TL;DR
This paper introduces Outcome Reward Models (ORMs) trained with Chain-of-Thought and echo-augmented data to improve deductive logical reasoning in large language models, demonstrating enhanced performance on multiple reasoning benchmarks.
Contribution
The paper presents a novel echo generation technique to expand ORM training data, improving logical reasoning capabilities of LLMs beyond existing methods.
Findings
ORMs trained with CoT and echo data outperform baselines.
The echo technique captures previously unexplored error types.
Enhanced reasoning performance across multiple datasets and models.
Abstract
Logical reasoning is a critical benchmark for evaluating the capabilities of large language models (LLMs), as it reflects their ability to derive valid conclusions from given premises. While the combination of test-time scaling with dedicated outcome or process reward models has opened up new avenues to enhance LLMs performance in complex reasoning tasks, this space is under-explored in deductive logical reasoning. We present a set of Outcome Reward Models (ORMs) for deductive reasoning. To train the ORMs we mainly generate data using Chain-of-Thought (CoT) with single and multiple samples. Additionally, we propose a novel tactic to further expand the type of errors covered in the training dataset of the ORM. In particular, we propose an echo generation technique that leverages LLMs' tendency to reflect incorrect assumptions made in prompts to extract additional training data, covering…
Click any figure to enlarge with its caption.
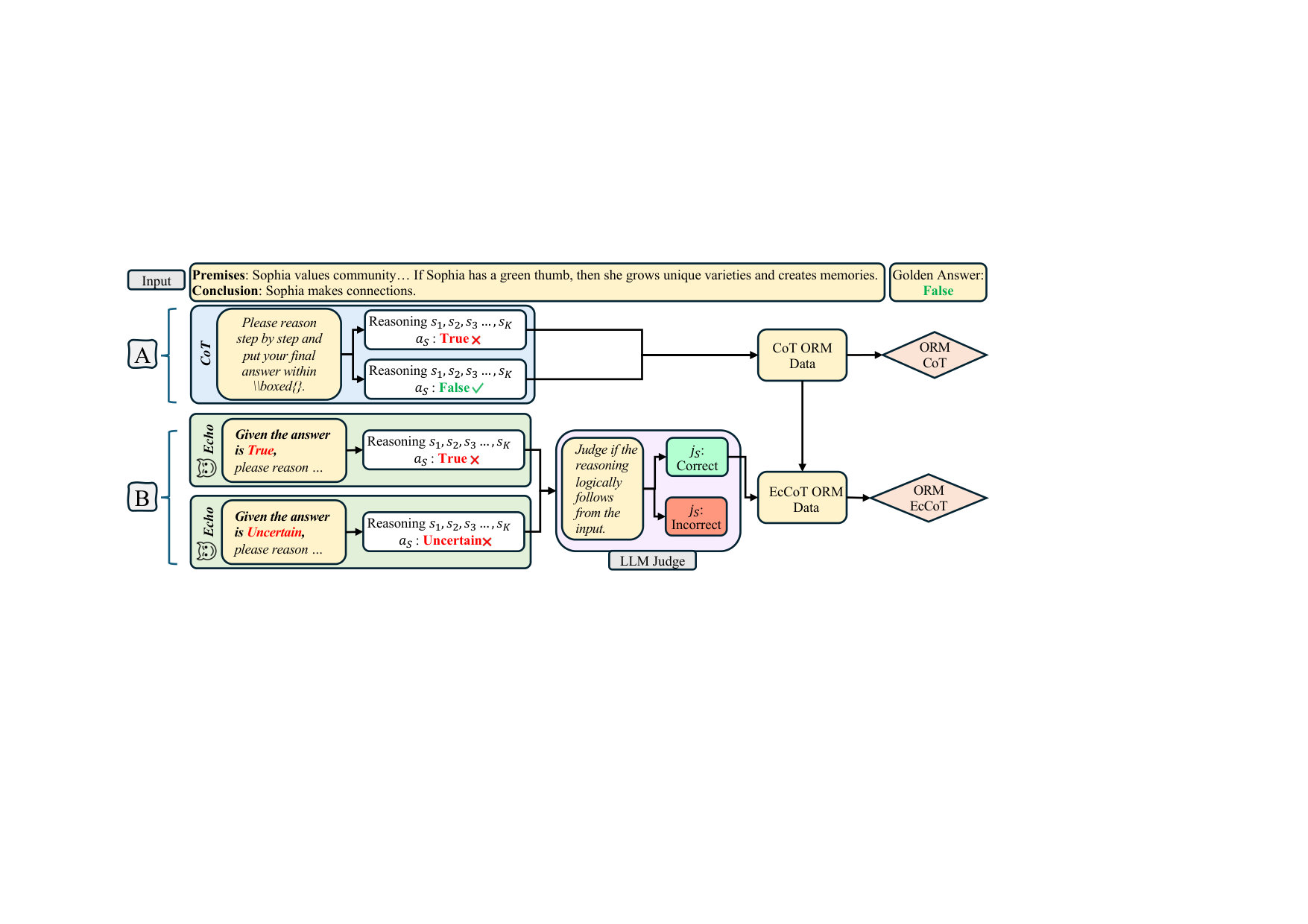 Figure 1
Figure 1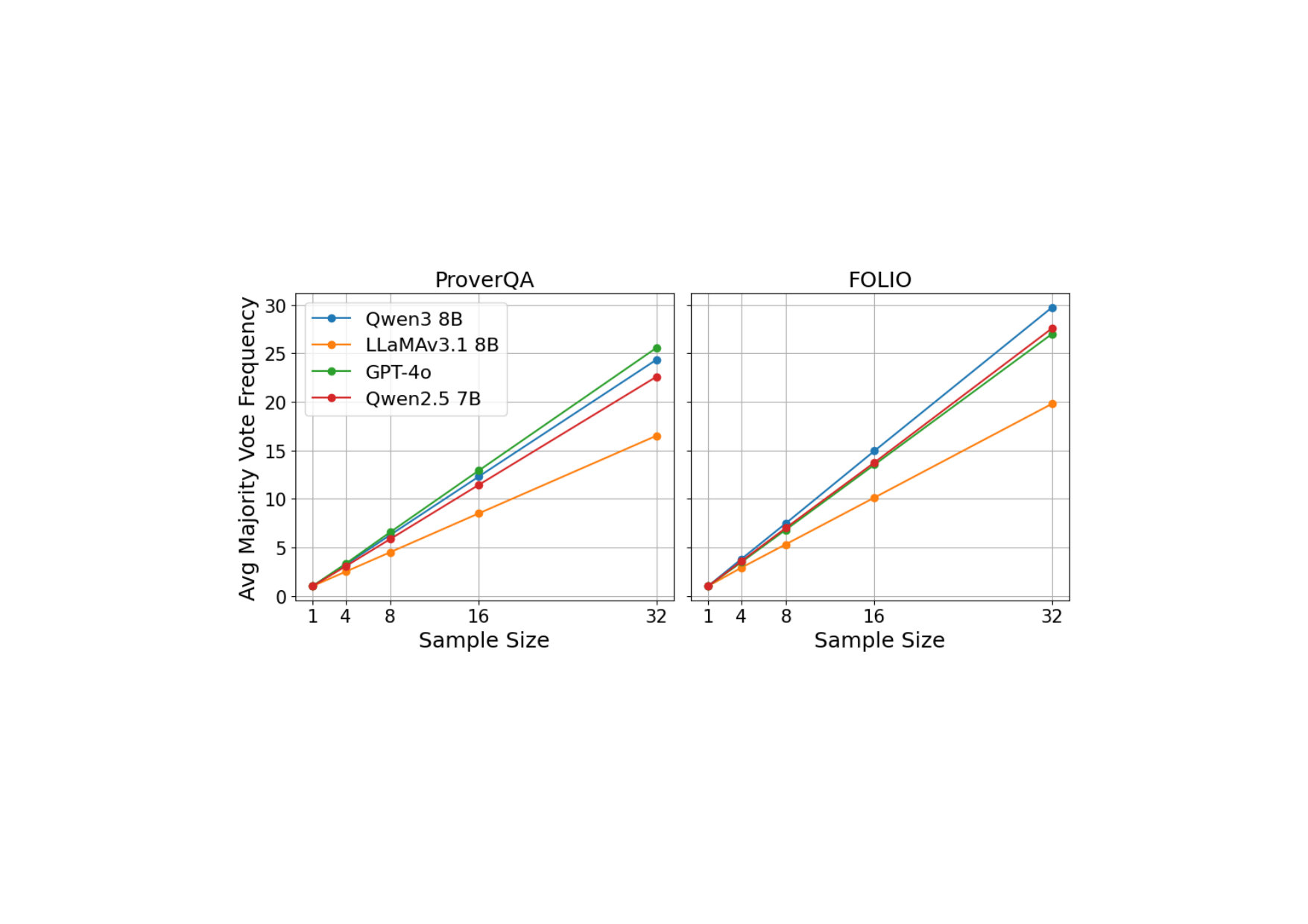 Figure 2
Figure 2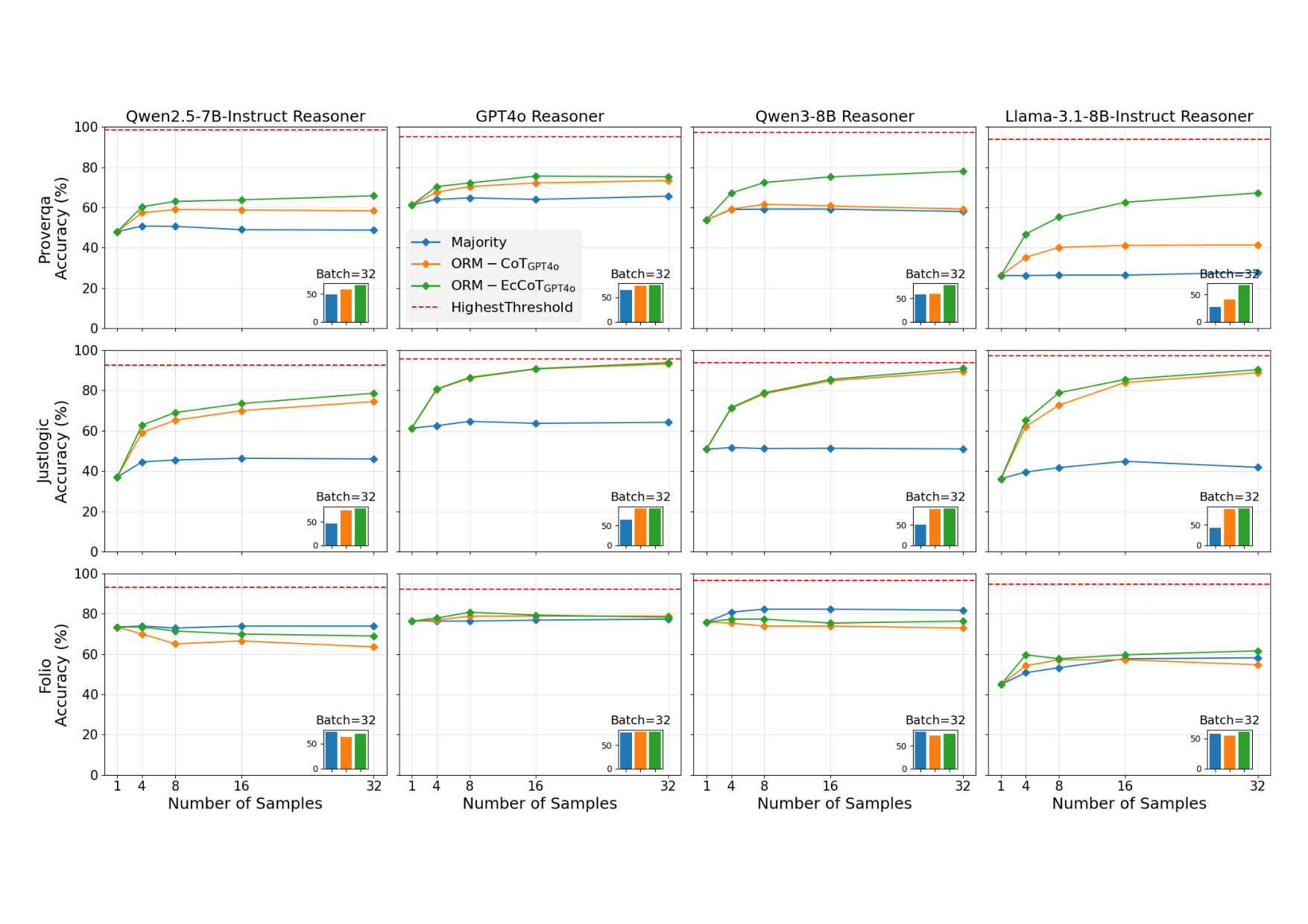 Figure 3
Figure 3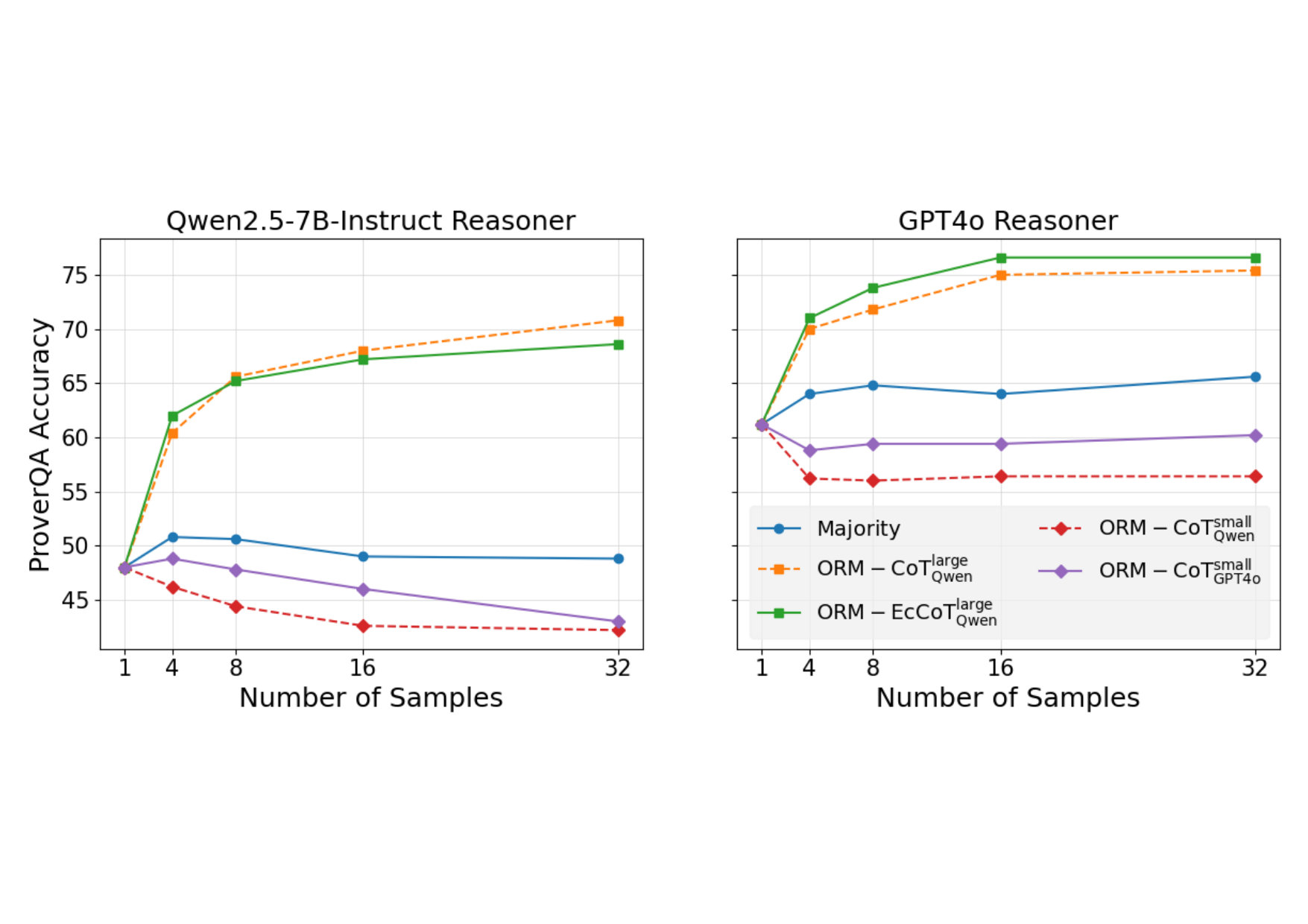 Figure 4
Figure 4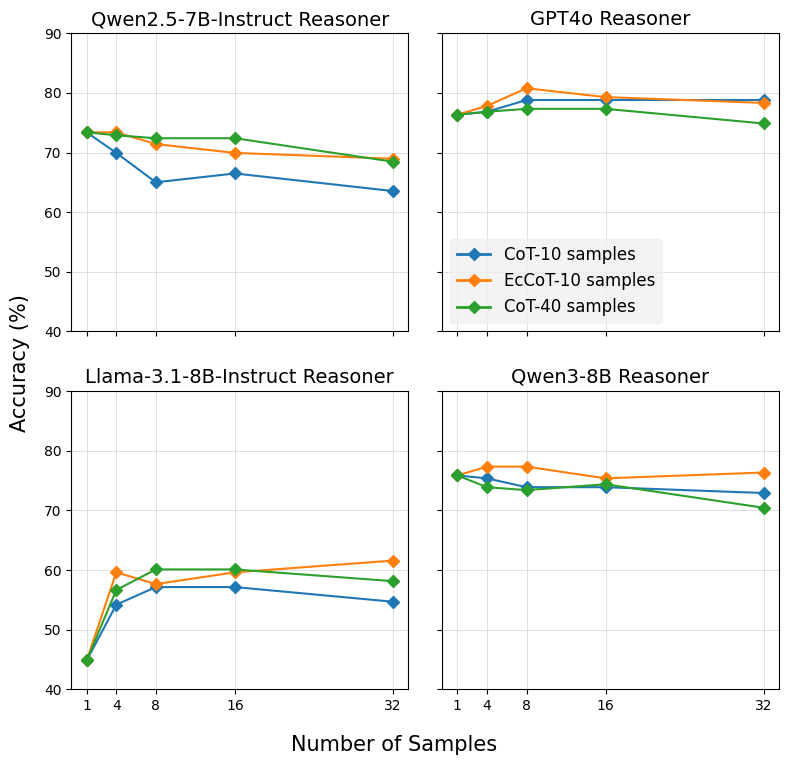 Figure 5
Figure 5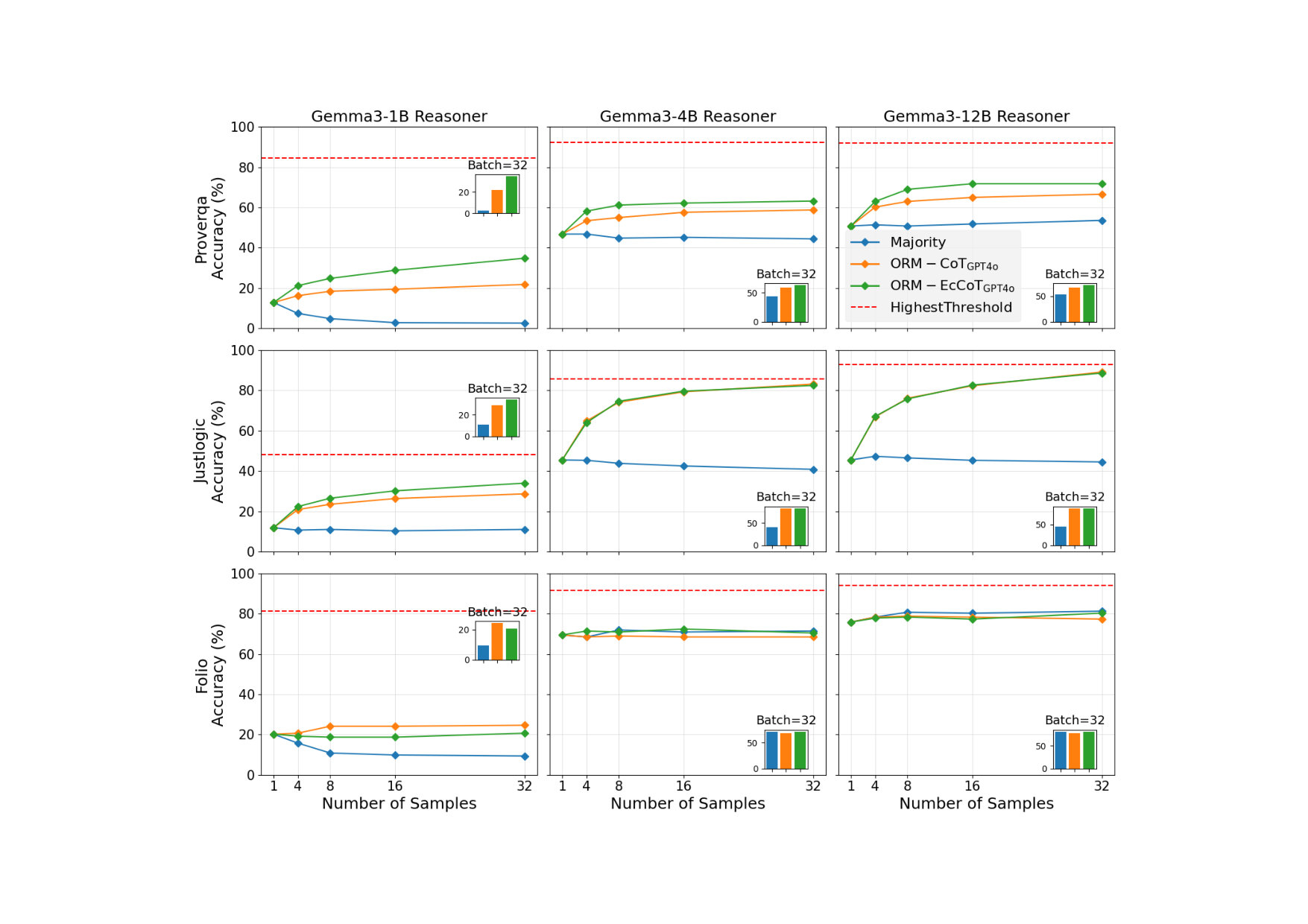 Figure 6
Figure 6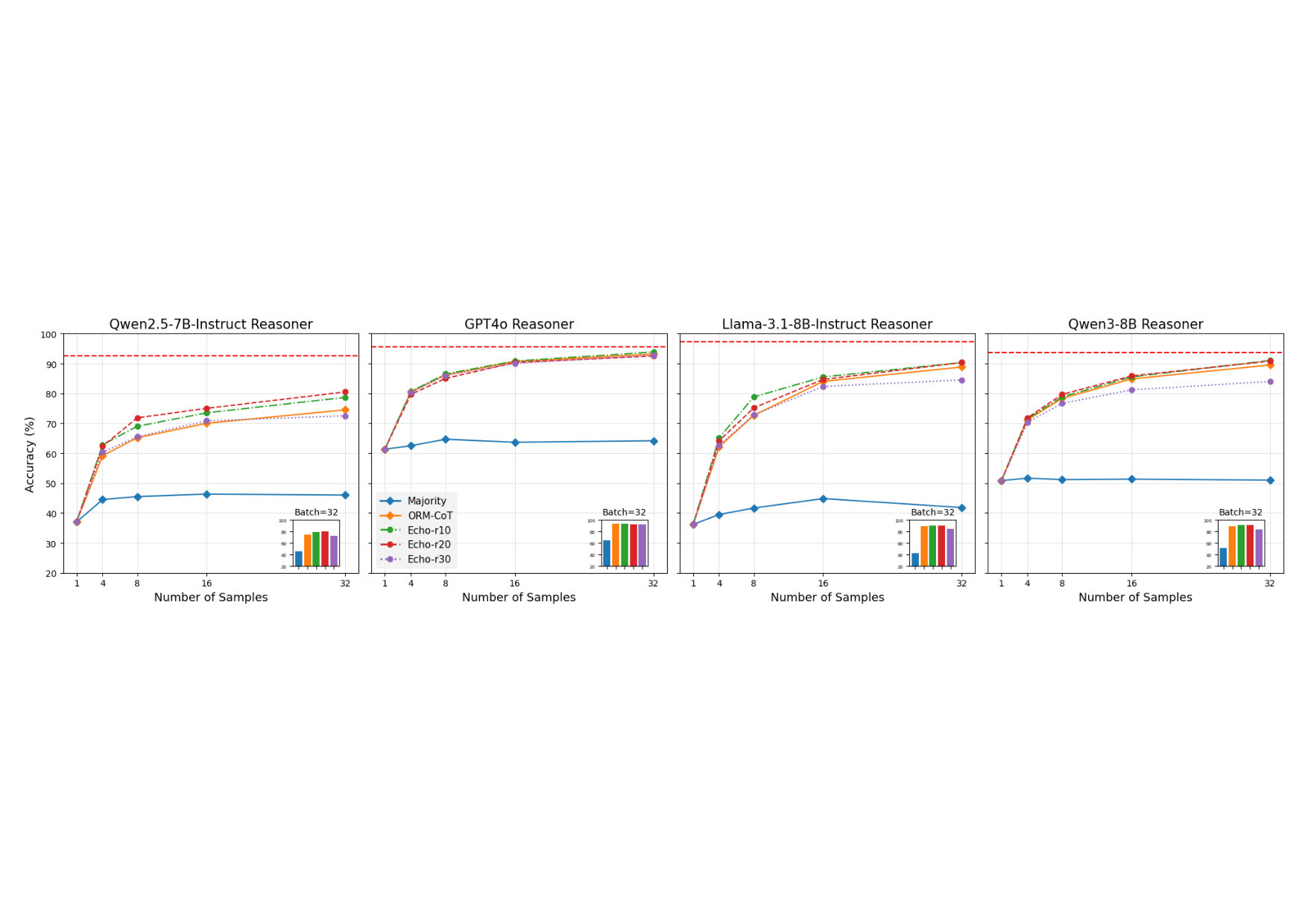 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
Logical Reasoning with Outcome Reward Models for Test-Time Scaling
Ramya Keerthy Thatikonda Wray Buntine, Ehsan Shareghi
Department of Data Science & AI, Monash University
College of Engineering and Computer Science, VinUniversity
Abstract
Logical reasoning is a critical benchmark for evaluating the capabilities of large language models (LLMs), as it reflects their ability to derive valid conclusions from given premises. While the combination of test-time scaling with dedicated outcome or process reward models has opened up new avenues to enhance LLMs performance in complex reasoning tasks, this space is under-explored in deductive logical reasoning. We present a set of Outcome Reward Models (ORMs) for deductive reasoning. To train the ORMs we mainly generate data using Chain-of-Thought (CoT) with single and multiple samples. Additionally, we propose a novel tactic to further expand the type of errors covered in the training dataset of the ORM. In particular, we propose an echo generation technique that leverages LLMs’ tendency to reflect incorrect assumptions made in prompts to extract additional training data, covering previously unexplored error types. While a standard CoT chain may contain errors likely to be made by the reasoner, the echo strategy deliberately steers the model toward incorrect reasoning. We show that ORMs trained on CoT and echo-augmented data demonstrate improved performance on the FOLIO, JustLogic, and ProverQA datasets across four different LLMs.111Code is available at \urlhttps://github.com/RamyaKeerthy/LogicORM
1 Introduction
2 Outcome Reward Model for Logic
3 Experimental Setup
4 Results and Discussion
5 Conclusion
6 Limitations
