Some Aspects of Geometric Computer Vision for Analysing Dynamical Scenes focusing Automotive Applications
Volker Willert, Martin Buczko

TL;DR
This paper reviews fundamental geometric computer vision principles for automotive applications, emphasizing robust, real-time algorithms for processing camera image streams on moving vehicles.
Contribution
It introduces key geometric relations and shares practical insights for implementing robust, real-time vision algorithms like optical flow and visual odometry in automotive contexts.
Findings
Highlights the importance of robustness in real-time vision algorithms
Provides practical considerations for algorithm implementation
Discusses interrelations and critical aspects of geometric estimates
Abstract
This draft summarizes some basics about geometric computer vision needed to implement efficient computer vision algorithms for applications that use measurements from at least one digital camera mounted on a moving platform with a special focus on automotive applications processing image streams taken from cameras mounted on a car. Our intention is twofold: On the one hand, we would like to introduce well-known basic geometric relations in a compact way that can also be found in lecture books about geometric computer vision like [1, 2]. On the other hand, we would like to share some experience about subtleties that should be taken into account in order to set up quite simple but robust and fast vision algorithms that are able to run in real time. We added a conglomeration of literature, we found to be relevant when implementing basic algorithms like optical flow, visual odometry and…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1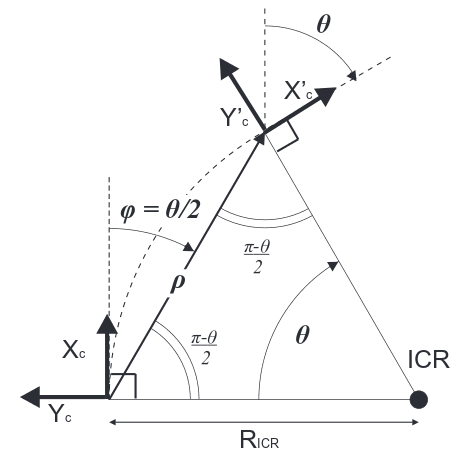 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7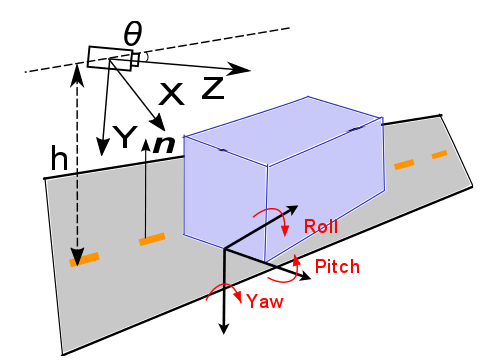 Figure 8
Figure 8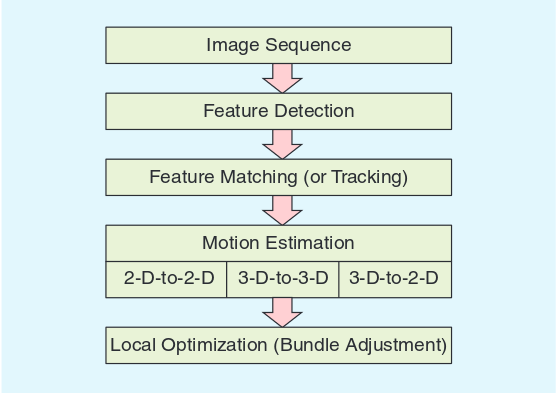 Figure 9
Figure 9 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Vision and Imaging · Image and Object Detection Techniques
Some Aspects of Geometric Computer Vision for Analysing Dynamical Scenes focusing Automotive Applications
Volker Willert and Martin Buczko
Abstract
This draft summarizes some basics about geometric computer vision needed to implement efficient computer vision algorithms for applications that use measurements from at least one digital camera mounted on a moving platform with a special focus on automotive applications processing image streams taken from cameras mounted on a car. Our intention is twofold: On the one hand, we would like to introduce well-known basic geometric relations in a compact way that can also be found in lecture books about geometric computer vision like [1, 2]. On the other hand, we would like to share some experience about subtleties that should be taken into account in order to set up quite simple but robust and fast vision algorithms that are able to run in real time. We added a conglomeration of literature, we found to be relevant when implementing basic algorithms like optical flow, visual odometry and structure from motion. The reader should get some feeling about how the estimates of these algorithms are interrelated, which parts of the algorithms are critical in terms of robustness and what kind of additional assumptions can be useful to constrain the solution space of the underlying usually non-convex optimization problems.
1 Introduction
To get an idea about what kind of estimation problems are relevant when analysing dynamical scenes, we sketch the task of moving object separation from visual observations of a moving platform starting with an illustrative example taken from [3]. Assume, a mobile platform – in this special case a mobile humanoid robot as can be seen in figure 1 – with a camera mounted on its head is moving around in a static environment – in this special case a gym – while watching different moving objects – in this special case the different players – playing a basketball game.
In case of ego-movements of the robot while observing moving objects, like turning the head left sketched in Fig. 1 A, the visual flow is a superposition of projected movements of the objects ②, like the movement of the player running to the left and the egomotion induced flow field of the robot ①. Hence, the optical flow holds all the information describing the dynamics of the scene and to separate moving objects from the background using images taken from a moving camera, a separation of the different relative motions between the camera movement and the differently moving scene parts has to be realized. In this case, the movement of the player like depicted in Fig. 1 B can only be separated if the relative movement of the robot to the background can be estimated properly.
More precisely speaking, the movement of the robot in relation to the static background and the moving objects induces an optical flow field onto the image plane, which is a vector field consisting of vectors for each pixel of the image and every vector shows the projection of the movement of the correspondent world point projected onto the pixel. So the optical flow field separates into different groups corresponding to different movements of projected rigid-object/background-parts [4, 5] having some certain 3D structure. Hence, there is a defined geometrical relation between the optical flow, the relative movement between the observer and the object/background-parts, and the 3D structure. This relation is the essence to realize a separation of the moving objects from the static background using observations of a moving platform and was first formulated by Longuet-Higgins et al. in 1980 [6]. Based on this famous geometrical constraint – which today is called the continuous epipolar constraint [1] – one can solve for one of the three unknowns (flow, ego-motions, structure) once two unknowns can be estimated from suitable measurements and a segmentation of the different object parts is provided. Here, we are faced with a difficult dilemma: If the relative motions are not known and there is no other cue than optical flow to segment the parts that move differently, then both problems, the segmentation problem and the multiple motion estimation problem rely on each other [7, 8].
For the special case, if the robot moves around in a purely static environment, then the estimation-segmentation dilemma does not arise. The projection of the environment onto the robot cameras induces a flow field that is exclusively caused by the egomotion of the robot and varies with the 3D profile of the scene. Hence, there is only one relative motion and no segmentation is needed. Visual SLAM and egomotion computation approaches (also called visual odometry approaches) utilize these dependencies to estimate only the pose of a moving camera or the pose and in addition the scene structure usually assuming that a sparse and temporal stable set of point-to-point correspondences of static image features can be extracted.
Additional sensing of the body movement via proprioception combined with the information of the visual flow allows for dense depth estimation which is called Structure from Motion. As a reverse operation to egomotion-based depth estimation, the expected visual flow generated by egomotion can be inferred by combining body movement and scene depth information using depth cues like e.g. extracted from binocular disparity (Motion from Structure).
Unfortunately, in most cases the environment is not static but contains moving objects. As already mentioned beforehand, these induce flow field components onto the robot cameras which deviate from the flow field as it is predicted from egomotion for static scenes.
Before delving into basic algorithms needed to realize applications like moving object detection from a moving camera system mounted on a car, we provide the basic geometric relations. We start with a mathematical description of the intertwining of optical flow, structure and ego-motion whereas a camera moves in a purely static scene. Then, we move on to a moving camera that moves in relation to a static background and several other moving objects.
2 Relation between Ego-motion, Optical Flow, and Structure of the Background
The relation between ego-motion, optical flow, and structure can be formulated for the continuous and the discrete time case. Historically, the continuous time case was formulated first [6]. Practically, the differetiation is relevant, because the continuous motion case better models the case when the camera motion is slow compared to the camera frame rate and vice versa for the discrete motion case. Formally, in the continuous motion case the twist of the camera motion is estimated whereas in the discrete case a pose change is estimated.
2.1 Continuous Rigid-Body-Transformations
The 3D coordinates of a fixed point (in the background) with respect to the world frame and the 3D coordinates of the same point with respect to a moving camera frame are related by a rigid-body transformation at time in the following way:
[TABLE]
with a rotational part denoted by a translation vector and a rotational part denoted by the rotation matrix . This relation is also shown in figure 3. The origin of the moving camera frame is given by
[TABLE]
and therefore the rigid-body transformation can also be formulated by the translation of the camera with respect to the word frame as follows:
[TABLE]
also shown in figure 3.
If we now take the temporal derivative of the camera coordinates
[TABLE]
solve (1) for the point in world frame
[TABLE]
considering the inverse of the rotation matrix , and insert the result in (4), we arrive at the differential equation system
[TABLE]
with the twist consisting of a rotational velocity and the corresponding skew-symmetric matrix , and the translational velocity .
Practically, equation (7) is relevant if the camera motion is slow compared to the camera frame rate. So, for low-speed car applications in inner-city scenarios with for example stop-and-go movements this continuous rigid-body-transformation is relevant. One has to keep in mind, that equation (7) is a purely kinematic model and the real dynamics (like taking care of the mass of the car) is neglected. Also, changes in camera acceleration are not taken into account. Nevertheless, this pure kinematic model is accurate enough because inertia of the car is large, so acceleration changes are very small in practice.
Now, the perspective projection
[TABLE]
with being an arbitrary scaling factor and the projection matrix
[TABLE]
has to be taken into account to derive the relation between image coordinates , the optical flow , and the structure/depth . The general projection is shown in figure 4 all the way from 3D coordinates in world frame written in homogeneous coordinates , along the transformation to the camera frame in homogeneous coordinates , then the projection to the image frame in homogeneous coordinates , and finally the transformation to the pixel frame . If we assume a calibrated camera and the kalibration matrix
[TABLE]
with the focal length , the principal point , and the scaling factors to be known (these are the intrinsic parameters of the camera), then we can always transform from pixel coordinates to the normalized image coordinates as follows
[TABLE]
Neglecting the time index for brevity, we can now derive the relation between image coordinates , the optical flow , and the structure/depth using the normalized projection
[TABLE]
and its temporal derivative
[TABLE]
Inserting equation (20) into equation (7), we obtain
[TABLE]
Solving the third row for the temporal derivative of the depth and inserting the result into the first two rows of matrix equation (21), we get the basic relation between optical flow, structure, and ego-motion:
[TABLE]
The relations are shown in figure 5. The optical flow is therefore the vector sum of a translational component that is independent of the rotational velocity but dependent on the depth of the projected 3D points and a rotational component that is independent of the 3D structure of the scene but dependent on second order monomials of the image coordinates . This knowledge is very important to tune visual odometry algorithms, because it clearly shows the different levels of sensitivity to measurement noise in the image coordinates and the optical flow of the different ego-motion parameters [10]. It also clearly proves, that the rotational velocity should be estimated first [11], because no structure information is needed and thus, also no error propagation from noisy depth measurements can enter. Finally, it proves, that monocular odometry approaches [12] can only estimate the rotational velocity and the translational velocity up to an unknown scale. So the scale is purely dependent on the scene structure and if no scene structure can be measured via for example a stereo camera system, then additional prior assumptions about the scene structure or additional sensors have to be taken into account to estimate this scale.
Equation (22) shows, that if the depth is not known, then only the ratios or in other words only the direction of the translational velocity vector can be estimated. Thus, the unknown scale can be eliminated from equation (21) considering the inner product of the vectors in equation (21) with the vector . This leads to the continuous epipolar constraint
[TABLE]
2.2 Discrete Rigid-Body-Transformations
If the camera motion is fast compared to the camera frame rate a discrete rigid-body-transformation can be used instead
[TABLE]
with the time difference , the relative translation , and the relative rotation between two camera frames at two time instants and .
Practically, equation (25) better models high-speed car-applications in outer-city/highway scenarios. Equation (25) assumes a constant twist of the camera motion between two different consecutive camera poses, Thus, it is violated in case of large camera accelerations.
If you now plug equation (19) for two different time instants
[TABLE]
into equation (25) you arrive at the discrete relation between image coordinate displacements , the depths and and the discrete camera motion which reads
[TABLE]
This equation is the discrete equivalent to equation (21). As in the continuous case the depths can be eliminated and the discrete motion can be estimated up to a scale with a monocular camera solving the discrete epipolar constraint which reads
[TABLE]
2.3 The Discrete versus the Continuous Epipolar Constrained
There do exist several well known algorithms to solve equation (24) and (31) for the ego-motion up to the unknown scale of translation, namely the discrete and continuous 8-point- [1] and the five-point-algorithm [13] with different kinds of realisations, like [14]. Here, it is common sense within the community and confirmed on lots of test data and different visual odometry configurations that the five-point-algorithm outperforms the eight-point-algorithm [15, 16]. Two important aspects have to be mentioned. On the one hand, since the five-point-algorithm provides an analytical solution that solves a nonlinear equation system using the minimal number of points the system designer has to take care of chosing the right five points to base the estimate on (e.g. using a RANSAC algorithm). Thus, this kind of solution outperforms linear least squares approaches, like the eight-point-algorithm in terms of accuracy. On the other hand, in terms of robustness, the least squares approaches are more robust. Sometimes, the five-point-algorithm fails because of bad feature configurations.
One conclusion from this knowledge could be: In order to bring together both advantages nonlinear least squares approaches could be a step towards very precise and robust solutions also for fairly bad feature configurations. This could be one direction to be evaluated more thoroughly.
It is very important for the algorithms to work properly that the points used for solving the equations are in general position. If the points are on so called critical surfaces the algorithms fail to solve uniquely for the ego-motion because several solutions do exist. A case of practical importance occurs when all the points happen to lie on the same plane. This has to be known in advance and can be solved uniquely with a reduced four-point-algorithm.
There is another requirement for the algorithms to work properly which is sufficient parallax. This means, the translation between two frames cannot be zero and should have some certain absolute value. Otherwise, the translation estimate is wrong but the rotation estimate is usually correct.
The discrete case assumes a distingtion of the vantage points from two consecutive views. If this is not the case only the continuous motion case works. Further on, the twisted-pair ambiguity that occurs in the discrete case and can be solved by imposing a positive depth constraint does not appear in the continuous motion case. Further details on the algorithms can be found in [1].
2.4 Structure reconstruction without known scale
If only a mono camera is used the structure can only be reconstructed up to an unknown scale. This is important for monocular visual odometry approaches that want to add a local mapping for improving motion estimates. Once the pose change has been estimated up to the single universal unknown scale the depth’s for all points can be recovered up to this scale ambiguity using equation (28):
[TABLE]
Since the depth with respect to the current frame is redundant to the depth with respect to the next frame , one depth can be eliminated
[TABLE]
Stacking all these linear equations for all points into one matrix leads to a linear least squares estimate for all depth’s up to the unknown scale . Details can be found in [1].
2.5 The Reprojection Error
Up to now, we considered an ideal pinhole camera model with a calibrated camera and ideal point correspondences . In practice, these coordinates are noisy because of the limited resolution of the camera chip and the ambiguities in the correspondence search. In addition, the camera cannot be calibrated such that the ideal pinhole model holds very precisely. Finally, the correspondences are obtained with an optical flow algorithm that usually does not consider the epipolar constraint. Hence, the measured (noisy) coordinates do not satisfy the epipolar constraint precisely.
To account for these errors both the pose estimate and the coordinate correspondences can be refined using the reprojection error which is the euklidean distance between the measured and reprojected coordinates from last and current time frame subject to the epipolar constraint:
[TABLE]
Here denotes the projection given in (19). The reprojection error is heavily used to formulate non-convex optimization problems if a precise ego-motion and structure reconstruction is needed.
2.6 Bundle Adjustment
In order to use the reprojection error for ego-motion and structure refinement several solutions do exist that are summarized with bundle adjustment (BA). The most general one is the full bundle adjustment approach that optimizes some likelihood function of the reprojection errors at different times of a bundle of points . In order to find the global optimum of the non-convex objective for several ego-motions along several frames within a time interval the selection of so called keyframes to get a good initialization is a crucial point. If the initialization is too bad such that the inital guess of the ego-motions is too far away from the optimum, the frames cover bad configurations like insufficient parallax and there is no sufficient overlap between the points of the bundle projected to the different frames then the iterative gradient-based optimization schemes do not converge to a proper solution [17].
For visual odometry applications a local bundle adjustment approach (using only a small number of timely consecutive frames) is more suitable which in the simplest case boils down to a two-frame bundle adjustment for each frame pair. If the objective should not account for outliers then the sum of squared reprojection errors is a proper objective function and one arrives at the classical least squares estimator chosing the current frame as the reference frame:
[TABLE]
The optimization of this objective drastically reduces the drift in visual odometry applications but needs some extra time for computation. Since it is solved iteratively based on a gradient descent approach the choice of the gradient method and which parameters to optimize at which iteration influences the final result. Thus, a lot of different approaches are around with difference in accuracy, convergence speed and computational cost. Optimizing for the ego-motion only assuming the depth’s and 2D coordinates are given, which means the structure is not refined and the errors because of calibration are negligible, is called motion-only BA. Optimizing for the depth’s and 2D coordinates only , thus refining the 3D points given a suitable ego-motion estimate, is called structure-only BA or structure triangulation. Recent approaches try to find alternating optimization schemes that switch between motion-only, structure-only and full-local BA to reach extremely precise ego-motion estimates with only a small amount of additional computational cost [18].
3 Optical Flow
Optical flow is one of the main ingredients to visual odometry, moving object detection and motion analysis approaches. Thus, it is very important to rely on a robust and computationally efficient optical flow estimation technique.
3.1 Photometric Constraint – The Brightness Constancy Assumption
The basic equation included in all optical flow estimation techniques is a photometric constraint also called the brightness constancy assumption. It assumes that the brightness of a 3D point projected onto an image plane of a camera and measured by the camera chip at position at time does not change during the movement of the point in space. The resulting projection after some time and pixel movement should have the same brightness . Here, the pixel movement is the forward movement from frame to frame in accordance to the Lucas-Kanade formulation. Thus, the brightness constancy assumption can be formulated as follows:
[TABLE]
3.2 Lucas-Kanade Optical Flow
Lucas and Kanade extended this assumption to some neighborhood around each pixel and assumed that the movement of the projection of this neighborhood (patch) is constraint by an image warp whereas the warp defines a local optical flow field parameterized with . For the warp a lot of different models with different complexity and number of parameters can be defined, e.g. a homography, an affine warp, or simply a translation. Also the way how to parameterize the same warp can be different. Now you have some additional contraint on the movement of the pixels within some neighborhood and you can formulate an objective function based on the photometric constraint (37). The one proposed by Lucas-Kanade is the most prominent one and simply realizes a sum of least squares objective:
[TABLE]
This is a nonlinear optimization problem even if we have a warp function that is linear in because the pixel values are in general non-linear in or in fact totally un-related. The optimization problem to find the optimal motion parameters can be formulated as follows:
[TABLE]
Such nonlinear optimization problems are solved iteratively via a proper linearization. In order to find a good local minimum a suitable initialization has to be given and each iteration solves for an increment of these parameters such that
[TABLE]
The iteration is repeated until the norm of the increment is below some threshold or a maximum number of iterations is reached. In order to solve the optimization (40) a first order Taylor expansion on the second image is applied
[TABLE]
Inserting this approximation into the optimization problem (40) leads to a closed form solution:
[TABLE]
For the most simplest warp which is the same shift for all pixels in the neighborhood the Jacobian of the warp equals the identity and the equations reduce to the well-known Lucas-Kanade optical flow equations:
[TABLE]
Usually, the neighborhood is weighted using a Gaussian window to relax the Lucas-Kanade constraint with distance to the center point of the neighborhood.
3.3 Why to use Lucas-Kanade?
The local and linear differential method of Lucas and Kanade [20] is one of the most popular approaches for optical flow computation when it comes to real time applications with restricted computational power. There are several reasons for that. Compared to global smoothness constraints used for example by Horn and Schunk, their local explicit method is more accurate and more robust with respect to errors in gradient measurements. It is very easy to compute and real-time capable. Nevertheless, the local approach suffers from the aperture problem and the linearisation of the underlying constancy assumption for image intensity. Lucas’ and Kanade’s basic idea to assume that the optical flow field is spatially constraint within some neighborhood is in many cases not enough to resolve motion ambiguities and does in particular not hold at motion boundaries. Further on, the linearised intensity constancy assumption is suitable only for small displacements.
However, if only a sparse flow is needed and a proper feature detector is used in advance to operate only on patches that have unambiguous structure, like corners, which is especially true for all sparse visual odometry approaches, the Lukas-Kanade approach is still one of the most efficient and robust optical flow methods if used in combination with a pyramidal approach [21].
3.4 Efficient Implementation of Lucas-Kanade
The implementation of the pyramidal approach is straight forward and details about implementation can be found for example in [21] that describes an efficient implementation done by Intel Corporation.
A more interesting detail on implementation is the way how the warp should be applied along the iterations within a scale. Here, a computationally efficient method is proposed by Baker and Matthews, called the inverse compositional algorithm [22]. Since this is relevant for real-time applications the basic idea is outlined in the following. In equation (42), it is important to mention that the gradient must be evaluated at and the Jacobian must be evaluated at . So, both depend in general on . Thus, in general both have to be re-calculated at each interation step because both depend on . For simple motion models, like linear motion models, the Jacobian is constant and needs not to be re-calculated. In equation (42), the computation of the Hessian is the computationally most expensive step with computational complexity of . Here, is the number of motion parameters and the number of pixels.
So, the idea of the inverse compositional algorithm [22] is to reformulate the Lucas-Kanade approach such that the Hessian needs not to be re-calculated for each iteration . The compositional approach is an alternative way to optimize equation (40) but is completely equivalent. First optimize the following objective for
[TABLE]
and then update the warp
[TABLE]
The inverse compositional approach now reverses and and inverts the warp of the motion increment:
[TABLE]
and then updates the warp
[TABLE]
Following this equivalence the optimization via Taylor expansion reads:
[TABLE]
Inserting this approximation into the optimization problem (46) leads to a closed form solution:
[TABLE]
For the most simplest warp which is the same shift for all pixels in the neighborhood the Jacobian of the warp equals the identity and the Hessian does not depend on anymore. Thus, the Hessian needs to be computed only once and is constant along iterations . This reduces the computational complexity because a large part of the iterative update can be pre-computed:
[TABLE]
Inverting and composing of the warps in equation (47) need some small extra costs that is almost negligible. So, if more than one iteration is applied, the inverse compositional approach should be considered. If a pyramidal approach is chosen, then usually only one iteration at each scale is enough because the result of the current scale is used as an initialization for the next finer scale and thus needs not to be very precise. Only at the scale with highest resolution several iterations could be beneficial because this scale deliveres the final result with highest precision.
3.5 Extensions to Lucas-Kanade
The basic idea of Lucas and Kanade is to constrain the local motion measurement by assuming a constant velocity within a spatial neighborhood. In [23, 24] this spatial constraint is reformulated in a probabilistic way assuming Gaussian distributed uncertainty in spatial identification of velocity measurements and extended to scale and time dimensions. Thus, uncertain velocity measurements observed at different image scales and positions over time can be combined. This leads to a recurrent optical flow filter formulated in a Dynamic Bayesian Network applying suitable factorisation assumptions and approximate inference techniques. The introduction of spatial uncertainty allows for a dynamic and spatially adaptive tuning of the constraining neighborhood. The tuning is realized dependent on the local structure tensor of the intensity patterns of the image sequence. It is demonstrated that a probabilistic combination of spatiotemporal integration and modulation of a purely local integration area improves the Lucas and Kanade estimation. This idea is further extended in [25, 26] to deal with any kind of distribution providing a general belief propagation scheme.
Other attempts to extend and improve the Lukas-Kanade approach are second order approaches and robust norms [27]. Unfortunately, those extensions do only lead to marginal improvement or even worsen the results but requiring a much higher computational cost.
4 Prior Models for Automotive Applications
Prior models are models that include knowledge that is known a priori, that is before running an algorithm, taking measurements and making observations. In the car domain that includes kowledge about the kinematics and dynamics of the ego-car [28] or a car in general if one observes also other traffic participants [29] and knowledge about the geometry of the scene, like the surface [30, 31, 32]. Beside prior models, there is also prior information about the scenario for example from digital maps and other categories like inner city or highway, property of the ground and weather conditions. Additional to the prior models and informations there are helpful quantities, like the calibration parameters including the hight over ground of the camera.
Prior information can be used to adapt the algorithms to the scenario using most suitable parameters or switch between different algorithms solving the same task under different conditions. Prior models are more powerful and can help to reduce the parameter space and thus lead to more efficient and robust algorithms but less accuracy because the model does not cover all effects of the real physical world in all situations.
4.1 Prior Scene Models
The most often used scene model is moving on a planar ground. There are only a few extensions to the plane, like curved surfaces.
4.1.1 The planar ground assumption
In the automotive domain a lot of approaches include the planar ground assumption (e.g. MobileEye and many others). Here, the free space to drive on (e.g. the road) is assumed to be a plane. Figure 6 shows the dependencies of a camera with a planar ground (grey) projected onto the image plane (blue). This special kind of projection is called a homography. A plane with and being the surface normal and being the distance from the optical center to the plane in camera coordinates is given by equation . Solving for and inserting into the projective equation (15) leads to a homography:
[TABLE]
whereas are the columns of the canonical projection matrix [1].
4.1.2 Extended ground ssumptions and Free Space Detection
There are some few extensions to the ground plane assumption. Especially in situations with slope changes in the road course ahead due to appraoching a hill or a dip cannot be modelled apropriately with a planar model. One interesting approach as can be seen in figure 7 is a B-spline extension fitted into the longitudinal structure of the surface extracted from a V-disparity map and stabilized via a Kalman-filter of the B-spline parameters along frames [33]. The most general representation of drivable space is the so called free space detection. One example of a free space detection is shown in figure 8. A nice review on current approaches can be found in [34].
4.2 Prior Motion Models
There are several suitable approximations for the camera motion mounted on a car including more or less explicit knowledge about the motion constraints of the camera due to inertia of the car (e.g. slow motions) and a constraint motion set because of the ability of a car to move (e.g. single-track-model).
Repeating the general motion equations and the relation to optical flow and structure (22)
[TABLE]
we have three translational components, , and for the velocities along the -, -, and -axis respectively and the rotational velocity components, namely yaw , pitch , and roll , shown again in figure 9.
4.2.1 The small rotation approximation
A suitable approximation if rotations are small is the following: . This can be used if translational motion components are dominating and no turns are driven. It could be interesting if only an instantaneous motion estimate is needed to separate moving objects from the background at high speeds of a car moving on a highway. In addition, this is a suitable approximation in post-processing recursive refinement schemes that are based on optimizing an objective to refine the motion estimates incrementally (e.g. using the reprojection error).
4.2.2 The three parameter motion model
Especially for outlier rejection it is advantageous to reduce the general motion model to a minimum [35, 16]. The motion of a car can be modeled as a translation along the axis and rotation around the and axes. Limiting the equations (22) to this motion constraints, we get:
[TABLE]
4.2.3 One parameter motion models
A very simple motion model, considering high-speed scenarios, assumes very small rotations, such that they can be neglected . Hence, the rotation matrix approximately equals the identity. In addition it is assumed that much larger longitudinal than horizontal and vertical movements exist, thus the lateral and transversal components of the translation approximately equal zero . This pure 1D translational model is for example used for outlier rejection in highway scenarios [10]:
[TABLE]
The most advanced one parameter motion model is the one introduced by Scaramuzza [36], the so called circular motion model. It assumes locally planar motion , so there is only translational velocity in the plane parallel to the camera frame and yaw . Under planar motion, the two relative poses of a camera can be described by two parameters, namely the yaw angle and the polar coordinates of the second position relative to the first position as can be seen in figure 10. Since when using only one camera the scale factor is unknown, we can arbitrarily set at 1. From this it follows that only two parameters need to be estimated and so only two image points are required. However, if the camera moves locally along a circumference and the x-axis of the camera is set perpendicular to the radius , then we have ; thus, only needs to be estimated and so only one image point is required. Observe that straight motion is also described through the circular motion model; in fact in this case we would have and thus . Comparing the derivation in [36] for the discrete motion case with the continuous motion case, we get , and and arrive at (22) with the following re-parametrization:
[TABLE]
In [36] there is an efficient way to solve the epipolar constraint under the circular motion model with the 1-point-RANSAC method.
5 Ego-motion Estimation Techniques
5.1 The Indirect Method
The indirect method is the most often used classical visual odometry pipeline [15] as shown in figure 11. It consists of a purely feedforward system architecture, first applying some feature detection, afterwards applying some feature matching, then estimating the ego-motion and finally refine the ego-motion estimate using some variant of local bundle adjustment. Here, the brightness constancy assumption is used for the feature matching and afterwards the epipolar constraint is used for the ego-motion estimation.
5.2 The Direct Method
Instead of deviding the two optimization problems for feature matching and ego-motion estimation, each driven by a different constraint alone, namely the photometric and the epipolar constraint, the direct method combines the two constraints into one objective function and directly solves for the ego-motion without explicitly matching features. In other words, the feature matching is constraint not only by the brightness constancy assumption but also by the epipolar constraint that reduces the space of possible feature matches to the subspace that is reachable by some ego-motion. Starting from the Lucas-Kanade objective function (38)
[TABLE]
we define the reprojected coordinates after some ego-motion already formulated in (35) for the reprojection error as a warp
[TABLE]
and plug this warp into the Lucas-Kanade objective
[TABLE]
Now, this new objective is minimized for the ego-motion
[TABLE]
instead of the flow (which corresponds to the feature matches). As a result, the formulation in one objective function is just the Lucas-Kanade objective function with a warp that is given by the reprojected coordinates after some ego-motion and applied to the whole feature set (sparse approach) or to all pixels in the image (dense approach).
This approach was used by a lot of researchers, like [18, 19] and many others. Note, that for the general case, the depth needs to be known for optimization. A more constraint variation of the direct method is used by Stein et al. [35]. Here, a reduced motion model (see section 4.2) and the planar ground assumption (see section 4.1) is integrated to reduce the parameter space and get rid of the depth.
5.3 Direct versus Indirect Method
To answer the question which technique should be used cannot clearly be answered because it depends on the application you would like to realize and what constraints you have in terms of computational effort and accuracy. Best results can be found by careful intertwining the different optimization objectives of the direct and indirect method. Having a look at the currently best visual odometry approaches in the Kitti benchmark [18, 38, 11] it turns out that the direct method is best for a fast and robust outlier rejection plus a good initialization of the ego-motion. For refinement and most accurate estimates the indirect method including bundle adjustment outperforms the direct method.
In general, the non-convex optimization problem of visual odometry is solved best via linearization and iterative least squares including both a careful initialization of the motion hypothesis and a careful feature selection integrated in a stepwise optimization procedure that adds different constraints and relaxation of constraints in an alternating fashion. The secret lies in the careful intertwining of all those ingredients. So the classical visual odometry pipeline is extended to have several feedback loops along the feed forward path [28].
5.4 Monocular Visual Odometry: How to get the unknown scale?
As seen so far and derived in section 2.4, the motion of a car can be estimated from only one camera up to an unknown scale . So the only difference between mono and stereo odometry is the estimation of the scale. In stereo systems the scale can directly be estimated from measurements of 3D point coordinates. In monocular systems the scale has to be estimated via additional apriori knowledge of the scene. That means, each stereo visual odometry and all the different methods that are based on 3D coordinates can also be used by a monocular system if the scale is estimated in parallel. Once the scale is known, the 3D coordinates can be reconstruced using scene reconstruction algorithms like sketched in section 2.4. To summaries, scale drift correction is an integral component of monocular visual odometry. In practice, it is the single most important aspect that ensures accuracy [39]. For automotive applications the most prominent way to estimate this unknown scale is to have an apriori model of the structure of the environment as pointed out in section 4.1 and an additional absolute reference value between at least two 3D points in the scene. The apriori knowledge about an absolute reference can be for example the width or length of a car or a traffic sign [39]. The most often used reference is the height above ground of the camera mounted on the car and the most often used scene model is a planar surface of the ground [35, 40, 41], like visualized in figure 12. In [41] two methods are combined, in order to obtain the orientation of the ground plane: First, fitting a plane to the reconstructed point cloud (see figure 13) and second, deducing the plane normal from vanishing points in the image of a calibrated camera (see figure 14). These methods are complementary. In rural areas, where the vanishing directions are challenging to be calculated correctly, the plane computation from reconstructed points leads to an accurate plane estimate. In contrast, the vanishing point estimation performs best in urban areas, where the scene structure is more dense and the ground plane is more likely to be occluded.
6 Outlier Rejection
The essential part of any visual odometry system is the detection of outliers. Therefore, a broad variety of methods has been introduced: Purely flow-based approaches can be found in [42, 43, 44]. All of them are based on the assumption, that the flow follows patterns which are induced by the egomotion of the car. Next, motion model-based approaches for outlier detection exist, that explicitly constrain the flow using a certain motion model as in [36].
The majority of existing systems use reprojection error-based approaches. Here mainly two different ways for finding a proper inlier set are used. The first one is RANSAC [48], which is based on the following principle: In each iteration, a minimum number of random samples is taken from the correspondences to create a motion hypothesis. Then, a score for each feature is calculated that describes whether it supports the hypothesis. If the motion estimate reaches a predefined support of the features, the non-supporting features are marked as outliers. Otherwise, a new random sample is drawn and the next iteration starts. In order to define the support of a feature in this RANSAC-scheme, the authors of [51, 50, 49, 52] calculate the reprojection error for each feature and compare it to a constant threshold. Trying to optimize the random process of finding the right hypothesis to separate the features into inliers and outliers, numerous extensions were created. A comparison between the most prominent ones can be found in [53].
Due to the random selection of correspondences one can not expect a steady improvement of the resulting motion estimation during the iterations. Coping with this problem, an alternative method was applied in [47, 45, 46]. Following the naming that was used for RANSAC this class of methods can be united under the notation MAximum Subset Outlier Removal (MASOR). Here the maximum number of features instead of a minimum random sample is taken to calculate a motion hypothesis. This motion estimation and a subsequent outlier rejection step are repeated in an iterative scheme. Then a support score is calculated for every feature. Instead of judging the hypothesis, the score is interpreted as a measure for the quality of each feature, as the hypothesis is considered to be a good estimate. Non-supporting features are rejected and the next iteration starts with the remaining features. The process is repeated until a termination criterion is met. This approach is a good alternative to RANSAC if the number of inliers is sufficient enough to create a hypothesis that is good enough to separate the outliers.
Following the classical visual odometry pipeline, it can be assumed that for each point the depth is measured by some stereo vision algorithm, the image coordinates are extracted by some feature detector and the correspondent image coordinates in the next frame are measured by some optical flow algorithm. To find the optimal estimate of the pose change very precisely some bundle adjustment approach minimizing reprojection errors with an iterative gradient descent method has to be carried out like explained in section 2.6. Here, some carefully chosen initial guess for the pose change has to be given.
The problem of outlier rejection can be formulated as follows: Given the set of all extracted features, we need to find suitable features – the inliers – and reject all other features from the set – the outliers. This is usually done by selecting only features with reliable measurements and defining some criterion to evaluate how well these measurements fit to some hypothesis of the estimate .
6.1 Reliability of a measurement
In general it is already known and stated in [39] that high translational errors occur at large longitudinal pose changes along the optical axis. The translation estimates get especially poor for long distance features [54].
Thinking about reliability taking into account the principles of projection, the image resolution, basics of epipolar geometry and the umbiguity of patch matching, the reliability of a measurement has two aspects.
First, since in most of the visual odometry systems depth is reconstructed from disparity using a stereo rig with a fixed known baseline and both the disparity and the pairs are based on a correspondence search that is done with some optical flow algorithm, for both types of correspondences (within and across time) only unambiguous correspondences, e.g. not facing the aperture problem, should be taken into account.
Second, the accuracy of these correspondences are limited by the resolution of the images. So even if the correspondences are unambiguous the smaller their distances and , the less accurate the pose change can be estimated. This is because the ratios and between distances , and the limited image resolution are getting smaller with smaller distances and thus the signal-to-resolution-ratio decreases. Especially for the accuracy of the reconstructed depth , this is crucial because the resolution of depth reduces quadratically with distance.
Considering these facts, it seems to be easy to figure out good features. Choose near features with large optical flow that are based on highly confident correspondence estimates.
From an algorithmic point of few, there are some further techniques to rely on in order to reduce the number of unreliable measurements that check the measurements for consistency. Three different consistency checks can befound in the literature: First, the forward-backward consistency check for optical flow correspondences. Second, the left-right consistency check for stereo-vision corresponences. Third, so called circular matching is the combination of forward-backward and left-right in a circle around a set of four images of two consecutive stereo image pairs.
Additionally, each correspondence has to fulfill the epipolar constraint for one optimal estimate , thus the features have to be projections of static points in the scene only. Since we cannot guarantee that the measurements are all confident and we do not have the optimal pose change estimate at hand, we need to find a good hypothesis and a proper criterion to keep as much suitable features as possible.
6.2 Using Only Optical Flow
If only the optical flow is used to detect outliers a certain assuption about the spatial configuration of the flow field has to be given. The most general assumption is local continuity of the flow field which means that the gradient in the flow field does not exceed some certain threshold. Here, the threshold separates between a smooth and a discontinuous flow. Most often used continuity assumptions are parameterized motion models like locally affine flow fields which is true for front-to-parallel moving planes or locally homographic flow fields which is true for any moving plane.
6.3 Using Optical Flow and Motion Model
As already pointed out in 6 there are two different categories to recursively get a robust motion hypothesis by alternating between motion hypothesis estimation based on a fixed feature set and feature set optimization based on a fixed motion hypothesis. The RANSAC method is very well known and different ways how to realise can be found in the literature (see also section 6). The MASOR approaches do not rely on a random sample but on a fixed deterministic feature set that is iteratively reduced to some minimal set. The two most important variations are given in the following. Starting from a fixed set at iteration number , in each iteration the motion hypothesis is refined using the reprojection error for all current inliers and afterwards the feature set is updated using some adaptive threshold.
In 2005, the authors of [46] applied the following criterion to classify outliers:
[TABLE]
With mean error and squared standard deviation . The total number of iterations was set to a fixed value. In 2011, the authors of [47] changed the criterion slightly:
[TABLE]
6.4 Using Optical Flow and Constraint Scene & Motion Models
In order to reduce the space of possible inliers even more, scene knowledge and reduced motion models can be applied to get a more robust motion estimation that is more robust against outliers. A very efficient way is the constraint direct method published in [35]. Here, a reduced motion model (see section 4.2) and the planar ground assumption (see section 4.1) is integrated to reduce the parameter space, get independent on depth measurements and robustify the ego-motion estimate.
Starting from equation (62) which is a reduced motion model
[TABLE]
and replace the inverse of the depth by the ground plane assumption
[TABLE]
leads to the reduced ground-plane-motion model
[TABLE]
If one assumes that the ground plane is parallel to the -plane, then , and the ground-plane-motion model reduces to
[TABLE]
This model has to be plugged into the objective (65) of the direct method and can then be optimized for , and . If the height over ground which now equals is known, then can be solved for .
In [55] an additional constraint is used to detect moving objects exploiting the available constraint envelope of a 3D point. The epipolar constraint expresses that the viewing rays of a static 3D point (the lines joining the projection centers and the 3D point) must meet. A moving 3D point in general induces skew viewing rays violating the constraint.
The fact that all points seen by the camera must lie in front of it is known as the positive depth constraint. See figure 15 for details. This constraint is independent of the scene structure. In order to apply the constraint the translation direction (forward or backward) of the camera has to be known (in addition to the essential matrix). If points intersect behind the camera, the 3D point itself must be moving.
Traffic driving in front of the ego-vehicle with lower or identical speed (preceding traffic) is detected by the positive height constraint. For details see figure 16. All 3D points must lie above the road. This constraint is not as powerful as the positive depth constraint since it applies only for image points under the horizon. Furthermore the geometry of the road has to be known.
6.5 Explicit Segmentation of Multiple Objects
Instead of just finding outliers that do not fit to some ego-motion hypothesis and classifying these outliers as individually moving objects the multiple ego-motions of all of the traffic participants could in principle explicitly be estimated in parallel using the multibody epipolar constraint for the discrete motion case [1]. The minimal setting is the existence of two independent moving objects with motions and . This leads to the following multibody epipolar constraint:
[TABLE]
If there are only two independent moving objects (or at least enough features for both motions that are far more than the number of outliers) then both ego-motions can be recovered with an algorithm. For more then two rigid-body motions it is getting hard to solve but is still possible under some constraints [1]. Here, we have another problem, that is to find the correct number of multiple motions. This is an additional segmentation problem that has to be solved in advance or in conjunction with the estimation of the multiple motions. Several approaches do already exist that use this basic idea, for example [56]. Here for example simplifications are introduced and solutions are provided to circumvent the segmentation problem e.g. using the planar epipolar constraint for a large number of fixed small motion patches [57, 58]. To segment moving objects that are non-rigid which are composed of rigid moving parts with arbitrary shape learning techniques (preferably unsupervised) can be applied to learn specific motion patterns related to certain movement classes [59, 60, 61].
6.6 Robust estimators
There is an alterative (or additional) method to handle outliers. Instead of rejection via some consistency check, one could use robust estimators that weaken the influence of an outlier within the objective function [15]. Therefore, the squared error for the estimates of the unknowns has to be replaced by a different robust error norm, like the infinity-norm (the absolute values) to set up objective functions. The advantage of such an approach is that no additional rejection mechanism has to be set up to reject outliers. The drawback of robust estimators is, that the outliers still do influence the estimation result and the minimization of robust objective functions is computationally much harder than simple squared error norms. Of course, robust estimators can be applied in conjunction with an outlier rejection mechanism.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Ma, Y., Soatto, S., Kosecka, J., Sastry, S. S. (2012): An invitation to 3-d vision: from images to geometric models. Springer Science & Business Media.
- 2[2] Hartley, R., Zisserman, A. (2003): Multiple view geometry in computer vision. Cambridge university press.
- 3[3] Willert, V., Schmuedderich, J., Eggert, J., Goerick, C., Koerner, E. (2008): Probabilistic Optical Flow Estimation for Large Pixel Displacements Utilizing Egomotion Flow Compensation. In British Machine Vision Conference (BMVC) (pp. 1-10).
- 4[4] Schmuedderich, J., Willert, V., Eggert, J., Rebhan, S., Goerick, C., Sagerer, G., Koerner, E. (2008): Estimating Objects Proper Motion using Optical Flow, Kinematics and Depth Information. In: IEEE Transactions on Systems, Man and Cybernetics, Part B, 38 (4) 1139 - 1151.
- 5[5] Willert, V., Schmuedderich, J., Rebhan, S., Eggert, J. (2009): Estimating objects proper motion using optical flow, kinematics, and depth information. European Patent.
- 6[6] Longuet-Higgins, H. C., Prazdny, K. (1980): The interpretation of a moving retinal image. Proceedings of the Royal Society of London B: Biological Sciences, 208(1173), 385-397.
- 7[7] Willert, V. (2006): Recurrent visual motion segmentation. Ph D Thesis, TU Darmstadt, VDI Fortschritt-Berichte, Reihe 8, Nr. 1101.
- 8[8] Toussaint, M., Willert, V., Eggert, J., Koerner, E. (2007): Motion Segmentation Using Inference in Dynamic Bayesian Networks. In BMVC (pp. 1-10).