TL;DR
This paper introduces a global optimization algorithm for sparse measure minimization problems using over-parameterized gradient descent, achieving logarithmic complexity in accuracy under certain conditions.
Contribution
It demonstrates that discretized non-convex gradient descent can efficiently solve measure-based convex problems with sparsity penalties, with complexity scaling as log(1/ε).
Findings
Algorithm achieves complexity scaling as log(1/ε).
Global convergence is established under non-degeneracy assumptions.
Bounds involve exponential dependence on the dimension d.
Abstract
Minimizing a convex function of a measure with a sparsity-inducing penalty is a typical problem arising, e.g., in sparse spikes deconvolution or two-layer neural networks training. We show that this problem can be solved by discretizing the measure and running non-convex gradient descent on the positions and weights of the particles. For measures on a -dimensional manifold and under some non-degeneracy assumptions, this leads to a global optimization algorithm with a complexity scaling as in the desired accuracy , instead of for convex methods. The key theoretical tools are a local convergence analysis in Wasserstein space and an analysis of a perturbed mirror descent in the space of measures. Our bounds involve quantities that are exponential in which is unavoidable under our assumptions.
Click any figure to enlarge with its caption.
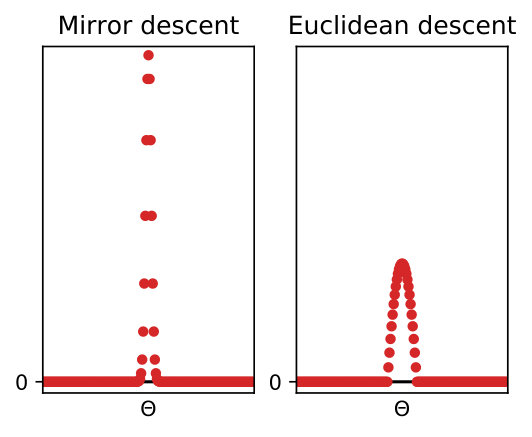 Figure 1
Figure 1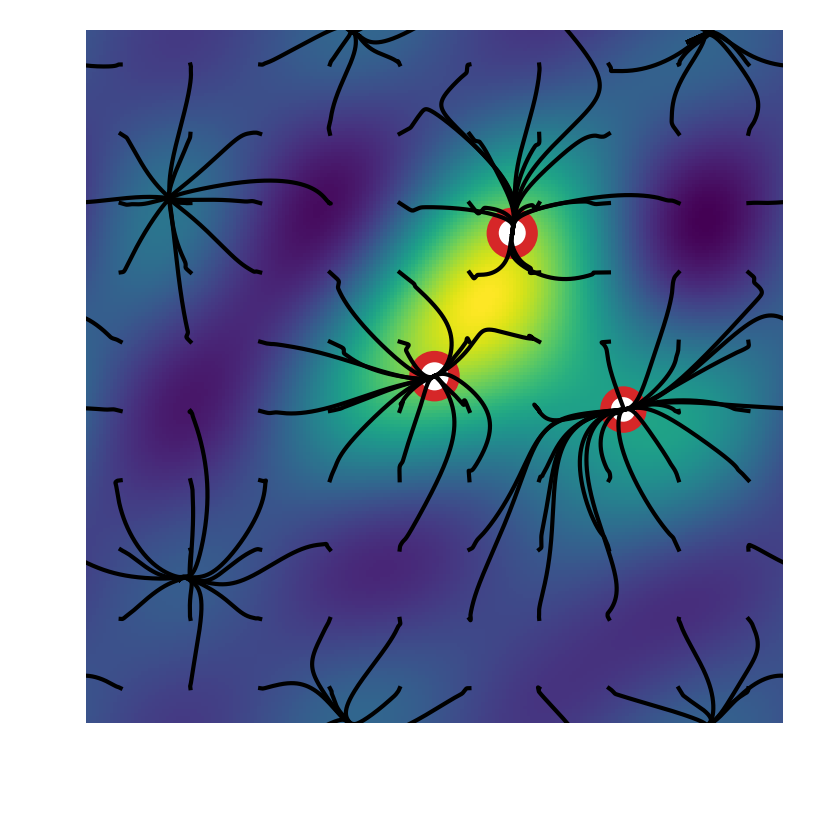 Figure 2
Figure 2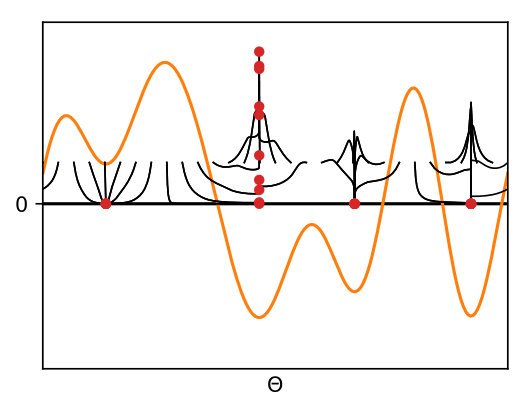 Figure 3
Figure 3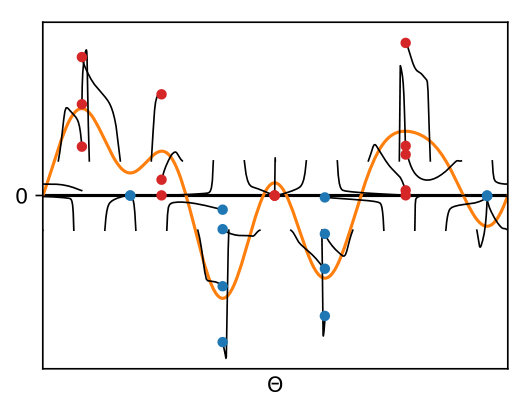 Figure 4
Figure 4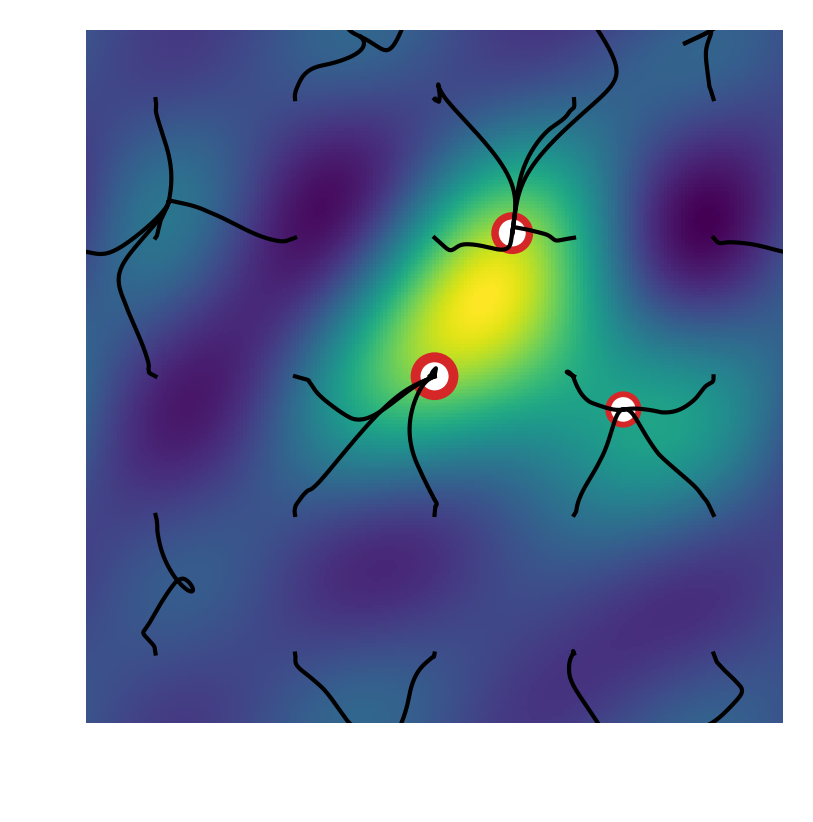 Figure 5
Figure 5 Figure 6
Figure 6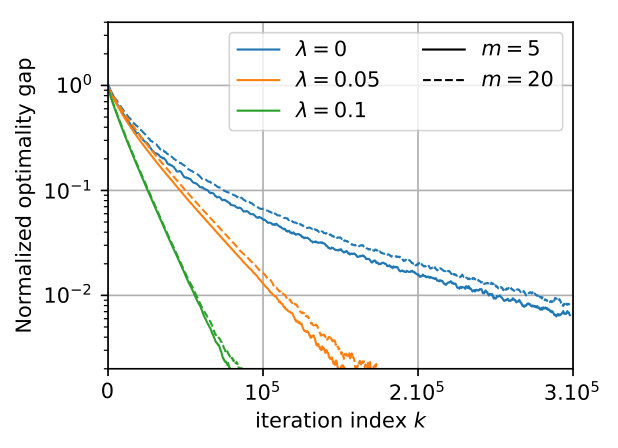 Figure 7
Figure 7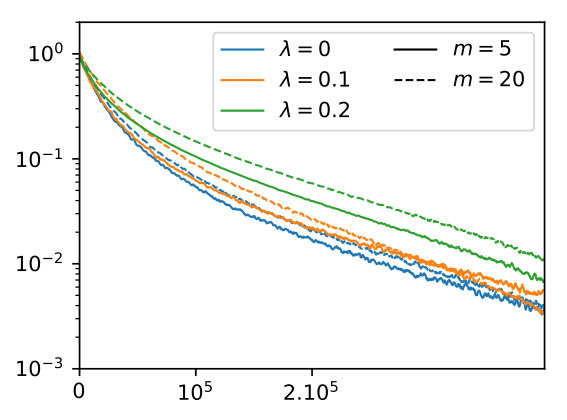 Figure 8
Figure 8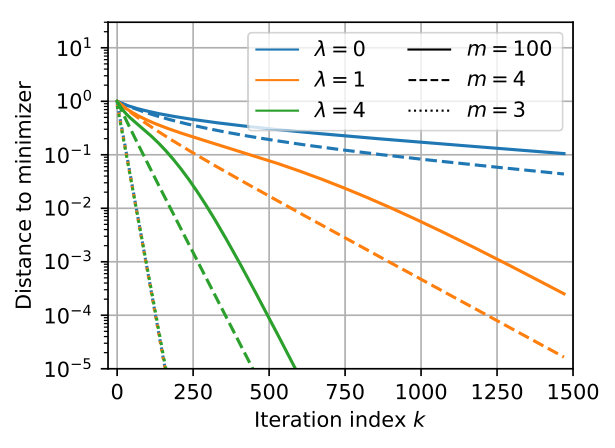 Figure 9
Figure 9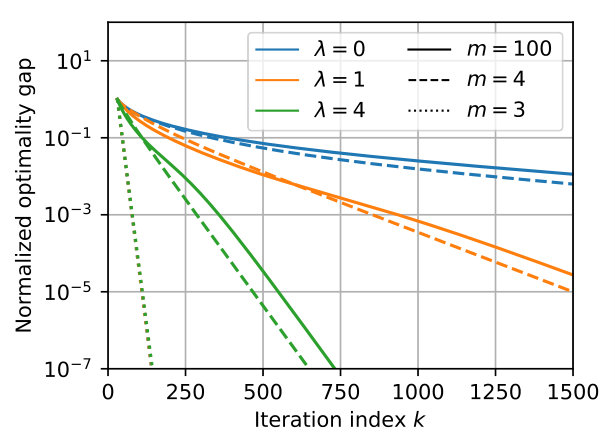 Figure 10
Figure 10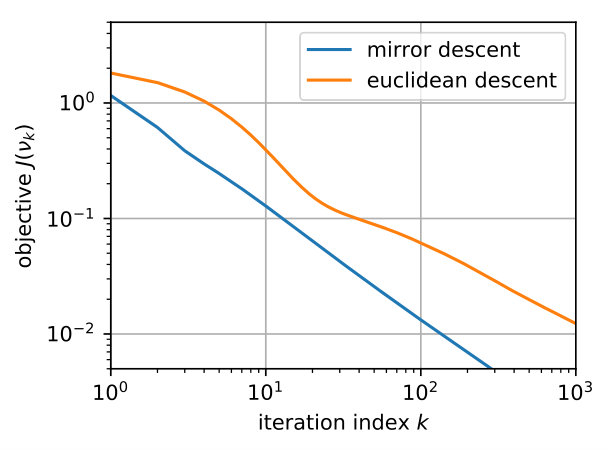 Figure 11
Figure 11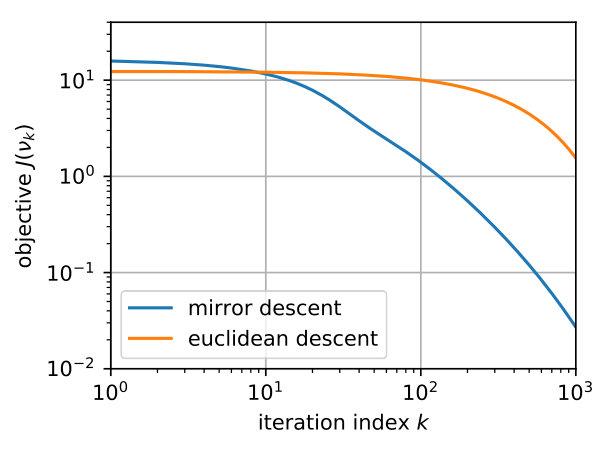 Figure 12
Figure 12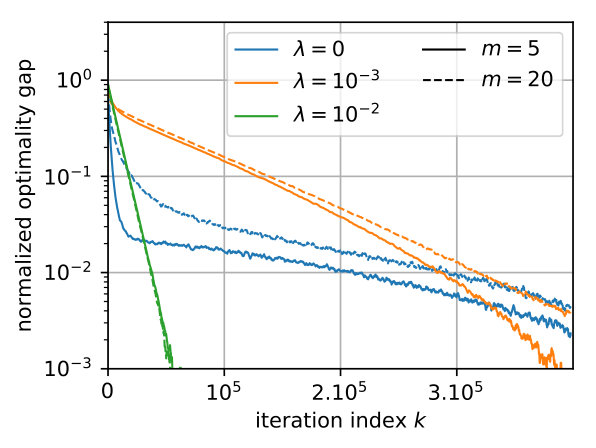 Figure 13
Figure 13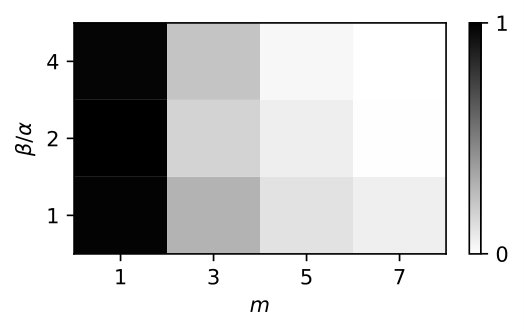 Figure 14
Figure 14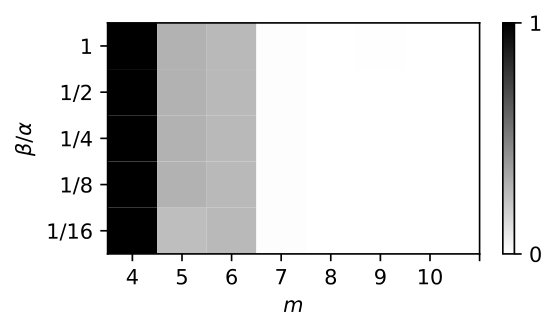 Figure 15
Figure 15Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Sparse Optimization on Measures
with Over-parameterized Gradient Descent
Lénaïc Chizat CNRS, Laboratoire de Mathématiques d’Orsay, Université Paris-Saclay, 91405, Orsay, France.
Abstract
Minimizing a convex function of a measure with a sparsity-inducing penalty is a typical problem arising, e.g., in sparse spikes deconvolution or two-layer neural networks training. We show that this problem can be solved by discretizing the measure and running non-convex gradient descent on the positions and weights of the particles. For measures on a -dimensional manifold and under some non-degeneracy assumptions, this leads to a global optimization algorithm with a complexity scaling as in the desired accuracy , instead of for convex methods. The key theoretical tools are a local convergence analysis in Wasserstein space and an analysis of a perturbed mirror descent in the space of measures. Our bounds involve quantities that are exponential in which is unavoidable under our assumptions.
1 Introduction
Finding parsimonious descriptions of complex observations is an important problem in machine learning and signal processing. In its simplest form, this task boils down to searching for an element in a Hilbert space that is close to a certain — the observations — and that is a linear combination of a few elements from a parameterized set — the parsimonious description. This can be formulated as a minimization problem where the linear combination is expressed through an unknown measure and the distance to is quantified using a smooth convex loss function , such as the square loss . The problem to solve is then
[TABLE]
where is the set of nonnegative measures on the parameter space with finite total mass and is the regularization strength. This formulation also covers minimization over signed measures with total variation regularization, by replacing with the disjoint union of two copies of where takes opposite values, see Appendix A. A large body of research has exhibited the favorable properties of minimizers of such problems [4, 23, 43] with a statistical or variational viewpoint, showing in particular that favors sparser solutions and increases stability as it gets larger, at the expense of introducing a stronger bias. The present paper deals with the optimization aspect: our goal is to design algorithms that return -accurate solutions with a guaranteed computational complexity. When the set is a finite set, this is a finite dimensional convex optimization problem that is well understood [9, 5]. However, convex approaches are generally inefficient when is a continuous space, such as a -dimensional manifold, where the need to discretize the space leads to a complexity scaling as in the accuracy . We consider the following setting:
- (A1) is a compact -dimensional Riemannian manifold without boundaries. The functions and are twice Fréchet differentiable, with locally Lipschitz second-order derivatives, and is bounded on sublevel sets.
The algorithm that we analyze in this paper is simple to describe: initialize with a discrete measure and run gradient descent on the positions and weights of the particles. We will see that when the problem (1) admits sparse solutions and is non-degenerate, this over-parameterized non-convex gradient descent has a complexity scaling as in the accuracy . We make the following contributions:
- –
In Section 2, we introduce the conic particle gradient descent algorithm to solve optimization problems in the space of measures and discuss several of its interpretations.
- –
In Section 3, we show under under certain non-degeneracy assumptions that there is a sublevel of starting from which this algorithm converges exponentially fast to minimizers.
- –
In Section 4, we show that for suitable choices of gradient and initialization, this algorithm converges to global minimizers. The proof combines the result of Section 3 with an analysis of a perturbed mirror descent in the space of measures. The number of iterations required to reach an accuracy is polynomial in the characteristics of the problem and logarithmic in . In contrast, the required number of particles depends exponentially on the dimension , which is unavoidable under our assumptions.
- –
We report results of numerical experiments in Section 5, where the various insights brought by our analysis about local and global behaviors are investigated.
1.1 Examples of applications
As the problem of finding the simplest linear decomposition over a continuous dictionary is a very natural one, problems of the form (1) appear in a large variety of situations, see [8] for an extensive list. In this paper, our numerical illustrations are focused on two applications, chosen for their practical importance and also because they illustrate the variety of behaviors that can be encountered. We also mention a third example to emphasize on the extreme generality — and thus the intrinsic limits — of our analysis. These three cases are illustrated on Figure 1.
Sparse deconvolution.
In this application, we want to recover a signal that consists of a mixture of spikes/impulses on given a noisy and filtered observation in the space of square-integrable real-valued functions on . When one defines the translations of the filter impulse response and the squared loss, solving (1) allows to reconstruct the mixture of impulses with some guarantees, see e.g. [28, 23, 50]. In this typically low dimensional application, solving (1) to a high accuracy is crucial. Both the signed and nonnegative case have practical motivations (see Appendix A for how to handle the signed case). Figure 1-(a) illustrates the behavior of particle gradient descent for the signed case on the -torus, where the observed signal is shown in orange. Figure 2 illustrates the unsigned case on the -torus.
Two-layer neural networks.
Here the goal is to select, within a specific class, a function that maps features in to labels in from the observation of a joint distribution of features and labels. This corresponds to being the space of real-valued functions on which are square-integrable under the distribution of features, being e.g., the quadratic or the logistic loss function, and with an activation function . Common choices are the sigmoid function or the rectified linear unit [35, 33]. In this application, is typically large and it is not clear yet how to verify the non-degeneracy assumptions a priori, so our global convergence bounds are not useful. Still, the local analysis in Section 3 gives insights on the local behavior in the over-parameterized regularized setting and explains well the behavior observed in numerical experiments. With the ReLU activation, the method we analyze boils down to the classical gradient descent algorithm, see the remark in Section 2.2 about the -homogeneous case. Figure 1-(b) illustrates this case, by plotting the trajectories of where is the output weight of neuron and its hidden weights (the color represents the sign of ).
Non-convex optimization.
Lastly, the minimization of any smooth function on a manifold is covered by (1), as proved in Appendix B. For this problem, our algorithm is analogous to running independently several gradient-based minimization with diverse initializations, because the various particles simply follow the gradient field of and only interact through their masses. This case is illustrated on Figure 1-(c) where the function to minimize (here on the -torus) is plotted in orange. We recover the standard fact that random search as to be complemented with local search if one wants complexity that is reasonable in the precision. We stress that this is not the situation that motivates our analysis. Instead, we are interested in the case of general interactions between the particles, which is when we obtain novel insights.
1.2 Related work
Sparse optimization on measures.
Problems with the structure (1) have a long history in optimization when is discrete, and is typically solved with ISTA [22], mirror descent [47, 6] or variants of those algorithms. When is continuous, the one dimensional case can sometimes be dealt with specific algorithms [13, 15]. In higher dimensions, the classical algorithms are conditional gradient algorithms (also known as Franck-Wolfe) [11, 25, 8], moment methods [24, 14, 27] and adaptive sampling/exchange algorithms [30, 29]. Often, these algorithms are complemented with non-convex updates on the particle positions, which considerably improves their behavior. Given an initial condition that is close to the optimum and with the same structure (i.e. without over-parameterization), the local convergence for non-convex gradient descent is studied in [56, 29].
Wasserstein gradient flows for optimization.
The dynamics of two-layer neural networks optimization when the number of hidden units grows unbounded is studied in [48, 17, 45, 52, 54]. This series of work has led to various insights related to stochastic fluctuations and global convergence. The present paper can be seen as a quantitative counterpart to [17], although we consider a more restrictive setting111The algorithm we study in this paper corresponds to the “-homogeneous case” in [17]. Also, [17] allows non-smooth regularizers and does not require non-degeneracy.. A global rate of convergence is obtained in [60] but for a modified dynamic where particles are re-sampled at each iteration. Instead, we focus on the basic case where particles are only sampled once at the beginning of the algorithm. It should be mentioned that our analysis is different from the line of research on lazy over-parameterized models [18] initiated by [26, 36], which does not apply to the regularized case and to the unsigned case. Finally, in the parametric case where the unknown measure is assumed to belong to a finite dimensional probability model, Wasserstein natural gradient [2, 41, 16] or accelerated versions [58] have been proposed. Our analysis is however of non-parametric nature because the number of parameters is not fixed a priori in the analysis.
Related techniques.
Our framework involves the theory of optimization on manifolds [1] and of Wasserstein gradient flows [3]. Some inspiration and interpretations of the algorithm under consideration come from unbalanced optimal transport theory [42, 38, 19] and in particular, from the lifting construction in [42]. Finally, our local analysis includes a functional and a gradient Łojasiewicz inequality of order in Wasserstein space. Such inequalities were studied in [34, 7] for displacement convex functions, which does not cover our setting.
1.3 Notation
The set of signed (resp. nonnegative) finite Borel measures on a metric space is denoted by (resp. ). The relative entropy, a.k.a. Kullback-Leibler divergence, is defined for as if is absolutely continuous w.r.t. , and otherwise. The -Wasserstein distance on the set of probability measures with finite -th moment is defined, for as
[TABLE]
where is the set of measures on with marginals and . The distance between compactly supported probabilities is defined as the limit of as and can be directly defined as [53]. We also define the Bounded-Lipschitz norm for a continuous function as where is the Lipschitz constant of and its dual norm on as . For a Riemannian manifold , we denote by the tangent space of at and by the metric at .
2 Particle gradient descent
2.1 General case
Consider a smooth increasing bijection (such as a power function ) and a number of particles . The idea behind particle gradient-based algorithms is to parameterize the unknown measure as and to perform gradient-based optimization on the corresponding objective
[TABLE]
where the parameters of each particle belong to endowed with a specific choice of metric. Clearly, if admits a minimizer that is a mixture of atoms with , then it is sufficient to minimize from Eq. 2 for solving (1). While (2) is finite dimensional, it is typically non-convex with possibly some strict local minima. Still, when is convex and for for , the message from [17] (see Theorem 2.2) is that solving (2) to global optimality with first-order methods is still possible by using over-parameterization, i.e. choosing much larger than . Such a method involve various key hyper-parameters which role is discussed throughout the paper. They include (i) the choice of the function (ii) the choice of the metric on and (iii) the choice of the initialization.
Expression of the gradient.
Under (A1), the objective , seen as a function on the space endowed with the total variation norm, is Fréchet-differentiable. Its differential at can be represented by the function given by
[TABLE]
in the sense that for any , it holds . Now, consider a metric on that is the average of metrics on each factor , where is the set of positive real numbers, of the form
[TABLE]
where and are smooth functions to be specified222Extension of the metric and gradients to the whole of can be made on a case by case basis, see Section 2.2., , and . Using the fact that gradients are characterized by the relation , we get that the gradient of is given, in components, by
[TABLE]
Lifted problem in Wasserstein space.
Assume now that has at most quadratic growth, and that the metric is defined on the whole of . One can then see the discrete problem (2) as a discretization of a problem on the space of probability measures on with finite second moment endowed with the Wasserstein- metric given by
[TABLE]
This point of view leads to insights on the properties of that are independent of , which is crucial for our theoretical analysis. For a measure , we define following [42] the homogeneous projection operator where is characterized by
[TABLE]
for any continuous function . With this operator, we simply have .
Gradient flow.
There are various ways to optimize (2) with first order methods. Instead of directly focusing on a specific method, we first consider the gradient flow of , as it is known that (stochastic) gradient descent [32, 40] approximates this dynamics. Let us call the variable of . A gradient flow of is an absolutely continuous curve in that satisfies
[TABLE]
for , with the gradient given in Eq. (5). Note that if does not tend to [math] as , then the non-negativity constraint on should be explicitly enforced, which requires the notion of subgradient flows, see [17] for details in our setting.
Wasserstein gradient flow.
It is also possible to directly study the optimization dynamics in the space for the functional of Eq. (6). For a measure , consider the vector field on with expression
[TABLE]
We refer to as the Wasserstein gradient of at (this notation emphasizes that it only depends on through ). Gradient flows of are particular cases of Wasserstein gradient flows of . The latter are defined as the absolutely continuous curves in that satisfy
[TABLE]
in the weak sense, which means that for any differentiable function , it holds , for almost every , see [53]. This is a proper extension of the notion of gradient flow for in the sense that if is a gradient flow of then it can be directly checked that is a Wasserstein gradient flow of .
2.2 The conic case
As seen in Eq. (5), the choice of the homogeneity degree and of the metric on determine a specific way to combine the vertical and the spatial components of the gradient (along the variable and , respectively). From now on, we focus on what we refer to as the conic case, which corresponds to the following assumption:
- (A2)
The mass parameterization is and the metric on is of the form Eq. (4) with for some .
The corresponding geodesic distance is where . This metric can be extended as a proper metric on , defined as the set where the subset is identified to a single point, known as the cone metric, which is the canonical way to define a metric on [12]. In our context, identifying to a single point is desirable because a particle located in this set is a “dead” particle carrying no mass.
Plugging the metric into Eq. (5) gives the gradient (extended by continuity to )
[TABLE]
and the Wasserstein gradient is represented by the vector field
[TABLE]
Existence of Wasserstein gradient flows under (A1-2), for any initialization in can be proved along the same lines as in [17], see details in Appendix C.1. Abstracting away its geometric derivation, the important aspects about our choice of gradient (8) are that its leads updates in which are multiplicative and updates in which are independent of . These two properties are crucial for our local convergence analysis (Section 3). Moreover, multiplicative updates enjoy favorable convergence rates (Section 4). The resulting structure and dynamics admits several interpretations.
Transport-growth interpretation.
First, the projection of the gradient flow solves an advection-reaction equation. Importantly, this dynamics depends on only via the initialization , which is a property specific to the conic setting.
Proposition 2.1**.**
Under (A1-2), let be a Wasserstein gradient flow for , with . Then satisfies (in the weak sense)
[TABLE]
Proof.
For any differentiable function , since is a Wasserstein gradient flow it holds
[TABLE]
which is the definition of weak solutions for (9). ∎
When , we recover the gradient flow of for the Fisher-Rao (or Hellinger) metric, which also corresponds to continuous time mirror descent on for the entropy mirror map [39]. When , this is the gradient flow of for the Wasserstein metric [3]. When , this is the gradient flow of the functional for the Wasserstein-Fisher-Rao metric, a.k.a. Hellinger-Kantorovich metric, see e.g. [31]. Under Assumption (A2), the dynamics (7) and (9) are directly related by Proposition 2.1. In the rest of this paper, we present the statements in terms of the projected dynamics , although they also could be stated in terms of . Note that an alternative discretization of the dynamic (9) was proposed in [51] using particle birth-death.
Spherical coordinates interpretation.
Consider the case when is the -dimensional sphere in . Then, the space endowed with the cone metric and are isometric, through the spherical to Euclidean change of coordinates . Identifying with through this isometry, the class of functions of the form on , for is simply the class of -homogeneous functions on .
It follows that the conic setting we consider boils down, when and , to objectives defined on of the form
[TABLE]
with positively -homogeneous. Moreover, the Wasserstein gradient on with the cone metric can be identified with the Wasserstein gradient on with the Euclidean metric. One can thus understand our choice of conic metric and as a way to emulate the structure of -homogeneous problems on in more general situations.
Asymptotic global convergence.
Let us recall the global convergence result of [17, Thm. 3.3], in our setting and notations. We give in Appendix C.1 a simplified proof, enabled by our stronger smoothness assumptions.
Theorem 2.2**.**
Under (A1-2), assume that is convex, that is -times continuously differentiable, that has full support and that the projected gradient flow converges weakly to some . Then is a global minimizer of .
This theorem can be understood as a consistency result for conic particle gradient descent. It also raises several questions: under which conditions does exist? Can we guarantee a convergence rate ? Can we relax the full support condition on the initialization? In this paper, we answer positively to these questions in the particular case of non-degenerate sparse problems.
2.3 Conic particle gradient descent algorithm
Cone compatible retractions.
The definition of discrete gradient descent in a Riemannian setting requires to introduce the notion of retraction. In general, a retraction on a Riemannian manifold with tangent bundle is a smooth map such that its restriction to satisfies and , see [1, Def. 4.1.1]. In our case, we need to slightly adapt the definition to deal with the cone structure.
Definition 2.3**.**
We say that is a retraction compatible with the cone structure, if it satisfies the following:
- (i)
(Retraction property)* It is a proper retraction on . It is not necessarily defined everywhere but there exists such that is defined as long as .* 2. (ii)
(Zero preserving)* It satisfies for some arbitrary measurable .* 3. (iii)
(Homogeneity)* For any , , and satisfying , denoting and , then and .*
These properties are satisfied in the following examples, where denotes any retraction defined on (we give them names for future reference):
- –
the canonical retraction (here );
- –
the mirror retraction , which allows to recover a version of mirror descent when (here );
- –
the induced retraction when is the -sphere, which is the retraction induced by the isometric embedding into , see Section 2.2. It is defined as where (here ). With this retraction, the iterates of gradient descent on with the cone metric can be identified with the iterates of (Euclidean) gradient descent in .
Gradient descent in .
Given a retraction compatible with the cone structure, we define the gradient descent as follows. Let and for define recursively
[TABLE]
where and . The notation stands for the pushforward operator333The pushfoward measure is characterized by for any continuous function .. When is a finite discrete probability measure with uniform weights, this gives Algorithm 1, which is a gradient descent for in the cone metric.
Transport-growth interpretation.
Just like the continuous-time gradient flow, the discrete time gradient descent has a corresponding projected dynamics in . Here the equivalence also relies on the properties of compatible retractions.
Proposition 2.4**.**
Under (A1-2), let be a retraction compatible with the cone structure and let for some . Let . Then, the projected iterates satisfy
[TABLE]
Proof.
First, remark that by Property (i) of Definition 2.3, is well-defined if is small enough and that so . For any continuous function , using Properties (ii)-(iii) of Definition 2.3, we get
[TABLE]
which proves the claim. ∎
Descent property of conic particle gradient descent.
The following lemma shows that, for sufficiently small step-sizes, the iterates (11) are well-defined and monotonously decrease the objective. As usual in optimization, this property is useful to convert results on gradient flows into results on gradient descent.
Lemma 2.5** (Descent property).**
Assume (A1-2) and let be a retraction compatible with the cone structure (Definition 2.3). For any , there exists such that if satisfies then the gradient descent iteration with is well defined for all and satisfies
[TABLE]
Proof.
Let us first look at one step starting from . By Property (i) of Definition 2.3, there exists such that this iteration is well-defined as long as . We first consider and as constants, where (we will see later that they can be upper bounded independently of the iteration ). With the notations of Proposition 2.4, we have where and, in normal coordinates, where the hidden constants are uniform in . It follows that for any twice continuously differentiable , it holds
[TABLE]
In particular, using this expression with where (which have uniformly bounded norms under our assumptions), we get that
[TABLE]
By a first order expansion of , we have for , . Thus, using the expression of from Eq. (3), it follows
[TABLE]
So there exists such that if , we have . Finally, since we have assumed that and is bounded on sublevel sets, the quantities and are finite. By the decrease property we just proved, these quantities decrease after one iteration if . So , which depends on these quantities, can be chosen independently of . ∎
3 Exponential local convergence
We now proceed to the theoretical analysis of the projected gradient flow (9) and projected gradient descent (12) in the conic setting. In light of Propositions 2.1 and 2.4, these dynamics correspond to the gradient flow and gradient descent of , seen through the projection operator .
3.1 Non-degeneracy assumptions
In order to derive global optimality conditions, we assume the following.
- (A3)
The loss is convex.
Commonly used losses that satisfy the smoothness and convexity conditions are the square loss and the logistic loss. Under this assumption, we have existence of minimizers and a global optimality condition.
Proposition 3.1** (Optimality condition).**
Under (A1) and (A3), problem (1) admits minimizers. Moreover, a measure is a minimizer if and only if it holds for all and whenever in the support of .
Proof.
As is assumed positive, the sublevel sets of on are bounded in total variation, and are thus weakly pre-compact. It follows that any minimizing sequence for admits at least one weak limit point , which is a minimizer of (1) since is weakly continuous. The stated optimality condition is equivalent to having for all . The latter is a sufficient optimality condition since by convexity of , . It is also necessary since it holds . ∎
Sparse minimizer.
Our local analysis requires sparsity of the minimizers of the objective , which can be guaranteed a priori in several settings (e.g. [28, 10]).
- (A4)
Problem (1) admits a unique global minimizer on which is of the form with . We denote .
Without loss of generality, we assume for all and whenever , so that is uniquely well-defined, up to re-ordering. Let us fix from now on normal coordinates frames on the neighborhood of each . This allows to identify tensors at with their expression in coordinates and also induces a set of coordinates on the direct sum of the tangent spaces , which is of dimension .
Kernels and non-degeneracy.
We define the global kernel by
[TABLE]
where can be interpreted as the gradient of at . Remark that is defined via the quadratic form associated to the Hessian of at . This interaction kernel appears naturally in the various statistical and optimization analysis of the minimization problem under consideration [28, 56]. We also use the notation for the local kernels for
[TABLE]
expressed in local coordinates. In order to simplify notations, we concatenate these matrices in a large matrix of the same size as defined as
[TABLE]
where here and in the proofs, we use [math] to label the ’s coordinate. The local analysis will be carried under the following non-degeneracy assumptions.
- (A5)
The minimizer is non-degenerate in the sense that is positive definite and, calling the smallest singular value of a linear operator , we have global curvature , local curvature , and strict slackness, i.e. the only points where vanishes are .
The first property is always satisfied if is strictly convex. The second property is satisfied when the kernel associated to the feature function is positive definite. The last two assumptions unfortunately depend on an a priori unknown object , but are often required to perform analysis of Problem (1) [29, 28]. Yet, in some cases, they can be guaranteed to hold, see e.g. [50, 55]. In spite of this drawback, the local analysis leads to interesting qualitative insights on the dynamics in practice, see Section 5.
3.2 Convergence in
A first consequence of these assumptions is that convergence in value implies convergence to minimizers. The distance on that naturally appears in the analysis is the Wasserstein-Fisher-Rao, a.k.a. Hellinger-Kantorovich metric , which is the extension of the Wasserstein metric to unnormalized measures. It admits many equivalent definitions [42, 38, 20], the most suitable to our context being [42, Thm. 7.20]
[TABLE]
where the Wasserstein distance on is defined relative to the cone metric (in this paragraph, with ). The proof of the following result involves the construction of a transport map in the lifted space and is postponed to Appendix D.4.
Proposition 3.2**.**
Under (A1-5), for all , there exists , such that if satisfies then .
3.3 Sharpness of the objective
Our first main result is a lower bound on the squared norm of the gradient in terms of the sub-optimality gap, an inequality known as sharpness, or Polyak-Łojasiewicz inequality [49, 37], which is a special case of Łojasiewicz gradient inequality. It involves the norm of the gradient, which we denote for by
[TABLE]
Theorem 3.3** (Sharpness).**
Under (A1-5), there exists and , such that for all satisfying and , one has
[TABLE]
While the objective is non-convex in the Wasserstein geometry and has typically an infinity of bad stationary points, this inequality guarantees exponential convergence to global minimizers of various gradient-based dynamics as long as their initialization has a small enough objective value. Crucially, the specific structure of does not matter, beyond the fact that is is close enough to optimality: it applies indifferently to discrete and absolutely continuous measures. Once Theorem 3.3 is established, it is straightforward to prove exponential convergence of gradient flow and gradient descent.
Corollary 3.4** (Local convergence of gradient flow).**
Under (A1-5), let and be given by Theorem 3.3. Consider a projected gradient flow for as in Eq. (9). If then
[TABLE]
Proof.
By Theorem 3.3 and direct computations, one has
[TABLE]
and the result follows by Grönwall’s lemma. ∎
Corollary 3.5** (Local convergence of gradient descent).**
Assume (A1-5), let and be given by Theorem 3.3, and let be a retraction compatible with the cone structure (Definition 2.3). There exists such that for any projected gradient descent for following recursion (11), if and , then
[TABLE]
Proof.
By Lemma 2.5, there exists such that if , then . Combining this inequality with Theorem 3.3, one has . Rearranging the terms, we get and the result follows by recursion. ∎
3.4 Proof strategy for the sharpness theorem
The proof of Theorem 3.3, in Appendix D, is based on a local expansion of in terms of some local moments of . For a radius (that shall be fixed at some small enough value in the course of the proof), we define the sets for ,
[TABLE]
We assume that is smaller than and small enough so that these sets together with form a partition of and that the exponential map at has injectivity radius larger than , for . We then say that is an admissible radius.
Definition 3.6** (Local moments).**
Given an admissible radius and a measure , we define for the local masses and the local means if and otherwise. Finally, we define for the weighted biases
[TABLE]
and the weighted covariances .
If has only atom in each then its spatial coordinate is and . When moreover , the optimization reduces to a more classical gradient flow in which local behavior has already been studied [56, 29], but obtaining measures of this form is typically almost as hard as solving the original problem. This decomposition can be reminiscent of proof techniques used to study log-Sobolev inequalities (another type of sharpness inequality in Wasserstein space [7]) in the small temperature regime [46].
It turns out that the local moments of Definition 3.6 are sufficient to characterize the behavior of near optimality. In particular, we have the following approximations for and its gradient around optimality. These formulas are obtained as an intermediate step in the proof of Theorem 3.3 and follow by combining the bounds of Proposition D.4 and Proposition D.5 with Lemma D.3.
Proposition 3.7** (Local expansion).**
Assuming (A1-5), for any it holds
[TABLE]
where and .
3.5 Discussion on the local behavior
Let us now explore what the expansion from Proposition 3.7 teaches us about the local behavior of the dynamics. In order to simplify the discussion, let us fix a small admissible radius and ignore the error terms in Proposition 3.7.
Effect of over-parameterization.
When there is no over-parameterization () and we have a single particle in the neighborhood of each optimal particle, then there is no local variance: for . In this case, we recover the Taylor expansion of around its minimizer
[TABLE]
and the local convergence rate is dictated by the conditioning of . Now, for an arbitrary over-parameterization i.e. but with the support of the solution approximately identified, i.e. , the objective is still entirely characterized locally by the local moments of , since
[TABLE]
This expression gives a clear picture of the energy landscape, so let us comment on it. If we think of the particles in as a cluster, then the first term consists in a global interaction between the clusters, which only depends on the biases of each cluster relatively to their respective ground truth particles. The two other terms are local interactions within each cluster, which are due to the local curvature of at each . Note in particular that the only term in this expansion that penalizes the variance of each cluster consists of local interactions.
Effect of the regularization parameter.
In this paper, the assumption that is non-zero is not crucial as such. Instead the crucial assumption for the local analysis is (A5). Still, this assumption is intimately connected to the regularization: in the signed case (detailed in Appendix A), it is necessary that to have (A5), because with , the minimizer is a global minimizer in the space of signed measures and thus the global optimality condition holds. In fact, a finer analysis of the behavior as is possible in the signed case: it can be shown that one has (emphasizing the dependency in in the notation):
[TABLE]
for some , and [28, Prop. 1 and Thm. 2] (where the result is proved for being the square loss but can be directly generalized to smooth and strongly convex around the minimizer). Under the assumption that is non-degenerate in the sense of (A5), as soon as or for some , the local rate is thus of order and for , the exponential convergence rate is lost. This shows that regularization is necessary for fast local convergence in the signed case, and in particular – remembering the previous paragraph – for the variance of each cluster of particles to vanish quickly. Note that it is an open question to even show local convergence when (A5) does not hold.
Choice of the metric and conditioning.
While our statements, in particular Corollary 3.5, seem to imply that it is best to choose , this is in fact just an artefact of the way the upper bounds are presented, with some hidden constants. Instead, these parameters should be chosen, as usual, so as to make the local expression of above well-conditioned. Without additional information, a possible heuristic is to make the block diagonal matrix well-conditioned by choosing satisfying .
Polynomial dependency.
It can be seen from the proof of Theorem 3.3 that and depend polynomially on the characteristics of the problem, which are the regularization , the regularity parameters of and , the ratio , the inverses of the , , and finally the quantity that quantifies the strict slackness assumption, in the following sense: is such that for any local minimum of , either for some or .
4 Quantitative global convergence
There are several convex optimization-based algorithms that are known to return approximate minimizers of which are mixtures of atoms (with typically ) with a guaranteed complexity, see Section 1.2. Starting from any such approximate minimizer, the results of the previous section imply that conic particle gradient descent converges exponentially fast to minimizers of . However, such a “two-algorithms” approach comes with a drawback: one has to decide when to switch from one algorithm to another. In this section, we show that it is possible to reach global optimality by only performing non-convex gradient descent. This is true under two main conditions: (i) the initialization samples densely enough, and (ii) the ratio is small, at least in the early stages of the algorithm.
4.1 Statement of the main results
In order to state the condition on the initialization, we first choose a reference measure with a smooth positive density, also denoted by , which represents our prior knowledge about the solution . We introduce the quantity (analogous to a log-likelihood)
[TABLE]
It quantifies how good is as a prior for the unknown minimizer and we will see that our convergence bounds are better when is smaller. If nothing is known about the optimal positions , we should choose as a uniform density over for some . Minimizing in suggests to choose .
To obtain an implementable algorithm, we then discretize and consider an initialization which is close to in the distance (our statements do not require to be discrete but this is necessary to obtain an implementable algorithm). We now state our main theorem.
Theorem 4.1** (Global convergence of gradient flow).**
Under (A1-5), let and given by Theorem 3.3, let an absolutely continuous reference measure with -Lipschitz and let , where is the initialization. For any , there exists that only depend on and bounds on the curvature of such that if it holds ,
[TABLE]
then the projected gradient flow initialized with converges to the global minimizer . Denoting it satisfies, for ,
[TABLE]
We also state a similar result for gradient descent, but without tracking the constants. The proof follows the same lines as that of Theorem 4.1 and is given in Appendix F.
Theorem 4.2** (Global convergence of gradient descent).**
Under (A1-5), let and be given by Theorem 3.3 and an absolutely continuous reference measure with Lipschitz. For any and , there exists that depends on the characteristics of the problem and increasingly on and , such that if
[TABLE]
then the projected gradient descent initialized with converges to the global optimum . Denoting it satisfies, for ,
[TABLE]
We can make the following comments:
- –
The non-asymptotic convergence rate does not appear explicitly in Theorem 4.1, because the result is obtained by trading-off various error terms. In an the idealized setting where and , a direct consequence of Lemma 4.3 and Lemma E.1 is that decreases as for the gradient flow and in for the gradient descent in general. For the specific case of the mirror retraction, we show in Appendix G that a faster rate in holds.
- –
The condition on the initialization can be achieved by taking a weighted empirical distribution of samples from (typically the normalized volume measure), and it is known that the rate of convergence in of such approximation is in , see [57]. Unfortunately, this exponential dependence in the dimension is unavoidable when approximating densities in Wasserstein distances [59]. This corresponds to a quantitative version of the condition on the initialization in Theorem 2.2. Also, note that gets smaller as the problem becomes more difficult, in which case the overparameterization must increase, and the convergence speed slows down. In particular, the necessary condition is implicitly implied by our assumptions.
- –
The fact that the sublevel from Theorem 3.3 does not depend on the metric parameters is crucial to prove these theorems. However, the local exponential rate of convergence in Theorem 4.2 may be deceptively bad if is extremely small. An natural fix is to start with a small ratio as required by Theorem 4.2, and to increase this ratio at each iteration so as to improve the conditioning of near optimality. The interest of Theorem 4.2 lies mostly in the qualitative insights it brings. In practice, we would advise to choose , and via heuristics or parameter search rather than trying to derive the constants of Theorem 4.2, which could be deceptively conservative.
4.2 Proof of global convergence for gradient flows
The proof of Theorem 4.1 mostly relies on the the following general lemma which applies to any type of initialization or any structure of minimizers. It gives an upper bound on the optimality gap during along gradient flows in terms of a mirror rate function defined for and as
[TABLE]
This is a continuous and decreasing function of that satisfies
[TABLE]
which is [math] if and only if . When , this function directly controls the rate of convergence of this mirror descent dynamics hence the name mirror rate function.
Lemma 4.3**.**
Assume and that admits a minimizer . Then for all , denoting , it holds for ,
[TABLE]
A direct consequence of this lemma is that is guaranteed to be small as gets smaller and as gets closer to . In Appendix E we give an upper bound on for the situation of interest here, leading to explicit convergence rates when combined with Lemma 4.3.
Proof.
Let be a measure to be specified later that satisfies , and let satisfy for weakly (this is a continuity equation with a smooth velocity field which admits a unique weak solution). Differentiating the relative entropy with respect to its second argument and using the invariance of the relative entropy under diffeomorphisms, it holds, for ,
[TABLE]
where the first term comes from the convexity of and the second from the definition of . After integrating in time and rearranging the terms we get
[TABLE]
For the last integral term, we use the triangular inequality
[TABLE]
where the last term is obtained by bounding the integrated flow of the velocity field . Since and is decreasing, it follows
[TABLE]
Proof of Theorem 4.1 (gradient flow).
By Lemma E.1, we have for , by writing ,
[TABLE]
Combining this bound with Lemma 4.3, we get that for ,
[TABLE]
In particular, for , we get
[TABLE]
Since this is valid only when , we require which leads to the first condition on . Now, we want the right-hand side of (16) to be smaller than so that we can conclude with Corollary 3.4. To this end, we require, on the one hand . On the other hand, we use the bound for , require and obtain the condition
[TABLE]
This leads to the second condition on is the theorem. ∎
4.3 Fully non-convex gradient descent
The results in the previous section require to set at a small initial value. This might appear undesirable because the asymptotic convergence result of Theorem 2.2 holds irrespective of the choice of . Also, in practice, this condition does not seem required, at least in the examples that we have considered (see Section 5). While the proof technique from Section 4.2 fails without controlling , the question of wether it is possible to obtain convergence rates for any ratio is a natural one.
For such a result, the key challenge is to obtain a convergence rate for the gradient flow dynamics (9) when initialized with a positive density, without conditions on . While we were not able to prove such a result, in order to point out at the theoretical difficulty, we show in Appendix H with a proof technique inspired by [60], that a convergence rate in objective value in holds as long as the density is lower bounded by some (at least on a certain subset of ).
Proposition 4.4**.**
Under (A1-3), for any , there exists such that for any and satisfying , if the projected gradient flow (9) satisfies for ,
[TABLE]
where , then
Unfortunately, this result is not sufficient to obtain a convergence rate because the lower bound on the density may decrease too fast. When this happens, the gradient flow may stagnate an a priori unbounded time in neighborhoods of saddle points, although it is guaranteed to eventually escape by Lemma C.1. Note that the result above does not requires to be finite dimensional nor while this would be needed for a proof based on the positive definiteness of the tangent kernel [36].
5 Numerical experiments
All experiments can be reproduced with the Julia code available online444https://github.com/lchizat/2019-sparse-optim-measures. Our goal here is not to demonstrate the superiority of Algorithm 1 over other algorithms, but rather to illustrate the insights obtained by the analysis. We consider the following problems introduced in Section 1.1 :
- –
(Sparse deconvolution) We consider the Dirichlet low-pass filter of order on the -torus with values in i.e. when . We use the square-loss and solve problem (1) with conic particle gradient descent (Algorithm 1) with the “mirror retraction” from Section 2.3.
- –
(Two-layer neural net) We consider the function which is -homogeneous on with . We use the square loss and solve problem (1) with stochastic gradient descent with a small fixed step-size for an input data distribution uniform on the sphere . This corresponds to a stochastic version of Algorithm 1 with the “induced retraction” from Section 2.3. For our purposes, the advantage of this architecture over classical ReLU neural networks (as presented in Section 1.1) is that here is differentiable on (see, e.g. [17, Lem. D.5]).
We focus in both cases on the “teacher-student” setting without noise with the square loss, because it guarantees that even the unregularized problem () has sparse solutions, in spite of being infinite dimensional. We thus have where and is the number of atoms for the teacher.
Local convergence rate.
We observe on Figure 3 the effect of the regularization parameter and of the over-parameterization parameter on the local convergence rates (in distance – approximated by mapping each particle to its final position/mass – or in optimality gap). In accordance with the expansion of Proposition 3.7, we observe exponential convergence whenever , with a rate that improves as increases. For sparse deconvolution, we observe fast exponential convergence when which is explained by only the first term in the local expansion (13) being non-zero. By adding just a single particle, the second term comes into play and the behavior is qualitatively similar than with particles. For Figure 3-(c), the initialization is random and . Here the behavior for follows that of which suggests that the first term in the local expansion of Eq. (13) dominates.
Global convergence.
We observe on Figure 4 the effect on the success/failure of optimization of the two main parameters that appear in Theorem 4.1: the over-parameterization parameter (used to decrease the criterion) and the ratio of the vertical/spatial step-sizes . In both (a) and (b) we have and , and the final loss is averaged over random experiments. Without surprise, minimizers cannot be reached when is too small. It is also observed that increasing increases the chances of success even when . In contrast, these experiments do not reveal a clear role for , beyond a change in the convergence speed (see Section 4.3).
Comparison of vertical geometries.
Finally, we compare on Figure 5 the behavior of mirror descent against that of Euclidean descent (here integrated with ISTA algorithm [22]). This corresponds respectively to and in Eq. 2 and . We consider the problem of recovering a single spike () for 1D and 2D sparse deconvolution, starting from the uniform measure on densely sampled on a grid (). We report the behavior in early stages of optimization, before the effect of the discretization comes into play. We observe that mirror descent outperforms Euclidean descent and enjoys a convergence rate of order around iteration number . This is in accordance with the result of Appendix G, where we show a convergence rate for mirror descent with continuous densities in , independent of the dimension. The difference in behavior is illustrated on Figure 5-(c) where we plot (in the setting of panel (a)).
6 Conclusion
In this paper, we have studied particle gradient descent for sparse convex optimization on measures and obtained complexity guarantees under non-degeneracy assumptions. One central idea underlying our analysis is to directly study the iterates in Wasserstein space. We believe that this approach, at the crossroads between analysis and optimization, may lead to other insights for over-parameterized and non-convex gradient descent.
An avenue for future research is to study the unregularized case. This may require to exploit finer properties of the problem than mere smoothness and could improve our understanding of the implicit bias of over-parameterized gradient descent. Another important question is to find theoretical explanations for the favorable behavior observed in high dimensions for two layer neural networks optimization.
Acknowledgments
The author thanks Francis Bach for fruitful discussions related to this work and the anonymous referees for their thorough reading and suggestions.
Appendix A Dealing with signed measures
Let us show that problems over signed measures with total variation regularization are covered by problem (1), after a suitable reformulation. Consider a function and the functional on signed measures defined as
[TABLE]
where is the total variation of . This is a continuous version of the LASSO problem, known as BLASSO [23]. Define as the disjoint union of two copies and of and define the symmetrized function as
[TABLE]
With this choice of , minimizing (17) or minimizing (1) are equivalent, in a sense made precise in Proposition A.1. This symmetrization procedure, also suggested in [17], is simple to implement in practice: in Algorithm 1, we fix at initialization the sign attributed to each particle — depending on whether it belongs to or — and do not change it throughout the iterations.
Proposition A.1**.**
The infima of (17) and (1) are the same and:
- (i)
if is a minimizer of and is its Jordan decomposition, then the measure which restriction to (resp. ) coincides with (resp. ) is a minimizer of ; 2. (ii)
reciprocally, if is a minimizer of then where (resp. ) is the restriction of to (resp. ) is a minimizer of .
Proof.
We recall that for any decomposition of a signed measure as the difference of nonnegative measures , it holds , with equality if and only if is the Jordan decomposition of [21, Sec. 4.1]. It follows that starting from any , the construction in (i) yields a measure satisfying . Also, starting from any , the construction in (ii) yields a measure satisfying , with equality if and only if is a Jordan decomposition. The conclusion follows. ∎
Appendix B Generic non-convex minimization
In this section, we show that any smooth optimization problem on a manifold is equivalent to solving a problem of the form (1). This corresponds to the case of a scalar-valued .
Proposition B.1**.**
Let be a smooth function with minimum that admits a global minimizer, and let
[TABLE]
where . Then so minimizers of can be built from . Reciprocally, from a minimizer of , one can build a minimizer for (18).
Proof.
For a measure , we define . It holds
[TABLE]
Now suppose that is a global minimizer of . Then the optimality condition in Proposition 3.1 implies that
[TABLE]
Solving for is possible if and leads to . We also deduce from the fact that that , and so . It remains to find under which condition . We use the fact that in Equation (19), and get
[TABLE]
which in particular satisfies . Thus, as long as , we have . Finally, we verify that global minimizers exist, so that the above reasoning makes sense. If , then satisfies the global optimality conditions. Otherwise, choose a minimizer for and define with the value above for , which also satisfies the global optimality conditions. ∎
Appendix C Wasserstein gradient flow
In this section, we recall and adapt some results and proofs from [17], for the sake of completeness.
C.1 Existence
For this result, we assume (A1-2). For a compactly supported initial condition , the proof of existence for Wasserstein gradient flows (Eq. (7)) in [17] goes through, as it is simply based on a compactness arguments which can be directly translated to this Riemannian setting (more precisely, we apply here Arzelà-Ascoli compactness criterion for curves in the Wasserstein space on the cone of , which is a complete metric space [42]). Note that these arguments do not require convexity of , but in order to guarantee global existence in time, we need to assume that is bounded in sub-level sets of .
For the existence of solutions for projected dynamics on for any , consider a measure such that (see [42] for such a construction) and the corresponding Wasserstein gradient flow for . Then is a solution to (9).
For the existence of Wasserstein gradient flows (Eq. (7)) for when is not compactly supported, proceed as follows: there exists a Wasserstein-Fisher-Rao gradient flow satisfying . Now we can simply define as the solution to . It can be directly checked that for and thus is a solution to Eq. (7).
We do not attempt to show uniqueness in the present work. Note that it is proved in [17] for the case where is a sphere, by applying the theory developed in [3].
C.2 Asymptotic global convergence
In this section, we give a short proof of Theorem 2.2, adapted from [17]. The next lemma is the crux of the global convergence proof. It gives a criterion to espace from the neighborhood of measures which are not minimizers.
Lemma C.1** (Criteria to espace local minima).**
Under (A1-3), let be such that . Then there exists and such that if is a projected gradient flow of satisfying for some and then there exists such that .
Proof.
We first assume that takes nonnegative values and let be a regular value of , i.e. be such that does not vanish on the level-set of . Such a is guaranteed to exist thanks to Morse-Sard’s lemma and our assumption that is -times continuously differentiable, which implies that is the same. Let be the corresponding sublevel set. By the regular value theorem, the boundary of is a differentiable orientable compact submanifold of and is orthogonal to . By construction, it holds for all , and, for some , by the regular value property, for all where is the unit normal vector to pointing outwards. Since the map is locally Lipschitz as a map , there exists such that if satisfies , then
[TABLE]
Now let us consider a projected gradient flow such that and let be the first time such that , which might a priori be infinite. For , it holds
[TABLE]
where the first inequality can be seen by using the “characteristic” representation of solutions to (9), see [44]. It follows by Grönwall’s lemma that which implies that is finite. Finally, if we had not assumed that [math] is in the range of in the first place, then we could simply take and conclude by similar arguments. ∎
Proof of Theorem 2.2.
Let be the weak limit of . It satisfies the stationary point condition . Then by the optimality conditions in Proposition 3.1, either is a minimizer of , or is not nonnegative. For the sake of contradiction, assume the latter. Let be given by Lemma C.1 and let which is finite since we have assumed that weakly converges to . But has full support since it can be written as the pushforward of a rescaled version of by a diffeomorphism, see [44, Eq. (1.3)] (note that this step is considerably simplified here by the fact that we do not have a potentially non-smooth regularizer, unlike in [17] where topological degree theory comes into play). Then the conclusion of Lemma C.1 contradicts the definition of . ∎
Appendix D Proof of the gradient inequality
In this whole section, we consider without loss of generality (we explain in Section D.7 how to adapt the results to arbitrary ). For simplicity, we only track the dependencies in and . Any quantity that is independent of and is treated as a constant and represented by , and the quantity these symbols refer to can change from line to line.
D.1 Bound on the transport distance to minimizers
Given a measure , we consider the local centered moments introduced in Definition 3.6 and in addition, for ,
[TABLE]
Finally, we will quantify errors with the following quantity
[TABLE]
which also controls the distance (introduced in Section 3.1) to the minimizer of , as shown in the next proposition.
Lemma D.1**.**
It holds .
Proof.
Note that for small enough, it holds for . Let be such that and consider the transport map defined as
[TABLE]
By construction, it holds . Let us estimate the transport cost associated to this map
[TABLE]
The geodesic distance associated to the cone metric is
[TABLE]
Now, if we only consider points with their coordinates in a normal frame centered at (note that in all other proofs, we do not need to distinguish between and ), we have the approximation
[TABLE]
Let us decompose as and estimate the two contributions forming separately. On the one hand, we have
[TABLE]
On the other hand, we have
[TABLE]
As a consequence, we have . Remark that this estimate does not depend on the chosen lifting satisfying . We then conclude by using the characterization in [42, Thm. 7.20] for the distance :
[TABLE]
Thus , and the result follows. ∎
D.2 Local expansion lemma
Lemma D.2** (Expansion around ).**
Let be any (vector or real-valued) smooth function on and . If is an admissible radius, then the following first and second-order expansions hold
[TABLE]
where is the remainder in the -th order Taylor expansion of around in local coordinates (and we recall that ).
Proof.
By a Taylor expansion of around for , it holds
[TABLE]
and substracting yields
[TABLE]
where we have used a bias-variance decomposition for the quadratic term. The result follows by summing the integrals over each and using the expression of . ∎
D.3 Bound on the distance to minimizers
In the next lemma, we globally bound the quantity from Eq. (20) in terms of the function values. It involves the quantity which is such that for any local minimum of , either for some or (which is non-zero under (A5)). We also recall that , as defined in Section D.1.
Lemma D.3** (Global distance bound).**
Under (A1-5), let be an admissible radius as in Definition 3.6, fix some and let
[TABLE]
Then there exists such that for all and such that , it holds
[TABLE]
Proof.
Let us write and . By strong convexity of at , and optimality of , there exists such that for all it holds
[TABLE]
To prove the first claim, we thus have to bound using the terms in the right-hand side of (21).
Step 1.
By a Taylor expansion, one has for for ,
[TABLE]
Thus, if , then for . Decomposing the integral of this quadratic term into bias and variance, we get
[TABLE]
and we deduce a first bound by summing the terms for ,
[TABLE]
Step 2.
In order to lower bound the integral over , we first derive a lower bound for on . This is a continuously differentiable and nonnegative function on a closed domain so its minimum is attained either at a local minima in the interior of or on its boundary. Using the quadratic lower bound from the previous paragraph, it follows that for ,
[TABLE]
Thus, if we also assume that then for and it follows that
[TABLE]
Using inequality (21) we have shown so far that
[TABLE]
Notice that is similar to but it does not contain the terms controlling the deviations of mass . These quantities can be controlled by using the coercivity of , i.e. the last term in (21), as we do now.
Step 3.
Using the first order expansion of Lemma D.2 then squaring gives
[TABLE]
Since we have assumed that is positive definite, it follows
[TABLE]
and thus, after rearranging the terms
[TABLE]
It follows that . Also, by inequality (21), if , then . Moreover, by inequality (22), we get
[TABLE]
We finally combine with the bound on to conclude since ∎
D.4 Proof of the distance inequality (Proposition 3.2)
By Lemma D.1, it holds
[TABLE]
Moreover, by Lemma D.3, there exists and such that
[TABLE]
Combining these two lemmas, it follows that for some , we have
[TABLE]
This also implies a control on the Bounded-Lipschitz distance since it holds , see [42, Prop. 7.18].
D.5 Local estimate of the objective
We now prove a local expansion formula for .
Proposition D.4** (Local expansion).**
It holds
[TABLE]
where . In particular, if is fixed small enough,
[TABLE]
Proof.
Let us write and . By a second order Taylor expansion of around , we have
[TABLE]
Using the first order expansion of Lemma D.2 for , we get . Also, using the second order expansion of Lemma D.2 for and using the fact that and its gradient vanish for all , we get
[TABLE]
and the expansion follows. Notice also that in the expression of , and are interchangeable up to introducing higher order error, since (and also ). ∎
D.6 Local estimate of the gradient norm
Proposition D.5** (Gradient estimate).**
For , it holds
[TABLE]
where . In particular, if is fixed small enough
[TABLE]
Proof.
For this proof, we write where
[TABLE]
where the decomposition follows from Lemma D.2. The expression for the norm of the gradient is as follows:
[TABLE]
where . We start with the following decomposition for (recall that ):
[TABLE]
Here we use the notation to denote the quadratic form associated to . Thanks to the optimality conditions for , we get
[TABLE]
where collects the higher order terms and is defined as
[TABLE]
where if and if . Expanding the square gives the following ten terms:
[TABLE]
Terms (I) to (II) are the main terms in the expansion, while the other terms are higher order. The term (I) is a local curvature term and can be expressed as . The term (II) is a global interaction term that writes
[TABLE]
where the entries of and differ from those of and by a factor . More precisely,
[TABLE]
and similarly for . Since we have . It follows, by expanding the square, that
[TABLE]
The remaining terms are error terms, that we estimate directly in terms of and . We use in particular the fact that by Hölder’s inequality, . One has
- •
;
- •
because the integral of the terms vanishes;
- •
;
- •
;
- •
;
- •
;
- •
.
It follows that overall, the error term is in . There remains to lower bound the norm of the gradient over , which can be done as follows. As seen in the proof of Lemma D.3, if is small enough then for . Considering only the first component of the gradient, it holds
[TABLE]
Using the expansion , we get
[TABLE]
The result follows by collecting all the estimates above. ∎
D.7 Proof of the sharpness inequality (Theorem 3.3)
By Proposition D.4 we have that for small enough
[TABLE]
where .
Similarly, by Proposition D.5, for small enough, it holds
[TABLE]
where . Now fix satisfying the hypothesis of Lemma D.3 and the two previous inequalities. By Lemma D.3, . We deduce that there exists and , such that whenever satisfies , one has
[TABLE]
Finally, notice that if different metric factors are introduced, one can always lower bound the new gradient squared norm as
[TABLE]
which proves the statement for any . Note however that if one wants to make a more quantitative bound, then there are values that would lead to a better conditioning and potentially higher values for . In this case, the factor appearing in the sharpness inequality should rather be .
Appendix E Estimation of the mirror rate function
We provide an upper bound for the mirror rate function in the situation that is of interest to us, with sparse. Note that this approach could be generalized to arbitrary .
Lemma E.1**.**
Under (A1), there exists that only depends on the curvature of , such that for all where and where is -Lipschitz, then
[TABLE]
Moreover, for any other , it holds
In the context of Lemma E.1, we introduce the quantity,
[TABLE]
which measures how much is a good prior for the (a priori unknown) minimizer . With this quantity, the conclusion of Lemma E.1 reads, for ,
[TABLE]
Proof.
Let us build in such a way that the quantity defining in Eq. (15) is small. For this, consider a radius and consider the measure defined as the normalized volume measure on each geodesic ball of radius around each , with mass on this ball, and vanishing everywhere else. Using the transport map that maps these balls to their centers , we get if is flat,
[TABLE]
where is the volume of a ball of radius in , that scales as . Using an integration by parts, it follows
[TABLE]
thus . In the general case where is a potentially curved manifold, this upper bound also depends on the curvature of around each , a dependency that we hide in the multiplicative constant so . Let us now control the entropy term. Writing and for the geodesic ball of radius around , it holds
[TABLE]
The integral term can be estimated as follows,
[TABLE]
Recalling that for some that only depends on the curvature of , we get that the right-hand side of (15) is bounded by
[TABLE]
Let us fix by minimizing , which gives . The first claim follows by plugging this value for in the expression above.
For the second claim of the statement, let us build a suitable candidate in order to upper bound the infimum that defines . Let be an optimal transport map from to for , i.e. a measurable map satisfying and (see [53, Sec. 3.2], the absolute continuity of is sufficient for such a map to exist). Now we define where is such that . Since the relative entropy is non-increasing under pushforwards, it holds . Moreover, it holds . Thus we have
[TABLE]
The claim follows by noticing that, by construction, and then by taking the infimum in . ∎
Appendix F Global convergence for gradient descent
In the following, result, we study the non-convex gradient descent updates and where
[TABLE]
with step-sizes . When , we recover mirror descent updates in with the entropy mirror map (more specifically, this is true when is the “mirror” retraction defined in Section 2.3).
Lemma F.1**.**
Assume and that admits a minimizer . Then there exists such that for all , denoting , if , it holds
[TABLE]
Proof.
As in the proof of Lemma 2.5, we define and we define recursively where is such that . Using the invariance of the relative entropy under diffeomorphisms (indeed, is a diffeomorphism of for small enough), and doing a first order expansion of it holds for small enough
[TABLE]
where the term in originates from a first order approximation of the retraction. Now, taking small enough to ensure decrease of (by Lemma 2.5) so that above can be chosen independently of , it follows
[TABLE]
by bounding each term by . ∎
Proof of Theorem 4.2 (gradient descent).
The proof follows closely that of Theorem 4.1 but we do not track the “constants” (this would be more tedious). By Lemma E.1, there exists (that depends on , the curvature of and ) such that . Combining this with Lemma F.1, we get that when ,
[TABLE]
Our goal is to choose and so that this is quantity smaller than . With and we get
[TABLE]
Then, using a bound , we may choose , and in order to have . This gives , and the regime of exponential convergence kicks off after iterations. ∎
Appendix G Faster rate for mirror descent
In this section, we show that for a specific choice of retraction, the convergence rate of for the gradient flow is preserved for the gradient descent.
Proposition G.1** (Mirror flow, fast rate).**
Assume (A1-4) and consider the infinite dimensional mirror descent update
[TABLE]
which corresponds to the so-called mirror retraction in Section 2.3 and . For any , there exists such that for it holds, denoting ,
[TABLE]
In particular, combining with Lemma E.1, if has a smooth positive density, then .
Proof.
Consider such that . It holds
[TABLE]
where the first equality is obtained by rearranging terms in the definition of , and the second one is specific to the mirror retraction. Let us estimate the two terms in the right-hand side. Using convexity inequalities, we get
[TABLE]
Here the term in comes from the proof of Lemma 2.5 (note that the iterates remain in a sublevel of for small enough). As for the relative entropy term, we have, using the convexity inequality ,
[TABLE]
We use this inequality in place of the strong convexity of the mirror function used in the usual proof of mirror descent (because there is no Pinsker inequality on ). Coming back to the first equality we have derived, it holds,
[TABLE]
Thus for small enough, it holds
[TABLE]
Summing over iterations and dividing by , we get
[TABLE]
Since for small enough is decreasing (by Lemma 2.5), the result follows. ∎
Appendix H Convergence rate for lower bounded densities
In this section, we justify the claim made in Section 4.3 about the convergence without condition on . Let us recall the result that we want to prove.
Proposition H.1**.**
Under (A1-3), for any , there exists such that for any and satisfying , if the projected gradient flow (9) satisfies for ,
[TABLE]
where , then
Proof.
Following [60], we start with the convexity inequality
[TABLE]
Let us control these two terms separately. On the one hand, one has by Jensen’s inequality
[TABLE]
Using the fact that on sublevels of , and are bounded, we have, for some ,
[TABLE]
On the other hand, we have
[TABLE]
where the last equality defines . Using the gradient flow structure, let us show that a non-zero and a lower bound on the density of (at least on the set }) guarantees a decrease of the objective. Indeed, letting (which could be empty), we get
[TABLE]
Moreover, the Lipschitz regularity of is bounded on sublevels of , and thus along gradient flow trajectories, so there exists such that . It follows
[TABLE]
Coming back to our first inequality, we have
[TABLE]
for some that, given , is independent of and . It remains to remark that a continuously differentiable and positive function that satisfies satisfies and, after integrating between [math] and , . We conclude by taking and . ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P.-A. Absil, Robert Mahony, and Rodolphe Sepulchre. Optimization algorithms on matrix manifolds . Princeton University Press, 2009.
- 2[2] Shun-Ichi Amari. Natural gradient works efficiently in learning. Neural computation , 10(2):251–276, 1998.
- 3[3] Luigi Ambrosio, Nicola Gigli, and Giuseppe Savaré. Gradient flows: in metric spaces and in the space of probability measures . Springer Science & Business Media, 2008.
- 4[4] Francis Bach. Breaking the curse of dimensionality with convex neural networks. The Journal of Machine Learning Research , 18(1):629–681, 2017.
- 5[5] Francis Bach, Rodolphe Jenatton, Julien Mairal, and Guillaume Obozinski. Optimization with sparsity-inducing penalties. Foundations and Trends® in Machine Learning , 4(1):1–106, 2012.
- 6[6] Amir Beck and Marc Teboulle. Mirror descent and nonlinear projected subgradient methods for convex optimization. Operations Research Letters , 31(3):167–175, 2003.
- 7[7] Adrien Blanchet and Jérôme Bolte. A family of functional inequalities: Łojasiewicz inequalities and displacement convex functions. Journal of Functional Analysis , 275(7):1650–1673, 2018.
- 8[8] Nicholas Boyd, Geoffrey Schiebinger, and Benjamin Recht. The alternating descent conditional gradient method for sparse inverse problems. SIAM Journal on Optimization , 27(2):616–639, 2017.
