Unsupervised Adversarial Domain Adaptation for Cross-Lingual Speech Emotion Recognition
Siddique Latif, Junaid Qadir, and Muhammad Bilal

TL;DR
This paper introduces a GAN-based unsupervised domain adaptation model for cross-lingual speech emotion recognition, effectively handling language differences without requiring labeled data, and demonstrates significant performance improvements across multiple languages.
Contribution
The paper presents a novel GAN-based approach for learning language-invariant features in speech emotion recognition without target language labels, addressing a key challenge in cross-lingual SER.
Findings
Significant performance improvements on four multilingual datasets.
Effective in low-resource languages like Urdu.
No need for labeled target-language data.
Abstract
Cross-lingual speech emotion recognition (SER) is a crucial task for many real-world applications. The performance of SER systems is often degraded by the differences in the distributions of training and test data. These differences become more apparent when training and test data belong to different languages, which cause a significant performance gap between the validation and test scores. It is imperative to build more robust models that can fit in practical applications of SER systems. Therefore, in this paper, we propose a Generative Adversarial Network (GAN)-based model for multilingual SER. Our choice of using GAN is motivated by their great success in learning the underlying data distribution. The proposed model is designed in such a way that can learn language invariant representations without requiring target-language data labels. We evaluate our proposed model on four…
Click any figure to enlarge with its caption.
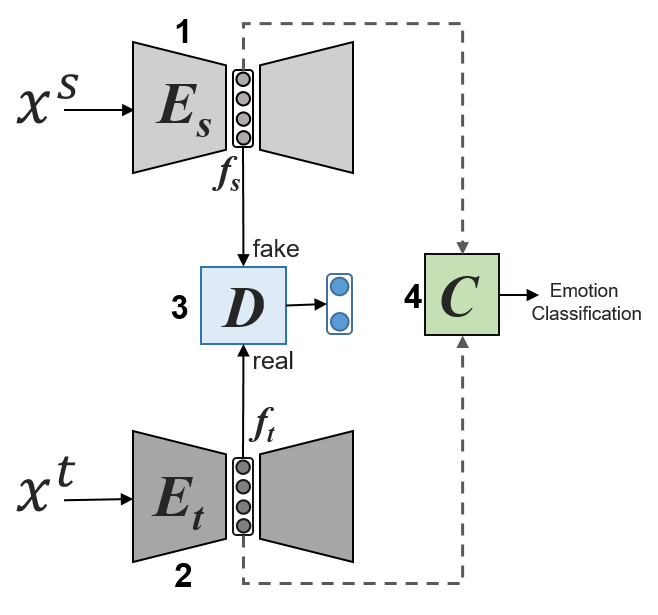 Figure 1
Figure 1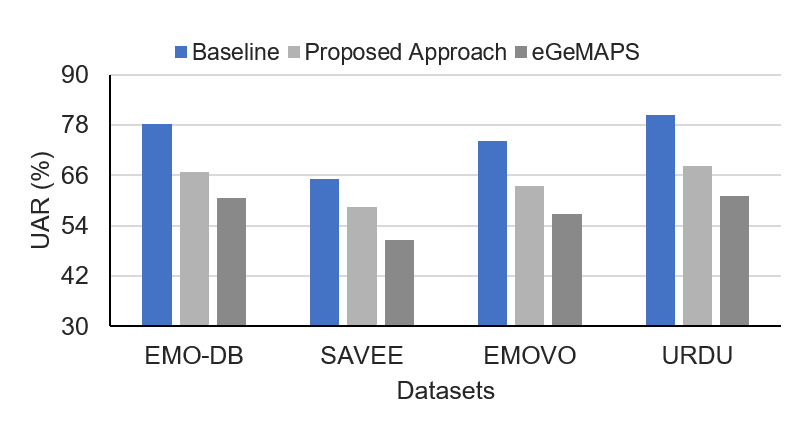 Figure 2
Figure 2| Corpus | Language | Age | Utterances | Negative Valance | Positive Valance | References | |||||||
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
| Corpus | EMO-DB | SAVEE | EMOVO | URDU |
| UAR (%) | 81.3 | 65.1 | 74.2 | 83.4 |
| Source | Target | UAR (%) | ||
| eGeMAPS | Latent Codes | eGeMaps+Latent Codes | ||
| EMO-DB | URDU | 57.8 | 64.2 | 65.2 |
| SAVEE | 45.8 | 52.3 | 58.0 | |
| EMOVO | 40.1 | 50.5 | 53.6 | |
| URDU | EMODB | 55.1 | 64.5 | 65.3 |
| SAVEE | 43.7 | 51.8 | 53.2 | |
| EMOVO | 50.8 | 59.8 | 61.3 | |
| Target Data | UAR (%) | ||
|---|---|---|---|
| eGeMAPS | Latent Codes | Latent Codes+eGeMAPS | |
| EMO-DB | 60.5 | 65.9 | 68.0 |
| SAVEE | 50.6 | 56.3 | 56.7 |
| EMOVO | 56.8 | 60.5 | 61.8 |
| URDU | 60.9 | 65.2 | 67.3 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Unsupervised Adversarial Domain Adaptation for Cross-Lingual Speech Emotion Recognition
Siddique Latif
University of Southern Queensland
Australia
Junaid Qadir
Information Technology University (ITU)
Lahore, Pakistan.
Muhammad Bilal
University of the West of England (UWE)
Bristol, United Kingdom.
Abstract
Cross-lingual speech emotion recognition (SER) is a crucial task for many real-world applications. The performance of SER systems is often degraded by the differences in the distributions of training and test data. These differences become more apparent when training and test data belong to different languages, which cause a significant performance gap between the validation and test scores. It is imperative to build more robust models that can fit in practical applications of SER systems. Therefore, in this paper, we propose a Generative Adversarial Network (GAN)-based model for multilingual SER. Our choice of using GAN is motivated by their great success in learning the underlying data distribution. The proposed model is designed in such a way that can learn language invariant representations without requiring target-language data labels. We evaluate our proposed model on four different language emotional datasets, including an Urdu-language dataset to also incorporate alternative languages for which labelled data is difficult to find and which have not been studied much by the mainstream community. Our results show that our proposed model can significantly improve the baseline cross-lingual SER performance for all the considered datasets including the non-mainstream Urdu language data without requiring any labels.
Index Terms:
Speech emotion recognition, Urdu, Multi-lingual, generative adversarial networks (GANs)
I Introduction
Speech emotion recognition (SER) is gaining more interest in recent years. The goal of SER is to identify different kinds of human emotion from the given speech, which has been proven very helpful in automating many real-life applications including health-related diagnostics [1, 2, 3, 4]. Existing SER systems can perform to a satisfactory level when training and test data belong to the same corpus [5, 6]. However, it is still an open challenge to design more robust SER systems that are more resilient to cross-lingual emotions recognition.
Due to recent advancement in the field of machine learning (ML), particularly deep learning (DL), researchers are attempting to solve various problems in audio and related fields [7, 8, 9, 10]. For SER. many researchers are also attempting to design more robust systems that can work best with applications involving multiple languages. One approach for the design of more robust SER systems is to use as diverse dataset (having multilingual data) as possible. Studies (e.g., [11, 12]) have shown that a model trained using multiple sources or corpora can help to achieve better results for SER. However, acoustic training from multiple language data is not a reasonable approach as it requires labelled data that might not be available for all languages. Alternatively, robustness in SER system can also be achieved by using a partial data from the source language to improve the performance [13, 14]; but some labelled target data for training the model is needed here as well.
A more practical approach is the use of domain adaptation, which generalises SER systems to the multilingual scenarios without the need for labelled data. Researchers have tried different domain adaptation methods in SER to improve the performance of models on cross-lingual or cross-corpus emotion recognition tasks [15, 16]. To this end, unsupervised domain adaptation methods are becoming very popular in such applications. Recently, Generative Adversarial Networks (GANs) [17] has become very popular and being employed in various vision [18] and speech related fields [19]. They are also exploited for unsupervised domain adaptation in several tasks related to voice user applications including speaker identification [20], automatic speech recognition (ASR) [21, 22, 23] and SER [24, 25]. However, multilingual SER is not explored using GAN based domain adaptation approaches.
In this study, we propose an adversarial domain adaptation for multilingual SER, particularly for languages like Urdu for which emotional labels are not available. Urdu is the official national language of Pakistan and is amongst the 22 official languages recognised in the Constitution of India. The performance of state-of-the-art SER systems degrades when unknown language data like Urdu is used in testing phase [26]. To the challenges introduced by such languages, it is crucial for developing more robust SER systems for their next-generation cross-cultural applications. Therefore, we evaluate the proposed approach on multilingual SER tasks including Urdu language data.
We assume that source language data with annotated emotional labels is available and is used for training the model while the target language data (which is considered as the target domain and is used for testing the model’s performance) does not have emotional labels. The proposed approach uses unsupervised adversarial domain adaptation for multilingual SER where the model aims to learn language invariant emotional representation from the given source language similar to target language features.
Our proposed model utilizes the following four networks in its architecture (illustrated in Figure 1):
- •
(1 and 2) feature encoding networks for the source language data and target language data, respectively;
- •
(3) a discriminator network that discriminates between the features encoded by source encoding network and by target encoding network; and
- •
(4) a classifier for emotion identification.
We have evaluated the proposed model on four publicly available language datasets and have compared our results with popular emotional features eGeMAPS. Our results indicate that our approach significantly improves the multilingual emotion identification predictive accuracy. Our results are a promising advance in the field since our model can be used to identify emotions for any unlabelled language data in an unsupervised adversarial manner.
II Related Work
Cross-language SER is important and has been studied in various research works. It aims to generalise the classifiers having different training and test conditions including different noise levels, microphone settings, and speaker variations and language. The performance of classifier on these different conditions have been highlighted in [27, 11, 28, 29]. These studies used SVM as a classifier and pointed out the need for in-depth research to improve the performance of cross-lingual SER. Researchers have also attempted different classifiers to improve the performance of cross-lingual SER. For instance, Neumann et al. [30] used CNN for binary arousal/valence classification for the French and English languages. They showed that fine-tuning the model on the target domain can help to produce better results. In another work, Albornoz et al. [26] developed an emotion profile-based ensemble SVM SER for different languages and demonstrated a substantial performance gain over baseline accuracy by training the ensemble model in a language-agnostic manner. Likewise, Li et al. [31] used a combination of different features along with speaker normalisation technique to improve multi-lingual emotion recognition.
Previous works have also attempted different techniques to minimise the differences in the feature space of both source and target domains. Zhang et al. [32] normalised the features of each corpus separately to decrease cross-corpus variability. To reduce the effect of covariate shift, Hassan et al. [33] used three algorithms to apply importance weights to the training data of SVM classifier to match the test data distribution. Deng et al. [34] used autoencoders with shared hidden layer to learn common feature representation across different datasets. These authors were able to reduce the discrepancy among corpora and improve the baseline results. In another study [35], authors used Universum autoencoder, to enhance the performance of SER in mismatched training and test conditions. They achieved promising results on cross-corpus evaluations due to the additional supervised learning capability of Universum autoencoders in contrast to conventional autoencoders.
In contrast to the studies mentioned above, we aim to minimise mismatch of training and test conditions in an unsupervised adversarial way for cross-lingual emotion recognition. Our attempt is motivated by the great success of GANs in computer vision for domain adaptation task [36, 37]. Very few studies exploited GANs for SER. For instance, Zhou et al. [38] used a class-wise domain adaptation method using adversarial training to address cross-corpus mismatch issue. They used two datasets, including AIBO and EMO-DB for the same language and showed that adversarial training is useful when the model is to be trained on target language with minimal labels. Wang et al. [20] exploited adversarial multitask training to learn a common representation for both the source and target language domains. Authors used two datasets of the English language and presented promising results for cross-corpus emotion recognition by creating more discriminant features that reduce the gap between the source and target datasets. Similarly, Gideon et al. [39] used three well-known English language datasets and proposed an adversarial discriminative domain generalisation method for cross-corpus emotion recognition. Besides these studies, we proposed a method for cross-lingual emotion recognition over four different language datasets. The proposed model is then evaluated for languages such as Urdu whose labelled emotional data is barely available.
III Model
We proposed a model for unsupervised domain adaptation of multilingual SER. Our proposed model leverages the unlabelled target language data and aims to learn common feature representations for both source and target language.
Fig. 1 shows the architecture of proposed model. Where source language data is fed to source language feature encoder and target language data is given to the target language feature encoder . Both and are connected to discriminator that is tasked to enforce to learn features from which are similar to of target language data . The intuition of this method is that emotional data of different languages have some common features [13, 43, 27, 11] that we are learning in this model in an unsupervised way. The features ( and ) encoded by and are given to the classifier for classification. Here we trained on by considering that source language data has labels while test is performed on target language data without considering its labels.
Our proposed model is trained like GANs [17] via an adversarial process to produce features similar to the target domain. In a simple GAN, the generator maps the latent vectors drawn from some known prior ( e.g. Gaussian) to fake data points . The discriminator is tasked with differentiating between samples generated (fake) and real data samples (drawn from a distribution ). Both generator and a discriminator play two-player min-max game using the following GAN loss:
[TABLE]
Here, we use GAN, where instead of latent vectors , generator is fed by source language features and is trained to learn representations similar to target language representations encoded by . The adversarial loss training loss for is defined as:
[TABLE]
The generator attempt to fool discriminator by generating features very similar to . The discriminator classifies whether features are drawn from the source language () as fake or the target language () as real using the following loss function:
[TABLE]
where and are the training samples for source and target language data respectively. In our model, both and are two autoencoder networks that encode the source and target data in latent code. The intuition of using autoencoders is that they encode the given data into underlying feature structures using reconstruction loss [44, 45]. Both autoencoders were trained separately using reconstruction loss while the encoder part of source autoencoders is updated using the adversarial loss (see Equation 2) to learn language invariant features. We use an SVM as the classifier for emotion identification.
IV Experimental Setup
We have selected EMO-DB, SAVEE, EMOVO, and URDU datasets in this work. The selection of these corpora is made to incorporate maximum diversity of languages especially to cover infrequently analysed languages such as Urdu. Further details on selected databases, speech features, and model configuration are presented below.
IV-A Speech Databases
IV-A1 EMO-DB
It is a well known and widely used corpus for SER. The language of EMO-DB dataset is German, and it was introduced by [40]. It comprises the recordings of ten professional actors in 7 emotions: anger, disgust, boredom, fear, neutrality, joy, and sadness. The linguistic content used for recordings is pre-defined emotionally neutral ten short sentences in the German language. Overall, it contains over 700 utterances, while only 494 utterances are emotionally labelled. We used only annotated utterances in this work.
IV-A2 SAVEE
Surrey Audio-Visual Expressed Emotion (SAVEE) database [41] is another popular multimodal emotional dataset. It includes the recordings from four male actors in 7 different emotions. The language of SAVEE dataset is British English. The recordings in this dataset were evaluated by ten different assessors under visual, audio, and audio-visual conditions to assure the quality of emotional acting. The scripts used for data recordings were selected from the standard TIMIT corpus [46]. In total, SAVEE contains 480 utterances in 7 emotions: neutral, happiness, sadness, anger, surprise, fear, and disgust. We used all these emotions in our experiments by mapping them on the binary valance.
IV-A3 EMOVO
This dataset is the first Italian language emotional corpus and contains 588 recordings [42]. There are 6 actors whose scripts of 14 different sentences in 7 different emotional states including disgust, fear, anger, joy, surprise, sadness and neutral. The recordings were evaluated by two separate groups of listeners to validate the performance of emotional actors. All the recordings in this corpus were made with equipment in the Fondazione Ugo Bordoni laboratories.
IV-A4 URDU
This corpus is the first Urdu language dataset that includes unscripted and spontaneous emotional speech [12]. It comprises the audio recordings collected from the discussion of the different guests of Urdu TV talk shows. In total, 400 utterances for four basic emotions (angry, happy, sad, and neutral) were collected. The recordings were given to four different annotators who were tasked to annotate them based on audio-visual conditions. There are 38 speakers including 27 males and 11 females. We utilised all 400 utterances in this work.
IV-B Feature Extraction
In this study, we have used a minimalistic feature set called eGeMAPS [47]. These features are widely used frame-level knowledge-inspired parameters. The eGeMAPS comprise Low-Level Descriptor (LLD) of speech which has been suggested as the most descriptive emotional feature by paralinguistic studies. Besides, eGeMAPS features also provide performance comparable and even better compared to large brute-force features[47]. In total, eGeMAPS consists of 88 parameters related to spectral, energy, frequency, cepstral, and dynamic information. The components of eGeMAPS selected from the arithmetic mean and coefficient of variation of 18 LLDs, 6 temporal features, 8 functionals applied to loudness and pitch, 4 statistics over the unvoiced segments, and 26 additional dynamic parameters and cepstral parameters. A list of these LLDs and functionals can be found in Section 3 of [47]. We computed eGeMAPS using openSMILE toolkit [48].
IV-C Model Configuration
We implemented our model using the Tensorflow library. Both the encoder parts ( and ) consist of two fully connected (FC) layers with the latent code dimension of . The discriminator also consists of two FC layers having 512 and 256 hidden units followed by a softmax layer. For regularisation, we used dropout layer between FC layers of , and , with a dropout rate of . We trained the models using the training set, and the validation set was used for hyper-parameter selection. For minimisation of cross-entropy loss function of discriminator , we used RMSProp optimiser [49], with an initial learning rate of . We input speech segments of length ms into the model for encoding the latent code of dimension . The selection of speech segment is made based on the previous studies [50, 51]. The latent code encoded by both and are then fed to SVM. The utterance level prediction, in testing phase, is obtained by averaging the posterior probabilities of the respective segments. For all experiments, the validation is performed within corpus in a speaker-independent manner to pick the optimal hyper-parameters. We select an RBF kernel due to its better performance compared to the linear and cubic kernel during experimentation.
V Experiments and Results
This section reports the experimental evaluations of the proposed model for cross-lingual SER. For this, we used four publicly available datasets. These databases are annotated differently; therefore, we consider binary positive/negative valence classification problem in this study (see Table I). We adopt the binary valence mapping of categorical emotions from [52, 13]. The input features of audio utterances are given to the model for encoding them into language invariant representations which are passed to SVM for classification. We performed experiments in speaker independent evaluation scheme for all datasets and results are reported in terms of unweighted average recall rate (UAR). For the Urdu dataset, we used 30 speakers as training data and the remaining 8 for testing with five-fold cross-validation. For other corpora, we used one-speaker-out evaluation scheme with cross-validation equal to the number of speakers in the respective dataset as per the accepted practice for computing the baseline results of SER [47].
For baseline results, we trained SVMs using eGeMAPS features to perform classification within a corpus using both training and testing data from the same language. The obtained baseline results provide us with an idea about the best achievable accuracy within each corpus. Table II shows the baseline results for all datasets.
Table III shows the results for cross-lingual emotion identification using latent code learned by the proposed model and eGeMAPS. SVM trained on eGeMAPS shows the performance degradation of SER in cross-lingual scenarios compared to baseline results (Table II) obtained using training and test data from the same corpus. Here, we use Urdu data as target language with no labels. Latent codes for source and target language data learned by the proposed model are given to the SVM. The source language data is used only for training and validation purposes. The testing is performed on target language data. The same evaluation is performed for other languages when Urdu data is used as source language (i.e., training data).
We also evaluated the proposed model using multi-language training as it helps to achieve better accuracy. Results are presented in Table IV. In this experiment, we use the one-language-data-out scheme, and the remaining corpora are mixed and used for training the model. The results are compared using eGeMAPS and latent code learned by the proposed architecture of domain adaptation in Table IV.
VI Summary of Findings
We have presented results for cross-lingual SER using unsupervised adversarial domain adaptation. We were able to improve the results of cross-lingual SER significantly. From the experiments, best results are obtained when data from multiple languages are used as source data and one language as the target. This essentially means that the proposed model is capable of learning many intrinsic features from a broad range of languages which are similar to the target language. Table IV shows that the results using the features learned by proposed model are significantly better compared to SVM trained on eGeMAPs using a similar multi-languages traning technique. We also compared the results for multi-language training using the latent codes and eGeMAPS with baseline results. Fig. 2 shows that baseline results using training and testing data from same corpus is better than latent codes learned by proposed model and eGeMAPS results in multi-lingual training scenario. However, the results using the proposed model outperformed significantly over the eGeMAPS. This shows the language invariant representations is able to improve the performance of cross-lingual emotion recognition.
Overall, the results for cross-lingual emotion recognition have improved for all datasets without any requirement of labels for the target language dataset. This is a substantial leap towards better SER models. The findings of this work are of vital importance to many real-life SER applications where we have multiple resource data available.
We also showed in Table III that the performance of the existing SER systems degrade significantly across languages compared to the baseline results (Table II) for all datasets. We have also presented results using the proposed model in Table III that shows significant improvement in cross-lingual SER. More importantly, results using language invariant latent codes learned by the proposed model is even better than the multi-language training of SVM with eGeMAPS. For instance, we have achieved accuracy for Urdu data while using the EMO-DB as training data. This is better than that we have achieved using eGeMAPS by training SVM in multi-language training scheme with the remaining three datasets. Similar results are obtained for other datasets when they were used as target language data. This highlights the critical functionality of GAN based proposed architecture that can learn language invariant features in a completely unsupervised manner and provides improved results compared to directly using eGeMAPS. This shows that the proposed solution for cross-language SER can fit in scenarios where labelled data is not available for languages like Urdu.
Another important insight learnt from this work is that the adversarially learned language invariant features when jointly used with eGeMAPS can help to achieve more excellent performance. The performance improvement is found for both cases including cross-lingual and multi-language training experiments. Results for cross-lingual SER using a combination of adversarially learned features (latent codes) and eGeMAPS are presented in Table III and for multi-language training are presented in Table IV.
VII Conclusions
In this paper, we proposed an unsupervised adversarial domain adaption approach for developing deep learning models for cross-lingual speech emotion recognition tasks. The proposed model is evaluated using the data from four emotional corpora. It is revealed that using GAN for learning language invariant features can provide better results compared to widely used emotional features like eGeMAPS. The proposed approach works in a completely unsupervised way, and adversarially learns language invariant features without the need of labels for the target language.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. Latif, R. Rana, J. Qadir, A. Ali, M. A. Imran, and M. S. Younis, “Mobile health in the developing world: Review of literature and lessons from a case study,” IEEE Access , vol. 5, pp. 11 540–11 556, 2017.
- 2[2] S. Latif, J. Qadir, S. Farooq, and M. Imran, “How 5g wireless (and concomitant technologies) will revolutionize healthcare?” Future Internet , vol. 9, no. 4, p. 93, 2017.
- 3[3] R. Rana, S. Latif, R. Gururajan, A. Gray, G. Mackenzie, G. Humphris, and J. Dunn, “Automated screening for distress: A perspective for the future,” European journal of cancer care , p. e 13033, 2019.
- 4[4] S. Latif, M. Y. Khan, A. Qayyum, J. Qadir, M. Usman, S. M. Ali, Q. H. Abbasi, and M. A. Imran, “Mobile technologies for managing non-communicable diseases in developing countries,” in Mobile Applications and Solutions for Social Inclusion . IGI Global, 2018, pp. 261–287.
- 5[5] S. Latif, R. Rana, J. Qadir, and J. Epps, “Variational autoencoders for learning latent representations of speech emotion: A preliminary study,” in Proc. Interspeech 2018 , 2018, pp. 3107–3111. [Online]. Available:
- 6[6] S. Latif, R. Rana, S. Khalifa, R. Jurdak, and J. Epps, “Direct modelling of speech emotion from raw speech,” ar Xiv preprint ar Xiv:1904.03833 , 2019.
- 7[7] B. Wei, M. Yang, R. K. Rana, C. T. Chou, and W. Hu, “Distributed sparse approximation for frog sound classification,” in Proceedings of the 11th international conference on Information Processing in Sensor Networks . ACM, 2012, pp. 105–106.
- 8[8] R. Rana, D. Austin, P. G. Jacobs, M. Karunanithi, and J. Kaye, “Gait velocity estimation using time-interleaved between consecutive passive ir sensor activations,” IEEE Sensors Journal , vol. 16, no. 16, pp. 6351–6358, 2016.