GLSim: Detecting Object Hallucinations in LVLMs via Global-Local Similarity
Seongheon Park, Sharon Li

TL;DR
GLSim is a training-free framework that improves detection of object hallucinations in vision-language models by combining global and local similarity signals, leading to more reliable results across scenarios.
Contribution
The paper introduces GLSim, a novel method that leverages combined global and local embedding similarities for more accurate hallucination detection in LVLMs.
Findings
GLSim outperforms existing detection methods significantly.
Benchmark results demonstrate superior accuracy of GLSim.
The approach is training-free and versatile across scenarios.
Abstract
Object hallucination in large vision-language models presents a significant challenge to their safe deployment in real-world applications. Recent works have proposed object-level hallucination scores to estimate the likelihood of object hallucination; however, these methods typically adopt either a global or local perspective in isolation, which may limit detection reliability. In this paper, we introduce GLSim, a novel training-free object hallucination detection framework that leverages complementary global and local embedding similarity signals between image and text modalities, enabling more accurate and reliable hallucination detection in diverse scenarios. We comprehensively benchmark existing object hallucination detection methods and demonstrate that GLSim achieves superior detection performance, outperforming competitive baselines by a significant margin.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1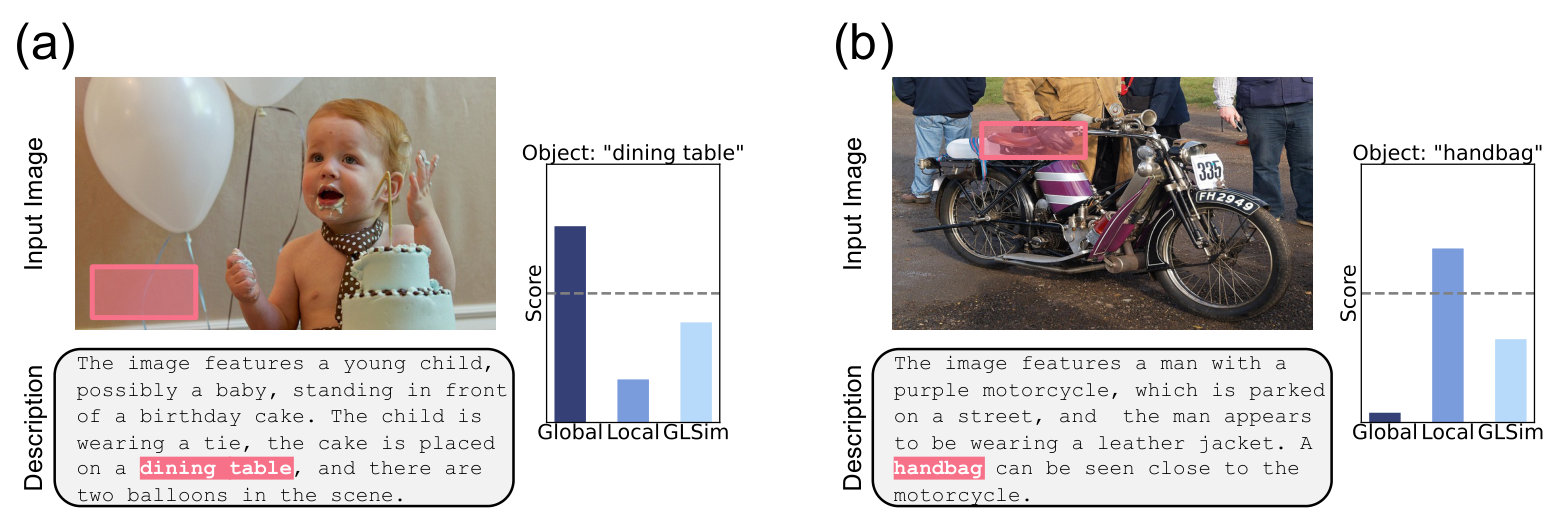 Figure 2
Figure 2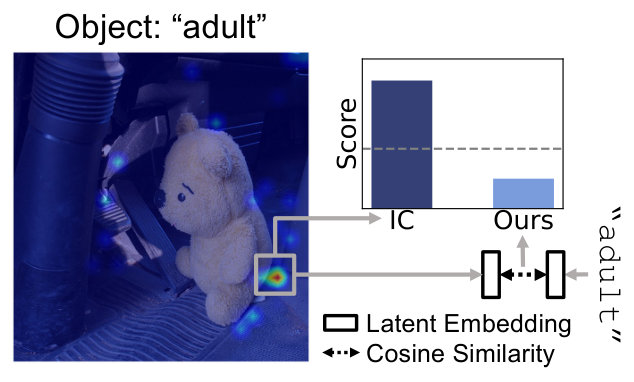 Figure 3
Figure 3 Figure 4
Figure 4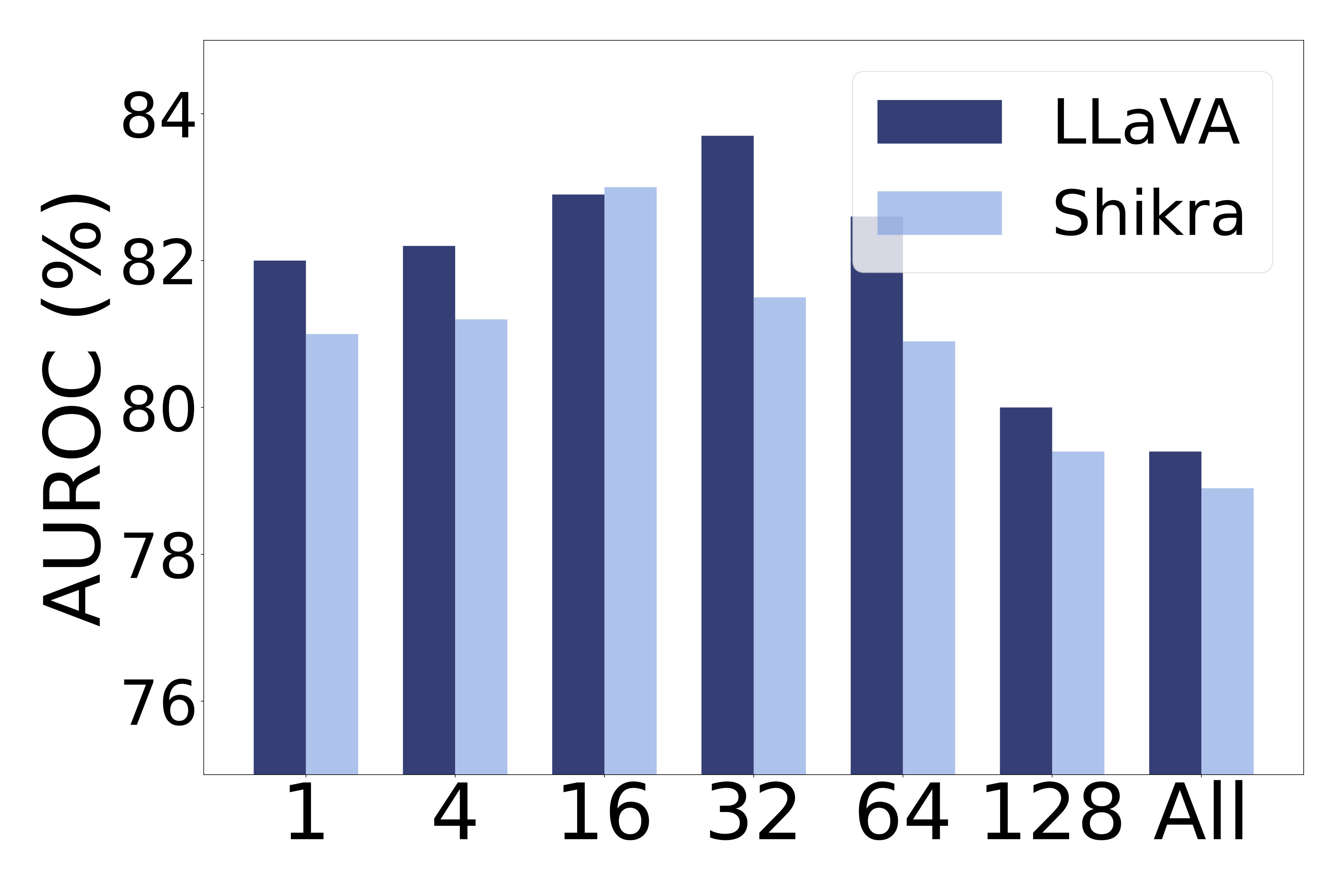 Figure 5
Figure 5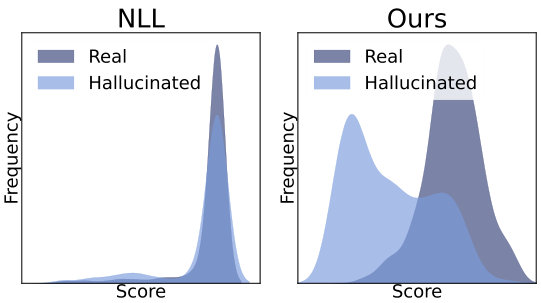 Figure 6
Figure 6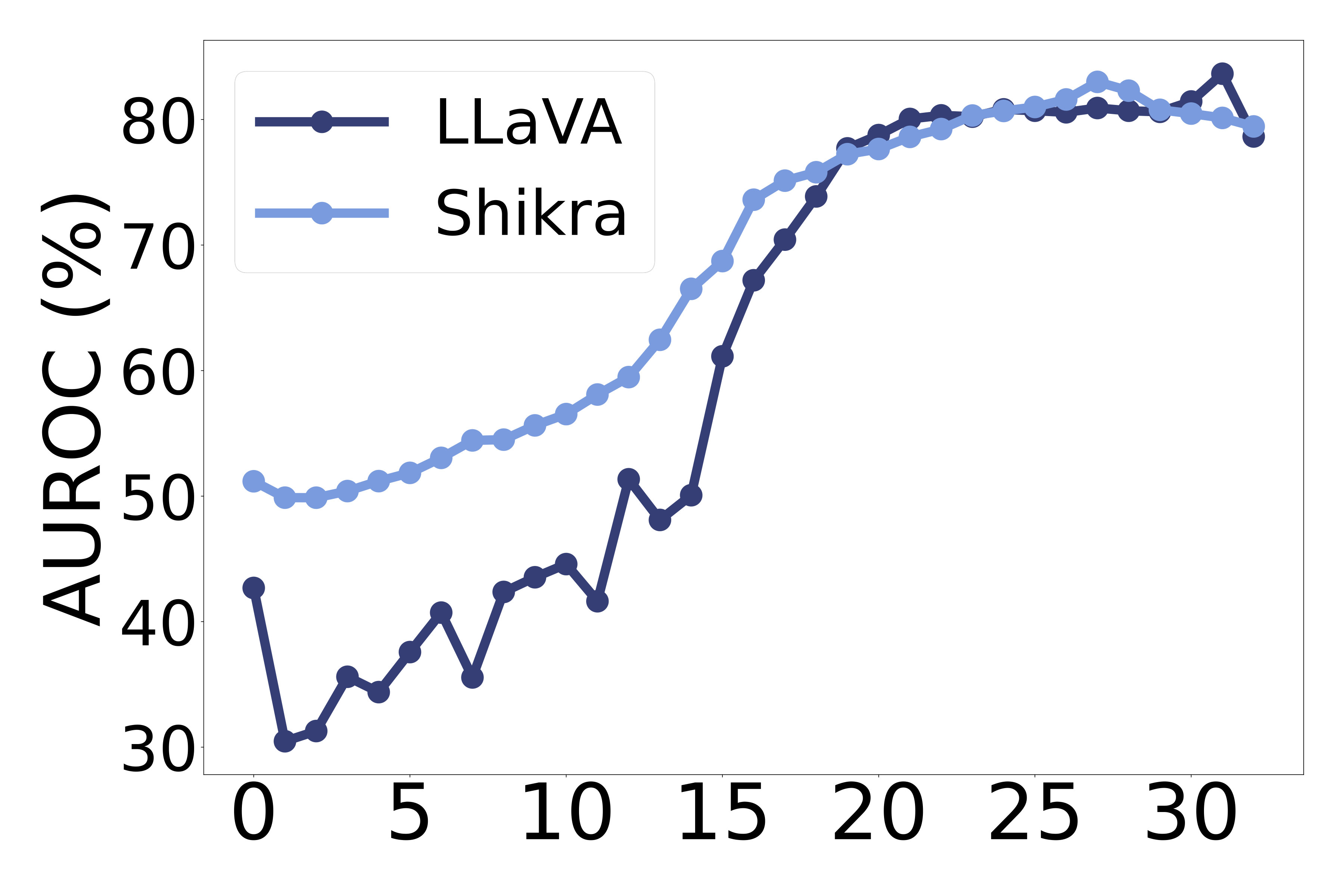 Figure 7
Figure 7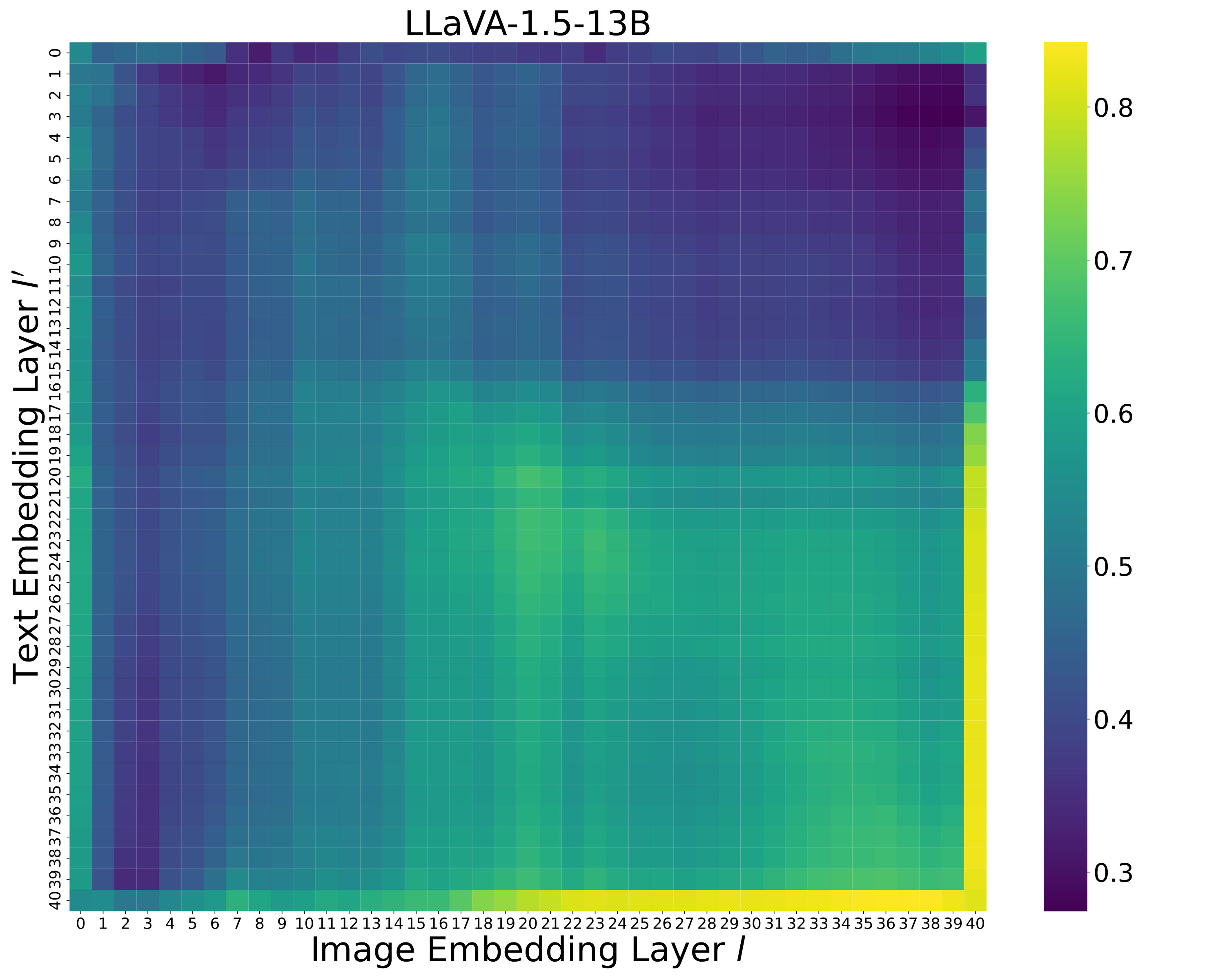 Figure 8
Figure 8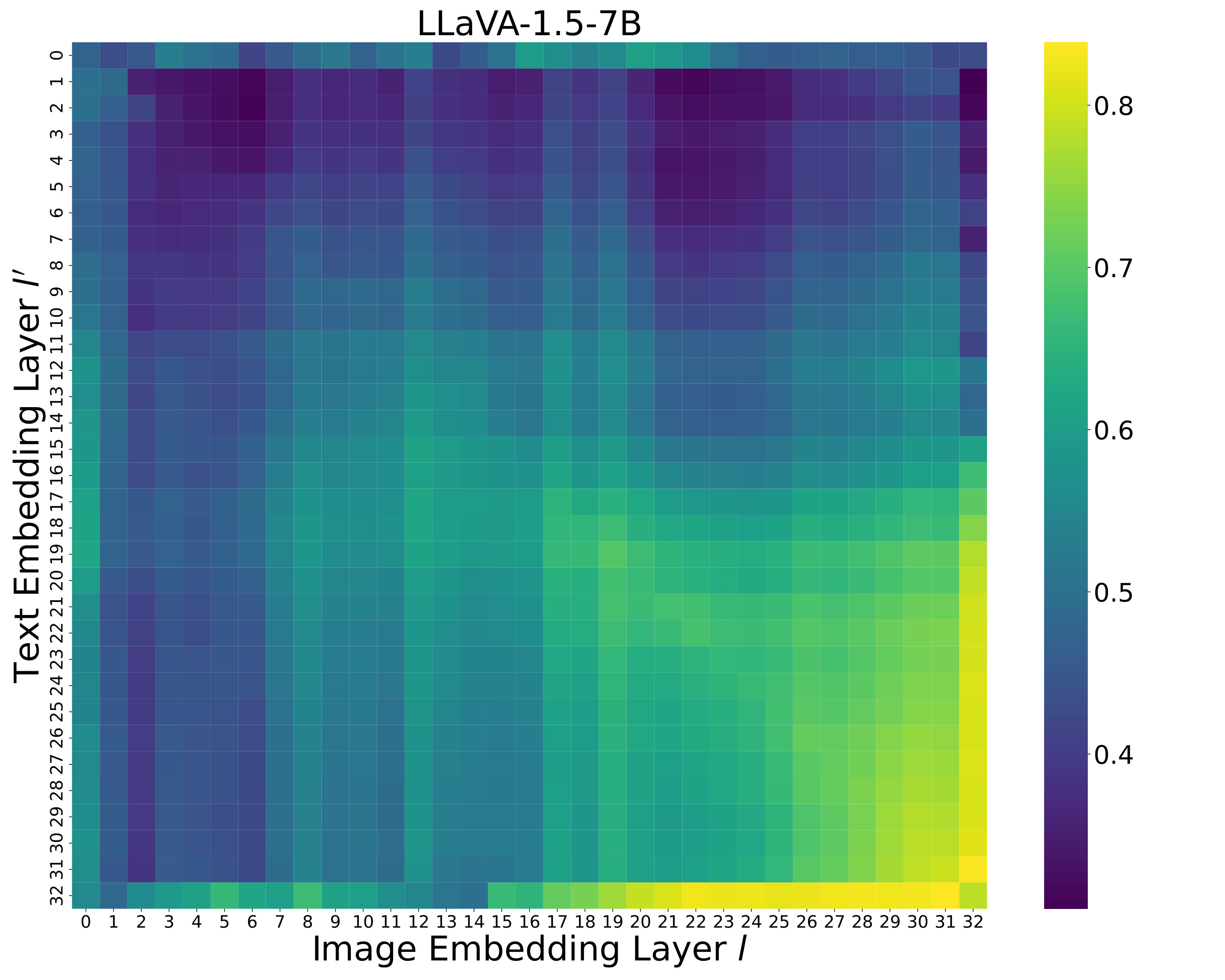 Figure 9
Figure 9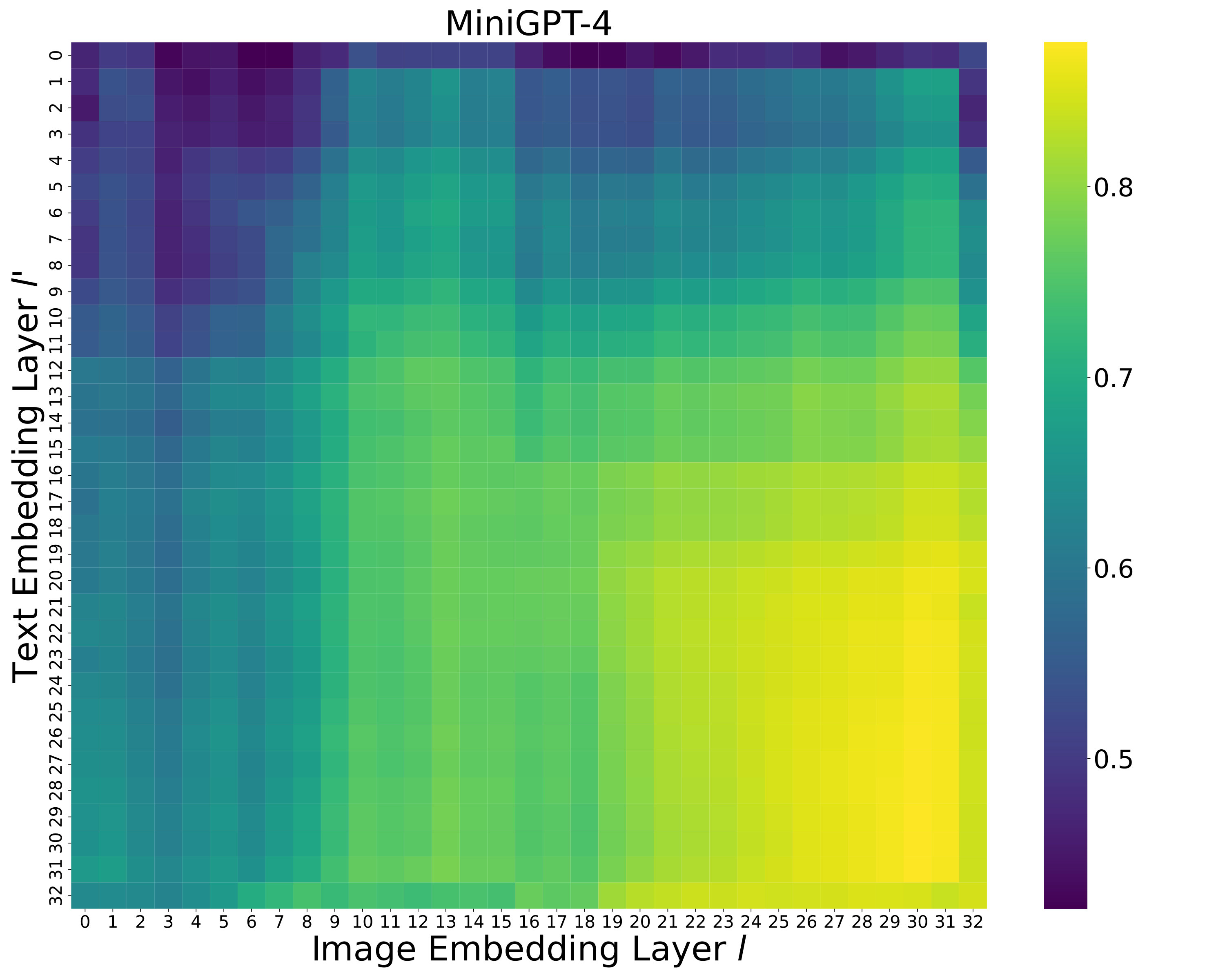 Figure 10
Figure 10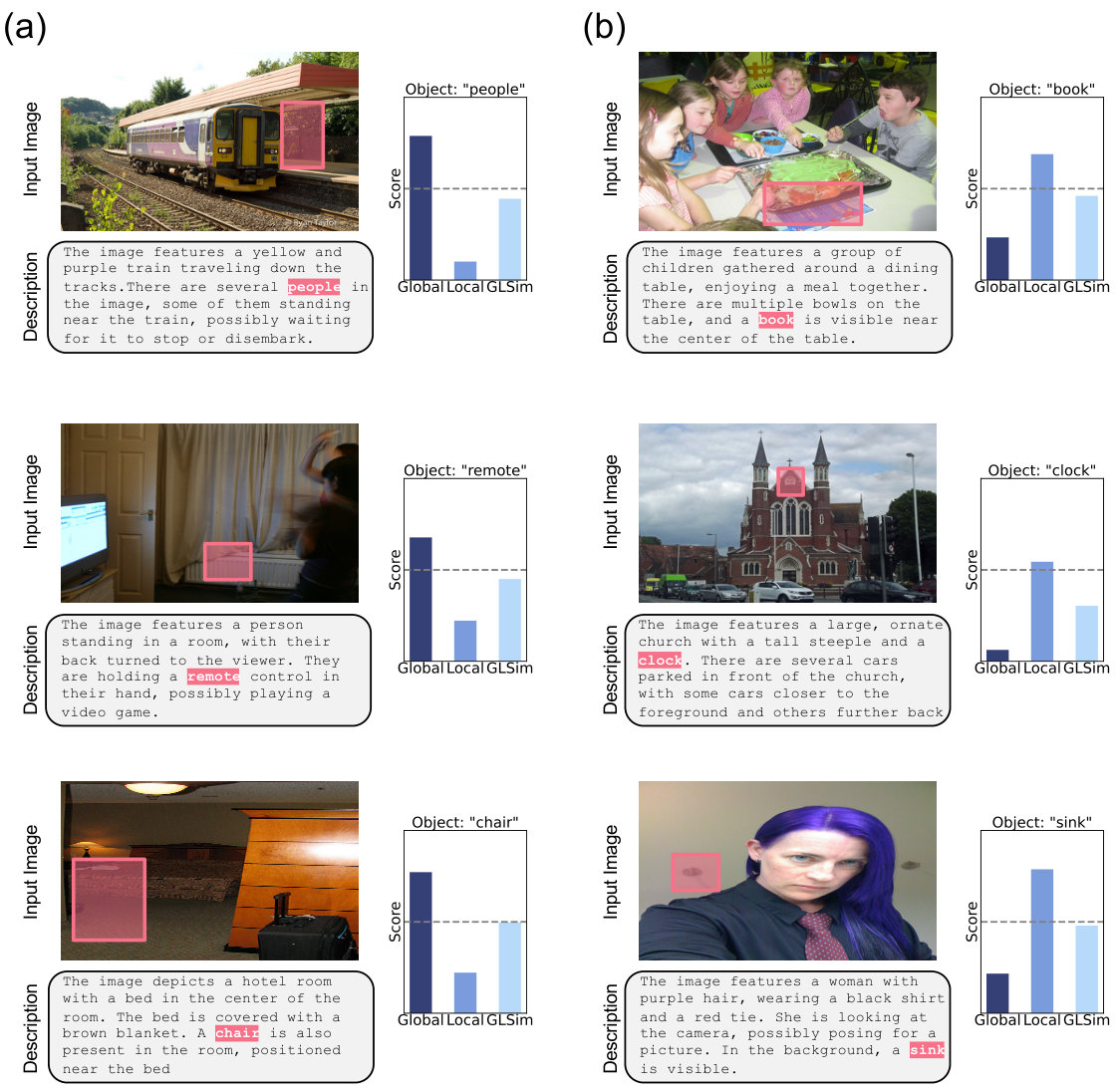 Figure 11
Figure 11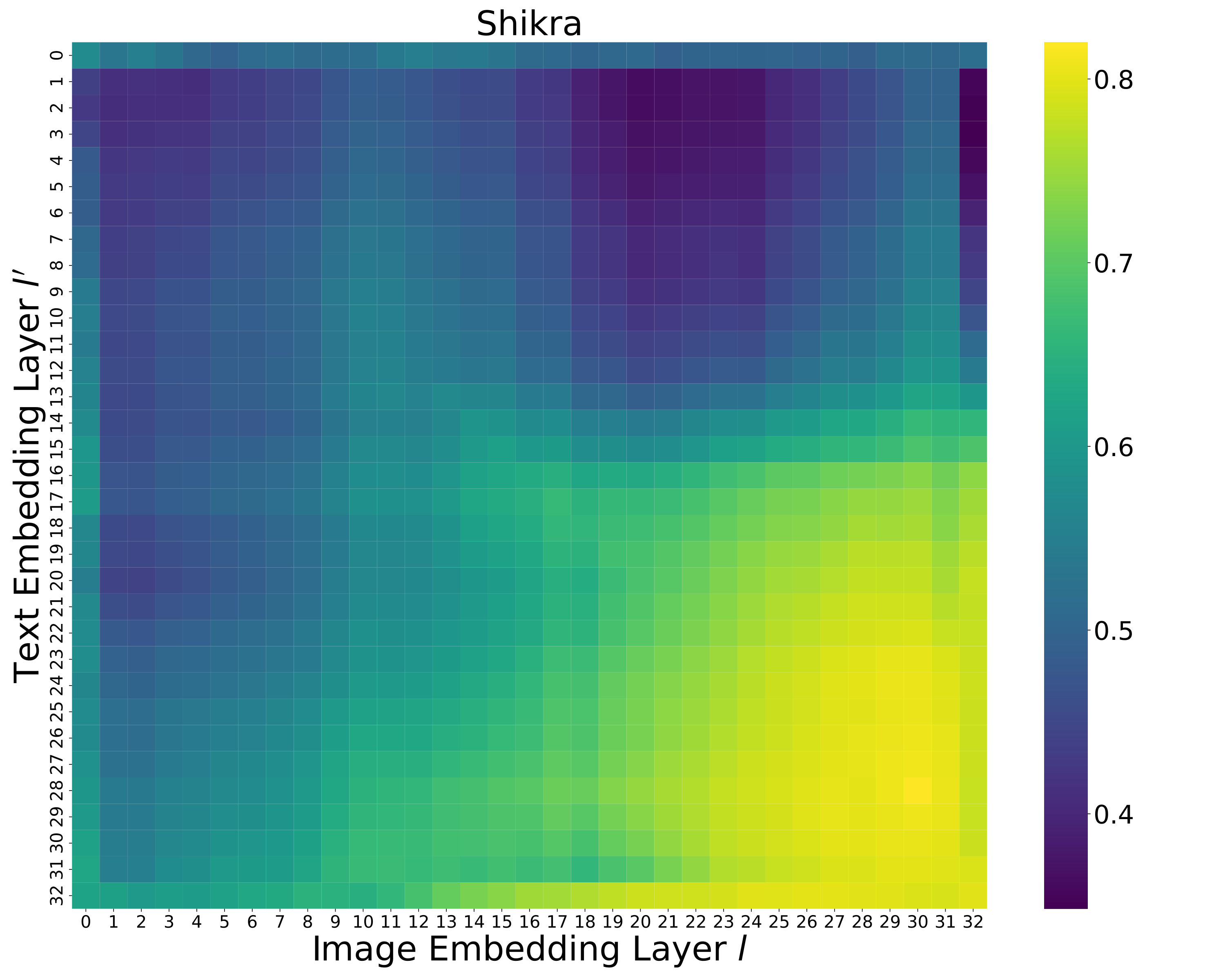 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14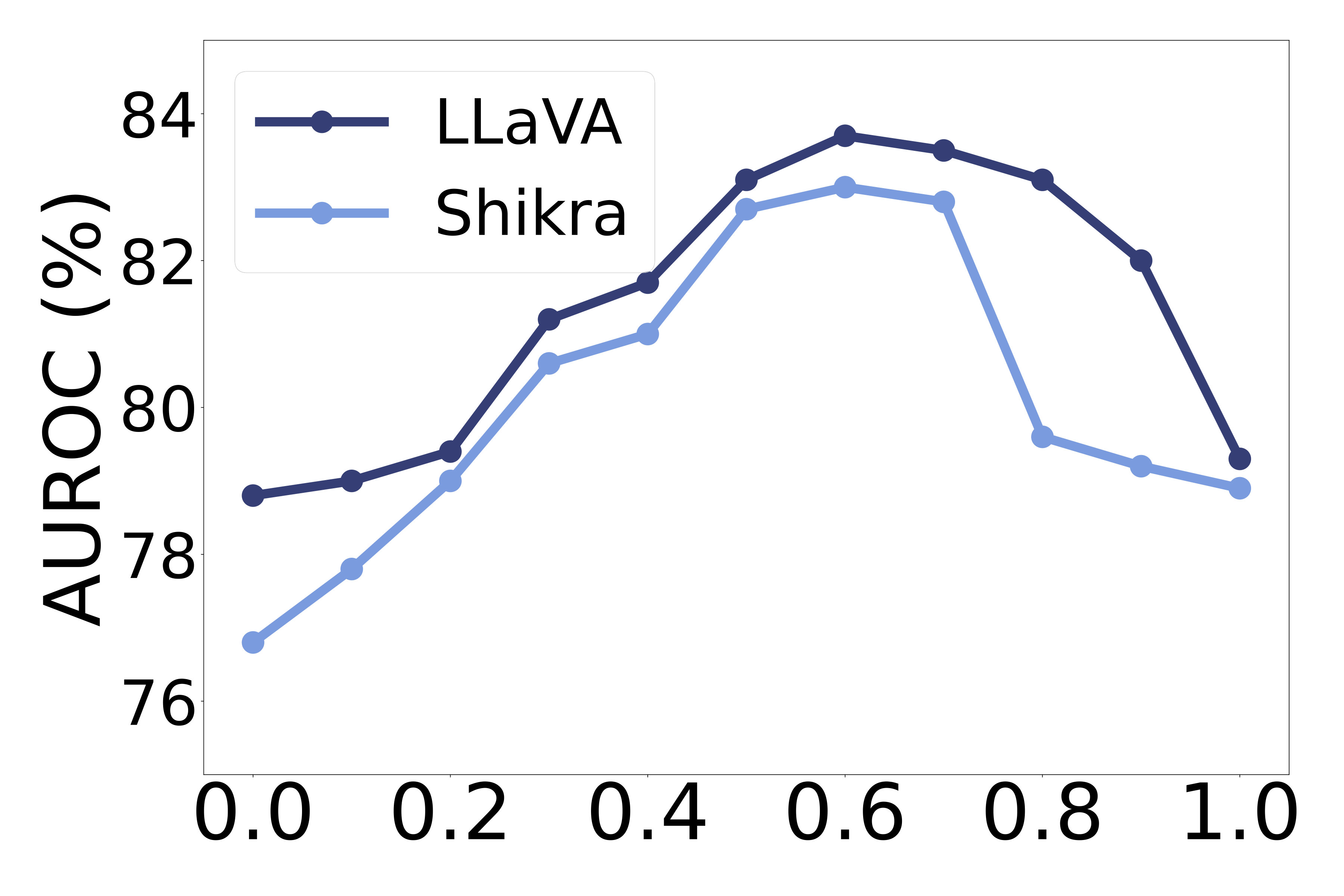 Figure 15
Figure 15| Method | Metric | LLaVA | Shikra | |
| Global | NLL zhou2023analyzing | TP | 63.7 | 60.4 |
| Entropy malinin2020uncertainty | TP | 64.0 | 62.9 | |
| SVAR jiang2024devils | AT | 74.7 | 70.7 | |
| (Eq. (4)) | ES | 79.3 | 78.9 | |
| Local | Internal Conf. zhou2023analyzing | LLP | 72.9 | 69.1 |
| jiang2024devils | ES | 75.4 | 69.5 | |
| (Top-) | ES | 76.5 | 73.1 | |
| (Top-) | ES | 78.8 | 76.8 | |
| G & L | (Top-) | ES | 82.0 | 81.0 |
| (Top-) | ES | 83.7 | 83.0 |
| Model | Hyperparameters | ||
|---|---|---|---|
| Layer indices | |||
| LLaVA-1.5-7b | (32, 31) | 32 | 0.6 |
| LLaVA-1.5-13b | (40, 38) | 32 | 0.6 |
| MiniGPT-4 | (32, 30) | 4 | 0.5 |
| Shikra | (30, 27) | 16 | 0.6 |
| Method | Attribute Hallucination | Relational Hallucination | ||||
|---|---|---|---|---|---|---|
| LLaVA-1.5-7B | LLaVA-1.5-13B | Qwen2.5-VL-7B | LLaVA-1.5-7B | LLaVA-1.5-13B | Qwen2.5-VL-7B | |
| NLL | 58.62 | 60.50 | 56.89 | 57.06 | 57.35 | 54.90 |
| Entropy | 52.21 | 55.32 | 55.84 | 55.72 | 56.27 | 55.03 |
| Internal Confidence | 74.24 | 73.67 | 70.06 | 69.38 | 68.94 | 62.09 |
| SVAR | 67.03 | 68.62 | 71.09 | 61.20 | 65.83 | 63.01 |
| Contextual Lens | 74.02 | 75.48 | 71.98 | 66.46 | 69.85 | 64.88 |
| GLSim (Ours) | 77.19 | 78.07 | 74.09 | 70.03 | 73.64 | 68.95 |
| Method | Time (s) | Accuracy | Precision (Real) | Precision (Halluc.) | Recall | F1 |
|---|---|---|---|---|---|---|
| External-based | 9.3 | 78.6 | 78.9 | 70.8 | 98.5 | 87.6 |
| GLSim (Internal) | 1.6 | 81.8 | 83.1 | 71.8 | 96.6 | 89.3 |
| Token | LLaVA-1.5-7B | LLaVA-1.5-13B |
|---|---|---|
| First | 83.7 | 84.8 |
| Last | 83.3 | 84.0 |
| Average | 83.4 | 84.2 |
| Metric | LLaVA | Shikra | |
|---|---|---|---|
| Global | L2 | 80.2 | 77.2 |
| Cosine | 79.3 | 78.9 | |
| Local | L2 | 79.9 | 75.6 |
| Cosine | 78.8 | 76.8 | |
| G & L | L2 | 84.0 | 81.3 |
| Cosine | 83.7 | 83.0 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
GLSim: Detecting Object Hallucinations in LVLMs via Global-Local Similarity
Seongheon Park Sharon Li
Department of Computer Sciences
University of Wisconsin-Madison
{seongheon_park, sharonli}@cs.wisc.edu
Abstract
Object hallucination in large vision-language models presents a significant challenge to their safe deployment in real-world applications. Recent works have proposed object-level hallucination scores to estimate the likelihood of object hallucination; however, these methods typically adopt either a global or local perspective in isolation, which may limit detection reliability. In this paper, we introduce GLSim, a novel training-free object hallucination detection framework that leverages complementary global and local embedding similarity signals between image and text modalities, enabling more accurate and reliable hallucination detection in diverse scenarios. We comprehensively benchmark existing object hallucination detection methods and demonstrate that GLSim achieves superior detection performance, outperforming competitive baselines by a significant margin111Code is available at https://github.com/deeplearning-wisc/glsim.
1 Introduction
Large Vision-Language Models (LVLMs) li2023llava ; dai2023instructblip ; zhu2023minigpt ; chen2024internvl ; ye2024mplug ; wang2024cogvlm ; bai2023qwen ; lu2024deepseek have made striking advances in understanding real-world visual data, enabling systems that can describe images, answer visual questions, and follow multi-modal instructions with fluency and creativity liu2023visual ; liang2024survey . Yet beneath this surface of impressive capability lies a critical vulnerability—object hallucinations (OH)—where the model generates plausible-sounding mentions of objects that are not present in the image rohrbach2018object . An example is illustrated in Figure 1, where the LVLM describes a “dining table” in a birthday party scene, even though the image contains no such object. These hallucinations can undermine user trust, and are particularly concerning in high-stakes domains including medical imaging li2023llava , autonomous navigation cui2024survey , and accessibility applications yang2024viassist . Detecting such hallucinations is thus essential for safe and reliable deployment of LVLMs, and has become an increasingly active area of research bai2024hallucination .
Existing approaches to object hallucination detection often rely on external knowledge sources, such as human-annotated ground truth annotations rohrbach2018object ; li2023evaluating ; fu2023mme ; wang2023amber ; chen2024multi ; petryk2024aloha . Others prompt or fine-tune external large language or vision-language models as judge to detect hallucinations jing2023faithscore ; sun2023aligning ; liu2023mitigating ; guan2024hallusionbench ; gunjal2024detecting ; chen2024mllm . However, these approaches face practical limitations: ground-truth references are often unavailable in real-world scenarios, and external LLMs are prone to hallucinating themselves, thereby limiting reliability. This highlights the need for a lightweight, model-internal approach that can detect and self-evaluate hallucinations without supervision or auxiliary models.
In this paper, we propose an object-level hallucination scoring function that operates without relying on external sources, leveraging the embedding similarity between image and text modalities within the latent space of LVLMs. We introduce Global-Local Similarity (GLSim) score, a method that unify two complementary perspectives: a global similarity score, which captures how well an object semantically fits the overall scene, and a local grounding score, which checks whether any specific region in the image actually supports the object’s presence. This fusion addresses a key shortcoming of prior approaches that rely on one perspective in isolation zhou2023analyzing ; jiang2024devils ; jiang2024interpreting ; phukan2024beyond . For instance, a global-only method may wrongly consider a “dining table” plausible in a birthday party scene (Figure 1), simply because such contextual associations are common in pretraining data—even if no table is visually present. On the other hand, local-only approaches may struggle when a hallucinated object is visually similar to real objects in the scene, as in Figure 2, where a model hallucinates a “handbag” due to confusion with a leather seat of a motorcycle. By integrating both global and local signals, our method can ask not only “does this object belong contextually to the scene?” but also “is there concrete visual evidence for it?”, resulting in more accurate, well-rounded, and interpretable hallucination detection across diverse scenarios.
As illustrated in Figure 1, GLSim works by evaluating each object mention along two axes. First, the global score measures the similarity between the object token’s embedding and the overall scene embedding—captured by the final token of the multimodal instruction prompt (highlighted in yellow). Next, we compute a local similarity score that checks for spatial grounding. Specifically, we identify the top image patches most relevant to the object using an adapted Logit Lens technique nostalgebraist2020logitlens , then assess whether these regions provide strong visual evidence for the object using the average similarity between the object token’s embedding and the top- image token embeddings (highlighted in green). By combining these two complementary signals, GLSim produces a holistic score that reflects both contextual fit and visual grounding—effectively distinguishing real objects from hallucinations.
We extensively evaluate GLSim across multiple benchmark datasets and LVLMs, including LLaVA-1.5 li2023llava , MiniGPT-4 zhu2023minigpt , and Shikra chen2023shikra , demonstrating strong generalization and state-of-the-art performance in detecting object hallucinations. On both MSCOCO and Objects365 datasets, GLSim consistently outperforms the latest baselines, including Internal Confidence jiang2024interpreting and attention-based grounding scores jiang2024devils , achieving up to a +12.7% improvement in AUROC. Ablation studies confirm the complementary roles of the global and local components: removing either degrades performance, while their combination yields the most reliable detection. Qualitative results further illustrate how GLSim accurately flags subtle hallucinations, making it a practical tool for real-world deployment.
Our key contributions are summarized as follows:
We propose GLSim, a novel object hallucination detection method that combines global and local similarity scores between latent embeddings. To the best of our knowledge, this is the first work to demonstrate their complementary effectiveness for the OH detection task. 2. 2.
We provide a comprehensive benchmarking of existing OH detection methods, addressing an important gap that has been overlooked in prior work. 3. 3.
We demonstrate the superior performance of GLSim through extensive experiments, conduct in-depth ablations to analyze the contributions of each component and design choice, and verify the generalizability of our method across various LVLMs and datasets.
2 Related Works
Object Hallucination Detection in LVLMs.
Object hallucination (OH) refers to the phenomenon where LVLMs generate textual descriptions that include non-existent objects in the image—a critical but underexplored problem in LVLMs with direct implications for reliable decision-making. Such hallucinations can stem from factors including statistical biases in training data deletang2023language , strong language model prior liu2023visual , or visual information loss favero2024multi . Recent studies have focused on evaluating and detecting OH by leveraging ground-truth annotations rohrbach2018object ; li2023evaluating ; fu2023mme ; wang2023amber ; chen2024multi ; petryk2024aloha . For instance, CHAIR rohrbach2018object suggests utilizing the discrete ratio of objects presented in the answer relative to a ground-truth object list to identify OH. Another line of work evaluates OH using external LLMs or LVLMs jing2023faithscore ; sun2023aligning ; liu2023mitigating ; guan2024hallusionbench ; gunjal2024detecting ; chen2024mllm . For instance, GAIVE liu2023mitigating leverages a stronger LVLM (e.g., GPT-4 achiam2023gpt ) as a teacher to assess the responses of a student model, while HaLEM wang2023evaluation fine-tunes an LLM (e.g., LLaMA touvron2023llama ) to score LVLM generations. While effective, these methods are resource-intensive and often lack transparency.
Several recent works have proposed object-level hallucination scores that self-evaluate OH likelihood without requiring an external judge model or additional training. For instance, LURE zhou2023analyzing utilizes the negative log-likelihood (NLL) of the object token generation probability; Internal Confidence (IC) jiang2024interpreting computes the maximum probability of the object token across all image hidden states nostalgebraist2020logitlens ; and Summed Visual Attention Ratio (SVAR) jiang2024devils leverages attention weights assigned to image tokens with respect to the object token. While promising, these methods primarily target hallucination mitigation and often fall short in detection performance: these methods typically leverage either global (e.g., NLL, SVAR) or localized (e.g., IC) signals in isolation and thus fail to capture the nuanced interplay between the overall semantic context and fine-grained visual grounding. Moreover, NLL often fails since LVLMs tend to favor linguistic fluency over factual accuracy radford2019language ; IC does not fully capture contextual information from the generated text; and SVAR can be biased toward previously generated text tokens liu2024paying and vulnerable to attention sink effects kang2025see .
Different from prior works, we introduce the first object hallucination detection method that explicitly integrates both global and local signals—unifying localized attribution with holistic semantic alignment between the image and generated text. We benchmark our approach against existing object-level hallucination detection methods across diverse settings to offer a comprehensive comparison in this space. Further related works are provided in Section˜C.2.
3 Problem Setup
Large Vision-Language Models for text generation typically consist of three main components: a vision encoder (e.g., CLIP radford2021learning ) which extracts visual features, a multi-modal connector (e.g., MLP) that projects these visual features into the language space, and an autoregressive language model that generates text conditioned on the projected visual and prompt embeddings.
Given an input image, the vision encoder processes it into a set of patch-level visual embeddings, commonly referred to as visual tokens. These tokens are then projected into the language model’s embedding space through the multi-modal connector, resulting in a sequence of visual embeddings: , where each corresponds to a transformed visual token of dimension . On the language side, the input text prompt (e.g., “Describe this image in detail.”) is tokenized and embedded into a sequence of language embeddings: , where is the prompt length. These two modalities—the projected visual tokens and the textual embeddings —are concatenated and passed as the input sequence to the language model. The language model then generates a sequence of output tokens: , where each is drawn from a vocabulary space and is the output length.
Object hallucination detection.
In this work, we focus on detecting object existence hallucination in LVLMs—cases where the model generates text that references objects not present in the image li2023evaluating ; zhai2023halle ; bai2024hallucination . This represents the most fundamental and critical form of errors affecting model reliability. We provide the formal task definition below.
Definition 3.1** (Object Hallucination Detector).**
Let denote the input to the LVLM, and be the sequence of generated tokens from the model. From , we extract a set of object mentions , where and denote the number of hallucinated and real objects, respectively. The task of object hallucination detection is to design a scoring function , where quantifies the likelihood that object is present in the input . Here and denote the space of objects and input, respectively. Based on this score, we define the object hallucination detector:*
[TABLE]
where is a decision threshold. Here, indicates that object is real (i.e., occurs in the image), while indicates a hallucinated object.
4 Method
Overview.
In this section, we propose an object-level hallucination scoring function that operates without relying on external sources, leveraging the embedding similarity between image and text modalities within the latent space of LVLMs. We introduce Global-Local Similarity (GLSim) score, a method that leverages both global and local similarity measures, and discuss how these complementary signals contribute to effective object hallucination detection.
4.1 Motivation: Both Local and Global Signals Matter
Object hallucination in LVLMs often arises when models generate plausible-sounding descriptions that are not visually grounded. But detecting such hallucinations is challenging: they can stem from subtle biases, background patterns, or statistical co-occurrence in training data li2023evaluating ; gong2024damro ; zhou2023analyzing . Critically, relying on a single perspective—either a global similarity or a local region-level score—is often not enough to reliably catch them. In particular, global similarity quantifies how semantically related the object is to the image as a whole. It captures holistic alignment between the object mention and the overall scene, and is useful for assessing whether the object “makes sense” in context. In contrast, local similarity measures how well the object is visually grounded in a specific region. It focuses on fine-grained evidence aligned with spatial areas most relevant to the object, helping verify whether it is actually present.
Qualitative evidence. Figure 2 illustrates how each signal alone can be insufficient. In panel (a), the LVLM-generated description includes a “dining table”, yet no table is present in the image. A global similarity score fails to flag this hallucination—likely because the overall scene (e.g., birthday cake, party setting) frequently co-occurs with tables in training data, leading to a high false-positive signal. In contrast, a local score that focuses on the visual region associated with “dining table” correctly assigns a low similarity, reflecting the absence of meaningful grounding in that region. In contrast, panel (b) shows a failure case for local similarity. The model hallucinates a “handbag,” and while the global similarity correctly captures that the handbag is not semantically compatible with the overall scene, the local score becomes unreliable—likely due to a visually similar object in the image (i.e., leather seat of the motorcycle).
These examples underscore the inherent limitations of using either signal in isolation. Global similarity can be overly influenced by high-level contextual associations, leading to false positives when hallucinated objects are contextually plausible within the scene but not visually present. On the other hand, local similarity is sensitive to spatial precision, but can misfire when localization is noisy or there are visually similar objects. As a result, each signal captures only a partial view of the grounding problem. To overcome this, we propose a unified approach, Global-Local Similarity (GLSim), that leverages the complementary strengths of both perspectives and offers more accurate and reliable detection of object hallucinations across a diverse range of visual-textual contexts. In the next subsections, we introduce the score definition in detail—explaining how we design global and local similarity for each object mention, and how they are integrated into a single decision score for hallucination detection. More qualitative results are presented in Section˜B.1.
4.2 Object Grounding via Local Similarity
A key component of our approach is the computation of the local similarity score, which captures how well an object mention is visually grounded in a specific region of the image. Unlike global similarity, which reflects scene-level plausibility, the local score focuses on verifying the presence of the object at the spatial level. The main challenge lies in identifying the most relevant region for each object mention—without relying on external annotations or bounding boxes.
Unsupervised object grounding. We leverage an unsupervised approach that leverages internal representations of the LVLM itself, to ground whether a predicted object token is hallucinated or not. Given the LVLM input , where are the visual tokens and are the prompt embeddings, we extract the hidden representations of each visual token at decoder layer . To project these representations into the vocabulary space, we can leverage Visual Logit Lens (VLL) as:
[TABLE]
where is the unembedding layer matrix. Unlike the original Logit Lens nostalgebraist2020logitlens , which operates solely in language models, our approach adapts it to a multimodal setting to attribute generated object mentions to relevant visual tokens. We apply a softmax and extract the predicted probability for the target object token : , probability quantifies how likely a visual token is to predict the object word , offering a model-internal signal of relevance between the image patch and object token. Importantly, we select the Top- image patches with the highest probabilities as the localized regions corresponding to the object :
[TABLE]
We visualize object grounding results in Section 5.3 and Section˜B.2.
Local similarity score.
Based on the localized regions , we compute average cosine similarity between each localized image embedding and object embedding:
[TABLE]
where denotes cosine similarity, and is the decoder layer used to represent the text embedding at the position of the object word. The score should be higher for real objects and relatively lower for hallucinated objects.
4.3 Scene-Level Grounding via Global Similarity
While the local similarity score focuses on spatially grounding an object in specific image regions, it alone may be insufficient—especially in cases where localization is ambiguous. To complement this, we introduce a global similarity score that measures scene-level semantic coherence between an object mention and the entire image. This can be useful for identifying out-of-context hallucinations (e.g., referencing a “handbag” in a motorcycle scene).
Global similarity score. We compute the global similarity as the cosine similarity between the embedding of the object/text token and the embedding of the final token in the instruction prompt. The final instruction token often encodes a condensed summary of the model’s understanding of both image and prompt context. By comparing the object token to this representation, the global score quantifies how well the object semantically aligns with the overall scene. This allows the model to down-weight mentions that may be contextually implausible, even if they are locally aligned with some visual region.
Formally, given an object mention and LVLM input , let be the object token representation at layer , and let be the hidden representation of the last visual-text prompt token at layer . The global similarity score is then defined as:
[TABLE]
where denotes cosine similarity.
Global-Local Similarity (GLSim) score.
To fully leverage the complementary strengths of both grounding signals, we define the final hallucination detection score as a weighted combination of local and global similarity. Specifically, we define the GLSim score as:
[TABLE]
where is a hyperparameter controlling the balance between local evidence and global context. This fused score captures both spatial alignment and scene-level plausibility, enabling more accurate detection of hallucinated objects. In practice, we find that a moderate value of (e.g., 0.6) yields consistently strong performance across diverse scenarios (see Section˜5.3). Based on the scoring function, the object hallucination detector is , where 1 indicates a real object and 0 indicates a hallucinated object.
5 Experiments
5.1 Setup
Datasets and models.
We utilize the MSCOCO dataset lin2014microsoft , which is widely adopted as the primary evaluation benchmark in numerous LVLM object hallucination studies and contains 80 object classes. In addition, we employ the Objects365 dataset shao2019objects365 , which offers a more diverse set of images and a larger category set comprising 365 object classes, along with denser object annotations per image. For evaluation, we randomly sample 5,000 images each from the validation sets of MSCOCO and Objects365. We conduct experiments on three representative LVLMs: LLaVA-1.5 li2023llava , MiniGPT-4 zhu2023minigpt , and Shikra chen2023shikra . For LLaVA-1.5, we evaluate both 7B and 13B model variants to study scalability. Implementation details are provided in Appendix˜A. We evaluate on three additional LVLMs—InstructBLIP dai2023instructblip , LLaVA-NeXT-7B liu2024improved , Cambrian-1-8B tong2024cambrian , Qwen2.5-VL-7B bai2025qwen2 , and InternVL3-8B zhu2025internvl3 in Appendix D.1.
Evaluation. We formulate the object hallucination detection problem as an object-level binary classification task, where a positive sample is a real object and a negative sample is a hallucinated object. We extract objects from the generated descriptions and perform exact string matching against the ground-truth object classes of each image and their synonyms, following CHAIR rohrbach2018object . To evaluate OH detection performance, we report: (1) the area under the receiver operating characteristic curve (AUROC), and (2) the area under the precision-recall curve (AUPR), both of which are threshold-independent metrics widely used for binary classification tasks.
Baselines. We compare our approach against a comprehensive set of baselines, categorized as follows: (1) Token probability-based approaches—Negative Log-Likelihood (NLL) zhou2023analyzing and Entropy malinin2020uncertainty ; (2) Logit Lens probability-based approach—Internal Confidence jiang2024interpreting ; (3) Attention-based approach—Summed Visual Attention Ratio (SVAR) jiang2024devils ; and (4) Embedding similarity-based approach— phukan2024beyond . To ensure a fair comparison, we evaluate all baselines on identical test sets using the default experimental configurations provided in their respective papers. As was originally proposed for sentence-level hallucination detection, we adapt it for object-level hallucination detection. Further details of these baselines are discussed in Appendix˜C.
5.2 Main results
As shown in Table˜1, we compare our method, GLSim, with competitive object hallucination detection methods, including the latest ones published in 2025. GLSim consistently outperforms existing state-of-the-art approaches across different models and datasets by a significant margin. Specifically, on the MSCOCO dataset with LLaVA-1.5-7B, GLSim outperforms SVAR by 9.0% AUROC, and achieves an 8.3% AUROC improvement over Contextual Lens, an embedding similarity-based baseline. Unlike Contextual Lens, which relies on the maximum cosine similarity between text embeddings and all image embeddings, GLSim integrates global and local signals, resulting in more robust detection performance. Notably, our method also demonstrates strong performance on Shikra, achieving a 12.7% improvement in AUROC on the MSCOCO dataset compared to SVAR. Given that Shikra is trained with a focus on region-level inputs and understanding, this result suggests that our method is effective in models with strong spatial alignment capabilities.
Comparison with Internal Confidence.
Recently, the Internal Confidence (IC) method jiang2024interpreting was proposed to detect hallucinations using visual logit lens probabilities. Our approach differs from IC in three key ways. First, IC directly uses the maximum probability from the visual logit lens across all image patches and layers, which can be overconfident—assigning high scores to hallucinated objects (see Figure˜3). In contrast, we compute the semantic similarity in representation space between the object token embedding and the Top- visual tokens, yielding a more reliable and semantically meaningful signal. For hallucinated objects, this leads to alignment with semantically irrelevant regions, resulting in lower similarity scores, thereby enabling more reliable object hallucination detection. Second, IC considers only the most probable patch, while we aggregate over the Top- most relevant patches. As shown in our ablation study (Section 5.3), using multiple visual regions improves performance by capturing spatially distributed evidence and reducing sensitivity to local noise. Third, IC is purely local in nature, whereas our framework also integrates a global similarity score that captures object-scene coherence at the image level. Together, these advantages enable our method to outperform IC by a substantial margin of 10.8% AUROC.
5.3 Ablation Studies
In this section, we provide various in-depth analysis of each component of our method. All experiments are conducted using LLaVA-1.5-7B and Shikra on the MSCOCO dataset, and results are reported in terms of AUROC (%). Further ablation studies are provided in Appendix˜D.
Analysis of global and local scores. We systematically compare global and local scores on the MSCOCO dataset, as shown in Table˜3. Finding 1: Embedding similarity is an effective scoring metric. Embedding similarity (ES)-based methods consistently outperform other scoring functions, with GLSim (Top-) achieving a 22.6% improvement over NLL on Shikra. In contrast, token probability (TP)-based approaches are optimized for linguistic fluency rather than object existence accuracy; attention weight (AT)-based methods often fail to align with causal attributions jain2019attention ; and Logit Lens probability (LLP) methods tend to exhibit overconfidence. By directly capturing the semantic alignment between image and text modalities, embedding similarity provides a more reliable signal for OH detection. Finding 2: Object grounding improves OH detection. Among local methods, our approach leverages grounded objects in the image and computes embedding similarity directly with those object representations, achieving a 7.7% improvement over Internal Confidence on the Shikra model. This enables fine-grained alignment, unlike Internal Confidence and Contextual Lens methods, which rely only on the maximum token probability or cosine similarity score. Finding 3: Combining global and local scores further improves performance. By combining global () and local () similarity scores, we observe additional gains of 2.7% in Top-1 and 4.4% in Top- for the LLaVA model. This demonstrates that our scoring function design in Equation˜5 effectively integrates the complementary strengths of both global and local signals.
Comparison of object grounding methods.
We explore several design choices for the patch selection for object grounding in Section˜4.2, with results summarized in Table˜3. Specifically, we vary the metric used for Top- () patch selection, comparing (1) attention weights, (2) cosine similarity, and (3) our method (visual logit lens). Our method outperforms attention weights by 12.5% and cosine similarity by 2.6% in local score evaluation. When combining global and local scores, our method achieves gains of 4.3% over attention weights and 3.0% over cosine similarity. We further visualize the Top- patch scores for each metric in Figure˜4. From the visualization, we observe that high attention weights tend to be assigned to irrelevant regions kang2025see ; cosine similarity better localizes object regions but still assigns spuriously high scores to background areas. In contrast, ours accurately highlights object regions, leading to more reliable patch selection for grounding.
Design choices for global and local scores.
We ablate several key design choices for each scoring function in Table˜4. For the global score (), we compare (1) similarity with the last image token embedding, (2) average similarity across all image tokens, and (3) similarity with the last instruction token. The last instruction token performs best, outperforming the average similarity by , highlighting its strength in capturing scene-level semantics. For the local score (), we compare (1) a Logit Lens probability-weighted average of local similarities among top- patches and (2) a non-weighted average as in Equation (3), where the latter works slightly better. Finally, combining global and local scores improves performance for both variants of the global score. This confirms that the two signals are complementary and supports the design of our scoring function.
How do the selected number of patches affect the performance? We analyze the impact of varying the number of selected patches in Equation˜2 on object hallucination detection performance in LABEL:fig:k_abl. Performance improves with increasing up to for LLaVA and for Shikra, after which it degrades. This trend suggests that a small may fail to capture sufficient object information, while a large introduces irrelevant regions, adding noise. Given that LLaVA processes 576 image tokens, the optimal roughly corresponds to of total image tokens. This highlights the importance of choosing relative to input resolution for effective OH detection.
How does the weighting parameter affect performance? In LABEL:fig:w_abl, we examine the effect of the weighting parameter in Equation˜5 on OH detection performance. Performance increases with up to 0.6, after which it declines. Smaller values of place greater emphasis on the local score, while larger values prioritize the global score. We find that moderate values consistently yield the best results across models, suggesting that global and local signals are complementarily informative—where the global score captures scene-level semantics, and the local score captures fine-grained, spatial-level semantics. These results support our design choice of combining both components through a balanced weighting scheme, effectively enhancing overall performance.
How does the text embedding layer index affect performance? We examine how the choice of text embedding layer influences overall performance when computing embedding similarity in Equation˜3 and Equation˜4. We fix the image embedding layer to the 32nd layer for LLaVA and the 30th layer for Shikra, as specified in Table˜6. As shown in LABEL:fig:text_embedding, the best performance is achieved at the 31st layer for LLaVA and the 27th layer for Shikra. Performance improves with later layers, suggesting that semantic representations are progressively refined in later layers. However, it slightly drops afterward, which supports the observation from skean2025layer that the optimal layer for downstream tasks may not necessarily be the final layer. These findings indicate that later-intermediate layers are particularly effective for object hallucination detection. The complete performance matrix over all layer pairs is provided in Appendix˜E.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. In Neur IPS , 2023.
- 2[2] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instruct BLIP: Towards general-purpose vision-language models with instruction tuning. In Neur IPS , 2023.
- 3[3] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. ar Xiv preprint ar Xiv:2304.10592 , 2023.
- 4[4] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR , 2024.
- 5[5] Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, and Fei Huang. mplug-owl 2: Revolutionizing multi-modal large language model with modality collaboration. In CVPR , 2024.
- 6[6] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Song Xi Xuan, et al. Cogvlm: Visual expert for pretrained language models. In Neur IPS , 2024.
- 7[7] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. ar Xiv preprint ar Xiv:2309.16609 , 2023.
- 8[8] Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision-language understanding. ar Xiv preprint ar Xiv:2403.05525 , 2024.