Measuring the Algorithmic Convergence of Randomized Ensembles: The Regression Setting
Miles E. Lopes, Suofei Wu, Thomas C. M. Lee

TL;DR
This paper introduces a bootstrap method to assess whether a randomized ensemble in regression has converged to near-optimal performance, providing practical guarantees and adaptability for variable selection.
Contribution
It develops a bootstrap approach for measuring ensemble convergence in regression, with weaker assumptions and applications to variable selection, complementing prior classification work.
Findings
Method effectively measures ensemble convergence in regression.
The approach requires weaker assumptions than previous methods.
Numerical experiments show strong performance across various scenarios.
Abstract
When randomized ensemble methods such as bagging and random forests are implemented, a basic question arises: Is the ensemble large enough? In particular, the practitioner desires a rigorous guarantee that a given ensemble will perform nearly as well as an ideal infinite ensemble (trained on the same data). The purpose of the current paper is to develop a bootstrap method for solving this problem in the context of regression --- which complements our companion paper in the context of classification (Lopes 2019). In contrast to the classification setting, the current paper shows that theoretical guarantees for the proposed bootstrap can be established under much weaker assumptions. In addition, we illustrate the flexibility of the method by showing how it can be adapted to measure algorithmic convergence for variable selection. Lastly, we provide numerical results demonstrating that the…
Click any figure to enlarge with its caption.
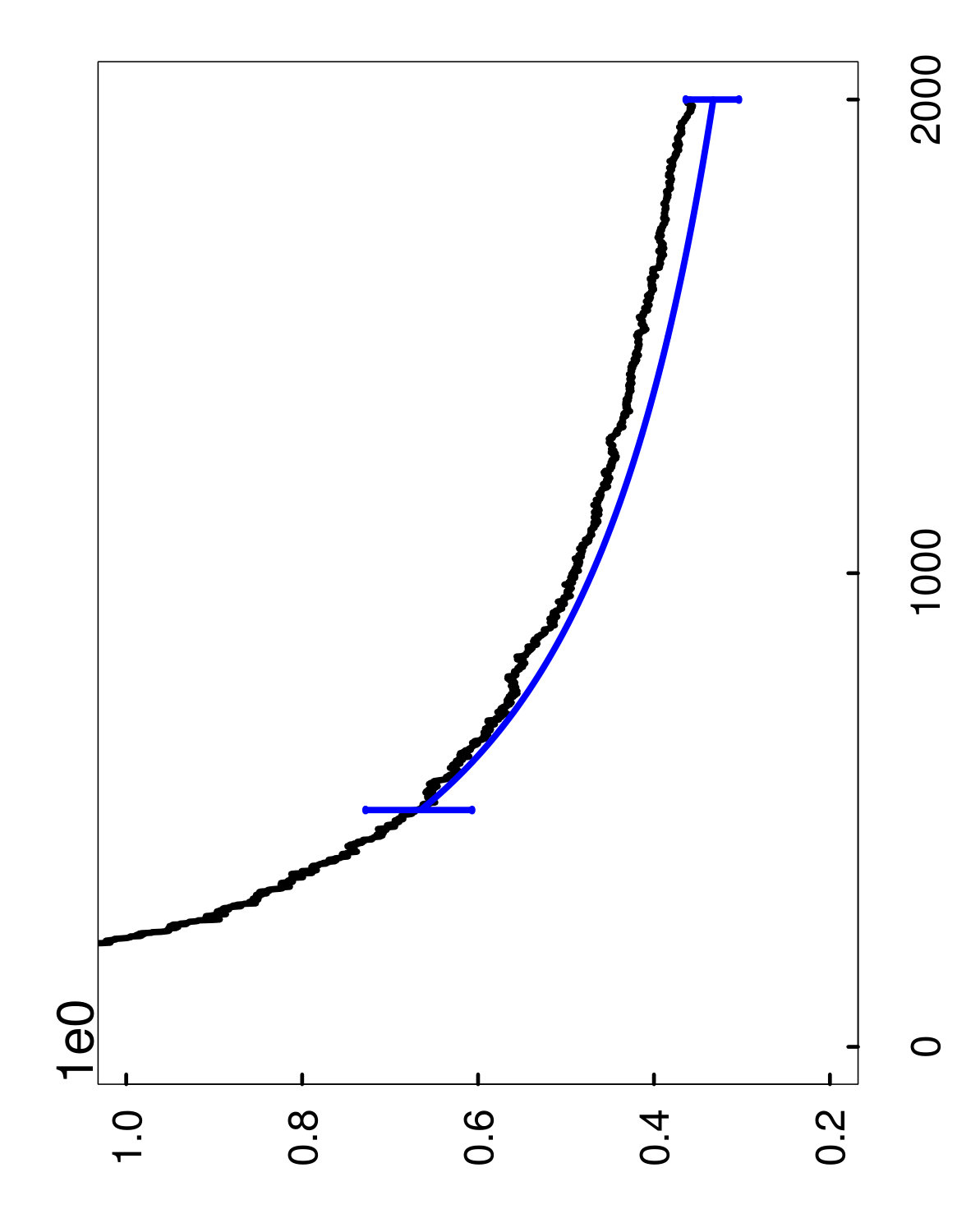 Figure 1
Figure 1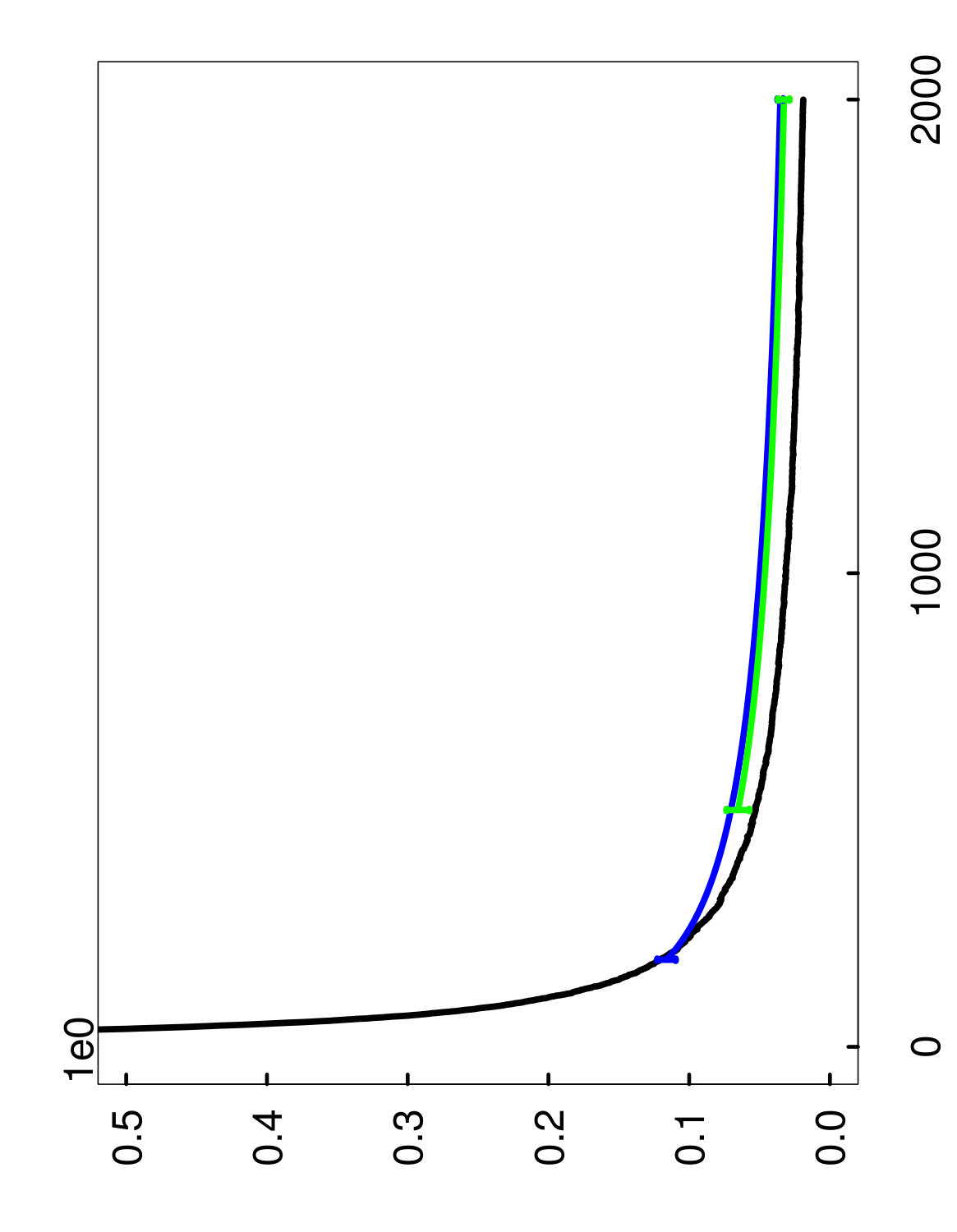 Figure 2
Figure 2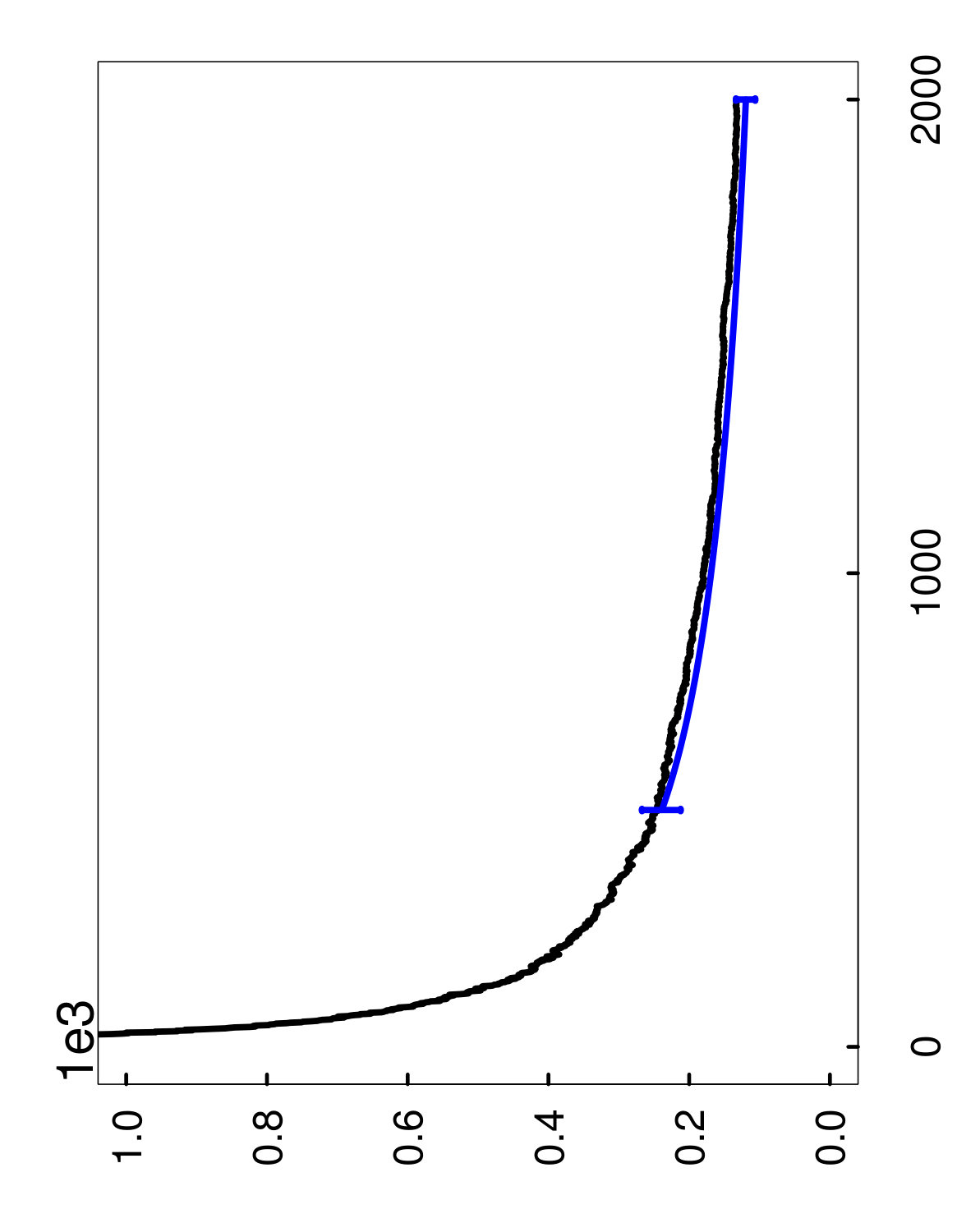 Figure 3
Figure 3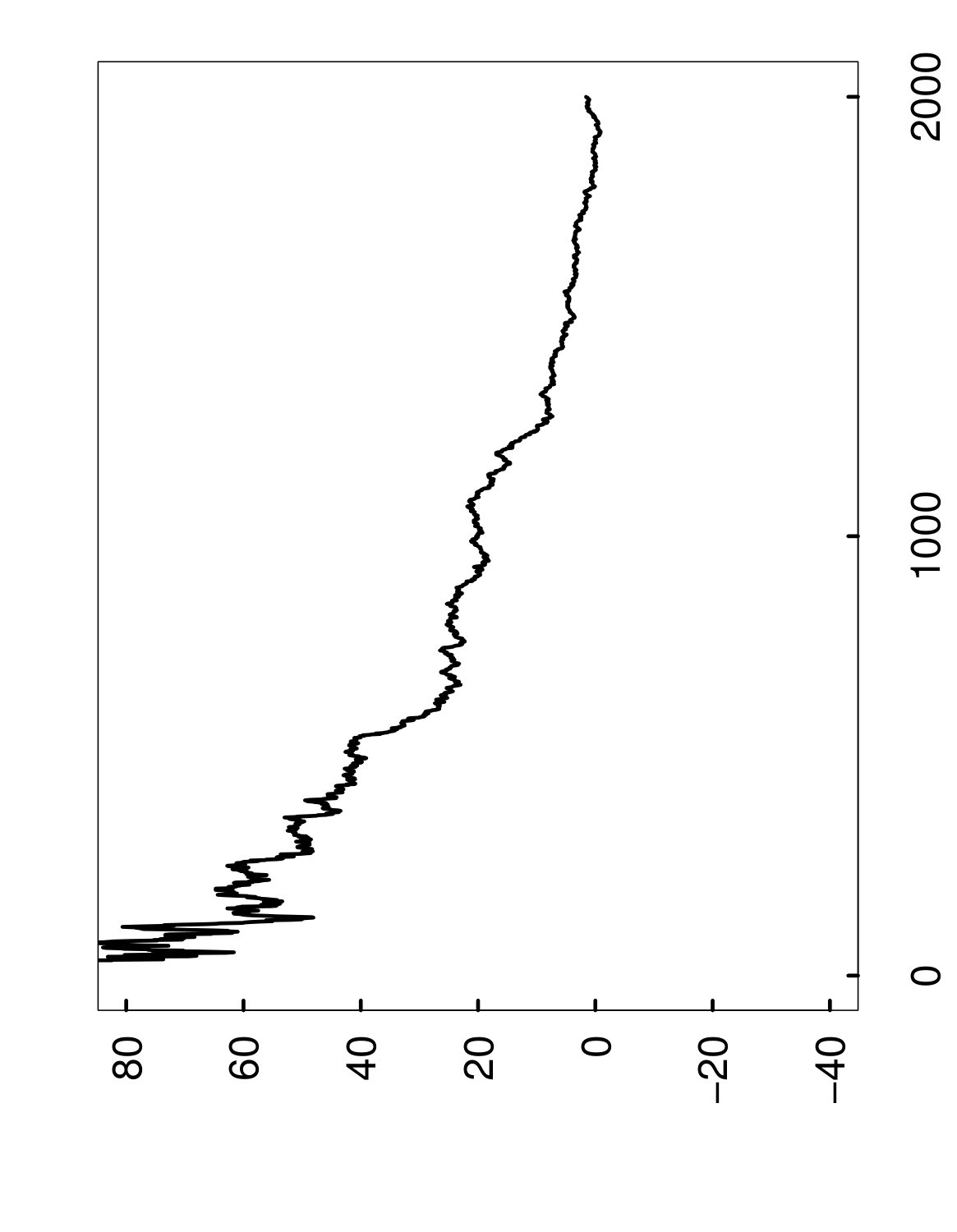 Figure 4
Figure 4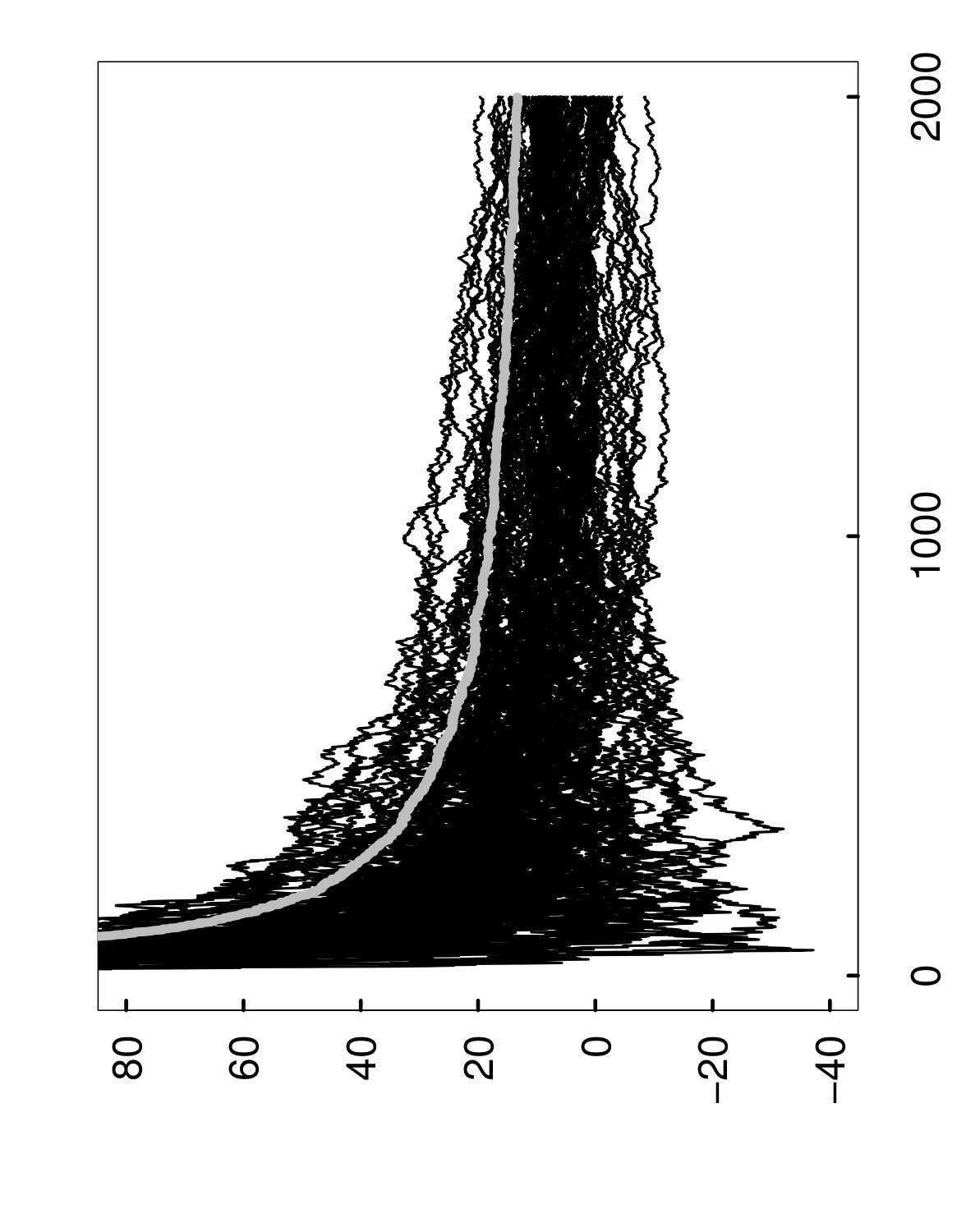 Figure 5
Figure 5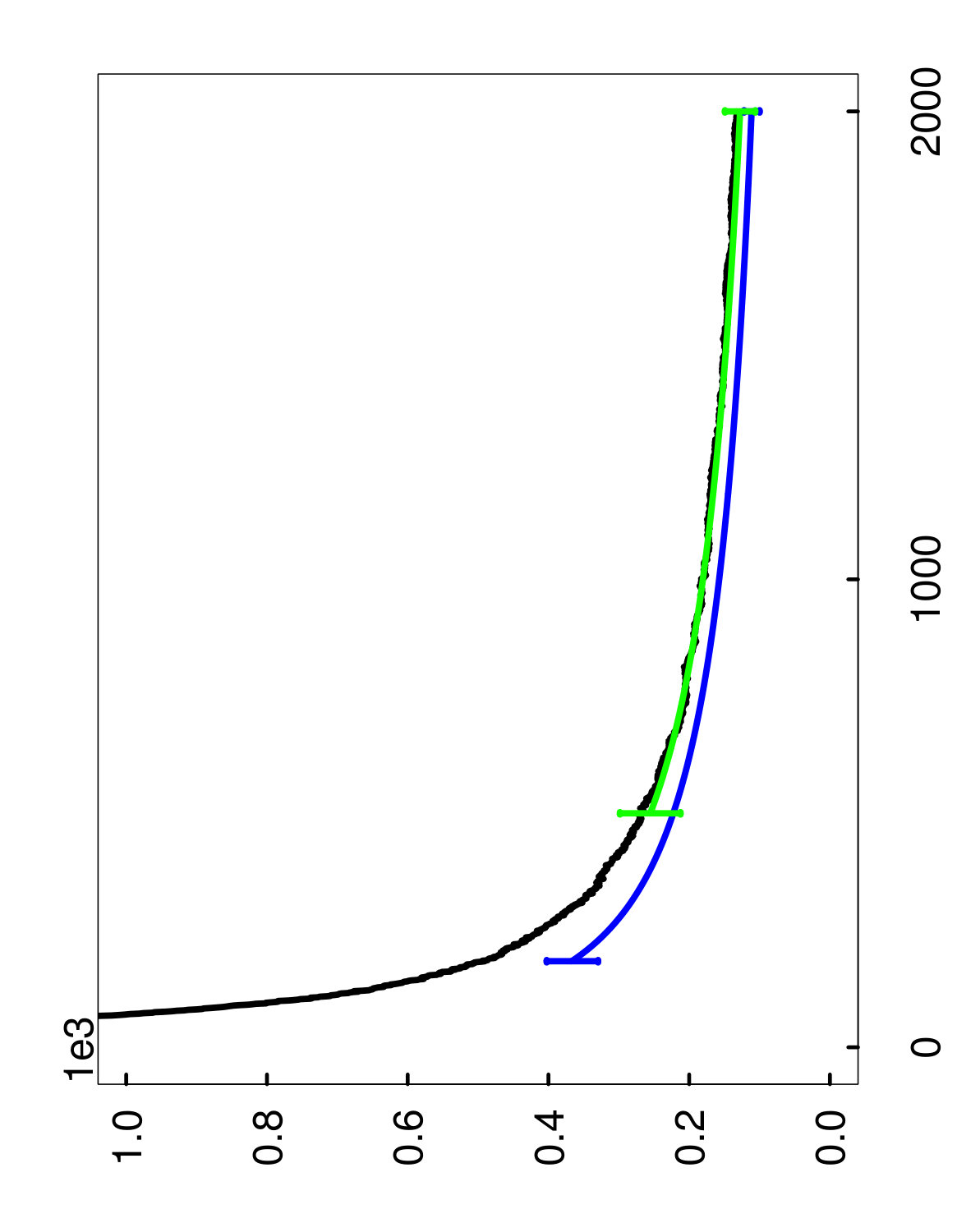 Figure 6
Figure 6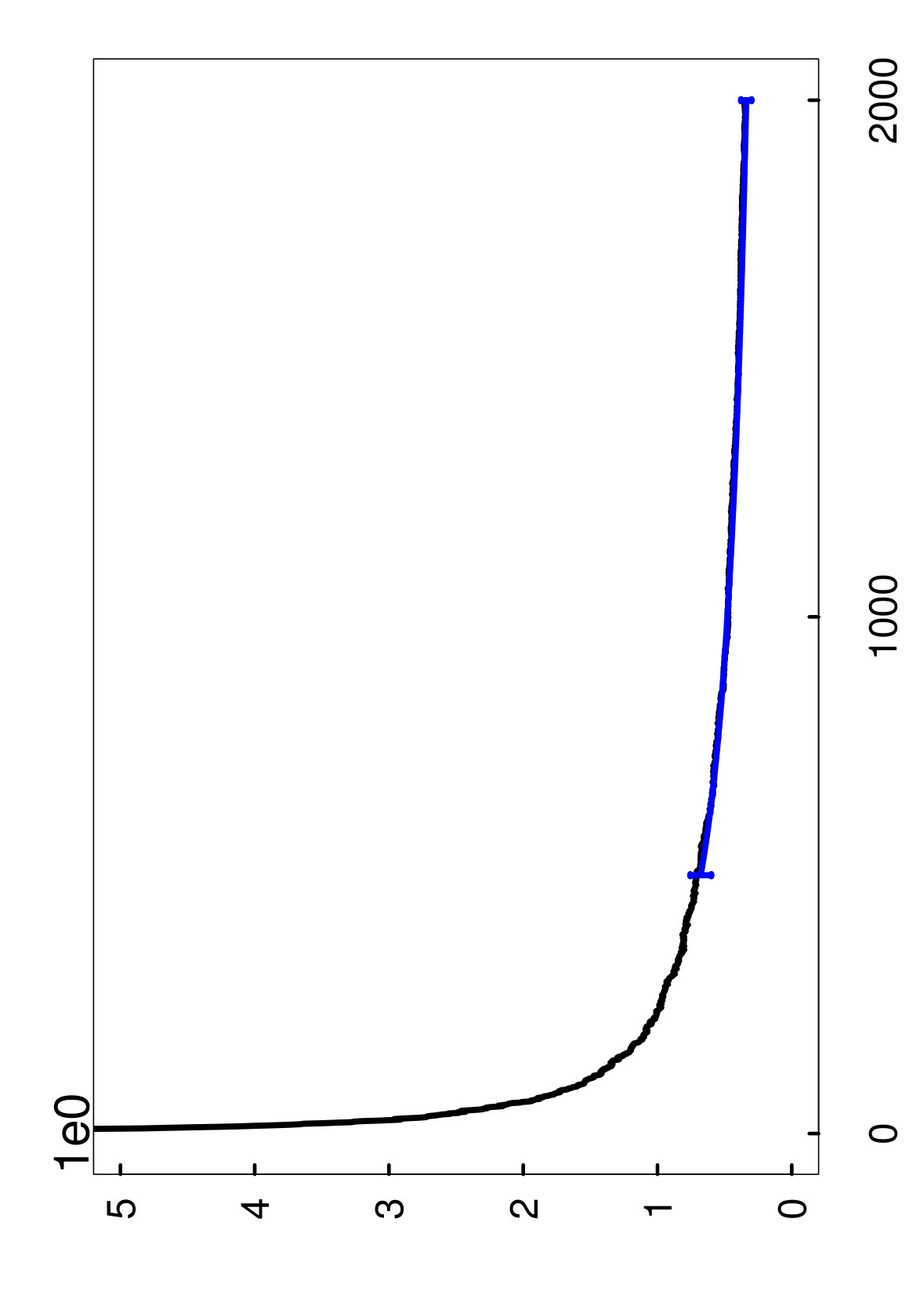 Figure 7
Figure 7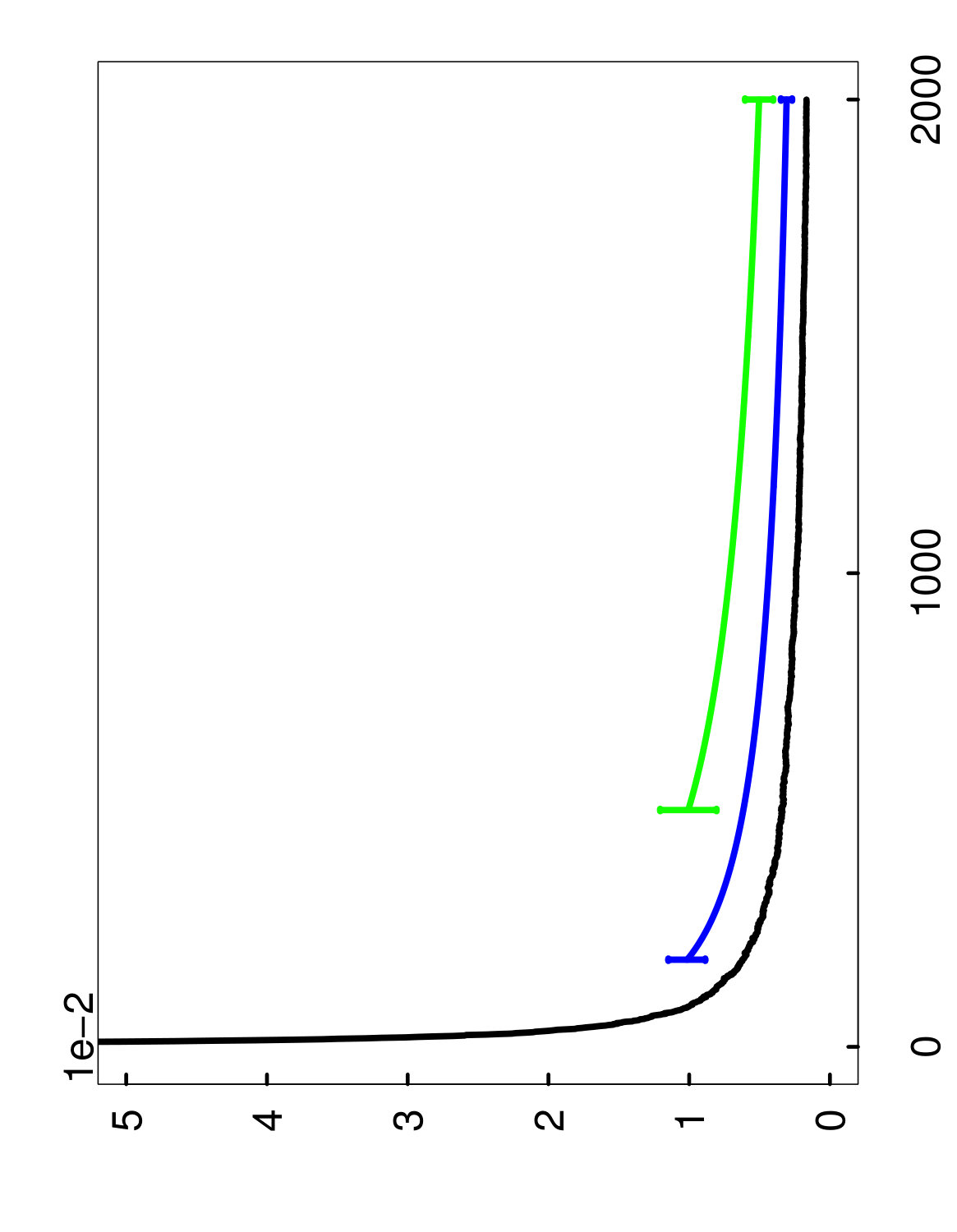 Figure 8
Figure 8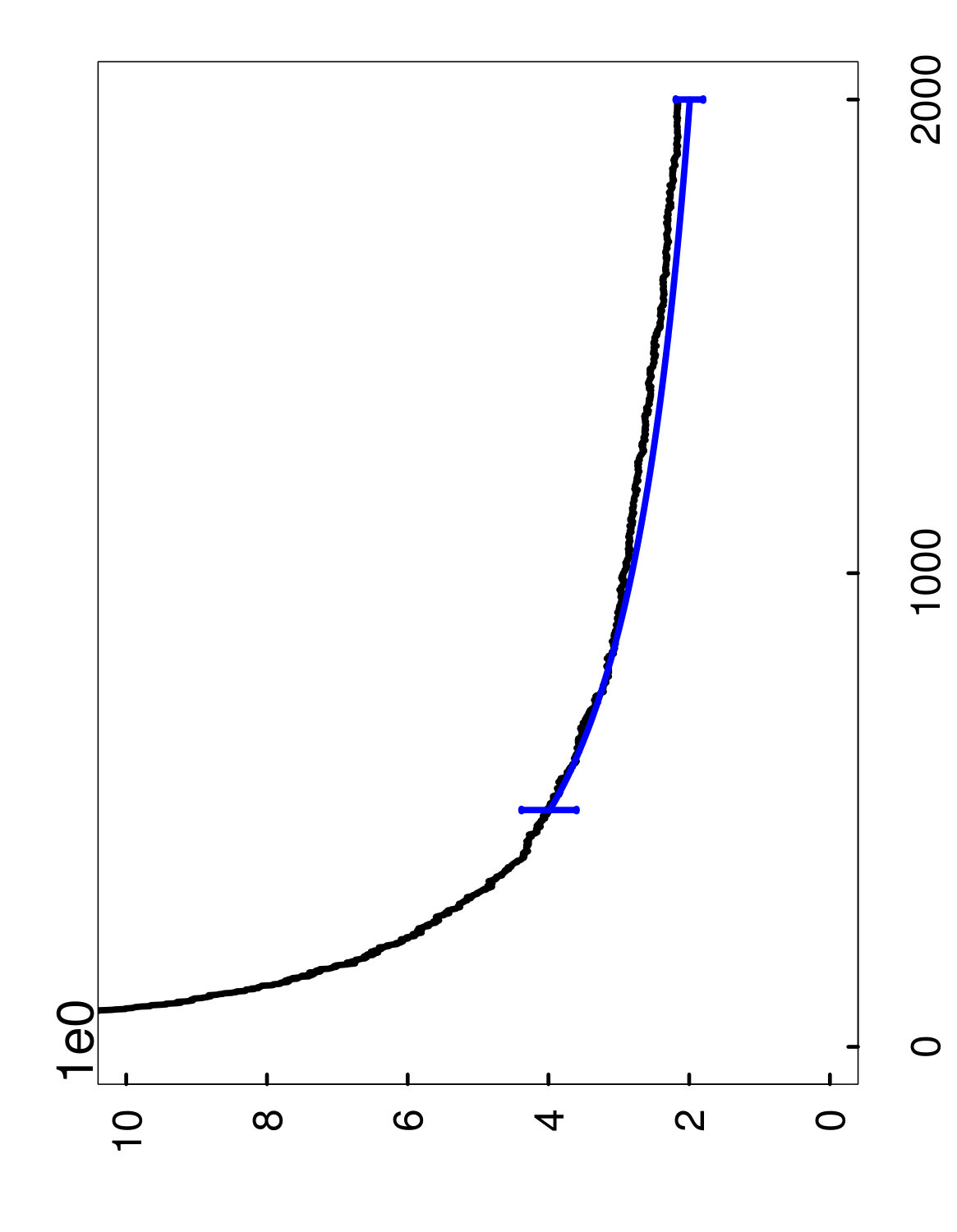 Figure 9
Figure 9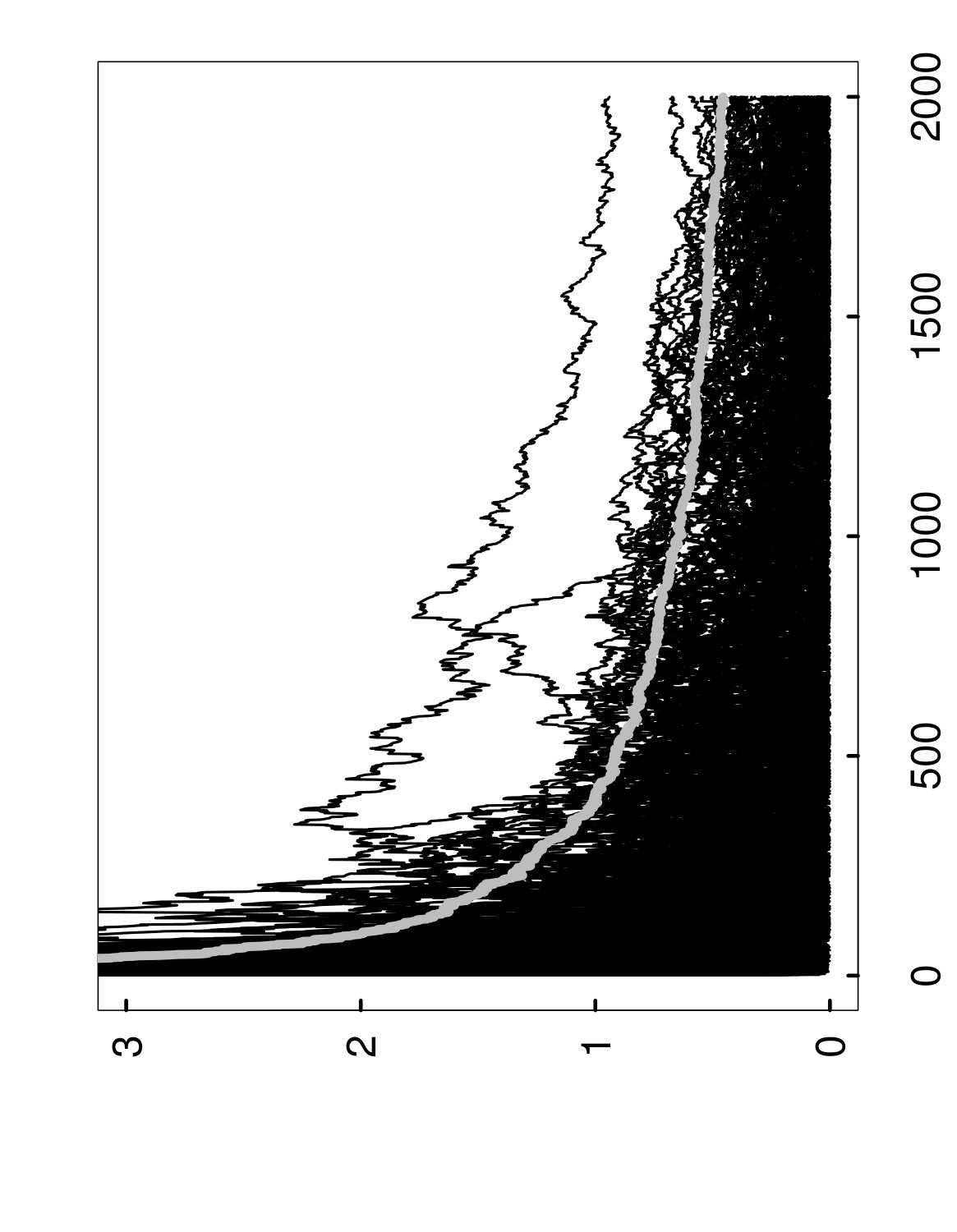 Figure 10
Figure 10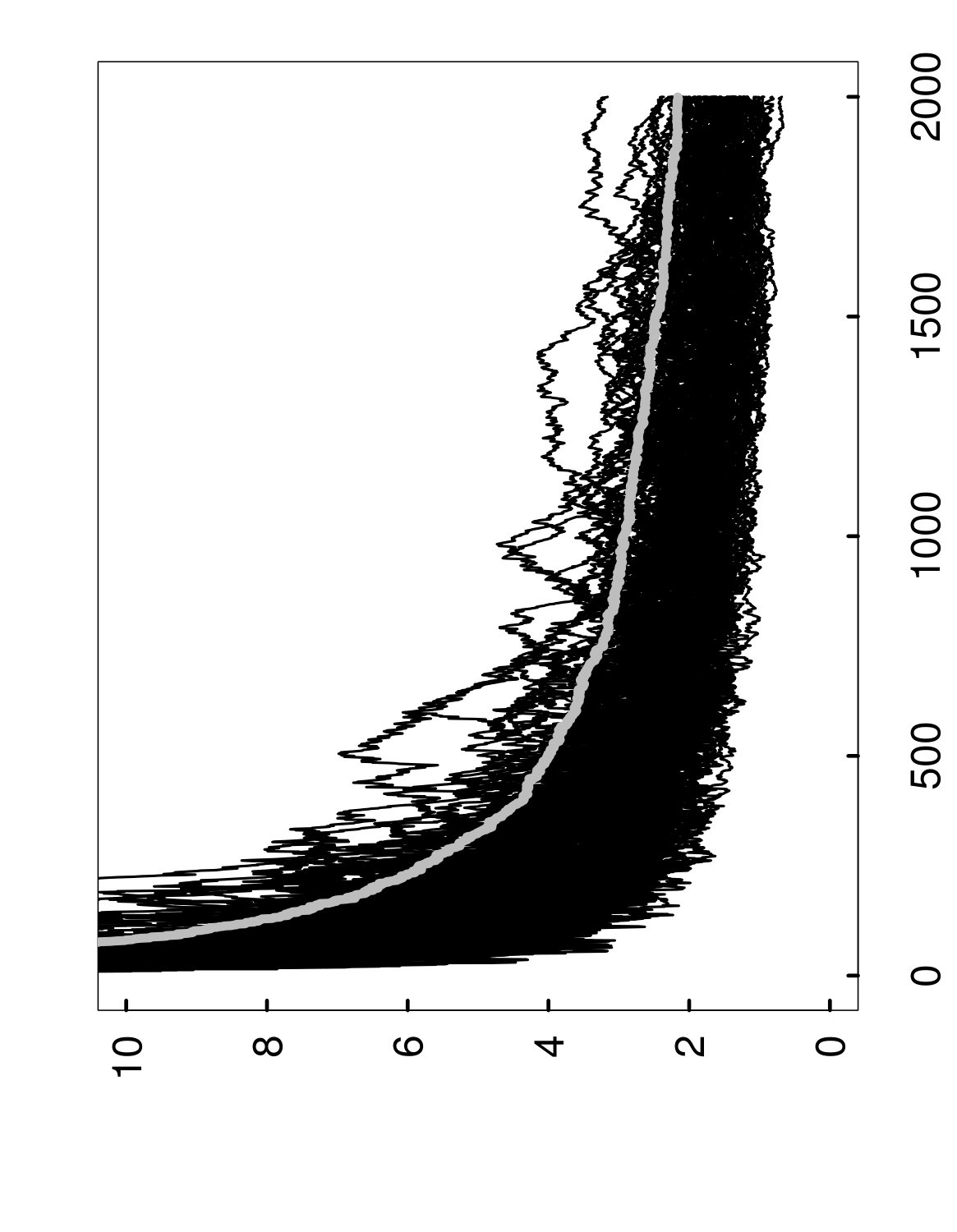 Figure 11
Figure 11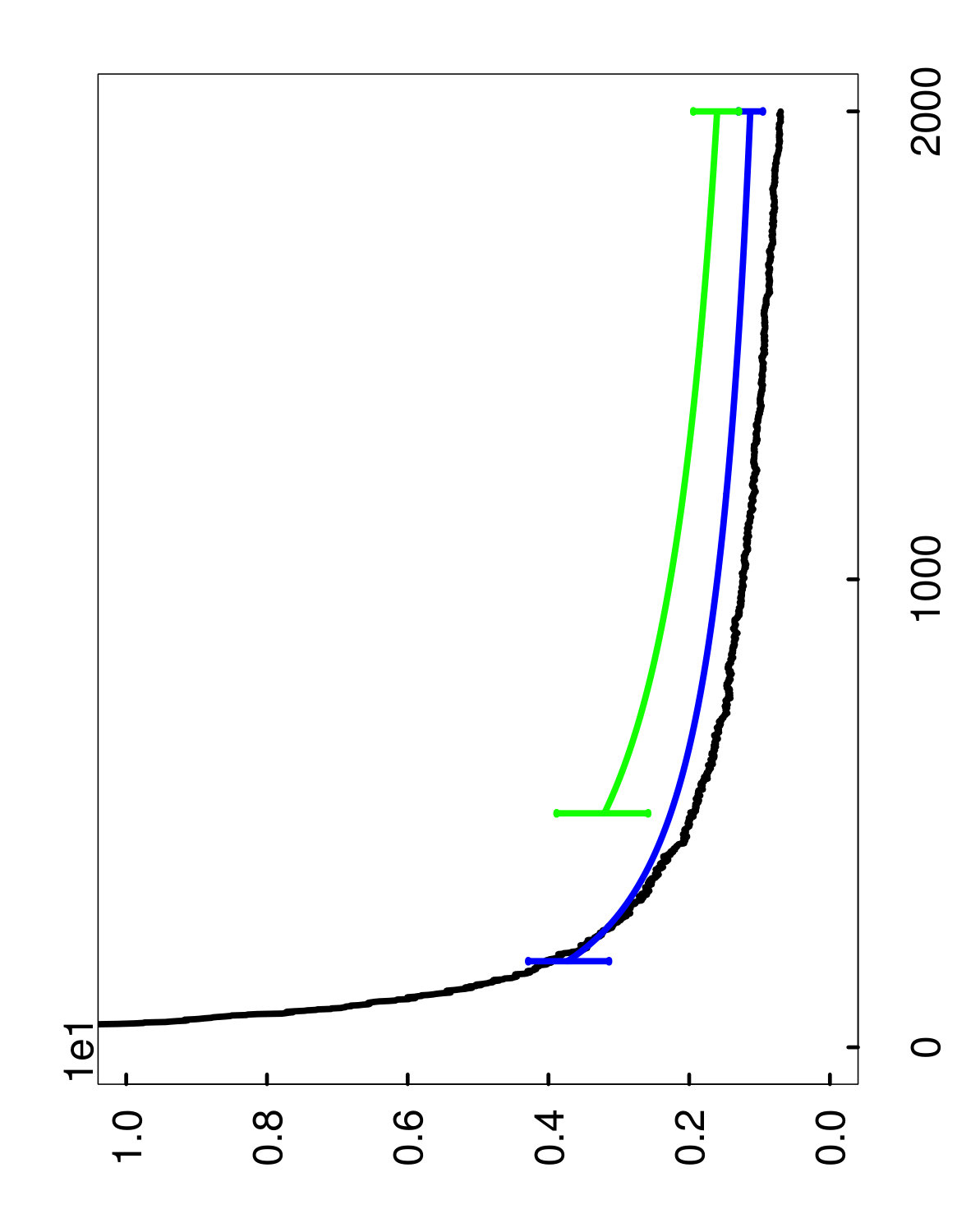 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Measuring the Algorithmic Convergence of Randomized Ensembles:
The Regression Setting
Miles E. Lopeslabel=e1] [
Suofei Wu
Thomas C. M. Lee label=e3]??? [ University of California, Davis
University of California, Davis
Abstract
When randomized ensemble methods such as bagging and random forests are implemented, a basic question arises: Is the ensemble large enough? In particular, the practitioner desires a rigorous guarantee that a given ensemble will perform nearly as well as an ideal infinite ensemble (trained on the same data). The purpose of the current paper is to develop a bootstrap method for solving this problem in the context of regression — which complements our companion paper in the context of classification (Lopes, 2019). In contrast to the classification setting, the current paper shows that theoretical guarantees for the proposed bootstrap can be established under much weaker assumptions. In addition, we illustrate the flexibility of the method by showing how it can be adapted to measure algorithmic convergence for variable selection. Lastly, we provide numerical results demonstrating that the method works well in a range of situations.
62F40 ,
65B05, 68W20, 60G25 ,
random forests, bagging, bootstrap, randomized algorithms,
keywords:
[class=MSC]
keywords:
\startlocaldefs\endlocaldefs
t1Supported in part by NSF grant DMS 1613218. t3Supported in part by NSF grants DMS 1811405 and DMS 1811661.
1 Introduction
Ensemble methods are a fundamental approach to prediction, based on the principle that accuracy can be enhanced by aggregating a diverse collection of prediction functions. Two of the most widely used methods in this class are random forests and bagging, which rely on randomization as a general way to diversify an ensemble (Breiman, 1996, 2001). For these types of randomized ensembles, it is generally understood that the predictive accuracy improves and eventually stabilizes as the ensemble size becomes large. Likewise, in the theoretical analysis of randomized ensembles, it is common to focus on the idealized case of an infinite ensemble (Bühlmann and Yu, 2002; Hall and Samworth, 2005; Biau et al., 2008; Biau, 2012; Scornet et al., 2015). However, in practice, the user does not know the true relationship between accuracy and ensemble size, and as a result, it is difficult to know if an ensemble is sufficiently large.
The purpose of the current paper is develop a solution to this problem for random forests, bagging, and related methods in the context of regression. More specifically, we offer a bootstrap method for estimating how far the prediction error of a finite ensemble is from the ideal prediction error of an infinite ensemble (trained on the same data). A precise description of the setup and problem formulation is given as follows.
1.1 Background and setup
To fix some basic notation for the regression setting, let denote a set of training data in a space , where each is the scalar response variable associated to , and the space is arbitrary. Also, an ensemble of regression functions trained on is denoted as , where , and the number is referred to as the ensemble size.
Randomized regression ensembles.
For the purpose of understanding our setup, it is helpful to quickly review the methods of bagging and random forests. The method of bagging works by generating random sets , each of size , by sampling with replacement from . Next, a standard “base” regression algorithm is used to train a regression function on for each . For instance, it is especially common to apply a decision tree algorithm like CART (Breiman et al., 1984) to each set . In turn, future predictions are made by using the averaged regression function, which is defined for each by
[TABLE]
Much like bagging, the method of random forests uses sampling with replacement to generate the same type of random sets . However, random forests adds an additional source of randomness when the base regression algorithm is applied to each . Namely, in the standard case when and CART is the base regression algorithm, random forests uses randomly chosen subsets of the features when “split points” are selected for the CART regression trees. Likewise, random forests also uses the average (1.1) when making final predictions. A more detailed description may be found in Friedman et al. (2001).
In order to unify the methods of bagging and random forests within a common theoretical framework, our analysis will consider a more general class of randomized ensembles. This class consists of regression functions that can be represented in the abstract form
[TABLE]
where are i.i.d. “randomizing parameters” generated independently of , and is a deterministic function that does not depend on or . In particular, the representation (1.2) implies that the random functions are conditionally i.i.d., given . To see why bagging is representable in this form, note that can be viewed as a random vector that specifies which points in are randomly sampled into . Similarly, in the case of random forests, each encodes the points in , as well as randomly chosen sets of features used for training . More generally, the representation (1.2) is relevant to other types of randomized ensembles, such as those based on random rotations (Blaser and Fryzlewicz, 2016), random projections (Cannings and Samworth, 2017), or posterior sampling (Ng and Jordan, 2001; Chipman et al., 2010).
Algorithmic convergence.
In our analysis of algorithmic convergence, we will focus on quantifying how the mean-squared error (MSE) of an ensemble behaves as the ensemble size becomes large. To define this measure of error in more precise terms, let denote the randomizing parameters of the ensemble, and let denote the joint distribution of a test point , which is drawn independently of and . Accordingly, we define
[TABLE]
where the expectation on the right is only over the test point . In this definition, it is important to notice that is a random variable that depends on both and . However, due to the fact that the algorithmic fluctuations of arise only from , we will view the set as a fixed input to the training algorithm, and likewise, our analysis will always be conditional on . Indeed, the conditioning on is motivated by the fact that the user would like to assess convergence for the particular set that they actually have, and this approach has been adopted in several other analyses of algorithmic convergence for randomized ensembles (Ng and Jordan, 2001; Lopes, 2016; Scornet, 2016a; Cannings and Samworth, 2017; Lopes, 2019).
As a way of illustrating algorithmic convergence, Figure 1 shows how evolves when the random forests method is applied to a fixed training set . More specifically, if denotes the limit of as , then the left panel displays successive values of the convergence gap as decision trees are added during a single run of random forests, from up to . After this entire process is repeated 1,000 times on the same set , we obtain many overlapping sample paths, as shown in the right panel of Figure 1. (Note also that none of these curves are observable in practice, and the figure is given only for illustration.)
From a practical standpoint, the user would like to know the size of the convergence gap as a function of . For this purpose, it is useful to consider the -quantile of , which is defined for any by
[TABLE]
In other words, the value is the tightest possible upper bound on the gap that holds with probability at least , conditionally on the set . This interpretation of can also be understood from the right panel of Figure 1, where we have plotted in gray, with .
The problem to be solved.
Although it is clear that the quantile represents a precise measure of algorithmic convergence, this function is unknown in practice. This leads to the problem of estimating , which we propose to solve.
Beyond the fact that is unknown, it is also important to keep in mind that estimating involves some additional constraints. First, the user would like to be able to assess convergence from the output a single run of the ensemble method, whereas the function describes the fluctuations of over repeated runs, as illustrated in the right panel of Figure 1. Hence, at first sight, it is not obvious that the output of a single run provides enough information to successfully estimate . Second, the method for estimating should be computationally inexpensive, so that the cost of checking convergence is manageable in comparison to the cost of training the ensemble itself. Later on, we will show that the proposed method is able to handle both of these constraints, in Sections 2 and 4 respectively.
1.2 Related work and contributions
The general problem of measuring the algorithmic convergence of randomized ensembles has attracted sustained interest over the past two decades. In particular, there have been numerous empirical studies of algorithmic convergence for both classification and regression (e.g. Latinne et al., 2001; Basilico et al., 2011; Schwing et al., 2011; Oshiro et al., 2012; Probst and Boulesteix, 2018).
With regard to the theoretical analysis of convergence, we will now review the existing results for classification and regression separately. In the setting of classification, much of the literature has studied convergence in terms of the misclassification probability for majority voting, denoted (a counterpart of , which is viewed as a random variable that depends on and . For this measure of error, the convergence of and as has been analyzed in the papers (Ng and Jordan, 2001; Lopes, 2016; Cannings and Samworth, 2017), which have developed asymptotic formulas for , as well as bounds for . Related results for a different measure of error can also be found in Hernández-Lobato et al. (2013). More recently, our companion paper (Lopes, 2019) has developed a bootstrap method for measuring the convergence of , which is able to circumvent some of the limitations of analytical results.
In the setting of regression, algorithmic convergence results on are scarce in comparison to those for . Instead, much more attention in the regression literature has focused on how the size of influences the variance of point predictions , with held fixed (e.g., Sexton and Laake, 2009; Arlot and Genuer, 2014; Wager et al., 2014; Mentch and Hooker, 2016; Scornet, 2016a). To the best of our knowledge, the only paper that has systematically studied algorithmic convergence in terms of an error measure is (Scornet, 2016a), which considers the risk , where is the true regression function, and the expectation in the definition of is over . In particular, the paper (Scornet, 2016a) develops an elegant non-asymptotic bound on the gap between and its limiting value as . Under the assumption of a Gaussian regression model with , this bound has the form
[TABLE]
where , and . In addition to this bound, the paper (Scornet, 2016a) gives further insight into algorithmic convergence by developing a precise uniform central limit theorem for as , with held fixed. More specifically, this limit theorem demonstrates that under certain conditions, the standardized process converges in distribution (conditionally on ) to a Gaussian process on .
Contributions.
From a methodological standpoint, the approach taken here differs in several ways from previous works in the regression setting. Most notably, our work looks at algorithmic convergence in terms of an error measure that is conditional on . (For instance, this differs from the analysis of , which averages over .) In particular, we provide a quantile estimate , such that the bound
[TABLE]
holds with a probability that is effectively , conditionally on . This conditioning is especially important from the viewpoint of the user, who is typically interested in convergence with respect to the actual dataset at hand. Another distinct feature of our method is that it provides the user with a direct numerical estimate of convergence, whereas formula-based results are more likely to involve conservative constants, or depend on unknown parameters, such as or in the bound (1.4).
In addition, the scope of the proposed method goes beyond , and in Section 2.2 we will show how the bootstrap method is flexible enough that it can also be applied to variable selection. In this context, the ensemble provides a ranking of variables according to an “importance measure”, and this ranking typically stabilizes as . However, the notion of convergence is somewhat subtle, because it is possible that the importance measure for some variables may converge more slowly than for others — which can distort the overall ranking of variables. As far as we know, this issue has not be addressed in the literature, and the method proposed in Section 2.2 provides a way to check that convergence has been achieved uniformly across all variables, so that they can be compared fairly.
With regard to theory, the most important aspects of our analysis is that it is based on very mild assumptions. To place our assumptions into context, it is worth emphasizing that most analyses of randomized ensembles deal with specialized types of prediction functions that are much simpler than the ones used in practice (e.g. Lin and Jeon, 2006; Arlot and Genuer, 2014; Biau et al., 2008; Biau, 2012; Scornet et al., 2015; Scornet, 2016a, b; Lopes, 2019). By contrast, our current results for regression only rely on the representation (1.2) and basic moment assumptions (to be detailed in Section 3). In particular, the crucial ingredient that enables us to handle general types of prediction functions is a version of Rosenthal’s inequality due to Talagrand (1989), which is applicable to sums of independent Banach-valued random variables. Moreover, this allows our analysis to be fully non-asymptotic.
Outline.
The remainder of the paper is organized as follows. The proposed methods are described in Section 2, and our main result on bootstrap consistency is presented in Section 3. Next, the computational cost of the methods is assessed in Section 4, and numerical experiments are given in Section 5. Finally, all proofs are given in the supplementary material.
2 Methodology
Below, we present our core method for measuring algorithmic convergence with respect to in Section 2.1. Next, we show how this approach can be extended to measuring convergence with respect to variable importance in Section 2.2.
2.1 Measuring convergence with respect to mean-squared error
The intuition for the proposed method is based on two main considerations. First, the definition of in equation (1.3) shows that it can be interpreted as a functional of . More specifically, if we let denote a generic function, then we define the functional according to
[TABLE]
and it follows that can be written as
[TABLE]
Second, it is a general principle that bootstrap methods are well-suited to approximating distributions derived from smooth functionals of sample averages — which is precisely what the representation (2.2) entails.
To make a more direct connection between these general ideas and the problem of estimating , recall that we actually need to approximate the distribution of the difference , rather than just itself. Fortunately, the limiting value can be linked with through function
[TABLE]
where the expectation is only over the algorithmic randomness in (i.e. over the random vector ). More specifically, when the functions satisfy the representation (1.2), the law of large numbers implies under basic integrability assumptions, which leads to the relation
[TABLE]
This relation is the technical foundation for the proposed method, since it suggests that in order to mimic the fluctuations of , we can develop a bootstrap method by viewing the functions as “observations”, and viewing as an estimator of . In other words, if we sample functions with replacement from , then we can formally define a bootstrap sample of according to
[TABLE]
where . In turn, after generating a collection of such bootstrap samples, we can use their empirical -quantile as an estimate of . However, as a technical point, it should be noted that (2.5) is a “theoretical” bootstrap sample of , because the functional depends on the unknown distribution of the test point . Nevertheless, the same reasoning can still be applied by replacing with an estimate , which will be explained in detail later in this subsection. Altogether, the method is summarized by the following algorithm.
Using hold-out or out-of-bag samples.
To complete our discussion of Algorithm 1, it remains to clarify how the functional can be estimated from either hold-out samples, or so-called “out-of-bag” (oob) samples. With regard to the first case, suppose a set of labeled samples has been held out from the training set . Using this set, the estimate in Algorithm 1 can be easily obtained as
[TABLE]
Analogously, we may also obtain by using instead of in the formula above.
If the regression functions are trained via bagging or random forests, it is possible to avoid the use of a hold-out set by taking advantage of oob samples, which are a unique attribute of these methods. To define the notion of an oob sample, recall that these methods train each function using a random set obtained from by sampling with replacement. Due to this sampling mechanism, it follows that each set is likely to exclude approximately of the training points in . So, as a matter of terminology, if a particular training point does not appear in , we say that is “out-of-bag” for the function . Also, we write to denote the index set corresponding to the functions for which is oob.
From a statistical point of view, oob samples are important because they serve as “effective” hold-out points. (That is, if is oob for , then the function “never touched” the point during the training process.) Hence, it is natural to consider the following alternative estimate of based on oob samples,
[TABLE]
where we define to be the average over the functions for which is oob,
[TABLE]
and refers to the cardinality of a set. Similarly, we define by replacing each function above with . Lastly, in the case when is empty, we arbitrarily define , but this occurs very rarely. In fact, it can be checked that for a given point , the set is empty with probability approximately equal to .
2.2 Measuring convergence with respect to variable importance
In addition to their broad application in prediction problems, randomized ensembles have been very popular for the task of variable selection (e.g. Díaz-Uriarte and De Andres, 2006; Strobl et al., 2008; Ishwaran, 2007; Genuer et al., 2010; Louppe et al., 2013; Genuer et al., 2015; Gregorutti et al., 2017). Although a variety of procedures have been proposed for variable selection in this context, they are generally based on a common approach of ranking the variables according to a measure of averaged variable importance (VI). Under this approach, the averaged VI assigned to each variable typically converges to a limiting value as the ensemble becomes large. However, in practice, the user does not know how this convergence depends on the ensemble size — much like we have seen already for .
Uniform convergence across variables.
Before moving on to the details of our extended method, it is worth emphasizing an extra subtlety of measuring algorithmic convergence for VI. Specifically, we must keep in mind that because variable selection is based on ranking, it is important that algorithmic convergence is reached for all variables. In other words, if the VI for some variables converges more slowly than for others, then the ranking of variables will be distorted by purely algorithmic effects. For this reason, our extended method will provide a way to ensure that algorithmic convergence is achieved uniformly across all variables.
Setup for variable importance.
To describe algorithmic convergence for VI in detail, let be a randomized ensemble that satisfies the representation (1.2), and consider a situation where the training samples have variables (i.e. the space is -dimensional). Also, suppose that for each function , we have a rule for assigning an importance value to each variable . Due to the fact that is a random function, it follows that the importance value is a random variable, denoted by . (Choices for computing this will be discussed shortly.) Likewise, the vector of such values associated with is denoted , and the averaged vector of importance measures is denoted as
[TABLE]
Hence, by comparing the entries of the vector , the user is then able to rank the variables, and this is commonly done using a built-in option from the standard random forests software package (Liaw and Wiener, 2002).
Up to this point, we have not specified a particular rule for computing the values , but several choices are available. For instance, two of the prevailing choices for regression are based on the notions of “node impurity” (for regression trees) or “random permutations” (for general regression functions). However, from an abstract point of view, our proposed method does not depend on the underlying details of these rules, and so we refer to the book (Friedman et al., 2001, Sec 15.3.2) for additional background. Indeed, our proposed method is applicable to any VI rule, provided that the random vectors are conditionally i.i.d. given . In particular, this property is satisfied by both of the mentioned rules when follow the representation (1.2).
When the conditional i.i.d. property for holds and is held fixed, the average will generally converge to a limiting vector as . In order to measure this convergence uniformly across , we will focus on the (unknown) random variable
[TABLE]
and our goal will be to estimate its -quantile, denoted as
[TABLE]
The bootstrap method for variable importance.
By analogy with our method for estimating the quantiles of , we propose to construct bootstrap samples of by resampling the vectors , and then estimating with the empirical -quantile. In algorithmic form, the procedure works as follows.
Numerical results illustrating the performance of this algorithm, as well as Algorithm 1, are given Section 5.
3 Main result
In this section, we develop the main theoretical result of the paper, which guarantees that a bootstrap estimate of serves its intended purpose. Namely, if this estimate is denoted by , then we will show that for a fixed set , the inequality
[TABLE]
holds with a probability that is effectively .
To establish this result, we will rely on a type of simplification that is commonly used in the analysis of bootstrap methods, which is to exclude sources of error beyond the resampling process itself. More specifically, we will focus on bootstrap samples of the form (defined in equation (2.5)), since these are not affected by the extraneous error from estimating the functional . A key benefit of this choice is that it clarifies how the performance of the bootstrap is related to the characteristics of the ensemble. Meanwhile, even with such a simplification, the proof of the result is still quite involved. Likewise, this choice was also used in our previous analysis of the classification setting for the same reasons (Lopes, 2019). Apart from this detail, the analysis in the current paper is entirely different.
With regard to the ensemble, the only assumptions used in our analysis are that it satisfies the representation (1.2), as well as some basic moment conditions. From the standpoint of existing theory for randomized ensembles, these assumptions are very mild — because the representation (1.2) is always satisfied by bagging and random forests. By contrast, it is much more common in the theoretical literature to work with ensembles that are simpler than the ones used in practice; and indeed, our previous work in the classification setting relied on a highly specialized type of ensemble. Furthermore, the moment parameters in our current result are guaranteed to be finite in the important case when are trained by CART, as will be explained shortly. Finally, it is notable that our result is fully non-asymptotic, whereas much existing work on the convergence of randomized ensembles has taken an asymptotic approach that does not always provide explicit rates of convergence.
Notation.
If and are real-valued functions on , we denote their inner product with respect to the test point distribution as
[TABLE]
and accordingly, we write . In addition, recall the function from equation (2.3), and define the random variable
[TABLE]
where the expression is interpreted as the function . When the random variable is conditioned on , we denote its standard deviation by
[TABLE]
and the finiteness of this quantity will follow from assumption A2 below. Also, all expressions involving will be understood as in the exceptional case when . Lastly, for each positive integer , we define the moment parameter
[TABLE]
which provides a convenient way to quantify the tail behavior of the random variables and .
Assumptions.
With the above notation in place, we can state the two assumptions needed for our main result.
A1. The ensemble can be represented in the form (1.2).
A2. There is at least one integer such that .
To interpret these assumptions, recall that A1 is always satisfied by bagging and random forests, as explained in Section 1.1. Regarding the finiteness of in A2, it is noteworthy that this condition is satisfied for arbitrarily large values of whenever the functions are trained by the standard method of CART. This is because the range of the functions is determined by the training labels . In particular, if we put , then every tree satisfies the bound , which implies
[TABLE]
for every . The same reasoning also applies beyond CART to any other method whose predictions fall within the range of the training labels. We now state the main result of the paper.
Theorem 3.1**.**
Suppose that A1 and A2 hold. In addition, let be as in A2, and let denote the empirical -quantile of bootstrap samples of the form (2.5). Lastly, define the quantity
[TABLE]
Then, there is an absolute constant such that satisfies
[TABLE]
Remarks.
In essence, the result shows that bounds the unknown convergence gap with a probability that is not much less than the ideal value of . To comment on some further aspects of the result, note that the inequality (3.5) has the desirable property of being scale-invariant with respect to the labels and the functions . More precisely, if we were to change the units of the labels and functions by a scale factor , it can be checked that both sides of (3.5) would remain unchanged.
Another important aspect of Theorem 3.1 deals with the dependence of on the value of . Specifically, it is interesting to develop a bound on that simplifies the role of . To do this, we now consider the situation when the regression functions are trained by CART, or more generally, when the boundedness condition holds for every , as in (3.3). In such cases, we may evaluate the particular choice
[TABLE]
which leads to the following bounds,
[TABLE]
for some absolute constant and all . These bounds imply that there is a number not depending on , , or , such that
[TABLE]
which considerably simplifies the interpretation of . Hence, at a high level, this indicates that as long as the regression functions have well-behaved moments, then for a fixed set , the quantity converges to 0 at nearly parametric rates with respect to both and .
4 Computation and speedups
In order for the proposed method to be a practical a tool for checking algorithmic convergence, its computational cost should be manageable in comparison to training the ensemble itself. Below, in Section 4.1, we offer a quantitative comparison, showing that under simple conditions, Algorithms 1 and 2 are not a bottleneck in relation to training regression functions with CART. Additionally, we show in Section 4.2 how an extrapolation technique from our previous work on classification can be improved in our current setting with a bias correction rule.
4.1 Cost comparison
Because the CART method is based on a greedy iterative algorithm, the exact computational cost of training a regression tree is difficult to describe. For this reason, the authors of CART analyzed its cost in the simplified situation where each node of a regression tree is split into exactly 2 child nodes (except for the leaves). To be more precise, suppose , and let denote the “depth” of the tree, so that there are leaves. In addition, suppose that when the algorithm splits a given node, it searches over candidate variables that are randomly chosen from , which is the default rule when CART is used by random forests (Liaw and Wiener, 2002). Based on these assumptions, the analysis in the book (Breiman et al., 1984, p.166) shows that the number of operations involved in training such trees is at least of order .
The cost of Algorithm 1.
To determine the cost of Algorithm 1, it is important to clarify that when bagging and random forests are used in practice, the prediction error of the ensemble is typically estimated automatically using either hold-out or oob samples. As a result, the predicted values of each tree on these samples can be regarded as being pre-computed by the ensemble method. Once these values are available, the subsequent cost of Algorithm 1 is simple to measure. Specifically, in the case of hold-out samples, equation (2.6) shows that the cost to obtain for each bootstrap sample is , which leads to an overall cost that is . Similarly, for the case of oob samples, the overall cost is . Altogether, this leads to the conclusion that the cost of Algorithm 1 does not exceed that of training the ensemble if the number of bootstrap samples satisfies the very mild condition
[TABLE]
and this applies to either the hold-out or oob cases, provided . Moreover, our discussion in Section 4.2 will show that the condition (4.1) can even be further relaxed via extrapolation.
Beyond the fact that Algorithm 1 compares well with the cost of training an ensemble, there are several other favorable aspects worth mentioning. First, the algorithm only relies on predicted labels for its input, and it never needs to access any points in the space . In particular, this means that the cost of the algorithm is independent of the dimension of . Second, the bootstrap samples in Algorithm 1 are simple to compute in parallel, which means that the cost of the algorithm can be reduced approximately by a factor of .
The cost of Algorithm 2.
Many of the previous considerations for Algorithm 1 also apply to Algorithm 2, but it turns out that the cost of Algorithm 2 can be much less when is large. Because each bootstrap sample in Algorithm 2 requires forming an average of vectors in , it is straightforward to check that the overall cost is , where we view the vectors as being pre-computed by the ensemble method. In particular, it is worth emphasizing that the cost of the algorithm is independent of , and is thus highly scalable. Furthermore, under the setup of our earlier cost comparison with CART, the cost of Algorithm 2 does not exceed the cost of training the ensemble if
[TABLE]
which allows for plenty of bootstrap samples in practice. In fact, our numerical experiments show that even can work well when is on the order of , indicating that Algorithm 2 is quite inexpensive in comparison to training.
4.2 Further reduction of cost by extrapolation
The basic idea of extrapolation is to check algorithmic convergence for a small “initial” ensemble, say of size , and then use this information to “look ahead” and predict convergence for a larger ensemble of size . This general technique has a long history in the development of numerical algorithms, and further background can be found in (Bickel and Yahav, 1988; Brezinski and Zaglia, 2013; Sidi, 2003) as well as references therein. In the remainder of this section, we first summarize how extrapolation was previously developed in our companion paper (Lopes, 2019), and then explain how that approach can be improved with a bias correction for oob samples.
A basic version of extrapolation.
At a technical level, our use of extrapolation is based on the central limit theorem, which suggests that the fluctuations of should scale like as a function of . As a result, we expect that the quantile should behave like
[TABLE]
for some quantity that may depend on all problem parameters except .
To take advantage of this heuristic scaling property, suppose that we train an initial ensemble of size , and run Algorithm 1 to obtain an estimate . We can then extract an estimate of by defining
[TABLE]
Next, we can rapidly estimate for all subsequent by defining the extrapolated estimate
[TABLE]
In particular, there are two crucial benefits of this estimate: (1) It is much faster to apply Algorithm 1 to a small initial ensemble of size than to a large one of size . (2) If we would like to be within some tolerance of the limit , then we can use the condition
[TABLE]
to dynamically predict how large must be chosen to reach that tolerance, namely .
Bias-corrected extrapolation.
If the initial estimate is obtained by implementing Algorithm 1 with oob samples, it turns out to be a biased estimate of . Fortunately however, it is possible to correct for this bias in a simple way, as we now explain.
To understand the source of the bias, recall that for each point in the training set, we write to index the regression functions for which is oob. Also, it is simple to check that for an initial ensemble of size , the expected cardinality of is given by
[TABLE]
In other words, this means that when an ensemble of size makes a prediction on an oob point, the “effective” size of the ensemble is , rather than . As a result, if we implement Algorithm 1 using oob samples with an initial ensemble of size , then the output should really be viewed as an estimate of , rather than .
Based on this reasoning, we can adjust our previous definition of the estimate in (4.2) by using
[TABLE]
Later on, in Section 5 we will demonstrate that this simple adjustment works quite well in practice.
Remark.
As a clarification, it should be noted that the definition (4.4) is only to be used when Algorithm 1 is implemented with oob samples, and the basic rule (4.2) should be used in the case of hold-out samples. Also, the basic rule (4.2) can be easily adapted to extrapolate the estimate produced by Algorithm 2, and so we omit the details in the interest of brevity.
5 Numerical results
We now demonstrate the bootstrap’s numerical accuracy at the tasks of measuring algorithmic convergence with respect to both mean-squared error and variable importance. Overall, our results show that the extrapolated oob estimate is accurate at predicting the effect of increasing . In fact, the results show that extrapolation succeeds at predicting what will happen when is increased by a factor of 4 beyond , and possibly much farther.
5.1 Organization of experiments
Data preparation.
Our experiments were based on several natural datasets that were each randomly partitioned in the following way. Letting denote the full set of observation pairs for a given dataset, we evenly split into a disjoint union , where the set was used for training, and the set was used to approximate the true quantile curves (namely or ) for assessing algorithmic convergence.
Since Algorithm 1 relies on a hold-out set, we also used a relatively small subset for that purpose. Specifically, the hold-out set was chosen so that its cardinality satisfied . This reflects a practical situation where the user can only afford to allocate of the available data for the hold-out set. In other words, the idea is to think of the user as only having access to , with the set as being used externally to establish “ground truth” for the rate of algorithmic convergence.
Each of the full datasets are briefly summarized below.
- •
Diamond: This dataset is available in the package ggplot2 (Wickham, 2016), and has been downsampled to 10,000 observations. Each observation contains 9 measured features of a distinct diamond, and the features are used to predict the diamond’s price.
- •
Housing: This dataset originates from 1990 California census and is available as part of the online supplement to the book (Géron, 2017). The observations are correspond to 20,640 homes, and for each home there are 9 features for predicting the home’s price.
- •
Music: This dataset consists of 1,059 audio recordings (observations) described by 68 features that are used to predict the geographic latitude of the recording, as described in (Zhou et al., 2014). The dataset is available at the UCI repository (Dua and Graff, 2017) under the title Geographical Origin of Music Data Set.
- •
Protein: This is dataset was collected from the fifth through ninth series of CASP experiments (Moult et al., 2011), and is available at the UCI repository (Dua and Graff, 2017) under the title Physicochemical Properties of Protein Tertiary Structure Data Set. The 45,730 observations correspond to artificially generated conformations of proteins (known as decoys) that are described by 9 biophysical features. Each decoy can be thought of as a perturbation of an associated “target” protein, and the features are used to predict how far the decoy is from its target.
Computing the true quantile curves and .
Once a full dataset was partitioned as above, we ran the random forests algorithm 1,000 times on the associated set , using the R package randomForest (Liaw and Wiener, 2002). The overall process was a serious computational undertaking, because regression trees were trained during every run, and hence a total of trees were trained on each dataset.
During each run, as the ensemble size increased from to , the corresponding true values of were approximated with the ensemble’s error rate on . Also, the true value of was approximated with the average of the 1,000 realizations of . In this way, the collection of runs produced 1,000 approximate sample paths of , similar to those illustrated in the right panel of Figure 1. Finally, the quantile curve was extracted by using the empirical 90% quantile of the 1,000 values of at each .
To handle the setting of variable importance, essentially the same steps were used. Specifically, we computed the vector at every value , for each of the 1,000 runs mentioned above. In addition, we approximated the vector with the average of the 1,000 realizations of . Altogether, these computations provided us with 1,000 approximate sample paths of , and then we used the empirical 90% quantile at each to approximate .
Applying the bootstrap algorithms with extrapolation.
For each of the described 1,000 runs of random forests, we applied the extrapolated versions of Algorithms 1 and 2 at the initial ensemble size of , using a small number of bootstrap samples. Hence, this provided us 1,000 realizations of each type of the proposed estimates, which allows for an assessment of their variability.
Below, in Sections 5.2 and 5.3, we will show the results obtained by extrapolating to the final ensemble size of . In addition, for Algorithm 1, we implemented both of the hold-out and oob versions, including the bias correction for the oob samples described in equation (4.4).
5.2 Numerical results for mean-squared error
Organization of the plots.
The two types of estimates for are illustrated in Figures 4 through 6, with the hold-out estimator in green, and the oob estimator in blue. More specifically, these curves represent the averages of the estimates over the 1,000 runs described above, and the error bars display the fluctuations of the estimates over repeated runs —corresponding to the 10th and 90th percentiles of the estimates. For the values of between the endpoints, we omit the error bars for clarity. Also, it is important to emphasize that these error bars should not be interpreted as confidence intervals for , and are only intended to show that the estimates have low variance.
With regard to computation, another point to mention is that the estimates were only computed for the initial ensemble size , and the rest of the green and blue curves were obtained essentially for free by extrapolation. Lastly, as a clarification, it should be noted that the blue oob curve is shifted to the left of the green hold-out curve because of the bias correction rule (4.4) for oob samples.
Remarks on performance.
The main point to take away from the plots is that the oob estimate performs quite well overall, and can be much more accurate than the hold-out estimate (cf. Figures 6 and 6). Furthermore, the oob estimate has an extra advantage because it does not require the user to hold out any data. For these reasons, we recommend the oob estimate in practice.
Another conclusion to draw from the plots is that the bias correction plays a significant role in the extrapolation of the oob estimate. If the bias correction were not used, this would be equivalent to shifting the blue curve so that it starts at the same point as the green curve, which would clearly lead to a loss in accuracy. Also, it is remarkable that the extrapolated oob estimator continues to be accurate at a final ensemble size of that is 4 times larger than the initial ensemble size . Hence, this provides the user with a very inexpensive way to predict how quickly the ensemble will converge. Moreover, even in the cases where the extrapolation starts from a mediocre initial estimate, the accuracy tends to improve as becomes larger.
To explain the inferior performance of the hold-out estimate, recall that it uses the small set in order to estimate . As a result, the estimates of using have much more variability, which inflates the upper extremes of the estimator’s sampling distribution, and thus leads to a larger estimate of . On the other hand, the oob estimator is able to take advantage of the oob samples in the much larger set , which reduces this detrimental effect.
5.3 Numerical results for variable importance
The results in the setting of variable importance are simpler to describe, since there is only one type of estimate for . In Figures 8 through 10, we plot the average of the 1,000 realizations of the estimates using a blue curve, while the error bars at the endpoints represent the 10% and 90% empirical quantiles of the estimates. In addition, the extrapolation procedure was based on an initial ensemble size of , as in the previous subsection. From the four plots, it is clear that the extrapolated estimate displays excellent overall performance, with its bias and variance both being very small.
Outline of proofs.
The key points of the proof of Theorem 3.1 are explained in Appendix A, and the primary lemmas are given in Appendix B. These lemmas rely on secondary technical results and background facts which are given in Appendices C and D respectively.
Notation and conventions.
To simplify presentation, letters such as etc., will be re-used to refer to positive absolute constants, not depending on , , or , and likewise, these letters may take a different value at each occurrence. Regarding the quantity defined in equation (3.4) of Theorem 3.1, we will omit the subscripts and write in order to lighten notation. In addition, if is an absolute constant, we may assume without loss of generality that
[TABLE]
because if the constant in Theorem 3.1 is chosen to satisfy , then the result is clearly true when . Next, we will often make use of the following basic moment relations involving quantities defined on page 3,
[TABLE]
These relations are straightforward to verify using the Cauchy-Schwarz and Jensen inequalities, and hence the details are omitted. Furthermore, under the above condition , these relations and the definition of in (3.4) imply that
[TABLE]
which will be useful in simplifying some expressions. Next, recall that the quantile function associated with a generic distribution function is defined as
[TABLE]
for any . Lastly, the supremum norm of a function is written as .
Appendix A High-level proof of Theorem 3.1
Define the following distribution functions at any ,
[TABLE]
and
[TABLE]
where each is an independent copy of the bootstrap sample (2.5), conditionally on and .
In Proposition A.1 below, we will show there is an absolute constant such that
[TABLE]
which is the most substantial part of the proof. Next, recall that and are defined to satisfy
[TABLE]
and let be an event defined by
[TABLE]
By intersecting the event with and , it follows that
[TABLE]
In turn, observe that if the event holds, then
[TABLE]
which implies that the event contains . In other words, the bound (A.3) implies
[TABLE]
Combining this with (A.5) gives
[TABLE]
Finally, it is clear that there is an absolute constant such that , and so the proof is complete. ∎
Proposition A.1**.**
Suppose the conditions of Theorem 3.1 hold. Then, there is an absolute constant such that
[TABLE]
Proof.
For any fixed , define the distribution function
[TABLE]
Clearly,
[TABLE]
The proof amounts to bounding the two terms on the right. To consider the first term , note that is the empirical distribution function based on i.i.d. samples from . Therefore, we may apply the Dvoretzky-Kiefer-Wolfowitz inequality (Lemma D.2) conditionally on and , and then take the expectation over to obtain
[TABLE]
Handling the second term is much more involved. To do this, we consider two random variables and , to be defined later, which allow the distance to be bounded in three parts:
[TABLE]
Specifically, each of the terms on the right side will be handled in Lemmas B.2, B.3, and B.1 respectively. Combining the results of those lemmas shows that there is an absolute constant such that
[TABLE]
Finally, the proof is completed by combining the inequalities (A.12) and (A.14).∎
Appendix B Primary lemmas
This section contains the three essential lemmas for proving Proposition A.1.
Lemma B.1**.**
Suppose that the conditions of Theorem 3.1 hold. Let be a Gaussian random variable generated conditionally on as . Also, for any , define . Then, there is an absolute constant , such that
[TABLE]
Proof.
A bit of algebra gives the relation
[TABLE]
where we define the random variables
[TABLE]
Also, for each , define the random variable
[TABLE]
which differs from the previous definition of in (3.2) only through the dependence on . The proof consists in showing that can be approximated by a Gaussian distribution, and that is negligible. Observe that can be written as
[TABLE]
and note that the summands are centered, and are i.i.d. conditionally on . If we define for any , then Lemma D.3 implies that the following inequality holds any ,
[TABLE]
where we note that is non-negative. Hence, it remains to bound the first and third terms on the right side, and then select a value of . The first term satisfies the Berry-Esseen bound
[TABLE]
where . Next, the third term is handled in Lemma C.1, which shows that if we take
[TABLE]
for some absolute constant , then
[TABLE]
Combining the three previous bounds gives
[TABLE]
Finally, we use the following bounds from (A0.2)
[TABLE]
and then the stated result follows from (B.7) after simplifying.∎
Remark.
For the statement and proof of the next lemma, define the random variables
[TABLE]
for each , which are conditionally i.i.d. given , with mean zero. Likewise, define the moments
[TABLE]
Lastly, recall that is the distribution function of given , as defined in (A.10).
Lemma B.2**.**
Suppose that the conditions of Theorem 3.1 hold. Let be a Gaussian random variable, generated conditionally on and according to . Also, for any , let . Then, there is an absolute constant , such that
[TABLE]
Proof.
The proof can be viewed as the bootstrap counterpart to the proof of Lemma B.1. It is straightforward to verify the relation
[TABLE]
where we define the random variables
[TABLE]
Also, observe that can be written as
[TABLE]
Next, for any , define the conditional distribution function
[TABLE]
In turn, Lemma D.3 gives the following bound for any realization of and , and any fixed ,
[TABLE]
The first term on the right satisfies the Berry-Esseen bound,
[TABLE]
Furthermore, the quantities and can be controlled with the help of the following tail bounds, which are direct consequences of Lemmas C.3 and C.2,
[TABLE]
and
[TABLE]
Next, to use an alternative notation for the third term on the right side of (B.15), let
[TABLE]
and also write its expectation with respect to as
[TABLE]
Then, Markov’s inequality gives
[TABLE]
In Lemma C.4, we show that if is chosen as
[TABLE]
for a sufficiently large absolute constant , then the bound
[TABLE]
holds for any realization of . Combining the ingredients above, we have
[TABLE]
Finally, the term involving can be simplified by making use of the simple inequalities
[TABLE]
This leads to the stated result.∎
Lemma B.3**.**
Suppose that the conditions of Theorem 3.1 hold. Let and be as defined in the statements of Lemmas B.1 and B.2. Then, there is an absolute constant such that
[TABLE]
Proof.
Recall that and correspond to centered Gaussian distributions. It is a basic fact about the function that the following bound holds for any positive numbers and
[TABLE]
where is an absolute constant. Since the respective variances of and are and , this means
[TABLE]
Combining this inequality with Lemma C.2 (below) completes the proof. ∎
Appendix C Secondary lemmas
Remark.
Recall that is defined in (B.3) as
Lemma C.1**.**
Suppose the conditions of Theorem 3.1 hold. Then, there is an absolute constant , such that
[TABLE]
Proof.
The proof is based on the inequality
[TABLE]
with a suitably chosen number . In order to control , we will use a version of Rosenthal’s inequality that is applicable to sums of independent Banach-valued random variables, as given in Lemma D.1. Specifically, this lemma shows that
[TABLE]
where is an absolute constant. Regarding the first term on the right, we may use the fact that are conditionally i.i.d. given to obtain
[TABLE]
The second term on the right side of (C.2) can be bounded as
[TABLE]
Recalling the prefactor of in the definition of , as well as the fact that , it follows that the previous work can be combined as
[TABLE]
Hence, if we take
[TABLE]
in the inequality (C.1), then the proof is complete.∎
Lemma C.2**.**
Suppose that the conditions of Theorem 3.1 hold. Then, there are absolute constants such that
[TABLE]
and
[TABLE]
Proof.
Note that the second bound (C.7) follows from the first bound (C.6) due to the inequality
[TABLE]
as well as the condition (A0.1). In order to prove (C.6), the main idea is to derive a quantity satisfying
[TABLE]
and then Chebyshev’s inequality gives
[TABLE]
To derive , first recall that
[TABLE]
Simple algebra gives the relation
[TABLE]
where we put
[TABLE]
This allows to be written as
[TABLE]
and so the triangle inequality for the conditional norm gives
[TABLE]
where the terms on the right are defined as
[TABLE]
To handle the term , a straightforward calculation based on the bound and Rosenthal’s inequality (Lemma D.1) shows that
[TABLE]
where is an absolute constant. Next, using the triangle and Cauchy-Schwarz inequalities, it is simple to check that the second term satisfies
[TABLE]
To complete the proof, it suffices to bound the quantity \big{(}\mathbb{E}\big{[}|\Delta_{1}|^{k}\big{|}\mathcal{D}\big{]}\big{)}^{\frac{1}{k}} for general . Using steps analogous to the ones in the bound (C.15), we obtain
[TABLE]
Next, recall that the argument following the bound (C.2) in the proof of Lemma C.1 leads to
[TABLE]
for some absolute constant . In addition, if we apply a discrete version of Jensen’s inequality
[TABLE]
and use Assumption A2 to get
[TABLE]
then
[TABLE]
To combine the work above, recall the condition (A0.3), and note that we must replace with when relating the bound (C.17) to \big{(}\mathbb{E}[|\Delta_{1}|^{2k}|\mathcal{D}]\big{)}^{\frac{1}{2k}}. Altogether, we conclude
[TABLE]
Hence, if we define to be the right side above, then the bound (C.8) completes the proof.∎
Lemma C.3**.**
Suppose the conditions of Theorem 3.1 hold. Then, there is an absolute constant such that
[TABLE]
Proof.
Recall that
[TABLE]
Also, if we recall the relation (C.9)
[TABLE]
with as defined in (C.10), then
[TABLE]
To derive a high probability upper bound on , it is enough to use Chebyshev’s inequality
[TABLE]
in conjunction with a bound on . By the triangle inequality for the conditional norm , we have
[TABLE]
It is straightforward to check that the first term on the right satisfies
[TABLE]
Meanwhile, the following crude (but adequate) bound for the second term on the right side of (C.22) can be obtained directly from (C.17) and the condition (A0.3),
[TABLE]
Altogether, we have
[TABLE]
and so the stated result follows from the Chebyshev bound (C.21). ∎
Remark.
Recall that is defined in equation (B.13) as
[TABLE]
Lemma C.4**.**
Suppose the conditions of Theorem 3.1 hold. Then, there is an absolute constant such that
[TABLE]
Proof.
The proof is similar to that of Lemma C.1, and proceeds by developing a bound on the conditional moment
[TABLE]
To begin, note that is a sum of i.i.d., zero-mean Banach-valued random variables, conditionally on and . So, if we apply Lemma D.1 with the inequality , then
[TABLE]
where is an absolute constant. Direct calculation shows that the first term on the right satisfies
[TABLE]
where Jensen’s inequality has been used in the last step. Likewise, the second term in (C.23) satisfies
[TABLE]
Hence, if we integrate with respect to , then (C.23) leads to
[TABLE]
The last factor on the right can be decomposed as
[TABLE]
Combining the last two displays, it follows after some simplification that
[TABLE]
and this completes the proof by using Chebyshev’s inequality in the same manner as in the proof of Lemma C.1.∎
Appendix D Background results
The following inequality is a modified version of the main result in (Talagrand, 1989). (See also (Johnson et al., 1985) and (Kwapień et al., 1991).)
Lemma D.1**.**
Let be independent and zero-mean elements of a Banach space with norm . Then, there is an absolute constant , such that for any ,
[TABLE]
In particular, if are scalar random variables, and , then
[TABLE]
The next lemma is the Dvoretzky-Kiefer-Wolfowitz inequality (Dvoretzky et al., 1956; Massart, 1990).
Lemma D.2**.**
Let be independent random variables with a common distribution function . Also, for any , let
[TABLE]
Then, for any fixed ,
[TABLE]
Lemma D.3**.**
Fix any . Let and be random variables, satisfying , and . Also let and denote the distribution functions of the first three variables. Then, for any ,
[TABLE]
Proof.
It is straightforward to check that the following inequalities hold for any ,
[TABLE]
and so
[TABLE]
Note also that for any fixed ,
[TABLE]
Here, the first probability on the right side can be bounded as
[TABLE]
Since , its distribution function is Lipschitz with parameter , and so we have
[TABLE]
for every . Combining the last several steps with the bound (D.5) gives
[TABLE]
In turn, adding to both sides leads to the stated bound on .∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arlot and Genuer (2014) Arlot, S. and Genuer, R. (2014) Analysis of purely random forests bias. preprint ar Xiv:1407.3939 .
- 2Basilico et al. (2011) Basilico, J., Munson, M., Kolda, T., Dixon, K. and Kegelmeyer, W. (2011) Comet: A recipe for learning and using large ensembles on massive data. In Data Mining (ICDM), 2011 IEEE 11th International Conference on , 41–50. IEEE.
- 3Biau (2012) Biau, G. (2012) Analysis of a random forests model. Journal of Machine Learning Research , 13 , 1063–1095.
- 4Biau et al. (2008) Biau, G., Devroye, L. and Lugosi, G. (2008) Consistency of random forests and other averaging classifiers. Journal of Machine Learning Research , 9 , 2015–2033.
- 5Bickel and Yahav (1988) Bickel, P. J. and Yahav, J. A. (1988) Richardson extrapolation and the bootstrap. Journal of the American Statistical Association , 83 , 387–393.
- 6Blaser and Fryzlewicz (2016) Blaser, R. and Fryzlewicz, P. (2016) Random rotation ensembles. The Journal of Machine Learning Research , 17 , 126–151.
- 7Breiman (1996) Breiman, L. (1996) Bagging predictors. Machine Learning , 24 , 123–140.
- 8Breiman (2001) Breiman, L. (2001) Random forests. Machine Learning , 45 , 5–32.