Kullback-Leibler Potential for Non-Ergodic Replication Dynamics:An Information-Theoretic Second Law
Tatsuaki Tsuruyama

TL;DR
This paper introduces an information-theoretic second law based on the Kullback-Leibler divergence to quantify information degradation during replication, with implications for biological processes like DNA replication.
Contribution
It develops a mathematical model using Markov processes and Gaussian convolution to analyze information degradation and extends the framework to biological information processes.
Findings
KLD decreases monotonically during replication, acting as a Lyapunov function.
The framework links free energy to information degradation in biological systems.
Provides a unified thermodynamic view of information replication and repair.
Abstract
This study aims to quantify and visualize the degradation of fidelity (information degradation) that inevitably accompanies the replication of information within the framework of information thermodynamics and to propose an information-theoretic formulation of the second law based on this phenomenon. While previous research in information thermodynamics has focused on the thermodynamic costs associated with information "erasure'' or "measurement'' through concepts such as Landauer's principle and mutual information, little systematic discussion has addressed the inherently irreversible nature of "replication'' itself and the accompanying degradation of information structure. In this study, we construct a mathematical model of information replication using a discrete Markov model and Gaussian convolution, and quantify changes in information at each replication step: Shannon entropy,…
Click any figure to enlarge with its caption.
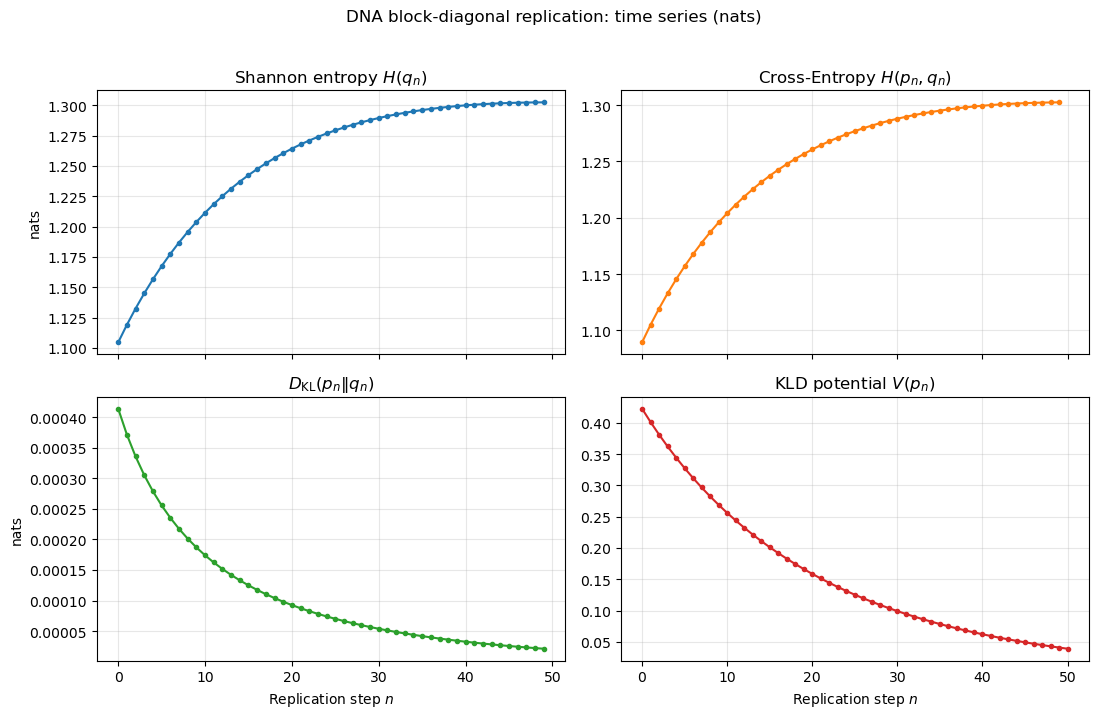 Figure 1
Figure 1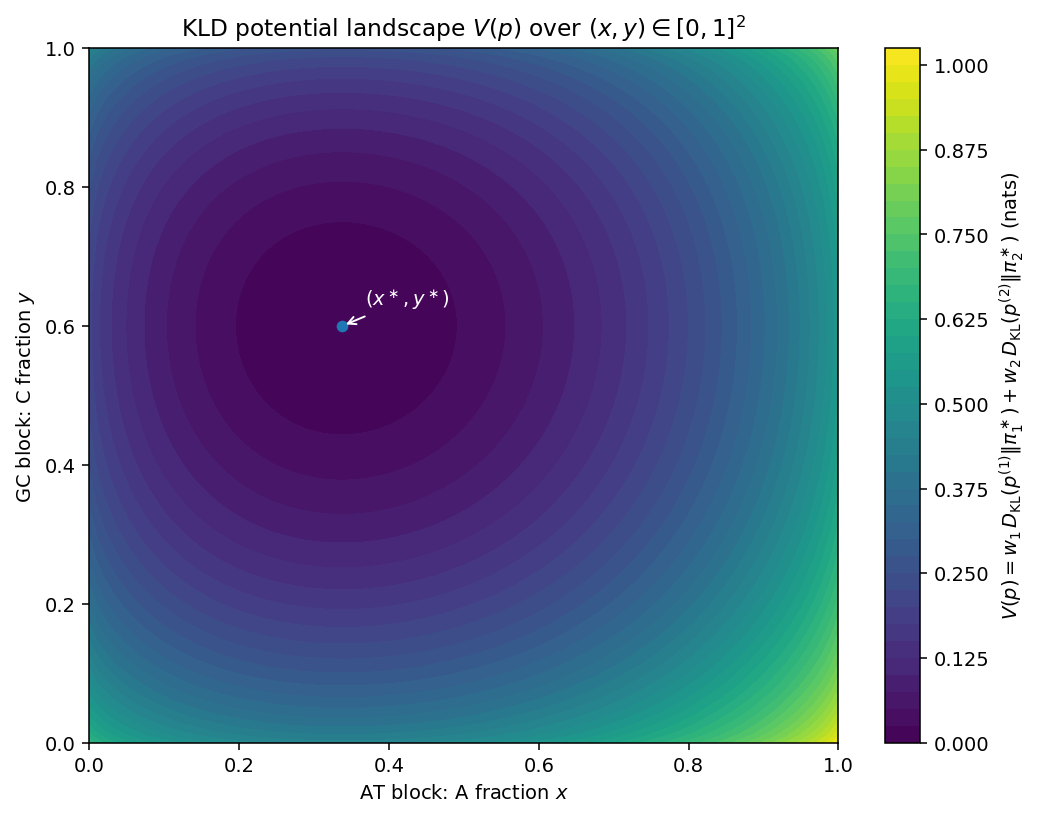 Figure 2
Figure 2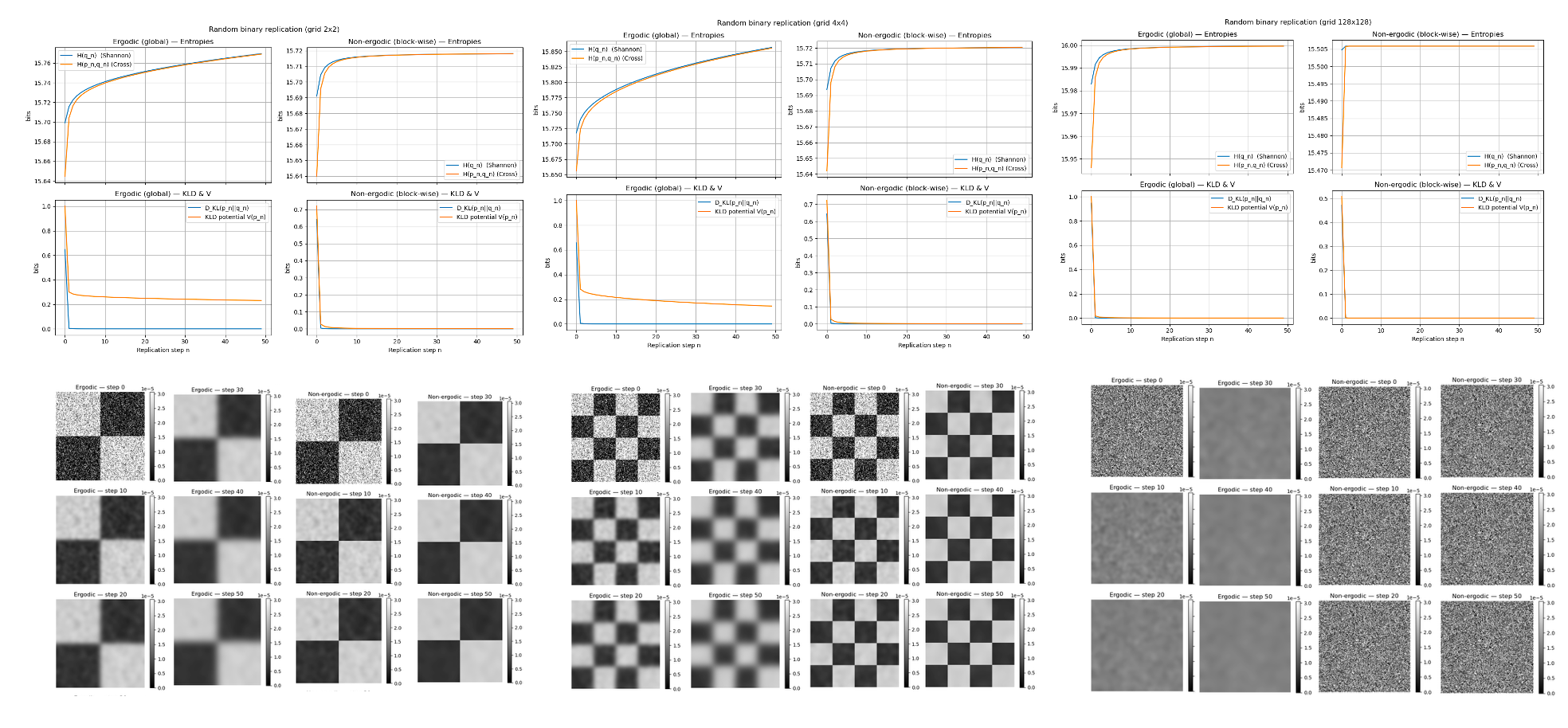 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Kullback–Leibler Divergence Potential for Non-Ergodic Replication Dynamics: An Information-Theoretic Second Law
Tatsuaki Tsuruyama E-mail: [email protected] Department of Physics, Tohoku University, Sendai 980-8578, Japan
Department of Drug Discovery Medicine, Kyoto University, Kyoto 606-8501, Japan
Department of Clinical Laboratory, Kyoto Tachibana University, Kyoto 607-8175, Japan
Abstract
While previous research in information thermodynamics has focused on the thermodynamic costs associated with information “erasure” or “measurement” through concepts such as Landauer’s principle and mutual information, little systematic discussion has addressed the inherently irreversible nature of “replication” itself and the accompanying degradation of information structure. In this study, we construct a mathematical model of information replication using a discrete Markov model and Gaussian convolution, and quantify changes in information at each replication step: Shannon entropy, cross-entropy, and the Kullback–Leibler divergence (KLD). The monotonic decrease of the KLD potential (the minimal KLD to a reachable steady set) exhibits a Lyapunov-like property, which can be interpreted as a potential analogous to the free energy in the process by which a nonequilibrium system converges to a particular steady state. Furthermore, we extend this framework to the potential applicability to biological information processes such as DNA replication, showing that the free energy required for degradation and repair can be expressed in terms of KLD. This contributes to building a unified information-thermodynamic framework for operations such as replication, transmission, and repair of information.
1 General framework and main theorem
1.1 Block invariance and reachable steady set
The information replication operations we study (image blurring, base substitution with proofreading, etc.) are inherently local: one step only rearranges probability mass within a constrained neighborhood (spatial or compositional), but does not freely mix all microscopic states. As a result, certain coarse observables, e.g., the total mass inside a spatial region of an image, or the adenine(A) -thymine (T) rich block and guanine(G) -cytosine (C) rich block in DNA to be replicated as a template, are effectively conserved by every replication step. Empirical mutation processes are asymmetric between the AT and GC blocks. First, in various bacteria, the spectrum of spontaneous mutation is generally biased toward AT (C/GT/A transitions dominate), implying a baseline GCAT pressure [1]. Second, cytosines in CpG dinucleotides (often methylated as 5mC) are hypermutable via deamination, which elevates CT transitions and locally accelerates GCAT decay [2, 3]. Third, germline substitution rates vary strongly with the local sequence context; in humans, the 7-mer sequence context explains most of the variability in polymorphism levels [4]. In contrast to AT-directed mutational bias, recombination-associated GC-biased gene conversion (gBGC) favors the fixation of GC alleles and can increase GC content in high recombination regions without invoking fitness differences [5, 6, 7].
These well-documented asymmetries motivate modeling replication on a block partition that separates AT- from GC-rich components. In our framework, block invariance captures slow exchange between AT and GC pools while allowing within-block relaxation; consequently, the KLD potential measures the departure from the stable block set under realistic composition-dependent mutation / repair biases. When such conserved coarse variables exist, the Markov dynamics does not converge to a single global invariant distribution; instead, the state space decomposes into components that evolve independently. We call this situation non-ergodic in the sense that long-term behavior retains memory of the initial coarse structure through the conserved weights.
(i) In the image model, a blockwise Gaussian convolution forbids smoothing across block boundaries; the total intensity in each block is preserved at every step. (ii) In the DNA model, a block diagonal substitution kernel reflects biochemical or sequence constraints (e.g., AT- vs. GC-rich segments); block masses (AT vs. GC) remain fixed while within-block compositions relax. (iii) More generally, locality, topological separation, or routing restrictions in copying channels induce invariant ’blocks’ that prevent global mixing. Because replication preserves these coarse variables, the appropriate equilibrium notion is not a single point but a set of steady states obtained by fully relaxing within each invariant component while keeping the initial coarse weights fixed. This motivates modeling the state space as a disjoint union of blocks and defining a reachable steady set against which we will measure the distance using a KL-based potential. We emphasise that non-trivial block partitions with are meaningful precisely when the dynamics itself possesses non-mixing components, so that probability mass cannot freely move between all microscopic states. In the fully mixing (ergodic) case, the only natural choice is the trivial partition with a single block, and our potential reduces to the standard KLD to a unique invariant steady state.
Framework and notation (matrix semantics made explicit)
We consider a finite state space partitioned into disjoint blocks
[TABLE]
with . The probability simplex over is
[TABLE]
and we write .
A one-step Markov kernel acts on the right by
[TABLE]
so is a row-stochastic matrix ( and for each row ). The matrix dimension equals the number of states . Rows index the current state, columns the next state. Each block kernel has size and updates the conditional while preserving its mass . This row-vector/right-action convention is used throughout: .
Semantics: the row index is the current state, the column index is the next state, and the matrix size equals the number of states. Restricting to a block yields a subkernel of size .
Block-invariant dynamics.
The dynamics is block-invariant if the transitions never cross the block boundaries:
[TABLE]
equivalently for whenever . Matrix-wise, is block diagonal: . Under (2), block masses are conserved and conditionals evolve block-wise:
[TABLE]
Coarse variables (block masses) and within-block conditionals.
For define
[TABLE]
Then decomposes as a convex mixture of conditionals within the block:
[TABLE]
For each block, invariant measures and nonemptiness of the steady set is given by:
[TABLE]
Existence. Since every is a finite row-stochastic matrix, it admits at least one invariant distribution (e.g. by Brouwer’s fixed point theorem on the simplex or Perron–Frobenius for ), hence for all . Given an initial distribution , the reachable steady set is
[TABLE]
which is nonempty. Intuitively, collects all steady states that (i) fully relax within each block and (ii) preserve the initial coarse masses fixed by non-ergodic constraints.
Block primitivity.
Primitivity of a block kernel (irreducible and aperiodic; equivalently, for some ) is invoked only to conclude that the within-block conditionals converge to a unique invariant . For a block kernel , with constant , means
[TABLE]
which implies total-variation contraction at most per step. We also define coefficient
[TABLE]
which bounds the one-step total-variation contraction by .
1.2 Key Lemmas
Lemma 1** (Preservation of block mass and conditional evolution).**
Let with block-invariant as in (2). Then for all ,
[TABLE]
and, whenever ,
[TABLE]
Proof.
By block invariance, for and [math] otherwise. Hence .
which proves (9). For any measurable ,
[TABLE]
establishing (10). ∎
Lemma 2** (Block decomposition of KLD).**
Let with and supported in disjoint blocks . Then, for any ,
[TABLE]
Proof.
Using the disjointness and writing for ,
[TABLE]
which is (12). ∎
Equations (9)–(10) show that the dynamics preserves coarse variables and evolves conditionals within each block, while (12) cleanly separates within-block divergences from a coarse-mass mismatch term. These identities will be the backbone for the Lyapunov property established in Sec. 1.3.
1.3 Lyapunov property of the KLD potential
Statement. Let with a block-invariant kernel (Sec. 1.1).
Theorem 1** (KLD potential is Lyapunov under block invariance).**
For all ,
[TABLE]
If, in addition, each block kernel is primitive (irreducible and aperiodic) with unique invariant , then
[TABLE]
Proof.
Fix and write with . Block masses are conserved along the trajectory (Lemma 1), hence . By the KL block decomposition (Lemma 2),
[TABLE]
Applying the data-processing inequality (DPI) blockwise,
[TABLE]
and inserting (17) into (16) yields
[TABLE]
Taking the infimum over proves (14). If each is primitive with invariant , then and (15) follows. ∎
Robustness to weak inter-block leakage and re-partitioning
Motivation.
Secs. 1.2–1.3 establish a Lyapunov principle for under exact block invariance. To examine robustness to weak violations (small inter-block leakage or re-partitioning), we introduce a leakage-tolerant potential that continuously extends and preserves its qualitative behavior up to slack.
Leakage-tolerant admissible set and closed form (corrected).
When leakage is small over the observation window, relax coarse masses by and define
[TABLE]
By KL block decomposition and KKT optimality, the optimizer has the form
[TABLE]
where is chosen so that . Hence
[TABLE]
Since is continuous and strictly decreasing in , is found by a short bisection on .
A self-contained derivation and a sufficient threshold for strict decrease under leakage are provided in Appendix A.
Continuity and small-leakage persistence.
As , . Hence, under sufficiently small leakage, the qualitative properties proved for (monotonicity along the dynamics, long-time limit, and the thermodynamic reading per refresh) persist up to an relaxation.
Coarsening by merging leaking blocks.
If mutually leaking blocks are merged to form a coarser partition , data processing implies . Coarsening restores exact block invariance at the partition level, at the price of a more conservative (smaller) KL-based potential and a weaker maintenance-cost bound.
2 Instantiations
2.1 Image replication via Gaussian convolution
Block-patterned model.
First, we model an image with an explicit block (mosaic) structure: the pixel grid is partitioned into disjoint rectangular regions that remain isolated in the non-ergodic variant (no cross-region mass transfer). Figure 2 uses three blockings of the same image: (top), (middle), and (bottom). The ergodic variant corresponds to the same update without any blocking (global mixing).
We model a single replication step as a Markov smoothing map implemented by a discrete Gaussian convolution on followed by re-quantization. The kernel coincides with here. The kernel (discrete, renormalized) is given by:
[TABLE]
so that . The (global) discrete convolution is
[TABLE]
and in the non-ergodic (blockwise) variant the sum is restricted to pixels belonging to the same predefined region, which simply makes the block diagonal.
Let denote the (normalized) mosaic block distribution, histogram, before step . The convolution (21) followed by the same binning induces the one-step Markov channel in the mosaic block distribution, denoted so that
[TABLE]
with row vectors acting on the right.
Recorded metrics.
We view the histogram on a finite state space (intensity bins).
[TABLE]
For Fig. 2 (Appendix B), values are shown in bits (base 2). Each panel annotates a certified and the corresponding for its (blockwise) kernel.
Changing minimizers.
When a block admits multiple invariant measures ( not a singleton, e.g. reducible blocks), the minimizer of can change along the trajectory even though remains nonincreasing. A concrete three-state reducible example with an explicit switching of the KLD minimizer is given in Appendix G.
2.2 DNA replication as a block-diagonal substitution process
Biophysical context.
Second, we model DNA replication with the proofreading/repairing mechanism after copying. DNA polymerases move on copied DNA stochastically with forward/backward steps, proofreading, and context-dependent kinetics [8, 9, 10, 11, 12]. To capture non-ergodicity induced by compositional structure (e.g. AT- vs. GC-rich segments), we model replication as a block-diagonal Markov process on nucleotides.
Modeling stance.
The AT/GC split is a biologically motivated stylized coarse-graining: it captures slow exchange between compositionally distinct pools. Small ATGC exchange can be handled by the leakage tolerance potential or by coarsening the partition (see “Robustness to weak interblock leakage”).
Block-diagonal dynamics.
Let with two blocks and . A one-step substitution kernel (copying) with block invariance (2) is
[TABLE]
with encoding effective substitution tendencies per step (arising from selectivity, context, and post-replicative processing). The block masses and are conserved by the lemma 1.
Proofreading/repair channel.
To incorporate proofreading/repair, we add a blockwise operator that is invoked with probability after extension:
[TABLE]
with typically (improved selectivity). The effective one-step kernel is the convex mixture.
[TABLE]
which remains block diagonal and therefore satisfies (2). The replication update reads
[TABLE]
Primitivity in this setting. For a two-state block , primitiveness is equivalent to and with ; in particular, suffices. Under the mixture , if has strictly positive entries then any makes all effective entries positive, hence each block becomes primitive and .
KLD potential with unique block invariants.
Assume that each block chain admits a unique invariant . Then, combining (1) with (12) gives
[TABLE]
By Theorem 1, is a Lyapunov function for the blockwise dynamics: for all , and as .
Local detailed balance derivation.
Within each two-state block, write the undriven rates as
[TABLE]
At equilibrium (no chemical drive), detailed balance with the block’s stationary distribution gives
[TABLE]
When a proofreading cycle provides a chemical affinity per round-trip, the local detailed balance (cycle thermodynamics) shifts log rate odds by :
[TABLE]
Equivalently, in odds form,
[TABLE]
Thus, the drive fixes odds (ratios) but not individual rates; pinning (or ) separately requires an additional timescale constraint (for example, keeping fixed), which we do not assume here. As is standard in stochastic thermodynamics, the exponential tilt of rate odds by the chemical cycle affinity follows from network cycle thermodynamics. Equations (32)–(33) encode local detailed balance for rate odds; they shape steady odds and relaxation speed but do not by themselves imply primitivity, which is a structural (irreducible+aperiodic) property; cf. Theorem 2.
Note. The exponential tilt in Eq. (33) biases odds but does not by itself specify the steady entropy production rate; the latter can remain positive even when under primitive blocks.
Energetic bias (phenomenology).
In kinetic proofreading a chemical drive provides an affinity per cycle (e.g., via nucleotide hydrolysis). Within each invariant block, this drive tilts the two-state odds toward the proofreading-favored direction according to Eq. (33), sharpening the steady composition. Because decomposes over blocks, a stronger drive typically steepens the within-block basins (reducing the Bernoulli variance around ) and thus accelerates the monotone decay of guaranteed by Theorem 1. Crucially, the existence and monotonicity of do not require a drive; the drive only modifies the speed and the steady odds.
Primitivity of blocks and relation to Eq. (35).
For the two-state blocks in Example 2, a practical sufficient condition for block primitivity is strict positivity of every entry of the effective transition kernel: . Then each block is irreducible and aperiodic (hence primitive), and (31) implies . If or , irreducibility fails; if (and analogously for CG), period-2 oscillations arise unless additional repair/proofreading steps restore positive diagonal entries. Equation (33) (Eq. 35) expresses how biases rate ratios; it determines the steady odds and relaxation speed but is not, by itself, a primitivity condition, which depends on positivity and aperiodicity of the effective kernels.
Notes. The sign of sets the favored direction; reversing the operating bias corresponds to . At stationarity the block-wise odds inherit the exponential tilt: and , consistent with the proofreading picture of Hopfield [13]. This connects proofreading accuracy to energetic cost in line with kinetic proofreading thermodynamics [13, 14].
Recorded metrics and bookkeeping.
At each step, we record: , , , and , with monotone ensured by Theorem 1. Because is block diagonal by construction, coarse transitions between vanish at one step. Block-level confusion rates under small inter-block leakage are analyzed in the leakage section.
Readouts and figures.
The trajectories in Fig.2 show an increase in and , a decrease in , and a monotone decay of , in agreement with Theorem 1. Figure 3 shows the potential landscape on , where is the A fraction in and the C fraction in (Appendix D).
The contour plot shows the KLD potential on , where is the fraction A in the AT block and is the fraction C in the GC block. The unique minimum (blue marker) occurs at , i.e., at the block-wise invariants determined by the effective rates. Because is a sum of blockwise KL terms, the level sets are nearly axis-aligned ellipses (here close to circular since and the curvatures are similar). A second-order expansion around gives with and , yielding coefficients and (nats), respectively—consistent with the nearly isotropic contours. Increasing proofreading bias decreases or , steepening the basin and accelerating the monotonic decay of (Theorem 1). The separable, convex landscape highlights that, under block invariance, the non-ergodic relaxation proceeds independently within blocks and converges to the reachable steady point (Fig. 3).
Note on parameter sets. Figure 2 uses a symmetric GC block (; ), whereas Figure 3 uses an asymmetric GC block leading to . The two figures illustrate, respectively, symmetric and biased within-block odds.
An information-theoretic second law
Standing assumptions.
We consider a discrete-time Markov evolution on a finite state space, with a block-invariant kernel as in Sect. 1. Let denote the one-step image of . The KLD potential is
[TABLE]
where is the reachable steady set (Def. (1)). By Theorem 1, for all .
Step variables and their roles.
Define the potential drop and the one-step mismatch by
[TABLE]
Nonnegativity holds as follows: (i) by the Lyapunov monotonicity of ; (ii) because KLD is nonnegative (and iff ).
Decomposition of the step production.
Define the dimensionless step production
[TABLE]
It gathers the irreversible loss within one update () and the progress toward the reachable steady set ().
Proposition 1** (Nonnegativity and telescoping sum).**
For any block-invariant trajectory ,
[TABLE]
Proof.
By (34) and Theorem 1, ; KLD nonnegativity gives , hence . Summing yields . ∎
Equation (36) states that for any horizon ,
[TABLE]
Thus the accumulated one-step mismatch and the state-function decrease are jointly nonnegative—an information-theoretic second-law inequality under non-ergodic (block-invariant) dynamics. The key departure from the classical ergodic setting is that references the reachable steady set rather than a single invariant distribution.
Theorem 2** (Primitivity of block kernels).**
Let be a block transition kernel. If each block is primitive (irreducible and aperiodic), then the system admits a unique invariant distribution within each block, and the dynamics converge to this invariant.
Theorem 3** (Second law for non-ergodic replication: minimal form).**
Equivalently to Proposition 1, for all and ,
[TABLE]
In physical units, set and .
Proof.
Immediate from Proposition 1. ∎
Remark 1** (Tightness conditions).**
* iff , i.e., (i) (a fixed point of ), and (ii) , which requires blockwise tightness of DPI as in Remark 1. Otherwise, .*
Thermodynamic reading.
measures the distance to the reachable steady set; its drop plays the role of an informational free-energy decrease, while quantifies stepwise dissipative loss of distinguishability. Hence acts as a nonnegative production:
[TABLE]
The monotonicity of uses Lemma 2 and DPI applied blockwise, with . If blocks leak, ceases to align with the one-step map and may increase in one step We describe the blocks leak in Appendix A.
Extensions (time-dependent/continuous-time).
(1) Time-dependent kernels. If each shares the same block partition holds blockwise, then still holds and the theorem remains valid with . (2) Continuous-time CTMC. For generator and propagator , small- expansions give , while for all (Theorem 2 ensures positivity/primitivity). Integrating yields the continuous-time analogue:
[TABLE]
Summary.
We (i) defined and , (ii) separated their sources of nonnegativity (KLD vs. Lyapunov monotonicity), (iii) derived the telescoping-form inequality, and (iv) characterized equality, interpretation, and extensions. This mirrors Hatano–Sasa/Esposito–Van den Broeck–type formulations for Markov jump processes while crucially referencing a set of reachable steady states rather than a single invariant measure.
3 Discussion
KLD potential as informational free energy.
Under block invariance, the coarse variables are conserved (Lemma 1) while the within-block conditionals relax toward block-wise invariants. The potential in (1) therefore measures the nonequilibrium information retained beyond the conserved coarse structure. Its monotone decay (14) provides an information-theoretic second law for non-ergodic replication: fine-scale distinguishability is irreversibly lost, whereas coarse composition is preserved.
Per-step bookkeeping and physical units.
The minimal second law above decomposes the step production into two nonnegative parts, and , cf. (45). In physical units, the potential drop defines a informational free-energy change.
[TABLE]
while quantifies the stepwise dissipated “informational heat.” Together they account for the net degradation incurred by one replication step.
Ergodic vs. non-ergodic limits.
If the reachable steady set collapses to a single invariant distribution (ergodic limit), reduces to the standard KL-to-steady Lyapunov function. Under non-ergodic block-invariant constraints, is minimal KLD to the steady set , so its decay quantifies relaxation under conserved coarse masses. This distinction is essential for replication processes where structural constraints inhibit global mixing.
Tightness and equality cases.
The equality in (14) requires blockwise tightness of the data processing inequality (Remark 1); operationally, this corresponds to being in (or effectively in) a blockwise steady state. Despite such fixed points, the decrease is strict and serves as a sensitive progress variable for replication-driven relaxation.
Thermodynamic meaning of a non-zero asymptotic .
Interpretation at long times. The following clarifies the thermodynamic reading of a non-zero asymptotic . Our KLD potential quantifies distance to the reachable steady set that preserves coarse variables (block masses). In a driven NESS with primitive blocks, even though steady dissipation (housekeeping heat) can remain positive; is a state function, not a direct measure of instantaneous entropy production. A strictly positive long-time value emerges only when the trajectory is persistently kept away from the reachable set, e.g. due to weak inter-block leakage, non-primitive blocks, or active enforcement of coarse masses. In that case, choosing yields
[TABLE]
so is the minimal informational free-energy cost to refresh the state back to the admissible coarse constraint. If refreshes occur with frequency , the corresponding maintenance power satisfies , where is the stationary value under the leak/drive. Thus, a non-zero asymptotic can be read as a lower bound on the energetic cost of maintaining a coarse-grained steady state while microscopic erasure/copying continuously occurs [15, 16].
4 Conclusion and Outlook
We formulate replication as a discrete Markov map under block invariance and prove that minimal KLD to the reachable steady set,
[TABLE]
is a Lyapunov function (Theorem 1). This yields an information-theoretic second law for non-ergodic replication, complementary to Landauer-type results for erasure. Instantiations in Gaussian image copying and DNA block-diagonal substitution with proofreading exhibit the predicted behavior: monotone , increasing and cross-entropy, and decreasing . Future directions include (i) force-resolved single-molecule tests of potential drops and no-free-copying bounds, (ii) extensions to multiscale block hierarchies and heterogeneous kinetics, and (iii) quantum/continuous-state analogues where contractive metrics (e.g. quantum -divergences) may provide replication second laws under conserved coarse observables.
Appendix A: Derivation and leakage threshold
Closed-form expression for (corrected).
Write with , and . By the block decomposition of KL,
[TABLE]
For fixed , the inner minimization is attained at . Thus
[TABLE]
with , . This is a convex program. The Lagrangian with multipliers (simplex) and (box) is
[TABLE]
KKT conditions (necessary and sufficient here) yield, for an optimum ,
[TABLE]
[TABLE]
Hence interior coordinates () satisfy ; active coordinates stick to the nearest bound. Equivalently, the solution is the scaled-and-clipped vector that also satisfies the simplex constraint:
[TABLE]
where is uniquely determined by the normalization. Substituting back gives
[TABLE]
The associated minimizer is on each block, i.e. .
Continuity.
As , the box collapses to , so and .
Sufficient threshold for strict decrease under leakage.
Let and . Define
[TABLE]
Using the KL block decomposition between steps,
[TABLE]
the second line is . By convexity of and , the first line is bounded by . Therefore
[TABLE]
and a sufficient condition for a strict one-step decrease is
[TABLE]
Appendix B:Simulation protocol for Fig. 1 (Gaussian-copy model)
Software and environment. All results in Fig. 1 were generated in Python (NumPy/SciPy/Matplotlib). Gaussian smoothing uses scipy.ndimage.gaussian_filter with boundary condition mode="reflect".
Domain and initialization. We use three types of pixel grid. The image domain is partitioned into a regular tiling of rectangular blocks (Fig. 1 uses ; we also verified , and ). Inside each block, a binary pattern is drawn i.i.d. from a Bernoulli law with a checkerboard success probability: even blocks use , odd blocks use . The random seed is fixed to . The resulting matrix is normalized to a probability mass function (pmf) .
Replication step (). Let denote the current pmf on pixels. We set pixels and apply a Gaussian smoothing, followed by renormalization so that . Two cases are considered:
- •
Ergodic (global): Gaussian smoothing is applied to the entire image to produce .
- •
Non-ergodic (blockwise): The image is split into blocks; the same Gaussian is applied independently within each block (no cross-block smoothing). The blocks are then stitched back together to form . This preserves the total mass inside each block at every step.
In both cases, we update . We run and store snapshots at .
Information measures (base , in bits). At each step we compute
[TABLE]
where terms with or are omitted in the sum to avoid . (To convert bits to nats multiply by .)
KLD potential . We use the Lyapunov-type potential consistent with the main text:
- •
Ergodic (global) case: , where is the unique invariant histogram under global convolution dynamics (approximated numerically by iterating to stationarity).
- •
Non-ergodic (blockwise) case: Let index blocks, , the normalized histogram within the block, and the uniform histogram over block . Then
[TABLE]
which coincides with the distance to the reachable steady set with fixed block masses.
Visualization and units. Time series plots show , , , and versus the replication step . Snapshots at the specified steps use a common grayscale colorbar. All values are reported in bits.
Sanity condition on . If the Gaussian width exceeds approximately one-quarter of the smallest block edge, boundary effects may dominate. In Fig. 1 (block size , ) this issue does not arise. The same qualitative trends were observed for and partitions.
Appendix C:Simulation details for Fig. 2 (time series)
Model reference & parameters (Fig. 2).
We use the two-block Markov model of App. C.2 (block-diagonal kernel; one-step mixture ; effective rates as in Eq. (43) and blockwise invariants therein). For Fig. 2 we set (nats)
[TABLE]
giving
[TABLE]
and invariants
[TABLE]
Initial condition and conserved masses.
We initialize and normalize. Block masses
[TABLE]
are conserved by block invariance; we store and for the potential below.
Recorded quantities (natural logs; nats).
At step we set (for ) and record
[TABLE]
[TABLE]
The KLD potential (Def. (1)) reduces to the sum of blocks.
[TABLE]
with and .
Iteration.
We iterate
[TABLE]
with . At each we first record ; then, if , we compute and record , , and , and finally set .
Appendix D: Simulation details for Fig. 3 (potential landscape)
D.1 Model and objective.
We consider two invariant blocks and . On the grid , we parameterize a block-wise distribution.
[TABLE]
where is the A fraction in the AT block and is the C fraction in the GC block. The KLD potential (Def. (1)) reduces to the separable sum
[TABLE]
in nats. We plot over and mark the minimum .
D.2 Effective rates and steady states.
One step is a convex mixture of an extension channel and a proofreading channel with probability . Each block is
[TABLE]
[TABLE]
so, the effective rates are
[TABLE]
AT block (Fig. 2): . GC block: . The blockwise invariants (for ) are
[TABLE]
[TABLE]
We take unless otherwise noted. The blue marker in Fig. 3 is placed at .
D.3 Grid and evaluation.
We use a grid on . For Bernoulli pairs we evaluate
[TABLE]
with safe clipping to avoid . The color scale shows in nats (“viridis” colormap). Axes: = A fraction (AT), = C fraction (GC).
D.4 Minimal Python excerpt (reproducibility).
import numpy as np
mixture rate
rho = 0.30
AT block (same as Fig.2)
alpha, beta = 0.020, 0.010 alpha_p, beta_p = 0.005, 0.003 ae = (1 - rho)alpha + rhoalpha_p # 0.0155 be = (1 - rho)beta + rhobeta_p # 0.0079
GC block (asymmetric, to place y* \approx 0.60)
gamma, delta = 0.014, 0.021 gamma_p, delta_p = 0.004, 0.006 ge = (1 - rho)gamma + rhogamma_p # 0.0110 de = (1 - rho)delta + rhodelta_p # 0.0165
block weights
w1, w2 = 0.5, 0.5
invariants for [[1-a, a],[b, 1-b]]
pi1_A = be/(ae+be); pi1_T = ae/(ae+be) # (0.338, 0.662) pi2_C = de/(ge+de); pi2_G = ge/(ge+de) # (0.600, 0.400)
def kl_bernoulli(p, q, eps=1e-12): p = np.clip(p, eps, 1.0 - eps) q = np.clip(q, eps, 1.0 - eps) return p*np.log(p/q) + (1-p)*np.log((1-p)/(1-q))
grid and potential values (nats)
N = 101 xs = np.linspace(0.0, 1.0, N) # A-fraction in AT ys = np.linspace(0.0, 1.0, N) # C-fraction in GC X, Y = np.meshgrid(xs, ys, indexing=’xy’) V = w1kl_bernoulli(X, pi1_A) + w2kl_bernoulli(Y, pi2_C)
minimum location for the blue marker:
x_star, y_star = pi1_A, pi2_C
This excerpt computes the potential field on the grid and the minimum . The plotted Fig. 3 uses a filled contour of , the “viridis” colormap, and annotates with a blue marker.
Appendix E:Block primitivity in DNA Example and convergence rate
Necessary and sufficient conditions for two-state blocks.
For , primitive and . Hence suffices.
Effect of proofreading/repair mixing.
If has strictly positive entries and , then all effective entries of are strictly positive, implying primitivity even when is period-2 ().
Relation to Eq. (33) and detailed balance.
Eq. (33) encodes local detailed balance on the enlarged network; the coarse two-state block remains reversible with invariant , so Eq. (35) sets steady odds and speeds but is not the primitivity criterion.
Convergence rate (sketch).
The second eigenvalue of a two-state block is ; thus total variation decays geometrically with factor .
Appendix F: A minimal non–block–invariant counterexample and a leakage threshold
Symbols and definitions.
State space and blocks:
[TABLE]
Initial distribution . Block (coarse) masses:
[TABLE]
Reachable steady set (coarse masses fixed).
[TABLE]
One-step update with a non–block–invariant kernel.
[TABLE]
Cross–block entries are and . Define the net leak
[TABLE]
(Numerical values can be read off directly from .)
Block KL decomposition and consequence.
For any ,
[TABLE]
Since is free, the minimizer sets ; for the singleton block, . Therefore
[TABLE]
(Thus measures the coarse-mass mismatch when leakage is present.)
A sufficient leakage threshold for one-step decrease.
Let and . Define
[TABLE]
A convenient sufficient condition for a strict one–step decrease is
[TABLE]
Proof sketch / origin of the constants.
By the block KL decomposition,
[TABLE]
The quadratic term is upper bounded by via convexity of and . The linear term is at most by definition of (within-block contraction toward ). Combining the two gives
[TABLE]
which yields the threshold (44).
Appendix G: Non-primitive block with a changing minimizer
Notation. Here denotes a within-block abstract Markov kernel (not the image-induced of Sec. 2.1).
Consider a single block with a reducible kernel
[TABLE]
States and are absorbing; is transient and jumps to or in one step with probabilities and , respectively. Hence the invariant set is
[TABLE]
Let denote the within-block law started from . Then
[TABLE]
For any ,
[TABLE]
which is minimized at .
Nonincrease of and minimizer switching.
If the global partition weight on this block is and other blocks are fixed, the contribution of block to is for some . From (47)–(48), for the minimizer is and
[TABLE]
If we perturb the initial condition to with a small , then at time [math] the minimizer is , whereas for it becomes . Thus the blockwise minimizer changes between steps, yet remains nonincreasing by Theorem 1. This shows that minimizer switching is generic whenever is not a singleton (reducible blocks).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] R. Hershberg and D. A. Petrov. Evidence That Mutation Is Universally Biased Towards AT in Bacteria. P Lo S Genet. , 6 (9):e 1001115, 2010. doi: 10.1371/journal.pgen.1001115 . · doi ↗
- 2[2] K. J. Fryxell and W. J. Moon. Cp G Mutation Rates in the Human Genome Are Highly Dependent on Local GC Content. Mol. Biol. Evol. , 22 (3):650–658, 2005. doi: 10.1093/molbev/msi 043 . · doi ↗
- 3[3] D. N. Cooper, M. Mort, P. D. Stenson, E. V. Ball, and N. A. Chuzhanova. Methylation-mediated deamination of 5-methylcytosine appears to give rise to mutations causing human inherited disease in Cp Np G trinucleotides, as well as in Cp G dinucleotides. Hum. Genomics , 4 (6):406, 2010. doi: 10.1186/1479-7364-4-6-406 . · doi ↗
- 4[4] V. Aggarwala and B. F. Voight. An expanded sequence context model broadly explains variability in polymorphism levels across the human genome. Nat. Genet. , 48 (4):349–355, 2016. doi: 10.1038/ng.3511 . · doi ↗
- 5[5] L. Duret and N. Galtier. Biased gene conversion and the evolution of mammalian genomic landscapes. Annu. Rev. Genom. Hum. Genet. , 10 :285–311, 2009. doi: 10.1146/annurev-genom-082908-150001 . · doi ↗
- 6[6] J. A. Capra, M. J. Hubisz, D. Kostka, K. S. Pollard, and A. Siepel. A Model-Based Analysis of GC-Biased Gene Conversion in the Human and Chimpanzee Genomes. P Lo S Genet. , 9 (8):e 1003684, 2013. doi: 10.1371/journal.pgen.1003684 . · doi ↗
- 7[7] C. C. Weber, B. Boussau, J. Romiguier, E. D. Jarvis, and H. Ellegren. Evidence for GC-biased gene conversion as a driver of between-lineage differences in avian base composition. Genome Biol. , 15 (12):549, 2014. doi: 10.1186/s 13059-014-0549-1 . · doi ↗
- 8[8] G. J. L. Wuite, S. B. Smith, M. Young, D. Keller, and C. Bustamante. Single-Molecule Studies of the Effect of Template Tension on T 7 DNA Polymerase Activity. Nature , 404 (6773):103–106, 2000. doi: 10.1038/35003614 . · doi ↗