WaveHiT-SR: Hierarchical Wavelet Network for Efficient Image Super-Resolution
Fayaz Ali, Muhammad Zawish, Steven Davy, Radu Timofte

TL;DR
WaveHiT-SR introduces a hierarchical wavelet transformer that efficiently captures multi-scale features for image super-resolution, outperforming existing methods in accuracy and computational efficiency.
Contribution
The paper presents a novel hierarchical transformer framework embedding wavelet transforms and adaptive windows, enabling better long-range dependency modeling and multi-frequency feature extraction in SR.
Findings
Achieves state-of-the-art super-resolution results.
Reduces computational complexity while maintaining performance.
Fewer parameters and faster inference speeds.
Abstract
Transformers have demonstrated promising performance in computer vision tasks, including image super-resolution (SR). The quadratic computational complexity of window self-attention mechanisms in many transformer-based SR methods forces the use of small, fixed windows, limiting the receptive field. In this paper, we propose a new approach by embedding the wavelet transform within a hierarchical transformer framework, called (WaveHiT-SR). First, using adaptive hierarchical windows instead of static small windows allows to capture features across different levels and greatly improve the ability to model long-range dependencies. Secondly, the proposed model utilizes wavelet transforms to decompose images into multiple frequency subbands, allowing the network to focus on both global and local features while preserving structural details. By progressively reconstructing high-resolution…
Click any figure to enlarge with its caption.
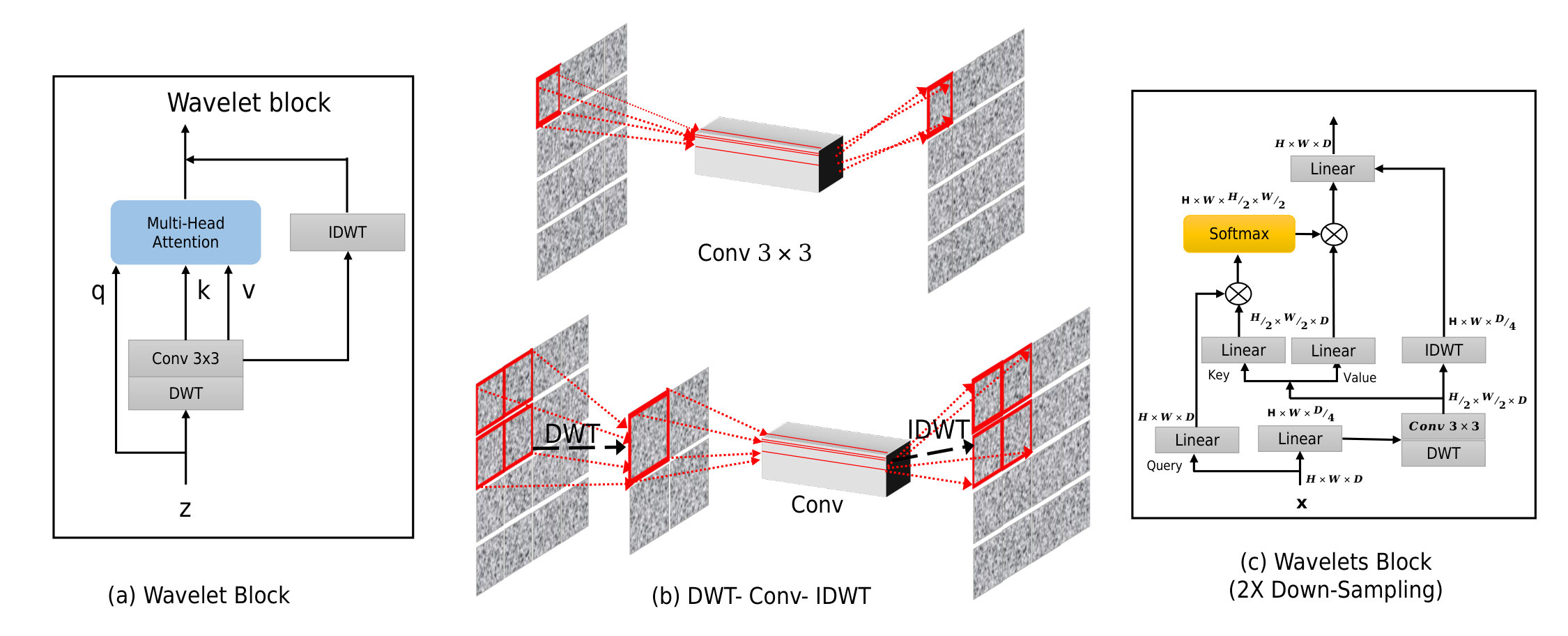 Figure 1
Figure 1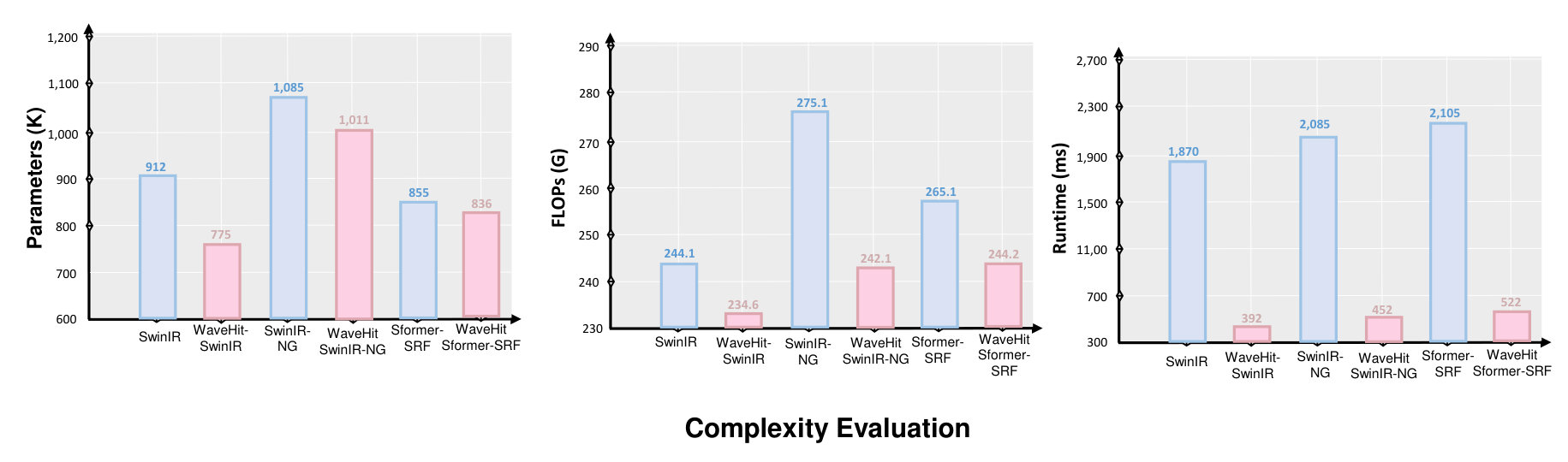 Figure 2
Figure 2 Figure 3
Figure 3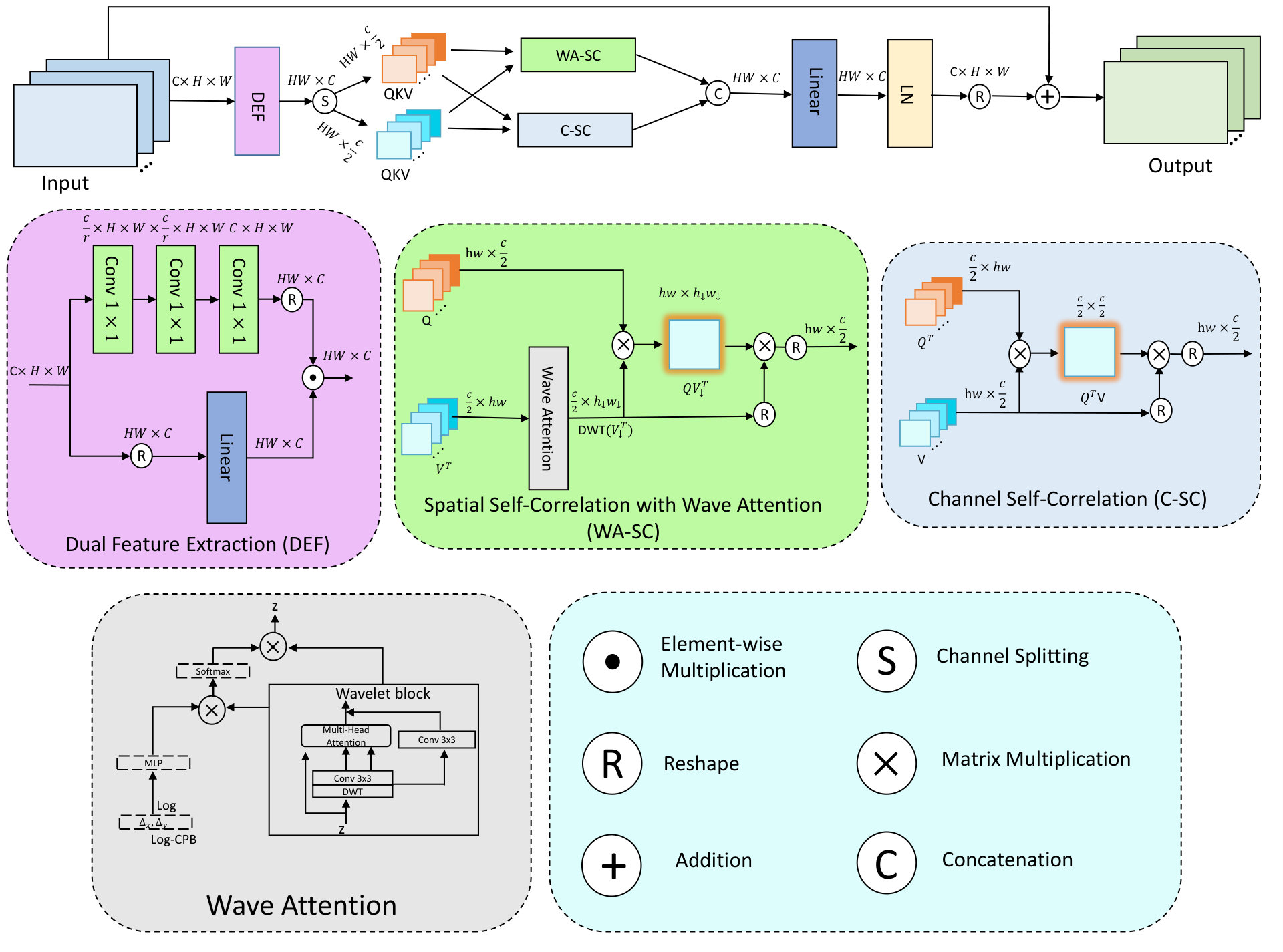 Figure 4
Figure 4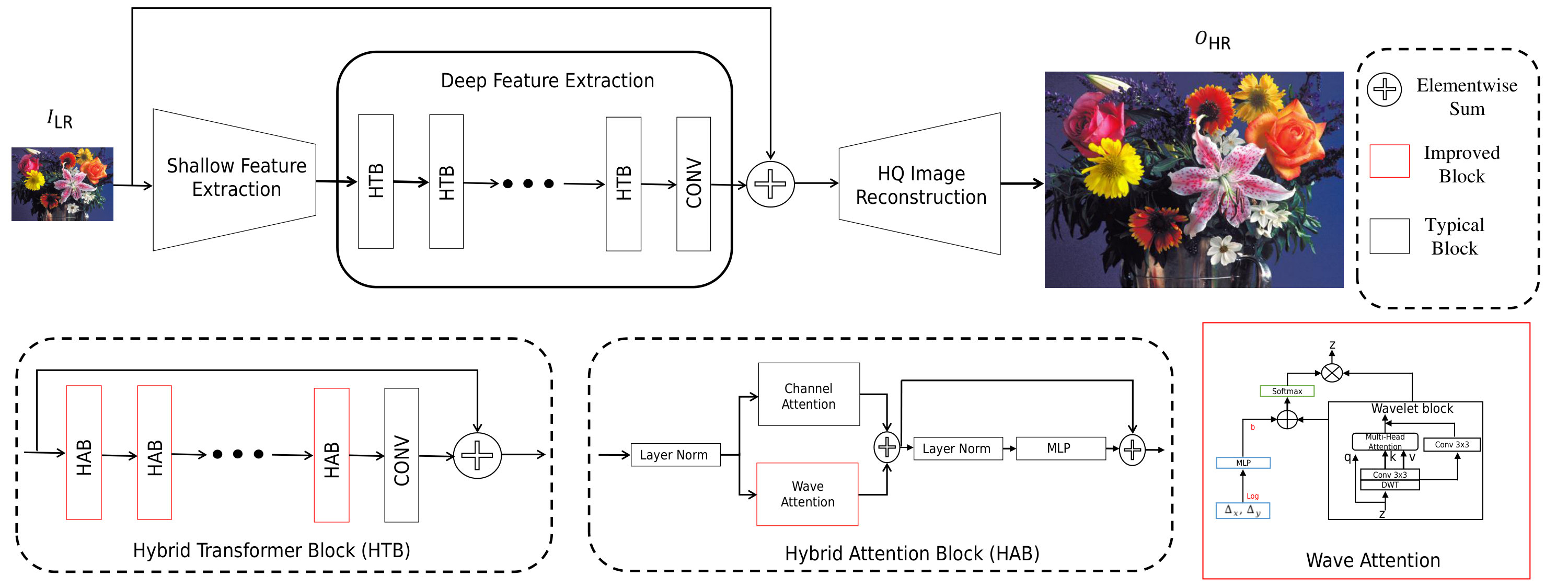 Figure 5
Figure 5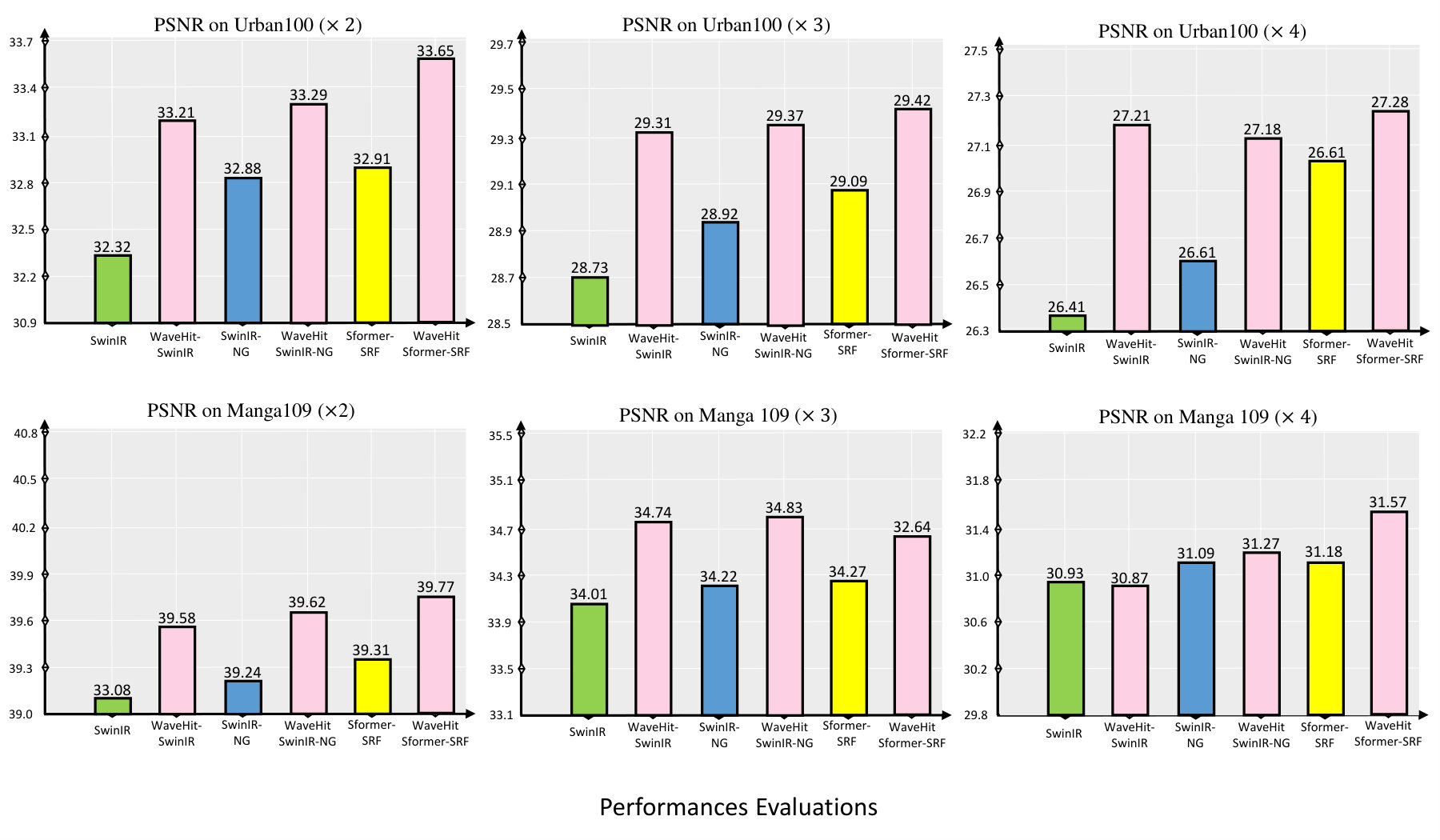 Figure 6
Figure 6 Figure 7
Figure 7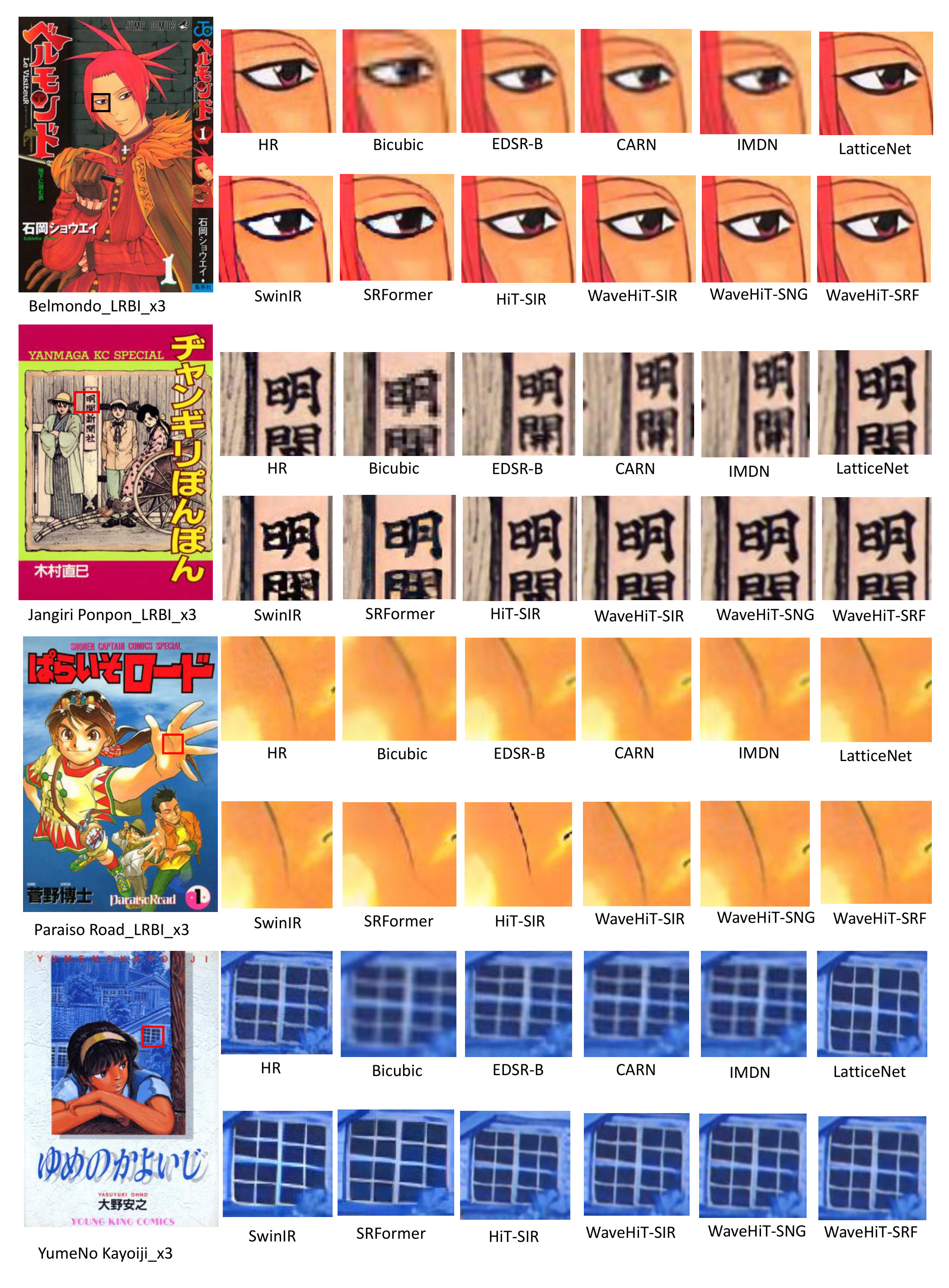 Figure 8
Figure 8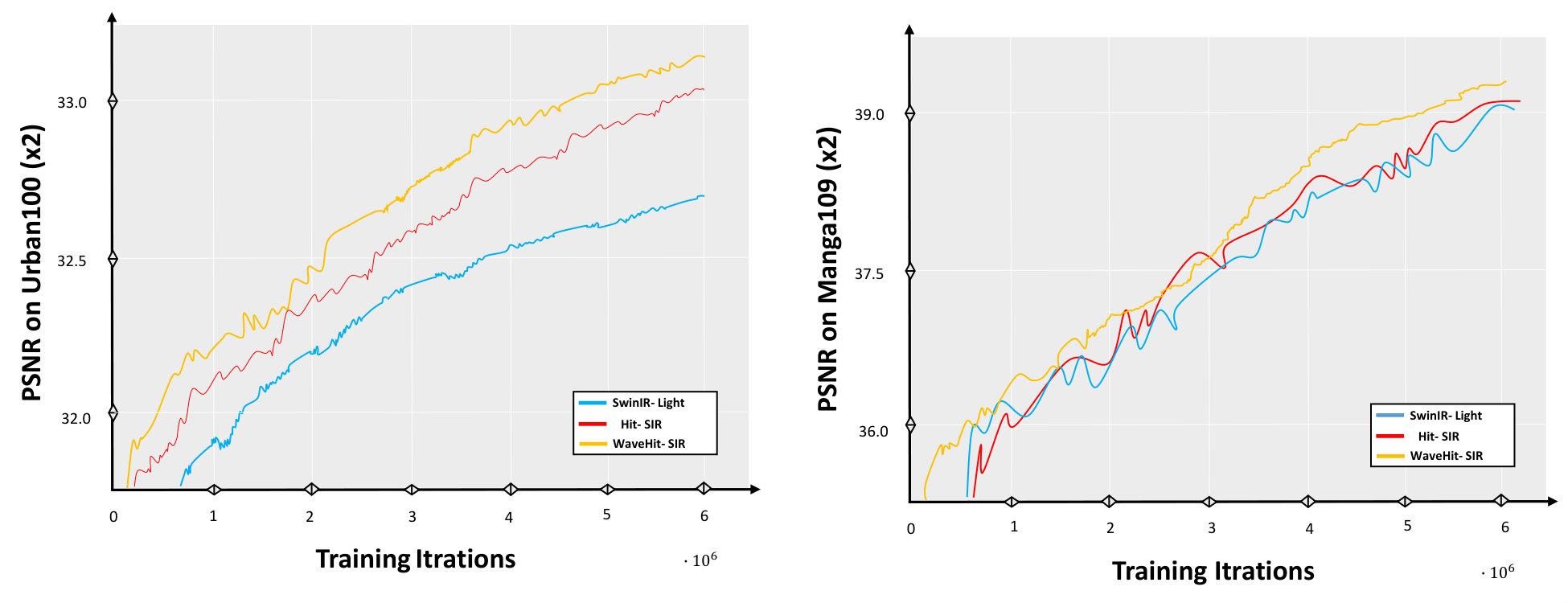 Figure 9
Figure 9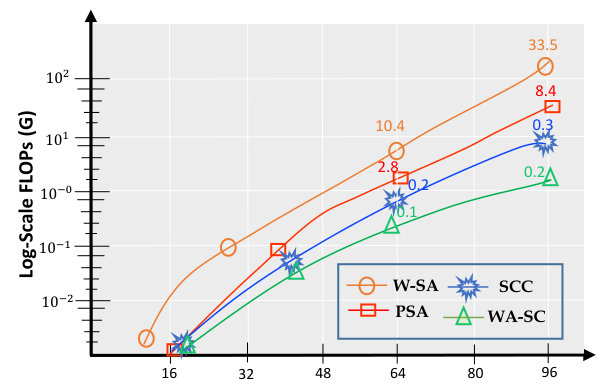 Figure 10
Figure 10 Figure 11
Figure 11 Figure 1
Figure 1 Figure 2
Figure 2| Attention Type | Complexity | Focus | Summary |
|---|---|---|---|
| Global Self-Attn | Quadratic | Scales with all pixel pairs | |
| Window Self-Attn | Local | Quadratic within windows | |
| WaveAttention | Efficient | Near-linear via wavelet transform |
| Method | Complexity | Scale | Benchmark Datasets | |||||
| Param. Count | FLOPs | Scale | Set5 | Set14 | B100 | Urban100 | Manga109 | |
| - | - | - | - | PSNR / SSIM | PSNR / SSIM | PSNR / SSIM | PSNR / SSIM | PSNR / SSIM |
| EDSR-B (Lim et al. 2017) | 1373K | 315.6G | 36.46 / 0.9604 | 34.49/ 0.9265 | 32.26 / 0.8996 | 31.97 / 0.9271 | 38.45 / 0.9758 | |
| CARN (Ahn, Kang, and Sohn 2018) | 1587K | 221.7G | 36.86 / 0.9530 | 34.32 / 0.9176 | 32.19/ 0.8987 | 31.82 / 0.9236 | 38.36 / 0.9765 | |
| IMDN (Hui et al. 2019) | 692K | 158.4G | 38.02 / 0.9606 | 33.66 / 0.9179 | 32.24 / 0.8998 | 32.25 / 0.9285 | 38.25 / 0.9759 | |
| LatticeNet (Luo et al. 2020) | 751K | 168.2G | 38.08 / 0.9611 | 33.72 / 0.9188 | 32.24 / 0.9010 | 32.35 / 0.9288 | 38.84 / 0.9754 | |
| SwinIR-L (Liang et al. 2021) | 911K | 244.5G | 38.12 / 0.9611 | 33.77 / 0.9216 | 32.36 / 0.9018 | 32.75 / 0.9345 | 39.08 / 0.9781 | |
| SwinIR-NG(Choi, Lee, and Yang 2023) | 1181K | 274.1G | 38.17 / 0.9612 | 33.94 / 0.9205 | 32.31 / 0.9013 | 32.78 / 0.9340 | 39.20 / 0.9781 | |
| SRFormer-L(Zhou et al. 2023) | 856K | 237.5G | 38.19 / 0.9643 | 33.92 / 0.9207 | 32.42 / 0.9025 | 32.96 / 0.9363 | 39.29 / 0.9787 | |
| HiT-SIR(Aslahishahri, Ubbens, and Stavness 2024) | 847K | 226.5G | 38.25 / 0.9613 | 34.11 / 0.9216 | 32.39 / 0.9026 | 33.15 / 0.9381 | 39.51 / 0.9788 | |
| WaveHiT-SIR | 785K | 211.5G | 38.29 / 0.9617 | 34.14 / 0.9223 | 32.69 / 0.9042 | 33.22 / 0.9392 | 39.57 / 0.9791 | |
| WaveHiT-SNG | 1038K | 221.2G | 38.32 / 0.9619 | 34.17 / 0.9226 | 32.49 / 0.9035 | 33.29 / 0.9395 | 39.61 / 0.9795 | |
| WaveHiT-SRF | 832K | 216.2G | 38.45 / 0.9659 | 34.26 / 0.9236 | 32.46 / 0.9029 | 33.66 / 0.9415 | 39.77 / 0.9825 | |
| EDSR-B (Lim et al. 2017) | 1557K | 160.3G | 34.35 / 0.9268 | 30.31 / 0.8527 | 29.19/ 0.8024 | 28.39 / 0.8544 | 33.55 / 0.9443 | |
| CARN (Ahn, Kang, and Sohn 2018) | 1594K | 118.9G | 34.25/ 0.9245 | 30.29 / 0.8407 | 29.07 / 0.8046 | 28.16 / 0.8496 | 33.52 / 0.9452 | |
| IMDN (Hui et al. 2019) | 713K | 72.4G | 34.46 / 0.9280 | 30.32 / 0.8417 | 29.14 / .8056 | 28.23 / 0.8523 | 33.61 / 0.9445 | |
| LatticeNet (Luo et al. 2020) | 774K | 76.7G | 34.42/ 0.9284 | 30.41 / 0.8426 | 29.10 / 0.8049 | 28.20 / 0.8511 | 33.72 / 0.9444 | |
| SwinIR-L (Liang et al. 2021) | 918K | 110.8G | 34.61 / 0.9289 | 30.53 / 0.8461 | 29.21 / 0.8084 | 28.68 /0.8626 | 34.01 / 0.9482 | |
| SwinIR-NG(Choi, Lee, and Yang 2023) | 1190K | 114.1G | 34.64 / 0.9293 | 30.58 / 0.8471 | 29.24 / 0.8090 | 28.75 / 0.8639 | 34.22 / 0.9488 | |
| SRFormer-L(Zhou et al. 2023) | 872K | 106.8G | 34.71 / 0.9297 | 30.58 / 0.8471 | 29.28 / 0.8099 | 28.82 / 0.8658 | 34.22 / 0.9489 | |
| HiT-SIR(Aslahishahri, Ubbens, and Stavness 2024) | 855K | 101.6G | 34.74 / 0.9301 | 30.62 / 0.8477 | 29.32 / 0.8117 | 29.02 / 0.8698 | 34.54 / 0.9504 | |
| WaveHiT-SIR | 774K | 93.2G | 34.81 / 0.9309 | 31.02 / 0.8537 | 29.57 / 0.8214 | 29.38 /0.8858 | 34.74 / 0.9574 | |
| WaveHiT-SNG | 1043K | 101.4G | 35.12 / 0.9420 | 30.82 / 0.8492 | 29.67 / 0.8222 | 29.37 /0.8813 | 34.84 / 0.9584 | |
| WaveHiT-SRF | 843K | 103.7G | 34.78 / 0.9306 | 30.90 / 0.8501 | 29.87 / 0.8275 | 29.42 / 0.8898 | 34.64 / 0.9544 | |
| EDSR-B (Lim et al. 2017) | 1526K | 114.2G | 32.07/ 0.8936 | 28.54 / 0.7809 | 27.55 / 0.7349 | 26.14 / 0.7856 | 30.34 / 0.9063 | |
| CARN (Ahn, Kang, and Sohn 2018) | 1594K | 91.5G | 32.11 / 0.8935 | 28.62 / 0.7819 | 27.59 /0.7352 | 26.09/ 0.7841 | 30.49 / 0.9086 | |
| IMDN (Hui et al. 2019) | 716K | 41.7G | 32.20 / 0.8947 | 28.56 / 0.7813 | 27.57 / 0.7359 | 26.09 / 0.7845 | 30.49 / 0.9079 | |
| LatticeNet (Luo et al. 2020) | 779K | 43.8G | 32.18 / 0.8943 | 28.64 / 0.7820 | 27.59 / 0.7361 | 26.14 / 0.7844 | 30.54 / 0.9076 | |
| SwinIR-L (Liang et al. 2021) | 931K | 63.8G | 32.45 / 0.8978 | 28.78 / 0.7859 | 27.70 / 0.7407 | 26.48 /0.7981 | 30.93/ 0.9152 | |
| SwinIR-NG(Choi, Lee, and Yang 2023) | 1201K | 64.4G | 32.44 / 0.8980 | 28.83 / 0.7870 | 27.73 / 0.7418 | 26.61 / 0.8010 | 31.09/ 0.9161 | |
| SRFormer-L(Zhou et al. 2023) | 875K | 63.9G | 32.51 / 0.8988 | 28.83 / 0.7874 | 27.73 / 0.7422 | 26.69 / 0.8035 | 31.18/ 0.9167 | |
| HiT-SIR(Aslahishahri, Ubbens, and Stavness 2024) | 869K | 58.2G | 32.55 / 0.8999 | 28.87 / 0.7880 | 27.75 / 0.7432 | 26.80/ 0.8069 | 31.26 /0.9171 | |
| WaveHiT-SIR | 781K | 52.6G | 32.57 / 0.9003 | 29.17 / 0.80050 | 27.88 / 0.7512 | 27.21 /0.8142 | 31.87 / 0.9282 | |
| WaveHiT-SNG | 1054K | 59.7G | 32.84 / 0.9023 | 29.13 / 0.7913 | 27.93 / 0.7562 | 27.17 /0.8122 | 31.27 /0.9182 | |
| WaveHiT-SRF | 857K | 56.4G | 32.98 / 0.9053 | 29.32 / 0.80253 | 27.91 / 0.7522 | 27.29 / 0.8173 | 31.57 /0.9262 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
WaveHiT-SR: Hierarchical Wavelet Network for Efficient Image Super-Resolution
Fayaz Ali1, Muhammad Zawish2, Steven Davy2, Radu Timofte1
Abstract
Transformers have demonstrated promising performance in computer vision tasks, including image super-resolution (SR). The quadratic computational complexity of window self-attention mechanisms in many transformer-based SR methods forces the use of small, fixed windows, limiting the receptive field. In this paper, we propose a new approach by embedding the wavelet transform within a hierarchical transformer framework, called (WaveHiT-SR). First, using adaptive hierarchical windows instead of static small windows allows to capture features across different levels and greatly improve the ability to model long-range dependencies. Secondly, the proposed model utilizes wavelet transforms to decompose images into multiple frequency subbands, allowing the network to focus on both global and local features while preserving structural details. By progressively reconstructing high-resolution images through hierarchical processing, the network reduces computational complexity without sacrificing performance. The multi-level decomposition strategy enables the network to capture fine-grained information in low-frequency components while enhancing high-frequency textures. Through extensive experimentation, we confirm the effectiveness and efficiency of our WaveHiT-SR. Our refined versions of SwinIR-Light, SwinIR-NG, and SRFormer-Light deliver cutting-edge SR results, achieving higher efficiency with fewer parameters, lower FLOPs, and faster speeds.
Introduction
Several downstream computer vision tasks require image enhancement to aid in accurate decision-making. Single-image super-resolution (SISR) is one of the prominent tasks for image enhancement. SISR is commonly adopted in plethora of usecases ranging from remote sensing (Dharejo et al. 2021), medical imaging (Dharejo et al. 2022) to facial recognition (Wang et al. 2024). It aids the decision making process by providing a high resolution (HR) output with improved perceptual quality from a low resolution (LR) input (Alexey 2020; Lim et al. 2017; Ahn, Kang, and Sohn 2018; Bittner et al. 2023). Despite its wide adoption, the task of SISR is inherently challenging because of its ill-posed nature. This drives the researchers in vision community to propose efficient but at the same time robust models for this low-level vision task.
The deep convolutional neural network (CNN) gained immense popularity among early methods to solve SISR. CNNs were attractive thanks to their effective architecture for retaining and generating fine grained details in images. This resulted in a rapid transition from classical statical approaches (Lee et al. 2017) to learning-based methods (Guo et al. 2017; Zhang et al. 2018, 2019; Dong et al. 2014) for improved SISR. Regardless of this, existing CNN based works heavily incorporate spatially invariant kernels with an aim to extract only local features. This hampers the adaptability of CNNs to observe and model pixel-level relationships, which is important for enhanced perceptual quality. In addition, researchers focus on making CNNs more deeper and complex to improve SR performance (Dong et al. 2014; Lim et al. 2017). However, it is observed that depth does not contribute to enhancement but overlooks vital information such as high frequency details of certain objects due to large number of downsampling operations
Recently, new architectures based on transformers offer great utility for tasks beyond natural language processing (NLP) (Vaswani et al. 2017; Zhu et al. 2020). Their ability to perform self-attention mechanism on given features has received enormous attention for various high (Yuan et al. 2021; Wang et al. 2021; Li et al. 2023; Zheng et al. 2021) and low level vision tasks (Liang et al. 2021; Li et al. 2021; Cao et al. 2021; Wang et al. 2022b; Chen et al. 2023; Wang et al. 2023; Zhou et al. 2023). Several vision transformers (ViTs) have been proposed based on sliding window and self-attention mechanisms that extend the legacy of swin transformers (Liang et al. 2021; Zhang et al. 2022a). We observe a common trend among such architectures is their inability to capture long-range dependencies without increasing additional computing complexity (Wang et al. 2021; Liang et al. 2021; Zhang et al. 2022a). Moreover, the self-attention mechanism, despite being powerful, leads to weak cross-window interaction within ViTs such as in SwinIR (Liang et al. 2021). To address these challenges, this work introduces a hybrid attention block that uses channel and wavelet attention. The wavelet block aids in reconstructing high frequency details within objects, while channel attention boosts the utilization of global information for efficient and robust SR. In addition, inspired by the importance of multiscale feature representation for SR, we also propose hierarchical windows in transformer layers. These windows allow ViT to capture multiscale features through moderately expanding receptive fields. Inspired by the advantages of multiscale feature integration (Hui et al. 2019; Kim, Lee, and Lee 2016; Lai et al. 2017), we offer a new approach that restructures common transformer-based SR networks into hierarchical transformers for more efficient and accurate image SR (WaveHiT-SR). In summary, the WaveHiT-SR framework consists of three key contributions:
- •
We introduce WaveHiT-SR, an effective approach that adapts popular transformer-based SR methods into a hierarchical transformer framework, enhancing SR performance by leveraging multiscale features and capturing long-range dependencies. A comparison with state-of-the-art is shown in Figure 1.
- •
We propose a WaveAttention mechanism within hierarchical transformers to capture texture and edge details efficiently, achieving linear complexity with respect to window size and enabling the use of large hierarchical windows, such as
- •
We reframe SwinIR-Light (SIR) (Liang et al. 2021), SwinIR-NG (SNG) (Choi, Lee, and Yang 2023), and SRFormer-Light (SRF) (Zhou et al. 2023) as WaveHiT-SR models specifically, WaveHiT-SIR, WaveHiT-SNG, and WaveHiT-SRF achieving enhanced performance with a reduced number of parameters, decreased FLOPs, and faster runtime
Related Work
A plethora of deep neural networks have been proposed to address the prevalent challenge of SR in the past decade.
SR with CNNs
CNNs were among early adopters for the task of SISR thanks to their remarkable performance and parametric efficiency. Among others, SRCNN (Dong et al. 2014) laid the foundation of CNNs being applied for the SISR by learning a non-linear function to map a bicubic interpolation based LR image to a HR output via a few convolutional layers. Inspired from this, a followup study by Kim et al. (Kim, Lee, and Lee 2016) involved a deeper VGG-19 with residual learning capacity to improve SR performance. Advanced models like EDSR (Lim et al. 2017) topped the NTIRE2017 challenge (Agustsson and Timofte 2017) by proposing residual blocks but skipping batch normalization layers for efficiency and accuracy. Recent works with CNNs attempted to develop more deeper and complex architectures. For example, MemNet (Tai et al. 2017) and RDN (Zhang et al. 2018) exploited dense blocks to leverage intermediate features from individual layers. Different from these works, RCAN (Zhang et al. 2019) and VDSR (Zhang et al. 2019) made great efforts to capture high-frequency details via residual structures. Inspired from the intuition that high-frequency details are important for improved SR, this work also aims to preserve such details by introducing wavelet based attention.
SR with Vision Transformers
Inspired from the natural success of transformers in NLP (Vaswani et al. 2017), several researchers incorporated ViTs for both high-level vision (Yuan et al. 2021; Wang et al. 2021; Li et al. 2023) and low level vision tasks such as SISR (Liang et al. 2021; Li et al. 2021; Cao et al. 2021; Wang et al. 2022b; Chen et al. 2023; Wang et al. 2023; Zhou et al. 2023). Building on the success of self-attention (SA) mechanism, SwinIR (Liang et al. 2021) is a prominent work which introduced shifted window self-attention for robust image restoration. As an extension of this, several works emerged such as omni self-attention (OSA) (Wang et al. 2023), and permuted self-attention (PSA) (Zhou et al. 2023) for more complex, multi-scale feature extraction through custom self attention modules. However, SwinIR and similar approaches compute SA on static, constant size windows overlooking the long-range feature dependency. In contrast, UFormer (Wang et al. 2022b) claims to capture local and global dependencies effectively by proposing a multi-scale restoration module. Following this, SRFormer based on OSA (Wang et al. 2023) strikes the balance between channel and spatial features by feeding an optimized SA mechanism for SR. Regardless of several such improvements, a common gap still exists in leveraging hierarchical features at multi scales with ViTs, which is filled by this work to boost the SR performance.
Frequency Domain for SR
Recent works have incorporated the low and high-frequency image features simultaneously for improved SISR. For example, authors in (Baek and Lee 2020) leveraged multi-branch CNN architectures to decompose feature set into frequency in fourier domain. Similarly, fourier-driven architectures based on ViTs were introduced such as SwinFIR (Zhang et al. 2022a) exploits fast Fourier convolution to incorporate image-wide receptive fields. Despite such innovations, fourier-based models tends to overlook the high-frequency features, limiting their SR performance gains. In contrast, several works such as such as DWSR (Guo et al. 2017), Wavelet-SRNet (Huang et al. 2017), PDASR (Zhang et al. 2022b) leverage wavelet transforms in SR to address such limitations. For example, authors in (Zhang et al. 2022b) improve the visual fidelity and avoids the artifacts by conditioning the reconstruction on low-level wavelet coefficients. Latest work from WGSR (Korkmaz, Tekalp, and Dogan 2024) replaced the traditional loss with a weighted combination of wavelet losses to efficiently eliminate the artifacts and improve the SR quality eventually. Inspired from the success of wavelets, this work introduces a hybrid attention block in ViT incorporating wave attention for multiscale and efficient SR.
Method
The foundational approach of WaveHiT-SR, described in the section on the Hierarchical Transformer, includes the Hybrid Attention Block (HAB), Layer-Based Architecture, and Dual Feature Extraction (DFE), with a particular emphasis on the layer-based design.
Hierarchical Transformer
First, we analyze the conventional structure typically used in transformer-based SR techniques (Choi, Lee, and Yang 2023; Liang et al. 2021; Zhou et al. 2023). As illustrated in Figure 2, these frameworks generally include an initial convolutional layer that extracts shallow features from the low-resolution input , a feature extraction stage using transformer blocks (TBs) to capture deep features , and a reconstruction module that produces the high-resolution output , with as the scaling factor. The feature extraction module comprises transformer blocks (TBs) with cascaded transformer layers (TLs) and convolutional layers. Each TL includes components for self-attention (SA), a feed-forward network (FFN), and layer normalization (LN). To alleviate the quadratic computational load of SA on large inputs (Alexey 2020), window partitioning is commonly applied in TLs, restricting SA to local regions through a technique known as window self-attention (W-SA) (Liang et al. 2021; Liu et al. 2021). To aggregate hierarchical features more effectively, we redesign the SR framework using hierarchical transformers enhanced with DWT (Discrete Wavelet Transform). As depicted in Figure 2 and Figure (DWT: Supplementary file), this approach involves applying DWT to downsample keys and values, which amplifies the impact of self-attention in feature learning by enabling more focused, noise-reduced attention across multiple scales. As depicted in Figure 3, this approach involves: (i) block-level hierarchical windows to enhance long-range and multi-scale information capture, (ii) a Wave Attention module to improve texture detail, and (iii) an efficient window self-attention, adapted from HiT-SR (Aslahishahri, Ubbens, and Stavness 2024), that reduces computational costs with large windows.
Hybrid Attention Block (HAB)
We introduce a Hybrid Attention Block (HAB) that combines channel attention and wave attention to enhance both local and global feature extraction. As shown in Figure 2, channel attention leverages global information to dynamically adjust attention weights across channels, selectively activating pixels and focusing on key features across multiple scales. To capture long-range dependencies and multi-scale information, the HAB incorporates wave attention, expanding spatial connections to capture detailed structures essential for high-resolution super-resolution outputs. This combined attention approach ensures fine detail retention across spatial regions. For the multi-head self-attention mechanism (illustrated in Figure 2 and Figure (DWT: Supplementary file) (a)), the input 2D feature map , where , , and denote height, width, and channel count, respectively, is reshaped into a sequence of patches, with D representing the dimensionality of each patch. The sequence X is then split into three parallel groups: queries (Q), Keys (K), and Values (V) where , keys , and values . The multi-head self-attention module partitions each (Q), Keys (K), and Values (V) into segments along the channel dimension, yielding queries , keys , and values for the . Existing multi-scale ViT backbones reduce computation for keys and values through average pooling (Wang et al. 2022a) and kernel pooling (Fan et al. 2021). In our approach, as illustrated in Figure 3, we replace spatial attention with wave attention, leveraging DWT for downsampling by a factor of . This reduces the spatial dimensions of the input feature map by half using the down-sampling operator.
Layer-Based Architecture
To replace the Layer-Level design in HiT-SR (Aslahishahri, Ubbens, and Stavness 2024) with wavelet-based techniques, we can redefine the key components of HiT-SR’s architecture using wavelet transforms. This approach will help achieve multi-level feature extraction, spatial and channel self-correlation (See Supplementary File), and efficient aggregation of hierarchical information. Below is a step-by-step breakdown of the methodology:
Dual Feature Extraction (DFE)
Given the input feature map from the previous layer, where and denotes spatial dimensions, and is the channel count, we apply the DWT to decompose into frequency-specific sub-bands. This yields both low- and high-frequency components that capture different levels of detail and spatial structures:
[TABLE]
Where and represents low-frequency components that capture global structure, and and represents high-frequency components that capture finer details and textures. In contrast to the traditional Dual Feature Extraction (DFE) approach in HiT-SR, we use the Discrete Wavelet Transform (DWT) to break the image into frequency sub-bands.
[TABLE]
[TABLE]
Here, represents the channel attention from a linear transformation of , while introduces wave attention through a wave-based convolution operation.
The notation refers to element-wise multiplication. The reshaped channel feature and spatial feature are extracted using linear layers and wavelet convolutional layers, respectively. In the spatial branch, we apply a wavelet transform to break the image into multiple frequency sub-bands. Instead of a traditional attention mechanism, wavelet attention is applied using the DWT, capturing both low- and high-frequency components efficiently. The multi-resolution features are aggregated by wavelet-based interactions, where spatial and channel features combine in the wavelet domain to form the DFE output. The queries are derived from the DFE output by splitting it, as depicted in Figure 3
[TABLE]
Next, we partition queries and keys into non-overlapping windows based on the assigned window size (e.g., for the TL)
Wave Attention: Unlike W-SA, our Wave Attention (WA) efficiently aggregates spatial information by adaptively summarizing the values across TLs, using linear layers on the wavelet-transformed components, as detailed in the supplementary material. The extracted features can then be processed separately or combined to ensure rich multi-channel representations. Instead of directly applying a linear transformation we can employ wavelet decomposition to process the feature, The DWT decomposes the input feature into multiple frequency sub-bands, capturing both coarse and fine details through low- and high-frequency components.
[TABLE]
This step captures the multi-resolution information from the input feature , breaking it into approximation and detail components. where denotes the projected values with:
- •
If , then downsampling keeps the resolution as
- •
If the resolution is modified to where and denote the adjusted downsampled dimensions.
**Downsampling: **After applying the wave attention (WA), the low-frequency (approximation) components are downsampled to reduce spatial resolution while preserving important hierarchical information. We define the resolution as:
[TABLE]
In this version, is replaced with to indicate wavelet-transformed values, the equation name is updated to “WA-SC” for DWT-based self-correlation, and normalization with and position encoding are retained as in the original.
Compared to standard W-SA, our WA-SC is more efficient and less complex: (i) Using correlation maps instead of attention maps removes the hardware-heavy softmax, improving inference speed (Cai et al. 2023); (ii) It supports large windows with linear complexity scaling to window size, as shown in 1. For an input with windows in , the multiply-add operation counts for W-SA and WA-SC are as follows:
[TABLE]
Applying DWT reduces the spatial dimensions (width and height) by half, which in turn reduces the computational cost associated with the spatial self-correlation by a factor of 4 for these dimensions combined (i.e., .
Note: We have provided in-depth information on Spatial and Channel Self-Correlation and Hierarchical Information Aggregation in the supplementary material along with Ablation Study.
Experimental Settings
We employ the WaveHiT-SR strategy with prominent SR models such as SwinIR-Light (Liang et al. 2021), SwinIR-NG (Choi, Lee, and Yang 2023), and SRFormer-Light (Zhou et al. 2023), referring to these versions as WaveHiT-SIR, WaveHiT-SNG, and WaveHiT-SRF. To provide a fair assessment, we adjust each method to the HiT-SIR(Aslahishahri, Ubbens, and Stavness 2024) version with minimal changes and maintain uniform hyperparameters across all SR transformers. Specifically, we adopt the original SwinIR-Light settings (Liang et al. 2021) and set the TB number, the TL number, the channel number, and the head number to 4, 6, 60, and 6. The size of the base window is , and the hierarchical ratios follow the same structure as HiT-SR. The training process for HiT-SIR (Liang et al. 2021), HiT-SNG (Choi, Lee, and Yang 2023), and HiT-SRF (Zhou et al. 2023) follows a consistent approach. All models are implemented in PyTorch (Paszke et al. 2019) and trained with 64×64 patches and a batch size of 64 for 500K iterations. We optimize the models using L1 loss and the Adam optimizer (Lai et al. 2017) , starting with a learning rate of , which is halved in iterations [250K, 400K, 450K, 475K].
Benchmarking: In line with previous approaches (Choi, Lee, and Yang 2023; Liang et al. 2021; Zhou et al. 2023), we train our model on the widely-used DIV2K (Agustsson and Timofte 2017) dataset and evaluate on five classic benchmarks: Set5 (Bevilacqua et al. 2012), Set14 (Zeyde, Elad, and Protter 2012), B100 (Martin et al. 2001), Urban100 (Huang, Singh, and Ahuja 2015), and Manga109 (Matsui et al. 2017). Low-resolution images are derived via bicubic degradation from high-resolution images. We evaluate performance at ×2, ×3, and ×4 upscaling levels, using PSNR and SSIM metrics computed on the Y channel in the YCbCr color space.
Qualitative Results
Figure 4 shows qualitative comparisons for challenging image SR tasks. Traditional SR methods often produce blurred images and artifacts (e.g. ) due to their focus on local features and small receptive fields. In contrast, WaveHiT-SIR and WaveHiT-SRF can capture long-range dependencies with larger windows, resulting in sharper details and more refined textures. Structure distortion is a typical problem in SR, particularly with complex images such as . Traditional methods struggle to restore image structure, resulting in blurred lines. WaveHiT-SR, however, leverages multiscale features to preserve structure and enhance detail. Models like WaveHiT-SIR and WaveHiT-SRF provide superior image structure restoration compared to SwinIR-Light (Liang et al. 2021) and SRFormer-Light (Zhou et al. 2023).
Quantitative Results
As shown in Table 2, our WaveHiT-SR methods achieve outstanding results in all benchmark datasets. Compared to existing state-of-the-art models such as EDSR-B (Lim et al. 2017), CARN (Ahn, Kang, and Sohn 2018), IMDN (Hui et al. 2019), LatticeNet (Luo et al. 2020), SwinIR-L (Liang et al. 2021), SwinIR-NG (Choi, Lee, and Yang 2023), SRFormer-Light (Zhou et al. 2023), and HiT-SR (Aslahishahri, Ubbens, and Stavness 2024), our proposed WaveHiT-SIR method delivers superior qualitative and quantitative performance while reducing both the model size and computational demands. Our updated WaveHiT-SRF models outperform the original versions in terms of performance, efficiency, and convergence. Table 2 illustrates the PSNR improvements our methods (WaveHiT-SIR, WaveHiT-SNG, WaveHiT-SRF) achieve, with gains of 0.49, 0.41, and 0.48 dB on Urban100 . Replacing the inefficient shifted window self-attention with WaveAttention-Channel Correlation (WA-SCC) results in lower computational demands and higher speed-up inference for all WaveHiT-SR models. Despite smaller FLOP and parameter improvements, WaveHiT-SRF outperforms SRFormer-Light in SR quality and offers a inference speed boost, benefiting practical applications. Figure 5 compares the convergence of SwinIR-Light and WaveHiT-SIR on Urban100 and Manga109 .
Conclusion
In this paper, we introduce WaveHiT-SR, a method that integrates wavelet transforms into a hierarchical transformer framework to advance image super-resolution (SR). Our strategy involves adapting popular transformer-based SR models to hierarchical transformers, enhancing SR efficiency (WaveHiT-SR). Our method incorporates WaveAttention, instead of spatial attention technique leveraging wavelet transforms to capture essential low- and high-frequency details, and employs both block-level and layer-level architectures. Each transformer block utilizes expanding hierarchical windows to capture long-range dependencies and multi-scale features, leading to improved SR outcomes. To address the high computational demands of self-attention, we introduce the WA-SCC, achieving linear complexity relative to window sizes for efficient hierarchical feature aggregation. This approach allows the model to focus on low-frequency details and enhance high-frequency textures, striking a balance between computational complexity and SR performance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Agustsson and Timofte (2017) Agustsson, E.; and Timofte, R. 2017. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops , 126–135.
- 2Ahn, Kang, and Sohn (2018) Ahn, N.; Kang, B.; and Sohn, K.-A. 2018. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European conference on computer vision (ECCV) , 252–268.
- 3Alexey (2020) Alexey, D. 2020. An image is worth 16x 16 words: Transformers for image recognition at scale. ar Xiv preprint ar Xiv: 2010.11929 .
- 4Aslahishahri, Ubbens, and Stavness (2024) Aslahishahri, M.; Ubbens, J.; and Stavness, I. 2024. Hi TSR: A Hierarchical Transformer for Reference-based Super-Resolution. ar Xiv preprint ar Xiv:2408.16959 .
- 5Baek and Lee (2020) Baek, S.; and Lee, C. 2020. Single image super-resolution using frequency-dependent convolutional neural networks. In 2020 IEEE International Conference on Industrial Technology (ICIT) , 692–695. IEEE.
- 6Bevilacqua et al. (2012) Bevilacqua, M.; Roumy, A.; Guillemot, C.; and Alberi-Morel, M. L. 2012. Low-complexity single-image super-resolution based on nonnegative neighbor embedding.
- 7Bittner et al. (2023) Bittner, M.; Hobeichi, S.; Zawish, M.; Diatta, S.; Ozioko, R.; Xu, S.; and Jantsch, A. 2023. An LSTM-based Downscaling Framework for Australian Precipitation Projections. In Neur IPS 2023 Workshop on Tackling Climate Change with Machine Learning .
- 8Cai et al. (2023) Cai, H.; Li, J.; Hu, M.; Gan, C.; and Han, S. 2023. Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision , 17302–17313.