Unbabel's Participation in the WMT19 Translation Quality Estimation Shared Task
Fabio Kepler, Jonay Tr\'enous, Marcos Treviso, Miguel Vera, and Ant\'onio G\'ois, M. Amin Farajian, Ant\'onio V. Lopes, Andr\'e, F. T. Martins

TL;DR
This paper details Unbabel's participation in the WMT19 Quality Estimation shared task, where they used advanced transfer learning and ensemble methods to achieve top results across multiple language pairs and levels.
Contribution
The paper introduces novel ensemble techniques and transfer learning approaches using BERT and XLM for quality estimation in machine translation.
Findings
Achieved the best results on all tracks and language pairs
Demonstrated effectiveness of transfer learning with BERT and XLM
Proposed a simple method for document-level prediction from word labels
Abstract
We present the contribution of the Unbabel team to the WMT 2019 Shared Task on Quality Estimation. We participated on the word, sentence, and document-level tracks, encompassing 3 language pairs: English-German, English-Russian, and English-French. Our submissions build upon the recent OpenKiwi framework: we combine linear, neural, and predictor-estimator systems with new transfer learning approaches using BERT and XLM pre-trained models. We compare systems individually and propose new ensemble techniques for word and sentence-level predictions. We also propose a simple technique for converting word labels into document-level predictions. Overall, our submitted systems achieve the best results on all tracks and language pairs by a considerable margin.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1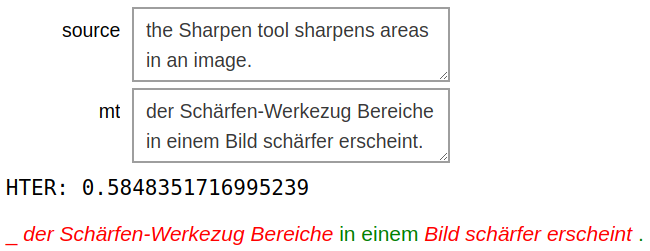 Figure 2
Figure 2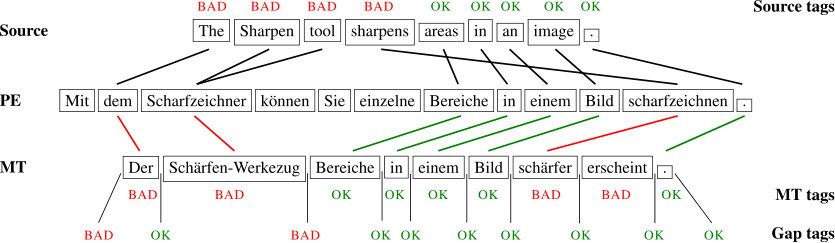 Figure 3
Figure 3| Method | Target |
|---|---|
| Stacked Linear | 43.88 |
| Powell | 44.61 |
| Pair | System | Target | Source | Pearson |
|---|---|---|---|---|
| En-De | Linear | 0.3346 | 0.2975 | - |
| APE-QE | 0.3740 | 0.3446 | 0.3558 | |
| APE-BERT | 0.4244 | 0.4109 | 0.3816 | |
| PredEst-RNN | 0.3786 | - | 0.5020 | |
| PredEst-Trans | 0.3980 | - | 0.5300 | |
| PredEst-XLM | 0.4144 | 0.3960 | 0.5810 | |
| PredEst-BERT | 0.3870 | 0.3310 | 0.5190 | |
| Linear Ens. | 0.4520 | 0.4116 | - | |
| (*)Powell’s Ens. | 0.4872 | 0.4607 | 0.5968 | |
| En-Ru | Linear | 0.2839 | 0.2466 | - |
| APE-QE | 0.2592 | 0.2336 | 0.1921 | |
| APE-BERT | 0.2519 | 0.2283 | 0.1814 | |
| NuQE | 0.3130 | 0.2000 | - | |
| PredEst-RNN | 0.3201 | - | - | |
| PredEst-Trans | 0.3414 | - | 0.3655 | |
| PredEst-XLM | 0.3799 | 0.3280 | 0.4983 | |
| PredEst-BERT | 0.3782 | 0.3039 | 0.5000 | |
| (*)Ensemble 1 | 0.3932 | 0.3640 | 0.5469 | |
| (*)Ensemble 2 | 0.3972 | 0.3700 | 0.5423 |
| Pair | System | Target | Target | Source | Source | Pearson |
|---|---|---|---|---|---|---|
| En-Ru | Baseline | 0.2412 | 0.2145 | 0.2647 | 0.1887 | 0.2601 |
| Ensemble 1 | 0.4629 | 0.4412 | 0.4174 | 0.3729 | 0.5889 | |
| Ensemble 2 | 0.4780 | 0.4577 | 0.4541 | 0.4212 | 0.5923 | |
| En-De | Baseline | 0.2974 | 0.2541 | 0.2908 | 0.2126 | 0.4001 |
| Linear Ensemble | 0.4621 | 0.4387 | 0.4284 | 0.3846 | - | |
| Powell’s Ensemble | 0.4752 | 0.4585 | 0.4455 | 0.4094 | 0.5718 |
| Dev | Dev0 | Test | |
|---|---|---|---|
| ann. (BERT) | 0.4664 | 0.4457 | 0.4811 |
| MQM (BERT) | 0.3924 | - | 0.3727 |
| MQM (LINBERT) | - | 0.4714 | 0.3744 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsLinear Layer · Residual Connection · Attention Dropout · Linear Warmup With Linear Decay · Byte Pair Encoding · Weight Decay · XLM · Refunds@Expedia|||How do I get a full refund from Expedia? · Dense Connections · Adam
Unbabel’s Participation
in the WMT19 Translation Quality Estimation Shared Task
Fábio Kepler
Unbabel &Jonay Trénous
Unbabel &Marcos Treviso
Instituto de Telecomunicações &Miguel Vera
Unbabel \ANDAntónio Góis
Unbabel &M. Amin Farajian
Unbabel &António V. Lopes
Unbabel &André F. T. Martins
Unbabel \AND
{kepler, sony, miguel.vera}@unbabel.com
{antonio.gois, amin, antonio.lopes, andre.martins}@unbabel.com
Abstract
We present the contribution of the Unbabel team to the WMT 2019 Shared Task on Quality Estimation. We participated on the word, sentence, and document-level tracks, encompassing 3 language pairs: English-German, English-Russian, and English-French. Our submissions build upon the recent OpenKiwi framework: we combine linear, neural, and predictor-estimator systems with new transfer learning approaches using BERT and XLM pre-trained models. We compare systems individually and propose new ensemble techniques for word and sentence-level predictions. We also propose a simple technique for converting word labels into document-level predictions. Overall, our submitted systems achieve the best results on all tracks and language pairs by a considerable margin.
1 Introduction
Quality estimation (QE) is the task of evaluating a translation system’s quality without access to reference translations Blatz et al. (2004); Specia et al. (2018). This paper describes the contribution of the Unbabel team to the Shared Task on Word, Sentence, and Document-Level (QE Tasks 1 and 2) at WMT 2019.
Our system adapts OpenKiwi,111https://unbabel.github.io/OpenKiwi. a recently released open-source framework for QE that implements the best QE systems from WMT 2015-18 shared tasks Martins et al. (2016, 2017); Kim et al. (2017); Wang et al. (2018), which we extend to leverage recently proposed pre-trained models via transfer learning techniques. Overall, our main contributions are as follows:
- •
We extend OpenKiwi with a Transformer predictor-estimator model (Wang et al., 2018).
- •
We apply transfer learning techniques, fine-tuning BERT (Devlin et al., 2018) and XLM (Lample and Conneau, 2019) models in a predictor-estimator architecture.
- •
We incorporate predictions coming from the APE-BERT system described in Correia and Martins (2019), also used in this year’s Unbabel’s APE submission (Lopes et al., 2019).
- •
We propose new ensembling techniques for combining word-level and sentence-level predictions, which outperform previously used stacking approaches (Martins et al., 2016).
- •
We build upon our BERT-based predictor-estimator model to obtain document-level annotation and MQM predictions via a simple word-to-annotation conversion scheme.
Our submitted systems achieve the best results on all tracks and all language pairs by a considerable margin: on English-Russian (En-Ru), our sentence-level system achieves a Pearson score of 59.23% (+5.96% than the second best system), and on English-German (En-De), we achieve 57.18% (+2.44%).
2 Word and Sentence-Level Task
The goal of the word-level QE task is to assign quality labels (ok or bad) to each machine-translated word, as well as to gaps between words (to account for context that needs to be inserted), and source words (to denote words in the original sentence that have been mistranslated or omitted in the target). The goal of the Sentence-level QE task, on the other hand, is to predict the quality of the whole translated sentence, based on how many edit operations are required to fix it, in terms of HTER (Human Translation Error Rate) (Specia et al., 2018). We next describe the datasets, resources, and models that we used for these tasks.
2.1 Datasets and Resources
The data resources we use to train our systems are of three types: the QE shared task corpora, additional parallel corpora, and artificial triplets (src, pe, mt) in the style of the eSCAPE corpus Negri et al. (2018).
- •
The En-De QE corpus provided by the shared task, consisting of 13,442 train triplets.
- •
The En-Ru QE corpus provided by the shared task, consisting of 15,089 train triplets.
- •
The En-De parallel dataset of 3,396,364 sentences from the IT domain provided by the shared task organizers. which we extend in the style of the eSCAPE corpus to contain artificial triplets. To do this, we use OpenNMT with 5-fold jackknifing (Klein et al., 2017) to obtain unbiased translations of the source sentences.
- •
The En-Ru eSCAPE corpus Negri et al. (2018) consisting of 7,735,361 artificial triplets.
2.2 Linear Sequential Model
Our simplest baseline is the linear sequential model described by Martins et al. (2016, 2017). It is a discriminative feature-based sequential model (called LinearQE). The system uses a first-order sequential model with unigram and bigram features, whose weights are learned by using the max-loss MIRA algorithm Crammer et al. (2006). The features include information about the words, part-of-speech tags, and syntactic dependencies, obtained with TurboParser Martins et al. (2013).
2.3 NuQE
We used NuQE (NeUral Quality Estimation) as implemented in OpenKiwi (Kepler et al., 2019) and adapted it to jointly learn MT tags, source tags and also sentence scores. We use the original architecture with the following additions. For learning sentence scores, we first take the average of the MT tags output layer and than pass the result through a feed-forward layer that projects the result to a single unit. For jointly learning source tags, we take the source text embeddings, project them with a feed-forward layer, and then sum the MT tags output vectors that are aligned. The result is then passed through a feed-forward layer, a bi-GRU, two other feed-forward layers, and finally an output layer. The layer dimensions are the same as in the normal model. It is worth noting that NuQE is trained from scratch using only the shared task data, with no pre-trained components, besides Polyglot embeddings (Al-Rfou et al., 2013).
2.4 RNN-Based Predictor-Estimator
Our implementation of the RNN-based prediction estimator (PredEst-RNN) is described in Kepler et al. (2019). It follows closely the architecture proposed by Kim et al. (2017), which consists of two modules:
- •
a predictor, which is trained to predict each token of the target sentence given the source and the left and right context of the target sentence;
- •
an estimator, which takes features produced by the predictor and uses them to classify each word as ok or bad.
Our predictor uses a biLSTM to encode the source, and two unidirectional LSTMs processing the target in left-to-right (LSTM-L2R) and right-to-left (LSTM-R2L) order. For each target token , the representations of its left and right context are concatenated and used as query to an attention module before a final softmax layer. It is trained on the large parallel corpora mentioned above. The estimator takes as input a sequence of features: for each target token , the final layer before the softmax (before processing ), and the concatenation of the -th hidden state of LSTM-L2R and LSTM-R2L (after processing ). We train this system with a multi-task architecture that allows us to predict sentence-level HTER scores. Overall, this system is capable to predict sentence-level scores and all word-level labels (for MT words, gaps, and source words)—the source word labels are produced by training a predictor in the reverse direction.
2.5 Transformer-Based Predictor-Estimator
In addition, we implemented a Transformer-based predictor-estimator (PredEst-Trans), following Wang et al. (2018). This model has the following modifications in the predictor: (i) in order to encode the source sentence, the bidirectional LSTM is replaced by a Transformer encoder; (ii) the LSTM-L2R is replaced by a Transformer decoder with future-masked positions, and the LSTM-R2L is replaced by a Transformer decoder with past-masked positions. Additionally, the Transformer-based model produces the “mismatch features” proposed by Fan et al. (2018).
2.6 Transfer Learning and Fine-Tuning
Following the recent trend in the NLP community leveraging large-scale language model pre-training for a diverse set of downstream tasks, we used two pre-trained language models as feature extractors, the multilingual BERT Devlin et al. (2018) and the Cross-lingual Language Model (XLM) Lample and Conneau (2019). The predictor-estimator model consists of a predictor that produces contextual token representations, and an estimator that turns these representations into predictions for both word level tags, and sentence level scores. As both of these models produce contextual representations for each token in a pair of sentences, we simply replace the predictor part by either BERT or XLM to create new QE models: PredEst-BERT and PredEst-XLM. The XLM model is particularly well suited to the task at hand, as its pre-training objective already contains a translation language modeling part.
For improved performance, we employ a pre-fine-tuning step by continuing their language model pre-training on data that is closer to the domain of the shared task. For the En-De pair we used the in-domain data provided by the shared task, and for the En-Ru pair we used the eSCAPE corpus Negri et al. (2018).
Despite the shared multilingual vocabulary, BERT is originally a monolingual model, treating the input as either being from one language or another. We pass both sentences as input by concatenating them according to the template: [CLS] target [SEP] source [SEP], where [CLS] and [SEP] are special symbols from BERT, denoting beginning of sentence and sentence separators, respectively. In contrast, XLM is a multilingual model which receives two sentences from different languages as input. Thus, its usage is straightforward.
The output from BERT and XLM is split into target features and source features, which in turn are passed to the regular estimator. They work with word pieces rather than tokens, so the model maps their output to tokens by selecting the first word piece of each token. For En-Ru the mapping is slightly different, it is done by taking the average of the word pieces of each token.
For PredEst-BERT, we obtained the best results by ignoring features from the other language, that is, for predicting target and gap tags we ignored source features, and for predicting source tags we ignored target features. On the other hand, PredEst-XLM predicts labels for target, gaps and source at the same time. As the predictor-estimator model, PredEst-BERT and PredEst-XLM are trained in a multi-task fashion, predicting sentence-level scores along with word-level labels.
2.7 APE-QE
In addition to traditional QE systems, we also use Automatic Post-Editing (APE) adapted for QE (APE-QE), following Martins et al. (2017). An APE system is trained on the human post-edits and its outputs are used as pseudo-post-editions to generate word-level quality labels and sentence-level scores in the same way that the original labels were created.
We use two variants of APE-QE:
- •
Pseudo-APE, which trains a regular translation model and uses its output as a pseudo-reference.
- •
An adaptation of BERT to APE (APE-BERT) with an additional decoding constraint to reward or discourage words that do not exist in the source or MT.
Pseudo-APE was trained using OpenNMT-py (Klein et al., 2017). For En-De, we used the IT domain corpus provided by the shared task, and for En-Ru we used the Russian eSCAPE corpus (Negri et al., 2018).
For APE-BERT, we follow the approach of Correia and Martins (2019), also used by Unbabel’s APE shared task system (Lopes et al., 2019), and adapt BERT to the APE task using the QE in-domain corpus and the shared task data as input, where the source and MT sentences are the encoder’s input and the post-edited sentence is the decoder’s output. In addition, we also employ a conservativeness penalty (Lopes et al., 2019), a beam decoding penalty which either rewards or penalizes choosing tokens not in the src and mt, with a negative score to encourage more edits of the MT.
2.8 System Ensembling
We ensembled the systems above to produce a single prediction, as described next.
Word-level ensembling.
We compare two approaches:
- •
A stacked architecture with a feature-based linear system, as described by Martins et al. (2017). This approach uses the predictions of various systems as additional features in the linear system described in §2.2. To avoid overfitting on the training data, this approach requires jackknifing.
- •
A novel strategy consisting of learning a convex combination of system predictions, with the weights learned on the development set. We use Powell’s conjugate direction method (Powell, 1964)222This is the method underlying the popular MERT method (Och, 2003), widely used in the MT literature. as implemented in SciPy (Jones et al., 2001) to directly optimize for the task metric (-MULT).
Using the development set for learning carries a risk of overfitting; by using -fold cross-validation we avoided this, and indeed the performance is equal or superior to the linear stacking ensemble (footnote 4), while being computationally cheaper as only the development set is needed to learn an ensemble, avoiding jackknifing.
Sentence-level ensembling.
We have systems outputting sentence-level predictions directly, and others outputting word-level probabilities that can be turned into sentence-level predictions by averaging them over a sentence, as in (Martins et al., 2017). To use all available features (sentence score, gap tag, MT tag and source tag predictions from all systems used in the word-level ensembles), we learn a linear combination of these features using -regularized regression over the development set. We tune the regularization constant with -fold cross-validation, and retrain on the full development set using the chosen value.
3 Document-Level Task
Estimating the quality of an entire document introduces additional challenges. The text may become too long to be processed at once by previously described methods, and longer-range dependencies may appear (e.g inconsistencies across sentences).
Both sub-tasks were addressed: estimating the MQM score of a document and identifying character-level annotations with corresponding severities. Note that, given the correct number of annotations in a document and their severities, the MQM score can be computed in closed form. However, preliminary experiments using the predicted annotations to compute MQM did not outperform the baseline, hence we opted for using independent systems for each of these sub-tasks.
3.1 Dataset
The data for this task consists of Amazon reviews translated from English to French using a neural MT system. Translations were manually annotated for errors, with each annotation associated to a severity tag (minor, major or critical).
Note that each annotation may include several words, which do not have to be contiguous. We refer to each contiguous block of characters in an annotation as a span, and refer to an annotation with at least two spans as a multi-span annotation. Figure 1 illustrates this, where a single annotation is comprised of the spans bandes and parfaits.
Across training set and last year’s development and test set, there are 36,242 annotations. Out of these, 4,170 are multi-span, and 149 of the multi-span annotations contain spans in different sentences. The distribution of severities is 84.12% of major, 11.74% of minor and 4.14% of critical.
3.2 Implemented System
To predict annotations within a document the problem is first treated as a word-level task, with each sentence processed separately. To obtain gold labels, the training set is tokenized and an ok/bad tag is attributed to each token, depending on whether the token contains characters belonging to an annotation. Note that besides token tags, we will also have gap tags in between tokens. A gap tag will only be labeled as bad if a span begins and ends exactly in the borders of the gap. Our best-performing model for the word-level part is an ensemble of 5 BERT models. Each BERT model was trained as described in §2.6, but without pre-fine-tuning. Systems were ensembled by a simple average.
Later, annotations may be retrieved from the predicted word-level tags by concatenating contiguous bad tokens into a single annotation. This is done for token-tags, while each gap-tag can be directly mapped to a single annotation without attempting any merge operation. Note that this immediately causes 4 types of information loss, which can be addressed in a second step:
- •
Severity information is lost, since all three severity labels are converted to bad tags. As a baseline, all spans are assigned the most frequent severity, “major.”
- •
Span borders are defined on character-level, whose positions may not match exactly the beginning or ending of a token. This will cause all characters of a partially correct token to be annotated with an error.
- •
Contiguous bad tokens will always be mapped to a single annotation, even if they belong to different ones.
- •
Non-contiguous bad tokens will always be mapped to separate annotations, even if they belong to the same one.
Although more sophisticated approaches were tested for predicting severities and merging spans into the same annotation, these approaches did not result in significant gains, hence we opted by using the previously described pipeline as our final system. To predict document-level MQM, each sentence’s MQM is first predicted and used to get the average sentence MQM (weighting the average by sentence length degraded results in all experiments). This is used together with 3 percentages of BAD tags from the word-level model (considering token tags, gap tags and all tags) as features for a linear regression which outputs the final document-level MQM prediction. The percentage of BAD tags is obtained from the previously described word-level predictions, whereas the sentence MQMs are obtained from an ensemble of 5 BERT models trained for sentence-level MQM prediction. Again, each BERT model was trained as described in §2.6 without pre-fine-tuning, and the ensembling consisted of a simple average.555Using the approach of Ive et al. (2018) proved less robust to this year’s data due to differences in the annotations. Particularly some outliers containing zero annotations would strongly harm the final Pearson score when mis-predicted.
4 Experimental Results
4.1 Word and Sentence-Level Task
The results achieved by each of the systems described in §2 for En-De and En-Ru on the validation set are shown in Table 2. We tried the following strategies for ensembling:
- •
For En-De, we created a word-level ensembled system with Powell’s method, by combining one instance of the APE-BERT system, another instance of the Pseudo-APE-QE system, 10 runs of the PredEst-XLM model (trained jointly for all subtasks), 6 runs of the same model without pre-fine-tuning, 5 runs of the PredEst-BERT model (trained jointly for all subtasks), and 5 runs of the PredEst-Trans model (trained jointly for MT and sentence subtasks, but not for predicting source tags). For comparison, we report also the performance of a stacked linear ensembled word-level system. For the sentence-level ensemble, we learned system weights by fitting a linear regressor to the sentence scores produced by all the above models.
- •
For En-Ru, we tried two versions of word-level ensembled systems, both using Powell’s method: emsemble 1 combined one instance of the APE-BERT system, 5 runs of the PredEst-XLM model (trained jointly for all subtasks), one instance of the PredEst-BERT model (trained jointly for all subtasks), 5 runs of the NuQE models (trained jointly for all subtasks), and 5 runs of the PredEst-Trans model (trained jointly for MT and sentence subtasks, but not for predicting source tags). emsemble 2 adds to the above predictions from the Pseudo-APE-QE system. In both cases, for sentence-level ensembles, we learned system weights by fitting a linear regressor to the sentence scores produced by all the above models.
The results in Table 2 show that the transfer learning approach with BERT and XLM benefits the QE task. The PredEst-XLM model, which has been pre-trained with a translation objective, has a small but consistent advantage over both PredEst-BERT and PredEst-Transf. A clear takeaway is that ensembling of different systems can give large gains, even if some of the subsystems are weak individually.
Table 3 shows the results obtained with our ensemble systems on the official test set.
4.2 Document-Level Task
Finally, Table 4 contains results for document-level submissions, both on validation and test set submissions. On annotations, results across all data sets are reasonably consistent. On the other hand, MQM Pearson varies significantly between dev and dev0. Differences in the training of the two systems shouldn’t explain this variation, since both have equivalent performance on the test set.
5 Conclusions
We presented Unbabel’s contribution to the WMT 2019 Shared Task on Quality Estimation. Our submissions are based on the OpenKiwi framework, to which we added new transfer learning approaches via BERT and XLM pre-trained models. We also proposed a new ensemble technique using Powell’s method that outperforms previous strategies, and we convert word labels into span annotations to obtain document-level predictions. Our submitted systems achieve the best results on all tracks and language pairs.
Acknowledgments
The authors would like to thank the support provided by the EU in the context of the PT2020 project (contracts 027767 and 038510), by the European Research Council (ERC StG DeepSPIN 758969), and by the Fundação para a Ciência e Tecnologia through contract UID/EEA/50008/2019.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Al-Rfou et al. (2013) Rami Al-Rfou, Bryan Perozzi, and Steven Skiena. 2013. Polyglot: Distributed Word Representations for Multilingual NLP. ar Xiv preprint ar Xiv:1307.1662 .
- 2Blatz et al. (2004) John Blatz, Erin Fitzgerald, George Foster, Simona Gandrabur, Cyril Goutte, Alex Kulesza, Alberto Sanchis, and Nicola Ueffing. 2004. Confidence Estimation for Machine Translation. In Proc. of the International Conference on Computational Linguistics , page 315.
- 3Correia and Martins (2019) Gonçalo Correia and André Martins. 2019. A Simple and Effective Approach to Automatic Post-Editing with Transfer Learning. In Proc. of the 57th annual meeting on association for computational linguistics . Association for Computational Linguistics.
- 4Crammer et al. (2006) Koby Crammer, Ofer Dekel, Joseph Keshet, Shai Shalev-Shwartz, and Yoram Singer. 2006. Online Passive-Aggressive Algorithms. Journal of Machine Learning Research , 7:551–585.
- 5Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding. ar Xiv preprint ar Xiv:1810.04805 .
- 6Fan et al. (2018) Kai Fan, Bo Li, Fengming Zhou, and Jiayi Wang. 2018. ”Bilingual Expert” Can Find Translation Errors. ar Xiv preprint ar Xiv:1807.09433 .
- 7Ive et al. (2018) Julia Ive, Carolina Scarton, Frédéric Blain, and Lucia Specia. 2018. Sheffield Submissions for the WMT 18 Quality Estimation Shared Task. In Proc. of the Third Conference on Machine Translation: Shared Task Papers , pages 794–800.
- 8Jones et al. (2001) Eric Jones, Travis Oliphant, Pearu Peterson, et al. 2001. Sci Py: Open source scientific tools for Python . [Online; accessed on May 17th, 2019].