Extent of occurrence reconstruction using a new data-driven support estimator
A. Rodr\'iguez-Casal, P. Saavedra-Nieves

TL;DR
This paper introduces a new data-driven method for estimating the probability support of a distribution, using an r-convex set estimator with an algorithm to determine the shape parameter from data, applicable to ecological data.
Contribution
The paper presents a stochastic algorithm to estimate the shape parameter r for r-convex support sets, enabling flexible and accurate support reconstruction from data.
Findings
Achieves convergence rates similar to convex hull estimators for convex sets.
Provides a practical algorithm for estimating the shape parameter r.
Demonstrates application to ecological data for invasive species.
Abstract
Given a random sample of points from some unknown distribution, we propose a new data-driven method for estimating its probability support S. Under the mild assumption that S is r-convex, the smallest r-convex set which contains the sample points is the natural estimator. The main problem for using this estimator in practice is that r is an unknown geometric characteristic of the set S. A stochastic algorithm is proposed for determining an optimal estimate of r from the data under mild regularity assumptions on the density function. The resulting data-driven reconstruction of S attains the same convergence rates as the convex hull for estimating convex sets, but under a much more flexible smoothness shape condition. The new support estimator will be used for reconstructing the extent of occurrence of an assemblage of invasive plant species in the Azores archipelago.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1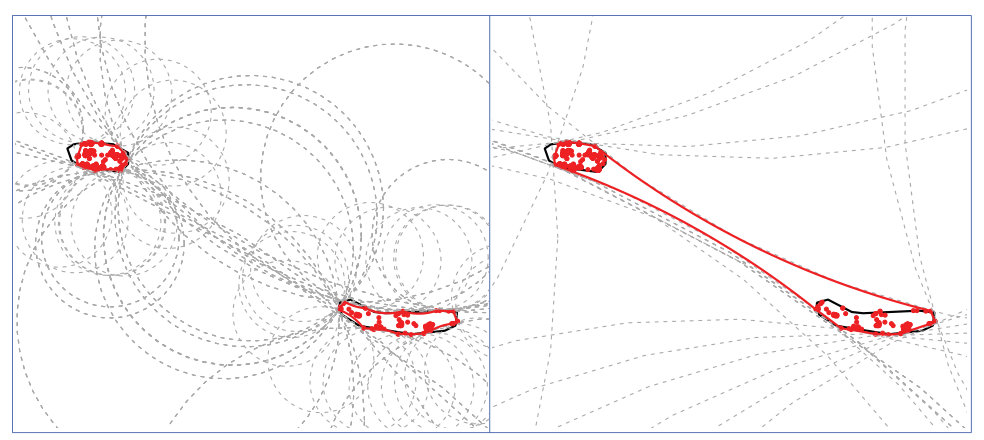 Figure 2
Figure 2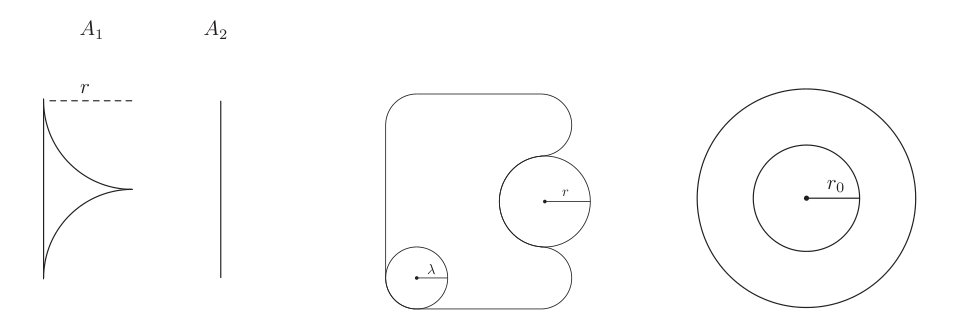 Figure 3
Figure 3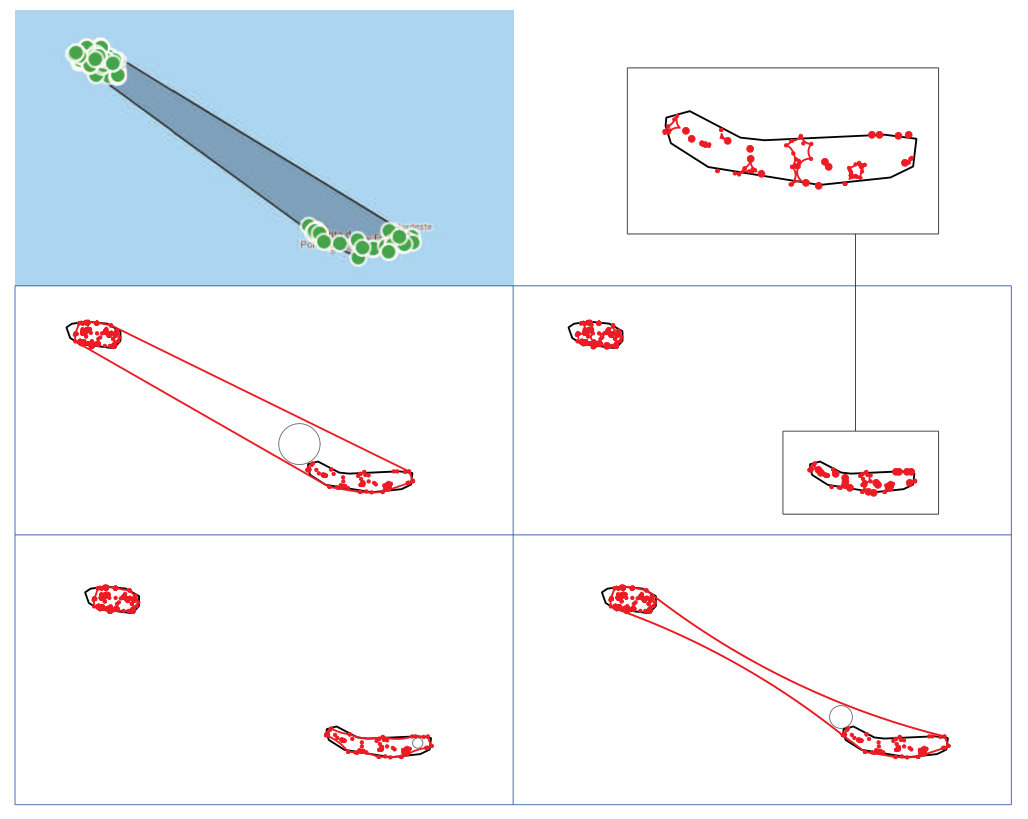 Figure 4
Figure 4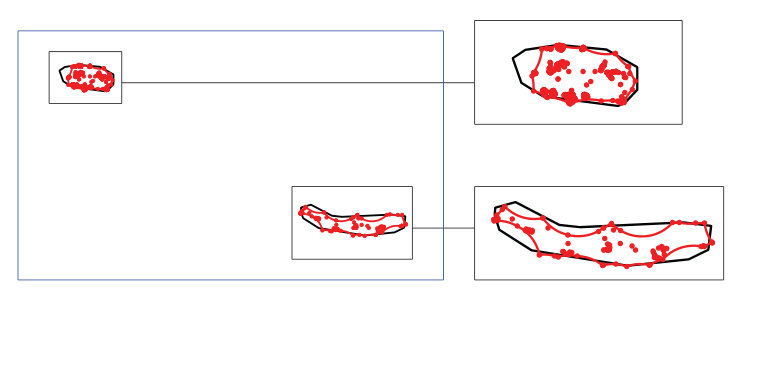 Figure 5
Figure 5 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Statistical Methods and Models · Pharmacological Effects of Medicinal Plants · Statistical Methods and Inference
Extent of occurrence reconstruction using a new data-driven support estimator
A. Rodríguez-Casal
P. Saavedra-Nieves
Department of Statistics, Mathematical Analysis and Optimization, Universidade de Santiago de Compostela, Spain
Abstract
Given a random sample of points from some unknown distribution, we propose a new data-driven method for estimating its probability support . Under the mild assumption that is convex, the smallest convex set which contains the sample points is the natural estimator. The main problem for using this estimator in practice is that is an unknown geometric characteristic of the set . A stochastic algorithm is proposed for determining an optimal estimate of from the data under mild regularity assumptions on the density function. The resulting data-driven reconstruction of attains the same convergence rates as the convex hull for estimating convex sets, but under a much more flexible smoothness shape condition. The new support estimator will be used for reconstructing the extent of occurrence of an assemblage of invasive plant species in the Azores archipelago.
keywords:
Support estimation, convex, testing convexity, spacing, extent of occurrence (EOO), area of occupancy (AOO)
††journal:
1 Introduction
Natural reserve network designs require information about species occurrence data. One of the most widely handled concepts is the extent of occurrence (EOO). In fact, the International Union for the Conservation of Nature (IUCN) establishes the EOO as a key measure of extinction risk. Roughly speaking, the IUCN defines the EOO as the area contained within the shortest continuous imaginary boundary which can be drawn to encompass all the known, inferred or projected sites of present occurrence of a taxon, excluding cases of vagrancy. For a complete review on this subject, see Rondinini et al. (2006).
The problem of EOO reconstruction will be illustrated via the analysis of a real dataset containing geographical coordinates (or occurrences) for species of terrestrial invasive plants distributed in two of the Azorean islands (Terceira and São Miguel) from 2010 until 2018. In Figure 1, a satellite image of major Azorean islands (top, left) and five of the invasive species are shown (bottom). The geographical locations (slightly jittered) are represented on the map of Terceira and São Miguel islands in Figure 1 (top, right). This dataset is available from the Global Biodiversity Information Facility (GBIF) website (see GBIF.org, 27th May 2019).
An initial estimation of the EOO for this assemblage of invasive plants was obtained from GeoCAT. It is an open source, browser based tool endorsed by IUCN that allows to reconstruct the EOO from the geographical locations of species or taxon. Users can quickly combine data from multiple sources including GBIF datasets which can be easily imported. The GeoCAT reconstruction of the EOO for the assemblage of plant species used here as an example is given by the convex hull of the sample of the coordinates, . Mathematically, is the smallest convex set that contains . In fact, it is computed as the intersection of all half spaces containing . For more details, compare Figure 4 (first row, left) and Figure 4 (second row, left). Note that this EOO estimation presents some limitations because a marine area is inside the . Obviously, none of the plant species considered here can occur in open sea which should remain outside the EOO. Therefore, convexity can be a too restrictive shape condition to be assumed in practice.
Our goal is to propose a more realistic and automatic EOO reconstruction from support estimation perspective. This methodological approach has proved to be useful in different disciplines such as image analysis (see Rodríguez-Casal and Saavedra-Nieves, 2016), quality control (see Devroye and Wise, 1980 or Chevalier, 1976) or animals home range estimation (see De Haan and Resnick, 1994 or Baíllo and Chacón, 2018). However, the problem of reconstructing the EOO has not been yet considered formally under this viewpoint.
In general, support estimation deals with the problem of reconstructing the compact and nonempty support of an absolutely continuous random vector from a random sample (see Cuevas and Fraiman, 2010 for a complete survey on the subject). Of course, when the support is assumed to be convex then the convex hull of the sample points, , provides a natural support estimator. See Schneider (1988, 1993), Dümbgen and Walther (1996) or Reitzner (2003), for thorough analysis of this estimator. This estimator is indeed simple, but it may not be suitable for practical situations, failing to provide a satisfactory support estimator when is disconnected as in the example of invasive plants in Azores archipelago where the occurrences are distributed in two different islands.
In this work, we will propose a new data-driven support estimator and, as a consequence, an original and realistic EOO reconstruction that will overcome the limitations derived from convexity restriction. Concretely, we assume that the support satifies the convexity shape condition for , a much more flexible property than convexity as it will be shown. Our proposal considers the smallest -convex set containing (convex hull of , namely ) as the natural estimator for the usually unknown support. This estimator is well known in the computational geometry literature for providing reasonable global reconstructions if the sample points are (approximately) uniformly distributed on the set (see Edelsbrunner, 2014). In fact, despite being convexity a more general condition than convexity, can achieve the same convergence rates than as proved by Rodríguez-Casal (2007). However, this estimator presents an important disadvantage: it depends on the commonly unknown parameter . Although the influence of is considerable, it must be specified by the practitioner (see Joppa et al., 2016). For the example of invasive species in Azorean islands, Figure 4 shows for different values of . Small values of provide fragmented estimators (many isotated points and connected components) leading to an EOO reconstruction which resembles (Figure 4: second row, right). If , a realistic reconstruction of the EOO is obtained since sea areas are not inside the estimator (Figure 4: third row, left). However, if large values of are considered then basically coincides with (Figure 4: third row, right). Therefore, arbitrary choices of may provide incongruous EOO estimations.
Most of the available results in the literature about support estimation make special emphasis on asymptotic properties, especially consistency and convergence rates but they do not usually give any criterion for selecting the unknown parameter in from the sample. The aim of this paper is to overcome this drawback and present a method for selecting the parameter for the convex hull estimator from the available data. This problem has scarcely been studied in the statistical literature with just a couple of references available on the topic. First, Mandal and Murthy (1997) proposed a selector for based on the concept of minimum spanning tree but only consistency of the method was provided without considering optimality issues. Later, Rodríguez-Casal and Saavedra-Nieves (2016) proposed an automatic selection criterion based on a very intuitive idea for the selection of but under the restriction that the sample distribution is uniform. According to Figure 4 (bottom, right), sea areas are contained in if the selected is too large. So, the estimator contains a large ball empty of sample points, see gray balls in Figure 4 (top, left) and (bottom, right). Janson (1987) calibrated the size of this maximal ball (or spacing) when the sample distribution is uniform on . Berrendero et al. (2012) used this result to test uniformity when the support is unknown. However, Rodríguez-Casal and Saavedra-Nieves (2016) followed the somewhat opposite approach. They assume that comes from a uniform distribution on and if a big enough spacing is found in then it is incompatible with the assumption that data are uniform. As a consequence, it is concluded that is too large. Therefore, it is proposed to select the largest value of compatible with the uniformity assumption on .
Recently, Aaron et al. (2017) extended the results by Janson (1987) to the case where the data are generated from a density that is bounded from below and Lipschitz continuous restricted to its bounded support. Here, we will use this extension in order to derive a test to decide, given a fixed , whether the unknown support is convex with no more information apart from . In this case, if a large enough spacing is found in then the null hypothesis of convexity will be rejected. A new data-driven selector for the index will be established from this test. Following the scheme in Rodríguez-Casal and Saavedra-Nieves (2016), it is proposed to choose the largest value of compatible with the convexity assumption.
Once the parameter is estimated from , a new data-driven support reconstruction, based on the estimator of , will be proposed. As a consequence, a flexible reconstruction for the EOO will be obtained.
This paper is organized as follows. Mathematical tools are introduced in Section 2. First, the geometric assumptions on and the optimal value of the parameter to be estimated are introduced. Then, the regularity assumptions on and a new nonparametric estimator are established. At last, the maximal spacing and its estimator are formally defined. In Section 3, we propose a procedure for testing the null hypothesis that is convex for a given . This test will play a key role in the definition of the consistent estimator of . Then, a new estimator for the support is proposed in Section 4 and it will be seen that it achieves the same convergence rates as the convex hull for estimating convex sets. The main numerical features involving the practical application of the algorithm are exposed in Section 5. In Section 6, the performance of the new support reconstruction will be analyzed estimating the EOO of an assemblage of terrestrial plant species in two Azorean islands. Conclusions are exposed in Section 7. In Section 8, we detail the proofs of theoretical results. Finally, some auxiliary results are deferred to Section 9.
2 Mathemathical tools
Regularity conditions, namely shape assumptions on , will be introduced next. In addition, we will discuss which is the optimal value of the shape index to be estimated. Then, required conditions on the density function and an original nonparemetric kernel estimator will be also presented. Finally, basic notions on maximal spacings are established.
2.1 About geometric assumptions on and the optimal value of
In this work, is assumed to be convex for some . Therefore, it is necessary to establish the formal definition of this geometric property in Definition 2.1.
Definition 2.1**.**
A closed set is said to be convex, for some , if , where
[TABLE]
denotes the convex hull of and , the open ball with center and radius .
In practice, can be computed as the intersection of the complements of all open balls of radius larger than or equal to that do not intersect . In Figure 2, the computation of for (left) and (right) is shown considering the example in Azorean islands. Note that is an acceptable EOO reconstruction equal to the intersection of the complements of all gray open balls represented. However, if we select , marine areas are clearly inside the .
Furthermore, the concept of convex hull is closely related to the closing of by from the mathematical morphology, see Serra (1982). It can be shown that
[TABLE]
where , , and , for and sets and .
As it has been mentioned in the Introduction, the problem of reconstructing a convex support using a data-driven procedure could be easily solved if the parameter is estimated from a random sample of points taken in . The first step is to determine precisely the optimal value of to be estimated, which is established in Definition 2.2: we propose to estimate the largest value of which verifies that is convex.
Definition 2.2**.**
Let a compact, nonconvex and convex set for some . It is defined
[TABLE]
For simplicity, it is assumed that is not convex (of course, if is convex would be infinity). Proposition 2.4 in Rodríguez-Casal and Saavedra-Nieves (2016) shows that, under mild regularity conditions, the supreme established in (1) is a maximum, that is, is convex and convex for all . Under this hypothesis, the optimality of the smoothing parameter defined in (1) can be justified. It is clear that is convex for but if , is a non admisible estimator since it is always outperformed by . This happens because, with probability one, . It should also noted that, for , even for very close to , would considerably overestimate . For instance, if is equal to the circular ring in Figure 3 (right) and , coincides with the outer circle. The mild regularity condition we need is slightly stronger than convexity:
() fulfills the rolling property and fulfills the rolling condition for some , .
Following Cuevas et al. (2012), it is said satisfies the (outside) rolling condition if each boundary point is contained in a closed ball with radius whose interior does not meet . There exist interesting relationships between this property and convexity. In particular, Cuevas et al. (2012) proved that if is compact and convex then fulfills the rolling condition. According to Figure 3 (left), the reciprocal is not always true. Proposition 2.2 in Rodríguez-Casal and Saavedra-Nieves (2016) shows that () is a (mild) sufficient condition to ensure the rolling condition implies convexity. Condition () was essentially analyzed by Walther (1997, 1999) but just the case was taken into account. In this work, the radius can be different from , see Figure 3 (center). Walther (1997, 1999) proved that, if , is a dimensional submanifold in and that is convex. Proposition 2.2 in Rodríguez-Casal and Saavedra-Nieves (2016) generalized this property since, for , Walther’s result would only imply -convexity but not convexity. So, for sets satisfying (), convexity is ensured, even for very small values of .
Proposition 2.2 in Rodríguez-Casal and Saavedra-Nieves (2016) is the key for proving that is a maximum. To see this, let be a sequence converging to such that . This sequence always exists by Definition 2.2. It can be proved, using the results by Cuevas et al. (2012), that satisfies the rolling condition and, by Proposition 2.3 in Rodríguez-Casal and Saavedra-Nieves (2016), this property is preserved in the limit, so is also -rolling. Finally, under (), -rolling implies that is convex.
The authors conjecture that the equivalence between convexity and rolling could be stated in a more general framework and it may be proved under milder conditions.
Remark 2.3**.**
Under certain conditions of (for instance, ), it is verified that where . Therefore, if is assumed to be convex, Proposition 2.4 in Rodríguez-Casal and Saavedra-Nieves (2016) remains true. For more details, see Walther (1999).
2.2 About regularity conditions on and its nonparametric estimation
All through this paper, we assume that the random sample of points, , is generated from a density that satisfies the next regularity condition:
() The restriction of the density to is Lipschitz continuous (there exists such that ,
() and there exists such that for all . Furthermore,
() .
As an example in the one-dimensional case, condition () is satisfied by if and , otherwise where and denote two real numbers verifying that .
Morever, a non-conventional density estimator will be introduced in Definition 2.4.
Definition 2.4**.**
Let and let be the Voronoi cell of the point (i.e. ). If is a kernel function and denotes the usual kernel density estimator, we define
[TABLE]
Note that this nonparametric estimator have a non-usual behaviour: it is expected to converge towards the unknown density when the support is convex, but not when the support is not convex.
Moreover, some technical hypotheses on the kernel function must be established.
() The kernel function belongs to the set of kernels such that where is a polynomial () and is a is bounded real function of bounded variation, verifying that , () and there exists and such that for all .
Condition () is satisfied, for instance, by the Gaussian kernel.
2.3 About maximal spacings and its nonparametric estimation
The optimal value of the shape index to be estimated is just established in Definition 2.2. Some concepts on maximal spacings theory must be handled to propose a consistent estimate of .
The notion of maximal-spacing in several dimensions was introduced and studied by Deheuvels (1983) for uniformly distributed data on the unit cube. Later on, Janson (1987) extended these results to uniformly distributed data on any bounded set and derived the asymptotic distribution of different maximal-spacings notions without conditions on the shape of the support . Aaron et al. (2017) generalized the results by Janson (1987) to the non-uniform case.
The shape of the considered spacings will be defined by a given set . For the validity of the theoretical results, it is sufficient to assume that is a compact and convex set. For practical purposes, the usual choices are or , the closed ball of center [math] and radius . For a general dimension , the first definition of maximal spacing is that used by Janson (1987) under the restriction of data are uniformly distributed:
[TABLE]
If the Lebesgue measure of the set is one, represents the Lebesgue measure of the largest set . The concept of maximal spacing can be related easily to the maximal inner radius when . If , the maximal inner radius of is defined as
[TABLE]
Note that the value of the maximal spacing depends on and also on . However, the definition of the maximal inner radius relies only on .
Aaron et al. (2017) extended the definition of maximal-spacing assuming that is drawn according to a density with bounded support , the Lebesgue measure of the set is one and its barycentre is the origin of . In this more general setting, the maximal spacing is defined as
[TABLE]
and
[TABLE]
The previous definition of maximal spacing relies on density . In this way, it distinguishes between low and high density regions. Throughout this paper, we will assume this latter choice where denotes the Lebesgue measure of .
Janson (1987) calibrated the volume of the maximal spacing under uniformity assumptions without conditions on the shape of the support . The corresponding extension established in Theorem 2 in Aaron et al. (2017) is shown in Theorem 2.5 modifying slightly the original hypotheses on and on the shape of . The result remains true if it is assumed that is under () and the density function satifies ().
Theorem 2.5**.**
Let be a random and i.i.d sample drawn according to a density that satisfies () with compact and nonempty support under (). Let be a random variable with distribution
[TABLE]
and let be a constant specified in Janson (1987). Then, we have that
[TABLE]
[TABLE]
where
[TABLE]
Remark 2.6**.**
The value of constant does not depend on . It is explicitly given in Janson (1987). Concretely,
[TABLE]
In particular, for the bidimensional case, .
A plug-in estimator of the maximal spacing will be proposed next. Note that the definition of relies on the support and also on the density function (both are usually unknown). Under the assumption of convexity, will be estimated as . As for the density function , the new nonparametric density estimator introduced in Definition 2.4 will be used. Then, we define the following plug-in estimator of :
[TABLE]
Note that if is convex, should converge to zero as the sample size increases. However, if , the plug-in estimator of is expected to converge to a positive constant.
3 A new test for convexity
We will introduce a consistent hypothesis test based on drawn according to an unknown density on the unknown support , to asses convexity for a certain . This test is crucial for defining an estimator of that would allow the data-driven estimation of the support .
Given , the null hypothesis that is convex will be tested taking the volume of as statistic. The idea that supports this procedure is simple: Under () and (), Theorem 2.5 allows us to detect which values of are large enough to be incompatible with these two assumptions. Since a similar reasoning can be also applied if we consider the volume of , the test is based on the opposite approach: Under () and (), if the test statistic takes large enough values, it will mean that the selected is not appropriate and a smaller one should be considered.
The performance of this test can be illustrated using the real database of invasive plants in Azorean islands. Given the sample , the practitioner could be interested in testing the null hythothesis that the EOO is convex, for instance, for . According to Figure 4 (third row, right), it is clear that large Atlantic Ocean areas are inside and the EOO is overestimated. Moreover, the volume of will be too large. In fact, although larger samples sizes were considered, its volume would take a constant value (see gray ball inside the EOO reconstruction). Therefore, the null hypothesis of convexity should be rejected. Note that the situation is the opposite if testing convexity for is the goal. The volume of should be clearly smaller. Furthermore, when the sample size increases, this volume tends to zero. Formally, the asymptotic behaviour of the test is stated in Theorem 3.1.
Theorem 3.1**.**
Let and let be a random and i.i.d sample drawn according to a density that satisfies () with compact and nonempty support under (). Let be the corresponding density estimator introduced in Definition 2.4 and let be the kernel function under (). Assume that for some . For the following decision problem,
[TABLE]
- (a)
The test based on the statistic with critical region , where
[TABLE]
has an asymptotic level less than .
- (b)
Moreover, if verifying (*) is not *convex, the power is for sufficiently large .
Remark 3.2**.**
Note that the optimal kernel sequence size, , satisfies the hypotheses under which Theorem 3.1 holds. Therefore, any reasonable bandwidth selector should be suitable for testing convexity.
3.1 Selection and consistency results of the optimal smoothing parameter
The optimal estimation of the smoothing parameter from is based on the test previously proposed. Specifically, according to Definition 2.2, will be estimated by
[TABLE]
That is, it is proposed to select the largest value of compatible with the convexity assumption. Note that this choice depends on the significance level of the test. Again, we use the example of invasive plants in Azorean islands in order to analyze this estimator. Under () and (), if the volume of is large enough, then the null hypothesis of convexity will be rejected. Therefore, a smaller value of should be selected. This case corresponds to Figure 4 (third row, right) taking . However, the situation is completely opposite in Figure 4 (second row, right) when . Here, the size of the maximal spacing found in does not allow to reject that the support is convex. As a consequence, a bigger than should be considered.
The technical properties for the estimator of are considered next. First, the existence of the supreme defined in (2) must be guaranteed, a result which is proved in Theorem 3.3. In addition, it is also proved that consistently estimates .
Theorem 3.3**.**
Let be a density function that satisfies () with compact, nonconvex and nonempty support under (). Let be the density estimator introduced in Definition 2.4 and let be the kernel function under (). Assume that for some . Let be the parameter defined in (1) and defined in (2). Let be a sequence converging to zero such that . Then, converges to in probability.
Remark 3.4**.**
For the sake of clarity, is assumed non-convex throughout the test. However, if is convex, it can be shown that goes to infinity (which is the value of in this case) because, with high probability, the test is not rejected for all values of .
4 Consistency of resulting support estimator
The behaviour of the random set as an estimator of can be studied once the consistency of has been proved. Two metrics between sets are usually considered in order to assess the performance of a support estimator. Specifically, let and be two closed, bounded, nonempty subsets of . The Hausdorff distance between and is defined by
[TABLE]
where and denotes the Euclidean norm. Besides, if and are two bounded and Borel sets then the distance in measure between and is defined by , where denotes the Lebesgue measure and , the symmetric difference, that is, Hausdorff distance quantifies the physical proximity between two sets whereas the distance in measure is useful to quantify their similarity in content. However, neither of these distances are completely useful for measuring the similarity between the shape of two sets. The Hausdorff distance between boundaries, , can be also used to evaluate the performance of the estimators (see Baíllo and Cuevas, 2001; Cuevas and Rodríguez-Casal, 2004; Rodríguez-Casal, 2007 or Genovese et al., 2012).
In particular, if then, the consistency of can be proved easily from Theorem 3.3. However, the consistency cannot be guaranteed if does not go to zero as goes to from above (as does, see Proposition 8.1 below). This problem can be solved by considering the estimator where with fixed. This ensures that, for large enough, with high probability, . From the practical point of view the selection of is not a major issue because is numerically approximated and the computed estimator always satisfies this property without multiplying by . In some sense, Theorem 4.1 gives the convergence rate of the numerical approximation of .
Theorem 4.1**.**
Let be a random and i.i.d sample drawn according to a density that satisfies () with compact, nonconvex and nonempty support under (). Let be the parameter defined in (1) and defined in (2). Let be a sequence converging to zero such that . Let be and . Then,
[TABLE]
The same convergence order holds for and .
5 Numerical illustration
The main numerical aspects of the estimation algorithm of in (1) are detailed in what follows. Although the method proposed in this work is fully data-driven from a theoretical point of view, its practical implementation depends on the specification of two parameters to be selected by the practitioner: the significance level of the test and the maximum number for connected components of the resulting support estimator. Choosing them is a much more flexible and simpler problem than the specification of the shape index .
With probability one, for a large enough , the existence of the estimator defined in (2) is guaranteed under the hypotheses of Theorem 3.3. However, in practice, this estimator might not exist for a specific sample and a given value of the significance level . Therefore, the influence of must be taken into account. The null hypothesis of convexity will be (incorrectly) rejected for with probability , approximately. This is not important from the theoretical point of view, since we are assuming that goes to zero as the sample size increases. But, what should be done, for a given sample, if is rejected for all (or at least all reasonable values of )? In order to fix a minimum acceptable value of , it is assumed that (and, hence, its estimator) will have no more than connected components. Too fragmented estimators will not be considered even in the case that we reject for all . The minimum value that ensures a number of connected components not greater than will be taken in this latter case. Therefore, this parameter can be interpreted as a geometric stopping criteria that does not appear in theoretical results because the sequence is assumed to tend to zero.
Dichotomy algorithms can be used to compute . The practitioner must select a maximum number of iterations and two initial points and with such that the null hypothesis of convexity is rejected and the null hypothesis of convexity is accepted. According to the previous comments, it is assumed that the number of connected components of must not be greater than . Choosing a value close enough to zero is usually sufficient to select . According to Figure 4 (second row, right), the maximal spacing in will be small enough to accept convexity. Therefore, taking will be a good choice. However, if selecting this is not possible because, for very low values of , the hypothesis of convexity is still rejected then is estimated as the positive closest value to zero such that the number of connected components of is smaller than or equal to . On the other hand, if a large enough spacing for having a statistically significant test cannot be found in then we propose as the estimator for the support.
To sum up, the following inputs should be given: the significance level , a maximum number of iterations , a maximum number of connected components and two initial values and . Given these parameters will be computed as follows:
In each iteration and while the number of them is smaller than :
- (a)
2. (b)
If the null hypothesis of convexity is not rejected then . 3. (c)
Otherwise, . 2. 2.
Then, .
Some technical aspects related to the computation of the maximal spacings must be also mentioned. In the proposed procedure, the null hypothesis needs to be tested times. Since it involves the calculation of the maximal spacing, one may be aware of computational cost of the method. Nevertheless, as noted by Rodríguez-Casal and Saavedra-Nieves (2016), this maximal spacing does not need to be specifically determined and it is enough to check if there exists a point such that
[TABLE]
In this case, and, therefore, the null hypothesis of convexity will be rejected. Furthermore, note that if this disc exists then where and denotes the sample point such that . Therefore, .
Then, the centers of the possible maximal balls that belong to the Voronoi tile with nucleus () necessarily lie in . We will follow the next steps:
Determine the set of candidates for ball centers where denotes the extremes of the shape of when , see Edelsbrunner (2014). If then we can guarantee that . Equivalently,
[TABLE] 2. 2.
Calculate . 3. 3.
If then the null hypothesis of convexity is not rejected.
It should be noted that if , for all , . Therefore, these points can be discarded in order to determine . Furthermore, , and can be easily computed (at least for the bidimensional case). See Pateiro-López and Rodríguez-Casal (2010) for further details.
6 Extent of occurrence estimation
The new support estimator introduced in this work will be used for reconstructing the EOO of an assemblage of terrestrial invasive plants in two islands of the Azores Archipelago, Terceira and São Miguel. For this real dataset, we have shown that convexity assumption is very restrictive. According to Figure 4 (first and second rows, left), sea areas are inside the classical estimator of the EOO. Obviously, it is overestimated given that terrestrial invasive plants does not occupy the Atlantic Ocean. The goal here is to reconstruct the EOO overcoming these limitations.
First, it is necessary to estimate the optimal value from the sample of geographical locations. If we select the significance level equal to and , the resulting estimator is . In Figure 5, is shown. According to the results obtained, the EOO reconstruction has two different connected components corresponding to the two Azorean islands. Unlike classical EOO estimator, sea areas are not inside the reconstruction. Therefore, if the sample size is large enough, a more sophisticated and realistic estimator of the EOO can be determined.
The new method, although designed for handling more complex situations, provides similar reconstructions to those corresponding to the convex hull in those cases where the classical reconstruction works appropiately. For showing this, we will focus on the geographical locations from São Miguel island. Separately, the EOO will be estimated from data corresponding to years and . A total of and geographical locations are available in and , respectively.
Figure 6 contains the EOO estimator in (left) and (center). In 2015, the resulting reconstruction of the EOO is equal to . In 2016, ; however, the estimation of the EOO obtained, , is not so different from the convex hull. This last illustration suggests that, if more amount of data are available by year, this kind of analysis could be useful for studying the temporal changes in the spatial pattern of organisms, including invasive plants, on an area of interest.
7 Conclusions and open problems
The main goal of this work is to propose a new data-driven method for reconstructing a convex support in a consistent way. The route designed to reach this goal can be summarized as follows: (1) Defining the optimal value of , , to be estimated, (2) establishing a nonparametric test to asess the null hypothesis that is convex for a given , (3) defining the estimator of that strongly relies on the previous test and (4) checking that the estimator of and the resulting support reconstruction are consistent.
The definition of the estimator depends on the convexity test established that, of course, could be used in an independent way. In many practical situations where the support is completely unknown and only a sample of points is available, it can be interesting to test if the corresponding support distribution is convex.
Futhermore, the behaviour of the proposed support estimator was illustrated through the estimation of the EOO of an assemblage of terrestrial invasive plants in two Azorean islands. In this particular case, where convexity assumption on the EOO is too restrictive, our support estimator provides a more realistic and sophisticated reconstruction. Besides, we have shown that when the classical convex reconstruction works appropiately, our estimator offers similar reconstructions. Furthermore, we have shown that estimating the EOO from annual (or any other time period) occurrences could be useful for detecting temporal changes in the spatial pattern of organisms.
Note that the resulting support estimator is spatially flexible. In other words, it is able to distinguish the different disconnected components of the support. Therefore, it could be used for reconstructing the support of an intensity function of a Poisson process.
Finally, another interesting problem and intimately related to the EOO reconstruction is to estimate the area of occupancy (AOO). The IUCN defined the AOO as the area within its extent of occurrence. Under convexity, we could estimate the AOO as the area of the convex hull of the sample points. However, this estimator suffers from the drawback of not being rate-optimal. Arias-Castro et al. (2018) proposed an optimal volume estimator based on the sample convex hull using a sample splitting strategy that attains the minimax lower bound. Therefore, the problem of estimating the AOO could be studied from a different perspective in future.
8 Proofs
In this section the proofs of the stated theorems are presented.
Proof of Theorem 2.5.
First, Aaron et al. (2017) assumed that is Hölder continuous with respect to Lebesgue measure. Under (), this condition is satisfied. See Aaron et al. (2017) for more details.
Furthermore, Aaron et al. (2017) also assumed that there exists and such that where denotes the inner covering number of . Under (), Theorem 1 in Walther (1997) guaranteed that is a dimensional submanifold. Therefore, the previous assumption is fulfilled for . See Aaron et al. (2017) for more details.
Proof of Theorem 3.1.
First, we will prove (a) and then, (b).
- (a)
Under (), . Then,
[TABLE]
If we apply Lemma 9.1, we get, with probability one, for large enough,
[TABLE]
Equivalently, and, therefore, from where it follows that can be majorized by,
[TABLE]
[TABLE]
According to Theorem 2.5, when . Furthermore, notice that has a continuous distribution, so convergence in distribution implies that
[TABLE]
Therefore, using that tends to zero, we get that
[TABLE]
As a consequence,
[TABLE]
- (b)
From Lemma 9.1 (ii),
[TABLE]
where tends to zero, almost surely. Under ( is not convex, ), we will prove that, with probability one and for large enough,
[TABLE]
In particular, we will find a closed ball of radius that, with probability one and for large enough, is inside .
Then, let be such that and . Since is under (), Proposition 2.2 in Rodríguez-Casal and Saavedra-Nieves (2016) ensures that is convex. However, under , is not convex. Therefore, it is easy to guarantee the existence of .
According to Lemma 8.3 in Rodríguez-Casal and Saavedra-Nieves (2016),
[TABLE]
It can be assumed, without loss of generality, that . If this is not the case then it would be possible to replace by satisfying . For this ,
[TABLE]
Now, we can apply Lemma 3 in Walther (1997) in order to ensure that
[TABLE]
If then , that is, . This imply that
[TABLE]
In addition,
[TABLE]
where we have used that, for sets and , . Finally, since and , we have . This part of the proof is concluded by taking .
Therefore,
[TABLE]
Then, with probability one and for large enough,
[TABLE]
The proof is finished taking into account that tends to zero.
Proof of Theorem 3.3.
Some auxiliary results are necessary. First we will prove that, with probability tending to one, is at least as big as .
Proposition 8.1**.**
Let be a density function that fulfils condition () with compact, nonconvex and nonempty support under (). Let be the corresponding density estimator introduced in Definition 2.4 and let be the kernel function under (). Assume that for some . Let be the parameter defined in (1) and defined in (2). Let be a sequence converging to zero. Then,
[TABLE]
Proof.
Equivalently, we will prove that
[TABLE]
From the definition of , see (2), it is clear that
[TABLE]
where and . Therefore,
[TABLE]
Since, with probability one, , applying Lemma 9.1, and, therefore, from where it follows that can be majorized by,
[TABLE]
According to Theorem 2.5, when . Furthermore, notice that has a continuous distribution, so convergence in distribution implies that
[TABLE]
Since and , we can prove
[TABLE]
This ensures that
[TABLE]
Therefore, .
∎
It remains to prove that cannot be arbitrarily larger that . Some auxiliary results must be proved next.
Lemma 8.2**.**
Let be a random and i.i.d sample drawn according to a density that satisfies () with compact, nonconvex and nonempty support under (). Let be the parameter defined in (1). Then, for all , there exists an open ball such that and
[TABLE]
Proof.
Let be such that . Since , according to Lemma 8.3 in Rodríguez-Casal and Saavedra-Nieves (2016),
[TABLE]
It can be assumed, without loss of generality, that . If this is not the case then it would be possible to replace by satisfying . For this ,
[TABLE]
Now, we can apply Lemma 3 in Walther (1997) in order to ensure that
[TABLE]
If then , that is, . This imply that
[TABLE]
In addition,
[TABLE]
where we have used that, for sets and , . Finally, since and , we have . This concludes the proof of the lemma by taking . ∎
Proposition 8.3**.**
Let be a random and i.i.d sample drawn according to a density that satisfies () with compact, nonconvex and nonempty support under (). Let be the parameter defined in (1) and a sequence converging to zero such that . Then, for any ,
[TABLE]
Proof.
Given let be . According to Lemma 8.2, there exists and such that and
[TABLE]
Since, with probability one, we have . Then, . Let the positive number . If then it is trivial to check that
[TABLE]
Therefore, and, consequently, . Similarly, for all . On the other hand, since , we have, with probability one,
[TABLE]
Then, with probability one, there exists such that if we have
[TABLE]
Therefore, . This last statement follows from for all and the definition of , see (2). ∎
Theorem 3.3 is a straightforward consequence of Propositions 8.1 and 8.3.
Proof of Theorem 4.1.
Theorem 3 of Rodríguez-Casal (2007) ensures that, under () when ), then , where
[TABLE]
and is some constant. Under the hypothesis of Theorem 4.1 this holds for any . Fix one such that and define . Since, by Theorem 3.3, converges in probability to and , we have that . If the events and hold (notice that ) we have and, therefore,
[TABLE]
This completes the proof of the first statement of Theorem 4.1. Similarly, it is possible to prove the result for the other error criteria considered in Theorem 4.1.
9 Auxiliary results
Lemma 9.1 shows that Lemma 5 in Aaron et al. (2017) remains true if satisfies () and the density estimator introduced in Definition 2.4 is considered. Concretely, Aaron et al. (2017) assumed that is a compact standard set. Roughly speaking, this condition prevents the support from being too spiky. Under the smoothness condition (), standardness is guaranteed. See Rodríguez-Casal (2007) or Cuevas and Fraiman (1997) for more details.
Lemma 9.1**.**
Let and let be a density function that satisfies () with compact and nonempty support under (). Let be the corresponding density estimator introduced in Definition 2.4 and let be the kernel function under (). Assume that with . Then,
- (i)
there exists a sequence such that tends to zero and for all ,
[TABLE]
- (ii)
there exists a sequence tending to zero and a constant such that for all , e.a.s.
Proof.
Next, some preliminary results established in Aaron et al. (2017) (see proof of Lemma 5) are detailed.
First, taking , it can be proved that
[TABLE]
Under (), verifies () and is bounded from below on a neighbourhood of the origin, there exist and such that
[TABLE]
Furthermore, for all ,
[TABLE]
Since is Lipschitz and it is verified that, for all ,
[TABLE]
where y is established in Condition B.
From (4) and the condition for all , it follows that
[TABLE]
First, we will prove (i). Using triangular inequality, we can ensure that
[TABLE]
As for the first term on the right hand side of this inequality, it is necessary to take into account that verifies () and with . Then, Theorem 2.3 in Giné and Gillou (2002) guarantees that, there exists a constant such that, with probability one, for large enough,
[TABLE]
Therefore,
[TABLE]
As a consequence,
[TABLE]
Next, the second term on the right hand side of inequality (7) will be bounded. For all ,
[TABLE]
[TABLE]
Since is compact, the Lebesgue dominate convergence theorem entails that there exists such that , and a sequence with tending to , , such that for large enough, with probability one,
[TABLE]
[TABLE]
Next, equation (5) and Lipschitz continuity of allow to prove that
[TABLE]
With the same type of argument, we can ensure that
[TABLE]
From equations (9), (10), (11) and (3), we get
[TABLE]
Taking such that tends to zero. From equations (7), (8), (12), we obtain that, with probability one, for large enough,
[TABLE]
Then, for all , , and thus,
[TABLE]
or equivalently,
[TABLE]
Finally, if then tends to zero. Therefore,
[TABLE]
This concludes the proof of (i).
In order to prove (ii), observe that
[TABLE]
Since we have already proved that tends to zero almost surely, it only remains to check that is bounded from below by a positive constant. From and (6), we get
[TABLE]
∎
Acknowledgements. The authors are grateful to Ignacio Munilla Rumbao for drawing his attention to the extent of occurrence estimation problem and to Rosa M. Crujeiras for her useful and enriching comments. This work has been supported by Projects MTM2016-76969P and MTM2017-089422-P from the Ministry of Economy and Competitiveness and ERDF.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Aaron, C., Cholaquidis, A., Fraiman, R.: On the maximal multivariate spacing extension and convexity tests. Ar Xiv preprint:1411.2482 (2014)
- 2[2] Arias-Castro, E., Pateiro-López, B., Rodríguez-Casal, A.: Minimax Estimation of the Volume of a Set Under the Rolling Ball Condition. JASA, 1-12 (2018)
- 3[3] Baíllo, A., Chacón, J. E.: A survey and a new selection criterion for statistical home range estimation. ar Xiv preprint ar Xiv:1804.05129. (2018)
- 4[4] Baíllo, A., Cuevas, A.: On the estimation of a star-shaped set. Adv. in Appl. Probab., 33, 717–726 (2001)
- 5[5] Berrendero, J. R., Cuevas, A., Pateiro-López, B.: A multivariate uniformity test for the case of unknown support. Stat. Comput., 22, 259–271 (2012)
- 6[6] Chevalier, J.: Estimation du support et du contour du support d’une loi de probabilité. Ann. Inst. Henri Poincaré Probab. Stat., 12, 339–364 (1976)
- 7[7] Cuevas, A., Fraiman, R.: Set estimation. New perspectives in stochastic geometry, 374–397 (2010)
- 8[8] Cuevas, A., Fraiman, R., Pateiro-López, B.: On statistical properties of sets fulfilling rolling-type conditions. Adv. in Appl. Probab., 44, 311–329 (2012)