Learning Visual Actions Using Multiple Verb-Only Labels
Michael Wray, Dima Damen

TL;DR
This paper proposes a multi-verb label approach for visual action recognition and retrieval in videos, enabling larger verb vocabularies and better handling semantic ambiguities compared to traditional single-verb labels.
Contribution
It introduces a novel multi-verb annotation and learning method that improves action recognition and retrieval performance over conventional single-verb labeling.
Findings
Multi-verb representations outperform single-verb labels in recognition tasks.
The approach enables cross-dataset retrieval and better semantic understanding.
Multi-label verb-only models handle contextual overlaps effectively.
Abstract
This work introduces verb-only representations for both recognition and retrieval of visual actions, in video. Current methods neglect legitimate semantic ambiguities between verbs, instead choosing unambiguous subsets of verbs along with objects to disambiguate the actions. We instead propose multiple verb-only labels, which we learn through hard or soft assignment as a regression. This enables learning a much larger vocabulary of verbs, including contextual overlaps of these verbs. We collect multi-verb annotations for three action video datasets and evaluate the verb-only labelling representations for action recognition and cross-modal retrieval (video-to-text and text-to-video). We demonstrate that multi-label verb-only representations outperform conventional single verb labels. We also explore other benefits of a multi-verb representation including cross-dataset retrieval and verb…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1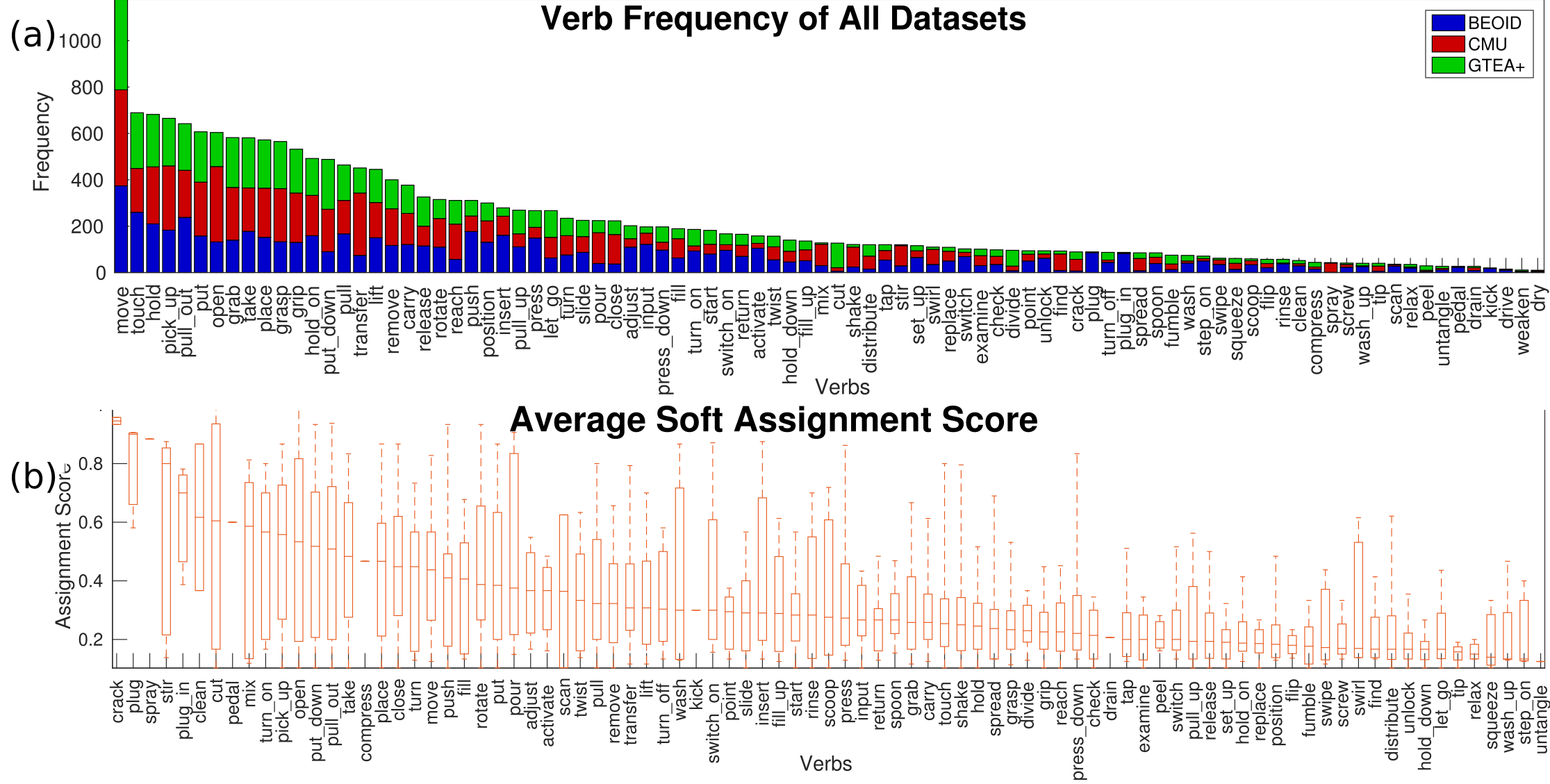 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6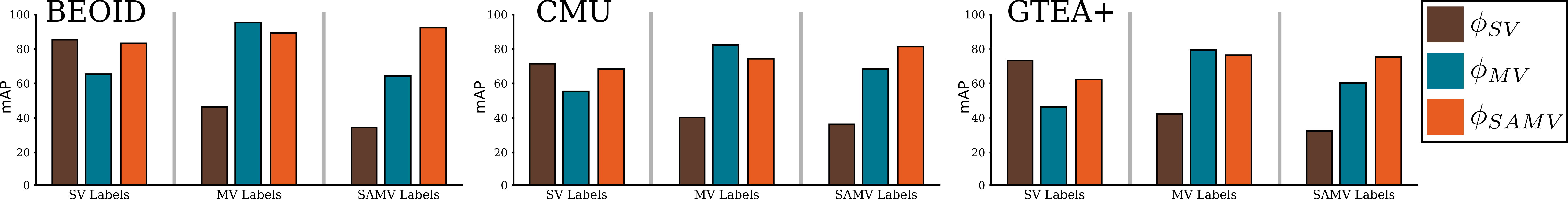 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11| Manner | Result | |
| carry, compress, drain, flip, fumble, grab, grasp, grip, hold, hold down, hold on, kick, let go, lift, pedal, pick up, point, position, pour, press, press down, pull, pull out, pull up, push, put down, release, rinse, reach, rotate, scoop, screw, shake, slide, spoon, spray, squeeze, stir, swipe, swirl, switch, take, tap, tip, touch, twist, turn | activate, adjust, check, clean, close, crack, cut, distribute, divide, drive, dry, examine, fill, fill up, find, input, insert, mix, move, open, peel, place, plug, plug in, put, relax, remove, replace, return, scan, set up, spread, start, step on, switch on, transfer, turn off, turn on, unlock, untangle, wash, wash up, weaken |
| BEOID | CMU | GTEA+ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. of verbs∗ | 20 | 40 | 42 | 90 | 12 | 29 | 31 | 89 | 15 | 63 | 34 | 90 | ||
| Accuracy | 78.1 | 93.5 | 93.0 | 87.8 | 59.2 | 76.0 | 74.1 | 73.5 | 59.2 | 61.2 | 71.9 | 72.9 | ||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMultimodal Machine Learning Applications · Human Pose and Action Recognition · Video Analysis and Summarization
\addauthor
Michael [email protected] \addauthorDima [email protected] \addinstitution University of Bristol, UK
Learning Visual Actions using Multiple Verb-Only Labels
Learning Visual Actions Using Multiple Verb-Only Labels
Abstract
This work introduces verb-only representations for both recognition and retrieval of visual actions, in video. Current methods neglect legitimate semantic ambiguities between verbs, instead choosing unambiguous subsets of verbs along with objects to disambiguate the actions. We instead propose multiple verb-only labels, which we learn through hard or soft assignment as a regression. This enables learning a much larger vocabulary of verbs, including contextual overlaps of these verbs. We collect multi-verb annotations for three action video datasets and evaluate the verb-only labelling representations for action recognition and cross-modal retrieval (video-to-text and text-to-video). We demonstrate that multi-label verb-only representations outperform conventional single verb labels. We also explore other benefits of a multi-verb representation including cross-dataset retrieval and verb type (manner and result verb types) retrieval.
1 Introduction
With the rising popularity of deep learning, action recognition datasets are growing in number of videos and scope [Damen et al.(2018)Damen, Doughty, Farinella, Fidler, Furnari, Kazakos, Moltisanti, Munro, Perrett, Price, and Wray, Goyal et al.(2017)Goyal, Ebrahimi Kahou, Michalski, Materzynska, Westphal, Kim, Haenel, Fruend, Yianilos, Mueller-Freitag, Hoppe, Thurau, Bax, and Memisevic, Kay et al.(2017)Kay, Carreira, Simonyan, Zhang, Hillier, Vijayanarasimhan, Viola, Green, Back, Natsev, et al., Sigurdsson et al.(2016)Sigurdsson, Varol, Wang, Farhadi, Laptev, and Gupta, Li et al.(2018)Li, Liu, and Rehg, Gu et al.(2018)Gu, Sun, Ross, Vondrick, Pantofaru, Li, Vijayanarasimhan, Toderici, Ricco, Sukthankar, et al.], leading to an increasingly large vocabulary required to label them. This introduces challenges in labelling, particularly as more than one verb is relevant to each action. For example, consider the common action of opening a door and the verbs that could be used to describe it. “Open” is a natural choice, with “pull” being used to specify the direction as well as “grab”, “hold” and “turn” characterising the method of turning the handle. Any action can thus be richly described by a number of different verbs. This is contrasted with current approaches which use a reduced set of semantically distinct verb labels, combined with the object being interacted with (e.g. “open-door”, “close-jar”). Sigurdsson et al\bmvaOneDot [Sigurdsson et al.(2017)Sigurdsson, Russakovsky, and Gupta] show that using only single verb labels, without any accompanying nouns, leads to increased confusion among human annotators. Conversely, verb-noun labels cause actions to be tied to instances of objects, i.e\bmvaOneDotopening a fridge is the same interaction as opening a cupboard. Additionally, using a single verb doesn’t explore the complex overlapping space of verbs in visual actions. In Fig. 1(a), four ‘open’ actions are shown, where the verb ‘open’ overlaps with four different verbs: ‘push’ and ‘pull’ for two doors, ‘turn’ when opening a bottle and ‘cut’ when opening a bag.
In this paper, we deviate from previous works which use a reduced set of verb and noun pairs [Damen et al.(2014)Damen, Leelasawassuk, Haines, Calway, and Mayol-Cuevas, Damen et al.(2018)Damen, Doughty, Farinella, Fidler, Furnari, Kazakos, Moltisanti, Munro, Perrett, Price, and Wray, Taralova et al.(2011)Taralova, De La Torre, and Hebert, Fathi et al.(2012)Fathi, Li, and Rehg, Kay et al.(2017)Kay, Carreira, Simonyan, Zhang, Hillier, Vijayanarasimhan, Viola, Green, Back, Natsev, et al., Kuehne et al.(2011)Kuehne, Jhuang, Garrote, Poggio, and Serre, Sigurdsson et al.(2016)Sigurdsson, Varol, Wang, Farhadi, Laptev, and Gupta, Soomro et al.(2012)Soomro, Zamir, and Shah], and instead propose using a representation of multiple verbs to describe the action. The combination of multiple, individually ambiguous verbs allow for an object-agnostic labelling approach, which we define using an assignment score for each verb. We investigate using both hard and soft assignment, and evaluate the representations on two tasks: action recognition and cross-modal retrieval (i.e\bmvaOneDotvideo-to-text and text-to-video retrieval). Our results show that hard-assignment is suitable for recognition while soft-assignment improves cross-modal retrieval.
A multi-verb representation presents a number of advantages over a verb-noun representation. Figure 1(b) demonstrates this by querying the multi-verb representation with “turn-off” combined with one other verb (“rotate” vs. “press”). Our representation can differentiate between a tap turned off by rotating (first row in blue) from one turned off by pressing (second row in blue). Both single verb representations (i.e. ‘turn-off’) and verb-noun representations (i.e. ‘turn-off tap’) cannot learn to distinguish these different interactions. In Fig 1(c), verbs such as “rotate” and “hold”, describing parts of the action, can also be learned via context of co-occurrence with other verbs.
To the best of the author’s knowledge, (our contributions): (i) this paper proposes to address the inherent ambiguity of verbs, by using multiple verb-only labels to represent actions, keeping these representations object-agnostic. (ii) We annotate these multi-verb representations for three public video datasets (BEOID [Wray et al.(2016)Wray, Moltisanti, Mayol-Cuevas, and Damen], CMU [Taralova et al.(2011)Taralova, De La Torre, and Hebert] and GTEA Gaze+ [Fathi et al.(2012)Fathi, Li, and Rehg]). (iii) We evaluate the proposed representation for two tasks: action recognition and action retrieval, and show that hard assignment is more suited for recognition tasks while soft assignment assists retrieval tasks, including for cross-dataset retrieval.
2 Related Work
Action Recognition in Videos.
Video Action Recognition datasets are commonly annotated with a reduced set of semantically distinct verb labels [Damen et al.(2018)Damen, Doughty, Farinella, Fidler, Furnari, Kazakos, Moltisanti, Munro, Perrett, Price, and Wray, Damen et al.(2014)Damen, Leelasawassuk, Haines, Calway, and Mayol-Cuevas, De La Torre et al.(2008)De La Torre, Hodgins, Bargteil, Martin, Macey, Collado, and Beltran, Fathi et al.(2012)Fathi, Li, and Rehg, Goyal et al.(2017)Goyal, Ebrahimi Kahou, Michalski, Materzynska, Westphal, Kim, Haenel, Fruend, Yianilos, Mueller-Freitag, Hoppe, Thurau, Bax, and Memisevic, Gu et al.(2018)Gu, Sun, Ross, Vondrick, Pantofaru, Li, Vijayanarasimhan, Toderici, Ricco, Sukthankar, et al., Sigurdsson et al.(2018)Sigurdsson, Gupta, Schmid, Farhadi, and Alahari, Sigurdsson et al.(2016)Sigurdsson, Varol, Wang, Farhadi, Laptev, and Gupta]. Only in EPIC-Kitchens [Damen et al.(2018)Damen, Doughty, Farinella, Fidler, Furnari, Kazakos, Moltisanti, Munro, Perrett, Price, and Wray], verb labels are collected from narrations with an open vocabulary leading to overlapping labels, which are then manually clustered into unambiguous classes. Ambiguity and overlaps in verbs has been noted in [Wray et al.(2016)Wray, Moltisanti, Mayol-Cuevas, and Damen, Khamis and Davis(2015)]. Our prior work [Wray et al.(2016)Wray, Moltisanti, Mayol-Cuevas, and Damen] uses the verb hierarchy in WordNet [Miller(1995)] synsets to reduce ambiguity. We note how annotators were confused, and often could not distinguish between the different verb meanings. Khamis and Davis [Khamis and Davis(2015)] used multi-verb labels in action recognition, on a small set of (10) verbs. They jointly learn multi-label classification and label correlation, using a bi-linear approach, allowing an actor to be in a state of performing multiple actions such as “walking” and “talking”. This work is the closest to ours in motivation, however their approach uses hard assignment of verbs, and does not address single-verb ambiguity, assuming each verb to be non-ambiguous. Up to our knowledge, no other work has explored multi-label verb-only representations of actions in video.
Action Recognition in Still Images.
Gella and Keller [Gella and Kella(2017)] present an overview of datasets for action recognition from still images. Of these, four use a large () number of verbs as labels [Chao et al.(2015)Chao, Wang, He, Wang, and Deng, Gella et al.(2016)Gella, Lapata, and Keller, Ronchi and Perona(2015), Yatskar et al.(2016)Yatskar, Zettlemoyer, and Farhadi]. ImSitu [Yatskar et al.(2016)Yatskar, Zettlemoyer, and Farhadi] uses single verb labels, however, they note ambiguities between verbs — with each verb having an average of 3.55 different meanings. They report top-1 and top-5 accuracies to account for the multiple roles each verb plays. The HICO dataset [Chao et al.(2015)Chao, Wang, He, Wang, and Deng] has multi-label verb-noun annotations for its 111 verbs, but the authors combine the labels into a powerset to avoid the overlaps between verbs. Two datasets, Verse [Gella et al.(2016)Gella, Lapata, and Keller] and COCO-a [Ronchi and Perona(2015)], use external semantic knowledge to disambiguate a verb’s meaning. For zero-shot action recognition of images, Zellers and Choi [Zellers and Choi(2017)] use verbs in addition to attributes such as global motion, word embeddings, and dictionary definitions to solve both text-to-attributes and image-to-verb tasks. While their labels are coarse grained (and don’t describe object interactions) they demonstrate the benefit of using a verb-only representation.
Although works are starting to use a larger number of verbs, the class overlaps are largely ignored through the use of clustering or assumption of hard boundaries. In this work we learn a multi-verb representation acknowledging these issues.
Action Retrieval.
Distinct from recognition, cross-modal retrieval approaches have been proposed for visual actions both in images [Gordo and Larlus(2017), Radenović et al.(2016)Radenović, Tolias, and Chum, Zhang and Saligrama(2016)] and videos [Dong et al.(2018)Dong, Li, Xu, Ji, and Wang, Guadarrama et al.(2013)Guadarrama, Krishnamoorthy, Malkarnenkar, Venugopalan, Mooney, Darrell, and Saenko, Xu et al.(2015)Xu, Xiong, Chen, and Corso]. These works focus on instance retrieval, i.e\bmvaOneDotgiven a caption can the corresponding video/image be retrieved and vice versa. This is different from our attempt to retrieve similar actions rather than only the corresponding video/caption. Only Hahn et al\bmvaOneDot [Hahn et al.(2018)Hahn, Silva, and Rehg] train an embedding space for videos and verbs only, using word2vec as the target space. They use verbs from UCF101 [Soomro et al.(2012)Soomro, Zamir, and Shah] and HMDB51 [Kuehne et al.(2011)Kuehne, Jhuang, Garrote, Poggio, and Serre] in addition to verb-noun classes from Kinetics [Kay et al.(2017)Kay, Carreira, Simonyan, Zhang, Hillier, Vijayanarasimhan, Viola, Green, Back, Natsev, et al.]. These are coarser actions (e.g\bmvaOneDot*“diving”* vs. “running”) and as such have little overlap allowing the target space to perform well on unseen actions.
As far as we are aware, ours is the first work to use the same representation for both action recognition and action retrieval.
Video Captioning.
Semantics and annotations have also been studied by the recent surge in generating captions for images [Mao et al.(2015)Mao, Xu, Yang, Wang, Huang, and Yuille, Devlin et al.(2015)Devlin, Cheng, Fang, Gupta, Deng, He, Zweig, and Mitchell, Anne Hendricks et al.(2016)Anne Hendricks, Venugopalan, Rohrbach, Mooney, Saenko, and Darrell, Aneja et al.(2018)Aneja, Deshpande, and Schwing, Anderson et al.(2018)Anderson, He, Buehler, Teney, Johnson, Gould, and Zhang] and videos [Venugopalan et al.(2015)Venugopalan, Xu, Donahue, Rohrbach, Mooney, and Saenko, Yao et al.(2015)Yao, Torabi, Cho, Ballas, Pal, Larochelle, and Courville, Yu et al.(2016)Yu, Wang, Huang, Yang, and Xu, Zhou et al.(2018)Zhou, Zhou, Corso, Socher, and Xiong, Wang et al.(2018b)Wang, Chen, Wu, Wang, and Yang Wang, Wang et al.(2018a)Wang, Ma, Zhang, and Liu]. These works assess success by the acceptability of the generated caption. We differ in our focus on learning a mapping function between an input video and verbs in the label set, thus providing a richer understanding of the overlaps between verb labels.
3 Proposed Multi-Verb Representations
In this section, we introduce types of verbs used to describe an action and note their absence from semantic knowledge bases (Sec. 3.1). We then define the single and multi-verb representations (Sec. 3.2). Next, we describe the collection of the multiple verb annotations (Sec. 3.3) and detail our approach to learn the representations (Sec. 3.4).
3.1 Verb Types
From the earlier example of a door being opened, we highlight the different types of verbs that can be used to describe the same action, and their relationships. Firstly, as with standard multi-label tasks, some verbs are related semantically; e.g. “pull” and “draw” are synonyms in this context. Secondly, verbs describe different linguistic types of the action: Result verbs describe the end state of the action, and manner verbs detail the manner in which the action is carried out [Hovav-Rappaport and Levin(1998), Gropen et al.(1991)Gropen, Pinker, Hollander, and Goldberg]. Here, “open” is the result verb, whilst “pull” is a manner verb. This distinction of verb types for visual actions has not been explored before for action recognition/retrieval. Finally, there are verbs that describe the sub-action of using the handle, such as “grab”, “hold” and “turn”. These are also result/manner verbs. We call such verbs supplementary as they are used to describe the sub-action(s) that the actor needs to perform in order to complete the overall action. Furthermore, they are highly dependent on context.
While these verb relationships can be explicitly stated, they are not available in lexical databases and are hard to discover from public corpora. We illustrate this for the two commonly used sources of semantic knowledge: WordNet [Miller(1995)] and Word2Vec [Mikolov et al.(2013)Mikolov, Chen, Corrado, and Dean].
[TABLE]
WordNet [Miller(1995)].
WordNet is a lexical English Database with each word assigned to one or more synsets, each representing a different meaning of the word. WordNet defines multiple relationships between synsets, including synonyms and hyponyms, but does not capture the other two types of relationships (result/manner, supplementary). Moreover, using WordNet requires prior knowledge of the verb’s synset.
Word2Vec [[Mikolov et al.(2013)Mikolov, Chen, Corrado, and
Dean](#bib.bibx26)].
Word2Vec embeds words in a vector space, where cosine distances can be computed. These distances are learned based on co-occurrences of words in a given corpus. For example, using Wikipedia, the embedded vector of the verb “pull” has high similarity to the embedded vector of “push” even though these actions are antonyms. Co-occurrences depend on the corpus used, and do not cover any of the relationships noted above. (“pull” and “draw”, for example do not frequently co-occur in Wikipedia). Even using a relevant corpus, such as TACoS [Rohrbach et al.(2014)Rohrbach, Rohrbach, Qiu, Friedrich, Pinkal, and Schiele], “push” is closest to “crush”, “rough” and “rotate” as the three most semantically similar verbs.
As these relationships cannot be discovered from semantic knowledge bases, we opt to crowdsource the multi-verb labels (see Sec. 3.3).
3.2 Representations of Visual Actions
Single-Verb Representations.
We start by defining the commonly-used single-label representation of visual actions. Each video has a corresponding label where is a one-hot vector. In Single-Verb Label (SV), this will be over verbs with representing the verb. For example, in Fig. 2 the verbs “pour” and “fill” are both relevant but only one can be labelled, and more general verbs like “move” won’t be labelled either. Additionally, we define a Verb-Noun Label (VN) representation over equivalent to the standard approach where a one-hot action vector is used.
Multi-Verb Representations.
We now propose two multi-verb representations. First, Multi-Verb Label (MV), which is a binary vector over (i.e\bmvaOneDothard assignment). Multiple verbs can be used to describe each video, e.g. “pour” and “fill”, allowing for manner and result verbs as well as semantically related verbs to be represented. Hard label assignment though can be problematic for supplementary verbs. Consider the verbs “hold”,“grasp” in Fig. 2. These do not fully describe the object interaction yet cannot be considered irrelevant labels. Including supplementary verbs in a multi-label representation would cause confusion between videos where the whole action is “hold”, e.g. “hold button”.
Alternatively, one can use a Soft Assigned Multi-Verb Label (SAMV), to increase the size of while accommodating supplementary verbs. Soft assignment assigns a numerical value to each verb, representing its relevance to the ongoing action. In SAMV, each video will have a label vector over . For two verb scores when the verb is more relevant to the action , while is still a valid/relevant verb. This ranking makes this representation suitable for retrieval, and allows the set of verbs, , to be larger due to the restrictions of the previous representations being removed (Fig. 2).
3.3 Annotation Procedure and Statistics
To acquire the multi-verb representations we now describe the process of collecting multi-verb annotations for three action datasets: BEOID [Damen et al.(2014)Damen, Leelasawassuk, Haines, Calway, and Mayol-Cuevas] (732 video segments), CMU [Taralova et al.(2011)Taralova, De La Torre, and Hebert] (404 video segments) and GTEA+ [Fathi et al.(2012)Fathi, Li, and Rehg] (1001 video segments). All three datasets are shot with a head mounted camera and include kitchen scenes. First, we constructed the list of verbs, , that annotators could choose from, by combining the unique verbs from all available annotations of the datasets [Fathi et al.(2012)Fathi, Li, and Rehg, De La Torre et al.(2008)De La Torre, Hodgins, Bargteil, Martin, Macey, Collado, and Beltran, Damen et al.(2014)Damen, Leelasawassuk, Haines, Calway, and Mayol-Cuevas, Wray et al.(2016)Wray, Moltisanti, Mayol-Cuevas, and Damen], giving a list of verbs - we exclude {rest, read, walk} to focus on object interactions. Table 1 includes the manual split of verbs between manner and result. We found that the datasets included an almost even spread of manner and result verbs with 47 and 43 respectively. We then chose one video per action, and asked 30-50 annotators from Amazon Mechanical Turk (2,939 total) to select all verbs which apply. We normalise the responses by the number of annotators, so that for each verb, the score lies in the range of .
Figure 3 shows samples of the collected scores, for two videos, one from BEOID (left) and one from GTEA (right). Annotators agree on selecting highly-relevant verbs (high score), and agree on not selecting irrelevant verbs (low scores). These represent both result and manner verb types. Additionally, supplementary verbs align with annotators disagreements: These are not fundamental to describing the action, but some annotators did not consider them irrelevant.
In Fig. 4 we present annotation statistics. Figure 4(a) shows the frequency of annotations for each verb in each of the datasets. We observe a long tail distribution with the top-5 most commonly chosen verbs being “move”, “touch”, “hold”, “pick up” and “pull out”.
Figure 4(b) sorts the verbs by their median soft assignment score over videos. We see that “crack” has the highest agreement between annotators when present, whereas a generic verb such as “move” is more commonly seen as supplementary.
From these annotations, we calculate the representations in Sec. 3.2. For SAMV, the soft score annotations are kept as is. For MV, the scores are binarised with a threshold of . Finally, SV is assigned by the majority vote.
3.4 Learning Visual Actions
For each of the labelling approaches described in Sec. 3.2, we wish to learn a function, which maps a video representation onto verb labels. For brevity, we define , where is the predicted value for verb of video and is the corresponding ground truth value for verb of video . Typically, single label (SL) representations are learned using a cross entropy loss over the softmax function which we use for both SV and VN:
[TABLE]
For our proposed multi-label (ML) representations, both MV and SAMV, we use the sigmoid binary cross entropy loss as in [Nam et al.(2014)Nam, Kim, Mencía, Gurevych, and Fürnkranz, Rai et al.(2012)Rai, Kumar, and Daume], where is the sigmoid function:
[TABLE]
This learns SAMV as a regression problem, without any independence assumptions. We note that due to SAMV having continuous values within the range [0,1], Eq. 2 will be non-zero when , however the gradient will be zero. We consciously avoid a ranking loss as it only learns a relative order and does not attempt to approximate the representation.
4 Experiments and Results
We present results on the three datasets, annotated in Sec. 3.3, using stratified 5-fold cross validation. We train/test on each dataset separately, but also include qualitative results of cross-dataset retrieval. The results are structured to answer the following questions: How do the labelling representations compare for (i) action recognition, (ii) video-to-text and (iii) text-to-video retrieval tasks? and (iv) Can the labels be used for cross-dataset retrieval?
Implementation.
We implemented as a two stream fusion CNN from [Feichtenhofer et al.(2016)Feichtenhofer, Pinz, and Zisserman] that uses VGG-16 networks, pre-trained on UCF101 [Soomro et al.(2012)Soomro, Zamir, and Shah]. The number of neurons in the last layer was set to . Each network was trained for 100 epochs. We set a fixed learning rate for spatial, , and used a variable learning rate for temporal and fusion networks in the range of to depending on the training epoch. For the spatial network a dropout ratio of 0.85 was used for the first two fully-connected layers. We fused temporal into the spatial network after ReLU5 using convolution for the spatial fusion as well as both 3D convolution and 3D pooling for the spatio-temporal fusion. We propagated back to the fusion layer. Other hyperparameters are the same as in [Feichtenhofer et al.(2016)Feichtenhofer, Pinz, and Zisserman].
4.1 Action Recognition Results
We first present results on action recognition, comparing the standard verb-noun labels, as well as single verb labels to our proposed multiple verb-only labels.
Evaluation Metric.
We compare standard single-label accuracy to multi-label accuracy as follows: Let to be the set of ground-truth verbs for video using the labelling representations , and the top-k predicted verbs using the same representations, where . For single-labels , , however for multi-labels, differs per video, based on the annotations. The accuracy is then evaluated as:
[TABLE]
Where is the total number of videos. is the same as reporting top-1 accuracy. For , given a video with 3 relevant verbs, if the model is able to predict two correct verbs in top-3 predictions then the video will have an accuracy of . This allows us to compare the recognition accuracy of all models. For SAMV, we threshold the annotations at 0.3 assignment score (denoted by ), and consider these as .
Results.
Table 2 shows the results of the four representations for action recognition. We also show the number of classes in each case. Over all three datasets we see that performs comparatively to on BEOID (), worse on CMU () and significantly better on the largest dataset GTEA+ () due to higher overlap in actions during the dataset collection i.e. the same action is applied to multiple objects and vice versa. is consistently worse than all other approaches reinforcing the ambiguity of single verb labels. Additionally, outperforms on all datasets but GTEA+, where it is comparable, suggesting it is more applicable for action recognition. We note that the GTEA+ has a higher number of overlapping actions compared to the other two datasets (i.e\bmvaOneDotthe number of unique objects per verb is much higher). However, is attempting to learn a significantly larger vocabulary.
In Fig. 5, we vary the threshold on the annotation scores for . Note that for , some videos in the datasets have and are not counted for accuracy leading to abrupt changes. The figure shows resilience in recognition suggesting the representation can correctly predict both relevant and supplementary verbs.
4.2 Action Retrieval Results
In this section, we consider the output of as an embedding space, with each verb representing one dimension. We also evaluate whether the verb labels we have collected are consistent across datasets and provide qualitative cross-dataset retrieval results.
Evaluation Metric.
We use Mean Average Precision (mAP) as defined in [Philbin et al.(2007)Philbin, Chum, Isard, Sivic, and Zisserman].
Video-to-Text Retrieval.
First, we evaluate for video-to-text retrieval. That is, given a video, can the correct verbs be retrieved and in the correct order? Figure 6 compares the representations on each of the labelling methods’ ground truth. Results show that is the most generalisable, regardless of the ground-truth used, even when not specifically trained for that ground-truth, whereas and only perform well on their respective ground-truth. This shows the ability of to learn the correct order of relevance.
Figure 8 compares the three labelling approaches. We also present qualitative retrieval results from in Fig. 8, separately highlighting top-3 result and manner verbs. We find that learns manner and result verbs equally well with an average root mean square error of 0.094 (for manner verbs) and 0.089 (for result verbs) respectively.
Text-to-Video Retrieval.
In the introduction we stated that a combination of multiple individually ambiguous verb labels allows for a more discriminative labelling representation. We test this by querying the verb representations with an increasing number of verbs for text-to-video retrieval, testing all possible combinations of co-occurring verbs for . We show in Fig. 9 that mAP increases for when the number of verbs rises for both BEOID and GTEA+ significantly outperforming other representations. This suggests that is better able to learn the relationships between the different verbs inherent in describing actions. There is a drop in accuracy on CMU due to the coarser grained nature of the videos and thus a much higher overlap between supplementary verbs. The representation still outperforms alternatives at and .
Cross Dataset Retrieval.
We show the benefits of a multi-verb representation across all three datasets using video-to-video retrieval (Fig. 11). We pair each video with its closest predicted representation from a different dataset. “Pull Drawer” and “Open Freezer” show examples of the same action with different types of verbs (manner vs. result) on different objects yet their representations are very similar. Note the object-agnostic facet of a multi-verb representation with “Stir Egg” and “Stir Spoon”.
In Fig. 11 we show the t-SNE plot of the representations of all three datasets. Each dot represents a video coloured by the majority verb. We highlight four videos in the figure. (a) and (b) are separated in due to the majority vote (“pull” vs “open”) but are close in and . Due to the hard assignment, (c) and (d) are far in as the actions require different manners (“rotate” vs. “push”) but are closer in .
5 Conclusion
In this paper we present multi-label verb-only representations for visual actions, for both action recognition and action retrieval. We collect annotations for three action datasets which we use to create the multi-verb representations. We show that such representations embrace class overlaps, dealing with the inherent ambiguity of single-verb labels, and encode both the action’s manner and its result. The experiments, on three datasets, highlight how a multi-verb approach with hard assignment is best suited for recognition tasks, and soft-assignment for retrieval tasks, including cross-dataset retrieval of similar visual actions.
We plan to investigate other uses of these representations for few-shot and zero-shot learning as well as further investigate the relationships between result and manner verb types, including for imitation learning.
Annotations The annotations for all three datasets can be found at
https://github.com/mwray/Multi-Verb-Labels.
Acknowledgement Research supported by EPSRC LOCATE (EP/N033779/1) and EPSRC Doctoral Training Partnerships (DTP). We use publicly available datasets. We would like to thank Diane Larlus and Gabriela Csurka for their helpful discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Anderson et al.(2018)Anderson, He, Buehler, Teney, Johnson, Gould, and Zhang] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In CVPR , 2018.
- 2[Aneja et al.(2018)Aneja, Deshpande, and Schwing] Jyoti Aneja, Aditya Deshpande, and Alexander G Schwing. Convolutional image captioning. In CVPR , 2018.
- 3[Anne Hendricks et al.(2016)Anne Hendricks, Venugopalan, Rohrbach, Mooney, Saenko, and Darrell] Lisa Anne Hendricks, Subhashini Venugopalan, Marcus Rohrbach, Raymond Mooney, Kate Saenko, and Trevor Darrell. Deep compositional captioning: Describing novel object categories without paired training data. In CVPR , 2016.
- 4[Chao et al.(2015)Chao, Wang, He, Wang, and Deng] Yu-Wei Chao, Zhan Wang, Yugeng He, Jiaxuan Wang, and Jia Deng. Hico: A benchmark for recognizing human-object interactions in images. In ICCV , 2015.
- 5[Damen et al.(2014)Damen, Leelasawassuk, Haines, Calway, and Mayol-Cuevas] Dima Damen, Teesid Leelasawassuk, Osian Haines, Andrew Calway, and Walterio Mayol-Cuevas. You-do, I-learn: Discovering task relevant objects and their modes of interaction from multi-user egocentric video. In BMVC , 2014.
- 6[Damen et al.(2018)Damen, Doughty, Farinella, Fidler, Furnari, Kazakos, Moltisanti, Munro, Perrett, Price, and Wray] Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Scaling egocentric vision: The epic-kitchens dataset. In ECCV , 2018.
- 7[De La Torre et al.(2008)De La Torre, Hodgins, Bargteil, Martin, Macey, Collado, and Beltran] Fernando De La Torre, Jessica Hodgins, Adam Bargteil, Xavier Martin, Justin Macey, Alex Collado, and Pep Beltran. Guide to the Carnegie Mellon University Multimodal Activity (CMU-MMAC) database. Robotics Institute , 2008.
- 8[Devlin et al.(2015)Devlin, Cheng, Fang, Gupta, Deng, He, Zweig, and Mitchell] Jacob Devlin, Hao Cheng, Hao Fang, Saurabh Gupta, Li Deng, Xiaodong He, Geoffrey Zweig, and Margaret Mitchell. Language models for image captioning: The quirks and what works. In ACL , 2015.