Scalable and Secure Computation Among Strangers: Resource-Competitive Byzantine Protocols
John Augustine, Valerie King, Anisur R. Molla, Gopal Pandurangan, and, Jared Saia

TL;DR
This paper introduces resource-competitive Byzantine protocols that ensure honest nodes' communication cost is proportional to adversarial nodes, enabling scalable and secure agreement in permissionless systems with unknown participants.
Contribution
It presents the first resource-competitive Byzantine agreement, leader, and committee election algorithms with provable bounds and resilience to a high fraction of Byzantine nodes.
Findings
Expected communication cost is O((T+n) log n) bits.
Algorithm achieves latency of O(polylog(n)).
Resilient to nearly 25% Byzantine nodes.
Abstract
Motivated, in part, by the rise of permissionless systems such as Bitcoin where arbitrary nodes (whose identities are not known apriori) can join and leave at will, we extend established research in scalable Byzantine agreement to a more practical model where each node (initially) does not know the identity of other nodes. A node can send to new destinations only by sending to random (or arbitrary) nodes, or responding (if it chooses) to messages received from those destinations. We assume a synchronous and fully-connected network, with a full-information, but static Byzantine adversary. A general drawback of existing Byzantine protocols is that the communication cost incurred by the honest nodes may not be proportional to those incurred by the Byzantine nodes; in fact, they can be significantly higher. Our goal is to design Byzantine protocols for fundamental problems which are {\em…
Click any figure to enlarge with its caption.
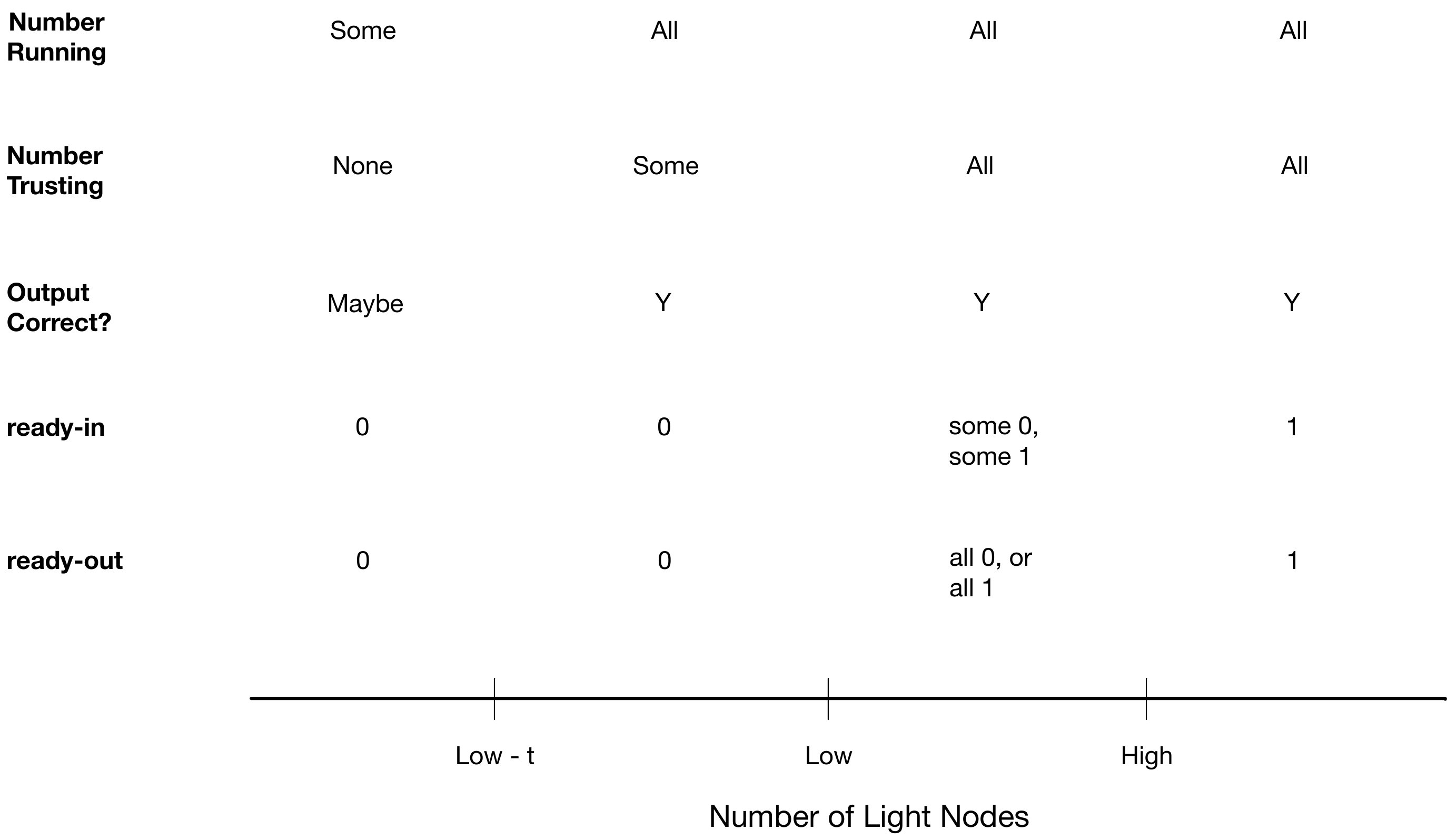 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Scalable and Secure Computation Among Strangers: Resource-Competitive Byzantine Protocols
John Augustine Department of Computer Science and Engineering, Indian Institute of Technology at Madras, Chennai, Tamil Nadu, 600036, India. Email: [email protected]. Research supported in part by an Extra-Mural Research Grant (file number EMR/2016/003016) and a MATRICS grant (file number MTR/2018/001198), both funded by the Science and Engineering Research Board, Department of Science and Technology, Government of India and by the VAJRA faculty program of the Government of India.
Valerie King Dept. of Computer Science, University of Victoria, Vancouver BC, Canada. Email: [email protected].
Anisur R. Molla Computer and Communication Sciences, Indian Statistical Institute, Kolkata, India. Email: [email protected]. Research supported by DST Inspire Faculty research grant DST/INSPIRE/04/2015/002801.
Gopal Pandurangan Department of Computer Science, University of Houston, Houston, TX 77204, USA. Email: [email protected]. Research supported, in part, by NSF grants CCF-1527867, CCF-1540512, IIS-1633720, CCF-BSF-1717075, BSF award 2016419, and by the VAJRA faculty program of the Government of India.
Jared Saia Dept. of Computer Science, University of New Mexico, NM, USA. Email: [email protected]. This work is supported by the National Science Foundation grants CNS-1318880 and CCF-1320994.
Abstract
The last decade has seen substantial progress on designing Byzantine agreement algorithms which are scalable in that they do not require all-to-all communication among nodes. These protocols require each node to play a particular role determined by its ID, and to send to specific neighbors. Motivated, in part, by the rise of permissionless systems such as Bitcoin where arbitrary nodes (whose identities are not known apriori) can join and leave at will, we extend this research to a more practical model where each node (initially) does not know the identity of its neighbors. In particular, a node can send to new destinations only by sending to random (or arbitrary) nodes, or responding (if it chooses) to messages received from those destinations. We assume a synchronous and fully-connected network, with a full-information, but static Byzantine adversary. A general drawback of existing Byzantine protocols is that the communication cost incurred by the honest nodes may not be proportional to those incurred by the Byzantine nodes; in fact, they can be significantly higher. Our goal is to design Byzantine protocols for fundamental problems which are resource competitive, i.e., the total number of bits sent by all the honest nodes is not significantly more than those sent by the Byzantine nodes.
We describe a randomized scalable algorithm to solve Byzantine agreement, leader election, and committee election in this model. Our algorithm sends an expected bits and has latency , where is the number of nodes, and is the minimum of and the number of bits sent by adversarially controlled nodes. The algorithm is resilient to Byzantine nodes for any fixed , and succeeds with high probability111I.e., with probability at least for some constant .. Our work can be considered as a first application of resource-competitive analysis to fundamental Byzantine problems.
To complement our algorithm we also show lower bounds for resource-competitive Byzantine agreement. We prove that, in general, one cannot hope to design Byzantine protocols that have communication cost that is significantly smaller than the cost of the Byzantine adversary.
Keywords: Byzantine protocol, Byzantine agreement, Leader election, Committee election, Resource-competitive protocol, Randomized protocol
1 Introduction
What happens when you don’t know your neighbors? Anonymity is critical in many modern networks including cryptocurrency [10, 22], anonymous communication [24, 56], and wireless [37, 41, 57, 54]. In anonymous networks, nodes are generally known only by self-generated identifiers222Such as the public key for a digital signature.; and communication primitives may be limited to: sending a message to all nodes, sending a message to a random (or arbitrary) node, and responding to a message sent directly. Unfortunately, all algorithms to coordinate such networks in the presence of malicious faults seem either to require all-to-all communication, or make cryptographic assumptions.
The open nature of permissionless systems such as Bitcoin allow many nodes to enter the network with little or no admission control. A major challenge in such systems is dealing with malicious (also called Byzantine) nodes, which can try to foil the protocols executed by honest (good) nodes. Byzantine-resistant protocols are at the heart of secure and robust networks that can tolerate malicious nodes, such as P2P networks. Consider the real-world example of Bitcoin — a decentralized P2P-based digital currency [10]. A crucial aspect of Bitcoin is a computational mechanism that allows fault-tolerant agreement on a set of ordered transactions. Agreement in Bitcoin is achieved via a computationally-expensive operation, called mining.
The problem of achieving agreement under Byzantine faults, Byzantine agreement, is a fundamental and long-studied problem in distributed computing [49, 6, 43]. In the Byzantine agreement problem, all good nodes start with an input bit, and we must ensure two conditions: (1) All good nodes output the same input bit (consensus condition) and (2) the common bit should be the input bit of some good node (validity condition). This must be done despite the presence of a constant fraction of Byzantine nodes that can deviate arbitrarily from the protocol executed by the good nodes. Byzantine agreement is a “keystone” problem in distributed computing, in that it provides a critical building block for creating attack-resistant distributed systems. Its importance can be seen from widespread and continued application in many domains: sensor networks [53], grid computing [5], peer-to-peer networks [52] and cloud computing [58]. However, despite intensive research, there has still not been a practical solution to the Byzantine agreement problem for large networks. A main reason for this is the large message complexity of currently known protocols, as has been suggested by many systems papers [2, 4, 16, 44, 59]. The best known protocols have quadratic message complexity, i.e., , where is the number of nodes in the network.
King and Saia [33] described the first Byzantine agreement algorithm in synchronous complete networks that breaks the quadratic message barrier under the assumption that nodes a priori know the identities of all their neighbors. This assumption is called the model [50], where it is assumed that each node has knowledge of the identities of its neighbors333Just the identities of the neighbors, not any other information such as the internal states of the neighbors is assumed. a priori. This is in contrast to the model [50], another standard model where nodes do not know the identity of the neighbors. In the model, [33] presented an algorithm where each processor sends only messages, and thus the total message complexity is bounded by . This was later improved by Braud-Santoni et al. [13] to total message complexity, however, this protocol might require some node to send messages.
The model seems more applicable to modern, permissionless networks. While we can convert algorithms for to by including an initial step where each node communicates with all its neighbors to obtain their identities, this incurs a message cost. Hence a fundamental question is: Can we design Byzantine protocols that require sub-quadratic messages in the setting?
In this paper, we take a step toward addressing the above question. Our focus is on the fundamental problems of Byzantine agreement, leader election and committee election. Our main result is an algorithm to solve these problems while sending a number of bits that is , where is the minimum of and the number of bits sent by adversarially controlled (Byzantine) nodes, and is the network size. This kind of result where algorithmic cost is measured with respect to adversarial cost, is an example of resource-competitive analysis [9, 28]. To the best of our knowledge, our result is the first of its kind that introduces resource-competitive analysis to the study of Byzantine agreement and related problems. In particular, our result shows that Byzantine protocols can be designed that compete well with the resources (messages) expended by the Byzantine nodes; if they send less messages then the protocol also sends less. An alternate way to interpret our result is that Byzantine nodes have to incur significant message complexity (up to quadratic in ) in order to make the honest nodes to have large message complexity. We note that prior work on Byzantine protocols all incurred quadratic message complexity (in the setting) regardless of the behavior of the Byzantine nodes. Our protocol is efficient, lightweight, and fast (has low latency) and can be used as a building block for designing secure and scalable systems.
1.1 Model
We consider a network of nodes: are bad and controlled by the adversary, and the remainder are good and follow our algorithm; we assume for some constant .
We consider a synchronous, fully-connected network in the model [48, 50]. In particular, we assume that a node has ports to every other node in the network, but learns the identity of each node reachable through a port only by receiving a communication from that node. Thus a node sends to a new destination only by selecting a port, or by responding to messages received. The nodes are assumed to have distinct ID’s which lie in for is a (large) constant.444This means that an ID can be represented using bits, which can be sent in a message. We assume the CONGEST model, i.e., only -sized messages are used in our algorithm. Our adversary is full-information in that it knows the states of all nodes at any time, is assumed to be computationally unbounded, and is also rushing in the sense that it can read messages sent by good nodes before sending out its own messages. However, the adversary is static, so that it must decide which nodes are bad prior to the start of the algorithm. We assume that Byzantine nodes cannot fake their own identities, however they can forward fake messages on behalf of other nodes.
1.2 Our Contributions
We solve three classic problems in this model. In Byzantine agreement, all good nodes must output the same bit, which is the input bit of some good node. In leader election, all good nodes must agree on a leader, and this leader must be good with constant probability. In committee election, all nodes must agree on a subset of nodes where the fraction of bad nodes in the subset is within a small fraction of the overall fraction of bad nodes.
Our main result is as follows.
Theorem 1.1**.**
There exists a randomized algorithm that solves Byzantine agreement, leader election and committee election in the above model. This algorithm sends an expected messages, and has latency , where is the minimum of and the number of bits sent by the bad nodes. It is resilient to Byzantine faults for any fixed , and succeeds with probability for any constant .
We note that our latency bound holds even in the CONGEST model, where each message is bits. The algorithm KT0-ByzantineAgreement described in Section 2 achieves the result in Theorem 1.1, and the proof of this theorem is in Section 3.
To complement the above result we also show lower bounds for resource-competitive Byzantine agreement (see Section 5). We prove that, in general, one cannot hope to design Byzantine protocols that have communication cost that is significantly smaller than the cost of the Byzantine adversary, i.e., the no. of messages send by bad nodes. We first show a lower bound for deterministic BA protocols which is essentially tight with respect to the upper bound of our resource-competitive randomized algorithm (see Section 5.1). We show that if is the budget on the message bits of the Byzantine nodes, then for any deterministic protocol, the total number of messages sent by the good nodes is (see Theorem 5.1). The deterministic lower bound holds even in the model. We then show a somewhat weaker lower bound on the resource competitiveness of randomized BA protocols (see Section 5.2). The argument for the randomized case is more involved compared to the deterministic case, as the algorithm’s (future) random choices are unknown to the Byzantine adversary. We show that if for some is the budget of the Byzantine nodes, then for any (randomized) BA algorithm in the setting, the total expected number of messages sent by good nodes, is at least (see Theorem 5.2). Another significance of this lower bound result is that it separates the message complexity of Byzantine agreement between and models in the randomized setting.
1.3 Techniques and other results
We focus first on Byzantine agreement, our solutions to leader and committee election use similar techniques. Our algorithm depends on solutions to two new problems: Implicit Agreement and Promise Agreement. In the Implicit Agreement problem, success means that strictly greater than a fraction of good nodes decide on the same (correct) bit and the remaining good nodes do not decide; and failure means that no good nodes decide. Next, the Promise Agreement problem assumes there has first been either success or failure in Implicit Agreement. In the case of success, Promise Agreement ensures all nodes decide on the same value and terminate; in the case of failure, no nodes decide.
KT0-ByzantineAgreement runs in epochs. In each epoch, we (1) run an algorithm for Implicit Agreement; (2) run an algorithm for Promise Agreement; and (3) terminate in the case of success, or increase computational effort in the case of failure.
The computational effort for Implicit Agreement is tuned by increasing the number of active nodes. In particular, during a run of Implicit Agreement, the active nodes first attempt to solve Byzantine agreement among themselves, and then to communicate the output to all other nodes in the network. Our Implicit Agreement algorithm ensures that, unless the bad nodes send a number of messages that is times the number of active nodes, then Implicit Agreement will succeed. Next, we solve Promise Agreement. This ensures that if Implicit Agreement succeeded, then all nodes will decide on the same value and terminate; and if Implicit Agreement failed, then no nodes decide. In the latter case, all nodes proceed to the next epoch, where the number of active nodes doubles in expectation.
LargeCoreBA. There are several technical challenges in the implementation of this main idea. The first is to enable Byzantine agreement among the active nodes when the bad nodes do not send out too many messages. We say that a node has a view of node if knows ’s ID and the port to . With a fair amount of technical work, we show that it is possible to modify an algorithm by King et al. [34] to ensure agreement even among nodes whose views only “mostly” overlap, provided that the range of all IDs is only polynomially large. We call this modified algorithm LargeCoreBA, and summarize its properties in Lemma 1 below; we believe the result may be of independent interest. The technical approach we used to prove Lemma 1 is (1) a counting argument to show there are not too many bad nodes in the views of key participants; and (2) the use of a sampler graph to ensure that these bad participants are well spread over the committees, as used in [34] (see Section 4.1).
Lemma 1**.**
Let be a set of good nodes which wish to come to agreement. For each , let be the set of nodes in the view of . Let be the set of bad nodes in . Assume ; for some fixed constant ; and all nodes have distinct ID’s in . Then there is an algorithm LargeCoreBA which computes almost everywhere agreement with high probability among fraction of nodes in in time and communication per node which is polylogarithmic in . In one more round, if each good node broadcasts to all other nodes, and then each node takes the majority, all nodes will come to agreement using total messages, and latency polylogarithmic in .
Implicit Agreement. Our solution to Implicit Agreement is given in Steps 1 to 6 of our main algorithm in Section 2.1. There are two key technical problems that must be addressed.
First, how do we ensure that each active node maintains a set so that the conditions of Lemma 1 are matched? Also, in order to achieve a good competitive ratio, we need the conditions of Lemma 1 to hold unless the adversary sends messages, where is the number of active nodes. If each active node naively adds to all nodes that it receives an initial message from, then the adversary can add Byzantine nodes to each while sending only messages. Thus, we must enlist the aid of non-active nodes to establish the sets. Initially, each active node sends its ID to all nodes. Call a good node light if it has received a number of IDs approximately equal to . Then the light nodes convey information about their sets to the nodes in . They can not send out all the IDs in , since that would be too many bits. Instead, they just send out a single random ID, and a node adds an ID to if it was received from “enough” (i.e. ) nodes that claim to be light.
Unfortunately, an adversary can still cause problems by making the size of the union of the bad nodes in each large, so that is large in Lemma 1, even when the advesary does not send out too many messages. To solve this problem, we use a “validation” step, whereby each active node, for each ID in , queries random nodes about whether they have the ID in their sets, and filters out the ID unless enough of these queries are answered affirmatively. Based on information obtained during this process (Step 1 through Step 3c in Section 2.1), the active nodes determine if the number of light nodes is sufficient for favorable success in this epoch.
This brings us to the second problem. How can the active nodes agree on one of two options for this epoch: (1) conditions are favorable for agreement; or (2) conditions are not favorable? We can make use of LargeCoreBA in coming to agreement on an option. However, this is still challenging given that, under certain conditions, some active nodes may run LargeCoreBA, while other active nodes may not even have a small enough set to run it. To address this issue requires careful decisions about whether a node will run LargeCoreBA, what its input will be, and whether or not it will trust the output, all based on the node’s estimate of the number of light nodes (See Step 4, Section 2.1 for details). In particular, nodes will sometimes run LargeCoreBA, because other nodes are relying on them to do so, even when they plan to ignore the output. If active nodes decide conditions are favorable via the first call to LargeCoreBA (Step 4), they will all run it again (Step 5) to decide on a bit. Lemma 4 in Section 3 shows that no matter what the number of light nodes, these two steps ensure all active nodes come to agreement on the same decision.
Finally, in Step 6, active nodes send their decision to all other nodes. Nodes that have small sets take the majority of the messages received in this step, whereas other nodes default to a decision to wait for the next epoch. We can thereby guarantee the post-condition for Implicit Agreement: either (1) a strictly greater than fraction of good nodes decide, or (2) no good nodes decide. We obtain this result even when the adversary floods some good nodes but not others.
Promise Agreement. A final technical challenge is to determine whether or not we need to run another epoch. After solving Implicit Agreement, either (1) strictly greater than a fraction of the good nodes have decided on the same correct bit; or (2) no good nodes have decided. We must then ensure that all good nodes decide either to terminate or to run another epoch. To do this, we run an algorithm, PromiseAgreement that solves the Promise Agreement problem (see Section 4.2). The solution simply has each node sample a logarithmic number of other nodes, and take a majority vote. It does not increase the overall asymptotic number of messages sent, but some non-active nodes can be forced by the adversary to respond to requests. If the outcome of PromiseAgreement is not agreement then all nodes proceed to the next epoch, where the number of active nodes doubles in expectation. In this way, we can guarantee that that KT0-ByzantineAgreement succeeds within expected epochs.
1.4 Related Work
and Communication Model.
and models are two well-studied standard models in distributed computing (e.g., see [30, 48, 50]). It turns out that message complexity of a distributed algorithm depends crucially (as explained below) on the initial knowledge of the nodes.555It is not hard to see that one can run the algorithms in the model after one round of communication between neighbors, (which is all-to-all communication in a complete network). For example, consider the situation where there are no Byzantine nodes. It is known that expected messages are needed for explicit leader election666For explicit leader election, where all nodes should know the identity of the elected leader. in a complete (fully-connected network) in the model (see e.g., [7, 40]), whereas in the it takes no communication at all (since all nodes know each other’s IDs, the minimum one can be selected). Similarly it has been shown for implicit leader election and implicit agreement777In implicit leader election, only the leader node should know that it is the leader. In implicit agreement, it is enough if a non-empty subset of nodes agree. that expected messages is a lower bound in the model [7]. It is known that for various fundamental problems such as broadcast, spanning tree construction, minimum spanning tree construction there is a significant gap in the message complexity between the two models. For example, for all the above problems in an arbitrary graph with edges, it is known that is a message lower bound in the model which holds even for randomized (Monte Carlo) algorithms. However, in the model, this lower bound can be breached: all these problems can be solved using randomized algorithms in messages [39]. For the complete network case, it is known that minimum spanning tree construction needs messages in the model, while it can be accomplished in messages in the model. The recent work of Gmyr and Pandurangan [30] gives several new algorithms in the model and shows many other separations between the two models.
Resource-Competitive Analysis.
This paper introduces resource-competitive analysis [9, 28] to the study of Byzantine agreement. In resource-competitive analysis, the computational cost of the attacker, , is incorporated as a parameter in performance analysis. That is, the cost of executing an algorithm over a network of nodes is measured not only as a function of , but also as a function of .
Resource competitive analysis has been applied to designing algorithms for: jamming-resistant wireless communication [27, 29, 36]; attack-resistance on multiple access channels [8], tolerating adversarial channel noise [3, 19, 20], and efficiently distributing bridges for anonymity networks such as TOR [60]. See [9, 28] for detailed surveys.
Related notions comparing the resources of good and bad nodes have been considered earlier, see e.g., the work of [25], that shows how to achieve fairness in secure computation (either both good and bad parties obtain the result of the computation or nobody does) in the dishonest majority setting with a constant competitive ratio in terms of computational costs/number of steps.
Other related works include [12] that focus on scalability of secure protocols and show how to achieve sublinear communication.
Byzantine Agreement and Election.
Byzantine agreement enables participants in a distributed network to reach agreement on a decision, even in the presence of a malicious minority. Thus, it is a fundamental building block for many applications including: cryptocurrencies [11, 23, 26, 31]; trustworthy computing [14, 15, 16, 17, 18, 38, 55]; peer-to-peer networks [1, 47]; and databases [46, 51, 61].
In 2006, King, Saia, Sanwalani, and Vee [34] gave a (randomized) algorithm to solve Byzantine agreement, leader election and committee election problems in a model differing from the one in this paper only in the assumption of communication. This was the first algorithm to use only bits of communication per node, and time to bring almost all processors to agreement. This result can also be achieved in a particular sparse network [35]. This initial work produced agreement among all but nodes. Further work extended this result to achieve everywhere agreement, while using a number of bits that is (load-balanced) [32]; and (not load-balanced) [13]. All of these algorithms required each node to play a particular role as determined by its unique ID in , and to send to specific neighbors. In other words, these algorithms critically rely on the model. These bounds hold even if the bad nodes send any number of bits. Establishing Byzantine agreement via the use of committees is a common approach; for examples, see [26, 34, 42].
Paper Organization.
Section 2 contains KT0-ByzantineAgreement. Section 2.2 formally defines Promise Agreement. Section 3 analyzes the correctness and cost of KT0-ByzantineAgreement and proves Theorem 1.1. In Section 4.1 we prove Lemma 1. In Section 4.2, we describe an algorithm to solve Promise Agreement. In Section 5, we prove lower bounds. Finally, we conclude in Section 6.
2 KT0-ByzantineAgreement
Here, we describe the main algorithm for resource-competitive Byzantine agreement. It calls LargeCoreBA and an algorithm PromiseAgreement that solves Promise Agreement. A node calls LargeCoreBA with a set of possible participants , which may include nodes which do not themselves participate.
The algorithm below runs correctly with probability for any constant , when constant below is chosen to be sufficiently large, depending on . We let be a small constant such that . We set and so that w.h.p. the number of active nodes lies in this range.
We call a good node active if it sets its state to active in Step 2. We call a good node light if the number of IDs received by it from alleged active nodes in Step 2 is less than . We use bounds and to describe the number of light and purported light nodes. For , if there are at least light nodes and each sends a random ID from their list of nodes that reported being active in Step 2, then w.h.p., at least copies of all their common IDs, in particular, the IDs of all active nodes, will be received by every active node. Finally, an element in an active node ’s set is validated when queries a random set of nodes and nodes respond yes. is chosen so that w.h.p., every ID in active will be validated but not many ID’s of nodes which are bad.
2.1 Pseudocode for KT0-ByzantineAgreement
Initialize: Every node sets . Each node sets , and sets its state to and . 2. 2.
Nodes become active and notify others: With probability , sets its state to active and sends its ID to all nodes. Every node sets to the set of IDs received. A node sets its state to light if . 3. 3.
Active** nodes learn of other active nodes:**
- (a)
Every light node randomly selects an ID in and sends it to the nodes in . 2. (b)
Every active node sets to be the number of nodes which send to in Step 3a. If then resets to be the set of IDs which were received from at least nodes. For each in , sends the query to a random set of nodes. 3. (c)
Every light node answers a query if ID is in and the query is sent by a node in . An ID in is considered validated if received at least responses to the query for ID. Each active node that sent queries removes from all IDs which are not validated. 4. 4.
Can we proceed? Each active node with runs LargeCoreBA with the other nodes in . The input bit to LargeCoreBA, iff . If then output of LargeCoreBA. 5. 5.
Compute Byzantine Agreement Each active node with runs LargeCoreBA with nodes in , with input bit, , set to the node’s initial input bit.
Node then sets to the output of this LargeCoreBA. 6. 6.
Take Majority: Each active node, , sends (, ) to all nodes. Then, each node with sets to the majority ready-out bit received from nodes in . If this bit is , then is set to the majority value bit received from nodes in . 7. 7.
Promise Agreement: Each node runs PromiseAgreement with the tuple , and resets the tuple based on the outcome.
- (a)
If , then node terminates and outputs value ; 2. (b)
Else if , doubles and repeats from Step 2. 3. (c)
Else {} every node sends to all its neighbors to determine their IDs and all nodes execute LargeCoreBA to compute Byzantine agreement.
2.2 Promise Agreement
Here we define a variant of the almost-everywhere to everywhere Byzantine agreement problem, which we call Promise Agreement. In Section 4.2, we describe an algorithm, PromiseAgreement, to solve this problem.
Definition 1**.**
An algorithm is said to solve the Promise Agreement problem if it has the following properties.
If (i) there is at least a fraction of good nodes with tuple , for the same bit ; and (ii) all remaining good nodes have ready-out value of [math], then all nodes terminate with tuple . 2. 2.
If all good nodes have , then all nodes terminate with .
3 Analysis of KT0-ByzantineAgreement
3.1 Correctness
We call one run of all the steps in the KT0-ByzantineAgreement algorithm an epoch. We assume for and fixed . We also assume that except in Step 7c.
Lemma 2**.**
The following events occur w.h.p. in .
The number of active nodes is between and . 2. 2.
If there are at least light nodes, then all active nodes receive at least copies of the ID of every active node in Step 3a. 3. 3.
If there are at least light nodes, then all active nodes will consider all IDs of active nodes validated after Step 3c. 4. 4.
If an ID is contained in the sets of at most light nodes in Step 3b, then that ID will not be validated.
Proof.
For each of these items there is a random variable which is the number of successful independent trials. In each case, we will show that for some constant . Then, Chernoff bounds imply that , for any fixed , and any fixed , for sufficiently large [45].
-
Let be the number of active nodes. Each node of at least good nodes is active with probability . Since and , then , where in Step 1 is chosen sufficiently large.
-
Fix an active ID. That ID is sent out from a particular light node with probability at least . Let be the total number of copies sent of that ID. Then the expected number of copies sent out is at least , for any fixed C’, where constant C in Step 3b is chosen sufficiently large. Hence, by Chernoff bounds, w.h.p., at least copies of the fixed active ID are received by each active node. Finally, a union bound over at most possible active IDs that could be sent out establishes the result.
-
Fix an active node and an ID , such that queries about in Step 3b. Let be the number of light nodes queried by about ID in this step. Then , for any fixed for in Step 3b chosen sufficiently large. Thus, by Chernoff bounds, w.h.p., at least nodes will answer queries for the ID , and so node will consider validated. Finally, taking union bounds over all choices for and shows that, w.h.p., all active nodes will be considered validated by all active nodes.
-
Fix an active node and an ID , such that queries about in Step 3b. Assume there are exactly light nodes that contain the ID in their sets. Having fewer such nodes only decreases the probability that node is validated. Let be the number of light nodes queried by that answer the query for ID . Then
[TABLE]
where the last step holds for any for chosen sufficiently large, provided that . Thus, by Chernoff bounds, by setting , we get that , for any fixed , for sufficiently large. Let be the number of bad nodes that are queried by about ID . Again by Chernoff bounds, for any fixed for chosen sufficiently large. Putting these two facts together shows that the number of nodes in the sample that may answer ’s query about ID is, w.h.p., less than .
A union bound over all nodes and IDs completes the proof.∎
For a fixed epoch, let CORE be the set of active nodes that run LargeCoreBA in Step 4. We show that the nodes participating in LargeCoreBA have the desired properties to successfully complete it when there are at least light nodes. (See Lemma 1.)
From Lemma 2, we can observe the following.
Lemma 3**.**
If there are at least light nodes then w.h.p., we have the following
Every active node is in the CORE, and therefore . 2. 2.
For all , after Step 3c. 3. 3.
Let be the bad nodes in . At the conclusion of Step 3, if there are at least light nodes, for any , and for any .
Proof.
-
Follows from the way is set in Step 3b, and also from Lemma 2(1).
-
We note that no bad ID will be present in an unless it is validated, and by Lemma 2(4) w.h.p., this requires at least
[TABLE]
light nodes which contain this ID in their sets. A light node contains no more than IDs, of which at least number are active.
Since , there can be at most IDs of bad nodes contained in for each light node . As there are no more than light nodes, Lemma 2 implies that the total number of bad nodes which are validated is less than
[TABLE]
Where the last line follows for any , provided that is sufficiently small, and ; and the second to last line follows since was chosen such that . Thus the total number of bad nodes in is less than .
Since CORE contains at least good nodes, , and hence . ∎
Lemma 3 and Lemma 1 imply that LargeCoreBA can be successfully run when there are at least light nodes. The following lemma follows from this fact and from Lemma 2. Figure 1 illustrates part of this lemma.
Lemma 4**.**
Let be the number of light nodes in an epoch of KT0-ByzantineAgreement. Then w.h.p.,
If ,
-
All active nodes have , they run LargeCoreBA and decide on when run in Step 4; and
-
All active nodes run LargeCoreBA in Step 5 and set their bit to the input bit of some active node .
If ,
-
All active nodes successfully run LargeCoreBA but they may start with differing values for ready-out in Step 4.
-
If the output is a 1, all active nodes set and they will successfully run LargeCoreBA in Step 5 and set to the input for some active node .
-
If the output is a 0, all active nodes set .
If , all active nodes will successfully run LargeCoreBA in Step 4, though some nodes will disregard the output. All active nodes will start with and all active nodes will have . 4. 4.
If , some active nodes may run a possibly flawed LargeCoreBA in Step 4, though all active nodes will disregard the output. All active nodes will start with and end with .
Proof.
If , then for all nodes , thus in Step 4, all active nodes have , disregard the output of LargeCoreBA, and set .
By Lemmas 3 and 1, when , LargeCoreBA will run successfully. If , then all active nodes have , so in Step 4, all active nodes have . Thus, by the consistency property of LargeCoreBA, all active nodes have .
If , then all active nodes running LargeCoreBA in Step 4 may start with different ready-in values, but by the correctness of LargeCoreBA, they will all end with the same ready-out value. If the ready-out vale is , in Step 5, LargeCoreBA will run correctly and they will all set their bit to the input bit, of some active node .
If , then any active node has , and so has . Thus, after Step 4, by the validity of LargeCoreBA, all active nodes will have . Thus, they will all run LargeCoreBA in Step 5 and will all set their value bit to the input value bit of some active node. ∎
Lemma 5**.**
At the end of each epoch, w.h.p., all nodes either terminate and output the same value or they all go to the next epoch.
Proof.
By Lemma 4, if any active node sets after Step 5, all active nodes will set their tuple to the value , and will be the input bit of some node in CORE. Moreover, there must be at least light nodes. Since every light node has at least IDs of active nodes in , and , in Step 6, the majority of the messages received from nodes with IDs in will be and will set and . Since , all good nodes will come to agreement on in Step 7, when the Promise Agreement problem is solved correctly (by Lemma 9 in Section 4.2).
On the other hand, if any active node sets their value to 0, then we must be in Case 2, 3 or 4 of Lemma 4. In these cases, all active nodes have , at the end of Step 5. Thus, all light nodes set since it is the majority value received in Step 6, and all nodes which are not light do not change their initial ready-out value from 0. Therefore, all nodes agree on . With , all nodes execute Steps 7b or 7c, depending on the value of . ∎
3.2 Resource Costs
Lemma 6**.**
In any epoch, w.h.p., the algorithm sends messages, where is the minimum of and the number of messages sent by bad nodes in that epoch. Moreover, in any epoch, the algorithm takes time polylogarithmic in .
Proof.
There are active nodes which send to all nodes and each light node sends one message to nodes, for a total of messages. When is reset, it is reset to be no larger than . To validate its , each active node sends messages for each element in . There are active nodes, each with . Hence, issuing queries requires messages by good nodes. There are at most queries sent by bad nodes, so responding to queries requires messages.
Computing LargeCoreBA in Steps 4 and 5, requires messages by Lemma 1. Then in Step 6, all active nodes send to all nodes for messages. Finally, in Step 7, all nodes send messages to solve PromiseAgreement, as shown in Lemma 9. Thus, the total number of messages sent in the epoch is .
The time to perform all steps in an epoch is dominated by the cost of performing LargeCoreBA which is polylogarithmic. ∎
Lemma 7**.**
The algorithm terminates in a decision in a given epoch, unless the adversary sends messages.
Proof.
There are at least light nodes unless the adversary causes bad nodes to send more than messages to nodes, for a total of messages. If there are at least light nodes in an epoch, then by Lemma 4 the algorithm terminates with a decision. ∎
Note that except when , in which case our algorithm runs LargeCoreBA on all the nodes, by messaging all of their neighbors, for a total cost of . This is the bottleneck in the algorithm which causes it to be -competitive instead of -competitive.
Let be the minimum of and the total number of messages sent by the adversary, and be the number of nodes in the network. We can now prove Theorem 1.1.
3.3 Proof of Theorem 1.1
Proof.
By Lemma 7, the algorithm will terminate in an epoch, unless the adversary sends messages in that epoch, for some constant . In epoch , . If we do not terminate in epoch , then . In epoch , by Lemma 6, the total number of messages sent is .
We first consider the case where it’s always true that , and note that . Thus, the message cost in epoch is , where is the number of messages sent by the adversary in epoch . The terms clearly sum to . If is the last epoch, then . Thus the total number of messages sent in this case is .
We next consider the case where . In this case, our algorithm runs LargeCoreBA on all the nodes, by messaging all of their neighbors, for a total cost of . The value of in this case is , so our total message cost is .
Since epoch has latency polylogarithmic in (by Lemma 1), and there are at most epochs, the total latency is . Additionally, we note that when the algorithm terminates, by Lemma 7, all good nodes come to agreement on an input bit of some node in CORE.
Finally we note that we can also solve the leader election and committee election problems. To do this, the active nodes use Feige’s leader election algorithm to elect a committee in one step, or a leader in steps among the sets for every active node . This is done instead of selecting an agreement value as in the KSSV algorithm. ∎
4 Additional Algorithms
4.1 LargeCoreBA
Here we prove Lemma 1. We do this by adapting the algorithm from [34]. In that paper, all nodes have a view of all of other nodes and nodes are numbered .
The main idea of our adaptation is to show that for any , , there exists a deterministic assignment of IDs in to a set of committees, so that for every subset of size IDs, a fraction of committees are (1) “sufficiently large”; and (2) contain a nearly representative fraction of both good and bad nodes.
The algorithm in [34] is built upon a family of bipartite graphs with expansion-like properties. The existence of such graphs are proved using the probabilistic method (see Section 3 of [34]). We need the same properties here, but for a possibly much smaller subset of identities, which come from a much larger name space (). We show that we can start with identities in the range , of which are active and generate a set of committees which have the required properties with respect to the active nodes, as is needed in each layer of the “election graph” in [34], Corollary 3.2.
The following lemma achieves the needed result for the “static” network in that paper. We note that, in our algorithm, each node in epoch knows that the number of active nodes lies in the range for a fixed constant , .
Lemma 8**.**
Let be any positive constants, where , and . Let be an integer such that , and . Further, let , and and be any disjoint subsets where and . Also for any bipartite graph over nodes , let denote the neighbors of node .
Then there exists a bipartite graph , where each node in has degree , , such that for all but a fraction of nodes , all the following hold, with probability :
Let . Then . 2. 2.
Let . Then . 3. 3.
Let . Then .
Proof.
Consider a bipartite multigraph with sides and where each node in has neighbors chosen uniformly at random with replacement from . Fix disjoint sets where and ; and fix , .
Let be the number of edges from nodes in to . Then
[TABLE]
By Chernoff bounds, for any positive , we have . Setting , we get
[TABLE]
Let be the event that for all nodes in , condition (3) above fails. Let , for all , of appropriate size. Then by a union bound,
[TABLE]
The last line in the above holds for . Thus, with high probability, a random bipartite graph satisfies condition (3) for all sets and . A similar analysis shows the same results for conditions (1) and (2). Putting these three facts together, the probability that a random graph fails any one of these properties is no more than . In particular, such a graph exists. ∎
If we regard each node in as a committee whose members are the set of neighbor nodes contained in , and if and , the nodes in which are mapped to the same committee can successfully run a linear time deterministic Byzantine agreement algorithm by Dolev et al. [21], even if they do not know the exact number and names of all the bad nodes participating, since the total number of bad nodes in any good node’s view mapped to the same committee is less than one third of the good nodes mapped to the committee. Each good node may fail to send a message to some bad node, or may fail to hear from some bad node, but a Byzantine agreement algorithm is resilient to a bad node which fails to send a message. Thus, the algorithm from [34] will work correctly with high probability. Moreover, this LargeCoreBA algorithm has latency that is polylogarithmic in the number of participants (active ndoes), and requires each active node to send only a polylogarithmic number of bits.
Note that the algorithm from [34] is almost everywhere, i.e., all but fraction of good nodes come to agreement. If we follow the last step with a step in which all active nodes send to each other, each can take the majority, so that all active good nodes come to the same correct decision, for a total number of messages messages in phase .
4.2 PromiseAgreement
We now present a simple algorithm to solve the Promise Agreement problem, defined in Section 2.2.
PromiseAgreement
Each node sends a request to a random set of nodes. 2. 2.
Each node , upon receiving a request from a node , responds to the request by reporting . 3. 3.
If greater than a fraction of nodes sampled by respond with , then sets and sets to the majority of the value bits sent by sampled nodes. Else .
Lemma 9**.**
PromiseAgreement solves the Promise Agreement problem (Definition 1), with latency, and sending bits, where is the minimum of and the number of messages sent by the adversary during this algorithm.
Proof.
Assume there are at least a fraction of good nodes with for the same bit , and all remaining good nodes have ready-out values of [math]. By Chernoff and union bounds, every good node then has greater than a fraction of good nodes with ready-out values of , and less than a fraction of bad nodes in their sample. Hence, all good nodes will terminate with tuple values of .
Assume that all good nodes have ready-out values of [math]. Then by Chernoff and union bounds, each sample has less than a fraction of bad nodes. Hence, all good nodes will terminate with ready-out values of [math].
The number of bits sent is just the number of queries sent which is . ∎
5 Lower Bounds for Resource-Competitive Byzantine Agreement
We now study the lower bounds for resource-competitive Byzantine agreement (BA). We first show a tight lower bound on the resource competitiveness of deterministic BA protocols. Then we show a lower bound on the resource competitiveness of randomized BA protocols.
5.1 Deterministic Lower Bound
As per our model (cf. Section 1.1) we assume a complete -node network with Byzantine nodes and good nodes (i.e., non-Byzantine) for some small constant . We assume the model. The Byzantine nodes are controlled by a non-adaptive rushing adversary. It is assumed that Byzantine nodes cannot fake their own identities.
In the above setting, the goal is to show a lower bound on the message bits spent by the good nodes in any deterministic algorithm solving Byzantine everywhere agreement. The lower bound also holds in the model, in which a node knows the ID of its neighbors.
The output of the algorithm, i.e., the agreed value depends on the ID, input distribution of the nodes and the information exchanged among the nodes during the execution of the algorithm. More precisely, the output of a node (with id ) is a function , where the argument is the input bit of and is the set of received message bits during the execution of the algorithm. Let us call this information as “transcript” of . The algorithm is deterministic and known to the adversary which controls the Byzantine nodes. Further, the algorithm should work for any input distribution (i.e., the value distribution). Given an input distribution over the nodes, the complete execution of the algorithm is known to the adversary. Based on the execution, the adversary selects Byzantine nodes (in the beginning) in such a way that the algorithm fails to achieve agreement everywhere unless it spends enough messages. In fact, we prove the following result.
Theorem 5.1**.**
Suppose the budget of messages of the Byzantine nodes is bits, for some constant . Then any deterministic algorithm, which solves Byzantine everywhere agreement, incurs an expected bits of messages.
Proof.
Let there be a deterministic algorithm that solves the Byzantine agreement everywhere and incurs only messages. We show a contradiction that the agreement is wrong in the sense that there exists two nodes with two different output value for some input distribution. Consider an arbitrary input distribution over nodes. Since the total messages send by the good nodes is , there must exist a node, say, that exchanges (sends and receives) less than message bits in total for some small constant (the actual value of to be fixed later); otherwise the sum of the messages of all the good nodes would be (in fact, is the node which spends minimum number of messages throughout the execution of ). Let be the set of nodes which exchange messages with throughout the execution of on the given input . Note that, given and , and are fixed and known to the adversary in the beginning. Further, for different input , the pair (, ) might be different. The adversary then selects all the nodes in as Byzantine nodes before the execution starts. Thus the transcript of is fully controlled by the Byzantine nodes as is determined by the nodes in . The transcript of is the total history of messages between and the rest of the nodes. Clearly, the decision of depends on the choice of ’s input value (0 or 1), ’s ID and its transcript (which might also include the IDs of the nodes that it communicated with). Also, in a valid protocol, every node (with every distinct ID and input value) will have a distinct transcript for deciding 0 or 1, respectively. Essentially, the adversary can decide a transcript for (depending on its input value and ID) such that the output value of would be different than the output value of all other good nodes (assuming all other good nodes execute the algorithm without any influence from the Byzantine nodes). This will give a contradiction to the everywhere agreement.
We now show that there are enough Byzantine nodes and each Byzantine node has sufficient budget to select all the nodes in as the Byzantine nodes (in the beginning). As explained above, the size of could be at most . Clearly (otherwise, it won’t be a valid protocol). In other words, . Now consider the following cases.
Case 1: . That is exchanges at most messages with a single node, say , throughout the execution of . If is selected to be a Byzantine node, it must have a budget of at least bits to be sent to . Since the number of Byzantine nodes is and their total budget is , each Byzantine node can send (up to) messages on average, i.e., the average budget of each Byzantine node can be (up to) . We need,
[TABLE]
which is satisfied for . Note that the remaining Byzantine nodes (i.e., which are not in ) may behave as the good nodes and response to the good nodes by following the algorithm . They are chosen from the nodes who spend lesser messages than the other nodes throughout the execution of . Thus the remaining Byzantine nodes is not spending more messages than the good nodes.
Case 2: . Then Byzantine nodes are sufficient to select all the nodes in in the beginning since (by assumption) where the constant is determined as:
[TABLE]
Further, all the Byzantine nodes in have enough budget to communicate with .
Case 3: . This follows from Case 1 and Case 2. Case 1 says that a single Byzantine node has sufficient budget to communicate with . Thus all the nodes in have enough budget to communicate with . Also Case 2 says there are sufficient number of Byzantine nodes to select all the nodes in as Byzantine nodes.
Thus we claim that, given any input distribution there is a good node whose output (i.e., agreed value) is completely controlled by the adversary as the adversary controls the transcript of . Now we argue that the algorithm fails to achieve agreement everywhere for at least one of the following four input distributions:- all the nodes get value , all the nodes get value [math], gets and rest get [math], and gets [math] and rest get . Suppose the output of the algorithm is constant, say all the nodes always output , then the agreement is invalid for the input distribution . (Similarly invalid for if output is always [math]). If the output is non-constant, i.e., the output depends on the input, IDs and the execution, then we show that there exists two good nodes (one is and any one from the remaining good nodes) that agree on two different bits for one of the input distributions and . Based on the input value of (which is for , and [math] for ) and its ID, the adversary decides the transcript of in such a way that ’s output bit will be opposite to the rest of the good nodes’ output bit. This contradicts that solves the Byzantine agreement everywhere. Thus the number of message bits sent by the good nodes is . ∎
The above argument holds even if the IDs are known to the neighbors (i.e., model). The good nodes, in particular the node , can never determine the Byzantine nodes, since the adversary selects the Byzantine nodes in the beginning and can have interactions with the Byzantine nodes only.
5.2 Randomized Lower Bound
Let us first consider a complete network with nodes in the anonymous setting, i.e., nodes do not have any identifiers. This can be extended to the non-anonymous setting, where nodes have unique identities. Each node has ports through which it connects to the other nodes. Thus, if a node sends a message through a port to another node , then any message receives through is guaranteed to be from . As before, among the nodes, a small fraction (assumed to be integral) for a fixed are Byzantine and denoted ; let . Nodes can individually generate uniform and independent random bits as needed, but we do not assume the availability of common coins.
Our goal is to show a lower bound on the message complexity for Byzantine Agreement in the above setting (everywhere and with success probability 1) assuming that the adversary has full information and is a rushing adversary. Let us recall the definition of the message complexity.
Definition 2**.**
For a given BA algorithm , the message complexity (or just when clear from context) is defined as the maximum expected number of the sum of the bits sent by good nodes. The maximum is taken over all possible adversarial strategies (i.e., choice of IDs, port assignments, input bits, and the behaviour of the Byzantine nodes) and the expectation is over the random bits used by the nodes.
Overview of our approach.
We show that if bad nodes can send messages, then the good nodes must send at least messages, for any . If we assume not (for the sake of contradiction), then, good nodes can reach agreement while only sending messages on average. Under this situation, when any good node sends a message to any other good node , the bad nodes can bombard with messages intended for denial of service (DoS). Node will be unable to distinguish between the legitimate message from and these DoS messages from bad nodes. As a result, will have to respond, on average, to messages from bad nodes first. This is more number of messages than what a good node can afford on average. Thus, several good nodes will not be able to establish two-way contact with any other good node, which we then exploit to show the impossibility via an indistinguishability argument.
Theorem 5.2**.**
Consider any BA algorithm that guarantees that good nodes reach a valid agreement in the anonymous setting as long as the number of messages sent by Byzantine nodes is at most for some . Then, the message complexity , i.e., the expected number of messages sent by good nodes, is at least .
Proof.
Suppose for the sake of contradiction that there is a BA algorithm for which despite an adversarial budget of . A quick upshot is that the average number of messages sent by good nodes is .
Our argument to show contradiction is structured as follows. We condition our entire argument on the total number of messages sent by good nodes to be bounded by at most , which occurs with probability at least 1/2 by Markov’s Inequality. We first observe in Lemma 10 that good nodes receive messages from at most different other good nodes. Exploiting this, we then give three adversarial scenarios. In all these scenarios, the Byzantine adversary employs a strategy in which half the Byzantine nodes use a denial-of-service style attack to suppress responses from good nodes. Under this adversarial strategy, we show in Lemma 11 that most good nodes are unable to establish two-way communication with any other good node. The remaining half of the Byzantine nodes exploit this situation to make it difficult for good nodes to distinguish between different scenarios that require different agreement values.
We begin with the following lemma that holds due to an elementary counting argument.
Lemma 10**.**
Recall the condition that at most messages are sent by good nodes. Under this condition, with high probability, each good node receives messages from at most different good nodes.
Proof.
Fix a good node . Let be an indicator random variable taking the value 1 if good node sent a message to . Notice that , where is the number of different nodes to which sent messages. The number of different good nodes from which received messages is given by and these ’s are independent owing to the fact that the ports at each node are independently permuted randomly. By linearity of expectation,
[TABLE]
Thus, we can apply Chernoff bounds to show that . If , and applying the union bound over all , we get the required result. On the other hand, if , then, and , but we can still apply Chernoff bounds and get
[TABLE]
Again, we get the desired bound when we apply the union bound over all . The claim follows when we combine the two Chernoff bounds. ∎
We now wish to show a certain adversarial strategy under which, with non-zero probability, at least one node will violate agreement. The Byzantine adversary’s strategy is as follows.
Port assignments.
The nodes are interconnected randomly in the sense that each node has port numbers 1 through through which it connects to the other nodes and the adversary connects a random permutation of the nodes to the ports. The permutations used for each of the nodes are (mutually) independent. Of course, the adversary will be aware of the port assignments.
Input bits.
Recall that there are honest nodes . The Byzantine adversary chooses one of the following three different scenarios.
Scenario 0:
All good nodes are assigned 0.
Scenario 1:
All good nodes are assigned 1.
Scenario 2:
Exactly half of them (chosen uniformly at random) are assigned an input bit 0 and the rest of them are assigned 1.
Denial of Service (DoS) Attackers.
Out of the Byzantine nodes, the adversary designates nodes as DoS attackers (denoted ). These DoS attackers behave in a specific manner towards nodes in . We now describe this behavior of the DoS attackers for a fixed node . Whenever a node sends a message to any good node , the Byzantine adversary can observe this immediately and rushes in with replicas of the (same message) from DoS attackers denoted ; the same is used every time sends a message to . However, for any pair and , , the adversary seeks to ensure that . The adversary can ensure this pairwise disjointness as long as the number of nodes that send messages to is at most . This condition is in fact satisfied with sufficient probability (cf. Lemma 10) as long as the Byzantine adversary ensures that the number of nodes in that contact is at most . Thus, from ’s perspective, to establish two-way contact with some good node , it must intuitively respond to messages (on expectation), which is asymptotically more than its average budget.
Byzantine nodes that are not DoS attackers.
The strategy of nodes in will be discussed later. We reiterate that the strategy must ensure that no good node is contacted by more than nodes from .
A message from a node to a node is called a response if it is the first message from to and had sent a message to no later than . Under this definition, note that two messages, one from to and the other from to , sent in the same round will be considered responses to each other when no message transpired between them at any earlier point in time. This is however a rare event that we can safely ignore. Furthermore, a response from to is called a good response if both and .
Lemma 11**.**
The total number of good responses sent by nodes in is with probability at least .
Proof.
To aid in this proof, we first prove a claim about a simplified problem that we call the good apples problem (GAP). In this problem, we have containers, but , and each container has apples (where for some ), but exactly one apple is good in each container and the rest are bad. We are allowed to pick a total of apples, where but for some . Each pick can be from an arbitrarily chosen bin, but the apple that is picked must be chosen uniformly at random (UAR) and without replacement from the apples remaining in the chosen container. The goal is to pick as many good apples as possible. As a preliminary observation, notice that it doesn’t help to pick from a container after we have already picked the good apple from it. We now show that there is no strategy that guarantees picking good apples with any reasonable probability.
Claim 5.3**.**
The probability that the number of good apples picked exceeds for any fixed is regardless of the strategy used.
Proof Sketch.
We argue that the optimal strategy to solve GAP is to greedily pick from a single (arbitrarily chosen) container until we get the good apple in it and then moving to next container (chosen arbitrarily) and repeating. The intuition behind this strategy is that, once we have invested in a container with at least one pick (while all others are unpicked), a pick from is more likely to get the good apple than a pick from any other container.
Now under the optimal strategy, we can let be the indicator random variable that is 1 if the number of picks from container was at least given that the good apple in was picked. Clearly, . Moreover, given the budget of on the number of picks allowed, . Let denote the total number of good apples that were picked. Notice that is dominated by , the negative binomial distribution where and we are required to see successes. Clearly, the probability that exceeds can be viewed as the probability that the binomial random variable is no more than , which is by Chernoff bound. ∎
We now return to proving that the number of responses is with probability at least . We can model the problem as a GAP. Each time a node sends a message to , recall that nodes in send the exact same message. These messages sent by can be viewed as a container with exactly one good message (i.e., the one sent by ) that needs to respond to. Since the total budget of messages that good nodes can send is , the total number of such “containers” can be at most and each container has apples (corresponding to the DoS messages and the good message). Since the total message complexity is at most , we get the GAP instance by setting and . From Claim 5.3, we know that the number of good apples picked is with probability at least , which translates to the claim that the number of good responses is with probability at least . ∎
The upshot is that a randomly chosen node will not send any good response with probability at least a constant both under Scenario 0 and Scenario 1. Thus, this node (with constant probability) will have only managed to establish one-way communication with other good nodes. Let denote the set of good nodes that sent messages to . By Lemma 10, . Since guarantees BA everywhere, will be able to correctly decide on 0 (resp., 1) for Scenario 0 (resp., Scenario 1).
Let denote the strategy used by the nodes in under Scenario for . For our lower bounding purpose, we can assume that all decisions by are made by a single coordinator within . The coordinator executing decides the content and timing of the messages sent by nodes in to . We assume that the coordinator is aware of from the beginning. We even assume that it is aware of all messages sent by . We are justified in making these assumptions because they only strengthen the algorithm. This strategy always ensures that correctly decides on under Scenario , . In particular, it is resilient to all counter strategies by the Byzantine adversary.
Notice however that can be executed by as well because these strategies only entail the Byzantine adversary playing the role of coordinator, choosing Byzantine nodes and using them to send appropriate messages to at appropriate times. Of course, the Byzantine nodes are also aware of all messages sent by .
Now, in order to complete the indistinguishability argument, we let the Byzantine adversary pick two nodes and uniformly at random under Scenario 2 and interact with them in such a way that they decide contradicting values. We condition on and starting with input values 0 and 1, respectively, which is anyway guaranteed to occur with probability 1/4 under Scenario 2. Moreover, the two nodes will not send any good response with constant probability. The Byzantine adversary then uses nodes in to execute and towards and , respectively. Specifically, the Byzantine adversary picks the nodes from to execute (resp., ) and – upon observing messages sent and received by and in each round – coordinates the chosen nodes to rush in with responses just as (resp., ) would towards under Scenario [math] (resp., Scenario ). Since decided correctly under both Scenarios 0 and 1, the two nodes must decide on [math] and , respectively, because their executions in Scenario 2 is indistinguishable from their respective executions in in Scenarios 0 and 1. Thus, with some constant probability, they reach contradicting decision values under Scenario 2. ∎
Extension to non-anonymous setting
We finally point out how to extend easily the above result to the non-anonymous setting, where honest nodes have unique identifiers; however, Byzantine nodes can fake their identifiers.888We note that this extension does not apply to setting where the Byzantine nodes are a bit weaker, i.e., they cannot fake their identities. This can be done by an easy reduction to the anonymous setting. Suppose in the non-anonymous setting there is a protocol that violates the lower bound shown in the anonymous setting. At the beginning of the protocol in the anonymous setting, honest nodes choose a random ID between ; it is easy to see that they are all unique with high probability. They then execute the protocol of the non-anonymous setting.
6 Conclusion
We have described an efficient randomized resource-competitive algorithm to solve Byzantine agreement, Leader election and Committee election, in the , synchronous communication model, with a static and full-information adversary. Our algorithm is efficient in the sense that message cost and latency grow slowly with the number of messages sent by the adversary. In particular, our algorithm uses bits of communication, and has latency , where is the minimum of and the number of bits sent by the nodes controlled by the adversary. Further, it succeeds with high probability. We also show lower bounds on resource-competitive Byzantine agreement algorithms. Our lower bounds show that in general, it is not possible to do significantly better than our algorithm with respect to the number of bits sent by Byzantine nodes. A key open problem is to close the gap between upper and lower bounds for randomized protocols across all budget values.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Atul Adya, William J. Bolosky, Miguel Castro, Gerald Cermak, Ronnie Chaiken, John R. Douceur, Jon Howell, Jacob R. Lorch, Marvin Theimer, and Roger P. Wattenhofer. FARSITE : Federated, Available, and Reliable Storage for Incompletely Trusted Environment. In 5 t h superscript 5 𝑡 ℎ 5^{th} USENIX Symposium on Operating Systems Design and Implementation (OSDI) , pages 1–14, 2002.
- 2[2] A. Agbaria and R. Friedman. Overcoming byzantine failures using checkpointing. University of Illinois at Urbana-Champaign Coordinated Science Laboratory technical report no. UILU-ENG- 03-2228 (CRHC-03-14) , 2003.
- 3[3] Abhinav Aggarwal, Varsha Dani, Thomas P. Hayes, and Jared Saia. Sending a message with unknown noise. In Proceedings of the 19th International Conference on Distributed Computing and Networking (ICDCN) , pages 8:1–8:10, 2018.
- 4[4] Yair Amir, Claudiu Danilov, Jonathan Kirsch, John Lane, Danny Dolev, Cristina Nita-Rotaru, Josh Olsen, and David John Zage. Scaling byzantine fault-tolerant replication towide area networks. In Proceedings of International Conference on Dependable Systems and Networks (DSN) , pages 105–114, 2006.
- 5[5] D. P. Anderson and J. Kubiatowicz. The worldwide computer. Scientific American , 286(3):28–35, 2002.
- 6[6] Hagit Attiya and Jennifer Welch. Distributed Computing: Fundamentals, Simulations and Advanced Topics (2nd edition) . John Wiley Interscience, 2004.
- 7[7] John Augustine, Anisur Rahaman Molla, and Gopal Pandurangan. Sublinear message bounds for randomized agreement. In Proceedings of the ACM Symposium on Principles of Distributed Computing (PODC) , pages 315–324, 2018.
- 8[8] Michael A. Bender, Jeremy T. Fineman, Seth Gilbert, and Maxwell Young. How to Scale Exponential Backoff: Constant Throughput, Polylog Access Attempts, and Robustness. In Proceedings of the 27 t h superscript 27 𝑡 ℎ 27^{th} Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages 636–654, 2016.