Concurrent Parsing of Constituency and Dependency
Junru Zhou, Shuailiang Zhang, Hai Zhao

TL;DR
This paper introduces a novel joint parsing model that simultaneously handles constituent and dependency parsing, enabling mutual enhancement and achieving state-of-the-art results on standard benchmarks.
Contribution
It presents the first model capable of concurrent constituent and dependency parsing, demonstrating the benefits of shared network components and improved performance.
Findings
Dependency parsing benefits more from constituent structure.
Achieved new state-of-the-art results on PTB and CTB datasets.
Shared network components improve parsing accuracy.
Abstract
Constituent and dependency representation for syntactic structure share a lot of linguistic and computational characteristics, this paper thus makes the first attempt by introducing a new model that is capable of parsing constituent and dependency at the same time, so that lets either of the parsers enhance each other. Especially, we evaluate the effect of different shared network components and empirically verify that dependency parsing may be much more beneficial from constituent parsing structure. The proposed parser achieves new state-of-the-art performance for both parsing tasks, constituent and dependency on PTB and CTB benchmarks.
Click any figure to enlarge with its caption.
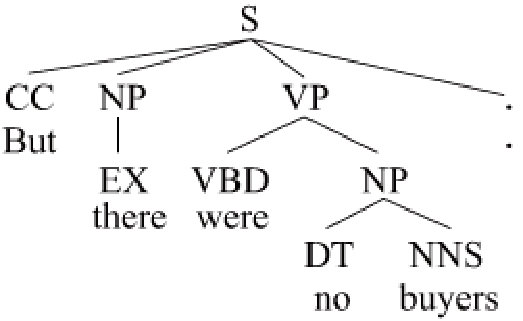 Figure 1
Figure 1 Figure 2
Figure 2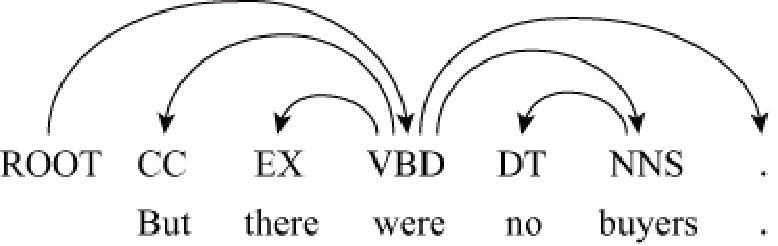 Figure 3
Figure 3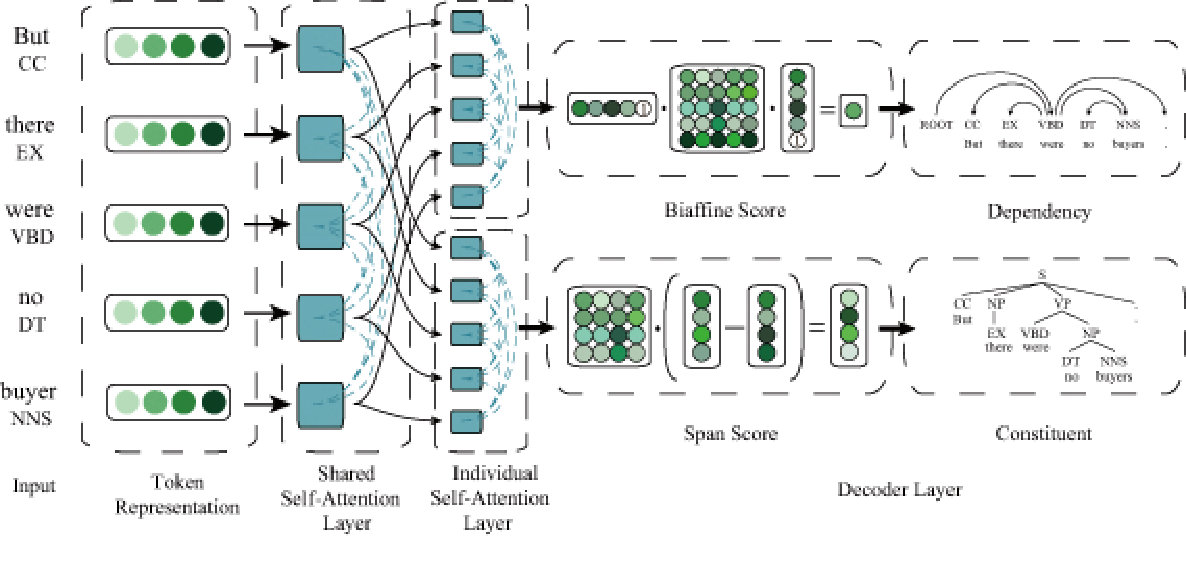 Figure 4
Figure 4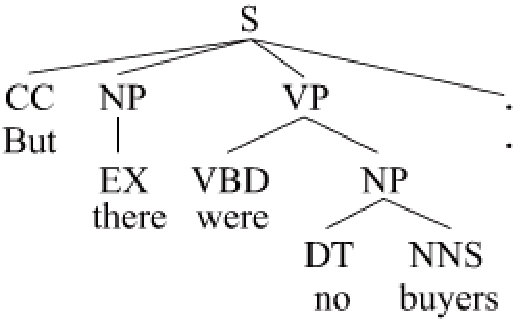 Figure 5
Figure 5 Figure 6
Figure 6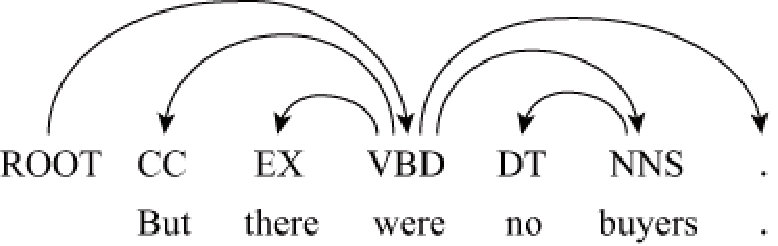 Figure 7
Figure 7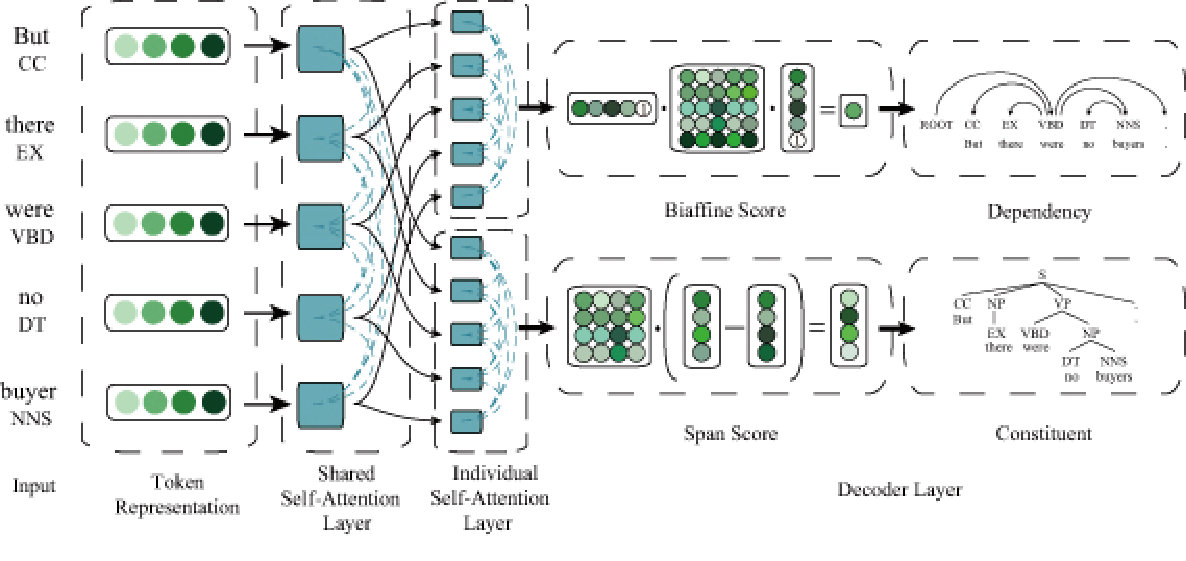 Figure 8
Figure 8| Lexical Representation | F1 | UAS | LAS |
|---|---|---|---|
| Word, POS, CharLSTM | 93.50 | 95.41 | 93.35 |
| Word, POS, CharCNNs | 93.46 | 95.43 | 93.30 |
| Word, CharLSTM | 93.83 | 95.71 | 93.68 |
| Word, CharCNNs | 93.70 | 95.43 | 93.35 |
| POS, CharLSTM | 93.16 | 95.06 | 92.82 |
| CharLSTM | 93.80 | 95.46 | 93.46 |
| Joint Component | F1 | UAS | LAS | |
|---|---|---|---|---|
| Separate | 93.44 | 94.59 | 92.15 | |
| Shared | self-att 0layers | 93.76 | 95.63 | 93.56 |
| self-att 2layers | 93.70 | 95.48 | 93.41 | |
| self-att 4layers | 93.59 | 95.24 | 93.12 | |
| self-att 6layers | 93.68 | 95.50 | 93.51 | |
| self-att 8layers | 93.83 | 95.71 | 93.68 | |
| Single Model | English | Chinese | ||
|---|---|---|---|---|
| UAS | LAS | UAS | LAS | |
| Weiss et al. (2015) | 94.26 | 92.41 | _ | _ |
| Andor et al. (2016) | 94.61 | 92.79 | _ | _ |
| Dozat and Manning (2017) | 95.74 | 94.08 | 89.30 | 88.23 |
| Ma et al. (2018) | 95.87 | 94.19 | 90.59 | 89.29 |
| Our model(Sum) | 94.80 | 92.45 | 88.66 | 86.58 |
| Our model(Concat) | 94.68 | 92.32 | 88.59 | 86.17 |
| Our model (Sum) | 95.90 | 93.99 | 90.89 | 89.34 |
| Our model (Concat) | 95.91 | 93.86 | 90.85 | 89.28 |
| Pre-training | ||||
| Wang et al. (2018)(ELMo) | 96.35 | 95.25 | _ | _ |
| Our model (ELMo) | 96.82 | 94.91 | _ | _ |
| Our model (BERT) | 96.88 | 95.12 | _ | _ |
| Ensemble | ||||
| Choe and Charniak (2016) | 95.9 | 94.1 | _ | _ |
| Kuncoro et al. (2017) | 95.8 | 94.6 | _ | _ |
| Single Model | LR | LP | F1 |
|---|---|---|---|
| Stern et al. (2017a) | 93.2 | 90.3 | 91.8 |
| Gaddy et al. (2018) | 91.76 | 92.41 | 92.08 |
| Stern et al. (2017b) | 92.57 | 92.56 | 92.56 |
| Kitaev and Klein (2018a) | 93.20 | 93.90 | 93.55 |
| Our model (Sum) | 92.92 | 93.90 | 93.41 |
| Our model (Concat) | 93.26 | 93.95 | 93.60 |
| Our model (Sum) | 93.52 | 94.00 | 93.76 |
| Our model (Concat) | 93.71 | 94.09 | 93.90 |
| Pre-training | |||
| Kitaev and Klein (2018a)(ELMo) | 94.85 | 95.40 | 95.13 |
| Kitaev and Klein (2018b)(BERT) | 95.46 | 95.73 | 95.59 |
| Our model (ELMo) | 94.73 | 95.25 | 94.99 |
| Our model (BERT) | 95.51 | 95.87 | 95.69 |
| Ensemble | |||
| Liu and Zhang (2017a) | _ | _ | 94.2 |
| Fried et al. (2017) | _ | _ | 94.66 |
| Kitaev and Klein (2018b) | 95.51 | 96.03 | 95.77 |
| Single Model | LR | LP | F1 |
|---|---|---|---|
| Liu and Zhang (2017b) | 85.9 | 85.2 | 85.5 |
| Shen et al. (2018) | 86.6 | 86.4 | 86.5 |
| Fried and Klein (2018) | _ | _ | 87.0 |
| Teng and Zhang (2018) | 87.1 | 87.5 | 87.3 |
| Kitaev and Klein (2018b) | 91.55 | 91.96 | 91.75 |
| Our model (Sum) | 91.35 | 91.65 | 91.50 |
| Our model (Concat) | 91.36 | 92.02 | 91.69 |
| Our model (Sum) | 91.79 | 92.31 | 92.05 |
| Our model (Concat) | 91.41 | 92.03 | 91.72 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNatural Language Processing Techniques · Topic Modeling · Advanced Text Analysis Techniques
Concurrent Parsing of Constituency and Dependency
Junru Zhou , Shuailiang Zhang, Hai Zhao
Department of Computer Science and Engineering
Key Lab of Shanghai Education Commission
for Intelligent Interaction and Cognitive Engineering
MoE Key Lab of Artificial Intelligence, AI Institute
Shanghai Jiao Tong University, Shanghai, China
{zhoujunru,zsl123}@sjtu.edu.cn, [email protected] Corresponding author. This paper was partially supported by National Key Research and Development Program of China (No. 2017YFB0304100) and key projects of Natural Science Foundation of China (No. U1836222 and No. 61733011)
Abstract
Constituent and dependency representation for syntactic structure share a lot of linguistic and computational characteristics, this paper thus makes the first attempt by introducing a new model that is capable of parsing constituent and dependency at the same time, so that lets either of the parsers enhance each other. Especially, we evaluate the effect of different shared network components and empirically verify that dependency parsing may be much more beneficial from constituent parsing structure. The proposed parser achieves new state-of-the-art performance for both parsing tasks, constituent and dependency on PTB and CTB benchmarks.
1 Introduction
Constituent and dependency are two typical syntactic structure representation forms as shown in Figure 1, which have been well studied from both linguistic and computational perspective Chomsky (1981); Bresnan (2001). In earlier time, linguists and NLP researchers discussed how to encode lexical dependencies in phrase structures, like Tree-adjoining grammar (TAG) Joshi and Schabes (1997) and head-driven phrase structure grammar (HPSG) Pollard and Sag (1994).
Typical dependency treebanks are usually converted from constituent treebanks, though they may be independently annotated as well for the same languages. Meanwhile, constituent parsing can be accurately converted to dependencies (SD) representation by grammatical rules or machine learning methods Marneffe et al. (2006); Ma et al. (2010). Such mutual convertibility shows a close relation between constituent and dependency representation for the same sentence. Thus, it is a natural idea to study the relationship between constituent and dependency structures, and the joint learning of constituent and dependency parsing Collins (1997); Charniak (2000); Klein and Manning (2004); Charniak and Johnson (2005); Farkas et al. (2011); Green and Žabokrtský (2012); Ren et al. (2013); Xu et al. (2014); Yoshikawa et al. (2017); Strzyz et al. (2019).
For further exploit both strengths of the two representation forms for even better parsing, in this work, we propose a new model that is capable of synchronously parsing constituent and dependency.
Multitask learning (MTL) is a natural solution in neural models for multiple inputs and multiple outputs, which is adopted in this work to decode constituent and dependency in a single model. Søgaard and Goldberg (2016) indicates that when tasks are sufficiently similar, especially with syntactic nature, MTL would be useful. In contrast to previous work on deep MTL Collobert et al. (2011); Hashimoto et al. (2017), our model focuses on more related tasks and benefits from the strong inherent relation. At last, our model is evaluated on two benchmark treebanks for both constituent and dependency parsing. The empirical results show that our parser reaches new state-of-the-art for all parsing tasks.
2 Our Model
Using an encoder-decoder backbone, our model may be regarded as an extension of the constituent parsing model of Kitaev and Klein (2018a) as shown in Figure 2. The difference is that in our model both constituent and dependency parsing share the same token representation and shared self-attention layers and each has its own individual Self-Attention Layers and subsequent processing layers. Our model includes four modules: token representation, self-attention encoder, constituent and dependency parsing decoder.
2.1 Token Representation
In our model, token representation is composed by character, word and part-of-speech (POS) embeddings. For character-level representation, we explore two types of encoders, CharCNNs Ma and Hovy (2016); Chiu and Nichols (2016) and CharLSTM Kitaev and Klein (2018a), as both types have been verified their effectiveness. For word-level representation, we concatenate randomly initialized and pre-trained word embeddings. We consider two ways to compose the final token representation, summing and concatenation, =++, =[;;].
2.2 Self-Attention Encoder
The encoder in our model is adapted from Vaswani et al. (2017) to factor explicit content and position information in the self-attention process Kitaev and Klein (2018a). The input matrices in which is concatenated with position embedding are transformed by a self-attention encoder. We factor the model between content and position information both in self-attention sub-layer and feed-forward network, whose setting details follow Kitaev and Klein (2018a). We also try different numbers of shared self-attention layers in section 3.
2.3 Constituent Parsing Decoder
The score of the constituent parsing tree is to sum every scores of span (, ) with label ,
The goal of constituent parser is to find the tree with the highest score: We use CKY-style algorithm to obtain the tree in time complexity Cocke, John (1970); Younger, Daniel H. (1975); Kasami, Tadao (1965); Stern et al. (2017a); Gaddy et al. (2018).
This structured prediction problem is handled with satisfying the margin constraint:
where denote correct parse tree and is the Hamming loss on labeled spans with a slight modification during the dynamic programming search. The objective function is the hinge loss,
[TABLE]
2.4 Dependency Parsing Decoder
Similar to the constituent case, dependency parsing is to search over all possible trees to find the globally highest scoring tree. We follow Dozat and Manning (2017) and Zhang et al. (2017) to predict a distribution over the possible head for each word and find the globally highest scoring tree conditional on the distribution of each word only during testing.
We use the biaffine attention mechanism Dozat and Manning (2017) between each word and the candidates of the parent node:
where and are calculated by a distinct one-layer perceptron network.
Dependency parser is to minimize the negative log likelihood of the golden tree , which is implemented as cross-entropy loss:
where is the probability of correct parent node for , and is the probability of the correct dependency label for the child-parent pair .
During parsing, we use the first-order Eisner algorithm Eisner (1996) to build projective trees.
2.5 Joint training
Our joint model synchronously predicts the dependency tree and the constituent tree over the same input sentence. The output of the self-attention encoder is sent to the different decoder to generate the different parse tree. Thus, the share components for two parsers include token representation layer and self-attention encoder.
We jointly train the constituent and dependency parser for minimizing the overall loss:
where is a hyper-parameter to control the overall loss. The best performance can be achieved when is set to 1.0, which turns out that both sides are equally important.
3 Experiments
We evaluate our model on two benchmark treebanks, English Penn Treebank (PTB) and Chinese Penn Treebank (CTB5.1) following standard data splitting Zhang and Clark (2008); Liu and Zhang (2017b). POS tags are predicted by the Stanford Tagger Toutanova et al. (2003). For constituent parsing, we use the standard evalb111http://nlp.cs.nyu.edu/evalb/ tool to evaluate the F1 score. For dependency parsing, we apply Stanford basic dependencies (SD) representation Marneffe et al. (2006) converted by the Stanford parser222http://nlp.stanford.edu/software/lex-parser.html. Following previous work Dozat and Manning (2017); Ma et al. (2018), we report the results without punctuations for both treebanks.
3.1 Setup
We use the same experimental settings as Kitaev and Klein (2018a). For dependency parsing, we employ two 1024-dimensional multilayer perceptrons for learning specific representation and a 1024-dimensional parameter matrix for biaffine attention. We use 100D GloVe Pennington et al. (2014) for English and structured-skipgram Ling et al. (2015) embeddings for Chinese.
3.2 Ablation Studies
All experiments in this subsection are running from token representation with summing setting.
Token Representation Different token representation combinations are evaluated in Table 1. We find that CharLSTM performs a little better than CharCNNs. Moreover, POS tags on parsing performance show that predicted POS tags decreases parsing accuracy, especially without word information. If POS tags are replaced by word embeddings, the performance increases. Finally, we apply word and CharLSTM as token representation setting for our full model333We also evaluate POS tags on CTB which increases parsing accuracy, thus we employ the word, POS tags and CharLSTM as token representation setting for CTB..
Shared Self-attention Layers As our model providing two outputs from one input, there is a bifurcation setting for how much shared part should be determined. Both constituent and dependency parsers share token representation and 8 self-attention layers at most. Assuming that either parser always takes input information flow through 8 self-attention layers as shown in Figure 2, then the number of shared self-attention layers varying from 0 to 8 may reflect the shared degree in the model. When the number is set to 0, it indicates only token representation is shared for both parsers trained for the joint loss through each own 8 self-attention layers. When the number is set to less than 8, for example, 6, then it means that both parsers first shared 6 layers from token representation then have individual 2 self-attention layers.
For different numbers of shared layers, the results are in Table 2. We respectively disable the constituent and the dependency parser to obtain a separate learning setting for both parsers in our model. The comparison in Table 2 indicates that even though without any shared self-attention layers, joint training of our model may significantly outperform separate learning mode. At last, the best performance is still obtained from sharing full 8 self-attention layers.
Besides, comparing UAS and LAS to F1 score, dependency parsing is shown more beneficial from our model which has more than 1% gain in UAS and LAS from parsing constituent together.
3.3 Main Results
Tables 3, 4 and 5 compare our model to existing state-of-the-art, in which indicator Separate with our model shows the results of our model learning constituent or dependency parsing separately, (Sum) and (Concat) respectively represent the results with the indicated input token representation setting. On PTB, our model achieves 93.90 F1 score of constituent parsing and 95.91 UAS and 93.86 LAS of dependency parsing. On CTB, our model achieves a new state-of-the-art result on both constituent and dependency parsing. The comparison again suggests that learning jointly in our model is superior to learning separately. In addition, we also augment our model with ELMo Peters et al. (2018) or a larger version of BERT Devlin et al. (2018) as the sole token representation to compare with other pre-training models. Since BERT is based on sub-word, we only take the last sub-word vector of the word in the last layer of BERT as our sole token representation . Moreover, our single model of BERT achieves competitive performance with other ensemble models.
4 Conclusions
This paper presents a joint model with the constituent and dependency parsing which achieves new state-of-the-art results on both Chinese and English benchmark treebanks. Our ablation studies show that joint learning of both constituent and dependency is indeed superior to separate learning mode. Also, experiments show that dependency parsing is much more beneficial from knowing the constituent structure. Our parser predicts phrase structure and head-word simultaneously which can be regarded as an effective HPSG Pollard and Sag (1994) parser.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Andor et al. (2016) Daniel Andor, Chris Alberti, David Weiss, Aliaksei Severyn, Alessandro Presta, Kuzman Ganchev, Slav Petrov, and Michael Collins. 2016. Globally Normalized Transition-Based Neural Networks . In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL) , pages 2442–2452. · doi ↗
- 2Bresnan (2001) Joan Bresnan. 2001. Lexical-Functional Syntax .
- 3Charniak (2000) Eugene Charniak. 2000. A Maximum-Entropy-Inspired Parser . In 1st Meeting of the North American Chapter of the Association for Computational Linguistics (NAACL) .
- 4Charniak and Johnson (2005) Eugene Charniak and Mark Johnson. 2005. Coarse-to-Fine n-Best Parsing and Max Ent Discriminative Reranking . In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05) , pages 173–180.
- 5Chiu and Nichols (2016) Jason Chiu and Eric Nichols. 2016. Named Entity Recognition with Bidirectional LSTM-CN Ns . Transactions of the Association for Computational Linguistics(TACL) , 4:357–370.
- 6Choe and Charniak (2016) Do Kook Choe and Eugene Charniak. 2016. Parsing as Language Modeling . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 2331–2336. · doi ↗
- 7Chomsky (1981) N. Chomsky. 1981. Lectures on government and binding .
- 8Cocke, John (1970) Cocke, John. 1970. Programming languages and their compilers :preliminary notes .