Adaptive and Compressive Beamforming Using Deep Learning for Medical Ultrasound
Shujaat Khan, Jaeyoung Huh, Jong Chul Ye

TL;DR
This paper introduces a deep learning-based beamformer for ultrasound imaging that adaptively processes full or sub-sampled RF data, significantly enhancing image quality across various measurement conditions and channel configurations.
Contribution
It presents a novel deep neural network approach that improves adaptive beamforming in ultrasound by handling diverse data sampling patterns with a single model.
Findings
Enhanced image resolution and contrast-to-noise ratio.
Robust performance across different subsampling rates.
Theoretical analysis of input-dependent adaptivity.
Abstract
In ultrasound (US) imaging, various types of adaptive beamforming techniques have been investigated to improve the resolution and contrast-to-noise ratio of the delay and sum (DAS) beamformers. Unfortunately, the performance of these adaptive beamforming approaches degrade when the underlying model is not sufficiently accurate and the number of channels decreases. To address this problem, here we propose a deep learning-based beamformer to generate significantly improved images over widely varying measurement conditions and channel subsampling patterns. In particular, our deep neural network is designed to directly process full or sub-sampled radio-frequency (RF) data acquired at various subsampling rates and detector configurations so that it can generate high quality ultrasound images using a single beamformer. The origin of such input-dependent adaptivity is also theoretically…
Click any figure to enlarge with its caption.
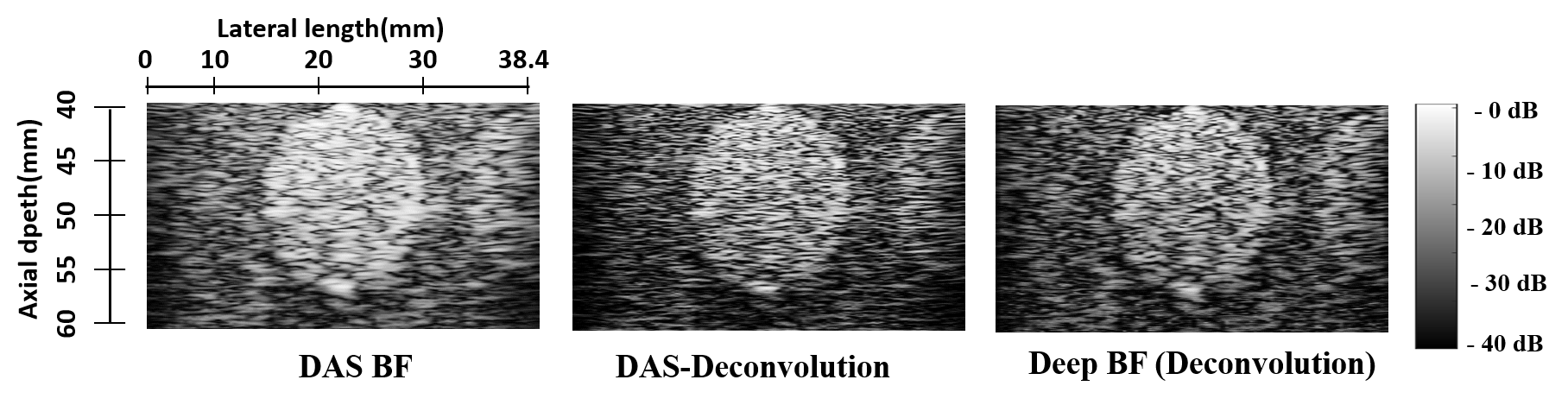 Figure 1
Figure 1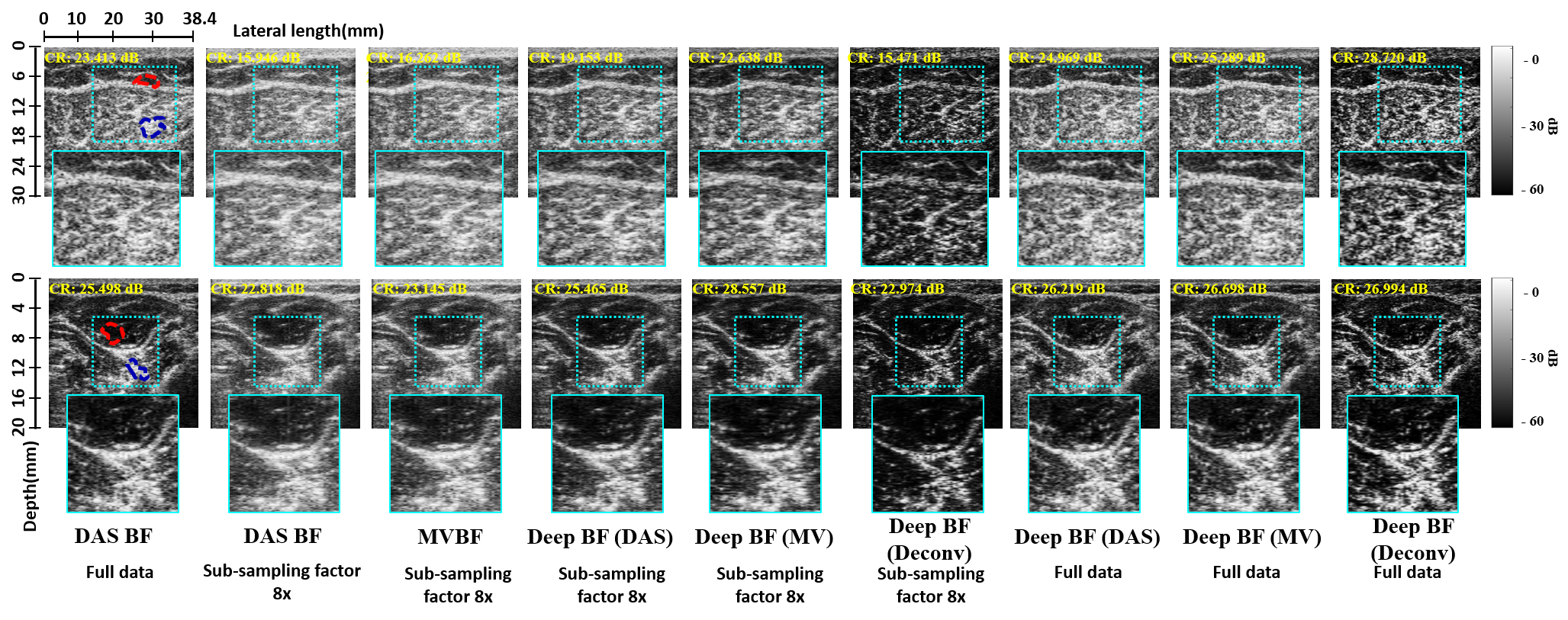 Figure 2
Figure 2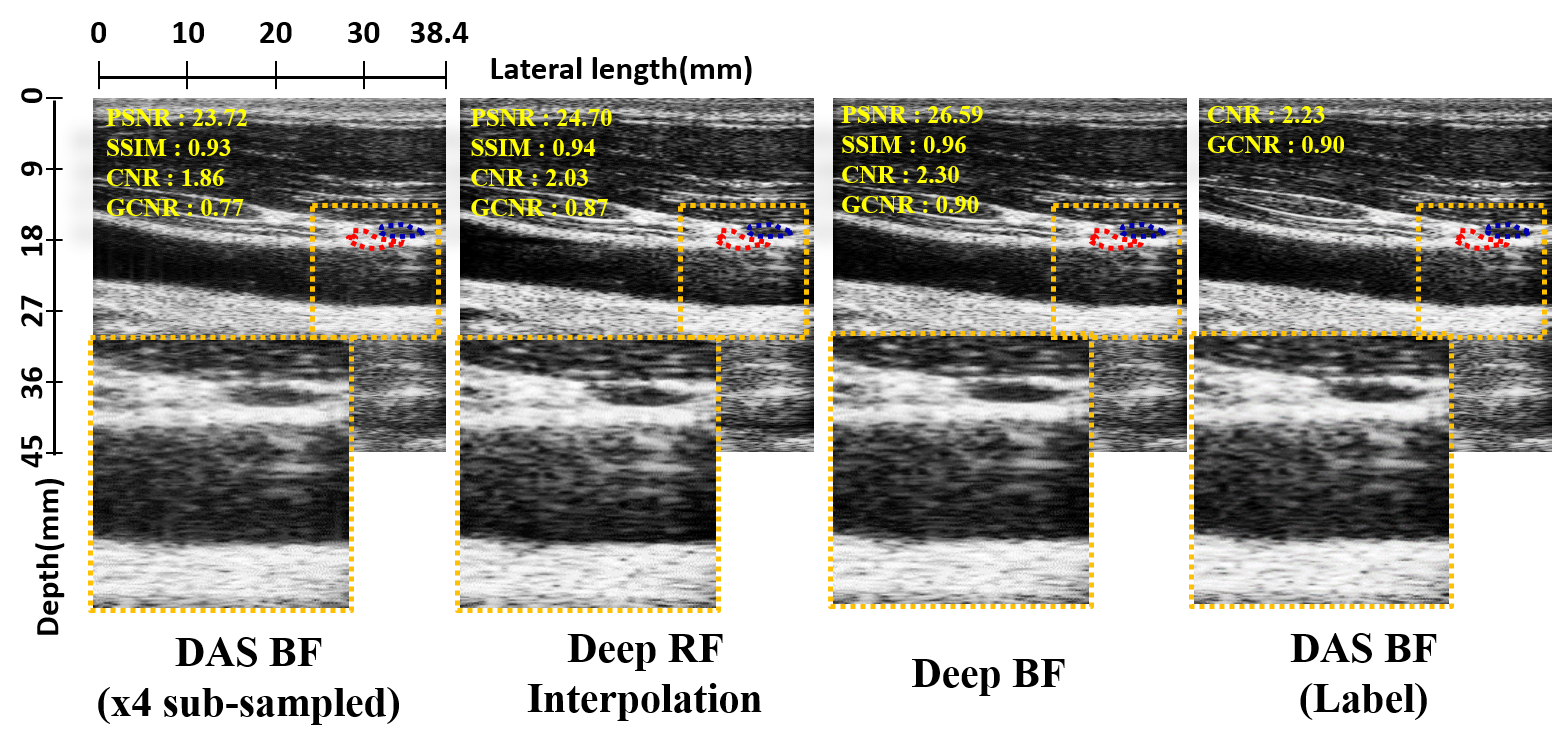 Figure 3
Figure 3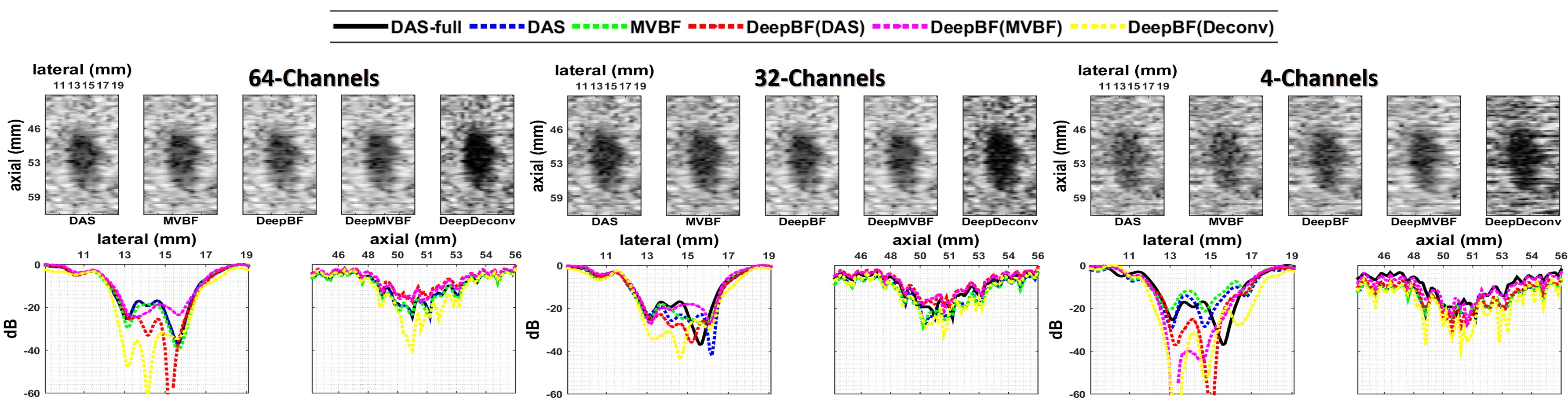 Figure 4
Figure 4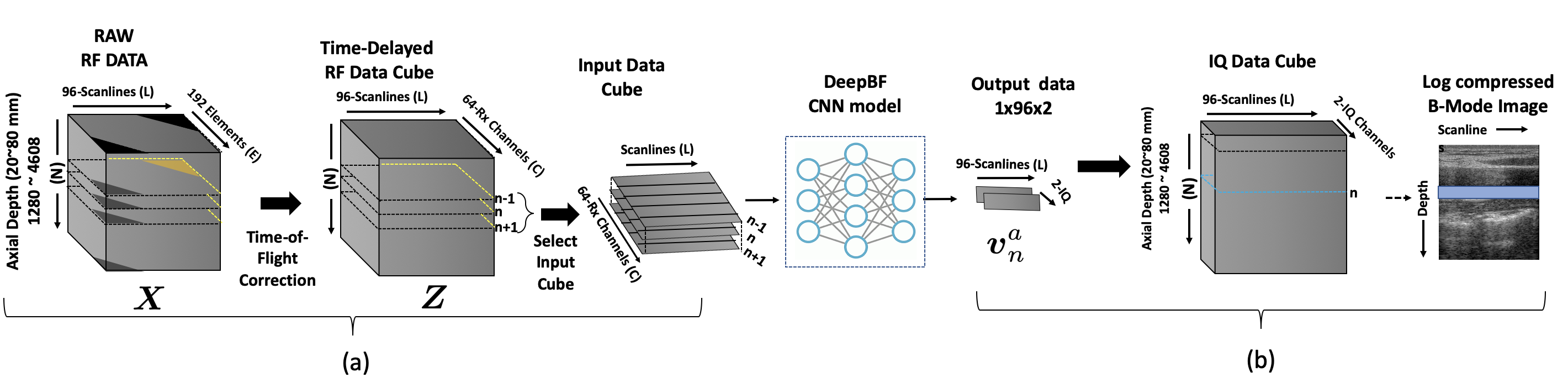 Figure 5
Figure 5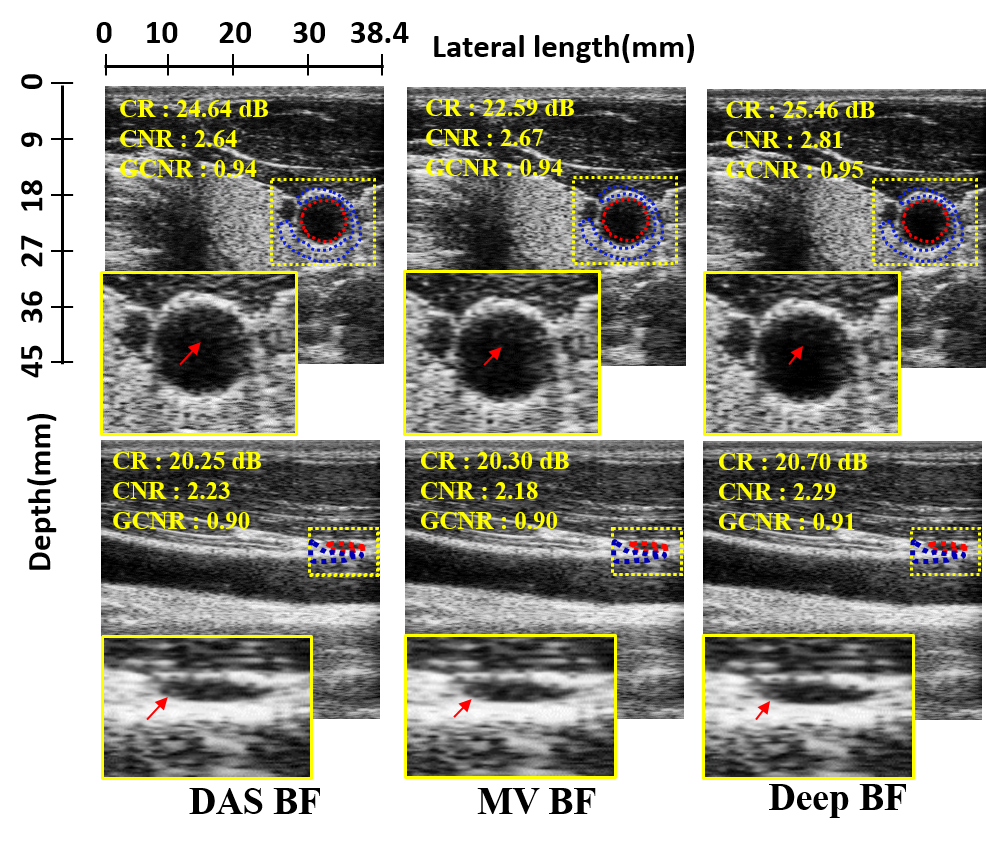 Figure 6
Figure 6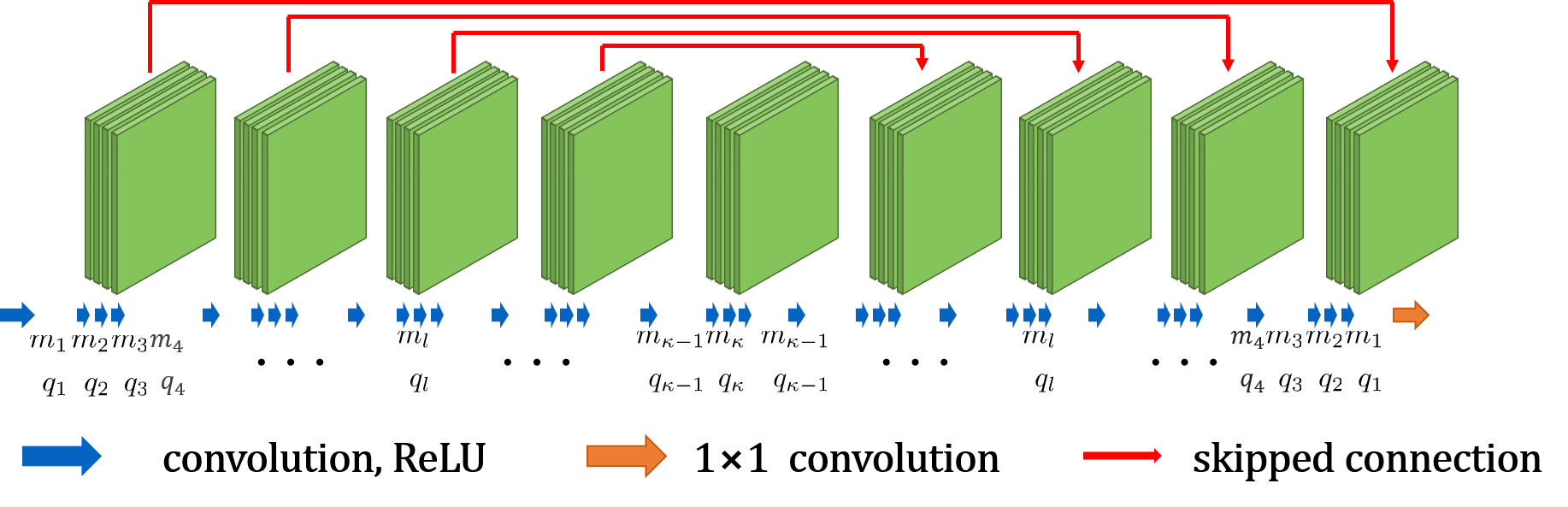 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11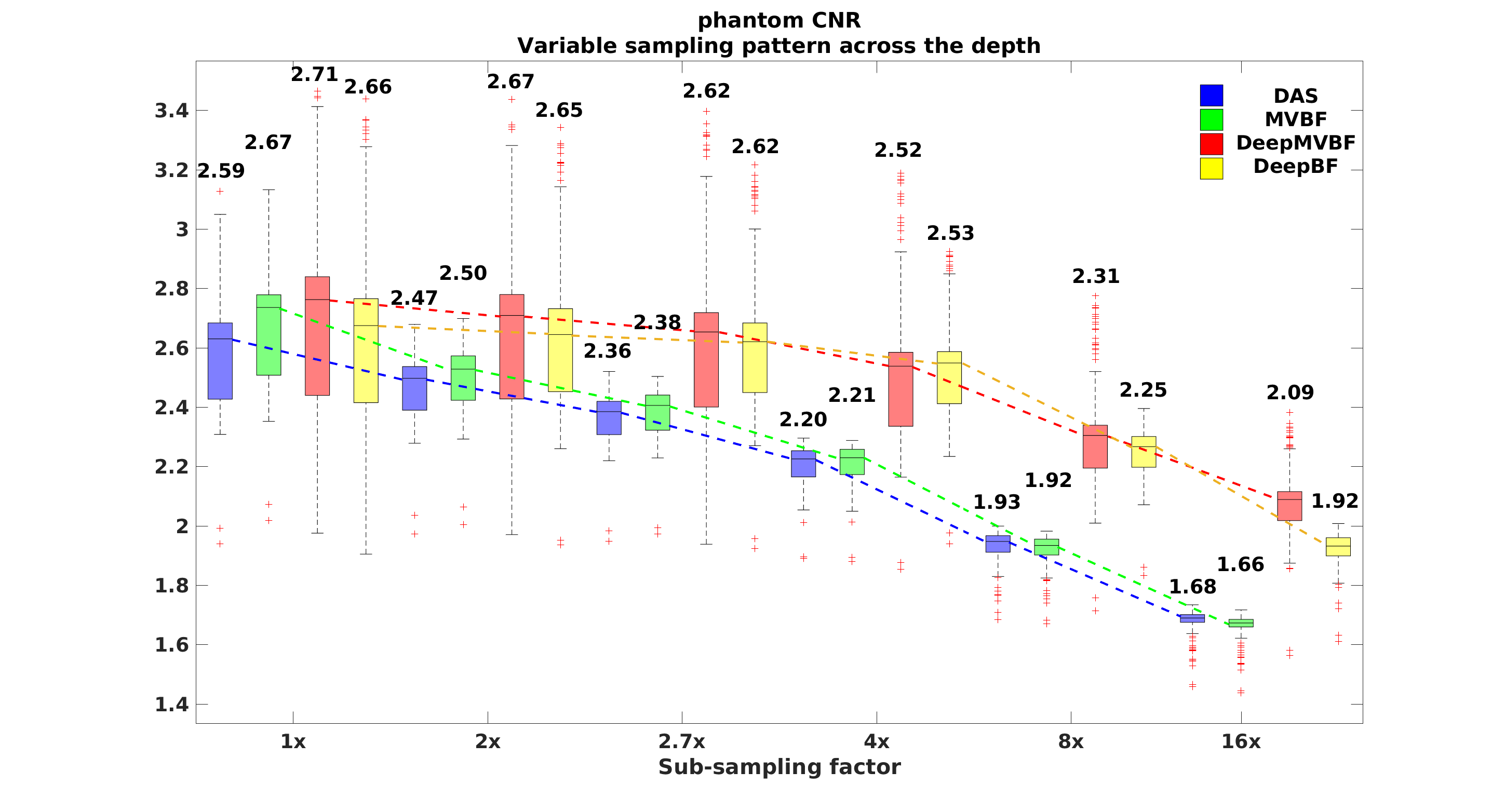 Figure 12
Figure 12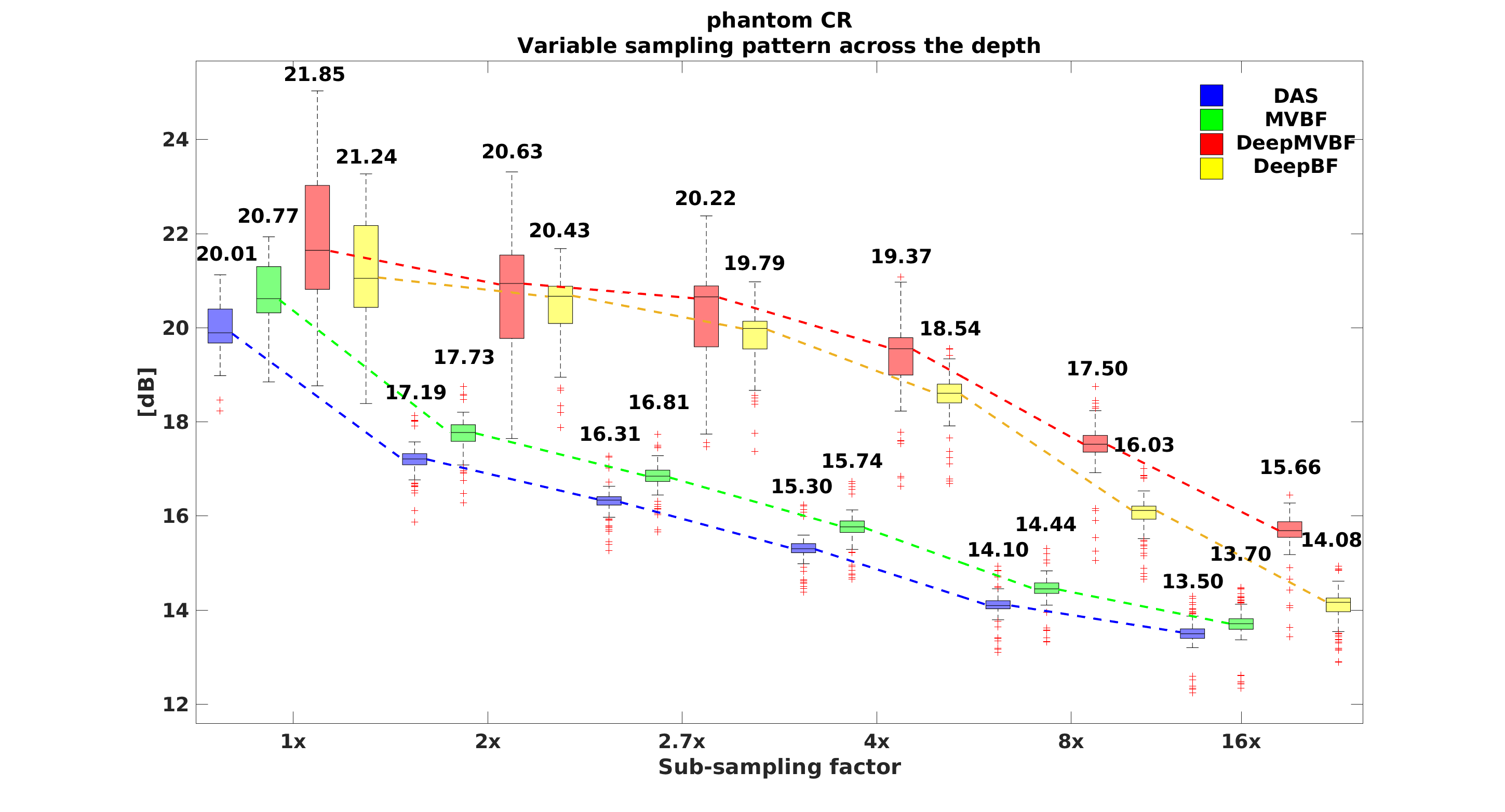 Figure 13
Figure 13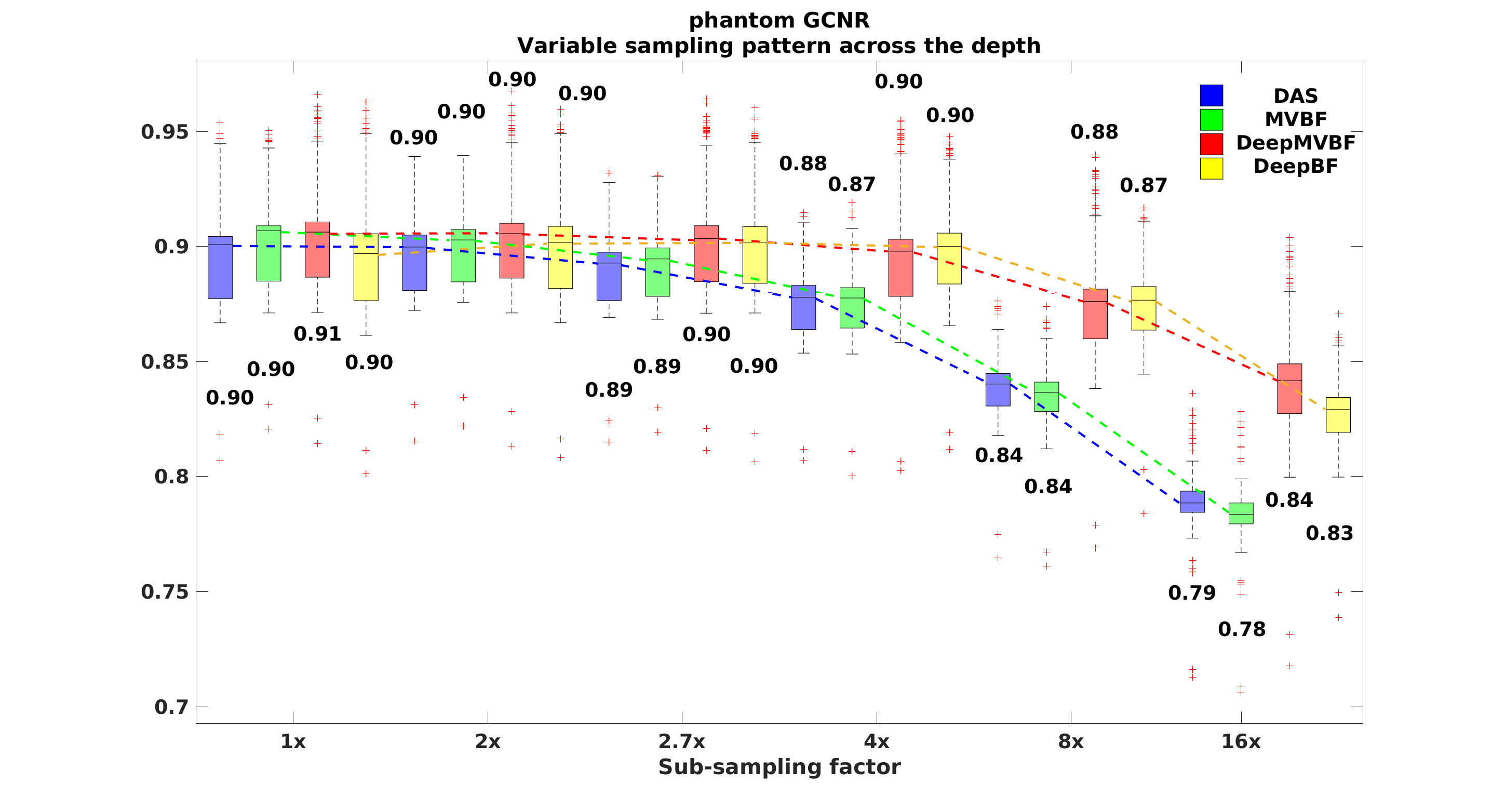 Figure 14
Figure 14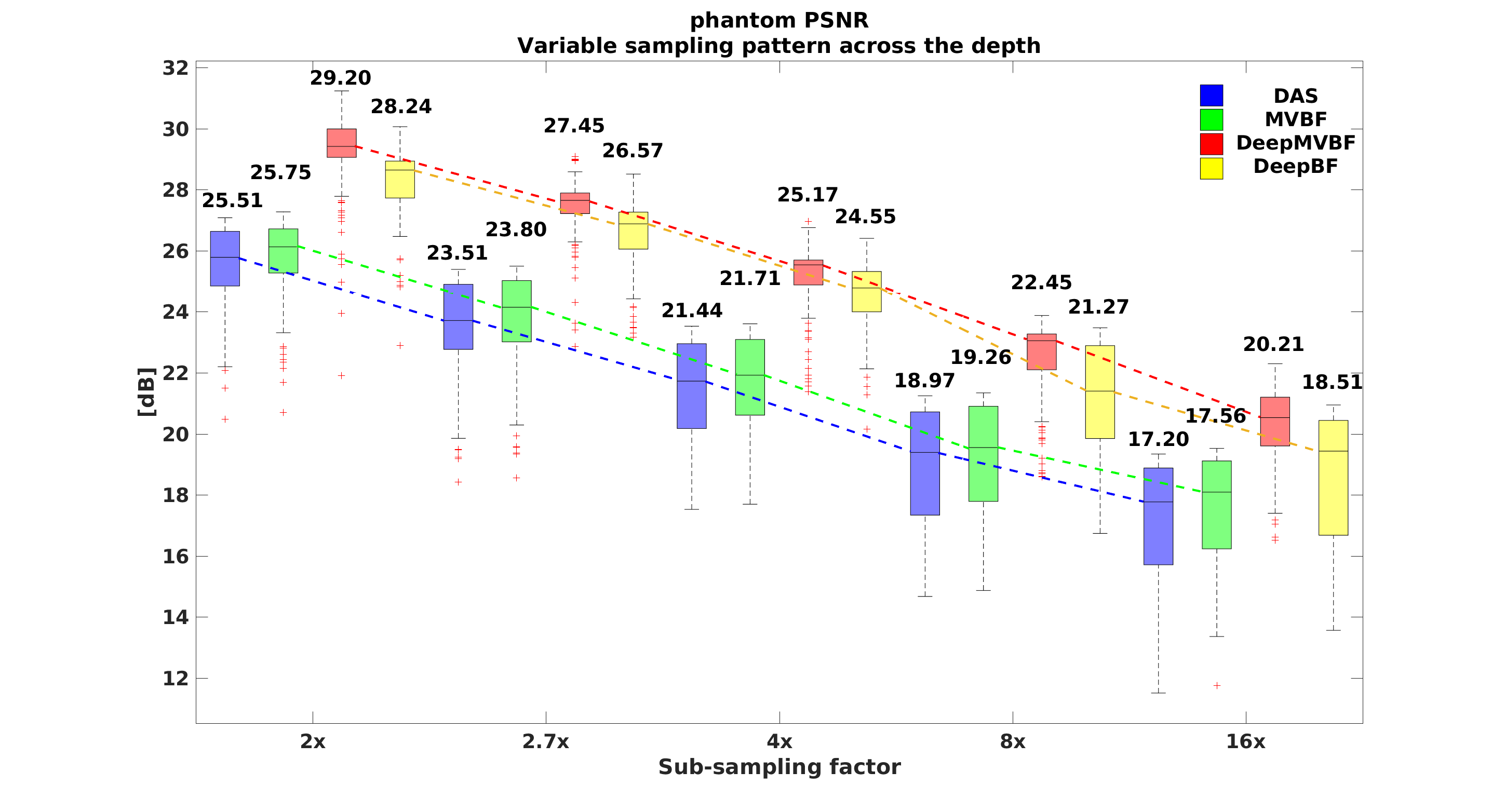 Figure 15
Figure 15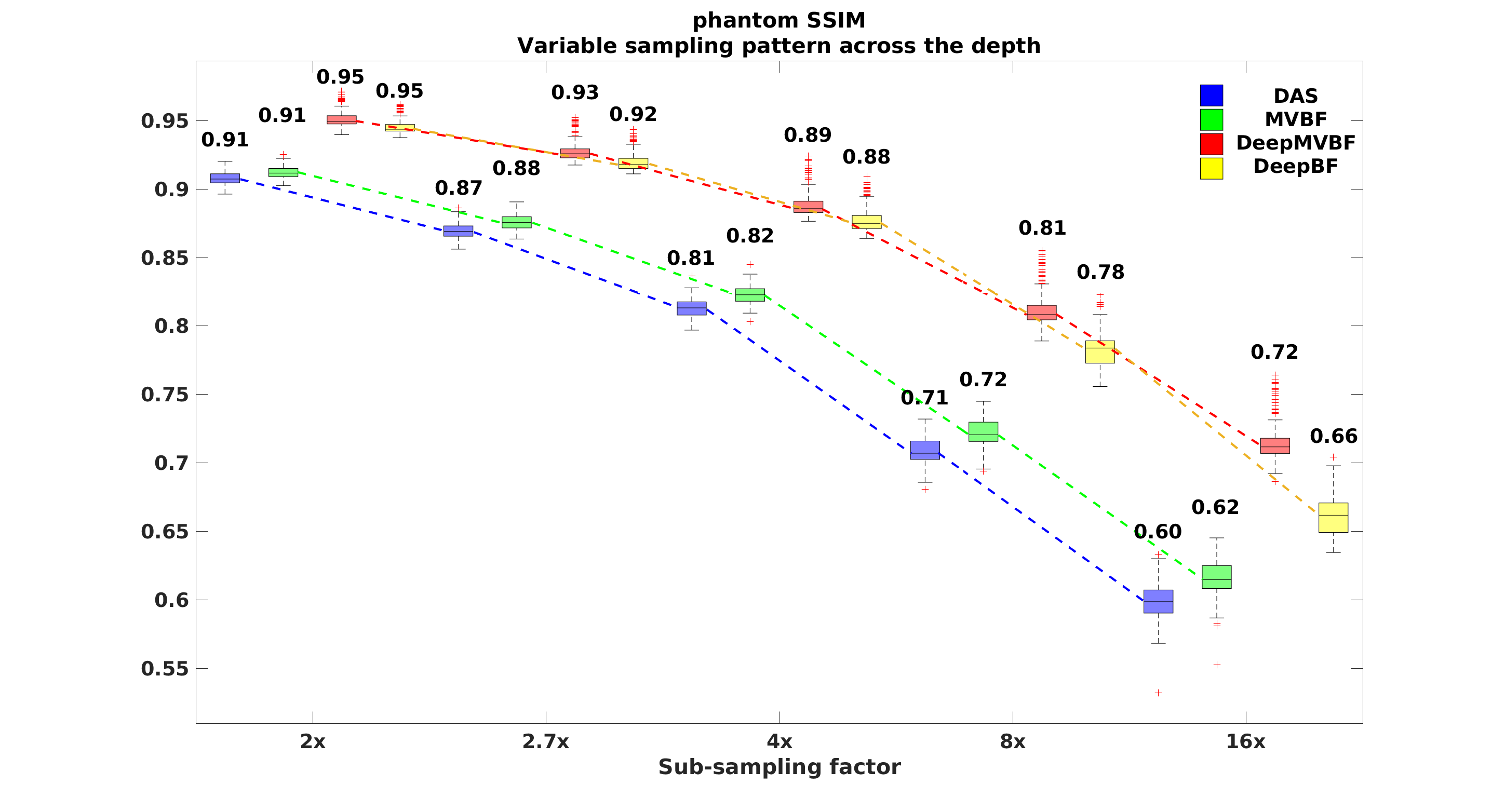 Figure 16
Figure 16| Parameter | Linear Probe |
|---|---|
| Probe Model No. | L3-12H |
| Carrier wave frequency | 8.5/10.0 MHz |
| Sampling frequency | 40 MHz |
| Scan wave mode | Focused |
| No. of probe elements | 192 |
| No. of Tx elements | 128 |
| No. of TE events | 96 |
| No. of Rx elements | 64 (from center of Tx) |
| Elements pitch | 0.2 mm |
| Elements width | 0.14 mm |
| Elevating length | 4.5 mm |
| sub-sampling | CR (dB) | CNR | GCNR | PSNR (dB) | SSIM | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| factor | DAS | MVBF | DeepBF | DeepMVBF | DAS | MVBF | DeepBF | DeepMVBF | DAS | MVBF | DeepBF | DeepMVBF | DAS | MVBF | DeepBF | DeepMVBF | DAS | MVBF | DeepBF | DeepMVBF |
| 1 | 12.37 | 12.39 | 13.25 | 13.25 | 1.38 | 1.38 | 1.45 | 1.45 | 0.64 | 0.64 | 0.66 | 0.66 | 1 | 1 | 1 | 1 | ||||
| 2 | 10.55 | 10.62 | 13.05 | 13.26 | 1.33 | 1.33 | 1.47 | 1.47 | 0.63 | 0.63 | 0.66 | 0.66 | 24.59 | 24.63 | 27.38 | 27.71 | 0.89 | 0.89 | 0.95 | 0.95 |
| 2.7 | 10.06 | 10.16 | 12.63 | 13.29 | 1.30 | 1.30 | 1.44 | 1.48 | 0.62 | 0.62 | 0.66 | 0.67 | 23.15 | 23.17 | 25.54 | 26.08 | 0.86 | 0.86 | 0.92 | 0.93 |
| 4 | 9.54 | 9.65 | 11.80 | 13.14 | 1.25 | 1.25 | 1.38 | 1.47 | 0.60 | 0.60 | 0.65 | 0.66 | 21.68 | 21.75 | 23.55 | 24.29 | 0.81 | 0.81 | 0.87 | 0.89 |
| 8 | 9.05 | 9.21 | 10.47 | 12.17 | 1.18 | 1.19 | 1.26 | 1.37 | 0.58 | 0.58 | 0.61 | 0.64 | 19.99 | 20.02 | 21.03 | 21.96 | 0.74 | 0.74 | 0.78 | 0.82 |
| 16 | 8.98 | 9.11 | 9.73 | 10.99 | 1.12 | 1.11 | 1.17 | 1.25 | 0.56 | 0.56 | 0.58 | 0.61 | 18.64 | 18.68 | 19.22 | 20.24 | 0.67 | 0.67 | 0.69 | 0.74 |
| sub-sampling | CR (dB) | CNR | GCNR | PSNR (dB) | SSIM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| factor | DAS | MVBF | DeepBF | DAS | MVBF | DeepBF | DAS | MVBF | DeepBF | DAS | MVBF | DeepBF | DAS | MVBF | DeepBF |
| 1 | 12.37 | 12.39 | 13.25 | 1.38 | 1.38 | 1.45 | 0.64 | 0.64 | 0.66 | 1 | 1 | 1 | |||
| 2 | 10.69 | 10.74 | 12.50 | 1.21 | 1.20 | 1.37 | 0.60 | 0.59 | 0.64 | 22.69 | 22.74 | 24.91 | 0.85 | 0.85 | 0.90 |
| 2.7 | 10.24 | 10.34 | 11.97 | 1.15 | 1.16 | 1.31 | 0.58 | 0.58 | 0.63 | 21.36 | 21.44 | 23.18 | 0.80 | 0.81 | 0.86 |
| 4 | 9.67 | 9.80 | 11.00 | 1.10 | 1.10 | 1.22 | 0.56 | 0.56 | 0.60 | 20.08 | 20.19 | 21.38 | 0.75 | 0.76 | 0.80 |
| 8 | 9.25 | 9.40 | 9.97 | 1.04 | 1.05 | 1.11 | 0.54 | 0.54 | 0.56 | 18.63 | 18.75 | 19.10 | 0.68 | 0.69 | 0.70 |
| 16 | 9.08 | 9.25 | 9.58 | 1.02 | 1.03 | 1.08 | 0.53 | 0.53 | 0.55 | 17.84 | 17.95 | 17.83 | 0.63 | 0.63 | 0.64 |
| Training/Design | CNR | GCNR | PSNR (dB) | SSIM | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| methods | 1 | 2 | 4 | 8 | 1 | 2 | 4 | 8 | 1 | 2 | 4 | 8 | 1 | 2 | 4 | 8 |
| RF-sum only | 2.256 | 2.320 | 2.302 | 2.171 | 0.842 | 0.863 | 0.873 | 0.857 | 25.37 | 21.12 | 18.62 | 1 | 0.924 | 0.832 | 0.737 | |
| fixed rate training | 2.325 | 2.505 | 2.341 | 2.121 | 0.850 | 0.890 | 0.883 | 0.853 | 22.30 | 21.30 | 19.88 | 1 | 0.880 | 0.840 | 0.777 | |
| single-depth design | 2.752 | 2.659 | 2.505 | 2.253 | 0.913 | 0.907 | 0.895 | 0.873 | 27.92 | 23.57 | 19.27 | 1 | 0.930 | 0.852 | 0.739 | |
| DeepBF(DAS) | 2.655 | 2.650 | 2.527 | 2.248 | 0.897 | 0.900 | 0.898 | 0.874 | 28.24 | 24.55 | 21.27 | 1 | 0.946 | 0.878 | 0.783 | |
| DeepBF(MVBF) | 2.701 | 2.666 | 2.523 | 2.306 | 0.905 | 0.904 | 0.897 | 0.876 | 29.20 | 25.17 | 22.45 | 1 | 0.952 | 0.890 | 0.812 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\epstopdfDeclareGraphicsRule
.tiffpng.pngconvert #1 \OutputFile \AppendGraphicsExtensions.tiff
Adaptive and Compressive Beamforming Using Deep Learning for Medical Ultrasound
Shujaat Khan, Jaeyoung Huh, and Jong Chul Ye, This work was supported by the National Research Foundation (NRF) of Korea grant NRF-2016R1A2B3008104.The authors are with the Department of Bio and Brain Engineering, Korea Advanced Institute of Science and Technology (KAIST), Daejeon 34141, Republic of Korea (e-mail:{shujaat,woori93,jong.ye}@kaist.ac.kr).
Abstract
In ultrasound (US) imaging, various types of adaptive beamforming techniques have been investigated to improve the resolution and contrast-to-noise ratio of the delay and sum (DAS) beamformers. Unfortunately, the performance of these adaptive beamforming approaches degrade when the underlying model is not sufficiently accurate and the number of channels decreases. To address this problem, here we propose a deep learning-based beamformer to generate significantly improved images over widely varying measurement conditions and channel subsampling patterns. In particular, our deep neural network is designed to directly process full or sub-sampled radio-frequency (RF) data acquired at various subsampling rates and detector configurations so that it can generate high quality ultrasound images using a single beamformer. The origin of such input-dependent adaptivity is also theoretically analyzed. Experimental results using B-mode focused ultrasound confirm the efficacy of the proposed methods.
Index Terms:
Ultrasound imaging, B-mode, beamforming, adaptive beamformer, Capon beamformer
I Introduction
Excellent temporal resolution with reasonable image quality makes the ultrasound (US) modality a first choice for variety of clinical applications. Moreover, due to its non-invasive nature, US is an indispensable tool for some clinical applications such as cardiac, fetal imaging, etc.
In US, an image reconstruction is usually done by back-propagating the preprocessed measurement data and adding all the contributions. For example, in focused B-mode US imaging, the return echoes from individual scan lines are recorded by the receiver channels (Rx), after which a delay and sum (DAS) beamformer applies appropriate time-delays to the channel measurements and additively combines them for each depth to form an image at each scan line. Despite the simplicity, large number of receiver elements are often necessary in DAS beamformer to improve the image quality by reducing the side lobes. Moreover, to calculate accurate time delay, sufficiently large bandwidth transducers are required.
To deal with unfavorable acquisition conditions, various adaptive beamforming techniques have been developed over the several decades [1, 2, 3, 4, 5, 6, 7, 8, 9]. The main idea of adaptive beamforming is to change the receive aperture weights based on the received data statistics to improve the resolution and enhance the contrast. One of the most extensively studied adaptive beamforming techniques is Capon beamforming, also known as the minimum variance (MV) beamforming [2, 3, 4]. The aperture weight of Capon beamfomer is derived by minimizing the side lobe while maintaining the gain in the look-ahead direction. Unfortunately, Capon beamforming is computationally heavy for practical use due to the calculation of the spatial covariance matrix of channel data and its inverse [5]. Moreover, the performance of Capon beamformer is dependent upon the accuracy of the covariance matrix estimate. To address these problems, many improved versions of MV beamformers have been proposed [4, 5, 6, 7]. Some of the notable examples include the beamspace adaptive beamformer [6], multi-beam Capon based on multibeam covariance matrices[8], etc. In addition, a parametric form of iterative update covariance matrix calculation has been proposed instead of calculating the empirical covariance matrix [9].
On the other hand, compressive beamforming method have been also extensively investigated to reduce the data rate [10]. Specifically, high-quality ultrasound imaging demands for significantly high sampling rates, which eventually increases the volume of data transmitted from the system’s front end. Moreover, in 3-D ultrasound imaging, 2-D transducer arrays are used and more scan lines are needed, which leads to vastly increased amount of sampled data with respect to 2-D imaging. To achieve the aforementioned data rate reduction, random RF sub-sampling has been employed in various ultrasound imaging researches, e.g. [11], etc. Many researches also suggested the buffered probe sampling which can reduce the number of scan lines at the cost of complexity in probe design. Then specially designed compressive beamforming techniques were used to exploit the redundancy in the image to compensate for the reduced measurement data [12, 10]. Unfortunately, most of the existing compressive beamformers require either hardware changes [13] or computationally expensive optimization methods [10].
Recently, inspired by the tremendous success of deep learning, many researchers have investigated deep learning approaches for various inverse problems [14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]. In US literature, the works in [26, 27] were among the first to apply deep learning approaches to US image reconstruction. In particular, Allman et al [26] proposed a machine learning method to identify and remove reflection artifacts in photo-acoustic channel data. Luchies and Byram [27] proposed a frequency domain deep learning method for suppressing off-axis scattering in ultrasound channel data. In [28], a deep neural network is designed to estimate the attenuation characteristics of sound in human body. In [29, 30], ultrasound image denoising method is proposed for the B-mode and single angle plane wave imaging. Rather than using deep neural network as a post processing method, the authors in [31, 32, 33, 34] employed deep neural networks for the reconstruction of high-quality US images from limited number of received RF data. For example, the work in [32] uses deep neural network for coherent compound imaging from small number of plane wave illumination. In focused B-mode ultrasound imaging, [31] employs the deep neural network to interpolate the missing RF-channel data with multiline aquisition for accelerated scanning.
While these recent deep neural network approaches provide impressive reconstruction performance, the designed neural network cannot completely replace a DAS beamformer, since they are designed as pre- or post- processing steps for specific acquisition scenarios and many of the works employ the standard DAS beamformer. Therefore, one of the most important contributions of this paper is to replace the DAS, adaptive, or compressive beamformers with a deep learning-based data-driven adaptive deep beamformer (DeepBF) so that a single DeepBF can generate high quality images robustly for various detector channel configurations. Moreover, unlike the MV beamformer that can be used only for uniform array, our DeepBF is designed for various detectors and RF subsampling schemes, in spite of significantly reduced run-time computational complexity. In contrast to [31], where the deep learning approach was developed to interpolate missing RF data to be used as input to the standard beamformer, the proposed method is a CNN-based beamforming pipeline, without requiring additional beamformer. Consequently, this approach is much simpler and can be easily incorporated to replace the standard beamforming pipeline. Despite the simplicity, our experiments show that direct reconstruction using the proposed DeepBF produces better results compared to [31].
The consistent performance improvement over widely varying subsampling rates using a single CNN may appear mysterious. Inspired by the recent theoretical understanding of deep convolutional framelets [35, 36], another important contribution of this paper is a detailed theoretical analysis to identify the origin of the input adaptivity and the performance improvement of DeepBF. Our theoretical analysis suggests that the deep learning-based beamformer may be the right direction for medical ultrasound.
After the initial work of this paper became available on Arxiv [37], a related work on deep learning based adaptive beamformer appeared [38]. In contrast to the proposed method, [38] is interested in estimating the adaptive beamformer weights using a deep neural network. Moreover, the results are only available for simple phantom data, the application of compressive beamforming was not considered, and the theoretical analysis to unveil why the deep learning beamformer works was not provided. Therefore, our work is more general and provides a systematic understanding in designing deep learning based beamformer.
This paper is organized as follows. In Section II, a brief survey of the existing adaptive beamforming methods are provided, which is followed by the detailed explanation of the proposed deep beamformer in Section III. Section IV then describes the data set and experimental setup. Experimental results are provided in Section V, which is followed by Discussion and Conclusions in Section VI and Section VII, respectively.
II Mathematical Preliminaries
II-A Notation
In this paper, the uppercase boldface letter such as are used to refer matrices and tensors, whereas the lowercase boldface letters such as represent the vectors. Non-bold letters such as denote scalars.
Measured RF data is a three-dimensional cube from the B-mode ultrasound as shown in Fig. 1 (a), where and denote the number of scan lines (or transmit events (TE)), depth planes, and the number of probe elements, respectively. The RF data cube is often represented as , where is the -th element of the data cube, representing the RF data measured by the receiver channels from the the -th scan line at the depth index . The time-delay corrected data cube is similarly denoted by , where
[TABLE]
with
[TABLE]
where ⊤ denotes the transpose, is the time delay for the -th receiver elements to obtain the -th scan line at the depth .
In many US imaging, only a subset of receiver channels are used to process return echoes to save power consumption and/or data rate. Usually, the aperture, which refers to the span of the active receiver, varies depending on the scan lines, so that symmetric set of receivers along the scan lines are used. In this case, the received RF data can be explicitly modeled as , where
[TABLE]
and
[TABLE]
where denotes the specific detector offset to indicate the active channel elements, which is determined for each scan line index , and is the aperture size. See Fig. 1(a) for the conversion between the data cube and , where the dark triangular regions in , which correspond to inactive receiver elements, are removed in constructing .
II-B Classical Beamforming
II-B1 DAS beamforming
The standard delay and sum (DAS) beamformer for the -th scanline at the depth sample can be expressed as
[TABLE]
where denotes a -dimensional column-vector of ones, and is the number of active channels.
II-B2 Adaptive beamforming
The DAS beamformer is designed to extract the low-frequency spatial content that corresponds to the energy within the main lobe; thus, it is difficult to control side lobe leakage. Reduced side lobe leakage can be achieved by replacing the uniform weights by tapered weights:
[TABLE]
where Specifically, in adaptive beamforming the objective is to find the that minimizes the variance of , subject to the constraint that the gain in the desired beam direction equals unity. For example, the minimum variance (MV) estimation task can be formulated as [2, 3, 4]
[TABLE]
where is the expectation operator over RF data distribution, and is a spatial covariance matrix given by:
[TABLE]
Then, can be obtained by Lagrange multiplier method [39] and expressed as
[TABLE]
II-C Deconvolution Ultrasound
One of the main limitations of the aforementioned beamforming methods is that they are based on the ray approximation of the wave propagation, whereas the real sound propagations exhibits many wave phenomenon such as scattering, diffraction, etc. Moreover, the precision of the time delay calculation is determined by bandwidth of the transducers, which limits the accuracy of delayed signal . These modeling inaccuracies may affect the spatial resolution and the contrast of standard US images.
In order to overcome these issues, many researchers have explored the deconvolution of US images [40, 41]. Specifically, the deconvolution US tries to find the filter kernel such that the filtered signal given by
[TABLE]
produces high resolution images.
II-D Imposing Causality Condition
Another important step after the beamforming is to convert the processed data to a causal signal using Kramers–Kronig relation [42]. This step is necessary to detect the signal envelope. More specifically, this process is performed by
[TABLE]
where , and is a discrete Dirac delta function, and denotes the filter kernel for Hilbert transform. The filter kernel for Hilbert transform is in principle one-dimensional since it is applied along the depth direction. Here, is often referred to as the in-phase (I) and quadrature (Q) representation.
II-E Putting Together
By using (5), (8) and (9), we can obtain the following representation:
[TABLE]
If we define
[TABLE]
and
[TABLE]
then the following matrix representation can be obtained:
[TABLE]
where is a 2-D convolution matrix composed of the filter kernel , and
[TABLE]
where is a Kronecker product and is the input-dependent beamformer adaptive weight matrix given by
[TABLE]
Accordingly, Eq. (13) can be equivalently represented as a nonlinear mapping:
[TABLE]
where Then, the goal of the US reconstruction is to find the nonlinear mapping so that the processed image has a high resolution with good contrast and better signal-to-noise ratio.
III Main Contribution
III-A Piecewise linear approximation using CNN
In practice, the estimation of in (14) is technically challenging. This is because the beamformer weights are dependent on each RF data . Moreover, the deconvolution filter matrix could be also spatially varying. Therefore, the exact calculation is usually computationally expensive. A quick remedy to overcome this would be precalculating nonlinear mapping . Unfortunately, it requires huge memory to store for all .
In this regard, a convolutional neural network (CNN) using ReLU nonlinearities provides an ingenious way of addressing this issue. Specifically, in our recent theoretical work [36], we have shown that an encoder-decoder CNN with ReLU nonlinearity generates large number of distinct linear mappings depending on inputs. More specifically, the input space is partitioned into non-overlapping regions where input for each region share a common linear representation or mapping. [36].
Specifically, consider an encoder-decoder CNN with the output with respect to input as shown in Fig. 2, where there exists skipped connection for every four convolution operations. As shown in Appendix, the output of the encoder-decoder CNN with respect to input can be represented by the following nonlinear mapping
[TABLE]
where refers to all the convolution filter parameters, and and denote the -th column of the matrices (VII) and (VII), respectively.
The expression (A.7) reveals many important aspects of neural networks. First, the CNN representation in (A.7) has explicit dependency on the input in (A.7), due to the input dependent ReLU activation pattern. Accordingly, even from the same filter set, the input-dependent ReLU activation pattern makes the resulting mapping vary depending on the input signals. Furthermore, the number of distinct linear representation increases exponentially with the number of neurons determined by network depth and width [36], since the distinct ReLU activation pattern is in principle combinatorially many up to . Second, the number of blocks in and in (VII) and (VII) are determined by the number of skipped connections, so the skipped branch makes the representation more redundant, which again makes the neural network have more piecewise linear regions [36].
Note that the piecewise linear representation using (15) is useful for approximating our nonlinear mapping in (14). Specifically, the piecewise linear representation by the DeepBF can be obtained by learning the filters from the following optimization problem:
[TABLE]
where denotes the training data set composed of RF data and the target IQ data, which are collected across all subjects and subsampling patterns. Although the piecewise linear property of CNN may appear as a limitation to approximate arbitrary nonlinear functions, it also provides good architectural prior known as inductive bias, which results in inherent regularization effects. As will be shown in experimental results, we found that this inductive bias works favorably for US reconstruction.
III-B Proposed Deep Beamformer Pipeline
One of the limitations of the original training framework in (16) is that the RF data input and the target requires too big memory to store using GPU memory. Therefore, rather than training a neural network to learn the mapping between all RF data, we implemented a separable form of a neural network such that the neural network is trained to estimate one depth at a time. Specifically, with a slight abuse of notation, our neural network is designed as
[TABLE]
where is a sub-set of input RF data collected from three depth planes around the depth :
[TABLE]
where and are defined in (11) and (12), respectively. Then, the resulting neural network training is given by
[TABLE]
where denotes the training data set collected across all depth planes.
One of the potential limitations of using the restricted architecture (17) is the reduction of the depth-dependent adaptivity of the neural network, since all the depth information is used together as a target data. This issue will be revisited in experimental section.
Fig. 1 illustrates the proposed DeepBF pipleline using the reflected sound waves in the medium measured by the transducer elements. As a preprocessing for DeepBF pipeline, each measured RF signal is time-delayed to generate focused RF data cube based on the traveled distance. Then, our DeepBF generates IQ data directly from the time delayed RF data. Compared to the standard DAS beamformer, this corresponds to the replacement of the deconvolution, beamforming and Hilbert transform parts with a deep neural network. Then, the signal envelope is generated by calculating the sum of squares of the in-phase and quadrature phase signals generated from the Hilbert transform. Finally, log compression is applied to generate the B-mode images.
IV Method
IV-A Dataset
For experimental verification, we used an E-CUBE 12R US system (Alpinion Co., Korea). For data acquisition, we used a linear array transducer (L3-12H), whose configuration is given in Table I. Specifically, using the linear probe with a center frequency of MHz, we acquired RF data from the carotid/thyroid area of volunteers using focused B-mode US imaging. The in vivo data consist of temporal frames per subject, providing sets of TE-Depth-Rx data cube . In addition, we acquired frames of RF data from the ATS-539 multipurpose tissue mimicking phantom using MHz center frequency. The phantom dataset was only used for test purposes and no additional training of CNN was performed on it. In addition to the carotid/thyroid and phantom datasets we also acquired datasets from forearm and calf muscles. In particular, they were acquired using MHz carrier frequency and consist of frames from each body part. These data set were used to further validate the generalization power of our trained model, and no additional training of CNN was performed on it.
For all scans the axial depth was in the range of 2080 mm, while lateral length was 38.4mm. Depending on the object of interest, the focal depth is adjusted accordingly, in particular it varies in the range of 1040 mm.
IV-B Network specification
Fig. 2 illustrates the schematic diagram of our deep beamformer. One minor improvement is the channel augmentation at the skipped branch of the decoder rather than simple addition. Moreover, to make the neural network process only real-valued data, the real and image components of are separately processed to generate two channel IQ output.
The proposed CNN consists of convolution layers (i.e. ) composed of a contracting path with concatenation, batch normalization, and ReLUs except for the last convolution layer. The first convolution layers as shown in Fig. 2 use convolutional filters (i.e., the 2-D filter has a dimension of ), and the last convolution layer uses a filter followed by an average pooling to contract the data-cube from Depth-TE-Rx sub-space to Depth-TE-IQ plane. The number of CNN filter channel for each layer is and the dimension of the signal is up to the last layer which shrinks it to Depth-TE-IQ data.
IV-C RF data sampling scheme
The input and output data configurations are shown in Fig. 1 (a) and (b) respectively. The time-delayed RF data cube is a three-dimensional data cube composed of total depths of data in TE-Rx direction. We trained our neural network using multiple input/output pairs, where an input consists of data-cube in the Depth-TE-Rx volume and the output is composed of pairs of I/Q data in the Depth-TE plane. Each target IQ pair corresponds to two output channels, each representing real and imaginary parts. Using carotid/thyroid dataset, a set of Depth-TE-Rx cubes of size were randomly selected from frames of four different subject’s datasets, which are divided into samples for training and samples for validation. The remaining dataset of carotid/thyroid, phantom were used as a test data. In addition, to see the generalization capability of the algorithm, frame data from totally different anatomical regions (forearm/calf muscles) were used as a test dataset.
For compressive beamforming experiments, in addition to the full RF data with RF-channels, we generated five sets of sub-sampled RF data at different down-sampling rates. More specifically, the subsampling cases included , , , and Rx-channels at two subsampling schemes, such as variable down-sampling patterns across the depth and fixed down-sampling patterns across the depth. Since the active receivers at the center of the scan line get RF data from direct reflection, the two channels in the center were always included, the remaining channels are randomly selected from the other active receiving channels and unselected Rx channels are zero-padded. In variable sampling scheme, different sampling pattern (mask) is used for each depth plane, whereas in fixed sampling we used same sampling pattern (mask) for all depth planes. The network was trained for variable sampling scheme only and both sampling schemes were used in test phase. The variable sub-sampling patterns can be implemented using a software changes by randomly selecting the A/D converter, of which procedure is similar to various compressive US researches, e.g. [11].
IV-D Network training
As for the target IQ data, we mainly used the IQ data from DAS beamforming results from the full RF data. We also use IQ data from an adaptive beamformer and deconvolution beamformer [43] to demonstrate that the proposed beamformer can be trained to mimic various types of beamformers.
The network was implemented with MatConvNet [44] in the MATLAB 2015b environment. Specifically, for network training, the parameters were estimated by minimizing the norm loss function using a stochastic gradient descent with a regularization parameter of . The learning rate started from and exponentially decreased to in epochs. The weights were initialized using Gaussian random distribution with the Xavier method [45].
It is noteworthy to highlight this important aspect of our DeepBF model that for each target beamformer e.g., DAS, MVBF or deconvolution, a single (one time trained) CNN model is used for all data types and sub-sampling rates.
IV-E Comparison methods
For the evaluation purpose, we compared our proposed DeepBF method with standard DAS and MV beamformers. In DAS, the beamforming step is a simple weighted sum. Specifically, for DAS formulation in (4), is varied from 64 to 4 depending on the sub-sampling ratios so that data from active receivers is added to generate beamformed output.
For the adaptive beamforming case, must be estimated with a limited amount of data. A widely used method for the estimation of is spatial smoothing (or subaperture averaging) [46], in which the sample sub-aperture covariance matrix is calculated by averaging covariance matrices of consecutive channels in the receiving channels. Here we use . Then, the weight for the minimum variance beamformer is calculated using the sub-aperture covariance estimate, after which the final beamforming result is obtained by averaging the contribution from the adaptive beamforming results from each subaperture array.
IV-F Performance metrics
To quantitatively show the advantages of the proposed deep learning method, we used the contrast-recovery (CR), contrast-to-noise ratio (CNR) [47], generalized CNR (GCNR) [48], peak-signal-to-noise ratio (PSNR), structure similarity (SSIM) [49] and the reconstruction time.
The contrast is measured for the background () and anechoic structure () in the image, and quantified in terms of CR and CNR:
[TABLE]
[TABLE]
where , , and , are the local means, and the standard deviations of the background () and anechoic structure () [47], respectively. Another improved measure for the contrast-to-noise-ratio called generalized-CNR (GCNR) was recently proposed [48]. The GCNR compare the overlap between the intensity distributions of two regions. The GCNR is defined as
[TABLE]
where is the pixel intensity, and and are the probability distributions of the background () and anechoic structure (), respectively. If both distribution are completely independent, then GCNR will be equals to one, whereas, if they completely overlap then GCNR will be zero [48]. The GCNR measure is difficult to tweak, so we believe that GCNR is an objective performance metric. For CNR and GCNR calculations, we generated separate ROI masks for each image.
The PSNR and SSIM index are calculated on reference () and Rx sub-sampled () images of common size as
[TABLE]
where denotes the Frobenius norm and is the dynamic range of pixel values (in our experiments this is equal to ), and
[TABLE]
where , , , , and are the local means, standard deviations, and across-covariance for images and calculated for a radius of units. The default values of , , and .
V Experimental Results
In this section we present extensive comparison results of our method with DAS and the minimum variance beamformer (MVBF) for various acquisition scenarios. Our DeepBF was first trained with DAS data obtained from full RF data, and we compare our results with those by DAS and the minimum variance beamformer (MVBF). We also trained our neural network using the MVBF from full RF data. With a slight abuse of terminology, this is often referred to as DeepMVBF, although we use the term DeepBF to refer general deep neural network-based beamformers regardless of specific target data for training.
V-A Quantitative comparison
We compared the CR, CNR, GCNR, PSNR, and SSIM distributions of reconstructed B-mode images of in vivo and phantom test datasets. Table II shows the comparison of DAS, MVBF, proposed DeepBF, and DeepMVBF methods on in vivo test frames for random sub-sampling scheme. In terms of CR, CNR and GCNR, the overall performance of DAS and MVBF were relatively similar. However, the results by the proposed methods are significantly superior to those of DAS and MVBF at various subsampling factors. To investigate the performance degradation with respect to the subsampling, in Table II we also show the PSNR and SSIM values with respect to the results of the full scan. Again, the performance degradation in terms of PSNR and SSIM was much less by the proposed DeepBF and DeepMVBF.
In Fig. 3, we provide distribution plots for various performance measures for phantom test dataset. In fully sampled case, our DeepBF shows overall gain of around dB in CR, and units improvement in CNR compared to DAS. In sub-sampling cases, unlike DAS and MVBF in which the performance is highly sensitive to the rate of sub-sampling, the proposed DeepBF shows consistent GCNR performance even at reduced sampling rate. This can be easily seen in Fig. 3 (third row), where the average value of GCNR remain constant at units for to sampling factors and only drop by and units at and sampling factors respectively. The performance of DeepBF and DeepMVBF were similar, although DeepMVBF has slight better CR values.
The CR, CNR, and GCNR are measure for local regions, whereas the PSNR and SSIM are global metric. To calculate the PSNR and SSIM, images generated using Rx-channels were considered as reference images for all algorithms. As shown in Fig. 3 the proposed methods show significantly higher PSNR and SSIM values, confirming that the proposed methods successfully recover actual structural detail in sub-sampled images.
V-B Qualitative Comparison
To verify the performance improvement in terms of visual quality, here we provide representative reconstruction results. Due to the similarity between the DeepBF and DeepMVBF, we only provide the results by DeepBF in this section.
V-B1 Full RF data cases
In Fig. 4 we compared two phantom examples scanned using MHz center frequency. In phantom test dataset, the proposed DeepBF achieves comparable or even better performance compared to DAS and MVBF methods. From the figures we found that the visual quality of DeepBF reconstruction, especially around anechoic regions, is comparable or better than that of MVBF method, which is better than DAS beamformer. Quantitatively, CR, CNR, and GCNR values of Deep BF were slightly improved compared to the existing methods. It is also noteworthy to point-out that even though the proposed DeepBF was only trained on in vivo carotid/thyroid data scanned with MHz operating frequency, its performance in very diverse test scenarios is still remarkable, which clearly shows the generalization power of the proposed method.
To further validate the performance gain on fully-sampled data, in Fig. 5 we showed the results of two in vivo examples for fully-sampled data. The images are generated using standard DAS, MVBF and the proposed DeepBF method. In Fig. 5, it can be easily seen that our method provides visual quality comparable to DAS and MVBF methods. Interestingly, it is remarkable that the CR, CNR and GCNR values are improved by the DeepBF. To investigate the origin of the quantitative improvement, we showed the magnified views as inset in Fig. 5. With a careful look, we can see that there are several artifacts around the wall of anechoic regions in DAS and MVBF methods, which can be confused with structure. On the other hand, those artifacts are not visible in DeepBF, which makes the the visual quality of the US images and quantitative values higher compared to DAS and MVBF methods.
V-B2 Compressive beamforming
Fig. 6 show the results of a phantom example for , , and Rx-channels down-sampling schemes on random sampling scheme. Since 64 channels are used as a full sampled data, this corresponds to the full data as well as subsampled data with and sub-sampling factors. The images are generated using the proposed DeepBF, MVBF and the standard DAS beamformer methods. Our method significantly improves the visual quality of the US images by estimating the correct structural details and eliminating artifacts caused by sub-sampling. The residual of fully-sampled and sub-sampled images are shown in pseudo colors on normalized scale. From the normalized difference images it can be easily seen that DeepBF produces uniformly distributed noise-like errors across various subsampling ratios, whereas DAS and MVBF produce structure-dependent errors that can reduce the image contrast. Note that the training data consist of only in vivo carotid/thyroid scans; but relative improvement in diverse test scenarios is nearly the same for both in vivo and phantom cases. This further confirms the generalization power of the proposed method.
Fig. 7 illustrates representative examples of in vivo data at x acceleration. By harnessing the spatio-temporal (multi-depth and multi-line) learning, the proposed CNN-based beam-former successfully reconstructs the images with good quality in all down-sampling schemes. From residual images it can be seen that in contrast to DAS and MVBF, the proposed DeepBF maintains good visual quality at even at highest sub-sampling rate. Unlike DAS and MVBF, DeepBF preserves the original structural details as well as the contrast of the sub-sampled data much closer to the fully-sampled image.
V-C Computational time
One big advantage of ultrasound image modality is its run-time imaging capability, which allows for fast reconstruction times. Although training required hours for epochs using MATLAB, once training was completed, the reconstruction time for the proposed deep learning method is not very long. The average reconstruction time for each depth planes is around (milliseconds), which could be easily reduced by optimized implementation and reconstruction of multiple depth plane in parallel.
VI Discussion
VI-A Expressivity and Generalization
To confirm that the proposed neural network learns various target data, we also trained our model using deconvolution of DAS results. The training was performed using fine-tuning method using target data generated by a deconvolution method using sparse representation as described in [43]. In Fig 8, we compared the reconstruction results by DAS, deconvolution of DAS, and the proposed DeepBF trained with deconvoluted DAS as target, using phantom anechoic cyst of mm diameter at mm depth on fully sampled RF-data. From the results it can be easily seen that the proposed method can successfully learn to mimic the deconvolution method.
To further compare the effect of various choices of target data and its generalization power, we evaluated the network trained with different label data by testing on completely different datasets. Specifically, we trained our neural network models using fully sampled carotid/thyroid DAS images, MVBF images, and deconvolution results. Then, new test dataset were acquired from forearm and calf muscles using MHz carrier frequency. In Fig 9, it is evident that the proposed DeepBF method can successfully process RF-data from different anatomical region and operating frequencies. Among the various choices of the target data, the performance using the deconvoluted DAS target was best with less clutters, which was followed by DeepBF trained using MVBF targets and DAS targets. It is also noteworthy to point out that neural network trained with DAS targets still provides better results than the standard DAS and MVBF for x8 subsampling cases. In particular, on average DAS and MVBF showed dB and dB CR which is dB and dB less than the DeepBF respectively. Moreover, the performance of DeepBF and DeepMVBF were again somewhat similar.
VI-B Dependency on the Sampling Patterns
So far we showed that a considerable reduction in data rate can be achieved by applying DeepBF method, leading to a sub-Nyquist sampling rate, which uses only a portion of the bandwidth of the ultrasound signals to reconstruct the high quality image. Another application of sub-sampled US is the reduction of active Rx elements. For this purpose we also evaluated our model using uniform sub-sampling scheme to confirm whether relative performance gain with uniform sub-sampling is also similar to the random sub-sampling. In Table III we compared the performance of proposed DeepBF method with DAS and MVBF on in-vivo data for uniform sub-sampling pattern. We can see in uniform sub-sampling case DeepBF achieves relatively similar performance gain as in the case of random sub-sampling. In Fig 10 two visual examples are shown for in-vivo and phantom data, and we found that the proposed method successfully reconstructs the uniformly sub-sampled RF-data in both cases with equal error rates.
VI-C Ablation Studies
We also compared our method with Deep RF interpolation method [31]. Again, the proposed method also outperform the Deep RF interpolation method [31]. Fig 11 shows reconstruction results of various methods at 4 subsampling rate, which is compared with the full data reconstruction. The contrast of the DeepBF, especially at anechoic regions, are very close to the full sampled case, whereas the other methods generates artifacts like patterns. Quantitatively, for 4 sub-sampled in vivo test dataset, the Deep RF interpolation [31] achieves CNR, GCNR, PSNR, and SSIM values of , units, dB and units, which are , units, dB and units inferior to the proposed method respectively. Here we would like to point out that, in [31], deep learning approach was designed for interpolating missing RF data, which are later used as input for standard beamformer. On the other hand, the proposed method is a CNN-based beamforming pipeline, without requiring additional beamformer. Consequently, this approach is much simpler and can be easily incorporated to replace the standard beamforming pipeline.
The proposed multi-line, multi-depth method is also compared with different design strategies which include (1) reconstruction of RF sum without Hilbert transform (RF-sum only), (2) reconstruction of IQ data after training on fixed sub-sampling ratios (fixed sampling), and reconstruction of IQ data using only single depth plane (single-depth). Specifically, Table IV compares the performance of different design choices on phantom data for random sub-sampling case. The results clearly show that the proposed methods of data-driven learning to generate IQ data using training data from multiple sub-sampling rates and multiple depths provides the best quantitative values. Especially at higher sampling rates the multi-depth method show high PSNR and SSIM measures. Although we just used 3 depth planes in this experiment, for further improvements the idea can be generalized to different number of depth planes.
VI-D Improved Lateral Resolution
In Fig 12, we compared lateral and axis profiles through the center of a phantom anechoic cyst using DAS, MVBF and proposed methods. In particular, an anechoic cysts of mm diameter scanned from the depth of mm and B-mode images were obtained for full data as well as random sampling with and sub-sampling factors using DAS, MVBF and proposed DeepBF methods. From the figures it can be seen that under all sampling schemes, on the boundary of cysts the proposed method show sharp changes in the pixel intensity with respect to the lateral position in the image. Although the axial profile shows similar trend to DAS for all subsampling rates, there are considerable gains in lateral resolution by the proposed DeepBF compared to its DAS, MVBF counterparts. Again, similar qualitative performance improvement was seen using DeepBF and DeepMVBF, but the contrast enhancement was noticeable using the proposed methods with deconvoluted targets (DeepDeconv). This phenomenon was consistently observed for all sub-sampling factors.
We believe that this may be originated from the inherent synthetic aperture that are originated from our training that uses multiple scanlines, Rx, and depths as shown in (18). Recall that the input data is composed of which are composed of multiple scan line data as defined in (12). On the other hand, the resolution improvement along the axial directions was not significant, which may be due to depth-independent training scheme in (18), which may lose the depth-dependent adaptivity. The original training scheme in (16) may be a solution for this, but requires huge memory. The way to overcome this technical limitation is important, and will be investigated in other publications.
In spite of the memory reduction using (18), it still requires larger memory compared to the standard DAS, since it should store multiple scan line data. In our future work we will explore the possible solutions to design an end-to-end beamformer method using a single-scanline data, which can learn the time delay but still provides better performance that the classical beamformers. In addition, although the performance of the proposed deep learning approach is better than the classical beamformer, after sub-sampling factor, the proposed method still degrades the image quality. Additional strategy to improve the performance of the proposed method is still required, which is the another important research direction. Finally, the average reconstruction time of (milliseconds) per depth is still slow for real time implementation. This is believed to be an engineering issue where optimized software implementation other than Matlab in addition to use of multiple GPUs may address the problem.
VII Conclusion
In this paper, we presented a novel deep learning-based adaptive and compressive beamformer to generate high-quality B-mode ultrasound image. The proposed method is purely a data-driven method which exploits the spatio-temporal redundancies in the raw RF data, which help in generating improved quality B-mode images using various transducer numbers. The proposed method can be trained using various targets, such as DAS, MVBF, and deconvoluted beamforming results from full RF data to satisfy the desired IQ for each application. The proposed method improved the contrast of B-modes images by preserving the dynamic range and structural details of the RF signal in both the phantom and in vivo scans. Therefore, this method can be an important platform for ultrasound imaging.
Although this part is basically a summary of [36], we have included it to make the paper self-contained.
Consider encoder-decoder networks in Fig. 2. The network has symmetric configuration so that both encoder and decoder have the same number of layers, say ; the input and output dimensions for the encoder layer and the decoder layer are symmetric:
[TABLE]
where denoting the set . At the -th layer, and denote the dimension of the signal, and the number of filter channel, respectively. The length of filter is assumed to be .
We now define the -th layer input signal for the encoder layer from number of input channels
[TABLE]
where ⊤ denotes the transpose, and refers to the -th channel input with the dimension . The -th layer output signal is similarly defined. Then, we have the following representation of the convolution and pooling operation at the -th encoder layer [36]:
[TABLE]
where is defined as an element-by-element ReLU operation , and
[TABLE]
where denotes the matrix that represents the pooling operation at the -th layer, and represents the -th layer encoder filter to generate the -th channel output from the contribution of the -th channel input, and represents a multi-channel convolution [36].
Similarly, the -th decoder layer can be represented by [36]:
[TABLE]
where
[TABLE]
where denotes the matrix that represents the unpooling operation at the -th layer, and represents the -th layer decoder filter to generate the -th channel output from the contribution of the -th channel input.
Next, consider the skipped branch signal by concatenating the output for each skipped branch as shown in Fig. 2. Then, the -th encoder layer with the skipped connection can be represented by [36]:
[TABLE]
With these definition, by following the derivation in [36], it is straightforward to show that the neural network output is given by
[TABLE]
where refers to all the convolution filter parameters, and and denote the -th column of the matrices (VII) and (VII), respectively, which are defined as
[TABLE]
[TABLE]
where and denote the diagonal matrix with 0 and 1 values that are determined by the ReLU output in the previous convolution steps. Note that there are skipped connections at every third convolution operations in Fig. 2, so that the last blocks in (VII) and (VII) are indexed accordingly.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] F. Viola and W. F. Walker, “Adaptive signal processing in medical ultrasound beamforming,” in IEEE Ultrasonics Symposium, 2005. , vol. 4, Sep. 2005, pp. 1980–1983.
- 2[2] J. Capon, “High-resolution frequency-wavenumber spectrum analysis,” Proceedings of the IEEE , vol. 57, no. 8, pp. 1408–1418, Aug 1969.
- 3[3] F. Vignon and M. R. Burcher, “Capon beamforming in medical ultrasound imaging with focused beams,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control , vol. 55, no. 3, pp. 619–628, March 2008.
- 4[4] K. Kim, S. Park, J. Kim, S. Park, and M. Bae, “A fast minimum variance beamforming method using principal component analysis,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control , vol. 61, no. 6, pp. 930–945, June 2014.
- 5[5] W. Chen, Y. Zhao, and J. Gao, “Improved capon beamforming algorithm by using inverse covariance matrix calculation,” in IET International Radar Conference 2013 , April 2013, pp. 1–6.
- 6[6] C. . C. Nilsen and I. Hafizovic, “Beamspace adaptive beamforming for ultrasound imaging,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control , vol. 56, no. 10, pp. 2187–2197, October 2009.
- 7[7] A. M. Deylami and B. M. Asl, “A fast and robust beamspace adaptive beamformer for medical ultrasound imaging,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control , vol. 64, no. 6, pp. 947–958, June 2017.
- 8[8] A. C. Jensen and A. Austeng, “An approach to multibeam covariance matrices for adaptive beamforming in ultrasonography,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control , vol. 59, no. 6, pp. 1139–1148, June 2012.