TL;DR
This paper introduces a novel approach combining deep reinforcement learning with Earth system models to discover sustainable management strategies that respect planetary and social boundaries.
Contribution
It develops a general DRL framework for Earth system models and demonstrates its ability to identify policies promoting sustainability within complex constraints.
Findings
DRL can learn effective climate mitigation policies.
Timing of taxes and subsidies is crucial for sustainability.
Framework finds policies respecting planetary boundaries.
Abstract
Increasingly complex, non-linear World-Earth system models are used for describing the dynamics of the biophysical Earth system and the socio-economic and socio-cultural World of human societies and their interactions. Identifying pathways towards a sustainable future in these models for informing policy makers and the wider public, e.g. pathways leading to a robust mitigation of dangerous anthropogenic climate change, is a challenging and widely investigated task in the field of climate research and broader Earth system science. This problem is particularly difficult when constraints on avoiding transgressions of planetary boundaries and social foundations need to be taken into account. In this work, we propose to combine recently developed machine learning techniques, namely deep reinforcement learning (DRL), with classical analysis of trajectories in the World-Earth system. Based on…
Click any figure to enlarge with its caption.
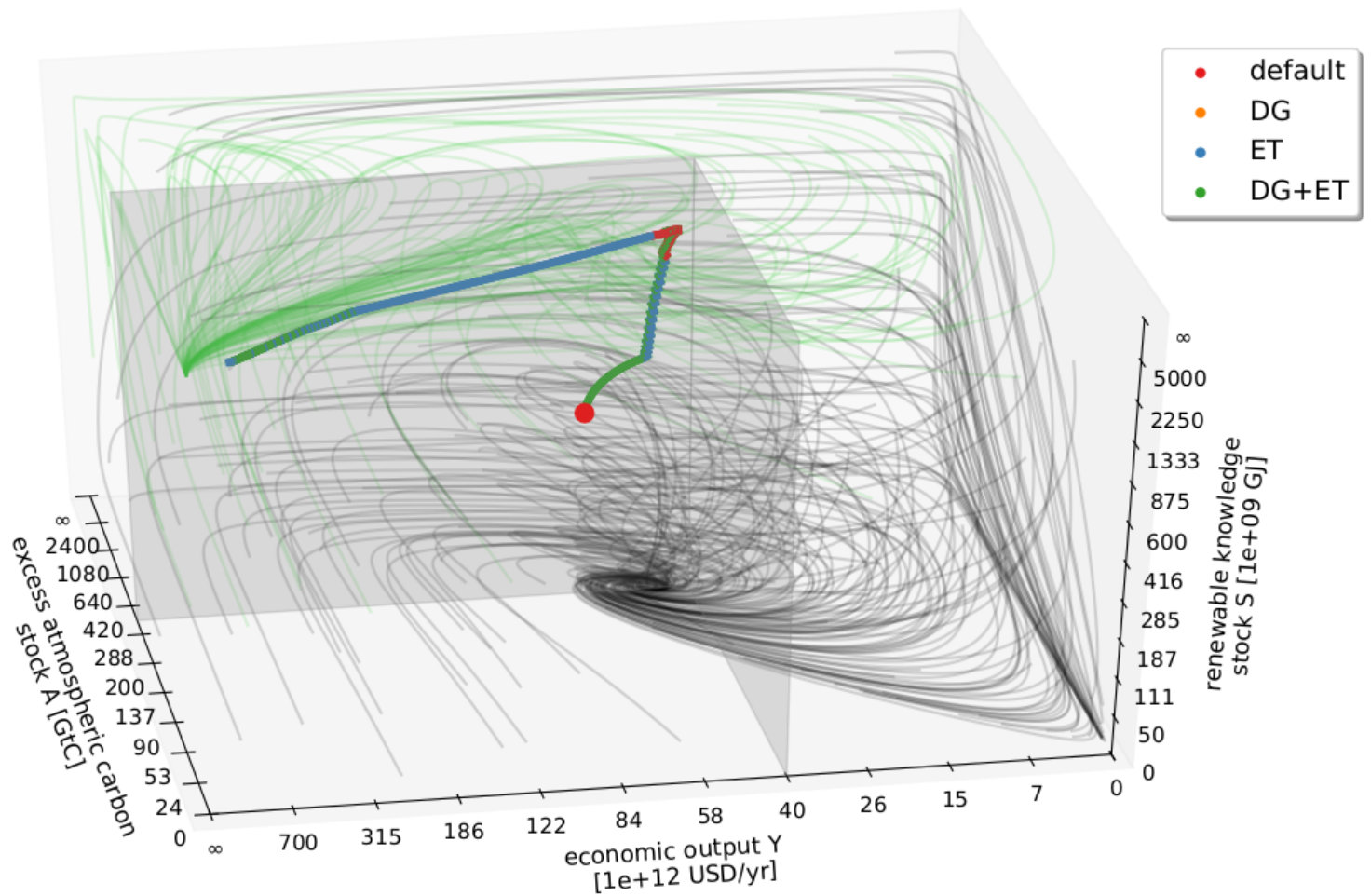 Figure 1
Figure 1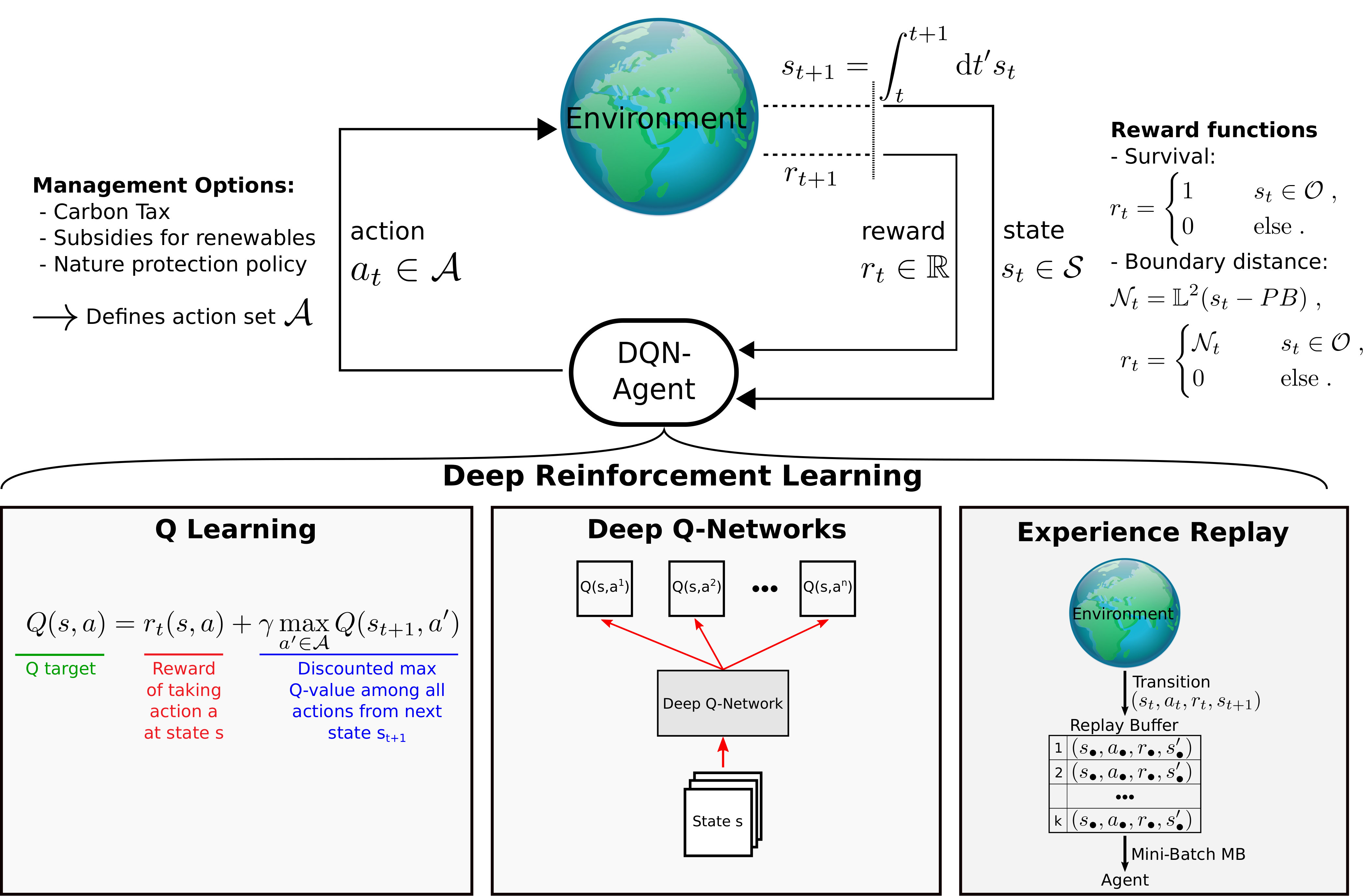 Figure 2
Figure 2 Figure 3
Figure 3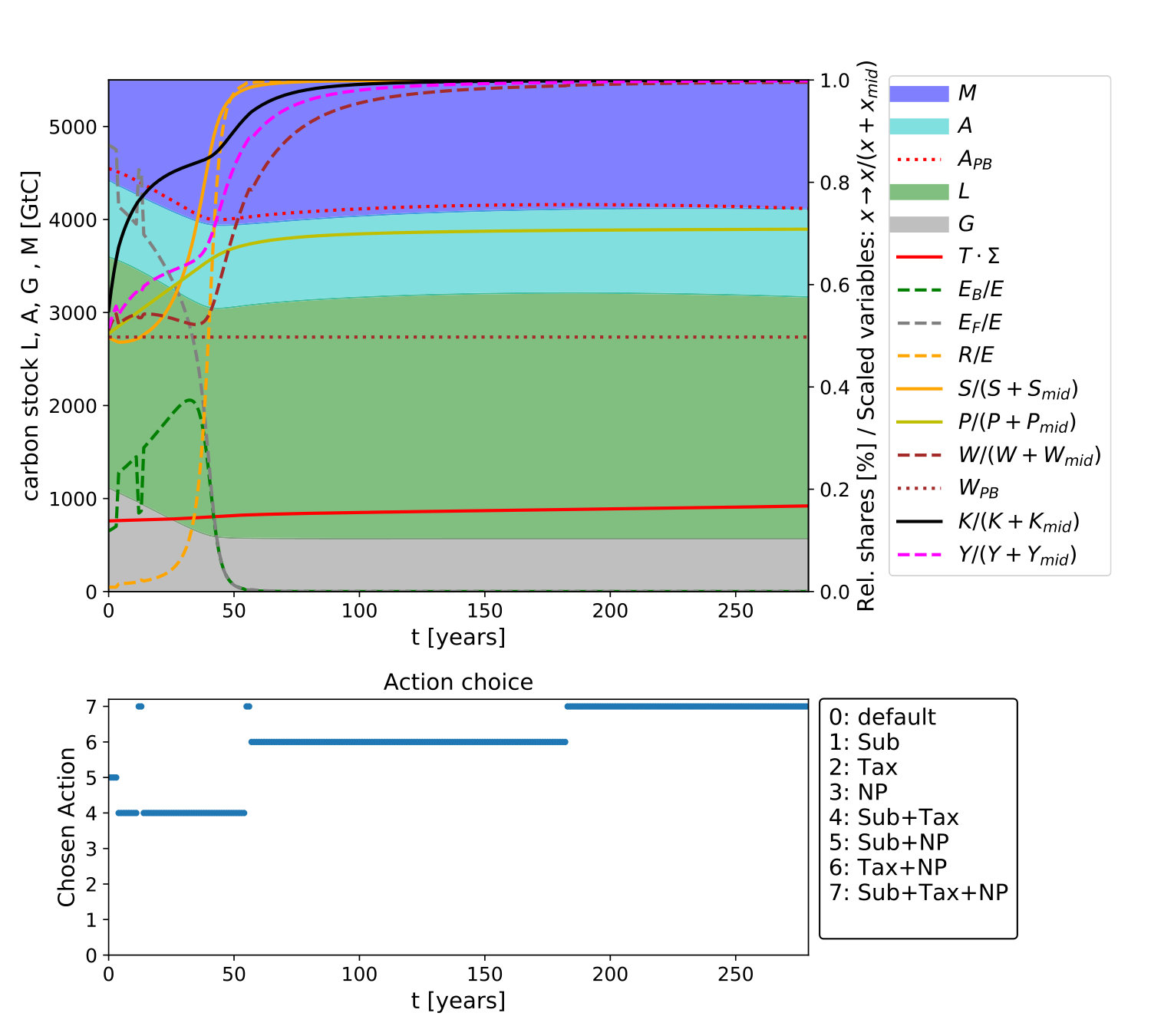 Figure 4
Figure 4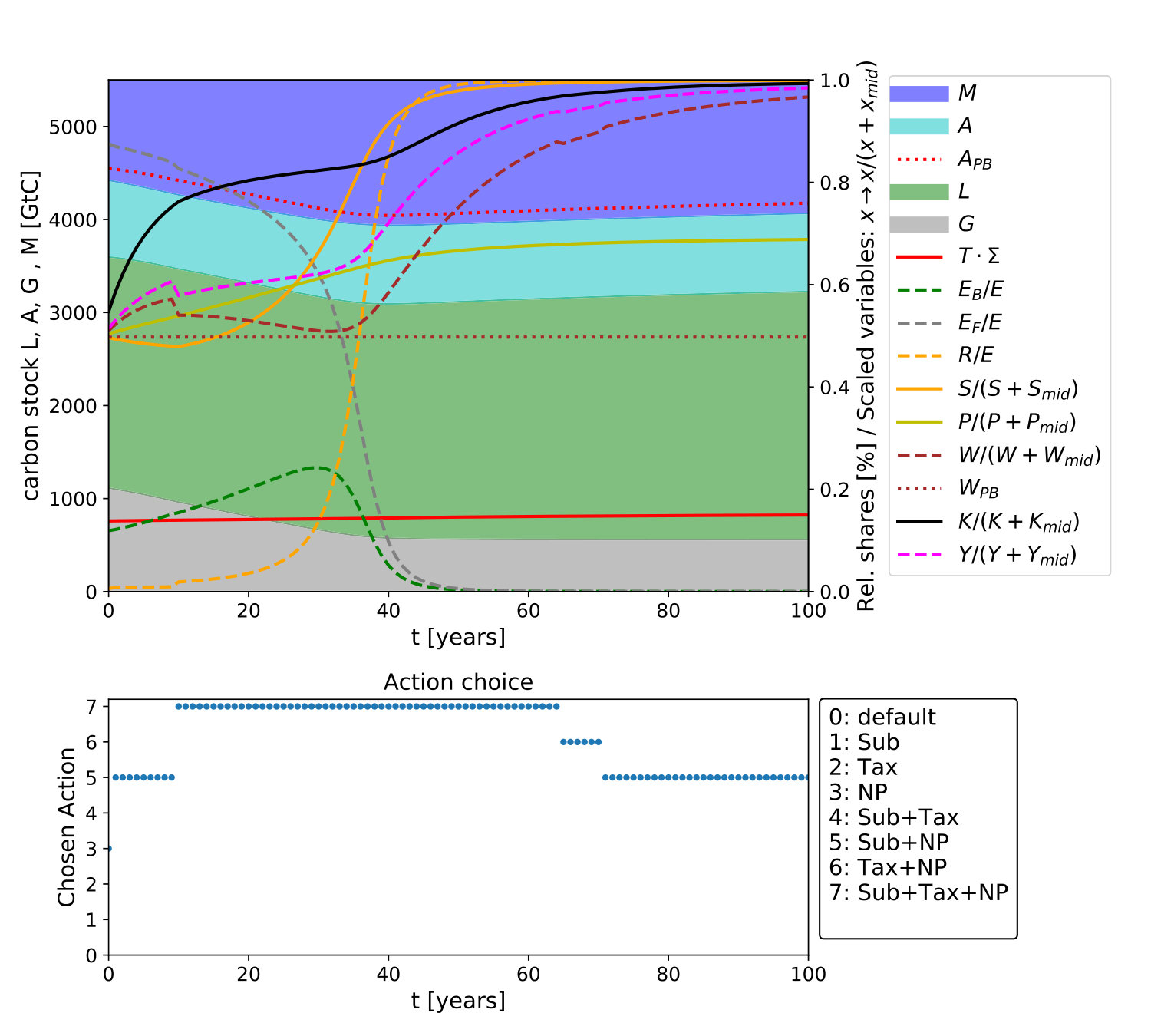 Figure 5
Figure 5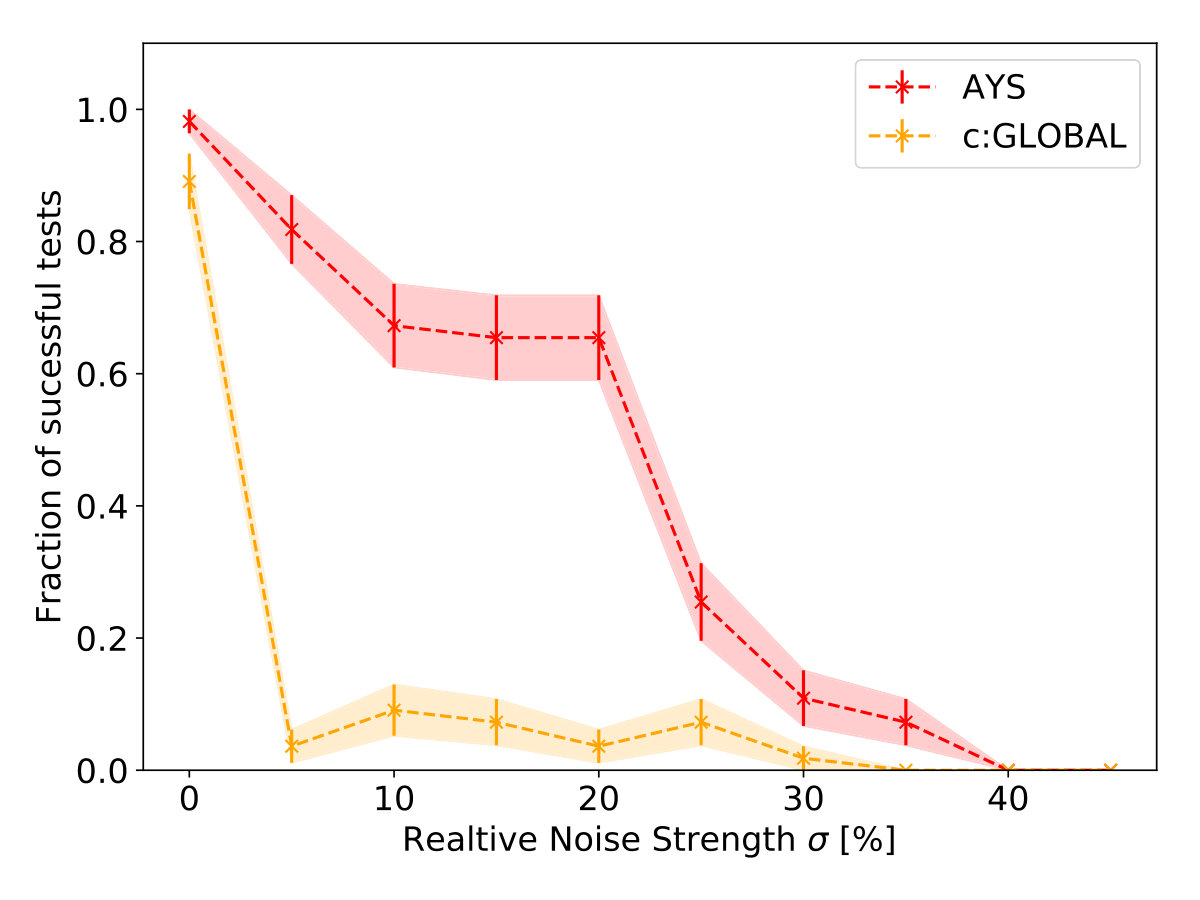 Figure 6
Figure 6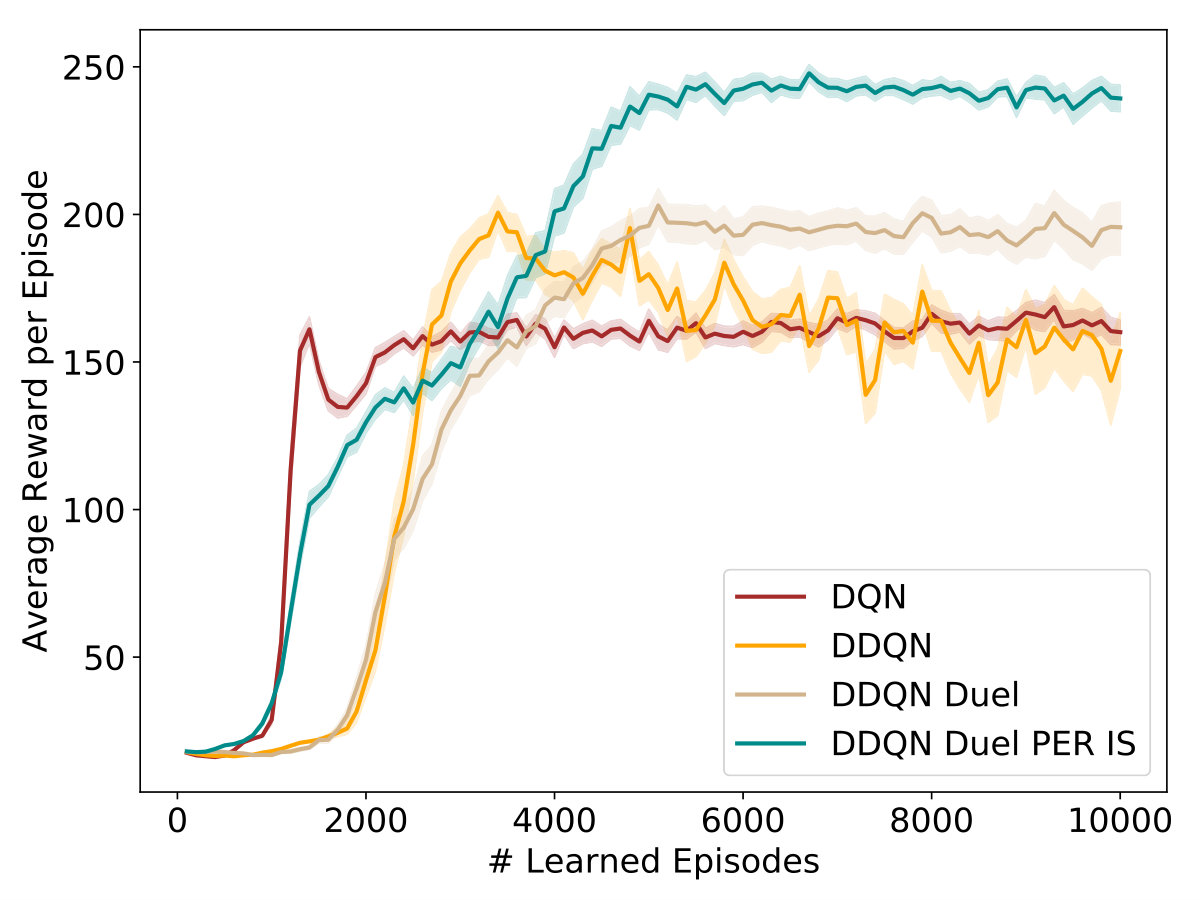 Figure 7
Figure 7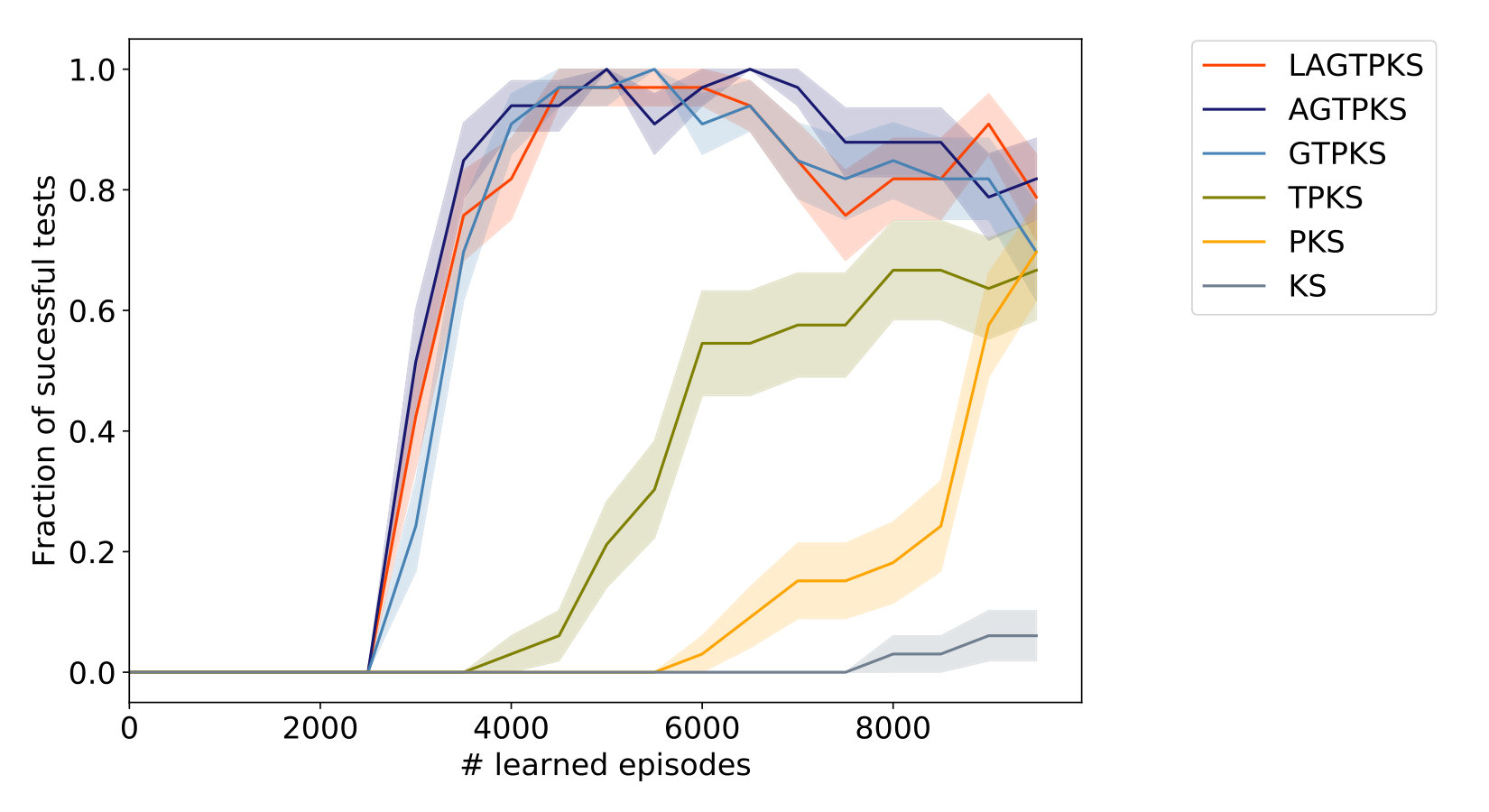 Figure 8
Figure 8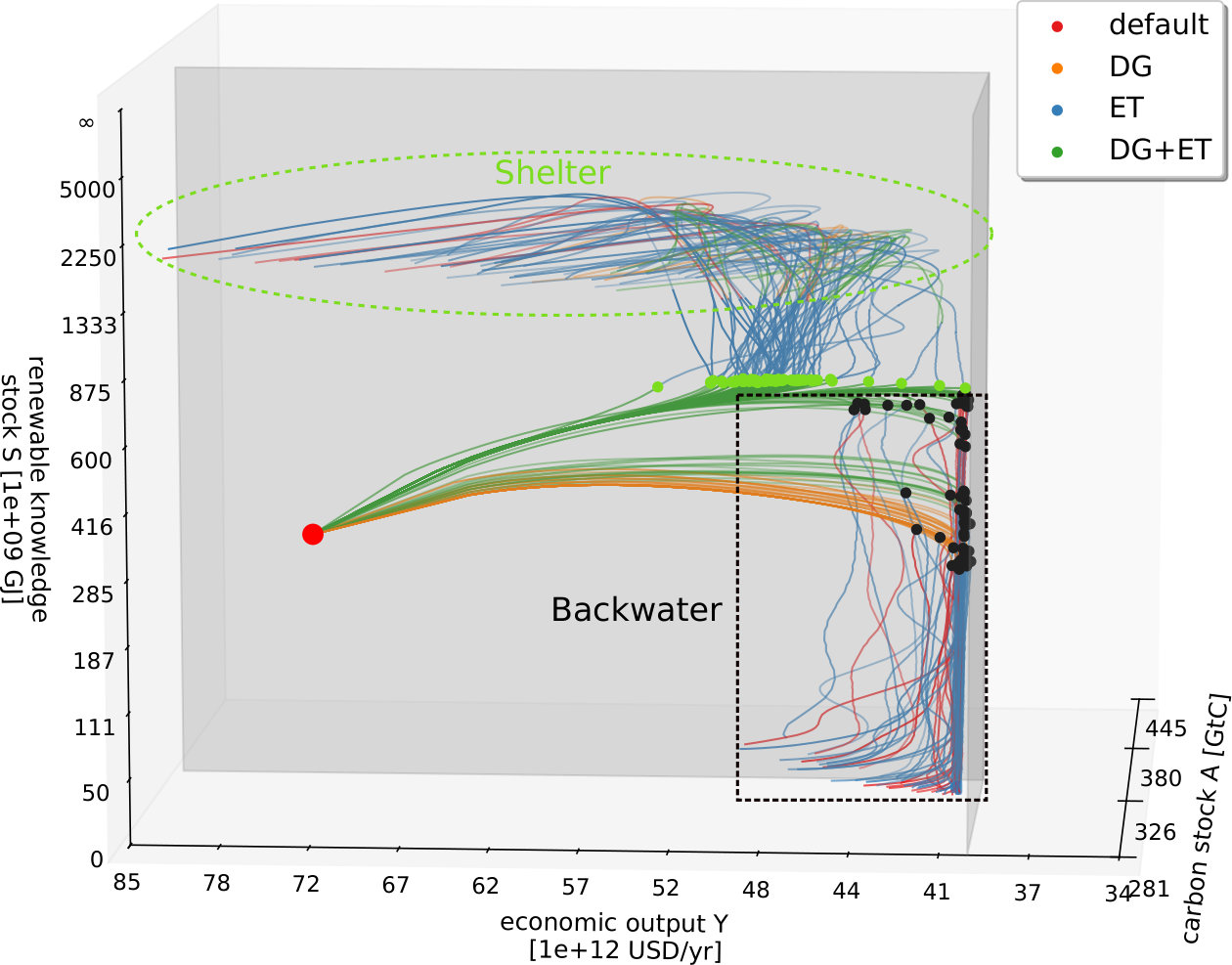 Figure 9
Figure 9| Hyperparameter | Value AYS | Value c:Global | Description | |||
|---|---|---|---|---|---|---|
| batch size | 32 | 32 |
|
|||
| replay memory size | Number of stored observations in replay memory. | |||||
| initial exploration | 1 | 1 | Initial value in -greedy policy. | |||
| final exploration | 0.01 | 0.001 | Final value in -greedy. policy | |||
| decay rate exploration | 0.001 | 0.001 | Exponential decay of towards final value. | |||
| target network update frequency | 100 | 200 |
|
|||
| Adam learning rate | 0.00025 | 0.00025 | The initial learning rate in Adam optimizer | |||
| discount factor | 0.96 | 0.96 | Discount factor used in Q-learning. update | |||
| priority of transition | 0.6 | 0.6 |
|
|||
| initial importance sampling weight | 0.4 | 0.4 |
|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Deep reinforcement learning in World-Earth system models to discover sustainable management strategies
Felix M. Strnad
Potsdam Institute for Climate Impact Research, FutureLab on Game Theory and Networks of Interacting Agents, Research Department 4: Complexity Science, 14473 Potsdam, Germany
Department of Physics, University of Göttingen, 37077 Göttingen, Germany
Wolfram Barfuss
Potsdam Institute for Climate Impact Research, FutureLab on Earth Resilience in the Anthropocene, Research Department 1: Earth System Analysis, 14473 Potsdam, Germany
Max Planck Institute for Mathematics in the Sciences, 04103 Leipzig, Germany
Jonathan F. Donges
Potsdam Institute for Climate Impact Research, FutureLab on Earth Resilience in the Anthropocene, Research Department 1: Earth System Analysis, 14473 Potsdam, Germany
Stockholm Resilience Center, Stockholm University, 104 05 Stockholm, Sweden
Jobst Heitzig
Potsdam Institute for Climate Impact Research, FutureLab on Game Theory and Networks of Interacting Agents, Research Department 4: Complexity Science, 14473 Potsdam, Germany
Abstract
Increasingly complex, non-linear World-Earth system models are used for describing the dynamics of the biophysical Earth system and the socio-economic and socio-cultural World of human societies and their interactions. Identifying pathways towards a sustainable future in these models for informing policy makers and the wider public, e.g. pathways leading to a robust mitigation of dangerous anthropogenic climate change, is a challenging and widely investigated task in the field of climate research and broader Earth system science. This problem is particularly difficult when constraints on avoiding transgressions of planetary boundaries and social foundations need to be taken into account. In this work, we propose to combine recently developed machine learning techniques, namely deep reinforcement learning (DRL), with classical analysis of trajectories in the World-Earth system. Based on the concept of the agent-environment interface, we develop an agent that is generally able to act and learn in variable manageable environment models of the Earth system. We demonstrate the potential of our framework by applying DRL algorithms to two stylized World-Earth system models. Conceptually, we explore thereby the feasibility of finding novel global governance policies leading into a safe and just operating space constrained by certain planetary and socio-economic boundaries. The artificially intelligent agent learns that the timing of a specific mix of taxing carbon emissions and subsidies on renewables is of crucial relevance for finding World-Earth system trajectories that are sustainable on the long term.
††preprint: AIP/123-QED
We propose a framework for using deep reinforcement learning (DRL) as an approach to extend the field of Earth system analysis by a new method. We build our framework upon the agent-environment interface concept. The agent can apply management options to models of the Earth system as the environment of interest and learn by rewards provided by the environment. We train our agent with a deep Q-neural network extended by current state-of-the-art algorithms. We find that the agent is able to learn novel, previously undiscovered policies that navigate the system into sustainable regions in two exemplary conceptual models of the World-Earth system.
I Introduction
Efforts invested in identifying pathways towards global sustainability need to account for critical feedback loops between the socio-economic and socio-cultural World and the biophysical Earth system Schellnhuber (1999); Donges et al. (2017). These pathways may require novel, yet undiscovered multi-level policies, from local to the global scale, for the governance of this coupled World-Earth system leading towards a safe and just operating space Rockström et al. (2009a, b). Striving for a safe and just operating space, policymakers of the United Nations agreed on global political cooperation for a sustainable future at the resolution of the 17 Sustainable Development Goals (SDG) Assembly (2015) and the adoption of the Paris Agreement on Climate Change on Climate Change (2015). The safe and just operating space is based on a set of biophysical planetary boundaries (defined on dimensions such as climate change or biosphere integrity loss) as they are formulated by Rockström et al. in Rockström et al. (2009a, b); Anderies et al. (2013); Steffen et al. (2015) extended by social foundations (e.g. poverty alleviation) by Raworth Raworth (2012). If respected together, staying within these boundaries is seen as a prerequisite to ensuring sustainable human development. The field of Earth system modeling develops computer models to show possible pathways towards a sustainable future. However, the identification and characterization of concrete trajectories within the planetary boundaries and above social foundations remains a problem requiring ongoing research efforts Rogelj et al. (2018); Steffen et al. (2018).
In this paper, we consider this problem on a globally aggregated level assuming the following basic structure: An abstract single decision-maker interacts with a dynamical, in most cases non-linear environment to find sustainable trajectories within certain boundaries. The field of Integrated Assessment Modeling (IAM) addresses this issue via optimizing a social welfare function in order to estimate the design of sustainable management strategies Müller-Hansen et al. (2017). IAM models integrate data and knowledge from established climate models Kelly and Kolstad (1999); Pahl-Wostl et al. (2000). To identify pathways in IAM, numerical solvers such as GAMS Bussieck and Meeraus (2004) are frequently used. However, these IAM models are highly dependent on the choice of the target function of the optimization. In many cases, this choice may not be obvious and depends on the IAM developers Pindyck (2017).
As another approach, optimal control theory (OCT) can be used to solve problems where dynamical systems are supposed to stay within certain constraints. In these systems, OCT tries to find an optimal choice for some control variable by optimizing a specific objective function Kamien and Schwartz (2012). Applied to Earth system models, the focus has been set on the design of climate regulators and their impact on climate modification Liang (2008); Botta, Jansson, and Ionescu (2018). Viability theory (VT) as a subfield of OCT can be stated as an example. In this field, such problems of identifying trajectories are typically addressed by methods that rely on a discretization of the state space, followed by the application of local linear approximations Deffuant and Gilbert (2011). It is however not well applicable in systems with more than just a small number of variables due to the curse of dimensionality Kittel et al. (2017).
The use of reinforcement learning (RL) Sutton, Barto et al. (1998) can also be considered as a possible approach for intelligent decision making within World-Earth system modelsvon der Osten (2017). It is designed for finding optimal policy strategies as well. But in contrast to the previously presented approaches, RL does not detect solutions based on numerically solving an optimization problem, but by a dynamic search process via exploration and exploitation of past experiences, guided by a reward function. However, tabular methods, which are mainly used for classical RL solutions, cannot be straightforwardly applied to the systems of interest here, due to the continuous state spaces that we mostly find in World-Earth system models.
The common point of all the presented methods outlined above is that they reach their limits as the complexity of the environments increases. However, deep reinforcement learning (DRL) Mnih et al. (2015) algorithms have been shown to detect solutions in other highly complex environments surprisingly well Mnih et al. (2013, 2015). In this paper, we propose using DRL as a novel approach for Earth system analysis. Even though first successful reinforcement learning experiments by using neural networks as nonlinear function approximators were reported already in 1995 Tesauro (1995), the breakthrough of DRL was achieved only in 2013 Mnih et al. (2013, 2015). Since then, DRL algorithms have become increasingly popular in the field of Artificial Intelligence Arulkumaran et al. (2017); Li (2018). The key to success of this approach lies in the combination of Q-learningWatkins (1989), neural networks LeCun, Bengio, and Hinton (2015) and experience replay Lin (1993) which has been shown to learn policies up to a super-human performance in a variety of different environments Mnih et al. (2013, 2015). Often DRL-applications come up with unexpected and novel solutions Silver et al. (2016, 2018). Many extensions have been proposed addressing both speed and efficiency Hessel et al. (2018). Due to its general applicability to various environments, DRL is used in a wide range of different fields, e.g. resources management in computer clusters Mao et al. (2016), optimization of chemical reactions Zhou, Li, and Zare (2017), playing abstract strategy games like chess and Go Silver et al. (2016, 2018), autonomous driving Lillicrap et al. (2016), and in particular robotics Levine et al. (2016); Zhu et al. (2017); Gu et al. (2017); Haarnoja et al. (2018).
Due to the wide applicability of DRL, we propose a framework that uses DRL as a tool that is both robust and easy to use at the same time to identify and classify trajectories in Earth system models effectively. As a proof of concept, we use our DRL framework within various stylized World-Earth system models Donges et al. (2017, 2018). These models are designed to investigate the coevolutionary dynamics of humans and nature in the Anthropocene. Some first applications of reinforcement learning methods within resource use models have been carried out Arthur (1991); Lindkvist and Norberg (2014); Lindkvist, Ekeberg, and Norberg (2017), but as far as we know, there are no approaches yet applying DRL to Earth system models. We believe this approach will open so far unused possibilities to discover so far unknown management strategies that keep the Earth system within planetary boundaries, while, at the same time, respecting social foundations of the world’s societies. Recently, various ways of how to tackle problems related to anthropogenic climate change by using machine learning techniques have been outlined Rolnick et al. (2019). Our work proposes a novel strand to this list.
II Methods
This work uses the agent-environment interface Sutton, Barto et al. (1998) as a formal mathematical framework which allows for making a fruitful connection between reinforcement learning and the modeling of social-ecological systems, as it was, e.g., proposed by Barfuss, Donges, and Kurths Barfuss, Donges, and Kurths (2019). In the case of a single agent as studied here, RL problems are based on the concept of Markov decision processes (MDPs) Sutton, Barto et al. (1998). Therefore, we will provide a brief introduction to MDPs, followed by a description of how we included the learning process by using neural networks. We will further give a short overview of possible extensions and conclude this section by outlining how we translate Earth system models into the formal framework of an MDP.
II.1 Markov Decision Processes
RL is designed for problems where an agent observing the environment output consisting of a state and a scalar reward signal is acting upon this observation Sutton, Barto et al. (1998). Formally, this interaction is described by a so-called Markov decision process (MDP) Wiering and Van Otterlo (2012). At each step the environment is in a certain state , where describes the set of all possible states. The agent chooses an action from a given finite action set . Environmental dynamics are now determined by the transition probability which does not depend on explicitly. When for a given action the environment transits from state to , the agent receives an immediate numerical value , called the reward, that generally depends on the state and action . The tuple defines the MDP. The agent chooses its action according to its behavior policy which maps state to a probability distribution over all actions , expressed as .
II.2 Deep Reinforcement Learning
Every decision the agent takes is followed by a reward it gets from the environment. In all types RL algorithms, the goal of an agent is to maximize its exponentially discounted sum of future rewards Sutton, Barto et al. (1998), called the gain , where the discount factor expresses how much the agent cares for future rewards. This lets us define a state-action value function quantifying the value of a state , given that the agent applies action , as the expected return, following a given policy , . The average can be understood as the sum over all actions for a policy times the sum over all possible state transitions to . Inserting the gain yields the Bellman equation Bellman (1957),
[TABLE]
The best possible solution of an MDP is the optimal state-action-value function which is the maximum state-action value function over all policies
[TABLE]
The problem of maximizing the expected discounted reward sum is transformed to find the optimal state-action value function . The optimal value function allows the following consideration. If for all possible actions for the next time step the value of was known, then the optimal strategy would be to choose that resulting in the highest value of . This identity is known as the Bellman Optimality Equation Sutton, Barto et al. (1998),
[TABLE]
averages over all possible state transitions, given by the transition probability . The task is now to find a way to estimate the optimal action-value function . Estimating the state-action value function by performing rollouts on the environment are called model-free. Mnih et al. Mnih et al. (2013, 2015) address this issue with the combination of Q-learning, deep neural networks and experience replay successfully, called Deep Q-learning (DQL). Briefly, we will provide an overview of their approach.
Q-learning
Q-learning is a specific type of RL which converges to the optimal solution. In Q-learning we use the function representing the state-action value when performing action in state . The temporal difference error of expected value and experienced value is used to estimate the current value of the state Sutton, Barto et al. (1998). It is used to incrementally estimate Q-values for actions, based on an iteratively updated -value function Watkins (1989),
[TABLE]
Action selection when acting in the environment is usually made with an -greedy policy, i.e., with probability the action is used and with probability a random action is used. Here, the parameter regulates this exploration-exploitation trade-off. Q-learning is an off-policy algorithm, i.e. to estimate the current state-action value the agent uses the maximum state-action value of the next state, regardless which action is actually chosen there. Still, one can prove that for this algorithm will converge to the optimal action value function Sutton, Barto et al. (1998).
Deep Q-Networks
In practice, this convergence is only applicable in state spaces with a small number of states. However, continuous state spaces make it impossible to learn state-action pairs independently Sutton, Barto et al. (1998). Using multi-layered neural networks as function approximators, , called Deep Q-Networks (DQN), is a possibility to overcome this issue Mnih et al. (2015). As target function one can use different RL variants Sutton, Barto et al. (1998). Here the Q-learning update from equation (4) is adjusted by setting . The parameters (i.e., the weights) of the neural network are optimized by gradient descent to minimize the loss at iteration between the target and the current value via
[TABLE]
The parameter describes the learning rate of the network. To account for a more stable learning a second network with parameters is used. This network is a copy of the first one but is frozen in time for iteration steps. It is used as the target function in equation (5). The fixed -values of make it possible, that the optimization process converges to a stable target Mnih et al. (2015). The target network is updated every iteration steps by copying the parameters from the current network: .
Experience replay
Instead of learning from state-action pairs as they occur during simulation, updates for the state action value function ) are applied on samples (called Mini-Batches) randomly drawn from a replay memory – typically a large table of stored observations, that are collected during the training process. This separates the learning process itself from gaining experience Lin (1993) which breaks the similarity of subsequent training samples and leads consequently to more stable learning Mnih et al. (2015).
II.3 Extensions to DQN
After the convincing performance of the DQN network presented by Mnih et al. Mnih et al. (2015) the algorithm has been further developed and significant improvements regarding stability and learning speed could be achieved. By using double Q-learning Van Hasselt, Guez, and Silver (2016) harmful overestimation of the values Hasselt (2010) can be reduced. With the introduction of dueling network architectures Wang et al. (2015) the value of a state and the advantage of taking a certain action at that state could be decoupled. Furthermore, the distributional DQL algorithm by Bellemare, Dabney, and Munos Bellemare, Dabney, and Munos (2017) addresses the issue that the value of future rewards is restricted to the expected return (i.e., to the function) and replaces it with a distribution of -values per action. These improvements are often combined with prioritized experience replay Schaul et al. (2015) that privileges experiences from which the agent can learn more. In Hessel et al. (2018) Hessel et al. compare and combine improvements to a new state-of-the-art DQL algorithm, they called Rainbow, which we will also use in this paper.
II.4 Agent-Environment Interface
In this work, we transfer the theoretical framework of an MDP to concrete applications in Earth system dynamics by using the agent-environment interface. In this context, the concept of the agent is solely defined by its action set. The action set can be regarded as a collection of possible measures the international community could use to influence the system’s trajectory. The agent uses a DRL algorithm outlined in section II.2. Concerning the detection of sustainable governance policies, we are mostly interested in the final outcomes the agent has learned rather than in letting the agent make real-world decisions later on. To assess the feasibility of finding sustainable policies, we also investigate the learning process. In this work, we intend to test our framework in the context of Earth system models. We focus on a particular type of Earth system models, which has been termed “World-Earth models” Donges et al. (2017, 2018). In World-Earth modeling, one tries to capture the coevolving dynamics between biophysical dynamics of the Earth system on the one hand and on the other hand the social and economic dynamics of the World community. Since optimizing welfare may lead to policies which are neither sustainable nor safe Barfuss et al. (2018), we are interested in governance policies whose resulting trajectories stay within certain “sustainability boundaries” of the state space. These include both planetary and socio-economic boundaries. We set up the environments based on Kittel et al. Kittel et al. (2017) and Nitzbon, Heitzig, and ParlitzNitzbon, Heitzig, and Parlitz (2017), both using deterministic nonlinear World-Earth models including planetary boundaries and social foundations. The dynamics are described by a set of coupled autonomous differential equations that define a continuous state space. In our setting, time is discretized in integration steps . At each -th step, the environment’s dynamics are numerically solved (i.e., integrated) for a single timestep . Therefore, the environments fulfill the Markov property of the MDP.
A scheme of how this framework is implemented is shown in Fig. 1. In the following paragraphs, we provide more details on how we map the required parts for an MDP (i.e., concrete states in the environment, actions and reward function) to World-Earth models. We conclude this section with some technical notes about implementation and hyper-parameter search.
Environment 1: The AYS model
This model is a low-complexity model in three dimensions studied in Heitzig, Barfuss, and Donges (2018) and described in more detail by Kittel et al. Kittel et al. (2017). It includes parts of climate change, welfare growth and energy transformation. As compared to classical Earth system models the AYS model is adapted. For simplicity carbon dynamics is not modeled in an explicit carbon cycle but assumed to follow an exponential relaxation towards equilibrium. The relation of the wealth of a society is modeled through the economic output , where the economy is assumed to have a constant basic growth rate. A renewable energy source with learning by doing dynamics is implemented via a renewable energy knowledge stock . The state the agent observes at time is therefore given by the tuple , consisting of three numerical values. As sustainability boundaries we use a planetary boundary GtC and a social foundation boundary $/yr. For details, we refer to the Appendix or Kittel et al. (2017).
Environment 2: The copan:GLOBAL model
This model, studied by Nitzbon, Heitzig, and Parlitz Nitzbon, Heitzig, and Parlitz (2017), is a conceptual model that describes the coevolution of natural and economic subsystems of the Earth. The model is meant for qualitative understanding of the complex interrelations rather than for quantitative predictions. Climate is represented as a global carbon cycle involving stocks of terrestrial carbon , atmospheric carbon and geological carbon , which influence the global mean temperature . On the other hand socio-economic concepts, expressed through population with capital , are used to describe the flows of biomass and fossil fuels between society and nature. In Nitzbon, Heitzig, and Parlitz (2017), the authors consider a scenario where renewable energy does not exist. We extend the model for this study by including renewable energy use via a learning-by-doing dynamics for the renewable energy knowledge stock , in the same fashion as it was done in Donges et al. (2018) for a regionalized version of Nitzbon, Heitzig, and Parlitz (2017). The state is thus determined by the tuple . Similarly, we use again GtC and a social foundation boundary for consumption of $/yr per-capita as sustainability boundaries. For details of the system dynamics the reader is refereed to the Appendix or Nitzbon, Heitzig, and Parlitz (2017); Donges et al. (2018).
Action set
The action set represents certain governance management options. It consists of no extra management (called default), a carbon tax, subsidies of renewable energies, for the c:GLOBAL environment of a nature protection policy and all possible combination of these management options. Depending on the specific environment, each action alters the dynamics of the state variables. For details, we refer to the Appendix.
Reward function
Reward functions express the agent’s preferences over state-action pairs and therefore control the learning process. Since we implemented our own environments and are only interested in keeping them within certain bounds, we have freedom of choice for the reward function. The very simple reward functions we used are the following:
- •
Survival reward: provide a reward of if the state is the within the boundaries, else 0.
- •
Boundary distance reward: calculate the distance of the state to the boundaries in units of distances from the current state of the Earth to the boundaries. This distance is provided as a reward.
Depending on the chosen reward function, the trajectories found by the agent differ. In the case of survival reward, the agent is only interested in staying within the boundaries, whereas in the latter case of the boundary distance reward the agent tries to detect trajectories resulting in a large distance to the boundaries.
Implementation
After the experience replay memory is filled with experiences from an agent that acts randomly in the environment, the learning process runs as follows. The agent is trained for a fixed number of episodes. A start position within the boundaries is randomly drawn from a uniform distribution of states around the current state. The number of iteration steps during one single learning episode is limited to a maximum of . The end of one learning episode is determined either when is reached or ended prematurely at time either when a boundary is crossed or when approximate convergence to a fixed point is detected. In the latter case, the remaining future rewards are estimated with a discounted reward sum for the remaining time of the reward . In any case, after the end of a learning episode, the environment is reset to time and a new start point within the boundaries of the environment is randomly drawn.
Hyper-parameter tuning
For each environment, we trained a different network. We systematically investigated the effect of various parameters for the learning success, such as the discount factor, the training data set size or the exploration-exploitation trade-off to get an optimal hyper-parameter set for every environment. The exploration rate starts with and decays over time. We achieved the best performance for a replay buffer (i.e., the memory size) of which is less than the default value in many DRL algorithms (e.g., Mnih et al. (2013); Wang et al. (2015); Hessel et al. (2018)) but in accordance with the work of Zhang and Sutton (2017) stating that the size of the replay buffer is crucially environment-dependent and needs a careful tuning. A full list of all hyper-parameters can be found in Table 1 in the Appendix.
The neural network is based on the following architecture. The input layer of the size equalling the dimension of the state space is followed by two fully-connected hidden layers each one consisting of 256 units. The output layer is a fully connected linear layer that provides an output value for each possible action in the action set, representing the estimated Q-value of that action for the state given by the inputs. For minimizing the loss function, instead of simple stochastic gradient descent (SGD) the Adam optimizer Kingma and Ba (2014) is used due to its better performance than SGD in DRL applications as reported in Hessel et al. (2018).
III Application to World-Earth Models
Based on our proposal outlined above, we implemented an agent that learns by using a DRL (see section II.2) to manage the environments described in Sect. II.4. The agent is trained for a maximum number of episodes, where the learning success is evaluated every episodes. Single simulation experiments can be carried out on standard notebook computers in a reasonable computing time (one to two hours on a single machine). Using a tuned hyper-parameter set (see Table 1 in the Appendix for details), we can formulate three key findings of this work that is outlined below. First, we find that learning in terms of increasing rewards in the environments is indeed possible. Second, we investigate the specific pathways found by the learner and observe that the agent acts with great farsightedness. Moreover, we see a general strategy behind the detected trajectories that the learner has developed. Third, we explore that the agent also achieves good performance in scenarios in which the state space is only partially observable to the agent.
III.1 Training and Stability
In order to verify the overall applicability of our algorithm, we first analyze the learning behavior in general. Unlike in supervised learning, where one can evaluate the performance of an algorithm by evaluating it on a set of test data, it is not obvious how to evaluate accurately the training progress an agent makes in RL problems. Here, we stick to the method used by Mnih et al. Mnih et al. (2013) visualizing the training properly. We plot the total reward the agent collects during one run over the number of learning episodes. Each value is computed as a running average over 50 episodes. Each curve is the average of 100 independent simulations.
As a result, we see that after a certain number of episodes the average reward per episode significantly increases in our environments (see Fig. 2). Obviously, the agent finds trajectories that reveal a high reward. In other words, it learns to manage the environment. We conclude that management can indeed be learned by the agent.
Furthermore, we observe that the learning of the agent is stabilized by using the extensions to DQN-Learning as outlined in II.3. The plot suggests that the usage of dueling network architectures combined with double-Q-learning (DDQN + Duel) and prioritized experience replay with importance sampling (PER IS) significantly increases the performance of our DQN-Agent. This is in good agreement with the results in Wang et al. (2015). Therefore, all results outlined below are achieved by using our best performing agent (DDQN + Duel + PER IS), if not stated otherwise.
Moreover, this is in qualitatively good accordance with other comparisons of different learning architectures, as, e.g., presented in Hessel et al. (2018) and the learning curves show a similar shape as seen in other DRL applications Mnih et al. (2013, 2015); Hessel et al. (2018).
III.2 Management Pathways in World-Earth System Models
In the following, we discuss the pathways in the two environments described in section II.4 that were found by using the outlined framework of DRL. In III.2.1 we explore the AYS model, in III.2.2 the copan:GLOBAL model. Specifically, in both environments, we are interested whether the learner finds trajectories towards regions which we can associate with a safe and just operating space without violating sustainability boundaries. First, we present some successful examples. As a next step, we look at the specific trajectories in more detail, hoping to understand the general strategy the agent found to reach its aim (i.e., maximize the total reward).
III.2.1 Pathways in the AYS-model
In the AYS model, the agent can choose between the following actions: “energy transformation” (taxing carbon emissions and/or subsidizing renewables) or “degrowth management” (reducing the basic economic growth rate) or neither or both of them. As a first analysis step, we look at the pathways the agent takes after it was trained for a sufficiently long time (i.e., the convergence of the learning is reached, see Fig. 2). We find that even though the dynamics of the environment is unknown to the agent in advance, it is able to find trajectories within sustainability boundaries (see Fig. 3) that were deemed impossible in another study based on a viability theory algorithm that used state space discretization Kittel et al. (2017).
Due to the setup of our framework, each of the two management options can only be switched on and off. In Fig. 3, in the region near to the boundaries, the energy transformation (ET) option (representing an energy tax or subsidy) is switched on and off in short alternations, achieving essentially the effect that a continuous application of a smaller tax/subsidy would have. Hence, offering different tax levels as individual options might improve the learning success further.
To get a deeper understanding of the found solutions, we take a closer look at the different trajectories that were detected by using the DRL framework. Depending on the chosen reward function, the paths found by the agent differ. If the boundary distance reward is chosen, after sufficiently long learning, the agents always finds a path towards the "green fixpoint" at where the distance to the boundaries is maximized. For the survival reward, the agent is only interested in staying within the boundaries. Therefore, it finds pathways leading to the green fixpoint as well as pathways towards a region close to the boundaries with where it then manages to stay. Although many viable paths are found by the learner, we find that the learning strategies that were found can be generalized. We analyzed the management options the agent uses most on different parts of the trajectories. They are depicted in Fig. 4. These different regions of predominant management options are now used for the following discussion. The different regions colored in Fig. 4 may be analyzed with respect to a mathematical theory of the qualitative topology of the state space of a dynamical system with management options and desirable states, called topology of sustainable management (TSM) Heitzig et al. (2016). Interestingly, these regions can be seen to correspond roughly to some concepts from the TSM-framework, in particular, the concept of "shelter" and "backwaters". The approximate locations of these regions are depicted by dashed lines in Fig. 4.
We identify a general strategy the agent uses. Starting from the current state, we found that in order to stay within the boundaries forever, it is not sufficient to use only one single management option of energy transformation (ET) or degrowth (DG) in the beginning. Rather, both ET and DG have to be applied to ensure keeping the system within the sustainability boundaries also in future times. However, to stay above the social foundations’ boundary, at a certain time only ET has to be applied predominantly, leading to more or less sharp "turns" in the trajectory. If is large enough at this point, the turn is "upwards" and after some time, a region is reached where every trajectory is now leading towards unlimited growth of economic output and renewable knowledge regardless of the chosen management option, so that management can be "stopped". In TSM, such a secure region is called a shelter. But if is too small at the turning point, the turn is "downward" towards , staying close to the social foundation boundary. In Kittel et al. (2017), it was shown that this leads to a region called the backwaters, from which the shelter could not be reached any longer, but one can still stay within the boundaries by managing over and over again.
Summarizing, the agent learns that the timing of the particular change of management is of crucial relevance. A general interpretation of the resulting pathways would be that ET, e.g. via taxing fossils, is highly important to ensure further development. However, to reach a secure state without violating the sustainability boundaries, a degrowth policy is needed for some time as well.
III.2.2 Pathways in the c:GLOBAL-model
We verify that our framework works as well in higher-dimensional environments by applying it to the c:GLOBAL model. While classical approaches like viability theory are no longer well applicable because of the dimension, our DRL learner is also capable of detecting solutions towards a sustainable future in this model, see Fig. 5. Here, one learning episode has a maximum length of . Successful trajectories often converge already after around . However, to account for long-term effects, simulations were executed for times up to since we observed that seemingly converged trajectories sometimes transgressed boundaries at much later times, posing an additional challenge for the learner.
The general strategy found by the learner turns out to be this. The NP option is used throughout and renewables are subsidized during most of the time. The crucial point is the timing of the carbon tax, which cannot be used immediately without violating the social foundation boundary. It is switched on only later and switched off again once renewables have passed through most of their learning curve.
An interesting observation regarding the farsightedness of the agent is the following. After some episodes, the agent often uses trajectories that do not use any management during the years –, which keeps the system within the boundaries for some time but leads to a violation of later for some . Only after many more episodes, the agent learns to act with foresight and use management options early on that only make a recognizable difference much later and avoid crossing the boundaries. This is indeed a key feature for the success of DRL and shows the potential power of the method. One example trajectory can be found in Fig. 7 in Appendix.
However, taking a look at the stability of the learning (see Fig. 6), we observe that the learning success in the copan:GLOBAL model also decreases again after a still larger number of episodes. As a possible explanation, we suggest that this is connected to the replay buffer. To avoid this phenomenon, the replay buffer needs to contain experiences especially about the timesteps where the dynamics of the system changes significantly Zhang and Sutton (2017). After many successful runs, we still continue collecting observations in the memory buffer at every timestep. Therefore, it mostly contains experiences for time points . However, especially the first timesteps are crucial to avoid transgressing boundaries at later times as outlined above. These are therefore essential for the learning success. It seems that the agent tends to forget about experiences from early timesteps and the learning success decreases. Further investigation considering the question which experiences should be stored in the replay buffer could be a first step to overcome this issue.
III.3 Partial Observability and Noise
As a generalization of Markov decision processes, partially observable Markov decision processes (POMDP) are of great research interest. Here, the agent is only able to observe only part of the actual system state Spaan (2012). We are interested in the performance of our DRL agent under such observational constraints since a real-world manager will only have access to vastly restricted information about the Earth system’s current state. Moreover, we added noise to the observations of the agent. Our experiments show (see Fig. 6) that even under partial observability of the state, the agent is still capable of detecting sustainable solutions.
We observe that the learning curves for observing either the full state or only the variable combinations or have very similar shape. So it seems that there is little added value in observing the carbon stocks and when already observing the geological stock whose decline is essential for the timing of the carbon tax (but which is also the hardest to observe in reality). However, even if we limit the agent’s observation capabilities to the socio-economic variables the agent achieves a similar performance after a certain number of episodes, only considerably later. This can be explained by the dominant force humans exert on the Earth system.
To test the robustness of the DRL algorithm for a noisy state input, we added white observational noise on the input state the agent receives from the environment. Not surprisingly, noise can disturb the agent’s learning and lead to a massive decrease in performance if the environment gets more complex. See Fig. 8 in Appendix for details. Neural networks are known to be vulnerable by perturbed input Szegedy et al. (2013); Papernot et al. (2016) and the harmful effect of noise has already been observed and discussed as well in DRL applications Behzadan and Munir (2017a, b); Huang et al. (2017). Still, for further experiments with more realistic scenarios, the influence of noise has to be investigated more systematically.
For the analysis of trajectories in the Earth system, we can deduce the following. Even if the full state will not be observable to the agent, it is just based on the distance boundary reward signal still able to sufficiently “understand" the system’s dynamics in order to find appropriate management pathways. Furthermore, in our experiments, we see that noise will be a limiting factor for some DRL algorithms. In simulations with very noisy environments, some preprocessing of the input state might be necessary to use DRL successfully.
IV Conclusion
The main contribution of this work is the development of a framework for using DRL in Earth system models, mathematically formalized in a Markov decision process. Throughout this paper, we have combined the technique of deep reinforcement learning with Earth system modeling in order to detect global sustainable management strategies. We have presented a prototype for which we hope extensions based on our work will become a helpful tool to discover and analyze management pathways and to get a deeper understanding of the impact of global governance policies.
As a proof of concept, we have applied it to two exemplary models from Earth system science, taken from the World- Earth modeling literature. They include components of Earth system modeling as well as constraints of planetary boundaries and social foundations. We have shown that our algorithm successfully identified trajectories towards a secure region for the Earth system which a competing approach using viability theory and a discretization of the state space was not able to find Kittel et al. (2017). Even very simple reward functions were sufficient and only partial observations of the system state were necessary for the learner to understand the complex, non-linear system’s dynamics. However, noisy observations have presented a challenge. We have found significant learning improvements by using the combination of DQN with dueling network architectures and prioritized experience replay and importance sampling.
With respect to management strategies that the learner found in the AYS and the c:GLOBAL model, we can support the intuition that neither there is one single way for staying within the boundaries nor can the impact of global management be observed immediately. Rather we conclude from our models that only an intelligent combination and timing of global policies may lead to a sustainable future. We found that besides making renewables more attractive, also a temporary slowing down of economic growth might be necessary for staying within planetary boundaries.
Moreover, we have shown that our method is applicable as well in environments with only partially observable state spaces. Due to its connection to real-world problems Spaan (2012), for example in 3D navigation Mirowski et al. (2016), partial observability of state spaces is widely discussed in the reinforcement learning community. Hence, in future work, the effects of reducing the dimensionality of the state space in our World-Earth system models need to be studied in more detail.
We used DRL to identify trajectories under certain constraints. Formally, this can be regarded as an optimization problem, which could be approached with other methods as well. E.g., the IAM community typically uses commercial solvers for the optimization of long-term social welfare functions which are influenced by nonlinear underlying dynamics. However, the choice of the welfare function is not directly intuitive and hard to justify straightforwardly Pindyck (2017). As an example, Pindyck Pindyck (2017) puts forward the significant differences in the outcome of two established models in IAM. The results in Nordhaus (2011) and Stern and Stern (2007) differ widely, mainly based on the different values of the discount rates for the choice of which no uniform theory exists. However, in our models, the constraints imposed by sustainability boundaries, as well as the choice of simple reward functions, could be argued to be easier to justify and to understand intuitively in some contexts.
We encourage the reader to apply our framework to his or her preferred models. Since we formulated our problem as an MDP, our approach is not restricted to deterministic environments but can be generalized to environments that include stochastic dynamics and agent-based components. One could think about replacing the global society used in the models above by agent-based models of regionally distributed interacting societies. Following the model developed by Wiedermann et al. Wiedermann et al. (2015); Barfuss et al. (2017) which is a stochastic environment based on an adaptive network model, could be a first step in this direction. On the other hand, the biophysical dynamics could be incorporated in more detail as well by using more complex global vegetation models such as LPJ Sitch et al. (2003).
Further, an interesting next step could be to use DQN agents to represent major real-world agents such as governments in a multi-agent environment setting. Here, first experiments in simple grid worlds have already been performed to investigate sequential social dilemmas Leibo et al. (2017) and common-pool resource appropriation Perolat et al. (2017). Connections to game theory in the climate context are conceivable as well Heitzig, Lessmann, and Zou (2011); Barfuss, Donges, and Kurths (2019).
Another approach that might be promising is to include model-based RL in our framework. Regarding computation time, model-based RL tends to be much more efficient Nagabandi et al. (2018). The key difference is that model-free methods act in the real environment in order to collect rewards and update the action-value functions accordingly. In contrast, the agent in model-based methods uses RL to learn a model of the environment and then predicts the system dynamics in a second step. Once the model is learned, actions can be chosen by using optimal control theory. Especially as environments in World-Earth models are often based on a set of biophysical and socio-economic differential equations, this approach might be promising. However, highly complex environments often cannot be learned perfectly, such that solutions of this method involve the risk of being suboptimal. A possible approach to overcome this issue are recently developed algorithms that aim to combine advantages of both methods in one algorithm Pong et al. (2018).
Another fruitful exchange could emerge between the field of Earth system analysis and the field of safe and beneficial AI Amodei et al. (2016). For example, the important question of the latter field of how self-learning agents can safely explore an environment without pursuing catastrophic action directly translates to finding sustainable policies in Earth system analysis. Here as well, management strategies need to navigate uncertain environments without activating tipping elements in the Earth system with potentially catastrophic impacts on human societies Lenton et al. (2008); Schellnhuber (2009).
Acknowledgements
This work was developed in the context of the COPAN collaboration at the Potsdam Institute for Climate Impact Research (PIK). The authors thank the COPAN group for helpful discussions and comments. Moreover, FMS thanks the participants and organizers of the Eastern European Machine Learning (EEML) Summerschool for inspiring suggestions to this work. We are grateful for financial support by the European Research Council (via the ERC advanced grant project ERA), the Stordalen Foundation (via the Planetary Boundaries Research Network PB.net), the Earth League’s EarthDoc program and the Leibniz Association (project DOMINOES). The authors gratefully acknowledge the European Regional Development Fund (ERDF), the German Federal Ministry of Education and Research and the Land Brandenburg for providing resources on the high-performance computer system at PIK.
Appendix
The AYS model environment
In this environment, the observable state is composed of three real-valued components, the excess atmospheric carbon stock over pre-industrial levels [GtC], the gross world economic product [S\geq 0UGURFEFY1/\epsilon$ of energy and the two energy sources are used in proportion of relative price (see Kittel et al. (2017) for a justification), so that
[TABLE]
We assume the absolute price of fossils to remain constant and that of renewable energy to depend on the renewable knowledge stock in a power law relationship, so that the relative price of renewables vs. fossils has the form
[TABLE]
Instead of assuming a carbon cycle as in the c:GLOBAL model (see below), we here simply assume atmospheric carbon stock declines exponentially towards its equilibrium value where excess atmospheric carbon vanishes, so that
[TABLE]
Likewise, instead of assuming a classical economic growth model as in c:GLOBAL, we here simply assume gross world product grows at a fixed basic rate which is reduced in proportion to (interpreted as a proxy for climate damages),
[TABLE]
Finally, learning-by-doing makes the renewable knowledge stock grow with renewable energy production, and forgetting makes it decline exponentially:
[TABLE]
We use the following initial conditions and parameter estimates from Kittel et al. (2017): energy efficiency \phi=4.7\cdot 10^{10}\sigma=4\cdot 10^{12}\rho=2\tau_{A}=50\beta=0.03\theta=8.57\cdot 10^{-5}\tau_{S}=50A_{0}=840Y_{0}=7\cdot 10^{13}/yr, GJ.
The AYS environment is an interesting minimum-complexity toy model for sustainability science because one can represent both the climate change planetary boundary and a wellbeing social foundation boundary in it by studying whether may stay below some threshold GtC and does not drop below some minimum value S=0A>\bar{A}Y<\bar{Y}A=0S,Y=\infty\bar{\beta}=\beta/2\bar{\sigma}=\sigma\cdot(1/2)^{\rho}$ by subsidizing renewables and/or taxing fossils, and she can also use neither or both of these options.
The c:GLOBAL model environment
The model underlying this environment is of a similar type but more complex, having seven dynamic variables, of which the agent can observe different subsets in our experiments, as well as several additional unobserved auxiliary variables.
Here, terrestrial carbon stock changes due to temperature-dependent photosynthesis (1st term) and respiration (2nd term), and due to harvesting of biomass ,
[TABLE]
Absolute atmospheric carbon stock changes due to photosynthesis, respiration, combustion of harvested biomass (), and ocean-atmosphere diffusion,
[TABLE]
Geological carbon stock declines because of extraction of fossil fuels ,
[TABLE]
Global mean temperature converges to a value dependent on due to the greenhouse effect and is hence measured for simplicity on a nonlinear scale in units of atmospheric carbon per land surface area, so that
[TABLE]
Population has a fertility (1st term) and mortality (2nd term) that depend on wellbeing ,
[TABLE]
Physical capital grows since part of GWP is invested, and decays exponentially,
[TABLE]
For renewable knowledge stock , we assume the same dynamics as in the AYS model,
[TABLE]
Since total carbon is fixed at , maritime carbon stock is
[TABLE]
Usage of the three assumed perfectly substitutable energy forms of biomass , fossil , and renewable energy flow is determined by a general price equilibrium model (see Nitzbon, Heitzig, and Parlitz (2017); Donges et al. (2018)) that leads to these equations:
[TABLE]
Economic output is proportional to energy input,
[TABLE]
Finally, wellbeing is determined by per-capita consumption and ecosystem services which are assumed proportional to terrestrial carbon density:
[TABLE]
We use the following initial conditions and parameter estimates from Nitzbon, Heitzig, and Parlitz (2017); Donges et al. (2018), which are based on data from year 2000: initial values 2480\text{,}\mathrm{GtC}\text{/} (GtC=gigatons carbon), $A_{0}=$830\text{\,}\mathrm{GtC}\text{/}, 1125\text{,}\mathrm{GtC}\text{/}, $T_{0}=$5.05\text{\cdot}{10}^{-6}\text{\,}\mathrm{GtC}\text{\,}\mathrm{m}\text{\,}\mathrm{{}^{-2}}\text{/}, (global mean surface air temperature is not measured in Kelvin but for simplicity in carbon-equivalent degrees, i.e. GtC), 6\text{\cdot}{10}^{9}\text{,}\mathrm{H}\text{/} (H=humans), $K_{0}=$5\text{\cdot}{10}^{13}\text{\,}\mathrm{\$}\text{/}, 5\text{\cdot}{10}^{11}\text{,}\mathrm{bits}\text{/}$$.
The parameters are: photosynthesis parameters 26.4\text{,}\mathrm{km}\text{,}\mathrm{yr}\text{,}\mathrm{{}^{-1}}\text{,}\mathrm{GtC}\text{/} and 26.4\text{,}{\mathrm{km}}^{3}\text{,}\mathrm{yr}\text{,}\mathrm{{}^{-1}}\text{,}\mathrm{GtC}\text{/}, total land mass 1.5\text{\cdot}{10}^{8}\text{,}{\mathrm{m}}^{2}\text{/}, respiration parameters $a_{0}=$0.03\text{\,}\mathrm{yr}\text{\,}\mathrm{{}^{-1}}\text{/} and 1.1\text{\cdot}{10}^{6}\text{,}{\mathrm{km}}^{2}\text{,}\mathrm{yr}\text{,}\mathrm{{}^{-1}}\text{,}\mathrm{GtC}\text{,}\mathrm{{}^{-1}}\text{/}, diffusion coefficient $\delta=$0.01\text{\,}\mathrm{yr}\text{\,}\mathrm{{}^{-1}}\text{/}, solubility coefficient , strength of greenhouse effect 0.02\text{,}\mathrm{yr}\text{,}\mathrm{{}^{-1}}\text{/}, peak fertility wellbeing level $W_{p}=$2000\text{\,}\mathrm{\$}\text{\,}\mathrm{yr}\text{\,}\mathrm{{}^{-1}}\text{\,}\mathrm{H}\text{\,}\mathrm{{}^{-1}}\text{/}, peak fertility 0.04\text{,}\mathrm{yr}\text{,}\mathrm{{}^{-1}}\text{/}, mortality coefficient $q=$20\text{\,}\mathrm{\$}\text{\,}\mathrm{yr}\text{\,}\mathrm{{}^{-2}}\text{/}, savings and capital depreciation rates and 0.1\text{,}\mathrm{yr}\text{,}\mathrm{{}^{-1}}\text{/}, knowledge accumulation $s_{R}=$1.0\text{\,}\mathrm{bits}\text{\,}\mathrm{GtC}\text{\,}\mathrm{{}^{-1}}\text{/} and forgetting parameters 1\text{/}50\text{,}\mathrm{yr}\text{,}\mathrm{{}^{-1}}\text{/}, total carbon $C^{\ast}=$5500\text{\,}\mathrm{GtC}\text{/}, energy subsector productivities a_{B}=1.5\cdot 10^{4}\text{GJ}^{5}\text{yr}^{-5}\text{GtC}^{-2}\text{\}^{-2}\text{H}^{-2}a_{F}=2.7\cdot 10^{5}\text{GJ}^{5}\text{yr}^{-5}\text{GtC}^{-2}\text{$}^{-2}\text{H}^{-2}a_{R}=9\cdot 10^{-15}\text{GJ}^{5}\text{yr}^{-5}\text{bits}^{-2}\text{$}^{-2}\text{H}^{-2}e_{B}=4\text{\cdot}{10}^{10}\text{\,}\mathrm{GJ}\text{\,}\mathrm{GtC}\text{\,}\mathrm{{}^{-1}}\text{/}$$, e_{F}=4\text{\cdot}{10}^{10}\text{\,}\mathrm{GJ}\text{\,}\mathrm{GtC}\text{\,}\mathrm{{}^{-1}}\text{/}$$, final sector productivity y_{E}=120\text{\,}\mathrm{\}\text{,}\mathrm{GJ}\text{,}\mathrm{{}^{-1}}\text{/}$$, wellbeing-sensitivity on ecosystem services .
Unsuccessful Management in c:GLOBAL
Noisy input to environments
List of hyper-parameters
In Table 1 the list of the hyper-parameters in AYS and c:Global environment is shown. The hyper-parameter search was mainly done based on own exploration. Due to high computational costs, no systematic grid search was performed, but as one parameter was tested the remaining were fixed at their previously explored optimal values. For the priority of transition , the initial importance sampling weighting and the Adam optimizer learning rate the recommended values in Schaul et al. (2015) and Hessel et al. (2018) were used.
References
- Schellnhuber (1999) H. J. Schellnhuber, “‘earth system’analysis and the second copernican revolution,” Nature 402, C19 (1999).
- Donges et al. (2017) J. F. Donges, R. Winkelmann, W. Lucht, S. E. Cornell, J. G. Dyke, J. Rockström, J. Heitzig, and H. J. Schellnhuber, “Closing the loop: Reconnecting human dynamics to earth system science,” The Anthropocene Review 4, 151–157 (2017).
- Rockström et al. (2009a) J. Rockström, W. Steffen, K. Noone, Å. Persson, F. S. Chapin III, E. F. Lambin, T. M. Lenton, M. Scheffer, C. Folke, H. J. Schellnhuber, et al., “A safe operating space for humanity,” Nature 461, 472 (2009a).
- Rockström et al. (2009b) J. Rockström, W. L. Steffen, K. Noone, Å. Persson, F. S. Chapin III, E. Lambin, T. M. Lenton, M. Scheffer, C. Folke, H. J. Schellnhuber, et al., “Planetary boundaries: exploring the safe operating space for humanity,” Ecology and society (2009b).
- Assembly (2015) U. G. Assembly, “Transforming our world: The 2030 agenda for sustainable development,” Tech. Rep. (United Nations, 2015).
- on Climate Change (2015) U. N. F. C. on Climate Change, “Conference of the parties - adoption of the paris agreement,” Tech. Rep. (United Nations, 2015).
- Anderies et al. (2013) J. M. Anderies, S. R. Carpenter, W. Steffen, and J. Rockström, “The topology of non-linear global carbon dynamics: from tipping points to planetary boundaries,” Environmental Research Letters 8, 044048 (2013).
- Steffen et al. (2015) W. Steffen, K. Richardson, J. Rockström, S. E. Cornell, I. Fetzer, E. M. Bennett, R. Biggs, S. R. Carpenter, W. De Vries, C. A. De Wit, et al., “Planetary boundaries: Guiding human development on a changing planet,” Science 347, 1259855 (2015).
- Raworth (2012) K. Raworth, “A safe and just space for humanity: Can we live within the doughnut,” Oxfam Policy Pract. Clim. Change Resil 8 (2012).
- Rogelj et al. (2018) J. Rogelj, D. Shindell, K. Jiang, S. Fifita, P. Forster, V. Ginzburg, C. Handa, H. Kheshgi, S. Kobayashi, E. Kriegler, et al., “Mitigation pathways compatible with 1.5 c in the context of sustainable development,” IPCC report (2018).
- Steffen et al. (2018) W. Steffen, J. Rockström, K. Richardson, T. M. Lenton, C. Folke, D. Liverman, C. P. Summerhayes, A. D. Barnosky, S. E. Cornell, M. Crucifix, J. F. Donges, I. Fetzer, S. J. Lade, M. Scheffer, R. Winkelmann, and H. J. Schellnhuber, “Trajectories of the earth system in the anthropocene,” Proceedings of the National Academy of Sciences 115, 8252–8259 (2018), https://www.pnas.org/content/115/33/8252.full.pdf .
- Müller-Hansen et al. (2017) F. Müller-Hansen, M. Schlüter, M. Mäs, J. F. Donges, J. J. Kolb, K. Thonicke, and J. Heitzig, “Towards representing human behavior and decision making in earth system models–an overview of techniques and approaches,” Earth System Dynamics 8, 977–1007 (2017).
- Kelly and Kolstad (1999) D. L. Kelly and C. D. Kolstad, “Integrated assessment models for climate change control,” International yearbook of environmental and resource economics 2000, 171–197 (1999).
- Pahl-Wostl et al. (2000) C. Pahl-Wostl, C. Schlumpf, M. Büssenschütt, A. Schönborn, and J. Burse, “Models at the interface between science and society: impacts and options,” Integrated assessment 1, 267–280 (2000).
- Bussieck and Meeraus (2004) M. R. Bussieck and A. Meeraus, “General algebraic modeling system (gams),” in Modeling languages in mathematical optimization (Springer, 2004) pp. 137–157.
- Pindyck (2017) R. S. Pindyck, “The use and misuse of models for climate policy,” Review of Environmental Economics and Policy 11, 100–114 (2017).
- Kamien and Schwartz (2012) M. I. Kamien and N. L. Schwartz, Dynamic optimization: the calculus of variations and optimal control in economics and management (Courier Corporation, 2012).
- Liang (2008) W. Liang, “Climate modification directed by control theory,” arXiv preprint arXiv:0805.0541 (2008).
- Botta, Jansson, and Ionescu (2018) N. Botta, P. Jansson, and C. Ionescu, “The impact of uncertainty on optimal emission policies,” Earth System Dynamics 9, 525–542 (2018).
- Deffuant and Gilbert (2011) G. Deffuant and N. Gilbert, Viability and resilience of complex systems: concepts, methods and case studies from ecology and society (Springer Science & Business Media, 2011).
- Kittel et al. (2017) T. Kittel, R. Koch, J. Heitzig, G. Deffuant, J.-D. Mathias, and J. Kurths, “Operationalization of topology of sustainable management to estimate qualitatively different regions in state space,” arXiv preprint arXiv:1706.04542 (2017).
- Sutton, Barto et al. (1998) R. S. Sutton, A. G. Barto, et al., Introduction to reinforcement learning, Vol. 135 (MIT press Cambridge, 1998).
- von der Osten (2017) F. B. von der Osten, Intelligent decision-making in coupled socio-ecological systems, Ph.D. thesis, University of Melbourne (2017).
- Mnih et al. (2015) V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., “Human-level control through deep reinforcement learning,” Nature 518, 529 (2015).
- Mnih et al. (2013) V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602 (2013).
- Tesauro (1995) G. Tesauro, “Temporal difference learning and td-gammon,” Communications of the ACM 38, 58–68 (1995).
- Arulkumaran et al. (2017) K. Arulkumaran, M. P. Deisenroth, M. Brundage, and A. A. Bharath, “A brief survey of deep reinforcement learning,” arXiv preprint arXiv:1708.05866 (2017).
- Li (2018) Y. Li, “Deep reinforcement learning,” arXiv preprint arXiv:1810.06339 (2018).
- Watkins (1989) C. J. C. H. Watkins, Learning from delayed rewards, Ph.D. thesis, King’s College, Cambridge (1989).
- LeCun, Bengio, and Hinton (2015) Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature 521, 436 (2015).
- Lin (1993) L.-J. Lin, “Reinforcement learning for robots using neural networks,” Tech. Rep. (DTIC Document, 1993).
- Silver et al. (2016) D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, et al., “Mastering the game of go with deep neural networks and tree search,” Nature 529, 484 (2016).
- Silver et al. (2018) D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis, “A general reinforcement learning algorithm that masters chess, shogi, and go through self-play,” Science 362, 1140–1144 (2018), https://science.sciencemag.org/content/362/6419/1140.full.pdf .
- Hessel et al. (2018) M. Hessel, J. Modayil, H. Van Hasselt, T. Schaul, G. Ostrovski, W. Dabney, D. Horgan, B. Piot, M. Azar, and D. Silver, “Rainbow: Combining improvements in deep reinforcement learning,” in Thirty-Second AAAI Conference on Artificial Intelligence (2018).
- Mao et al. (2016) H. Mao, M. Alizadeh, I. Menache, and S. Kandula, “Resource management with deep reinforcement learning,” in Proceedings of the 15th ACM Workshop on Hot Topics in Networks (ACM, 2016) pp. 50–56.
- Zhou, Li, and Zare (2017) Z. Zhou, X. Li, and R. N. Zare, “Optimizing chemical reactions with deep reinforcement learning,” ACS central science 3, 1337–1344 (2017).
- Lillicrap et al. (2016) T. P. Lillicrap, J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning (2015),” arXiv preprint arXiv:1509.02971 (2016).
- Levine et al. (2016) S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,” The Journal of Machine Learning Research 17, 1334–1373 (2016).
- Zhu et al. (2017) Y. Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” in 2017 IEEE international conference on robotics and automation (ICRA) (IEEE, 2017) pp. 3357–3364.
- Gu et al. (2017) S. Gu, E. Holly, T. Lillicrap, and S. Levine, “Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates,” in 2017 IEEE international conference on robotics and automation (ICRA) (IEEE, 2017) pp. 3389–3396.
- Haarnoja et al. (2018) T. Haarnoja, A. Zhou, S. Ha, J. Tan, G. Tucker, and S. Levine, “Learning to walk via deep reinforcement learning,” arXiv preprint arXiv:1812.11103 (2018).
- Donges et al. (2018) J. F. Donges, J. Heitzig, W. Barfuss, J. A. Kassel, T. Kittel, J. J. Kolb, T. Kolster, F. Müller-Hansen, I. M. Otto, M. Wiedermann, et al., “Earth system modelling with complex dynamic human societies: the copan: Core world-earth modeling framework,” Earth System Dynamics Discussions , 1–27 (2018).
- Arthur (1991) W. B. Arthur, “Designing economic agents that act like human agents: A behavioral approach to bounded rationality,” The American Economic Review 81, 353–359 (1991).
- Lindkvist and Norberg (2014) E. Lindkvist and J. Norberg, “Modeling experiential learning: The challenges posed by threshold dynamics for sustainable renewable resource management,” Ecological economics 104, 107–118 (2014).
- Lindkvist, Ekeberg, and Norberg (2017) E. Lindkvist, Ö. Ekeberg, and J. Norberg, “Strategies for sustainable management of renewable resources during environmental change,” Proc. R. Soc. B 284, 20162762 (2017).
- Rolnick et al. (2019) D. Rolnick, P. L. Donti, L. H. Kaack, K. Kochanski, A. Lacoste, K. Sankaran, A. S. Ross, N. Milojevic-Dupont, N. Jaques, A. Waldman-Brown, et al., “Tackling climate change with machine learning,” arXiv preprint arXiv:1906.05433 (2019).
- Barfuss, Donges, and Kurths (2019) W. Barfuss, J. F. Donges, and J. Kurths, “Deterministic limit of temporal difference reinforcement learning for stochastic games,” Phys. Rev. E 99, 043305 (2019).
- Wiering and Van Otterlo (2012) M. Wiering and M. Van Otterlo, “Reinforcement learning,” Adaptation, learning, and optimization 12, 51 (2012).
- Bellman (1957) R. Bellman, “A markovian decision process,” Journal of Mathematics and Mechanics , 679–684 (1957).
- Van Hasselt, Guez, and Silver (2016) H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” Thirtieth AAAI Conference on Artificial Intelligence, Proceedings ofthe AAAI Conference on Artificial Intelligence (2016).
- Hasselt (2010) H. V. Hasselt, “Double q-learning,” in Advances in Neural Information Processing Systems (2010) pp. 2613–2621.
- Wang et al. (2015) Z. Wang, T. Schaul, M. Hessel, H. Van Hasselt, M. Lanctot, and N. De Freitas, “Dueling network architectures for deep reinforcement learning,” arXiv preprint arXiv:1511.06581 (2015).
- Bellemare, Dabney, and Munos (2017) M. G. Bellemare, W. Dabney, and R. Munos, “A distributional perspective on reinforcement learning,” in Proceedings of the 34th International Conference on Machine Learning-Volume 70 (JMLR. org, 2017) pp. 449–458.
- Schaul et al. (2015) T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” arXiv preprint arXiv:1511.05952 (2015).
- Barfuss et al. (2018) W. Barfuss, J. F. Donges, S. J. Lade, and J. Kurths, “When optimization for governing human-environment tipping elements is neither sustainable nor safe,” Nature communications 9, 2354 (2018).
- Nitzbon, Heitzig, and Parlitz (2017) J. Nitzbon, J. Heitzig, and U. Parlitz, “Sustainability, collapse and oscillations in a simple world-earth model,” Environmental Research Letters 12, 074020 (2017).
- Heitzig, Barfuss, and Donges (2018) J. Heitzig, W. Barfuss, and J. Donges, “A thought experiment on sustainable management of the earth system,” Sustainability 10, 1947 (2018).
- Zhang and Sutton (2017) S. Zhang and R. S. Sutton, “A deeper look at experience replay,” arXiv preprint arXiv:1712.01275 (2017).
- Kingma and Ba (2014) D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980 (2014).
- Heitzig et al. (2016) J. Heitzig, T. Kittel, J. F. Donges, and N. Molkenthin, “Topology of sustainable management of dynamical systems with desirable states: from defining planetary boundaries to safe operating spaces in the earth system.” Earth System Dynamics 7 (2016).
- Spaan (2012) M. T. Spaan, “Partially observable markov decision processes,” in Reinforcement Learning (Springer, 2012) pp. 387–414.
- Szegedy et al. (2013) C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” arXiv preprint arXiv:1312.6199 (2013).
- Papernot et al. (2016) N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, and A. Swami, “The limitations of deep learning in adversarial settings,” in 2016 IEEE European Symposium on Security and Privacy (EuroS&P) (IEEE, 2016) pp. 372–387.
- Behzadan and Munir (2017a) V. Behzadan and A. Munir, “Vulnerability of deep reinforcement learning to policy induction attacks,” in International Conference on Machine Learning and Data Mining in Pattern Recognition (Springer, 2017) pp. 262–275.
- Behzadan and Munir (2017b) V. Behzadan and A. Munir, “Whatever does not kill deep reinforcement learning, makes it stronger,” arXiv preprint arXiv:1712.09344 (2017b).
- Huang et al. (2017) S. Huang, N. Papernot, I. Goodfellow, Y. Duan, and P. Abbeel, “Adversarial attacks on neural network policies,” arXiv preprint arXiv:1702.02284 (2017).
- Mirowski et al. (2016) P. Mirowski, R. Pascanu, F. Viola, H. Soyer, A. J. Ballard, A. Banino, M. Denil, R. Goroshin, L. Sifre, K. Kavukcuoglu, et al., “Learning to navigate in complex environments,” arXiv preprint arXiv:1611.03673 (2016).
- Nordhaus (2011) W. D. Nordhaus, “Estimates of the social cost of carbon: background and results from the rice-2011 model,” Tech. Rep. (National Bureau of Economic Research, 2011).
- Stern and Stern (2007) N. Stern and N. H. Stern, The economics of climate change: the Stern review (cambridge University press, 2007).
- Wiedermann et al. (2015) M. Wiedermann, J. F. Donges, J. Heitzig, W. Lucht, and J. Kurths, “Macroscopic description of complex adaptive networks coevolving with dynamic node states,” Physical Review E 91, 052801 (2015).
- Barfuss et al. (2017) W. Barfuss, J. F. Donges, M. Wiedermann, and W. Lucht, “Sustainable use of renewable resources in a stylized social–ecological network model under heterogeneous resource distribution,” Earth System Dynamics 8, 255–264 (2017).
- Sitch et al. (2003) S. Sitch, B. Smith, I. C. Prentice, A. Arneth, A. Bondeau, W. Cramer, J. O. Kaplan, S. Levis, W. Lucht, M. T. Sykes, et al., “Evaluation of ecosystem dynamics, plant geography and terrestrial carbon cycling in the lpj dynamic global vegetation model,” Global change biology 9, 161–185 (2003).
- Leibo et al. (2017) J. Z. Leibo, V. Zambaldi, M. Lanctot, J. Marecki, and T. Graepel, “Multi-agent reinforcement learning in sequential social dilemmas,” in Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems (International Foundation for Autonomous Agents and Multiagent Systems, 2017) pp. 464–473.
- Perolat et al. (2017) J. Perolat, J. Z. Leibo, V. Zambaldi, C. Beattie, K. Tuyls, and T. Graepel, “A multi-agent reinforcement learning model of common-pool resource appropriation,” in Advances in Neural Information Processing Systems (2017) pp. 3643–3652.
- Heitzig, Lessmann, and Zou (2011) J. Heitzig, K. Lessmann, and Y. Zou, “Self-enforcing strategies to deter free-riding in the climate change mitigation game and other repeated public good games,” Proceedings of the National Academy of Sciences 108, 15739–15744 (2011).
- Nagabandi et al. (2018) A. Nagabandi, G. Kahn, R. S. Fearing, and S. Levine, “Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning,” in 2018 IEEE International Conference on Robotics and Automation (ICRA) (IEEE, 2018) pp. 7559–7566.
- Pong et al. (2018) V. Pong, S. Gu, M. Dalal, and S. Levine, “Temporal difference models: Model-free deep rl for model-based control,” arXiv preprint arXiv:1802.09081 (2018).
- Amodei et al. (2016) D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané, “Concrete problems in ai safety,” arXiv preprint arXiv:1606.06565 (2016).
- Lenton et al. (2008) T. M. Lenton, H. Held, E. Kriegler, J. W. Hall, W. Lucht, S. Rahmstorf, and H. J. Schellnhuber, “Tipping elements in the earth’s climate system,” Proceedings of the National Academy of Sciences 105, 1786–1793 (2008), https://www.pnas.org/content/105/6/1786.full.pdf .
- Schellnhuber (2009) H. J. Schellnhuber, “Tipping elements in the earth system,” Proceedings of the National Academy of Sciences 106, 20561–20563 (2009), https://www.pnas.org/content/106/49/20561.full.pdf .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Schellnhuber (1999) H. J. Schellnhuber, “‘earth system’analysis and the second copernican revolution,” Nature 402 , C 19 (1999).
- 2Donges et al. (2017) J. F. Donges, R. Winkelmann, W. Lucht, S. E. Cornell, J. G. Dyke, J. Rockström, J. Heitzig, and H. J. Schellnhuber, “Closing the loop: Reconnecting human dynamics to earth system science,” The Anthropocene Review 4 , 151–157 (2017).
- 3Rockström et al. (2009 a) J. Rockström, W. Steffen, K. Noone, Å. Persson, F. S. Chapin III, E. F. Lambin, T. M. Lenton, M. Scheffer, C. Folke, H. J. Schellnhuber, et al. , “A safe operating space for humanity,” Nature 461 , 472 (2009 a).
- 4Rockström et al. (2009 b) J. Rockström, W. L. Steffen, K. Noone, Å. Persson, F. S. Chapin III, E. Lambin, T. M. Lenton, M. Scheffer, C. Folke, H. J. Schellnhuber, et al. , “Planetary boundaries: exploring the safe operating space for humanity,” Ecology and society (2009 b).
- 5Assembly (2015) U. G. Assembly, “Transforming our world: The 2030 agenda for sustainable development,” Tech. Rep. (United Nations, 2015).
- 6on Climate Change (2015) U. N. F. C. on Climate Change, “Conference of the parties - adoption of the paris agreement,” Tech. Rep. (United Nations, 2015).
- 7Anderies et al. (2013) J. M. Anderies, S. R. Carpenter, W. Steffen, and J. Rockström, “The topology of non-linear global carbon dynamics: from tipping points to planetary boundaries,” Environmental Research Letters 8 , 044048 (2013).
- 8Steffen et al. (2015) W. Steffen, K. Richardson, J. Rockström, S. E. Cornell, I. Fetzer, E. M. Bennett, R. Biggs, S. R. Carpenter, W. De Vries, C. A. De Wit, et al. , “Planetary boundaries: Guiding human development on a changing planet,” Science 347 , 1259855 (2015).
