Composing Neural Learning and Symbolic Reasoning with an Application to Visual Discrimination
Adithya Murali, Atharva Sehgal, Paul Krogmeier, P. Madhusudan

TL;DR
This paper introduces a neurosymbolic framework for visual discrimination puzzles that combines neural networks with symbolic reasoning to produce interpretable classifiers, outperforming purely neural methods.
Contribution
It presents a novel compositional neurosymbolic approach for solving visual discrimination puzzles with interpretable outputs, bridging neural perception and symbolic reasoning.
Findings
Framework performs well on diverse VDP datasets
Neurosymbolic approach yields interpretable classifiers
Outperforms several neural-only methods
Abstract
We consider the problem of combining machine learning models to perform higher-level cognitive tasks with clear specifications. We propose the novel problem of Visual Discrimination Puzzles (VDP) that requires finding interpretable discriminators that classify images according to a logical specification. Humans can solve these puzzles with ease and they give robust, verifiable, and interpretable discriminators as answers. We propose a compositional neurosymbolic framework that combines a neural network to detect objects and relationships with a symbolic learner that finds interpretable discriminators. We create large classes of VDP datasets involving natural and artificial images and show that our neurosymbolic framework performs favorably compared to several purely neural approaches.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1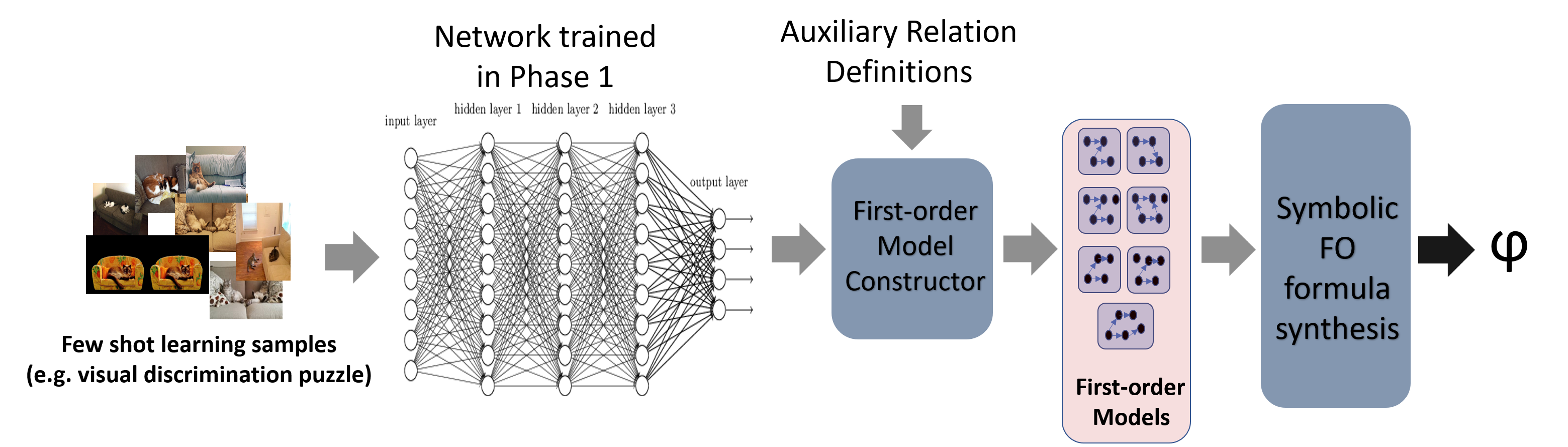 Figure 2
Figure 2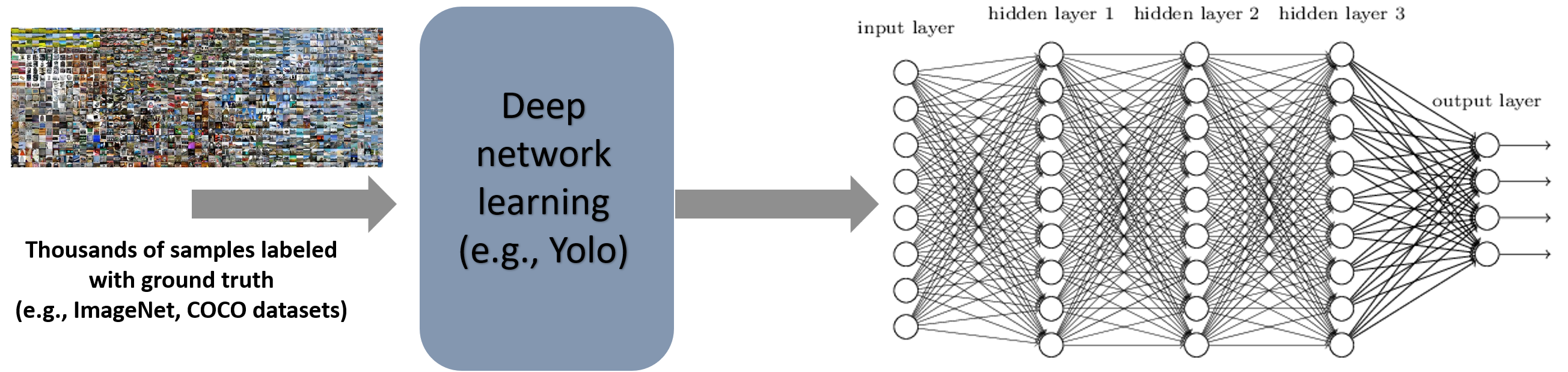 Figure 3
Figure 3| ID | Class Description | ID | Class Description |
| 1 | All teddy bears on a | 2 | There is an SUV |
| sofa | |||
| 3 | Onward lane (person | 4 | Fruit in separate piles |
| on left sidewalk) | (apples & oranges) | ||
| 5 | Kickoff position (ball | 6 | Laid out place setting |
| b/w two people) | (v/s dirty dishes) | ||
| 7 | Person kicking ball | 8 | Dog herding sheep |
| 9 | Parking spot | 10 | People carrying |
| umbrellas | |||
| 11 | Bus filled with people | 12 | All dogs on sofas |
| 13 | Desktop PC | 14 | People wearing ties |
| 15 | Person sleeping on | 16 | All cats on sofas |
| bench | |||
| 17 | Kitchen | 18 | TV is switched on |
| 19 | Two cats on same sofa | 20 | Cat displayed on TV |
| ID | Concept Class Schema |
| 1 | Every shapeX has a shapeY to its left and right. |
| 2 | There is a shapeX of color colorA to the left of a |
| shapeY of color colorB. | |
| 3 | There is a shapeX to the right of every shapeY. |
| 4 | There is a shapeX and there is a shapeY to the left |
| of all shapeX. | |
| 5 | Every shapeX has a shapeY to its right. |
| 6 | All shapeXs and shapeYs have the same color. |
| 7 | There is no color such that there is only one shapeX |
| of that color. | |
| 8 | There is a leftmost shapeX and a rightmost shapeX. |
| 9 | All shapeX are to the left of all shapeYs and the |
| rightmost shapeY is made of materialQ. | |
| 10 | All shapeXs are to the left of a shapeY of color |
| colorB. | |
| 11 | All shapeXs are to the left of all shapeYs. |
| 12 | Every shapeX has a shapeY to its right. |
| 13 | Every shapeX has a shapeY behind it. |
| 14 | There are three shapeXs of the same color. |
| 15 | There is a materialQ shapeX to the left of |
| all shapeYs. |
| Target discriminator | Sample Discriminators |
| All teddy bears on a sofa | |
| There is an SUV | |
| Onward lane | |
| (pedestrians to the right of traffic) | |
| Fruit in separate piles | |
| Kickoff position | |
| (football in between two people) | |
| Laid out place setting | |
| Person kicking a ball | |
| Dog herding sheep | |
| Parking spot | |
| People carrying umbrellas | |
| Bus with people in it | |
| All dogs on sofas | |
| Desktop computer | |
| People wearing ties | |
| Person sleeping on a bench | |
| (versus animals sleeping) | |
| All cats on sofas | |
| Kitchen | |
| Two cats on the same sofa | |
| Cat displayed on TV | |
| TV is on | – |
| Target Concept | Sample Discriminators | Natural Language Reading |
| Two cats on a couch | “There is some cat or some thing that all things are to the right of” | |
| All cats are on sofas | “There is no chair and there is some non-sofa” | |
| All dogs are on sofas | “There is something that is sitting on all sofas” | |
| “There is a non-dog sitting on something” | ||
| Cat on TV | “For every pair of things, either one is to the right of the other or else it is not within the other” | |
| “Either there is a dog or everthing is a tv monitor” | ||
| “There is something displayed on all tv monitors” | ||
| Desktop computer | “There is no sofa and there is nothing placed on anything else” | |
| Dog herding | “There is a truck or there is no person” | |
| “Every sheep has something that it is to the right of” | ||
| Driving direction | “Every car has something to its left” | |
| “There is a truck or there is no car” | ||
| Kitchen | “There is either a banana or an oven” | |
| “Every cup is to the left of something” | ||
| Parking meter in sight | “There is a parking meter or else everything is to the left of something” | |
| Person and ball | “Everything is either a person or else it has nothing” | |
| Bus with people inside | “There is a bus to the right of something” | |
| “There is a non-bus and something that it is not inside” | ||
| People and ties | “There is a tie or else everything is wearing something” | |
| People wearing ties | “There is a tie or else there is something to the right of everything” | |
| Someone sleeping on a bench | “There is something with nothing to the left of it and nothing on it” | |
| “There is something to the right of a non-bench” | ||
| Umbrella weather | “There is an umbrella or else there is something had by everything” |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural Networks and Applications · Image Retrieval and Classification Techniques
Composing Neural Learning and Symbolic Reasoning with an Application to Visual Discrimination
Adithya Murali1111Contact Authors
Atharva Sehgal
Paul Krogmeier1&P. Madhusudan1
1Department of Computer Science, University of Illinois at Urbana-Champaign
2Department of Computer Science, University of Texas at Austin
[email protected], [email protected], [email protected], [email protected]
Abstract
We consider the problem of combining machine learning models to perform higher-level cognitive tasks with clear specifications. We propose the novel problem of Visual Discrimination Puzzles (VDP) that requires finding interpretable discriminators that classify images according to a logical specification. Humans can solve these puzzles with ease and they give robust, verifiable, and interpretable discriminators as answers. We propose a compositional neurosymbolic framework that combines a neural network to detect objects and relationships with a symbolic learner that finds interpretable discriminators. We create large classes of VDP datasets involving natural and artificial images and show that our neurosymbolic framework performs favorably compared to several purely neural approaches.
1 Introduction
Deep learning has made significant strides in solving specialized tasks, especially in areas such as vision and NLP Goodfellow et al. (2016). In this paper we study how these specialized models can be composed and integrated into solutions for high-level tasks with clear specifications. We are especially interested in solutions for settings without a lot of data.
We believe the problem of integrating learned models is important and can have many applications. For example, a robot may need to formulate a complex plan that utilizes pretrained vision components to detect objects and prediction of human behavior. It is challenging to utilize pretrained components to achieve a high-level task. In this paper, we investigate neurosymbolic techniques for higher level symbolic reasoning using neural components for such problems.
1.1 Visual Discrimination Puzzles
In this paper, we propose a new high-level task called a Visual Discrimination Puzzle (VDP). Figure 1 shows an example of a VDP. The first row contains some example images (, , and ), and the second row consists of candidate images (, , and ). To solve the puzzle we are asked to answer the following question:
Which candidate image is most similar to all of the
example images? Explain why.
Humans have no prior experience with VDPs, but seem to be able to solve them with ease. We invite the reader to try solving the puzzle in Figure 1 before reading further.
When solving a VDP, different people can (and do, in our limited experience) come up with different answers. Many people select as the answer to the puzzle in Figure 1 and explain that, in each example image as well as candidate image , all dogs are sitting on sofas while this is not true in the other candidate images.
A natural formalization of the specification for VDP puzzles is the following:
Is there a property that holds in all example images and exactly one candidate image, but does not hold in the other candidate images?
We call such a property a discriminator. Solving a VDP reduces to finding a discriminator.
Observe the following salient aspects of the problem. First, the set of example images is small. A VDP solver must learn the common concept using only - images. Second, unlike visual question answering (VQA), where one computes a query over a scene, solving VDPs requires searching in a large space of discriminators for one that satisfies the puzzle specification. Third, the logical specification of the problem makes the solution sensitive to every image. A solver cannot merely identify a candidate image that is similar to all example images— it must also exclude the other candidates. Consequently, a candidate may be a solution for one puzzle but not in another where different candidate images are present. For example, if we modified the non-answer image in Figure 1 so that the dog is on the sofa, the solution might be different from as the concept ‘all dogs are on sofas’ no longer corresponds to a unique candidate. Even swapping the solution candidate image with an example image could potentially change the solution (as there could be a simpler discriminator for this new puzzle that chooses a different solution). E.g., can choose in the first puzzle and can be a simpler discriminator that chooses in the second puzzle, but is not a solution for the first puzzle. Finally, we would accept an answer from a person or machine only if it is justified— we want a precise, interpretable concept that can be evaluated on images to see that it indeed satisfies the puzzle specification.
1.2 A Neurosymbolic Framework
We propose that effective integrative frameworks can be obtained by composing learned neural models for vision and symbolic reasoning, where the latter caters to the higher-level task specification. Designing such a framework poses several challenges, including (1) Interface: determining the exact communication between the neural and symbolic components; (2) Interpretability: explaining decisions of symbolic components, potentially in terms of inputs received from neural components; and (3) Robustness: symbolic components should ideally be robust to vagaries of individual neural components and to different implementations.
In this paper, we instantiate a neurosymbolic architecture for solving VDPs that addresses these three challenges in novel ways. In this work, the neural components are realized with state-of-the-art vision models that are trained offline on thousands of images. Given an image, the vision model detects a scene graph consisting of objects, their labels, bounding boxes or relative positions, and their relationships. Given a puzzle, we extract one scene graph for each image in the puzzle.
We propose an interface to the symbolic component using first-order logic scene models, which can be automatically computed from scene graphs. The symbolic component uses discrete search (realized efficiently using a SAT solver) to synthesize a discriminator expressible in first-order logic over scene models, which identifies a candidate as a solution to a given puzzle. The symbolic synthesis not only solves the puzzle by finding an appropriate candidate, but also justifies the choice using a first-order formula that is eminently interpretable. For the puzzle in Figure 1, our system would potentially find the discriminator:
[TABLE]
The robustness of such a system certainly depends on the robustness of the vision model (for example, it is hard to solve the puzzle in Figure 1 if a dog is not detected). However, there are other robustness properties of interest. In particular, if the vision component improves and detects new objects or relationships, we would like any discriminator found before the improvement to remain a discriminator with respect to richer scene models that contain these new objects and relationships. We call this the extension property. We build a domain-specific logic called First-Order Scene Logic (FO-SL), prove that it has the extension property, and use it to express discriminators.
The problem of synthesizing quantified discriminators in FO, and in particular FO-SL, is a relatively new problem (as opposed to program synthesis). Reducing the problem to off-the-shelf synthesizers does not scale, and we build our own SAT-based symbolic solvers for synthesizing quantified discriminators.
Evaluation
We create three VDP datasets. Two of these are based on real-world scenes and contain puzzles, and the other (synthetic) dataset is based on the CLEVR domain and consists of 825 puzzles. We implement and evaluate our framework on the real-world datasets and show that it is effective and robust. It solves 68% and 80% of the puzzles in the two datasets and gives sensible discriminators. We perform ablation studies that examine the effectiveness of the domain-specific logic FO-SL as well as the synthesis algorithm. The ablation for FO-SL involves implementing a second synthesis solver based on a different technique. We also compare our framework with purely neural baselines based on image similarity models Wang et al. (2014) and prototypical networks Snell et al. (2017), and we show that they perform poorly (). This comparison is made using the CLEVR VDP dataset, which is designed to have unique minimal discriminators in FO-SL. Finally, we also create a dataset called OddOne consisting of 1872 puzzles, which involves a different specification (picking the “odd one out” from a set of images) adapted from the CLEVR VDP dataset. We use this dataset to evaluate how well various approaches adapt to new high-level specifications without retraining.
Contributions
The primary contributions of this paper are: (1) the VDP problem, which (cognitively) involves visual perception as well as a search for interpretable concepts, (2) sets of VDP and OddOne puzzles that span both natural scenes and synthetic scenes, (3) an instantiation of the neurosymbolic framework with a novel interface between neural and symbolic components, the FO-SL logic for robust visual discriminators, and an efficient discriminator synthesis algorithm based on SAT solving, (4) an evaluation including ablation studies and comparisons to purely neural baselines.
2 Related Work
The idea of learning in two phases, with a first phase involving specific concepts learned from a large dataset and a second phase involving few-shot learning with concepts from the first phase, is not new. The work on recognizing handwritten characters Lake et al. (2015) explores a similar idea. In that work, the first phase learns a generative model of handwritten characters using strokes and the second phase uses Bayesian learning. In our work, we use neural models for object detection and then SAT-based synthesis of first-order formulas. VDP puzzles, however, are different because they require the chosen candidate to be discriminated from other candidates, and this suggests the use of logic. Synthesizing programs to explain behavior and generalize has been explored in various other work recently Ellis et al. (2018); Liu et al. (2019).
Synthesizing programs from discrete data has been studied by both the AI and programming languages communities; the former in inductive logic programming (ILP) Nédellec (1998) and the latter in program synthesis Alur et al. (2018); Gulwani et al. (2015) (including the use of SAT/SMT solvers Solar-Lezama et al. (2006); Alur et al. (2015) ).
There has been a flurry of recent work in combining neural and symbolic learning techniques Amizadeh et al. (2020); Yi et al. (2018); Mao et al. (2019) for problems where large datasets are available. In some cases the goal is to learn a program (e.g., learning programs as models of natural scenes Liu et al. (2019), assisting programmers by learning from large code repositories Raychev et al. (2019)) , and several new techniques have emerged Balog et al. (2017); Parisotto et al. (2017); Murali et al. (2018); Devlin et al. (2017); Bunel et al. (2018); Sun et al. (2018); Evans and Grefenstette (2018) . In this context, our work is novel in that it combines the neural and symbolic components in two different layers, where the symbolic layer is used to synthesize interpretable logical discriminators and handle few-shot learning effectively.
A closely related problem is that of Visual Question Answering (VQA) Antol et al. (2015). Neurosymbolic approaches Yi et al. (2018); Amizadeh et al. (2020) have been used to disentangle visual and NLP capabilities from reasoning in order to solve VQA on artificially rendered images. VQA involves queries about a single image or scene and end-to-end learning algorithms are commonly used. However, VDP puzzles require searching through a large class of potential discriminators, which is inherently a higher-level task. In a sense, we are asking whether there is some question for which a VQA engine would say ‘yes’ on some images and ‘no’ on others. discriminator. The work in Andreas et al. (2018) solves few-shot classification problems in this manner, but does not handle specifications like that of VDPs, which involve negation.
The works on Neural Module Networks Andreas et al. (2016) and Concept Bottleneck Models Koh et al. (2020) explore methods of embedding symbolic representations or concepts into neural network architectures. However, it is unclear whether there are methods to search for concepts (say, satisfying specifications) using these architectures.
Another related problem is solving puzzles from Raven’s Progressive Matrices Santoro et al. (2018); Zhang et al. (2019). While the puzzles are similar to ours in specification, the space of concepts is minuscule and does not require any synthesis. The work in Zhang et al. (2019) shows that simply enumerating the concepts achieves 100% accuracy on these datasets.
3 Composing Neural Learning and Symbolic Reasoning for Discriminating Scenes
Prior to solving VDPs, humans have first learned to distinguish objects (dogs, sofas, detect relationships (dog sitting on sofa), poses (woman standing), and other attributes (cat has closed eyes) by drawing from a rich visual experience accumulated from childhood. Upon first encountering a VDP puzzle, humans do not have the same rich experience to go by (they likely haven’t solved any VDPs previously). Despite this lack of prior experience, they quickly formulate a mechanism to identify a solution by composing high-level concepts that use learned lower-level concepts.
Our framework is built on this intuition and involves two similar phases. We propose a neurosymbolic approach to solve VDPs, as illustrated in Figure 2222A part of this image is taken from https://commons.wikimedia.org/wiki/File:NeuralNetwork.png which is public domain.. Phase 1 involves long-term learning using large training sets that is independent of any high-level task. Phase 2 depends on the specification of a particular task (solving a VDP), and it utilizes the concepts learned in Phase 1 to meet the higher-level specification (few-shot discrimination of scenes). More precisely, we propose:
{kind=link}
Neural Learning Algorithms for Phase 1
Learning a scene representation in terms of objects (“dog”), attributes (“dog is black”), and relationships (“dog is sitting on sofa”) — called a scene graph — is a well-studied problem in literature, and convolutional neural networks (CNNs) are effective models. In this paper we use Yolov4 Wang et al. (2021), a CNN-based object detector trained on the ImageNet and COCO datasets to predict multiple objects with bounding boxes and class labels.
Interfacing Phase 1 and Phase 2 using Scene Models
The interface between the output of the neural component and the input of the symbolic synthesis component is an important challenge. We propose a novel interface, namely First-Order Scene Models, that capture object classes, attributes, and relationships.
Symbolic Synthesis Algorithms for Phase 2
In this phase we build novel algorithms to synthesize quantified first-order logic formulas that satisfy the VDP puzzle specification and which discriminate between the finite first-order scene models for each image.
If solving VDPs were the only goal, we could train models on a large class of puzzles. Our goal instead is to focus on a different kind of solution; we want to study how to solve puzzles and tasks afresh, i.e., without access to a rich experience in solving them.
4 Synthesis of First-Order Logic Discriminators
4.1 First-Order Logic and Scene Models
We work with first-order relational logic over a signature , where is a finite set of relation symbols and is a set of unary symbols we call labels (which we use to model categories of objects). Each relation symbol is associated with an arity , .
The syntax of first-order logic formulas is given by:
We use the standard notions of models and semantics for first-order logic (see a standard logic textbook Enderton (2011)).
Given a set of images for a VDP puzzle, we build a first-order model for each image by feeding to the pretrained neural network. The model’s universe corresponds to the set of objects detected by the network. We model the class labels identified by the network as unary predicates (e.g. or ), and the identified relationships between objects as relations . The resulting First-Order Scene Models are used by the symbolic synthesizer.
4.2
First-Order Scene Logic and the Extension Property
We argue that a first-order logic over scene models (that are obtained from neural networks) should satisfy a particular robustness property. In a suitable logic, we would like any discriminator to remain a discriminator whenever additional objects or relationships are discovered by a vision model.
Suppose that we have found a discriminator for a puzzle, say, all dogs are on sofas. We would like it to remain a discriminator if new irrelevant objects and relationships are detected and added to the scene model. For example, if we add to a scene model a previously unrecognized pen then our discriminator should still work as a solution.
Standard first-order logic does not have this property. For example, in the puzzle in Figure 1, if only dogs and sofas were recognized then we could express “all dogs are on sofas” using the formula , which says that all objects other than a sofa are on a sofa. If the vision model begins to recognizes tables in the images, then the formula fails to be a discriminator (it would be false on the example images).
We define model extensions as follows:
Definition 1** (Model Extension).**
A model over extends a model over (where ) if agrees with on the interpretation of all relations in .
Thus, given (1) the imprecision of vision models, (2) that different systems will likely have different detection rates for various object classes and relationships, and (3) that the choice of visual system crucially affects the scene model and consequently the discriminators, we propose the following property for discriminators:
Definition 2** (Extension Property).**
A logic has the extension property if any discriminator for a set of models remains a discriminator for any extended models .
We formulate First-order Scene Logic (FO-SL) based on guarded logics, wherein any quantified object is always guarded by an assertion that it has a specific object label:
[TABLE]
In the grammar above, ranges over label relations, e.g. , and ranges over relation symbols (attributes and object relationships).
FO-SL can express properties of all cats in a scene, but not of all objects of any kind (a variable cannot range over cats, pens, paintings, and specks of dust). We then show the following result (see Appendix A.1 for the proof):
Theorem 1**.**
The guarded fragment has the extension property.
We thus propose the use of FO-SL as our space of possible discriminators.
4.3
Solving VDP by Synthesizing Formulas
We solve VDPs by synthesizing formulas that serve as discriminators for scene models. Let us fix a puzzle with example images and candidate images , as well as a signature that is determined by a given vision model. Let the corresponding scene models be and .
Definition 3** ( Discriminator).**
An first-order sentence is a discriminator for if there is a model such that:
(D1) For every model ,
(D2)
(D3) For every such that ,
This definition formally captures the puzzle specification: a discriminator is a formula that is true in all example images (D1) and true in exactly one candidate image (D2 and D3).
4.3.1 Learning FO Discriminators
We describe an algorithm for synthesizing FO-SL discriminators to solve a given VDP puzzle. In particular, we build an algorithm that finds conjunctive discriminators.
We tried using state-of-the-art program synthesis engines that handle the SyGuS format (Syntax-Guided Synthesis) Alur et al. (2015) . These did not scale well (see Section 5.3), so we implemented our own solution using SAT solvers.
If is the number of quantifiers in the discriminator, then we initially set to and iteratively increment it whenever we cannot find a discriminator with quantifiers. We introduce a Boolean variable for every atomic formula that can occur in the matrix, i.e., the quantifier-free part of the formula. The intention is that is true if and only if the atomic formula occurs as a conjunct in the matrix of the discriminator. We also introduce Boolean variables that determine whether the quantifiers are existential or universal, as well as variables that determine the guards (labels in FO-SL) for each quantified variable. Given a valuation for these variables, we can write a formula that evaluates the discriminator encoded by on all scene models. With extra Boolean variables that encode the choice of candidate scene model, we can formulate a constraint that reflects the specification of the puzzle and the definition of discriminator above.
We then use a SAT solver (such as Z3 de Moura and Bjørner (2008)) to determine whether the constraint is satisfiable. If the SAT solver finds a satisfying valuation, we can construct the FO-SL discriminator and the chosen candidate from the valuation. If the constraint is unsatisfiable, then we know there is no conjunctive discriminator with quantifiers.
5 Evaluation
5.1 Datasets
We create 11,600 puzzles across four datasets. We describe these briefly. We also invite the reader to browse the static website of VDPs333The datasets, code, and the website of VDPs can be found at: https://github.com/muraliadithya/vdp for a sample of puzzles across the datasets.
Natural Scenes
The Natural Scenes VDP dataset is created from 20 base real-world concept classes such as “all dogs are on sofas”. For each class, we collect positive images that satisfy the concept and negative images that do not. We create puzzles by choosing all examples from the positive set and all candidates from the negative set except for one positive image (the intended candidate). We sample 3864 puzzles randomly. We provide a description of these concepts in Table 1.
GQA VDP dataset
The GQA VDP dataset is created automatically using the GQA dataset Hudson and Manning (2019), which is a VQA dataset. It consists of real-world scenes along with scene graphs, as well as questions and answers about the images. We use questions with yes/no answers such as: Is there a fence made of wood? We create puzzles as described above (with “yes” images being the positive category) and sample 5000 random VDPs. Note that the proposition corresponding to the question, i.e. there is a fence made of wood, is hence a discriminator.
CLEVR VDP dataset.
The CLEVR domain Johnson et al. (2017) is an artificial VQA domain consisting of images with 3D shapes such as spheres, cubes, etc. The objects possess a rich combination of attributes such as shape, colour, size, and material. The CLEVR VDP dataset consists of 15 base concept classes as described in Table 2. Each concept class is a schema such as ‘ShapeX and ShapeY have the same color’, where the variables ShapeX and ShapeY denote distinct shapes. We create abstract VDPs whose unique minimal discriminator is contained in the FO-SL schema (e.g., ). We instantiate these variables with various combinations of shapes, colours, etc., and we sample 825 VDPs with unique solutions in the FO-SL conjunctive fragment. See Appendix A.2 for more details.
OddOne Puzzles dataset.
We create a dataset of discrimination puzzles that are different from VDPs. An OddOne puzzle consists of images with the objective of identifying the image that is the odd one out. We formalize this task similar to VDPs by demanding a concept that satisfies exactly three images. We create these from the CLEVR VDP dataset by choosing three example images and one non-answer candidate image from each puzzle. Finally, we only include the 1872 puzzles that have a unique minimal discriminator in FO-SL.
Note that only the CLEVR VDP and OddOne datasets have unique discriminators in conjunctive FO-SL.
5.2 Implementation
We use a pretrained model of Yolov4 Wang et al. (2021) for the Natural Scenes dataset, which outputs object labels and bounding boxes. For the CLEVR domain, we use a pretrained model from the work in Yi et al. (2018) . The model produces a set of objects with their coordinates in 3D space and other attributes like shape, color, or material. We compute first-order scene models based on the outputs automatically.
The symbolic synthesizer implements an algorithm that searches for conjunctive discriminators in FO-SL. The algorithm creates the constraints described in Section 4.3 and uses the SAT-solver Z3 de Moura and Bjørner (2008). We also implement another synthesizer that searches for discriminators in full first-order logic to perform ablation studies. See Appendix A.3 for more details about implementation.
5.3 Experiments
We report on the evaluation of our tool on the datasets and various ablation studies in terms of the research questions (RQs) below.
Experiments on Natural Scenes and GQA VDP Datasets
5.3.1 RQ1: Effectiveness
We evaluate our tool on the Natural Scenes dataset, applying the SAT-based symbolic synthesizer with a timeout. Since it is always possible to discriminate a finite set of (distinct) models with a complex (but perhaps unnatural) formula, we restrict our search to discriminators with complexity smaller than or equal to the target discriminator. We present the results in Figure 3. Our tool is effective and solves 68% of the 3864 puzzles, with an average accuracy of 71% per concept class.
Our tool finds varied discriminators with multiple quantifiers and complex nesting. For example, “Football in between two people” (kickoff position) is expressed by , which has three quantifiers with alternation. The tool also generalizes intended discriminators.
Note that the Natural Scenes VDPs do not have unique solutions since smaller discriminators may exist. For example, in the concept class of “Laid out place settings”, a particular puzzle always displayed cups in example images. Our tool picked an unintended candidate satisfying “There is a cup” rather than the intended candidate satisfying a more complex discriminator (utensil arrangements). Our tool picks an unintended candidate in 17% of solutions. We provide more examples of discriminators found in Table 3 (Appendix).
5.3.2 RQ2: Generality
How general is our framework? The GQA VDP dataset consists of automatically generated puzzles where neither the images nor the discriminators are curated. However, the pipeline fails if the vision model fails. In fact, most failures on the Natural Scenes dataset are of this kind. In our experience, although vision models are good at detecting objects, many report several bounding boxes for the same object and are not accurate. We experimented with SOTA scene graph generators (similar to the work in Zellers et al. (2018)) and found many issues.
To better study the generality of our formulation, we ablate the vision model errors and use the ground-truth scene graphs of images given in the GQA dataset to extract scene models. Our tool performs very well: it solves 81% of the puzzles (4% unintended). See the website of VDPs for examples of (un)solved puzzles.
5.3.3 RQ3: Failure Modes
The primary failure mode of the tool is failure of the vision model, as discussed above. This failure manifests as nonsensical discriminators. We leave the problem of designing frameworks that are robust despite vision model failures to future work.
We identify two other failure modes where the solver was not able to find any discriminator, namely (1) expressive power of the interface: we do not solve puzzles with discriminators like There is a bag in the bottom portion of the image, since information about the region of the image in which an object was present is not typically expressed in scene graphs. Many of the unsolved puzzles in the GQA VDP dataset belong to this failure mode; and (2) expressive power of the FO-SL fragment: consider the concept class TV is switched on in the Natural Scenes dataset, expressed as . This requires unguarded quantification and cannot be expressed in FO-SL. Another example is There is a dog that is not white, which requires negation and is not expressible in the conjunctive fragment.
5.3.4 RQ4: Ablation of Synthesis Algorithm
Our SAT-based synthesis algorithm is quite effective and finds discriminators in a few seconds. However, there are other possible synthesis engines, in particular those developed in the program synthesis literature for SyGuS problems Alur et al. (2015) . The specification of a discriminator can be encoded as a SyGuS problem, and so we perform an ablation study using CVC4Sy Reynolds et al. (2019) (winner of SyGuS competitions) to find discriminators. CVC4Sy did not scale and took at least 10 minutes for even moderately difficult puzzles, often not terminating after 30 minutes.
5.3.5 RQ5: Ablation of FO-SL
Evaluation of RQ1 shows that FO-SL is a rich logic that expresses many interesting discriminators. However, would a more expressive logic find more natural or better discriminators? We perform an ablation study on Natural Scenes VDPs by implementing a second solver for symbolic synthesis. This solver searches for discriminators in full first-order logic rather than FO-SL: the quantifiers are not guarded and the matrix need not be conjunctive. Note that FOL does not satisfy the extension property.
This solver is slower and times out for 57% of the puzzles. Among solved puzzles, solutions are sometimes more general, e.g. There is something that is within all sofas, instead of All dogs on sofas. However, we almost always obtain unnatural discriminators, e.g. There is no chair and there is some non-sofa. We therefore conclude that the guarded quantification in FO-SL is important, and full first-order logic is not suitable for finding natural discriminators. See Appendix A.8 for a detailed description of the solver as well as Table 4 in the Appendix for more examples of unnatural discriminators.
Experiments on CLEVR VDP Dataset
5.3.6 RQ4: Neural Baselines
The CLEVR VDP dataset consists of puzzles with unique discriminators by construction, and our tool performs (unsurprisingly) very well (99%). Since solutions are unique, we can ask if solving VDPs is learnable using neural models.
We first construct a baseline from an image similarity model trained using triplet loss Wang et al. (2014). To solve a VDP, we choose the candidate that maximizes the product of similarity scores with all the example images. We present the class-wise performance of this model in Figure 4. It does not perform very well and is rarely better than chance (33%). This shows that VDP solutions are not aligned well with commonly learned image features. Therefore, we evaluate another baseline based on prototypical networks Snell et al. (2017) by training on VDPs. Such networks aim to learn embeddings such that the average embedding of a class of images acts as a prototype, which can then be used to compute similarity with respect to the class. We fine-tune a ResNet18 He et al. (2016) + MLP architecture pretrained on CIFAR10 using concept classes, validated against a held-out set of classes. We then evaluate it on the unseen classes and other unseen puzzles. This model achieves a slightly better overall accuracy of 40% as shown in Figure 4, but is still not performant.
Experiments on OddOne Puzzles Dataset
5.3.7 RQ7: Adaptive Mechanisms
We evaluate the adaptability of mechanisms (without retraining) when the higher-level puzzle description is changed. Our framework is evidently highly adaptable and we can solve OddOne puzzles without retraining by simply changing the synthesis objective (the constraint).
We evaluate the adaptability of the baseline models learned for VDP on the new task by adapting the scoring function (see Appendix A.7) and find that they perform very poorly. The similarity and prototypical network baselines perform at 13% and 23% respectively, compared to a random predictor at 25%. Therefore, we conclude that the neural representations learned using the two baselines for one task do not lend themselves well to newer high-level task specifications without retraining.
6 Conclusions
The results of this paper argue that building symbolic synthesis and reasoning over outputs of a neural network lead to robust interpretable reasoning for solving puzzles such as VDP. For a future direction, the following problem formulation for VDPs seems interesting: given a VQA engine, find a property expressed in natural language that acts as a discriminator, as interpreted by the VQA engine. Solving the above would result in natural language discriminators (which would be more general than FO-SL), but the problem of searching over such discriminators seems nontrivial. We would also like to adapt the neurosymbolic approach in this paper to real-world applications that require learning interpretable logical concepts from little data, including obtaining differential diagnoses from medical images and health records, and learning behavioral rules for robots from interaction with humans and the environment.
Acknowledgments
This work is supported in part by a research grant from Amazon and a Discovery Partner’s Institute (DPI) science team seed grant.
General Information
Citations for assets:
Tools used for the pipeline are presented below (and also on the website).
- •
CLEVR dataset generator:The image generation script was modified and used for generating the CLEVR domain VDP puzzles. Original code available at: https://github.com/facebookresearch/clevr-dataset-gen. Modified code available at: https://github.com/anonymousocean/vdp-tool-chain/tree/master/clevr-generate. The original code is available under a BSD license.
- •
Natural Scenes inference engine: Object recognition in the natural scenes dataset was performed using YOLOv4. The original weights and code were used with slight modifications. Original code available at: https://github.com/pjreddie/darknet. Modified code available at: https://github.com/anonymousocean/vdp-tool-chain/tree/master/vdp/darknet. The original code is available under a MIT license.
- •
NS-VQA inference pipeline: The MaskRCNN + Attribute net model was used for inferring object attributes from the CLEVR domain puzzles. Original code available at: https://github.com/kexinyi/ns-vqa. Modified code available at: https://github.com/anonymousocean/vdp-tool-chain/tree/master/clevr-inference. The original code is available under a MIT license.
- •
Deep Ranking Similarity Baseline: The deepranking model and code was used as a baseline for our tool. Original code available at: https://github.com/USCDataScience/Image-Similarity-Deep-Ranking. Modified code available at: https://github.com/anonymousocean/vdp-tool-chain/tree/master/pt-baseline. The original code is available under an Apache v2 license.
- •
Images for Natural Scenes dataset: Since these images are taken from the internet, we can only allow access under fair use for research if users sign a permission form. Please contact us to get access.
Total amount of compute and the resources used
: We used an AWS p2.xlarge (4vCPUs, 61GB RAM, 150GB HDD, 1 NVIDIA K80 GPU) instance for running our experiments. Apart from time taken to generate the various datasets, the experiments took about 120 hours to attempt solving all 11000 puzzles.
Appendix A Appendix
A.1 Extension Property of FO-SL
Theorem**.**
The guarded fragment (i.e., FO-SL) has the extension property.
Proof**.**
Consider a set of models and a discriminator for that set. Let be a set of models that extends with respect to . Observe that is a sentence of the form , where has no quantifiers, and each is shorthand for a guarded quantifier with label . The truth of the sentence is completely determined by how evaluates for those assignments to that make all the guards true. Since each (over some ) extends over and , we have that this set of assignments is identical for each and . Thus they must agree on the truth of , and therefore is also a discriminator for .∎
A.2 CLEVR VDP Dataset
We describe the process of generating variants. Each base puzzle has a groundtruth configuration that identifies the position and material attributes for each object in the scene. To obtain a variant for a given puzzle, we applied a transformation to the groundtruth configurations of all the images in the puzzle. These transformations would yield isomorphic FO models.
Informally, an isomorphism in this our is a transformation that maps objects and relation symbols in a consistent and invertible fashion. A simple example is that of uniformly replacing cubes with spheres and the attribute red with the attribute metallic in every image. Of course, one has to ensure that such a transformation is invertible, so if one replaced red items with the corresponding green items in an image with only red and green shapes, then the resulting image would only have green shapes and we would not be able to recover the original image using any transformation. One can show easily that such isomorphic transformations on puzzles with unique solutions will yield variants with unique solutions.
Second, we swap the intended candidate image with one of the example images. We then check using the technique described in Appendix A.3 that this swapped puzzle continues to have a unique (and in fact the same) discriminator, with the solution being the example image that was swapped in for the original candidate image. These are called allowable swaps, and for a puzzle with 3 example images (as is the case with our Clevr VDP Dataset) there are upto 3 allowable swaps since the intended candidate image can be swapped with any of the training images. Such allowable swaps are computed for each base puzzle and one is then applied at random.
Finally, we randomly jitter the positions of each object in every image in the variant configuration obtained by the isomorphic transformation to obtain the final configurations. These are then rendered into images using blender.
A.3 Details of Implementation
Code for pretrained model
The code for the pretrained model provided by the authors of Yi et al. (2018) can be found at: https://github.com/kexinyi/ns-vqa
Extracting FO Models
We use yolov4 Wang et al. (2021) for the first phase on the Natural Scenes Dataset. For each image, the model provides a list of objects that are identified by class labels and bounding boxes. We then extract First-Order models from this representation by computing proxies for relationships such as left or sitting on by using the bounding boxes. We use the labels as unary predicates over the universe of objects, which then appear as guards in FO-SL.
Similarly, for the Clevr VDP Dataset we use a pretrained model from the work in Yi et al. (2018). The model returns a set of objects identified by attributes such as shape, color, or size, along with co-ordinate positions in 3D space (with respect to a fixed predefined origin and axis orientations). We then use treat the values for shape, color, etc as unary predicates (say or ) and compute spatial relationships such as or between objects using their co-ordinates. Finally, we use the labels as guards in the FO-SL fragment corresponding to this logic.
SAT-based Synthesis
The SAT-based synthesis formulation for our symbolic synthesis engine is given in the main paper. Since discriminators are represented by boolean variables, for any given discriminator it is possible to negate the corresponding valuations of the boolean variables and add it as an additional constraint to the SAT solver. This new SAT query would yield a discriminator that is different from the previous one. We used this technique to do an exhaustive search and ensure that the puzzles in the Clevr VDP dataset have unique discriminators.
A.4 Evaluation on Natural Scenes Dataset
Table 3 expands our reporting of the evaluation described in the main text. For each puzzle class, we give the English description of the intended discriminator and some examples of discriminators found in FO-SL by our tool.
A.5 Details of the Neural Baseline solver for the Clevr VDP Dataset
We detail the metric used for the baseline evaluation using image similarity.
We use a pretrained model of the similarity network based on the work in Wang et al. (2014) (code can be found at https://github.com/USCDataScience/Image-Similarity-Deep-Ranking). Given two images, this model computes a non-negative distance measure .
Given a puzzle with example images and candidate images we compute the solution (choice of candidate) in the following manner:
[TABLE]
i.e., we select the candidate whose product of distances from each of the training images is the least.
The comparison of the efficacy of finding the target candidate by our tool and this baseline is depicted in Figure 4.
A.6 Details of the Prototypical Networks-based Baseline solver for the Clevr VDP Dataset
We provide further detail about the Prototypical Networks Snell et al. (2017) based baseline.
The idea behind a prototypical network is to learn an embedding of an image such that the ‘average’ of several images belonging to a class behaves as the embedding of a prototypical member of that class. One can then use such prototypes computed from, say, a few positive and negative images to build a few-shot classifier. The classification is performed using a softmax over euclidean distances computed from the query point and the class prototypes.
We adapt this philosophy to develop a baseline for VDP. First initialise a ResNet-18 He et al. (2016) with pretrained weights from CIFAR 10. Then, we add a small MLP (linear + ReLU + linear) to the end of that network and ‘fine-tune’ the weights of the entire network on 6 concept class schemas (150 puzzles). The loss is computed as follows: given a puzzle with example images and candidate images , we consider each candidate in turn to compute the score it achieves using the prototypical embedding and select the one with the maximum score. To compute the score, we consider that all the example images are in one class (say pos), and each other candidate is in its own class (say neg1 and neg2). We then compute the softmax score over distances with each of these ‘classes’ for the candidate under consideration. The intuition, similar to the notion of discrimination, is that we compute the probability of the considered candidate belonging to the example set given that the other two candidates represent different ways of exhibiting non-membership in the example set. Formally:
[TABLE]
where is the prototype embedding computed from the example images, and is Euclidean distance.
We fine-tune with this score as the loss while validating on a held-out set of 4 schemas (100 puzzles). We then select the model that had the best validation loss and evaluate it on the entire dataset. The results are presented in Figure 4. In developing this model, we found that this architecture worked better and somewhat consistently across all the concept classes. A similar architecture with a VAE initialised by pretraining on either CLEVR or the VDP dataset itself overfit very quickly, and performed extremely well (80%) on a few concept classes while achieving 0% on most others.
A.7 Adapting Baselines for OddOne Dataset
We adapt the baselines for the CLEVR VDP dataset to the CLEVR OddOne puzzle dataset. Recall that the puzzle calls for choosing the odd one among a given set of images. Therefore, we choose the odd candidate by picking the one that maximises the distance to all other images. In the case of the image similarity baseline we use the similarity score given by the network as the inverse of distance, and in the case of the prototypical networks we use Euclidean distance computed over the learned embeddings.
A.8 Bottom-Up Solver for Full First-Order Logic
The bottom-up solver takes a set of positive- and negatively-labelled FO models and a grammar, and searches for a classifier in the grammar that partitions the models (without using SAT solvers). It iterates from simpler to more complex formulas, heuristically growing the formula towards making it a discriminator. In order to use this solver as a VDP solver, given a puzzle we create possible partitions by separating the images into the example images and one candidate image among the given candidates (positive), versus the rest of the candidates (negative). From our definition of a discriminator we know that any of the classifiers obtained thus would be discriminators, and the smallest and sensible discriminator would be the smallest sensible classifier among the possible classifiers across any partition. Therefore we extract FO models from the images in the puzzle, create partitions and use the bottom-up solver.
However, in practice if a particular partition is so malformed that the choice of candidate among the positive images is extremely incongruous with respect to the example images, then (especially for large grammars) it can take very long to exhaust the search space. Thus we run the solver for each possible choice of candidate image concurrently and return the first solution found, or wait until all runs fail to find a solution or times out.
A.9 Ablation Study on FO-SL
We provide further details of the ablation study on FO-SL. Recall that the study was performed by replacing the symbolic synthesis engine that searches for discriminators over FO-SL with another solver that searches for discriminators in full First-Order Logic by building formulas in a bottom-up manner (details of this bottom-up solver are given below). The discriminators returned by this solver need not have guarded quantifiers or conjunctions.
A complete description of the discriminators found by this solver on the Natural Scenes VDP Dataset is given in Table 4. As is evident, the symbolic synthesis picks on many discriminators that are unnatural— unguarded quantification leads to talking about “things” rather than more natural kinds of objects and disjunction leads to picking on weird coincidences that happen to tie images together (like the discriminator found on the class “All cats are on sofas” being “There is no chair and there is some non-sofa”, or “Desktop computer” being “There is no sofa and there is nothing placed on anything else”). A key observation here is that it is easy to tie almost any set of few (say 4) images with a concept that involves disjunction, and hence disjunctive concepts do not pick up on true similarity between images.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alur et al. [2015] Rajeev Alur, Rastislav Bodík, Eric Dallal, Dana Fisman, Pranav Garg, Garvit Juniwal, Hadas Kress-Gazit, P. Madhusudan, Milo M. K. Martin, Mukund Raghothaman, Shambwaditya Saha, Sanjit A. Seshia, Rishabh Singh, Armando Solar-Lezama, Emina Torlak, and Abhishek Udupa. Syntax-guided synthesis. Dependable Software Systems Engineering , 2015.
- 2Alur et al. [2018] Rajeev Alur, Rishabh Singh, Dana Fisman, and Armando Solar-Lezama. Search-based program synthesis. Commun. ACM , 61(12):84–93, November 2018.
- 3Amizadeh et al. [2020] Saeed Amizadeh, Hamid Palangi, Oleksandr Polozov, Yichen Huang, and Kazuhito Koishida. Neuro-symbolic visual reasoning: Disentangling ”visual” from ”reasoning”. ICML , 2020.
- 4Andreas et al. [2016] Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Neural module networks. CVPR , 2016.
- 5Andreas et al. [2018] Jacob Andreas, Dan Klein, and Sergey Levine. Learning with latent language. ACL , 2018.
- 6Antol et al. [2015] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. ICCV , 2015.
- 7Balog et al. [2017] Matej Balog, Alexander L. Gaunt, Marc Brockschmidt, Sebastian Nowozin, and Daniel Tarlow. Deepcoder: Learning to write programs. ICLR , 2017.
- 8Bunel et al. [2018] Rudy Bunel, Matthew J. Hausknecht, Jacob Devlin, Rishabh Singh, and Pushmeet Kohli. Leveraging grammar and reinforcement learning for neural program synthesis. ICLR , 2018.