Space Efficient Approximation to Maximum Matching Size from Uniform Edge Samples
Michael Kapralov, Slobodan Mitrovi\'c, Ashkan Norouzi-Fard, Jakab, Tardos

TL;DR
This paper presents a space-efficient algorithm that estimates the maximum matching size in a graph from uniform edge samples with a constant factor approximation, requiring only logarithmic space, and establishes sample complexity lower bounds.
Contribution
It introduces a novel peeling-based matching algorithm with recursive sampling, achieving the first sublinear sample complexity lower bound and a highly space-efficient approximation method.
Findings
Requires $m^{1-o(1)}$ samples for approximation
Uses only $O( ext{log}^2 n)$ bits of space for estimation
Provides a constant factor local computation algorithm with $O(d ext{log} n)$ exploration
Abstract
Given a source of iid samples of edges of an input graph with vertices and edges, how many samples does one need to compute a constant factor approximation to the maximum matching size in ? Moreover, is it possible to obtain such an estimate in a small amount of space? We show that, on the one hand, this problem cannot be solved using a nontrivially sublinear (in ) number of samples: samples are needed. On the other hand, a surprisingly space efficient algorithm for processing the samples exists: bits of space suffice to compute an estimate. Our main technical tool is a new peeling type algorithm for matching that we simulate using a recursive sampling process that crucially ensures that local neighborhood information from `dense' regions of the graph is provided at appropriately higher sampling rates. We show that a delicate balance…
Click any figure to enlarge with its caption.
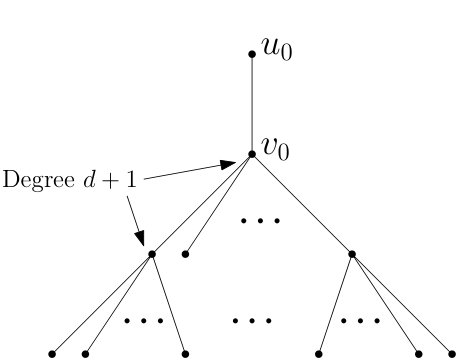 Figure 1
Figure 1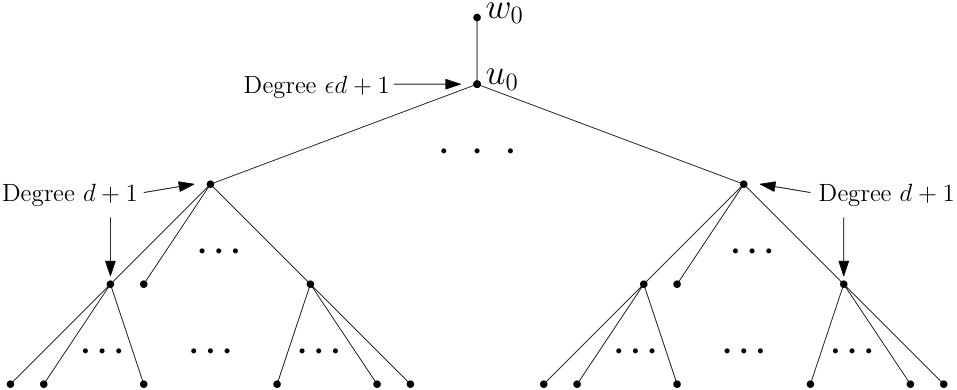 Figure 2
Figure 2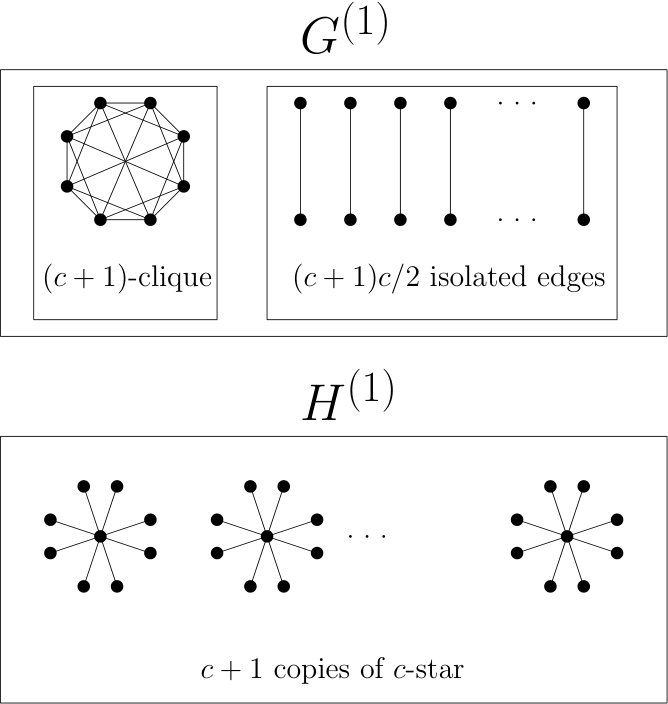 Figure 3
Figure 3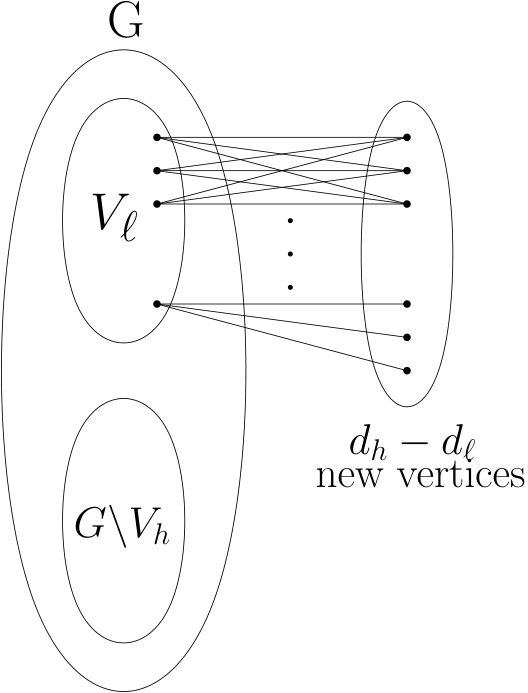 Figure 4
Figure 4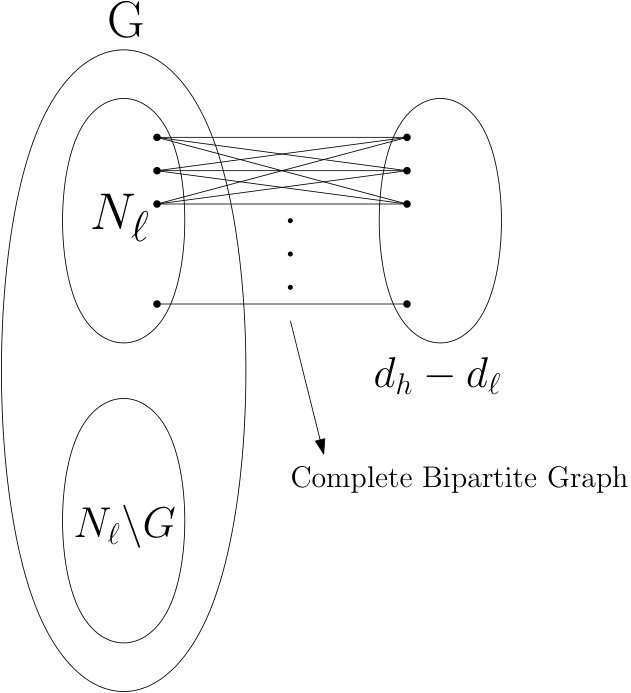 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.