AR3n: A Reinforcement Learning-based Assist-As-Needed Controller for Robotic Rehabilitation
Shrey Pareek, Harris Nisar, Thenkurussi Kesavadas

TL;DR
AR3n is a reinforcement learning-based assist-as-needed controller designed for robotic handwriting rehabilitation, providing adaptive assistance without relying on patient-specific parameters, validated through simulations and human experiments.
Contribution
Introduces AR3n, a novel RL-based AAN controller that generalizes across patients using a virtual model, eliminating the need for patient-specific tuning.
Findings
AR3n effectively reduces robotic assistance in real-time.
AR3n outperforms traditional rule-based controllers in assistance modulation.
The virtual patient model enables generalization across multiple subjects.
Abstract
In this paper, we present AR3n (pronounced as Aaron), an assist-as-needed (AAN) controller that utilizes reinforcement learning to supply adaptive assistance during a robot assisted handwriting rehabilitation task. Unlike previous AAN controllers, our method does not rely on patient specific controller parameters or physical models. We propose the use of a virtual patient model to generalize AR3n across multiple subjects. The system modulates robotic assistance in realtime based on a subject's tracking error, while minimizing the amount of robotic assistance. The controller is experimentally validated through a set of simulations and human subject experiments. Finally, a comparative study with a traditional rule-based controller is conducted to analyze differences in assistance mechanisms of the two controllers.
Click any figure to enlarge with its caption.
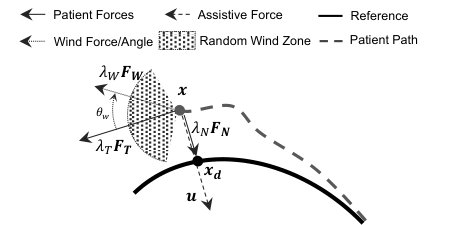 Figure 1
Figure 1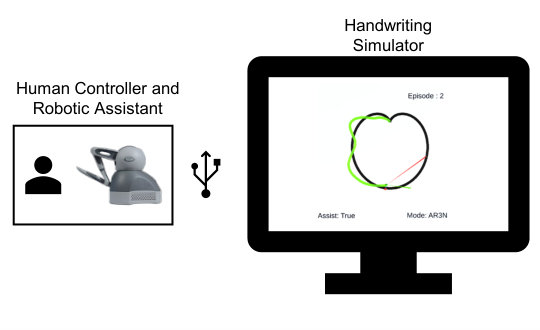 Figure 2
Figure 2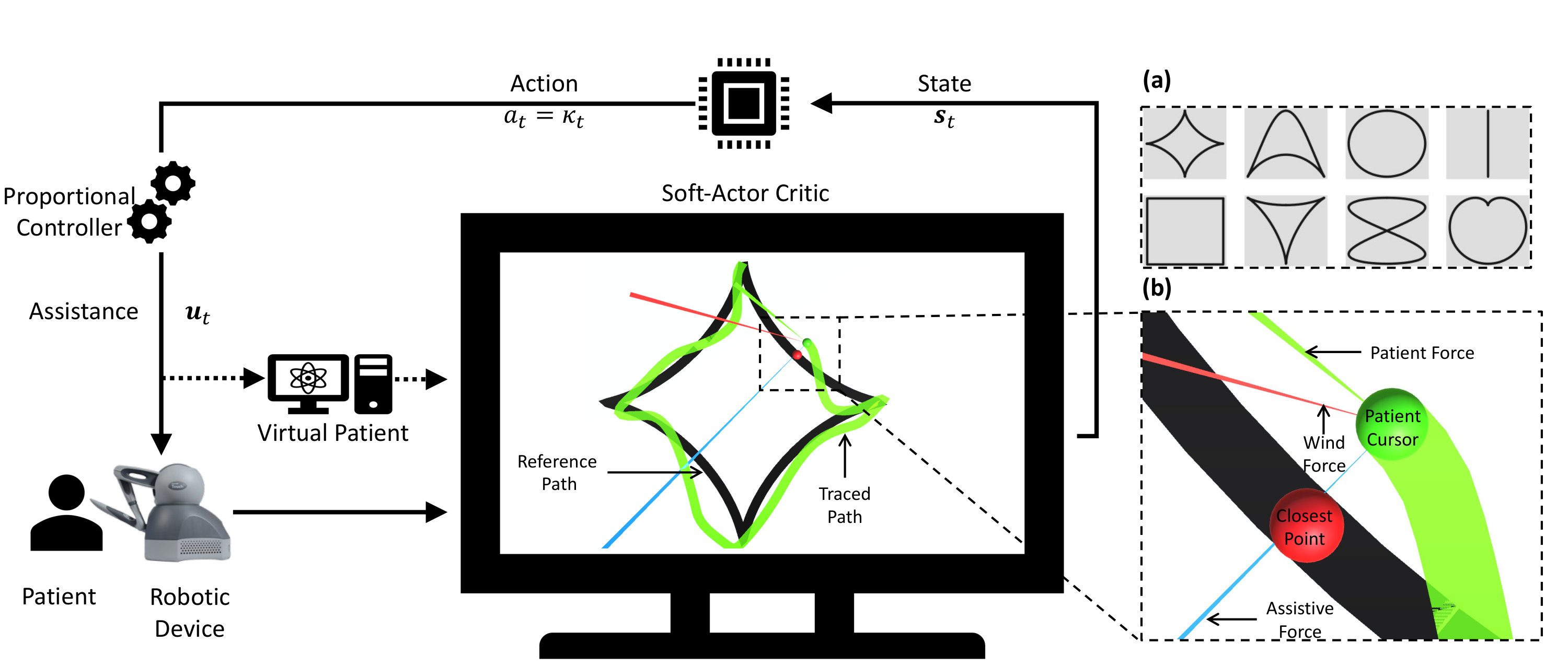 Figure 3
Figure 3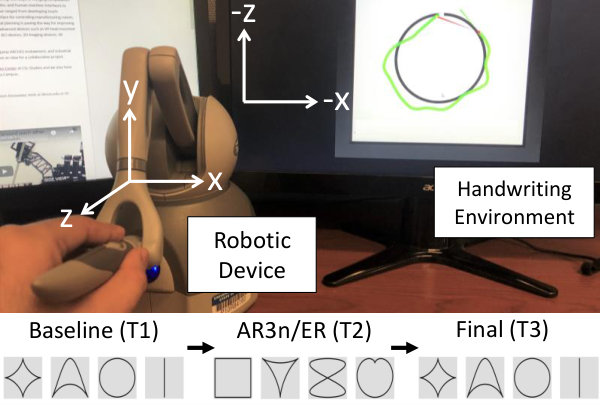 Figure 4
Figure 4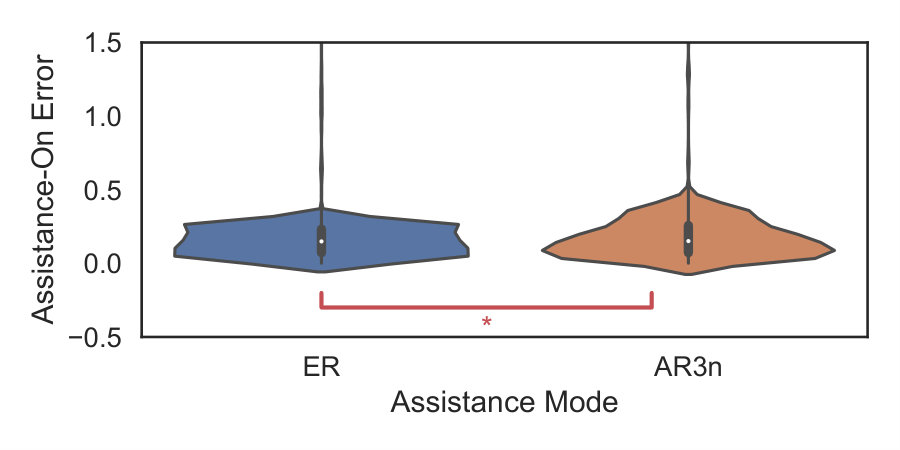 Figure 5
Figure 5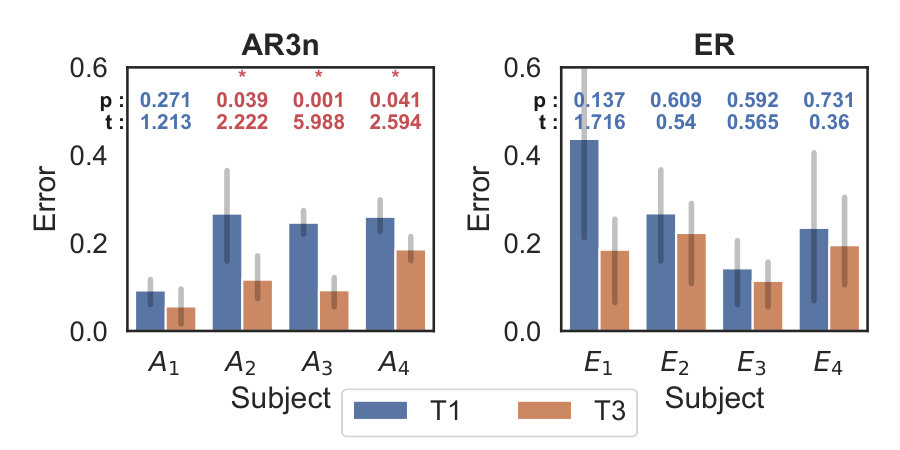 Figure 6
Figure 6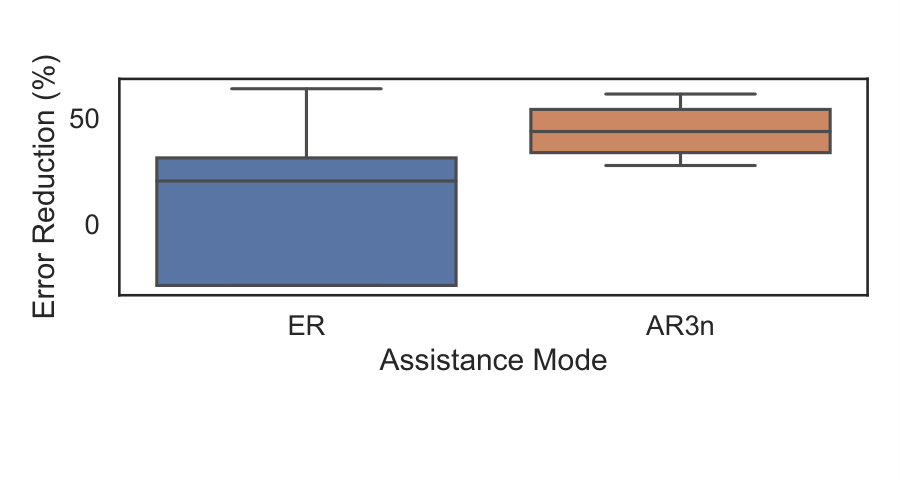 Figure 7
Figure 7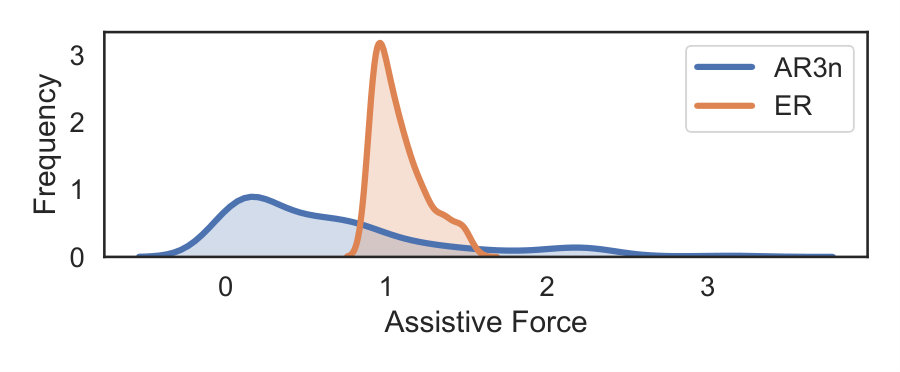 Figure 8
Figure 8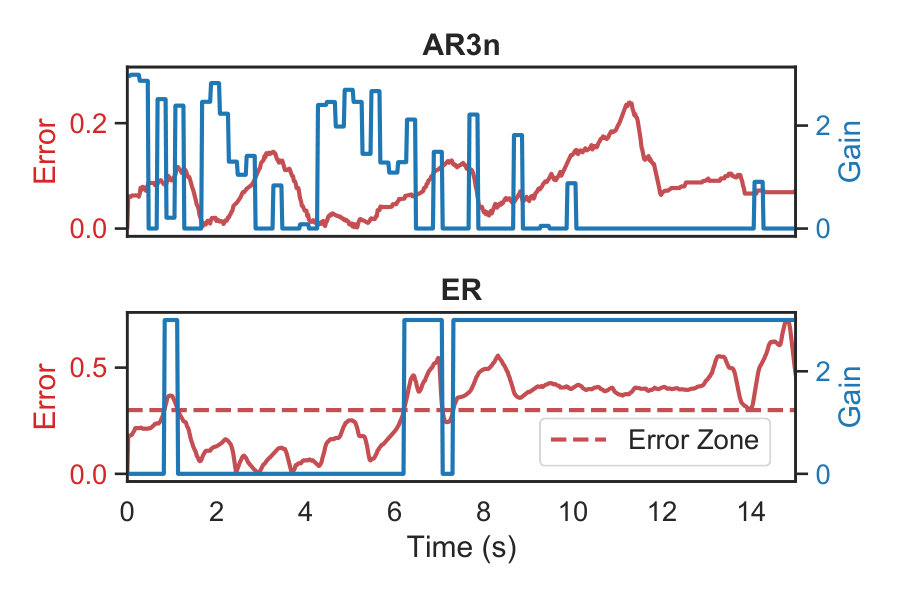 Figure 9
Figure 9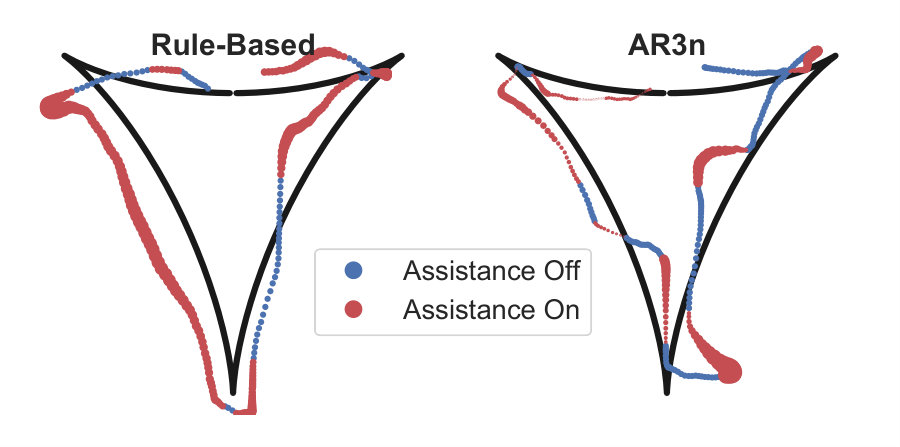 Figure 10
Figure 10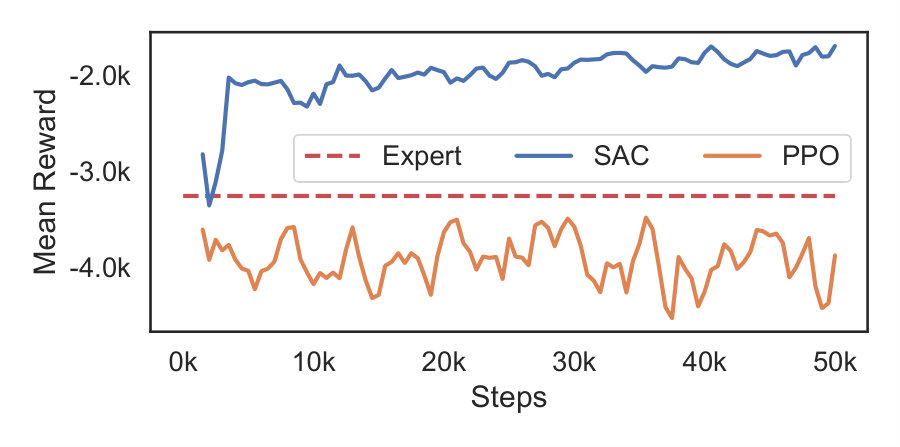 Figure 11
Figure 11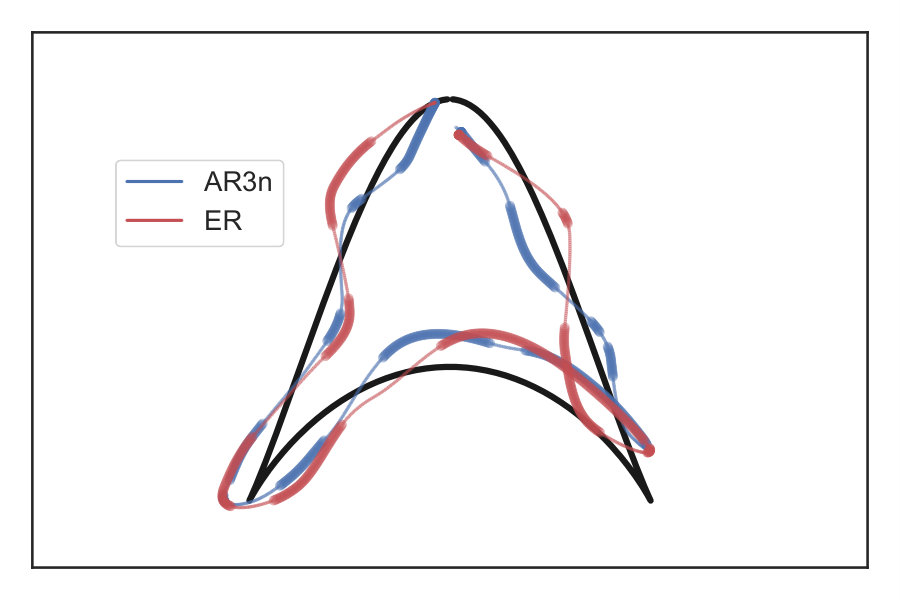 Figure 12
Figure 12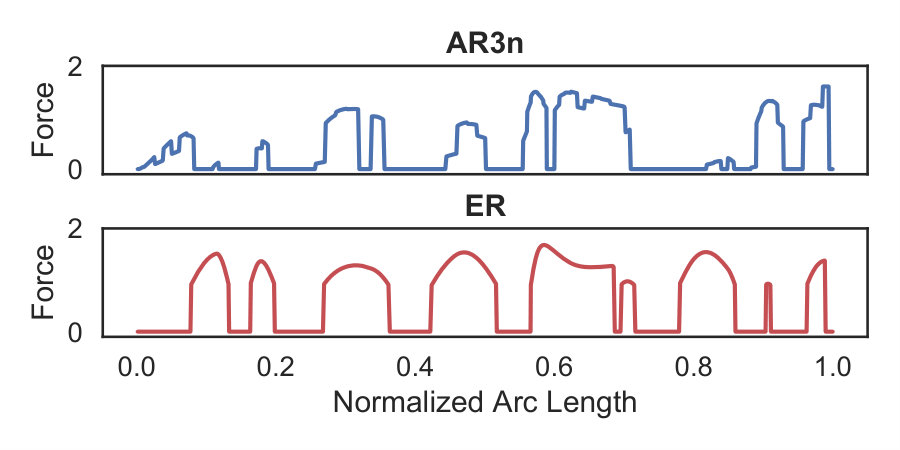 Figure 13
Figure 13Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStroke Rehabilitation and Recovery · Assistive Technology in Communication and Mobility
AR3n: A Reinforcement Learning-based Assist-
As-Needed Controller for Robotic Rehabilitation
Shrey Pareek1, Harris J Nisar2, and Thenkurussi Kesavadas3 This work was supported by the National Science Foundation (NSF) under Grant No. 1502339.1Shrey Pareek* is with the Data Science Department at Target, Minneapolis, MN, USA2Harris J Nisar and Thenkurussi Kesavadas are with the Department of Industrial and Enterprise Systems Engineering, University of Illinois, Urbana-Champaign, IL, USA.3Thenkurussi Kesavadas is the Vice President for Research and Economic Development Executive Council at State University of New York at Albany, NY, USA *[email protected] Object Identifier (DOI): 10.XXXX.2020.XXXX
Abstract
In this paper, we present AR3n (pronounced as Aaron), an assist-as-needed (AAN) controller that utilizes reinforcement learning to supply adaptive assistance during a robot assisted handwriting rehabilitation task. Unlike previous AAN controllers, our method does not rely on patient specific controller parameters or physical models. We propose the use of a virtual patient model to generalize AR3n across multiple subjects. The system modulates robotic assistance in realtime based on a subject’s tracking error, while minimizing the amount of robotic assistance. The controller is experimentally validated through a set of simulations and human subject experiments. Finally, a comparative study with a traditional rule-based controller is conducted to analyze differences in assistance mechanisms of the two controllers.
Index Terms:
Rehabilitation Robotics, Deep Learning in Robotics and Automation, Reinforcement Learning.
I INTRODUCTION
Recent years have seen the advent of robot-based rehabilitation systems as a reliable tool for home-based stroke therapy [1]. These systems can provide autonomous robotic assistance to a patient as they perform prescribed therapy tasks using a simulation system. Robotic assistance is usually based on a set of rules that govern when and how to provide assistance to a patient. The choice of this assistance mechanism is a non-trivial task and serves as a crucial factor towards the success of robotic therapy [2]. Inadequate assistance may render a task too difficult for the patient, inducing anxiety and forcing them to quit the rehabilitative task early [3]. Conversely, excessive assistance can lead to over-reliance on the robot [2].
Assist-As-Needed (AAN) controllers [4] provide adequate assistance by dynamically adjusting robotic assistance levels based on patient performance. In other words, as the user’s performance improves, robotic assistance is reduced; and vice-versa.
The simplest AAN controller is a rule-based error reduction (ER) [1] mechanism. ER describes a strategy that minimizes tracking error in a path following task. Assistance is supplied based on two manually tuned parameters viz. robotic gain and maximal allowable error threshold. This strategy describes a force field at the boundary of the error threshold that restricts free subject motions to within the boundaries of this zone. If the subject deviates outside this zone, the robotic device provides a corrective force and guides them back inside this zone. However, the selection of robotic gain and zone size is not automatized and needs to be determined by a therapist. The lack of automation may lead to over-reliance on robotic assistance and can limit the rehabilitation outcome [2].
Several studies have proposed AAN methodologies that circumvent the above over-reliance issue by automating and adapting robotic impedance based on subject performance. They implemented non-trivial mechanisms to obtain a model of subject performance. These models can be broadly categorized as physical models [5, 6, 4, 7] and physiological signal-based models [8, 9, 10]. Such models are generally patient specific and cannot be generalized to larger populations. In this paper, we propose a Reinforcement Learning (RL)-based generalizable adaptive AAN controller that automatically adjusts robotic assistance based on a subject’s performance.
The paper is organized as follows: Section II surveys existing AAN controllers. Section III provides a description of the key components of the proposed system and presents experimental evaluations under various settings. Results are presented in Section IV and we conclude in Section V.
II LITERATURE REVIEW
II-A Assist-As-Needed Controllers
According to the guidance hypothesis [2], humans demonstrate a tendency of over-reliance on external assistance, which may inhibit motor recovery. This has led to the inception of AAN controllers that adapt degree of robotic assistance based on subject performance.
Reinkensmeyer’s group [5] proposed the use of patient-specific computational learning models that predict how subjects adjust their motor behavior in the presence of varying external forces. Crespo et al. [6] developed a wheelchair steering AAN controller. However, the approach requires 25-40 trials per subject to develop a subject-specific assistance model. Maaref et al. [4] proposed a task difficulty model to estimate the difference between a patient’s motor skills and task difficulty to toggle robotic assistance. However, the algorithm relies on learning the ideal impedance and/or position tracking behavior exhibited by an expert through multiple demonstrations while conducting a therapy task. [7] used the concept of passivity to describe the maximum amount of assistive force that can be safely absorbed by a patient’s arms. Robotic impedance can then be modulated within this safety limit to deliver stable and adaptive assistance. Estimation of maximal assistive force is non-trivial and requires periodic calibrations sessions with the patient. In our previous work [11], we proposed iART, that uses demonstrations from an expert to mimic and recreate their assistance behavior.
Brain Computer Interface (BCI) and Surface Electromyography (sEMG) sensors can be used to develop physiological models instead of the patient specific physical models described above. These methods use BCI [8, 9] and sEMG [10] signals to adapt robotic assistance based on a patient’s mental engagement and amount of physical effort applied by them, respectively. These sensors need a considerable amount of time to set up and usually require the assistance of another person in doing so. This limits their feasibility as a home-based rehabilitative tool. [1] provides a scoping review of adaptive assistance techniques for rehabilitation robotics. In this paper, we propose the use of a RL-based controller that circumvents the challenges associated with deriving complex subject-specific physical models and the feasibility issues of external sensor-based systems.
II-B Reinforcement Learning-based AAN Controllers
RL describes a set of learning mechanisms that learn an optimal mapping between situations and actions so as to maximize a numerical reward signal [12]. An RL agent derives the optimal policy for a given Markov Decision Process (MDP) based on data acquired through exploration and experience. RL has gained popularity in recent years across various robotics-based domains. However, very few endeavours have been made towards the development of RL-based robotic AAN controllers. Obayashi et al. [13] developed one of the earliest RL-based AAN controllers. Using dart-throwing as a case study, the authors proposed a user-adaptive robotic trainer that aims at maximizing the score in a game of darts while minimizing physical robotic assistance. [14] demonstrated the use of model-based RL in conjunction with sEMG for formulating effective assistive strategies for exoskeleton-based systems.
Inverse RL (IRL) is another strategy wherein a desired policy is derived from expert demonstrations. Scobee et al. [15] demonstrated the use of IRL to provide haptic assistance. [16] proposed a human-in-the-loop RL algorithm to demonstrate shared autonomy through the Lunar Lander video game and a real quadcopter. Luo et al. [17] used the Proximal Policy Optimization (PPO) RL algorithm to provide assistance via an exoskeleton during squatting motion. Their approach relies on a task specific reference motion demonstration for learning. The reliance on expert human demonstrations serves as a limitation to these IRL-based studies. The method proposed in this paper aims at eliminating the reliance on human participation/demonstrations during the RL model training phase.
More recently, [18] used an actor-critic RL algorithm to modify robotic impedance for ankle mobilization. Impedance is adjusted to minimize tracking error while a control objective determines the amount of assistance to be supplied to the subject. The RL agents learns an optimal policy that modifies robotic impedance to achieve the desired control objective. The results were reported on a predefined sinusoidal trajectory and showed greater improvements in learning when compared with a conventional AAN controller. The above methods [13, 14, 18] yield subject-specific controllers based on online RL training. The method proposed here uses Soft Actor Critic (SAC)-based RL [19] to generalize assistance mechanism across multiple patient behaviors.
We introduce AR3n111pronounced as Aaron., an Assitive Robotic Rehabilitation system based on Reinforcement LearNing. AR3n uses RL to dynamically adjust robotic assistance and does not require patient-specific physical models or physiological sensors to estimate the same. We achieve this by simulating a plethora of patient behaviors through a virtual patient model and training a RL-based assistant to generalize across these behaviors. First use human-subject studies are conducted to test the assistance behavior of the virtual patient trained model on healthy subjects. The development of a virtual patient model and an RL-based AAN controller are the key contributions of this work. To the best of the authors’ knowledge, this is the first study that uses a simulation-based upper-limb RL-AAN controller. A demo video for AR3n may be found here 222https://youtu.be/hTVjd7uzMz8.
III METHODS
AR3n comprises of three key components (see Fig. 1), viz. (i) simulation environment: with which the RL agent interacts, (ii) RL module: that uses SAC to learn and predict robotic assistance, and (iii) robotic motor task: that uses the trained RL agent from (ii) to deliver realtime adaptive robotic assistance.
III-A Motor Task
In this study, we have used the example of handwriting rehabilitation. A subject uses a robotic end effector to control the position of a virtual pen in a handwriting simulation environment (see Fig. 1). The robotic device provides kinesthetic assistance to the patient based on prescribed control mechanisms such as ER or AR3n. The writing simulation environment was developed using Unity3D333https://unity.com and consists of a virtual environment wherein, a reference trajectory to be followed by the patient can be chosen from Fig. 1 Inset-(a).
A robotic device assists the user along the trajectory based on a proportional (P) controller. Traditionally, the gain of a P-controller is chosen by a therapist. In this paper, we propose a methodology to adapt this parameter automatically based on the subject’s performance. A 6 degrees-of-freedom (6 revolute joints: 3 actuated and 3 passive) Geomagic® TouchTM was used in this study to provide kinesthetic feedback to the user at a sampling rate of 1000 Hz. The actuated joints can provide force feedback up to to the user.
III-B Reinforcement Learning Module
This module comprises of a SAC-based agent that interacts with a simulation environment to learn the optimal assistance policy. The agent’s goal is to derive a mapping between state () and action () that maximizes the cumulative return from the current reward [12]. This is usually achieved through the means of a simulation environment within which an agent must be able to take actions that affect the state of the environment. To formalize the problem being addressed in this paper, we first describe a handwriting simulation task which has been modelled as an MDP.
III-B1 Training Environment
In this paper, we use a robot-assisted hand writing task as the case study. The patient’s goal is to track a reference path using the robotic device. However, the patient’s motor deficits may prevent them from achieving low tracking error. The RL agent serves the role of a therapist and decides when and how to assist a patient based on their performance (see Fig. 1). The agent learns this assistance behavior by interacting with the environment for data acquisition through exploration and experience. The need for large quantities of data for effective learning prevents the use of real subject-robot interaction (see Section III-A) while training the RL agent. As a result, we simulate the handwriting environment as well as the patient. The training task is designed as an episodic task, wherein each episode involves a virtual patient tracking a reference shape chosen randomly from the top row of Fig. 1 Inset-(a). An episode in RL refers to a sequence of states, actions, and rewards with a terminal state. Terminal state in this scenario refers to reaching the end point of the reference trajectory to be tracked.
III-B2 Virtual Patient Force Model
We present a virtual patient model (see Fig. 2) that enables us to simulate numerous patient behaviors and allows the RL agent to train and generalize across these behaviors. This circumvents the requirement of human subjects during training.
The patient is simulated as a combination of three different types of forces, viz. a tangential force (), a normal force () and a wind force (). refers to a force tangential to the reference path that enables the patient to travel along the path. is normal to and describes the ability of the patient to minimize their tracking error by pulling them towards the reference path. and collectively describe the ability of a patient to track the reference path in the absence of any motor impairments. Motor impairments are simulated as a random wind force () acting in a random direction () along the path. Total resultant patient forces are described as:
[TABLE]
where, is a scaling factor that decides the strength of force . We chose and experimentally as they enabled low error trajectory tracking similar to that expected from a healthy person. and served as baselines around which all other forces were scaled experimentally such that they yielded realistic-looking trajectories. Realistic here refers to a heuristic wherein we visually verified that generated trajectories appeared similar to those that would be reasonably exhibited by patients.
is randomly set to a value between and . is set higher than to ensure deviations from the path. The wind angle () is randomly chosen between and 444 was chosen as the wind angle range since values larger than this did not yield realistic looking trajectories. (hatched sector of influence in Fig. 2). Wind direction and magnitude () are varied every to during simulation runs. This high variability in terms of wind direction, magnitude, and variation frequency enables us to simulate multiple patient behaviors on which to train the RL agent. Since these parameters are not explicitly supplied to the agent, the proposed methodology operates as model-free RL.
III-B3 Formulating the Reinforcement Learning Problem
Formulating the RL problem requires formalizing it as an MDP. A well posed MDP consists of a tuple of states (), actions () and reward (). The state at any time-step is given as: .
Where, refers to the perpendicular distance between the current patient position its orthogonally projected closest point () on the reference path at time-step . Since only tracking error is used to describe the state of the system, the behavior of RL agent is reference trajectory agnostic and does not require retraining for generalization to reference trajectories not used during training. We also provide the tracking error at the previous steps as the state. This takes into account historic performance of the patient in addition to their instantaneous behavior. We set in this study which is equivalent to of history (sampling rate of the simulation environment is ).
The agent action is given by , which is the gain of the proportional controller given as:
[TABLE]
where, is the assistive force being supplied to the patient. and denote the current cursor position and the desired point on the path. is a scaling factor to scale the gain predicted by the agent. This value ensures that the maximum assistance is strong enough to assist the subject.
The assistive force derived from (2) acts on the existing patient forces described by in the same direction as to give the net patient force . In case of the actual motor task (Section III-A), the assistive force is converted to torque values applied at the joints of the robotic device.
[TABLE]
The instantaneous reward is a continuous function of tracking error and amount of assistive force applied. The expected cumulative return is the discounted sum of future rewards given by:
[TABLE]
where, describes a quadratic penalty associated with the average tracking error over the past steps. is the average assistive force magnitude applied over this interval. The final term () in (4a) is a penalty associated with fast changes in values of the proportional gain predicted by the SAC network. This promotes a smoother assistance behavior. In other words, the reward function penalizes tracking error while penalizing any assistive force being applied and/or changed by the agent.
We conducted numerous training runs to arrive at these values. First, was set to a unit reference value and and were varied from . The weights for each term in (4a) were empirically determined as as these values demonstrated more consistent training results with reasonable assistive performance.
in (4b) refers to a discounting factor which decides the importance of future v/s current rewards while calculating the expected returns of the current state-action pair. We give equal weightage to both and hence set . This ensures quick adaptation to the current state while preventing an overly short-sighted agent. Most RL applications use , to maximize cumulative reward over a larger time horizon. Since the reward window in this case is around as described earlier in the section, was a viable choice.
III-B4 Soft-Actor-Critic Network
SAC [19] is an off-policy method that uses a replay buffer to improve sample efficiency. This implies that network parameters are updated with experience collected from a different policy than the current one; allowing the algorithm to generalize over a larger state space without explicitly visiting them. Off-policy SAC was chosen by conducting a preliminary comparison of training performance with the PPO algorithm. We describe this analysis in Section III-B5.
SAC is based on maximum entropy RL, with the following entropy augmented objective function:
[TABLE]
An optimal policy , maximizes the expected return and entropy (-term in (5)). The entropy term can be viewed as a trade off between exploration (maximize entropy) and exploitation (maximize return). The trade-off between the two is controlled by the non-negative temperature parameter . We set throughout the training process.
A soft Q-function describes the critic, while a Gaussian policy function entails the actor. In other words, given a state the actor chooses an action based on the stochastic policy . Meanwhile, the critic estimates the expected returns of the current state-action pair using a soft Q-function . As mentioned earlier, the action corresponds to gain , which modulates the assistive force through (3). We refer the reader to [19] for more details on SAC. Both networks (actor and critic) use the same neural network architecture with three hidden layers and 32 units in each layer. The learning rate was set at and a batch size of 128 was used. These hyperparameters were chosen as they yielded stable training with high average rewards during preliminary testing.
The SAC model was trained for 50K steps using the training environment and virtual patient model described above. Only the 4 shapes in the top row of Fig. 1 Inset-(a) were used for training as the proposed formulation here is reference trajectory agnostic as described in Section III-B3. Once the model was trained, it was used for realtime inference. Training was performed on an Intel Core i7 5820K Processor with a NVIDIA GeForce GTX 970 - 4GB graphics card and training times averaged around minutes.
III-B5 SAC Training Performance
We conduced a pilot experiment to substantiate the choice of SAC for this study. We compared SAC’s training performance in terms of average reward per episode with the PPO on-policy algorithm. PPO is a widely used policy gradient RL method [12] that finds applications in continuous action tasks.
Fig. 3 shows average reward per episode v/s training steps for SAC and PPO. The constant dotted line demonstrates performance of an expert human. One of the authors served as the expert and toggled assistance on and off as the virtual patient model simulated 10 episodes. It should be noted that the expert reward here is only presented as reference and not for comparative analysis.
Unsurprisingly, SAC outperformed PPO by a large margin and demonstrated very fast learning in terms maximizing the cumulative reward. This fast learning is attributed to the temporal difference learning methodology used by SAC. The superior performance of SAC when compared with PPO is in agreement with other studies [19]. These results affirm the choice of SAC as a valid RL algorithm for this study and discard we PPO from further analysis.
III-C Experimental Evaluation
We designed experiments aimed at evaluating AR3n’s ability to (i) conduct realtime inference in a simulated environment, and (ii) verify its ability to provide realtime assistance and induce motor learning with human subjects. We also compared differences between assistance mechanisms of AR3n and a traditional ER-based controller.
III-C1 Simulated Testing
We evaluated AR3n in terms of delivering reliable online assistance with the ER assistance mechanisms. ER refers to the error reduction assistance mechanism described in Section I. In this experiment, we used the virtual patient to test differences between the two assistance mechanisms. Both methods were used to modulate assistance in realtime for 50 virtual episodes. The same random seed was used for both cases. This enabled us to compare the assistance behavior of the two methods, subject to the exact same initial conditions.
III-C2 Human Subject Study
Next, we conducted a first-use human subject study to (i) verify AR3n’s ability to use the assistance behavior learnt using the virtual patient model to deliver realtime assistance to human subjects; and (ii) study differences in AR3n and ER as rehabilitative tools. Eight healthy subjects (5 males; 3 females; average age 26 years; range 19-33 years) were recruited for a single session approved by the University of Illinois at Urbana-Champaign’s Institutional Review Board (IRB #15990).
The experimental setup is shown in Fig. 4 and involved the subject using a robotic device for the trajectory tracking task described in Section III-A. In order to increase the task difficulty and simulate motor impairment, the subjects were required to use their non-dominant arm and the robot motions were mirrored in the horizontal () and transverse () direction (see Fig. 4). In other words, if the robot end-effector was moved to the right, the onscreen cursor would move to the left, and vice-versa. A similar reversal was implemented in the direction.
Each subject participated in three trials (Fig. 4). A baseline trial (T1) followed by a training trial (T2), and a final post training trial (T3). Each trial involved the subject executing the four shapes shown in Fig. 4. This set of shapes was chosen as it contains both straight line and curved sections. The size of these shapes was scaled to be roughly equivalent to a standard A4 sized paper to stimulate larger movements of the subject’s arm. All trials lasted around 2 minutes with 2 minute breaks between subsequent sessions. A brief acclimatization trial (T0) was conducted so that subjects could familiarize themselves with the system.
Baseline and final trials involved no robotic assistance and used the same 2D shapes. During the training session (T2), robotic assistance was provided either through a conventional ER-based AAN or the proposed AR3n controller. The maximal allowable error for ER was set as . This means that robotic assistance was toggled on only when tracking error was greater than . The gain for ER was set at .
The eight subjects were randomly assigned to the conventional ER (, ) controller or AR3n (, ). The subjects were unaware of the type of assistance being supplied. The goal of this experiment was to compare the change in tracking error from T1 to T3 among the two groups.
IV RESULTS AND DISCUSSIONS
IV-A Simulated Testing
Fig. 5-Left shows tracking behavior executed by the virtual patient under AR3n and ER for the same trajectory and random seeds. Fig. 5-Right shows the corresponding assistive force modulation v/s arc length by the above assistance mechanisms. It can be observed that both mechanisms demonstrate similar assistance profiles in terms of when assistance was provided, but differed how assistance was provided. Owing to the rule-based nature of ER, assistance is provided in short busts similar to a step function. These bursts can be smoothed using a mathematical function, however the key drawback of ER remains the use of a rule-based controller with manually determined thresholds.
AR3n on the other hand modulates degree of assistance based on complex rules learnt using the virtual patient behavior. This smoother modulation of AR3n is attributed to the quadratic penalty associated with rapid gain switching ( term in (4a)). Eliminating this term would lead to an RL controller that learns a bang-bang optimal control policy, which is not suitable for assisted robotic rehabilitation.
We also compared the tracking error at which assistance was switched on (gain) under AR3n and ER. These error distributions are shown as violin plots in Fig. 6. Under ER, assistance-on error was concentrated around the error zone (). This was expected, since ER only prevents the subject from exiting the force field and does not assist them by guiding them back towards the reference trajectory. As with ER, AR3n demonstrates a denser distribution around the error zone but with a wider spread overall. Assistance-on error for AR3n and ER shows significant differences (, ).
IV-B Human Subject Study
Fig. 7 shows gain variation (blue) under AR3n and ER w.r.t. tracking error (red) for two subjects. The dotted line demonstrates the size of error zone for ER. ER assists the subject only when the tracking error is higher than this threshold. AR3n on the other hand, does not follow a strict error-based rule while deciding how much to assist the subject.
Under ER the subject tends to over-rely on the robotic assistance as is evident from the near continuous assistance provided from . Additionally, ER merely prevents the subject from deviating outside the error zone boundary, it does not assist them by guiding them back to the reference trajectory.
The over-reliance tendency under ER can be visualized in Fig. 8-Left. The figure presents trajectories executed by a subject under ER. It can be observed that the subject tends to stay at the boundary of the force field, as at the boundary, the robotic device provides minimal assistance enabling the subject to correctly follow the trajectory with minimal effort and low tracking error. AR3n (8-Right) on the other hand guides the subject back to the reference trajectory and then switches off assistance. This is also evident from the reduction of tracking error from a large value to near-zero whenever assistance was switched on in Fig. 7.
Fig. 9 shows the distribution of assistive forces provided by AR3n and ER. ER’s behavior was concentrated over a narrow region. The relatively narrow distribution signifies the force field behavior of ER. In case of AR3n, assistive force was spread over a larger range. While AR3n mostly applied small corrective forces (higher density closer to zero), in some cases, it applied larger forces depending on the subject’s performance. These observations reaffirm the ability of AR3n to provide assistance over multiple scenarios and highlight the inherent challenges of ER.
Next, we compared the performance of AR3n and ER as rehabilitative tools by comparing the change in tracking error between the baseline (T1) and final trial (T3) across the two assistance groups i.e. AR3n () and ER (). The Shapiro-Wilk test was conducted on tracking error to verify normality at a p-value of . All samples demonstrated normality and hence pairwise t-test were conducted.
Fig. 10-Top shows tracking errors for different subjects during T1 and T3. The blue bars denote the tracking error during the baseline recording (T1) while the red bars signify the final trial (T3). p-values and t-statistics obtained for pairwise t-tests on tracking error between T1 and T3 are also shown above the corresponding pairs. Pairs that demonstrated significant differences at are shown in red. p-values in blue denote that no significant differences were observed.
None of the subjects in the ER group demonstrated significant reductions in tracking error over the duration of the experiment. The inferior performance from ER was expected and is attributed to the tendency of subjects to over-rely on robotic assistance, which led to a decline in performance when robotic assistance was removed.
Three out of the four subjects under AR3n showed significant error reduction within the two trials. Only one subject () under AR3n that did not demonstrate significant error reduction. On closer inspection, ’s tracking error for T1 was lowest across the board when compared with all other subjects and trials, leaving very little scope for performance improvement over trials. Subjects under AR3n demonstrate a reduction in error variability as shown by the reduction in lengths of error bars from T1 to T3. On the other hand, subjects under ER display lower reduction in variance between sessions.
Finally, we also compared the percent error reduction across all subjects under AR3n and ER (see Fig. 10-Bottom). Subjects in the AR3n group demonstrated higher improvements when compared to those within ER.
V CONCLUSION AND FUTURE DIRECTIONS
This paper describes a novel RL-based AAN controller called AR3n. AR3n uses SAC to modulate assistance in realtime based on a subject’s performance. Using a reward function that minimizes tracking error while minimizing amount of assistive force enables the realization of a truly adaptive AAN controller.
As opposed to traditional force field-based AAN controllers, AR3n does not require hand tuning of controller parameters. The system distinguishes itself from more sophisticated AAN controllers as our method does not require patient specific physical models. Instead, we simulate numerous virtual patients to generalize the controller over a larger population of subjects. The use of a virtual patient also distinguishes our method from previous RL-based AAN controllers [13, 14, 18] that use online learning methods to generate subject-specific RL models.
We tested the proposed algorithm under numerous simulated and human subject experiments, and highlighted critical differences between AR3n and ER. AR3n demonstrated generalizability across multiple human subjects and efficacy as a rehabilitative tool. It was also observed that the method proposed here avoids over-reliance tendencies inherent of ER controllers.
Our system relies on offline learning to generate a subject-independent AAN controller. This method may not be suitable for patients with very specific needs. Use of online learning methods such as GARB [20] in conjunction with AR3n will enable the realization of controllers tuned to the specific needs of a patient without requiring extensive data collection. Future work should explore this option.
Currently AR3n only modifies the gain of a proportional controller. It would be meaningful to design a study where derivative and integral gain values are modulated as well. Finally, the human subject study described in this paper was conducted on a fairly small pool of healthy subjects. Moving forward, the system needs to be tested with stroke patients and/or a larger subject pool to verify its scalability in the clinical setting.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] H. Manjunatha, S. Pareek, S. S. Jujjavarapu, M. Ghobadi, T. Kesavadas, and E. T. Esfahani, “Upper limb home-based robotic rehabilitation during covid-19 outbreak,” Frontiers in Robotics and AI , p. 75, 2021.
- 2[2] R. A. Schmidt and C. A. Wrisberg, Motor learning and performance: A situation-based learning approach . Human kinetics, 2008.
- 3[3] J. Nakamura and M. Csikszentmihalyi, “The concept of flow,” in Flow and the foundations of positive psychology . Springer, 2014, pp. 239–263.
- 4[4] M. Maaref, A. Rezazadeh, K. Shamaei, R. Ocampo, and T. Mahdi, “A bicycle cranking model for assist-as-needed robotic rehabilitation therapy using learning from demonstration,” IEEE Robotics and Automation Letters , vol. 1, no. 2, pp. 653–660, 2016.
- 5[5] J. L. Emken and D. J. Reinkensmeyer, “Robot-enhanced motor learning: accelerating internal model formation during locomotion by transient dynamic amplification,” IEEE Transactions on Neural Systems and Rehabilitation Engineering , vol. 13, no. 1, pp. 33–39, 2005.
- 6[6] L. M. Crespo and D. J. Reinkensmeyer, “Haptic guidance can enhance motor learning of a steering task,” Journal of motor behavior , vol. 40, no. 6, pp. 545–557, 2008.
- 7[7] M. Shahbazi, S. F. Atashzar, M. Tavakoli, and R. V. Patel, “Position-force domain passivity of the human arm in telerobotic systems,” IEEE/ASME Transactions on Mechatronics , vol. 23, no. 2, pp. 552–562, 2018.
- 8[8] L. George, M. Marchal, L. Glondu, and A. Lécuyer, “Combining brain-computer interfaces and haptics: Detecting mental workload to adapt haptic assistance,” in International conference on human haptic sensing and touch enabled computer applications . Springer, 2012, pp. 124–135.