A Note on Exploratory Item Factor Analysis by Singular Value Decomposition
Haoran Zhang, Yunxiao Chen, and Xiaoou Li

TL;DR
This paper revisits a singular value decomposition algorithm for exploratory item factor analysis, establishing its statistical consistency, computational advantages, and practical utility in determining the number of factors.
Contribution
It provides the statistical foundation and asymptotic theory for an SVD-based exploratory IFA algorithm, highlighting its advantages over existing methods.
Findings
Algorithm guarantees a unique solution.
Demonstrates statistical consistency under double asymptotics.
Shows good finite sample performance in simulations.
Abstract
We revisit a singular value decomposition (SVD) algorithm given in Chen et al. (2019b) for exploratory Item Factor Analysis (IFA). This algorithm estimates a multidimensional IFA model by SVD and was used to obtain a starting point for joint maximum likelihood estimation in Chen et al. (2019b). Thanks to the analytic and computational properties of SVD, this algorithm guarantees a unique solution and has computational advantage over other exploratory IFA methods. Its computational advantage becomes significant when the numbers of respondents, items, and factors are all large. This algorithm can be viewed as a generalization of principal component analysis (PCA) to binary data. In this note, we provide the statistical underpinning of the algorithm. In particular, we show its statistical consistency under the same double asymptotic setting as in Chen et al. (2019b). We also demonstrate…
Click any figure to enlarge with its caption.
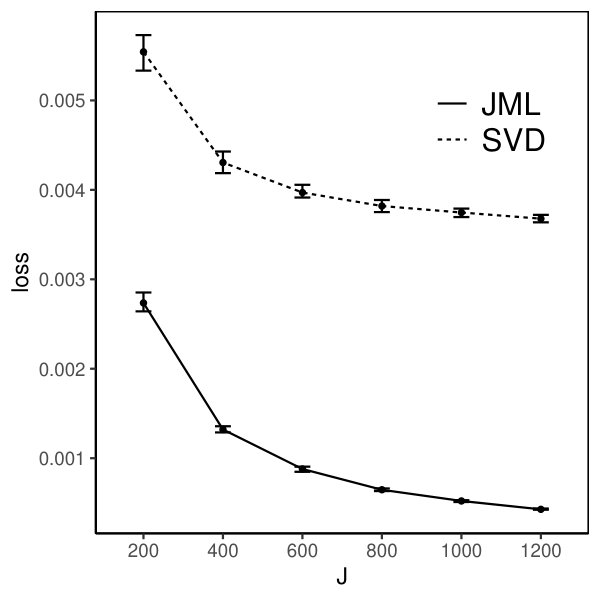 Figure 1
Figure 1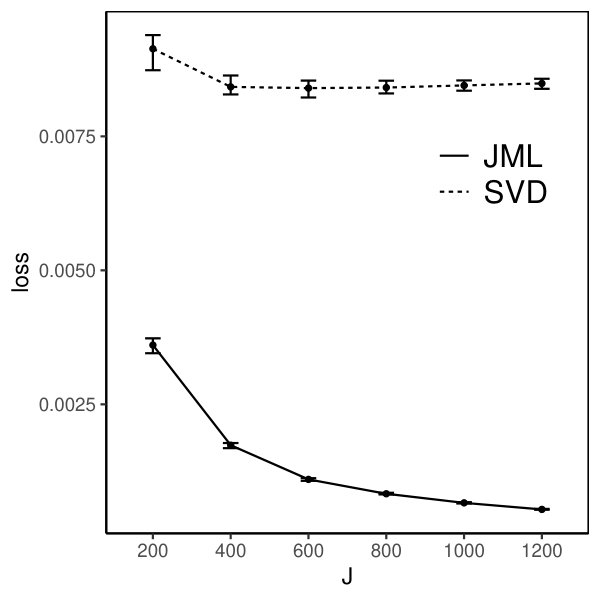 Figure 2
Figure 2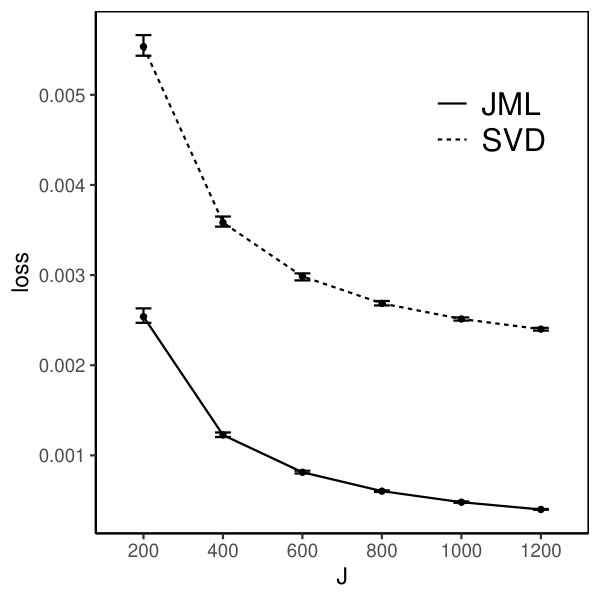 Figure 3
Figure 3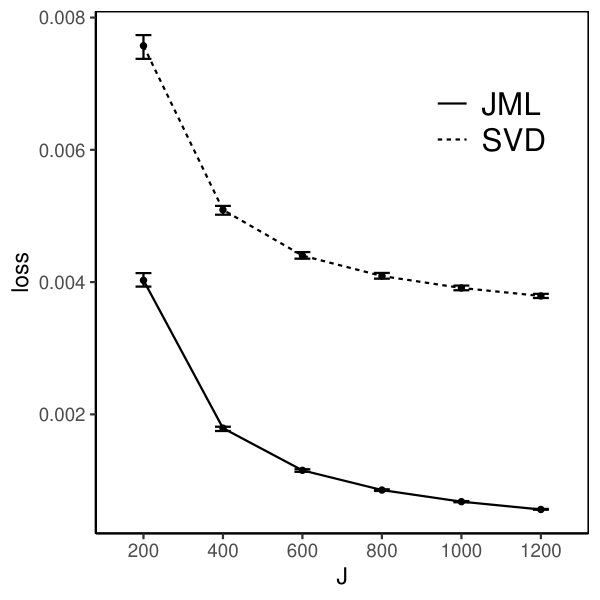 Figure 4
Figure 4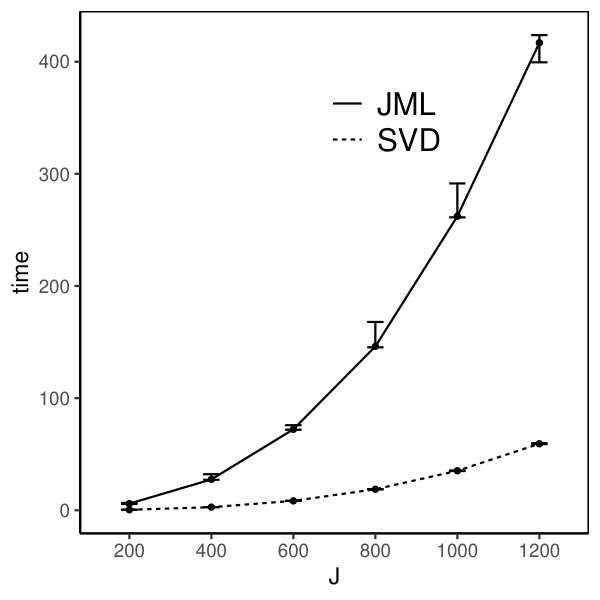 Figure 5
Figure 5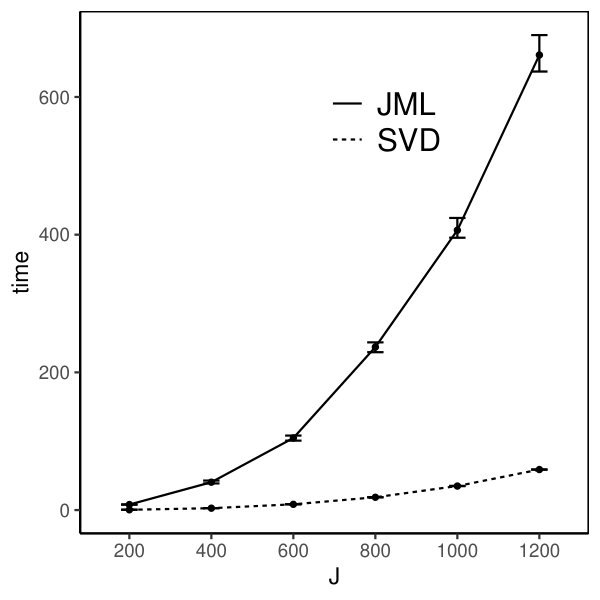 Figure 6
Figure 6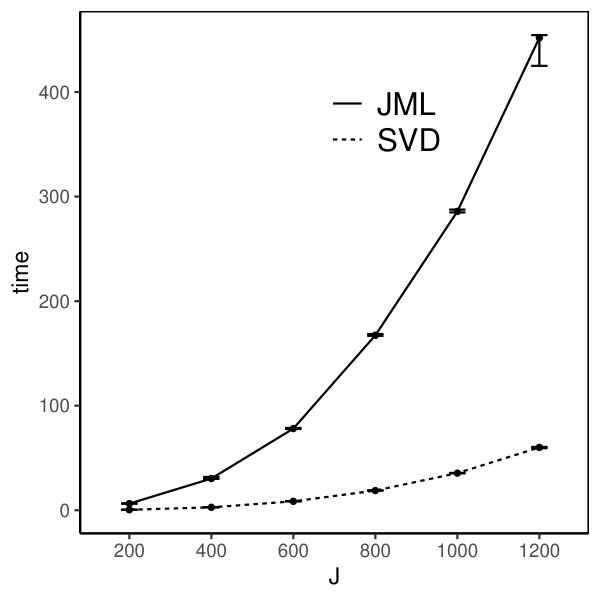 Figure 7
Figure 7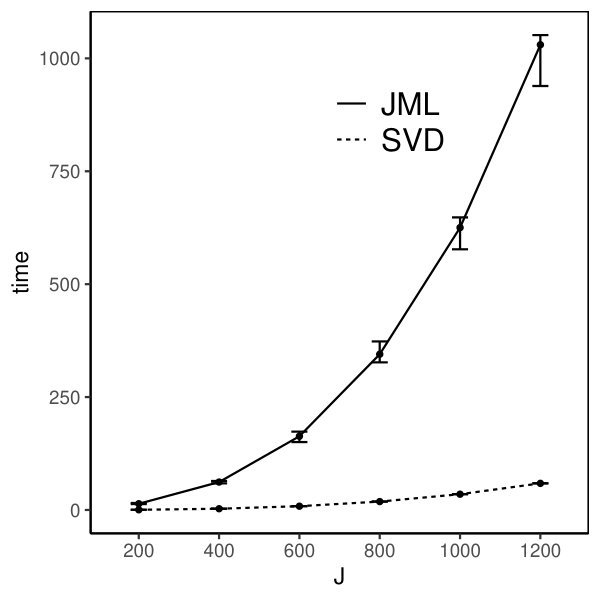 Figure 8
Figure 8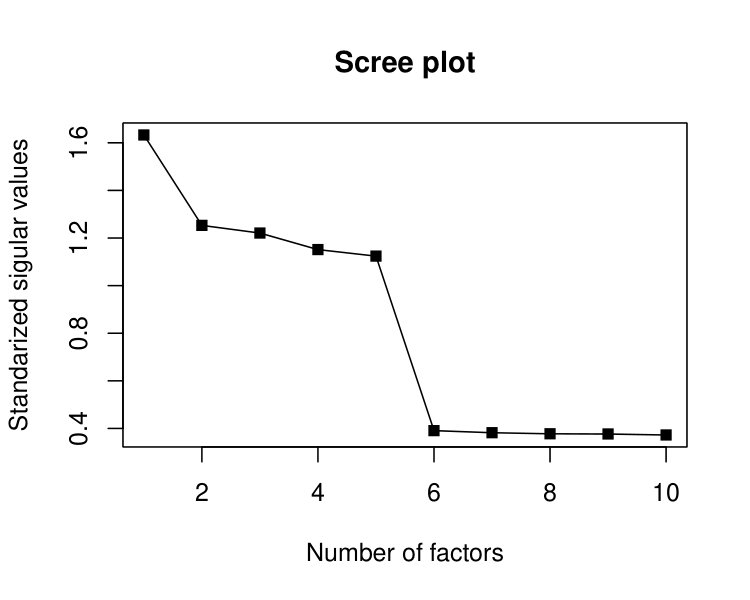 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Note on Exploratory Item Factor Analysis by Singular Value Decomposition
Haoran Zhang, Yunxiao Chen and Xiaoou Li
Abstract
We revisit a singular value decomposition (SVD) algorithm given in Chen et al. (2019b) for exploratory Item Factor Analysis (IFA). This algorithm estimates a multidimensional IFA model by SVD and was used to obtain a starting point for joint maximum likelihood estimation in Chen et al. (2019b). Thanks to the analytic and computational properties of SVD, this algorithm guarantees a unique solution and has computational advantage over other exploratory IFA methods. Its computational advantage becomes significant when the numbers of respondents, items, and factors are all large. This algorithm can be viewed as a generalization of principal component analysis (PCA) to binary data. In this note, we provide the statistical underpinning of the algorithm. In particular, we show its statistical consistency under the same double asymptotic setting as in Chen et al. (2019b). We also demonstrate how this algorithm provides a scree plot for investigating the number of factors and provide its asymptotic theory. Further extensions of the algorithm are discussed. Finally, simulation studies suggest that the algorithm has good finite sample performance.
KEY WORDS: Exploratory item factor analysis, IFA, singular value decomposition, double asymptotics, generalized PCA for binary data
1 Background
Exploratory IFA (Bock et al., 1988) has been widely used for analyzing item-level data in social and behavioral sciences (Bartholomew et al., 2008). We consider a standard exploratory IFA setting for binary item response data. Let be a random variable, denoting individual ’s response to item , where , and . Moreover, IFA assumes that an individual ’s responses are driven by latent factors, denoted by . We consider a general family of multidimensional IFA models (Reckase, 2009), which assumes that
[TABLE]
where is typically known as the loading parameters, is an intercept parameter, and is a pre-specified monotone increasing function which guarantees (1) to be a valid probability. Using the terminology from generalized linear models, is called the inverse link function. Note that (1) includes the widely used multidimensional two-parameter logistic (M2PL) model and multidimensional normal ogive model as special cases, for which and , respectively. Moreover, we assume local independence; that is, , …, are conditionally independent given . Finally, , , are independent and identically distributed, following an unknown distribution .
A major focus of exploratory IFA is to estimate the loading matrix , which helps to understand the latent structure underlying the set of items. It is worth noting that the loading matrix can only be recovered up to an oblique rotation (Browne, 2001).111We only discuss oblique rotation here, as our general exploratory IFA model does not require the factors to be uncorrelated. If the factors are further required to be uncorrelated, then the loading matrix can be recovered up to an orthogonal rotation, for which the rotation matrix is an orthogonal matrix (e.g., Kaiser, 1958). That is, model (1) will remain unchanged, with a rotated loading vector and , where is an invertible matrix that is also known as an oblique rotation. Recognizing the rotational indeterminacy issue, exploratory IFA typically proceeds in two steps. In the first step, an estimate is obtained, using an arbitrary way to fix the rotation. Then in the second step, analytic rotational methods are applied to to obtain a more sparse loading matrix for better interpretability. An analytic rotation finds a rotation matrix such that minimizes a certain “complexity function”, where a lower value of the complexity function indicates more sparsity in the loading matrix (see Browne, 2001, for a review of analytic rotations). It implicitly assumes that the true loading matrix has a sparse pattern; i.e., each item is only directly associated with a small number of factors.
In this note, we focus on the first step of exploratory IFA. In particular, we study an estimator given in Chen et al. (2019b) that is based on SVD. Comparing with other estimators, this estimator is computationally much faster and does not suffer from convergence issues. It was used to obtain a starting point for a constrained joint maximum likelihood estimator (CJMLE). Simulation studies showed that the convergence of CJMLE can be improved by using the SVD-based estimator as a starting point. Moreover, this SVD-based estimator itself is reasonably accurate when both and are large. Thus, it can be used not only as a starting point for the CJMLE, but also as a quick and high-quality solution to large-scale exploratory IFA problems. In what follows, we investigate the statistical properties of this estimator.
2 Main results
SVD-based estimator.
We restate this SVD-based algorithm below.222The original algorithm was described in the supplementary material of Chen et al. (2019b). The algorithm here is a slightly modified version. The major modification is in step 3 of the algorithm that requires at least singular values to be retained. This modification can improve the finite-sample performance of the algorithm; see Remark 4 for more discussions. The other modifications are mainly to simplify the exposition of the algorithm.
Algorithm 1** (SVD-based estimator for exploratory IFA).**
Input response , the number of factors , inverse link function , and truncation parameter . 2. 2.
*Apply the singular value decomposition to and obtain , where are the singular values, and **s and *s are left and right singular vectors, respectively. 3. 3.
Let where \tilde{K}=\max\big{\{}K+1,\operatornamewithlimits{arg\,max}_{k}\{\sigma_{k}\geq 1.01\sqrt{N}\}\big{\}}. 4. 4.
Let be defined as
[TABLE] 5. 5.
Let where 6. 6.
Let \hat{}\mbox{\mathbf{d}}=(\hat{d}_{1},...,\hat{d}_{J}), where . 7. 7.
*Apply singular value decomposition to to have , where are the singular values, and **s and *s are the left and right singular vectors, respectively. 8. 8.
Output
Remark 1**.**
SVD is a powerful tool for the factorization of rectangular matrices that has been widely used in multivariate statistics for the dimension reduction of data (Wall et al., 2003). Thanks to the mathematical properties of SVD, the estimator given by Algorithm 1 is analytic that does not suffer from convergence issues. On the other hand, as the objective functions of the CJMLE and the marginal maximum likelihood estimator (MMLE; Bock and Aitkin, 1981) are nonconvex, there is no guarantee for finding their global optima. In addition, this SVD approach is also much faster than the other estimators, including the CJMLE and MMLE. In particular, the computation of the MMLE based on the vanilla expectation maximization algorithm is not affordable when the latent dimension is of a moderate size (e.g., ). Even the stochastic algorithms for the MMLE (Cai, 2010a, b; Zhang et al., 2020) and the alternating minimization algorithm for the CJMLE (Chen et al., 2019b, c) are much slower than the SVD algorithm, as these algorithms typically need a large number of iterations to converge. A speed comparison is provided in the simulation study between the SVD method and the CJMLE.
Remark 2**.**
Algorithm 1 can be viewed as a generalization of PCA to binary data. PCA is an SVD-based algorithm (e.g., Chapter 14, Friedman et al., 2001) that is fast and commonly used for exploratory linear factor analysis. Unfortunately, PCA cannot be applied to exploratory IFA, due to the nonlinear link function in IFA models. Unlike PCA which applies SVD only once, Algorithm 1 applies SVD twice. The first application of SVD and the inverse transformation (steps 2-5) denoise and linearize the data. Then, the second application of SVD (steps 6-7) is essentially doing PCA to the linearized data.
Remark 3**.**
Similar as the CJMLE (Chen et al., 2019b, c), this SVD-based estimator does not require the latent distribution to be known or to take a parametric form as is required in the MMLE approach. Moreover, exploratory IFA based on tetrachoric/polychoric correlations (Muthén, 1984; Lee et al., 1990, 1992; Jöreskog, 1994) or composite-likelihood-based estimator (Katsikatsou et al., 2012) requires to be multivariate normal, with the former approach further requiring the inverse link to be probit. In this sense, the SVD-based estimator and the CJMLE require less model assumptions than the other estimators. As a price, their consistency requires stronger conditions, specifically, a double asymptotic regime where both and diverge.
Remark 4**.**
Steps 2-4 of the algorithm essentially follow the same procedure of Chatterjee (2015) for matrix estimation. We thus refer the readers to Chatterjee (2015) for the details. A small difference is that we require in step 3 of the algorithm. This modification does not affect the asymptotic behavior of the estimator. However, it can improve the finite-sample performance when and are not large enough. Intuitively, we need to be at least , in order to recover the matrix which is of rank . The constant 1.01 in step 3 of the algorithm follows Theorem 1.1 of Chatterjee (2015), which makes use of the fact that . This constant can be replaced by any fixed constant in the open interval , without affecting its consistency given in Theorem 1 below. We set it to be 1.01, because according to Theorem 1.1 of Chatterjee (2015) this constant should be chosen close to 1 for better accuracy.
Remark 5**.**
The truncation step (step 4) is necessary, as it guarantees the existence of a solution. This is because, even though in step 3 is approximating the true probability , it is not guaranteed to be in the interval . As a consequence, may not be well-defined. The pre-specified truncation parameter determines the truncation level. As shown in the sequel, the choice of affects the statistical consistency of the proposed algorithm. Under certain circumstances, we will need the truncation parameter to decay to zero as and grow to infinity, which is why we attach subscripts and to the truncation parameter. In practice, the performance of the proposed method tends to be insensitive to the choice of when it is chosen sufficiently small, which is justified theoretically by Propositions 1 and 2 below, under two specific settings. In the numerical analysis of this paper, we use as a default value.
Statistical consistency.
In what follows, we establish the theoretical consistency of this method. In particular, we show that this SVD-based algorithm is consistent under similar asymptotic setting and notion of consistency as in Chen et al. (2019b) and Chen et al. (2019c). The proofs of our theoretical results are given in the supplementary material. More precisely, we consider a loss function on the recovery of the true loading matrix up to an oblique rotation
[TABLE]
where the subscripts and are used to emphasize that the loss function depends on the sample size and the number of items , and denotes the Frobenius norm of a matrix . Under mild technical conditions and a double asymptotic setting where both and grow to infinity, we show the loss function converges to zero in probability. The regularity conditions and the consistency result are formally described in Theorem 1, with two special cases discussed in the sequel. Similar double asymptotic settings have been considered in psychometric research, including the analyses of unidimensional IRT models (Haberman, 1977, 2004) and diagnostic classification models (Chiu et al., 2016). The following regularity conditions are needed for our main result in Theorem 1. As will be discussed in the sequel, these conditions are mild.
- A1.
There exists a constant such that , for , where and are the true item parameters.
- A2.
The true person parameters are independent and identically distributed (i.i.d.) following a distribution which has mean and positive definite covariance matrix
- A3.
The inverse link function is strictly monotone increasing, continuously differentiable, and Lipschitz continuous with Lipschitz constant . We further assume that
[TABLE]
- A4.
There exists a constant such that the th singular value of , denoted by , satisfies for all .
- A5.
The sample size is no less than the number of items , i.e., .
Theorem 1**.**
Suppose that conditions A1-A5 are satisfied. Further suppose that and satisfies
[TABLE]
where
[TABLE]
Then the estimate given by Algorithm 1 satisfies , as
Remark 6**.**
We remark that the notion of consistency for the estimation of the loading matrix is weaker than that in the traditional sense, since the loss function (2) is an average of the entry-wise losses when grows. Let minimize the right hand side of (2) and let . Then (2) converges to 0 means that for any , also converges to 0. That is, the proportion of inaccurately estimated loading parameters converges to zero in probability under the optimal rotation. Due to the double asymptotic setting, our theoretical result only suggests the sensible use of the SVD-based algorithm when the sample size and the number of items are both large.
Remark 7**.**
It has been well-understood that PCA can consistently estimate a linear factor model under a similar double asymptotic setting (Stock and Watson, 2002), which provides the theoretical justification for the use of PCA in exploratory linear factor analysis. Theorem 1 can be viewed as a similar result for exploratory item factor analysis.
Remark 8**.**
We provide some discussions on the regularity conditions required in Theorem 1. Assumption A1 requires that the parameters of each item, including the intercept and slope parameters, should not be too large. That is, the presence of an extreme item is likely to distort the analysis. Assumption A2 is a very standard assumption in exploratory IFA. It is more flexible than many exploratory IFA settings, as it does not require the distribution to be multivariate normal. Assumption A3 is satisfied by the logistic and probit link functions, two most commonly used link functions in exploratory IFA, but it excludes, for example, the multidimensional version of the three-parameter logistic model, as a special case. Assumption A4 requires that there is sufficient variability in the items. The same assumption is also required in Chen et al. (2019b) and Chen et al. (2019c). In fact, this assumption is satisfied with probability tending to one, when the true loadings are i.i.d. samples from a -variate distribution whose covariance matrix is non-degenerate. Finally, assumption A5 is practically reasonable, as in large-scale measurement, the sample size is usually larger than the number of items. Since people and items are almost mathematically symmetric in the IFA model, similar asymptotic results can be derived when .
Remark 9**.**
We further provide some intuitions on the reason why the algorithm works. Steps 2-4 essentially follow the same procedure of Chatterjee (2015) for matrix estimation. The procedure guarantees the loss to be small with high probability, where and denote the true item specific parameters and denotes the true person parameters sampled from distribution . Further with conditions A1 and A3, steps 5 and 6 guarantee the average loss to be small with high probability. Finally, under conditions A2 and A4, the famous Davis-Kahan-Wedin theorem from matrix perturbation theory (see e.g., Stewart and Sun, 1990; O’Rourke et al., 2018) guarantees that is small with high probability.
Remark 10**.**
Equations (3) and (4) are requirements on the truncation parameter , which depends on both the tail of distribution and the properties of the inverse link function. Roughly speaking, Equation (3) is saying that cannot be too large. This is because, given and , the probability in (3) is increasing in . Requiring the probability being implies that cannot be large. This requirement is intuitive, because can be a poor approximation to , when many entries of are larger than . The function transforms the truncation on to a truncation on . Using instead of is for technical reasons.
Equation (4) requires that cannot be too small, as the left hand side of (4) is decreasing in . This requirement is also intuitive. Note that , where is decreasing in . Therefore, a sufficiently large choice of avoids the approximation error being too large when there exist some extreme estimates . Function measures the local flatness of the inverse link . The true matrix is more difficult to estimate when is smaller. This is because can be large, even when is small, due to the local flatness of the inverse link function.
Remark 11**.**
We take a stochastic design for the true person parameters and a fixed design for the true item parameters, following the convention of item factor analysis (e.g., Bartholomew et al., 2008). It is worth pointing out that whether taking a stochastic or fixed design is not essential under our double asymptotic regime. For example, the consistent result of Theorem 1 still holds, if we can replace condition A2 by a corresponding fixed design as in Chen et al. (2019b).
Following the discussion on in Remark 10, we consider two concrete settings under which the requirement on becomes more specific. These results are given in Propositions 1 and 2.
Proposition 1**.**
Suppose that has a compact support. More precisely, there exists a constant , satisfying
[TABLE]
under the law of . If we fix to be a constant independent of and , satisfying
[TABLE]
then (3) and (4) are satisfied. This choice of , together with the regularity conditions in Theorem 1, guarantees to converge to zero in probability.
Proposition 2**.**
Consider exploratory IFA based on the M2PL model, where is a multivariate sub-Gaussian distribution333We say the distribution of a K-variate random vector is sub-Gaussian, if there exist constant such that for any and , . In particular, the multivariate normal distribution is sub-Gaussian. and is the logistic link. Suppose that there exists a constant such that
[TABLE]
Then (3) and (4) hold, for any taking the form
[TABLE]
where and are any constants satisfying and . The choice of following (9), together with the regularity conditions in Theorem 1, guarantees to converge to zero in probability.
According to the result of Proposition 1, it suffices to choose as a sufficiently small positive constant, when has a bounded support. Under the setting of Proposition 2, to ensure consistency, one has to let decay to zero at an appropriate rate. Note that even in the second setting where the support of is unbounded, is almost like a constant, as it decays to zero very slowly when grows. These results suggest that we may choose to be a sufficiently small constant in practice.
On the choice of .
In the previous discussion, the number of factors is assumed to be known. In practice, however, this information is often unknown and an important task in exploratory IFA is to determine the number of factors based on data. When conducting exploratory linear factor analysis, one typically gains the first idea by examining the scree plot from principal component analysis. Thanks to the connection between Algorithm 1 and PCA as discussed in Remark 2, a similar scree plot is available from the current method.
The scree plot is produced as follows. We first run Algorithm 1, but replace the unknown in step 1 of the algorithm by a reasonably large number . Then, a scree plot can be obtained by plotting in a descending order, for s produced by step 7 of Algorithm 1. Figure 1 shows such a scree plot, for which the data are generated from a five-factor model () with and , and the input number of factors is set to be in step 1 of the algorithm. Unsurprisingly, an obvious gap is observed between and . In fact, when data follow an IFA model, such a gap in the singular values is guaranteed to exist asymptotically, no matter what the input dimension is. In practice, the latent dimension can be chosen by identifying the singular value gap from the scree plot.
Theorem 2**.**
Under the same conditions as Theorem 1 and when the input dimension in Algorithm 1 is set fixed (i.e., independent of and ) but not necessarily equal to the true number of factors, there exists a constant such that for the true number of factors ,
[TABLE]
as and grow to infinity simultaneously.
Remark 12**.**
As shown in the proof, the input dimension does not affect the asymptotics, as long as it does not grow with and . However, for relatively small and , obtained in step 3 of the algorithm may not reserve enough information when the input dimension is smaller than , which may lead to an underestimation of the number of factors. Thus, in practical applications, we recommend to choose the input dimension to be slightly larger than the maximum number of factors one suspects to exist in the data.
Statistical efficiency.
We further point out that a price is paid for the computational advantage of the SVD-based estimator. To elaborate on this point, we compare it with the CJMLE (Chen et al., 2019b, c). The CJMLE treats both item parameters and latent factors as fixed parameters and maximizes a joint likelihood function with respect to all the fixed parameters. The SVD-based estimator is statistically less efficient than the CJMLE, in the sense that the SVD-based estimator converges to the true parameters in a much slower rate. To make this comparison, we consider the same setting as in Proposition 1. The following proposition establishes the convergence rate for which determines the convergence of . Here, is the true item response probability matrix.
Proposition 3**.**
Suppose that the same assumptions as in Proposition 1 hold and choose as in Proposition 1. Then we have
[TABLE]
On the other hand, as shown in Chen et al. (2019c), the CJMLE achieves the optimal rate (in minimax sense) for estimating , that is, where denotes the CJMLE. This result suggests that the SVD-based estimator converges in a much slower rate than the CJMLE.
3 Extensions
Dealing with missing data.
With slight modification, Algorithm 1 can handle item response data with missing values. We use matrix to indicate the data nonmissingness, where indicates the response is not missing and otherwise. The modified algorithm is described as follows.
Algorithm 2** (SVD-based estimator for exploratory IFA with missing data).**
Input nonmissing indicator , nonmissing responses , the number of factors , inverse link function , and truncation parameter . 2. 2.
Compute as the proportion of observed responses. 3. 3.
For each and , let , if , and if . 4. 4.
*Apply the singular value decomposition to to obtain , where are the singular values and **s and *s are left and right singular vectors, respectively. 5. 5.
Let
[TABLE]
where \tilde{K}=\max\big{\{}K+1,\operatornamewithlimits{arg\,max}_{k}\{\sigma_{k}\geq 1.01\sqrt{N(\hat{p}+3\hat{p}(1-\hat{p}))}\}\big{\}}. 6. 6.
Let be defined as
[TABLE] 7. 7.
Let where 8. 8.
Let \hat{}\mbox{\mathbf{d}}=(\hat{d}_{1},...,\hat{d}_{J}), where . 9. 9.
*Apply singular value decomposition to to have , where are the singular values and *s and are the left and right singular vectors, respectively. 10. 10.
Output
Remark 13**.**
It is easy to see that when there is no missing data. In that case, Algorithm 2 becomes exactly the same as Algorithm 1. Steps 2-5 essentially follow the same procedure of Chatterjee (2015) for matrix completion and the rest of the steps are the same as those in Algorithm 1. Specifically, missing data are first imputed by zero in step 3 of the algorithm. The bias brought by the simple imputation procedure is corrected in Step 5, by multiplying the factor . Similar to Algorithm 1, the choice of in step 5 is determined by the procedure of Chatterjee (2015) with a small modification which guarantees .
In fact, when the entries of the item response matrix are missing completely at random, using a similar proof, one can show that given by Algorithm 2 is still consistent, under some mild condition on the missing data mechanism and the same conditions as in Theorem 1. Specifically, the following condition is needed, in addition to conditions A1-A5.
- A6.
The s are independent and identically distributed from a Bernoulli distribution with where is a constant which does not depend on and .
Under conditions A1-A6, the following proposition holds that guarantees the consistency of the proposed SVD estimator.
Proposition 4**.**
Under the same conditions as Theorem 1 plus condition A6, the estimate given by Algorithm 2 satisfies , as
Dealing with ordinal data.
In exploratory IFA, ordinal data are also commonly encountered, due to the wide use of Likert-scale items. With slight modification, the SVD method can also be used to analyze ordinal data. This is achieved by applying Algorithm 1 to multiple dichotomized versions of data.
More precisely, consider data , where . We consider a general family of graded response type models,
[TABLE]
where is an item- and category-specific intercept parameter, and the rest of the notations are the same as that of model (1). Note that the linear combination of the factors does not depend on the response category and appears in all the submodels for . When takes the logistic form, model (11) becomes the multidimensional graded response model (Muraki and Carlson, 1995).
Model (11) is closely related to the general model (1) for binary data. In fact, if we dichotomize data at response category , i.e., , then binary data follows model (1) with the same loading parameters. Therefore, the loading matrix can be estimated by applying Algorithm 1 to dichotomized data , for some . The estimation accuracy may be further improved by aggregating the results from multiple dichotomized versions of data. This aggregation method is summarized by Algorithm 3 below.
Algorithm 3** (SVD-based estimator for exploratory IFA with ordinal data).**
Input response , the number of categories , the number of factors , inverse link function , and truncation parameter . 2. 2.
For , apply Algorithm 1 to dichotomized data and obtain from step 7 of Algorithm 1. 3. 3.
*Let . Apply singular value decomposition to and obtain , where are the singular values and *s and are left and right singular vectors, respectively. 4. 4.
Output
4 Simulation
Simulation setting.
We consider and , , , and , and . For each combination of , , and , two different latent distributions are considered, one is a -variate standard normal distribution, and the other is a -variate normal distribution , where if and if . The inverse link is chosen to be logistic, i.e. . This leads to 24 different simulation settings, for all possible combinations of , , , and .
For each simulation setting, 100 independent replications are generated, with the item parameters keeping fixed across replications. When and given , the item parameters are generated as follows.
, …, are i.i.d. from a uniform distribution over interval . 2. 2.
, …, are i.i.d., with . Here s are i.i.d. from a uniform distribution over interval , and are i.i.d. from a uniform distribution over . Specifically,
[TABLE]
and
[TABLE]
The s lead to sparse loading vectors.
When , we set the item parameters by repeating multiple times the parameters under and the same . For example, when , we set parameters for items 1-200 and those for items 201-400 to be the same as the parameters generated under the setting .
Results.
Each simulated dataset is analyzed using the SVD-based estimator, with the truncation parameter set to be . The performance of the SVD-based estimator is compared with that of the CJMLE.444The CJMLE is implemented using R package mirtjml (Zhang et al., 2018). All the computation is conducted on a single Intel®Gold 6130 core.
The loss for the SVD-based estimator decreases when and simultaneously grow, under all settings. Reasonable accuracy can be achieved when and are reasonably large, in which case the SVD-based estimator may be directly used for data analysis. For example, under the setting that and is multivariate standard normal, the loss function is already around 0.006 when is 200. It suggests that the average entrywise error is around . In addition, the loss for the SVD-based estimator tends to be smaller when the factors are independent than that when they are correlated, for the same , , and . This is because, the signal in the data is weaker in the latter case, due to the redundant information in correlated factors.
Moreover, we compare the performance of the two estimators. The CJMLE is always more accurate than the SVD-based estimator. This is consistent with the asymptotic theory that the CJMLE is statistically more efficient. However, if we compare the computation time of the two approaches, the SVD-based estimator is substantially faster. Under the most time consuming setting where and the factors are correlated, the SVD approach only takes about 60 seconds, while the CJMLE takes about 17 minutes. Note that as shown in Chen et al. (2019b), CJMLE is already substantially faster than the marginal maximum likelihood estimator. Given its reasonable accuracy and computational advantage, the SVD-based estimator may be a good alternative to the CJMLE and the MMLE in large-scale exploratory IFA problems.
5 Concluding Remarks
As shown in this note, the proposed SVD-based algorithm is statistically consistent and has good finite sample performance in large-scale exploratory IFA problems. Although not statistically most efficient, the algorithm has its unique strengths over other exploratory IFA methods. In particular, it is computationally much faster. In addition, it guarantees a unique solution, while most of the other estimators can suffer from convergence issues for involving nonconvex optimization, including the CJMLE and MMLE.
Given its computational advantages and good finite sample performance, the SVD-based estimator can be used, not only as a starting point for other estimators to improve their numerical convergence, but also as an alternative estimator for data analysis. Specifically, in large-scale exploratory IFA applications, we suggest to start data exploration with the SVD-based estimator. Using this estimator, we can quickly gain some understanding about the number of factors underlying the data, and the loading structures of IFA models assuming different numbers of factors. Such initial knowledge helps us to focus on a smaller set of latent dimension . For these latent dimensions, we tend to further investigate their loading structures by the CJMLE, using the corresponding SVD solutions as starting points. When sample and item sizes are relatively smaller, the traditional methods may be more suitable, such as the MMLE and the composite-likelihood-based estimator.
One limitation of the SVD-based estimator is that it is not easy to make statistical inference on the estimated loading matrix, such as constructing a confidence interval for an estimated loading parameter. This type of inference problem is not an issue for estimators based on the marginal likelihood, for which the asymptotic regime let diverge and keep fixed. However, it is a general challenge for both the SVD-based estimator and the CJMLE, whose consistency relies on a double asymptotic regime and the notion of consistency is weaker than that in the traditional sense. In recent years, this type of inference problems has received much attention in statistics (Chen et al., 2019a; Xia and Yuan, 2019). However, to the best of our knowledge, no results have been obtained under an IFA model. We leave this problem for future investigation.
Appendix
Appendix A Notations
Let and \mbox{\mathbf{d}}^{*}=(d_{1}^{*},...,d_{J}^{*}) denote the true person parameters, factor loadings and intercept parameters, respectively. We also denote We use to denote dimensional vectors with all entries being and [math] respectively, and to denote the ball in centered at with radius For a matrix and a function , let . Let denote the -th largest singular value of and denote the spectrum norm and nuclear norm of , which is the largest singular value and the sum of all singular values, respectively. If is a square matrix, let denote the -th largest eigenvalue of
We denote
[TABLE]
as the true probability matrix and define by
[TABLE]
where is defined in step 5 of Algorithm 2.
Throughout the proof, we use to denote constant, whose value may change from line to line or even within a line. We will drop the subscripts in and write for notional simplicity.
Appendix B Proof of Theorems
Proof of Theorem 1.
Since Theorem 1 is a special case of Proposition 4 when and we refer the readers to the proof of Proposition 4. ∎
Proof of Theorem 2.
Let denote the th largest singular value of Then we have
[TABLE]
By (D.12) in the proof of Lemma 1, we can get
[TABLE]
Notice that (B.2) holds as long as the input dimension in the algorithm is fixed. Combine (B.1) and (B.2) to have
[TABLE]
Notice that and we get
[TABLE]
For we get
[TABLE]
for any and thus
[TABLE]
For we have
[TABLE]
The last inequality is due to condition A4. Let and it is not hard to verify that
[TABLE]
By law of large number, we know
[TABLE]
which leads to
[TABLE]
and thus
[TABLE]
Combining (B.3), (B.4), (B.5) and choosing we have
[TABLE]
We complete the proof by choosing ∎
Appendix C Proof of Propositions
Proof of Proposition 1.
According to the choice of , we have Then,
[TABLE]
We complete the proof by Theorem 1. ∎
Proof of Proposition 2.
For the logistic link function, we have
[TABLE]
Since is a sub-Gaussian random vector, then is an sub-exponential random variable, which means there exist constant such that for any we have
[TABLE]
Then,
[TABLE]
Recall we choose in (9). Consequently,
[TABLE]
Therefore,
[TABLE]
where the second inequality is due to the assumption that . The above display together with (C.2) verifies (3). We proceed to verify (4). According to (C.1), we have
[TABLE]
Plugging in , the above equation becomes
[TABLE]
Thus, for ,
[TABLE]
This verifies (4) and completes the proof by applying Theorem 1.
∎
Proof of Proposition 3.
The proof of Proposition 3 is similar to proof of Lemma 1. We will only state the main steps and omit the repeating details. According to Lemma 3 in Appendix D, we have
[TABLE]
Recall that we assume . Following the similar arguments as in the proof of Lemma 1, we have
[TABLE]
There is a difference from the proof of Lemma 1 that the rank of matrix is upper bounded by
[TABLE]
Choose , then
[TABLE]
Let . By taking expectation, we have
[TABLE]
For any , by Chebyshev’s inequality, we have
[TABLE]
Thus, for any sequence satisfying , we have
[TABLE]
In what follows, we restrict our analysis to the event . By (7), we have which leads to
[TABLE]
Following the similar procedure as in proof of Lemma 1, we can further bound by
[TABLE]
To summarize, we have
[TABLE]
for any . This implies , where the second equation is due to . ∎
Proof of Proposition 4.
We have
[TABLE]
where Let . Then , and s are independent and identically distributed from a distribution which has mean and covariance matrix . Therefore, it suffices to show when . We prove it through the following two lemmas whose proofs are given in Appendix D.
Lemma 1**.**
Assume conditions A1, A2, A3, A5 and A6 are satisfied and further assume that (3) and (4) are satisfied. Then,
[TABLE]
where and are given in Algorithm 2.
Lemma 2**.**
Suppose conditions A1, A2 and A4 are satisfied and further suppose that
[TABLE]
Then,
We complete the proof. ∎
Appendix D Proof of Lemmas
Proof of Lemma 1.
We first give a lemma regarding the error bound for recovering the probability matrix
Lemma 3**.**
Given , we have
[TABLE]
Let
[TABLE]
where is a quantity depending on . Let
[TABLE]
Then, according to the condition (3)
[TABLE]
In what follows, we restrict the analysis to the event . Let be two -nets for and respectively. This means and
[TABLE]
For any let be a point in such that
[TABLE]
which implies
[TABLE]
With a little abuse of notation, we use to denote For any let be a point in such that
[TABLE]
It is not hard to see that we can find such such that
[TABLE]
This is due to definition of and condition A1. Let , where then we have
[TABLE]
Now we provide an upper bound for on the right-hand side of (D.1). We have
[TABLE]
The second term on the right-hand side of the above display is bounded above by
[TABLE]
Now we consider the first term. We have
[TABLE]
So
[TABLE]
We have used the Lipschitz continuity in condition A3 here. Then the first term in (D.2) is bounded from above as
[TABLE]
Here we used the fact that the rank of the matrix cannot exceed according to condition A5. Combined (D.1), (D.2), (D.3) and (D.4), then on the event
[TABLE]
Choose , then
[TABLE]
which implies
[TABLE]
where we define . By Chebyshev’s inequality, for any ,
[TABLE]
Thus,
[TABLE]
Let then according to (D.5) for any sequence satisfying , we have
[TABLE]
We will restrict our analysis on in what follows. Let , then on we have
Recall . Then, according to the definition of the function and , we can see that This interval is non-empty because Thus, when the event happens, we have which leads to
[TABLE]
Since and are not far away from each other by definition, we can bound by
[TABLE]
where the last inequality is because . According to condition A3 and the above inequality, we have
[TABLE]
The first inequality holds because on the event .
We proceed to an upper bound of . Recall that Let and We have
[TABLE]
We first bound the trace term in the above display,
[TABLE]
Through simple algebra, we have By the definition of we have Then
[TABLE]
which leads to
[TABLE]
So we can bound by
[TABLE]
According to condition A2 and law of large number, we have
[TABLE]
for any Let
[TABLE]
then we have
[TABLE]
for any On according to (D.7) , (D.10) and (D.11),
[TABLE]
Recall how we get in algorithm 2 and we have
[TABLE]
So
[TABLE]
which leads to
[TABLE]
where the first inequality is due to \textrm{rank}\big{(}\hat{\Theta}\hat{A}^{\top}-\Theta^{*}(A^{*})^{\top}\big{)}\leq 2K, the second inequality is due to (D.13) and the last inequality is due to (D.12). Thus, on the event
[TABLE]
Recall
[TABLE]
where could be any sequence satisfying . By (3), (4) and condition A5, there exists such that . So fix any for large enough, we have Then there is a constant such that for large enough, on with , we have,
[TABLE]
This combined with for any sufficiently small completes the proof. ∎
Proof of Lemma 2.
Let
[TABLE]
and in the following we will show that
[TABLE]
For any let
[TABLE]
Applying Theorem 5.39 of Vershynin (2010) to the matrix , we have for any . We restrict our analysis on in what follows and denote
[TABLE]
Then,
[TABLE]
We consider first:
[TABLE]
For (a), notice that
[TABLE]
So
[TABLE]
Combine (D.17), (D.18) and (D.19), we get on
[TABLE]
Recall that can be arbitrarily small and we complete the proof. ∎
Proof of Lemma 3.
This lemma is almost the same as Theorem 1.1 of Chatterjee (2015) by setting, in his notations, and except two small differences. The first is that the probability can be changed through in the setting of Chatterjee (2015) while is a constant in our setting. Therefore we absorb into constants in the LHS of (D.1). The second difference is a modification in step 5 of Algorithm 2 that we require to include at least singular values of This does not change the result of Theorem 1.1 of Chatterjee (2015) given the following lemma which is based on Lemma 3.5 of Chatterjee (2015).
Lemma 4**.**
For fixed and a matrix , let be the singular value decomposition of A. Fix any and integer , and define
[TABLE]
where Then
[TABLE]
where
Notice that we have another term in (D.20) compared with Lemma 3.5 in Chatterjee (2015), which is due to the composition of In the proof of Theorem 1.1 in Chatterjee (2015), by replacing Lemma 3.5 in Chatterjee (2015) by the above lemma with , we get
[TABLE]
The term in (D.21) results from the first term in (D.20). Notice that if
[TABLE]
then
[TABLE]
which leads to
[TABLE]
Therefore we can remove the term in (D.21) to complete the proof. ∎
Proof of Lemma 4.
Let
[TABLE]
and by Lemma 3.5 of Chatterjee (2015), we have
[TABLE]
Note that
[TABLE]
and we complete the proof by triangular inequality. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bartholomew et al. (2008) Bartholomew, D. J., Moustaki, I., Galbraith, J., and Steele, F. (2008). Analysis of multivariate social science data . CRC Press, Boca Raton, FL.
- 2Bock and Aitkin (1981) Bock, R. D. and Aitkin, M. (1981). Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. Psychometrika , 46:443–459.
- 3Bock et al. (1988) Bock, R. D., Gibbons, R., and Muraki, E. (1988). Full-information item factor analysis. Applied Psychological Measurement , 12:261–280.
- 4Browne (2001) Browne, M. W. (2001). An overview of analytic rotation in exploratory factor analysis. Multivariate Behavioral Research , 36:111–150.
- 5Cai (2010 a) Cai, L. (2010 a). High-dimensional exploratory item factor analysis by a Metropolis–Hastings Robbins–Monro algorithm. Psychometrika , 75:33–57.
- 6Cai (2010 b) Cai, L. (2010 b). Metropolis-Hastings Robbins-Monro algorithm for confirmatory item factor analysis. Journal of Educational and Behavioral Statistics , 35(3):307–335.
- 7Chatterjee (2015) Chatterjee, S. (2015). Matrix estimation by universal singular value thresholding. The Annals of Statistics , 43:177–214.
- 8Chen et al. (2019 a) Chen, Y., Fan, J., Ma, C., and Yan, Y. (2019 a). Inference and uncertainty quantification for noisy matrix completion. Proceedings of the National Academy of Sciences , 116:22931–22937.