Personalised novel and explainable matrix factorisation
Ludovik Coba, Panagiotis Symeonidis, Markus Zanker

TL;DR
This paper introduces NEMF, a matrix factorisation-based recommendation model that balances accuracy, novelty, and explainability, supported by a new explainability metric and user study insights.
Contribution
The paper presents NEMF, a novel model that incorporates trade-offs between accuracy, novelty, and explainability in recommendations.
Findings
NEMF achieves high accuracy while enhancing novelty and explainability.
A new nDCG-based explainability metric effectively distinguishes explainability levels.
User study confirms positive perception of explanations and attributes.
Abstract
Recommendation systems personalise suggestions to individuals to help them in their decision making and exploration tasks. In the ideal case, these recommendations, besides of being accurate, should also be novel and explainable. However, up to now most platforms fail to provide both, novel recommendations that advance users' exploration along with explanations to make their reasoning more transparent to them. For instance, a well-known recommendation algorithm, such as matrix factorisation (MF), optimises only the accuracy criterion, while disregarding other quality criteria such as the explainability or the novelty, of recommended items. In this paper, to the best of our knowledge, we propose a new model, denoted as NEMF, that allows to trade-off the MF performance with respect to the criteria of novelty and explainability, while only minimally compromising on accuracy. In addition,…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1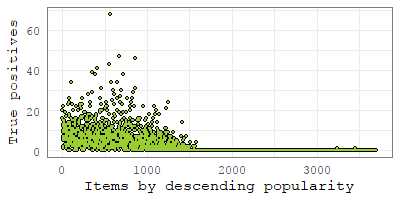 Figure 2
Figure 2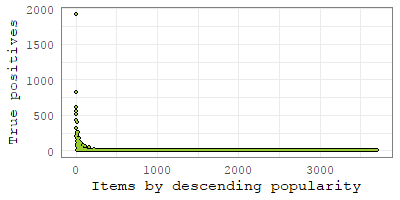 Figure 3
Figure 3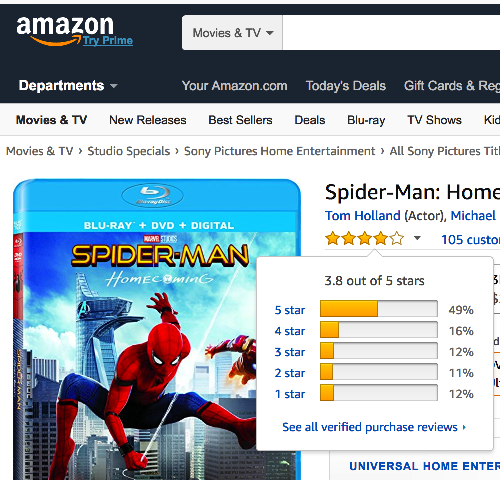 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15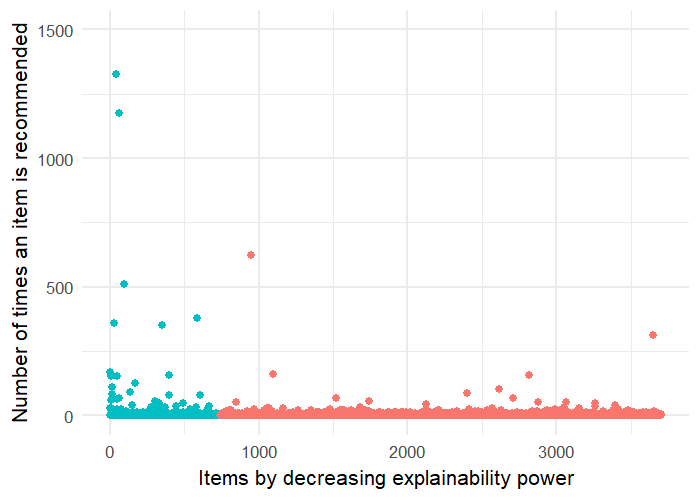 Figure 16
Figure 16 Figure 17
Figure 17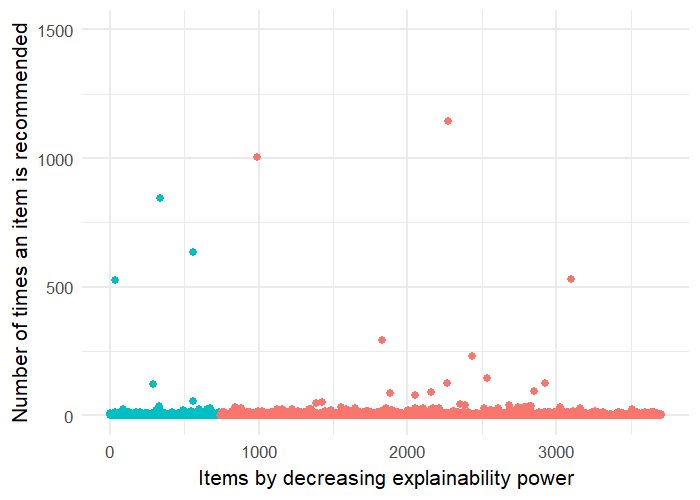 Figure 18
Figure 18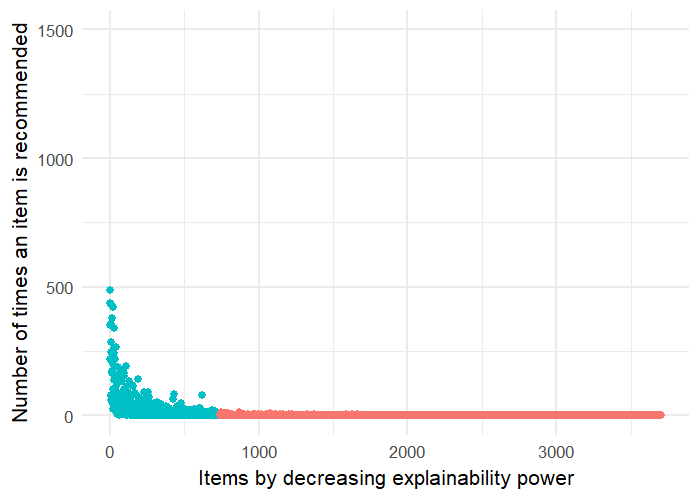 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22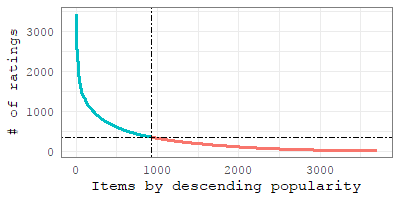 Figure 23
Figure 23 Figure 24
Figure 24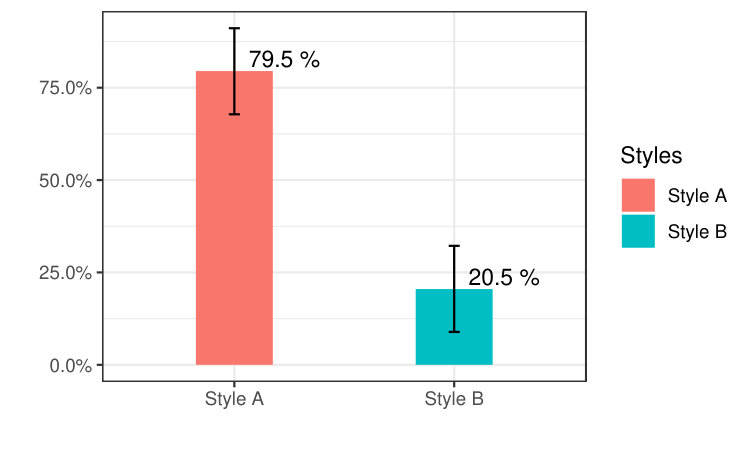 Figure 25
Figure 25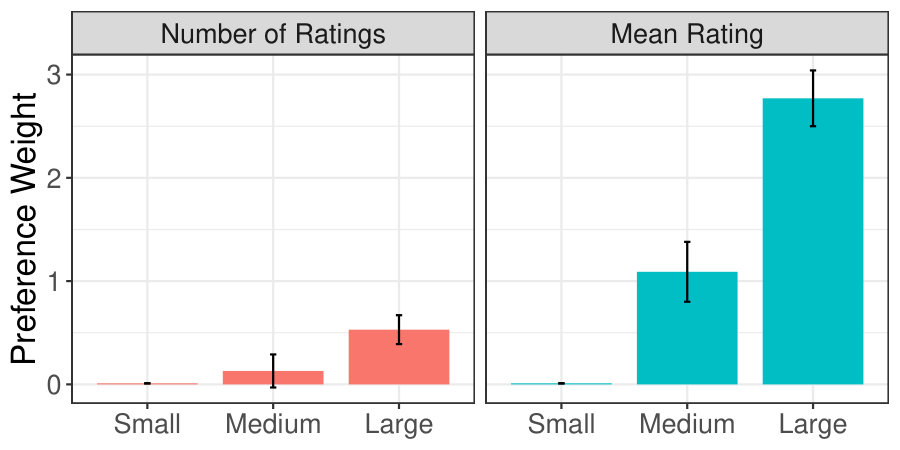 Figure 26
Figure 26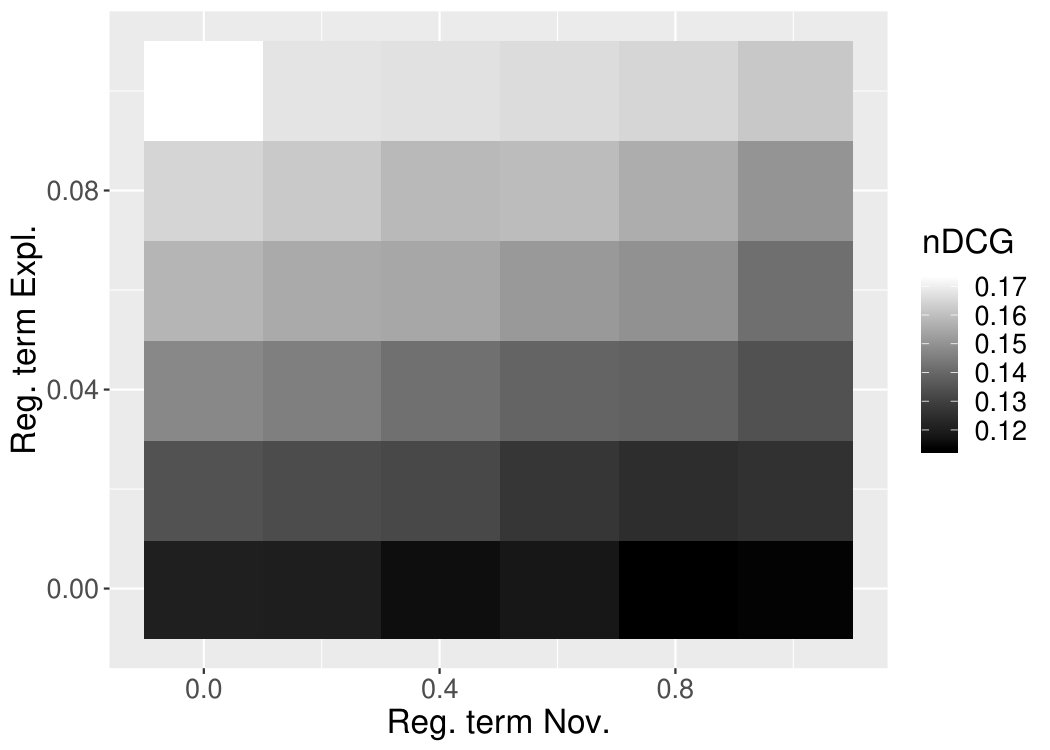 Figure 27
Figure 27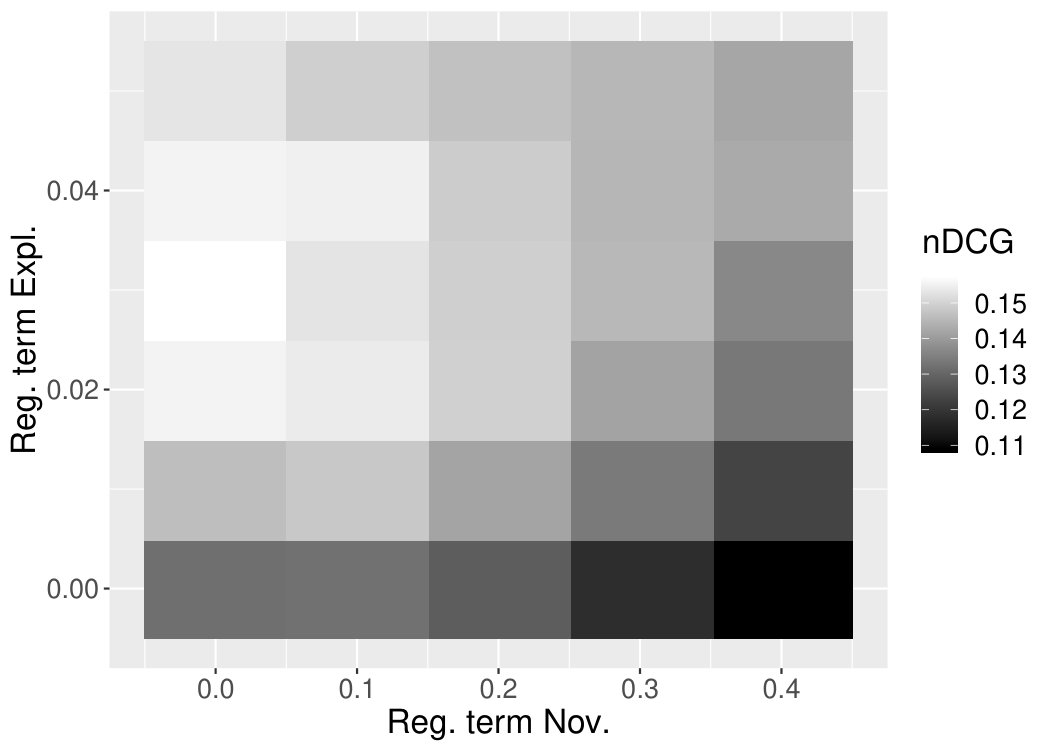 Figure 28
Figure 28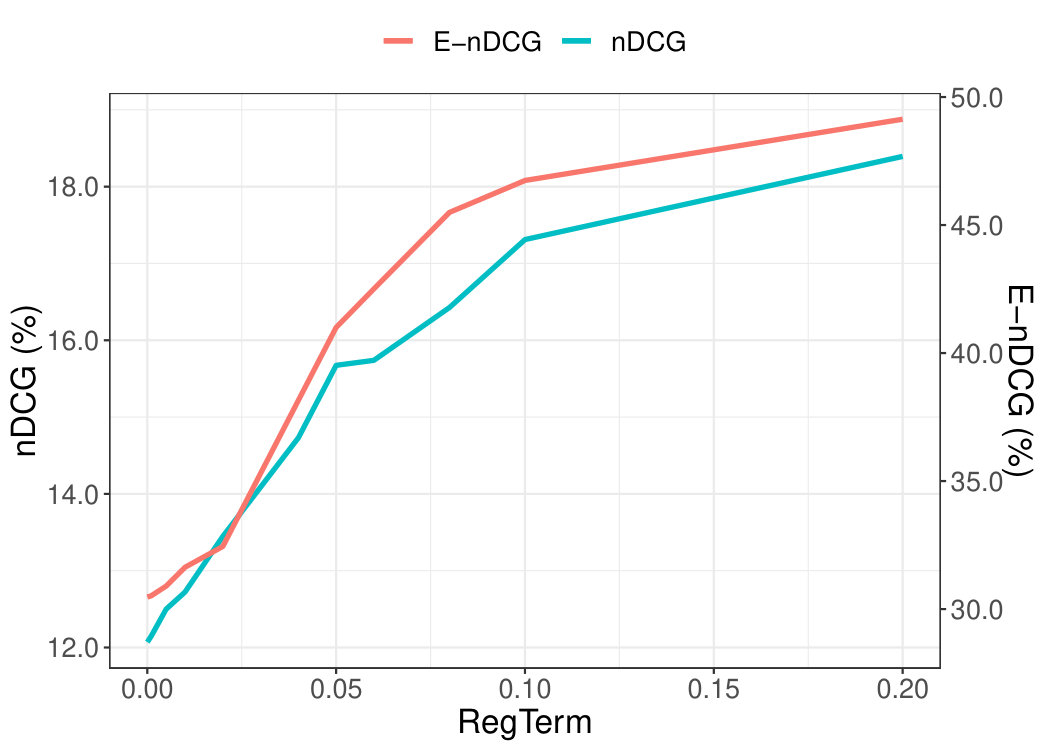 Figure 29
Figure 29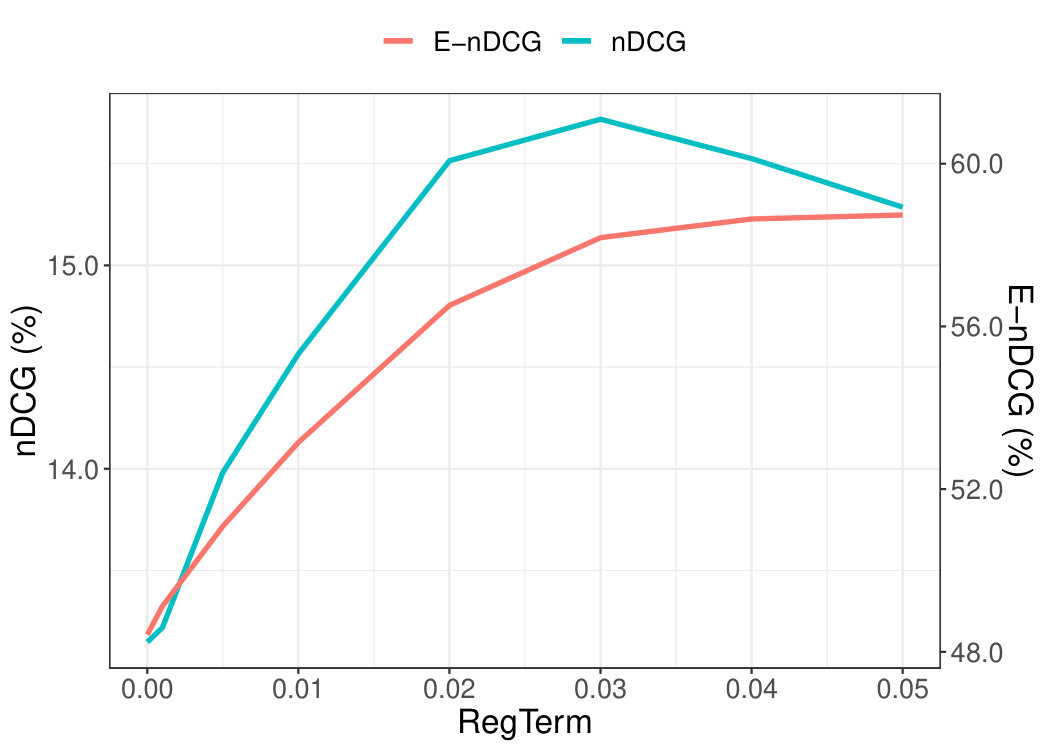 Figure 30
Figure 30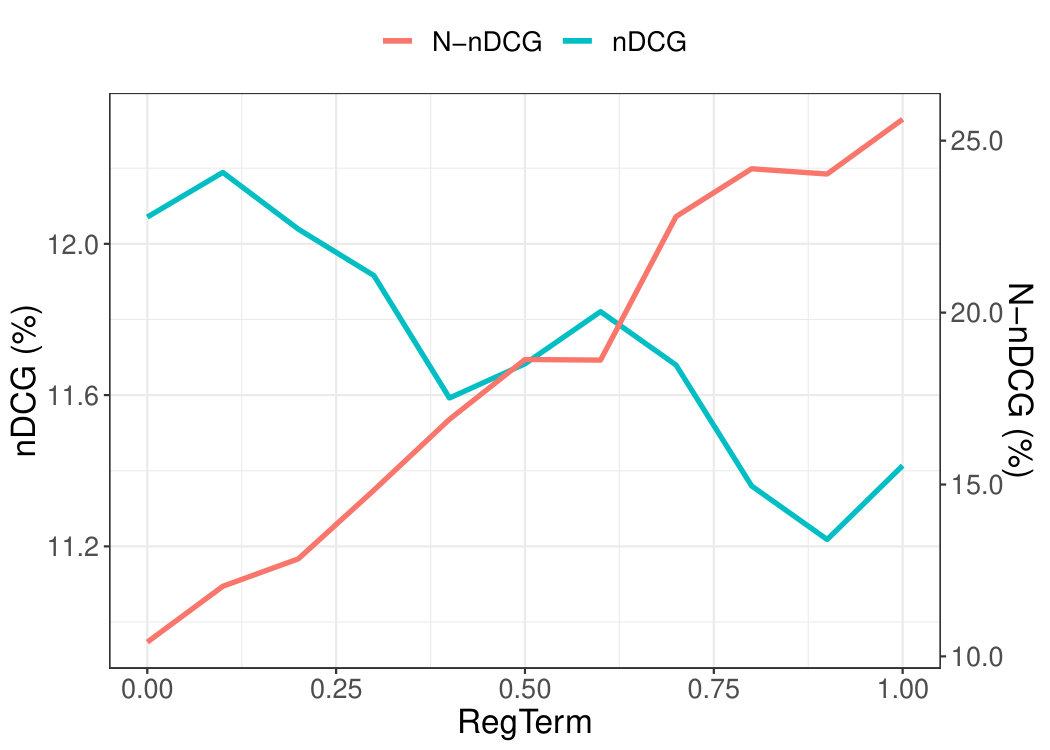 Figure 31
Figure 31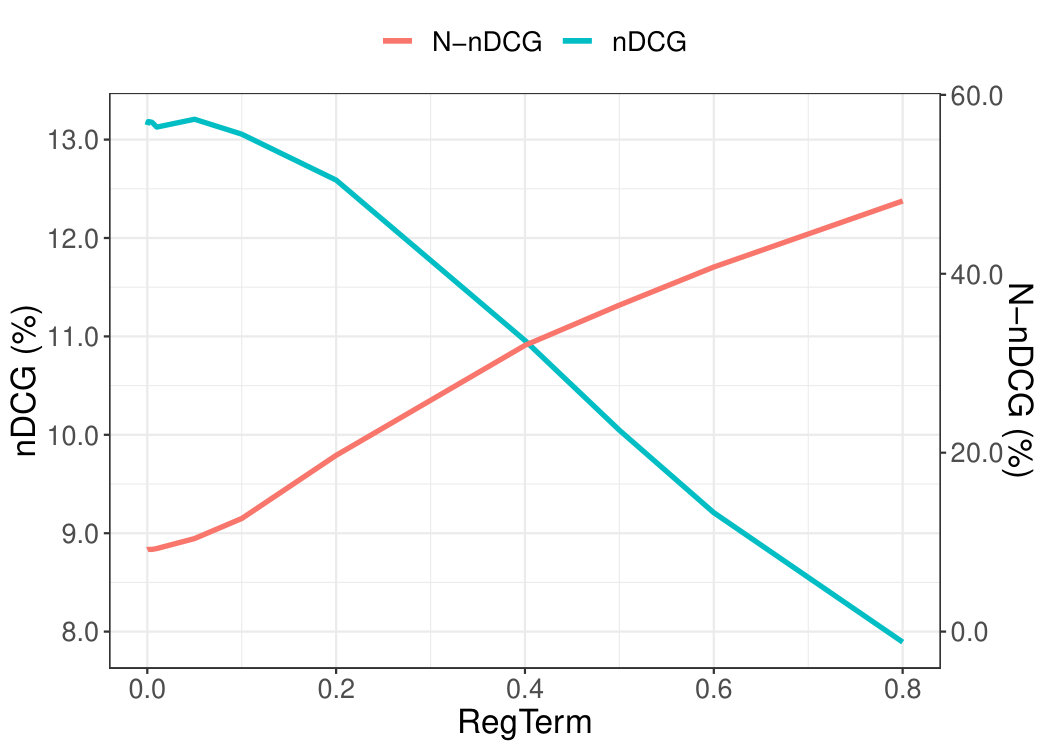 Figure 32
Figure 32| Symbol | Definition |
|---|---|
| number of nearest neighbours | |
| recommendation list for user | |
| size of recommendation list | |
| () | nearest neighbours of user |
| threshold for positive ratings | |
| domain of all items | |
| domain of all users | |
| domain of the rating scale | |
| some users | |
| some items | |
| set of items rated by user | |
| set of users rated item | |
| the rating of user on item | |
| mean rating value for user | |
| mean rating value for item | |
| predicted rate for user on item | |
| size of the test set | |
| number of training users | |
| number of items | |
| novelty of item | |
| Explainability of item for user |
| Attribute | Level | Level Value | Coefficient | |
|---|---|---|---|---|
| Number of Ratings | Large | L3: 2970 | 0.53 (0.14) | *** |
| Medium | L2: 560 | 0.13 (0.16) | ||
| Small | L1: 290 | - | ||
| Mean Rating | High | L3: 3.6 | 2.77 (0.27) | *** |
| Average | L2: 3.3 | 1.09 (0.29) | *** | |
| Low | L1: 2.9 | - | ||
| FreqA | PercA | Conf.IntA | FreqB | PercB | Conf.IntB |
|---|---|---|---|---|---|
| 58 | 79.5% | 15 | 20.5% |
| Characteristic | ML-100K | ML-1M |
|---|---|---|
| # of ratings | 100,000 | 1,000,209 |
| # of users | 943 | 6,040 |
| # of items | 1,682 | 3,952 |
| # of genres | 19 | 18 |
| Average # of genres per item | 1.7 | 1.6 |
| Rating’s domain | [1,5] | [1,5] |
| Algorithm | Prec. | nDCG | MEP | E-nDCG | N-nDCG |
|---|---|---|---|---|---|
| MF | 11.02 % | 12.07 % | 80.26 % | 30.47 % | 10.40 % |
| MF + MMR | 10.88 % | 12.23 % | 78.23 % | 29.52 % | 13.07 % |
| NMF | 10.52 % | 11.41 % | 89.45 % | 33.68 % | 25.62 % |
| EMF- | 11.28 % | 12.39 % | 83.16 % | 31.76 % | 8.74 % |
| EMF- | 14.34 % | 17.01 % | 98.47 % | 46.69 % | 5.78 % |
| NEMF† | 12.29 % | 14.17 % | 90.86 % | 39.40 % | 14.14 % |
| Algorithm | Prec. | nDCG | MEP | E-nDCG | N-nDCG |
|---|---|---|---|---|---|
| MF | 11.80 % | 13.15 % | 93.64 % | 48.42 % | 9.15 % |
| MF + MMR | 9.05 % | 10.39 % | 91.13 % | 42.17 % | 9.41 % |
| NMF | 7.96 % | 7.89 % | 95.94 % | 41.60 % | 48.14 % |
| EMF- | 11.77 % | 13.13 % | 93.70 % | 48.20 % | 9.16 % |
| EMF- | 13.63 % | 15.29 % | 99.81% | 58.74 % | 7.36 % |
| NEMF† | 11.02 % | 11.52 % | % 98.33 % | 50.01 % | 28.55 % |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Personalised Novel and Explainable
Matrix Factorization
Ludovik Coba, Panagiotis Symeonidis, Markus Zanker
Free University of Bolzano, Italy
[email protected], [email protected], [email protected]
Abstract
Recommendation systems personalise suggestions to individuals to help them in their decision making and exploration tasks. In the ideal case, these recommendations, besides of being accurate, should also be novel and explainable. However, up to now most platforms fail to provide both, novel recommendations that advance users’ exploration along with explanations to make their reasoning more transparent to them. For instance, a well-known recommendation algorithm, such as matrix factorisation (MF), optimises only the accuracy criterion, while disregarding other quality criteria such as the explainability or the novelty, of recommended items. In this paper, to the best of our knowledge, we propose a new model, denoted as NEMF, that allows to trade-off the MF performance with respect to the criteria of novelty and explainability, while only minimally compromising on accuracy. In addition, we recommend a new explainability metric based on nDCG, which distinguishes a more explainable item from a less explainable item. An initial user study indicates how users perceive the different attributes of these “user” style explanations and our extensive experimental results demonstrate that we attain high accuracy by recommending also novel and explainable items.
1 Introduction
Recommender systems aim primarily at providing accurate item recommendations while ignoring many times additional quality criteria such as the novelty of a recommended item [5] or the system’s ability to be able to explain to users why specific items are recommended [15].
As far as explainability is concerned, Abdollahi and Nasraoui [1, 2] recently proposed Explainable Matrix Factorization (EMF), where recommendations are not only optimised according to their presumed accuracy but also based on their explainability to users. However, they have not considered the novelty aspect, which risks to recommend explainable items because they are just popular. Such recommendations can be expected items, which might already be known to the user and finally resulting in trivial recommendations.
As far as novelty is concerned, there are many definitions [5]. For instance, popularity-based novelty focuses on discovering non-popular products that match the crowd’s interest. However, this definition of novelty does not capture how novel an item is for an individual. In the context of traditional MF to provide novel item recommendations, related work [8, 30] observed that by raising the dimensionality of the MF model (i.e., by increasing the number of latent factors), we can more accurately recommend items coming from the long tail (i.e. more novel items). However, please note that this can seriously harm the efficiency of the MF model.
In this paper, inspired by the work of both [8, 30], who measured the novelty of item recommendations using MF, and Abdollahi and Nasraoui [2], who proposed Explainable MF, we provide simultaneously personalised novel and explainable item recommendations based on matrix factorization. To the best of our knowledge, we are the first to propose an MF method that accurately recommends simultaneously novel and explainable items.
In terms of explainability, we improve the EMF [2] by reformulating its formula, which now overcomes the problem of Euclidean distance’s metric over high dimensional spaces, since it does not put more emphasis on outliers, which may dominate other smaller weights computed for the other data points. Furthermore, we have noticed that the Mean Explainability Precision (MEP) [2] metric is not adequate for measuring explainability, because it does not takes the exact rank of the recommended and explainable items into consideration. Instead, we build a new metric, denoted as explainable-nDCG, which is based on the well-known nDCG, and distinguishes a more explainable item from a less explainable item.
In terms of novelty of a recommended item, since the concept of explainability is based on many ratings among peers, and, thus, it correlates with item popularity [8, 30], we propose an algorithmic framework to trade-off between explainability and novelty in matrix factorisation. Our proposed method, denoted as personalised NEMF, has the advantage of controlling through a regularisation term how novel items will be recommended, without having to increase the number of latent factors of MF, which can harm the efficiency of the MF model. Furthermore please note, that item novelty should not be confused with the diversity of recommendation lists, which is later in the discussion section.
In the remainder of this paper, Section 2 discusses the related work. In Section 3, we define a new metric for explainability based on the well-known nDCG. Section 4 describes our findings from a user study so that we consider them in our proposed method. Next, in Section 5 we propose a framework for personalized novel and explainable MF. Section 6 presents and discusses our experimental results on two well-known datasets. Finally, Section 8 concludes the paper and describes future work.
2 Related Work
The utility of a recommender systems cannot be measured by solely considering the accuracy of recommendations. Jannach et al. [15], mentions that additional system aspects, which heavily impact the user experience like explanations, novelty and serendipity gain more attention.
2.1 Explainability
Several works discussed explanations for recommender systems up to date. Friedrich and Zanker [9], for instance, proposed a taxonomy to classify different approaches to generate explanations for recommendations. According to their taxonomy the explanations we consider in this work are categorised as collaborative explanations, i.e., explanations that justify recommendations based on the amount as well as the concrete values of ratings that derive from similar users, where similarity is typically determined based on similar behaviour and preference expressions during past interactions. The explanation taxonomy proposed by [22] extends this classification by making a distinction based on the three fundamental concepts used for explaining recommendations which are users, items and item features. They can be used to denote the following explanation styles: (i) User Style, which provides explanations based on similar users, (ii) Item style, which is based on choices made by users on similar items, and (iii) Feature Style, which explains the recommendation based on item features (content). Please note, that any combination of the aforementioned styles is then categorised as a multi-dimensional hybrid explanation style. For the “User” Style, several collaborative filtering recommender systems, such as Amazon, adopted the following style of justification: “Customers who bought item also bought items ”. This is the so called “User” style [3] of justification, which is based on users performing similar actions like buying or rating items. When the “Item” style of explanation is concerned, justifications are of the form: “Item is recommended because you highly rated or bought item ”. Thus, the system depicts those items i.e., , that influenced the recommendation of item the most. Bilgic et al. [3] claimed that the Item style is preferable over the User style, because it allows users to accurately formulate their true opinion of an item. In case of “Feature style” explanations the description of items are exploited to determine a match between a current recommended item and observed user’s interests. For instance, restaurants may be described by features such as location, cuisine and cost. Now, if a user has demonstrated a preference for Chinese cuisine and Chinese restaurants are recommended, then explanations will note the Chinese cuisine or their cost aspect. As part of this work we tested users’ preference for different explanation styles in a pre-study and determined that the so-called User Style (or collaborative user-based [9]) explanations scored highest and therefore focused only on this category of explanations for our algorithm development. However, we also discuss if and how our proposed method and metrics can be applied to build or test the quality of other explanation styles in the Discussion section.
2.2 Novelty
As far as the item novelty is concerned, Jannach et al. [14] mention in their research that recommender systems aim at boosting recommendations from the long tail of the item popularity distribution, supposedly increase the sales of novel items. Several works try to provide both accurate with novel [5, 6, 28] or diversified item recommendations [6, 7], where diversified item recommendation lists try to capture even more potential aspects of users’ interest. In terms of MF, related work [8, 30] has claimed that by increasing the number of latent factors of the basic matrix factorisation model [17], we can more accurately recommend novel items.
Given a ranking of recommended items a so-called re-ranker can be employed to increase the novelty or diversity of the final recommendation list, no matter which algorithm generated it initially. Particularly the trade-off between precision and novelty are based on the two criteria: (i) the items’ relevance to the user’s preferences (e.g. how similar is the item to previous user’s choices) and/or (ii) the item’s contribution in diversifying the item recommendation list (how different is an item from those items are already placed in the top positions of the recommendation list). Thus, re-ranking approaches apply a secondary or post-processing ranking step before delivering the final item recommendation list to the target user.
A well-known re-ranking approach, which was originally proposed for ranking documents in the information retrieval (IR) domain, is Maximal Marginal Relevance (MMR) [4]. MMR chooses a document to be placed in the top positions of the ranking list, if it has the maximum similarity with the user’s query/profile and also the minimum similarity to the previously suggested documents. Another re-ranking approach is known as xQuAD (eXplicit Query Aspect Diversification) [25]. This is a probabilistic model that takes under consideration both (i) the document’s relevance probability and (ii) the aspect’s diversity probability, towards a user’s query/profile. Recently, xQuAD was adapted accordingly to consider within the same user profile different tastes/aspects by performing Sub-Profile Aware Diversification, denoted as SPAD [16]. Another probabilistic re-ranking model [27] represented items and the categories they belong to, as a linear combination of their global and local appearance probability over item and user profiles, respectively.
A different research direction in matrix factorisation formulates the item recommendation problem not as a rating prediction problem, but as a ranking problem using pairs of positive items (in the train set) and negative items (not in the train set) as pairwise input. For example, Bayesian Personalised Ranking (BPR) [23] optimises a simple ranking loss such as AUC (the area under the ROC-curve) and uses matrix factorisation as the ranking function, that can be optimised directly using a stochastic gradient algorithm. Similarly to BPR, Ning and Karypis [20, 21] proposed a set of Sparse LInear Methods (SSLIM), which involve an optimisation process to learn a sparse aggregation coefficient matrix based on both user-item purchase matrices and item side information.
In the same direction, Wasilewski and Hurley [13, 29] have proposed a matrix factorisation framework to trade-off between the accuracy of item recommendations and the diversity of the items in the recommendation list. Please notice that in Wasilewski and Hurley [13, 29], there is some discussion about the appropriate sign of their regularisation term. In particular, the sign in front of the gradient term should be chosen as negative when maximisation of the regularisation term is required and positive when minimisation is required. They argue for a maximisation of their objective formula, such that the distance between item factors is small when the diversity is large. Moreover, TagiCoFi [31] adds an additional term to the classic MF formula to employ the user similarities defined based on tagging information to regularise the MF procedure in order to make the user-specific latent feature vectors as similar as possible if the corresponding users have similar tagging history. In particular, TagiCoFi [31] requires the additional factor to be minimised, such that the distance between item factors is small when their social distance is small. Please notice that TagiCoFi aims at increasing the accuracy of recommendations and not on novelty and/or explainability of recommendations. Furthermore, it tries to minimise the distance between users in the latent factor space, which can be stressed as a similarity of our work with TagiCoFi [31]. While [31] minimises the distance between two users in the latent space, we minimise the distance between a user and a novel/explainable item within this space.
In the following, we argue further why there is very small overlap between the work of Wasilewski and Hurley [13, 29] and our work, by identifying four important differences. The first is that similar to the previous approaches, their MF model computes the pair-wise ranking loss of the objective function (not the element-wise square loss like our methodology). In other words, our MF model is element-wise and predicts the missing values of the user-item rating matrix, whereas their model tries to optimise items’ pairwise ranking. The second difference is that we are exploring the trade-off between item recommendation accuracy and item novelty, whereas they explored the trade off between item recommendation accuracy and item diversity. This difference is discussed further in the discussion section. The third difference is the fact that items’ diversity by nature is not personalised, whereas in our case item’s novelty is personalised. That is, in our case, users based on their experiences can consider the same exact item as more or less novel (i.e., differently), whereas in both of their models the diversity between any two or more items in a recommendation list is always the same for all users. The last difference is that we add two additional terms to our objective formula to minimise the distance between a user with a novel or/and explainable item in the latent space, whereas they add only one additional term to the classic MF objective formula and try to maximise the distance between these two items instead of the distance between a user and an item. In addition, we have to note that they separately try to maximise only by considering the regularisation term that captures how much items differ to each other based on their content by minimising their basic pair-wise ranking loss function. In other words, the reason that they use different signs for adding the gradient of their regularisation term to their update rule is based on the fact that they try to maximise or minimise only this regularisation term by following the goal to minimise the pairwise loss function.
In contrast to the aforementioned works of Abdollahi and Nasraoui [2], Cremonesi et al. [8], Wasilewski and Hurley [13, 29], and Yin et al. [30], our proposed method incorporates two additional constraint terms (one for novelty and one for explainability) into the basic matrix factorisation formula. This additional information is taken from two external resources namely the user-item explainability matrix and the user-item novelty matrix, which will both be defined in the next section. While both novelty and explainability are seen as a key feature of recommendation utility in real scenarios, to our knowledge, there is no work on relating to both of them simultaneously and measuring their trade-offs.
3 Item Explainability and Novelty
Based on the framework of Vargas and Castells[5, 28], who already defined the novelty of an item for a specific target user, we will use it to define the explainability of an item for a given user in this section. This enables us to measure besides accuracy also the degree of novel and explainable items an algorithm recommends to users.
Table 1 summarises the symbols used in the following sections.
3.1 Personalised Item Explainability
There are different ways for explaining a recommendation [12]. Herlocker et al. [12] explored 21 different interfaces for explaining collaborative filtering (CF) recommendations. They demonstrated that the “User” style is persuasive in supporting explanations. To prove this, they conducted a survey with 210 users of the MovieLens recommender system, demonstrating that explanations can improve the acceptance of CF systems.
In this paper, we consider the “user” style of explanations [3], which provides explanations based on what items similar others to a target users have favourably rated. In other words, the “user” style of explanation is based on other users performing similar actions (buying items, rating items, etc). Please notice that the qualitative user study of Herlocker et al. [12] has shown already the merit of the “user” style of explanation, and many other user studies followed, showing its effectiveness [3, 22]. Thus, the burden of proof that this type of explanation is insightful for users is out of scope of this paper. The merit of this explanation style is also indicated by the fact that several big product retailers, such as Amazon, Zalando, etc., adopted this user style of justifications: “Customers who bought item also bought items ”. For example, as shown at the right-bottom of Figure 1, Amazon’s interface displays a histogram of users’ ratings for an item.
We can also see two variations of the same “User” style of explanation interface in Figures 2 and Figures 3. In Figure 2 the user is presented with the exact ratings his neighbours have entered while in Figure 3 the interface displays a histogram of neighbours’ ratings for the recommended item.
3.1.1 Defining how explainable is a Recommended Item
When computing the explainability power of an item for a user based on her/his neighbourhood preferences, we first have to identify the similar neighbours of a target user from the original user-item rating matrix. In particular, we can use the Pearson correlation (Equation 1), which measures the similarity between two users, and .
[TABLE]
where , are the ratings on item of user and user , respectively. and are the set of items rated by user and , respectively. Means , are the mean ratings of and over their co-rated items. Equation 1 takes into account only the set of items, , that are co-rated by both users.
Then, we set a number of nearest neighbours for the target user , and inside this neighbourhood, we define as the number of nearest neighbours of target user who have given rating on item . Please notice that [1..R] rating scale.
Then, for a user , who is recommended an item , we compute how explainable item is for by measuring in the identified neighbourhood (i.e. the most similar user profiles) how frequently item has been highly rated. In other words, we construct a user-item explainability matrix that holds the explainability power of an item for a user as given in Equation 2:
[TABLE]
where is the set of nearest neighbours of a user, and being the set of all different ratings in the rating scale. Please also note that is the set of nearest neighbours of target user who gave a “positive” rating (above threshold) on item in the past. As expected, the values of matrix should be higher for items that are highly rated from many users and low in the opposite case.
Please notice that using Equation 2, we are able to define the explainability power of an item for a target user based on the weighted frequency sum of ratings for a particular item among the nearest neighbours of a given user.
Based on Equation 2 we can measure how explainable an item is for both examples given in figures 2 and 3, respectively. As far as Figure 2 is concerned, the explainability power for justifying the recommendation of Movie 1 is 159 (), while for Figure 3 the explainability power for justifying the recommendation of Movie 2 is 127 (). Thus, following this approach Movie 1 is supposedly more explainable than Movie 2 since neighbours were more likely to give higher ratings while still the overall number of ratings is the same for this example. In the next section we will present results from an initial user study that confirms these assumptions underlying our proposed explainability measure.
3.1.2 Evaluating the explainability of a recommendation list
As already discussed in the user-based style of explanation, we want to understand if the recommended items are also explainable w.r.t. the explainability distribution of items.
For instance, Abdollahi and Nasraoui [2] measure the explainability of an item recommendation list , which is provided to user , as the ratio of the number of explainable items inside to the size of the number of recommended items (i.e., Mean Explainability Precision), as shown in Equation 3:
[TABLE]
where is the set of all users. As will be shown experimentally later, the main drawback of MEP is the fact that it can not distinguish a more explainable item from a less explainable one. Moreover, it is obvious that for small values of the explainability threshold, , MEP is almost always equal to 1, even if consist of items with small explainability power. Thus, to obtain a finer level of granularity in the aforementioned problems, we adopt the notion of Explainable normalized Discounted Cumulative Gain (), which also takes under consideration the relative position of the recommended items inside .
The first step in the computation of the not normalised is the creation of the gain vector. In our case, the gain vector for each item in , consists of its explainability power (), as it is defined in Equation 2 for the user style of explanation.
The second step in the computation of applies the Discounted Cumulative Gain to the aforementioned gain vector, as shown in Equation 4.
[TABLE]
Based on Equation 4, we discount the gain at each item rank inside to penalise items, which are recommended lower in the ranking, reflecting the additional user effort in order to reach the lower ranks and appreciate the corresponding explanation[6].
The third step is to normalise the against the “ideal” gain vector. In our case, the “ideal” gain vector considers all recommended items in as having maximum explainability power, . That is, all recommended items in are considered as being rated with the maximum rating (e.g., with 5 in the rating scale 1 to 5), from all neighbours of the target user and item, for the two explanation styles, respectively. Thus, the ideal E-IDCG is calculated as:
[TABLE]
[TABLE]
where is the size of the neighbourhood that is used for explaining a recommendation. Finally, is the ratio between E-DCG to E-IDCG, as shown in Equation 7.
[TABLE]
3.2 Personalised Item Novelty
The premise of recommender systems is to suggest users non-popular items that match their interests, i.e. to make novel item recommendations. By doing this, businesses can increase their returns, since these novel items usually might have higher margins, or lower customer churn rates, since users would get bored and disappointed by receiving trivial recommendations of already known popular items. In the following, we will therefore define the novelty of a recommended item and how to measure the novelty of a recommendation list.
3.2.1 Defining how Novel is a Recommended Item
Related work [5] in recommender systems has proposed several definitions of item novelty. The popularity-based novelty definition [5], for instance, also known as global long-tail novelty, focuses on discovering relatively unknown items coming from the long-tail of the item popularity distribution. However, by using the popularity-based novelty, we can capture only the novelty of an item over the whole crowd of the recommender system, but we miss to address the novelty for a particular person (i.e., personalised item novelty).
Differently to the case of popularity-based item novelty, we will use a distance-based model [5, 28], also known as unexpectedness, where item novelty is defined by a distance function between the target item from the set of items and the set of items that a user has already interacted with (the user’s past experience). We can formulate this novelty as shown in Equation 8:
[TABLE]
Please note, that the distance between two items can be also considered as the complement (i.e. ) of any similarity measure (cosine-based, Jaccard coefficient, etc.) in terms of the item features (i.e., the category that an item belongs to, the features of an item, etc.) or the user’s item categories profile 111To capture the interaction between users and the item categories they have interacted with, we can build a user-category profile, composed of the user-item rating profile and the item-category profile (e.g., their dot product). (i.e. the item categories that a user presumably prefers). For example, in news recommendation, we know the category to which an article belongs to (i.e., politics, sports, etc.). Thus, when we recommend an article about sports to a user, who has already seen a lot of stories about sports, this will obviously not be considered to be as novel as for a person, who has never seen an article about sports before. In order to capture how novel a topic category is for a user, we can use Equation 9, which is based on the well-known subtopic recall metric (S-recall) [5], but adjusted to our case scenario:
[TABLE]
where is an item and is the set of all topic categories. Thus, when a user has interacted with many items that belong to the same category , then any additional item from this category will be considered to be less novel for user .
3.2.2 Evaluating the Novelty of a Recommendation List
In this Section, we will define an integrated way of measuring the novelty of a recommendation list, which can be used either for popularity-based or personalised item novelty. For a user who is recommended items, we adopt the following definition of novelty of a recommendation list of items [5, 28]:
[TABLE]
where is the novelty of item for the target user that can be any of the item novelty models shown in column 3 of Table 2. Please note that the last column of Table 2 shows the context of the user’s experience. For the popularity-based model it consists of all the users that interacted with item (i.e., ), whereas for the distance-based model, it consists of the items that only user has interacted with in the past (i.e. ).
A drawback of Equation 10, which captures the novelty of a recommendation list , is that it cannot penalise the fact that a less novel item is ranked at a better position in than another more novel item. In analogy to the E-nDCG defined in Section 3.1.2, we therefore introduce the following Novel - normalized Discounted Cumulative Gain ().
considers the relative position of the recommended novel items inside . We compute the gain vector for each item in , which consists of its novelty (), as it is defined in column three of Table 2, and apply the Discounted Cumulative Gain to the aforementioned gain vector, as shown in Equation 11.
[TABLE]
In Equation 11, we discount the gain at each item’s rank inside to penalise items, which are recommended lower inside . Next, we normalise the against the “ideal” gain vector. In our case, the “ideal” gain vector considers each item in as having maximum novelty, . is different for each item novelty model, as shown in column four of Table 2. Please notice that the variable, which is shown in the fourth column of Table 2 depends on the range of the used distance function. Thus, the ideal N-IDCG is calculated as:
[TABLE]
Finally, the is the ratio between to N-IDCG:
[TABLE]
4 User Study
Collaborative explanations that justify recommendations by showing rating summaries such as the total number of similar users and the mean value of their ratings helps users to understand the reasoning behind recommendations and thus ease the decision making.
Next we will therefore present results from an initial user study that researched if and how collaborative explanations building on rating summary statistics actually guide users’ choices.
Between January and February 2018 a group of 73 people was invited to participate in a controlled experiment to explore how users perceive different configurations of user style explanations. We base our analysis on the Choice-Based Conjoint (CBC) [18] methodology. In CBC designs, products (a.k.a., profiles) are modelled by sets of categorical or quantitative attributes, which can have different levels. In CBC experiments, participants have to repeatedly select one profile from different sets of choices, which nicely matches real-world recommendation settings where users are confronted with lists of items alongside with explanations. The participants were presented with the following hypothetical situation, and had to repeatedly select one profile from choice sets containing 3 items each. The choice task was accompanied with the following briefing of participants:
“Assume that you find yourself in the situation that you need to make a choice between three movies to watch on a movie platform. These three movies are equally preferable to you with respect to all other movie information you have access to (title, plot, actors etc.). Other similar users’ ratings are aggregated and summarised by their number of ratings, the mean rating value and their distribution. Therefore, we would like to know your choice, by solely considering these rating summary statistics.”
4.1 Results on Users’ Favourite Attributes
Detailed results for estimating users’ preference weights are presented in Table 3. The fourth column of Table 3 shows the coefficients (or preference weights) for each level of the two attributes, where the base levels (i.e. small number of ratings and low mean ratings) have been constrained to be zero. The fifth and the sixth column of Table 3 report the standard errors and the P-values for the respective levels of each attribute.
Figure 4 visually depicts the preference weights of the multinomial logit model for each level of the two selected attributes (i.e. total number and mean of ratings). As expected, there was a general higher is better tendency for the two attributes - i.e., users prefer bigger numbers of ratings and higher mean values. There was a clear and statistically significant preference relation over the three levels for mean rating values. However, in terms of the total number of ratings, users did not seem to care that much. The large number of ratings was statistically significant, and clearly preferred over the other two levels, but between the medium and small level, the P-value was above the threshold of .05 (cmp. Table 3) and thus no statistically noticeable difference in the users’ perception existed.
Thus, the conjoint analysis clearly supports our modelling assumptions, that higher mean rating values have a strong influence on the explainability of a rating summary statistic. Please notice that in future, we want to comprehensively exploit these findings in our algorithm to provide more effective explanations.
4.2 Results about Users’ Favourite Style
Next, we measured users’ perception over different explanation types based on the origin of the ratings used (i.e., if the ratings derived from friends or from similar users). In other words, we have used two styles of explanations, based on the origin of the ratings. That is, if the target user takes an explanation based on the ratings of other users that are similar or based on the ratings of her/his friends in social networks like Facebook or Instagram. The first approach can be considered the “User’ style of explanations (denoted as style ), and the second one the “Friend’ style (denoted as style ).
We assumed that explanation style will be the users’ favourite on due to homophily. However, our results as illustrated in Table 4 have a surprising result: the relative importance in terms of percentage of style is only = 20.5%, whereas is 79.5%. This contradicts our initial assumption that explanation style would be users’ favourite choice, see Table 4.
Finally, Figure 5 visually represents the preference for the explanation styles and including confidence intervals.
Thus, the outcome of the initial user study clearly supports our algorithmic focus on collaborative explanations exploiting ratings from users’ nearest neighbours.
5 Proposed NEMF method
As mentioned before we address novelty in analogy to explainability and propose an algorithmic framework to trade-off between explainability and novelty in matrix factorisation. In this Section, we present our method and the steps that took us there.
5.1 Explainable Matrix Factorization
As far as the items’ explainability is concerned, to provide more explainable items, Abdollahi and Nasraoui [2] proposed Explainable Matrix Factorisation (EMF), where they put an additional constraint on the classic regularised matrix factorisation formula as shown in Equation 14:
[TABLE]
where is the set of ratings for user on item , are the regularisation terms and holds the information of how explainable is item for user . Please notice that constraints the representations of the user/item vectors in the latent space, in such a way so that they are close to each other (i.e., their difference is close to zero), in order to minimise the objective function.
Then, to minimise the objective function , they compute the error of the difference among the real and the predicted rating values of items by using a numerical method, such as Gradient Descent, and by applying the following update rules:
[TABLE]
where is the learning rate, whose value determines the step rate for detecting the minimum. Parameter is used to control the magnitudes of the user-latent feature and item-latent feature vectors, whereas parameter controls the explainability matrix.
In this Section, we reformulate the objective function of EMF of Equation 14, to overcome the problem of Euclidean distance’s metric over high dimensional spaces. That is, Euclidean distance (L2 norm) places more emphasis on outliers, computing a much higher weight (i.e., by squaring the difference) for them, which may dominate other smaller weights computed for other normal data points. In contrast, Manhattan distance (L1 norm) tries to reduce all errors equally since its gradient has constant magnitude. We have experimentally identified that Manhattan distance (L1 norm) is preferable to Euclidean distance (L2 norm) for the case of high dimensional data. Based on the aforementioned argument, we change the additional soft explainability constraint of Equation 14, by using the Manhattan distance, as shown by Equation 5.1:
[TABLE]
Then, to minimise the objective function , we apply the following update rules:
[TABLE]
where 0 and the explainablity regularisation term 0. Please notice that is the signum or else the sign function and for a vector = [,, ], = [,, ], and = 1 when 0, and = -1 when 0, and = 0 when = 0.
5.2 Novel Matrix Factorisation
For the personalised novelty, in analogy to the EMF-manhattan case, which we described in the previous section, we add an additional soft constraint for novelty into the classic regularised matrix factorisation formula as shown in Equation 5.2:
[TABLE]
where controls the novelty vector and holds the information of how novel is item and the update rules of are in accordance to those that are shown of the EMF-manhattan. Then, to minimise the objective function , we use the Gradient Descent method.
5.3 Novel and Explainable MF
Consequently, we want to define the objective function such that we can push for more novel and more explainable items into top- recommendation lists at the same time with minimal losses in the recommendation accuracy. To do this, we incorporated the additional constraint terms from Sections 5.1 and 5.2 into the objective function as shown in the following:
[TABLE]
The new update rules change as follows:
[TABLE]
where 0, the explainability regularisation term 0, and the novelty regularisation term 0. An attractive property of L1 norm is that it induces sparsity into the predicted model and thus, it can create more compact and interpretable models. In particular, to induce more sparsity into our predicted model, we need to increase the value of parameter . That is, with L1 norm our model can attain as many zero elements as possible [19] giving the simplest and most interpretable and explainable solution to account for the data. In other words, L1 norm has the tendency to select sparse solutions (i.e., few nonzero components) for the predicted model, and it is particularly effective for high-dimensional data with many non-correlated user and/or non co-rated item features. Thus, L1 norm identifies those item/user features with zero coefficients and effectively discards them. In summary, the main advantage of L1 norm over L2 norm is not always the one of performance in terms of accuracy, but the fact that it is highly interpretable and explainable [19]. Henceforth, we call this method Novel and Explainable Matrix Factorisation (NEMF). Please notice that MF, EMF, and NMF methods, are just simplified special cases of NEMF and can be easily derived from it.
6 Experimental Results
In this Section, we experimentally compare our approach NEMF with other recommendation algorithms. We use the Explainable Matrix Factorisation (EMF)[2] algorithm, and the Matrix Factorisation [17] algorithm (MF) for the comparison. Moreover, we will use the Maximal Marginal Relevance re-ranker (MMR) [4] combined with the MF algorithm, such that we have in our experiments also a variation of MF, which focuses on providing novel item recommendations. In particular, for re-ranking with MMR the item recommendation list provided from classic MF algorithm, we adapt the following greedy objective function of Saúl Vargas [26], as shown by Equation 19:
[TABLE]
where is the normalised predicted rating of user over item . It is normalised in [0,1] scale, such that it can be combined with the Jaccard similarity222The Jaccard similarity is particularly adequate for binary data. In this case we are considering the similarity in the context of the topic coverage. (see the second term of Equation 19), which measures the dissimilarity of items. In particular, it measures the average similarity of an item with all other items which have already taken a position inside the recommendation list, which is to be re-constructed for user . As can be shown by the parameter of Equation 19, there is a trade-off between how relevant an item is being considered by a user, and how much this item differs from the items, which have been already included inside the currently constructed recommendation list. In our experiment we kept the trade-off . We also distribute the code for reproducing the experiments online.333https://github.com/proton35/explainable_MF
6.1 Data Sets
Our experiments are performed on two datasets, MovieLens 100K (ML100K) and MovieLens 1ML (ML1M) [11]. ML100K consists of 100,000 ratings assigned by 943 users on 1,682 movies. ML1M contains 1,000,209 anonymous ratings of approximately 3,900 movies made by 6,040 users. The range of ratings is between 1(bad)-5(excellent). The datasets also contain the movie genres, whereas a movie may belong to one or more genres, as shown in Table 5. Please note that since the data sets contain information about the genres of the movies, we have used the distance-based item novelty for our experiments, thus the novelty of an item may not be the same for different users.
6.2 Experimental Protocol and Evaluation
Our evaluation considers the division of items of each target user into two sets: (i) the training set T is treated as known information and, (ii) the probe set P is used for testing and no information in the probe set is allowed to be used for prediction. It is obvious that, E=E$${{}^{T}}\cup EP and E$${{}^{T}}\cap E$${{}^{P}}=\oslash. Therefore, for a target user we generate the recommendations based only on the items in T.
Except for the metrics E-nDCG and N-nDCG, that are introduced in Sections 3.1.2 and 3.2.2, respectively, we use precision, and nDCG metrics as classic accuracy performance measures for item recommendations.
Finally, in our experiments we will also present MEP, which is presented in Section 3.1.2 for comparisons reasons, as proposed by the work of Abdollahi and Nasraoui [2].
We perform all experiments with -fold cross validation, with a training-test split percentage, 75%-25%. The default size of the recommendation list is set to 10, except for cases that denoted differently. The presented measurements, based on two-tailed t-test, are statistically significant at the 0.05 level. All algorithms predict the items of the target users’ in the probe set.
We evaluate NMF, EMF, and NEMF by varying the novelty and explainability regularisation terms, while we keep the other parameters fixed to values denoted next. For ML100K, the number of latent factors and the learning rate for all algorithms is set to 80 and 0.001, respectively, whereas the number of users used for explaining a recommendation is set to 10. For ML1ML, the number of latent factors for all algorithms is set to 50, parameter is set to 0.001 and the number of users used for explaining a recommendation is set to 10.
6.3 Sensitivity analysis of NMF
In this Section, we want to explore how the performance of NMF is affected when we increase the impact of the regularisation term , which controls novelty in Equation 5.2. Both Figures 6(a) and 6(b) show that as we increase , N-nDCG increases, whereas nDCG decreases. That is, as we increase , NMF recommends more novel items but the recommendation accuracy drops drastically, which indicates that novelty and precision accuracy are negatively correlated.
On ML100K, we achieved the best novelty, in terms of N-nDCG, when parameter equal to 1. As can be seen from Figure 6(a), novelty (N-nDCG) and accuracy (nDCG) balance at , where the two lines cross. On ML1M, the best novelty was achieved for equal to 0.8. As before, we can see in Figure 6(b), novelty and accuracy balance at , where the two lines cross.
This trade-off is something that we will try to balance experimentally later with our proposed NEMF method.
6.4 Sensitivity Analysis of EMF
In this Section, we want to explore how the performance of EMF in terms of providing explainable and accurate recommendations is affected, as we increase the impact of the regularisation term , which controls explainability in Equation 5.1.
Both Figures 7(a) and 7(b) show that, up to a point, as we increase , both E-nDCG and nDCG increase too. That is, as we increase , EMF recommends more explainable items and the recommendation accuracy continues to increase, which means that explainability and precision accuracy are positively correlated.
On ML100K we achieved best precision and explainability for , while for ML1M the best explainability was achieved with .
Thus, by recommending explainable items, you might recommend the more popular ones, which is presumably a major reason for getting increased accuracy performance. However, these types of recommendations of popular items, even if accurate, might be perceived as boring by users due to their lack of serendipity and novelty. This type of trade-off we want to balance with our proposed NEMF method.
6.5 Sensitivity Analysis of NEMF
In this Section, we want to explore how NEMF performs in terms of providing novel, explainable and accurate recommendations, when we increase the impact of the regularisation terms and , controlling novelty and explainability, respectively, in Equation 18. In terms of accuracy, as shown in Figure 8(a) and Figure 8(b), respectively for ML100K and ML1M, we change simultaneously the weights of both regularisation terms of explainability and novelty.
Thus, we can observe how the recommendation accuracy in terms of nDCG varies as the other two parameters change. The brightness of the cells denotes the nDCG, brighter colours denote higher scores of the nDCG, while darker colours are for lower scores of nDCG. The two axes denote the corresponding weight values of the explainability and novelty regularisation terms.
In terms of novelty and explainability performance of NEMF, we also run experiments to identify their best possible values. However, we have to note that it is impossible to determine the parameters’ combination that achieves for all three metrics (i.e. accuracy, novelty and explainability) the maximum values. Thus we need to compromise in order to achieve reasonable results for all three target metrics.
6.6 Comparison with other methods
In this Section, we compare our NEMF against MF, NMF, and EMF-Euclidean and EMF-Manhattan in terms of their accuracy (with precision and nDCG), explainability (with E-nDCG and MEP), and novelty (with N-nDCG) performance.
Tables 6 and 7 give the performance results for all algorithms on the ML100K and the ML1M datasets, respectively, when we provide top-10 item recommendations. For both data sets, the best accuracy and explainability performance is attained by EMF-Manhattan, which is a method that is proposed in this paper. However, EMF-Manhattan does not perform well in terms of novelty. As expected, the best novelty is attained by NMF, but with severe losses in terms of precision/nDCG. As shown, only NEMF (see in the last row of both Tables 6 and 7) is able to recommend high accuracy in combination with both good levels of novel and explainable item recommendations.
7 Discussion
The idea of explaining recommendations based on the number of nearest neighbours may help users to better understand the relevance of items. Of course, when a user style of explanations is applied on a social network, it provides the number of friends of the target user as explanations. In such cases, the recommendation along with its explanation would be as follows: “We recommend you Item 1 because it is highly rated by 14 of your friends”. However, in this paper, we have focused on the user style of explanations as also supported by our initial user study. Please note, that our proposed explainability and novelty evaluation metrics can be used to evaluate the performance of other explainable recommendation algorithms, too. However, based on the fact that in our paper the explainability/novelty of an item is defined based on how many neighbour users rated highly the recommended item, the creation of the explainability and novelty user-item matrices (i.e., Equations 2 and 8, respectively) would require adaptations in order to be applicable for other explanation styles/algorithms. For example, we need to change Equation 2 to apply our methodology to the item-based knn algorithm along with the so-called “Item” style of explanation [3], where the justifications are of the following form: “Item is recommended because you highly rated/bought item ”. Thus, the system depicts those items i.e., , that influenced the recommendation of item the most.
To compute the explainability power of an item for a user based on her/his preferences on other items (high ratings/purchases in the past), we have to first find the similar items of the recommended item , from the original user-item rating matrix. Then, we create the recommended item’s neighbourhood, by getting the number of most similar items of . That is, for an item , which is recommended to a user , we can define as the set of the similar items of , which were also given from user a “positive” rating (above ) in the past. Please notice that [1..R] rating scale. Then, for a user that is recommended an item , we can compute how well explainable is for , by summing up the ratings that he has made on the most nearest (similar) items to . Thus, we can construct a user-item explainability matrix that holds the explainability power of an item for a user as it is shown in Equation 20:
[TABLE]
and is the number of similar items to the recommended item , which were also given from user a “positive” rating (above threshold) in the past. Please note that we would need to make analogous adaptations in Equation 8, such that we are able to capture how novel an item is for a user, in respect to the ’item’ style of explanation. As part of our future work, we want to explore NEMF also for the “Item” style of explanations as well as other explanation styles/ algorithms.
In this paper, we focused on the novelty of a recommendation list, but we did not see the diversity of the recommendation list, where a diversified item recommendation list tries to capture more aspects of a user’s interest. For measuring an item’s novelty, we need at least one recommended item (i.e., we can just measure if an item is novel for a user), whereas for measuring the diversity of a recommendation list we need at least 2 recommended items (e.g., intra-list diversification with topic coverage). In particular, the intra-list diversification, which measures how diversified are the recommended items inside the list based on the percentage of coverage of different topics that are covered with the items of the recommendation list. As a next step, we want to evaluate personalised NEMF in terms of the intra-list diversification on different data sets.
In a multi-objective optimisation scenario of matrix factorisation, finding acceptable trade-offs between aspects such as, for instance, accuracy, explainability or novelty is challenging and requires further research. While we do not provide the full answer w.r.t. how to trade-off these system objectives, the paper, however, sheds additional light on the relationships between these objectives and proposes an algorithmic mechanism to adjust the weighting of these different goals. Moreover, we have to mention that there are also other methods, in which explainability is not being exactly aligned to the prediction algorithm, such as the Local Interpretable Model-agnostic Explanations (LIME) [24] approach, which does not depend on the type of data, nor on a particular type of comprehensible local predictor or explanation. The main intuition of LIME is that the explanation may be derived locally from the records generated randomly in the neighbourhood of the record to be explained, and weighted according to their proximity to it.
8 Conclusions
In this paper, we proposed a framework for matrix factorisation, denoted as NEMF, that simultaneously considers both the novelty and explainability of recommended items. Our empirical results have revealed the trade-off relationships between algorithmic accuracy, explainability and novelty. We have also experimentally shown that, MF, EMF and NMF approaches are simplified special cases of NEMF and can be easily derived from it. As future work, we plan to assess the users’ perception for more explanation styles, e.g. item-based style of explanation. Moreover, we want to explore how to apply the proposed NEMF in the context of social networks, where the idea of explaining a recommendation using similar users will be replaced by the user’s friends, which can support many more application scenarios on the Social Web.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] B. Abdollahi and O. Nasraoui. Explainable matrix factorization for collaborative filtering. In Proceedings of the 25th International Conference Companion on World Wide Web , WWW ’16 Companion, pages 5–6, 2016.
- 2[2] B. Abdollahi and O. Nasraoui. Using explainability for constrained matrix factorization. In Proceedings of the Eleventh ACM Conference on Recommender Systems , Rec Sys ’17, pages 79–83, New York, NY, USA, 2017. ACM.
- 3[3] M. Bilgic and R. Mooney. Explaining recommendations: Satisfaction vs. promotion. In Proccedings Recommender Systems Workshop (IUI Conference) , 2005.
- 4[4] J. Carbonell and J. Goldstein. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval - SIGIR 98 . ACM Press, 1998.
- 5[5] P. Castells, N. J. Hurley, and S. Vargas. Novelty and diversity in recommender systems. In F. Ricci, L. Rokach, and B. Shapira, editors, Recommender Systems Handbook, 2nd edition , pages 881–918, 2015.
- 6[6] C. Charles, M. Kolla, G. Cormack, O. Vechtomova, A. Ashkan, S. Buttcher, and I. Mac Kinnon. Novelty and diversity in information retrieval evaluation. In SIGIR Conference , SIGIR ’08, pages 659–666, 2008.
- 7[7] P. Cheng, S. Wang, J. Ma, J. Sun, and H. Xiong. Learning to recommend accurate and diverse items. In Proceedings of the 26th International Conference on World Wide Web , WWW ’17, pages 183–192, 2017.
- 8[8] P. Cremonesi, Y. Koren, and R. Turrin. Performance of recommender algorithms on top-n recommendation tasks. In Proceedings of the Fourth ACM Conference on Recommender Systems , Rec Sys ’10, pages 39–46, New York, NY, USA, 2010. ACM.