On Usefulness of the Deep-Learning-Based Bug Localization Models to Practitioners
Sravya Polisetty, Andriy Miranskyy, Ayse Bener

TL;DR
This paper evaluates whether deep-learning-based bug localization models meet practitioners' needs, finding they perform better than traditional models but still fall short of criteria like trustworthiness and scalability for practical use.
Contribution
It provides an empirical comparison of deep learning and traditional bug localization models, highlighting gaps between model performance and practical adoption criteria.
Findings
Deep learning models outperform classic machine learning models.
Current models only partially meet practitioners' trust and scalability criteria.
Standardization of performance benchmarks is necessary for fair assessment.
Abstract
Background: Developers spend a significant amount of time and efforts to localize bugs. In the literature, many researchers proposed state-of-the-art bug localization models to help developers localize bugs easily. The practitioners, on the other hand, expect a bug localization tool to meet certain criteria, such as trustworthiness, scalability, and efficiency. The current models are not capable of meeting these criteria, making it harder to adopt these models in practice. Recently, deep-learning-based bug localization models have been proposed in the literature, which show a better performance than the state-of-the-art models. Aim: In this research, we would like to investigate whether deep learning models meet the expectations of practitioners or not. Method: We constructed a Convolution Neural Network and a Simple Logistic model to examine their effectiveness in localizing bugs.…
Click any figure to enlarge with its caption.
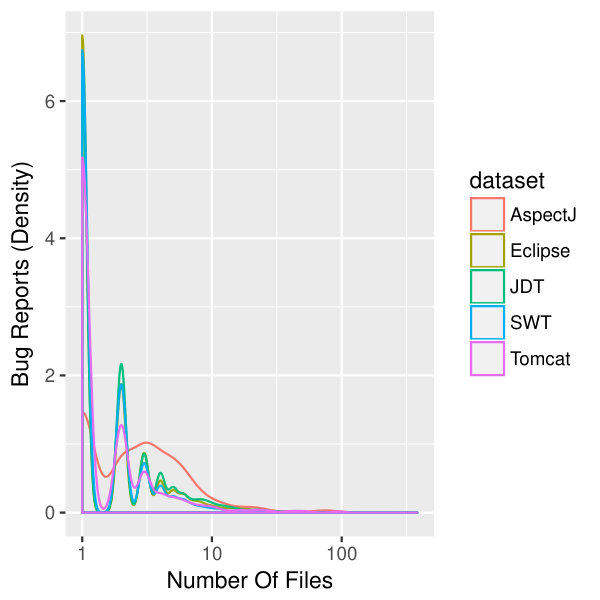 Figure 1
Figure 1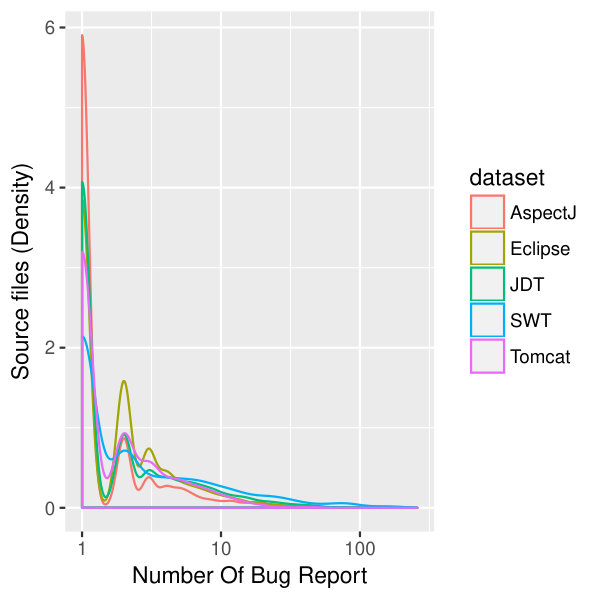 Figure 2
Figure 2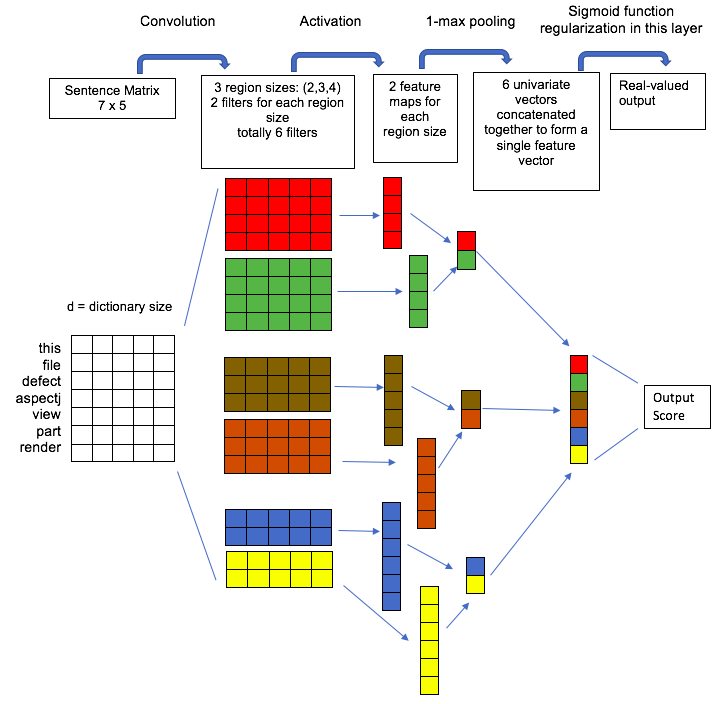 Figure 3
Figure 3| Dataset | Bug Reports | Source Files | Linked Pairs | Non-linked Pairs | |||||
|---|---|---|---|---|---|---|---|---|---|
| All Files | Buggy Files | Very Buggy Files | All / Buggy | Very Buggy | All | Buggy | Very Buggy | ||
| AspectJ | 593 | 4,439 | 2,281 | 602 | 2,394 | 1,301 | 1,350,239 | 355,361 | 163,553 |
| Tomcat | 1,056 | 2,682 | 1,041 | 437 | 2,571 | 1,966 | 2,829,621 | 1,096,726 | 459,506 |
| SWT | 4,151 | 2,249 | 1,181 | 657 | 8,281 | 7,757 | 9,327,318 | 4,894,050 | 2,719,450 |
| Eclipse | 5,262 | 4,614 | 2,868 | 1,581 | 10,907 | 9,620 | 33,206,245 | 24,267,961 | 8,309,602 |
| JDT | 6,269 | 11,273 | 4,610 | 1,817 | 16,310 | 11,940 | 70,654,127 | 28,885,357 | 11,378,833 |
| Parameter | Value |
|---|---|
| CNN Model | |
| Input Encoding | One-Hot |
| Filter Size | |
| Number Of Filters | |
| Number Of Hidden Units | |
| Activation Function | ReLU |
| Drop-out Rate | |
| Batch Size | |
| Optimiser | Adam |
| Learning Rate | |
| Epochs | |
| Simple Logistic Model | |
| Fixed Iterations | |
| Max Boosting Iterations | |
| Weight Trimming | |
| Dataset | CNN | Simple Logistic | ||||
| Memory (GB) | GPUs | Time (days) | Time per epoch (days) | Memory (GB) | Time (days) | |
| ‘All Files’ | ||||||
| AspectJ | 40 | 2 | 21 | 0.4 | 250 | 17 |
| Tomcat | 80 | 3 | 70 | 7 | 550 | * |
| SWT | 145 | 0 | 150 | 15 | 3000 | * |
| Eclipse | 170 | 0 | 150 | 30 | 3000 | * |
| JDT | - | - | - | - | * | |
| ‘Buggy Files’ | ||||||
| AspectJ | 10 | 1 | 7 | 0.1 | 50 | 4 |
| Tomcat | 80 | 3 | 24 | 2.4 | 80 | 13 |
| SWT | 120 | 3 | 110 | 11 | 2500 | 25 |
| Eclipse | 120 | 3 | 110 | 22 | 2500 | * |
| JDT | - | - | - | - | * | |
| ‘Very Buggy Files’ | ||||||
| AspectJ | 10 | 1 | 3 | 0.1 | 50 | 2 |
| Tomcat | 100 | 3 | 6 | 0.6 | 300 | 4 |
| SWT | 120 | 3 | 60 | 6 | 800 | * |
| Eclipse | 120 | 3 | 50 | 10 | 2500 | * |
| JDT | 120 | 3 | 80 | 16 | 2500 | * |
| Dataset | CNN Model | Simple Logistic Model | ||||||
| AUC | MAP | MRR | Top-5 | AUC | MAP | MRR | Top-5 | |
| ‘All Files’ | ||||||||
| AspectJ | 0.9 | 0.25 | 0.27 | 44% | 0.9 | 0.3 | 0.33 | 52% |
| Tomcat | 0.84 | 0.16 | 0.17 | 23% | * | * | * | * |
| SWT | 0.86 | 0.24 | 0.26 | 38% | * | * | * | * |
| Eclipse | 0.6 | 0.04 | 0.04 | 5% | * | * | * | * |
| JDT | - | - | - | - | * | * | * | * |
| ‘Buggy Files’ | ||||||||
| AspectJ | 0.86 | 0.34 | 0.38 | 61% | 0.84 | 0.43 | 0.47 | 63% |
| Tomcat | 0.84 | 0.29 | 0.32 | 40% | 0.77 | 0.05 | 0.05 | 5% |
| SWT | 0.87 | 0.3 | 0.3 | 51% | * | * | * | * |
| Eclipse | 0.72 | 0.13 | 0.14 | 18% | * | * | * | * |
| JDT | - | - | - | - | * | * | * | * |
| ‘Very Buggy Files’ | ||||||||
| AspectJ | 0.83 | 0.44 | 0.47 | 64% | 0.79 | 0.16 | 0.17 | 24% |
| Tomcat | 0.81 | 0.35 | 0.37 | 52% | 0.66 | 0.25 | 0.26 | 36% |
| SWT | 0.82 | 0.3 | 0.3 | 51% | * | * | * | * |
| Eclipse | 0.75 | 0.16 | 0.17 | 23% | * | * | * | * |
| JDT | 0.67 | 0.11 | 0.12 | 17% | * | * | * | * |
| Dataset | Model | Top-5 | ||
|---|---|---|---|---|
| AspectJ | HyLoc | 71.2% | 0.52 | 0.32 |
| LR | 45.5% | 0.33 | 0.25 | |
| BL | 47.7% | 0.32 | 0.22 | |
| NB | 16% | 0.1 | 0.07 | |
| Tomcat | HyLoc | 72.9% | 0.6 | 0.52 |
| LR | 66.5% | 0.55 | 0.49 | |
| BL | 61.8% | 0.48 | 0.43 | |
| NB | 9% | 0.08 | 0.07 | |
| SWT | HyLoc | 69.0% | 0.45 | 0.37 |
| LR | 58.2% | 0.41 | 0.36 | |
| BL | 38.3% | 0.28 | 0.25 | |
| NB | 19% | 0.14 | 0.11 | |
| Eclipse | HyLoc | 70.5% | 0.51 | 0.41 |
| LR | 60.1% | 0.47 | 0.40 | |
| BL | 49.3% | 0.37 | 0.31 | |
| NB | 10.6% | 0.07 | 0.06 | |
| JDT | HyLoc | 65% | 0.45 | 0.34 |
| LR | 55.2% | 0.42 | 0.34 | |
| BL | 40.2% | 0.30 | 0.23 | |
| NB | 15% | 0.11 | 0.08 |
| Dataset | Model | Top-10 | |
|---|---|---|---|
| AspectJ | BL | 62.2% | 0.41 |
| BLUiR | 65.9% | 0.43 | |
| AmaLgam | 69.3% | 0.42 | |
| CNN | 77.3% | 0.51 | |
| NP-CNN | 83.6% | 0.54 | |
| LSTM | 79.2% | 0.51 | |
| LSTM+ | 85.5% | 0.54 | |
| LS-CNN | 86.9% | 0.56 | |
| Eclipse | BL | 72.7% | 0.42 |
| BLUiR | 75.4% | 0.44 | |
| AmaLgam | 77.3% | 0.44 | |
| CNN | 82.1% | 0.49 | |
| NP-CNN | 87.2% | 0.54 | |
| LSTM | 86.9% | 0.52 | |
| LSTM+ | 87.2% | 0.54 | |
| LS-CNN | 89.5% | 0.56 | |
| JDT | BL | 70.3% | 0.44 |
| BLUiR | 74.5% | 0.43 | |
| AmaLgam | 75.7% | 0.44 | |
| CNN | 85.9% | 0.51 | |
| NP-CNN | 88.2% | 0.53 | |
| LSTM | 86.8% | 0.52 | |
| LSTM+ | 88.3% | 0.54 | |
| LS-CNN | 91.7% | 0.58 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
On Usefulness of the Deep-Learning-Based Bug Localization Models to Practitioners
Sravya Polisetty
Andriy Miranskyy
Ayse Bener
Abstract
Background: Developers spend a significant amount of time and efforts to localize bugs. In the literature, many researchers proposed state-of-the-art bug localization models to help developers localize bugs easily. The practitioners, on the other hand, expect a bug localization tool to meet certain criteria, such as trustworthiness, scalability, and efficiency. The current models are not capable of meeting these criteria, making it harder to adopt these models in practice. Recently, deep-learning-based bug localization models have been proposed in the literature, which show a better performance than the state-of-the-art models.
Aim: In this research, we would like to investigate whether deep learning models meet the expectations of practitioners or not.
Method: We constructed a Convolution Neural Network and a Simple Logistic model to examine their effectiveness in localizing bugs. We train these models on five open source projects written in Java and compare their performance with the performance of other state-of-the-art models trained on these datasets.
Results: Our experiments show that although the deep learning models perform better than classic machine learning models, they meet the adoption criteria set by the practitioners only partially.
Conclusions: This work provides evidence that the practitioners should be cautious while using the current state of the art models for production-level use-cases. It also highlights the need for standardization of performance benchmarks to ensure that bug localization models are assessed equitably and realistically.
1 Introduction
Software quality assurance is the process that ensures that the software being developed, meets all the expected quality standards [49]. However, software systems are often shipped with bugs. A software bug is an anomaly in the software product that causes the software to perform incorrectly or to behave in an unexpected way [6]. Large software projects contain large number of bugs that are encountered by users. For instance, the Eclipse [51] project had nearly 13,016 bugs reported in a span of one year (2004 - 2005), with an average of 37 bugs reported per day, and a maximum of 220 bugs reported in a single day [2].
On detecting a bug or fault in the software, a user or a software tester, reports the bug in a document called a bug report and logs it in a bug tracking system, such as Bugzilla [7] or JIRA [21]. Before a bug report is considered valid, it goes through various stages of quality checks. During these stages, a bug is checked for duplicity, validity, and completeness. After a bug passes through these stages, it is assigned to an expert (“Assignee”), who refers to the information in the bug report to identify the source files which need to be modified, in order to solve the issue in the bug report. Bug reports typically consist of various fields (such as Title, Version, Component, Product, Quality Assurance Contact, Assignee, Reported Date, Importance, and Attachments), which contain description of the bug, screen shots or snapshots of an error message, stack traces, etc.
After a bug is assigned to a developer, he/she has to find the root cause of the bug in the source code and then fix the root cause. This process is typically manual and can take 30%-40% of the total time needed to fix a problem [38]. This is a painstaking process, especially for large software projects with hundreds of thousands of source files. As a result, the bug fixing time increases, along with maintenance cost of the project. Although the bug fixing task constitutes sub-tasks like understanding the bug, validating the bug, locating the cause of the bug, and finally fixing the bug, it is the “locating the cause of the bug (Bug Localization)”, that consumes most of the developer’s time [8]. Hence the need for automated tools or approaches which perform bug localization.
Many researchers have proposed various automated approaches or models, to pinpoint the locations of bugs in the source files. Though all these state-of-the-art models are able to localize bugs to some extent, none of them could meet the expectations of the software practitioners, who are the end users of these models [26]. These models are unable to bridge the lexical gap between the bug reports and source code. To bridge this gap, recently, researchers [20, 29] have proposed deep-learning-based bug localization models.
Deep Learning [11] is becoming increasingly popular. This is because deep-learning-based models have proved to perform better than traditional machine learning (ML) models in the areas of image processing [27], speech recognition [16], and natural language processing (NLP) [9]. This is why many recent works apply deep learning to software data to solve various software engineering problems, such as defect prediction [65], user profiling [10], software artifact traceability [15], code suggestion [61], processing programming languages [37], and bug localization [20, 29]. In the past few years, different architectures of Deep Neural Nets (DNN) have been proposed to localize bugs. The motivation behind our study is based on the fact that these deep-learning-based models have shown to outperform the state-of-the-art traditional ML-based bug localization models [20, 29, 28, 19]. Hence, our primary objective is to examine the effectiveness of these models, in meeting the expectations of the software practitioner. Our secondary objectives are (a) to compare the performance of our deep learning model with a traditional ML model, (b) to train deep-learning-based bug localization models independently on five open source software datasets and compare the performance of these models on each of the datasets, and (c) to observe the effect of varying source files on the performance of the model.
Many DNNs have been introduced in the literature; thus, we can leverage previously reported statistics for many of them. We also implement a particular Convolutional Neural Network, deemed CNN, that is based on a popular network architecture [25] to run custom tests. We reach our objectives by answering the following research questions:
RQ1: How can we minimize the lexical gap between natural language texts in bug reports and technical/domain corpus in source code files in order to automatically localize bugs?
RQ2: How effective are the state-of-the-art traditional and the recent deep-learning-based models, in meeting the expectations of the software practitioner?
RQ3: How do the CNN models perform compared to baseline ML models, such as Simple Logistic model, on software bug localization data?
RQ4: How do the CNN models perform when trained on different open source software bug localization datasets?
RQ5: How does varying the source files in the dataset affect the performance of the CNN and Simple Logistic Models?
In order to address RQ1, we give a detailed explanation of the existing state-of-the-art traditional and deep learning models and why a deep-learning-based model like CNN could be a potential solution for bridging the lexical gap between bug reports and source files. For addressing RQ2, we train CNN on open source datasets, which have been widely used in the past bug localization studies. We then compare the performance of the CNN models and other state-of-the-art traditional and deep learning models, with the expectations of the software practitioner [26]. In order to address RQ3, we train a Simple Logistic model on our datasets. As bug localization is a Learning-To-Rank Information Retrieval (IR) problem, we need calibrated results (those which do not have ties between the scores assigned to the suggested source files for a bug report) in order to be able to correctly measure the performance of the resultant IR model. Therefore, we need a logistic regression model, like the Simple Logistic model, that can give us calibrated output scores and can also meet the computation and memory constraints, which are inherent when dealing with large datasets like the ones used in this study. Next, for answering RQ4, we train the CNN model on five open source bug localization datasets and evaluate the performance of the model on each of them. We address the next research question, RQ5 by varying the buggy source files in each dataset. The major contributions of this study can be summarized as follows:
- •
We examine the relevance of a deep-learning-based bug localization model to the software industry.
- •
We evaluate a deep learning model (CNN) against a traditional ML model (Simple Logistic) on bug localization data111We chose “vanilla” CNN and logistic regression models as simple baselines, since (based on parsimony principle) we prefer simple models to complex ones [5]. The former model has shown good results for sentence classification in general [25] and traceability in particular [19]. The latter model is one of the simplest classic binary classifiers. We created them to 1) measure required timing and amount of resources and 2) assess the effect of the search space size on the performance of these models, which helped us in answering RQs..
- •
We extract the source files for all the bug reports based on the bug-commit mapping (reported in a widely used dataset [67]) for five open source datasets and train bug localization models on all of them. We publicly share our dataset via figshare [1].
- •
We empirically show the effect of varying the source files on the performance of both the CNN and Simple Logistic bug localization models.
2 Background and Related Literature
We now provide an overview of a survey [26], which has been one of the motivating factors of this study. Kochhar et al. [26] surveyed 386 practitioners from more than 30 countries across 5 continents, about their expectations of research in bug localization. They then compared what practitioners need, and the current state of research, by performing a literature review of papers on bug localization techniques. The survey found that even the best performing studies could not satisfy even 75% of the respondents in the survey. Many of the studies that can satisfy 50% of the practitioners, work at a granularity that is considered very coarse by most of the practitioners, i.e., class- or file-level. The survey revealed that almost all the practitioners are willing to adopt a bug localization technique, if it satisfies the below criteria:
- •
Preferred level of granularity: 52% of practitioners in the survey prefer method-level granularity. Only 26% of practitioners prefer file-level granularity.
- •
Minimum success criteria: About 91% of developers gave Top-5 (or better) as the minimum success criteria, i.e., an artifact of interest should be reported in the Top-5 records returned by the localization technique. Only 17% of the practitioners would be satisfied with Top-10 (or better).
- •
Trustworthiness: In order to achieve a satisfaction rate of 50%, 75%, and 90%, a bug localization model has to be successful 50%, 75%, and 90% of the time respectively.
- •
Scalability: In order to achieve a developer satisfaction rate of 50%, 75%, and 90%, the bug localization model needs to be scalable enough to deal with programs of size 10,000, 100,000, and 1,000,000 Lines Of Code (LOC), respectively.
- •
Efficiency: In order to achieve a developer satisfaction rate of at least 50%, the model should have a run time of less than a minute. This threshold for efficiency was approved by almost 90% of the practitioners who participated in the survey.
We now discuss some significant research in bug localization, that uses the traditional IR and ML approach. We also briefly mention research related to the application of deep learning models to different software engineering problems.
2.1 Traditional Approaches
The automated approaches in bug localization can be broadly classified into two categories: dynamic and static approaches. The semantics of the program and its execution information with test cases, i.e., pass/fail execution traces are used in the dynamic approach. These approaches can be categorized into: Spectrum-based fault localization and Model-based fault localization. The Spectrum-based approach uses program traces to correlate program elements at statement-, block-, function-, or component-level in a program to the program failures. Saha et al. [43] have proposed a model that uses this approach for localizing faults in data-centric programs, which interact with databases. Model-based fault localization techniques have been proposed by Feldman et al. [12] and Mayer et al. [34]. These models are based on expensive logical reasoning of formal models of programs but are often more accurate than the Spectral-based models.
The second type of automated approach, i.e., the static approach rely only on the source code and the bug reports information. These static approaches can be further classified into two groups: program analysis-based and IR-based. The program analysis-based approach uses predefined bug patterns to localize bugs. Hovemeyer et al. [17] used this approach to propose a model called FindBugs. This model does not perform well as it gives a large number of false positives and also false negatives [52]. The second type of static approach uses IR or ML techniques like TF-IDF, LSA, LDA, VSM, rVSM, and Naive Bayes [23]. These approaches treat the bug localization problem as a Learning-To-Rank IR problem.
Rao et al. [41] probed into many of these IR techniques and concluded that simpler techniques, such as TF-IDF, work better than complex ones. Lukins et al. [33] proposed a bug localization model using LDA, which is a topic-modelling approach. Zhou et al. [71] proposed the rVSM approach, which is a refined vector space model to leverage the similarity between the bug reports and source files. Saha et al. [44] proposed a structured retrieval model that employs the structure of bug reports and source code files, to achieve better performance. Kim et al. [24] have also experimented using Naive Bayes algorithm, with the previously fixed files as classification labels. Ye et al. [66] used the adaptive Learning-To-Rank approach, to train the features extracted from source files, API (Application Programming Interface) descriptions, bug-fixing, and change history. Most of these state-of-the-art models consider the source code and bug reports to be of the same lexical space and try to correlate these artifacts by measuring their similarity in the same space. None of these traditional approaches for bug localization meet all the adoption criteria set by the practitioners [26].
2.2 Deep Learning for NLP and Software Engineering
Kim [25] has experimented on a basic Convolution Neural Network (CNN) on open source datasets, like Movie Reviews and proved that a simple CNN (with minimal hyper-parameter tuning while using static word vectors), is capable of performing exceptionally well on the sentence classification task. Kim’s experiments proved that learning task-specific word vectors instead of static vectors improves the performance of the model. Zhang et al. [64, 69] experimented on character-level CNN models for classifying text. Their experiments proved that CNN perform better than other traditional models (such as bag-of-words, n-grams, and TF-IDF models) and also other deep learning models (such as word-based CNN and Recurrent Neural Networks (RNN)). They also proved that CNNs do not require knowledge of words in terms of semantics or context of words, to perform text classification. Zhang et al. [70] performed a sensitivity analysis on the effect of varying hyper-parameters in a CNN model. This model proves to be very useful to researchers aiming to train CNN models on different datasets. Nguyen et al. [39] built a CNN model for relation extraction and classification tasks.
Recently, deep learning models are being widely used to solve software engineering problems. Mou et al. [37] have proposed a novel tree-based CNN architecture (TBCNN) for processing programming languages. Curro et al. [10] proposed an automatic approach using Deep Convolutional Neural Network (DCNN) to extract information about user actions from publicly available video tutorials of a product. Guo et al. [15] applied RNN and their variants to establish links between software engineering artifacts, namely Requirements and Design documents. Lam et al. [29] applied Restricted Boltzmann Machine (RBM)-based [48] DNN in combination of rVSM on bug localization datasets. Huo et al. [20] adopted a Pairwise Learning-To-Rank approach to classify the combined corpora of bug reports and source files into linked and non-linked records. They proposed a new architecture called Natural Language And Programming Language CNN (NP-CNN) which outperformed the other state-of-the-art bug localization models. They also proposed yet another new architecture using a combination of LSTM and CNN called LS-CNN. They compared the performance of this model with other state-of-the-art bug localization models and deep-learning-based models. Their experiments proved that the LS-CNN model outperforms all the models on the same datasets.
3 Methodology
This section describes some of the concepts pertaining to the Pairwise Learning-To-Rank bug localization problem, deep learning, CNNs, Simple Logistic models. We also discuss the evaluation metrics used to measure the performance of the models in our study.
3.1 The Pairwise Learning-To-Rank Problem
The automated bug localization approaches use IR to identify the source files which have the potential fix for a given bug report. The query of such an IR model is a bug report and the retrieved documents is a ranked list of source files, with the most relevant source file at the top and the least relevant at the bottom of the list. The Pairwise approach for the Learning-To-Rank problem is approximated by a classification problem. The text of each bug report and source file are merged into a single sentence and fed into a classification model. If a given bug was fixed by the change in a given file, then it is labeled as linked, otherwise – as non-linked. The Learning-To-Rank problem is now converted into a binary classification problem, with linked and non-linked class labels.
3.2 Deep Learning
Modern deep learning models and training methods originated from research in Artificial Neural Networks (ANNs). ANNs are inspired from biological neural networks that constitute the brain [14]. A DNN is an ANN with multiple hidden layers between the input and output layers [3, 45]. The benefit of this complex structure of a DNN, is the ability to represent the data in multiple layers. This is one of the key advantages of DNNs over traditional machine learning models, in which humans have to explicitly extract features from the data, before training the model. ANNs automatically discover “good internal representations”, i.e., features that make the learning easier and more accurate, through backpropagation [42]. The extra layers in a DNN enable composition of features from lower layers, potentially modeling complex data with fewer units than a similarly performing shallow network [3]. They can model complex non-linear relationships and generate compositional models where an object is expressed as a layered composition of primitives [50]. In case of text, the object is a sentence encoded using Word2Vec [35], GloVe word embeddings, or One-Hot Encoding [46]. In One-Hot Encoding, each word is converted into a sparse representation with only one element of the vector set to 1, the rest being 0. For each token, its index in the vocabulary dictionary defines the position of the one-hot element in the resultant vector. For natural language data, Word2Vec or GloVe encoding proves better than One-Hot encoding, however different representations perform better for different tasks [70]. For natural language sentence classification, One-Hot encoding performs poorly compared to the other two encodings. However this may not be the case if the training data are very large [70]. Nevertheless, prior work [25] on sentence classification using CNN showed that Word2Vec gives the best performance compared to the other forms of encoding. We first experimented with Word2Vec encoding on our data. The resultant models performed poorly, which could be due to the fact that our corpus has more domain-related words/tokens than natural language words or tokens. We then experimented on One-Hot encoding of the corpus, which proved to be function better than the Word2Vec encoded models.
3.3 Convolution Neural Nets (CNNs)
In this section we discuss basic concepts of CNNs. CNNs are responsible for a major breakthrough in the field of Image Classification [27]. A CNN consists of an input and an output layer, as well as multiple hidden layers. The hidden layers of a CNN typically consist of convolutional layers, pooling layers, and fully connected layers [31]. The convolution operation can be visualized as a sliding window function applied to a matrix. CNNs consist of several layers of convolutions with non-linear activation functions applied to the convolution results. Each region of the input is connected to a neuron in the output. These local connections are a result of convolutions applied to the input to compute the output. Each layer in a CNN consists of hundreds or even thousands of filters of varied sizes. The pooling layers subsample the input from the convolution layer.
Local Invariance is another important aspect of CNN which means that the information about the exact occurrence of a feature is lost. This occurs because of the max pooling operation. Compositionality is yet another important feature of a CNN. As explained earlier, CNNs are feedforward neural networks, where each neuron in a layer receives input from the neurons in the previous layer. These local receptive fields, allow CNN to recognize more and more complex patterns in a hierarchical way, by combining lower-level, elementary features into higher-level features.
CNNs perform well on textual data for many text-related tasks like sentiment analysis, text classification, question answering, and machine translation, due to the Local Invariance and Compositionality features. In text, n-grams can be constructed from lower-order features and ordering is crucial locally but not at the document or record level. For example, in trying to classify a movie review as positive or negative, we need to only capture local order, e.g., the fact that “not” precedes ”bad” and so forth.
We now discuss the architecture of the CNN model used in our study. Figure 1 illustrates the CNN model used in our study. The architecture of this model has been proposed by Kim [25]. In Figure 1, is the length of the dictionary, i.e., the number of unique words/tokens in the entire corpus of our dataset. Hence the dimensions of the input sentence matrix will be equal to , where is the maximum sentence length and is the dictionary size. There are three filter regions of size 2, 3, and 4, each of which have 2 filters. Each filter performs convolution on the input sentence matrix and generates feature maps of variable length, i.e., 2 feature maps for each region size. After this step, 1-max pooling is applied to each of these feature maps, which results in 6 univariate vectors. These vectors are then combined to form a single feature vector which is then fed into a sigmoid layer. The sigmoid layer uses the feature vector to produce a real-valued score which gives the degree of likeliness that the documents belongs to the positive class. For a given bug report, we rank its corresponding source files based on this score.
3.4 Simple Logistic
We now discuss the Simple Logistic model used in our study. This model was proposed by Landwehr et al. [30]. It is a standalone logistic regression model with in-built attribute selection. Landwehr et al. built these regression models using the LogitBoost [13] algorithm which selects a subset of attributes from the data. The pseudo code for the LogitBoost algorithm [13] for classes is given below:
Start with weights , , , and . 2. 2.
Repeat for :
- (a)
Repeat for :
- i.
Compute working responses and weights in the class
[TABLE]
[TABLE] 2. ii.
Fit the function by a weighted least-squares regression of to with weights . 2. (b)
Set , . 3. (c)
Update
[TABLE] 3. 3.
Output the classifier .
is the class label of example , gives the observed class membership probabilities for instance and is defined as:
[TABLE]
The are the estimates of the class probabilities for an instance given by the model fit so far. LogitBoost performs forward stage-wise fitting and tries to improve the model by adding a function to the committee , fit to the response by weighted least-squared error. If we constrain to be a linear function of only the attribute that results in a least squared error, then we arrive at the Simple Logistic algorithm that performs automatic attribute selection.
3.5 Evaluation Metrics
In this section we discuss the evaluation metrics used to measure the performance of the models in our study. From hereon, we will use the terms relevant file and buggy file interchangeably, as by relevant file we mean the file that has to be fixed to address a given bug report. Similarly, the terms non-relevant and non-buggy are used interchangeably, as by non-relevant we mean the source files which do not have to be altered to fix a given bug report.
Mean Average Precision ()
is computed as follows:
[TABLE]
where , are the number of candidate source files and retrieved bug reports, respectively, and is the number of relevant files to a bug report , and indicates whether the instance in rank is relevant or not (buggy or non-buggy). is the precision at the given cut-off rank defined as
[TABLE]
where is the number of relevant source files in the top positions.
Mean Reciprocal Rank ()
The reciprocal rank of a query response is the multiplicative inverse of its rank of the first correctly retrieved document: for the first place, for the second place, for the third place and so on. is the average of the reciprocal ranks of results for a sample of queries and is given by:
[TABLE]
Top- Rank
It is the number of bugs whose relevant source files are ranked in the top of the returned results. Given a bug report, if the top query results contain at least one source file that is relevant (buggy) to the bug report, then the particular bug is considered to be located. The percentage of all such located bugs gives the Top- Rank.
Area Under Curve ()
is the area under the Receiver Operating Characteristic Curve (ROC), which is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied. values lie between and , where denotes a bad classifier and denotes an excellent classifier.
Cross Entropy Loss
Cross entropy loss measures the performance of a classifier which outputs a probability score in the range . For binary classification, it is given by:
[TABLE]
where is a binary indicator ([math] or ) which gives the actual class label of a sample and is the model’s predicted probability that a sample belongs to a class.
4 Evaluation
In this section we discuss the steps followed to prepare the datasets and the experiments performed, along with a brief discussion of the results obtained in our study.
4.1 Data Extraction
We performed our experiments on the five open source benchmark datasets. The bug reports and bug-commit mappings are publicly available via figshare [67]. Using these mappings, we extracted the actual source files from GitHub [18] repository of each project. We iterate over all the commits associated with fixing a bug; and for each commit, we checkout the before-fix version of the source code. The end result of the above extraction process will be the bug reports and their corresponding before-fix version of each file needed to fix a bug. For extracting the content of all the other source files (which were never altered to fix a bug), we clone the latest git repository of the project and extract all the Java source files in it. We identify the previously fixed files from the entire list of source files and label them as buggy. The rest of the source files are labelled as non-buggy. We share the resulting dataset via figshare [1].
4.2 Data Analysis
Table 1 shows the statistics for the datasets under study. In order to address RQ5, we perform all our experiments on three variations of source files. They are as follows:
All Files: We consider all the source files and all the linked records in the traceability matrix.
Buggy Files: We consider only the source files which have at least one bug report linked to it in the traceability matrix.
Very Buggy Files: We consider only the set of source files which have more than one bug linked to it in the traceability matrix.
4.3 Data Preprocessing
After we extract the data, we preprocess the corpus of bug reports (which is obtained from combining the summary and the description fields of the bug report) and the corpus of the source files by first removing punctuation symbols and numbers. Then, we remove Java-related keywords, comments, and package names from the source code corpus. Next, we apply Camel-case split and Porter stemming [40] on the bug report and source code corpus. Finally, we convert all the words/tokens to lowercase.
We then replicate data preprocessing scheme of [29, 15], to be in line with the state-of-the-art models222Note that this scheme allows a look ahead into the future for non-linked files, which may make predictions overly-optimistic [53]. In the spirit of replication study, we stick to this scheme. As we will see in the following sections, even these overly-optimistic predictions are not stellar.. Next, we build the traceability matrix. We create an Cartesian product of the list of all source files (both buggy and non-buggy files) and bug reports. I.e., if we have bug reports and source files, we end up with a total of records. We identify the linked or the relevant records (positive) in the records, based on the bug-file mapping. The remaining records in the traceability matrix, after removing the linked records will be the non-linked records, deemed (negative). Thus, the number of non-linked records in the traceability matrix will be . Table 1 shows the linked and non-linked records statistics for each project. After this step, we merge the corpus of each bug report and its corresponding source file in the traceability matrix. Table 1 shows that the datasets for all three variations of source files are highly imbalanced, with ; the imbalance as well as the search space decrease from All to Buggy to Very Buggy variation.
Next, we analyze the linked records in our traceability matrix. Figure 2 shows the number of source files changed across the bug reports for all the projects in this study. As observed from the density plot, of bug reports have one source file mapped to the bug report, – two files, – three files, etc. Rarely, namely in of the cases, more than 100 files are mapped to a bug. This shows that in order to resolve of bug report, a developer has to fix code in more than one source file, which is not uncommon [32, 22]. It is also known that not all files in a bug-fixing commit may be directly related to that bug report [36]. However, the authors of the original study took all files in a bug-fixing commit. Therefore, we also took them all to follow the replication process.
Figure 3 shows a density plot of the number of bug reports associated with source files for all the projects. This density plot shows that of files are associated with a single bug, – with two bugs, – with three bugs, etc. There also exists a small percentage () of outlier files associated with more than a 100 bugs. Note that this does not necessarily imply that these files are error-prone: they may not be related to an actual fix [36], as discussed above. Using the same rationale as in the previous paragraph, we retain all of the files.
4.4 Experimental Setup
In this section, we discuss the experiments performed in our study on the five open source datasets along with the exact setup used to train the CNN and Simple Logistic models.
4.4.1 CNN Model
The CNN model is implemented using the Keras deep learning library v.2.1.2 [55] with TensorFlow v.1.4.1 [54] as the back-end. I/O and other non-compute intensive operations were performed on a CPU and the compute-intensive operations were carried out on 2 - 3 GPUs (depending on the availability of the resources in a high performance compute cluster).
For each dataset, we first set aside 10% of the data as test set and the remaining 90% are be used for training and validation. The 90% data are split into 10 folds. Then 10-fold cross-validation is performed. We balance the training data by applying higher class weights to the smaller class (i.e., positive class) which will penalize the model for every misclassificaltion of a positive sample (linked record). After each epoch, the trained model is tested on the imbalanced validation set and its cross entropy loss is recorded. At this point, we also compare the validation loss of the model with the previously recorded validation losses. If at a particular epoch the validation loss is lower than its previous values, then we save the weights of the model and use the same model to do the prediction on the 10% test set. After all the epochs for a fold, the best model is obtained, i.e., the one with the lowest validation loss will be the final model that is used to make predictions on the imbalanced test set. The performance of the model is calculated based on the predictions made by the model on the test set. We repeat the same process for all the folds. The final performance of the model is the average of the performance of the model in each fold.
Table 2 shows the hyper parameters used for training the model on all the datasets. Note that we are training the models on Eclipse and JDT corpuses for 5 epochs, on SWT and Tomcat – for 10 epochs, and on AspectJ – for 50 epochs. The reason for this partitioning lies in the correlation between the size of the text corpus and the amount of time needed to train the model. While the performance of the model may degrade with the decrease of the number of epochs, the duration to train the model may make it impractical, as we will further discuss in Section 4.5.3.
4.4.2 Simple Logistic Model
We use Weka v.3.8.2 [58] command-line interface to run the Simple Logistic models on all our datasets. The experimental set up is the same as that used to train the CNN models. In this case, we first convert the string attributes into numeric attributes representing the word occurrence information from the text contained in the strings using Weka’s StringToWordVector [60]. Next, we apply a Class Balancer [57] to the training data, to reweight the instances in the data so that each class has the same total weight. After this step, we apply the Simple Logistic [59] models on the dataset with 10-fold cross validation. The hyperparameters used to train the Simple Logistic models are given in Table 2.
4.5 Results & Discussion
We discuss answers to each of our research questions in the following sections.
During this discussion we will analyze the results of our experiments reported in Tables 3 and 4. The dash ‘-’ in Tables 3 and 4 denotes experiments where 36GB of GPU RAM was insufficient to carry the computations. The star ‘*’in Tables 3 and 4 indicates that the computations for a given experiment could not be carried out, due to the lack of resources on a high performance computing cluster. We also could not get the resources on the compute cluster to process SWT and Eclipse ‘All Files’ datasets on the cluster, so we leveraged the resources of our local server without GPUs (hence the zero GPU count in Table 3), but with 28 hyper-threading Intel Xeon CPU cores. Thus, the timing and resource utilization of these experiments should not be compared with those of the remaining CNN calibrations, due to different hardware setup. The calibration of Simple Logistic model for SWT ‘Buggy Files’ corpus timed out after 25 days due to quota on resources of the compute cluster. However, even with missing data points, we can extrapolate our findings based on the remaining computations, as discussed below.
4.5.1 RQ1: Minimizing the Lexical Gap Between Bug Reports And Source Files
The key drawback of the state-of-the-art bug localization approaches is that, they are unable to minimize the lexical gap [4, 39, 66] between the natural language corpus of the bug reports and the technical corpus of the source code. Some attempts have been made in the past to overcome this drawback. Ye et al.[66] used additional corpus from the documentation of the APIs used in source files. This approach did not help as the documentation of APIs does not have the buggy information specific to a project, rather they contain information regarding more general tasks. Kim et al. [24] used the names of the previously fixed source files as classification labels on the bug reports instead of the actual source file content. In recent years some researchers have proposed deep-learning-based models to localize bugs. Lam et al. [29, 28] and Huo et al. [20, 19] proposed deep learning models based on RBM, CNN, LSTM. Their work proved that, unlike the other state-of-the-art traditional models, the deep learning models are able to minimize the lexical gap between bug reports and source files. They concluded that DNNs are able to do this by learning to link high-level, abstract concepts between bugs reports and source code files.
As mentioned earlier, a simple CNN with little hyper-parameter tuning has been shown to perform significantly well for classifying text [25]. CNNs construct higher-order features from lower-order features and preserve the local information about locality. They lose the global information about locality due to Local Invariance. Nevertheless, this does not affect the performance of the model when performing sentiment analysis or text classification, as in these cases the ordering of words is not of importance at the document level. This means that, CNNs are good at identifying the polarity of a sentence but cannot encode long-range dependencies in a sentence.
As discussed earlier, bug localization is a Learning-To-Rank IR problem which can be solved using the Pairwise approach, where each sentence is a combination of bug reports and source files and the task is to identify the positive (linked) and negative (non-linked) records. Hence a CNN model, which has been widely used in the past for learning the polarity of a sentence [25] could be a potential model that can correctly classify the corpus related to bug report and source code files, by learning to relate the natural language or domain-related terms/tokens in bug reports and different code tokens in source files.
A deep-learning-based model like CNN could be a potential approach that could eliminate or minimize the lexical gap between bug reports and source code files.
4.5.2 RQ2: Effectiveness
To assess practical relevance of the models we analyze our results (shown in Tables 3 and 4) with the results of other state-of-the-art models assessed in [29, 19] for which the results are shown in Tables 5 and 6. These models include DNNs (namely, HyLoc [29], NP-CNN [20], and LS-CNN [19]) as well as state of the art classic ML models (namely, BugLocator (BL) [72], Two-Phase (NB) [24], Learning-To-Rank (LR) [66], BLUiR (Bug Localization Using Information Retrieval) [44], AmaLgam [56]).
Direct comparison of the performance of the models is challenging, as every group of authors uses different data preparation techniques, hardware, and software. Our data preparation process resembles that of [20, 19] (the latter paper is an extension of the former one). Performance of the CNN model is assessed in [19], but their dataset has a different number of bugs and files.
When comparing these two sets of tables, we notice that the performance of the CNN model in our experiments is inferior to those of [19]. This can be attributed to the fact that they experimented on the reduced set of source files (as we found out based on direct communication with the authors). This setup may be acceptable to compare the performance of a set of models, but it may be misleading the practitioners, as the resulting values of the metrics do not reflect the performance of the model on a complete set of files, which is what practitioners are interested in. The actual effectiveness of any bug localization model can only be determined when the model is trained on the entire set of source code files available in the project repository.
Let us assess the effectiveness of the model based on survey [26] summarized in Section 2.
Granularity: Since all of the models mentioned above operate on the file-level, they satisfy only 26% of the practitioners in terms of granularity.
Success Criteria: Huo and Li [19] report performance of the models using Top-10 metric and do not provide Top-5 values; based on [26], only 17% of practitioners would be satisfied with Top-10 results. Lam et al. as well our experiments do provide Top-5 metrics. Let us see if practitioners would find these results trustworthy.
Trustworthiness: Based on [26] the value of Top-5 metric is directly correlated with the measure of trustworthiness: that is Top-5 = 70% translates into 70% trustworthiness. Based on Tables 4 and 5, the trustworthiness varies between 17% and 73%, depending on the model.
Given that Table 6 reports Top-10 values, it is more challenging to assess these results. We conjecture that the values of Top-5 (reported in Table 6) will be lower than Top-10 and would probably be even lower if the models were tested on the full set of files.
Overall, while comparing “goodness-of-fit” of the DNN-based and classic-ML-based models in Tables 4, 6, and 6, we see that the former outperform the latter most of the time (with two exceptions in 4).
Scalability: Conceptually, the models in our study can process code bases as large as JDT (which has more than 1,000,000 LOC), satisfying up to 90% of practitioners. However, the required amount of time or compute resources needed to train a model may be excessive. As Table 3 shows, in the worst case scenario, we may require terabytes of RAM, multiple GPUs, and months of compute time, making training impractical. Huo and Li [19] do not provide their timing data, but Lam et al. [29] do share these data. The HyLoc model [29] can be trained in less than 1 day on a 32 core Xeon computer with 126GB of RAM. This is an excellent performance which can probably be attributed to the fact that Huo and Li extract salient features from the text corpuses, reducing the dimensionality of the input data. This may be more challenging for practitioners, as they will need to find an expert capable of configuring and running such NLP dimensionality reduction techniques, which is more challenging than running off-the-shelf models implemented in Keras or Weka.
Efficiency: as stated in [26], a trained model should return a prediction in less than a minute. Our predictions take approximately 4 seconds per 1000 files (easily satisfying the constraint). Huo and Li [19] do not report their timing. Lam et al. HyLoc model takes “a few minutes”[29]. Given that prediction involves evaluation of each bug-file pair individually and independently, this embarrassingly parallel problem can be easily parallelized reaching the desired threshold of one minute (assuming that a practitioner is willing to pay for compute resources).
•
Researchers should use the entire set of source files from the repository when assessing practicality of a particular bug localization approach.
•
DNN-based models outperform classic ML-based models most of the time. Yet, researchers should verify if their models meet the criteria stated by software practitioners in [26].
•
Software developers should be cautious while using the current bug localization models, as their performance varies.
4.5.3 RQ3: CNN vs Simple Logistic Models
We now compare a non-linear DNN (CNN model) and a traditional ML (Simple Logistic model) in terms of performance, training time and memory.
Performance: While we could not assess performance of the model for all datasets due to lack of compute resources (as shown in Tables 3 and 4), we do have complete results for AspectJ and partial – for Tomcat. In case of AspectJ, the Simple Logistic model outperforms the CNN model in terms of , , and Top-5 Rank, when considering all the source files in the dataset.The same trend continues even when we train the model on only the buggy source files in the dataset. This trend is reversed when we further reduce the buggy source files. In this case, the CNN model performs significantly better than the Simple Logistic model. In the case of Tomcat, the Simple Logistic model outperforms CNN for ‘Buggy Files’ and ‘Very Buggy Files’; we do not have results for ‘All files’, which can be explained by the smaller number of epochs used in our study (10 epochs for Tomcat vs 50 epochs for AspectJ).
Training Time: The training time for each dataset (given in Table 3), is influenced by the number of GPUs used. If we compare the training times across projects, per GPU, then CNN takes between 3 and 42 days for the smallest project and between 150 and 330 days for larger projects like Eclipse. For the Simple Logistic model and small datasets, the training time is comparable magnitude-wise to the overall training time of the CNN model.
However, we have to keep in mind that the number of epochs for large datasets was smaller than that for small datasets (as discussed in Section 4.4.1). Thus, we need to look at the per-epoch training time in Table 3. In this case we can see that Simple Logistics model outperforms CNN, if we keep the number of epochs at 50: e.g., calibration of CNN for Tomcat ‘Buggy Files‘ dataset would take 120 ( 2.4 50) days.
Memory: To train, the CNN models need from 10GB to 150GB of memory, while the Simple Logistic models require 50GB to 3000GB of memory. Economically, CNN is cheaper to train as, at the time of writing, the cost of three GPUs is cheaper than 3000GB of RAM.
•
Obtaining the computation resources needed to train the deep-learning-based or the traditional ML-based bug localization models, is both expensive and challenging for the mainstream software practitioners.
•
The CNN model outperforms the Simple Logistic model in most of the cases, but they have high training time. Simple Logistic models are faster but need a lot of memory to train (and, thus, are less feasible economically).
4.5.4 RQ4: Generalizability
From Table 4, we can observe that for all the three variations of source files, the for the CNN models for all the datasets is between 0.6 and 0.9 (yielding some separation of classes). The higher the , the better is the performance of the IR model. As most of the values are around 0.8, we can conclude that the CNN can successfully classify different bug localization dataset. The trend in performance of the across all the projects, for all the three variations of the source files, shows that the CNN models perform poorly for larger projects like Eclipse and JDT. This could be attributed to the fact that, for the larger projects, the datasets are more imbalanced and the search space is larger as compared to the smaller projects (see Table 1 for details). This makes it even more difficult for the models to identify or learn patterns in the few sets of linked records are present in the dataset. The and metrics trends are similar.
The performance of the CNN models is dependent on the size of the dataset under study, as it performs significantly better on smaller datasets than on the larger datasets for all the three variations of source files.
- •
Obtaining the computation resources needed to train the deep-learning-based or the traditional ML-based bug localization models, is both expensive and challenging for the mainstream software practitioners.
- •
The CNN model outperforms the Simple Logistic model in most of the cases, but they have high training time. Simple Logistic models are faster but need a lot of memory to train (and, thus, are less feasible economically).
4.5.5 RQ5: Effect of Varying Buggy Files
We now examine the effect of varying the buggy source files in the datasets. When reducing the number of source files, the performance of the CNN models improves, which can observed in Table 4. For all the projects, i.e., AspectJ, Tomcat, SWT, and Eclipse, the scores increase from 0.25 to 0.44, 0.16 to 0.35, 0.26 to 0.3, 0.04 to 0.17, respectively. The same observation can also be made for and Top-5 Rank metrics. We conjecture that this improvement may be because reducing the number of files is reducing the search space, i.e., reserving more relevant files actually enables the model to easily identify the linked or the relevant files in the dataset. As for the Simple Logistic models, the effect of varying source files is not very clear, as in some cases it tends to improve the performance of the model, whereas in some cases it does not.
Considering ‘Very Buggy’ files improves the performance of the CNN models. An important point to note from the above observation is that, most of the recent deep-learning-based models [20, 29, 28, 19] consider only a subset of files when assessing the performance of the DNN models. This leads to overly-optimistic performance assessment results from the practitioners’ perspective.
4.6 Threats to Validity
In this section we discuss the threats to validity, classified as per [63, 68].
Internal Validity: We mitigate the bias in our study, by reusing the bug reports dataset that has been used in prior studies [20, 29, 28, 19, 66, 72]. To reduce the experimental errors, we have carefully checked our implementation to the best of our abilities.
Construct Validity: Construct validity relates to the applicability of the set of evaluation metrics used in this study. The metrics like , and Top- Rank are well-known information retrieval metrics and have been used before to evaluate many past bug localization approaches [41, 44, 47, 71]. Thus, we believe there is little threat to construct validity. Another threat comes from the data preprocessing scheme as per [29, 15], which has deficiencies discussed in Section 4.3. However, we retain the scheme to preserve the spirit of replication and align this work with the prior art. These deficiencies may lead to overly-optimistic predictions; however, even these inflated results may not be adequate for the practitioners, as was discussed in the previous sections.
Conclusion Validity: We made sure the model is generalizable by avoiding overfitting. In order to prevent overfitting, we have employed the dropout technique, 10-fold cross validation, regularization and early stopping. Also, the risk of insufficient generalization is reduced by evaluating the models on five open source projects.
External Validity: Software engineering studies suffer from the variability of the real world, and the generalization problem cannot be solved completely [62]. Although we have used five open source projects in this study, our empirical evaluation may not be generalizable to other open source projects or industrial projects. The goal of the study was not to build a new model, but to experiment on the recently proposed deep-learning-based bug localization models and examine their relevance in research and industry. The same empirical examination can also be applied to other software products with well-designed and controlled experiments.
5 Conclusion
In this study we examine the effectiveness of deep-learning-based bug localization models from the practitioners’ perspective and compare them with traditional ML models. To achieve this, we assess performance of multiple models on five open source bug localization datasets. We assess the performance of two models directly and use readily available statistics [29, 19] for the remaining models. Finally, we evaluate the models against the expectations of software practitioners (reported in [26]) and discuss the drawbacks of the models. Our study includes the following key findings:
- •
The deep-learning-based models perform well, compared to the traditional ML models on bug localization data in most cases, but have high training time and need large amount of hardware resources, such as GPUs and memory.
- •
It is both expensive and challenging for the mainstream software practitioners to be able to use these models.
- •
It is challenging to compare the performance of different models when no standard approach for data preparation exists. Moreover, reductions in the sets of files used for testing the model may lead to overly optimistic performance evaluation from a practical standpoint.
- •
Most researchers consider only the IR metrics to evaluate the performance of their proposed approach or model to localize bugs. In addition to this, the models should be examined to verify if they meet the expectations of a software practitioner.
This work is of interest to software practitioners, as it provides evidence that the practitioners should be cautious while using the current state of the art models. It is also of interest to researchers as it highlights the need for standardization of performance benchmarks to ensure realistic assessment of bug localization models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Anonymous “The dataset of six open source Java projects containing text of source code and bug reports”, 2018 URL: https://figshare.com/s/4bde 89c 7167 f 58b 6927 f
- 2[2] J. Anvik “Automating Bug Report Assignment” In Proceedings of the 28th International Conference on Software Engineering , ICSE ’06 New York, NY, USA: ACM, 2006, pp. 937–940 DOI: 10.1145/1134285.1134457 · doi ↗
- 3[3] Y. Bengio “Learning deep architectures for AI” In Foundations and trends® in Machine Learning 2.1 Now Publishers, Inc., 2009, pp. 1–127
- 4[4] Nicolas Bettenburg et al. “What makes a good bug report?” In Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of software engineering , 2008, pp. 308–318 ACM
- 5[5] Christopher M Bishop “Pattern recognition and machine learning” Springer, 2011
- 6[6] E.J. Braude and M.E. Bernstein “Software Engineering: Modern Approaches, Second Edition” John Wiley, 2016 URL: https://books.google.ca/books?id=k I Ll Cw AAQBAJ
- 7[7] “Bugzilla”, https://bugs.eclipse.org/bugs/
- 8[8] K. Chang, V. Bertacco and I. L. Markov “Simulation-based bug trace minimization with BMC-based refinement” In IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 26.1 IEEE, 2007, pp. 152–165