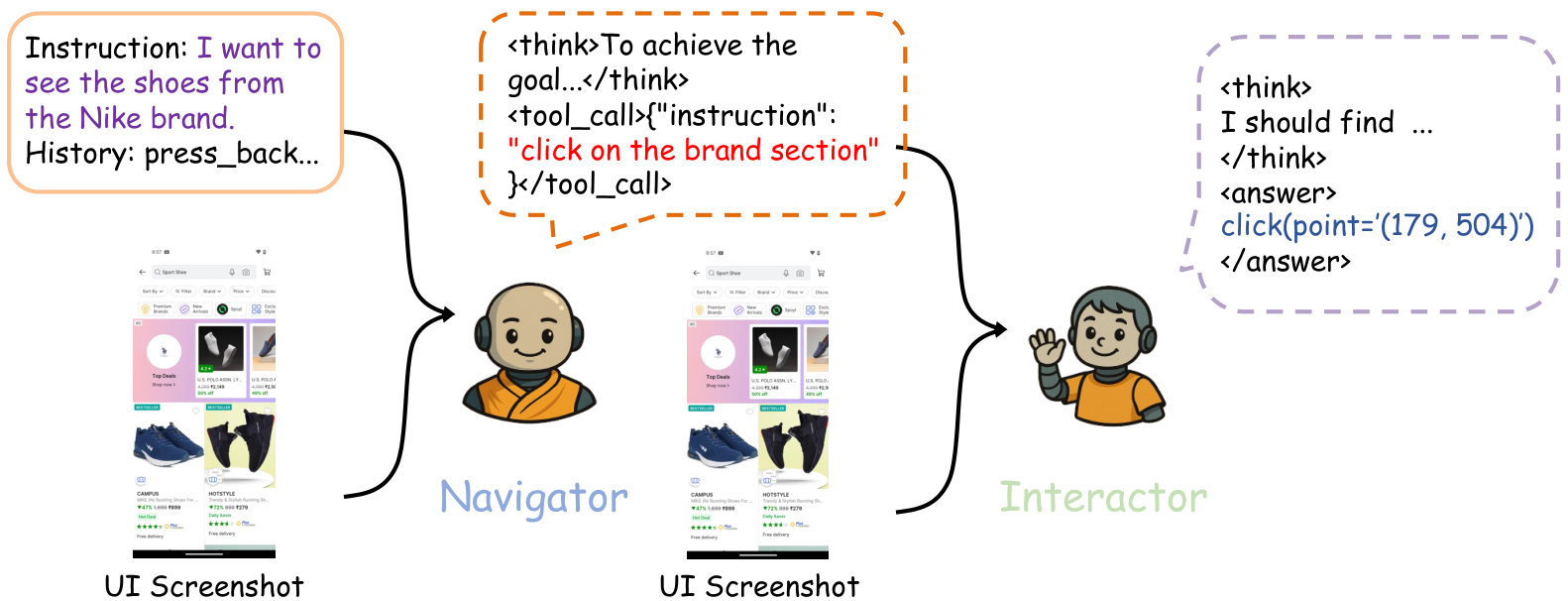 Figure 9
Figure 9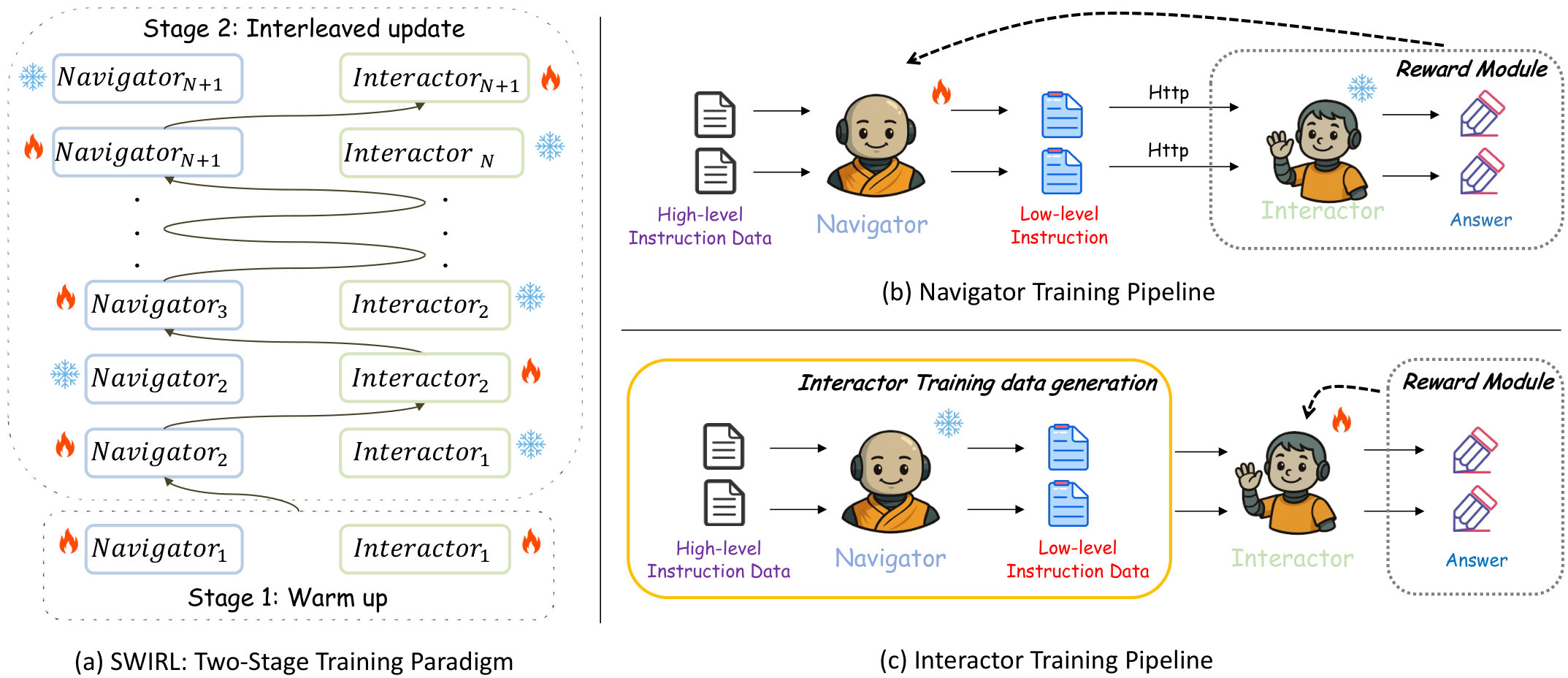 Figure 10
Figure 10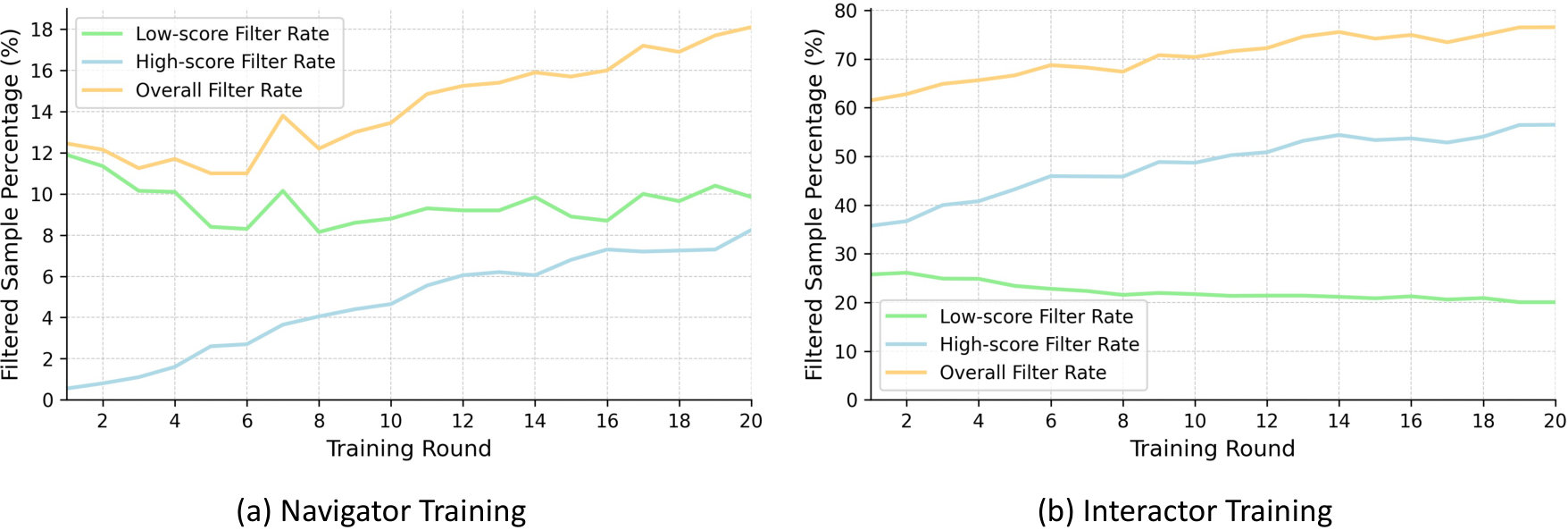 Figure 11
Figure 11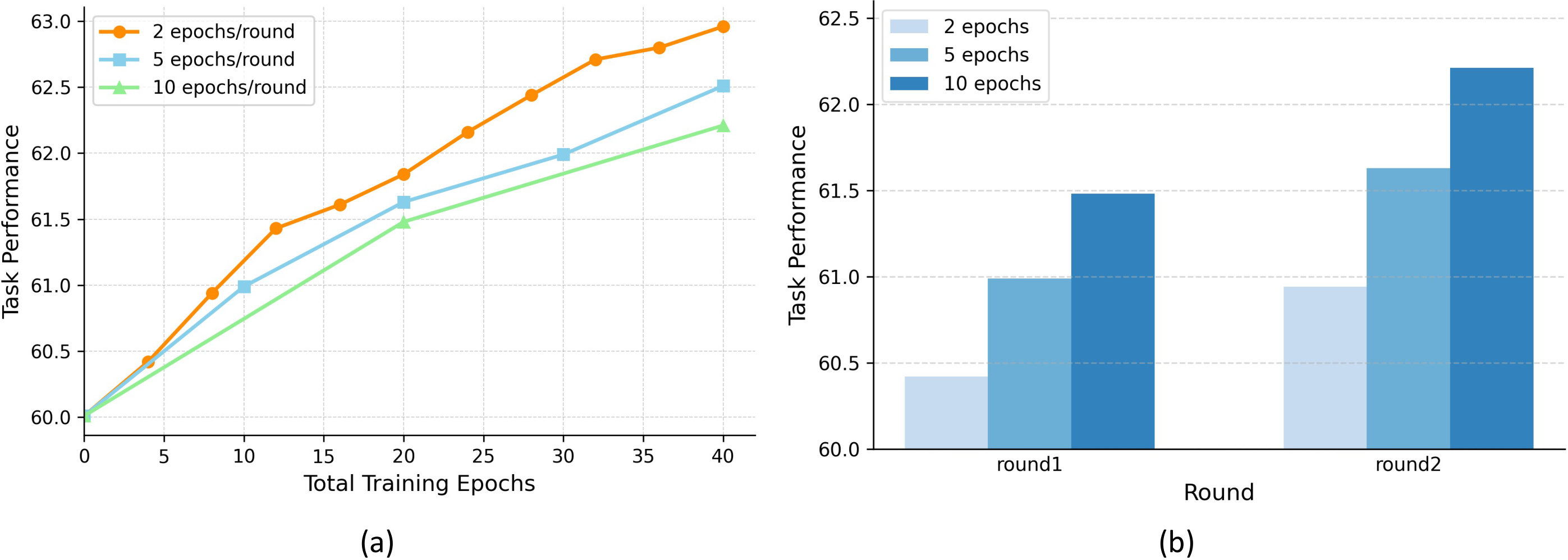 Figure 12
Figure 12| Method | Actor parameters |
| HAPPO | |
| A2PO | |
| MARFT | |
| SWIRL (Ours) |
| Models | Method | AndroidControl-High | GUIOdyssey | Overall | ||||
| Type | GR | SR | Type | GR | SR | |||
| GPT-4o | Closed-Source | 63.06 | 30.90 | 21.17 | 37.50 | 14.17 | 5.36 | 28.69 |
| OS-Atlas-4B | SFT | 49.01 | 49.51 | 22.77 | 49.63 | 34.63 | 20.25 | 37.63 |
| OS-Atlas-7B | SFT | 57.44 | 54.90 | 29.83 | 60.42 | 39.74 | 26.96 | 44.88 |
| UI-R1-3B | RFT | 43.97 | 63.99 | 26.30 | 20.93 | 56.35 | 8.65 | 36.70 |
| UI-R1-E-3B | RFT | 29.67 | 61.50 | 14.37 | 7.59 | 62.87 | 1.94 | 29.66 |
| GUI-R1-3B | RFT | 58.04 | 56.24 | 46.55 | 54.84 | 41.52 | 41.33 | 49.75 |
| GUI-R1-7B | RFT | 71.63 | 65.56 | 51.67 | 65.49 | 43.64 | 38.79 | 56.13 |
| ReGUIDE-7B | RFT | – | – | 50.00 | – | – | – | – |
| GPT-5 / UI-R1-3B | Multi-Agent | 55.08 | 73.47 | 37.27 | 62.97 | 62.42 | 35.93 | 54.52 |
| GPT-5 / UI-R1-E-3B | Multi-Agent | 60.36 | 74.79 | 40.65 | 65.28 | 63.41 | 38.22 | 57.12 |
| \rowcolorgreen!12 GPT-5 / Interactor | Multi-Agent | 64.68 | 74.62 | 49.53 | 68.77 | 62.70 | 44.21 | 60.75 |
| \rowcolorvarysorange!25 Navigator / Interactor | SWIRL | 66.72 | 71.19 | 51.24 | 74.87 | 66.39 | 51.65 | 63.68 |
| Models | GUI-Act-Web | OmniAct-Web | OmniAct-Desktop | Overall | ||||||
| Type | GR | SR | Type | GR | SR | Type | GR | SR | ||
| GPT-4o | 77.09 | 45.02 | 41.84 | 79.33 | 42.79 | 34.06 | 79.97 | 63.25 | 50.67 | 57.11 |
| OS-Atlas-4B | 79.22 | 58.57 | 42.62 | 46.74 | 49.24 | 22.99 | 63.30 | 42.55 | 26.94 | 48.02 |
| OS-Atlas-7B | 86.95 | 75.61 | 57.02 | 85.63 | 69.35 | 59.15 | 90.24 | 62.87 | 56.73 | 71.51 |
| UI-R1-3B | 75.89 | 79.43 | 67.31 | 75.42 | 61.35 | 61.33 | 73.41 | 64.12 | 63.98 | 69.14 |
| GUI-R1-3B | 89.86 | 87.42 | 76.31 | 88.58 | 75.10 | 75.08 | 91.86 | 78.37 | 78.31 | 82.32 |
| GUI-R1-7B | 90.85 | 88.06 | 80.31 | 91.16 | 77.29 | 77.35 | 92.20 | 83.36 | 83.33 | 84.88 |
| \rowcolorgreen!12 Interactor | 95.00 | 87.85 | 84.85 | 94.52 | 81.67 | 77.32 | 94.65 | 77.09 | 72.97 | 85.10 |
| Model | AndroidControl-Low | ||
| Type | GR | SR | |
| GPT-4o | 74.33 | 38.67 | 28.39 |
| OS-Atlas-4B | 64.58 | 71.19 | 40.62 |
| OS-Atlas-7B | 73.00 | 73.37 | 50.94 |
| UI-R1 | 72.49 | 88.48 | 57.37 |
| UI-R1-E | 73.91 | 91.91 | 55.58 |
| GUI-R1-3B | 83.58 | 81.59 | 64.41 |
| GUI-R1-7B | 85.17 | 84.02 | 66.52 |
| ReGUIDE-7B | – | – | 67.40 |
| SE-GUI-7B | – | 79.60 | 68.20 |
| \rowcolorgreen!12 Interactor | 84.62 | 92.20 | 78.81 |
| Model | Method | Training Data | MATH500 | CMATH | GSM8K | Overall |
| Qwen2.5-Coder-3B-Instruct | Multi-Agent | – | 47.2 | 81.1 | 77.3 | 68.5 |
| MARFT | Multi-Agent | MATH | 49.8 | 83.0 | 78.7 | 70.5 |
| SWIRL (ours) | Multi-Agent | MATH | 64.6 | 83.5 | 81.4 | 76.5 |
| Dataset | Action Space |
| AITW, AMEX | click(point=‘(x1, y1)’) type(content=‘xxx’) scroll(direction=‘down|up|right|left’) press_home() press_back() press_enter() finished() |
| AndroidControl | click(point=‘(x1, y1)’) long_press(point=‘(x1, y1)’) type(content=‘xxx’) scroll(direction=‘down|up|right|left’) open_app(app_name=‘xxx’) press_home() press_back() wait() finished() |
| GUIOdyssey | click(point=‘(x1, y1)’) long_press(point=‘(x1, y1)’) type(content=‘xxx’) scroll(direction=‘down|up|right|left’) press_home() press_back() press_appselect() error(content=‘xxx’) finished() |
| GUI-Act-Web | click(point=‘(x1, y1)’) scroll(direction=’down|up’) |
| OmniAct-Web) | click(point=‘(x1, y1)’) rightclick(point=‘(x1, y1)’) scroll(direction=‘down|up’) |
| OmniAct-Desktop | click(point=‘(x1, y1)’) rightclick(point=‘(x1, y1)’) doubleclick(point=‘(x1, y1)’) moveto(point=‘(x1, y1)’) scroll(direction=‘down|up’) |
| Training Strategy | AndroidControl-High | GUIOdyssey | Overall | ||||
| Type | GR | SR | Type | GR | SR | ||
| Stage 1 Stage 1 | 63.77 (+0.90) | 70.25 (+0.35) | 48.04 (+1.21) | 72.25 (+1.52) | 66.19 (+2.87) | 49.64 (+3.22) | 61.69 (+1.68) |
| Stage 1 Stage 2 | 66.72 (+3.85) | 71.19 (+1.29) | 51.24 (+4.41) | 74.87 (+4.14) | 66.39(+3.07) | 51.65(+5.23) | 63.68 (+3.67) |
| Training Strategy | GUI-Act-Web | OmniAct-Web | OmniAct-Desktop | AndroidControl-Low | Overall | ||||||||
| Type | GR | SR | Type | GR | SR | Type | GR | SR | Type | GR | SR | ||
| Stage 1 | 94.31 | 88.22 | 77.00 | 89.22 | 81.62 | 72.40 | 91.38 | 74.45 | 68.03 | 85.48 | 71.91 | 68.87 | 80.24 |
| Stage 1 Stage 2 | 95.00 | 87.85 | 84.85 | 94.52 | 81.67 | 77.32 | 94.65 | 77.09 | 72.97 | 84.62 | 92.20 | 78.81 | 85.13 |
| Stage 2 Training | AndroidControl-High | GUIOdyssey | Overall | ||||
| Type | GR | SR | Type | GR | SR | ||
| ✗ | 63.16 | 54.65 | 39.91 | 73.19 | 60.49 | 46.51 | 56.32 |
| ✓ | 66.72 | 71.19 | 51.24 | 74.87 | 66.39 | 51.65 | 63.68 |
| Rounds | Epochs/round | AndroidControl | GUIOdyssey | Overall | ||||
| Type | GR | SR | Type | GR | SR | |||
| 2 | 10 | 65.74 | 70.42 | 49.88 | 73.13 | 64.85 | 49.27 | 62.21 |
| 5 | 4 | 65.26 | 70.94 | 49.81 | 73.85 | 65.21 | 49.98 | 62.51 |
| 10 | 2 | 66.00 | 70.91 | 50.56 | 74.03 | 65.71 | 50.58 | 62.96 |
Peer Reviews
Decision·Submitted to ICLR 2026
Clear role decomposition (auditable plan to act chain). Practical pipeline that reuses mature single-agent RL tooling. Theoretical footing (safety bound, round-wise monotonic improvement). Solid empirical wins for low-level execution and planner replacement. Transferable beyond GUI with modest data.
Training always freezes one agent (Navigator or Interactor) and optimizes the other, effectively decomposing the multi-agent problem into a sequence of single-agent GRPO/PPO/TRPO steps. This is closer to modular alternating optimization than classic concurrent cooperative MARL. As a result, non-stationarity and coordination that arise when both agents evolve simultaneously are not directly learned. The GUI evaluation relies on offline single-step accuracy (Type/GR/SR)—e.g., a click landing in t
**Impressive empirical results** - SWIRL outperforms or achieves near state-of-the-art in a variety of benchmarks. This is a major strength of the paper. **Problem is important** - Mobile GUI control is a useful area of research, so I believe the paper is well-motivated and will be of use to the community. **Transfer beyond GUI** - I appreciate that this paper extends its results to more than one benchmark, namely mathematical benchmarks. Validity of the work is improved by showing results are
- **Support for $>2$ agents** - While the proposed SWIRL framework is reported to support N different agents, all experiments focus on settings with only two agents. Do you have any results demonstrating a setting with more than 2 agents? - **Walltime** - Currently, the paper does not disclose any information about the wall time of this method. I would imagine that the alternating nature of the approach may increase this substantially. - **Limitations Section?** - There appears to be no limit
- Interesting idea - Good experiments on replacing the Navigator with SOTA models such as GPT5 etc. to get Interactor performance
- It is not clear to me why this is formulated as a multi-agent problem, as the setup is stated as a "...sequential single-agent... enabling reuse of standard RL..." - I believe the main weakness of the paper is the experiment design to answer the question above. In the experiment, I would have expected the following experiments: 1. End-to-end RL training of Navigator and Interactor, potentially sharing rewards 2. Isolated training of the Navigator until convergence and then isolated training o
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
SWIRL: A Staged Workflow for Interleaved Reinforcement Learning in Mobile GUI Control
Quanfeng Lu111footnotemark: 1 , Zhantao Ma1 , Shuai Zhong1 , Jin Wang1 , Dahai Yu3 , Michael K. Ng2 , Ping Luo1
1The University of Hong Kong 2Hong Kong Baptist University
3TCL Corporate Research (Hong Kong) Co., Ltd
https://github.com/Lqf-HFNJU/SWIRL Equal ContributionCorresponding Author: [email protected]
Abstract
The rapid advancement of large vision language models (LVLMs) and agent systems has heightened interest in mobile GUI agents that can reliably translate natural language into interface operations. Existing single-agent approaches, however, remain limited by structural constraints. Although multi-agent systems naturally decouple different competencies, recent progress in multi-agent reinforcement learning (MARL) has often been hindered by inefficiency and remains incompatible with current LVLM architectures. To address these challenges, we introduce SWIRL, a staged workflow for interleaved reinforcement learning designed for multi-agent systems. SWIRL reformulates MARL into a sequence of single-agent reinforcement learning tasks, updating one agent at a time while keeping the others fixed. This formulation enables stable training and promotes efficient coordination across agents. Theoretically, we provide a stepwise safety bound, a cross-round monotonic improvement theorem, and convergence guarantees on return, ensuring robust and principled optimization. In application to mobile GUI control, SWIRL instantiates a Navigator that converts language and screen context into structured plans, and an Interactor that grounds these plans into executable atomic actions. Extensive experiments demonstrate superior performance on both high-level and low-level GUI benchmarks. Beyond GUI tasks, SWIRL also demonstrates strong capability in multi-agent mathematical reasoning, underscoring its potential as a general framework for developing efficient and robust multi-agent systems.
1 Introduction
With the rapid progress of large vision–language models (LVLMs) (OpenAI, 2025; Zhu et al., 2025; Bai et al., 2025; Guo et al., 2025), increasing attention has been devoted to mobile GUI agents capable of translating natural language instructions into reliable interface manipulation (Qin et al., 2025; Xu et al., 2024; Wu et al., 2024b; Lu et al., 2024; Luo et al., 2025). These agents ground user instructions in the current screenshot and interaction history, reason over this evolving state, and iteratively generate the next action until the task is completed. Effective mobile GUI control depends on two key competencies: task planning, which forms global, goal-conditioned decisions under evolving contexts, and task execution, which translates these plans into executable actions with precise localization. Most existing systems adopt a single-agent design, which complicates the robust integration of these competencies.
We identify two fundamental challenges. First, coupling high-level planning with fine-grained perception and precise actuation makes single end-to-end policies prone to interference and brittleness (Wang et al., 2024; Erdogan et al., 2025; Mo et al., 2025; Wang et al., 2025). Second, end-to-end systems often exhibit a weak linkage between reasoning traces and executed actions, sometimes producing correct outcomes for spurious reasons or plausible traces paired with faulty actions (Turpin et al., 2023; Arcuschin et al., 2025; Li et al., 2024a), thereby undermining safety and accountability in assurance-critical applications (Zhang et al., 2025; Shi et al., 2025; Kuntz et al., 2025).
A multi-agent design provides a principled approach to decoupling core competencies by assigning planning and execution to specialized agents. Beyond this division of labor, structured interactions between agents further enhance transparency by making the reasoning process more interpretable and the resulting actions more auditable. This explicit linkage between decision-making and execution not only improves accountability but also facilitates supervision and error analysis, which are essential for building reliable GUI control systems. However, training-free adaptation of generic LVLMs rarely suffices for domain-specific GUI control due to insufficient cooperation (Niu et al., 2024). Naive multi-agent reinforcement learning (MARL) further introduces practical challenges: joint optimization of multiple policies inflates compute budgets and limited capabilities (Wang et al., 2022; Gogineni et al., 2023). Meanwhile, high-throughput reinforcement learning (RL) frameworks developed for LVLMs are almost exclusively engineered for single-agent training (Hu et al., 2024; Sheng et al., 2025), making them ill-suited for MARL (Liao et al., 2025). These limitations motivate a central question: can we train multi-agent systems that are resource-friendly while ensuring provable stability during training?
We introduce SWIRL, a staged workflow for interleaved reinforcement learning. SWIRL decomposes multi-agent training into two phases: independent pre-warming of each module, followed by alternating optimization where one module is frozen while the other is updated. During this alternating process, we further incorporate an online reweighting mechanism to enhance training stability and accelerate convergence. SWIRL in Fig. 2(c) updates exactly one agent at a step. After several updates on one agent, it then switches to the next, turning joint optimization into sequential single-agent problems and enabling reuse of standard RL toolchains in agent training while maintaining effective coordination. Beyond practicality, we offer theoretical and system-level benefits: we establish a per-step safety bound, prove monotonic improvement across rounds, and derive a corollary for return convergence. In implementation, SWIRL requires only the currently updated agent to be resident on the training device, yielding actor memory usage, smooth compatibility with standard stacks, and support for heterogeneous model sizes and update budgets, contrasting with the memory usage of other methods. Table 1 details the count of actor parameters loaded during training without extra optimizations.
We instantiate SWIRL on mobile GUI control with a dual-agent architecture. The Navigator interprets instructions, interaction history, and the current screenshot to form a task context and produce structured low-level instructions (LLI). The Interactor consumes the LLI together with the current UI view and outputs atomic actions such as click, scroll, and text input with precise localization.
Fig. 1 presents the inference pipeline. Training alternates between the two agents: when optimizing the Navigator, the Interactor is fixed and executes the Navigator’s instructions to yield actions and rewards; when optimizing the Interactor, the Navigator remains fixed and supplies instructions for each step. This instantiation separates planning from execution and enforces a tight linkage between reasoning and action. With this decoupled design and the stability of interleaved updates, our system attains state-of-the-art zero-shot performance on both high-level and low-level mobile GUI benchmarks using only training examples, outperforming baselines trained under diverse SFT and RL regimes. We further apply the same interleaved recipe to a mathematics setting following prior multi-agent work (Liao et al., 2025) and observe significant gains, including a improvement on MATH500.
The contributions of this paper are as follows: (i) we introduce SWIRL, a multi-agent training framework that interleaves single-agent updates and transforms MARL to a sequence of single-agent RL problems; it achieves actor memory usage by loading only the currently updated agent, and accommodates heterogeneous model sizes, data schedules, and update budgets; (ii) we establish formal guarantees, including a per step safety bound, a monotonic improvement result across rounds, and convergence of returns; (iii) we instantiate SWIRL for mobile GUI control with a Navigator and an Interactor and, through extensive experiments, show stable training and state-of-the-art zero-shot performance, together with ablations that clarify when interleaving helps; and (iv) we demonstrate transferability by applying the same training recipe to a non-GUI domain (e.g., mathematics) and observe consistent gains on standard benchmarks, indicating potential for broader multi-agent applications.
2 Related Work
Reinforcement Learning for Mobile GUI Control
Reinforcement learning (RL) has recently emerged as a promising paradigm for GUI tasks. Unlike supervised fine-tuning (SFT), which requires large-scale annotated data, RL can learn effective policies from comparatively fewer samples while exhibiting stronger generalization to new tasks (Chu et al., 2025). A number of recent studies have investigated RL for GUI grounding, with research directions ranging from reward function design to policy optimization (Lu et al., 2025; Luo et al., 2025; Liu et al., 2025; Zhou et al., 2025; Yuan et al., 2025; Tang et al., 2025; Lee et al., 2025). By contrast, applications of RL to more complex mobile control scenarios that involve executing coarse-grained natural language instructions remain relatively limited (Luo et al., 2025). Furthermore, existing work has predominantly adopted single-agent settings, leaving multi-agent approaches largely unexplored.
Multi-Agent Systems Based on Large Language Models
A parallel line of research explores multi-agent systems powered by LLMs to address complex tasks (Hu et al., 2025; Xiao et al., 2024; Xiang et al., 2025; Zhao et al., 2024b; Wu et al., 2024a; Zhao et al., 2024a; Du et al., 2023). These systems typically assign specialized roles such as debating, voting, or negotiation, thereby structuring interactions and facilitating coordination without training. To enhance robustness and mitigate distribution shift (Han et al., 2024), recent studies have proposed strategies including persuasion-aware training (Stengel-Eskin et al., 2024) and iterative self-improvement via SFT (Subramaniam et al., 2025; Zhao et al., 2025). An important challenge is how to effectively train model cooperation when only limited training data is available (Tran et al., 2025).
Multi-Agent Reinforcement Learning
Works in Multi-Agent Reinforcement Learning (MARL) largely falls into value-based methods (Sunehag et al., 2017; Rashid et al., 2020) and actor-critic approaches (Chu et al., 2019; De Witt et al., 2020). A core challenge is non-stationarity, as one agent’s update changes others’ observations. Alternating optimization (e.g., A2PO (Wang et al., 2023), HARL (Zhong et al., 2024)) update agents sequentially at the step level but still face scalability issues (Canese et al., 2021; Tran et al., 2025). MARFT (Liao et al., 2025) combines MARL with LLMs for mathematical problem but suffers from gradient conflicts and parameter drift as the scale increases. It further argues that unifying MARL and LLMs is harder than addressing either alone, highlighting the need for scalable frameworks to integrate them efficiently.
3 Method
In Sec. 3.1, we introduce a theoretical multi-agent interleaved updating methodology in Alg. 1 and give the theoretical guarantees. In Sec. 3.2, we formulate the multi-agent framework for GUI navigation. Following that, Sec. 3.3 introduces SWIRL, a practical mobile GUI implementation of the multi-agent interleaved updating method, executed as a two-phase process involving warm-up and round-level alternating RL with online reweighting.
3.1 Preliminary of Interleaved Updating
The integration of MARL and LVLMs poses challenges, as each introduces unique complexities while being closely interlinked. Similar frictions have long been recognized in mathematical optimization. The Alternating Direction Method of Multipliers (ADMM) (Boyd et al., 2011) provides an effective strategy for tackling challenges formed by complex coupled problems: it decomposes an interconnected problem into manageable subproblems that are solved in turns. This divide-and-conquer approach is widely used in optimization, especially advantageous for challenging non-convex or non-differentiable objectives that can be decomposed into feasible subproblems (Glowinski, 2014; Yang et al., 2022). Consider the following constrained optimization problem and its augmented Lagrangian form: . To solve this, ADMM performs alternating optimization via the following iterative process: . It exemplifies problem decomposition and alternating optimization: rather than tackling a complex problem, alternating between simpler subproblems can achieve the overall objective.
From ADMM to Multi-Agent Interleaved Updating.
In practical ADMM, each subproblem is solved by an inner loop to a prescribed accuracy before the outer iteration advances. The key is that these inner steps deliver enough improvement for the outer objective to make steady progress. Therefore, we propose a multi-agent round-level interleaved updating training scheme in Alg. 1. The algorithm first independently pre-warms each agent using any single-agent method to obtain initial policies. It then performs interleaved updates: one agent is continuously optimized while the others are fixed, then sequentially switches to the next agent until all are updated, repeating this cycle to decompose MARL into a sequence of single-agent optimization tasks. This structure leads to the following findings: Proposition 1 provides a safety bound for each micro-step, Theorem 1 confirms that the return increases consistently across rounds, and Corollary 1 says the returns converge, and all policy limits attain this value. A summary of notation can be found in Appendix A.1, with complete proofs located in Appendix A.2.
Proposition 1** (Lower bound at a micro-step).**
In round , if agent updates to , the new joint policy is , and the performance satisfies
[TABLE]
Theorem 1** (Monotonic improvement).**
Every micro-step updates in Alg. 1 satisfies , and for all outer rounds we have .
Corollary 1** (Return convergence).**
The sequence approaches a limit, referred to as , and the collection of limit points from is non-empty. For any subsequence that converges such that , it holds that .
Alg. 1 provides a methodology: in each round, a single active agent performs several micro-steps while all other agents are frozen. Since the baseline stays constant throughout these micro-steps, each step simplifies to a typical single-agent policy update. As a result, the surrogate goal can be estimated using well-established single-agent techniques like TRPO (Schulman et al., 2015), PPO (Schulman et al., 2017), and GRPO (Shao et al., 2024), which apply feasible trust region or clipped KL updates. Previous studies have verified both the theoretical validity and empirical effectiveness of this approximation (Schulman et al., 2015; Zhong et al., 2024). We then apply this methodology to the GUI navigation task.
3.2 Multi-Agent Framework for GUI Control
Task Formulation.
We formulate GUI control task as a sequential decision-making problem. With a natural language instruction , the agent reviews a series of historical screenshots and actions along with the current screenshot to craft a structured text reply at each time step . Here, and denote the counts of past screenshots and actions, respectively. This reply includes a reasoning () and a low-level instruction (LLI, ) that outlines the next planned step. The LLI is then succeeded by the actual action (), where The objective is to generate the next action that complies with the given instruction . Appendix E presents illustrative examples of GUI agents completing GUI control tasks. Nevertheless, navigating GUI-based instructions introduces specific challenges: it necessitates high-level navigation to deduce the next-step instruction and detailed perception to engage with UI components, each demanding distinct skills.
Architecture and Training Objective.
To proficiently manage the complexities of GUI operations, we utilize a multi-agent system that distinctly separates the responsibilities between the Navigator () and the Interactor (). The Navigator is responsible for high-level planning, where it interprets the natural language instructions, merges past actions with the UI views, and establishes a coherent task context with reasoning. It then creates a detailed LLI, reflecting the intended next actions, based on the reasoning process. Subsequently, the Interactor combines the LLI and the current UI view to generate concrete atomic actions, including actions like click, scroll, etc. This involves precise cursor positioning and visual interpretation to ensure accurate execution of the planned steps within the interface. The inference pipeline of the system is illustrated in Fig. 1.
Building on the system architecture above, we train the two agents with a round-level interleaved scheme (Alg. 1). In each round, we select one role, either the Navigator or the Interactor, and run multiple inner updates on its parameters while freezing the other agent. We then swap roles and repeat. Optimizing the theoretical update for an individual agent demands the calculation of advantage , surrogate , and , which is cost-prohibitive. Consequently, we implement practical relaxations, similar to (Zhong et al., 2024), by approximating the theoretical goal using a GRPO objective (Shao et al., 2024). Concretely, we calculate single-agent improvements using group-relative advantages, denoted as , which are derived from multiple rollouts (standardized across the batch). We control intractable with two tractable terms: clipped ratios around and a KL anchor to , ensuring local trust-region control and curbing drift for stable. This preserves the ascent direction of the theoretical target , whilst ensuring stability and efficiency. Each agent’s action is an autoregressive sequence, responses for rollouts are . We compute token-wise importance ratios aligned with GRPO, in line with (Luo et al., 2025). Each token is assigned to either the navigator or interactor by the indicator if and only if (and [math] otherwise), securing agent-specific credit assignment without breaching the “freeze-the-complement” rule. In conclusion, our overarching multi-agent training objective is:
[TABLE]
The clipped surrogate is: where the value of importance ratio is: The scalar reward is composed of: where denotes the reward for format correctness (e.g., proper usage of required tags), and is the reward for action accuracy, defined as , where measures the correctness of the predicted action type, and quantifies the accuracy of the action parameters (e.g., the click location). Finally, the normalized advantage is computed as , where and are the mean and standard deviation of rewards across sampled trajectories.
3.3 SWIRL: Staged Workflow for Interleaved Reinforcement Learning
Building on the multi-agent architecture and learning objective described above, we introduce SWIRL, a Staged Workflow for Interleaved Reinforcement Learning. This approach is crafted to efficiently coordinate and enhance the performance of both the Navigator and Interactor concurrently, as demonstrated in Fig. 3 and Alg. 2. The benefits of SWIRL are listed in Appendix. B.2.
Stage 1: Warm-up initialization. The Navigator is first initialized through lightweight Chain-of-Thought (Wei et al., 2022) SFT, while the interactor is bootstrapped via initial reinforcement learning. The primary goal of this stage is to let each agent clearly learn its designated role: the navigator focuses on producing reasoning steps and LLI, whereas the interactor outputs the corresponding action. This warm-up phase establishes a robust foundation and minimizes variability at the outset.
Stage 2: Interleaved update. After warm-up, SWIRL progresses into a round-level alternating training stage. Within each round, one agent undergoes continuously optimization via reinforcement learning, while the other is kept static. This approach simplifies the intertwined multi-agent learning challenge into a series of static single-agent tasks. Therefore, it allows us to directly leverage modern single-agent RL algorithms, such as GRPO (see Alg. 3), thereby decreasing implementation complexity while preserving training stability and cooperative efficiency. In the Navigator training process, the Navigator generates a reply at each step. The frozen Interactor then executes to produce the final action . Rewards are computed as described in Sec. 3.2, with the accuracy reward of serving as the Navigator’s . To further enhance training efficiency and scalability, we deploy the Interactor on a separate server and integrate it within the reward module. The Navigator communicates with the Interactor via HTTP requests, enabling efficient reward computation during RL optimization. For Interactor training, we first use the frozen Navigator to generate low-level instructions for each training sample. The Interactor is then optimized via RL using these instructions as input, with rewards also computed according to Sec. 3.2. The training pipelines for the Navigator and Interactor are illustrated in Fig. 3b and Fig. 3c, respectively.
Online reweighting. After computing the GRPO-type advantages for each batch, we exclude those low-quality samples (Meng et al., 2025; Cui et al., 2025) by regulation . These low-quality samples typically arise due to collaborator mistakes, noise, or simplicity (Shi et al., 2025). As the model’s performance increases, it might happen that the number of high-quality samples meeting our filtering standard becomes fewer than the batch size, leading to partially filled batches. To address this, we replenish the batch by randomly resampling from the remaining high-confidence instructions. This process produces reliable batches without introducing additional rollout cost, implicitly up-weights the informative samples to enhance training stability and convergence.
4 Experiment
The experimental setup is described in Sec. 4.1, and the complete experimental details are provided in Appendix C. Sec. 4.2 and Sec. 4.3 present evaluations of SWIRL’s zero-shot performance on high-level and low-level tasks, respectively. Sec. 4.4 investigates the proposed multi-agent training framework in the mathematics domain. Comprehensive ablation studies are reported in Appendix D.
4.1 Settings
Implementation Details.
We use Qwen2.5-VL-3B (Bai et al., 2025) as the base model for both the Navigator and Interactor agents. For historical context, we include only the sequence of past actions, excluding previous screenshots (i.e., , ). The weighting coefficients in the reward function in Sec. 3.2 are set to , , , and . For online reweighting, we define the rule as: where denotes the average reward of sample across rollouts.
Training.
We collected and mobile-control samples for Stage 1 and Stage 2, respectively (see Appendix C.1 for details). In Stage 1 (warm-up), the Navigator is trained for epoch with SFT and the Interactor for epochs with GRPO (Shao et al., 2024), both using a learning rate of , batch size , and DeepSpeed ZeRO-1 for the Navigator; the Interactor uses rollouts per sample. In Stage 2 (SWIRL alternating updates), the two agents are alternately trained for epochs each per round over 20 rounds, maintaining the same hyperparameters; the Navigator uses rollouts per sample and the Interactor . Stage 1 runs on NVIDIA A800 GPUs; Stage 2 uses A800s, with half for Interactor deployment as a vLLM-based (Kwon et al., 2023) inference service and half for training. The training framework builds on Qwen2.5-VL111https://github.com/QwenLM/Qwen2.5-VL/tree/main/qwen-vl-finetune (Bai et al., 2025) for SFT and VeRL222https://github.com/volcengine/verl (Sheng et al., 2025) for RL.
Evaluation.
We evaluate SWIRL on high-level tasks (AndroidControl-High (Li et al., 2024b), GUIOdyssey (Lu et al., 2024)) and low-level tasks (AndroidControl-Low (Li et al., 2024b), GUI-Act (Chen et al., 2024), OmniAct (Kapoor et al., 2024)). Following the previous work (Wu et al., 2024b; Luo et al., 2025), we report Type, GR, and SR in a zero-shot prompt setting to assess out-of-domain generalization. Appendix C.2 provides detailed information. All evaluations are conducted in a zero-shot prompt setting to assess the models’ out-of-domain generalization ability.
4.2 High-Level Task Zero-shot Performance
We benchmark our approach against models trained under different paradigms and observe substantial gains. As shown in Table 2, our multi-agent framework with two 3B models achieves state-of-the-art zero-shot performance, surpassing the SFT-trained OS-Atlas-7B(Wu et al., 2024b) by points and the RFT-trained GUI-R1-7B (Luo et al., 2025) by points. When GPT-5 (OpenAI, 2025) is used as a high-level to low-level planner for UI-R1-3B and UI-R1-E-3B (Lu et al., 2025), the scores increase by and points, confirming the advantage of separating planning from execution. Replacing GPT-5 with our Navigator trained using SWIRL and interleaved updates yields a further improvement of points, demonstrating the effectiveness of our training strategy in enhancing coordination and boosting downstream performance.
4.3 Low-Level Task Zero-shot Performance
The Interactor trained with SWIRL interleaved updates can also operate independently as a low-level task executor. Although its low-level instruction inputs during Stage 2 training are generated by the Navigator, it still achieves strong results, recording the highest SR and GR scores ( and ) and the second-highest Type score () on the AndroidControl-Low benchmark (Li et al., 2024b), as shown in Table 4. Notably, despite all training samples across both stages originating exclusively from mobile devices, the model achieves an overall score of on low-level tasks in the web- and desktop-based GUI-Act (Chen et al., 2024) and OmniAct (Kapoor et al., 2024) datasets, representing the best average performance (Table 3). This remarkable cross-domain generalization underscores the robustness of our model and provides strong empirical evidence for the effectiveness of our training methodology.
4.4 Multi-Agent Training Framework in the Mathematics Domain
We adapt SWIRL to the mathematics domain to validate the generalizability and transferability of our multi-agent training framework. In line with the prior framework MARFT (Liao et al., 2025), we employ Qwen2.5-Coder-3B-Instruct (Hui et al., 2024) as the base model to construct a dual-agent architecture, which is then trained on the MATH (Hendrycks et al., 2021) training set. Implementation details are provided in Appendix C.3. As shown in Table 5, SWIRL delivers consistent improvements across all benchmarks, achieving a -point gain over MARFT on the in-domain MATH500 test set, and further surpassing it on the cross-domain CMATH (Wei et al., 2023) ( vs. ) and out-of-domain GSM8K (Cobbe et al., 2021) ( vs. ) datasets. These results demonstrate that SWIRL not only excels in its original GUI mobile control domain but also transfers effectively to substantially different problem settings, highlighting its robustness and broad applicability.
5 Conclusion
In this paper, we presented SWIRL, an interleaved reinforcement learning paradigm that reformulates multi-agent training into tractable single-agent updates. The central principle of SWIRL lies in its round-level alternating training strategy, where in each round one agent is continuously optimized through reinforcement learning while the others remain fixed. We provided theoretical guarantees for stable optimization and validated the effectiveness of SWIRL through extensive experiments in both mobile GUI control and multi-agent mathematical reasoning. Looking forward, we hope that SWIRL can inspire new approaches to multi-agent training in broader domains, such as finance and AI for science, where efficient coordination and reliable optimization remain critical challenges.
Appendix A Preliminary and Proofs
A.1 Preliminary with Notation
Environment and policies.
We consider a cooperative Markov game with agents: . Let be the joint action space. For each , the (stochastic Markov) policy together form the joint policy , which induces the joint action distribution for . Here denotes the set of probability distributions over a set. The environment transitions according to , written , with initial state and joint reward . Let be the average state-visitation distribution induced by the joint policy . For agent-wise decomposition we can write and denote .
Joint return .
For discount and any fixed initial-state distribution,
[TABLE]
It represents the expected total reward from this point forward under the policy : summing the reward from each subsequent step and applying a discount factor of at step . The notation indicates “assess each future step”; in tasks with a finite horizon, this sum naturally concludes upon task completion. The discount factor dictates the temporal range: focuses only on immediate rewards, suitable for offline tasks, where , whereas a higher value of emphasizes rewards further in the future.
Rounds, order, and micro-steps.
Outer rounds are indexed by . Agent executes a block of micro-steps indexed by , and we denote a micro-step by . The joint policy at the start (resp. end) of round is (resp. ). During agent ’s block, is its temporary policy after micro-steps, initialized by ; after finishing the block, set . Other agents are held fixed according to the rolling baseline defined next.
Rolling baseline and complement policy.
The baseline joint policy at micro-step is
[TABLE]
where the complement policy (all agents except ) is
[TABLE]
During micro-step of agent in the th round, agents positioned earlier in the sequence () have already adopted their policies for round , the current agent follows its internal iterate , and those positioned later () continue to use their round- policies.
Value, , and advantages.
Define
[TABLE]
The joint advantage is .
For agent , define the marginal state–action value and the single-agent advantage by
[TABLE]
is the local (per-state/per-action) improvement if agent takes at while others act according to . A basic identity we use is the zero-mean property \mathbb{E}_{a^{i}\sim\pi^{i}(\cdot\mid s)}\!\big{[}A^{\,i}_{\pi}(s,a^{i})\big{]}=0 for every .
Surrogate improvement.
Given the baseline , the complement , and a candidate policy for agent , define
[TABLE]
aggregates the local signal into a policy-level surrogate by averaging. It satisfies the baseline-zero property L^{\,i}_{\Pi_{k,i,j}}\!\big{(}\tau^{-i}_{k},\pi^{\,i}_{k,j}\big{)}=0, because for all .
Micro-step objective.
Let and . Define the max conditional KL by D^{\max}_{\mathrm{KL}}(\mu,\nu):=\sup_{s}\mathrm{KL}\big{(}\mu(\cdot\mid s)\,\|\,\nu(\cdot\mid s)\big{)}, and the per-micro-step surrogate
[TABLE]
scores a candidate update as “local surrogate improvement minus a KL safety penalty”. Taking the current iterate as the candidate reveals that it possesses the baseline-zero property: This is because equals zero due to the zero-mean property of the single-agent advantage under the policy , and .
A.2 Theoretical Proofs
Proposition 1. In round , if agent updates to , the new joint policy is , and the performance satisfies
[TABLE]
Proof of Proposition 1.
Set and . Apply Lemma 6 in (Zhong et al., 2024) with and . Because only agent changes, the multi-agent surrogate in Lemma 6 reduces to , and the max-conditional KL reduces to . With and , this yields exactly inequality 3. ∎
Theorem 1. Every micro-step updates in Alg. 1 satisfies , then for all outer rounds we have .
Proof of Theorem 1.
Leveraging the baseline-zero characteristic, , it follows that . Therefore, by Proposition 1 and the update rule,
[TABLE]
for every micro-step . Summing these inequalities in order over all micro-steps within round gives
[TABLE]
hence for all . ∎
Corollary 1. The sequence has a limit, denoted as , and the set comprised of limit points of is not empty. Additionally, for any convergent subsequence :, .
Proof of Corollary 1.
By Theorem 1, the performance sequence is nondecreasing. With discount and bounded rewards , every policy satisfies , so is bounded above and converges to some . Furthermore, as in (Zhong et al., 2024), the sequence of policies is bounded, hence it admits a convergent subsequence by the Bolzano-Weierstrass Theorem. Therefore, the set of limit points of is nonempty. Let be any subsequence converging to a limit policy . By continuity of in , we have
[TABLE]
∎
Appendix B Details in Method
B.1 Illustration of Algorithm 3
In Alg. 3, denotes GRPO-type single agent RL based on the objective defined in equation 2 and hyperparameter , where the first argument is the parameter to be updated.
- When updating the navigator, the interactor parameters are frozen. In this case, the input serves as the initial setting for the navigator, whereas pertains to the fixed interactor:
[TABLE]
- When updating the interactor, the navigator parameters are frozen. In this case, the input serves as the initial setting for the interactor, whereas pertains to the fixed navigator:
[TABLE]
Below, we take the case of freezing the interactor and updating the navigator as an example.
B.2 Benefits of SWIRL
Different from MARL methods such as HAPPO (Zhong et al., 2024) (Fig. 2a), A2PO (Wang et al., 2023), and MARFT (Liao et al., 2025) (Fig. 2b), our approach (Fig. 2c) offers four key advantages:
Seamless compatibility. SWIRL reformulates complex MARL tasks into an alternating sequence of simpler single-agent reinforcement learning problems. This design naturally integrates with modern distributed single-agent RL frameworks (e.g., veRL (Sheng et al., 2025), OPEN-RLHF (Hu et al., 2024)), eliminating intrusive modifications to communication protocols and enabling rapid adaptation to future efficient RL frameworks. Consequently, our divide-and-conquer alternating solution fundamentally resolves the integration challenges between MARL and contemporary LVLM-based training pipelines. 2. 2.
Resource-friendly scalability. Consider a system with agents, each with model size . Table 1 quantitatively summarizes the number of actor parameters loaded on the device during training. In practice, A2PO, HAPPO, and MARFT keep all agents resident on the training device for local rollout. Under this setting, these methods typically load all actor parameters in the training device during learning, leading to a total parameter size of and memory consumption that scales linearly with the number of agents . In contrast, SWIRL only loads the currently updated agent model locally, while executing the remaining agents as “Model-as-a-Service” modules remotely. As a result, the memory usage of the training device remains constant regardless of (i.e., ), greatly reducing hardware requirements and improving scalability for large-scale multi-agent systems. 3. 3.
Adaptation to heterogeneity. Our method allows agents to adopt diverse model architectures and training configurations, such as different numbers of training steps or heterogeneous datasets. Because SWIRL decomposes multi-agent training into per-agent optimization, it enables online, agent-conditioned reweighting that adapts to each agent’s distribution by filtering samples that are low-quality for that agent. As a result, heterogeneous agents receive tailored, high-confidence training signals; experiments on Appendix D.5 empirically confirms reduced uninformative or misleading samples and improved overall training performance. 4. 4.
Stability. The alternating update methodology efficiently addresses the non-stationary challenges present in concurrent multi-agent training, thereby minimizing policy misalignment and distributional shift, as shown in Appendix D.2 and D.5. Experimental results in Fig. 4 consistently demonstrate stable performance enhancements with each alternating phase, thus facilitating effective coordination among multiple agents.
Appendix C Experiment Details
C.1 Training Data
Training Data Collection.
We construct our two-stage training dataset based on the AITW(Rawles et al., 2023) (using the expanded version from AITZ(Zhang et al., 2024)) and AMEX(Chai et al., 2024) (adopting the Aguvis variant(Xu et al., 2024)), as both provide richer low-level annotations. In Stage 1, we leverage Qwen2.5-VL-3B to generate rollouts for each low-level instruction, then select samples whose average reward falls within the range . These high-quality samples are used in two ways: (1) the low-level instruction data is employed as RL training data for the Interactor, and (2) the reasoning traces associated with each sample are used to construct Chain-of-Thought supervised fine-tuning data with high-level instructions for the Navigator. In Stage 2, we utilize the multi-agent system trained in Stage 1 to generate rollouts for each high-level instruction, filtering for samples with an average reward below and variance more than . Notably, samples in Stage 2 include only high-level instructions and do not contain additional semantic annotations. In total, we curate high-quality training samples across both stages, supporting robust chain-of-thought reasoning and effective RL optimization for both agents.
Action Space.
Following the action space design style of UI-Tars (Qin et al., 2025), we define dataset-specific action spaces for different GUI benchmarks, as shown in Table 6.
Prompt.
Fig. 8 illustrates the prompts used for the Navigator and Interactor.
C.2 Evaluation Details
Metrics.
Following prior work (Wu et al., 2024b; Luo et al., 2025), we evaluate our models using three standard metrics for GUI agents: Type, GR, and SR, which assess the accuracy of action type prediction, coordinate prediction, and step success rate, respectively. Type measures the exact match between the predicted action type (e.g., click, scroll) and the ground truth. GR evaluates the performance of GUI grounding in downstream tasks. SR (step-wise success rate) is computed by considering a step correct only if both the predicted action type and all associated arguments (e.g., coordinates for a click action) match the ground truth. For click-based actions (e.g., click, long_press), the model must predict both the action type and the target coordinates (x, y). When the ground-truth bounding box is available, a prediction is considered correct if its coordinates fall within the box. If no bounding box is provided, or the prediction lies outside it, correctness is determined by whether the predicted coordinates are within of the screen width from the ground-truth position. For type-based actions (e.g., type, open_app), both the action type and content must match the ground truth. We compute the F1 score between the predicted and reference text, and an action is considered correct if . For scroll actions, the predicted direction argument (up, down, left, or right) must exactly match the ground truth. For all other actions (e.g., press_enter), correctness requires an exact match between the predicted action and the ground truth.
Baselines.
To ensure a fair comparison of cross-domain generalization, we select baseline models that have not been trained on the corresponding training sets of the evaluation domains. For high-level tasks, the comparison includes four categories of models: the proprietary GPT-4o(OpenAI, 2024); the state-of-the-art OS-Atlas-4B/7B(Wu et al., 2024b), trained via supervised fine-tuning (SFT) on large-scale GUI grounding datasets; models trained with reinforcement fine-tuning (RFT) on GUI grounding datasets, including UI-R1-3B, UI-R1-E-3B(Lu et al., 2025), GUI-R1-3B/7B(Luo et al., 2025), and ReGUIDE-7B(Lee et al., 2025); and a multi-agent approach employing GPT-5(OpenAI, 2025) as the planner to translate high-level instructions into low-level actions. For low-level tasks, the baselines consist of GPT-4o, OS-Atlas-4B/7B, and RFT-trained GUI grounding models, including UI-R1-3B, UI-R1-E-3B, GUI-R1-3B/7B, ReGUIDE-7B, and SE-GUI-7B(Yuan et al., 2025).
Evaluation Datasets.
AndroidControl(Li et al., 2024b) is a mobile control dataset in which each GUI interaction trajectory is annotated with both coarse-grained high-level instructions and fine-grained low-level instructions, along with detailed XML metadata from which the bounding boxes of individual UI elements can be parsed. For click actions, we iterate over all bounding boxes in the XML, identify those containing the ground-truth coordinates, and select the smallest one by area as the candidate bounding box for click action evaluation. GUIOdyssey(Lu et al., 2024) consists of tasks involving cross-application operations, posing a significant challenge for models’ planning abilities. In its latest release333https://huggingface.co/datasets/hflqf88888/GUIOdyssey, each click action is supplemented with the bounding box of the corresponding UI element obtained via SAM2(Ravi et al., 2024) segmentation, which we also use for click action evaluation. Notably, the latest version contains samples, compared to in the earlier release444https://huggingface.co/datasets/OpenGVLab/GUIOdyssey, with changes in the test set size. To ensure consistency with other baselines, we use the Test-Random split from the earlier version. GUI-Act-Web(Chen et al., 2024) contains web-based interaction data. To better assess GUI manipulation capabilities, we remove several QA-style samples from the test set and retain the remaining samples for evaluation. Bounding boxes are not used for click action evaluation in this dataset. OmniAct(Kapoor et al., 2024) includes both web and desktop interaction data. Due to action space compatibility constraints, we filter out samples whose original action space involves hotkeys and keep the remaining samples for evaluation. Similarly, bounding boxes are not used for click action evaluation in this dataset.
C.3 Mathematics Domains
Implementation Details.
We design a dual-agent framework in which one agent acts as the Teacher, providing a concise outline of the problem-solving approach, and the other acts as the Student, generating the final solution by incorporating the Teacher’s guidance. The detailed prompt formulations for both agents are provided in Fig. 9. Both agents are initialized from the Qwen2.5-Coder-3B-Instruct(Hui et al., 2024) model. For the reward function, we assign a reward of if the generated answer is correct and [math] otherwise, i.e., . For online reweighting, we define the rule as follows: we retain samples whose average reward across multiple rollouts lies strictly between and , i.e., where denotes the mean reward of sample over all rollouts.
Training.
We train the dual-agent framework on the MATH(Hendrycks et al., 2021) training set, which contains samples, by directly initiating Stage 2 of the SWIRL alternating-update procedure and bypassing the warm-up stage. In each round, the Teacher is updated first, followed by the Student, with each agent trained for epoch per round over a total of rounds. Both agents use a batch size of and a learning rate of . The Teacher and Student perform and rollouts per sample, respectively. Training is conducted on NVIDIA A800 GPUs, with half allocated to deploying the Student as a vLLM-based (Kwon et al., 2023) inference service and the remaining half for model training.
Appendix D Ablation Study
D.1 Effect of Interleaved Update
To isolate the effect of SWIRL’s second training stage (interleaved updates), we compare two models trained on the same total dataset of samples. Both start from the Stage 1 warm-up with samples. The first continues training on the remaining samples using the Stage 1 strategy until convergence, while the second proceeds with our Stage 2 alternating update scheme. The only difference between them is the training strategy applied in the second stage. As shown in Table 7, although extended warm-up training with more data yields performance gains, its upper bound remains lower than that achieved by our interleaved update approach ( vs. ), highlighting the latter’s effectiveness.
D.2 Co-evolution of Navigator and Interactor
We investigate the impact of the proposed interleaved update on individual agents within the multi-agent framework. For the Interactor, Table 8 compares its performance on low-level tasks with and without Stage 2 interleaved updates. The results show a substantial improvement of points with Stage 2, particularly in SR (a metric that directly measures the correctness of individual actions and thus serves as a more critical indicator of the Interactor’s precision), which increases by nearly points. For the Navigator, direct evaluation is less straightforward because its outputs are low-level instructions rather than executable actions. To address this, we adopt an indirect evaluation approach: we feed the Navigator’s outputs into a fully trained Interactor and assess the resulting task performance. As shown in Table 9, pairing the Interactor with a Navigator trained using Stage 2 interleaved updates delivers consistently higher performance on high-level tasks, raising the overall score from to and yielding notable improvements in both GR and SR across benchmarks. This demonstrates that the updated Navigator produces more detailed and accurate low-level instructions from high-level goals. Overall, these findings provide strong evidence that interleaved updates effectively enhance each agent’s ability to fulfill its specific role, enabling them to co-evolve and achieve better collaborative performance within the multi-agent system.
D.3 Stability and Potential
As illustrated in Fig. 4, even with only samples used during the SWIRL’s stage 2, the proposed training paradigm consistently enhances the model’s generalization capability. The model’s performance improves steadily with each training round, demonstrating the stability of the alternating optimization process. Furthermore, its out-of-domain generalization continues to increase in the later rounds, suggesting that the performance upper bound has not yet been reached. These results highlight the effectiveness and scalability of SWIRL for robust multi-agent training in GUI navigation tasks.
D.4 Synergy and Individual Competence in Multi-Agent Training
In multi-agent training, overall system performance depends not only on enhancing the capabilities of individual agents but also on achieving effective coordination among them. To disentangle and quantify the relative contributions of these two factors, we vary the number of alternating training rounds (i.e., the frequency and intensity of inter-agent coordination) and the number of epochs per round (i.e., the depth of single-agent training), while keeping the total number of training epochs constant. As shown in Fig.5(a) and Table 10, increasing the number of alternating rounds, thereby providing more opportunities for inter-agent interaction and iterative policy refinement, consistently leads to greater performance gains than allocating the same budget to deeper single-agent training within fewer rounds. At the same time, Fig. 5(b) indicates that increasing the training depth per round still brings incremental benefits, demonstrating that single-agent optimization remains valuable. Taken together, these results suggest that, under a fixed training budget, inter-agent coordination is the primary driver of performance improvement, while individual agent refinement plays a complementary yet meaningful role.
D.5 Effectiveness Analysis of Online Reweighting
To assess the impact of the online reweighting mechanism, we conduct comparative experiments with and without weighted resampling. As shown in Fig. 7(a), models trained without online reweighting perform significantly worse and even exhibit a degradation trend, underscoring the necessity of this mechanism. We hypothesize that online reweighting dynamically prioritizes informative samples, ensuring that they exert greater influence during training, which is essential for the stable improvement of multi-agent systems. Further analysis, as illustrated in Fig. 6, reveals two important findings. First, the Interactor filters out approximately four times as many samples as the Navigator (\sim$$75 vs. \sim$$18), indicating a substantial difference in how the same dataset contributes to the learning process of each agent. The online reweighting strategy thus adapts to the evolving capabilities of each agent, assigning dynamic weights to those training samples most beneficial at each stage. Second, it is important to recognize that not all samples filtered for being completely incorrect are attributable solely to the deficiencies of a single agent. Some errors may arise from noisy data or from mistakes originating with another agent (e.g., if the Planner generates an erroneous instruction, the Executor may repeatedly fail to execute the correct action). In these cases, the online reweighting mechanism helps to exclude uninformative or misleading samples, thereby further improving the robustness and effectiveness of the training process.
D.6 Sequential Updates versus Parallel Updates
Our default SWIRL implementation employs a strictly sequential update scheme, in which the Navigator is updated first in each training round, followed by the Interactor. We also explore a parallel update strategy, where both agents are updated simultaneously within each round, rather than following a fixed order, i.e., . This approach aligns with the update mechanism of Jacobian ADMM (Yang et al., 2022), which relaxes the sequential constraints in standard ADMM and allows for simultaneous updates, i.e., , thereby increasing training efficiency. As shown in Fig. 7(b), parallel updates can achieve performance comparable to or surpassing that of sequential updates, even without strict alternation. This finding suggests that relaxing the sequential constraint in alternating multi-agent training can improve efficiency without sacrificing model quality.
Appendix E Examples
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arcuschin et al. (2025) Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. Chain-of-thought reasoning in the wild is not always faithful. ar Xiv preprint ar Xiv:2503.08679 , 2025.
- 2Bai et al. (2025) Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen 2.5-vl technical report. ar Xiv preprint ar Xiv:2502.13923 , 2025.
- 3Boyd et al. (2011) Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, Jonathan Eckstein, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends® in Machine learning , 3(1):1–122, 2011.
- 4Canese et al. (2021) Lorenzo Canese, Gian Carlo Cardarilli, Luca Di Nunzio, Rocco Fazzolari, Daniele Giardino, Marco Re, and Sergio Spanò. Multi-agent reinforcement learning: A review of challenges and applications. Applied Sciences , 11(11):4948, 2021.
- 5Chai et al. (2024) Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Dingyu Zhang, Peng Gao, Shuai Ren, and Hongsheng Li. Amex: Android multi-annotation expo dataset for mobile gui agents. ar Xiv preprint ar Xiv:2407.17490 , 2024.
- 6Chen et al. (2024) Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, et al. Guicourse: From general vision language models to versatile gui agents. ar Xiv preprint ar Xiv:2406.11317 , 2024.
- 7Chu et al. (2019) Tianshu Chu, Jie Wang, Lara Codecà, and Zhaojian Li. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE transactions on intelligent transportation systems , 21(3):1086–1095, 2019.
- 8Chu et al. (2025) Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. ar Xiv preprint ar Xiv:2501.17161 , 2025.
