AI-Powered Detection of Inappropriate Language in Medical School Curricula
Chiman Salavati, Shannon Song, Scott A. Hale, Roberto E. Montenegro, Shiri Dori-Hacohen, Fabricio Murai

TL;DR
This study evaluates small language models and large language models for detecting inappropriate language in medical educational materials, finding that fine-tuned small models outperform large models with prompt engineering.
Contribution
It introduces a comprehensive evaluation of SLMs and LLMs for IUL detection in medical curricula, highlighting the effectiveness of fine-tuned models over prompt-based LLMs.
Findings
SLama-3 8B and 70B underperform compared to SLMs.
Multilabel classifiers achieve highest accuracy on annotated data.
Adding unflagged excerpts as negative examples improves classifier performance.
Abstract
The use of inappropriate language -- such as outdated, exclusionary, or non-patient-centered terms -- medical instructional materials can significantly influence clinical training, patient interactions, and health outcomes. Despite their reputability, many materials developed over past decades contain examples now considered inappropriate by current medical standards. Given the volume of curricular content, manually identifying instances of inappropriate use of language (IUL) and its subcategories for systematic review is prohibitively costly and impractical. To address this challenge, we conduct a first-in-class evaluation of small language models (SLMs) fine-tuned on labeled data and pre-trained LLMs with in-context learning on a dataset containing approximately 500 documents and over 12,000 pages. For SLMs, we consider: (1) a general IUL classifier, (2) subcategory-specific binary…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2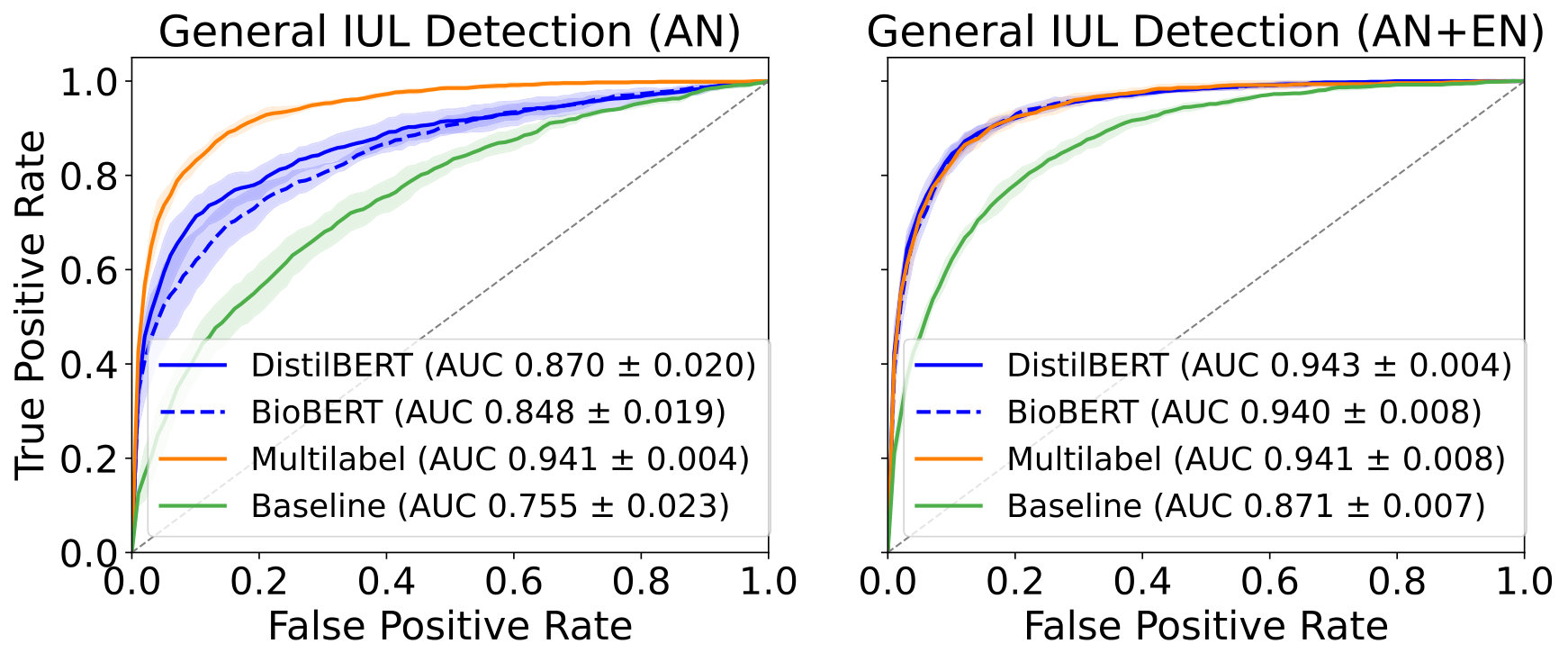 Figure 3
Figure 3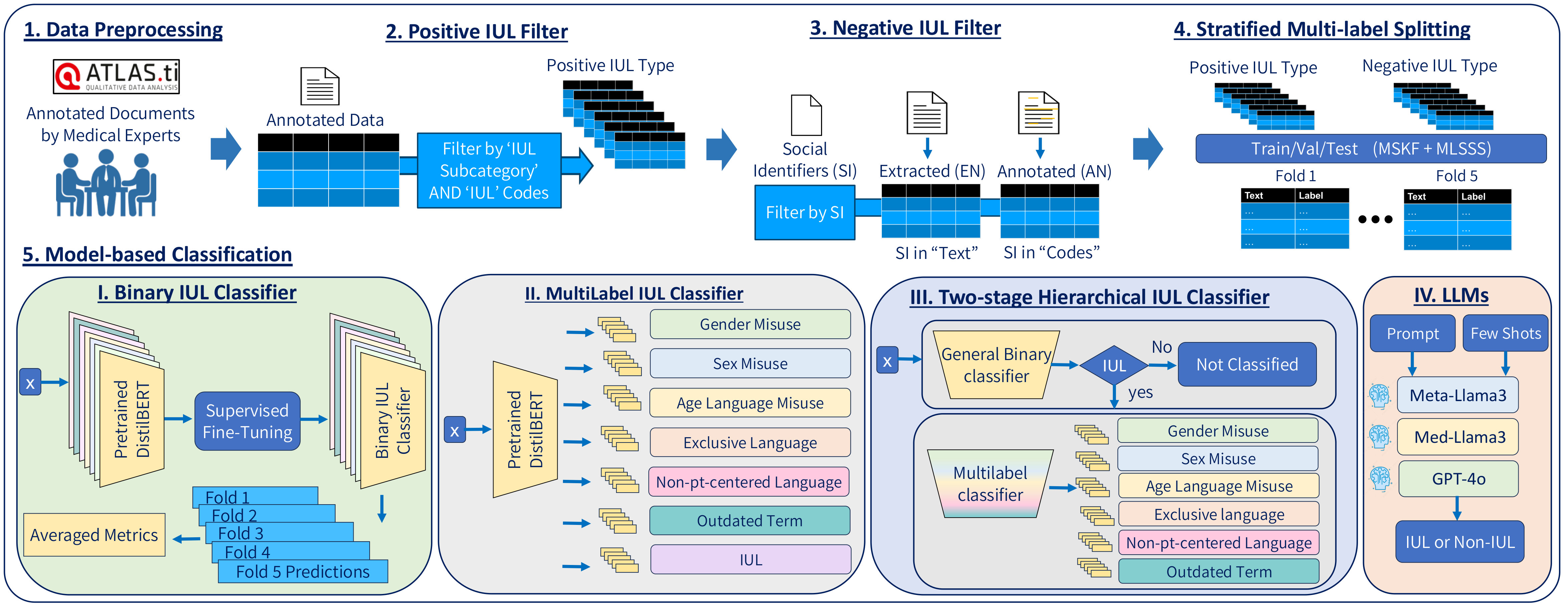 Figure 4
Figure 4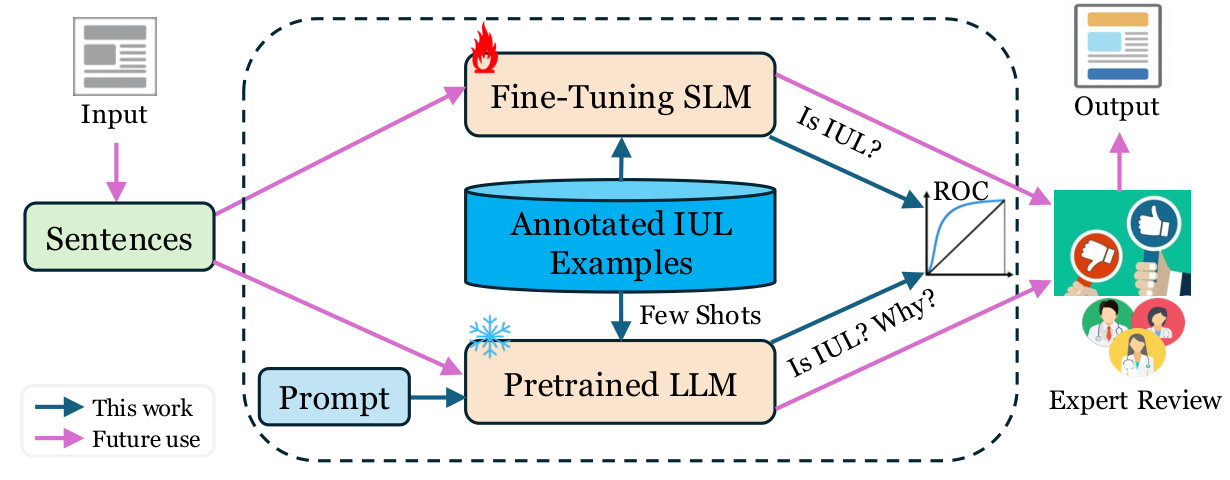 Figure 5
Figure 5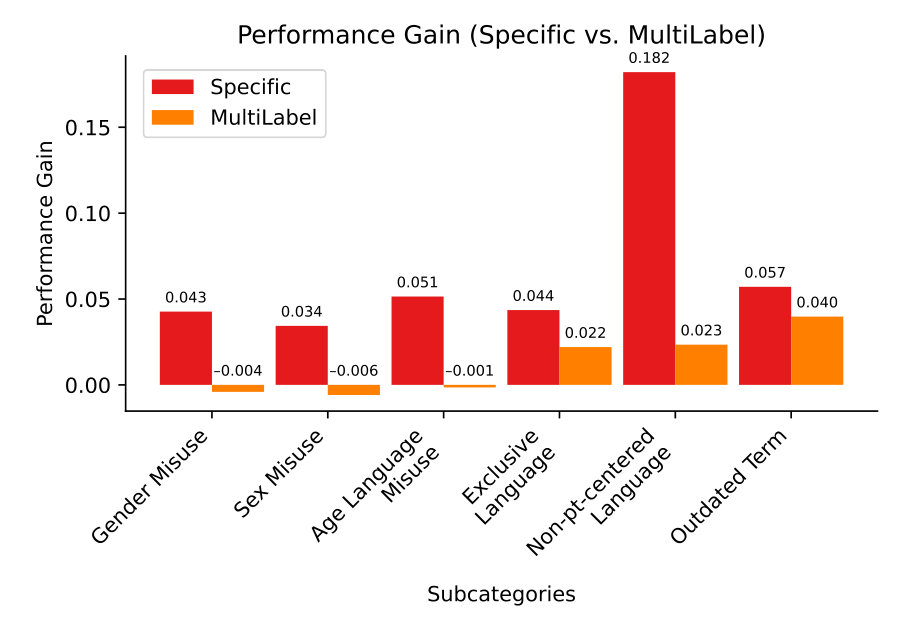 Figure 6
Figure 6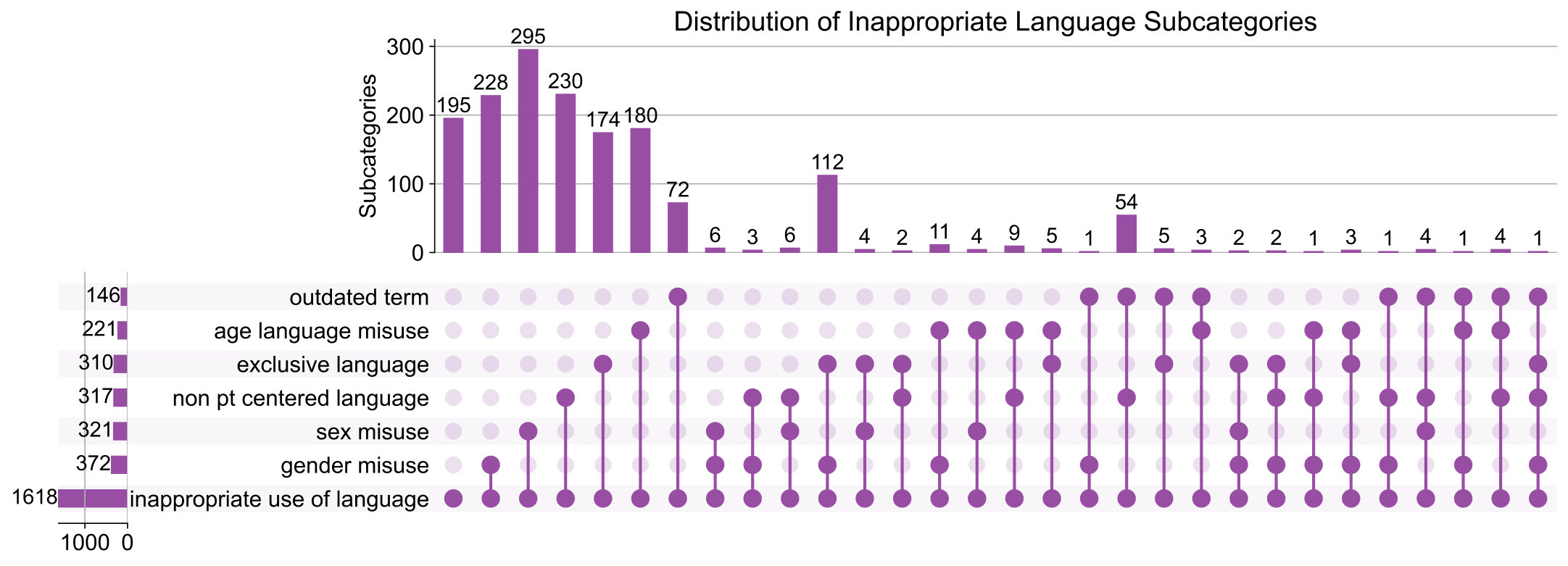 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.