Learning to Generalize to Unseen Tasks with Bilevel Optimization
Hayeon Lee, Donghyun Na, Hae Beom Lee, Sung Ju Hwang

TL;DR
This paper introduces a bilevel optimization framework called learning to generalize (L2G) for metric-based meta-learning, explicitly improving the model's ability to generalize to unseen classes in few-shot classification tasks.
Contribution
It proposes a novel bilevel optimization approach that explicitly constrains meta-learning to enhance generalization to unseen classes during training.
Findings
L2G significantly improves performance over episodic training on mini-ImageNet and tiered-ImageNet.
L2G produces a metric space that better clusters and separates unseen classes.
The framework is validated with Prototypical and Relation Networks.
Abstract
Recent metric-based meta-learning approaches, which learn a metric space that generalizes well over combinatorial number of different classification tasks sampled from a task distribution, have been shown to be effective for few-shot classification tasks of unseen classes. They are often trained with episodic training where they iteratively train a common metric space that reduces distance between the class representatives and instances belonging to each class, over large number of episodes with random classes. However, this training is limited in that while the main target is the generalization to the classification of unseen classes during training, there is no explicit consideration of generalization during meta-training phase. To tackle this issue, we propose a simple yet effective meta-learning framework for metricbased approaches, which we refer to as learning to generalize (L2G),…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1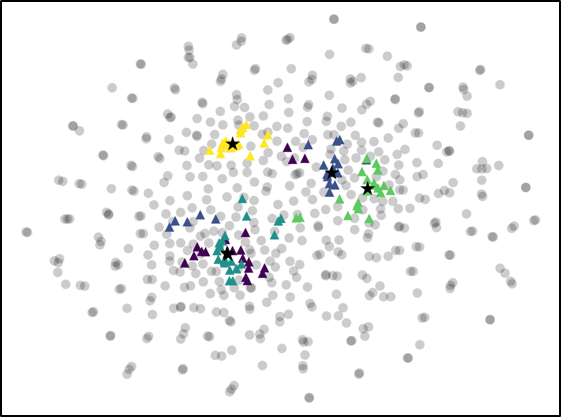 Figure 1
Figure 1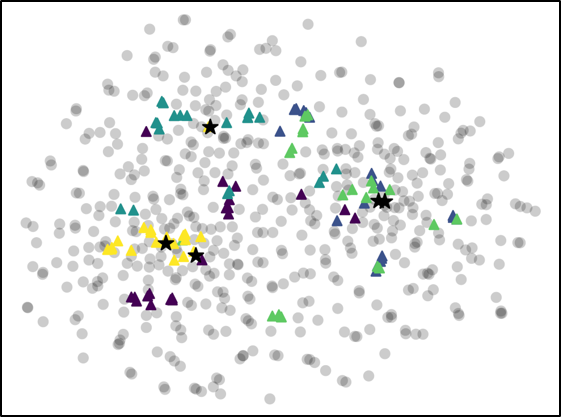 Figure 1
Figure 1 Figure 1
Figure 1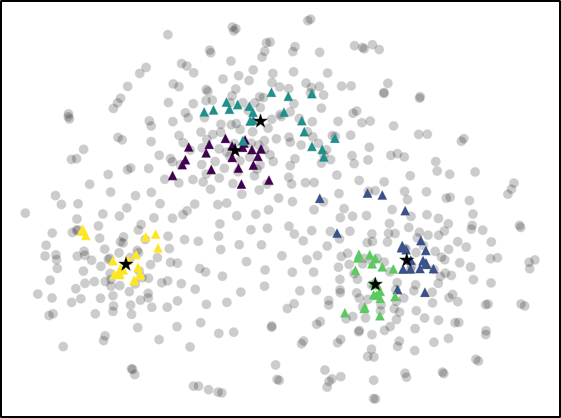 Figure 1
Figure 1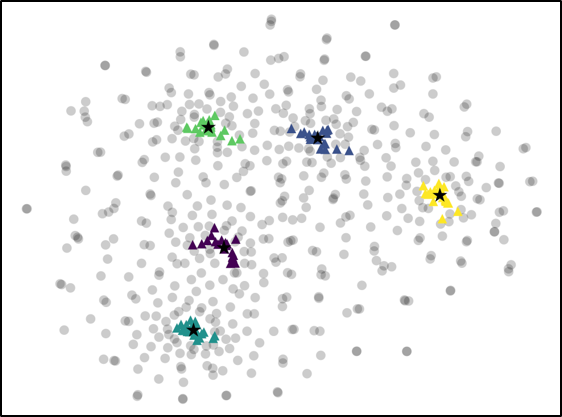 Figure 1
Figure 1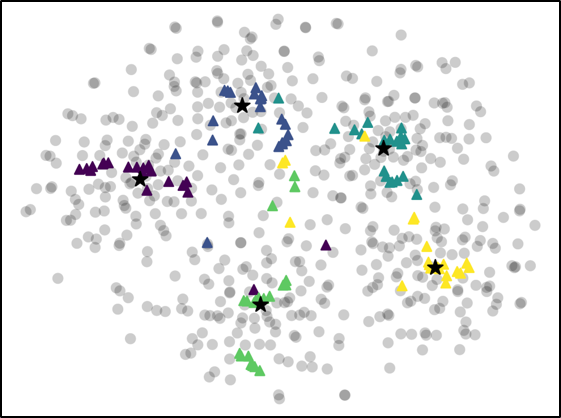 Figure 1
Figure 1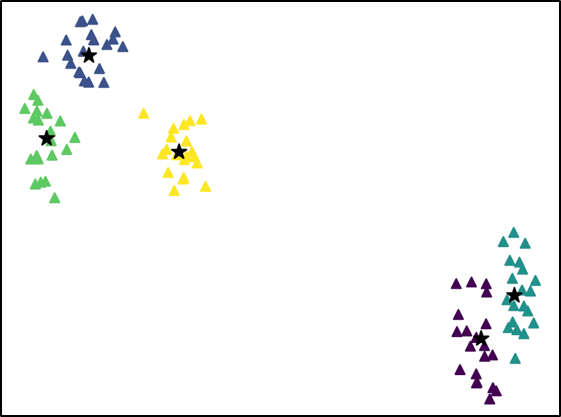 Figure 1
Figure 1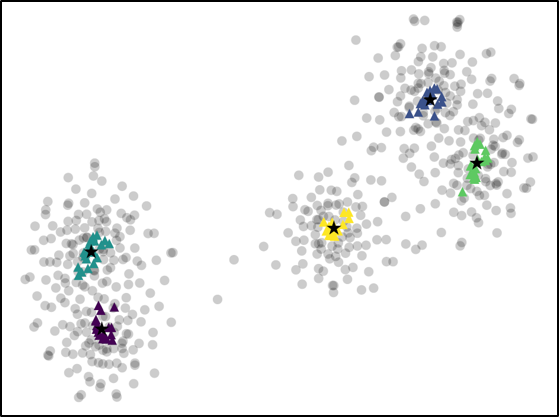 Figure 1
Figure 1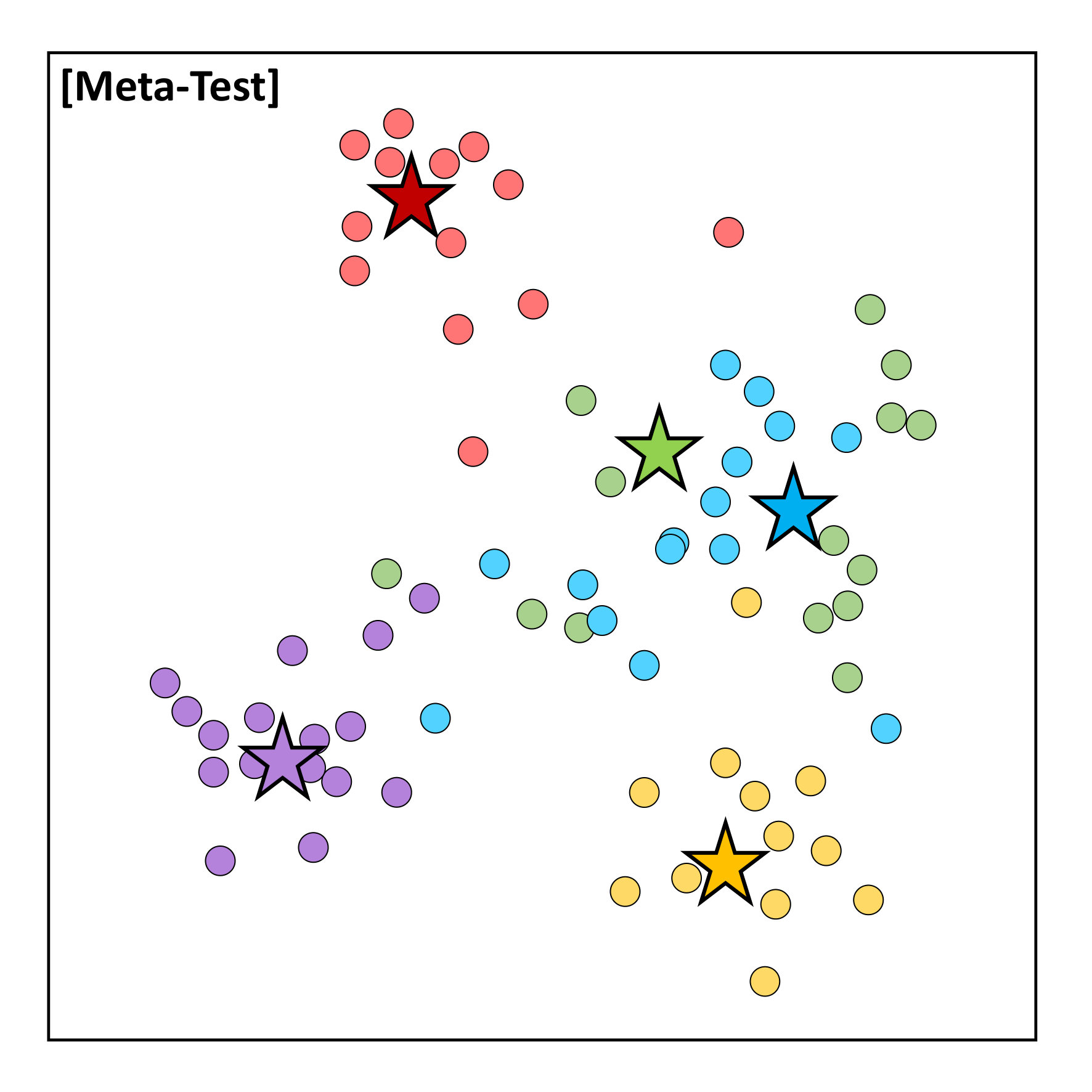 Figure 10
Figure 10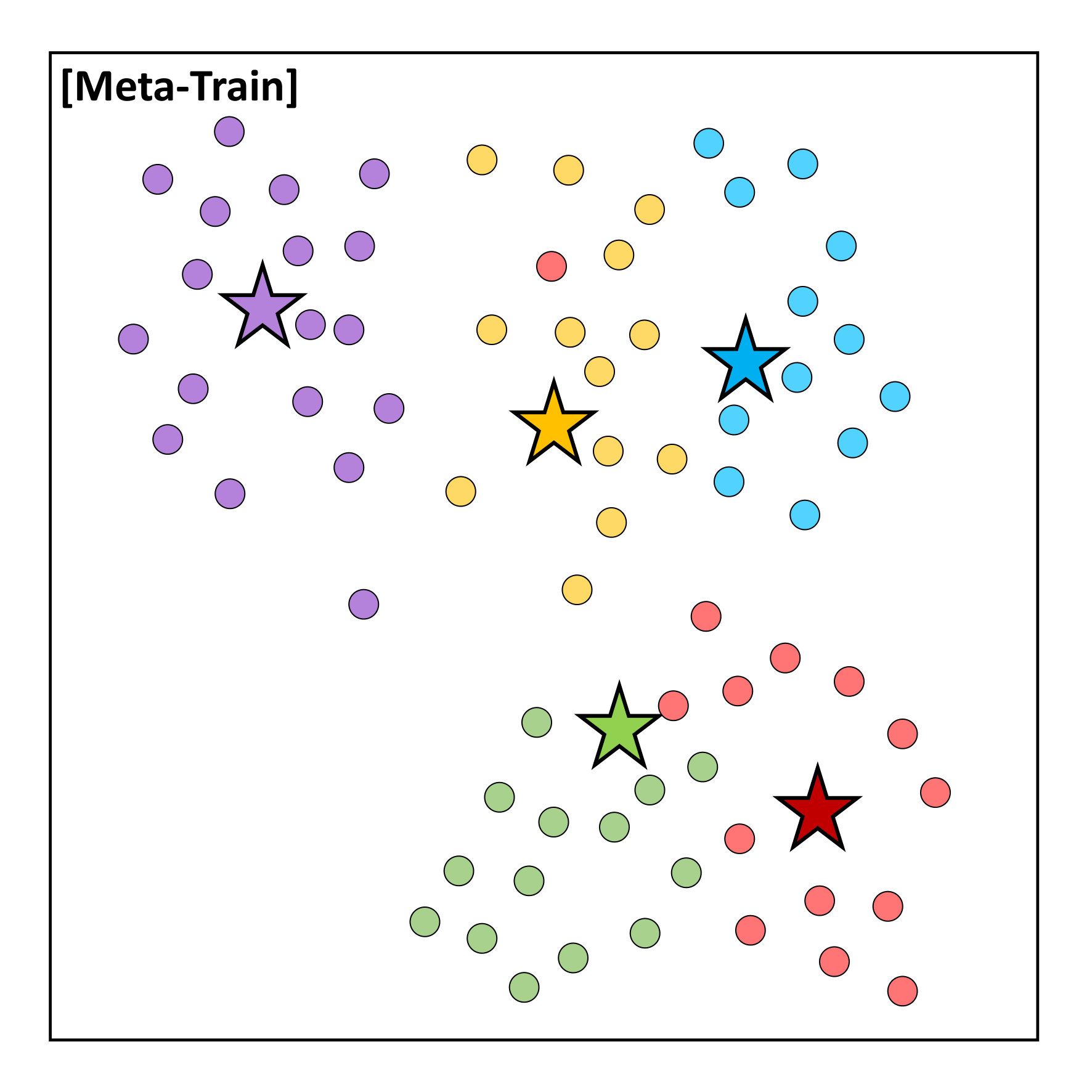 Figure 11
Figure 11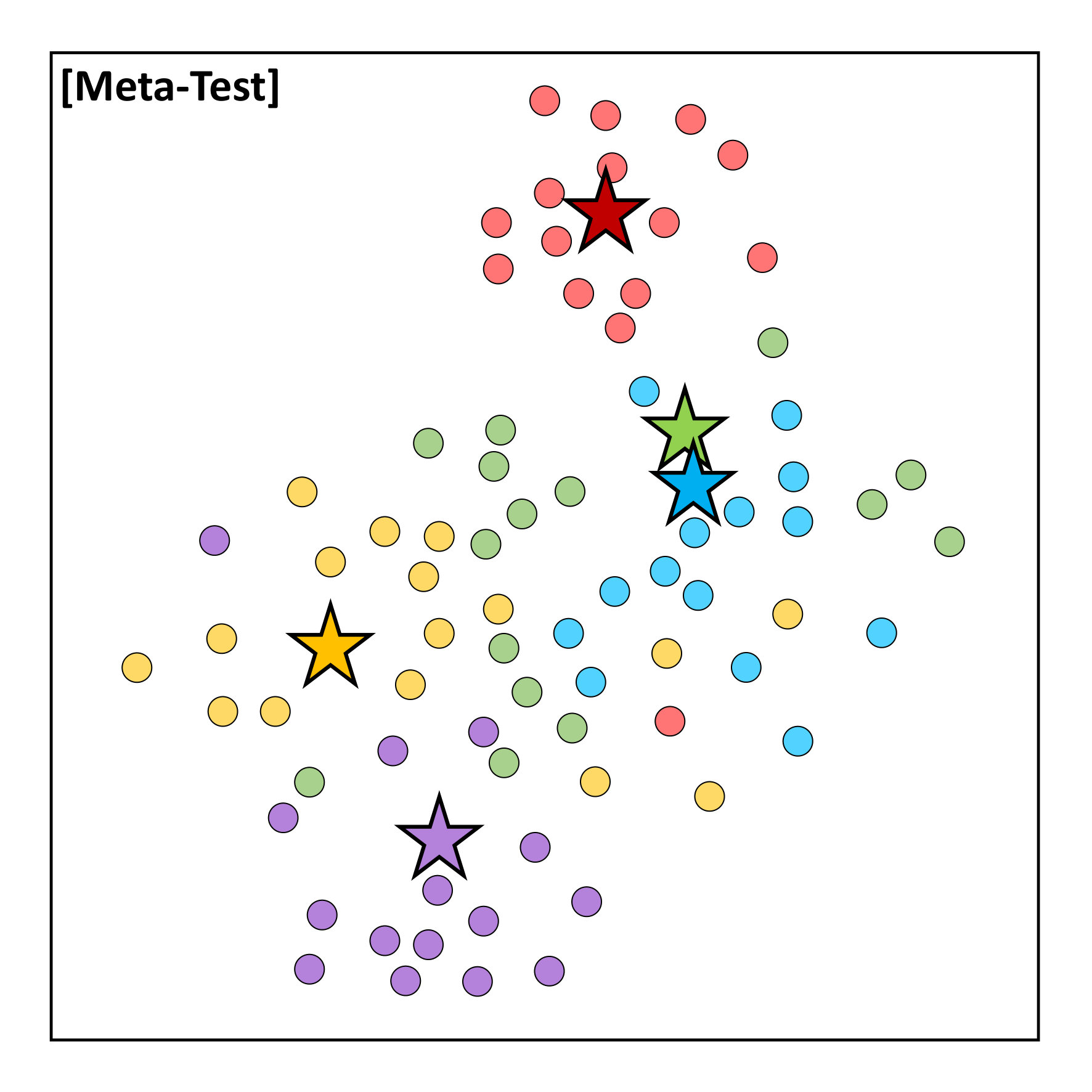 Figure 12
Figure 12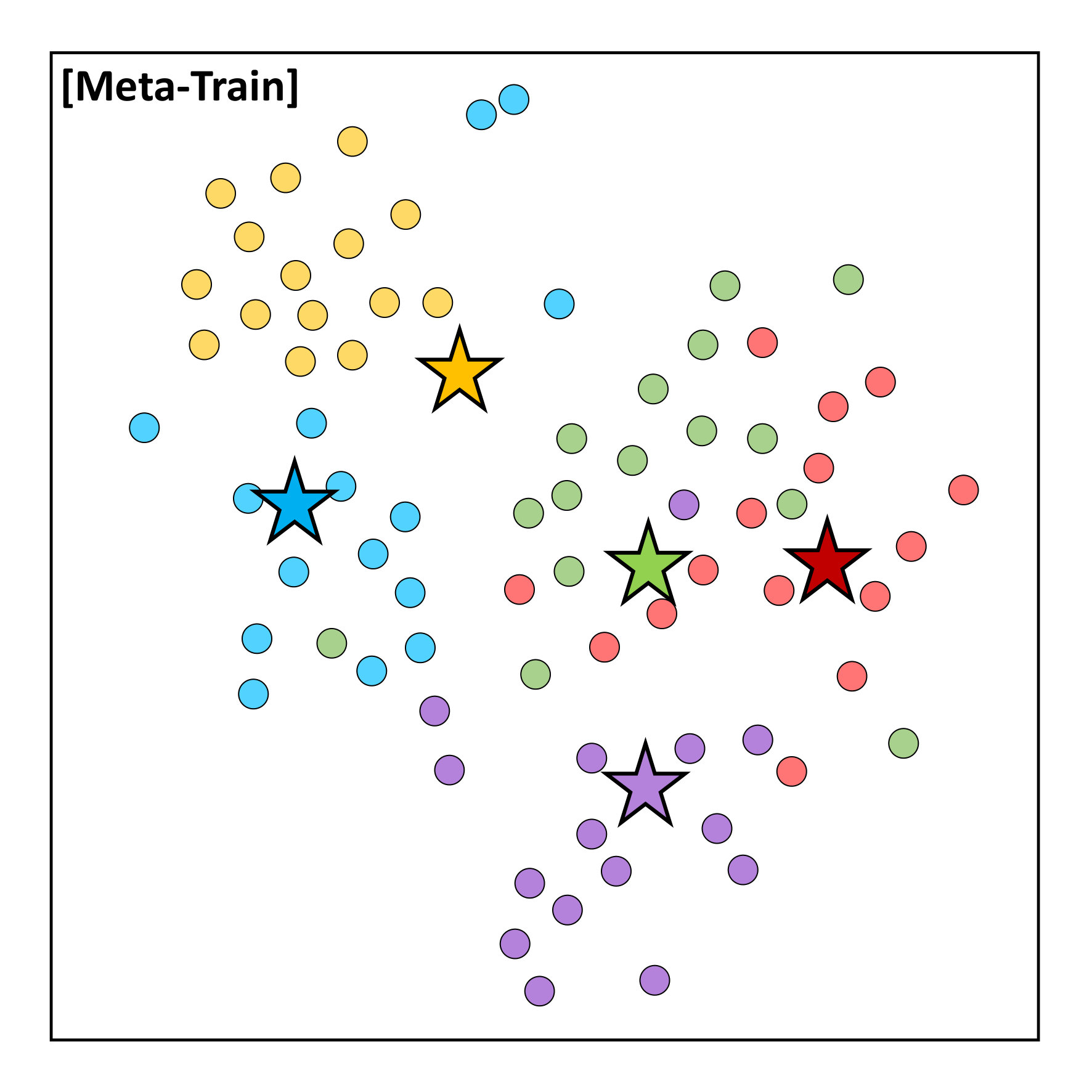 Figure 13
Figure 13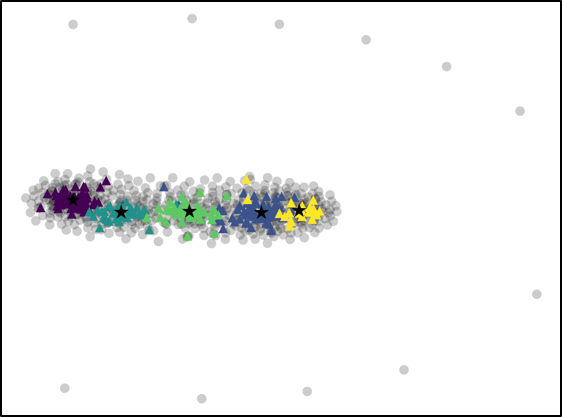 Figure 14
Figure 14 Figure 15
Figure 15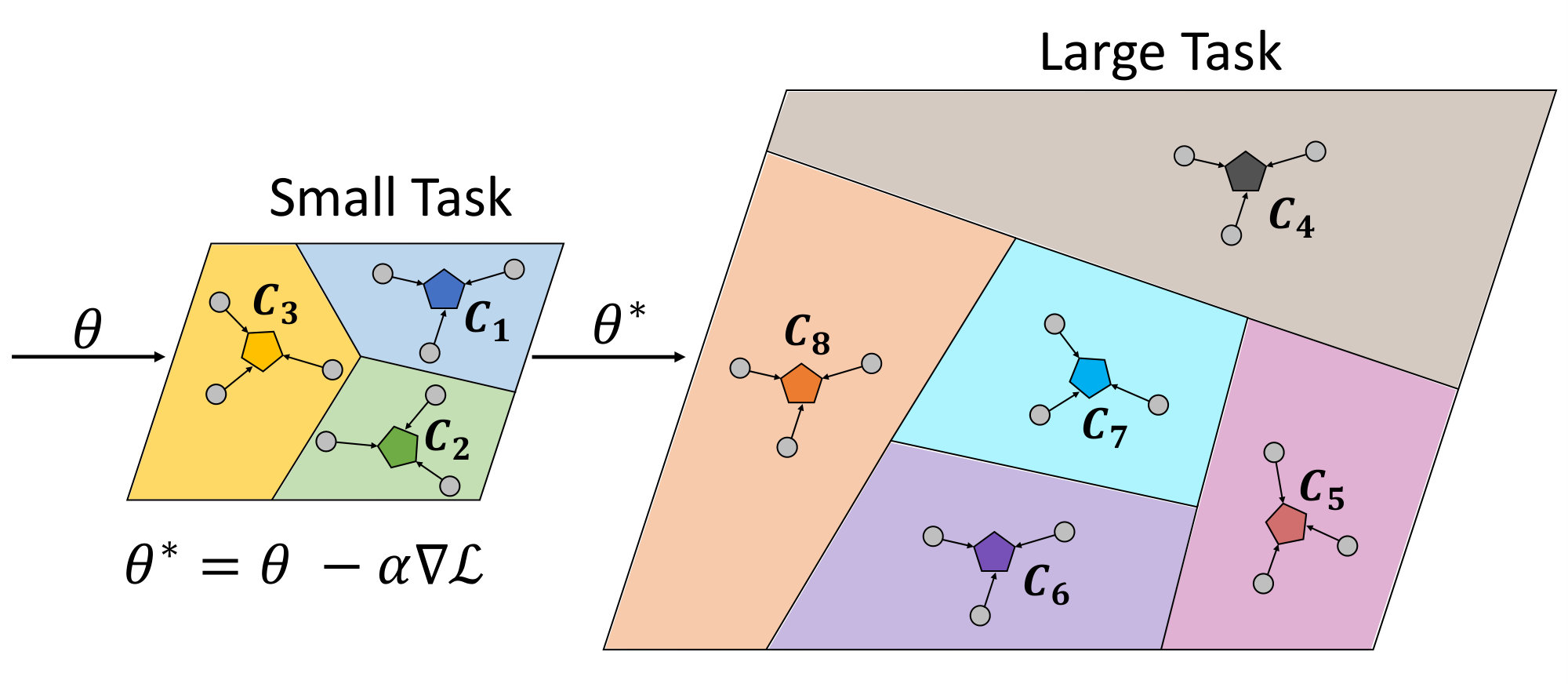 Figure 16
Figure 16 Figure 17
Figure 17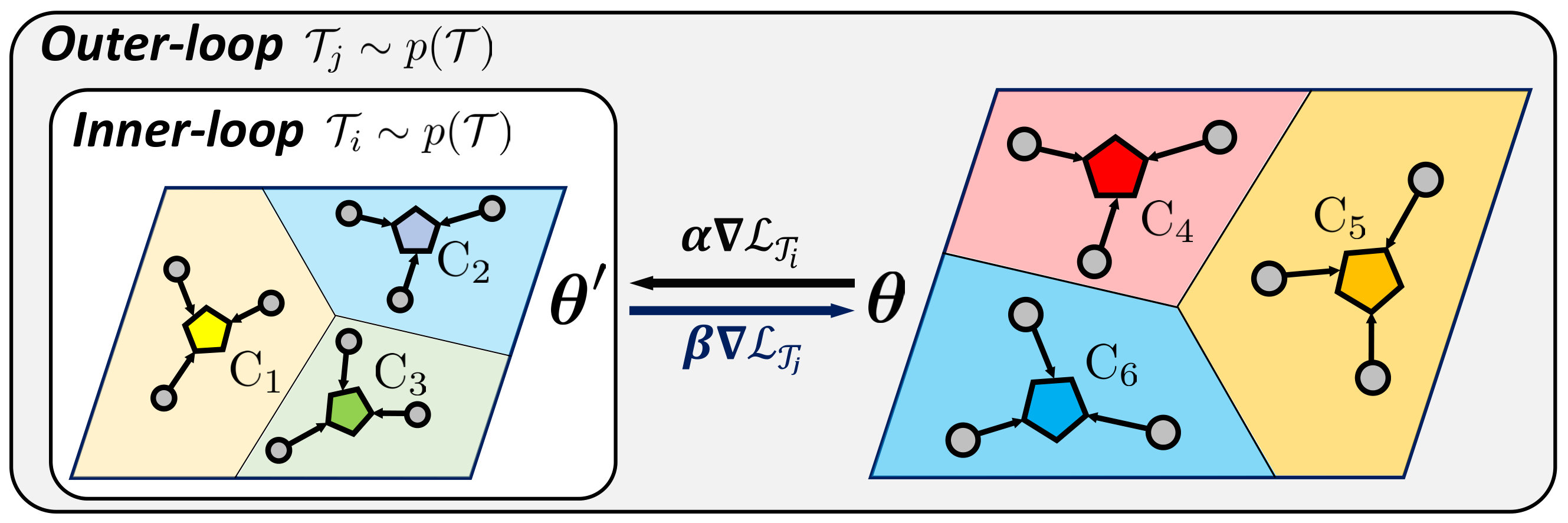 Figure 18
Figure 18 Figure 19
Figure 19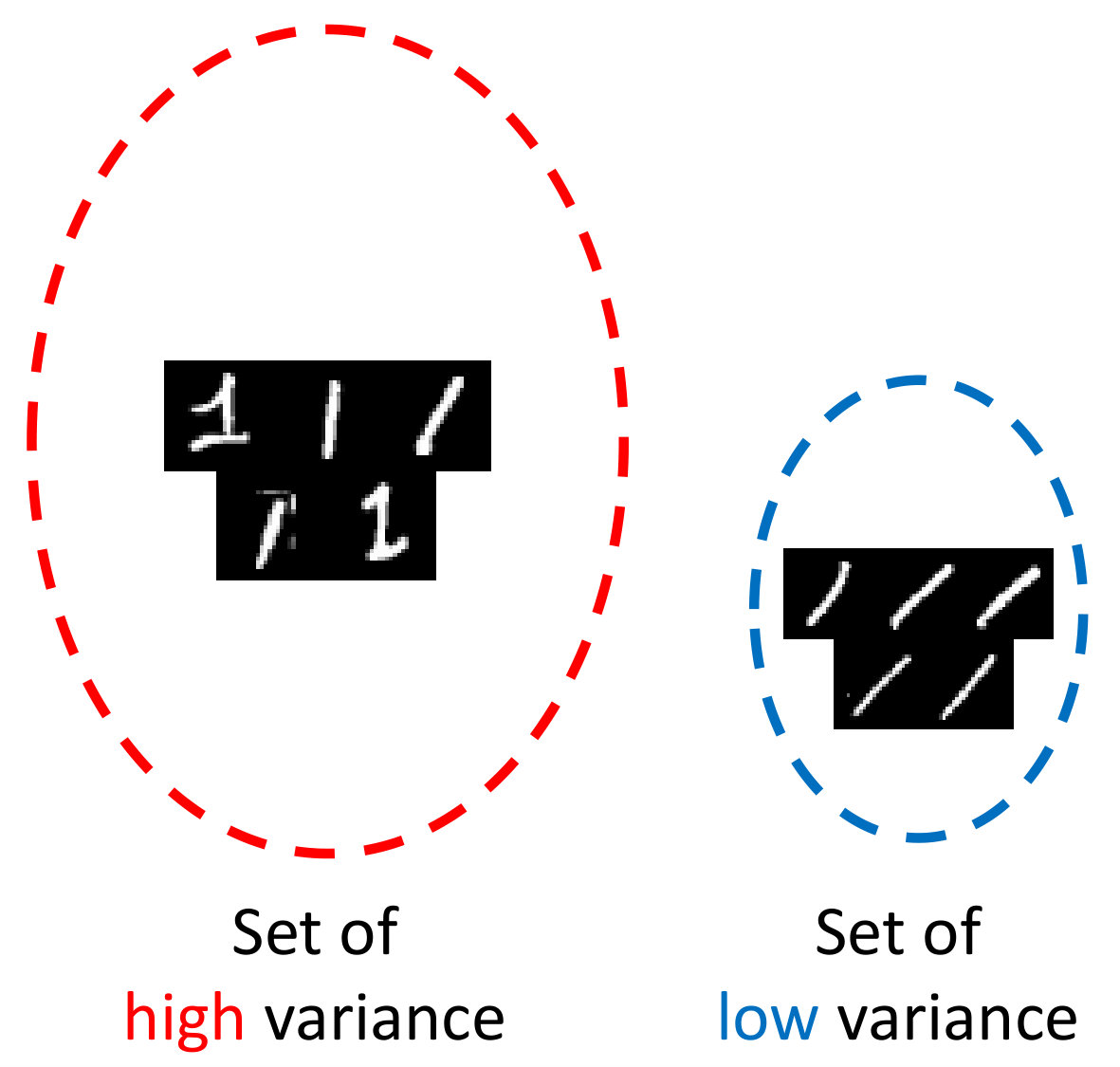 Figure 20
Figure 20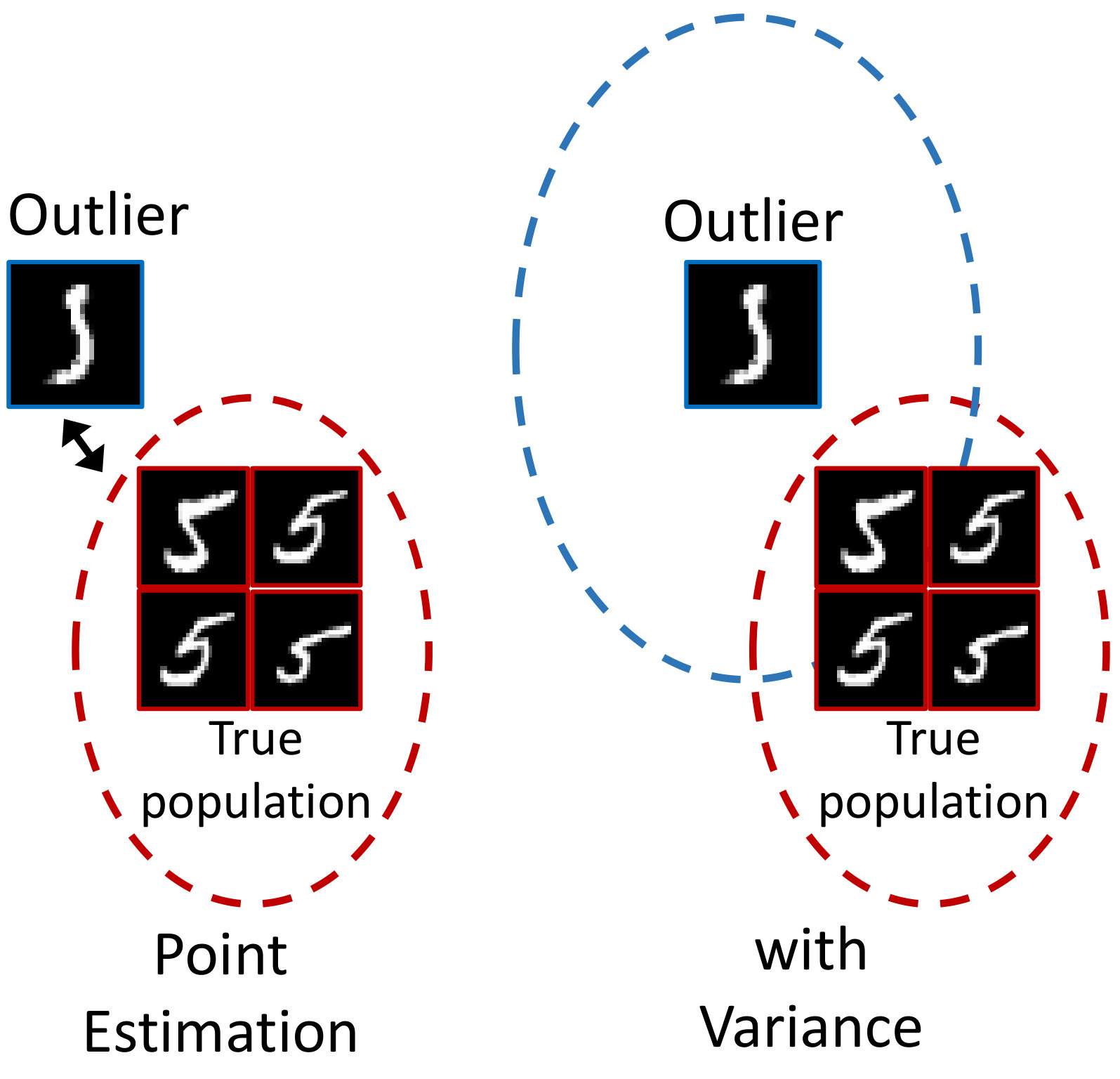 Figure 21
Figure 21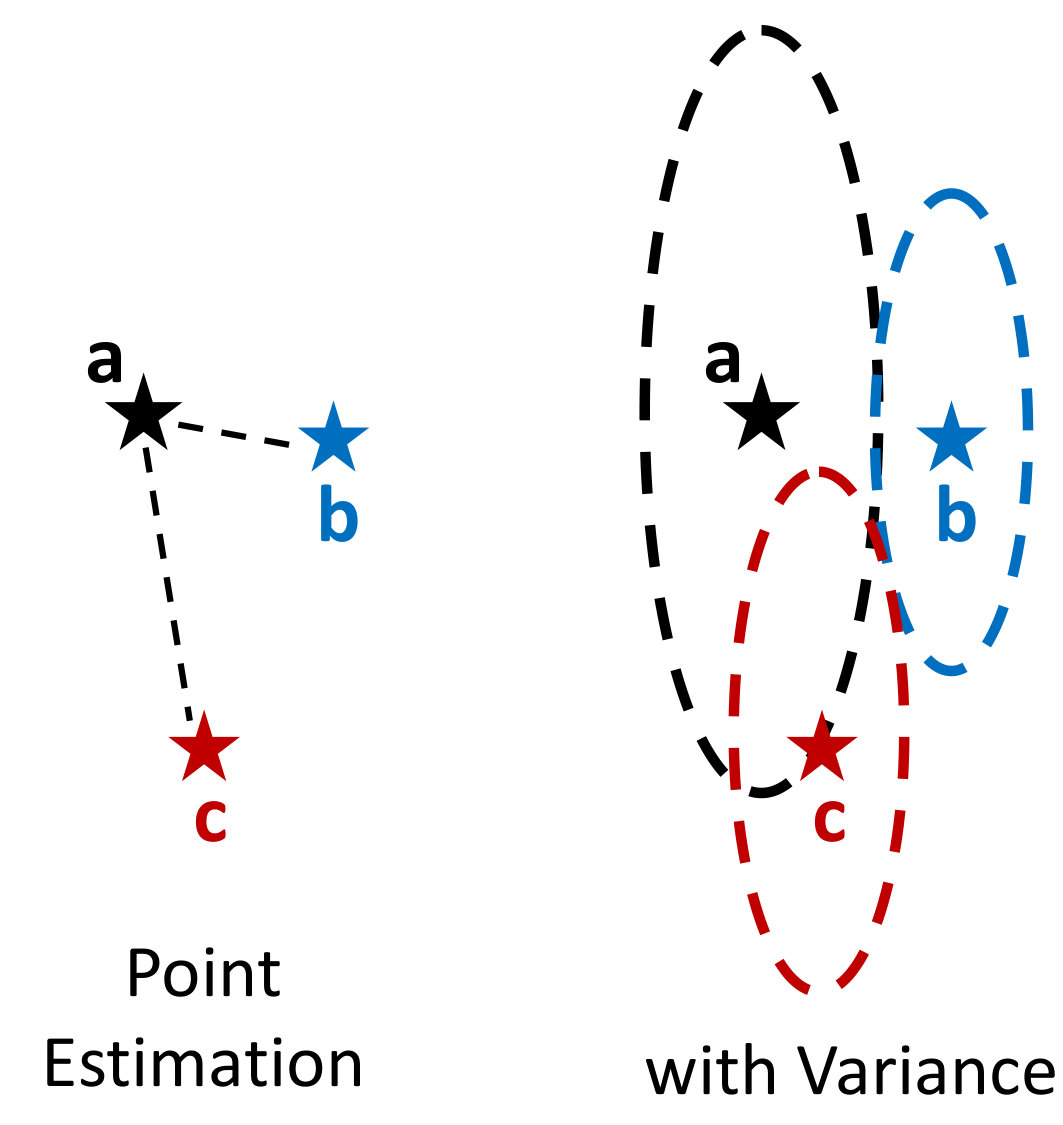 Figure 22
Figure 22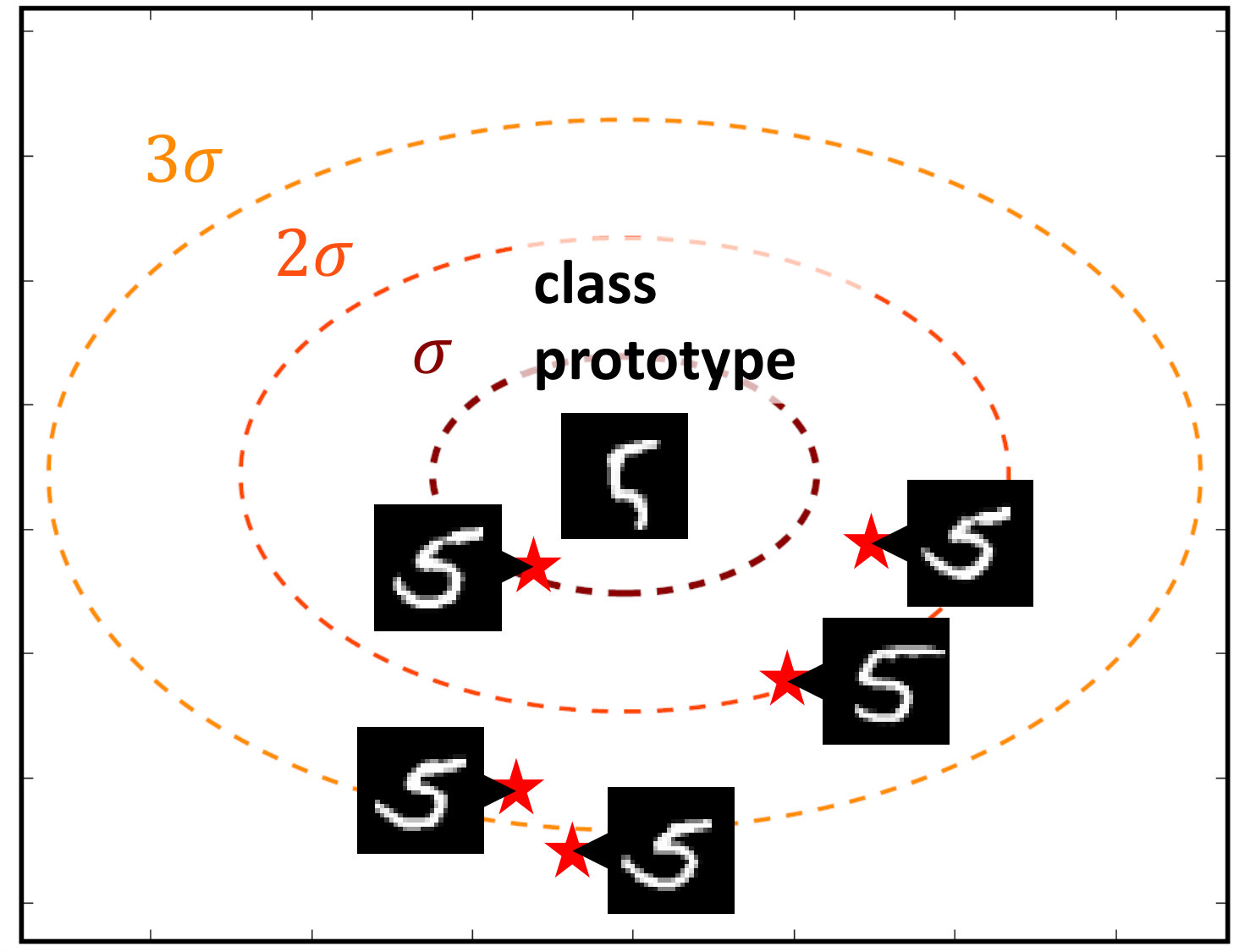 Figure 23
Figure 23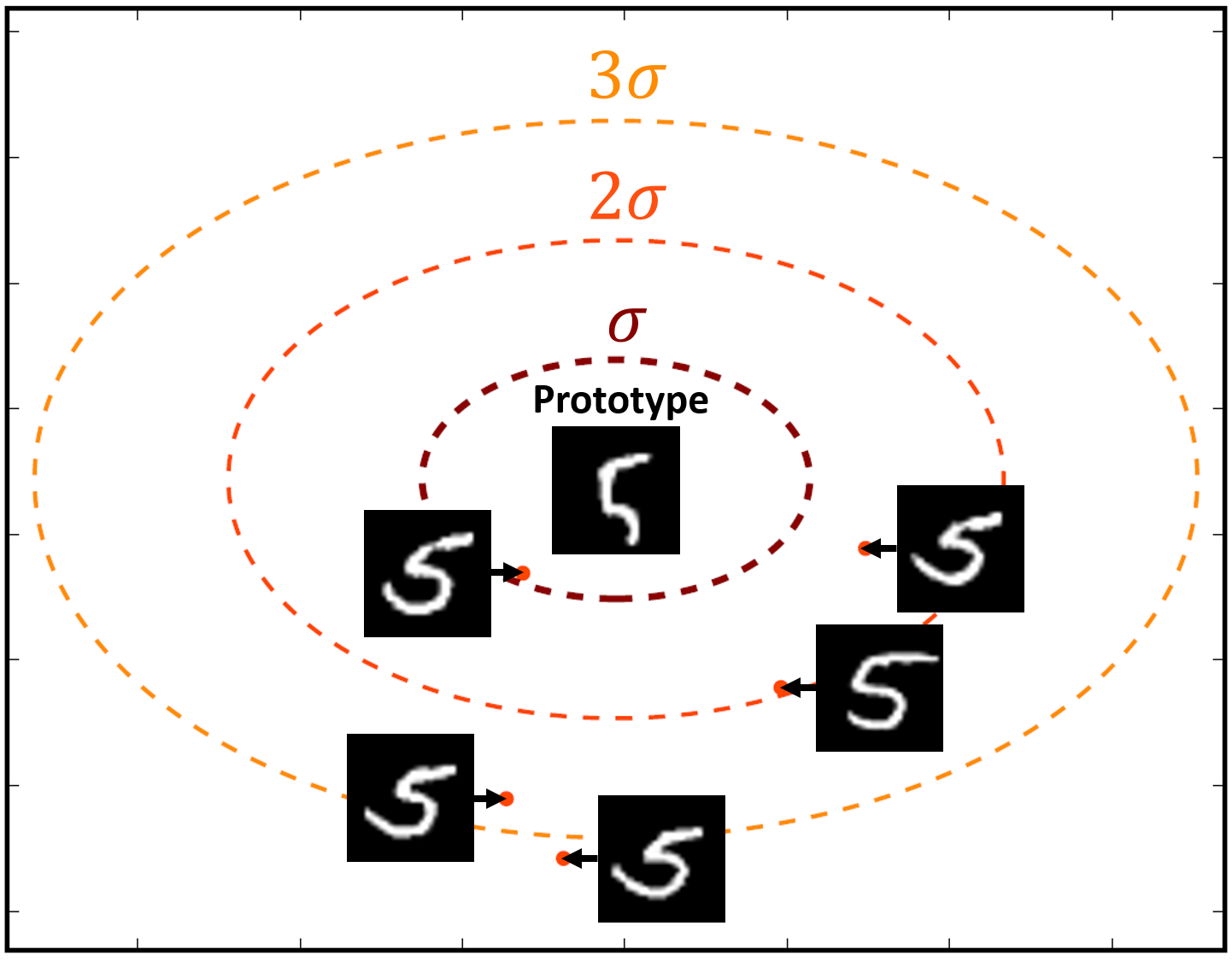 Figure 24
Figure 24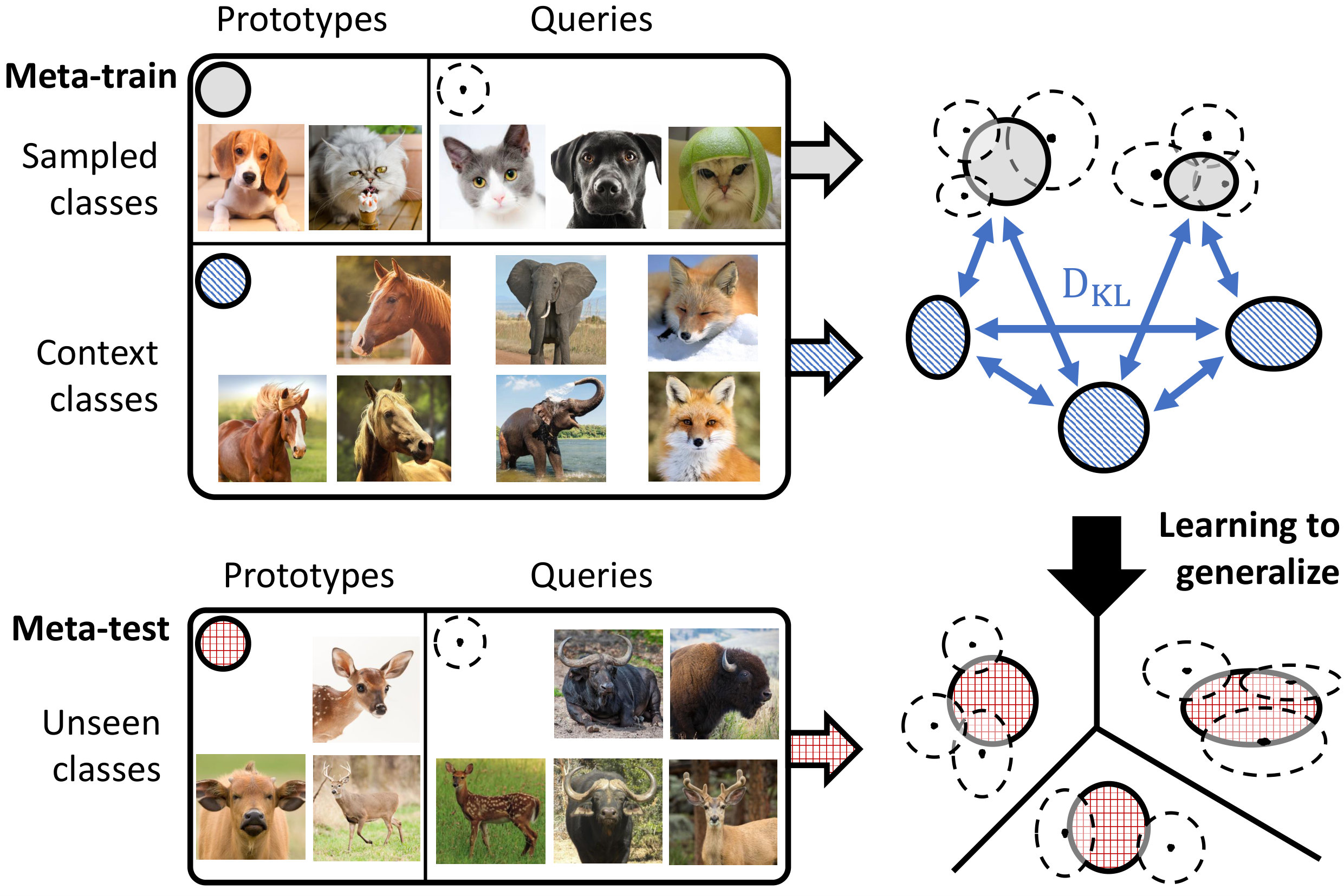 Figure 25
Figure 25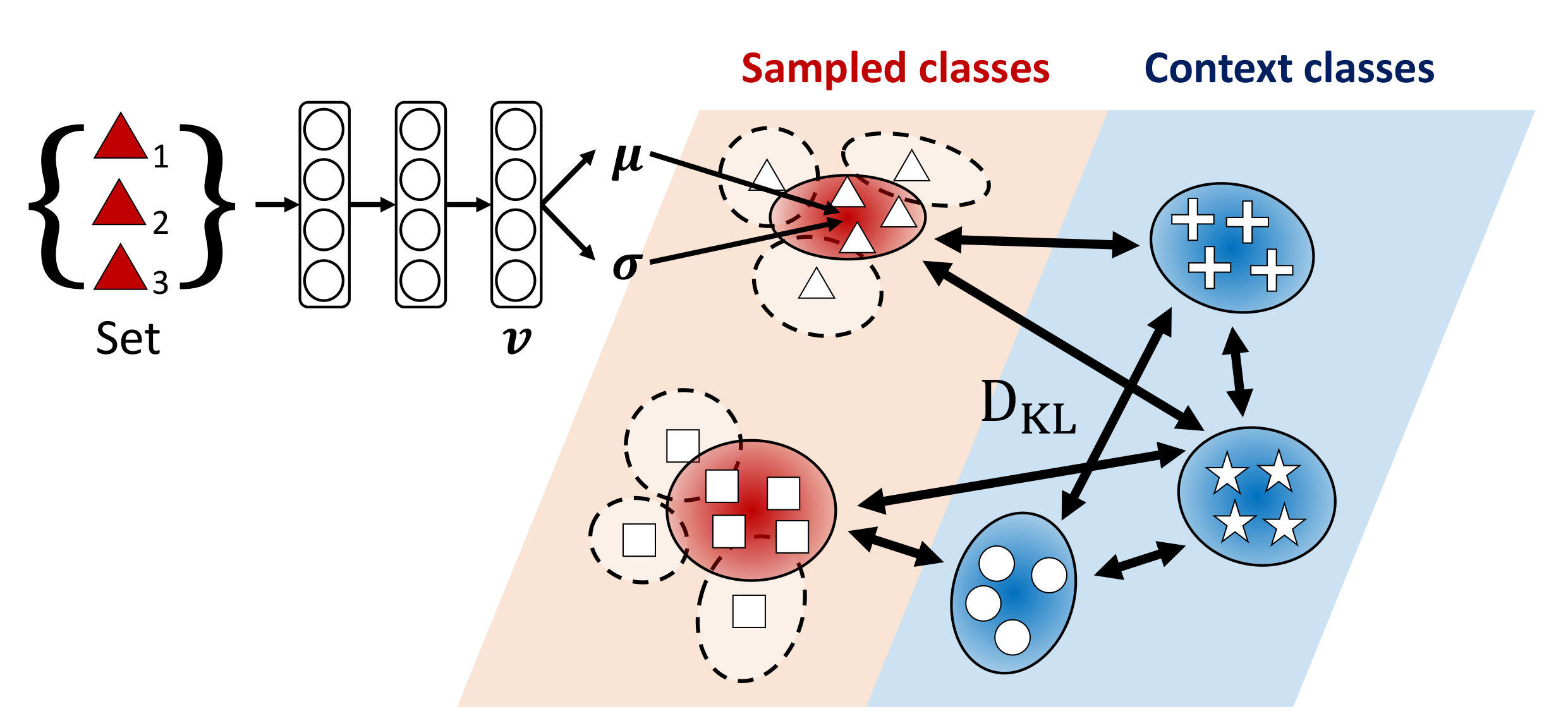 Figure 26
Figure 26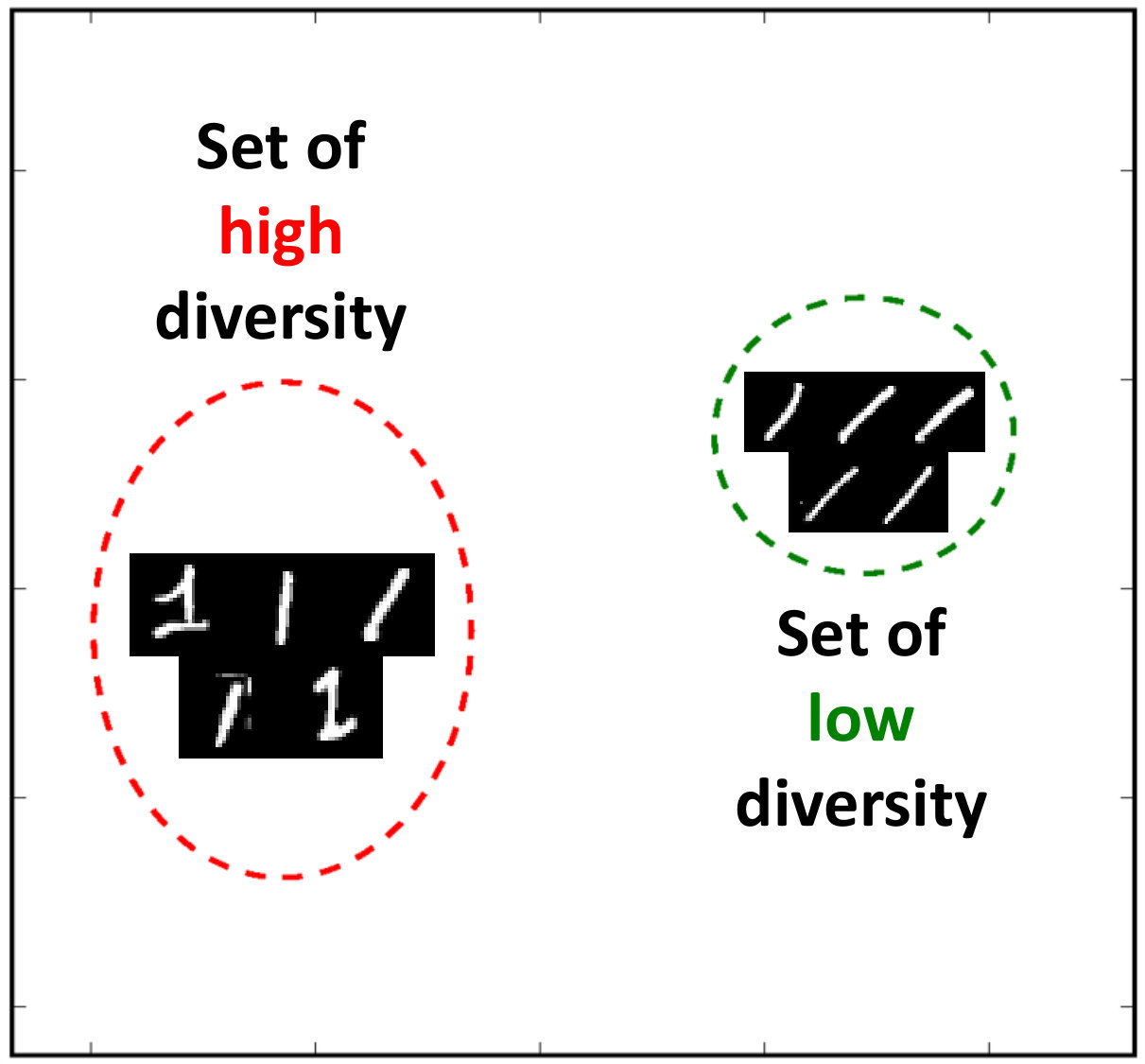 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29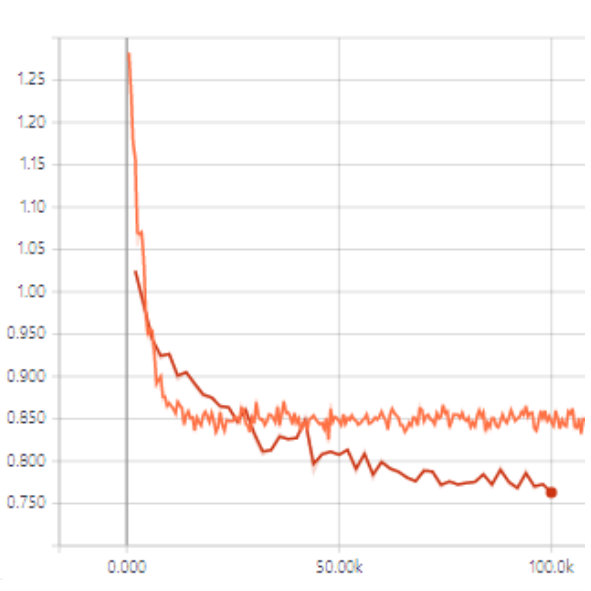 Figure 30
Figure 30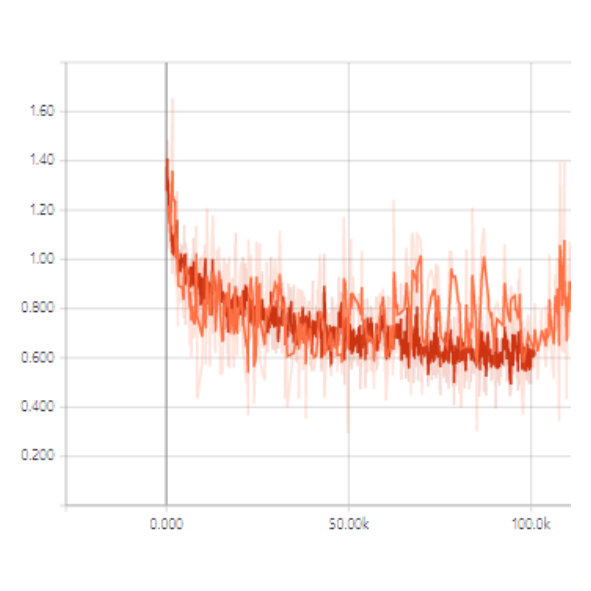 Figure 31
Figure 31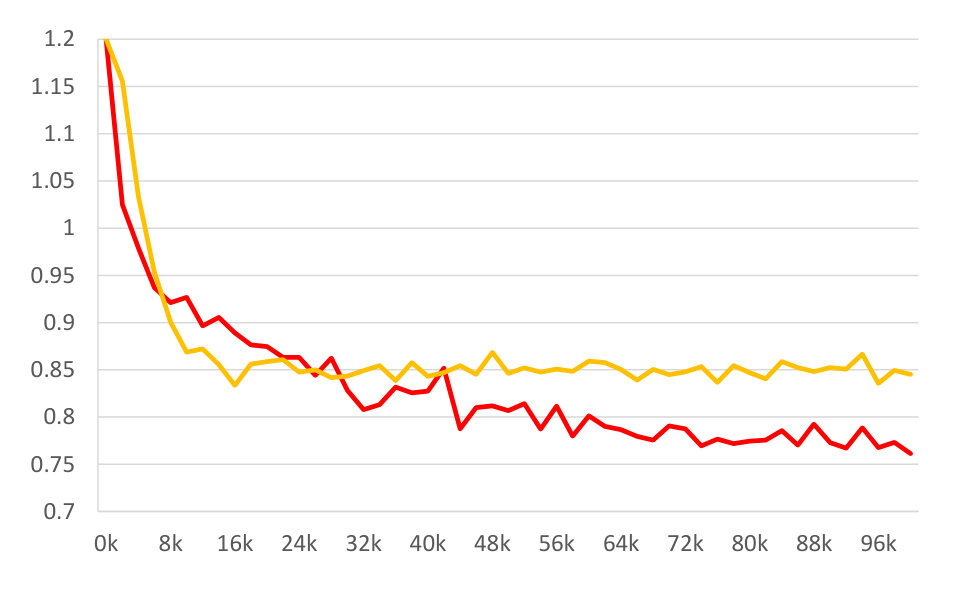 Figure 32
Figure 32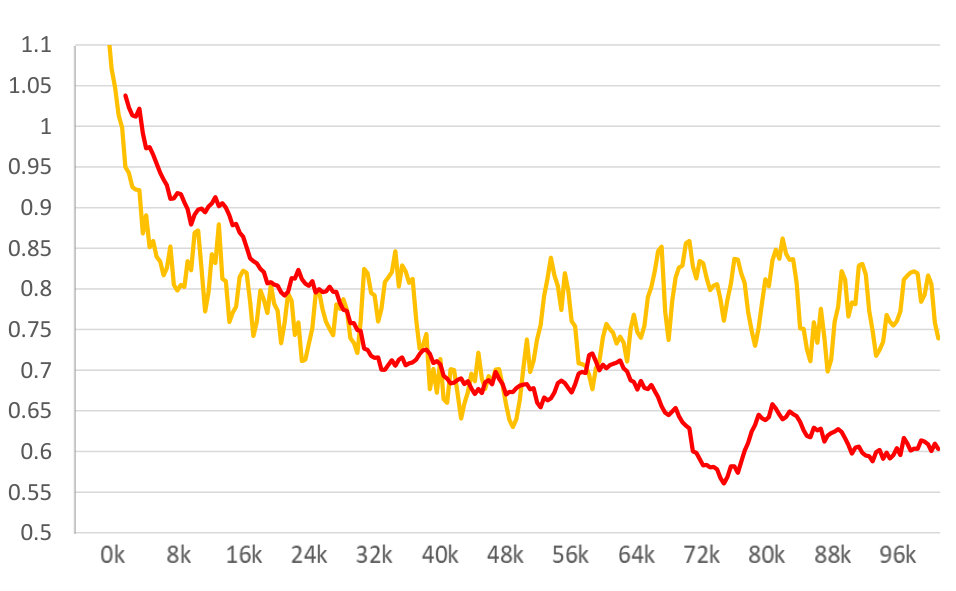 Figure 33
Figure 33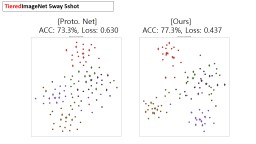 Figure 34
Figure 34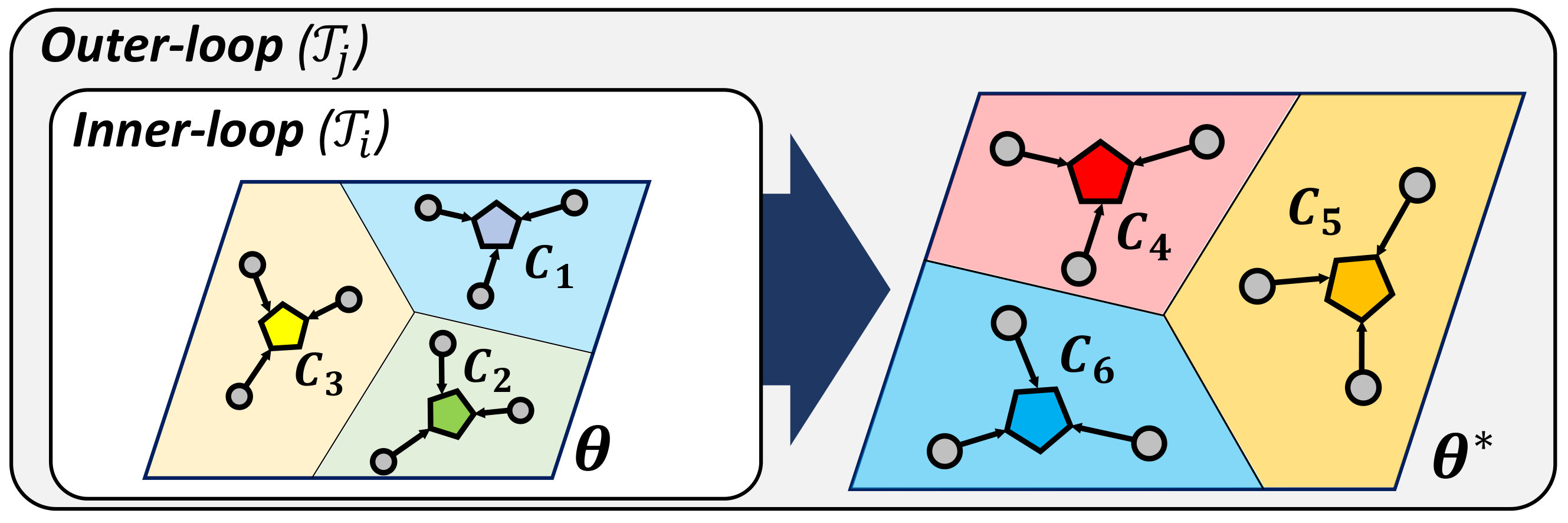 Figure 35
Figure 35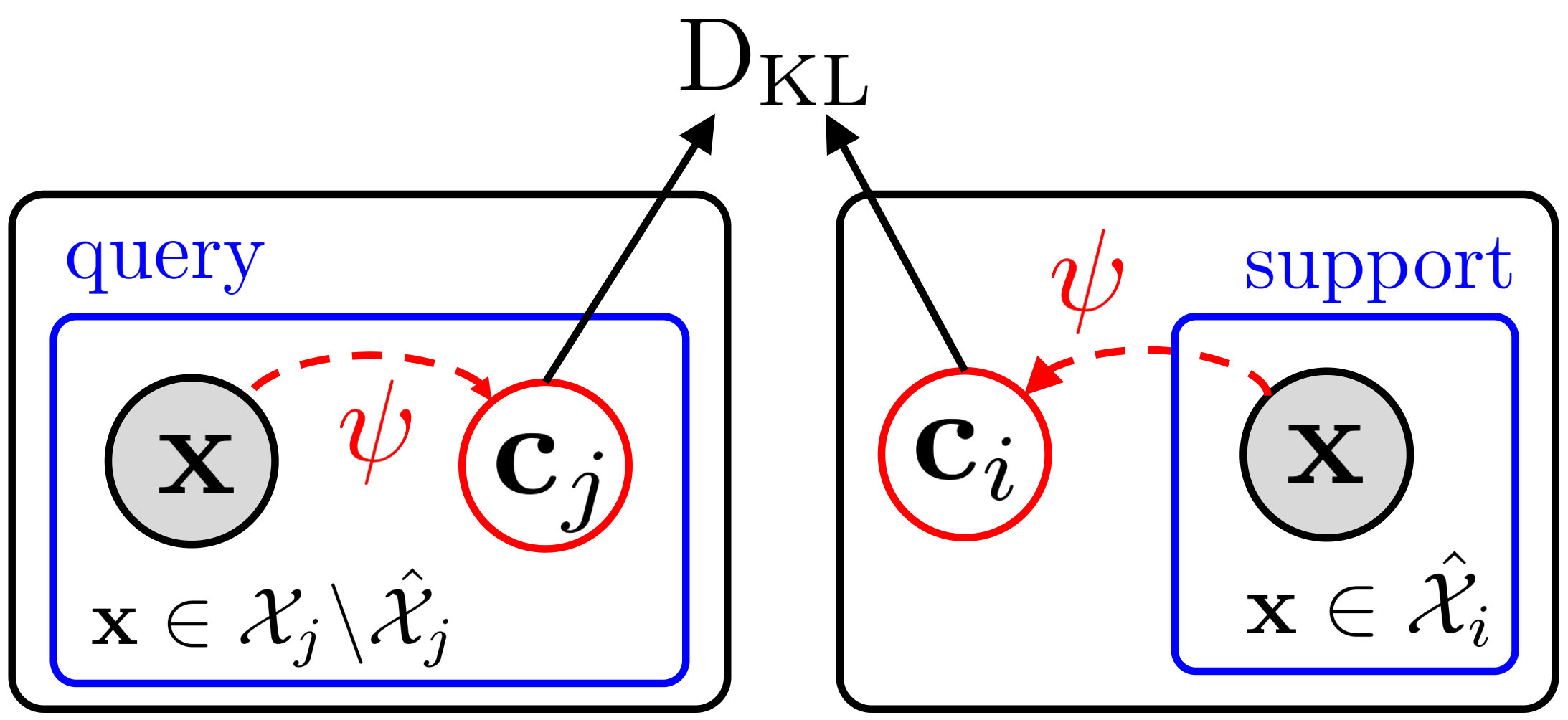 Figure 36
Figure 36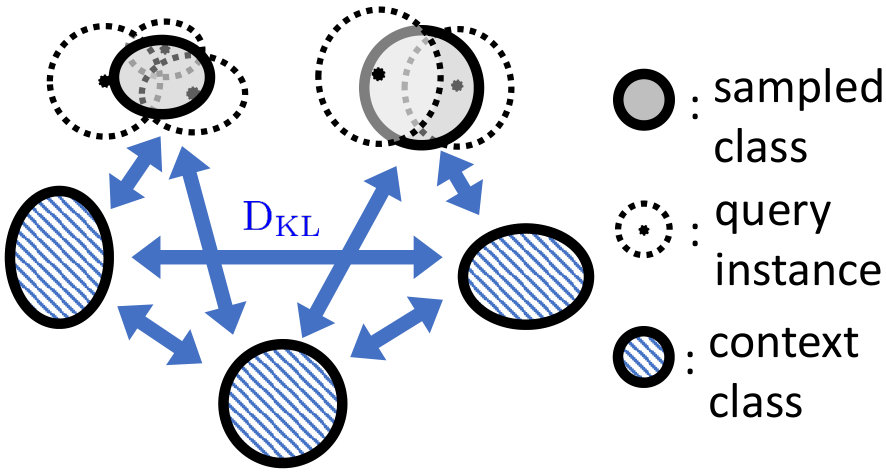 Figure 37
Figure 37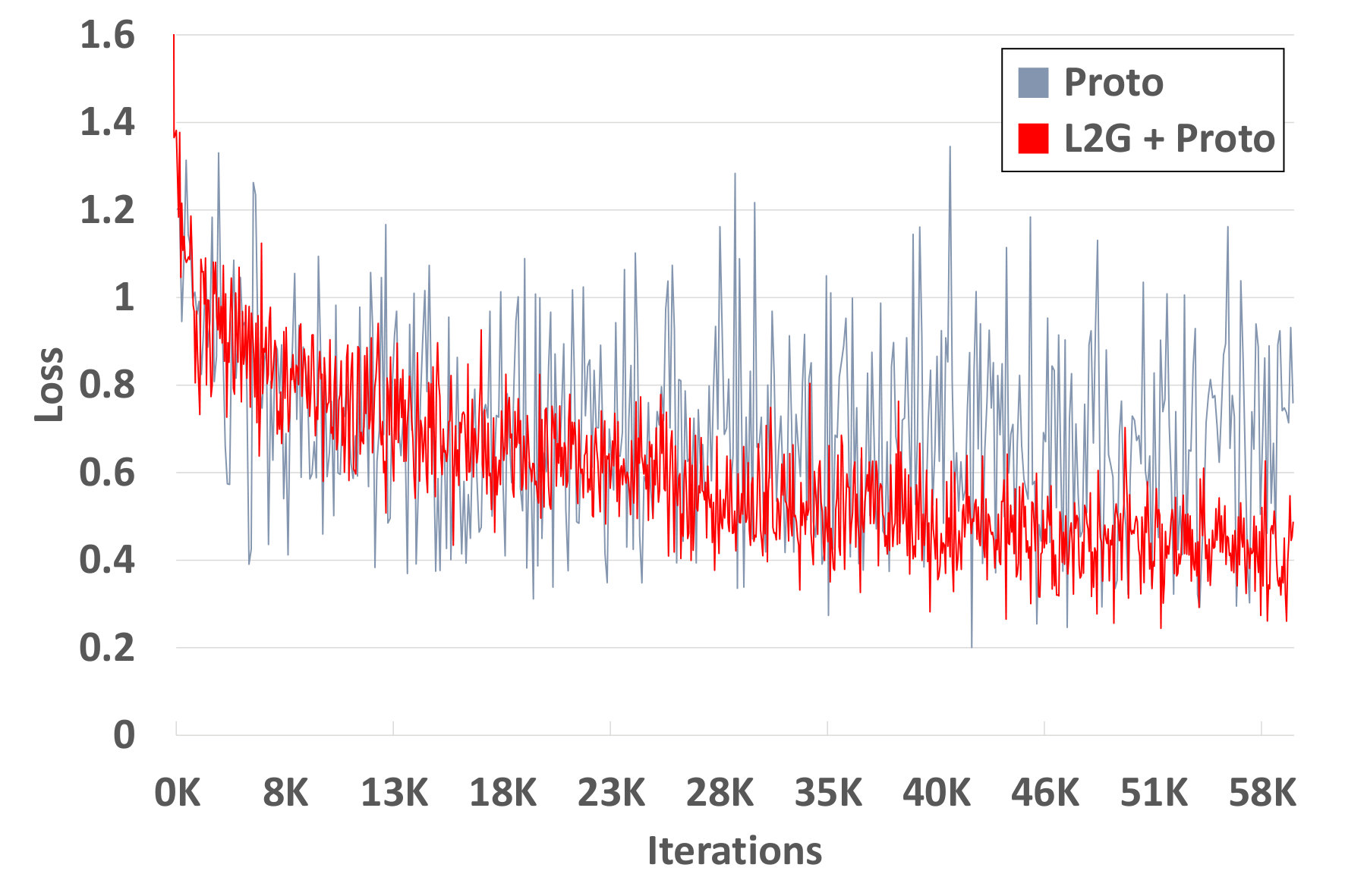 Figure 38
Figure 38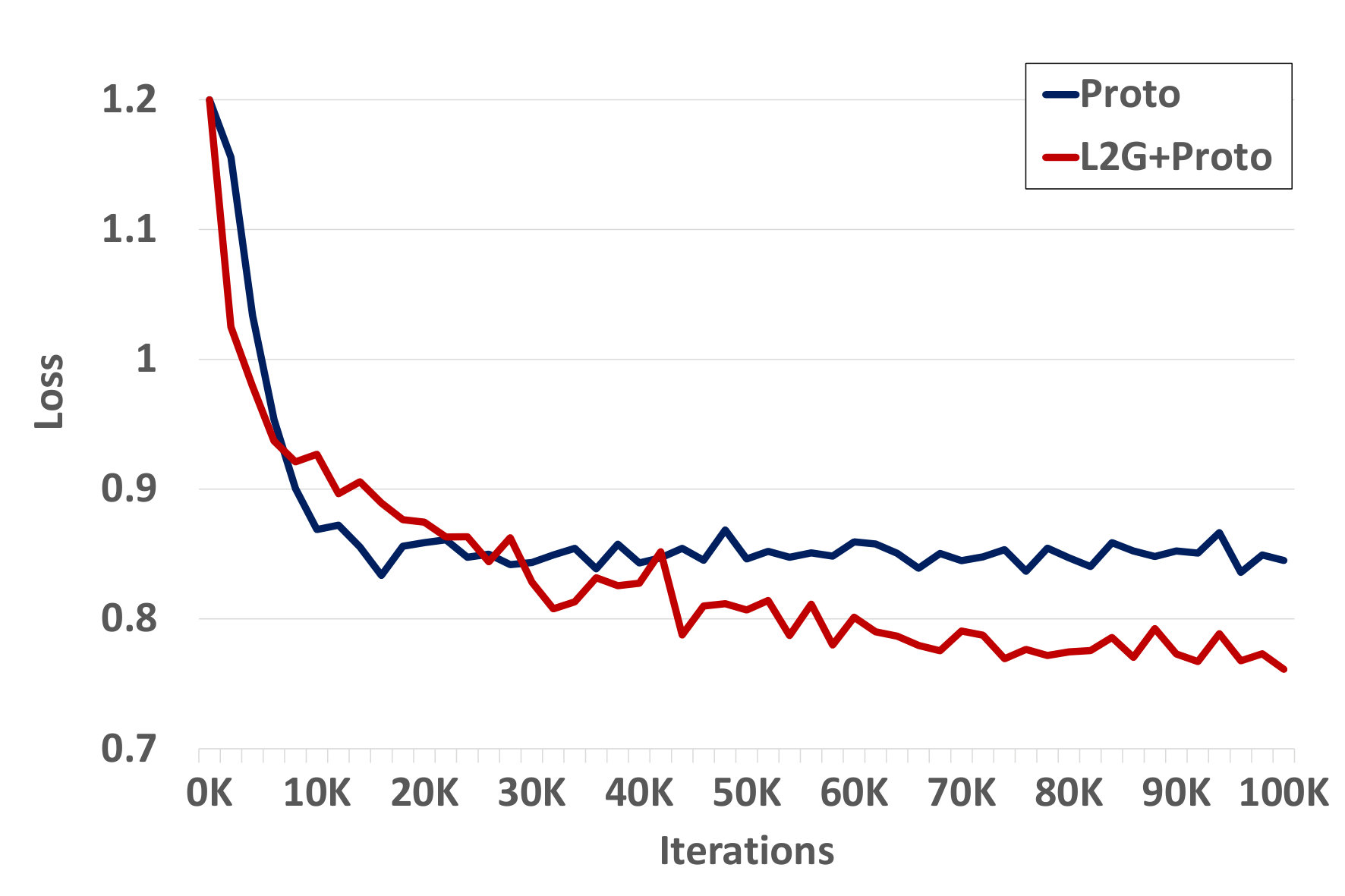 Figure 39
Figure 39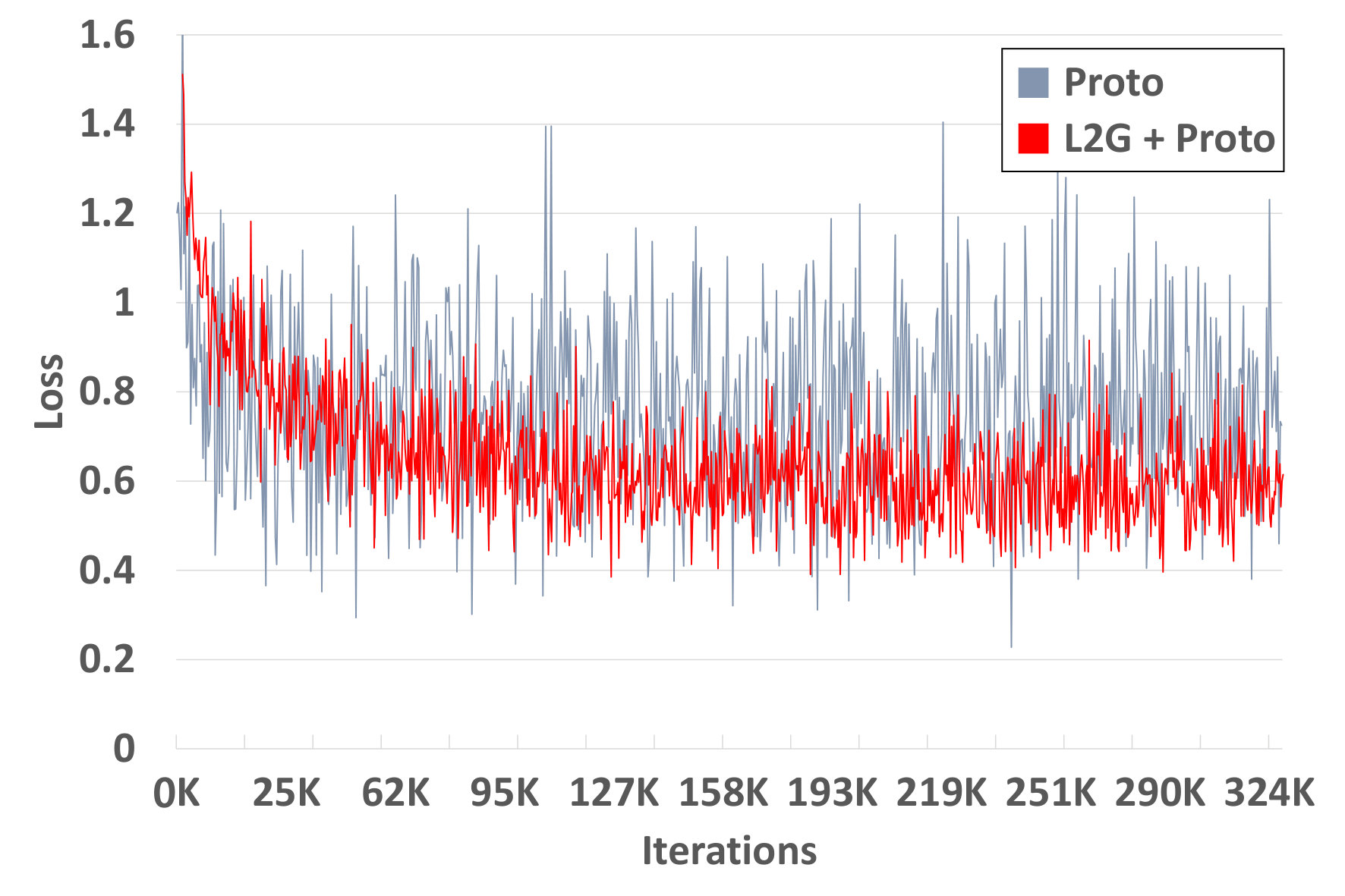 Figure 40
Figure 40| 5-way | 10-way | |||
| Models | 1-shot | 5-shot | 1-shot | 5-shot |
| Matching Nets [5] | 43.56 0.84 | 55.31 0.73 | - | - |
| Meta-learn LSTM [19] | 43.44 0.77 | 60.60 0.71 | - | - |
| MAML [14] | 48.70 1.84 | 63.11 0.92 | 31.27 1.15 | 46.92 1.25 |
| Prototypical Network [8] | 46.14 0.77 | 65.77 0.70 | 32.88 0.47 | 49.29 0.42 |
| MAML + Prototypical Network | 46.73 0.27 | 65.58 0.32 | 32.31 0.23 | 47.61 0.21 |
| L2G + Prototypical Network | 50.20 0.45 | 66.19 0.33 | 33.82 0.24 | 50.71 0.12 |
| Relation Network [13] | 51.38 0.82 | 67.07 0.69 | 34.86 0.48 | 47.94 0.42 |
| MAML + Relation Network | 52.08 0.37 | 66.70 0.28 | 35.07 0.18 | 51.52 0.14 |
| L2G + Relation Network | 52.38 0.36 | 68.11 0.15 | 36.11 0.30 | 51.40 0.16 |
| 5-way | 10-way | |||
| Models | 1-shot | 5-shot | 1-shot | 5-shot |
| MAML [14] | 51.67 1.81 | 70.30 1.75 | 34.44 1.19 | 53.32 1.33 |
| Prototypical Network [8] | 48.58 0.87 | 69.57 0.75 | 37.35 0.56 | 57.83 0.55 |
| L2G + Prototypical Network | 53.47 0.56 | 72.19 0.19 | 37.38 0.27 | 58.44 0.23 |
| Relation Network [13] | 54.48 0.93 | 71.31 0.78 | 36.32 0.62 | 58.05 0.59 |
| L2G + Relation Network | 56.09 0.32 | 71.97 0.21 | 39.15 0.34 | 57.82 0.46 |
| Models | Any-shot | Any-way | Any-shot & Any-way |
|---|---|---|---|
| Prototypical Networks | 58.52 0.38 | 57.94 0.25 | 51.02 0.30 |
| L2G + Prototypical Networks | 60.64 0.31 | 58.08 0.48 | 53.00 0.28 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Machine Learning and Algorithms · Stochastic Gradient Optimization Techniques
Learning to Generalize to Unseen Tasks
with Bilevel Optimization
Hayeon Lee1, Donghyun Na1, Hae Beom Lee1, Sung Ju Hwang1,2
KAIST1, AITRICS2
South Korea
{hayeon926, donghyun.na, haebeom.lee, sjhwang82}@kaist.ac.kr
Abstract
Recent metric-based meta-learning approaches, which learn a metric space that generalizes well over combinatorial number of different classification tasks sampled from a task distribution, have been shown to be effective for few-shot classification tasks of unseen classes. They are often trained with episodic training where they iteratively train a common metric space that reduces distance between the class representatives and instances belonging to each class, over large number of episodes with random classes. However, this training is limited in that while the main target is the generalization to the classification of unseen classes during training, there is no explicit consideration of generalization during meta-training phase. To tackle this issue, we propose a simple yet effective meta-learning framework for metric-based approaches, which we refer to as learning to generalize (L2G), that explicitly constrains the learning on a sampled classification task to reduce the classification error on a randomly sampled unseen classification task with a bilevel optimization scheme. This explicit learning aimed toward generalization allows the model to obtain a metric that separates well between unseen classes. We validate our L2G framework on mini-ImageNet and tiered-ImageNet datasets with two base meta-learning few-shot classification models, Prototypical Networks and Relation Networks. The results show that L2G significantly improves the performance of the two methods over episodic training. Further visualization shows that L2G obtains a metric space that clusters and separates unseen classes well.
1 Introduction
While deep learning models such as CNNs have been proven effective on multi-class classification [1, 2, 3], even surpassing human level performances [4], such impressive performances are obtained with the availability of large number of training instances per class. However, in more realistic settings where we could have very few training instances for some classes, deep learning models may fail to obtain good accuracies due to overfitting. On the other hands, humans can generalize surprisingly well even with a single example from each class. This problem, known as the few (one)-shot learning problem, has recently attracted wide attention, leading to the proposal of many prior work that aim to prevent the model from overfitting when trained with few instances.
Recently, metric-based meta-learning approaches that learn to generalize over a distribution of task rather than a distribution of a single task [5, 6, 7, 8] have obtained impressive performances on the few-shot learning tasks. They tackle the low-data challenge in few-shot learning problems by iteratively training a common metric space over large number of randomly sampled classification problems. Specifically, at each episode, the embedding function that embeds instances onto the metric space, is learned to minimize the distance between the instance embeddings (query) and their correct class embeddings (supports), which are randomly sampled from the entire dataset, based on some distance measure. Matching Networks [5], Prototypical Networks [8], and Relation Networks [9] are examples of such metric-based few-shot learning approaches, which are known to perform well and are computationally efficient as well.
However, these approaches are limited in that training for each episode optimizes the embedding function to discriminate between classes belonging to a very small subset of the entire class set, without explicit consideration of how this training will affect the classification between classes that are not sampled at this episode. Thus, while the model is trained with the hope that it will generalize to a novel classification task, this effect is only implicitly obtained and cannot clearly separate and cluster the newly given tasks at meta-test time. Using ‘higher way’ or ‘higher shot’ during meta-training to consider classification between more number of classes with larger shots than what they will observe at meta-test time, is one possible solution to improve the generalization performance. Yet, this makes meta-learning expensive since the number of pairs between supports and queries will increase quadratically.
To tackle this limitation of conventional metric-based meta-learning approaches, we propose a novel meta-training framework that explicitly learns to generalize, by enforcing the training of the metric space in one task to be also effective for classification between other classes in another task. Specifically, at each training episode, we sample two tasks and to solve a bilevel optimization problem [10], where we train on task in the inner loop starting from a common model parameter which not only minimizes the loss on this task but should also minimize the loss on an unseen task . Please see Figure 1 for the high-level concept. While in general it may not make sense to train a task-specific model parameter to generalize to another task; however in case of metric-learning approaches, this is possible since the model learns a generic space for classification. With this regularization enforcing the learning on each task to generalize to another, the model learns generic knowledge useful for classification. For example, this will learn that instances for each class should be well clustered in the metric space, in order to classify well between instances from unseen classes. Since our model requires the task-shared initial parameters to generalize well, it fits well to metric-based meta-learning framework whose solution obtained during meta-training should generalize to unseen tasks without any further training.
Our meta-learning to generalize (L2G) framework is simple yet effective, and can generalize to any metric-based meta-learning approaches regardless of the specific model details. We validate our L2G framework on benchmark datasets, namely mini-ImageNet and tiered-ImageNet with Prototypical Networks and Relation Networks as the base model. The results show that the L2G framework significantly improves the performances of the both meta-learning models over episodic training. Further visualizations of the learned metric space show that this improvement comes from our model’s ability to obtain well-clustered and separable space even on unseen classes.
In summary, our contribution is twofold:
- •
We propose a novel and generic meta-learning framework which we refer to as learning to generalize (L2G), that trains a metric-based meta-learning model to explicitly generalize to a different classification task from a sampled classification task at each episode.
- •
We validate our model on two benchmark datasets with two base metric-based meta-learning models, whose results suggest that our L2G framework can significantly improve the generalization performance, regardless of the base model, by obtaining a well-separable metric space on unseen classes.
2 Related Work
Meta-learning
Meta-learning [11] is an approach to generalize over tasks from a task distribution, rather than over samples from a single task. Meta-learning approaches could be categorized into memory-based, metric-based, and gradient-based appraoches. MANN [12] is a memory-based method, which learns task-generic knowledge by learning to store the instance and its correct label into the same slot, and retrieve it later to predict the label of unseen instances. Metric-based meta-learning approaches tackle the task generalization problem by learning a common metric space that could be shared across any tasks from the same task distribution. Matching networks [5] proposed to train a model over multiple episodes (tasks), where at each episode the training set for each class is divided into support instances that represent the class and query instances that is trained to have large similarity to the support instances. Prototypical networks [8] proposed to use Euclidean distance for the same purpose, constraining the instances from the same class to be clustered around a single class prototype, and Relation networks [13] further learn the distance metric with additional nonlinear transformation. Gradient-based approaches, such as Model Agnostic Meta-Learning (MAML) [14] aim to learn an initialization parameter that enables to quickly adapt to new tasks with few gradient update steps, and F that learns good initialization parameter for fast adaptation. While meta-learning approaches generalize well to new tasks, this was an effect rather than an explicit objective. On the other hand, in our learning to generalize framework, we explicitly aim for generalization.
Meta-learning with bilevel optimization
Bilevel optimization, a special kind of optimization that forms nested strucutre of optimization problems, where we have an upper-level problem and a lower-level problem [10]. The lower-level problems or the inner loop, which expects to hand over the feasible candiates for the upper-level optimization, often includes simpler optimization problems in a constrained situation. Recently, MAML [14] proposed to leverage this hierarchical optimization technique to obtain an optimal initialization parameter for a variety of tasks, which became popular as it allowed meta-learning of any models for fast adaptation and generalization to new tasks. Li et al. [15] and Lee et al. [16] further provides regularization on these update stages by introducing learnable learning rate and parameter mask. However, all these models update the outer parameter with respect to the same task used for the inner loop. On the other hand, with our model, the update on the inner loop should solve another task at the outer loop, and thus it is more similar to the original concept of bilevel optimization, which largely focuses on transferring generic information from the pre-simulated tasks, whereas the others simply try to obtain parameters for the given task.
3 Approach
3.1 Problem Definition
We start by introducing the episodic training strategy which is widely used for solving few-shot classification problem. Since few-shot learning problems suffer from low-data challenge, many existing works [5, 6, 7, 8] resort to meta-learning, which trains the model to generalize over a task distribution . This is done by training it over large number of tasks, where at each task we train the model on a randomly sampled tasks . By training the model over randomly sampled few-shot classification tasks(or episodes) , we expect to obtain generic knowledge for classification that can be utilized to solve any few-shot classification problems.
Formally, at meta-training time, for each episode , the task consists of classes are randomly selected from the training dataset. Then for each class , we randomly sample the support set and the query set , where each of and denotes the number of support and query instance. By aggregating the support and the query set for all classes as and , we can define an task is as a tuple , which is for -way -shot classification problem. At meta test time, we are given a task where and contain examples of classes unseen during meta-training time.
3.2 Embedding-based Few-shot Learning Apporaches
We briefly describe a generic framework for metric-based few-shot meta-learning methods [8, 13, 5]. The goal of metric learning approaches is to obtain the optimal embedding function with parameters for the given series of task . We can handle diverse forms of learning objective depending on modeling assumption. For now we simply denote it as a . For a given task , the metric learning apporaches encode each support instance and query instance with the embedding function for all . Then, the prototype for class is constructed by adding or averaging embedding vectors to represent each class:
[TABLE]
where is function which generate a prototype from the embedding vectors of the sample instances. We can construct loss by computing distance between a query instance and a set of prototypes for all class within the given task. The distance measure could either be a fixed measure, as with Prototypical Networks [8] which leverage the Euclidean distance, or could be learned as with Relation Networks [13] that trains the similarity measure between the two instances using a separate network with additional parameters. Then for a given task consisting of the support and query set, we minimize the following loss for all query examples :
[TABLE]
The loss should be minimized if , the distance between and its correct class prototype , is minimized and is large, where .
3.3 Learning to Generalize to Unseen Classes
Existing embedding-based approaches learn a metric space over large number of episodes, where given a single episode, a classifier tries to correctly classify query instances based on the class prototypes. However, the main limitation of such an approach is that the embedding function is only trained for classifying given small set of classes at a time, which does not consider generalization of the learned embedding to unseen classes. This explains the reason the metric-based methods such as Prototypical Networks converge fast, but at the same time, trained embedding function may be suboptimal with its myoptic optimization process.
To overcome this shortcoming, we propose a framework which enforces a model to explicitly learn transferrable meta-knowledge applicable to any tasks. Specifically, we pair two tasks as a single training unit at each iteration, and train the embedding function by constraining the learning in one task to be helpful to another task during meta-training. The intuition behind this approach is that the network learns more generalizable and transferrable internal features rather than task-specific features. Toward this goal, we adopt a bilevel optimization framework that is similar to MAML [17]. The goal of MAML [17] is to learn most amenable initialization parameters and to reach specific parameters adapted to the given task through gradient-based parameter updates with this bilevel optimization framework. However, our goal is to learn generalizable parameters for unseen tasks by regularizing the first task which considers the task loss on the second task when it performs optimization. Therefore, differently from MAML [17], in the meta-testing time, our model solves the few-shot classification problems with generalized initial parameters, which do not need fine-tuning with gradient updates for the given tasks. Specifically, we learn for the first task in the inner loop while constraining it to obtain low loss on the second task in the outer optimization loop, such that we update the shared network parameters for the second task with the gradients generated from the loss of the first task. Since learning on the task is regularized to work well for the task , this will allow task to learn a transferrable generic knowledge useful for few-shot classification of any given set of classes.
Note that this is only possible with the models where the same model parameter could be used to solve two different tasks. MAML is not compatible with our learning to generalize framework, since the parameters of the softmax classifier for a few-shot classification task will not work for another few-shot classification task with different sets of classes. On the other hand, with metric-based models, a learned metric for one task is readily generalizable to another task without any modification, as it is essentially a task-generic space where we could embed any instances from any classes onto. Thus we use metric-based meta-learning models for our learning to generalize framework. In Table 1 and 2, we show that our model outperforms baselines without finetuning since initial parameter is already optimized to minimize classification error on a task consisting of unseen classes.
Formally, we construct an inner-gradient update step with the model parameters :
[TABLE]
In our case, the step size is a fixed hyperparameter, but we can learn it as done with Meta-SGD [15]. We sample the second task from a disjoint set of classes to the classes in the task , and compute the loss with updated parameters by encoding all query input and prototypes of . Then our goal is to meta-learn a that minimizes the following meta-objective:
[TABLE]
Note that when the model parameters are updated using the gradients computed from the first task , the model parameters are optimized to perform the classfication of the second task . This allows the model to effectively learn the generalized classification for unseen classes across episodes. Then we can perform the meta-update as follows:
[TABLE]
where is the meta step size. Algorithm 1 describes the detailed steps of our meta-learning algorithm.
3.4 Learning to Generalize with Embedding-based Meta-Learners
While our framework could work with any metric-based meta-learning methods, we apply it to two most popular models, namely Prototypical Networks [8] and Relation Networks [13].
Prototypical Networks [8]
This is a metric-based few-shot meta-learning model which is discriminatively trained to minimize the relative Euclidean distance between each instance and its correct class prototype over its distances to other class embeddings. Each prototype is a mean vector of the support instance embeddings :
[TABLE]
For distance measure, we use Euclidean distance:
[TABLE]
Objective function is based on a softmax over distances to the prototypes in the embedding space with the negative log-probability :
[TABLE]
Relation Networks [13]
This model learns a distance metric using a subnetwork on the concatenated vectors of each class prototype and query instance to generate relation scores between them. An embedding function of a Relation Network produces features of query instances and sample instances of each class. Relation Networks create prototypes by adding features from sample instances of each class.
[TABLE]
After concatenating each prototype and query instance, the relation module with learnable distance measure computes the relation score between each of the query instances and class prototypes:
[TABLE]
Relation Net uses Mean Square Error (MSE) for the objective as follows:
[TABLE]
where and denotes the labels. The model is trained to match the support and query instances in each class with the relation score that penalizes the incorrect predictions.
4 Experiment
Datasets
We validate our framework on two benchmark datasets for few-shot classification.
1) mini-ImageNet. This dataset is a subset of a ImageNet [18] which consists of classes with examples for each. We follow the dataset split and pre-processing procudure described in [19], which divides the dataset into 64/16/20 classes for training/validation/test, and resizes original image into pixels.
2) tiered-ImageNet. This dataset is also a subset of the ImageNet [20] with classes. We split the dataset into 351/97/160 classes for train/validation/test set and follow other experiment settings as described in [21].
Baselines
We compare models trained with our framework against various meta-learning baselines.
1) Matching Networks. This is another metric-based model [5] that is trained using episodic training. However, this model leverages cosine distance instead of Euclidean distance.
2) Meta-learner LSTM. An optimization-based meta-learning model which trains an LSTM based optimizer [19] over a distribution of tasks during meta-training, which is used to optimize the target problem at meta-test time.
3) MAML Model-Agnostic Meta-Learning(MAML) model [17], which aims to learn a shared initialization parameters that can adapt to any given tasks with only a few gradient update steps.
4) Prototypical Network Prototypical Networks [8] described in the previous section.
5) Relation Network Relation Networks [13] described in the previous section.
6) MAML + X This is a metric-based meta-learning models trained in the original MAML framework, which is trained with bilevel optimization scheme, but is not trained to generalize to another task. In our experiments, we use MAML + Prototypical Networks and MAML + Relation Networks which are basically Prototypical Networks and Relation Networks trained in MAML framework.
7) L2G + X L2G + X denotes our proposed model, which trains the model to generalize well to another task, in a bilevel optimization framework. We implement both L2G + Prototypical Networks and L2G + Relation Networks.
Implementation Details
We adopt the same network architectures as baselines for fair comparison. The base networks of Prototypical Network [8] have four layers of convolutional blocks where each block contains 64 filters, convolution layer, a batch normalization, a ReLU activation function and max pooling layer at the end of each block. The base networks of Relation Net [13] have four convolutional blocks as the embedding function and two convolutional blocks and two fully connected layers which are the relation module to compute the relation score. The former two convolutional blocks of Relation Net have the same architecture to the block of Prototypical Network while the max-pooling layers of the latter two blocks are removed.
We use Adam optimizer [22] for training in all experiments. We set the update step size to , the number of tasks for the backward propagation to 5 and the initial learning rate to which is multiplied by at every 10K episode for L2G + Proto and 100K episodes for L2G + RN.
-way -shot Classification
We evaluate our L2G framework first on the conventional -way -shot classification task against relevant baselines [14, 8, 13]. Following [8], we train and evaluate models over large number of episodes, where at each episode we randomly sample classes with supports for each class. For our L2G framework, we generate and sample two tasks at each iteration in meta-training time. Note that the episode used for inner loop does not participate in the outer loop classification, which is clearly different from the "higher way" or "higher shot" setttings described in [8] where they use larger number of sampled classes or examples which participate in the classification. At meta-test time, our model sample only one task for each iteration and classifies between the unseen classes of the given task with the initial model without any further training.
We provide few-shot classification result under 5 and 10-way settings of mini-ImageNet in Table 1 and tiered-ImageNet in Table 2 respectively. The results clearly show the effectiveness of L2G framework, since both models trained with our meta-learning framework outperform the baselines across all conditions. Specifically, when it comes to 1-shot classification, which has insufficient information for the inference, the L2G framework yields even larger performance improvements, with at most 4.89% gain for 5-way 1-shot on tiered-ImageNet over the baseline. These are impressive performance gains, considering the simplicity of the learning framework. MAML + ProtoTypical Networks and MAML + RelationNetworks models do now show noticeable improvements except for 10-way 5-shot tasks on mini-ImageNet comparing to the original models which are Prototypical Network and Relation Net. This suggest that simple combinations between MAML and embedding models are not effective to learn generalization to unseen classes.
For further analysis of the behavior of our L2G meta-learning, we show the convergence plot in Figure 2, which shows the meta-training loss. Models trained with our L2G framework converge only slightly slower compared to the base models, and eventually converge at lower loss. We also provide the visualizations of the learned embeddings in Figure 3, which confirms the effectiveness of our framework. While the embeddings of the supports and queries from the with the original Prototypical Networks look scatters and overlapping, the model with L2G shows clean separation between classes. This may be due to its training objective whose main objective is to work well on unseen tasks.
Any-way & Any-shot Classification
To validate the leverage of generic information transfer, we introduce a novel any-way any-shot classification task, where both the number of shots and classes in each episode can largely vary. Table 3 shows the results of the base model and ours on the mini-ImageNet dataset. For any-shot classification, the number of shot randomly varies between -shots for each episode, and simliarly, the number of classes at each episode randomly varies between -ways for any-way setting. For training our L2G models, we fix the first task to a 5-shot classification problem and the generalization task to contain any-shot any-way classification problems. In the same manner, we train the Prototypical Network for any-shot and any-way classification. In the meta-test phase, we iteratively change the number of shots between and ways between with 600 episodes. Table 3 shows the results. We observe that combining L2G framework with the model consistently improves over the base model, suggesting that it learned to generalize to unseen tasks with varying number of classes and instances.
5 Conclusion
We proposed a novel meta-learning framework which we refer to as Learning to Generalize (L2G), which constrains the meta-learning process such that training on one task should generalize to unseen tasks. Specifically, we proposed a bilevel optimization problem, where we solve for a task by optimizing with respect to the task-shared parameter that should generalize well to another task. This framework goes well with metric-based meta-learning models, which learns a space that generalizes over any classification tasks. Based on this observation, we combine our model with two metric-based models, namely Prototypical Networks and Relation Networks. The models combined with our L2G framework significantly outperforms the base models when validated on standard few-shot classification tasks with fixed number of support instances, as well as on a novel task with varying number of support shots or classes. Further analysis with the embedding space visualization and the convergence plot shows the effectiveness of the learning to generalize framework, as it provides clear separation between unseen classes when applied to a meta-test time and allows the model to converge to much lower test loss.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Krizhevsky, A., I. Sutskever, G. E. Hinton. Image Net Classification with Deep Convolutional Neural Networks. In NIPS . 2012.
- 2[2] He, K., X. Zhang, S. Ren, et al. Deep Residual Learning for Image Recognition. In CVPR . 2016.
- 3[3] Huang, G., Z. Liu, L. van der Maaten, et al. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . 2017.
- 4[4] Deng, J., W. Dong, R. Socher, et al. Imagenet: A Large-Scale Hierarchical Image Database. In CVPR . 2009.
- 5[5] Vinyals, O., C. Blundell, T. Lillicrap, et al. Matching networks for one shot learning. In Advances in Neural Information Processing Systems , pages 3630–3638. 2016.
- 6[6] Santoro, A., S. Bartunov, M. Botvinick, et al. Meta-learning with memory-augmented neural networks. In International conference on machine learning , pages 1842–1850. 2016.
- 7[7] Rezende, D. J., S. Mohamed, I. Danihelka, et al. One-shot generalization in deep generative models. ar Xiv preprint ar Xiv:1603.05106 , 2016.
- 8[8] Snell, J., K. Swersky, R. Zemel. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems , pages 4080–4090. 2017.