Predictive Triggering for Distributed Control of Resource Constrained Multi-agent Systems
Jos\'e Mario Mastrangelo, Dominik Baumann, Sebastian Trimpe

TL;DR
This paper introduces a predictive triggering framework for distributed control in resource-limited multi-agent systems, optimizing communication and control performance through future demand prediction and probabilistic prioritization.
Contribution
It presents a novel predictive triggering approach that anticipates communication needs, enhancing resource allocation and control accuracy in multi-agent systems.
Findings
Reduces network utilization compared to existing event-triggered methods.
Improves control error in cooperative systems.
Effective in both simulations and real experiments.
Abstract
A predictive triggering (PT) framework for the distributed control of resource constrained multi-agent systems is proposed. By predicting future communication demands and deriving a probabilistic priority measure, the PT framework is able to allocate limited communication resources in advance. The framework is evaluated through simulations of a cooperative adaptive cruise control system and experiments on multi-agent cart-pole systems. The results of these studies show its effectiveness over other event-triggered designs at reducing network utilization, while also improving the control error of the system.
Click any figure to enlarge with its caption.
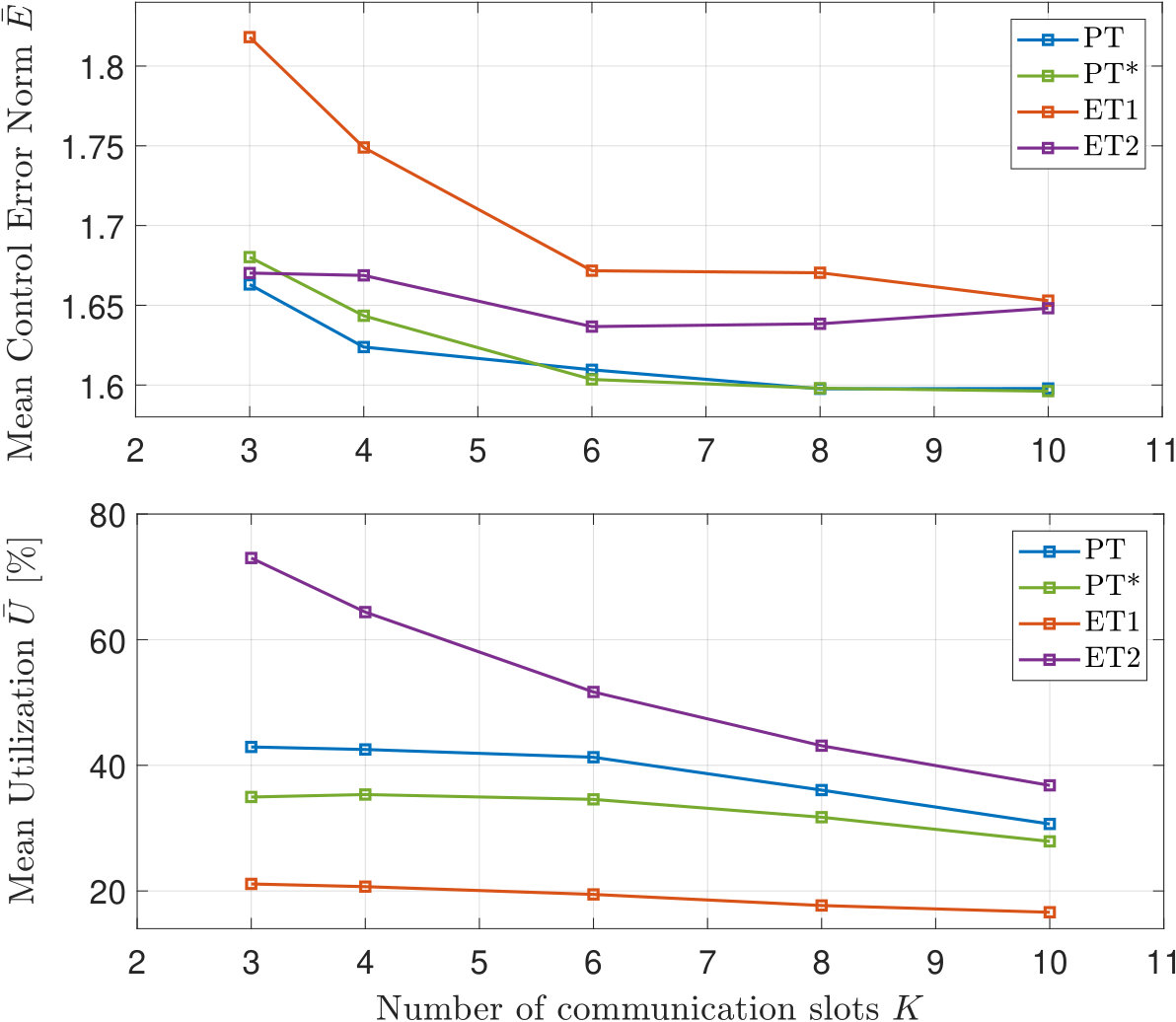 Figure 1
Figure 1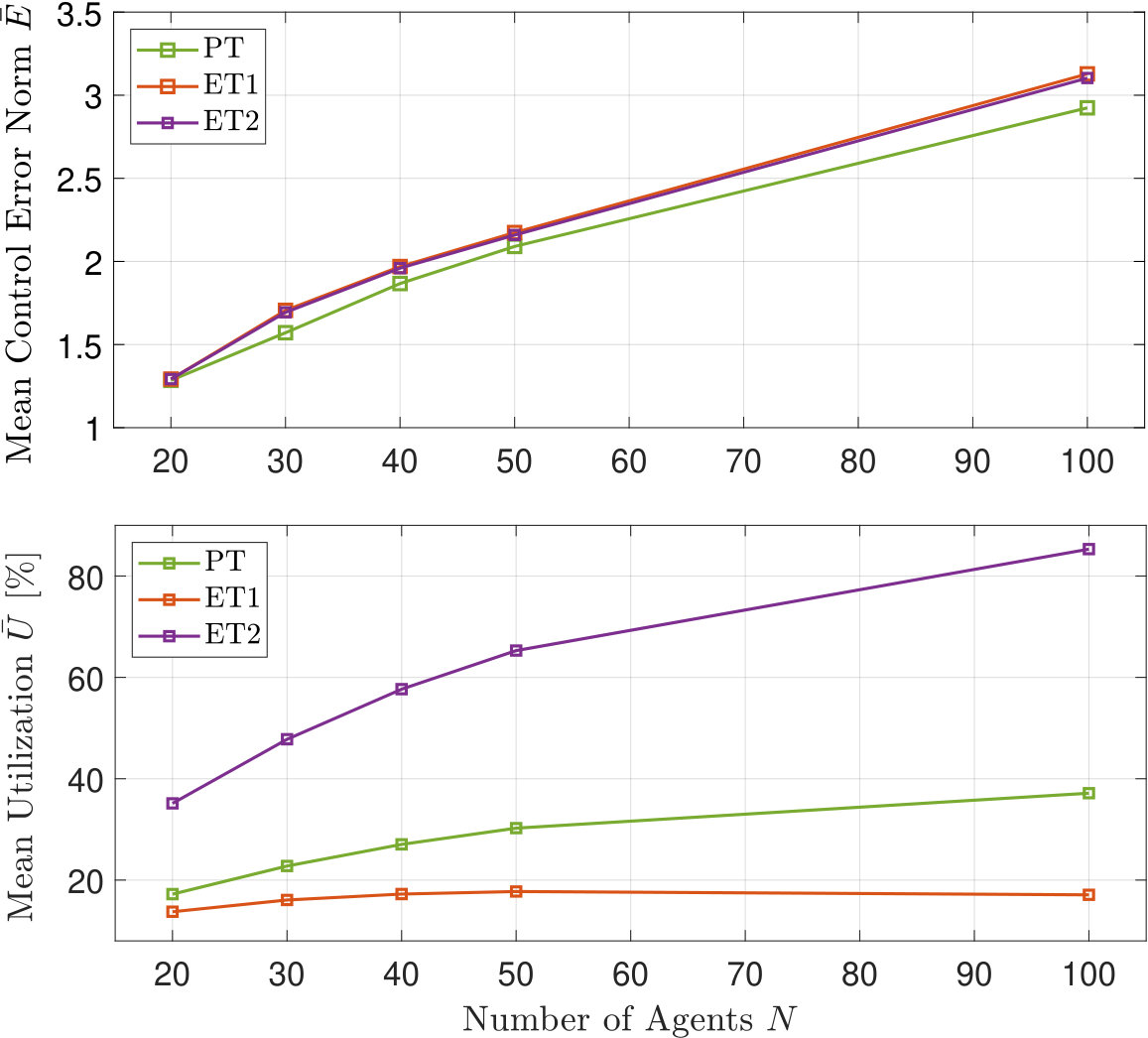 Figure 2
Figure 2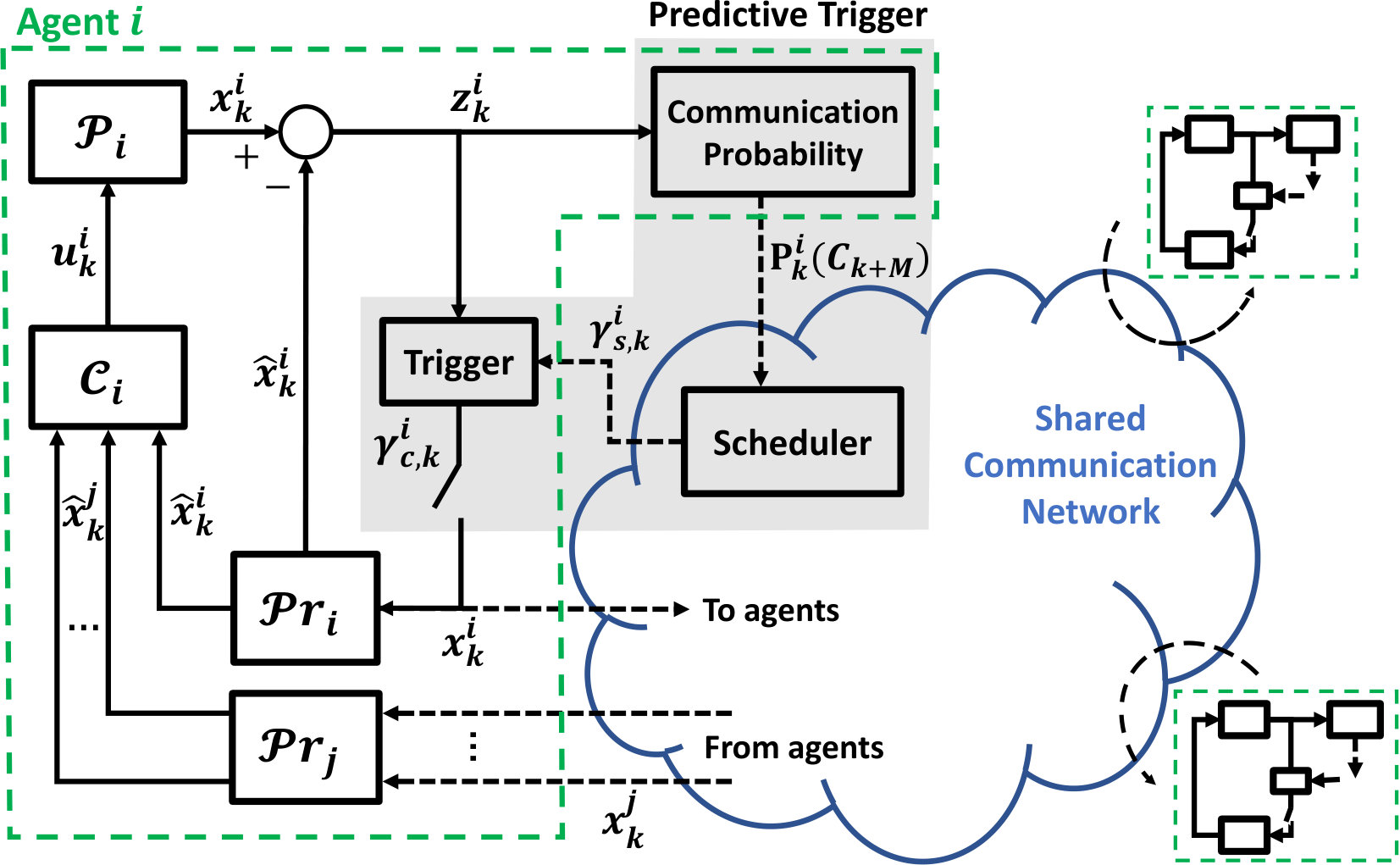 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Predictive Triggering for Distributed Control
of Resource Constrained Multi-agent Systems
José Mario Mastrangelo
Dominik Baumann
Sebastian Trimpe
Intelligent Control Systems Group, Max Planck Institute for Intelligent Systems, Stuttgart, Germany. (e-mail: mastrangelo, trimpe@is.mpg.de, [email protected])
Corresponding Author
Abstract
A predictive triggering (PT) framework for the distributed control of resource constrained multi-agent systems is proposed. By predicting future communication demands and deriving a probabilistic priority measure, the PT framework is able to allocate limited communication resources in advance. The framework is evaluated through simulations of a cooperative adaptive cruise control system and experiments on multi-agent cart-pole systems. The results of these studies show its effectiveness over other event-triggered designs at reducing network utilization, while also improving the control error of the system.
keywords:
Predictive triggering, event-triggering, multi-agent systems, distributed control, resource constrained control, networked control systems.
††thanks: This work was supported in part by the German Research Foundation (DFG) within the priority program SPP 1914 (grant TR 1433/1-1), the Cyber Valley Initiative, and the Max Planck Society.
1 Introduction
Multi-agent systems often require communication between agents to maintain system-level control. In traditional control design, sufficient communication resources are taken for granted and the control input is applied periodically, typically at high rates. Such designs become challenging when information needs to be transmitted over a communication network shared amongst multiple agents. To reduce the number of samples in such networked control systems (NCS), event-triggered (ET) designs have been developed, see, e.g., Heemels et al. (2012); Miskowicz (2016). In ET control, information is transmitted when certain events occur, e.g., some error growing too large. However, these binary decisions are typically taken instantaneously, i.e., communication must be possible for all agents at every time instant. In this work, we target a setting where the limited bandwidth of the communication network only allows for a subset of agents to communicate at every time instant. Therefore, communication decisions need to be taken in advance, a method referred to as predictive triggering (PT), allowing prioritized scheduling.
The setup of a distributed multi-agent system communicating over a shared network is depicted in Fig. 1. Each agent estimates the state of either all other agents or a subset of the system agents. Through communication, updates are received and help improve said estimates. By computing a probabilistic priority measure in the Communication Probability block, each agent is able to communicate this measure to a centralized Scheduler. The predictive nature of the setup is such that we compute future communication demands at a horizon, thereby providing the Scheduler a time window at which to allocate communication resources, i.e., resources are allocated in advance. Finally, when allocated a resource, each agent decides whether or not to communicate its state information, in the Trigger block, in order to further reduce energy consumption.
1.0.1 Contributions:
We present the following contributions:
- •
proposal of a PT framework for distributed control of multi-agent systems with limited network bandwidth;
- •
derivation of a probabilistic priority measure for sche-
duling limited resources at a prediction horizon; and
- •
comparison of the proposed framework with ET designs, demonstrating improved network utilization and control performance in cooperative adaptive cruise control (CACC) simulations and in multi-agent cart-pole hardware experiments.
Simulation code and videos of experiments are available at https://sites.google.com/view/ptformas.
1.0.2 Related work:
For general overviews of ET control, we refer the reader to Heemels et al. (2012); Miskowicz (2016). In most ET control approaches, communication is triggered instantaneously, with no possibility to reallocate freed resources. Methods of predicting future communication demands have been presented in Heemels et al. (2012); Trimpe (2016); Trimpe and Baumann (2019) and have largely focused on self-trigger designs, while the latter works also propose the novel concept of predictive triggering for the first time. These designs, however, still take binary communication decisions requiring that in the worst case all agents can communicate simultaneously. In emerging applications of NCS, such as formation control of drone swarms, the number of agents wanting to communicate may still exceed the available resources with such designs. This leads to unresolved contention of resource access. Therefore, we build on the general PT but derive a priority measure instead of a binary decision, allowing for prioritized resource allocation.
The inherent resource constraint in large-scale NCS has led to the development of contention resolution algorithms for scheduling limited resources. Deterministic scheduling policies have been proposed in Walsh and Bushnell (2002); Molin and Hirche (2011), which consider error-dependent prioritization, while a decentralized stochastic policy is considered in Balaghi et al. (2018). Decentralized designs address the scalability constraint of NCS but suffer from inevitable collisions. Herein, we consider a system with a centralized scheduler as in Mamduhi et al. (2017), where an error-dependent policy is proposed. We, on the other hand, derive a probabilistic priority measure (i.e., a purely stochastic policy), and send this probability to the scheduler. Sending a probability instead of state-information allows us to consider a low dimensional and system independent priority measure, resulting in reduced bandwidth consumption, as we will show in simulation studies and real experiments. Recently, Demirel et al. (2018) proposed DeepCAS, a deep reinforcement learning (RL) algorithm for the control-aware scheduling of NCS. However powerful RL may be, difficulties arise in training and when implementation on embedded hardware is required.
The probabilistic priority measure proposed herein is represented by the probability of communicating at a horizon, and is derived according to the exit times of stochastic processes. Exit/stopping time analysis has been applied to arrive at optimal communication decisions in Xu and Hespanha (2004); Rabi et al. (2008), while Baumann et al. (2019) and Solowjow et al. (2018) use such analysis to evaluate model performance and trigger learning experiments. However, neither design considers predicting future communications with limited resources.
2 Problem Setting and Main Idea
In this paper, we consider the setup presented in Fig. 1, depicting a multi-agent system of agents communicating over a network with communication slots, and formulate the resource constrained predictive triggering problem that each agent solves. Herein, a distributed control setting is considered, in which agents communicate their sensor information to other agents over a shared communication network. The components of Fig. 1 are detailed in the following sections.
2.1 Process dynamics
The uncoupled dynamics of agent follow the stochastic, linear time-invariant dynamics
[TABLE]
with the discrete time index, the state, the input, and initial states chosen from a Gaussian distribution. We assume that the full state of each agent can be measured (i.e., ), however, state reconstruction via estimation techniques is also possible, as in Solowjow and Trimpe (2019), but not considered herein. The process noise , which captures for instance model uncertainty, is assumed to be i.i.d. Gaussian noise, where , with constant variance .
2.2 State predictors
At every time step , each agent may decide to communicate its state to all or a subset of agents if allocated a slot. The binary communication decision , denoting positive () or negative () decisions, determines when agents send their state. As such, agent runs predictors , to estimate the states of agents , where is the set of agents communicating to agent . These predictors, initialized with , are given by
[TABLE]
where is the predicted state of agent at time and may be used for control, as will be demonstrated in later sections. In the case when an agent computes a positive communication decision (i.e., ), agent resets its prediction of agent ’s state. Agent can then also run a predictor of its own state, similar to (2), to determine when deviations occur between its state and prediction. We define this deviation as the estimation error , which resets to zero when communication occurs, and whose Euclidean norm we want to prevent from growing beyond a user-defined threshold .
2.3 Controller
The distributed controller considered herein represents a static linear feedback controller given by
[TABLE]
with the current agents prediction and the predictions of communicating agents, while and are chosen to render the closed-loop system stable.
2.4 Network configuration
In this paper, we assume an ideal network, in that we do not consider delays or packet drops, but have a limited bandwidth. Due to the bandwidth limitation, only communication slots are available for state communication, no matter the trigger design. A limited bandwidth implies a limited network capacity at each time step (in bytes), which is divided such that , where is the state dimension. This division allows all agents to send scheduling information and agents to communicate their state at every time step (as 4-byte floats). We can now define the network utilization:
Definition 1
Given a network with capacity , the network utilization of the system at time is defined as
[TABLE]
The size of the scheduling information (in bytes) is denoted by , while , and are the number of agents communicating their scheduling information to the network scheduler and their state, respectively, at time .
2.5 Main idea
Given the limited network, the objective of this paper is to develop a resource-aware scheduling method based on predicted future communication demands. We propose a resource constrained PT framework, which prioritizes resource allocation according to a probabilistic priority measure, defined as the probability of wanting to communicate steps in the future (i.e., -step horizon). Each agent computes this probability and communicates it periodically to a Scheduler, as in Fig. 1, thereby reducing state communication and will be shown empirically to result in net utilization savings. The Scheduler takes allocation decisions in advance, according to this priority measure, while the Trigger takes state communication decisions.
3 Resource Constrained PT Framework
In this section, we design a PT framework capable of allocating limited resources in advance, according to a probabilistic priority measure. By computing the exit probability of a stochastic process in Sec. 3.1, we are able to derive the probability of communicating at a horizon in Sec. 3.2, and arrive at communication decisions in Sec. 3.3.
3.1 Exit probability
In order to obtain tractable exit times, we consider a continuous time Ornstein-Uhlenbeck (OU) process , whose solution at time is expressed as
[TABLE]
with the closed-loop Hurwitz matrix obtained from (1), the positive definite state covariance matrix, and a Wiener process. For ease of presentation, we omit the agent subscript for the derivation.
Similarly, the deterministic predictors (2) are given by
[TABLE]
The error process , which is itself an OU process starting at zero and is reset to zero when the state is communicated, will exit any bounded domain with non-zero probability due to the unboundedness of Gaussian distributions. If we consider a threshold domain , the exit time representing the first time the error process exits domain , is defined as
[TABLE]
We are now able to define the exit probability
[TABLE]
as the probability that the error process, starting at , exits domain before the time . For the OU process , the following lemma results in the exit probability.
Lemma 2
Consider the initial boundary value problem
[TABLE]
with and the trace of a matrix. Then the solution denotes the survival probability of an OU process, starting at and remaining inside region until time , and the resulting exit probability .
{pf}
Itô’s formula applied to an OU process results in the partial differential equation (9), whose solution represents the survival probability , as given in Schuss (2009). The exit probability then results from the probability complement law.
To compute , Monte Carlo simulations of the process are performed and the empirical probability of exiting domain is obtained. Approximating (9) at each time step proves to be too computationally demanding, particularly if the framework is to be implemented on embedded hardware. Thus, solutions are computed offline and stored in lookup tables for quick runtime access.
3.2 -step communication probability
Utilizing the exit probability , we can now derive the probability of communicating at an -step time horizon, taking into account communication occurrences within said horizon. This probability is defined as the -step communication probability , with the time step size. Let be probabilistic events denoting communication at time , and whose outcomes represent negative and positive communication decisions, respectively. The -step communication probability is then expressed as
[TABLE]
To render the problem tractable, the joint probability in (10) is assumed to depend on current and future communication events, but not on past events. For instance, the communication probability for a prediction horizon may be expanded as
[TABLE]
where are used above as shorthand to denote the outcomes , respectively. Since the PT framework may only allocate slots to a subset of agents, the actual probability that an agent will communicate at a future time step within the horizon is unknown at the current time. The following assumption is then required to estimate the conditional probabilities in (10).
Assumption 3
At the current time , the probability of communicating at times , given preceding communication events, is approximated by
[TABLE]
where the error and time to exit are obtained based on the outcomes of the conditional communication events.
A few examples of how to obtain and are now presented. If we consider a horizon , is expanded into several conditional probabilities, one of which being . Since communication resets the error to , and communications occur at times and , it is only necessary to consider the latest communication event at when applying Assumption 3. A single time step remains between the last positive communication event and , resulting in . Similarly, if we consider where no communications occur within the horizon, the conditional probability is approximated by , where is the current error.
All agents compute and communicate it periodically to the scheduler, which utilizes these probabilities to prioritize allocation. Prior to communicating the probability, each agent casts said probability into a 1-byte integer, thereby reducing bandwidth consumption, e.g., if , send . An extension to further reduce communication may also be applied:
Remark 4
The PT framework can be extended by applying a lower bound on the probabilities sent to the scheduler by agent . Formally, this is expressed as
[TABLE]
This extension allows the scheduler to disregard agents that are unlikely to require communication in steps, thereby further reducing the network utilization.
3.3 Communication decisions
The network scheduler proposed herein, allocates resources at time by ranking agents according to their probabilities, i.e., the agents with the largest probabilities receive a slot. This is represented as
[TABLE]
where is the set of largest probabilities sent ot the scheduler at time . The Trigger, located in each agent, then takes communication decisions , based on the slot allocation and the estimation error. This is given by
[TABLE]
where is a design parameter and denotes the logical AND operator. If , communication occurs whenever the agent is allocated a slot. Increasing improves the utilization, but has a negative impact on performance.
4 Autonomous Vehicle Platooning
In this section, we apply the PT framework to CACC-equipped autonomous vehicle platoons. Through intervehicle communication and radar-sensed information, CACC improves traffic throughput and reduces fuel consumption by maintaining small intervehicle distances, as shown in Besselink et al. (2016); Dolk et al. (2017).
4.1 Control design
The following control design, vehicle model, and control law are taken from Dolk et al. (2017). CACC systems obey two control objectives: 1) each vehicle , of length , must follow the preceding vehicle with a desired distance , known as individual vehicle stability, and, 2) disturbances are attenuated along the platoon, known as string stability. Consider the vehicle model:
[TABLE]
where , , , and are the velocity, acceleration, desired acceleration, and control input of vehicle at time , respectively. The spacing error between vehicle and is denoted by , is a time constant representing the engine dynamics, and is the time gap, with the standstill distance of vehicle .
The CACC system considered herein follows a predecessor-following communication topology (i.e., each vehicle receives communication from its preceding vehicle ), with the state of vehicle defined as . The cooperative control law is given by
[TABLE]
with the gain matrix and the most recent information received by vehicle regarding .
4.2 PT and ET designs
Due to the communication topology, each vehicle only needs to run predictions of the preceding vehicle , and control law (3) may be expressed as
[TABLE]
of the predicted state of vehicles and , respectively.
The PT is implemented with parameters , , and extended with as defined in Remark 4, while the exit probability is computed from Monte Carlo simulations. The ET designs are implemented for comparison, by setting the PT horizon to . Since ETs decide instantaneously whether communication is necessary, the scheduler must preallocate resources independently from the triggering decisions. We compare the approach developed herein to the following two methods: ET1) allocation to random agents at each time step , as in Molin and Hirche (2011), and, ET2) allocation according to an error-dependent priority measure, as in Mamduhi et al. (2017).
4.3 Results
Simulations of a CACC-equipped vehicle fleet of varying system size , divided evenly over an lane highway, are performed for 120\text{,}\mathrm{s}$$. Each lane consists of a single platoon and follows a virtual reference vehicle with velocity . The simulations are analyzed with:
Example 4.1
* slots, 0.01\text{,}\mathrm{s}, $L_{i}\!=\!$4\text{\,}\mathrm{m}, 2.5\text{,}\mathrm{m}, $\tau_{i}\!=\!$0.01\text{\,}\mathrm{s}, 0.7\text{,}\mathrm{s}$$, , and .*
All vehicles adopt controller (17) with gains set to , , and , satisfying the stability criteria needed to provide individual vehicle stability as in Dolk et al. (2017). The performance of the CACC system is evaluated using the control error of vehicle at time , defined as
[TABLE]
with the radar-sensed intervehicle distance and the desired intervehicle distance computed as in Dolk et al. (2017), dependent on the time gap . For the comparison, we consider the mean control error norm , and mean network utilization as performance metrics, defined as
[TABLE]
The number of time steps , while is the control error of agent , and is the network utilization at time , defined in (18) and (4), respectively.
For varying system size , the tradeoff between mean control error norm and mean network utilization is depicted in Fig. 2. Since the ET1 design does not require sending information to a scheduler, as slots are allocated randomly (i.e., in (4)), we take its utilization curve as a lower bound, achieving the lowest utilization while expectedly resulting in the worst performance. We observe that while the ET designs result in similar performance, the PT is able to reduce by allocating resources in advance. The PT is also able to significantly reduce , compared to the ET2 design. This is because with the PT, agents send a byte (integer) probability to the scheduler, whereas with the ET2 design agents send a byte (float) error norm. The utilization improvements resulting from the PT also allow us to either increase energy savings by shutting off unused resources, or allocating them for other purposes.
5 Cart-Pole Hardware Experiments
To validate the framework, we consider an experimental multi-agent cart-pole system composed of a single self-built physical agent and several simulated agents, all of which are implemented on and communicate through a laptop running Matlab/Simulink. The cart position , pole angle , and their velocities, form the state , where and of the physical agent are measured through encoder sensors and and are obtained via finite differences. Identifying the physical agent model through least-squares estimation results in:
[TABLE]
The simulated agents are corrupted by process noise , as in (1), while the physical agent is corrupted by input noise . The experiments are run with:
Example 5.1
, 30\text{,}\mathrm{s}, $\Delta t\!=\!$0.01\text{\,}\mathrm{s}, , , PT parameters: , , , and Monte Carlo simulations.
5.1 Synchronization
First, we run a synchronization experiment with the goal to synchronize the cart positions of all agents. This synchronization problem provides a comprehensive example of a distributed system since communication occurs between all agents. Such systems require bus-like networks, some of which have been successfully used for feedback control, both in wired (Thomesse (2005)) and wireless (Mager et al. (2019)) settings. A homogeneous system is considered, with the simulated agent models also given by (19), and we adopt the control design from Mager et al. (2019), which is based on a linear quadratic regulator (LQR). The LQR parameters , , and , represent positive definite weight matrices penalizing deviations from the control objective, high control inputs, and deviations from the synchronization objective, respectively. As we aim to synchronize the cart positions, we select , and choose and for stabilization, where denotes a block-diagonal matrix. To make the synchronization more challenging, a sinusoidal disturbance is applied to one of the simulated agents. This agents cart position is used as the reference when computing the control error of each agent, i.e., the difference between each agents position and the position of the disturbed agent. The PT is compared to the ET allocation designs presented in Sec. 4.2, and to the PT extended with (Remark 4), denoted by PT*.
For varying number of available communication slots , the tradeoff between mean control error norm and mean network utilization , is illustrated in Fig. 3. For , the systems become unstable due to insufficient resources, no matter the triggering method. Similar to Sec. 4.3, the results show that the regular and extended PTs result in lower than both ET designs, and are once again able to reduce compared to the ET2 design. The extended PT* design is also shown to further reduce utilization, compared to the regular PT, while maintaining the control error. This occurs since agents only send their probability when it is above the imposed lower bound , i.e., when agents have a high enough communication demand.
5.2 Stabilization
Finally, we run a stabilization experimengt, where the feedback loop is closed over a network. A heterogeneous system is considered, with simulated agent models as in Mager et al. (2019), and each agent runs an LQR controller with parameters as above. An impulse disturbance is applied to the simulated agents at a random time and to the physical agent at . The experiments demonstrate that slots are required to stabilize the physical agent with the PT, whereas slots are required for the ET1 design. For , the physical agent goes unstable prior to the disturbance, with ET1, but with the PT it remains stable throughout (see https://sites.google.com/view/ptformas for videos).
6 Conclusion
This paper presents a resource constrained predictive triggering framework capable of allocating limited communication resources in multi-agent systems. By computing the exit probability of a stochastic process, a probabilistic measure is derived to prioritize resource allocation. We have shown that by communicating this probability periodically, network utilization may be reduced while also improving the control performance of distributed systems. The effectiveness of the proposed framework is demonstrated in CACC platooning simulations and in experiments featuring real and simulated cart-pole systems. {ack}
The authors would like to thank Joel Bessekon Akpo for his help with building the experimental platform and Friedrich Solowjow for helpful discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Balaghi et al. (2018) Balaghi, M., Antunes, D., Mamduhi, M., and Hirche, S. (2018). A decentralized consistent policy for event-triggered control over a shared contention: based network. In IEEE Conference on Decision and Control .
- 2Baumann et al. (2019) Baumann, D., Solowjow, F., Johansson, K.H., and Trimpe, S. (2019). Event-triggered pulse control with model learning (if necessary). In American Control Conference .
- 3Besselink et al. (2016) Besselink, B., Turri, V., van de Hoef, S.H., Liang, K., Alam, A., Mårtensson, J., and Johansson, K.H. (2016). Cyber–physical control of road freight transport. Proceedings of the IEEE , 104(5).
- 4Demirel et al. (2018) Demirel, B., Ramaswamy, A., Quevedo, D., and Karl, H. (2018). Deep CAS: A deep reinforcement learning algorithm for control-aware scheduling. IEEE Control Systems Letters , 2(4).
- 5Dolk et al. (2017) Dolk, V.S., Ploeg, J., and Heemels, W.P.M.H. (2017). Event-triggered control for string-stable vehicle platooning. IEEE Transactions on Intelligent Transportation Systems , 18(12).
- 6Heemels et al. (2012) Heemels, W.P.M.H., Johansson, K.H., and Tabuada, P. (2012). An introduction to event-triggered and self-triggered control. In IEEE Conference on Decision and Control .
- 7Mager et al. (2019) Mager, F., Baumann, D., Jacob, R., Thiele, L., Trimpe, S., and Zimmerling, M. (2019). Feedback control goes wireless: Guaranteed stability over low-power multi-hop networks. In ACM/IEEE International Conference on Cyber-Physical Systems .
- 8Mamduhi et al. (2017) Mamduhi, M.H., Molin, A., Tolic, D., and Hirche, S. (2017). Error-dependent data scheduling in resource-aware multi-loop networked control systems. Automatica , 81.