Applying Plain Transformers to Real-World Point Clouds
Lanxiao Li, Michael Heizmann

TL;DR
This paper explores the use of plain transformers for real-world point cloud understanding, emphasizing fundamental components and self-supervised pre-training to achieve state-of-the-art results efficiently.
Contribution
It revisits plain transformers for complex point clouds, introduces a drop patch method for better MAE pre-training, and establishes new benchmarks in semantic segmentation and object detection.
Findings
Achieved SOTA results on S3DIS and ScanNet datasets.
Improved efficiency and performance with plain transformers.
Proposed drop patch method enhances self-supervised learning.
Abstract
To apply transformer-based models to point cloud understanding, many previous works modify the architecture of transformers by using, e.g., local attention and down-sampling. Although they have achieved promising results, earlier works on transformers for point clouds have two issues. First, the power of plain transformers is still under-explored. Second, they focus on simple and small point clouds instead of complex real-world ones. This work revisits the plain transformers in real-world point cloud understanding. We first take a closer look at some fundamental components of plain transformers, e.g., patchifier and positional embedding, for both efficiency and performance. To close the performance gap due to the lack of inductive bias and annotated data, we investigate self-supervised pre-training with masked autoencoder (MAE). Specifically, we propose drop patch, which prevents…
Click any figure to enlarge with its caption.
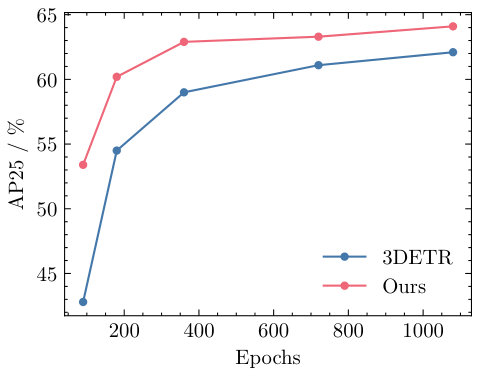 Figure 1
Figure 1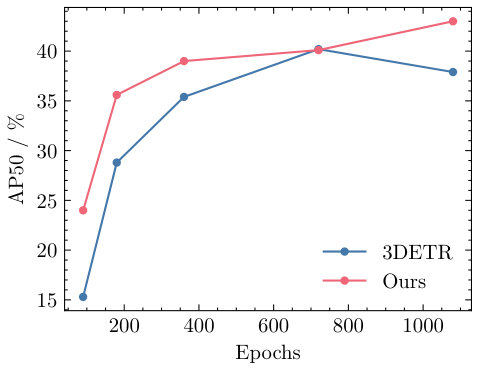 Figure 2
Figure 2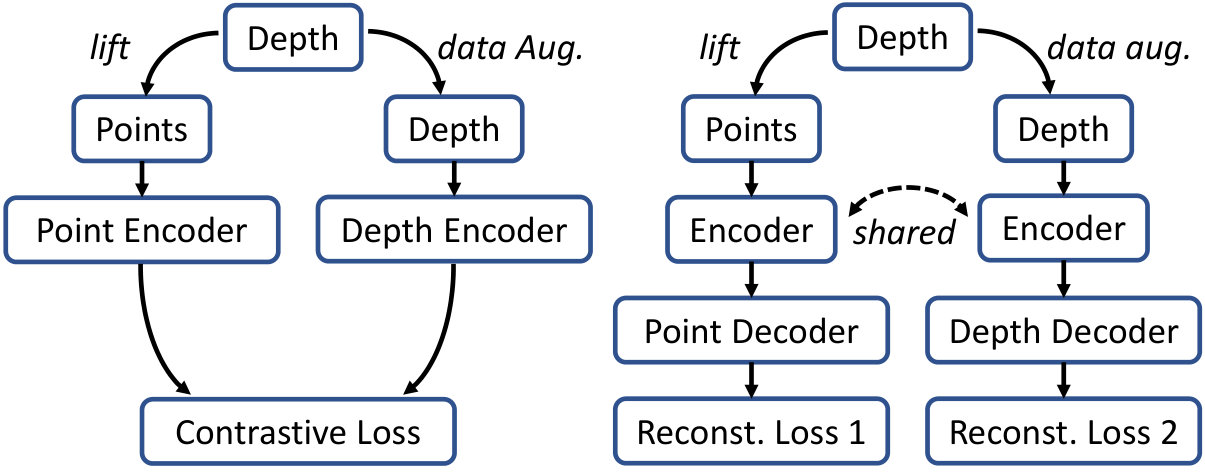 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5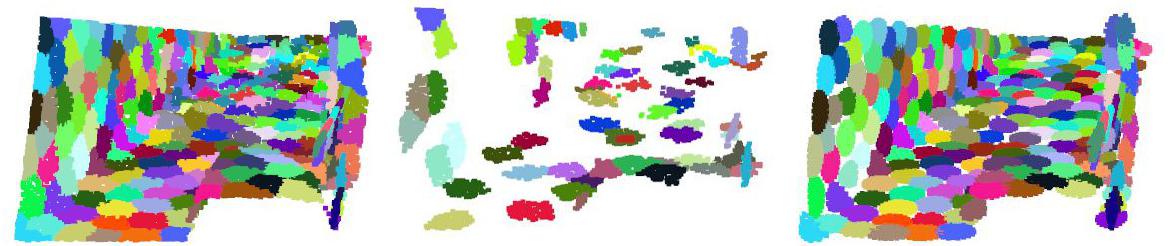 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9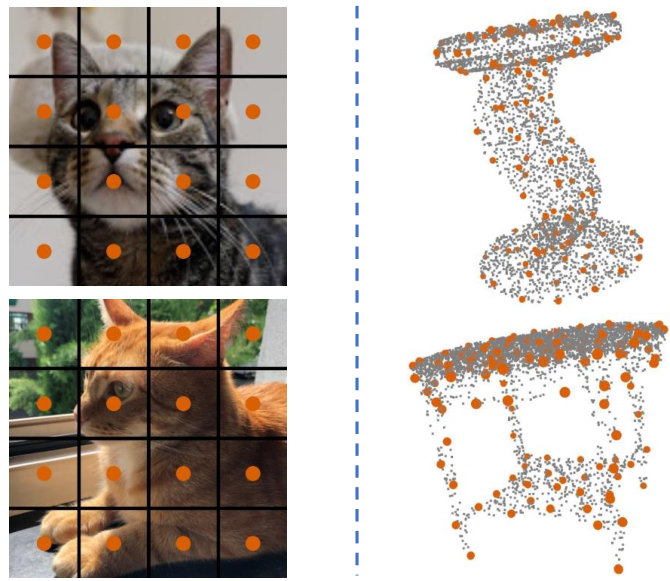 Figure 10
Figure 10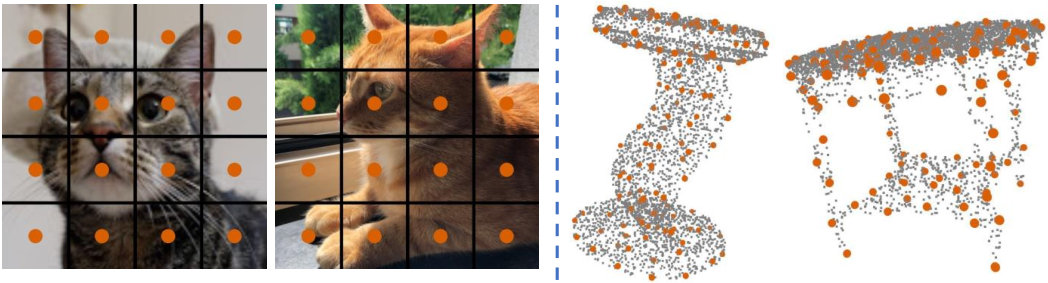 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14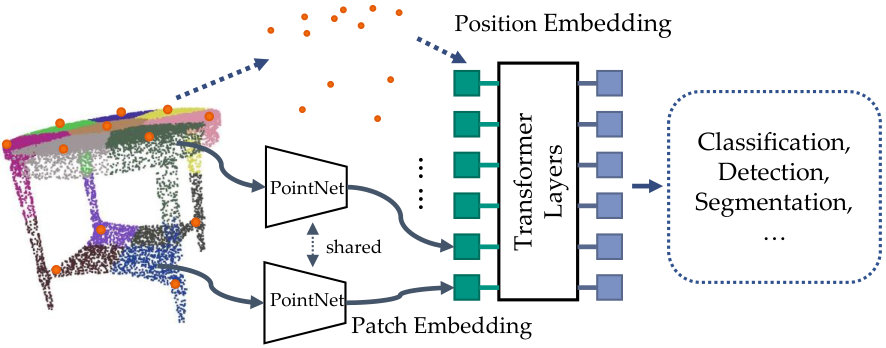 Figure 15
Figure 15| Methods | Pre. | Tr. | AP25 | AP50 |
| VoteNet [43] | 58.6 | 33.5 | ||
| PointContrast [58] | ✓ | 59.2 | 38.0 | |
| Hou et al. [21] | ✓ | - | 39.3 | |
| 4DContrast [9] | ✓ | - | 38.2 | |
| DepthContrast (1) [64] | ✓ | 61.3 | - | |
| DepthContrast (3) [64] | ✓ | 64.0 | 42.9 | |
| DPCo [25] | ✓ | 64.2 | 41.5 | |
| 3DETR [36] | ✓ | 62.1 | 37.9 | |
| PointFormer [37] | ✓* | 64.1 | 42.6 | |
| MaskPoint (L3) [29] | ✓ | ✓ | 63.4 | 40.6 |
| MaskPoint (L12) [29] | ✓ | ✓ | 64.2 | 42.1 |
| \rowcolorgray!25 Ours (512 patches) | ||||
| – from scratch | ✓ | 61.6 | 38.8 | |
| – MAE | ✓ | ✓ | 62.7 | 42.2 |
| – MAE + DP | ✓ | ✓ | 64.1 | 43.0 |
| \rowcolorgray!25 Ours (1024 patches) | ||||
| – from scratch | ✓ | 62.4 | 41.3 | |
| – MAE | ✓ | ✓ | 64.6 | 44.8 |
| – MAE + DP | ✓ | ✓ | 65.6 | 45.3 |
| Methods | Pre. | Tr. | mAcc | mIoU |
|---|---|---|---|---|
| PointNet++ [41] | - | 53.5 | ||
| MinkowskiNet-32 [10] | 71.7 | 65.4 | ||
| KPConv [51] | 72.8 | 67.1 | ||
| PointNeXt-B [45] | 74.3 | 67.5 | ||
| PointNeXt-L [45] | 76.1 | 69.5 | ||
| pixel-to-point [30] | ✓ | 75.2 | 68.3 | |
| PointContrast [58] | ✓ | - | 70.3 | |
| DepthContrast [64] | ✓ | - | 70.9 | |
| PCT [18] | ✓* | 67.7 | 61.3 | |
| PatchFormer [61] | ✓* | - | 68.1 | |
| PointTransformer [65] | ✓* | 76.5 | 70.4 | |
| Pix4Point [46] | ✓ | ✓ | 73.7 | 67.5 |
| \rowcolorgray!25 Ours (3 layers) | ||||
| – from scratch | ✓ | 66.4 | 60.0 | |
| – MAE | ✓ | ✓ | 73.6 | 67.2 |
| – MAE + DP | ✓ | ✓ | 74.7 | 67.6 |
| \rowcolorgray!25 Ours (12 layers) | ||||
| – from scratch | ✓ | 70.0 | 63.2 | |
| – MAE | ✓ | ✓ | 75.9 | 69.5 |
| – MAE + DP | ✓ | ✓ | 77.0 | 70.4 |
| ID | Group | Pre | PE | AP25 | AP50 | |
|---|---|---|---|---|---|---|
| 1 | Ball | 512 | 59.8 | 37.9 | ||
| 2 | kNN | 512 | 60.8 | 38.0 | ||
| 3 | k-means | 512 | 59.5 | 36.3 | ||
| 4 | FPC | 512 | 60.3 | 38.1 | ||
| 5 | Ball | 512 | ✓ | 61.1 | 39.7 | |
| 6 | kNN | 512 | ✓ | 61.7 | 41.0 | |
| 7 | k-means | 512 | ✓ | 60.2 | 34.0 | |
| 8 | FPC | 512 | ✓ | 61.6 | 38.8 | |
| 9 | Ball | 512 | ✓ | ✓ | 63.4 | 42.1 |
| 10 | kNN | 512 | ✓ | ✓ | 63.7 | 42.4 |
| 11 | k-means | 512 | ✓ | ✓ | 62.7 | 38.7 |
| 12 | FPC | 512 | ✓ | ✓ | 64.1 | 43.0 |
| 13 | Ball | 1024 | ✓ | 62.4 | 41.3 | |
| 14 | kNN | 1024 | ✓ | 63.5 | 39.9 | |
| 15 | k-means | 1024 | ✓ | 59.0 | 36.6 | |
| 16 | FPC | 1024 | ✓ | 61.6 | 36.9 | |
| 17 | Ball | 1024 | ✓ | ✓ | 65.6 | 45.3 |
| 18 | kNN | 1024 | ✓ | ✓ | 65.0 | 43.5 |
| 19 | k-means | 1024 | ✓ | ✓ | 63.8 | 40.3 |
| 20 | FPC | 1024 | ✓ | ✓ | 64.6 | 44.3 |
| ID | Group | Pre | PE | Add | AP25 | AP50 | |
|---|---|---|---|---|---|---|---|
| 1 | Ball | 512 | - | - | 59.8 | 37.9 | |
| 2 | Ball | 512 | ✓ | - | - | 60.4 | 38.3 |
| 3 | FPC | 512 | - | - | 60.3 | 38.1 | |
| 4 | FPC | 512 | ✓ | - | - | 59.7 | 37.2 |
| 5 | FPC | 512 | Fourier | first | 59.9 | 38.6 | |
| 6 | FPC | 512 | MLP | first | 61.1 | 37.9 | |
| 7 | FPC | 512 | Global | first | 61.6 | 38.8 | |
| 8 | FPC | 512 | ✓ | Fourier | first | 61.6 | 40.9 |
| 9 | FPC | 512 | ✓ | MLP | first | 62.4 | 42.6 |
| 10 | FPC | 512 | ✓ | Global | first | 64.1 | 43.0 |
| 11 | FPC | 512 | Fourier | all | 60.3 | 38.6 | |
| 12 | FPC | 512 | MLP | all | 60.7 | 39.0 | |
| 13 | FPC | 512 | Global | all | 61.3 | 36.7 | |
| 14 | FPC | 512 | ✓ | Fourier | all | 61.4 | 39.2 |
| 15 | FPC | 512 | ✓ | MLP | all | 61.4 | 38.6 |
| 16 | FPC | 512 | ✓ | Global | all | 63.3 | 42.0 |
| 17 | Ball | 1024 | MLP | first | 62.1 | 40.1 | |
| 18 | Ball | 1024 | Global | first | 62.4 | 41.3 | |
| 19 | Ball | 1024 | ✓ | MLP | first | 64.3 | 44.0 |
| 20 | Ball | 1024 | ✓ | Global | first | 65.6 | 45.3 |
| ID | AP25 | AP50 | |||
| \rowcolorgray!25 1 | 50 | 25 | 25 | 64.1 | 43.0 |
| 2 | 0 | 90 | 10 | 62.8 | 40.5 |
| 3 | 0 | 75 | 25 | 62.7 | 42.2 |
| 4 | 10 | 65 | 25 | 63.3 | 42.4 |
| 5 | 20 | 55 | 25 | 63.6 | 43.1 |
| 6 | 30 | 45 | 25 | 63.9 | 43.0 |
| 7 | 40 | 35 | 25 | 63.4 | 44.3 |
| \rowcolorgray!25 | 50 | 25 | 25 | 64.1 | 43.0 |
| 8 | 60 | 15 | 25 | 63.8 | 42.4 |
| 9 | 70 | 5 | 25 | 63.2 | 41.2 |
| 10 | 50 | 10 | 40 | 63.6 | 40.2 |
| 11 | 50 | 20 | 30 | 63.8 | 43.2 |
| \rowcolorgray!25 | 50 | 25 | 25 | 64.1 | 43.0 |
| 12 | 50 | 30 | 20 | 63.7 | 43.1 |
| 13 | 50 | 40 | 10 | 62.7 | 43.2 |
| Patches | Layers | ScanNet Det. | S3DIS Seg. | ||
|---|---|---|---|---|---|
| AP25 | AP50 | mAcc | mIoU | ||
| 512 | 3 | 64.1 | 43.0 | 74.7 | 67.6 |
| 512 | 6 | 63.1 | 42.1 | 76.8 | 70.1 |
| 512 | 12 | 62.1 | 40.7 | 77.0 | 70.4 |
| 256 | 3 | 60.8 | 40.4 | 71.5 | 65.0 |
| 1024 | 3 | 65.6 | 45.3 | 73.5 | 67.1 |
| 2048 | 3 | 65.0 | 45.2 | 73.6 | 66.7 |
| Method | Op. | Mem. | Lat. | AP25 | AP50 |
|---|---|---|---|---|---|
| DPCo | 5.7 | 6.6 | 134 | 64.2 | 41.5 |
| MaskPoint (L3) | 21.4 | 17.3 | 187 | 63.4 | 40.6 |
| MaskPoint (L12) | 46.9 | 32.0 | 301 | 64.2 | 42.1 |
| Ours (=512) | 8.2 | 7.0 | 73 | 64.1 | 43.0 |
| Ours (=1024) | 11.7 | 8.7 | 108 | 65.6 | 45.3 |
| Model | Patch | Layer | All | Tr. | AP25 |
|---|---|---|---|---|---|
| Ours | 512 | 3 | 8.2 | 3.6 | 64.1 |
| Ours | 1024 | 3 | 11.7 | 6.7 | 65.6 |
| MaskPoint | 2048 | 3 | 21.4 | 14.1 | 63.4 |
| MaskPoint | 2048 | 12 | 46.9 | 39.5 | 64.2 |
| Method | Op. | Param. | TP | mAcc | mIoU |
|---|---|---|---|---|---|
| PointNeXt-S | 3.6 | 0.8 | 227 | 70.7 | 64.2 |
| PointNeXt-B | 8.9 | 3.8 | 158 | 74.3 | 67.5 |
| PointNeXt-L | 15.2 | 7.1 | 115 | 76.1 | 69.5 |
| Ours (3 layers) | 6.0 | 1.9 | 147 | 74.7 | 67.6 |
| Ours (6 layers) | 7.2 | 3.5 | 138 | 76.8 | 70.1 |
| Ours (12 layers) | 9.7 | 6.7 | 123 | 77.0 | 70.4 |
| Pre-train | Fix Patch Embed | AP25 | AP50 |
|---|---|---|---|
| Scratch | 61.6 | 38.8 | |
| MoCo | 57.5 | 38.1 | |
| MoCo | ✓ | 60.0 | 38.4 |
| MAE | 62.7 | 42.2 | |
| MAE + Drop Patch | 64.1 | 43.9 |
| Pre-Training | AP25 (%) | AP50 (%) |
|---|---|---|
| From Scratch | 61.6 | 38.8 |
| MAE | 62.7 | 42.2 |
| MAE + Drop Patch | 64.1 | 43.0 |
| MAE + Data Aug. | 62.1 | 39.4 |
| Fine-Tune | Pre-Train | Group | |||
|---|---|---|---|---|---|
| 256 | 256 | 128 | 256 | 128 | FPC |
| 512 | 128 | 64 | 256 | 128 | FPC |
| 1024 | 64 | 64 | 512 | 64 | Ball |
| 2048 | 64 | 64 | 1024 | 64 | Ball |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
Topics3D Surveying and Cultural Heritage · 3D Shape Modeling and Analysis · Advanced Neural Network Applications
MethodsMasked autoencoder
Applying Plain Transformers to Real-World Point Clouds
Lanxiao Li Michael Heizmann
Karlsruhe Institute of Technology, Karlsruhe, Germany
[email protected] [email protected]
Abstract
To apply transformer-based models to point cloud understanding, many previous works modify the architecture of transformers by using, e.g., local attention and down-sampling. Although they have achieved promising results, earlier works on transformers for point clouds have two issues. First, the power of plain transformers is still under-explored. Second, they focus on simple and small point clouds instead of complex real-world ones. This work revisits the plain transformers in real-world point cloud understanding. We first take a closer look at some fundamental components of plain transformers, e.g., patchifier and positional embedding, for both efficiency and performance. To close the performance gap due to the lack of inductive bias and annotated data, we investigate self-supervised pre-training with masked autoencoder (MAE). Specifically, we propose drop patch, which prevents information leakage and significantly improves the effectiveness of MAE. Our models achieve SOTA results in semantic segmentation on the S3DIS dataset and object detection on the ScanNet dataset with lower computational costs. Our work provides a new baseline for future research on transformers for point clouds.
1 Introduction
Transformers [53] have shown promising performance in computer vision tasks in recent years [14, 32]. The most representative model is Vision Transformer (ViT) [14], which models an image as a sequence and extracts features using a plain transformer encoder. It is called plain since ViT consists of stacked transformer layers and does not incorporate inductive biases, e.g., translation equivariance and locality, which are, on the contrary, essential ingredients in CNNs. Although simple and effective, a plain transformer requires more training data or careful design to achieve good performance in image processing [8, 14, 57].
Because of their capability to capture informative features, transformer-based methods are also attractive in 3D compuer vision. A lot of methods have been proposed to utilize transformers for point cloud understanding [15, 18, 22, 33, 55, 65]. Since 3D data and annotation are scarcer and more expensive than the 2D counterparts, which makes it hard to train plain transformers, previous works inject inductive bias by using, e.g., hierarchical sub-sampling and local attention.
Although the modified transformers have achieved impressive results, a strong baseline, which shows the potential of plain transformers in point cloud understanding, is still missing. We believe that plain transformers are worth more research interest in the context of 3D computer vision. First, a plain transformer consists of fundamental operations, e.g., matrix multiplication and the softmax activation, which makes it relatively easy to deploy on hardware [66, 44]. However, modified transformers are non-trivial to deploy due to special operations [28], e.g., the modified attention. Furthermore, the local attention provides inductive bias but also hurts the capability to capture long-range dependencies, which are important in some tasks, e.g., detecting large objects from point clouds [43, 33]. Moreover, multi-modal transformers have invoked research interest recently, as they unify language, vision, and audio understanding [2, 23, 48, 49]. Although the inductive bias improves performance on one specific modality, it usually cannot generalize to others [2]. Thus, a baseline of plain transformers for point clouds is necessary for future research on multi-modal models.
Another issue of previous works is the complexity of evaluation tasks. Many works [15, 16, 18, 38, 60, 65] focus on classification using either clean synthetic data, e.g., ShapeNet dataset [4] or single-object real-world data, e.g., ScanObjectNN dataset [52]. We speculate that these data and tasks are too simple to convincingly justify the network design and show the full potential of transformers, which are known to have a large model capacity. Also, the design based on simple data might not generalize well on complex real-world point clouds, which limits the application of transformers in real-world tasks, e.g., robotics and autonomous driving. Moreover, due to the quadratic complexity of multi-head attention [53], plain transformers are usually computationally expensive for real-world 3D data. However, this problem could be neglected if solely small point clouds are studied.
In this work, we revisit the design of plain transformers and evaluate our methods on complicated large-scale real-world point clouds. To narrow the scope of this work, we focus on transformers as backbones and do not consider the usage as task-specific necks or heads [33, 55]. While keeping the overall architecture plain, we optimize some components of transformers for point clouds, e.g., the patchifier and position embedding. We systematically investigate existing patchifiers, e.g., ball query and kNN. Also, we introduce Farthest Point Clustering (FPC) to study the effect of non-overlapping patchifers. Furthermore, we propose incorporating global information into position embedding to better describe the patches’ position. To close the performance gap caused by lack of inductive bias, we also explore the self-supervised pre-training of our models. Based on the successful masked autoencoder (MAE) [20], we propose a novel method drop patch. It suppresses the information leakage caused by the position embedding in the decoder by only reconstructing a proportion of unseen patches. This simple method significantly improves the results of pre-training and reduces the computation.
The contribution of our work is many-fold:
We optimize some essential components of plain transformers, e.g., the patchifier and position embedding, for more effective point cloud understanding. 2. 2.
We investigate the information leakage problem in the standard masked autoencoder for 3D vision and propose drop patch for better transfer learning results. 3. 3.
We focus on complex real-world point clouds to evaluate our designs. 4. 4.
We show that with proper designs and self-supervised pre-training, plain transformers can achieve SOTA results in real-world 3D object detection and semantic segmentation while being efficient.
2 Related Works
Transformers for Point Clouds. Many previous works modify the architecture of vision transformer (ViT) [14] for point cloud understanding. Common approaches are applying local attention and down-sampling. For instance, [15, 37, 39, 65] limit the attention mechanism in a local region, which integrates the locality into transformers and reduces the computational cost. Also, Hui et al. [22] perform hierarchical down-sampling to build a pyramid architecture for large-scale point clouds. PatchFormer [61] down-samples the queries to improve efficiency. PCT [18] uses transformers to aggregate high-level features after set abstraction modules [41]. On the contrary, we intend to keep the transformer plain in this work. We use multi-head attention [53] globally and only down-sample point clouds once for patchifying.
Pre-Training without 3D Annotation. A lot of works have investigated the pre-training without 3D annotation to improve convergence and performance in 3D vision tasks. Some works attempt to directly initialize 3D networks using pre-trained 2D models, e.g., by mapping weights of 2D ConvNets to 3D ones [59] or adopting a pre-trained ViT [46]. Also, PointCLIP [63] utilizes pre-trained CLIP-models [47] to classify point clouds. Contrastive methods are usually based on the invariance of 3D features. Previous works use invariances to create a correspondence between two point clouds viewed from different view angles [58, 21], between point clouds and color images [30], between voxels and point clouds [64] or between depth maps and point clouds [25]. Also, 4DContrast [9] uses dynamic spatial-temporal correspondence in pre-training. Generative methods restore missing information from partially visible inputs. Wang et al. [54] reconstruct complete point clouds from occluded single-view ones. Point-BERT [60] follows the successful BERT [13] framework to predict the missing tokens from masked point clouds. POS-BERT [16] combines the BERT pipeline with momentum tokenizers and contrastive learning. Following masked autoencoder (MAE) [20], Point-MAE [38] reconstructs the coordinates of masked points. Point-M2AE [62] extends the MAE pipeline to hierarchical multi-scale networks. MaskPoint [29] models an implicit representation to avoid information leakage.
3 Methods
In this section, we first review the basic architecture of plain transformers for point clouds (Section 3.1). Then, we investigate two crucial but long-overlooked components in plain transformers, i.e., the patchifier (Section 3.2) and position embedding (Section 3.3). Later, we show how to pre-train our models using self-supervision (Section 3.4).
3.1 Plain Transformers for Point Clouds
As shown in Figure 1, a plain transformer can be separated into five components: a patchifier, patch embedding, position embedding, a transformer encoder consisting of multiple transformer layers, and a task-specific head. The patchifier divides the input point cloud into small patches. The patch embedding encodes each point patch into a feature vector. A PointNet [42] is usually used for patch embedding [29, 36, 38, 60]. All patch features build up a sequence, which is then fed into the transformer encoder. Since the multi-head attention is permutation-equivariant and unaware of the position of each patch, transformers require position embedding [53], which directly injects positional information into the sequence. The transformer encoder then extracts informative features, which are utilized by the task-specific head.
3.2 Patchifier
The process to build patches (i.e. patchify) can be further separated into sampling and grouping. Without loss of generality, we only consider inputs with 3D coordinates and ignore other channels, e.g., colors, because they do not affect patchifying and are assigned to respective coordinates afterward [29, 36, 38, 41, 60]. Given a point cloud with points, the patchifier first sub-samples key points using farthest point sampling (FPS) [41]. Then, the patchifier searches neighbors for each key point to build patches with . In previous works, ball query [41, 36] and k-Nearest-Neighbor (kNN) [60, 38, 46, 29] are used for grouping. The former searches points in a sphere with a given radius around each key point, while the latter assigns closest neighbors to each key point. Then, each patch is encoded into a -dimensional feature vector by the patch embedding, which is usually a shared PointNet.
Despite the different choices of patchifiers, previous works usually use a large patch number with . For instance, 3DETR [36] divides an input of 40K points into 2048 patches, which is an order of magnitude greater than a common ViT [14]. As the complexity of the multi-head attention is quadratic to the sequence length, it results in high computational costs, which limits the application of plain transformers in point cloud understanding, especially for large real-world point clouds. Also, the patchifiers in previous works generate overlapping patches. Although such a design can improve the stability of plain transformers [57], it causes information leakage during pre-training with MAE, since the masked and reserved patches might share points (see Section 3.4).
To our best knowledge, the impact of shorter sequences and different choices of patchifiers have not drawn much attention in previous research. In our work, we use a shorter sequence with to improve the efficiency of plain transformers. Also, we systematically compare different patchifiers with various setups. In addition to the aforementioned two overlapping patchifiers, we evaluate non-overlapping ones, e.g., k-means and our proposed method Farthest Point Clustering (FPC).
**Farthest Point Clustering. ** We still use FPS to sample key points . We cluster the input points into patches by assigning each point to its nearest key point . Note that, unlike kNN, each point is assigned to only one key point, so that the generated patches do not overlap. Then, we further sample points in each cluster so that each patch has the same number of points, following ball query [41]. This algorithm’s pseudo-code and implementation details are provided in the supplementary material.
3.3 Position Embedding
Position embedding is a mapping , which encodes the coordinate of each key point into a vector:
[TABLE]
Previous works use Fourier features [36, 50] or multi-layer perceptron (MLP) [38, 29] as position embedding for point clouds. They all treat each position separately, as formulated in Equation 1, and neglect the global information in all key points . While the “positions” in natural languages and images are fixed and shared across all data samples, they are content-dependent and more informative in point clouds, as shown in Figure 2. Our intuition is that the global information in position embedding might benefit point cloud understanding since it directly makes each patch aware of others’ positions. In this work, we first transform each coordinate into a high dimensional space using an MLP. Then we aggregate the global feature via global max pooling. The global feature is then concatenated to each coordinate and further projected with another MLP. Our position embedding can be formulated as follows:
[TABLE]
Then, is added to its respective patch feature , following the common practice in previous works. Note that in pre-training with MAE (Section 3.4), the global pooling in the encoder aggregates global features only from visible patches. Thus, the pooling operation does not leak information about masked patches in pre-training.
3.4 Self-Supervised Pre-Training
In this work, we use MAE to pre-train our models.
Masked Autoencoders for Point Clouds. The idea of MAE [20] is to randomly divide input patches into two disjoint subsets and . Patches are masked out, and the transformer encoder only sees the reserved patches . With a transformer-based decoder, the model is trained to reconstruct the masked patches based on their positions and visible patches. After pre-training, the decoder is abandoned, and the encoder (with patch embedding, position embedding, etc.) can be used for downstream tasks. He et al. [20] propose using a large mask ratio (e.g., ) for good performance.
However, for point clouds, MAE encounters two possible information leakage problems. On the one hand, the patches might overlap with each other, i.e., might share points with , making the pre-training less effective. MaskPoint [29] suggests using an extremely high mask ratio (e.g., ) as a workaround. With non-overlapping patchifiers, e.g., k-means and FPC, this problem can be avoided. On the other hand, the decoder uses the positional information of both masked and reserved patches as the query. As discussed in Section 3.3, the position embedding of point clouds corresponds to the sub-sampled input (i.e., key points) and leaks the positional information of the points to be reconstructed. In this case, reconstructing the masked patches is equivalent to up-sampling the key points and becomes trivial (see Figure 3).
Drop Patch. To address the information leakage in the decoder, Liu et al. [29] discriminate if a randomly generated point is close enough to the original input point cloud, instead of reconstructing masked patches directly. However, this method is still complex and has more hyper-parameters, e.g., the distance threshold and distribution of the random points. On the contrary, we propose an awkwardly simple yet effective method. For each iteration, we randomly split input patches into three disjoint sets , and , instead of two. Then, patches are immediately dropped. The transformer decoder reconstructs by using features from and the positional information of both and . We name this method drop patch. With enough patches dropped, the decoder sees too few key points to perform the trivial up-sampling. In this work, we use , which is similar to the original MAE with a mask ratio of , as the encoder sees patches in both cases. The principle of drop patch is illustrated in Figure 3. Note that drop patch also reduces the patches to be reconstructed and thus decreases the computational cost of pre-training.
Loss Function. After the decoder, we use a fully connected layer to generate a prediction. For each masked patch consisting of a key point and its neighbors, we predict offsets from the key point to its neighbors. We apply L2 Chamfer distance as loss function and only apply it on masked patches, following [20].
4 Experiments
We first introduce our experiment setups in Section 4.1. Then, we show our main results compared with SOTA in Section 4.2. After that, we justify our design choices of patchifiers, position embedding, and drop patch with extensive ablation studies in Section 4.3. Also, we compare the efficiency of our models with previous works.
4.1 Setups
In this work, we use a transformer encoder with 3 layers as the backbone if it is not otherwise specified. Each transformer layer has 256 channels and 4 heads, while the feed-forward sub-net has 512 channels. Unlike ViT, we don not use the class token [14]. For all experiments, we use an AdamW optimizer [35] with a weight decay of 0.01, the cosine annealing schedule [34] and gradient clip of 0.1. All training is warmed up for 10 epochs. Other task-specific configurations are explained as follows. More technical details are provided in our supplementary material.
Pre-Training. We use a decoder with 2 transformer layers. Each layer has 256 channels and 4 heads. The feed-forward dimension is 256. We use ScanNet [11] to pre-train our models. The dataset consists of 2.5M frames of RGB-D images captured in 1513 indoor scenes. We sample every 25 frames from the train set, following previous works [21, 25, 58]. For each frame, we randomly sample 20K points for pre-training. Our patchifier divides each point cloud into 256 patches and samples 128 points in each patch. We use an initial learning rate of and train for 120 epochs with a batch size of 64. The color channels are handled differently in the pre-training since a lot of object detectors [5, 36, 43, 58, 64] do not use color information, whereas the models for semantic segmentation methods do [10, 41, 45, 51, 58, 64]. For object detection, we only use 3D coordinates (i.e., geometry) in pre-training. For semantic segmentation, we pre-train with geometry and color. However, we do not reconstruct color channels, as we empirically find it has no significant effect.
Object Detection. We adopt the detection pipeline from 3DETR [36], an end-to-end transformer-only detector consisting of 3 encoder layers and 8 decoder layers. We simply replace the encoder with our plain transformers. Other configurations are as same as 3DETR. We train detectors on ScanNet [11]. We follow the official train/val split and use 1201 multi-view point clouds for training and 312 for validation. As input, we randomly sample 40K points. Point clouds are divided into 512 patches with 128 points ( and ). All models are trained for 1080 epochs with an initial learning rate of and a batch size of 8. Metrics are mean average precision with 25%- and 50% 3D-IoU threshold (i.e., AP25 and AP50) over 18 representative classes.
Semantic Segmentation. Since the segmentation task requires point-wise output, we up-sample the features from the transformer encoder using nearest neighbor interpolation [41]. The point-wise features are further projected by a shared MLP and fed into an MLP-based prediction head. We evaluate our models on the S3DIS [1] dataset, which consists of real-world scans from 6 large indoor areas. Following previous works, we report the validation results on Area 5 and train models in other areas. Due to the large size of each point cloud, we voxelize the point clouds with a voxel size of and randomly crop 24K points for each forward pass. We use and . We apply the same data augmentation as [45]. All models are trained for 300 epochs with a batch size of 16. Metrics are mean accuracy (mAcc) and mean IoU (mIoU) over 13 classes.
4.2 Results and Analysis
Object Detection. We first compare our results with SOTA methods in object detection on ScanNet (Table 1). With 512 patches, our detector without pre-training performs similarly to the original 3DETR with 2048 patches. This demonstrates that it is possible to use a shorter sequence length without a significant performance drop. With MAE, our results are improved by AP25 and AP50 (absolute), showing the power of pre-training. Drop patch further raises the AP25 by and AP50 by . Our results with 512 patches ( AP25 and AP50) surpass the previous SOTA MaskPoint (L3 variant, i.e., with 3 encoder layers) with a clear margin while showing similar performance as the heavy 12-layer variant. We further evaluate our models using 1024 patches. The model already surpasses 3DETR without pre-training. When pre-trained, it achieves AP25 and AP50, significantly outperforming previous works. Note that we use FPC for 512 patches, but ball query for 1024 patches since FPC brings sub-optimal results with a longer sequence. More discussions are provided in Section 4.3.
Semantic Segmentation. We report the semantic segmentation results in Table 2. While the performance without pre-training is low ( mAcc and mIoU), the standard MAE improves the metrics by and , respectively. Since the S3DIS dataset is relatively small, we believe the results on this dataset benefit more from the pre-training. Also, drop patch further improves the mAcc und mIoU by and , respectively. When scaled up from 3 to 12 layers, our model achieves significantly better results with mAcc and mIoU. The performance surpasses some highly optimized models, e.g., PointTransformer [65] and PointNeXt [45]. It implies that self-supervised pre-training brings comparable improvement to architecture optimization.
4.3 Ablation Studies and Computational Costs
We conduct ablations studies primarily on the object detection task, as object detection with plain transformers is better understood in previous works [29, 36]. Also, we use AP25 as the primary metric, following [36].
Patchifiers. With this ablation study, we attempt to clarify the impact of different patchifiers. Their interaction with position embedding, pre-training, and patch numbers is also researched.
As shown in Table 3, k-means achieves the worst performance with all setups. It is because k-means is sensitive to the spatial density of points. Since real-world point clouds are usually captured with depth sensors and the point density varies with depth, k-means leads to irregular patch sizes and is sub-optimal.
When models are not pre-trained, the kNN patchifier achieves the best performance (experiment 2, 6, and 14). Similar results are also observed in image processing, where early convolutions improve the performance of a standard ViT [57]. However, when models are pre-trained with MAE, it is sub-optimal compared to FPC (experiment 10 and 12). Since kNN generates overlapping patches, it leaks the information of points to be reconstructed and thus degrades the effect of MAE.
FPC performs best when the patch number is small (e.g., 512) and models are pre-trained. However, when it comes to 1024 patches, it is inferior compared to kNN and ball query. Since patches cannot overlap, FPC generates small and irregular patches in this case, which harms the performance.
Ball query outperforms other methods for a large patch number (e.g., 1024), because it guarantees a consistent scale and shape of patches, which helps models learn spatial features. Such an advantage is also reported in [51]. However, ball query is sub-optimal for a small patch number (e.g., 512) since it is difficult to set a suitable radius in this case. While the patch embedding cannot capture fine-grained details with a large radius, the patches cannot cover the entire point clouds with a small radius.
To sum up, the performance of patchifiers is often affected by competing factors, which makes the optimal option of patchifiers conditional. Depending on patch numbers and pre-training, ball query, FPC, and kNN can deliver the best result. We pay more attention to pre-trained models, as pre-training is crucial to compensate for the performance gap due to the lack of inductive bias. Thus, this work uses FPC for a smaller patch number () and ball query for a larger patch number ().
Position Embedding. With this ablation study, we systematically compare different types of position embedding. Besides Fourier features, MLP, and our method with global information, we also evaluate models without position embedding in the transformer encoder. Note that besides the transformer encoder (i.e., the backbone), the decoder in MAE and the detection head in 3DETR also require position embedding. For simplicity, we use the same type of position embedding in the transformer encoder, the MAE decoder, and the detection head. For variants without position embedding in the encoder, we use Fourier features for other components, following [36]. We primarily use FPC in this ablation study to highlight the impact of position embedding since overlapping patchifiers can implicitly encode the relative position of patches [36].
Comparing experiment 3, 5, 6, and 7 in Table 4, one can see that Fourier features degrade the performance when trained from scratch, which is also observed in previous work [36]. On the contrary, MLP and our method bring significant improvement compared to the variant without position embedding. Also, experiment 1-4 show that pre-training is ineffective if position embedding is not added. It is feasible since the positional information of input patches is necessary for the reconstruction task in MAE. On the other hand, experiment 8-10 show that position embedding makes the pre-training more effective. Meanwhile, the results in 5-10 show that parametric position embedding (i.e., MLP and Global) performs better than the non-parametric Fourier features. Also, our method performs better than MLP, which verifies our intuition in Section 3.3 that the global information in position embedding is beneficial. The results are consistent when a larger patch number is applied, as shown in experiment 17-20.
Another important design choice is the location where the position embedding is added. While many previous methods add it to all encoder layers [60, 38, 29], experiment 11-16 show that it degrades the performance (compared to 5-10). We believe the contradiction is due to the domain gap between datasets. Since position embedding is more informative in point clouds, injecting it into all encoder layers makes the model pay more attention to the key points. Previous works mainly validate their design on small point clouds (e.g., ModelNet40 [56]). Such behavior might be beneficial in this case since the overall shape is crucial. Nevertheless, for complex point clouds and tasks, the model might neglect fine-grained details. Thus, only injecting patch positions once performs better in our experiments using real-world point clouds.
Drop Patch. With the benefit of drop patch shown in Table 1 and 2, we now conduct an ablation study on its hyper-parameters. As explained in Section 3.4, drop patch addresses the issue that the position embedding of masked patches makes the MAE pre-training trivial. MaskPoint [29] proposes using an extremely high masked ratio (). Experiment 2 and 3 in Table 5 show that it does not bring significant improvement because this approach aims to reduce the information leakage caused by overlapping patches. The information leakage due to position embedding is not solved. In experiment 3-9, we fix the ratio of reserved patches and observe the impact of the drop ratio. With only percent patches dropped, the model gains an improvement of AP25 and AP50. The improvement becomes larger with a higher drop ratio and reaches the maximum at . A very high drop ratio ( and ) is sub-optimal since is low. In this case, the model receives less supervision in the pre-training. In experiment 10-13, the drop ratio is fixed. The best performance is achieved when and are approximately equal.
More Patches vs. More Layers. Now we observe the impact of the numbers of encoder layers and patches, with the detection and segmentation head unchanged. The upper half of Table 6 shows that more encoder layers harm the performance in object detection. Even though the models are pre-trained, only 78K frames are available for pre-training.
Since the detection head of 3DETR already consists of 8 transformer layers, an encoder with more layers leads to over-fitting. However, adding layers to the encoder improves the performance in segmentation tasks, as the segmentation head is simpler and has fewer parameters.
The lower half of Table 6 shows that using more patches is generally beneficial, as it increases the computation without increasing the number of trainable parameters. However, the effect shows saturation with a large patch number (e.g., 1024 for detection or 512 for segmentation).
Computational Costs. We compare the computational costs of our models with SOTA methods. Models in Table 7 are all pre-trained on ScanNet with self-supervision. MaskPoint [29] uses 2048 patches, following 3DETR. Our model with 512 patches performs similarly to MaskPoint (L12), while having 5 times lower FLOPs, 4 times less memory usage, and 4 times higher speed, which highlights the efficiency of our model design and the effectiveness of our pre-training. Also, the VoteNet pre-trained with DPCo [25] is slower than our model because it has more random memory access [31]. When scaled up to 1024 patches, our model achieves significantly higher AP than previous methods with lower costs than MaskPoint (L3).
More experiments and discussions are available in our supplementary material.
5 Conclusion
In this work, we rethink the application of plain transformers to point clouds. We show that with appropriate designs and self-supervised pre-training, plain transformers are competitive in 3D object detection and semantic segmentation in terms of performance and efficiency. Our work also implies the necessity of evaluating transformers with real-world data, as the designs based on simple and small point clouds might not generalize well. We hope our work can provide a new baseline and inspire more future research on transformers for point cloud understanding.
Appendix A Results on Synthetic Point Clouds
In this work, we focus on large real-world point cloud, while a lot of previous works explore the self-supervised pre-training for transformers on synthetic point clouds. In a standard pipeline, a transformer-based model is pre-trained on ShapeNet [4] and then fine-tuned for object classification on ModelNet40 [56]. In this experiment, we follow this pipeline and compare our results with previous works.
We follow the standard setup to use a transformer encoder with 12 layers. Each input sample with 1024 points is split into 64 patches. Our models are pre-trained with drop patch. As shown in Table 8, our model using kNN achieves overall accuracy on ModelNet40, slightly better than the FPC variant.
Among previous methods, PointMAE and MaskPoint are most comparable with ours. The former applies a vanilla masked autoencoder for point clouds, whereas the latter addresses the information leakage by learning an implicit function instead of reconstructing the masked patches. Despite different designs, MaskPoint and our method achieve the same accuracy as the plain PointMAE on ModelNet40. On the contrary, they perform differently on real-world data, as shown in Table 1 in the main paper. Thus, we speculate that synthetic point clouds e.g., ShapeNet and ModelNet40, are too simple to reveal the full potential of transformers, so a vanilla MAE (i.e., PointMAE) already reaches the upper bound of the task. The benefit of further optimization is marginal or even unnoticeable.
This experiment can be viewed as the pilot study of our work. Based on the observation, we believe evaluating transformer-based models on more complex data and tasks is important. Therefore, synthetic single-object point clouds are not the main focus of this work, although they are frequently researched in previous works.
Appendix B More Discussions on Computational Costs
Transformer Layers. We report the overall GFLOPs (giga floating point operations) of our models in the main paper. In Table 9, we further show the GFLOPs of transformer layers. Although the multi-head attention has quadratic complexity, the overall GFLOPs of our model only increase from 8.2 to 11.7, when the patch number is doubled (from 512 to 1024). It’s because our model has relatively fewer channels and transformer layers. Other components, e.g., patch embedding and feed-forward nets, have a greater impact on the overall costs. On the other head, the transformer layers in MaskPoint [29] with 3 layers have 3.2 times as much GFLOPs as our model with 1024 patches, which is in line with the quadratic complexity.
Drop Patch. Besides suppressing the information leakage, our proposed method drop patch has the side effect of reducing the computational cost of MAE. With a fixed ratio of reserved patches, the computation in the encoder is unchanged. Meanwhile, the sequence length in the decoder is reduced by the drop ratio, since the decoder ignores the dropped patches. For instance, with 50% patches dropped, the sequence length of the decoder is halved.
However, we do not observe a significant training time decrease using drop patch. Despite different drop patch ratios, all models require approximately 8 hours of wall-clock time on a single GPU for pre-training. There are two main reasons. First, since the encoder in MAE is heavier than the decoder and cannot be accelerated, the speed up due to drop patch is upper bounded. Second, since we convert depth maps into point clouds and perform data augmentation on the flight and the MAE framework has high efficiency [20], our pre-training is bottlenecked by the preprocessing on the CPU. Therefore, decreasing the computation on the GPU has no significant impact on the overall wall-clock time.
Semantic Segmentation. We report the results on the semantic segmentation task in Table 10. We compare our methods with SOTA PointNeXt [45], a modernized variant of PointNet++ [41]. Our model with 3 encoder layers shows similar performance and throughput as PointNeXt-B. Also, our 12-layer variant achieves higher performance and is more efficient than PointNeXt-L. Note that PointNeXt models are not pre-trained but with a more optimized architecture and more inductive bias. The results demonstrate that self-supervised pre-training can close the performance gap between plain transformers and highly optimized models.
Appendix C MAE vs. Contrastive Learning
In this work, we pre-train our models based on the MAE framework. Another possibility is contrastive learning. To compare the two schemes, we pre-train our models using MoCoV3 [7, 8, 19], as previous work [25] shows that it performs better than methods without negative samples (e.g., BYOL [17] and SimSiam [6]) in pre-training with ScanNet data. As shown in Table 11, contrastive learning generates worse results than training from scratch. It implies that contrastive learning, which only supervises the global features, is not necessarily beneficial for tasks that require dense features. The observation is also reported in 2D detection [27, 26]. On the contrary, MAE significantly improves the results. Therefore, we use MAE-based pre-training instead of contrastive learning in this work.
Appendix D Drop Patch vs. Data Augmentation
The drop patch technique is similar to a data augmentation that randomly removes some regions from a point cloud. The difference is that drop patch is applied after a point cloud is patchified, so the patchifier is not affected by drop patch. On the contrary, if the data augmentation is used instead of drop patch, the input point cloud of the patchifier has “holes” in pre-training but does not in fine-tuning. Therefore, the generated point patches have different distributions in the two stages, which results in a domain gap between pre-training and fine-tuning.
We implement a data augmentation that mimics the behavior of drop patch. Assuming the MAE with drop patch uses patches (before dropping), the data augmentation randomly removes regions with totally points from a point cloud to obtain a similar effect. Furthermore, when the data augmentation is applied, the patch number of the MAE is reduced to , and the mask ratio is set to . Also shown in Table 12, using data augmentation instead of drop patch significantly worsens the results.
Appendix E Fune-Tuning with Fewer Epochs
In our main paper, we train our 3D detectors for 1080 epochs, following the original setup of 3DETR [36]. With the backbone pre-trained, a detector usually converts faster than trained from scratch. In this experiment, we fine-tune our model on the ScanNet detection benchmark with fewer epochs. As shown in Figure 4, the pre-trained model achieves consistently higher AP25 and AP50 than 3DETR. Moreover, the difference is more significant when the models are trained with fewer epochs. For instance, our detector reaches higher AP25 and higher AP50 (absolute) than 3DETR with 90 epochs, whereas the differences are and at 1080 epochs.
We also notice that the pre-trained model still requires a lot of epochs (i.e., 1080) to reach convergence. In 2D object detection, a detector with a backbone pre-trained on ImageNet [12] usually needs much fewer epochs than trained from scratch. We believe two factors cause the difference. First, our pre-training dataset is much smaller than ImageNet (i.e., 80K samples vs. 1M samples). Also, the 3DETR pipeline is trained with a set-based loss via bipartite matching [24], which is known to have a slow convergence [3, 24].
Appendix F Details of Models
Patch Embedding. We use a PointNet [40] for patch embedding. The shared MLP consists of 3 layers with 64, 128, and 256 output channels, respectively. The MLP is with Batch Normalization and ReLU activation. Features after the global max-pooling are used as output.
Position Embedding. Our position embedding consists of two MLPs and a global pooling. The first MLP has 3 layers with 64, 64, and 256 output channels, respectively. The global feature after pooling is concatenated with the 3D coordinates of each key point. The second MLP has 3 layers with 256 channels. All fully connected layers except the last layer are followed by Batch Normalization and ReLU activation.
Backbone. We use stacked transformer layers as the backbone. The architecture is similar to the backbone in 3DETR [36]: each layer has 256 channels, 4 heads, ReLU activation, and a drop out rate of 0.1. The main difference is that we use feed-forward layers with 512 channels instead of 128, as 128 channels lead to under-fitting in our experiments.
**Pre-Training. ** The MAE decoder consists of 2 transformer layers. Each layer comprises 256 channels, 4 heads, ReLU activation, and a dropout rate of 0.1. The feed-forward sub-network has 256 channels as well. The features from the encoder are projected with a 3-layer MLP, before being fed into the decoder. The approach to reconstructing the masked patches is the same as the original MAE.
The encoder only encodes reserved patches. Then, the encoder features are appended with a shared learnable masked token, so that the original sequence length is recovered. Also, the position embedding of masked and reserved patches is added to the corresponding features. The decoder then reconstructs masked patches using the sequence as input. When drop patch is applied, the dropped patches are neither encoded by the encoder nor reconstructed by the decoder. For each point cloud patch, we use a shared linear layer to predict the offset from the key point in the patch to its neighbors. For a patch with points, the output of the linear layer has channels.
Semantic Segmentation. We first project patch features to 96 channels with two fully connected layers to generate the point-wise semantic prediction. Then, we up-sample the patch features by using nearest neighbor up-sampling [41]. For each target coordinate, we search 5 nearest key points. Their distance to the target coordinate is concatenated to their features and projected to 96 channels with an MLP with two layers. Then, we aggregate features by applying a weighted sum according to their inverse distance to the target coordinate. At last, we use an MLP with a drop out rate of 0.5 to perform classification.
Unlike previous works [41, 45], we do not use any custom CUDA kernels in the segmentation head for simplicity and flexibility. It might have a negative impact on the run-time of our implementation.
Appendix G Details of Training Setups
Pre-Training Data. Since the ScanNet dataset consists of registered RGB-D images, we generate point clouds from depth maps on the flight, following [25]. We randomly crop depth maps and lift them into 3D space using the camera intrinsic. Then, we randomly sample 20K points from each point cloud. We rotate point clouds to revert the pitch and roll of the camera. We apply horizontal flipping, scaling, and translation. Also, point clouds are randomly rotated around the vertical axis. If color channels are applied, we apply Random Contrast and Random Grayscale. We also randomly drop all colors for entire point clouds, following [45]
Hyper-Parameters in Patchifier. With our default setup, each point cloud is divided into 512 patches in 3D object detection and semantic segmentation task. In the main paper, we also present results with 1024 and 2048 patches. The setups with different patch numbers are summarized in Table 13. Notice that we only apply farthest point clustering for 512 or fewer patches. For 1024 and more patches, we use ball query with a radius of following previous works [36, 43].
Evaluation Metrics. For object detection, we use AP25 and AP50 as metrics. We adopt the evaluation protocol in 3DETR, which reports both metrics when AP25 reaches the maximum. It means the AP25 is the primary metric since AP25 and AP50 might not reach the maximum simultaneously, although they show a similar trend in most cases. For semantic segmentation, we report mAcc and mIoU when mIoU reaches the maximum, since mIoU is commonly used as the primary metric in previous works.
Appendix H Pseudo-Code for FPC
The pseudo-code of farthest point clustering is shown in Algo. 1. As mentioned in our main paper, we sample points in each patch so that each patch has the same number of points (line 1 to 1). The motivation is to make our method more comparable with ball query, since it also applies such sampling. However, this sampling can be omitted if the PointNet patch embedding uses scatter operations111e.g., https://github.com/rusty1s/pytorch_scatter. In this case, the algorithm can directly return the point-wise assignment after line 1. Although the sampling slightly increases the computation, we empirically find it has no noticeable impact on performance. Thus, we still perform the sampling for better comparability with previous methods.
Appendix I Implementation Details
We use PyTorch 1.8.1 with CUDA 10.2 for all training and experiments. For pre-training, we generate data based on the code of [25]222https://github.com/lilanxiao/Invar3D. For object detection tasks, we modify the open-source code base of 3DETR [36]333https://github.com/facebookresearch/3detr. For semantic segmentation, we modify the official code of PointNeXt [45]444https://github.com/guochengqian/PointNeXt. All speed tests are performed on a cluster node with an Intel Xeon Gold 6230 CPU and 4 NVIDIA Tesla V100 GPUs, each of which has memory. However, only one GPU is used for the experiments. FLOPs are counted using the open-source library fvcore555https://github.com/facebookresearch/fvcore. Our code will be made publicly available.
Appendix J Reconstruction Results in Pre-Training
Here we provide qualitative results of pre-training. We pre-train a model using MAE with drop patch. However, no patch is dropped during the evaluation and the mask ratio is set to . The reconstruction for point clouds is illustrated in Figure 5. Each patch is painted with a unique color. One can see that MAE mainly reconstructs the low-frequency information of point clouds. Also, the reconstructed patches usually have symmetry, although the ground truth patches have irregular shapes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Armeni et al. [2017] Iro Armeni, Sasha Sax, Amir Roshan Zamir, and Silvio Savarese. Joint 2d-3d-semantic data for indoor scene understanding. Co RR , abs/1702.01105, 2017.
- 2Baevski et al. [2022] Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. Data 2vec: A general framework for self-supervised learning in speech, vision and language. ar Xiv preprint ar Xiv:2202.03555 , 2022.
- 3Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European conference on computer vision , pages 213–229. Springer, 2020.
- 4Chang et al. [2015] Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository. ar Xiv preprint ar Xiv:1512.03012 , 2015.
- 5Chen et al. [2020 a] Jintai Chen, Biwen Lei, Qingyu Song, Haochao Ying, Danny Z. Chen, and Jian Wu. A hierarchical graph network for 3d object detection on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2020 a.
- 6Chen and He [2021] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 15750–15758, 2021.
- 7Chen et al. [2020 b] Xinlei Chen, Haoqi Fan, Ross B. Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. Co RR , abs/2003.04297, 2020 b.
- 8Chen et al. [2021] Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 9640–9649, 2021.