Object Perception and Grasping in Open-Ended Domains
S. Hamidreza Kasaei

TL;DR
This paper explores how service robots can learn to recognize objects and grasp affordances in open-ended, human-centric environments by leveraging incremental learning from experience and interaction, addressing challenges in real-time perception.
Contribution
It proposes interactive open-ended learning methods for robots to recognize multiple objects and affordances, highlighting the importance, challenges, and evaluation metrics for such approaches.
Findings
Robots can learn object categories incrementally from online experiences.
Open-ended learning enhances adaptability in dynamic environments.
Limitations of deep learning in open-ended, real-time learning are discussed.
Abstract
Nowadays service robots are leaving the structured and completely known environments and entering human-centric settings. For these robots, object perception and grasping are two challenging tasks due to the high demand for accurate and real-time responses. Although many problems have already been understood and solved successfully, many challenges still remain. Open-ended learning is one of these challenges waiting for many improvements. Cognitive science revealed that humans learn to recognize object categories and grasp affordances ceaselessly over time. This ability allows adapting to new environments by enhancing their knowledge from the accumulation of experiences and the conceptualization of new object categories. Inspired by this, an autonomous robot must have the ability to process visual information and conduct learning and recognition tasks in an open-ended fashion. In this…
Click any figure to enlarge with its caption.
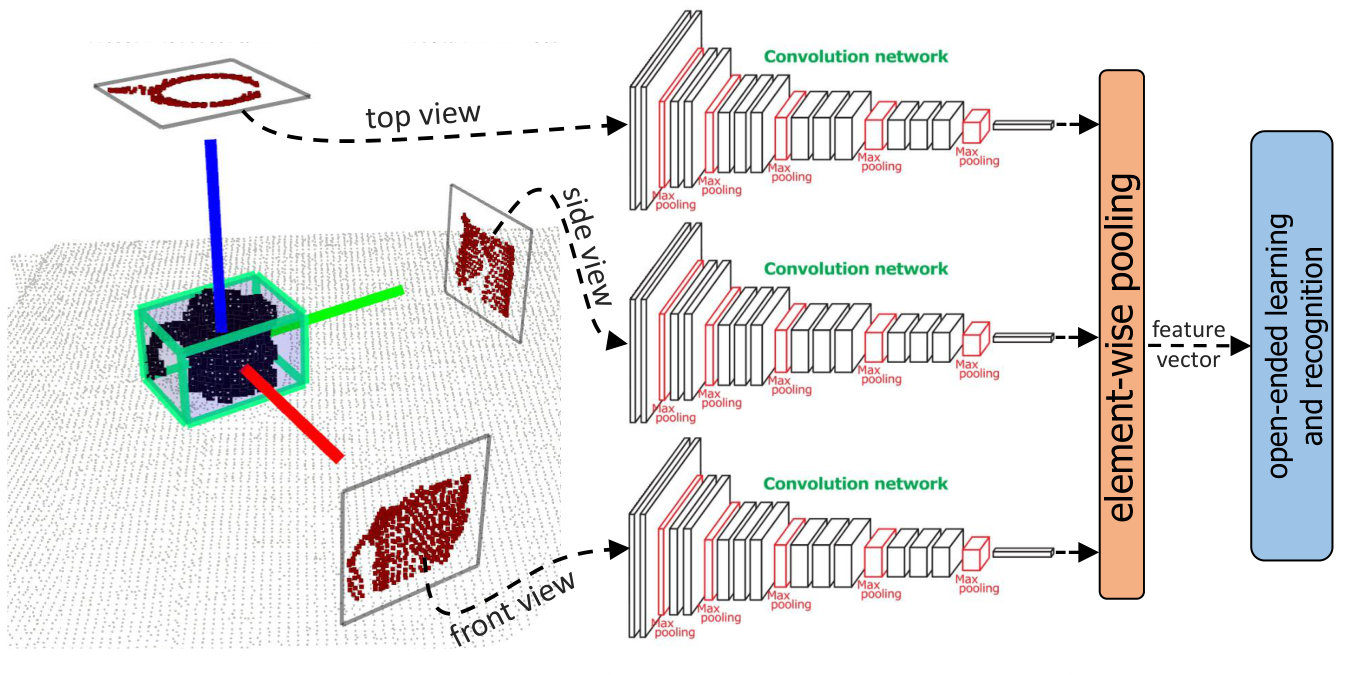 Figure 1
Figure 1 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobot Manipulation and Learning · Domain Adaptation and Few-Shot Learning · Multimodal Machine Learning Applications
RSS Pioneers 2019 - Freiburg, Germany, June 2019
Object Perception and Grasping in Open-Ended Domains
S. Hamidreza Kasaei
Department of Artificial Intelligence, University of Groningen, The Netherlands.
[email protected] – www.ai.rug.nl/hkasaei
I Introduction
Nowadays service robots are leaving the structured and completely known environments and entering human-centric settings. For these robots, object perception and grasping are two challenging tasks due to the high demand for accurate and real-time responses. Although many problems have already been understood and solved successfully, many challenges still remain. Open-ended learning is one of these challenges waiting for many improvements. Cognitive science revealed that humans learn to recognize object categories and grasp affordances ceaselessly over time. This ability allows adapting to new environments by enhancing their knowledge from the accumulation of experiences and the conceptualization of new object categories. Inspired by this, an autonomous robot must have the ability to process visual information and conduct learning and recognition tasks in an open-ended fashion. In this context, “open-ended” implies that the set of object categories to be learned is not known in advance, and the training instances are extracted from online experiences of a robot, and become gradually available over time, rather than being completely available at the beginning of the learning process.
As an example, consider a cutting task, if the robot does not know what a “Knife” is, it may ask a user to show one instance and demonstrate how to grasp the “Knife” to execute the task. Such situations provide opportunities to collect training instances from actual experiences of the robot and the system can incrementally update its knowledge rather than retraining from scratch when a new task is introduced or a new category is added. This way, it is expected that the competence of the robot increases over time.
In my research, I mainly focus on interactive open-ended learning approaches to recognize multiple objects and their grasp affordances concurrently. In particular, I try to address the following research questions:
- •
What is the importance of open-ended learning for autonomous robots?
- •
How robots could learn incrementally from their own experiences as well as from interaction with humans?
- •
What are the limitations of Deep Learning approaches to be used in an open-ended manner?
- •
How to evaluate open-ended learning approaches and what are the right metrics to do so?
II Related Work
Several projects have been conducted to develop robots to assist people in daily tasks. Some examples of service robot platforms that have demonstrated perception and action coupling include Rosie [1], HERB [25], ARMAR-III [27] and Walk-Man [26]. Unlike our approach, these projects broadly employ static perception systems to perform object recognition and manipulation tasks. In these cases, the knowledge of robots is fixed, in the sense that the representation of the known object categories or grasp templates does not change after the training stage. Our works enable a robot to improve their knowledge from accumulated experiences through interaction with the environment [5], and in particular with humans. A human user may guide the process of experience acquisition, teaching new concepts, or correcting insufficient or erroneous concepts through interaction.
In recent studies on object recognition and grasp affordance detection, much attention has been given to deep Convolutional Neural Networks (CNNs). It is now clear that if in a scenario,* we have a fixed set of object categories* and a massive number of examples per category that are sufficiently similar to the test images, CNN-based approaches yield good results, notable recent works include [22][15][2][18]. In open-ended scenarios, these assumptions are not satisfied, and the robot needs to learn new concepts on-site using very few training examples. While CNNs are very powerful and useful tools, there are several limitations to apply them in open-ended domains. In general, CNN approaches are incremental by nature but not open-ended, since the inclusion of new categories enforces a restructuring in the topology of the network. Furthermore, training a CNN-based approach requires long training times and training with a few examples per category poses a challenge for these methods. Deep transfer learning can relax these limitations and motivate us to combine deeply learned features with an online classifier to handle the problem of open-ended object category learning and recognition.
III Approaches and Contributions
My works contribute in several important ways to the research area of object perception and grasping. The primary goal of my researches is to concurrently learn and recognize objects as well as their associated affordances in an open-ended manner. I organize my works into three main categories and briefly explain the details of each category in the following subsections. All contributions have been evaluated using different standard object and scene datasets and empirically tested on different robotic platforms including PR2 and JACO robotic arm.
III-A Open-Ended Object Category Learning and Recognition
Two important parts of my works are concerned with the object representation [9, 14, 20, 24, 7, 17] and object category learning [11, 21, 6, 19, 16]. In our recent work, we presented a deep transfer learning based approach for 3D object recognition in open-ended domains named OrthographicNet. In particular, OrthographicNet generates a rotation and scale invariant global feature for a given object, enabling to recognize the same or similar objects seen from different perspectives. As depicted in Fig. 2, we first construct a unique reference frame for the given object. Afterward, three principal orthographic projections including front, top, and right-side views are computed by exploiting the object reference frame. Each projected view is then fed to a CNN, pre-trained on ImageNet [3], to obtain a view-wise deep feature. The obtained view-wise features are then merged, using an element-wise max-pooling function to construct a global feature for the given object. The obtain global feature is scale and pose invariant, informative and stable, and deigned with the objective of supporting accurate 3D object recognition. We finally conducted our experiments with an instance-based learning and a nearest neighbor classification rule. This approach was extensively evaluated in [4]. Experimental results show that OrthographicNet yields significant improvements over the previous state-of-the-art approaches concerning scalability, memory usage and object recognition performance.
III-B Grasp Affordance Learning and Recognition
Robots are still not able to grasp all unforeseen objects and finding a proper grasp configuration, i.e. the position and orientation of the arm relative to the object, is still challenging [8, 23, 12]. One approach for grasping unforeseen objects is to recognize an appropriate grasp configuration from previous grasp demonstrations. The underlying assumption in this approach is that new objects that are similar to known ones (i.e. they are familiar) can be grasped in a similar way. Towards this goal, two interconnected learning and recognition approaches are developed. First, an instance-based learning approach is developed to recognize familiar object views; and second, a grasp learning approach is proposed to associate grasp configurations (i.e., end-effector positions and orientations) to grasp affordance categories. The grasp pose learning approach uses local and global visual features of a demonstrated grasp to learn a grasp template associated with the recognized affordance category. It is worth mentioning the grasp affordance category and the grasp configuration are taught through verbal and kinesthetic teaching, respectively. This approach was extensively evaluated in [13]. The experimental results demonstrate the high reliability of the developed template matching approach in recognizing the grasp poses. Experimental results also show how the robot can incrementally improve its performance in grasping familiar objects. Fig. 1 shows four examples of our approach.
III-C Open-Ended Evaluation
The number of new open-ended learning algorithms proposed every year is growing rapidly. Although all the proposed methods have been shown to make progress over the previous one, it is challenging to quantify this progress without a concerted evaluation protocol. Moreover, the ability of different open-ended learning techniques to cope with context change in the absence of explicit cueing is not evaluated so far. It is worth mentioning off-line evaluation methodologies such as cross-validation are not well suited to evaluate open-ended learning systems, since they do not comply with the simultaneous nature of learning and recognition in autonomous robots. Moreover, they assume that the set of categories is predefined. We therefore propose a novel experimental evaluation methodology, that takes into account the open-ended nature of object category learning in multi-context scenarios [10]. This is an important contribution as published results are usually not comparable. A set of systematic experiments was carried out in [10] to thoroughly evaluate and compare a set of state-of-the-art methods in depth, not only in the classic single context setting but also in the multi-context open-ended settings. When an experiment is carried out, learning performance is evaluated using several measures including: (i) the number of learned categories at the end of the experiment, an indicator of How much the system was capable of learning; (ii) the number of question / correction iterations required to learn those categories and the average number of stored instances per category, indicators of How fast does it learn? and How much memory does it take? respectively; (iii) Global Classification Accuracy (GCA), computed using all predictions in a complete experiment, and the Average Protocol Accuracy (APA), i.e., average of all accuracy values successively computed to control the application of the teaching protocol. GCA and APA are indicators of How well does it learn?
IV Future Work
In the continuation of these works, I would like to investigate the possibility of using deep transfer learning methods for recognizing 3D object category and grasp affordance concurrently in open-ended domains. Moreover, it would be interesting to extend the proposed learning methods to other domains such as task-informed grasping and manipulation by addressing how people can learn new tasks extremely quickly?
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Beetz et al. [2011] Michael Beetz, Ulrich Klank, Ingo Kresse, Alexis Maldonado, L Mosenlechner, Dejan Pangercic, T Ruhr, and Moritz Tenorth. Robotic roommates making pancakes. In Humanoid Robots (Humanoids), 2011 11th IEEE-RAS International Conference on , pages 529–536. IEEE, 2011.
- 2Bousmalis et al. [2018] Konstantinos Bousmalis, Alex Irpan, Paul Wohlhart, Yunfei Bai, Matthew Kelcey, Mrinal Kalakrishnan, Laura Downs, Julian Ibarz, Peter Pastor, Kurt Konolige, et al. Using simulation and domain adaptation to improve efficiency of deep robotic grasping. In 2018 IEEE International Conference on Robotics and Automation (ICRA) , pages 4243–4250. IEEE, 2018.
- 3Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. 2009.
- 4Kasaei [2019] S Hamidreza Kasaei. Orthographicnet: A deep learning approach for 3D object recognition in open-ended domains. ar Xiv preprint ar Xiv:1902.03057 , 2019.
- 5Kasaei et al. [2015 a] S Hamidreza Kasaei, Miguel Oliveira, Gi Hyun Lim, Luís Seabra Lopes, and Ana Maria Tomé. An adaptive object perception system based on environment exploration and bayesian learning. In 2015 IEEE International Conference on Autonomous Robot Systems and Competitions , pages 221–226. IEEE, 2015 a.
- 6Kasaei et al. [2015 b] S Hamidreza Kasaei, Miguel Oliveira, Gi Hyun Lim, Luís Seabra Lopes, and Ana Maria Tomé. Interactive open-ended learning for 3D object recognition: An approach and experiments. Journal of Intelligent & Robotic Systems , 80(3-4):537–553, 2015 b.
- 7Kasaei et al. [2016 a] S Hamidreza Kasaei, Luís Seabra Lopes, Ana Maria Tomé, and Miguel Oliveira. An orthographic descriptor for 3d object learning and recognition. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 4158–4163. IEEE, 2016 a.
- 8Kasaei et al. [2016 b] S Hamidreza Kasaei, Nima Shafii, Luís Seabra Lopes, and Ana Maria Tomé. Object learning and grasping capabilities for robotic home assistants. In Lecture Notes in Computer Science , volume 9776. Springer, 2016 b.