Multivariate approximation of functions on irregular domains by weighted least-squares methods
Giovanni Migliorati

TL;DR
This paper develops weighted least-squares algorithms for approximating functions on irregular domains, enabling stable, quasi-optimal estimations with computational efficiency even without explicit basis functions.
Contribution
It introduces a method to construct stable weighted least-squares estimators on irregular domains using surrogate bases, extending previous work to more complex geometries.
Findings
Stable estimators achieved with m ~ n log n function evaluations.
Surrogate basis construction depends on Christoffel function of domain and space.
Numerical experiments confirm theoretical stability and accuracy.
Abstract
We propose and analyse numerical algorithms based on weighted least squares for the approximation of a real-valued function on a general bounded domain . Given any -dimensional approximation space , the analysis in [6] shows the existence of stable and optimally converging weighted least-squares estimators, using a number of function evaluations of the order . When an -orthonormal basis of is available in analytic form, such estimators can be constructed using the algorithms described in [6,Section 5]. If the basis also has product form, then these algorithms have computational complexity linear in and . In this paper we show that, when is an irregular domain such that the analytic form of an -orthonormal basis is not available, stable and quasi-optimally weighted…
Click any figure to enlarge with its caption.
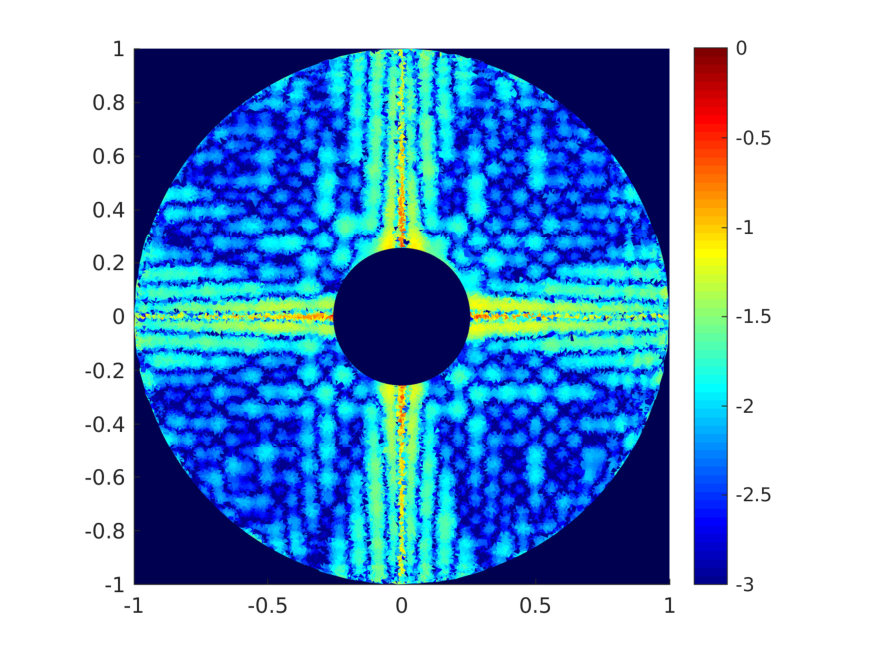 Figure 1
Figure 1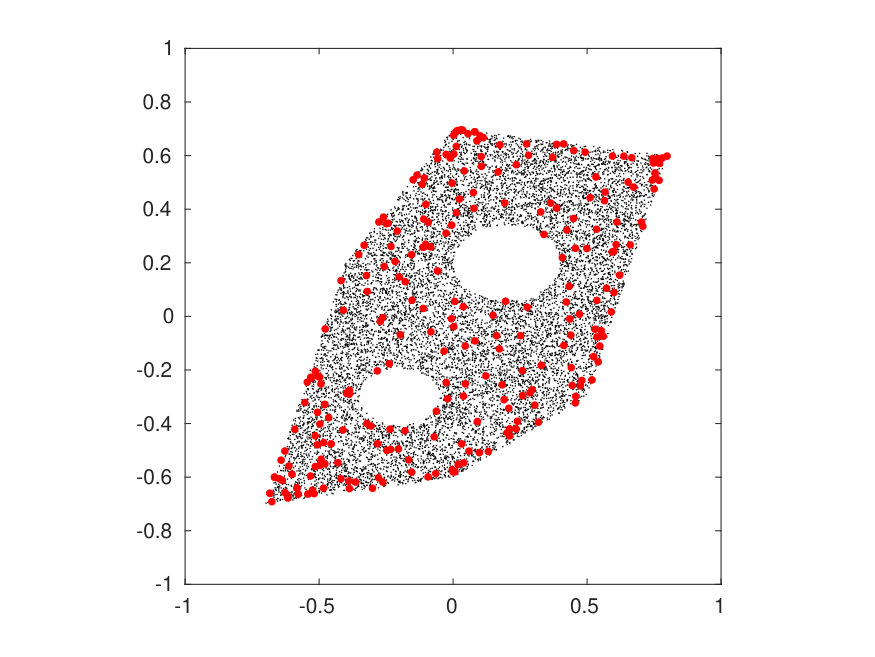 Figure 2
Figure 2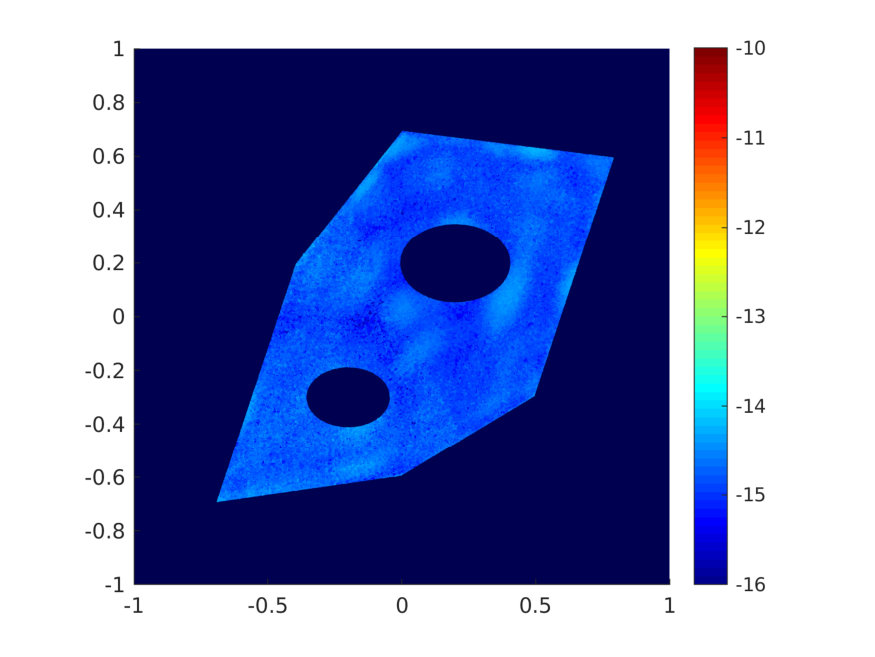 Figure 3
Figure 3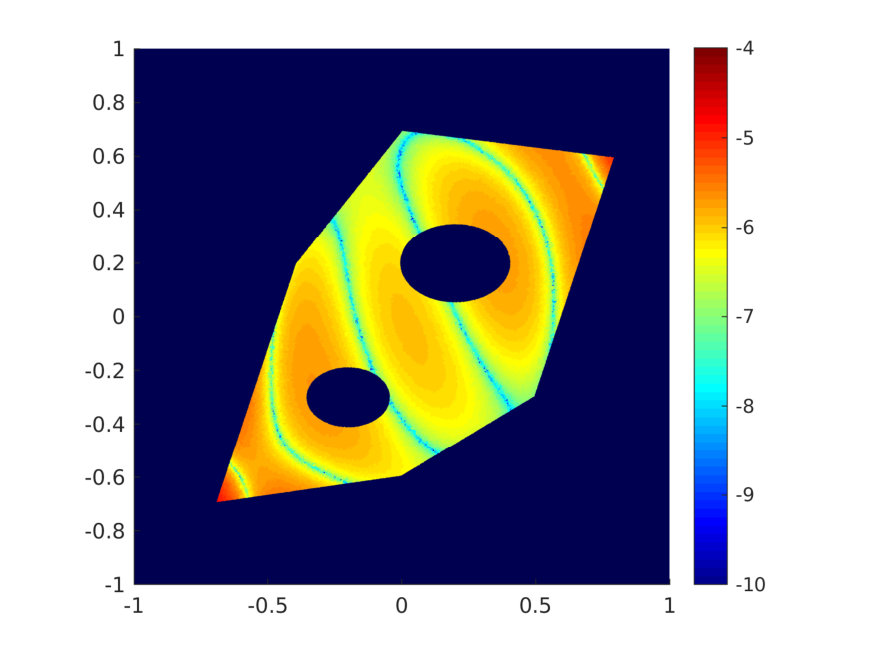 Figure 4
Figure 4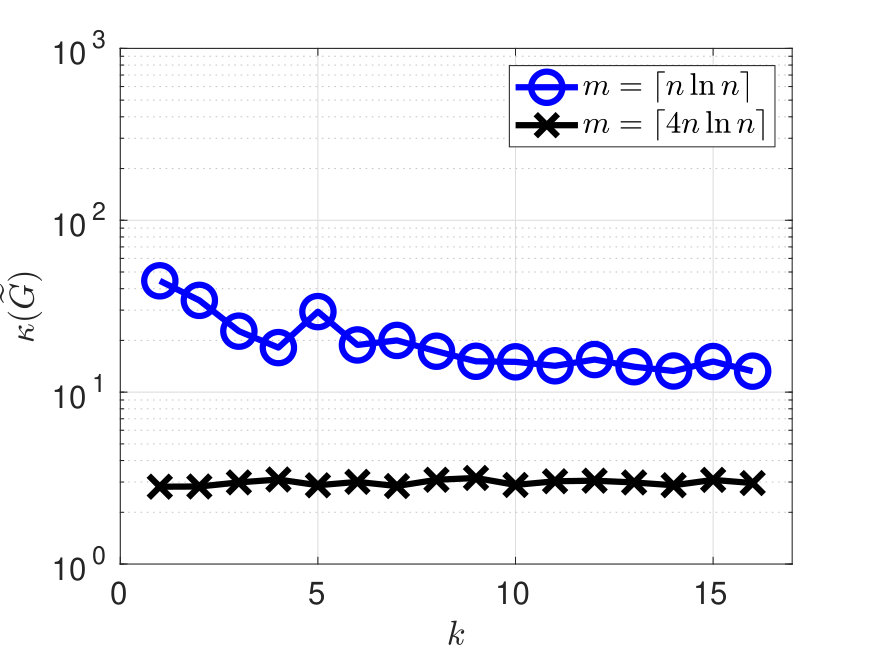 Figure 5
Figure 5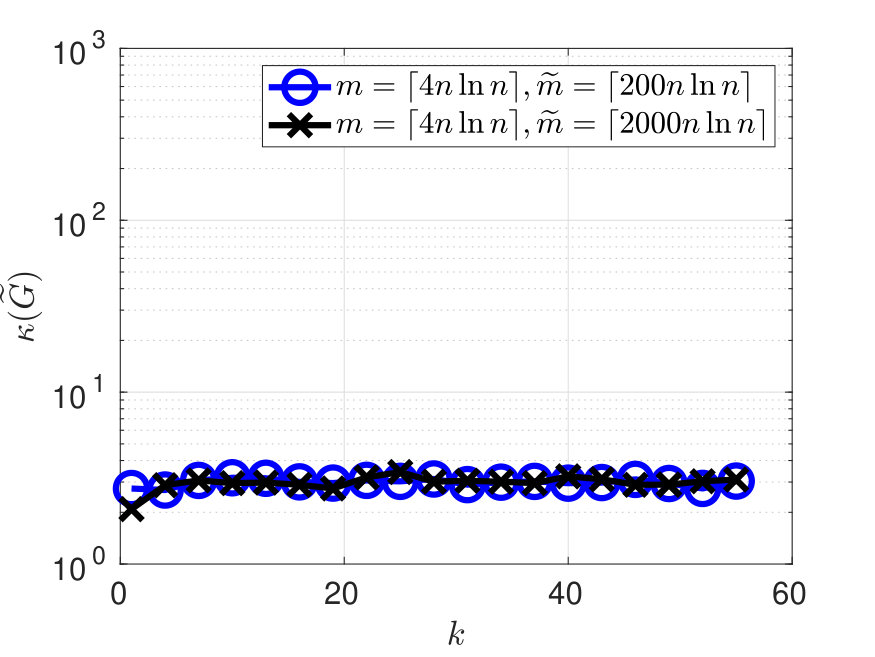 Figure 6
Figure 6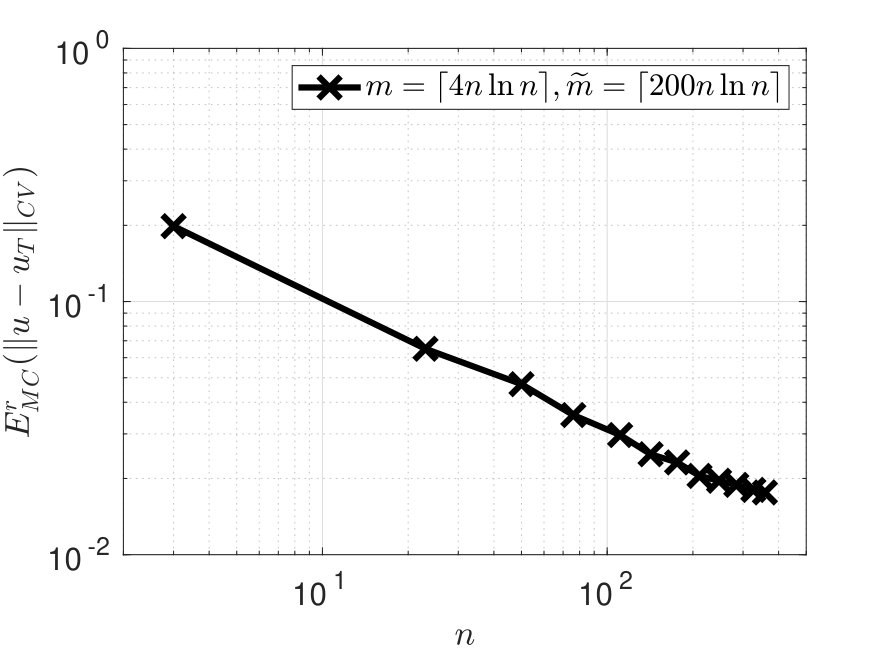 Figure 7
Figure 7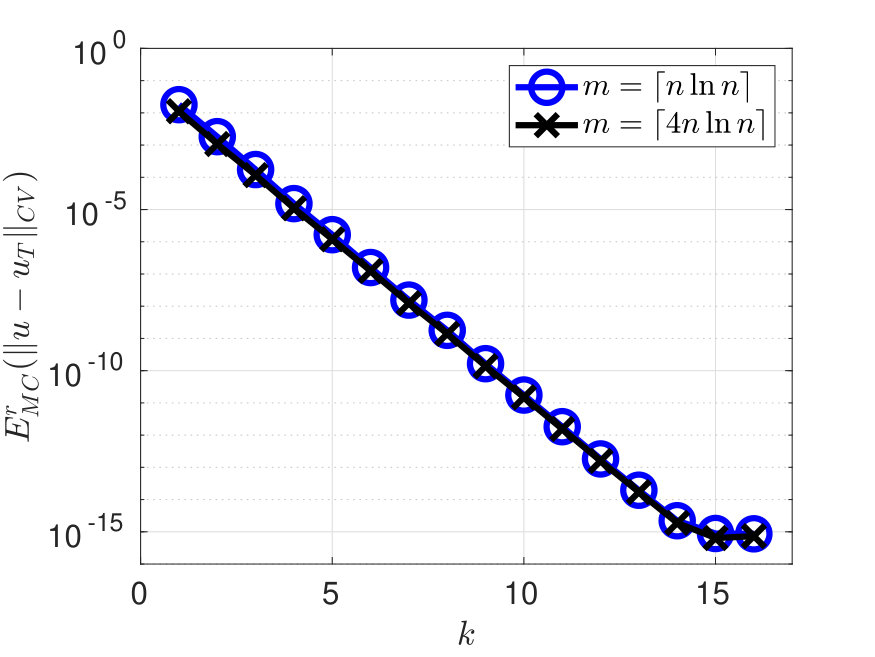 Figure 8
Figure 8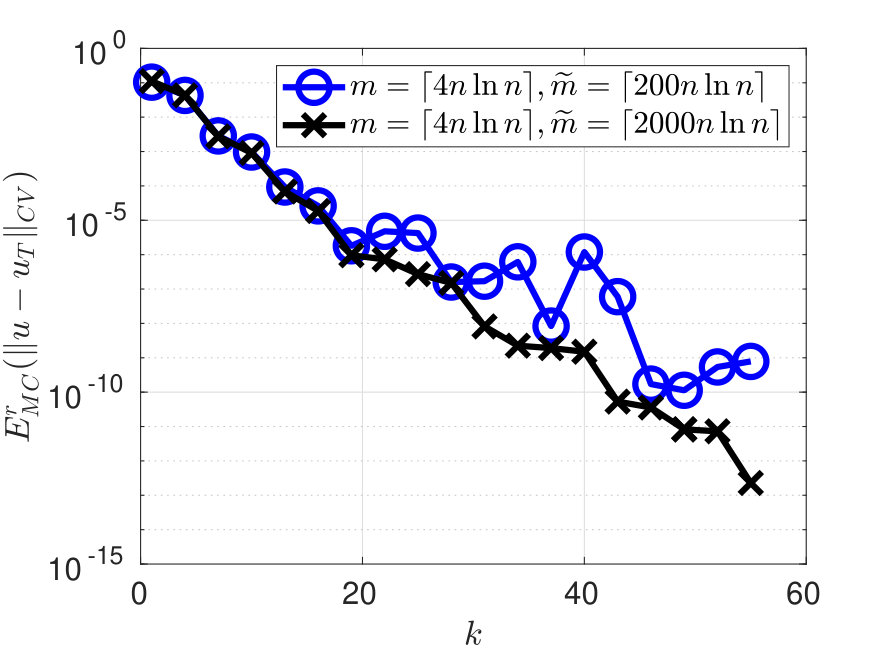 Figure 9
Figure 9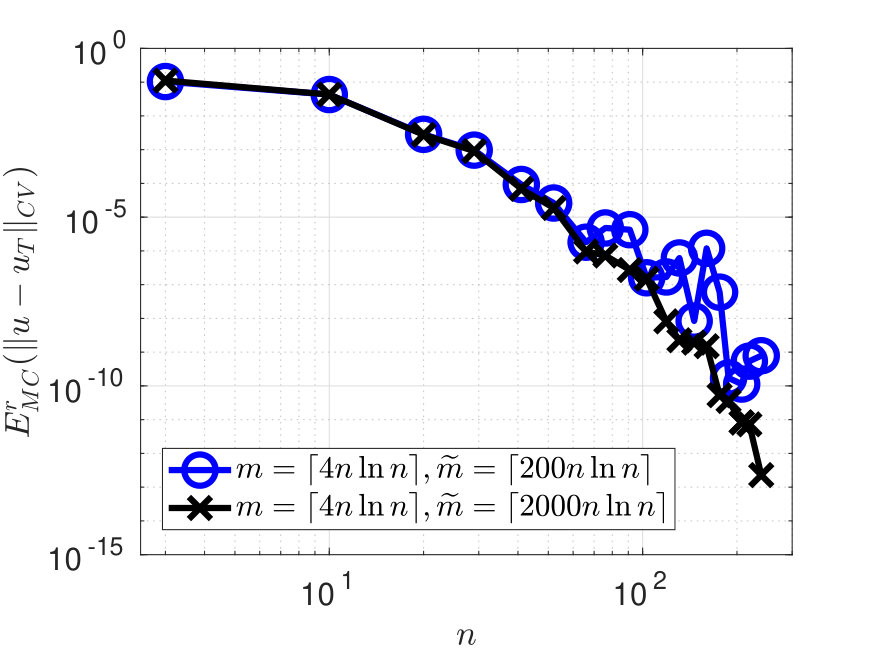 Figure 10
Figure 10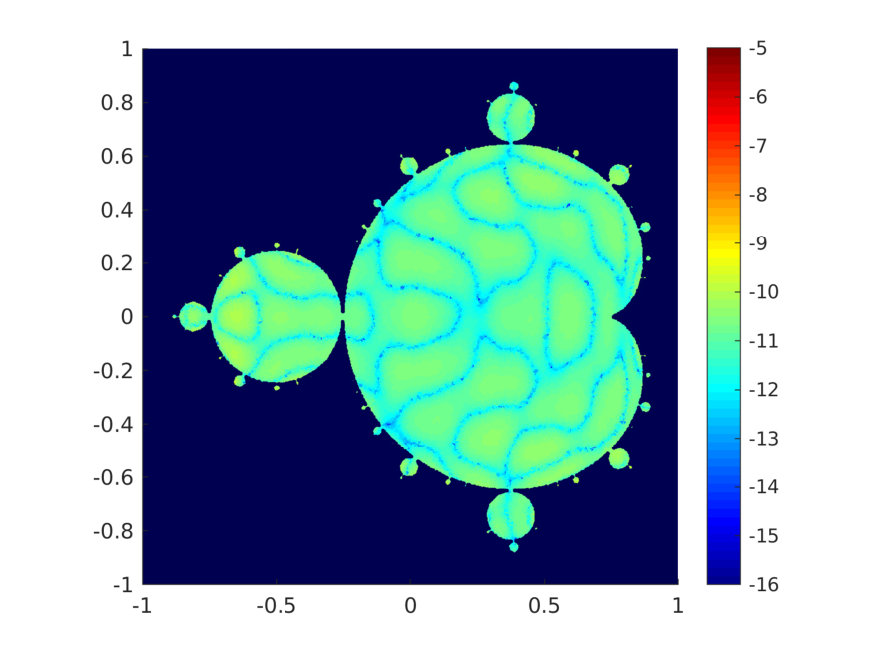 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multivariate approximation of functions on irregular domains
by weighted least-squares methods
Giovanni Migliorati Sorbonne Université, UPMC Univ Paris 06, CNRS, UMR 7598, Laboratoire Jacques-Louis Lions, 4, place Jussieu 75005, Paris, France. email: [email protected]
Abstract
We propose and analyse numerical algorithms based on weighted least squares for the approximation of a bounded real-valued function on a general bounded domain . Given any -dimensional approximation space , the analysis in [6] shows the existence of stable and optimally converging weighted least-squares estimators, using a number of function evaluations of the order . When an -orthonormal basis of is available in analytic form, such estimators can be constructed using the algorithms described in [6, Section 5]. If the basis also has product form, then these algorithms have computational complexity linear in and . In this paper we show that, when is an irregular domain such that the analytic form of an -orthonormal basis is not available, stable and quasi-optimally weighted least-squares estimators can still be constructed from , again with of the order , but using a suitable surrogate basis of orthonormal in a discrete sense. The computational cost for the calculation of the surrogate basis depends on the Christoffel function of and . Numerical results validating our analysis are presented.
1 Introduction and overview of the paper
Approximating an unknown function from its pointwise evaluations is a classical problem in mathematics. Interpolation and least squares are two approaches to such a problem, see e.g. [7, 13]. In this paper, we develop and analyse numerical methods based on least squares for the approximation of a bounded function on a general bounded domain in any dimension , that can be a challenging task due to the curse of dimensionality. Approximation takes place in , the space of square-integrable functions with respect to , the uniform probability measure on . Given a finite -dimensional linear space , projection-type numerical methods select that minimizes the approximation error of in . Standard least squares are an example of such numerical methods, that construct from pointwise evaluations of at iid random samples from . An important point in the analysis of least squares concerns how large has to be, compared to , to ensure stability and good approximation properties of the estimator .
Recent works [9, 10, 6] have pointed out weighted least-squares methods as a well-promising approach for approximation in arbitrary dimension . In any domain and with any finite-dimensional space , it was shown in [6] that weighted least-squares estimators are stable and optimally converging in expectation, when the evaluations of are taken at iid random samples from a suitable probability measure that depends on and , and with being only linearly proportional to up to a logarithmic term, and independent of the ambient dimension . This result is recalled in Theorem 1.
For the computation of with the above guarantees, the analytic expression of an -orthonormal basis is needed. If this is available, then one can generate the random samples from and construct as described in [6], and as recalled in Section 2 as well. Moreover, if the orthonormal basis has product form, like e.g. when is a product domain, then the numerical methods developed in [6] generate random samples from at a computational cost that scales linearly in both and .
In general, when is an irregular domain, the analytic expression of an -orthonormal basis is not known. Hence a suitable surrogate basis of is needed, that replaces and at the same time retains orthogonality with respect to some scalar product easy to evaluate on any domain . In this setting, a convenient choice is to orthonormalize using a discrete scalar product with iid random samples from . We denote by the new weighted least-squares estimator of computed using the basis , that differs from whose computation uses . In the present paper we show that the estimator can be constructed on general domains and that:
- •
is stable with high probability, quasi-optimally converging in expectation, and uses a number of evaluations of only linearly proportional to up to a logarithmic term, and independent of ;
- •
the numerical construction of requires iid random samples from and the QR factorisation of -by- matrices, where scales as the norm of the reciprocal of the Christoffel function of on . Such a construction does not use any evaluation of , nor does it require the knowledge of .
The novel stability and convergence result for the estimator are stated in Theorem 3, whose proof uses previous results from [5, 6] and matrix Bernstein inequality. The convergence estimate reads as follows, where we use the and best approximation errors of in , a parameter related to the construction of , two unnamed constants , and omit the technical details on the truncation of the estimator:
[TABLE]
The parameters and essentially scale linearly and superlinearly in , respectively.
The term arises from the missing discrete orthogonality of , that occurs in any orthonormalisation process due to numerical cancellation. When are constructed by Householder QR factorisation, provably does not exceed where is the machine precision of arithmetic calculations, and thus the term is completely negligible for wide ranges of and .
The construction of the estimator uses evaluations of at iid random samples drawn from a surrogate discrete probability measure that emulates , and that depends on and . The random samples from can be generated by subsampling the QR factorisation of a suitable matrix that depends on . Similar applications of QR factorisation have been used for the computation of Fekete points [19], and for the construction of randomised quadratures [16].
In [1] a different method based on SVD truncation has been analysed, for the same purposes of function approximation on irregular domains. For that method, similar error estimates as (1.1) have been obtained in [1], but requiring a number of function evaluations that scales superlinearly in , and using a different best approximation error that depends on the SVD truncation parameter.
In [2] a method similar to our forthcoming Algorithm 1 has been proposed, and its convergence in probability has been analysed assuming exact discrete orthonormality of the surrogate basis, i.e. assuming .
The structure of our paper is the following: in Section 2 we recall from [6] some results on approximation by weighted least-squares methods, and describe the additional challenges encountered when applying such methods to irregular domains. In Section 2.1 we state Theorem 3. Its proof is postponed to Section 2.2. In Section 2.3 we describe the construction of . In Section 3 we propose two algorithms (Algorithm 1 and Algorithm 2) that compute the weighted least-squares estimator . Section 4 contains some numerical tests that validate our analysis. In Section 5 we draw some conclusions.
2 Weighted least-squares approximation on irregular domains
Given a bounded domain , we consider the problem of approximating a bounded function from its pointwise evaluations at independent random samples uniformly distributed over . Without loss of generality we suppose that . Denote with the uniform probability measure on , and with an orthonormal basis of , where the norm is denoted as and for any . The Euclidean norm in is indicated with . For any , we denote by an -dimensional approximation space, and assume that contains the constant functions. We define the -projection of on as
[TABLE]
and denote by the best approximation error of in . We also denote by the best approximation error in . Using , we define the functions
[TABLE]
and the probability measure on as
[TABLE]
When is the total degree polynomial space, is known as the Christoffel function, see e.g. [17]. For any choice of points, we introduce the scalar product
[TABLE]
In general the exact projection (2.2) cannot be computed. This motivates the interest in the discrete least-squares approach, where the norm in (2.2) is replaced by the seminorm induced on by the scalar product (2.4). Define the weighted least-squares estimator
[TABLE]
that can be computed from the minimal -norm solution to the normal equations
[TABLE]
where the Grammian matrix is defined component-wise as and the right-hand side has components . Throughout the paper, denotes the identity matrix, and
[TABLE]
denotes the spectral norm, respectively the condition number, of any matrix . For any define , that can be sandwiched as when . As in [6], we suppose that satisfies a uniform bound with some known :
[TABLE]
We then introduce the truncation operator , and define the truncated estimator
[TABLE]
The following result was proven in [6, Theorem 2.1 and Corollary 2.2], in a slightly different form (here we rewrite it with , where is the same parameter as in [6]).
Theorem 1**.**
In any dimension , for any domain and any , if
[TABLE]
and are iid random samples from then
[TABLE]
and if satisfies (2.7) then the estimator satisfies
[TABLE]
The above result holds with any bounded or unbounded domain in any dimension, and in general approximation spaces . In practice, the computation of the estimator requires the analytic expression of an -orthonormal basis , for the generation of the random samples from (2.3) and for the construction of and in (2.6). When , many -orthonormal basis can be constructed by tensorization, e.g. tensorized Legendre polynomials or tensorized wavelets. Other examples are available when has a symmetric structure, e.g. spherical harmonics on the sphere .
In general, when is an irregular domain, the analytic expression of the is not known. This introduces additional challenges in the development and analysis of projection-type numerical methods for approximation on irregular domains. In principle, candidate replacements of are functions not necessarily orthonormal in that satisfy the following prescriptions:
- P1)
be orthonormal w.r.t. a discrete scalar product, that can be easily evaluated with any domain , in contrast to the scalar product that requires integration over ; 2. P2)
, since our goal is the approximation of in the space .
We now introduce some tools useful for the numerical construction of the basis . Let be iid random samples from , and define the discrete scalar product
[TABLE]
and . For any , we say that are -orthonormal if
[TABLE]
Orthonormalisation algorithms, e.g. Gram Schmidt-type or factorization-type algorithms, try to construct a set of functions orthonormal w.r.t (2.8), but they suffer from loss of orthogonality due to numerical cancellation. As a consequence, the constructed by any such numerical method are only -orthonormal for some , and prescription P1 can be fulfilled with the scalar product (2.8) up to a (hopefully small) loss of orthogonality quantified by (2.9).
Let us consider prescription P2. Define and denote with a collection of functions such that . These functions need not be orthonormal to a scalar product, but only linearly independent. Orthonormalisation algorithms construct each as linear combinations of , ensuring . The coefficients of the linear combinations are computed from evaluations of at . Although linearly independent, the and with could be indistinguishable when evaluated at , and when this happens the do not span the whole . Due to randomness in the , in general spaces one can ensure P2 only with large probability. When is a polynomial space, in Section 2.3 we show that P2 can be ensured with probability one.
For the time being we suppose that an -orthonormal basis is available for some . A concrete algorithm for the construction of such a basis is described in Section 2.3, together with suitable bounds for . Using , define the functions
[TABLE]
where is a normalisation term defined later. Consider the set containing iid random samples from , and define the discrete uniform probability measure on (i.e. for all ) and the probability measure on as
[TABLE]
with .
Let be iid random samples from . Using these random samples and the scalar product (2.4) with the weight chosen as in (2.10), we define the Grammian matrix with components , and the vector with components . We now introduce the discrete projection on and the weighted least-squares estimator as
[TABLE]
The estimator can be computed by solving the normal equations
[TABLE]
whose solution provides the coefficients of the expansion . Denote with the truncated estimator
[TABLE]
Define . Throughout the paper, all the probability events belong to the Borel -algebra and denotes the probability measure on . The only exceptions are in Theorem 1 that uses and as on , and in the forthcoming Theorem 2 that uses and as on .
The following probability events are related to the construction of satisfying P1 and P2:
[TABLE]
[TABLE]
In the notation , the subscript points out the dependence on in the construction of , further discussed in Section 2.3. Notice that both events and do not depend on .
We define the quantity
[TABLE]
that in general depends on and . Thanks to the inclusion on any bounded, the lower bound holds for any . When and is a downward closed polynomial space, we also have the following upper bound from [4] for any :
[TABLE]
For any , define the probability event:
[TABLE]
The next result was proven in [5] in a slightly different form, that we rewrite with , as in Theorem 1.
Theorem 2**.**
In any dimension , for any bounded , for any , and , if
[TABLE]
and are iid random samples from then .
It has been observed in [1] that the upper bound (2.14) can be generalised to bounded domains with the so-called -rectangle property, i.e. has the -rectangle property if such that , where is the set of (possibly overlapping) hyperrectangles such that .
If the domain has the -rectangle property and is a downward closed polynomial space then
[TABLE]
see [1, Theorem 6.6]. Simple domains that do not have the -rectangle property are e.g. the simplex and the ball. When is a convex or starlike domain and is a total degree polynomial space, asymptotic upper bounds for are available e.g. in [3, 14, 15, 22], see also [18] for estimates of when . With more general domains and/or approximation spaces , finding upper bounds for is an open problem.
2.1 Main results
This section contains Theorem 3 and the analysis of a numerical algorithm that constructs . Theorem 3 states conditions ensuring that with large probability stays close to the identity matrix in spectral norm, and that the estimator quasi-optimally converges in expectation, when the are -orthonormal. Theorem 3 applies in general to any orthonormalisation algorithm. Its proof is postponed to Section 2.2. In Theorem 3 we assume that for some . This assumption means that, with probability at least , the chosen orthonormalisation algorithm can construct that are -orthonormal and span the whole , using random samples . In this respect, represents the failure probability of the orthonormalisation algorithm. In some settings is known from the analysis, see Section 2.3, and if not, in any case, it can be numerically estimated for the given domain and threshold .
In Section 2.3 we discuss an orthonormalisation algorithm based on Householder QR factorisation, which constructs provably -orthonormal with , and achieves when is a multivariate polynomial space. Corollary 1 contains the application of Theorem 3 to such an algorithm.
Theorem 3**.**
In any dimension , for any bounded domain , for any , , , and , if the following conditions hold true
- i)
, 2. ii)
, 3. iii)
, 4. iv)
, 5. v)
,
then
- I)
the matrix satisfies
[TABLE] 2. II)
if satisfies (2.7) then the estimator satisfies
[TABLE]
where
[TABLE]
Remark 1** (Comparison with Theorem 1).**
Theorem 1 and Theorem 3 prove that and are well-conditioned, respectively, when is of the order , but with differently distributed random samples. In the proof of (2.16), does not need to satisfy ii), and only needs to ensure a large probability of the event in v). Condition ii) is needed for the proof of (2.17).
The convergence estimates in Theorem 1 and Theorem 3 differ due to term , whose presence is discussed in Remark 2, and due to the -best approximation error, whose coefficient satisfies for any such that . If satisfies ii) with replaced by , then decays to zero as .
Remark 2** (Missing orthogonality of the ).**
In the proof of (2.17), the additional term in (2.28) arises from the fact that are only -orthonormal with . The term propagates to and in (2.17), and is harmless as long as remains small. This is the case for wide ranges of and since provably does not exceed and , see Section 2.3. For example, if and then . The numerical tests in Section 4 show that even lower values of can be taken, of the order .
If are assumed -orthonormal with then, by Parseval’s identity, (2.28) simplifies to
[TABLE]
and the same proof of item II) gives (2.17) with
[TABLE]
being strictly decreasing functions that tend to zero as . Notice that .
2.2 Proofs and intermediate results
Given two events such that , we denote by the conditional probability of given .
Proof of item I) in Theorem 3.
For convenience we define the events , , and . The expectation is on the , for given . Indeed implies , and hence
[TABLE]
Using in sequence the definition of , linearity of expectation, iv) and (2.11) we obtain
[TABLE]
for any . On the event for any and we have
[TABLE]
As a consequence of the above bound
[TABLE]
From Lemma 2, under conditions i) and iv) it holds that
[TABLE]
Using (2.22) and (2.21), since we obtain
[TABLE]
Finally using in sequence (2.18), (2.23) and v) gives
[TABLE]
∎
Lemma 1**.**
On the event the following holds:
[TABLE]
[TABLE]
Proof.
The expression on the right-hand side below is equivalent to (2.24):
[TABLE]
For the proof of (2.25) take in (2.24) and then sum from to . ∎
The following result from [20] is a consequence of Bernstein inequality for self-adjoint matrices.
Theorem 4**.**
Let be a fixed matrix. Construct a symmetric random matrix that satisfies
[TABLE]
Compute the per-sample second moment . Form the matrix sampling estimator
[TABLE]
Then for all the estimator satisfies
[TABLE]
In the next lemma we apply Theorem 4 on the event and with the fixed matrix , where the expectation is taken over for given .
Lemma 2**.**
For any , and , under conditions i) and iv) it holds that
[TABLE]
Proof.
We define the random matrix whose components are
[TABLE]
and is distributed as . Using iv), define for as copies of the random matrix . Notice that, from iv), on the event the are mutually independent. They also satisfy
[TABLE]
From linearity of expectation, condition iv) and (2.19) we obtain . For any and , from (2.20) on the event we have , and this is equivalent to
[TABLE]
Notice that, from the expression of in (2.10),
[TABLE]
and therefore . Define now . Thanks to the previous bounds
[TABLE]
Since is a rank-one matrix,
[TABLE]
Finally, on the event , we apply Theorem 4 with the fixed matrix . On the event the parameter satisfies the uniform bound (2.25), and we obtain
[TABLE]
If condition i) holds true, since
[TABLE]
we obtain the thesis. ∎
Proof of item II) in Theorem 3.
The proof of the error estimate proceeds in the same way as the analogous proof of [6, Theorem 2.1], with some differences due to the missing orthogonality of the .
From Theorem 2 under ii) it holds . Since we obtain
[TABLE]
Define . Combining (2.26) and item I) it holds that . On the event it holds . Since for all , we also have . Denoting , on the event it holds that
[TABLE]
where we have used that is orthogonal to , that , and that . We expand over the , with being the solution to and .
Using in sequence the norm equivalence in the event , Lemma 1, , we obtain
[TABLE]
Thus replacing (2.28) in (2.27) provides the bound
[TABLE]
On the event item I) gives . Since we have
[TABLE]
Taking the total expectation over and using gives
[TABLE]
Denote with the expectation over and with the expectation over . For the second term above, using the independence of the random samples we have
[TABLE]
Summing term I over gives
[TABLE]
We now show that Term III is equal to zero. On the event for any and any it holds that , and therefore
[TABLE]
where the function is obtained as an average over of functions in , i.e. , multiplied by real-valued random variables, i.e. . Therefore does not depend on and . Hence for any the integral in the last line vanishes because is orthogonal to .
For term IV, from Lemma 1 we obtain
[TABLE]
Summing term II over and using Lemma 1 gives
[TABLE]
Finally
[TABLE]
and combining with ii) and i) gives (2.17). ∎
2.3 Construction of with QR factorisation
In this section we use Householder QR factorisation (hereafter HQRf) for the construction of . Let be linearly independent functions. Using the random samples in (2.8), we introduce the matrix defined component-wise as for and .
Recall the following result on HQRf, see e.g. [21, Theorem 4.24]: if has full rank, then it can be written uniquely in the form , where the columns of form an orthonormal basis of the column space of , and is an upper triangular matrix with positive diagonal elements. Hence we can take
[TABLE]
and the factor makes the orthonormal with (2.8), while the columns of are orthonormal with the Euclidean scalar product in . For any the analytic expression of is given as a linear combination of by
[TABLE]
where for any the vector is the solution to the linear system
[TABLE]
and is the standard basis of , i.e. and for any .
The result above shows that if then the constructed by (2.30) satisfy P2. Conversely, if then the linear system (2.31) is singular, and P2 does not hold. Depending on the space and on the localisation of the supports of , two situations can occur:
- •
are globally supported functions on . When is a multivariate polynomial space supported on a downward closed index set with , one can choose as the tensorized monomial basis. In one dimension, whenever more than over samples are distinct, the Vandermonde matrix has full rank. The same holds in higher dimension, but requiring that at least over samples do not fall on any polynomial surface supported on . In both cases, the probability that is formally zero, and also completely negligible when considering the numerical rank of , since from ii) is of the order .
- •
are locally supported functions on . In this case, the matrix is rank deficient whenever . The probability of such events is not zero, and can be calculated as a function of the size of . Moreover, it might not be small if some of the have very localized support and is large.
We now show that in (2.29) satisfy P1 with not exceeding , where is the machine precision. From (2.29) we obtain
[TABLE]
showing that -orthonormality of the is related to the loss of orthogonality of the matrix due to numerical cancellation. The right-hand side in (2.32) can be estimated using classical results on backward error analysis for HQRf, like [21, Theorem 1.5] or [11, Theorem 19.4]. Using such results (see e.g. [21, page 266]) upper bounds for the orthogonality error of take the form
[TABLE]
where is a slowly growing function of and . In particular [11, Theorem 19.4] shows that with being a small numerical constant depending on the floating-point arithmetic. Hence from (2.33), and thanks to (2.32) the constructed by (2.29)–(2.30) are provably -orthonormal with .
We now discuss the robustness of the construction of to ill-conditioning of . The matrix can be ill-conditioned, depending on the chosen basis for the given domain . As a remarkable property of HQRf, the error bound (2.33) does not depend on , ensuring -orthonormality of from (2.29) despite the ill-conditioning of . The matrix inherits the same ill-conditioning of , because and therefore . Nonetheless, the linear system with matrix in (2.31) can be solved with high accuracy by forward substitution, see [12]. Hence both P1 and P2 can be ensured also when is ill-conditioned.
The following corollary of Theorem 3 is an immediate consequence of the above results on QR factorisation.
Corollary 1**.**
Given linearly independent, and given as in Theorem 3, let be the matrix with components , and let be constructed from , the Householder QR factorisation of . Under the same assumptions of Theorem 3 but with item v) replaced by
v bis) ,
the conclusions of Theorem 3 in item I) and item II) hold true.
For given and the event in Corollary 1 can be checked if true or false, and thus its probability can be numerically estimated from the matrices and . If then the inclusion holds, and it is sufficient to check only the rank of . If is a multivariate polynomial space and then .
Before closing the section, we discuss the choice of the functions , that plays an important role in the numerical stability of the algorithm. The components of the solution to (2.31) satisfy
[TABLE]
and might attain large values, e.g. due to possible bad scaling of the diagonal elements of . Large values of in (2.30) reflect a poor choice of to represent on the given domain . Indeed can always be made sufficiently close to the identity matrix if are chosen sufficiently close (in the sense) to . Unfortunately are unknown if is irregular. In absence of a priori information on , we now show how to ensure that the in (2.30) are not too large, by adapting to the given domain . To this aim, in Section 3.2 we propose an algorithm that first rescales each as , where the factor depends on the domain , and then computes the HQR factorisation of the matrix with components . The crucial point is that the algorithm choses in such a way that has all unitary diagonal elements. Using the can be obtained as
[TABLE]
by solving the linear system
[TABLE]
with forward substitution for any . Denote by the upper triangular part of , that is a nilpotent matrix of index . Thanks to the structure of , using Neumann series we can write . From (2.36) it holds for all . Therefore the coefficients satisfy the safer bounds
[TABLE]
that do not depend on the scaling of the diagonal elements of . In practice the right hand-side of (2.37) exhibits only a slow growth w.r.t. thanks to the alternating sign in the summation and to being nilpotent. Therefore has at most nonzero components for any . The algorithmic construction of the is discussed in Section 3.2. It uses HQRf of suitable incremental updates of the matrix . Notice that each is obtained by rescaling , and therefore .
In Section 3 we describe two numerical algorithms that compute the estimator , and their implementation. Both algorithms obey to the theoretical guarantees of Corollary 1. The difference between the two algorithms is in the computation of . The first algorithm computes from (2.30) by solving (2.31), directly using any chosen . The second algorithm computes from (2.35) by solving (2.36), adapting the chosen to the domain . Both algorithms rely on the HQRf of -by- matrices whose cost is proportional to . The second algorithm is numerically more stable thanks to (2.37), but also computationally more demanding.
3 Description of the algorithms
This section describes the numerical algorithms and their implementation. We start by describing the first algorithm. Given the domain , the function , the space , the linearly independent functions , the threshold and the bound , the main tasks for the approximation of by the weighted least-squares estimator are the following, in the same sequential order:
Algorithm 1:
computes the estimator using the given .
- Step 1:
generate random samples ; 2. Step 2:
construct the matrix with components ; 3. Test 1:
IF THEN set and goto Step 9; ELSE continue; 4. Step 3:
rescale all the columns of such that (and keep track of the scaling factors); 5. Step 4:
compute , the Householder QR factorisation of ; 6. Test 2:
IF THEN set and goto Step 9; ELSE continue; 7. Step 5:
construct from (2.30) by solving the linear system (2.31); 8. Step 6:
generate random samples ; 9. Step 7:
evaluate ; 10. Step 8:
compute the estimator of by solving the normal equations and set ; 11. Step 9:
return .
The algorithms for the generation of the random samples at Steps 1 and 6 are presented in Section 3.1. The algorithm that computes the at Steps 2, 3, 4 and 5 is discussed in Section 2.3. The construction of the normal equations at Step 8 is described in Section 3.3. The main purpose of Test 1 and Test 2 is to avoid wasting computational resources at the following steps, and in particular at Step 7. We now discuss the failure probabilities of each test. The failure probability of Test 1 depends on the localisation properties of the supports of , as discussed in Section 2.3. Whenever Test 1 fails, one can restart the algorithm from Step 1 with the same or with a different choice. Concerning Test 2, the analysis of the orthogonality error in Section 2.3 shows that, if and , then the failure probability of Test 2 is zero. This condition is only sufficient: for example in all the numerical tests in Section 4 the failure probability is zero with .
The second algorithm is the following Algorithm 2. It is similar to Algorithm 1, and the differences are in the computation of at Steps 3, 4 and 5. The algorithm ADAPT at Step 3 performs several orthonormalisation sweeps combined with suitable rescaling of the columns of , as described in Section 3.2. At Step 8, the construction of the normal equations again follows Section 3.3 but using the QR factorisation of the matrix .
Algorithm 2:
computes the estimator adapting the given to .
- Step 1:
generate random samples ; 2. Step 2:
construct the matrix with components ; 3. Test 1:
IF THEN set and goto Step 9; ELSE continue; 4. Step 3:
compute the matrix ; 5. Step 4:
compute , the Householder QR factorisation of ; 6. Test 2:
IF THEN set and goto Step 9; ELSE continue; 7. Step 5:
construct from (2.35) by solving the linear system (2.36); 8. Step 6:
generate random samples ; 9. Step 7:
evaluate ; 10. Step 8:
compute the estimator of by solving the normal equations and set ; 11. Step 9:
return .
3.1 Generation of the random samples
The following sampling algorithms can be used, see e.g. [8]. Independent random samples from on can be generated by rejection sampling. First step: draw iid random samples from , the uniform probability measure on . Second step: accept any random sample drawn at the first step as a random sample from whenever , and reject it otherwise. On average, the number of accepted random samples is proportional to , where denotes the Lebesgue measure. When is small compared to , or when is large, the algorithm above suffers from the curse of dimensionality. For less general domains , e.g. polytopes or convex bodies, alternative MCMC sampling algorithms like hit and run or random walk can be used.
Independent random samples from the discrete distribution can be generated, for example, by inverse transform sampling. In this case, the computational cost for drawing one sample from is when using binary search, or when using the alias method, that however requires an additional cost for the preparation of the hash table.
3.2 Adapting to the domain
The algorithm ADAPT takes as input with components and produces as output with components such that the matrix in the Householder QR factorisation of has unitary diagonal elements. Each is constructed as rescaling by a factor that depends on . At the first iteration, with , is initialized as the first column of renormalized. At iteration , the algorithm creates an auxiliary matrix by juxtaposition of with the th renormalised column of . Then the QR factorisation of is computed. Finally, the matrix is updated again by juxtaposition of with the th column of but this time rescaled by an appropriately chosen factor that produces in the matrix such that . Notice that the rescaling operation when multiplying by corresponds to a simple renormalisation of in only when , due to the additional term when . For convenience, in the description of the algorithm we denote by the th column of , and we denote by the juxtaposition of any matrix with any vector .
3.3 Computation of the weighted least-squares estimator
The estimator can be calculated by solving the normal equations (2.13). The matrix can be rewritten as , where is a matrix obtained by subsampling and reweighting the rows of the matrix introduced in Section 2.3, as we now describe. After sampling the among the , we can build a deterministic function such that for any . Using the function and (2.29) we can build as
[TABLE]
The right-hand side of (2.13) can be calculated component-wise as
[TABLE]
It is worth to mention that the random samples in Theorem 3 are drawn from with replacement. This preserves independence, which is needed in the proof of Lemma 2 when using Bernstein inequality. As an alternative, one can draw again from but without replacement. The corresponding function is injective, and this avoids multiple occurrences of the same row in the matrix . However the generated are not independent anymore, and one cannot invoke Theorem 4. Nevertheless, such an approach is interesting because random samples generated without replacement can better concentrate around their mean than those generated with replacement.
4 Numerical examples with polynomial spaces
In this section the weighted least-squares estimator of on is computed by Algorithm 2, as described in Section 3. The functions are chosen as the tensorized monomial basis supported on the given polynomial space. When reporting the numerical results, we mainly focus on the stability of the estimator and on its approximation error. The stability is quantified by the condition number , and from item I) of Theorem 3, implies . In all the numerical tests in this section, the constructed by Householder QR factorisation are always -orthonormal with values of less than .
We now describe the numerical estimation of the error in Theorem 3. Denote with a set of iid random samples uniformly distributed on , chosen once and for all. For any draw of the approximation error is estimated as
[TABLE]
The error in expectation is then estimated as a Monte Carlo average by
[TABLE]
with the average being over independent draws of the random samples from their respective distributions. In the following numerical tests we choose and .
As illustrative examples in dimension , we choose as a Swiss cheese set, i.e. a compact set with holes, or the Mandelbrot set, or the annular set. With all the aforementioned domains , upper bounds for are not known. For the choice of , we define a parameter depending on and , and then take . In all the numerical tests, choosing and any largely suffices to maintain the condition number safely bounded as . As discussed in Remark 1, the choice of is important for the accuracy of . Unless otherwise specified, we empirically choose .
4.1 Example with a smooth function on a domain with holes
Define , where is the convex hull of the point set
[TABLE]
is a standard ellipse centered in with semiaxes of length and , and is a standard ellipse centered in with semiaxes of length and . The geometry of is shown in Figure 2. We consider the function
[TABLE]
The space is chosen as the polynomial space supported on the index set , a.k.a. the total degree polynomial space of order , whose dimension equals . Figure 1 shows the error and condition number when or , and . The error decreases exponentially w.r.t. , and remains well-conditioned even when choosing . Figure 2 shows one shot of the random samples (left figure) and two realizations of the pointwise error for (center and right figures).
4.2 Comparison with examples from the literature
The following two examples are taken from [1]. Consider the function
[TABLE]
when is the Mandelbrot set displayed in Figure 4-right, or the function
[TABLE]
when is the annular set displayed in Figure 5-right. With both functions, the space is chosen as the polynomial space supported on the hyperbolic cross index set of order defined as .
Figure 3 shows the error and condition number for the example with the function (4.40) on the Mandelbrot set. When choosing and , the error in Figure 3 decreases exponentially w.r.t up to , and then exhibits an increasing variability and suboptimal convergence rate for . This is due to an underestimation of when choosing for the given domain. Taking a larger restores the exponential convergence of the error, at least for up to . In Figure 4-left we report the same results as Figure 3-left but with in abscissa. Figure 4-right shows one realization of the pointwise error on , obtained from the simulation in Figure 4-left when , and the maximum error over is of the order .
Figure 5-left shows the error for the example with the nonsmooth function (4.41) on the annular set, with and . The corresponding results for the condition number are the same as the blue data in Figure 3-right, since both examples use the same polynomial space. The error in Figure 5-left decreases algebraically w.r.t. . One realization of the error is shown in Figure 5-right: the maximum error over equals and is attained along the discontinuities of on the Cartesian axes. The error in Figure 5-left does not manifest any instability, in contrast to the error in [1, Figure 5] obtained for the same testcase but with the different method there proposed. In general, the error of the estimator is not affected by the distance of from the boundary of , even when touches , like in this example.
5 Conclusions and perspectives
We have developed and analysed numerical algorithms for the construction of weighted least-squares estimators in any -dimensional space defined on a general bounded domain , when an explicit -orthonormal basis is not available. The estimator is stable with high probability, quasi-optimally converging in expectation, and uses a number of function evaluations of the order . The calculation of the estimator requires the numerical construction of a discretely orthonormal surrogate basis of , at a computational cost that depends on the Christoffel function of and .
The results in Theorem 3 apply to any general orthonormalisation algorithm that can construct an -orthonormal surrogate basis for with some probability . When using the Householder QR factorisation and is a multivariate polynomial space, is provably tiny for up to thousands, and .
An important point in the numerical construction of the surrogate basis is the robustness to ill-conditioning arising from the lack of knowledge of an -orthonormal basis. The algorithms proposed in this paper are extremely robust to such an ill-conditioning, and compute weighted least-squares estimators that are numerically stable and accurate with all the functions and domains tested.
As a final remark, the whole analysis in this paper immediately applies to the adaptive setting, using nested sequences of approximation spaces rather than a single a priori given approximation space.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] B. Adcock, D. Huybrechs: Approximating smooth, multivariate functions on irregular domains , ar Xiv:1802.00602
- 2[2] B. Adcock, J. M. Cardenas: Near-optimal sampling strategies for multivariate function approximation on general domains , ar Xiv:1908.01249
- 3[3] L. Bos: Asymptotics for the Christoffel function for Jacobi like weights on a ball in ℝ m superscript ℝ 𝑚 \mathbb{R}^{m} , New Zealand J. Math., 23:99–109, 1994.
- 4[4] A. Chkifa, A. Cohen, G. Migliorati, F. Nobile, R. Tempone: Discrete least squares polynomial approximation with random evaluations - application to parametric and stochastic elliptic PD Es , ESAIM Math. Model. Numer. Anal., 49(3):815–837, 2015.
- 5[5] A. Cohen, M. A. Davenport, D. Leviatan: On the stability and accuracy of least squares approximations , Found. Comput. Math., 13:819–834, 2013.
- 6[6] A. Cohen, G. Migliorati: Optimal weighted least-squares methods , SMAI Journal of Computational Mathematics, 3:181–203, 2017.
- 7[7] P. J. Davis: Interpolation and approximation , Dover, 1975.
- 8[8] L. Devroye: Non-Uniform Random Variate Generation , Springer, 1986.