TL;DR
The paper introduces ASPC, a dynamic framework for balancing policy constraints in offline RL, reducing the need for dataset-specific hyperparameter tuning and improving performance across diverse datasets.
Contribution
ASPC is a second-order differentiable method that adaptively scales policy constraints, outperforming existing methods with minimal tuning and computational overhead.
Findings
ASPC outperforms other adaptive constraint methods on 39 datasets.
ASPC requires only a single hyperparameter setting across datasets.
The code for ASPC will be publicly available at the specified GitHub link.
Abstract
Offline reinforcement learning (RL) enables learning effective policies from fixed datasets without any environment interaction. Existing methods typically employ policy constraints to mitigate the distribution shift encountered during offline RL training. However, because the scale of the constraints varies across tasks and datasets of differing quality, existing methods must meticulously tune hyperparameters to match each dataset, which is time-consuming and often impractical. We propose Adaptive Scaling of Policy Constraints (ASPC), a second-order differentiable framework that dynamically balances RL and behavior cloning (BC) during training. We theoretically analyze its performance improvement guarantee. In experiments on 39 datasets across four D4RL domains, ASPC using a single hyperparameter configuration outperforms other adaptive constraint methods and state-of-the-art offline…
Click any figure to enlarge with its caption.
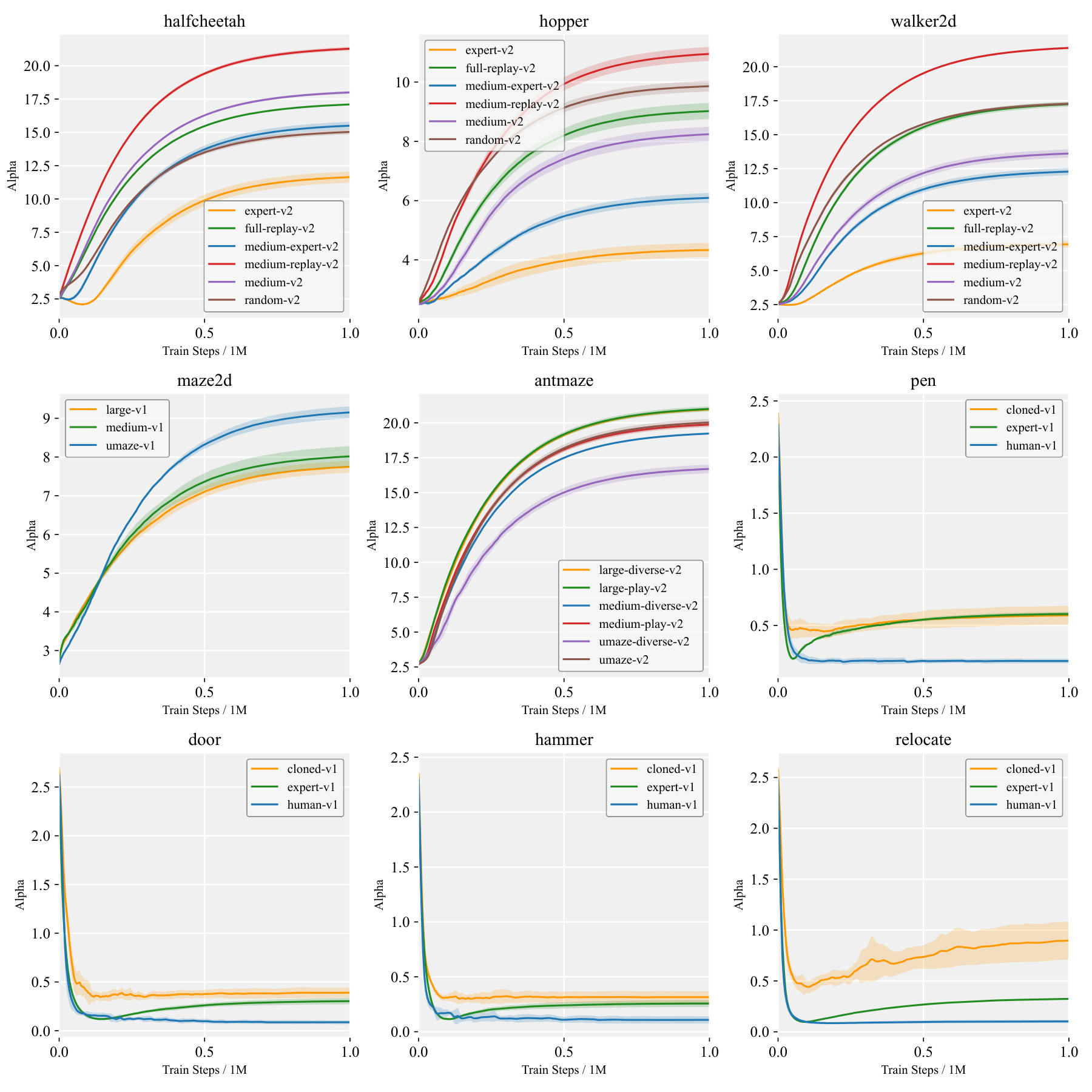 Figure 1
Figure 1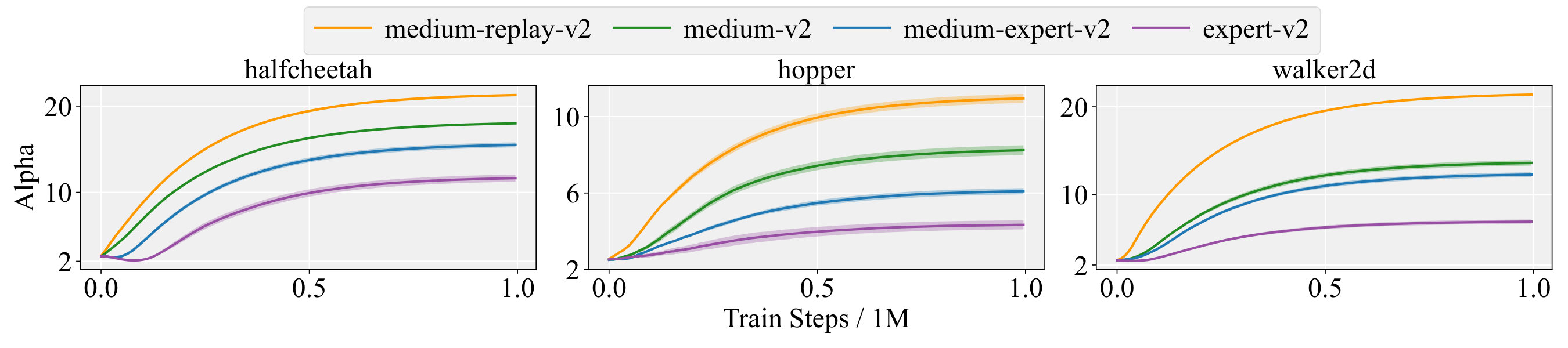 Figure 2
Figure 2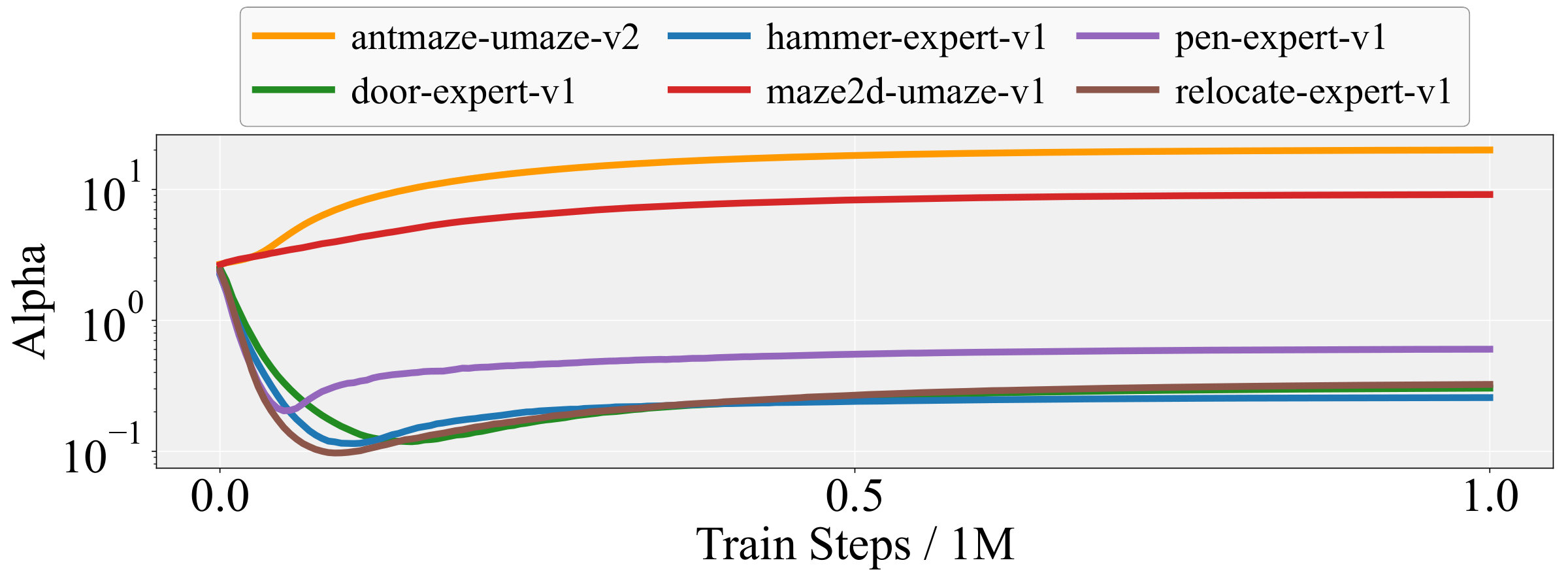 Figure 3
Figure 3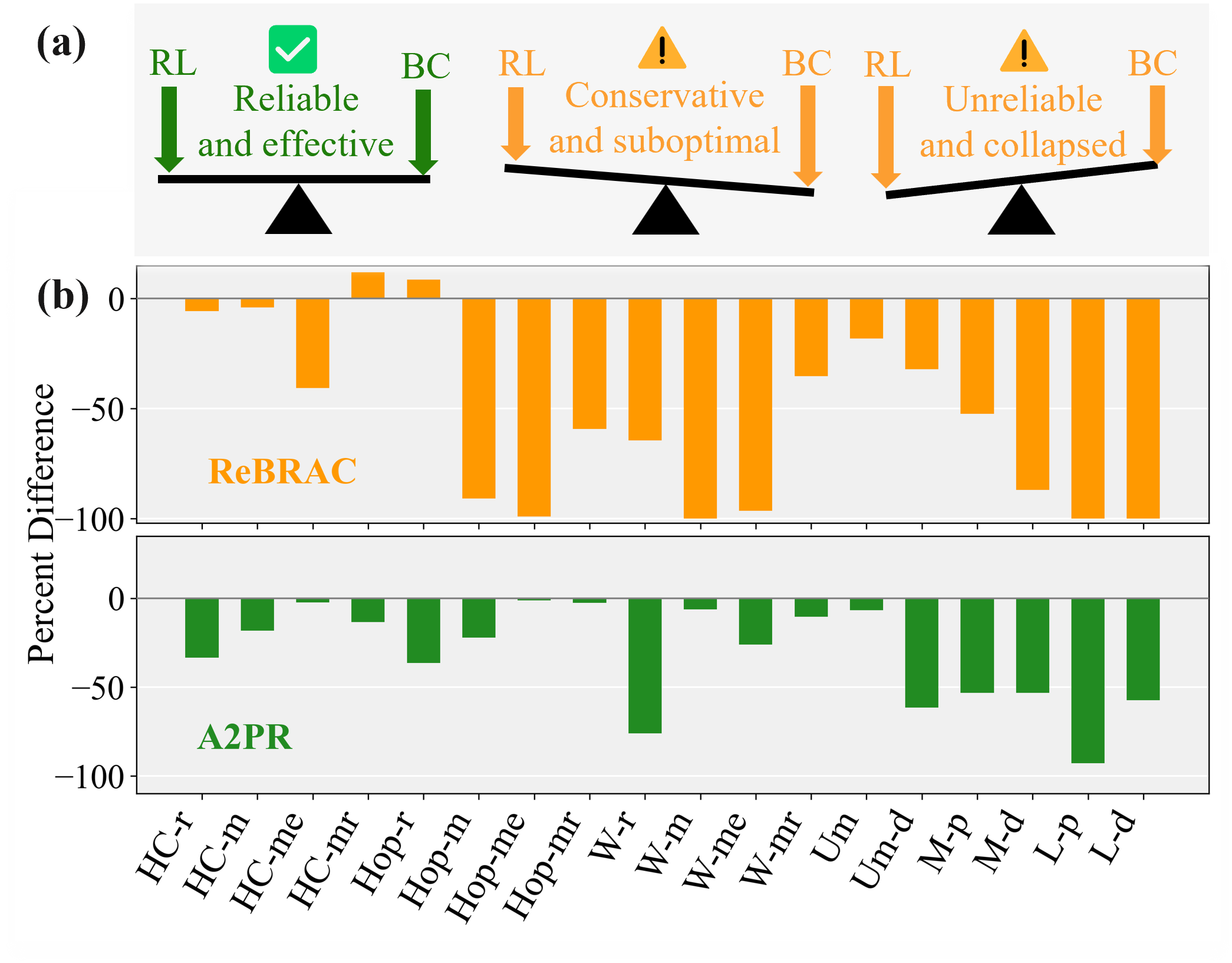 Figure 4
Figure 4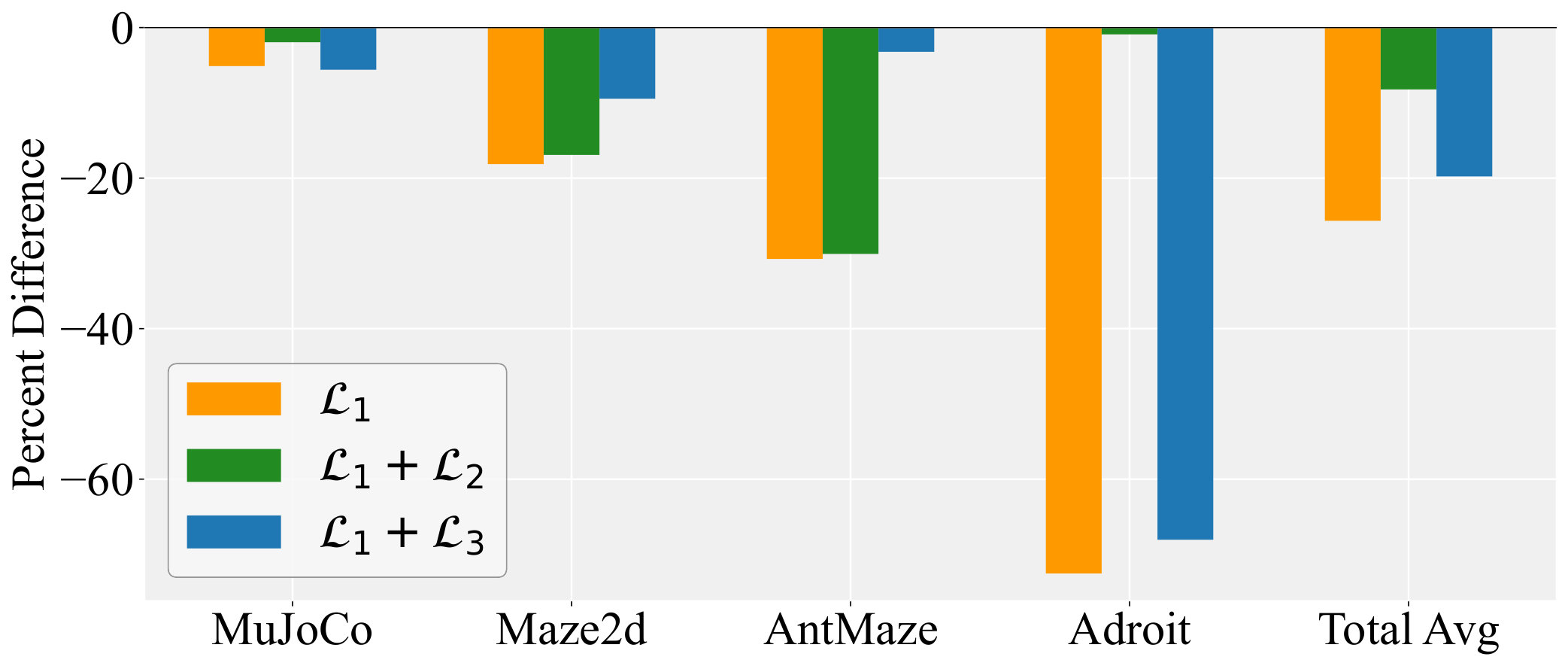 Figure 5
Figure 5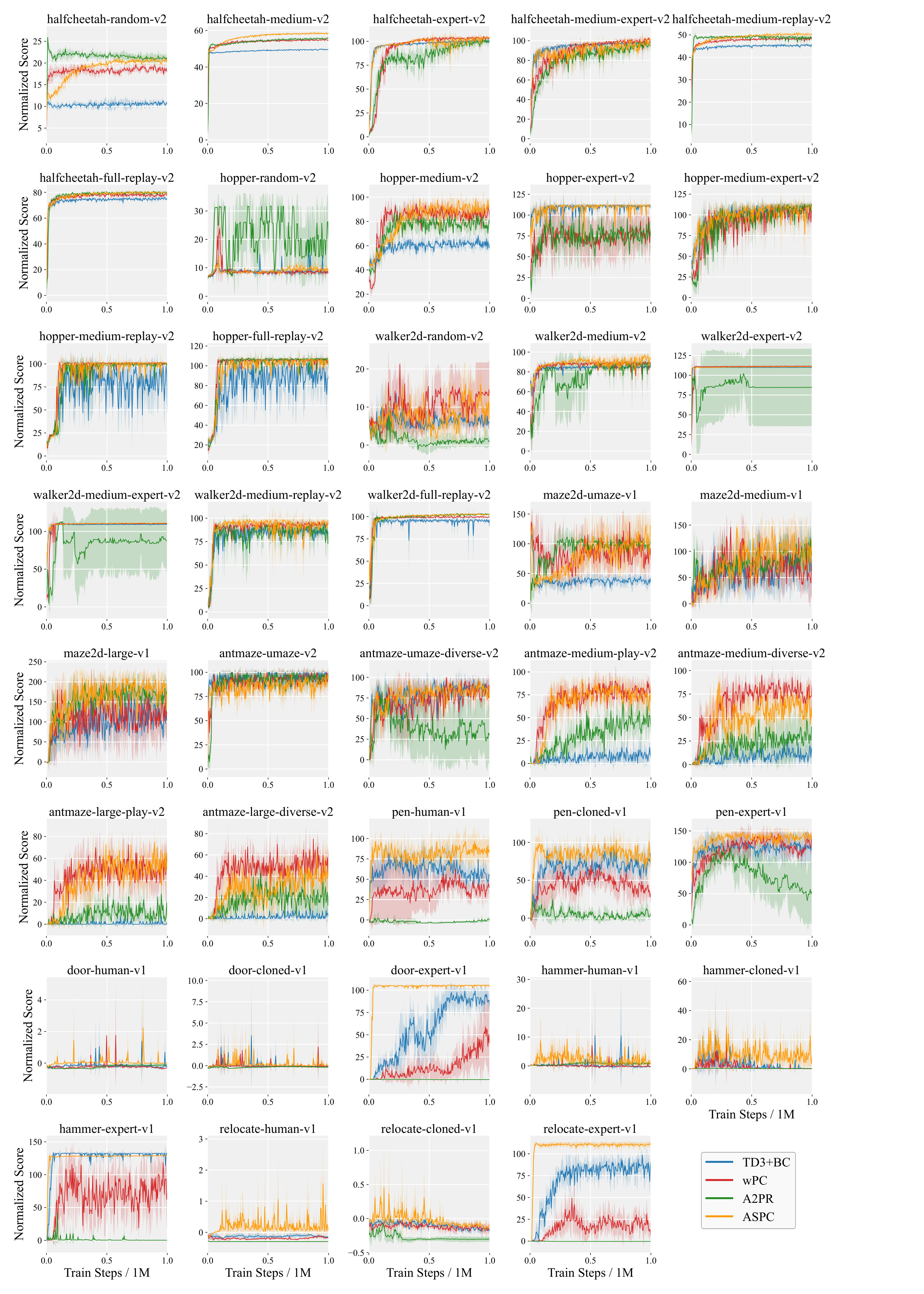 Figure 6
Figure 6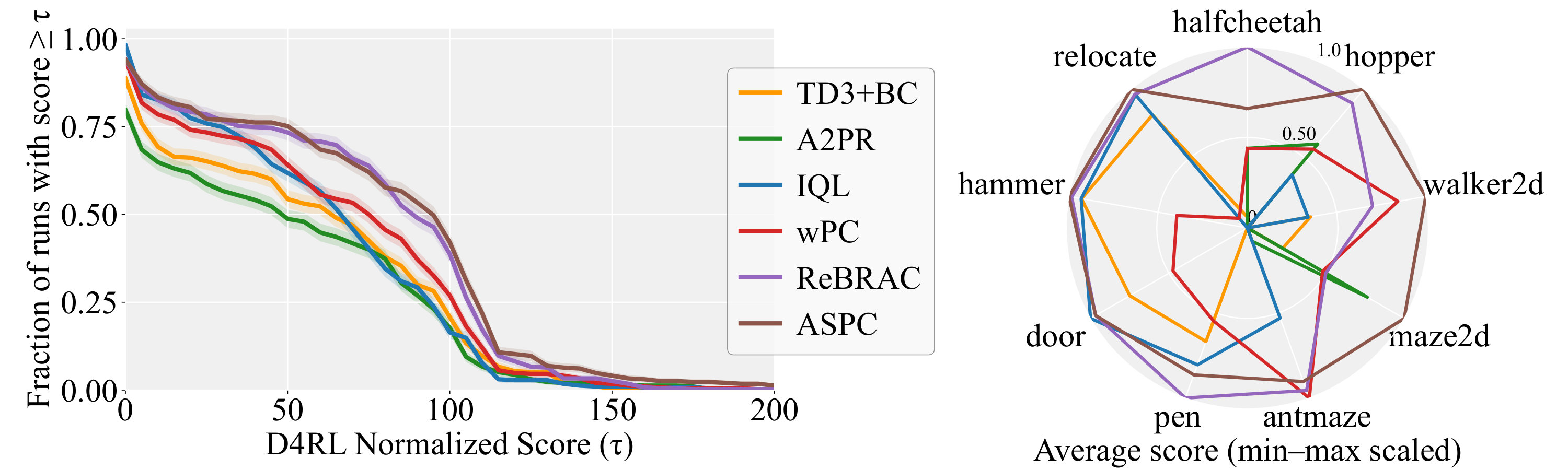 Figure 7
Figure 7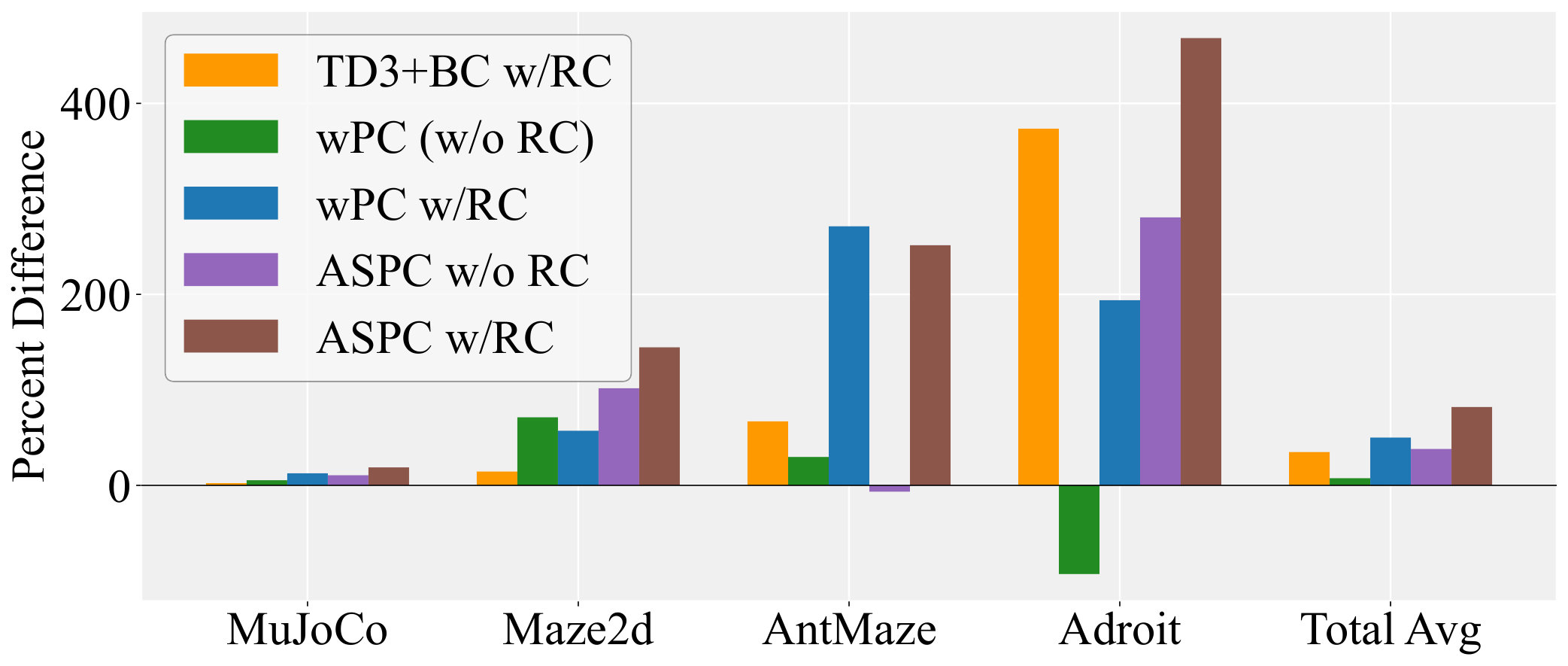 Figure 8
Figure 8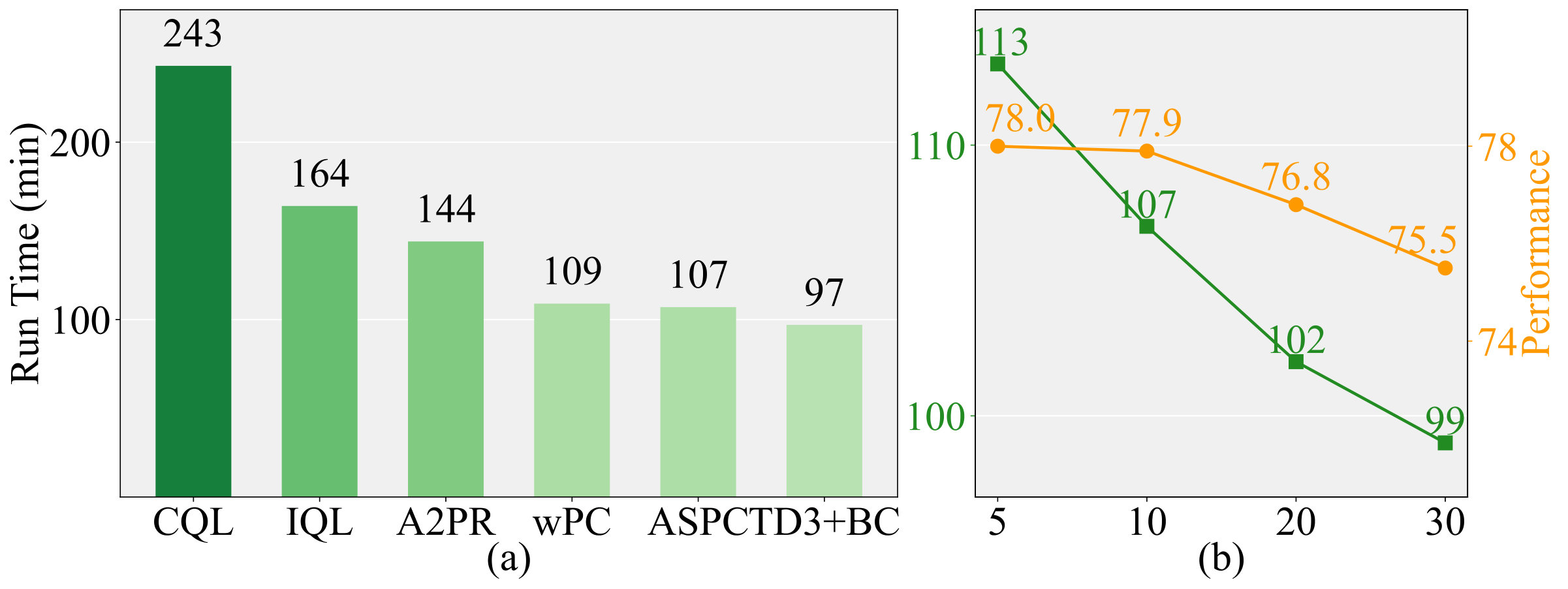 Figure 9
Figure 9| Task Name | TD3+BC*(✓) | A2PR(✓) | IQL(✗) | wPC*(✓) | ReBRAC(✗) | ASPC (Ours)(✓) | |
| HalfCheetah | Random | 10.6 0.7 | 21.1 0.8 | 19.5 0.8 | 18.8 0.7 | 29.5 1.5 | 20.8 0.9 |
| Medium | 49.6 0.2 | 56.1 0.3 | 50.0 0.2 | 54.8 0.2 | 65.6 1.0 | 58.7 0.4 | |
| Expert | 100.4 0.4 | 99.9 3.2 | 95.5 2.1 | 103.8 2.4 | 105.9 1.7 | 105.1 1.2 | |
| Medium-Expert | 97.9 1.6 | 95.9 6.0 | 92.7 2.8 | 98.9 8.5 | 101.1 5.2 | 99.9 1.2 | |
| Medium-Replay | 45.8 0.2 | 49.0 0.4 | 42.1 3.6 | 48.1 0.2 | 51.0 0.8 | 50.6 0.5 | |
| Full-Replay | 74.5 1.6 | 79.5 1.5 | 75.0 0.7 | 76.7 2.3 | 82.1 1.1 | 79.3 0.9 | |
| Hopper | Random | 8.6 0.2 | 20.1 11.6 | 10.1 5.9 | 8.5 1.4 | 8.1 2.4 | 9.4 1.5 |
| Medium | 62.0 3.0 | 78.3 4.4 | 65.2 4.2 | 81.8 9.8 | 102.0 1.0 | 92.7 7.2 | |
| Expert | 108.2 4.2 | 83.9 6.0 | 108.8 3.1 | 79.1 26.6 | 100.1 8.3 | 112.3 0.4 | |
| Medium-Expert | 103.3 9.2 | 110.8 2.6 | 85.5 29.7 | 109.1 4.5 | 107.0 6.4 | 111.0 2.1 | |
| Medium-Replay | 47.4 35.4 | 98.9 2.0 | 89.6 13.2 | 100.8 0.7 | 98.1 5.3 | 101.3 0.6 | |
| Full-Replay | 90.3 22.9 | 97.1 17.8 | 104.4 10.8 | 105.6 0.6 | 107.1 0.4 | 107.2 0.5 | |
| Walker2d | Random | 5.9 3.5 | 1.2 1.5 | 11.3 7.0 | 12.5 10.6 | 18.4 4.5 | 15.6 6.4 |
| Medium | 62.0 3.0 | 84.2 4.7 | 80.7 3.4 | 89.6 0.3 | 82.5 3.6 | 92.4 5.4 | |
| Expert | 108.2 4.2 | 84.8 49.0 | 96.9 32.3 | 111.5 0.1 | 112.3 0.2 | 110.8 0.1 | |
| Medium-Expert | 103.3 9.2 | 88.2 40.7 | 112.1 0.5 | 110.1 0.5 | 111.6 0.3 | 111.1 0.3 | |
| Medium-Replay | 76.6 12.7 | 84.5 12.3 | 75.4 9.3 | 93.4 3.0 | 77.3 7.9 | 97.6 0.5 | |
| Full-Replay | 88.3 11.7 | 102.5 0.0 | 97.5 1.4 | 99.5 0.5 | 102.2 1.7 | 102.1 0.2 | |
| MuJoCo Avg | 70.7 | 74.2 | 72.9 | 77.8 | 81.2 | 82.1 | |
| Maze2d | Umaze | 34.5 13.9 | 102.5 6.3 | -8.9 6.1 | 73.1 13.8 | 106.8 22.1 | 128.1 31.8 |
| Medium | 63.3 63.3 | 90.4 29.6 | 34.8 2.7 | 87.4 48.7 | 105.1 31.6 | 117.8 17.3 | |
| Large | 108.9 43.6 | 177.7 34.2 | 61.7 3.5 | 123.3 70.5 | 78.3 61.7 | 195.8 31.3 | |
| Maze2d Avg | 68.9 | 123.53 | 46.2 | 94.6 | 96.7 | 147.2 | |
| AntMaze | Umaze | 100.0 0.0 | 92.5 8.3 | 83.3 4.5 | 97.5 5.0 | 97.8 1.0 | 92.5 5.0 |
| Umaze-Diverse | 87.5 12.5 | 32.5 34.9 | 70.6 3.7 | 75.0 20.8 | 88.3 13.0 | 92.5 9.5 | |
| Medium-Play | 7.5 9.5 | 40.0 7.1 | 64.6 4.9 | 85.0 5.7 | 84.0 4.2 | 85.0 12.9 | |
| Medium-Diverse | 12.5 12.5 | 40.0 25.5 | 61.7 6.1 | 85.0 12.9 | 76.3 13.5 | 70.0 11.5 | |
| Large-Play | 2.5 5.0 | 5.0 8.7 | 42.5 6.5 | 65.0 19.1 | 60.4 26.1 | 55.0 5.7 | |
| Large-Diverse | 2.5 5.0 | 22.5 14.8 | 27.6 7.8 | 65.0 10.0 | 54.4 25.1 | 52.5 18.9 | |
| AntMaze Avg | 35.4 | 38.75 | 58.3 | 78.7 | 76.8 | 74.5 | |
| Pen | Human | 53.8 15.7 | -2.1 0.0 | 81.5 17.5 | 39.9 12.8 | 103.5 14.1 | 81.1 8.1 |
| Cloned | 71.7 21.5 | 6.5 6.0 | 77.2 17.7 | 34.6 11.3 | 91.8 21.7 | 87.2 4.2 | |
| Expert | 126.6 24.8 | 51.5 38.4 | 133.6 16.0 | 141.8 11.8 | 154.1 5.4 | 141.2 9.4 | |
| Door | Human | 0.0 0.0 | -0.2 0.0 | 3.1 2.0 | -0.2 0.0 | 0.0 0.0 | 0.0 0.0 |
| Cloned | 0.0 0.0 | -0.3 0.0 | 0.8 1.0 | 0.0 0.0 | 1.1 2.6 | 0.0 0.0 | |
| Expert | 81.6 16.3 | -0.3 0.0 | 105.3 2.8 | 51.4 55.3 | 104.6 2.4 | 105.6 0.4 | |
| Hammer | Human | 0.0 0.0 | 1.1 0.4 | 2.5 1.9 | 0.0 0.1 | 0.2 0.2 | 2.2 3.2 |
| Cloned | 0.1 0.0 | 0.3 0.0 | 1.1 0.5 | 0.1 0.1 | 6.7 3.7 | 12.0 9.1 | |
| Expert | 132.8 0.4 | 0.3 0.1 | 129.6 71.5 | 57.6 0.1 | 133.8 0.7 | 128.6 0.4 | |
| Relocate | Human | 0.0 0.0 | -0.3 0.0 | 0.1 0.1 | 0.1 0.0 | 0.0 0.0 | 0.1 0.2 |
| Cloned | 0.0 0.0 | -0.3 0.0 | 0.2 0.4 | 0.1 0.0 | 0.9 1.6 | 0.0 0.0 | |
| Expert | 90.6 18.2 | -0.3 0.0 | 106.5 2.5 | 6.7 4.6 | 106.6 3.2 | 111.2 2.4 | |
| Adroit Avg | 46.4 | 4.65 | 53.4 | 28.8 | 58.6 | 55.7 | |
| Total Avg | 57.7 | 51.2 | 62.6 | 64.2 | 74.8 | 77.9 |
| Domain | Naive | Converged | Linear | Dynamic (ASPC) |
| Mujoco | 70.3 | 79.3 (12.8%) | 77.0 (9.5%) | 82.1 (16.8%) |
| Maze2d | 61.9 | 133.2 (115.2%) | 103.3 (66.9%) | 147.2 (137.8%) |
| AntMaze | 28.7 | 64.1 (123.3%) | 56.3 (96.2%) | 74.5 (159.2%) |
| Adroit | 49.9 | 49.1 (1.6%) | 47.6 (4.6%) | 55.7 (11.6%) |
| Total Avg | 57.0 | 71.8 (25.9%) | 66.7 (17.0%) | 77.9 (36.6%) |
| Gym-MuJoCo | IQL | +ASPC | CQL | +ASPC | Diffusion-QL | +ASPC |
| halfcheetah-medium | 50.0 | 48.4 (3.2%) | 46.8 | 56.3 (20.3%) | 51.5 | 59.2 (15.0%) |
| halfcheetah-medium-expert | 92.7 | 94.4 (1.8%) | 94.2 | 93.6 (0.6%) | 96.8 | 96.7 (0.1%) |
| halfcheetah-medium-replay | 42.1 | 44.4 (5.5%) | 45.3 | 51.0 (12.6%) | 47.8 | 58.2 (21.8%) |
| hopper-medium | 65.2 | 61.4 (5.8%) | 61.3 | 71.6 (16.8%) | 90.5 | 101.0 (11.6%) |
| hopper-medium-expert | 85.5 | 100.2 (17.2%) | 90.1 | 106.9 (18.6%) | 111.1 | 111.1 (0.0%) |
| hopper-medium-replay | 89.6 | 88.3 (1.4%) | 77.5 | 79.9 (3.1%) | 101.3 | 100.4 (0.9%) |
| walker2d-medium | 80.7 | 83.9 (4.0%) | 82.6 | 83.8 (1.5%) | 87.0 | 80.3 (7.7%) |
| walker2d-medium-expert | 112.1 | 112.1 (0.0%) | 109.1 | 109.7 (0.6%) | 110.1 | 110.5 (0.4%) |
| walker2d-medium-replay | 75.4 | 77.5 (2.8%) | 74.5 | 81.7 (9.7%) | 95.5 | 95.2 (0.3%) |
| Average | 77.0 | 79.0 (2.5%) | 75.7 | 81.6 (7.8%) | 88.0 | 90.3 (2.6%) |
| OGBench | TD3+BC | IQL | ReBRAC | ASPC | FQL | FQL+ASPC |
| antmaze-large-navigate-singletask-task1-v0 | (5.0%) | |||||
| antmaze-large-navigate-singletask-task2-v0 | (10.5%) | |||||
| antmaze-large-navigate-singletask-task3-v0 | (5.4%) | |||||
| antmaze-large-navigate-singletask-task4-v0 | (12.5%) | |||||
| antmaze-large-navigate-singletask-task5-v0 | (3.6%) | |||||
| antmaze-giant-navigate-singletask-task1-v0 | (50.00%) | |||||
| antmaze-giant-navigate-singletask-task2-v0 | (188.9%) | |||||
| antmaze-giant-navigate-singletask-task3-v0 | (0.0%) | |||||
| antmaze-giant-navigate-singletask-task4-v0 | (135.7%) | |||||
| antmaze-giant-navigate-singletask-task5-v0 | (206.3%) | |||||
| Average | (13.5%) |
| Hyperparameter | Value | |
| TD3+BC hyperparameters | Optimizer | Adam Kingma (2014) |
| Critic learning rate | 3e-4 | |
| Actor learning rate | 3e-4 | |
| Mini-batch size | 256 | |
| Discount factor | 0.99 | |
| Target update rate | 5e-3 | |
| Policy noise | 0.2 | |
| Policy noise clipping | (-0.5, 0.5) | |
| Policy update frequency | 2 | |
| Architecture | Critic hidden dim | 256 |
| Critic hidden layers | 3 | |
| Critic activation function | ReLU | |
| Critic LayerNorm | True | |
| Actor hidden dim | 256 | |
| Actor hidden layers | 2 | |
| Actor activation function | ReLU | |
| ASPC hyperparameters | Initial | 2.5 |
| learning rate | 2e-3 | |
| learning rate decay | Exponential | |
| update interval | 10 | |
| EMA smoothing factor | 0.995 |
| Hyperparameter | Value | |
| TD3+BC hyperparameters | Optimizer | Adam Kingma (2014) |
| Critic learning rate | 3e-4 | |
| Actor learning rate | 3e-4 | |
| Mini-batch size | 256 | |
| Discount factor | 0.99 | |
| Target update rate | 5e-3 | |
| Policy noise | 0.2 | |
| Policy noise clipping | (-0.5, 0.5) | |
| Policy update frequency | 2 | |
| 2.5 | ||
| Architecture | Critic hidden dim | 256 |
| Critic hidden layers | 3 | |
| Critic activation function | ReLU | |
| Critic LayerNorm | True | |
| Actor hidden dim | 256 | |
| Actor hidden layers | 2 | |
| Actor activation function | ReLU |
| Hyperparameter | Value | |
| wPC hyperparameters | Optimizer | Adam Kingma (2014) |
| Critic learning rate | 3e-4 | |
| Actor learning rate | 3e-4 | |
| Value learning rate | 3e-4 | |
| Mini-batch size | 256 | |
| Discount factor | 0.99 | |
| Target update rate | 5e-3 | |
| Policy noise | 0.1 | |
| Policy noise clipping | (-0.5, 0.5) | |
| Policy update frequency | 2 | |
| 2.5 | ||
| Architecture | Critic hidden dim | 256 |
| Critic hidden layers | 3 | |
| Critic activation function | ReLU | |
| Critic LayerNorm | True | |
| Actor hidden dim | 256 | |
| Actor hidden layers | 2 | |
| Actor activation function | ReLU | |
| Value hidden dim | 256 | |
| Value hidden layers | 2 | |
| Value activation function | ReLU |
| Hyper-parameters | Value | |
| TD3+BC hyperparameters | Optimizer | Adam Kingma (2014) |
| Critic learning rate | 3e-4 | |
| Actor learning rate | 3e-4 | |
| Mini-batch size | 256 | |
| Discount factor | 0.99 | |
| Target update rate | 5e-3 | |
| Policy noise | 0.2 | |
| Policy noise clipping | (-0.5, 0.5) | |
| Policy update frequency | 2 | |
| 2.5 | ||
| Architecture | Q-Critic hidden dim | 256 |
| Q-Critic hidden layers | 3 | |
| Q-Critic Activation function | ReLU | |
| V-Critic hidden dim | 256 | |
| V-Critic hidden layers | 3 | |
| V-Critic Activation function | ReLU | |
| Actor hidden dim | 256 | |
| Actor hidden layers | 2 | |
| Actor Activation function | ReLU | |
| A2PR hyperparameters | Normalized state | True |
| 0 | ||
| , | 1.0 |
| Hyperparameter | Value | |
| IQL hyperparameters | Optimizer | Adam Kingma (2014) |
| Critic learning rate | 3e-4 | |
| Actor learning rate | 3e-4 | |
| Value learning rate | 3e-4 | |
| Mini-batch size | 256 | |
| Discount factor | 0.99 | |
| Target update rate | 5e-3 | |
| Learning rate decay | Cosine | |
| Architecture | Critic hidden dim | 256 |
| Critic hidden layers | 2 | |
| Critic activation function | ReLU | |
| Actor hidden dim | 256 | |
| Actor hidden layers | 2 | |
| Actor activation function | ReLU | |
| Value hidden dim | 256 | |
| Value hidden layers | 2 | |
| Value activation function | ReLU |
| Task Name | Deterministic policy | ||
| halfcheetah-random | 3.0 | 0.95 | False |
| halfcheetah-medium | 3.0 | 0.95 | False |
| halfcheetah-expert | 6.0 | 0.9 | False |
| halfcheetah-medium-expert | 3.0 | 0.7 | False |
| halfcheetah-medium-replay | 3.0 | 0.95 | False |
| halfcheetah-full-replay | 1.0 | 0.7 | False |
| hopper-random | 1.0 | 0.95 | False |
| hopper-medium | 3.0 | 0.7 | True |
| hopper-expert | 3.0 | 0.5 | False |
| hopper-medium-expert | 6.0 | 0.7 | False |
| hopper-medium-replay | 6.0 | 0.7 | True |
| hopper-full-replay | 10.0 | 0.9 | False |
| walker2d-random | 0.5 | 0.9 | False |
| walker2d-medium | 6.0 | 0.5 | False |
| walker2d-expert | 6.0 | 0.9 | False |
| walker2d-medium-expert | 1.0 | 0.5 | False |
| walker2d-medium-replay | 0.5 | 0.7 | False |
| walker2d-full-replay | 1.0 | 0.7 | False |
| maze2d-umaze | 3.0 | 0.7 | False |
| maze2d-medium | 3.0 | 0.7 | False |
| maze2d-large | 3.0 | 0.7 | False |
| antmaze-umaze | 10.0 | 0.7 | False |
| antmaze-umaze-diverse | 10.0 | 0.95 | False |
| antmaze-medium-play | 6.0 | 0.9 | False |
| antmaze-medium-diverse | 6.0 | 0.9 | False |
| antmaze-large-play | 10.0 | 0.9 | False |
| antmaze-large-diverse | 6.0 | 0.9 | False |
| pen-human | 1.0 | 0.95 | False |
| pen-cloned | 10.0 | 0.9 | False |
| pen-expert | 10.0 | 0.8 | False |
| door-human | 0.5 | 0.9 | False |
| door-cloned | 6.0 | 0.7 | False |
| door-expert | 0.5 | 0.7 | False |
| hammer-human | 3.0 | 0.9 | False |
| hammer-cloned | 6.0 | 0.7 | False |
| hammer-expert | 0.5 | 0.95 | False |
| relocate-human | 1.0 | 0.95 | False |
| relocate-cloned | 6.0 | 0.9 | False |
| relocate-expert | 10.0 | 0.9 | False |
| Hyperparameter | Value | |
| ReBRAC hyperparameters | Optimizer | Adam Kingma (2014) |
| Mini-batch size | 1024 on Gym-MuJoCo, 256 on others | |
| Learning rate | 1e-3 on Gym-MuJoCo, 1e-4 on AntMaze | |
| Discount factor | 0.999 on AntMaze, 0.99 on others | |
| Target update rate | 5e-3 | |
| Architecture | Hidden dim (all networks) | 256 |
| Hidden layers (all networks) | 3 | |
| Activation function | ReLU | |
| Critic LayerNorm | True |
| Task Name | (actor) | (critic) |
| halfcheetah-random | 0.001 | 0.1 |
| halfcheetah-medium | 0.001 | 0.01 |
| halfcheetah-expert | 0.01 | 0.01 |
| halfcheetah-medium-expert | 0.01 | 0.1 |
| halfcheetah-medium-replay | 0.01 | 0.001 |
| halfcheetah-full-replay | 0.001 | 0.1 |
| hopper-random | 0.001 | 0.01 |
| hopper-medium | 0.01 | 0.001 |
| hopper-expert | 0.1 | 0.001 |
| hopper-medium-expert | 0.1 | 0.01 |
| hopper-medium-replay | 0.05 | 0.5 |
| hopper-full-replay | 0.01 | 0.01 |
| walker2d-random | 0.01 | 0.0 |
| walker2d-medium | 0.05 | 0.1 |
| walker2d-expert | 0.01 | 0.5 |
| walker2d-medium-expert | 0.01 | 0.01 |
| walker2d-medium-replay | 0.05 | 0.01 |
| walker2d-full-replay | 0.01 | 0.01 |
| maze2d-umaze | 0.003 | 0.001 |
| maze2d-medium | 0.003 | 0.001 |
| maze2d-large | 0.003 | 0.001 |
| antmaze-umaze | 0.003 | 0.002 |
| antmaze-umaze-diverse | 0.003 | 0.001 |
| antmaze-medium-play | 0.001 | 0.0005 |
| antmaze-medium-diverse | 0.001 | 0.0 |
| antmaze-large-play | 0.002 | 0.001 |
| antmaze-large-diverse | 0.002 | 0.002 |
| pen-human | 0.1 | 0.5 |
| pen-cloned | 0.05 | 0.5 |
| pen-expert | 0.01 | 0.01 |
| door-human | 0.1 | 0.1 |
| door-cloned | 0.01 | 0.1 |
| door-expert | 0.05 | 0.01 |
| hammer-human | 0.01 | 0.5 |
| hammer-cloned | 0.1 | 0.5 |
| hammer-expert | 0.01 | 0.01 |
| relocate-human | 0.1 | 0.01 |
| relocate-cloned | 0.1 | 0.01 |
| relocate-expert | 0.05 | 0.01 |
| Formulation | Gym-MuJoCo | Maze2d | AntMaze | Adroit | Total Avg |
| (1) | 76.7 (-6.6%) | 97.2 (-34.0%) | 31.7 (-57.4%) | 55.2 (-0.9%) | 64.7 (-16.9%) |
| (2) | 76.8 (-6.5%) | 107.2 (-27.2%) | 31.9 (-57.2%) | 54.9 (-1.4%) | 65.5 (-15.9%) |
| (3) | 81.1 (-1.2%) | 151.8 (+3.1%) | 73.3 (-1.6%) | 56.1 (+0.7%) | 77.7 (-0.2%) |
| (4) | 82.1 | 147.2 | 74.5 | 55.7 | 77.9 |
| (5) | 82.0 (-0.1%) | 149.2 (+1.4%) | 74.6 (+0.1%) | 55.5 (-0.4%) | 77.9 (+0.0%) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
Adaptive Scaling of Policy Constraints for Offline Reinforcement Learning
Jing Tan
University of Science and Technology Beijing
Beijing, China
Hong Kong University of Science and Technology (Guangzhou)
Guangzhou, China
&Xiaorui Li, Chao Yao, Xiaojuan Ban & Zhaolin Yuan
University of Science and Technology Beijing
Beijing, China
&Yuetong Fang & Renjing Xu11footnotemark: 1
Hong Kong University of Science and Technology (Guangzhou)
Guangzhou, China
[email protected] Corresponding authors
Abstract
Offline reinforcement learning (RL) enables learning effective policies from fixed datasets without any environment interaction. Existing methods typically employ policy constraints to mitigate the distribution shift encountered during offline RL training. However, because the scale of the constraints varies across tasks and datasets of differing quality, existing methods must meticulously tune hyperparameters to match each dataset, which is time-consuming and often impractical. To bridge this gap, we propose Adaptive Scaling of Policy Constraints (ASPC), a second-order differentiable framework that automatically adjusts the scale of policy constraints during training. We theoretically analyze its performance improvement guarantee. In experiments on 39 datasets across four D4RL domains, ASPC using a single hyperparameter configuration outperforms other adaptive constraint methods and state-of-the-art offline RL algorithms that require per-dataset tuning, achieving an average 35% improvement in normalized performance over the baseline. Moreover, ASPC consistently yields additional gains when integrated with a variety of existing offline RL algorithms, demonstrating its broad generality.
1 Introduction
Offline reinforcement learning (RL) learns a policy exclusively from a fixed, pre-collected dataset without further interactions with the environment Levine et al. (2020). This characteristic is particularly crucial in real-world applications such as autonomous driving El Sallab et al. (2017); Kendall et al. (2019), healthcare Prasad et al. (2017); Wang et al. (2018), industry Zhan et al. (2022); Yuan et al. (2024), and other tasks, where interacting with the environment can be expensive and risky.
Despite the potential advantages, a critical challenge in offline RL is the distribution shift Levine et al. (2020) between the offline data and the training policies, often leading to suboptimal or even invalid policy updates. Many methods have been proposed to mitigate the adverse effects of the distribution shift. A common strategy is to impose explicit or implicit policy constraints Fujimoto et al. (2019); Kumar et al. (2020); Fujimoto and Gu (2021); Kostrikov et al. (2022), ensuring that the learned policy remains close to the behavior policy used to collect the dataset. By imposing constraints on policy updates, these methods can effectively mitigate the extrapolation error of the Q value Fujimoto et al. (2019) induced by the distribution shift while offering certain performance guarantees.
A central but often overlooked issue in policy constraint methods is the choice of the constraint scale, which crucially governs the balance between the RL objective and the behavior cloning (BC) term. Existing approaches fall into two categories. First, methods that rely on dataset-specific hyperparameter tuning can achieve strong results, but their performance collapses once a single configuration is applied across tasks or datasets of varying quality, as shown in Figure 1(b). Second, adaptive variants with fixed hyperparameters Peng et al. (2023); Yang et al. (2024) alleviate tuning costs, yet they only reweight actions locally and neglect the global trade-off scale, leaving a significant gap to carefully tuned baselines. In practical offline RL, where extensive tuning is prohibitively expensive or even infeasible, the pressing challenge is how to achieve robust performance with a single hyperparameter configuration across diverse datasets.
To enable a single hyperparameter configuration to match or exceed the performance of finely tuned methods across datasets of varying quality and tasks, we propose an adaptive scaling of policy constraints (ASPC) approach that dynamically adjusts the constraint scale during training. The intuition of this method is shown in Figure 1(a). Our approach leverages a second-order differentiable optimization framework Finn et al. (2017) to balance the goals of RL and BC. Specifically, we parameterize the scale factor as a learnable parameter that balances the RL objective and the BC objective in TD3+BC Fujimoto and Gu (2021). The combined objective is given by
[TABLE]
For the full definitions of , refer to equation 3. During training, is dynamically adjusted by constraining the rate of change of the Q-value and the BC loss, enabling the algorithm to discover a more stable learning path and exhibit remarkable adaptability across tasks and datasets.
We theoretically analyze the performance improvement guarantee of ASPC and extensively evaluate it on the D4RL benchmark Levine et al. (2020). Our empirical results demonstrate that ASPC outperforms other state-of-the-art offline RL algorithms that depend on meticulously tuned hyperparameters for each dataset, while adding only minimal computational overhead to the original TD3+BC backbone. In addition, ASPC improves a variety of offline RL algorithms beyond TD3+BC, further indicating its generality and broad applicability.
2 Related Works
2.1 Offline RL
Offline RL aims to learn policies purely from static datasets and suffers from distribution shift between the behavior policy and the learned policy, leading to value overestimation and policy collapse. Existing approaches address this challenge from several perspectives. Policy constraint methods explicitly Fujimoto et al. (2019); Fujimoto and Gu (2021) or implicitly Kumar et al. (2020); Kostrikov et al. (2022) regularize the learned policy toward the behavior distribution. Uncertainty-aware approaches penalize actions with high epistemic or aleatoric uncertainty An et al. (2021); Bai et al. (2022); Zhang et al. (2023). Sequence modeling methods reformulate RL as conditional trajectory modeling using transformers Chen et al. (2021); Janner et al. (2021). Among these, policy constraint methods have emerged as the most direct and widely adopted solution, but their effectiveness crucially depends on properly scaling the constraint. This motivates our focus on developing an adaptive scaling mechanism that eliminates the need for per-dataset tuning while retaining robustness across diverse offline RL benchmarks.
2.2 Adaptive Policy Constraints
Balancing the RL objective against BC is central to offline RL, and the strength of this constraint critically affects both stability and performance. Recent work has explored adaptive ways to tune this balance. Trajectory- or sample-weighting methods such as AW Hong et al. (2023), wPC Peng et al. (2023), and OAP Yang et al. (2023) reweight transitions or actions based on estimated value or expert preference, thereby adjusting constraint strength locally. Other approaches introduce auxiliary models to refine constraint scaling, for example PRDC Ran et al. (2023), GORL Yang et al. (2024), A2PR Liu et al. (2024), and IEPC Liu and Hofert (2024). Despite these advances, current approaches either rely on per-dataset hyperparameter tuning for optimal performance, or apply a fixed configuration that yields only limited gains across domains. Our ASPC method addresses this gap by dynamically adjusting the constraint scale during training, enabling robust performance across diverse datasets with a single hyperparameter configuration.
3 Preliminaries
RL problems are formulated as a Markov decision process (MDP), described by the tuple , . The set of states is , the set of actions is , the transition probability function is , the reward function is , and is the discount factor. The objective is to find a policy that maximizes the expected discounted return. This objective is equivalently expressed as maximizing the Q-value under , given by:
[TABLE]
where and represent the state and action at time . In practice, RL algorithms update Q-values using the Bellman equation as an iterative rule, seeking to converge to the optimal policy .
A central challenge for offline RL is the distribution shift. When a state–action pair lies outside the dataset , directly optimizing the Q–function may cause severe over-estimation. One remedy is to constrain the target policy to stay close to the behaviour policy . TD3+BC Fujimoto and Gu (2021) does so by solving:
[TABLE]
normalizes the RL term to the scale of the BC loss. In vanilla TD3+BC, is a fixed constant. Instead of keeping the scale factor static, we update it throughout training.
4 Method
We now present the ASPC algorithm in detail. We begin by introducing its core framework, a second-order differentiable optimization that adaptively balances the RL and BC objectives (Section 4.1). We then provide a theoretical analysis (Section 4.2), which explains the role of the mutual constraint term and establishes single-step and long-term performance guarantees. Finally, we describe a practical instantiation of ASPC built on TD3+BC (Section 4.3), which enables its application to standard offline RL benchmarks.
4.1 Adaptive Scaling of Policy Constraints
To adaptively adjust the relative scaling between the RL and BC objectives, ASPC adopts a meta-learning approach Finn et al. (2017); Franceschi et al. (2018). It converts the scale factor in equation 3 into a learnable parameter and optimizes it dynamically via bilevel training, utilizing inner updates and outer updates to maximize RL exploration near the behavior policy.
Inner Update To optimize the policy under offline data, we define the inner objective as
[TABLE]
where . The inner update is then obtained via a gradient descent step with learning rate :
[TABLE]
and denotes the updated policy parameters after one inner step.
Outer Update While the inner update optimizes the policy parameters for a given scale , the outer update is responsible for adjusting itself so as to dynamically balance the RL and BC objectives. The outer loss is composed of three coordinated components. mirrors TD3 + BC and steers toward a better balance between RL and BC. penalizes abrupt increases in the expected Q-value, while constrains large shifts in the BC loss. Together, and adaptively regulate the step prescribed by , preventing either RL or BC from dominating and thereby stabilizing training. Formally, we write:
[TABLE]
The outer objective is
[TABLE]
Here, and denote the policies before and after the inner update, respectively. indicates stopping gradients. While and are relatively standard, the design of requires clarification. Theoretically, its form follows directly from Theorem 4.4, with details in Appendix A.3. Intuitively, combines three factors: the rate of change in Q-values, the upper bound of the BC loss, and the variation in BC loss across iterations. Large Q-value fluctuations or a high BC-loss bound signal rapid policy change or significant deviation from the behavior policy. In such cases, strengthening the penalty on BC variation helps suppress distributional shift and stabilize training, consistent with our intuition. To update , we treat the inner update parameters as an implicit function of and use second-order derivatives. Lets be the learning rate of . The gradient-descent step is
[TABLE]
4.2 Theoretical Analysis
We now analyze the theoretical properties of ASPC. We show that the outer objective ensures stable updates and reduces the gap to the optimal policy.
Assumption 4.1**.**
The critic and the transition kernel are Lipschitz continuous with respect to the action variable. That is, there exist constants , independent of , such that for all and all ,
[TABLE]
Proposition 4.2** (Mutual constraints between and ).**
Under Assumption 4.1, the change in BC loss () and the squared change in Q-values () mutually constrain each other: provides a lower bound on , while provides an upper bound on .
This result shows that the two penalties in equation 7 and equation 8 are inherently coupled rather than independent. It explains why in practice some tasks succeed with only one of them, while others require both for stable training (see Section 5.5). The detailed proof is provided in Appendix A.1.
Proposition 4.3** (Single-step performance lower bound).**
For the update step from to , the performance improvement admits the following lower bound:
[TABLE]
where is a nonnegative function depending on the BC-loss variation upper bound and the BC-loss upper bound .
This proposition serves as the theoretical basis for Theorem 4.4. It also directly motivates the design of the penalty term (equation 8), whose form is derived from bounding . The detailed derivation of is deferred to Appendix A.2.
Theorem 4.4** (Single-step performance condition for ASPC).**
An idealized ASPC update that satisfies the condition leads to a non-decreasing policy performance:
ASPC employs a smooth relaxation of this condition via the outer objective, which is designed to guide updates toward this provably stable regime. The detailed proof is given in Appendix A.3.
Theorem 4.5** (Performance gap to optimal).**
With Theorem 4.4, after iterations when the single-step gain vanishes (), the gap to the optimal policy satisfies:
[TABLE]
where is a function of the mismatch between the behavior policy and the optimal policy, and denotes the minimal single-step improvement before convergence.
This theorem shows that ASPC progressively reduces the suboptimality gap until convergence, where the remaining gap is controlled by . The full derivation of is given in Appendix A.4.
4.3 Implementation on TD3+BC
To make ASPC practical, we instantiate it on top of the TD3+BC backbone with only two modifications: (i) a redesigned critic network, and (ii) a learnable scale factor . All other network components and hyperparameters remain unchanged. See Appendix B.2 for a full specification.
Recent studies show that deeper critics Kumar et al. (2022); Lee et al. (2022) and the insertion of LayerNorm between layers Nikulin et al. (2023); Ball et al. (2023); Tarasov et al. (2024a) can mitigate Q-value over-estimation and improve stability. Following this evidence, we extend the TD3+BC critic from two to three hidden layers and insert a LayerNorm after each layer. An ablation of this choice is provided in Section 5.5.
Algorithm 1 lists the ASPC procedure. Blue highlights indicate lines that differ from the TD3+BC backbone. Although second-order gradients increase cost, we set the -update interval far longer than the actor-update interval , which maintains performance while sharply reducing runtime. Section 5.4 analyses this trade-off in detail.
5 Experiments
In this section we evaluate ASPC on the D4RL benchmark. Section 5.1 compares ASPC with strong baselines to demonstrate its adaptability and overall effectiveness. Section 5.2 analyzes the learning curves of during training, further illustrating ASPC’s adaptive behaviour. Section 5.3 investigates the necessity of dynamically adjusting . Section 5.4 reports runtime results to highlight the efficiency of ASPC. Section 5.5 presents ablation studies on the key components of ASPC. Section 5.6 provides results on integrating the ideas of ASPC with other methods, and Section 5.7 presents the performance of ASPC on the OGBench benchmark.
5.1 Comparative Performance on Benchmark
We evaluate ASPC on 39 datasets spanning four D4RL domains Levine et al. (2020): MuJoCo (v2), AntMaze (v2), Maze2d (v1), and Adroit (v1). Our baselines include TD3+BC Fujimoto and Gu (2021) and IQL Kostrikov et al. (2022) as standard policy-constraint methods. wPC Peng et al. (2023) and A2PR Liu et al. (2024) are state-of-the-art (SOTA) adaptive policy constraint methods built on TD3+BC. ReBRAC Tarasov et al. (2024a) integrates multiple performance-boosting components into TD3+BC and has achieved SOTA results across a wide range of datasets. TD3+BC, wPC, A2PR, and ASPC are all set as the single hyperparameter set, whereas IQL and ReBRAC rely on dataset-specific hyperparameters found via grid search. We reproduce results for TD3+BC, wPC and A2PR. IQL and ReBRAC results are taken from Tarasov et al. (2024a; b). Complete experimental details for each algorithm are provided in the appendix B.2.
The performance comparison is summarized in Table 1. ASPC achieves the best performance on MuJoCo and Maze2d, and exhibits competitive results on Adroit and AntMaze. Most notably, ASPC attains SOTA performance on average across all four domains, which not only outperforms other adaptive policy constraint methods but also surpasses approaches that rely on meticulous per-dataset hyperparameter tuning, highlighting its remarkable adaptability. Figure 2 shows that the performance profile curves (left) place ASPC above all baselines for almost every threshold, and the min-max-scaled radar chart (right) gives ASPC the largest, most balanced polygon, visually confirming its strong and stable performance across tasks without per-dataset tuning.
5.2 Adaptability of the Sacle Factor
Dataset Adaptability Figure 3 shows the evolution of on HalfCheetah, Hopper, and Walker2d for four dataset quality levels, listed from highest to lowest as expert, medium-expert, medium, and medium-replay. Across all three tasks, higher-quality datasets lead to smaller , which places more weight on BC, whereas lower-quality datasets lead to larger , shifting the emphasis toward RL. The consistent ordering confirms that ASPC automatically adjusts the policy-constraint scale to dataset quality without any per-dataset hyperparameter tuning.
Task Adaptability Figure 4 plots the trajectories on six heterogeneous tasks. Tasks such as door, pen, hammer, and relocate possess narrow expert data distributions; here settles near , giving greater weight to BC. Conversely, antmaze and maze2d, whose datasets contain highly sub-optimal trajectories, drive above 10, shifting emphasis to RL. This task-aware scaling requires no manual tuning and highlights ASPC’s cross-task adaptability.
Training Adaptability Combining the curves from Figures 4 and 3, we observe a common learning dynamic: first drops (or rises only slightly) during the early training phase, indicating greater reliance on BC when the policy is still immature. As learning progresses and the critic stabilises, gradually increases, handing more control to RL. This smooth, stage-wise adjustment underpins ASPC’s stable convergence across tasks and datasets.
5.3 Necessity of Dynamic Scale Factor Adjustment
As shown in Table 1, the hyperparameters meticulously selected via grid search ultimately underperform compared to the ASPC algorithm, which dynamically adjusts hyperparameters during training. This observation raises the question: is grid search simply failing to find the best setting, or is the dynamic adjustment in ASPC the true source of its advantage? To answer this, we conduct three controlled tests. Naive . TD3+BC is run with a fixed scale factor . Converged . TD3+BC is run with fixed to the final value reached by ASPC on the same dataset. Linear . TD3+BC starts from and linearly interpolates to the above converged value over the training horizon. To ensure fairness, all TD3+BC variants utilize the same robust critic architecture as ASPC, comprising three hidden layers, each followed by a LayerNorm.
Table 2 summarises the mean normalised scores in the four D4RL domains. Percentages in blue report the relative gain over the naive baseline that fixes . Converged and Linear both outperform the naive setting, which confirms that the value to which ASPC eventually converges is a much more appropriate scale for the policy constraint. ASPC (Dynamic ) still exceeds the Converged variant by a wide margin, and the Linear schedule closes only part of the gap. These results show that simply finding a good fixed is not enough. Adapting the scale throughout training is essential for the best performance. ASPC provides this dynamic adjustment automatically and therefore achieves the highest overall score.
5.4 Runtime Analysis
ASPC employs second-order gradient computations for updating , which increases cost. However, its update interval () can be set substantially longer than that of the actor (), thereby minimizing the additional computational overhead. To evaluate runtime efficiency, we compare the execution time of one million iterations of ASPC against that of other baseline algorithms. Figure 5 presents a bar chart comparing the runtime of ASPC against TD3+BC, CQL, IQL, wPC and A2PR on the halfcheetah-medium-v2 dataset. The results indicate that ASPC introduces only a minimal additional computational overhead beyond that of TD3+BC.
We further analyze the relationship between , runtime, and performance, as illustrated in Figure 5. The baseline setting for is 10, we observe that reducing does not lead to significant performance degradation. This suggests that ASPC effectively captures the correct gradient optimization direction, maintaining robustness even when the gradient step size is large. When is set to 30, the runtime is nearly identical to that of TD3+BC while maintaining strong performance. This highlights the efficiency of the ASPC algorithm.
5.5 Ablation Studies
Robust Critic(RC) When using the original TD3+BC critic network (with two hidden layers and no LayerNorm), during the process of adjusting , Q-values exhibit significant instability, frequently leading to overestimation, causing catastrophic failure of the algorithm. Since wPC is also designed based on the original TD3+BC framework, we include it in our experiments related to RC (with three hidden layers and LayerNorm). Figure 6(a) presents the experimental results. The results indicate that when RC is not utilized, both wPC and ASPC achieve limited performance improvement and even exhibit performance degradation on certain tasks.
Loss Function Figure 6(b) reveals clear, domain-dependent effects when the regularization terms are added to the base loss . Adding neither term ( only) gives the poorest performance. Introducing only lifts performance in MuJoCo and Adroit to the level of full ASPC, while leaving AntMaze almost unchanged. Conversely, adding only significantly boosts AntMaze but has little effect on MuJoCo or Adroit. For Maze2D, neither single term suffices. Only the full loss attains the best result. These results can be explained by Proposition 4.2, which shows that and implicitly constrain one another. Consequently, adding in MuJoCo and Adroit implicitly bounds as well, so the single‐step performance guarantee of Theorem 4.4 is already satisfied. Conversely, in AntMaze a direct penalty implicitly limits , again meeting the theorem’s lower bound. For Maze2D, however, neither implicit relation is strong enough; both and must be enforced explicitly for the condition in Theorem 4.4 to hold.
5.6 Extending ASPC to Other Offline RL Methods
Many offline RL algorithms follow the form of equation 1. To evaluate the generality of ASPC, we integrate its adaptive policy constraint into three representative baselines, including IQL, CQL, and Diffusion-QL Wang et al. (2023). Each method contains a hyperparameter analogous to that controls the balance between value learning and conservatism. We replace this manually tuned coefficient with a learnable parameter and update it using the same bi-level second-order procedure as ASPC. The detailed objectives for each algorithm are provided in Appendix D.
As shown in Table 3, incorporating ASPC consistently improves the performance of all three baselines, which demonstrates the broad applicability of our approach. IQL yields the smallest improvement, and a possible reason is that it performs implicit Q learning, so increasing does not effectively shift the policy toward the RL objective. This implicit structure offers stability but limits the best achievable performance. CQL benefits more from ASPC because updating directly adjusts the level of conservatism. Diffusion-QL already achieves very strong results, and ASPC further improves its performance, which highlights the robustness of ASPC even when applied to a strong baseline.
5.7 Additional Experiments on OGBench
We further evaluate the generality and robustness of ASPC on OGBench Park et al. (2025a), a new benchmark for offline goal-conditioned RL. Results across ten datasets in Table 4 show that ASPC clearly surpasses all existing baselines, indicating strong applicability beyond D4RL. Since FQL Park et al. (2025b) also follows equation 1, we integrate ASPC by making its scale factor learnable and applying the same bi level optimization procedure, with details in Appendix D. This modification consistently improves FQL, further supporting the broad generality of ASPC across standard and goal-conditioned offline RL.
6 Conclusion
We presented ASPC, a bi-level framework that adapts the RL–BC trade off by optimizing the scaling factor through second-order updates. ASPC yields consistent improvements not only on TD3+BC but also when combined with other offline RL baselines, demonstrating strong generality. However, these simple integrations yield smaller gains than those seen with TD3+BC, indicating that different algorithms may require ASPC-style components tailored to their training dynamics. Future work includes developing such method-specific adaptive mechanisms under a unified principle and evaluating them on larger benchmarks and real-world datasets.
Acknowledgments
This work was supported by the National Science and Technology Major Project of the Ministry of Science and Technology of China (2024ZD0608100), the National Natural Science Foundation of China (62506031, 62332017, U22A2022), the Postdoctoral Fellowship Program of CPSF under Grant Number GZC20251093.
Ethics Statement
This work focuses on methodological advances in offline RL. All experiments are conducted on standard simulated benchmarks, which do not involve human subjects, personally identifiable information, or sensitive data. We strictly follow the licensing terms of all datasets and simulation platforms used in this study. Our method, Adaptive Scaling of Policy Constraints (ASPC), is designed to improve the stability and reliability of offline RL algorithms. While RL has the potential for deployment in safety-critical domains, such as robotics and autonomous systems, the experiments in this paper remain purely in simulation. Any real-world use of these methods should be preceded by domain-specific safety checks and human oversight to avoid unintended harm.
Reproducibility Statement
We have taken several measures to ensure the reproducibility of our work. The proposed method is described in detail in Section 4, and the complete theoretical derivations are provided in Appendix A. Experimental settings and hyperparameters are reported in Appendix B. Moreover, we include the full implementation code in the Supplementary Material to facilitate replication of all results.
Appendix A Theoretical Proofs
A.1 Proof of Proposition 4.2
Throughout the argument, we adopt the following shorthand. We index the policies as
[TABLE]
We write
[TABLE]
[TABLE]
Lemma A.1** (Reverse triangle inequality).**
For all one has .
Lemma A.2** (Cauchy–Schwarz).**
For square–integrable real random variables , .
Proof.
The proof proceeds in three steps.
Step 1: A lower bound on . Expand the definition of and simplify:
[TABLE]
Since by definition, combining with equation 14 yields
[TABLE]
Step 2: An upper bound on . Jensen’s inequality and the assumption 4.1 yield
[TABLE]
Step 3: Mutual bound. From equation 16 we have
[TABLE]
Since from equation 15, we relate this expression to as follows. The function is non-positive on and strictly increasing on . When , we have , and is non-positive; thus . When , we have and is increasing for all , which gives . Combining the two regimes yields the bound
[TABLE]
Similarly, using equation 15 we obtain the following upper bounds for :
[TABLE]
Combining equation 16 with equation 19 gives an upper bound on :
[TABLE]
equation 18 and equation 20 together yield the desired mutual bounds. ∎
A.2 Proof of Proposition 4.3
This section analyses conditions under which the one-step performance difference admits a tractable lower bound when training on a fixed offline dataset collected under behavior policy (so ).
Lemma A.3** (Performance‑difference lemma).**
For any policies and ,
[TABLE]
The proof of Lemma A.3 can be found in Kakade and Langford (2002).
Lemma A.4**.**
Under Assumption 4.1, the total variation distance between the visitation distributions of any policy and the behavior policy satisfies
[TABLE]
where is a constant.
The proof of Lemma A.4 can be found in the appendix of Xiong et al. (2022).
Lemma A.5** (Sup‐norm version of equation 19).**
Define
[TABLE]
Then
[TABLE]
Proof.
For each , let . Then
[TABLE]
Taking the supremum over gives the stated result:
[TABLE]
The proof of Lemma A.5 is finished. ∎
Proof.
In our deterministic setting, the conditional action distribution for any state is a Dirac measure concentrated at a single action. Specifically, for in Lemma A.3 we have:
[TABLE]
Applying Lemma A.3 with and gives:
[TABLE]
Write the performance–difference identity equation 27 as
[TABLE]
Thus, the one–step performance satisfies the lower bound
[TABLE]
The proof of Proposition 4.3 is finished. ∎
A.3 Proof of Theorem 4.4
We now show how our outer‐loss components ensure the performance lower bound equation LABEL:eq:per-lower-bound is maintained.
equation 6 updates based on the relative gradients of Q-value and the BC loss. Under the initialization assumption , so updates to favor Q‐improvement.
In our algorithm, the two regularizers and play complementary roles in guaranteeing safe single‐step improvements. Specifically, in equation 7 penalizes the squared change in the Q‐function, , to prevent overly large and unreliable Q‐updates. Due to the bootstrapping error inherent in RL, the single-step Q-value changes can be noisy, and therefore we apply an exponential moving average (EMA) for stabilization. In order to preserve the one‐step performance lower bound equation LABEL:eq:per-lower-bound, in equation 8 must impose a matching penalty on the bias term identified in that bound. By choosing so that its curvature mirrors that of , we ensure the single‐step performance guarantee remains non‐negative.
Proof.
We perform a second‐order Taylor expansion of around , assuming , discarding higher-order and constant terms. Substituting into the square and retaining only terms up to yields:
[TABLE]
In practice, we scale by the value of to match its regularization strength and simply set to 1:
[TABLE]
By setting an appropriate , the algorithm can guarantee that:
[TABLE]
The proof of Theorem 4.4 is finished. ∎
A.4 Proof of Theorem 4.5
Proof.
We split the total performance gap into two components:
[TABLE]
We first observe that the behavior‐cloning loss
[TABLE]
decreases rapidly during early training. Hence there exists a warm‐up time such that
[TABLE]
and we set
[TABLE]
then
[TABLE]
We define
[TABLE]
Next, each one‐step update produces the gain equation 32
[TABLE]
Summing these gains yields the unified bound
[TABLE]
With a fixed regularization weight , the sequence tends to decay rapidly toward zero or even become negative. Therefore, static leaves a large residual gap in equation 39. Our meta-update dynamically adjusts so that each stays bounded below by a positive constant over a long horizon. Thus
[TABLE]
The proof of Theorem 4.5 is finished. ∎
Appendix B Experimental Details
B.1 Hardware and Software
We use the following hadrward:
Intel(R) Xeon(R) Platinum 8352V CPU @ 2.10 GHz 2. 2)
NVIDIA GeForce RTX 4090 GPU
We use the following software versions:
Python 3.8.10 2. 2)
D4RL 1.1 3. 3)
MuJoCo 3.2.3 4. 4)
Gym 0.23.1 5. 5)
mujoco-py 2.1.2.14 6. 6)
PyTorch 2.2.2 + CUDA 12.1 7. 7)
TorchOpt 0.7.3 Ren* et al. (2023)
B.2 Hyperparameters
The network structures and hyperparameter configurations of each algorithm corresponding to Table 1 are as follows.
Appendix C Learning Curves
C.1 Scale Factor Curves
Figure 7 plots the learning curves for all 39 datasets. The curves show that our algorithm (i) drives toward distinct optima across tasks and (ii) merely modulates its step size and pace when the dataset quality changes within the same task. This dual behaviour highlights the method’s adaptability to both task differences and data-quality variations.
C.2 Performance Curves
Figure 8 shows the learning curves of all four algorithms on the 39 D4RL datasets. ASPC rises much more rapidly than the baselines, typically within the first M environment steps, and surpasses them long before the others stabilize. Its final normalized scores are almost always the highest (or very close to the highest) across all task families, maintaining a clear margin where the competing methods usually plateau. Moreover, the shaded regions (mean 1 s.d. over four seeds) remain consistently narrow for ASPC, and its curves show no late-stage collapses, pointing to lower variance and steadier adaptation across widely varying task dynamics and data quality. Overall, the figure suggests that ASPC combines greater sample efficiency, stronger ultimate performance, and more reliable behavior than the other approaches.
Appendix D Integrating ASPC with Other Offline RL Algorithms
D.1 Integration with IQL
In IQL, the policy is trained by advantage-weighted behavior cloning. Let denote the IQL advantage estimate and the temperature parameter. We integrate ASPC by treating as the adaptive policy-constraint coefficient.
Inner objective.
The IQL actor minimizes
[TABLE]
where . A single gradient step yields the updated policy .
Outer objective.
Following ASPC, we construct an outer loss on the updated policy using a normalized Q-improvement term and the corresponding BC loss:
[TABLE]
The second term measures the change in mean Q-value induced by the inner update:
[TABLE]
The outer objective for adapting is
[TABLE]
D.2 Integration with CQL
CQL constrains Q-values by penalizing larger Q-values on out-of-distribution (OOD) actions. Let denote the conservatism coefficient. Following ASPC, we treat as the adaptive policy-constraint parameter.
Inner objective.
Given a batch , the CQL critic update solves
[TABLE]
where
[TABLE]
A single gradient step produces the updated critic .
Outer objective.
ASPC evaluates the updated critic with a normalized Q-improvement term and the corresponding CQL penalty, forming
[TABLE]
The Q-value change induced by the inner update is
[TABLE]
The outer objective for adapting becomes
[TABLE]
D.3 Integration with Diffusion-QL
Diffusion-QL trains a diffusion policy by combining a behavior-cloning loss with a normalized Q-term. Let be the coefficient controlling the trade-off between policy improvement and imitation. Following ASPC, we treat as the adaptive constraint parameter.
Inner objective.
Given state–action pairs , the diffusion policy is trained under the objective
[TABLE]
A single gradient step produces the updated diffusion policy .
Outer objective.
ASPC evaluates the updated diffusion policy through a normalized Q-value term and the corresponding BC term:
[TABLE]
The Q-improvement induced by the inner update is captured by
[TABLE]
The outer objective becomes
[TABLE]
D.4 Integration with FQL
FQL employs two policies: (i) a teacher flow policy trained purely by flow-matching, and (ii) a student one-step flow policy trained via distillation and Q-improvement. Only the student policy interacts with the Q-function, making it the component that requires adaptive scaling. We integrate ASPC by treating the student’s trade-off coefficient as the adaptive constraint parameter.
Teacher objective (BC Flow).
The teacher flow policy is trained via standard flow-matching:
[TABLE]
where and denotes the flow velocity network. This loss is independent of .
Inner objective (Student Flow).
The student one-step policy predicts an action in a single step and matches the teacher via a distillation loss, while also incorporating a normalized Q-improvement term. The inner objective is
[TABLE]
A single gradient update produces the updated student policy .
Outer objective.
ASPC evaluates the updated student policy by combining its normalized Q-value and distillation loss, and the Q-improvement incurred by the inner update:
[TABLE]
The outer objective becomes
[TABLE]
Appendix E Additional Empirical Analyses
E.1 Performance on AntMaze and Adroit
As shown in Table 1, ASPC does not achieve state-of-the-art performance on AntMaze and Adroit. Both benchmarks are characterized by extremely sparse rewards, with AntMaze in particular using a binary [math]– success signal Fu et al. (2020). In such settings, even online RL methods struggle to learn effectively, and behavior cloning plays a dominant role in determining policy quality.
Although ASPC can adapt toward a more BC-dominated regime, the current BC term imitates all actions in the dataset, including suboptimal or unsuccessful trajectories. This limits the attainable performance on sparse-reward tasks. To address this issue, we experimented with augmenting the BC term using advantage-weighted behavior cloning, where high-advantage samples receive larger weights. The modified loss improves the selectivity of imitation by emphasizing demonstrably good behaviors. Experimental results, shown in Figure 9, indicate consistent performance gains on both AntMaze and Adroit when advantage-weighting is applied. This suggests that selectively imitating high-quality behaviors is crucial for sparse-reward offline RL tasks.
E.2 Ablation on the Formulation of the Term
To better understand the role of each component in the term, we consider five variants. The first variant keeps only the third component:
[TABLE]
The second variant multiplies the third component by the squared BC deviation:
[TABLE]
The third variant replaces the BC-deviation factor with the detached term:
[TABLE]
The fourth variant is the complete formulation used in our method:
[TABLE]
The fifth variant replaces both supremum operators in by dataset expectations:
[TABLE]
Table 13 summarizes the results. Variants (3)–(5), which include the detached term, provide clear gains on Maze2d and AntMaze, showing that this component is essential for these domains. By contrast, Adroit displays only minor differences across all variants, suggesting that Q-value gradients dominate BC-related gradients there, making the precise form of less influential. Finally, variant (5) achieves a performance nearly identical to the full formulation, implying that strict worst-case bounds using the operator are not essential in practice.
E.3 Case Study of ASPC Dynamics
Figure 10 shows the training dynamics on halfcheetah-medium-v2. ASPC consistently increases both the estimated Q-value and the BC loss, while simultaneously improving the normalized score. It is essential to note that the increase in BC loss under ASPC does not indicate instability or degradation. Since ASPC deliberately allows the policy to deviate from the behavior policy when such deviations yield sufficient Q-value improvement, the BC loss can increase while performance improves. This matches our theory: whenever the Q-value gain compensates for the increased deviation, the update remains beneficial. Thus, an increasing BC loss indicates that ASPC is escaping the behavior cloning regime and moving toward higher-value actions. In contrast, TD3+BC rapidly plateaus in all three curves, indicating that its fixed trade-off between RL and BC limits its ability to continue improving.
Appendix F Hyperparameter Sensitivity Analyses
F.1 Sensitivity to the Initial Value of
Figure 11 illustrates the influence of the initial value of on ASPC. Across Gym-MuJoCo, AntMaze, and Adroit, the intermediate setting provides the strongest overall performance, while a very small initialization () tends to bias the early update dynamics too strongly toward BC, limiting the contribution of the RL term. Conversely, an excessively large initialization (e.g., ) can overemphasize the RL component at the beginning, which weakens the intended stabilizing effect of the BC objective and leads to performance drops, particularly on Adroit. These observations indicate that a balanced initialization is important for achieving stable optimization.
F.2 Sensitivity to the Learning Rate of
We study the effect of the learning rate used for updating . The results show that different domains prefer different learning rate magnitudes. Too small values slow down the adjustment of the RL–BC trade-off, while too large values make the meta-update unstable and degrade performance.
Appendix G The use of LLM
Large Language Models (LLMs) were used to aid and polish the writing of this paper. In particular, they were applied to rephrase sentences for improved readability and refine grammar and wording to meet academic style requirements.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1G. An, S. Moon, J. Kim, and H. O. Song (2021) Uncertainty-based offline reinforcement learning with diversified q-ensemble . Advances in neural information processing systems 34 , pp. 7436–7447 . Cited by: §2.1 .
- 2C. Bai, L. Wang, Z. Yang, Z. Deng, A. Garg, P. Liu, and Z. Wang (2022) Pessimistic bootstrapping for uncertainty-driven offline reinforcement learning . ar Xiv preprint ar Xiv:2202.11566 . Cited by: §2.1 .
- 3P. J. Ball, L. Smith, I. Kostrikov, and S. Levine (2023) Efficient online reinforcement learning with offline data . In International Conference on Machine Learning , pp. 1577–1594 . Cited by: §4.3 .
- 4L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch (2021) Decision transformer: reinforcement learning via sequence modeling . Advances in neural information processing systems 34 , pp. 15084–15097 . Cited by: §2.1 .
- 5A. El Sallab, M. Abdou, E. Perot, and S. Yogamani (2017) Deep reinforcement learning framework for autonomous driv-ing . stat 1050 , pp. 8 . Cited by: §1 .
- 6C. Finn, P. Abbeel, and S. Levine (2017) Model-agnostic meta-learning for fast adaptation of deep networks . In International conference on machine learning , pp. 1126–1135 . Cited by: §1 , §4.1 .
- 7L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil (2018) Bilevel programming for hyperparameter optimization and meta-learning . In International conference on machine learning , pp. 1568–1577 . Cited by: §4.1 .
- 8J. Fu, A. Kumar, O. Nachum, G. Tucker, and S. Levine (2020) D 4rl: datasets for deep data-driven reinforcement learning . ar Xiv preprint ar Xiv:2004.07219 . Cited by: §E.1 .
