Automatic Calibration of Dynamic and Heterogeneous Parameters in Agent-based Model
Dongjun Kim, Tae-Sub Yun, Il-Chul Moon

TL;DR
This paper introduces methods for dynamic and heterogeneous parameter calibration in agent-based models to improve quantitative validation against real-world data, demonstrated through economic simulation case studies.
Contribution
It extends static parameter calibration to include dynamic and heterogeneous approaches, enhancing model validation accuracy in agent-based simulations.
Findings
Effective calibration methods demonstrated on economic models
Improved alignment with real-world data in case studies
Dynamic and heterogeneous calibration outperform static methods
Abstract
While simulations have been utilized in diverse domains, such as urban growth modeling, market dynamics modeling, etc; some of these applications may require validations based upon some real-world observations modeled in the simulation, as well. This validation has been categorized into either qualitative face-validation or quantitative empirical validation, but as the importance and the accumulation of data grows, the importance of the quantitative validation has been highlighted in the recent studies, i.e. digital twin. The key component of quantitative validation is finding a calibrated set of parameters to regenerate the real-world observations with simulation models. While this parameter calibration has been fixed throughout a simulation execution, this paper expands the static parameter calibration in two dimensions: dynamic calibration and heterogeneous calibration. First,…
Click any figure to enlarge with its caption.
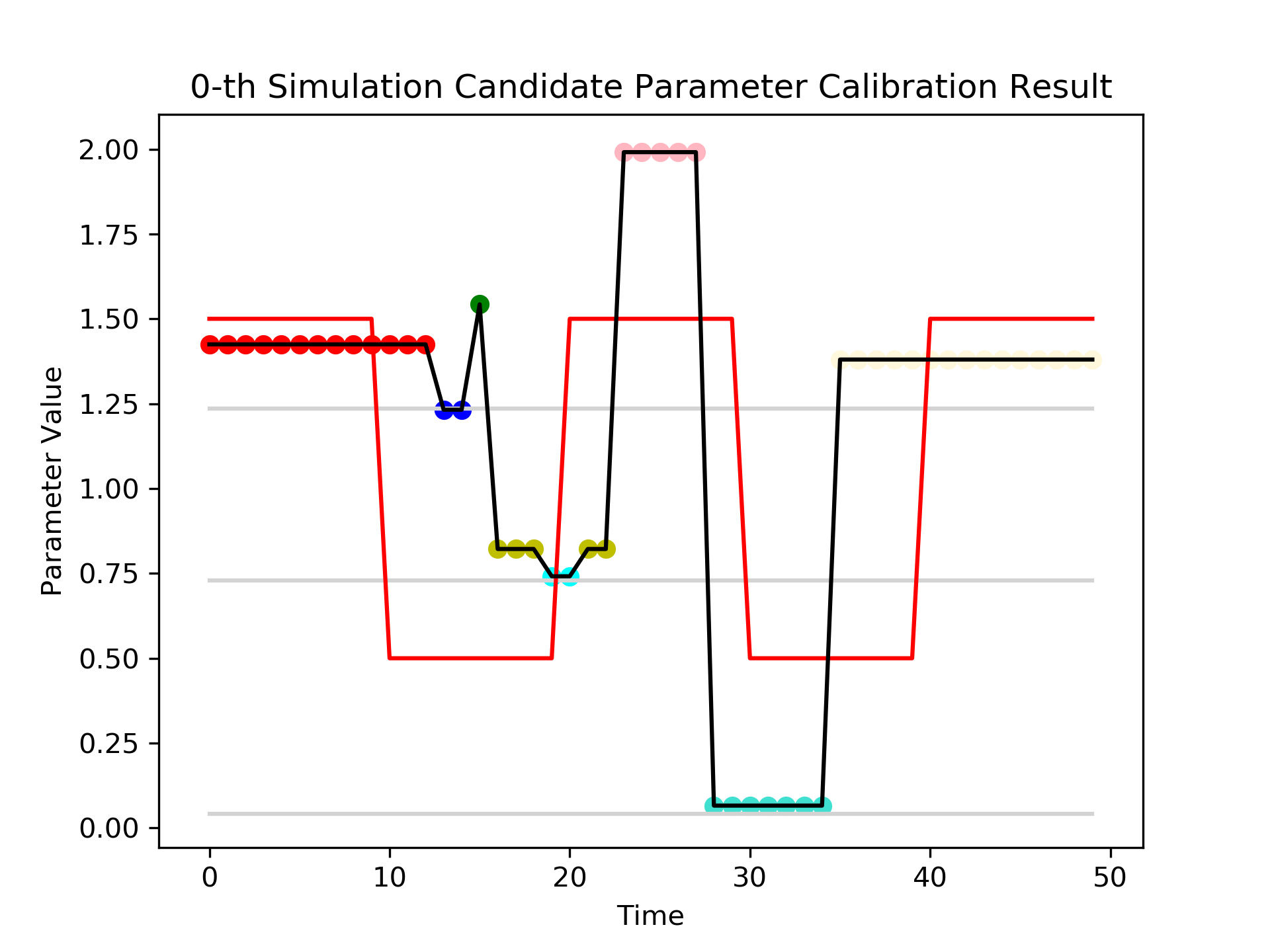 Figure 1
Figure 1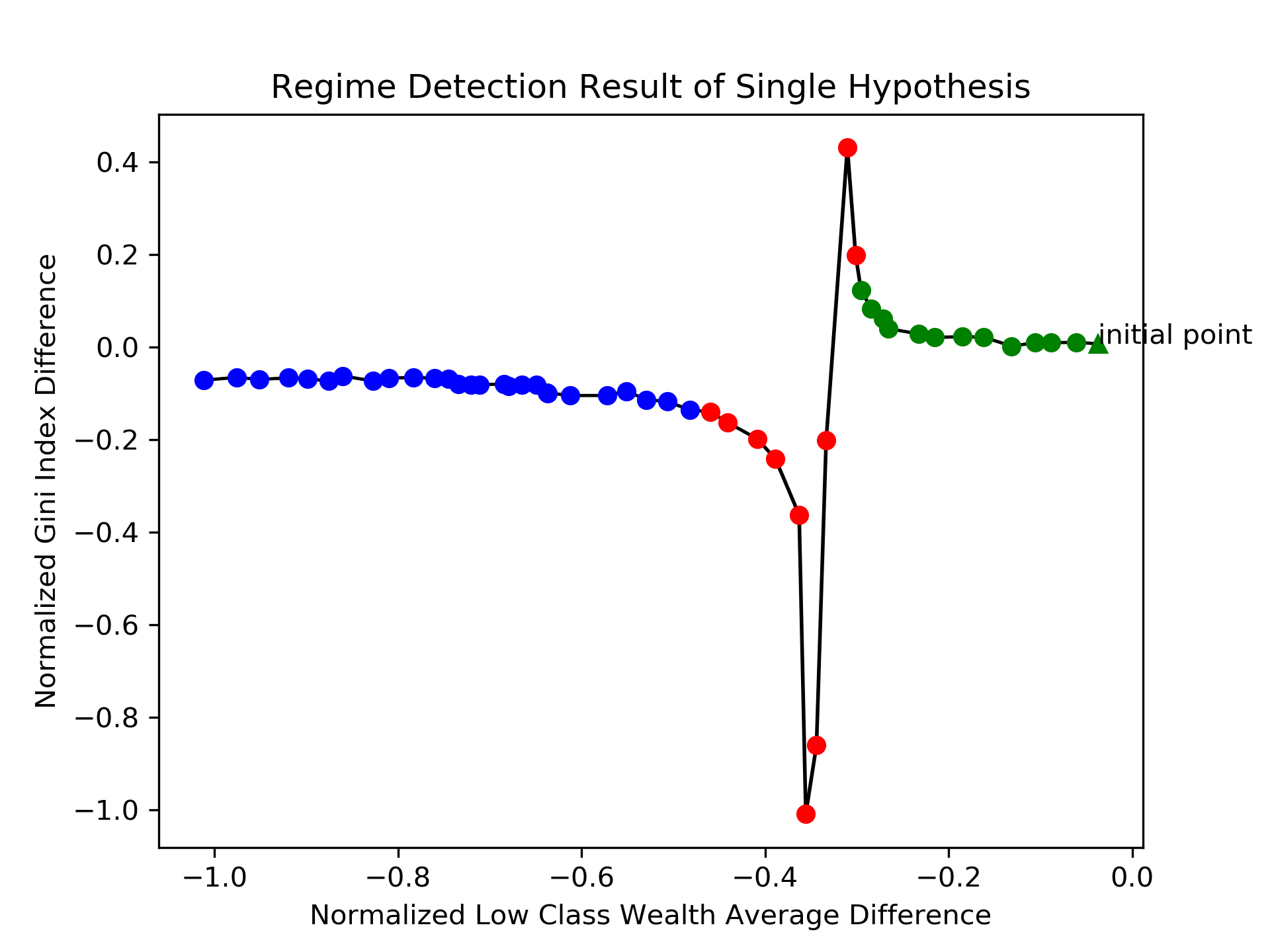 Figure 2
Figure 2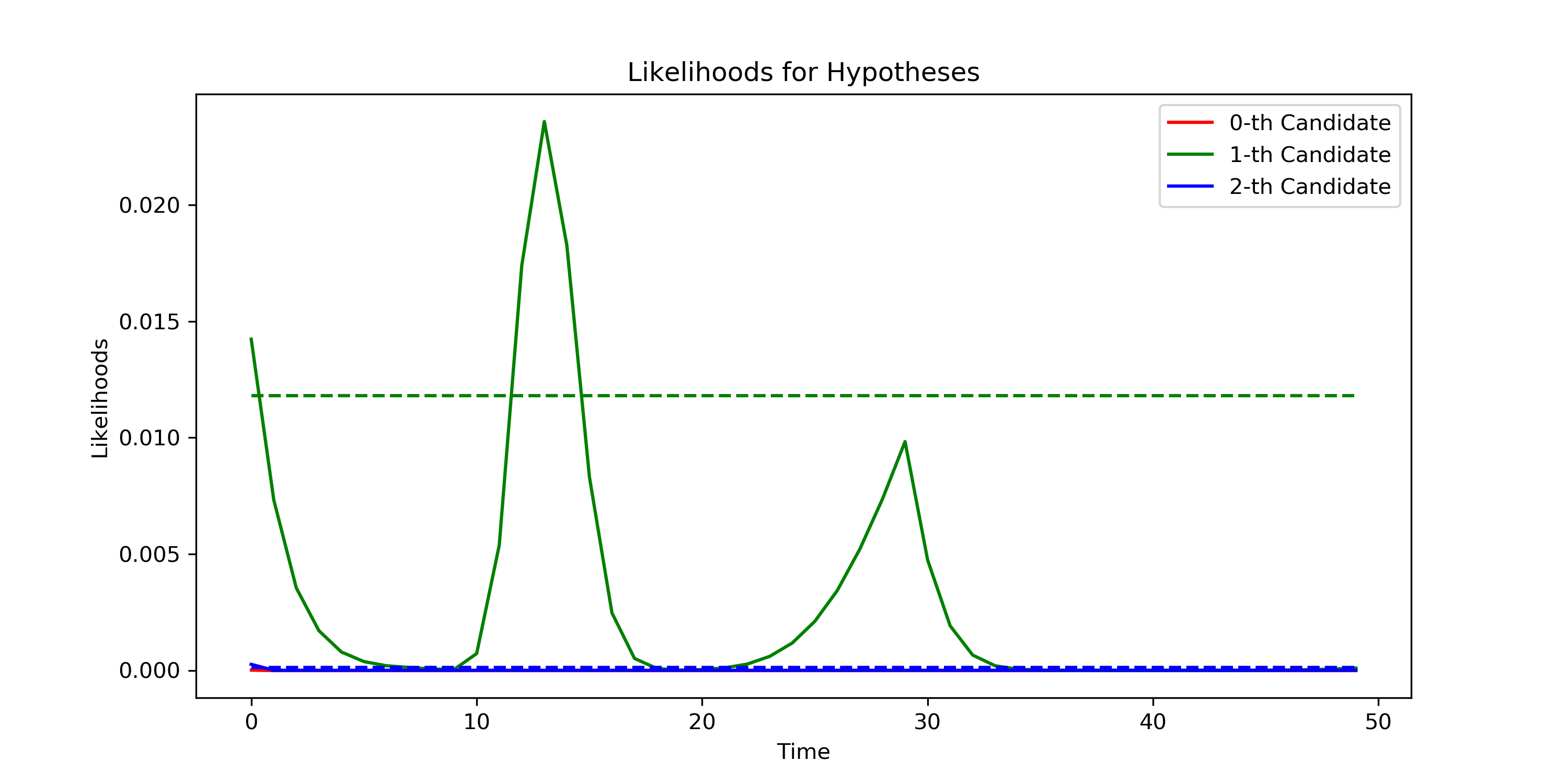 Figure 3
Figure 3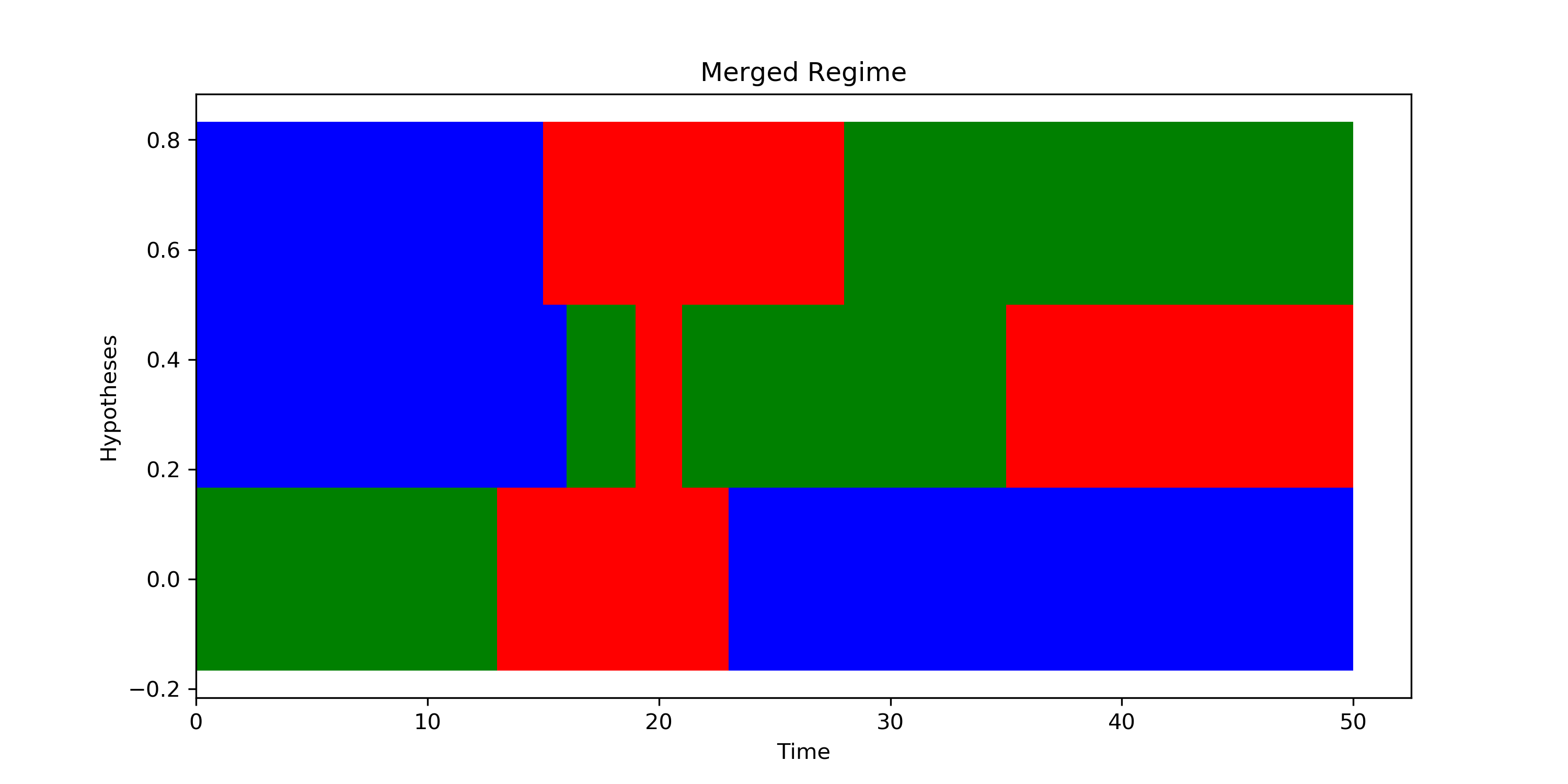 Figure 4
Figure 4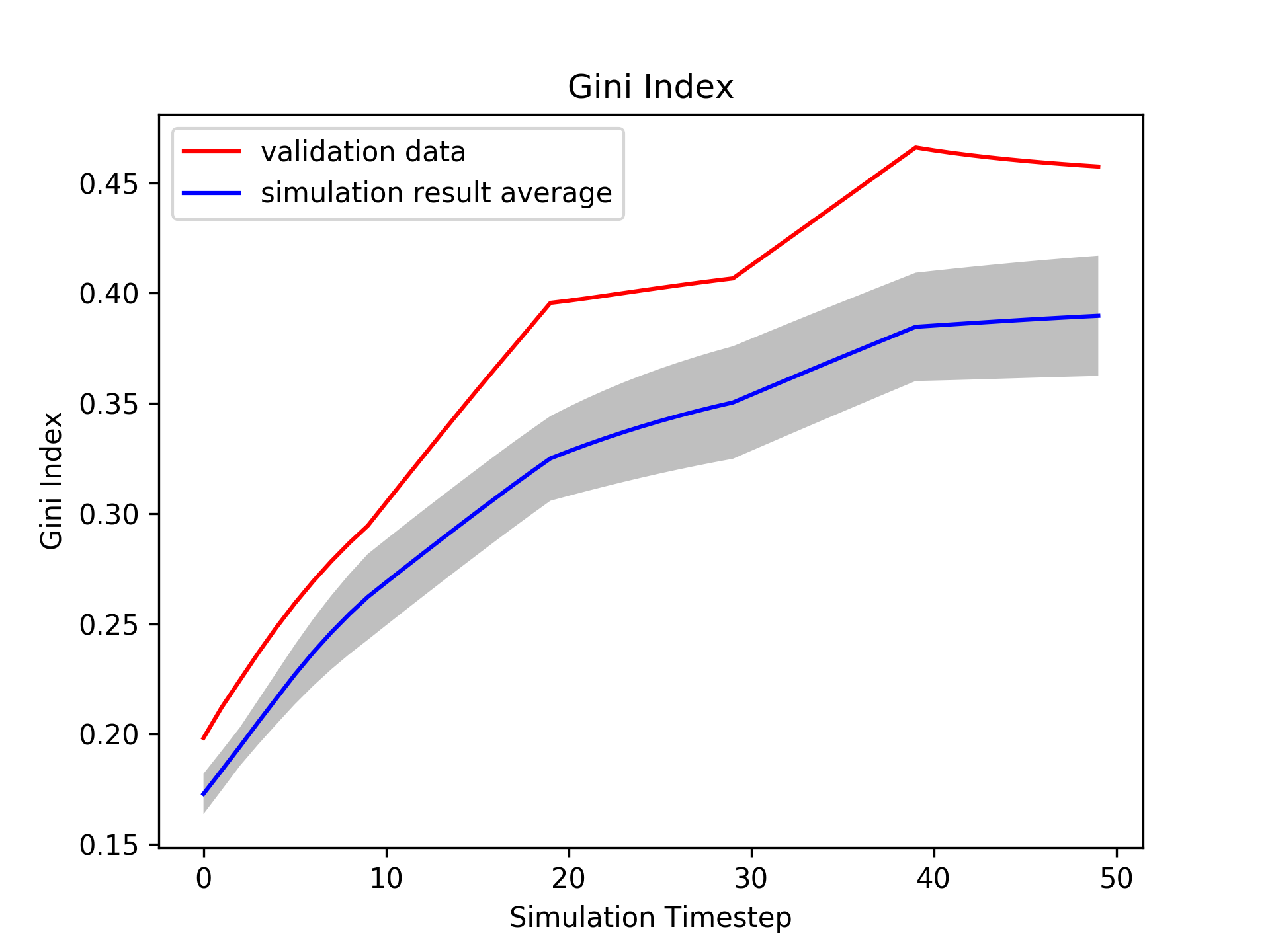 Figure 5
Figure 5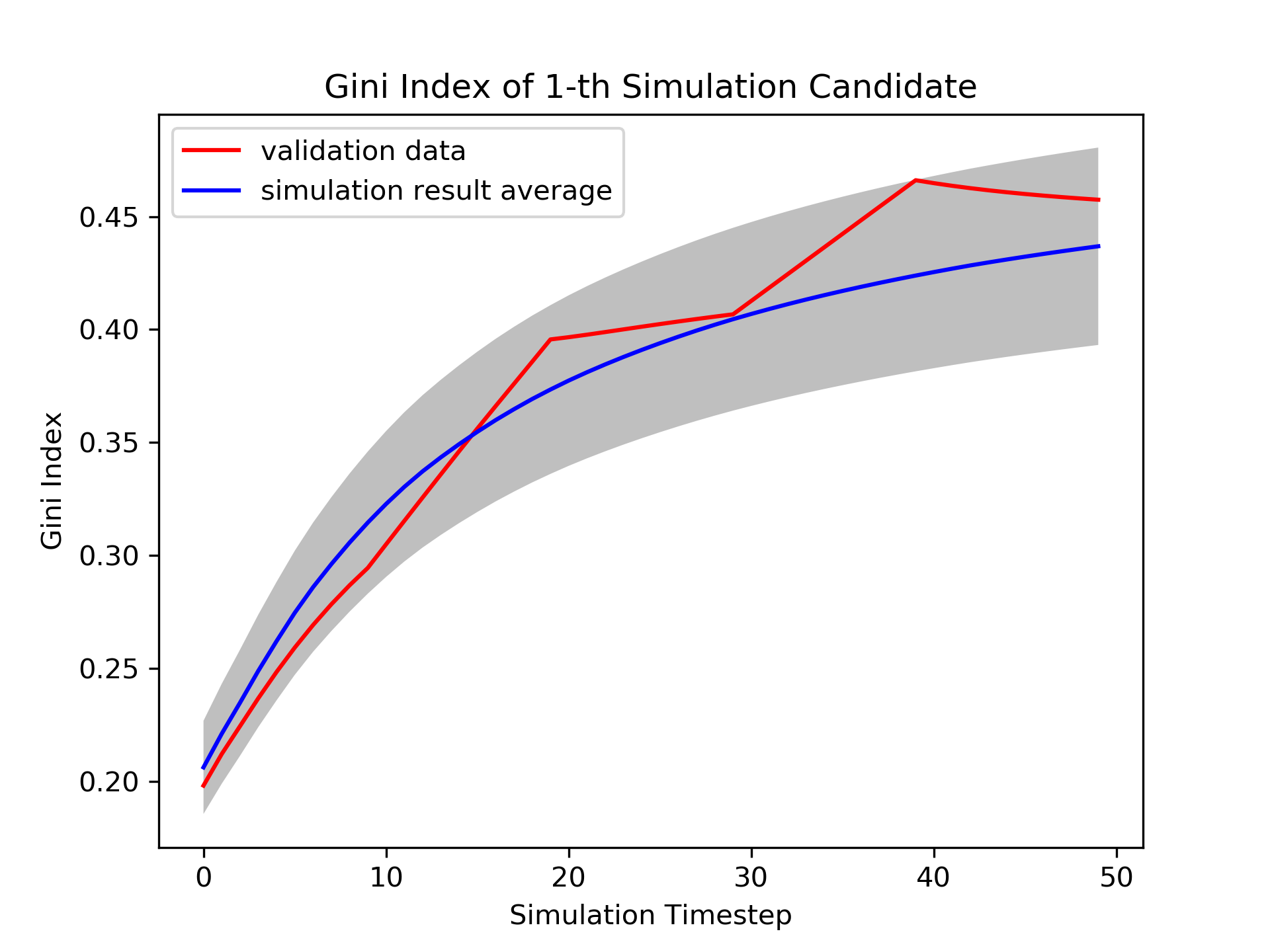 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8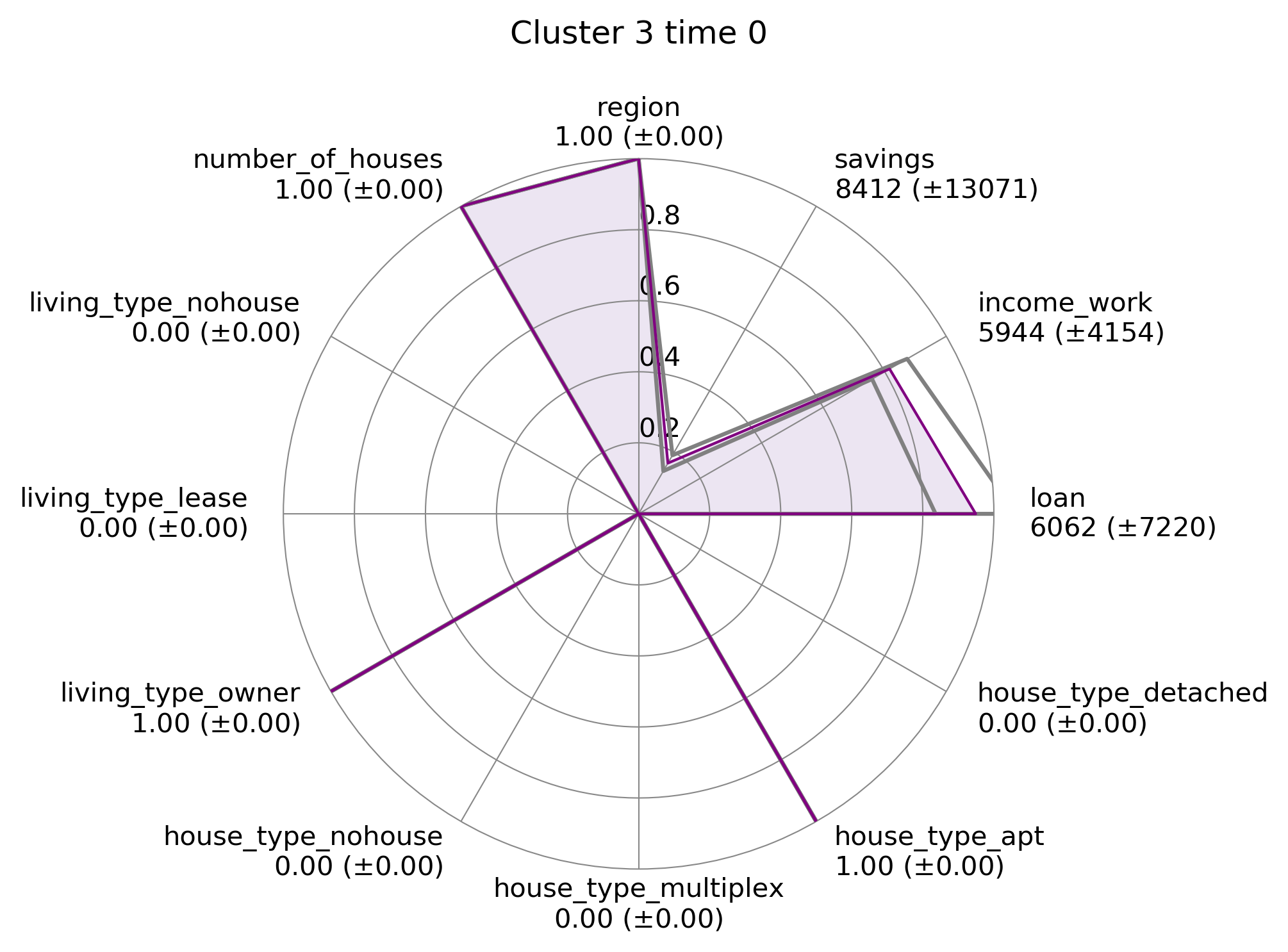 Figure 9
Figure 9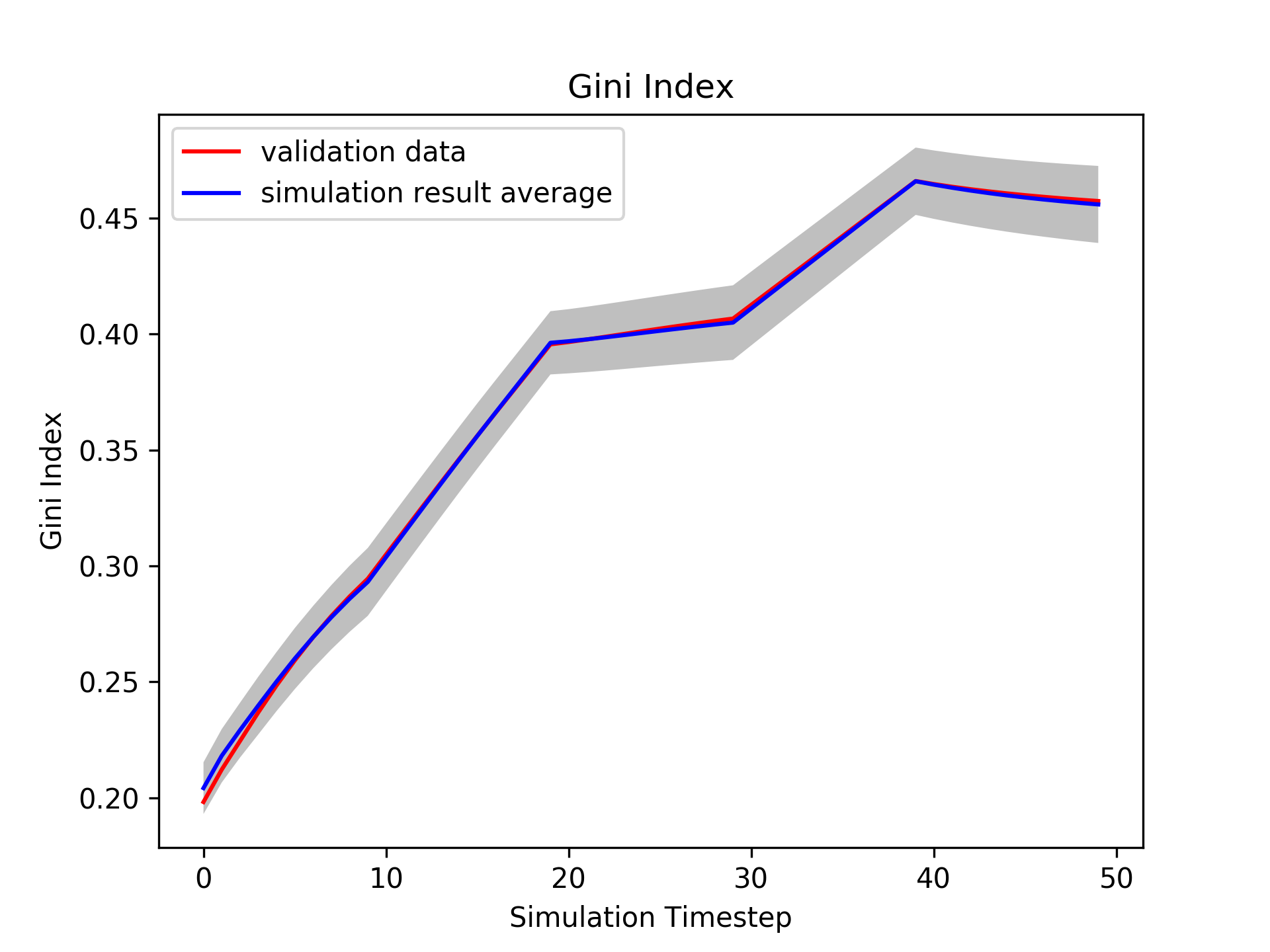 Figure 10
Figure 10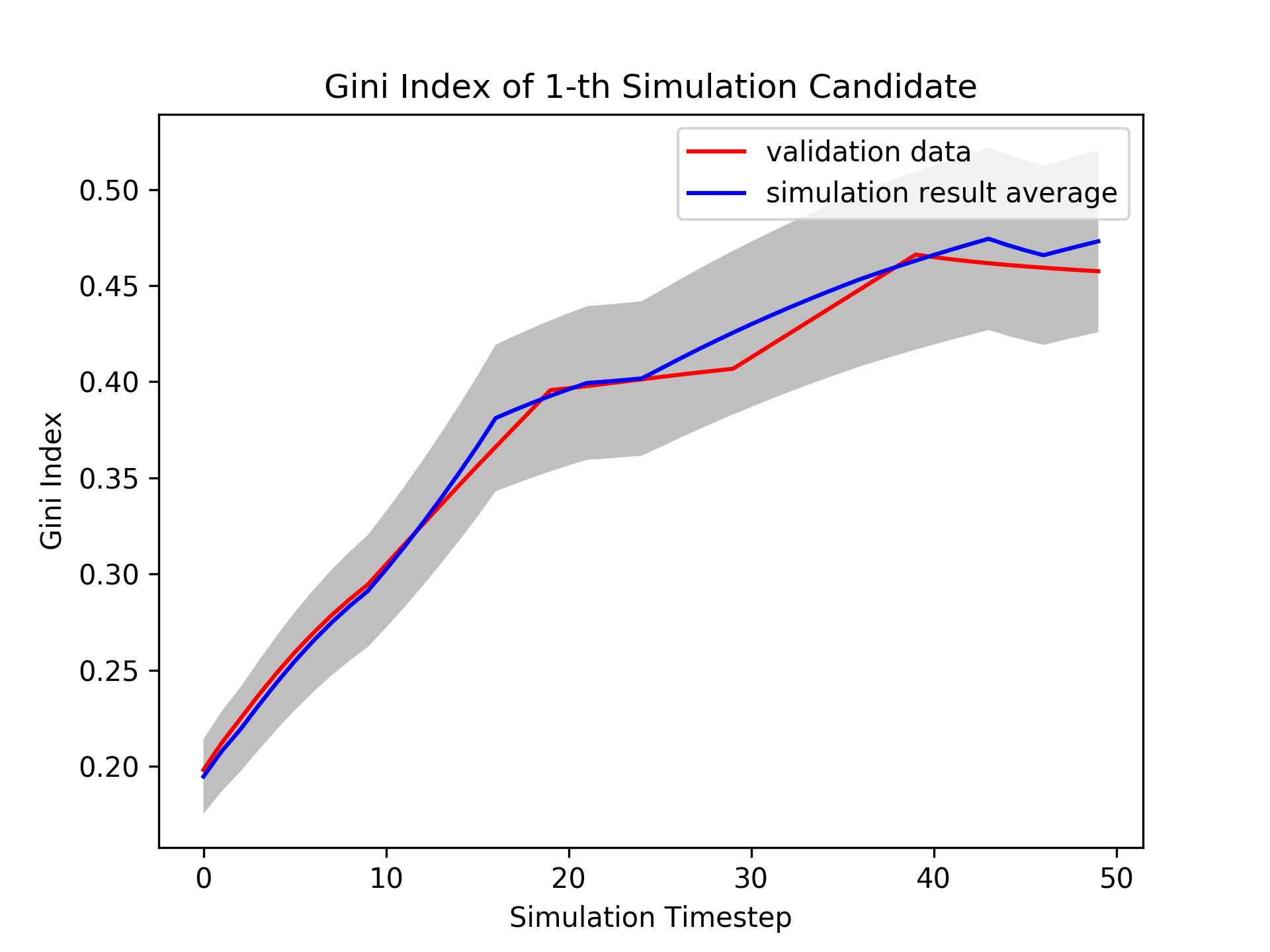 Figure 11
Figure 11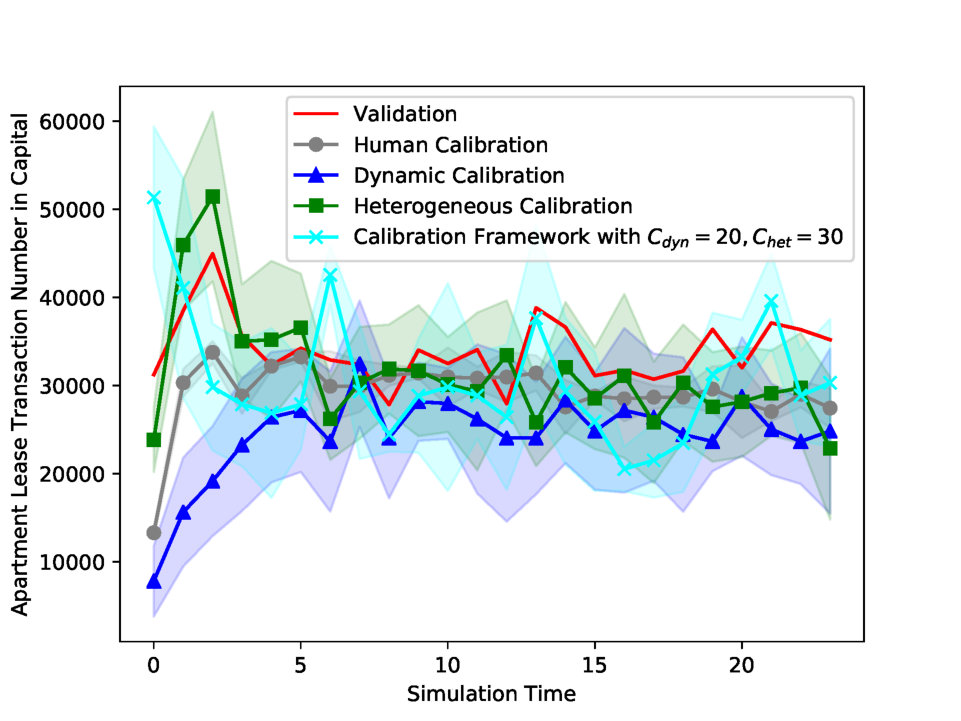 Figure 12
Figure 12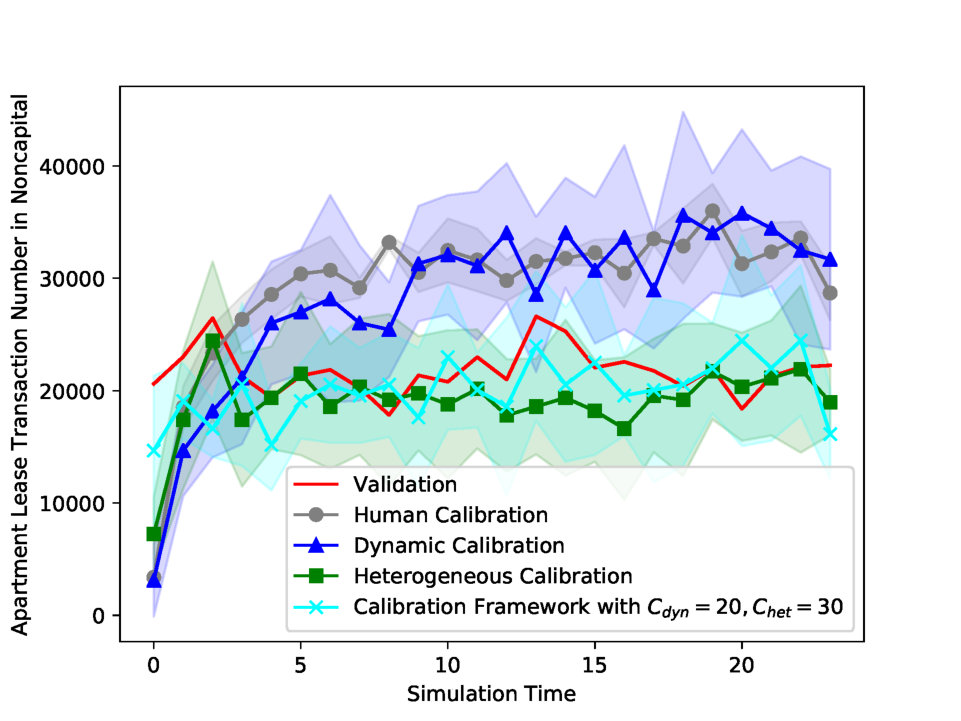 Figure 13
Figure 13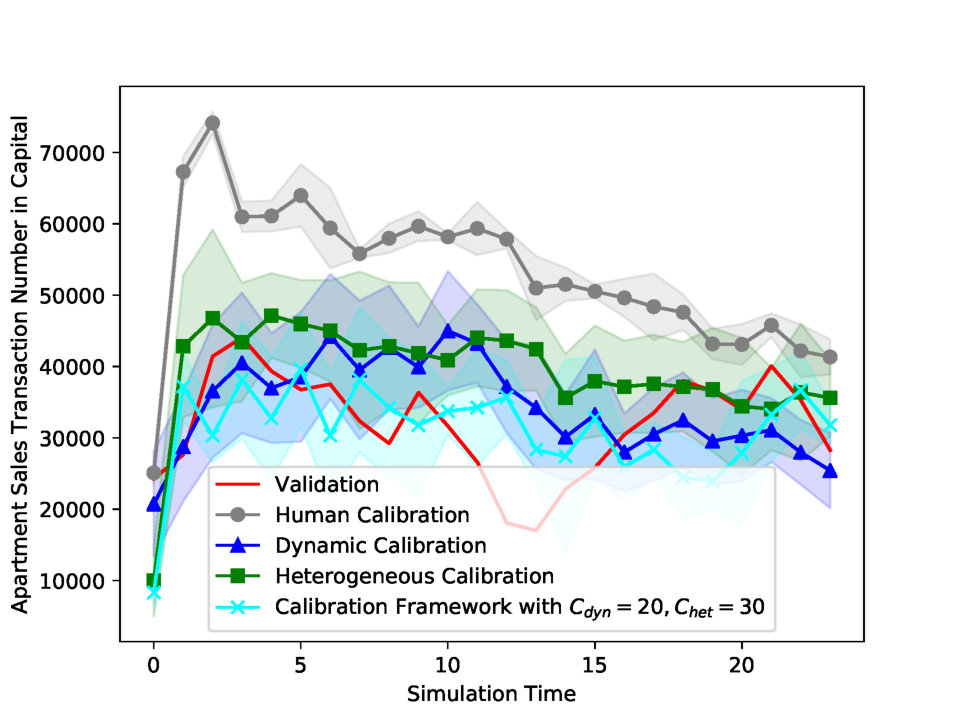 Figure 14
Figure 14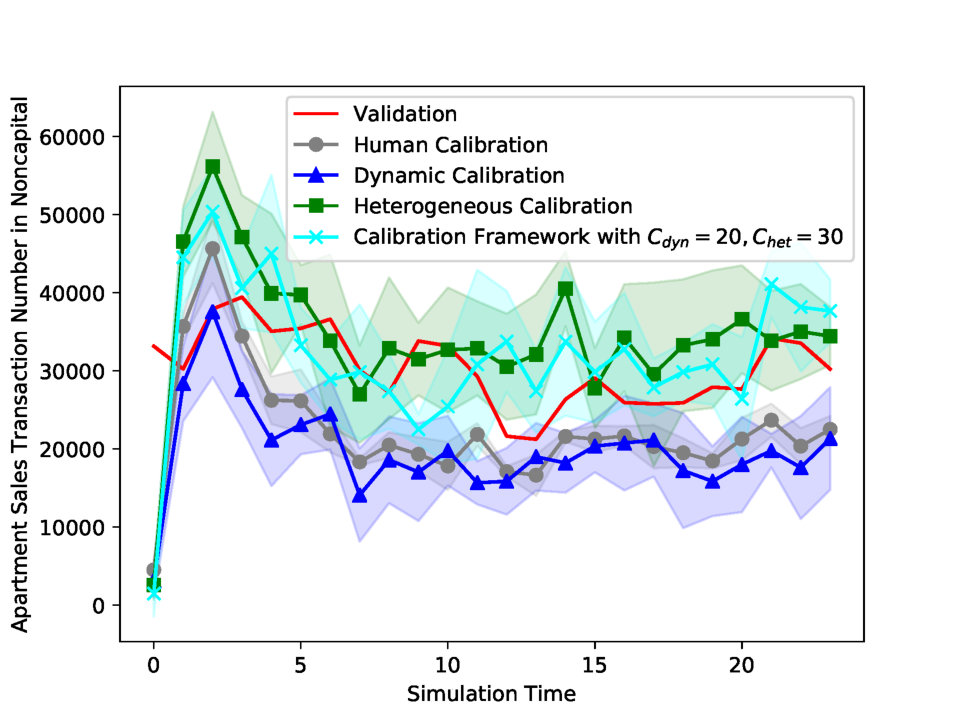 Figure 15
Figure 15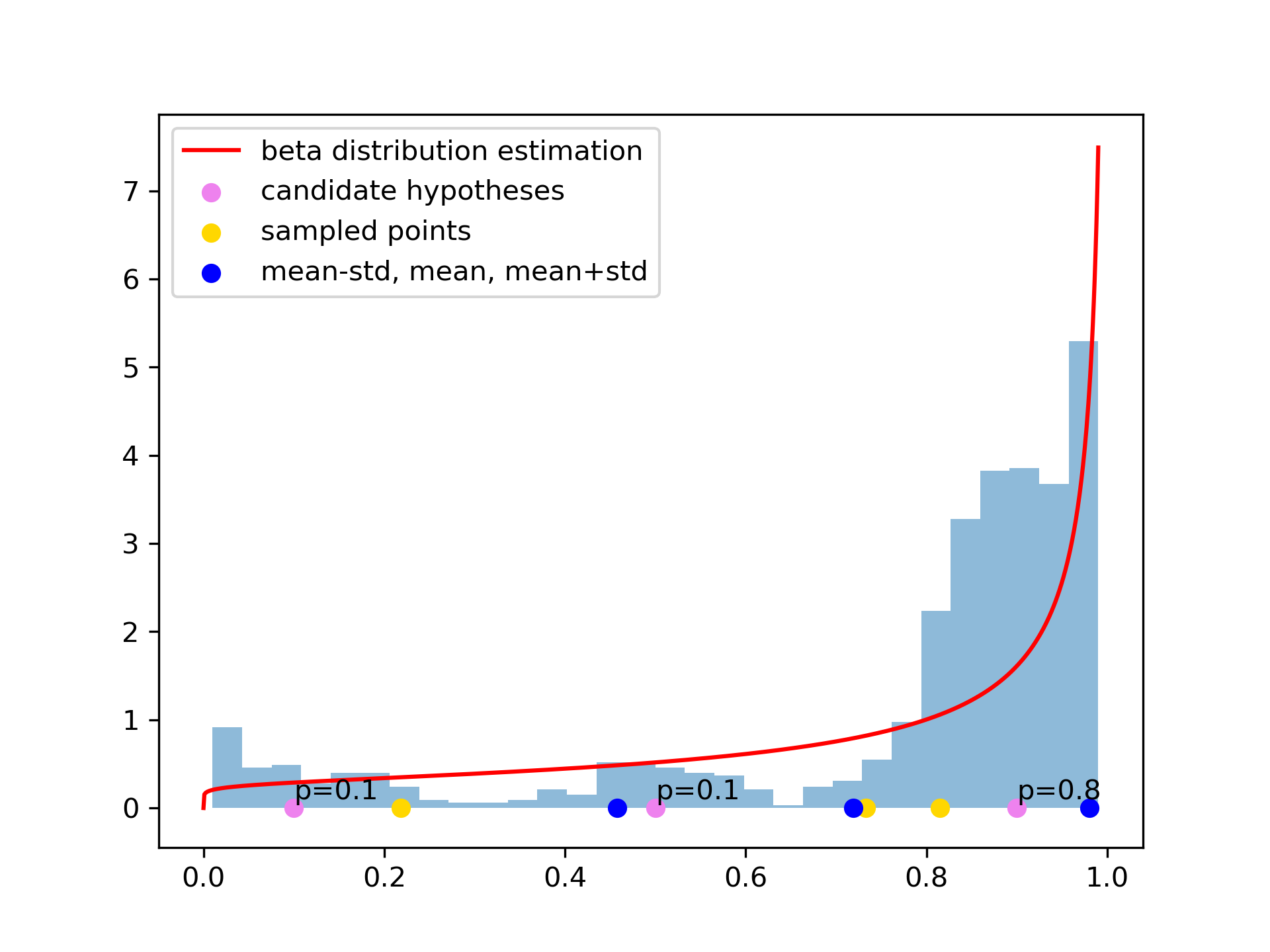 Figure 16
Figure 16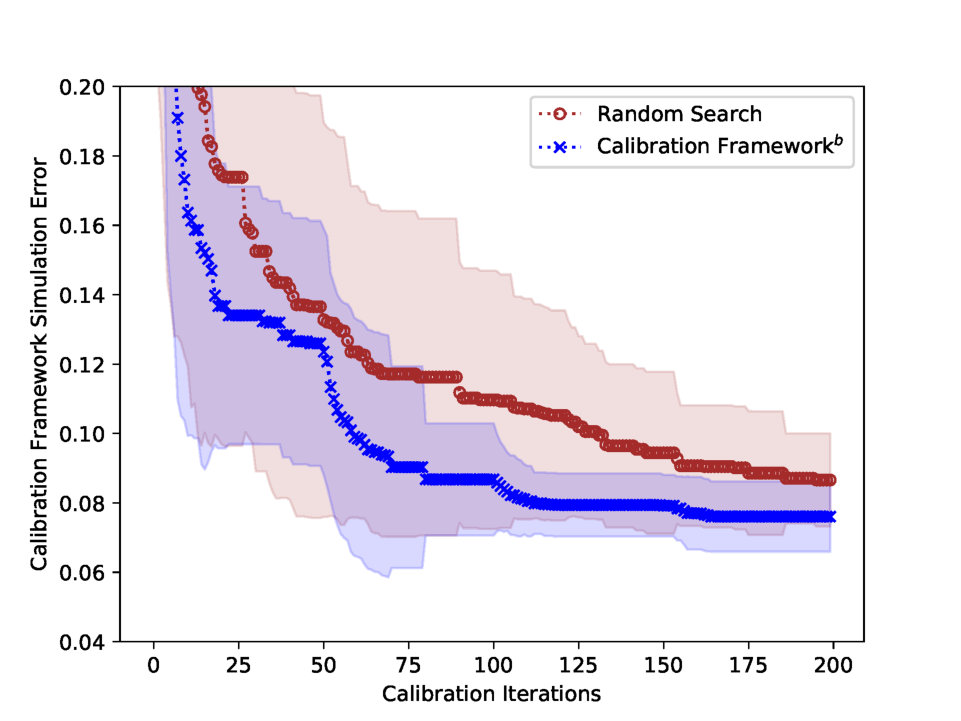 Figure 17
Figure 17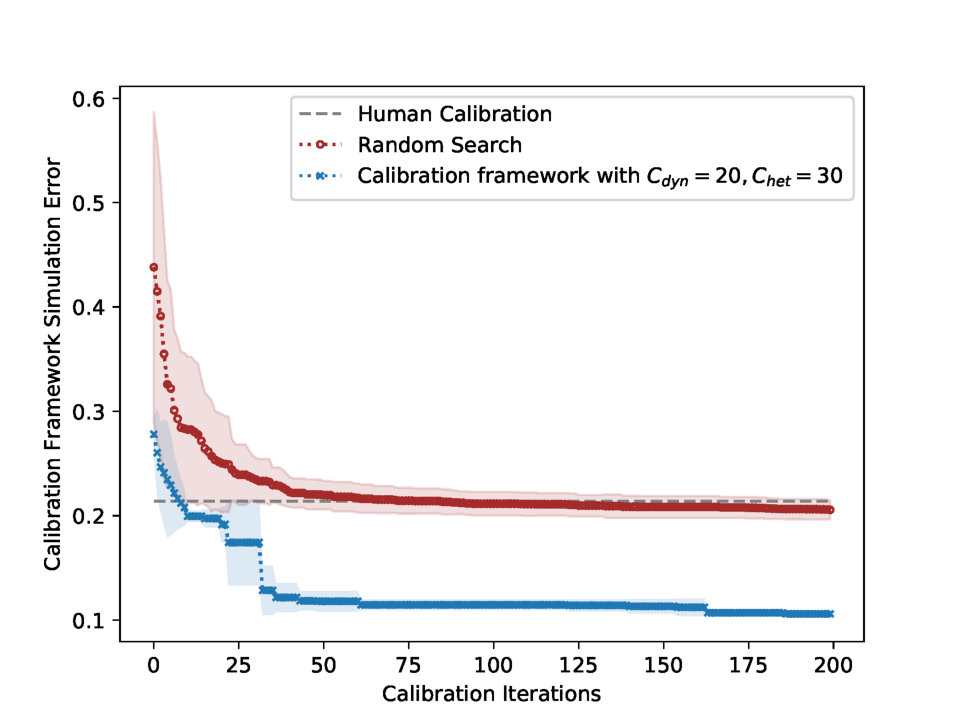 Figure 18
Figure 18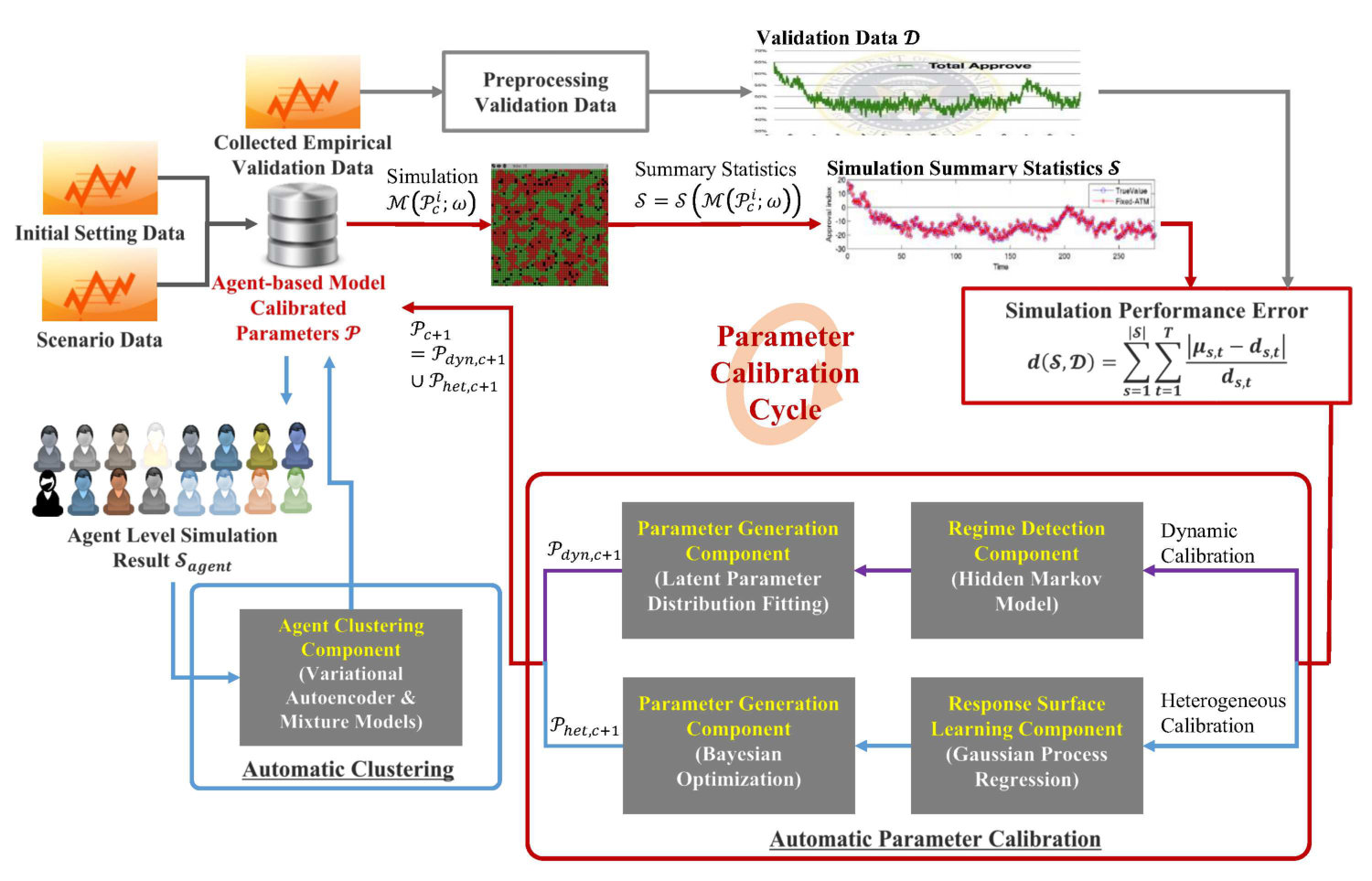 Figure 19
Figure 19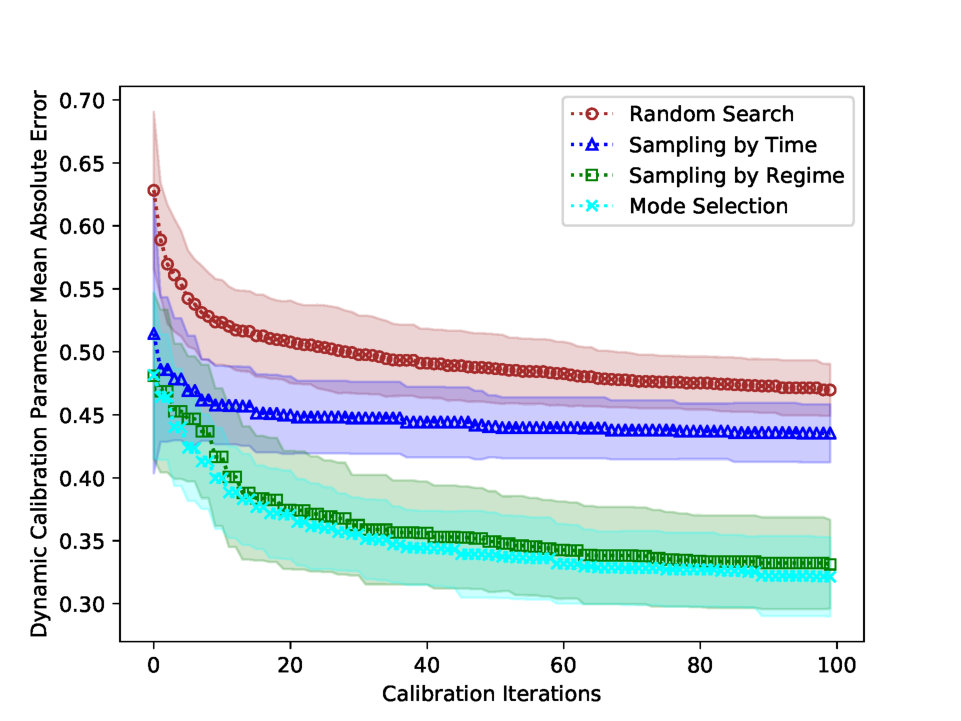 Figure 20
Figure 20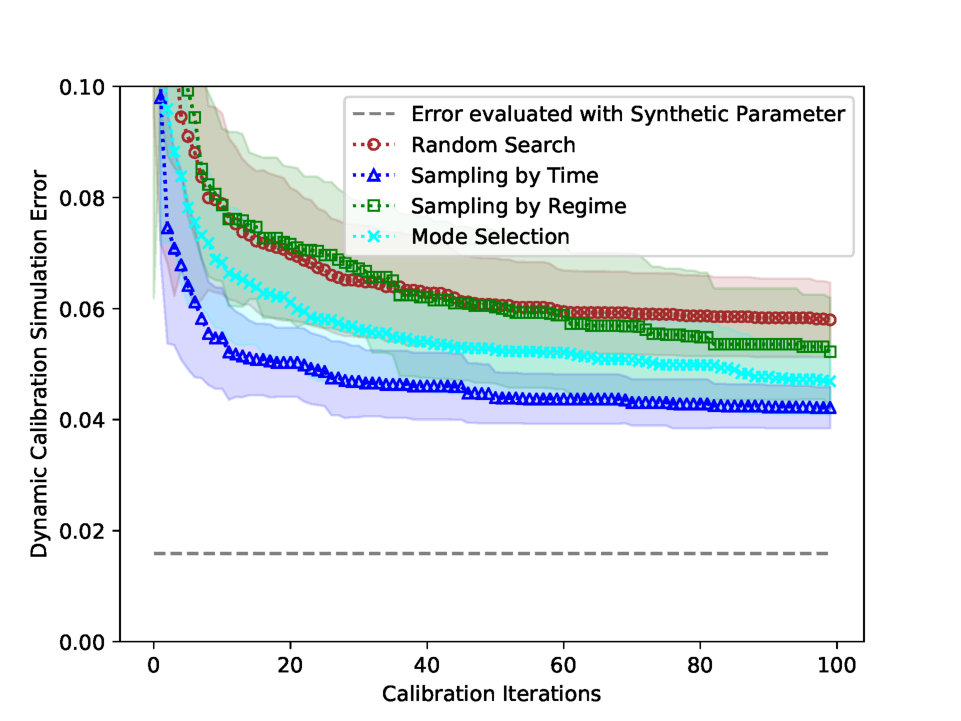 Figure 21
Figure 21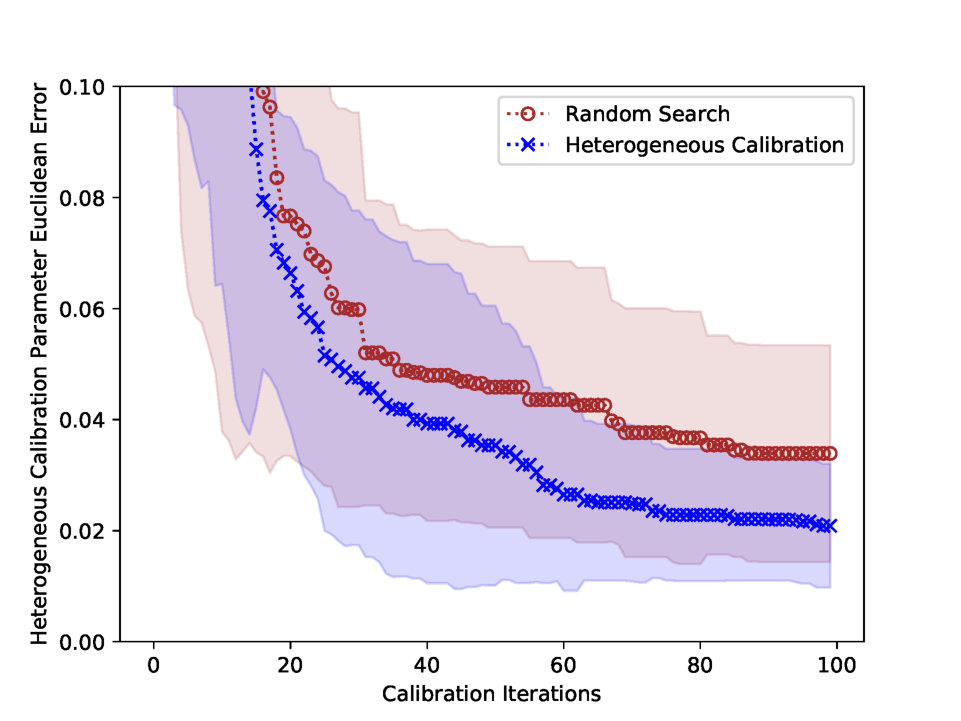 Figure 22
Figure 22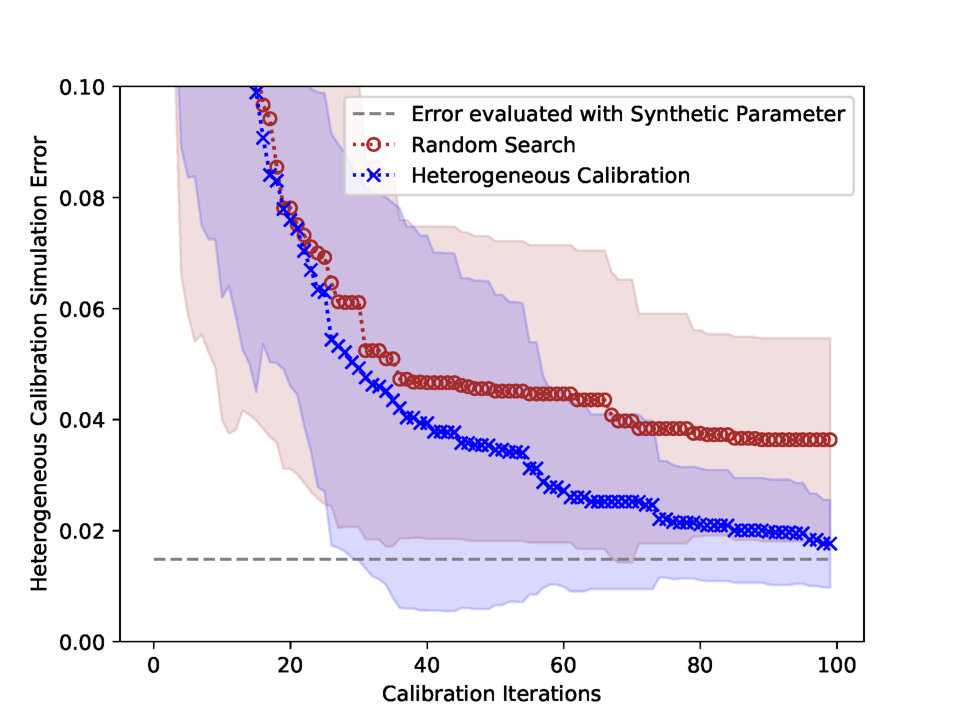 Figure 23
Figure 23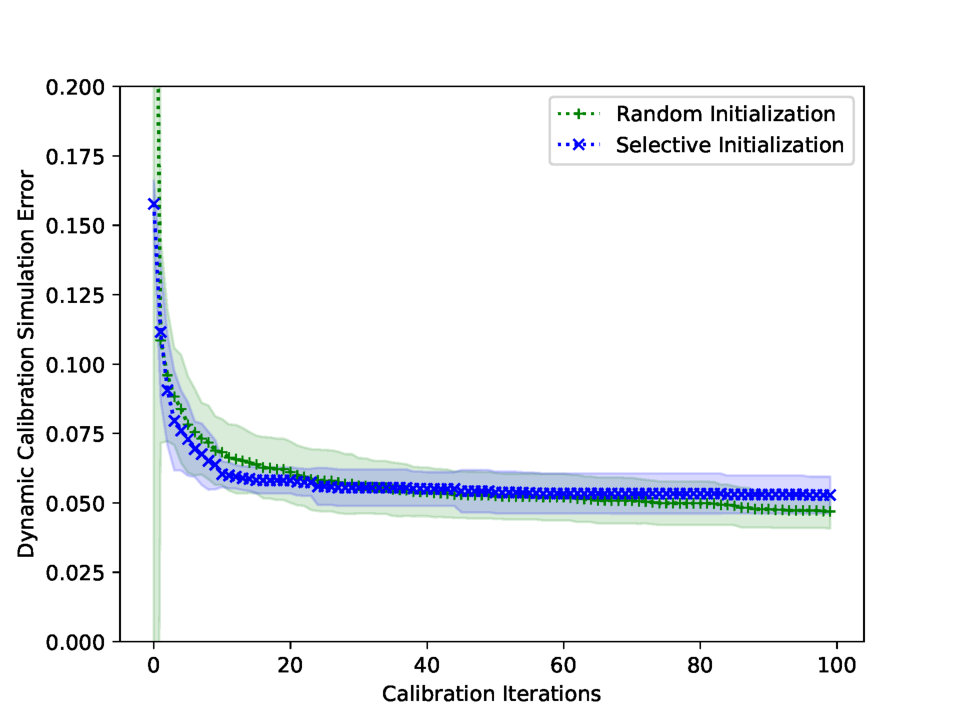 Figure 24
Figure 24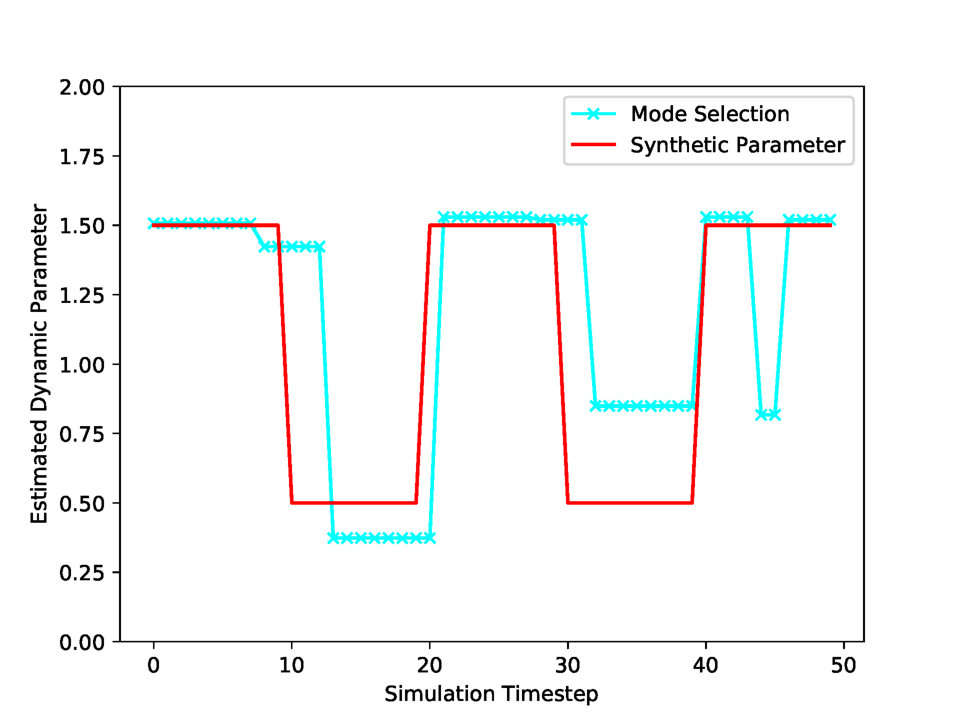 Figure 25
Figure 25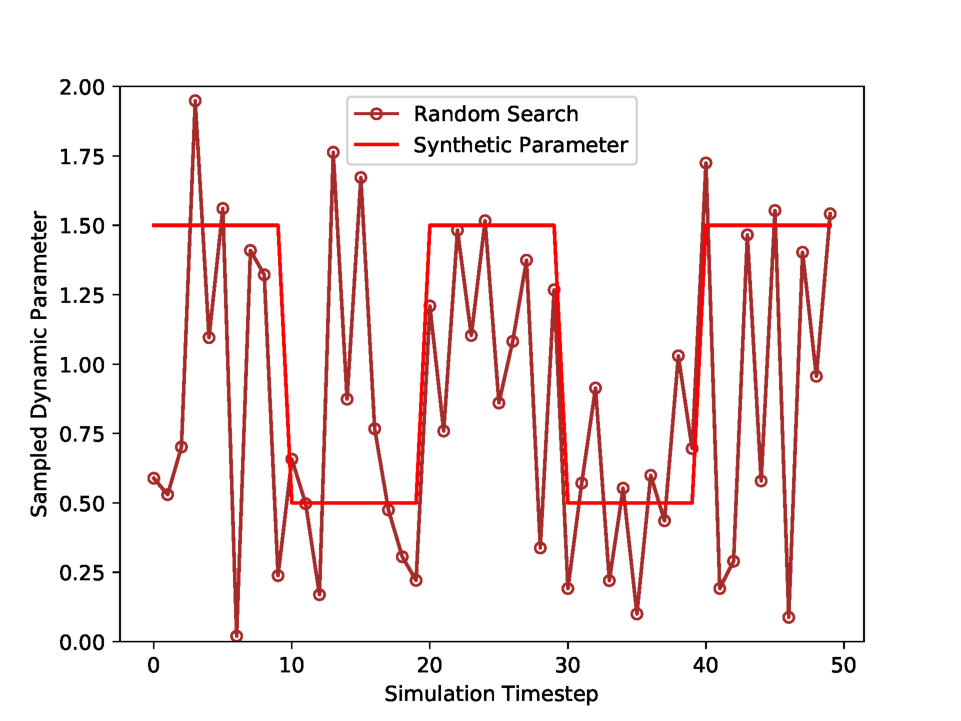 Figure 26
Figure 26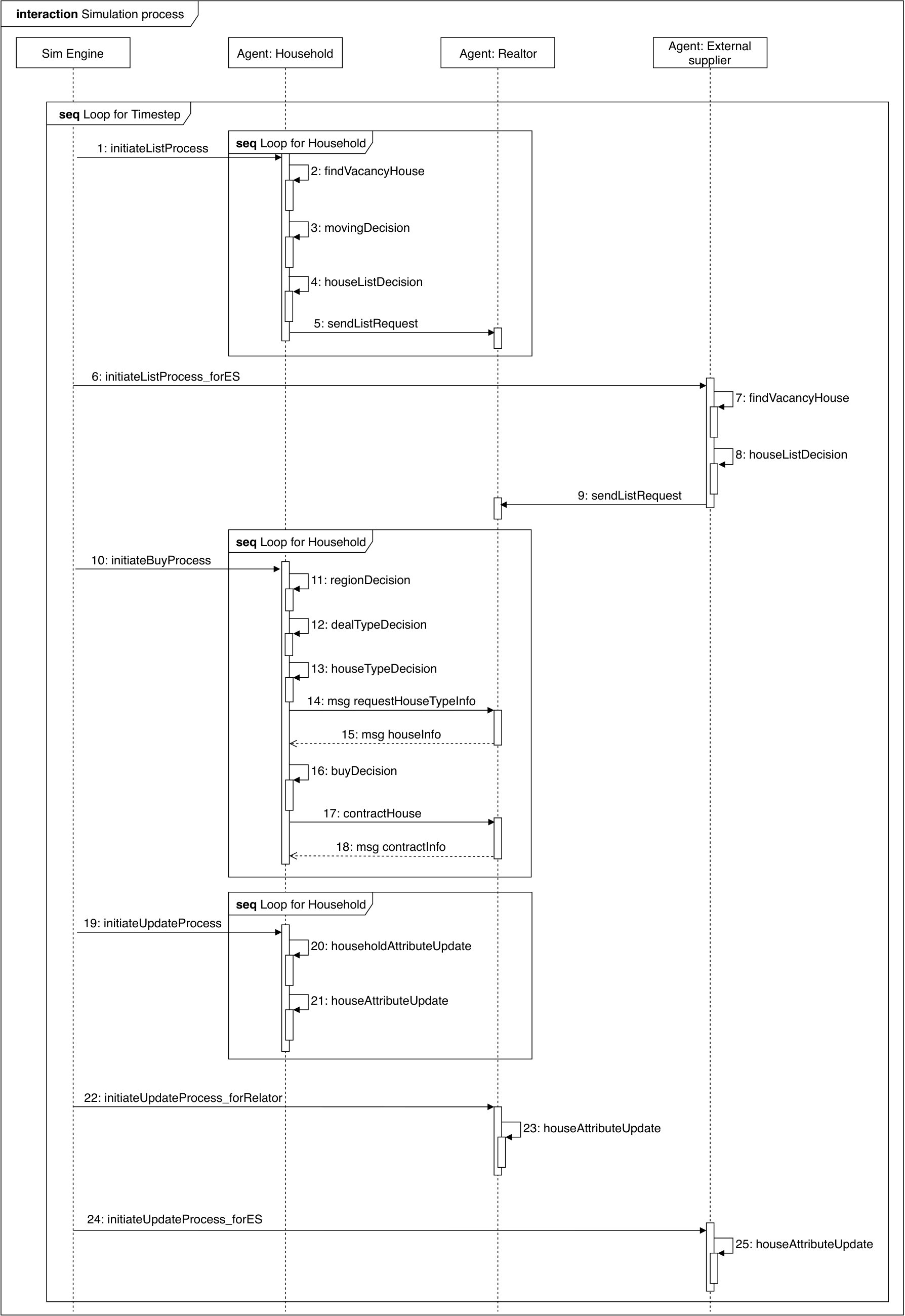 Figure 27
Figure 27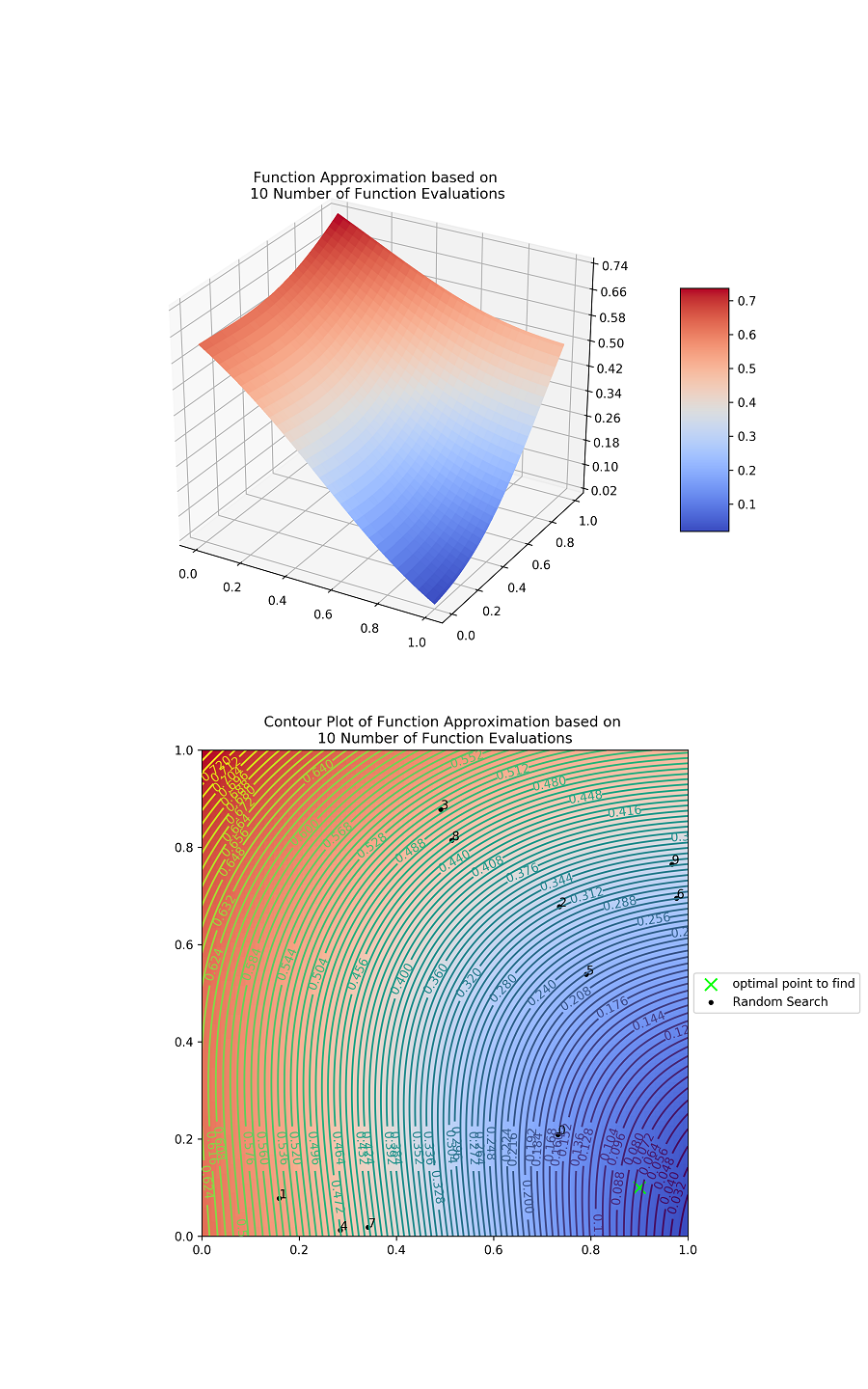 Figure 10
Figure 10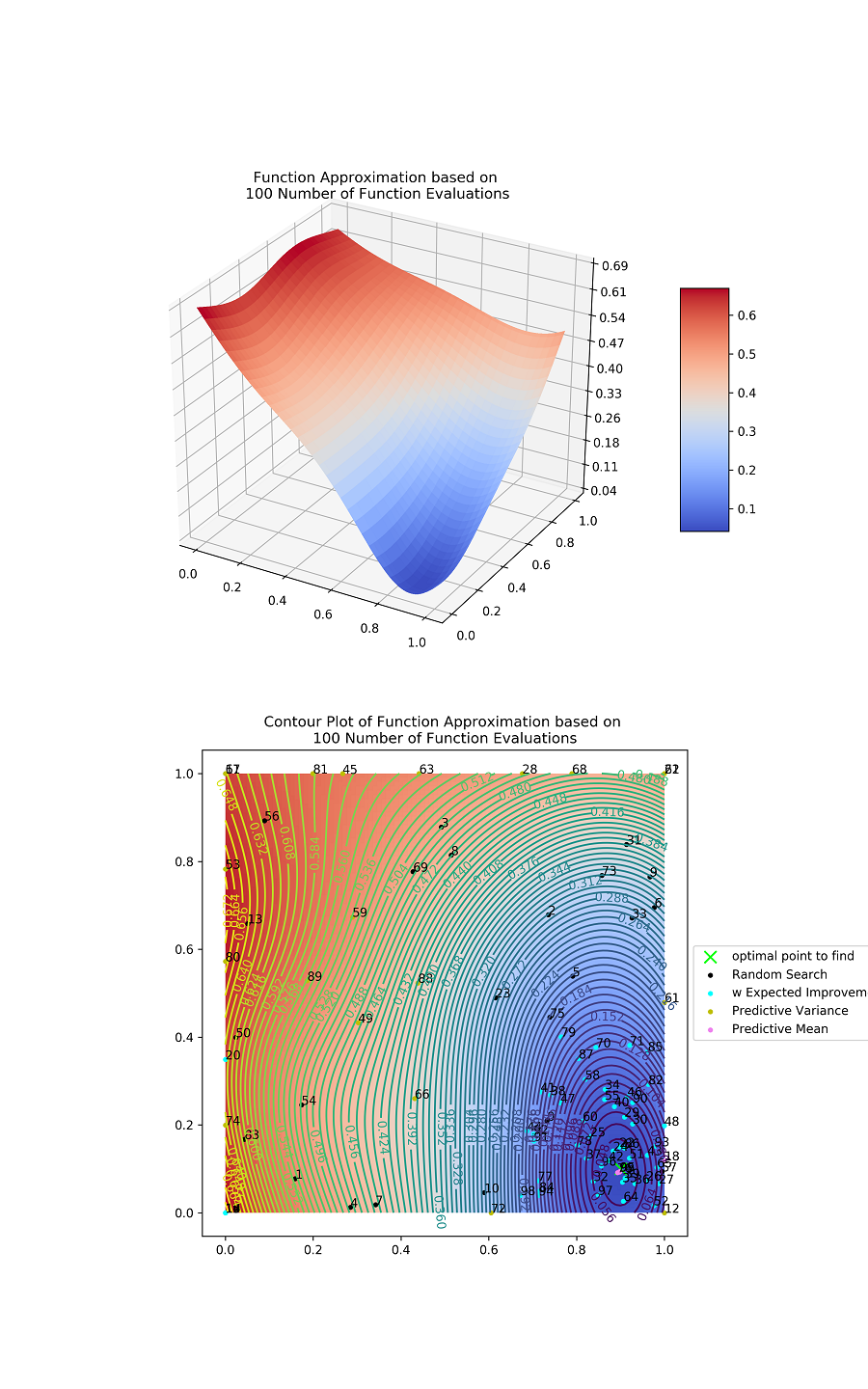 Figure 100
Figure 100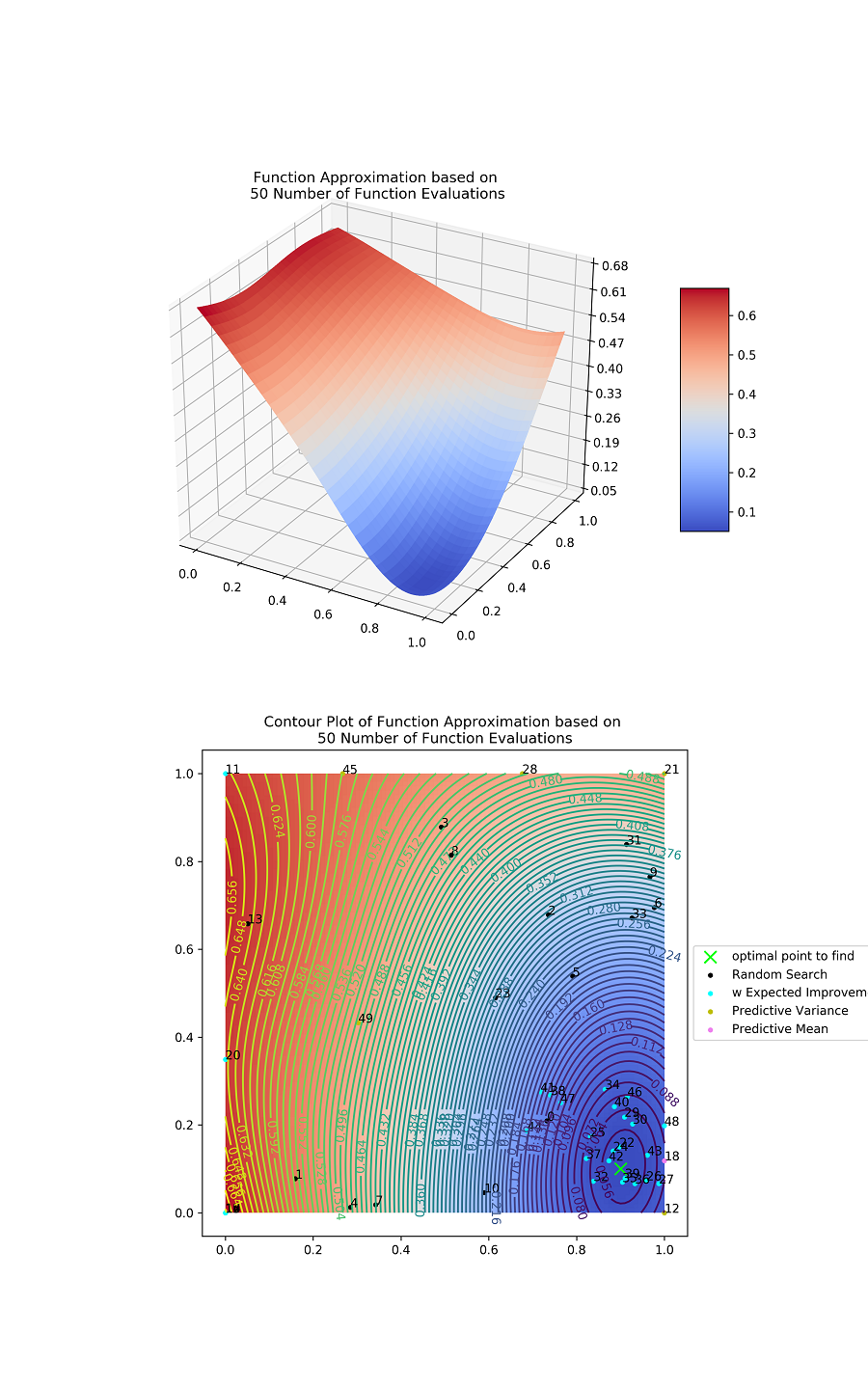 Figure 50
Figure 50| Notation | Description |
| Agent-based model | |
| Optimization algorithm | |
| Simulation error distance measure | |
| Simulation input parameters to optimize | |
| Simulation dynamic parametrs to optimize | |
| Simulation heterogeneous parameters to optimize | |
| Simulation output state variables | |
| Sample path space of stochastic simulation | |
| Empirical validation summary statistics | |
| Simulation summary statistics function | |
| Empirical validation summary statistics data used in dynamic calibration | |
| Empirical validation summary statistics data used in heterogeneous calibration | |
| Dynamic calibration summary statistics function | |
| Heterogeneous calibration summary statistics function | |
| Agent-level simulation result | |
| The representational compressed data of | |
| Aggregated data of simulation error in heterogeneous calibration | |
| The number of dynamic calibration target parameters | |
| The number of heterogeneous calibration target parameters | |
| The number of calibration framework iterations | |
| The number of dynamic calibration iterations | |
| The number of heterogeneous calibration iterations | |
| The dimension of summary statistics in dynamic calibration | |
| The dimension of summary statistics in heterogeneous calibration | |
| The number of hidden regimes in HMM | |
| The number of agent sub-populations | |
| The number of agents | |
| The number of total simulation time | |
| The number of simulation replications for each candidate hypothesis | |
| The number of candidate hypotheses | |
| The number of merged regimes | |
| The number of selected agent attributes for agent clustering | |
| The dimension of hidden representation of agent attributes |
| The name of algorithms | Search Method | Global optimality | Advantage | Disadvantage | |
| Design of Experiments | Full factorial Thiele et al. (2014) | Grid Search | Yes | Always find the global optimum within grid distance | Computationally expensive |
| Latin hypercube Thiele et al. (2014) | Space filling search | No | Sampling from equally probable axis-aligned hyperplanes | Computationally expensive | |
| Random Thiele et al. (2014) | Random search | No | Exploration | No exploitation | |
| Derivative -based Algorithms | Gradient Descent with finite difference | Gradient Descent | No | Model-free algorithm | Multiple evaluation required for an update |
| Gradient Descent with IPA Suri (1987) | Gradient Descent | No | Single evaluation required for an update | Limited applicability, high variance | |
| Heuristic Algorithms | Simulation Annealing Hara et al. (2013) | Local search with cooling mechanism | No | Able to escape from local minimum | Need to control the cooling rate |
| Particle Swarm Optimization Noel and Jannett (2004) | Update particles’ positions and velocities towards current best solution | No | Model-free optimization applicable to high dimensional parameters | No guarantee on the convergence to the global optimum | |
| Genetic Algorithm Stonedahl and Wilensky (2010a) | Selection, crossover, and mutation | No | Robust in optimization performance, model-free | No guarantee on the convergence to the global optimum | |
| Sampling -based Algorithms | Rejection Sampling Tavaré et al. (1997) | Rejection Sampling | Yes | Eventually converge to the target distribution | Highly inefficient if the prior is dissimilar with the target distribution, only feasible for the calibration task of few parameters |
| Monte-Carlo Markov Chain Marjoram et al. (2003) | Random walk from the previous evaluated particles | Yes | Eventually converge to the target distribution, much faster than rejection sampling | Sampled points are highly correlated, slow convergence rate | |
| Sequential Monte Carlo Sisson et al. (2007) | Sampling from a learned proposal distribution | Yes | Avoid sampling inefficiency through learning of intermediate distribution, less prone to get stuck in regions of low probability | Choice of the number of particles and the forward-backword kernels affects the performance | |
| Model -based Algorithms | Gaussian Process Regression-based Bayesian Optimization Tresidder et al. (2012) | GPR as surrogate, Bayesian Optimization as parameter search | Yes | Theoretic analysis, fast convergence | No standard criteria on the selection of kernel and acquisition function |
| XGBoost-based Nelder Mead Optimization Lamperti et al. (2018) | XGBoost as surrogate, Nelder Mead as parameter search | No | Applicable to high dimension | Parametric surrogate model | |
| Proposed Framework (Including interactions between dynamic and heterogeneous calibrations) | Proposed Dynamic Calibration | Sampling from a posterior distribution for each of merged regime | No | Able to calibrate the dynamic parameter | No theoretical convergence |
| Proposed Heterogeneous Calibration | GPR-based Bayesian Optimization | Yes | Able to calibrate the heterogeneous parameter | Injecting heterogeneity induces an optimization with higher dimension than original static calibration with the same parameters |
| Parameters | Parameter Type | Parameter Range | Synthetic Parameter Setting | |
| Value | Time or Cluster | |||
| Wealth Income | Dynamic | 0-2 | 1.5 | 1-10,21-30,41-50 |
| 0.5 | 11-20,31-40 | |||
| Wealth Consumption | Heterogeneous | 0-1 | 0.9 | Top in Initial Wealth |
| 0.1 | Bottom in Initial Wealth | |||
| Type of Summary Statistics | Name of Summary Statistics | Variable Description |
| Validation Summary Statistics | High Class Wealth Average | Average wealth of top 1/3 agents |
| Middle Class Wealth Average | Average wealth of middle 1/3 agents | |
| Low Class Wealth Average | Average wealth of bottom 1/3 agents | |
| Gini Index | The area ratio of the Lorenz curve to measure the wealth inequality |
| Dynamic Calibration | 100 | 1 | 0 | 3 | 2 | 100 | 50 | 10 | 3 |
| Heterogeneous Calibration | 100 | 0 | 1 | 3 | 2 | 100 | 50 | 10 | 1 |
| Calibration Framework | 200 | 2 | 3 | 3 | 2 | 100 | 50 | 10 | 3 |
| 200 | 20 | 30 | 3 | 2 | 100 | 50 | 10 | 3 |
| Test Case 1: Wealth Distribution ABM | |||||||||
| Experiments | Parameter Up- dating Rule | High Class Wealth Average MAPE | Middle Class Wealth Average MAPE | Low Class Wealth Average MAPE | Gini Index MAPE | Total MAPE | Parameter Mean Absolute Error | Parameter Euclidean Error | |
| Dyn- amic | Hetero- geneous | ||||||||
| Synthetic Parameter Experiment | True | True | 0.012 | 0.016 | 0.020 | 0.015 | 0.016 | 0 | 0 |
| (0.009) | (0.011) | (0.013) | (0.009) | (0.007) | (0) | (0) | |||
| Random Search | RS | True | 0.096 | 0.060 | 0.046 | 0.024 | 0.057 | 0.549 | 0 |
| (0.015) | (0.008) | (0.008) | (0.007) | (0.007) | (0.037) | (0) | |||
| True | RS | 0.052 | 0.031 | 0.035 | 0.028 | 0.036 | 0 | 0.034 | |
| (0.041) | (0.022) | (0.027) | (0.027) | (0.018) | (0) | (0.020) | |||
| RS | RS | 0.140 | 0.089 | 0.077 | 0.041 | 0.087 | 0.623 | 0.339 | |
| (0.031) | (0.018) | (0.024) | (0.015) | (0.013) | (0.060) | (0.238) | |||
| Dynamic Calibration | ST | True | 0.072 | 0.045 | 0.034 | 0.018 | 0.042* | 0.601 | 0 |
| (0.008) | (0.006) | (0.004) | (0.004) | (0.004) | (0.076) | (0) | |||
| SR | True | 0.088 | 0.055 | 0.043 | 0.021 | 0.052* | 0.537 | 0 | |
| (0.016) | (0.013) | (0.010) | (0.005) | (0.010) | (0.104) | (0) | |||
| MS | True | 0.080 | 0.048 | 0.039 | 0.021 | 0.047* | 0.500 | 0 | |
| (0.011) | (0.007) | (0.007) | (0.005) | (0.006) | (0.109) | (0) | |||
| Heterogeneous Calibration | True | BO | 0.025 | 0.015 | 0.018 | 0.013 | 0.018* | 0 | 0.021 |
| (0.018) | (0.010) | (0.012) | (0.007) | (0.008) | (0) | (0.011) | |||
| Calibration Frameworka | MS | BO | 0.124 | 0.085 | 0.074 | 0.044 | 0.082 | 0.462 | 0.110 |
| (0.017) | (0.020) | (0.031) | (0.021) | (0.021) | (0.044) | (0.020) | |||
| Calibration Frameworkb | MS | BO | 0.113 | 0.070 | 0.073 | 0.048 | 0.076* | 0.501 | 0.092 |
| (0.011) | (0.007) | (0.021) | (0.021) | (0.010) | (0.089) | (0.015) | |||
| Parameter | Parameter Type | Parameter Range |
| Market Participation Rate | Dynamic | 0-0.05 |
| Market Price Increase Rate | Dynamic | 0-0.1 |
| Market Price Decrease Rate | Dynamic | 0-0.1 |
| Willing to Pay | Heterogeneous | 0.3-0.9 |
| Purchase Rate | Heterogeneous | 0.3-0.9 |
| Types of Summary Statistics | Name of Summary Statistics | Variable Description | Variable Value |
| Validation-level Summary Statistics | Apartment Sales Price Index in Capital | Jevons price index of Apartment sales price | Housing Price is converted into a percentage, with base value as 100 at the initial timestep. |
| Apartment Sales Price Index in Noncapital | |||
| Apartment Lease Price Index in Capital | Jevons price index of Apartment lease price. | ||
| Apartment Lease Price Index in Noncapital | |||
| Apartment Sales Transaction Number in Capital | Transaction numbers of Apartment sales. | Simulation transaction number is scaled up to be compatible with the validation transaction number. | |
| Apartment Sales Transaction Number in Noncapital | |||
| Apartment Lease Transaction Number in Capital | Transaction numbers of Apartment lease. | ||
| Apartment Lease Transaction Number in Noncapital | |||
| Agent-level Summary Statistics | Living Region | Agent living region between capital/noncapital area. | 1: Capital, 0: Noncapital |
| Savings | Total savings. | 1 unit/1000 KRW | |
| Income | Sum of the labor income and transfer income. | 1 unit/1000 KRW | |
| Loan | Total amount of money agent have borrowed from bank. | 1 unit/1000 KRW | |
| House Type | Type of house where an agent lives. | 1: Detached House, 2: Apartment, 3: Multiplex House, 4: No House | |
| Living Type | Type of living where an agent lives | 1: Owner, 2: Lease, 3: No House | |
| Number of Own Houses | Number of houses agent owns | 1 unit/1 House |
| Dynamic Calibration | 100 | 1 | 0 | 3 | 1 | 10000 | 24 | 10 | 3 |
| Heterogeneous Calibration | 100 | 0 | 1 | 3 | 1,2,4,8, nonparametric | 10000 | 24 | 10 | 1 |
| Calibration Framework | 200 | 2 | 3 | 3 | 2, nonparametric | 10000 | 24 | 10 | 3 |
| 200 | 20 | 30 | 3 | 2, nonparametric | 10000 | 24 | 10 | 3 |
| Test Case 2: Real Estate Market ABM | ||||||||||||
| Experiments | Calibration Parameters | Number of Clusters | Apartment Sales Price Index in Capital MAPE | Apartment Lease Price Index in Capital MAPE | Apartment Sales Price Index in Noncapital MAPE | Apartment Lease Price Index in Noncapital MAPE | Apartment Sales Transaction Number in Capital MAPE | Apartment Lease Transaction Number in Capital MAPE | Apartment Sales Transaction Number in Noncapital MAPE | Apartment Lease Transaction Number in Noncapital MAPE | Total MAPE | |
| Human Calibration | All Parameters | — | 0.012 | 0.020 | 0.007 | 0.003 | 0.765 | 0.159 | 0.284 | 0.463 | 0.214 | |
| (0.001) | (0.001) | (0.000) | (0.000) | (0.027) | (0.012) | (0.016) | (0.017) | (0.005) | ||||
| Random Search | All Parameters | — | 0.025 | 0.011 | 0.009 | 0.008 | 0.554 | 0.291 | 0.338 | 0.397 | 0.204 | |
| (0.010) | (0.006) | (0.005) | (0.004) | (0.181) | (0.085) | (0.105) | (0.127) | (0.008) | ||||
| Dynamic Calibration | First Parameter | — | 0.005 | 0.025 | 0.003 | 0.005 | 0.266 | 0.277 | 0.343 | 0.409 | 0.167* | |
| (0.001) | (0.002) | (0.000) | (0.001) | (0.015) | (0.012) | (0.016) | (0.018) | (0.003) | ||||
| First and Second Parameters | — | 0.009 | 0.024 | 0.005 | 0.006 | 0.273 | 0.280 | 0.337 | 0.410 | 0.168* | ||
| (0.005) | (0.008) | (0.003) | (0.002) | (0.034) | (0.018) | (0.023) | (0.018) | (0.003) | ||||
| All Dynamic Parameters | — | 0.015 | 0.020 | 0.008 | 0.012 | 0.281 | 0.272 | 0.335 | 0.452 | 0.174* | ||
| (0.009) | (0.010) | (0.003) | (0.004) | (0.027) | (0.018) | (0.017) | (0.029) | (0.004) | ||||
| Heterogeneous Calibration | First Parameter | Undivided | 1 | 0.012 | 0.020 | 0.007 | 0.003 | 0.667 | 0.142 | 0.279 | 0.469 | 0.200* |
| (0.001) | (0.001) | (0.001) | (0.000) | (0.080) | (0.018) | (0.056) | (0.066) | (0.004) | ||||
| Parametric | 2 | 0.006 | 0.027 | 0.004 | 0.006 | 0.259 | 0.255 | 0.166 | 0.150 | 0.109* | ||
| (0.002) | (0.004) | (0.001) | (0.002) | (0.012) | (0.010) | (0.011) | (0.020) | (0.003) | ||||
| 4 | 0.006 | 0.026 | 0.004 | 0.005 | 0.266 | 0.244 | 0.202 | 0.161 | 0.114* | |||
| (0.002) | (0.002) | (0.001) | (0.001) | (0.030) | (0.005) | (0.020) | (0.015) | (0.002) | ||||
| 8 | 0.004 | 0.029 | 0.004 | 0.006 | 0.263 | 0.164 | 0.178 | 0.208 | 0.107* | |||
| (0.003) | (0.007) | (0.003) | (0.003) | (0.099) | (0.044) | (0.057) | (0.051) | (0.013) | ||||
| Nonparametric | 15.3 | 0.005 | 0.026 | 0.004 | 0.005 | 0.265 | 0.164 | 0.357 | 0.177 | 0.125* | ||
| (1.4) | (0.000) | (0.000) | (0.000) | (0.000) | (0.181) | (0.129) | (0.064) | (0.146) | (0.020) | |||
| Second Parameter | Undivided | 1 | 0.012 | 0.020 | 0.007 | 0.003 | 0.764 | 0.218 | 0.249 | 0.360 | 0.204* | |
| (0.001) | (0.000) | (0.000) | (0.000) | (0.039) | (0.033) | (0.021) | (0.057) | (0.004) | ||||
| Parametric | 2 | 0.013 | 0.019 | 0.007 | 0.003 | 0.835 | 0.104 | 0.184 | 0.256 | 0.178* | ||
| (0.001) | (0.000) | (0.000) | (0.000) | (0.038) | (0.029) | (0.020) | (0.044) | (0.009) | ||||
| 4 | 0.013 | 0.020 | 0.007 | 0.003 | 0.827 | 0.137 | 0.201 | 0.255 | 0.183* | |||
| (0.003) | (0.002) | (0.001) | (0.001) | (0.099) | (0.164) | (0.038) | (0.067) | (0.023) | ||||
| 8 | 0.011 | 0.021 | 0.006 | 0.003 | 0.567 | 0.164 | 0.185 | 0.205 | 0.145* | |||
| (0.006) | (0.015) | (0.008) | (0.008) | (0.097) | (0.113) | (0.041) | (0.080) | (0.013) | ||||
| Nonparametric | 15.9 | 0.012 | 0.020 | 0.006 | 0.003 | 0.414 | 0.144 | 0.192 | 0.211 | 0.125* | ||
| (1.2) | (0.001) | (0.000) | (0.000) | (0.000) | (0.102) | (0.085) | (0.038) | (0.058) | (0.021) | |||
| All Heterogeneous Parameters | Undivided | 1 | 0.008 | 0.012 | 0.004 | 0.004 | 0.398 | 0.255 | 0.424 | 0.461 | 0.196* | |
| (0.002) | (0.003) | (0.001) | (0.002) | (0.126) | (0.078) | (0.072) | (0.098) | (0.006) | ||||
| Parametric | 2 | 0.011 | 0.021 | 0.006 | 0.003 | 0.303 | 0.127 | 0.200 | 0.179 | 0.106* | ||
| (0.001) | (0.001) | (0.000) | (0.000) | (0.092) | (0.028) | (0.028) | (0.054) | (0.015) | ||||
| 4 | 0.009 | 0.023 | 0.005 | 0.004 | 0.289 | 0.241 | 0.168 | 0.181 | 0.115* | |||
| (0.003) | (0.002) | (0.001) | (0.001) | (0.054) | (0.106) | (0.039) | (0.077) | (0.017) | ||||
| 8 | 0.007 | 0.025 | 0.004 | 0.005 | 0.243 | 0.180 | 0.218 | 0.230 | 0.114* | |||
| (0.006) | (0.015) | (0.008) | (0.008) | (0.097) | (0.113) | (0.041) | (0.080) | (0.013) | ||||
| Nonparametric | 15.5 | 0.011 | 0.021 | 0.007 | 0.003 | 0.232 | 0.199 | 0.198 | 0.186 | 0.107* | ||
| (1.2) | (0.002) | (0.001) | (0.000) | (0.000) | (0.198) | (0.151) | (0.065) | (0.176) | (0.030) | |||
| Calibration Frameworka | All Model Parameters | Parametric | 2 | 0.028 | 0.016 | 0.020 | 0.021 | 0.286 | 0.178 | 0.232 | 0.202 | 0.123* |
| (0.012) | (0.015) | (0.009) | (0.013) | (0.073) | (0.067) | (0.055) | (0.048) | (0.016) | ||||
| Nonparametric | 15.6 | 0.031 | 0.022 | 0.019 | 0.018 | 0.324 | 0.183 | 0.215 | 0.264 | 0.135* | ||
| (1.3) | (0.018) | (0.016) | (0.015) | (0.014) | (0.108) | (0.033) | (0.063) | (0.116) | (0.019) | |||
| Calibration Frameworkb | All Model Parameters | Parametric | 2 | 0.016 | 0.016 | 0.005 | 0.004 | 0.219 | 0.195 | 0.252 | 0.136 | 0.105* |
| (0.001) | (0.001) | (0.003) | (0.001) | (0.007) | (0.018) | (0.049) | (0.000) | (0.002) | ||||
| Nonparametric | 15.4 | 0.024 | 0.021 | 0.009 | 0.011 | 0.320 | 0.197 | 0.195 | 0.265 | 0.130* | ||
| (1.1) | (0.023) | (0.012) | (0.006) | (0.005) | (0.084) | (0.031) | (0.004) | (0.083) | (0.001) | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSimulation Techniques and Applications · Complex Systems and Time Series Analysis · Advanced Control Systems Optimization
∎
11institutetext: Dongjun Kim 22institutetext: 22email: [email protected] 33institutetext: Tae-Sub Yun 44institutetext: 44email: [email protected] 55institutetext: Il-Chul Moon 66institutetext: 66email: [email protected]
Automatic Calibration of Dynamic and Heterogeneous Parameters in Agent-based Model
Dongjun Kim
Tae-Sub Yun
Il-Chul Moon
Abstract
While simulations have been utilized in diverse domains, such as urban growth modeling, market dynamics modeling, etc; some of these applications may require validations based upon some real-world observations modeled in the simulation, as well. This validation has been categorized into either qualitative face-validation or quantitative empirical validation, but as the importance and the accumulation of data grows, the importance of the quantitative validation has been highlighted in the recent studies, i.e. digital twin. The key component of quantitative validation is finding a calibrated set of parameters to regenerate the real-world observations with simulation models. While this parameter calibration has been fixed throughout a simulation execution, this paper expands the static parameter calibration in two dimensions: dynamic calibration and heterogeneous calibration. First, dynamic calibration changes the parameter values over the simulation period by reflecting the simulation output trend. Second, heterogeneous calibration changes the parameter values per simulated entity clusters by considering the similarities of entity states. We experimented the suggested calibrations on one hypothetical case and another real-world case. As a hypothetical scenario, we use the Wealth Distribution Model to illustrate how our calibration works. As a real-world scenario, we selected Real Estate Market Model because of three reasons. First, the models have heterogeneous entities as being agent-based models; second, they are economic models with real-world trends over time; and third, they are applicable to the real-world scenarios where we can gather validation data.
Keywords:
Simulation Validation Parameter Calibration Machine Learning Digital Twin Agent Based Model
††journal: Under review as a paper at Journal of Autonomous Agents and Multi-Agent Systems
1 Introduction
Simulation has been useful in market modeling Bonabeau (2002), traffic management Naiem et al. (2010), and urban planning Hosseinali et al. (2013), and these simulations are real-world based, validated simulations on well-defined scenarios. Because of the detail and the fitness to the real-world, the simulation becomes a meaningful tool for design, management, and analyses of modeled real-world. While modelers accept the fundamental requirement of the validation Beisbart and Saam (2018), many simulation models are validated through parameter calibrations that can be easily invalidated as time progresses or heterogeneity arises in the simulations. Some modelers manually calibrate the parameters to improve the fitness, but this manual effort is often limited to the inital state of the simulation.
A simulation world is naturally diverging from the real-world as the simulation progresses, and the parameter calibration should accommodate this natural divergence over the simulation period. If we utilize handpicked or heuristically calibrated parameters, we cannot mitigate the natural divergence as often as needed. Hence, a common practice in the field is calibrating simulation parameters at the up-front or over the predetermined period Thiele et al. (2014) , and the calibrated parameters are used by ignoring the simulation divergence from the real-world in the simulation run-time. Therefore, if we intend to accommodate the parameter calibration as often as needed, we need to design an automatic calibration method that can resolve the natural divergence of simulation from the real-world.
This automatic calibration requires two functionalities: when to calibrate and how to calibrate. As the simulation diverges from the real-world, the automatic calibration needs to determine when is the best time to calibrate by itself, i.e. calibrations for every simulation timestep in extreme cases. Moreover, if we consider the heterogeneity of simulated entities in the model as the source of divergence, the automatic calibration needs to determine which groups of entities to be calibrated. After these decisions on when to calibrate, the automatic calibration requires a component of how to calibrate. For instance, some parameters are temporal and simulation-widely applicable, and other parameters are static and selected entity-widely applicable.
This paper categorizes the calibrated parameters into two groups: dynamic parameters and heterogeneous parameters. First, the dynamic parameters are calibrated temporally, and the parameters are shared across simulated entities at a certain timestep. To remedy the divergence over simulation time, we extract unobservable regimes Hamilton (2016) that explain the temporal dynamics. In dynamic calibration, a hidden structure (regime) is extracted from the deviation of observations and simulation results by a variant of Hidden Markov Model (HMM) Fox et al. (2008); Bishop (2006). Then, the regimes separately calibrate the dynamic parameters by taking the validation level into account. These dynamic calibrations occur iteratively, so the iterative calibration cycle would result in improving the fitness to the validation set.
Second, the heterogeneous parameters are calibrated for selected entities with the parameters. To mitigate the simulation divergence from agent heterogeneity Rahmandad and Sterman (2008), we customize a static parameter by assigning different values for different agent sub-populations to impose heterogeneity through the parameter. A hidden structure, or agent sub-population, in this case is extracted from agent-level simulation results. Particularly, a cluster model groups agents with similar agent-level state variables. To extract agent sub-populations, due to the curse of dimension, we first reduce the dimension of agent-level state variables by applying a latent representation learning algorithm, Variational Autoencoder Kingma and Welling (2013). Afterwards, a probabilistic mixture model Bishop (2006); Teh (2010) is used to obtain hidden sub-populations of simulation entities. After the clustering, we adopt the surrogate model calibration methodology, Gaussian Process based Bayesian Optimization Snoek et al. (2012), applied to reduce the simulation divergence.
The suggested calibration methodologies, dynamic calibration and heterogeneous calibration, could be considered in a single framework that the methods utilize hidden structures extracted from simulation state variables. According to our framework, hidden structures fundamentally determines the target simulation validity. Hence, for instance, dynamic calibration fits the dynamic trend with capturing dynamically varying hidden regimes, and heterogeneous calibration fits the agent heterogeneity by uncovering agent sub-populations. Before we discuss the framework, we limit ourselves to the in-sample validation Windrum et al. (2007). In-sample validation focuses on constructing a highly descriptive model with calibrated parameters, and we expect the in-sample validated models to repeat the real-world scenario in the simulation.
2 Previous Research
Parameter calibration can be viewed as an inverse problem of estimating optimal simulation parameters that make the most consistent result with real-world observations:
[TABLE]
where is the set of parameters to calibrate and is the optimal parameters.
In detail, there are three steps in the parameter calibration Hartig et al. (2011). The first step is choosing summary statistics from observations that are selected as emprirical validation data. Total number of summary statistics are considered, with each of summary statistic is the characteristic quantity of the observational distribution. Simulation summary statistics are generated from the simulation output with summary statistics function , given by , by packing up the output distribution into few principal features, where the agent-based model is , as described in Tab. 1. For the next step, the simulation distance formula, , will be defined to measure the closeness between the simulation result and the summary statistics Rand (2012); Marks (2013). Simulation stochasticity is represented by , which is a sampled path from the sample path space . As the final step, the modeler applies an iterative stochastic function optimization algorithm to reduce the simulation average error, .
Since the optimization lies at the core of the calibration process Thiele et al. (2014); Brenner and Werker (2006), modelers have categorized optimization algorithms for simulations into the four taxonomies Fu (2002) listed below:
Category 1 finds an optimal solution of stochastic function (under certain condition). 2. 2.
Category 2 finds an optimal solution of deterministic function (under certain condition). 3. 3.
Category 3 finds an optimal solution with probability less than 1. 4. 4.
Category 4 finds a practically good solution stably.
These categories are generalized criteria, so each optimization algorithm is assessed by the criteria in the following survey.
2.1 Calibration with Design of Experiment
Besides of the algorithm-based adaptive calibration, the simplest systematic calibration is using the standard design of experiments, or DOE Lee et al. (2015). However, the classical DOE algorithms have pre-determined input parameters, so those do not adaptively generate the parameters. In addition, the DOEs are not specifically designed to handle the interference between the input parameters, which affects the simulation outputs, collectively.
The full factorial search, in Tab. 2, is powerful if there are few parameters to calibrate Thiele et al. (2014). However, the Latin hypercube, a near-uniformly spce filling search method by sampling from the equally probable axis-aligned hyperplanes, could be an alternative of full factorial search if there are too many grids to evaluate. The random search mainly acts as exploring the search space.
2.2 Calibration with Derivative-based Algorithms
The optimization algorithm could be a derivative-based calibration with gradient descents to minimize expected simulation errors. This derivative-based optimization belongs to the category of Category 4 in the above taxonomy. Since the derivative of simulation error is not attainable, the derivative-based calibration requires to use a derivative approximation techniques such as finite difference or Infinitesimal Perturbation Analysis (IPA) Suri (1987); Ho and Hu (1990). While the finite difference is attainable, this method is not appropriate for the calibration task with the expensive evaluation cost since it requires a number of evaluations, proportional to the optimization dimension, to get a derivative at a point. IPA approximates the derivative with a single function evaluation, but this single evaluation makes IPA too volatile to be used as a calibration method. In addition, IPA is less applicable than the variants of finite difference methods.
2.3 Calibration with Heuristic Algorithms
Among derivative-free optimization algorithms, Heuristic algorithm is frequently used for the calibration task. Heuristic algorithms search a next design point with a current parameter by , where is the optimization algorithm. Most of Heuristic algorithms, due to its memory-less property and simple selection process, are not proven to find global optimum. However, some Heuristic algorithms with simple idea work better than sophisticated designed optimization algorithms in the practice Stonedahl and Wilensky (2010a); Stonedahl and Wilensky (2010b), which makes the Heuristic algorithms to be Category 4.
While some research applies either Simulated Aneealing Hara et al. (2013); Kirkpatrick et al. (1983) or Particle Swarm Optimization Noel and Jannett (2004); Kennedy (2010); most of calibration articles, which construct calibration as an optimization problem, use Genetic Algorithm Calvez and Hutzler (2005); Yang et al. (2009); Nannen and Eiben (2006); Heppenstall et al. (2007); Stonedahl and Wilensky (2010b); Whitley (1994) as an optimization solver. There are four main reasons for using Genetic Algorithm Nguyen et al. (2014). First, Genetic Algorithm is robust on the task of global optimization for highly nonlinear multi-modal discontinuous functions. Second, Genetic Algorithm is designed to align well with parallel computations in multi-processor computers. Parallelizability is especially advantageous in a computationally expensive simulation optimization. Furthermore, unlike standard DOEs, Genetic Algorithm is suitable in treating functions with input parameters intricately entangled in its effect on outputs. Lastly, both continuous and discrete variables could be calibrated using Genetic Algorithm, which makes both simulation parameter and simulation structure to be optimized at one hand.
2.4 Calibration with Sampling-Based Algorithms
In statistical inference algorithms, the Approximate Bayesian Computation(ABC) Beaumont (2010); Tavaré et al. (1997); Marjoram et al. (2003); Sisson et al. (2007) is a class of sampling-based algorithms used when the likelihood, , is intractible Jabot et al. (2013). In ABC, the likelihood is approximately defined as , where is a summary statistics function, is a normalization constant, and is a pre-difined threshold. The likelihood might be analytically calculated in a simple stochastic simulation, but it is intractible in the case of agent-based simulation Hartig et al. (2011); Thiele et al. (2014), where the simple agent-level behavior merged up to the emergent system-level behavior. Also, this calculation is infeasible if the agent behaviors are the collection of discrete logics. Some sampling-based ABC algorithms use only the previous parameters to generate the next set of design points , by , and this generated parameters may form a stationary distribution which could be an inferred distribution that satisfies the calibration task. Hence, under the condition of converging to the stationary distribution, these sampling based ABC is categorized into either Category 1 or Category 2.
In spite of this optimization property, ABC inference algorithms suffers from the slow convergence rate since the model requires the tens of thousands of point evaluations Hartig et al. (2011); Thiele et al. (2014) in the case of large scale agent-based simulation. The proposed dynamic calibration algorithm in this article borrows an essential idea of Sequantial Monte Carlo ABC algorithm Sisson et al. (2007), in that the next set of evaluation points, a.k.a particles, are sampled from the proposal distribution generated from the current evaluation points with likelihoods.
2.5 Calibration with Model-Based Algorithms
Surrogate model-based optimization algorithms Tresidder et al. (2012); Lamperti et al. (2018) are derivative-free optimization algorithms to calibrate with two iterative steps: predicting response surface, , and setting new evaluation design parameter, . The variants of regression models, including parametric and nonparametric models, could be used in the construction of a response surface. In large scale simulation, nonparametric kernel-based Gaussian process regression, or a.k.a. kriging, Rasmussen and Williams (2006) would be flexible in estimating the response surface when only a small number of evaluations are obtained. Gaussian process regression is a Bayesian model that predicts a response surface, , as a normal distribution, . The predictive variance, , measures the uncertainty of the predictive mean . As a parameter generation algorithm, Bayesian optimization Schonlau (1997), using an acquisition function, with a Gaussian process regression is one of the most efficient tools to find the global optimum in terms of function evaluations Lizotte (2008). The proposed heterogeneous calibration could be categorized as one of surrogate model-based algorithm.
Theoretical analysis, in particular, on Bayesian optimization with Gaussian pocess regression has been studied Mockus (2012); Vazquez and Bect (2010); Grünewälder et al. (2010); Bull (2011); Ryzhov (2016), and these analysis provides the convergence of the stochastic function with conditionsBull (2011). Thus, the calibration with Gaussian process regression could be categorized in either Category 1, Category 2, or Category 3 by the specifics of the conditions. Having said that, the practical conditions would be different from the theoretical analyses, so we need to study the feasibility with an actual system with an implemented calibration model.
3 Preliminaries
This section introduces machine learning algorithms that we used for our calibration framework to extract hidden structures. These machine learning algorithms are used as components in our calibration framework. We present a set of clustering and latent representation models because the calibration needs to capture the divergence trend between the validation and the simulation results. Afterwards, we introduce a nonparametric response surface model and its corresponding optimization model because the calibration needs to suggest the next experimental point.
3.1 Clustering Models for Divergence Trend Detection
This subsection introduces multple clustering algorithms, Hidden Markov Model (HMM) Bishop (2006), Gaussian Mixture Model (GMM) Bishop (2006) and Dirichlet Process Mixture Model (DPMM) Teh (2010) in Section 3.1.1 and 3.1.2. Also, we present a latent structure modeling method, Variational Autoencoder (VAE) Kingma and Welling (2013), in Section 3.1.3.
3.1.1 Temporal Clustering Models (HMM)
HMM Bishop (2006) is a statistical graphical model that has an input as time-dependent data, and an output as time-dependent regimes. The graphical architecture of HMM consists of two random variables: 1) the latent variable for the hidden regime, and 2) the observable variable where the graphical relations and are assumed. The below is the generative process of HMM.
[TABLE]
is the initial probability of clustering; is the transition probability; and . denotes a categorical distribution; is the emission probability distribution; and is the emission parameter, which specify the type and the shape of the distribution on observation variable . If an observation is assumed to follow the Gaussian distribution, then the emission distribution becomes the Gaussian distribution, with the emission parameter of the mean and the standard deviation . The Baum-Welch algorithm, which is the Expectation-Maximization algorithm on HMM, estimates the parameters and the hidden regime assignments.
3.1.2 Clustering Mixture Models (GMM, DPMM)
In this subsection, we introduce an entity-wise static hidden structure extraction algorithm required in heterogeneous calibration. We define that a group has agents who share similarities in their state variables. Mixture models follows a probabilistic approach for representing the presence of sub-populations within the overall population by assuming the observation data is distributed multi-modally. The mixture models have a categorical cluster assignment variable, , as a latent variable for inference, which follows the categorical distribution of . Each mixture component has the emission probability parameter, , and the emission probability distribution, . The parametric model fixes the number of hidden groups, and the nonparametric model automatically finds the optimal number of sub-populations.
Gaussian Mixture Model (GMM) Bishop (2006) is a parametric clustering algorithm that the observation distribution is assumed to follow the mixture of the Gaussian distributions. The emission parameter, , is consisted of the mean and the standard deviation . We have the following generative process of GMM:
[TABLE]
Again, the Expectation-Maximization algorithm is used to maximize the likelihoods. In the Expectation step, is assigned by the expectation of the likelihoods. In Maximization step, we maximize the likelihoods by optimizing parameters, such as , , and in GMM.
A measure theoretic view of the parametric bayesian mixture distribution is , where and . Dirichlet process Teh (2010) is a prior for the nonparametric mixture clustering model, in which the data-adaptive optimal number of clusters are automatically extracted. As the mixture weight, , is no more finite dimension if the model is nonparametric, the infinite weight prior is not a distribution of a vector, Dirichlet distribution, rather it is a distribution of measures, Dirichlet process. Dirichlet Process Teh (2010) is a prior distribution of the infinitized mixture weight that makes the mixture distribution into the infinite weighted sum . The infinite weight, from the Dirichlet process, is constructed by the stick-breaking process, with . In general, base distribution and emission distribution are conjugate priors to make posterior computation tractable. The below specifies the generative process of DPMM.
[TABLE]
The parameters of DPMM are inferenced by maximizing the posterior distribution. A Gibbs sampling algorithm is used in maximizing a posterior in our implementation. At each iteration, the Gibbs sampling algorithm updates with fixed hidden structures of other assignments. After iterations, the Gibbs sampling method is known to find the equilibrium distribution.
3.1.3 Variational Autoencoder
Agent-level state variables often have a large dimension that causes failure in extracting meaningful clusters due to the curse of dimensionality. Assuming the data is distributed normally, as the dimension, , gets larger, most of the mass lies in the ellipsoidal shell of radius measured by the Mahalanobis distance, where is the covariance of the Gaussian distribution. This requires about sampled data points in order to get a single point with distance less than from the center of the distribution Dasgupta (1999). Therefore, we introduce a latent representation learning algorithm to compress the high dimensional data into low dimensional data.
Variational autoencoder Kingma and Welling (2013) is a probabilistic latent variable model that extracts the latent representation of data. The structure of Variational Autoencoder is consisted of two neural networks: an encoder network and a decoder network. An encoder network extracts the hidden latent representation from the input of the original data. The extracted representation propagated to the decoder network to regenerate the original data. The vanilla version of Variational Autoencoder assumes the encoder distribution to have a standard Gaussian distribution as a prior.
VAE parametrizes the posterior distribution with the neural network parameters. To make the reconstructed output similar to the original input, the log-likelihood of the Variational Autoencoder should be maximized. However, since the log likelihood is intractable to calculate, an alternative loss function, Evidence Lower BOund (ELBO), is suggested as a supporting lower bound function. In detail, the below formula shows ELBO.
[TABLE]
The reconstruction term, , calculates the expectation of the log-likelihood when the posterior latent representation follows a variational distribution of . The regularization term, Kullback-Leibler divergence , measures how much information is lost by using the encoder distribution, , to represent the prior distribution, . With a stochastic gradient descent method, the neural network parameters are learned.
3.2 Gaussian Process Regression-based Bayesian Optimization
After a sub-population of agents is obtained, heterogeneous calibration becomes an optimization problem with a heterogeneity-embedded loss function. This subsection introduces the surrogate based algorithm to optimize heterogeneous calibration problem, Gaussian process regression-based Bayesian optimization. Gaussian process regression (GPR) Rasmussen and Williams (2006) is a Bayesian nonparametric regression algorithm that estimates a response variable, or simulation error in this paper, as a black-box function of dependant variables, or simulation parameters in our case. If is an arbitrary input parameter, GPR estimates the predictive output distribution as a Gaussian distribution of .
Suppose the data \mathcal{G}=\big{\{}\big{(}\mathcal{P}_{c^{\prime}},d(E_{R}[\mathcal{S}(\mathcal{M}(\mathcal{P}_{c^{\prime}};\omega_{r}))],\mathcal{D})\big{)}\big{\}}_{c^{\prime}=1}^{c} is given, where is the average of summarizing (with a function of ) output results () from executing an agent based model (as a function of ) with a sample random path and a parameter with replications. Then, the predictive posterior distribution is specified in the below.
[TABLE]
; F=\big{[}d(E_{R}[\mathcal{S}(\mathcal{M}(\mathcal{P}_{1};\omega_{r}))],\mathcal{D}),...,d(E_{R}[\mathcal{S}(\mathcal{M}(\mathcal{P}_{c};\omega))],\mathcal{D})\big{]}^{T}; and . Here, is the kernel distance between and . The kernel distance is selected by considering the shape of the true function and the meaning of each input variable.
The kernel function, , plays the key role in GPR. Stationary kernel functions, such as Squared Exponential kernel and Matern kernel, are well-studied in theory and experiments. A kernel function has hyperparameters to determine the exact shape of distances where the hyperparameters could be learned by maximizing the log likelihood from data. Recently, a fully Bayesian treatment of kernel hyperparameters showed its usefulness Snoek et al. (2012); Wu et al. (2017).
The Bayesian optimization Snoek et al. (2012); Brochu et al. (2010); Frazier (2018); Lizotte (2008); Sasena et al. (2002); Preuss and von Toussaint (2018) is an adaptive optimization tool that selects a new design point to optimize the response. It finds the next evaluation point by optimizing an acquisition function, which is generated using and . This acquisition function optimization problem is represented in the below.
[TABLE]
This is called an inner optimization problem, where is an acquisition function, and \mathbb{H}=\big{\{}\mathcal{P}\big{|}\lVert\mathcal{P}-\mathcal{P}_{c^{\prime}}\rVert_{2}\geq r_{0}\text{ for all }\mathcal{P}_{c^{\prime}}\in\mathcal{G}\big{\}} with given radius . prevents a calibration optimization being stuck in a local optimum by forcing an exploration. A single calibration iteration contains an optimization of an easy-to-optimize inner problem.
The exploration-exploitation ratio affects the convergence speed of the calibration problem. The purely exploitation search algorithm is using the predictive mean acquisition function, . Minimizing the predictive mean will find a next evaluation point with a pure exploitation. For the pure exploration search algorithm, the predictive variance acquisition function, , is used. In this case, maximizing this function will find a design parameter that has never been visited before.
The Expected Improvement (EI) is a mixture of the exploration and the exploitation. The below formula is an acquisition function of EI.
[TABLE]
is a probability density function, and is a cumulative density function of the standard Gaussian distribution, . The integration in Eq. 8 is marginalized out as the addition of two terms, where the first term (exploitation) is the predicted difference between the minimum of simulation errors, , and the predicted mean, , at the current point, , penalized by the probability of improvement, . The second term (exploration) represents the uncertainty of the surrogate model predictions. Therefore, EI is a balanced exploration and exploitation method in its nature. By maximizing the EI acquisition function, the next design parameter, , is generated. EI gained its popularity with both theoretical analyses Mockus (2012); Vazquez and Bect (2010); Grünewälder et al. (2010); Bull (2011); Ryzhov (2016) and experimental successes Snoek et al. (2012); Lizotte (2008); Schonlau (1997).
EI is one-step Bayes optimal Wu and Frazier (2016), but EI becomes heuristic when we consider multi-steps. In calibration tasks, EI often fails to find a global optimum parameter in the following reasons. First, the effect of hyperparameters is not well-studied. If we estimate the hyperparameters via MLE Snoek et al. (2012), EI finds the basin of attraction only for certain circumstances because the hyperparameters are changing at every iterations Bull (2011). Meanwhile, if we adopt a fully Bayesian treatment of hyperparameter Snoek et al. (2012); Wu et al. (2017), then the theoretic analysis on asymptotic consistency of EI in continuous parameter space is not equipped Wu et al. (2017). In practice, EI, with either Bayesian treatment or pointwise treatment on hyperparameters, fails to detect the basin of attraction and stops exploring, which makes no improvement on the response surface after iterations.
More importantly, looking at the shape of the true error function, a well-modeled simulation is likely to have a sub-optimal plateau near the global minimum. As the simulation model becomes more insensitive on its input parameters, the sub-optimal plateau area becomes bigger. On the sub-optimal plateau, if we assume the predicted difference to be constant, denoted by , then the derivative of EI w.r.t. is specified in the below.
[TABLE]
The above formula is turned out to be positive in any cases. This suggests that EI is an increasing function of , so EI will explore on the sub-optimal plateau that it finds as a next design point that makes the biggest. In these reasons, some articles investigate the portfolio of the mixture of acquisition functions Hoffman et al. (2011) to accelerate optimization, which we follow in this calibration task.
Besides of using EI in its fundamental form, the ratio of the exploitation term and the exploration term could be controlled by adding weight as the below.
[TABLE]
We call this acquisition function as weighted Expected Improvement (w-EI) Sóbester et al. (2005).
Parallel Bayesian Optimization algorithms Wu and Frazier (2016); Wu et al. (2017); Wang et al. (2016) could enhance the calibration speed dramatically, that they could find a set of multiple heterogeneous parameters to test. The distributed parallel simulation then tests different set of heterogeneous parameters and yield different simulation errors. Parallel Bayesian Optimization also supports asynchronized situation where different simulation setup takes different error evaluation time.
4 Proposed Calibration Methodology
This section describes our calibration framework for agent-baed models with a validation dataset. The description starts from the overall illustration of the calibration framework. Then, we describe two detailed calibration components, which are dynamic calibration and heterogeneous calibration, in turn.
4.1 Overall Calibration Framework
Our calibration framework intends to optimize the parameters of a generic agent based model in order to reduce an error function between a validation dataset and a set of stochastic simulation summary statistics. Some of these components are already defined in the previous literature in the previous section. For instance, we represent the agent based model as ; parameter set as ; an error function as ; a validation dataset as ; and a set of stochsatic simulation output summary statistics as .
As all of the surveyed calibration methods can be executed in an iterative setting, our model assumes an iterative optimization of , which is illustrated in Fig. 1 and Alg. 1. Before we start our iterations, we create a set of agent clusters because our heterogeneous calibration will be applied to each group of agents, rather than an individual agent due to the time complexity, see line 3 in Alg. 1. Also, we assume that we obtained a pre-processed validation dataset that is a set of temporal sequence values. Afterwards, we start the calibration iterations from a randomly initialized parameter. Having said that, our calibration would better work if the initial parameter is close to the optimal parameter , and we provide this trade-off in Sec. 5.1.3.
Our iterations consist of one minor step and two major components with machine learning models.
Our iteration starts from a minor step of calculating from the most recent simulation outputs with the most recent parameter , see line 15 in Alg. 2 and line 26 in Alg. 3. The function is instantiated for each application case, and can be either simple Euclidean distance, KL divergence, negative log-likelihoods, etc. We specify for each of our examples in Section 4.2 and 4.3. 2. 2.
After calculating , we perform either dynamic calibration or heterogeneous calibration, which are the two major components of the calibration framework. The proposed calibration framework alternates each calibration with pre-determined iterations, to stabilize the estimation of each parameter: iterations for the dynamic component, and iterations for the heterogeneous component.
- (a)
Dynamic calibration takes the result of , , simulation mean, , and the current dynamic parameter candidate hypotheses, , to perform the regime detection, see line 17 in Alg. 2, and to generate the next dynamic parameter hypotheses , see line 18 in Alg. 2. 2. (b)
Heterogeneous calibration accepts the result of , , and to learn the response surface, see line 28 in Alg. 3, and to generate the heterogeneous parameter , see line 29 in Alg. 3. 3. 3.
Since the union of and becomes a new parameter input of candidate hypothesis for the next iteration, our iterative calibration becomes a loop that measures and optimizes , alternatively.
The following sections show the details of two major components.
4.2 Dynamic Parameter Calibration
Dynamic parameter calibration Moon et al. (2018) is an inverse problem of finding optimal parameters that yields the most consistent simulation summary statistics, , with given validation empirical data, . To further illustrate the calibration algorithm, we state two assumptions. First, we assume that we have a fixed parameter set of , which is . This assumption limit this algorithm to finding only , which is a subset of , without the joint consideration with . Second, we assume that the dynamic parameter is assigned to each timestep as a switching regime. Formally, if we assume to calibrate number of dynamically switching parameter, . We describe our optimization task as the below.
[TABLE]
We treat the dynamic parameters for each timestep, , as the static input determined prior to the simultion, so the dynamic parameters become the composition of such parameters multiplied by the execution timesteps, . This can be viewed as turning the dynamic parameters into the static parameters by increasing the number of parameters, which could be viewed as an identical problem of Eq. 11. However, this increment of parameter numbers is significant if the simulation becomes a long execution. Therefore, we limit the increment by assuming that the dynamic parameters are identical for identified temporal regimes over the simulation executions. This assumption enables limiting the multiplication of dynamic parameter numbers to the given regime number, .
Because of the above reasoning, our calibration algorithm divides simulation timesteps into a number of regimes to generate the dynamic parameters for each regime, separately. Also, we separate well-fitted regimes from poorly-fitted regimes. This separation enables that the poorly-fitted regimes can explore farther parameter spaces while the well-fitted regimes can exploit the bounded parameter spaces.
4.2.1 Dynamic Calibration Performance
This subsection explains line 12-15 in Alg. 2, which measures the performance of dynamic calibration. Dynamic calibration uses a posterior distribution inferred from number of candidate hypotheses, , to generate a new set of parameters, for iteration. To obtain statistically stable simulation summary statistics, we run simulation times for each candidate hypothesis, see line 13 in Alg. 2. Then, the simulation generates state variables of candidate hypothesis are post-processed to generate the simulation summary statistics means as follows.
[TABLE]
The distance function in dynamic calibration is the negative likelihood function, which requires the simulation variance. The simulation variance is set to be in this article. Then, the likelihood of true observation \mathcal{D}_{dyn}=\big{(}(d_{s,t})_{s=1}^{S}\big{)}_{t=1}^{T} being observed from the normal distribution with the output mean and the variance is calculated as below.
[TABLE]
The joint likelihood over all the summary statistics is . The implementation version utilizes the log-likelihood of Eq. 13.
4.2.2 Regime Detection Component
After calculating the likelihoods, we apply the regime detection algorithm of HMM to obtain temporal clustering results by regarding the deviations of the simulation result, , and the validation data, , as observed variables in Eq. 2, introduced in Section 3.1.1, as below.
[TABLE]
The temporal clustering results are for each of candidate hypothesis. After obtaining regimes of all the candidate hypotheses, we define merged regimes as the partition of simulation timesteps that satisfy the following conditions: if ,
[TABLE]
We utilize MR as the final regime detection result, which answers to the question of when to calibrate. Also, MR becomes the input to the algorithm of answering how to calibrate.
4.2.3 Parameter Generation Component
We generate the next set of paramter hypotheses from each merged regime, MR. In detail, from the merged regime , we infer the posterior distribution of the parameter space, , to sample the next parameter candidate hypotheses . To estimate the beta distribution parameters, we use the current parameter values and the likelihoods . In particular, the parameter and the likelihood values are normalized to estimate the beta distribution parameters and via maximum likelihood estimation. The parameter is normalized by
[TABLE]
where and are the maximum and the minimum of the parameter range, respectively. The likelihood is normalized by
[TABLE]
Then, the estimated beta distribution, , generates a next set of parameters by either sampling or Mode Selection, which is explained, later.
If a simulation is far from the validation for all the candidate hypotheses, additional parameter exploration is executed in order to avoid searching prohibitive region. If the likelihoods are less than given threshold for all the candidate hypotheses and for all the simulation timestep ,
[TABLE]
then the normalized likelihoods are set to be equal, . This equally distributed likelihoods make the estimated beta distribution equally distributed, and the next parameter will be randomly picked at the merged regime. The ratio is decreased in this article, with .
Given a posterior distribution, , we have three options to generate new parameters:
Sampling by Time: the dynamic parameters are sampled from for each and . 2. 2.
sampling by Regime: the dynamic parameters are set to be constant for all , where the constant is sampled from for each . 3. 3.
Mode Selection: the dynamic parameters are sampled from the modes of , where the modes are meaningful moments of the distribution. In this article, we use \big{\{}\mu_{u}^{\beta}+\big{(}i-\frac{I+1}{2}\big{)}\sigma_{u}^{\beta}\big{|}i=1,...,I\big{\}} to be the set of modes, where and are the mean and the standard deviation of the Beta distribution, respectively.
Sampling by Time searches the most rapidly switching parameters among three generation processes. However, the small parameter gap at the front timesteps affects to the simulation dynamics afterwards, and this dependency hinders dynamic calibration to estimate accurate time-varying parameters afterwards. Furthermore, Sampling by Time is expected to estimate the overfitted, unrealistic dynamic parameters. On the other hand, Sampling by Regime searches parameters with an identical value at the identical regimes, which makes the calibrated parameter to be less fluctuating. Besides of the sampling-based methods, Mode Selection focuses on exploitation in parameter generations. Exploration is implemented when the likelihoods are below the threshold, and Mode Selection do not explore the parameter space, additionally. We experiment all parameter generating rules in Section 5.1.
4.3 Heterogeneous Parameter Calibration
Heterogeneous calibration resolves the simulation divergence arisen from the agent heterogeneity by transforming the simulation result, , to the validation data, , through calibrating heterogeneous parameters. Before introducing the algorithm, we present two assumptions. First, we assume that we have a fixed set of dynamic parameters, , which are the complement of heterogeneous parameters from the set of model parameters, . Heterogeneous calibration focuses on calibrating the heterogeneous parameters, . Second, the heterogeneous parameters, , are static parameters differentiated by agent sub-populations. The heterogeneous calibration solves the following inverse problem.
[TABLE]
The heterogeneous parameters are not differentiated by agents, since the above optimization problem becomes infeasible. This infeasibility comes from the huge dimensionality of the problem, where the optimization dimension, , is the multiplication of the number of agents, , by the number of heterogeneous parameters, . The second assumption enables the problem to feasible by reducing the dimension, , where is the number of sub-populations.
4.3.1 Heterogeneous Calibration Performance
In heterogeneous calibrations of our experiments, the simulation error function, , is the Mean Absolute Percentage Error (MAPE), but this selection can change per application case. The experimental error, , corresponds to the noisy observation of the true error, . We generate the next design point by Bayesian optimization, with a predicted surrogate response surface obtained from the gathered data \mathcal{G}=\Big{\{}\big{(}\mathcal{P}_{het,c^{\prime}},d(E_{R}[\mathcal{S}_{het}(\mathcal{M}(\mathcal{P}_{dyn}\cup\mathcal{P}_{het,c^{\prime}};\omega_{r}))],\mathcal{D}_{het})\big{)}\Big{\}}_{c^{\prime}=1}^{c}.
4.3.2 Agent Clustering Component
A clustering algorithm divides agents into several sub-populations, using the simulation agent-level results, . Since the classical clustering algorithms, such as GMM and DPMM, suffers from the curse of large dimensionality, we compress the data through a latent representation learning algorithm, VAE (see Section 3.1.3). The vanilla VAE has an encoder-decoder neural network, and , where the two functions, embedded in a neural network, are learned by maximizing the ELBO, given in Eq. 5. The latent representation of an agent, when , is the output of the encoder-part network of the agent-level simulation results of the agent.
The next step executes the mixture models, introduced in Eq. 3 or 4, with the latent representation of agents, .
[TABLE]
We test both parametric mixture model, Eq. 3, and nonparametric mixture model, Eq. 4, in our calibration.
4.3.3 Response Surface Learning Component
Gaussian process regression estimates the predictive posterior distribution of the true error, . GPR, introduced in Section 3.2, predicts the mean and the variance by
[TABLE]
where , F=\big{[}E_{R}\big{[}d(\mathcal{S}_{het}(\mathcal{M}(\mathcal{P}_{dyn}\cup\mathcal{P}_{het,1};\omega_{r})),\mathcal{D}_{het})\big{]},...,E_{R}\big{[}d(\mathcal{S}_{het}(\mathcal{D}(\mathcal{P}\cup\mathcal{P}_{het,c};\omega_{r})),\mathcal{D}_{het})\big{]}\big{]}^{T}, and . Here, is the kernel distance between points and . We use the Matern- kernel as the prior covariance. The hyperparameters of kernel function are point-estimated by maximizing the likelihoods of collected data being sampled from the predictive distribution.
4.3.4 Parameter Generation Component
As a selective search algorithm, Bayesian optimization optimizes the acquisition function to find a next evaluation design point as follows.
[TABLE]
Here, stands for the acquisition function, and \mathbb{H}=\big{\{}\mathcal{P}_{het}\big{|}\lVert\mathcal{P}_{het}-\mathcal{P}_{het,c}\rVert_{2}\geq r_{0}\text{ for all }\mathcal{P}_{het,c}\text{ in the domain of }\mathcal{G}\big{\}} with a given radius . This adaptive parameter space, , forces the search algorithm to avoid the -neighborhood of the previous evaluated parameters. We use L-BFGS-B algorithm to optimize the acquisition function, with .
We apply three types of Acquisition Functions: weighted Expected Improvement, Predictive Mean and Predictive Variance. We use search strategy as follows:
- •
Choose random parameters for the first iterations
- •
For the next iterations,
With probability , choose random parameters
With probability , choose parameters that maximize Predictive Variance
With probability , choose parameters that minimize Predictive Mean
With probability , choose parameters that maximize weighted Expected Improvement with cooling weight
We use multiple acquisition functions to search parameter space without being trapped by local minima. In order to escape from local minima, the search strategy contains the exploration algorithms, such as Random Search and Predictive Variance, where Predictive Variance finds the least searched parameter region. The role of exploration in heterogeneous calibration is estimating the surrogate function closer to the true error function, globally. In order to estimate the optimal parameters, the search strategy executes the exploitation by Predictive Mean and weighted Expected Improvement. The cooling rate, , in weighted Expected Improvement controls the weight between exploration and exploitation in Eq. 10, to find a narrower region in large iterations. Predictive Mean is a pure exploitation algorithm to find the global minimum of the surrogate function.
5 Experimental Result
Section 5 introduces the experimental results of the suggested calibration framework in two test cases. First, we test the feasibility of our algorithm on Wealth Distribution Model Wilensky (1998). We synthesized a validation dataset with an arbitrailiy chosen parameter set, and this synthesis limits the source of simulation divergence to random effects and the pre-determined parameters set. Second, we experiment the real-world applicability with a Real Estate Market Model which uses a real validation dataset with elaborately designed model structures and real input scenarios. In such a realistic case, the additional sources of divergence exist, including the imperfect modeling and the highly noisy socio-economics data.
Both cases experiments the calibration framework suggested in Alg. 1. To investigate the effects of each component in the framework, we also experiment dynamic calibration and heterogeneous calibration, seperately. We evaluate dynamic calibration without heterogeneous calibration by setting the heterogeneous parameters to be either known optimal parameters, in test case 1, or human calibrated parameters, in test case 2. Similarily, we assess heterogeneous calibration without dynamic calibration by setting the dynamic parameters to be either optimal parameters or human calibrated parameters.
5.1 Test Case 1: Wealth Distribution ABM
5.1.1 Model Description
Wealth Distribution Model Wilensky (1998), adapted from the sugarscape model Epstein (2006), is an agent-based model to investigate the macroscopic wealth distribution via microscopic agent behaviors. In the model, a grid provides its wealth to agents located at the grid. At the end of each simulation timestep, agents consume their wealth to survive and move toward the wealthest neighboring grid to maximize their wealth income. Also, grids recover their wealth at the end of each timestep for future provision. The net-wealth of all grids is proportional to the dynamic parameter, Wealth Income, and agents consume their wealth, proprortional to the heterogeneous parameter, Wealth Consumption.
5.1.2 Virtual Experimental Design
5.1.2.1 Synthetic Parameter Setting
Tab. 3 presents the parameters used in Wealth Distribution ABM. The dynamic parameter, Wealth Income, represents the seasonal effects, or the up and down of economics business cycles. The synthetic dynamic parameter is alternating between 1.5 and 0.5 by a period of ten simulation timesteps. The heterogeneous parameter, Wealth Consumption, represents the agent level heterogeneous characteristics. Agent clusters are divided according to the initial wealth; agents with top in their initial wealth are clustered, and the other agents are separately clustered. The synthetic heterogeneous parameter is set to be 0.9 for the first cluster, and 0.1 for the second cluster.
5.1.2.2 Summary Statistics
The wealth inequality is the main interest in this model, which leads the validation data consisted of High Class Wealth Average, Middle Class Wealth Average, Low Class Wealth Average, and Gini Index as in Tab. 4. Here, High Class Wealth Average is the average wealth of the top agents, and Gini Index Gini (1936) is a index of measuring the wealth inequality. The synthetic validation data is generated from the synthetic parameter setting. The agent-level simulation result is not used, since the agent cluster is given a-priori to the calibration task in Wealth Distribution ABM to test the performance of the suggested Bayesian optimization.
5.1.2.3 Experimental Cases
There are three experimental cases: dynamic calibration, heterogeneous calibration, and calibration framework of joining two calibrations into a single framework. Dynamic calibration, proposed in Section 4.2, is evaluated with suggested parameter updating schemes: Sampling by Time, Sampling by Regime, Mode Selection, and Random Search. Dynamic calibration utilizes the synthetic heterogeneous parameter, in the calibration process. The heterogeneous parameter in dynamic calibration is fixed to the synthetic parameter in Tab. 3. The heterogeneous calibration, proposed in Sectioin 4.3, applies the surrogate-based calibration with known clustering assignments. In heterogeneous calibration, the dynamic parameter is fixed to be the synthetic parameter, presented in Tab. 3. The last experiment calibrates both dynamic and heterogeneous parameters to investigate the effects of the combination of two components. The two subcases are tested in Wealth Distribution Model. The first subcase calibrates the dynamic and the heterogeneous parameters alternatvely with the pre-determined iterations for dynamic calibration, , and for heterogeneous calibration, . The second subcase evaluates with , and , to investigate the effects of the pre-determined hyperparameters of the calibration framework. The model parameters are randomly initialized at the initial iteration. Tab. 5 presents the list of the experimental variables in each experiment.
5.1.2.4 Performance Measure
Since we know the synthetic parameters in Wealth Distribution Model, we calculate the Mean Absolute Error (MAE) to measure the distance from the estimated dynamic parameter to the synthetic dynamic parameter. We also calculate the Euclidean error to measure the distance from the estimated heterogeneous parameter to the synthetic heterogeneous parameter. To compare the simulation output, we use Mean Absolute Percentage Error (MAPE) to measure the distance from the simulation result to the validation data in all the experiments.
5.1.3 Dynamic Calibration Results
Fig. 2 presents the overall mechanism of dynamic calibration. Fig. 2 (a) presents a single dimension of summary statistics, Gini Index, of a parameter candidate hypothesis. (b) presents the result of HMM, on Alg. 2-Line 3, that divides the well-fitted regime, in green points, with the poorly-fitted regime, in red and blue points. The joint likelihoods, on Alg. 2-Line 15, are presented in (c). The dotted lines are the thresholds in Eq. 18. Exploration is executed in the most of the simulation timesteps for the first few iterations. Fig. 2 (d) presents the regime detection results for all three candidate hypotheses, on Alg. 2-Line 17. The estimated beta distribution of a single merged regime, on Alg. 2-Line 8, is presented in (e). Fig. 2 (f) presents one of the next candidate hypotheses, on Alg. 1-Line 6, generated from the estimated beta distributions. The current dynamic parameter candidates, , are plotted as the grey lines, and the generated dynamic parameter evaluated in the next simulation is plotted as the black line, with different colors represent different merged regimes.
The well-fitted regime in Fig. 2 (b) makes the parameter estimation at the front period success, as the red colored dots in (f), because the second candidate hypothesis at the well-fitted regime has high likelihoods that the next parameter will be generated near the second hypothesis. The simulation has failed to recover the validation statistics afterwards, and this leads the algorithm to force explorations at the latter simulation timesteps. Fig. 2 (g) is a simulation result, on Alg. 2-Line 14, evaluated with the estimated parameter in Fig. 2 (f). Iterative dynamic updates will change the simulation result to the synthetic generated validation data, as in Fig. 2 (h).
Fig. 3 presents the best estimated parameters with two updating rules: Mode Selection and Random Search. Mode Selection in (a) estimates the plausible parameter which shares the tendency with the synthetic parameter. However, Random Search in (b) finds the highly fluctuating parameter, which is unable to interpret. Fig. 4 (a) plots the parameter Mean Absolute Error (MAE) for the four updating rules. Mode Selection and Sampling by Regime performs better than other updating rules in parameter error. However, Fig. 4 (b) shows that the updating rule Sampling by Time performs the best in terms of simulation error.
Tab. 6 shows the experimental statistics of dynamic calibration. Sampling by Time performs the best in simulation error, but it has the highest parameter error, which implicates that Sampling by Time estimates the overfitted parameter. Sampling by Regime performance, on the other hand, is not significantly different from that of Random Search. Lastly, Mode Selection is the best updating rule in reducing the parameter error.
Fig. 5 shows the effect of the parameter initialization. The plus marked line is the calibration result with the randomly intialized dynamic parameters. Each parameter candidate has random static value at the initial calibration step, see gray lines in Fig. 2 (f). The x marked line is the simulation result of the selective initialization, where the parameter candidates are equally distributed in the parameter space, having values 0.5, 1.0, and 1.5. The selective dynamic parameters are believed to be initialized well, since the synthetic dynamic parameter is alternating between 0.5 and 1.5, see Fig. 3. Fig. 5 shows the selective initialization saturates faster than the random initialization, but at the same time, the random initialization performs as good as the selective initialization after iterations, due to the exploration in Eq. 18.
5.1.4 Heterogeneous Calibration Result
Fig. 6 (a), (b), and (c) illustrate the surrogate error functions of Gaussian process regression with 10, 50, and 100 evaluation points, respectively. The surrogate function is gradually sophisticated as the iteration increases. Fig. 6 (d), (e), and (f) present the contour plot to illustrate the evaluation paths of the suggested Bayesian optimization. The initial simulation result in Fig. 6 (g) is transformed to be close to the validation data as the best simulation result in Fig. 6 (h).
Fig. 7 (a) presents the parameter Euclidean error of heterogeneous calibration. The parameter Euclidean error of heterogeneous calibration saturates at 0.021, due to the observation error. In other words, the stochasticity of the simulation makes the surrogate function biased, and this biasness hinders the Bayesian optimization to estimate the exact synthetic parameter. However, in terms of the simulation error, heterogeneous calibration converges to the optimal error as in Fig. 7 (b), where the optimal error is the simulation MAPE evaluated with the synthetic parameter.
5.1.5 Calibration Framework Result
Tab. 6 demonstrates the calibration framework, with , outperforms the calibration framework, in terms of the simulation error. Although the calibration framework has the least dynamic parameter error among all the experiments in test case 1, the simulation error is large, due to the inaccuracy in the estimation of the heterogeneous parameter. The calibration framework, on the other hand, performs better than the calibration framework in terms of the simulation error, since the calibration framework estimates closer heterogeneous parameter than the calibration framework. Fig. 8 presents the experimental result of the calibration framework.
5.2 Test Case 2: Real Estate Market ABM
5.2.1 Model Description
Real Estate Market Model is an agent-based model to predict the housing price and the number of house transactions. The model consists of three types of agents: households, an external supplier and a realtor. Fig. 9 visualizes the interactions between agents. A household buy or sell houses to meet the residential needs. A household registers the owned houses in List Process and decides to buy a listed house in Buy Processes.
In List Process, a household register its vacant houses to the market through a realtor agent. A house is empty if the lease contract222Lease contract includes Jeonse and rental contract, where Jeonse is the lump-sum housing lease that is Korean specific residential form of living 2 years by paying a large amount of deposits at the initial contract, which is returned at the end of contract period, instead of paying rental fee monthly. is over, and no other bargain is made. When no household lives in a vacant house, and if a house owner does not move to the house, then a household register its house in a market looking for a leaseholder or a buyer. The external supplier lists its houses automatically in the housing market, since it acts as a house supplier in the model.
In Buy Process, a household purchase houses in three steps: participation step, selection step, and contract step. First, a household make a decision to participate in the market. A household without any house to remain unconditionally engage in the housing market, looking for a new house to reside. A household with a house for the residence participates with probability Market Participation Rate, to search for a new house to invest. Second, a household in the market selects a house out of the registered houses, according to its preferences. The preference of a household consists of area, contract type, and house type. A household first decides between capital area and noncapital area for a new house. A household, then, decides the contract type between lease and purchase, and the household decides the house type, among a house, an apartment and a condo. Leaseholders, who have remaining contract period, choose always to purchase a house if they make a deal with other house owners. Others, including 1) the house owners living in their house and 2) leaseholders with contract termination, purchase or lease a house with probability Purchase Rate or . A realtor receives the participated agents’ preferences, and the realtor replies the candidate houses to each household with matching preferences. Last, in contract step, a household makes a deal on a house within its budget from a replied house list. If other household contracts the house before, a household chooses other house to contract. The heterogeneous parameter, Willing to Pay, controls the budget, which is the maximum ratio out of the total asset an agent would raise, using savings and loan services.
Update Process updates all of required simulation state variables. A household saves the rest of its monthly salary after excluding the expenses, such as consumption, taxes, rental fee, and loan repayment. Housing price is decreased to
[TABLE]
up to ten times, if it is listed in the market, but no agents make a contract for the house at the timestep. Housing price is increased to
[TABLE]
if other houses with the same conditions are favored at the timestep. After updating state variables, an external supplier supplies new houses in the market. The newly produced houses have the state variables sampled from the real dataset.
5.2.2 Virtual Experimental Design
5.2.2.1 Calibration Parameters
Real Estate Market ABM has three dynamic parameters and two heterogeneous parameters: Market Participation Rate, Market Price Increase Rate and Market Price Decrease Rate for the dynamic parameters; and Willing to Pay and Purchase Rate for the heterogeneous parameters. The economic trends directly influence the supply and the demand in the reality, and the dynamic parameters are selected to reflect this seasonal bull and bear periods. A model uses an external supplier to reflect the supply, using a real dataset, and the model adopts Market Participation Rate to represent the demand. The seasonal outcome from the law of supply and demand is modeled by other dynamic parameters, Market Price Increase Rate and Market Price Decrease Rate. The agent heterogeneity is embedded in the heterogeneous parameters, Willing to Pay and Purchase Rate, of the investment portfolio. For instance, agents favor in real estate will be represented to have high Purchase Ratio.
5.2.2.2 Summary Statistics
The main interest in the model is predicting the housing price and the number of housing transactions closer to the validation dataset. Government official data on the price index and the transaction number is released in Korea Appraisal Board (KAB). We count the Jevons index Silver and Heravi (2007) as the housing price index, following the KAB index rule. We scale up the simulation transaction numbers by multipling the ratio of the real population, , over the simulation population, , to adjust the simulation results compatible with the validation transaction data.
KAB releases 24 types summary statistics, with each types are having the following different housing characteristics: two house regions (Capital/Noncapital), three house types (Detached/Apartment/Multiplex), two transaction types (Sales/Lease) and two summary statistics types (Index/Transaction number). We select eight Apartment summary statistics, as listed in Tab. 8, because Apartment forms the of the housing transactions in Korea.
In agent clustering, total seven simulation agent-level state variables are considered. Agents living in the capital area and the noncapital area are assigned separately in Living Region. Savings, Income and Loan variables are normalized to have values from zero to one. The one-hot encoding is executed for the variables House Type and Living Type, where the one-hot encoding is transforming the integer into a multi-dimensional zero vector but having one at the element.
5.2.2.3 Experimental Cases
There are three experimental cases: dynamic calibration, heterogeneous calibration, and the combined calibration framework. Dynamic calibration experiments three subcases: the first subcase calibrates the first parameter, the next subcase calibrates the first and the second parameter, and the last subcase calibrates all the dynamic parameters. Dynamic calibration accepts the manually calibrated heterogeneous parameter, in the calibration process. Heterogeneous calibration evaluates 15 subcases: first five subcases calibrate the first parameter, next five subcases calibrate the second parameter, and the last five subcases calibrate all heterogeneous parameters. Each of five subcases tests the different number of clusters: the first subcase calibrates the undivided parameters, the next four subcases calibrate the divided parameters, with first three subcases for the parametric clustering, and the last subcase for the nonparametric clustering. Heterogeneous parameter uses the manually human calibrated dynamic parameter, in the calibration process. The calibration framwork, combining dynamic and heterogeneous calibrations, investigates the effects of the combination of each calibration. The framework iteratively calibrates both the dynamic and the heterogeneous parameters, as in Tab. 9.
[FIGURE:]
5.2.3 Dynamic Calibration Result
The simulation price indices are more stable and better aligned with the validation dataset than the alignment of the simulation transaction numbers. Therefore, most of the error improvement is achieved by aligning the simulation transaction numbers to the validation, which heavily depends on the first dynamic parameter, Market Participation Rate. Comparing with the human calibration, Tab. 10 shows a significant error reduction in Total MAPE, which is gained from dynamic calibration experiments.
The second experimental subcase calibrates the first and the second dynamic parameters, where the second dynamic parameter influences to the housing prices. Comparing with the human calibration, Tab. 10 demonstrates that the analogous performance, with respect to the housing price indices, is achieved by counting the second parameter into the calibration parameter.
The last experimental subcase, calibrating all three dynamic parameters, provides an insight when parameters with similar effects, the second and the third parameters, are calibrated. The price indices are less correct than that of the second subcase. Also, total MAPE is slightly worse than the second experiment, which is mainly due to Apartment Lease Transaction Number in Noncaptial MAPE. The transaction numbers, relatively irrelavant with the second and the third dynamic parameters, are disturbed by adding the third parameter to calibrate, since the problem complexity is increased, without attaining any supplementary power to control the model output.
5.2.4 Heterogeneous Calibration Result
Comparing with the human calibration, no significant improvement is attained by calibrating the heterogeneous parameters without agent clustering. However, when the heterogeneous parameters are differentiated with the agent sub-populations, errors are considerably improved. This is because one of the error source, agent heterogeneity, is mediated through differentiating parameter values by clusters, which generates a micro controller for the elaboration of the agent behaviors.
Fig. 10 illustrates the detailed characteristics of agent clusters with radar charts. For example, the first cluster is the group of the leaseholder agents with middle-class salary, no debt, and low savings, who live in the apartments. As another example cluster, the third cluster is consisted of the house owners with high salary, high debt, and low savings, who live in the apartments located at the capital area.
When we calibrate all the heterogeneous parameters with agent clusters in Fig. 10, the first and the second calibrated heterogeneous parameters have the same values in the first cluster, 0.9, which indicates the agents are trying to buy their houses sooner or later. In the third cluster, Willing to Pay and Purchase Rate have their values 0.3 and 0.9, respectively. Since the third gouped agents have their own house with high debts, they are unlikely to have high-risk investment propensity. The low Willing to Pay indeed confirms their low-risk tendency, and high Purchase Rate reflects the fact that they are already living in their own house.
Calibrating the first parameter enhances the simulation performance, since the first parameter, Willing to Pay, directly controls the overall up and down of the transaction numbers. The error improvement from the second parameter is not as significant as from the first parameter. The second parameter, Purchase Rate, is only applicable for the minor agents whose lease contracts are finished. The simulation error gradually decreases as the number of the agent clusters increases, leading the nonparamtric clustering result performs the best. Although the two heterogeneous parameters plays different roles, there are considerable overlaps in their ramification on the simulation result. Thus, the calibration result with all the heterogeneous parameters reports the negligible error improvement, compare to the first parameter calibration.
5.2.5 Calibration Framework Result
Tab. 10 shows that the calibration framework outperforms both dynamic calibration alone and heterogeneous calibration alone. Also, the calibration framework with two clusters is remarkably stable in its error improvement. However, despite of the lowest error, calibrating all the parameters are not as effective as we expected, since the first heterogeneous parameter calibration with eight clusters reports the analogous error, , with the calibration framework error, . The reasons are two-folds. First, the price indices are relatively insensitive to the change of the parameter values, which leads that the error reduction relies mostly on the improvement in the transaction numbers. Second, the combination of the controller parameters on the transaction numbers hinders the response variables to be close to the validation, due to the increased dimensionality.
Fig. 11 presents the simulation errors of the calibration frameowork by calibration iterations. First, nearly 80 iterations for the random search are required to reach the human calibration result, and no significant improvement is made on the afterward iterations. Second, the calibration framework defeats the human calibration within 20 iterations, in average. After superseding the human calibration, the calibration framework saturates fast.
Fig. 12 illustrates the calibration results of dynamic calibration, heterogeneous calibration, and the calibration framework. All the calibration results fit to the validation data better than the human calibration result. Heterogeneous calibration generates better fitted simulation results than dynamic calibration, in all transaction numbers. The calibration framework fits better than heterogeneous calibration in (a) and (d).
6 Conclusion
This paper proposes an automatic data-driven calibration framework for the dynamic and the heterogeneous parameters, by extracting the hidden structures from the simulation outputs. Dynamic calibration controls the dynamically switching parameters, by extracting the hidden dynamic regimes, and by treating each regimes separately. Heterogeneous calibration calibrates the agent cluster-wise heterogeneous parameters, by extracting the hidden agent-subpopulations. The experimental results on dynamic calibration and heterogeneous calibration demonstrate that the proposed separate calibrations reduce simulation error, with plausible estimated parameters. The calibration framework, the combination of dynamic calibration and heterogeneous calibration, exhibits the expected results in both test cases with both Keep-It-Simple-and-Stupid (KISS) model as well as elaborated and complex model of housing markets.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Beaumont (2010) Beaumont MA (2010) Approximate bayesian computation in evolution and ecology. Annual review of ecology, evolution, and systematics 41:379–406
- 2Beisbart and Saam (2018) Beisbart C, Saam NJ (2018) Computer Simulation Validation: Fundamental Concepts, Methodological Frameworks, and Philosophical Perspectives . Springer
- 3Bishop (2006) Bishop CM (2006) Pattern recognition and machine learning . springer
- 4Bonabeau (2002) Bonabeau E (2002) Agent-based modeling: Methods and techniques for simulating human systems. Proceedings of the national academy of sciences 99(suppl 3):7280–7287
- 5Brenner and Werker (2006) Brenner T, Werker C (2006) A practical guide to inference in simulation models. Tech. rep., Papers on economics and evolution
- 6Brochu et al. (2010) Brochu E, Cora VM, De Freitas N (2010) A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. ar Xiv preprint ar Xiv:10122599
- 7Bull (2011) Bull AD (2011) Convergence rates of efficient global optimization algorithms. Journal of Machine Learning Research 12(Oct):2879–2904
- 8Calvez and Hutzler (2005) Calvez B, Hutzler G (2005) Automatic tuning of agent-based models using genetic algorithms. In: International Workshop on Multi-Agent Systems and Agent-Based Simulation , Springer, pp 41–57