TL;DR
iFixR is a novel bug report-driven program repair approach that leverages bug reports and fix patterns to generate and prioritize patches, addressing limitations of test suite-based methods.
Contribution
The paper introduces iFixR, a new repair pipeline that uses bug reports and IR-based fault localization, expanding automated repair beyond test suite reliance.
Findings
iFixR generates genuine patches for 21 out of 44 faults.
It ranks a correct patch in the top-5 for 8 out of 13 faults.
The approach does not depend on future test cases for validation.
Abstract
Issue tracking systems are commonly used in modern software development for collecting feedback from users and developers. An ultimate automation target of software maintenance is then the systematization of patch generation for user-reported bugs. Although this ambition is aligned with the momentum of automated program repair, the literature has, so far, mostly focused on generate-and-validate setups where fault localization and patch generation are driven by a well-defined test suite. On the one hand, however, the common (yet strong) assumption on the existence of relevant test cases does not hold in practice for most development settings: many bugs are reported without the available test suite being able to reveal them. On the other hand, for many projects, the number of bug reports generally outstrips the resources available to triage them. Towards increasing the adoption of patch…
Click any figure to enlarge with its caption.
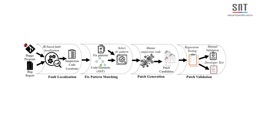 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4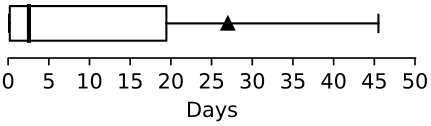 Figure 5
Figure 5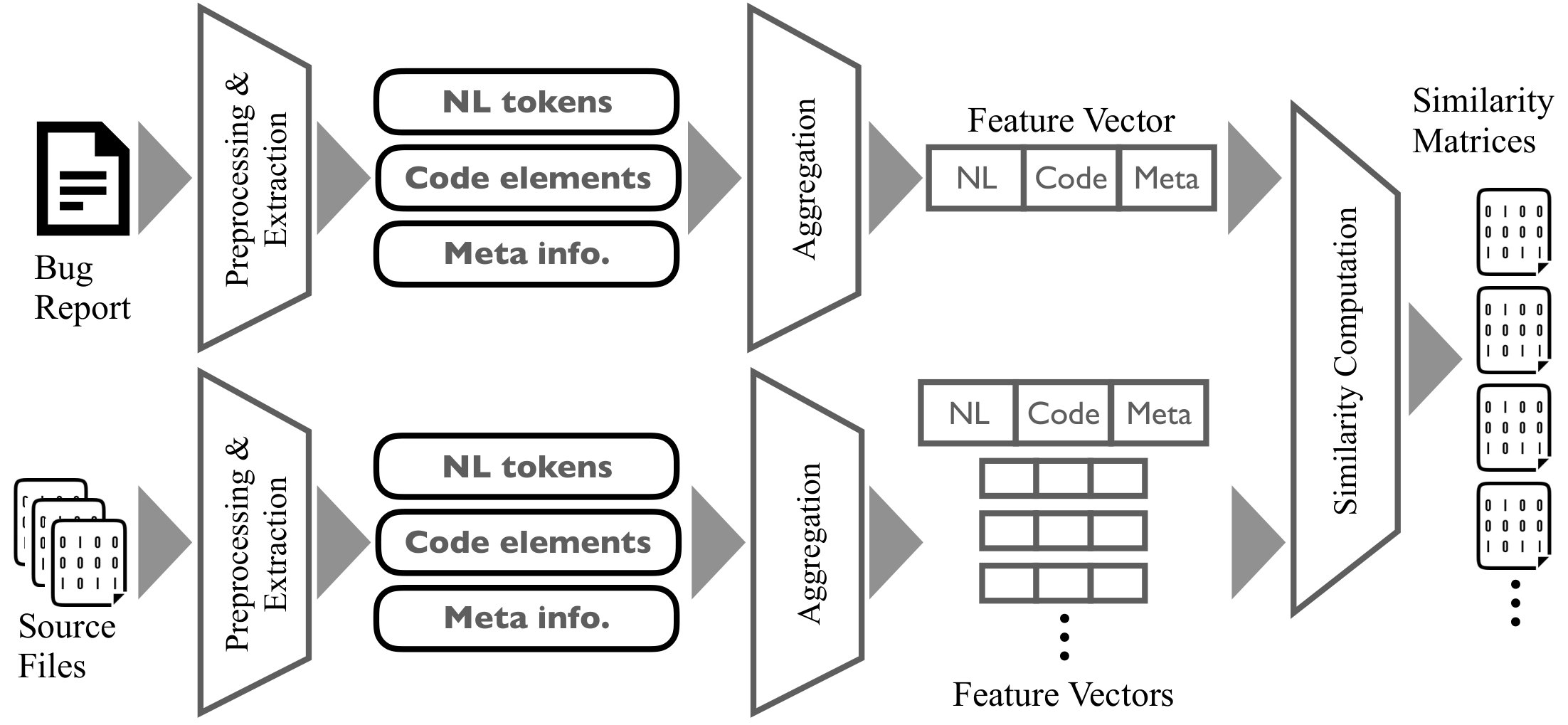 Figure 6
Figure 6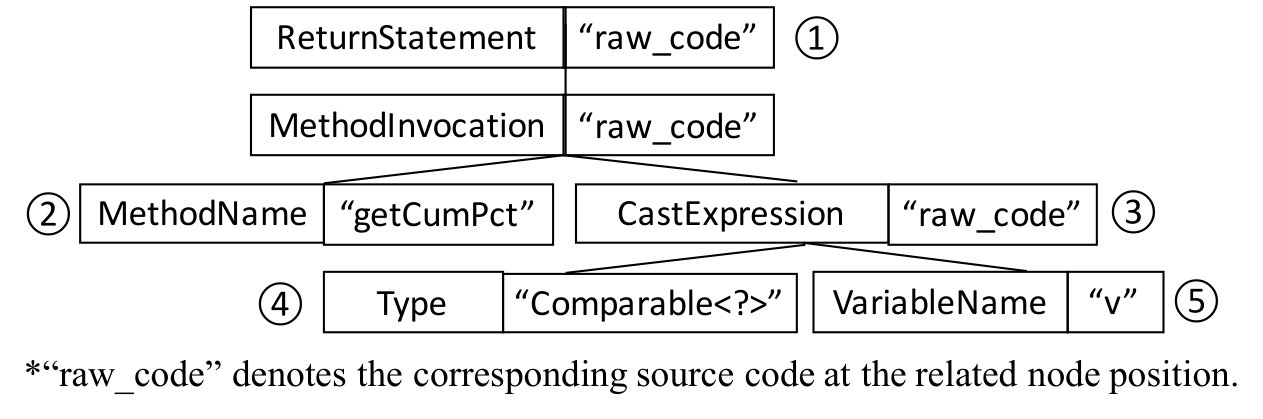 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10| Test case related commits | # bugs |
| Commit does not alter test cases | 14 |
| Commit is inserting new test case(s) and updating previous test case(s) | 62 |
| Commit is updating previous test case(s) (without inserting new test cases) | 76 |
| Commit is inserting new test case(s) (without updating previous test cases) | 243 |
| Failing test cases | # bugs |
| Failing test cases exist (and no future test cases are committed) | 14 |
| Failing test cases exist (but future test cases update the test scenarios) | 9 |
| Failing test cases exist (but they are fewer when considering future test cases) | 4 |
| Failing test cases exist (but they differ from future test cases which trigger the bug) | 3 |
| No failing test case exists (i.e., only future test cases trigger the bug) | 365 |
| Issue No. | LANG-822 |
| Summary | NumberUtils#createNumber - bad behaviour for leading ”–” |
| Description | NumberUtils#createNumber checks for a leading ”–” in the string, and returns null if found. This is documented as a work round for a bug in BigDecimal. Returning nulll is contrary to the Javadoc and the behaviour for other methods which would throw NumberFormatException. It’s not clear whether the BigDecimal problem still exists with recent versions of Java. However, if it does exist, then the check needs to be done for all invocations of BigDecimal, i.e. needs to be moved to createBigDecimal. |
| Pattern description | used by∗ | Pattern description | used by∗ |
| Insert Cast Checker | Genesis | Mutate Literal Expression | SimFix |
| Insert Null Pointer Checker | NPEFix | Mutate Method Invocation | ELIXIR |
| Insert Range Checker | SOFix | Mutate Operator | jMutRepair |
| Insert Missed Statement | HDRepair | Mutate Return Statement | SketchFix |
| Mutate Conditional Expression | ssFix | Mutate Variable | CapGen |
| Mutate Data Type | AVATAR | Move Statement(s) | PAR |
| Remove Statement(s) | FixMiner |
| (171 bugs) | Top-1 | Top-10 | Top-50 | Top-100 | Top-200 | All | |
| IRFL | 25 | 72 | 102 | 117 | 121 | 139 | |
| SBFL | GZv1 | 26 | 75 | 106 | 110 | 114 | 120 |
| GZv2 | 23 | 79 | 119 | 135 | 150 | 156 | |
| GZoltar + Ochiai (395 bugs) | Top-1 | Top-10 | Top-50 | Top-100 | Top-200 | All |
| without future tests | 5 | 10 | 17 | 17 | 19 | 20 |
| with future tests | 45 | 140 | 198 | 214 | 239 | 263 |
| Lang | Math | Total | |
| IRFL Top-1 | 1/4 | 3/4 | 4/8 |
| SBFL Top-1 | 1/4 | 6/8 | 7/12 |
| IRFL Top-5 | 3/6 | 7/14 | 10/20 |
| SBFL Top-5 | 2/7 | 11/17 | 13/24 |
| IRFL Top-10 | 4/9 | 9/17 | 13/26 |
| SBFL Top-10 | 4/11 | 16/27 | 20/38 |
| IRFL Top-20 | 7/12 | 9/18 | 16/30 |
| SBFL Top-20 | 4/11 | 18/30 | 22/41 |
| IRFL Top-50 | 7/15 | 10/22 | 17/37 |
| SBFL Top-50 | 4/13 | 19/34 | 23/47 |
| IRFL Top-100 | 8/18 | 10/23 | 18/41 |
| SBFL Top-100 | 5/14 | 19/36 | 24/50 |
| IRFL All | 11/19 | 10/25 | 21/44 |
| SBFL All | 5/14 | 19/36 | 24/50 |
| Localization Error | Pattern Prioritization | Lack of Fix ingredients | |
| w/ IRFL | 6 | 1 | 16 |
| w/ SBFL | 15 | 1 | 10 |
| Recommendation rank | Top-1 | Top-5 | Top-10 | Top-20 | All |
| without patch re-prioritization | 3/3 | 4/5 | 6/10 | 6/10 | 13/27 |
| with patch re-prioritization | 3/4 | 8/13 | 9/14 | 10/15 | 13/27 |
| APR tool | Lang∗ | Math∗ | Total∗ |
| jGenProg (Martinez and Monperrus, 2016) | 0/0 | 5/18 | 5/18 |
| jKali (Martinez and Monperrus, 2016) | 0/0 | 1/14 | 1/14 |
| jMutRepair (Martinez and Monperrus, 2016) | 0/1 | 2/11 | 2/12 |
| HDRepair (Le et al., 2016b) | 2/6 | 4/7 | 6/13 |
| Nopol (Xuan et al., 2017) | 3/7 | 1/21 | 4/28 |
| ACS (Xiong et al., 2017) | 3/4 | 12/16 | 15/20 |
| ELIXIR (Saha et al., 2017) | 8/12 | 12/19 | 20/31 |
| JAID (Chen et al., 2017) | 1/8 | 1/8 | 2/16 |
| ssFix (Xin and Reiss, 2017b) | 5/12 | 10/26 | 15/38 |
| CapGen (Wen et al., 2018) | 5/5 | 12/16 | 17/21 |
| SketchFix (Hua et al., 2018) | 3/4 | 7/8 | 10/12 |
| FixMiner (Koyuncu et al., 2018) | 2/3 | 12/14 | 14/17 |
| LSRepair (Liu et al., 2018a) | 8/14 | 7/14 | 15/28 |
| SimFix (Jiang et al., 2018) | 9/13 | 14/26 | 23/39 |
| kPAR (Liu et al., 2019b) | 1/8 | 7/18 | 8/26 |
| AVATAR (Liu et al., 2019c) | 5/11 | 6/13 | 11/24 |
| 11/19 | 10/25 | 21/44 | |
| 6/11 | 7/16 | 13/27 | |
| 3/7 | 5/6 | 8/13 |
| Change action | #bugs∗ | Impacted statement(s) | #bugs∗ | Granularity | #bugs∗ |
| Update | 5/7 | Single-statement | 8/12 | Statement | 1/2 |
| Insert | 3/5 | Multiple-statement | 0/1 | Expression | 7/11 |
| Delete | 0/1 |
| Patch Type | Defect4J Bug ID | Issue ID | Root Cause | Priority |
| G | L-6 | LANG-857 | String index out of bounds exception | Minor |
| G | L-24 | LANG-664 | Wrong behavior due missing condition | Major |
| G | L-57 | LANG-304 | Null pointer exception | Major |
| G | M-15 | MATH-904 | Double precision floating point format error | Major |
| G | M-34 | MATH-779 | Missing ”read only access” to internal list | Major |
| G | M-35 | MATH-776 | Range check | Major |
| G | M-57 | MATH-546 | Wrong variable type truncates double value | Minor |
| G | M-75 | MATH-329 | Method signature mismatch | Minor |
| P | L-13 | LANG-788 | Serialization error in primitive types | Major |
| P | L-21 | LANG-677 | Wrong Date Format in comparison | Major |
| P | L-45 | LANG-419 | Range check | Minor |
| P | L-58 | LANG-300 | Number formatting error | Major |
| P | M-2 | MATH-1021 | Integer overflow | Major |
| Proj. | Unique Bug Reports | w/ Patch Attached | Average Comments | w/ Stack Traces | w/ Hints | w/ Code Blocks |
| Lang | 62 | 11 | 4.53 | 4 | 62 | 31 |
| Math | 100 | 23 | 5.15 | 5 | 92 | 51 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
iFixR: Bug Report driven Program Repair
Anil Koyuncu1, Kui Liu1,∗, Tegawendé F. Bissyandé1, Dongsun Kim1,2, Martin Monperrus3, Jacques Klein1, and Yves Le Traon1
1University of Luxembourg, Luxembourg, {anil.koyuncu, kui.liu,tegawende.bissyande,jacques.klein, yves.letraon}@uni.lu
2Furiosa.ai, Republic of Korea, [email protected]
3KTH Royal Institute of Technology, Sweden, [email protected]
(2019)
Abstract.
Issue tracking systems are commonly used in modern software development for collecting feedback from users and developers. An ultimate automation target of software maintenance is then the systematization of patch generation for user-reported bugs. Although this ambition is aligned with the momentum of automated program repair, the literature has, so far, mostly focused on generate-and-validate setups where fault localization and patch generation are driven by a well-defined test suite. On the one hand, however, the common (yet strong) assumption on the existence of relevant test cases does not hold in practice for most development settings: many bugs are reported without the available test suite being able to reveal them. On the other hand, for many projects, the number of bug reports generally outstrips the resources available to triage them. Towards increasing the adoption of patch generation tools by practitioners, we investigate a new repair pipeline, iFixR, driven by bug reports: (1) bug reports are fed to an IR-based fault localizer; (2) patches are generated from fix patterns and validated via regression testing; (3) a prioritized list of generated patches is proposed to developers. We evaluate iFixR on the Defects4J dataset, which we enriched (i.e., faults are linked to bug reports) and carefully-reorganized (i.e., the timeline of test-cases is naturally split). iFixR generates genuine/plausible patches for 21/44 Defects4J faults with its IR-based fault localizer. iFixR accurately places a genuine/plausible patch among its top-5 recommendation for 8/13 of these faults (without using future test cases in generation-and-validation).
Information retrieval, fault localization, automatic patch generation.
∗Corresponding author, the same contribution as the first author.
††journalyear: 2019††copyright: acmcopyright††conference: Proceedings of the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering; August 26–30, 2019; Tallinn, Estonia††booktitle: Proceedings of the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE ’19), August 26–30, 2019, Tallinn, Estonia††price: 15.00††doi: 10.1145/3338906.3338935††isbn: 978-1-4503-5572-8/19/08††ccs: Software and its engineering Software verification and validation††ccs: Software and its engineering Software testing and debugging
1. Introduction
Automated program repair (APR) has gained incredible momentum in the last decade. Since the seminal work by Weimer et al. (Weimer et al*., 2009) who relied on genetic programming to evolve program variants until one variant is found to satisfy the functional constraints of a test suite, the community has been interested in test-based techniques to repair programs without specifications. Thus, various approaches (Nguyen et al., 2013; Weimer et al., 2009; Le Goues et al., 2012b; Kim et al., 2013; Coker and Hafiz, 2013; Ke et al., 2015; Mechtaev et al., 2015; Long and Rinard, 2015; Le et al., 2016a; Long and Rinard, 2016b; Chen et al., 2017; Le et al., 2017; Long et al., 2017; Xuan et al., 2017; Xiong et al., 2017; Jiang et al., 2018; Wen et al., 2018; Hua et al., 2018; Liu et al., 2019c; Liu et al., 2019b, a) have been proposed in the literature aiming at reducing manual debugging efforts through automatically generating patches. Beyond fixing syntactic errors, i.e., cases where the code violates some programming language specifications (Gupta et al., 2017), the current challenges lie in fixing semantic bugs, i.e., cases where implementation of program behavior deviates from developer’s intention (Mechtaev et al., 2018; Just et al.*, 2018).
Ten years ago, the work of Weimer et al. (Weimer et al*., 2009) was explicitly motivated by the fact that, despite significant advances in specification mining (e.g., (Le Goues and Weimer, 2009)), formal specifications are rarely available. Thus, test suites represented an affordable approximation to program specifications. Unfortunately, the assumption that test cases are readily available still does not hold in practice (Kochhar et al., 2013; Beller et al., 2015; Petrić et al., 2018). Therefore, while current test-based APR approaches would be suitable in a test-driven development setting (Beck, 2003), their adoption by practitioners faces a simple reality: developers majoritarily (1) write few tests (Kochhar et al., 2013), (2) write tests after the source code (Beller et al., 2015), and (3) write tests to validate that bugs are indeed fixed and will not reoccur (Juzgado et al.*, 2006).
Although APR bots (Urli et al*., 2018) can come in handy in a continuous integration environment, the reality is that bug reports remain the main source of the stream of bugs that developers struggle to handle daily (Anvik et al., 2006). Bugs are indeed reported in natural language, where users tentatively describe the execution scenario that was being carried out and the unexpected outcome (e.g., crash stack traces). Such bug reports constitute an essential artifact within a software development cycle and can become an overwhelming concern for maintainers. For example, as early as in 2005, a triager of the Mozilla project was reported in (Anvik et al.*, 2006, page 363) to have commented that:
“Everyday, almost 300 bugs appear that need triaging. This is far too much for only the Mozilla programmers to handle.”
However, very few studies (Liu et al*., 2013; Bissyandé, 2015) have undertaken to automate patch generation based on bug reports. To the best of our knowledge, Liu et al. (Liu et al., 2013) proposed the most advanced study in this direction. Unfortunately, their R2Fix approach carries several caveats: as illustrated in Figure 1, it focuses on perfect bug reports (Liu et al., 2013, page 283) (1) which explicitly include localization information, (2) where the symptom (e.g., buffer overrun) is explicitly indicated by the reporter, and (3) which are about one of the following three simple bug types: Buffer overflow, Null Pointer dereference or memory leak. R2Fix runs a straightforward classification to identify the bug category and uses a match and transform engine (e.g., Coccinelle (Padioleau et al.*, 2008)) to generate patches. As the authors admitted, their target space represents <1% of bug reports in their dataset. Furthermore, it should be noted that, given the limited scope of the changes implemented in its fix patterns, R2Fix does not need to run tests for verifying that the generated patches do not break any functionality.
This paper. We propose to investigate the feasibility of a program repair system driven by bug reports, thus we replace classical spectrum-based fault localization with Information Retrieval (IR)-based fault localization. Eventually, we propose iFixR, a new program repair workflow which considers a practical repair setup by imitating the fundamental steps of manual debugging. iFixR works under the following constraint:
When a bug report is submitted to the issue tracking system, a relevant test case reproducing the bug may not be readily available.
Therefore, iFixR is leveraged in this study to assess to what extent an APR pipeline is feasible under the practical constraint of limited test suites. iFixR uses bug reports written in natural language as the main input. Eventually, we make the following contributions:
- •
We present the architecture of a program repair system adapted to the constraints of maintainers dealing with user-reported bugs. In particular, iFixR replaces classical spectrum-based fault localization with Information Retrieval (IR)-based fault localization.
- •
We propose a strategy to prioritize patches for recommendation to developers. Indeed, given that we assume only the presence of regression test cases to validate patch candidates, many of these patches may fail on the future test cases that are relevant to the reported bugs. We order patches to present correct patches first.
- •
We assess and discuss the performance of iFixR on the Defects4J benchmark to compare with the state-of-the-art APR tools. To that end, we provide a refined Defects4J benchmark for APR targeting bug reports. Bugs are carefully linked with the corresponding bug reports, and for each bug we are able to dissociate future test cases that were introduced after the relevant fixes.
Overall, experimental results show that there are promising research directions to further investigate towards the integration of automatic patch generation in actual software development cycles. In particular, our findings suggest that IR-based fault localization errors lead less to overfitting patches than spectrum-based fault localization errors. Furthermore, iFixR offers provides comparable results to most state-of-the-art APR tools, although it is run under the constraint that post-fix knowledge (i.e., future test cases) is not available. Finally, iFixR’s prioritization strategy tends to place more correct/plausible patches on top of the recommendation list.
2. Motivation
We motivate our work by revisiting two essential steps in APR:
- (1)
During fault localization, relevant program entities are identified as suspicious locations that must be changed. Commonly, state-of-the-art APR tools leverage spectrum-based fault localization (SBFL) (Nguyen et al*., 2013; Weimer et al., 2009; Le Goues et al., 2012; Ke et al., 2015; Mechtaev et al., 2015; Long and Rinard, 2015; Le et al., 2016a; Chen et al., 2017; Le et al., 2017; Long et al., 2017; Xuan et al., 2017; Xiong et al., 2017; Liu et al.*, 2019d), which uses execution coverage information of passing and failing test cases to predict buggy statements. We dissect the construction of the Defects4J dataset to highlight the practical challenges of fault localization for user-reported bugs. 2. (2)
Once a patch candidate is generated, the patch validation step ensures that it is actually relevant for repairing the program. Currently, widespread test-based APR techniques use test suites as the repair oracle. This however is challenged by the incompleteness of test suites, and may further not be inline with developer requirements/expectations in the repair process.
2.1. Fault Localization Challenges
Defects4J is a manual curated dataset widely used in the APR literature (Xin and Reiss, 2017b; Chen et al*., 2017; Saha et al., 2017; Xiong et al., 2018; Wen et al., 2018; Hua et al.*, 2018). Since Defects4J was not initially built for APR, the real order of precedence between the bug report, the patch and the test case is being overlooked by the dataset users. Indeed, Defects4J offers a user-friendly way of checking out buggy versions of programs with all relevant test cases for readily benchmarking test-based systems. We propose to carefully examine the actual bug fix commits associated with Defects4J bugs and study how the test suite is evolved. Table 1 provides detailed information.
Overall, for 96%(=381/395) bugs, the relevant test cases are actually future data with respect to the bug discovery process. This finding suggests that, in practice, even the fault localization may be challenged in the case of user-reported bugs, given the lack of relevant test cases. The statistics listed in Table 2 indeed shows that if future test cases are dropped, no test case is failing when executing buggy program versions for 365 (i.e., 92%) bugs.
In the APR literature, fault localization is generally performed using the GZoltar (Campos et al*., 2012) testing framework and a SBFL formula (Wong et al., 2016) (e.g., Ochiai (Abreu et al.*, 2007)). To support our discussions, we attempt to perform fault localization without the future test cases to evaluate the performance gap. Experimental results (see details forward in Table 6 of Section 5) expectedly reveal that the majority of the Defects4J bugs (i.e., 375/395) cannot be localized by SBFL at the time the bug is reported by users.
It is necessary to investigate alternate fault localization approaches that build on bug report information since relevant test cases are often unavailable when users report bugs.
2.2. Patch Validation in Practice
The repair community has started to reflect on the acceptability (Kim et al*., 2013; Monperrus, 2014) and correctness (Smith et al., 2015; Xiong et al., 2018) of the patches generated by APR tools. Notably, various studies (Smith et al., 2015; Qi et al., 2015; Yang et al., 2017; Böhme et al., 2017; Le et al., 2018) have raised concerns about overfitting patches: a typical APR tool that uses a test suite as the correctness criterion can produce a patched program that actually overfits the test-suite (i.e., the patch makes the program pass all test cases but does not actually repair it). Recently, new research directions (Yu et al., 2017; Xin and Reiss, 2017a) are being explored in the automation of test case generation for APR to overcome the overfitting issue. Nevertheless, so far they have had minimal positive impact due to the oracle problem (Yu et al.*, 2018) in automatic test generation.
At the same time, the software industry takes a more systematic approach for patch validation by developers. For instance, in the open-source community, the Linux development project has integrated a patch generation engine to automate collateral evolutions that are validated by maintainers (Padioleau et al*., 2008; Koyuncu et al., 2017). In proprietary settings, Facebook has recently reported on their Getafix (Scott et al.*, 2019) tool, which automatically suggests fixes to their developers. Similarly, Ubisoft developed Clever (Nayrolles and Hamou-Lhadj, 2018) to detect risky commits at commit-time using patterns of programming mistakes from the code history.
Patch recommendation for validation by developers is acceptable in the software development communities. It may thus be worthwhile to focus on tractable techniques for recommending patches in the road to fully automated program repair.
3. The iFixR Approach
Figure 2 overviews the workflow of the proposed iFixR approach. Given a defective program, we consider the following issues:
- (1)
Where is the bug? We take as input the bug report in natural language submitted by the program user. We rely on the information in this report to localize the bug positions. 2. (2)
How should we change the code? We apply fix patterns that are recurrently found in real-world bug fixes. Fix patterns are selected following the structure of the abstract syntax tree representing the code entity of the identified suspicious code. 3. (3)
Which patches are valid? We make no assumptions on the availability of positive test cases (Weimer et al*.*, 2009) that encode functionality requirements at the time the bug is discovered. Nevertheless, we leverage existing test cases to ensure, at least, that the patch does not regress the program. 4. (4)
Which patches do we recommend first? In the absence of a complete test suite, we cannot guarantee that all patches that pass regression tests will fix the bug. We rely on heuristics to re-prioritize the validated patches in order to increase the probability of placing a correct patch on top of the list.
3.1. Input: Bug reports
Issue tracking systems (e.g., Jira) are widely used by software development communities in the open source and commercial realms. Although they can be used by developers to keep track of the bugs that they encounter and the features to be implemented, issue tracking systems allow for user participation as a communication channel for collecting feedback on software executions in production.
Table 3 illustrates a typical bug report when a user of the LANG library code has encountered an issue while using the NumberUtils API. A description of erroneous behavior is provided. Occasionally, the user may include in the bug description some information on how to reproduce the bug. Oftentimes, users simply insert code snippets or dump the execution stack traces.
In this study, among our dataset of 162 bug reports, we note that only 27 (i.e., 17%) are reported by users who are also developers111We rely on email addresses of committers and issue reporters to intersect users and developers contributing to the projects. 15 (i.e., 9%) bugs are reported and again fixed by the same project contributors. These percentages suggest that, for the majority of cases, the bug reports are indeed genuinely submitted by users of the software who require project developers’ attention.
Given the buggy program version and a bug report, iFixR must unfold the workflow for precisely identifying (at the statement level) the buggy code locations. We remind the reader that, in this step, future test cases cannot be relied upon. We consider that if such test cases could have triggered the bug, a continuous integration system would have helped developers deal with the bug before the software is shipped towards users.
3.2. Fault Localization w/o Test Cases
To identify buggy code locations within the source code of a program, we resort to Information Retrieval (IR)-based fault localization (IRFL) (Parnin and Orso, 2011; Wang et al*., 2015). The general objective is to leverage potential similarity between the terms used in a bug report and the source code to identify relevant buggy code locations. The literature includes a large body of work on IRFL (Zhou et al., 2012; Wen et al., 2016; Youm et al., 2017; Wong et al., 2014; Saha et al., 2013; Wang and Lo, 2014; Lukins et al.*, 2010) where researchers systematically extract tokens from a given bug report to formulate a query to be matched in a search space of documents formed by the collections of source code files and indexed through tokens extracted from source code. IRFL approaches then rank the documents based on a probability of relevance (often measured as a similarity score). Highly ranked files are predicted to be the ones that are likely to contain the buggy code.
Despite recurring interest in the literature, with numerous approaches continuously claiming new performance improvements over the state-of-the-art, we are not aware of any adoption in program repair research or practice. We postulate that one of the reasons is that IRFL techniques have so far focused on file-level localization, which is too coarse-grained (in comparison to spectrum-based fault localization output). Recently, Locus (Wen et al*., 2016) and BLIA (Youm et al.*, 2017) are state-of-the-art techniques which narrow down localization, respectively to the code change or the method level. Nevertheless, to the best of our knowledge, no IRFL technique has been proposed in the literature for statement-level localization.
In this work, we develop an algorithm to rank suspicious statements based on the output (i.e., files) of a state-of-the-art IRFL tool, thus yielding a fine-grained IR-based fault localizer which will then be readily integrated into a concrete patch generation pipeline.
3.2.1. Ranking Suspicious Files
We leverage an existing IRFL tool. Given that expensive extractions of tokens from a large corpus of bug reports is often necessary to tune IRFL tools (Lee et al*., 2018), we selected a tool for which the authors provide datasets and pre-processed data. We use the D&C (Koyuncu et al.*, 2019) as the specific implementation of file-level IRFL available online (dAN, 2019) , which is a machine learning-based IRFL tool using a similarity matrix of 70-dimension feature vectors (7 features from bug reports and 10 features from source code files): D&C uses multiple classifier models that are trained each for specific groups of bug reports. Given a bug report, the different predictions of the different classifiers are merged to yield a single list of suspicious code files. Our execution of D&C (Line 2 in Algorithm 1) is tractable given that we only need to preprocess those bug reports that we must localize. Trained classifiers are already available. We ensure that no data leakage is induced (i.e., the classifiers are not trained with bug reports that we want to localize in this work).
3.2.2. Ranking Suspicious Statements
Patch generation requires fine-grained information on code entities that must be changed. For iFixR, we propose to produce a standard output, as for spectrum-based fault localization, to facilitate integration and reuse of state-of-the-art patch generation techniques. To start, we build on the conclusions on a recent large-scale study (Liu et al*., 2018c) of bug fixes to limit the search space of suspicious locations to the statements that are more error-prone. After investigating in detail the abstract syntax tree (AST)-based code differences of over 16 000 real-world patches from Java projects, Liu et al. (Liu et al.*, 2018c) reported that the following specific AST statement nodes were significantly more prone to be faulty than others: IfStatements, ExpressionStatements, FieldDeclarations, ReturnStatements and VariableDeclarationStatements. Lines 7–17 in Algorithm 1 detail the process to produce a ranked list of suspicious statements.
Algorithm 1 describes the process of our fault localization approach used in iFixR. Top files are selected among the returned list of suspicious files of the IRFL along with their computed suspiciousness scores. Then each file is parsed to retain only the relevant error-prone statements from which textual tokens are extracted. The summary and descriptions of the bug report are also analyzed (lexically) to collect all its tokens. Due to the specific nature of stack traces and other code elements which may appear in the bug report, we use regular expressions to detect stack traces and code elements to improve the tokenization process, which is based on punctuations, camel case splitting (e.g., findNumber splits into find, number) as well as snake case splitting (e.g., find_number splits into find, number). Stop word removal222Stop words are from the NTLK framework :https://www.nltk.org/ is then applied before performing stemming (using the PorterStemmer (Karaa and Gribâa, 2013)) on all tokens to create homogeneity with the term’s root (i.e., by conflating variants of the same term). Each bag of tokens (for the bug report, and for each statement) is then eventually used to build a feature vector. We use cosine similarity among the vectors to rank the file statements that are relevant to the bug report.
Given that we considered files, the statements of each having their own similarity score with respect to the bug report, we weight these scores with the suspiciousness score of the associated file. Eventually, we sort the statements using the weighted scores and produce a ranked list of code locations (i.e., statements in files) to be recommended as candidate fault locations.
3.3. Fix Pattern-based Patch Generation
A common, and reliable, strategy in automatic program repair is to generate concrete patches based on fix patterns (Kim et al*., 2013) (also referred to as fix templates (Liu and Zhong, 2018) or program transformation schemas (Hua et al., 2018)). Several APR systems (Kim et al., 2013; Saha et al., 2017; Durieux et al., 2017; Liu and Zhong, 2018; Hua et al., 2018; Koyuncu et al., 2018; Martinez and Monperrus, 2018; Liu et al., 2019c; Liu et al., 2019b, 2018b) in the literature implement this strategy by using diverse sets of fix patterns obtained either via manual generation or automatic mining of bug fix datasets. In this work, we consider the pioneer PAR system by Kim et al. (Kim et al., 2013). Concretely, we build on kPAR (Liu et al.*, 2019b), an open-source Java implementation of PAR in which we included a diverse set of fix patterns collected from the literature. Table 4 provides an enumeration of fix patterns used in this work. For more implementation details, we refer the reader to our replication package. All tools and data are released as open source to the community to foster further research into these directions. As illustrated in Figure 3, a fix pattern encodes the recipe of change actions that should be applied to mutate a code element.
For a given reported bug, once our fault localizer yields its list of suspicious statements, iFixR iteratively attempts to select fix patterns for each statement. The selection of fix patterns is conducted in a naïve way based on the context information of each suspicious statement (i.e., all nodes in its abstract syntax tree, AST). Specifically, iFixR parses the code and traverses each node of the suspicious statement AST from its first child node to its last leaf node in a breadth-first strategy (i.e, left-to-right and top-to-bottom). If a node matches the context a fix pattern (i.e., same AST node types), the fix pattern will be applied to generate patch candidates by mutating the matched code entity following the recipe in the fix pattern. Whether the node matches a fix pattern or not, iFixR keeps traversing its children nodes and searches fix patterns for them to generate patch candidates successively. This process is iteratively performed until leaf nodes are encountered.
Consider the example of bug Math-75 illustrated in Figure 4. iFixR parses the buggy statement (i.e., statement at line 302 in the file Frequency.java) into an AST as illustrated by Figure 5. First, iFixR matches a fix pattern that can mutate the expression in the return statement with other expression(s) returning data of type double. It further selects fix patterns for the direct child node (i.e., method invocation: getCumPct((Comparable<?> v))) of the return statement. This method invocation can be matched against fix patterns with two contexts: method name and parameter(s). With the breadth-first strategy, iFixR assigns a fix pattern, calling another method with the same parameters (cf. PAR (Kim et al*.*, 2013, page 804)), to mutate the method name, and then selects fix patterns to mutate the parameter. Furthermore, iFixR will match fix patterns for the type and variable of the cast expression respectively and successively.
3.4. Patch Validation with Regression Testing
For every reported bug, fault localization followed by pattern matching and code mutation will yield a set of patch candidates. In a typical test-based APR system, these patch candidates must let the program pass all test cases (including some positive test cases (Weimer et al*.*, 2009), which encode the actual functional requirements relevant to the bug). Thus, the patch candidates set is actively pruned to remove all patches that do not meet these requirements. In our work, in accordance with our investigation findings that such test cases may not be available at the time the bug is reported (cf. Section 2), we assume that iFixR cannot reason about future test cases to select patch candidates.
Instead, we rely only on past test cases, which were available in the code base, when the bug is reported. Such test cases are leveraged to perform regression testing (Yoo and Harman, 2012), which will ensure that, at least, the selected patches do not obstruct the behavior of the existing, unchanged part of the software, which is already explicitly encoded by developers in their current test suite.
3.5. Output: Patch Recommendation List
Eventually, iFixR produces a ranked recommendation list of patch suggestions for developers. Until now, the order of patches is influenced mainly by two steps in the workflow:
- (1)
localization: our statement-level IRFL yields a ranked list of statements to modify in priority. 2. (2)
pattern matching: the AST node of the buggy code entity is broken down into its children and iteratively navigated in a breadth-first manner to successively produce candidate patches.
Eventually, the produced list of patches has an order, which carries the biases of fault localization (Liu et al*.*, 2019b), and is noised by the pre-set breadth-first strategy for matching fix patterns. We thus design an ordering process with a function333The domain of the function is a power set , and the co-domain () is a -dimensional vector space (Kolmogorov and Fomin, 1999) where is the maximum number of recommended patches, and denotes the set of all generated patches., , as follows:
[TABLE]
where are three heuristics-based prioritization functions used in iFixR. takes a set of patches validated via regression testing (cf. Section 3.4) and produces an ordered sequence of patches (). We propose the following heuristics to re-prioritize the patch candidates:
- (1)
[Minimal changes]: we favor patches that minimize the differences between the patched program and the buggy program. To that end, patches are ordered following their AST edit script sizes. Formally, we define where , and holds . Here, is a function that counts the number of deleted and inserted AST nodes by the change actions of . 2. (2)
[Fault localization suspiciousness]: when two patch candidates have equal edit script sizes, the tie is broken by using the suspiciousness scores (of the associated statements) yielded during IR-based fault localization. Thus, when , re-orders the two patch candidates. We define such that holds , where
is the result of and returns a suspicious score of the statement that a given patch changes. 3. (3)
[Affected code elements]: after a manual analysis of fix patterns and the performance of associated APR in the literature, we empirically found that some change actions are irrelevant to bug fixing. Thus, for the corresponding pre-defined patterns, iFixR systematically under-prioritizes their generated patches against any other patches, although among themselves the ranking obtained so far (through and ) is preserved for those under-prioritized patches. These are patches generated by (i) mutating a literal expression, (ii) mutating a variable into a method invocation or a final static variable, or (iii) inserting a method invocation without parameter. This prioritization, is defined by , which returns a sequence of top ordered patches (). To define this prioritization function, we assign natural numbers to each patch generation types (i.e., (i), (ii), and (iii), respectively) and () everything else, which strictly hold . This prioritization function takes the result of and returns another sequence that holds . is defined as and determines how a patch has been generated as defined above. From the ordered sequence, the function returns the leftmost (i.e., top) patches as a result.
4. Experimental Setup
We now provide details on the experiments that we carry out to assess the iFixR patch generation pipeline for user-reported bugs. Notably, we discuss the dataset and benchmark, some implementation details before enumerating the research questions.
4.1. Dataset & Benchmark
To evaluate iFixR we propose to rely on the Defects4J (Just et al*., 2014) dataset which is widely used as a benchmark in the Java APR literature. Nevertheless, given that Defects4J does not provide direct links to the bug reports that are associated with the benchmark bugs, we must undertake a fairly accurate bug linking task (Thomas et al.*, 2013). Furthermore, to realistically evaluate iFixR, we must reorganize the dataset test suites to accurately simulate the context at the time the bug report is submitted by users.
4.1.1. Bug linking
To identify the bug report describing a given bug in the Defects4J dataset we focus on recovering the links between the bug fix commits and bug reports from the issue tracking system. Unfortunately, projects Joda-Time, JFreeChart and Closure have migrated their source code repositories and issue tracking systems into GitHub without a proper reassignment of bug report identifiers. Therefore, for these projects, bug IDs referred to in the commit logs are ambiguous (for some bugs this may match with the GitHub issue tracking numbering, while in others, it refers to the original issue tracker). To avoid introducing noise in our validation data, we simply drop these projects. For the remaining projects (Lang and Math), we leverage the bug linking strategies implemented in the Jira issue tracking software. We use a similar approach to Fischer et al. (Fischer et al*., 2003) and Thomas et al. (Thomas et al.*, 2013) to link to commits to corresponding bug reports. Concretely, we crawled the bug reports related to each project and assessed the links with a two-step search strategy: (i) we check commit logs to identify bug report IDs and associate the corresponding changes as bug fix changes; then (ii) we check for bug reports that are indeed considered as such (i.e., tagged as ”BUG”) and are further marked as resolved (i.e., with tags ”RESOLVED” or ”FIXED”), and completed (i.e., with status ”CLOSED”).
Eventually, our evaluation dataset includes 156 faults (i.e., Defects4J bugs). Actually, for the considered projects, Defects4J enumerates 171 bugs associated with 162 bug reports: 15 bugs are indeed left out because either (1) the corresponding bug reports are not in the desired status in the bug tracking system, which may lead to noisy data, or (2) there is ambiguity in the buggy program version (e.g., some fixed files appear to be missing in the repository at the time of bug reporting).
4.1.2. Test suite reorganization
We ensure that the benchmark separates past test cases (i.e., regression test cases) from future test cases (i.e., test cases that encode functional requirements specified after the bug is reported). This timeline split is necessary to simulate the snapshot of the repository at the time the bug is reported. As highlighted in Section 2, for over 90% cases of bugs in the Defects4J benchmark, the test cases relevant to the defective behavior was actually provided along the bug fixing patches. We have thus manually split the commits to identify test cases that should be considered as future test cases for each bug report.
4.2. Implementation Choices
During implementation, we have made the following parameter choices in the iFixR workflow:
- •
IR fault localization considers the top 50 (i.e., in Algorithm 1) suspicious files for each bug report, in order to search for buggy code locations.
- •
For patch recommendation experiments, we limit the search space to the top 20 suspected buggy statements yielded by the fine-grained IR-based fault localization.
- •
For comparison experiments, we implement spectrum-based fault localization using the GZoltar testing framework with the Ochiai ranking strategy. Unless otherwise indicated, GZoltar version 0.1.1 is used (as it is widely adopted in the literature, by Astor (Martinez and Monperrus, 2016), ACS (Xiong et al*., 2017), ssFix (Xin and Reiss, 2017b) and CapGen (Wen et al.*, 2018) among others).
4.3. Research Questions
The assessment objective is to assess the feasibility of automating the generation of patches for user-reported bugs, while investigating the foreseen bottlenecks as well as the research directions that the community must embrace to realize this long-standing endeavor. To that end, we focus on the following research questions associated with the different steps in the iFixR workflow.
- •
RQ1 [Fault localization] : To what extent does IR-based fault localization provide reliable results for an APR scenario? In particular, we investigate the performance differences when comparing our fine-grained IRFL implementation against the classical spectrum-based localization.
- •
RQ2 [Overfitting] : To what extent does IR-based fault localization point to locations that are less subject to overfitting? In particular, we study the impact on the overfitting problem that incomplete test suites generally carry.
- •
RQ3 [Patch ordering] : What is the effectiveness of iFixR’s patch ordering strategy? In particular, we investigate the overall workflow of iFixR, by re-simulating the real-world cases of software maintenance cycle when a bug is reported: future test cases are not available for patch validation.
5. Assessment Results
In this section, we present the results of the investigations for the previously-enumerated research questions.
5.1. RQ1: [Fault Localization]
Fault localization being the first step in program repair, we evaluate the performance of the IR-based fault localization developed within iFixR. As recently thoroughly studied by Liu et al. (Liu et al*.*, 2019b), an APR tool should not be expected to fix a bug that current fault localization systems fail to localize. Nevertheless, with iFixR, we must demonstrate that our fine-grained IRFL offers comparable performance with SBFL tools used in the APR literature.
Table 5 provides performance measurements on the localization of bugs. SBFL is performed based on two different versions of the GZoltar testing framework, but always based on the Ochiai ranking metric. Finally, because fault localization tools output a ranked list of suspicious statements, results are provided in terms of whether the correct location is placed under the top-k suspected statements. In this work, following the practice in the literature (LUCIA et al*., 2012; Liu et al.*, 2019b), we consider that a bug is localized if any buggy statement is localized.
Overall, the results show that our IRFL implementation is strictly comparable to the common implementation of spectrum-based fault localization when applied on the Defects4J bug dataset. Note that the comparison is conducted for 171 bugs of Math and Lang, given that these are the projects for which the bug linking can be reliably performed for applying the IRFL. Although performance results are similar, we remind the reader that SBFL is applied by considering future test cases. To highlight a practical interest of IRFL, we compute for each bug localizable in the top-10, the elapsed time between the bug report date and the date the relevant test case is submitted for this bug. Based on the distribution shown in Figure 6, on mean average, IRFL could reduce this time by 26 days.
Finally, to stress the importance of future test cases for spectrum-based fault localization, we consider all Defects4J bugs and compute localization performance with and without future test cases.
Results listed in Table 6 confirms that in most bug cases, the localization is impossible: Only 10 bugs (out of 395) can be localized among the top-10 suspicious statements of SBFL at the time the bug is reported. In comparison, our IRFL locates 72 bugs under the same conditions of having no relevant test cases to trigger the bugs.
Fine-grained IR-based fault localization in iFixR is as accurate as Spectrum-based fault localization in localizing Defects4J bugs. Additionally, it does not have the constraint of requiring test cases that may not be available when the bug is reported.
5.2. RQ2: [Overfitting]
Patch generation attempts to mutate suspected buggy code with suitable fix patterns. Aside from having adequate patterns or not (which is out of the scope of our study), a common challenge of APR lies in the effective selection of buggy statements. In typical test-based APR, test cases drive the selection of these statements. The incompleteness of test suites is however currently suspected to often lead to overfitting of generated patches (Yang et al*.*, 2017).
We perform patch generation experiments to investigate the impact of localization bias. We compare our IRFL implementation against commonly-used SBFL implementations in the literature of test-based APR. We recall that the patch validation step in these experiments makes no assumptions about future test cases (i.e., all test cases are leveraged as in classical APR pipeline). For each bug, depending on the rank of the buggy statements in the suspicious statements yielded the fault localization system (either IRFL or SBFL), the patch generation can produce more or less relevant patches. Table 7 details the repair performance in relation to the position of buggy statements in the output of fault localization. Results are provided in terms of numbers of plausible and correct (Qi et al*.*, 2015) patches that can be found by considering top- statements returned by the fault localizer.
Overall, we find that IRFL and SBFL localization information lead to similar repair performance in terms of the number of fixed bugs plausibly/correctly. Actually IRFL-supported APR outperforms SBFL-supported APR on the Lang project bugs and vice-versa for Math project bugs: overall, 6 bugs that are fixed using IRFL output, cannot be fixed using SBFL output (although assuming the availability of the bug triggering test cases to run the SBFL tool).
We investigate the cases of plausible patches in both localization scenarios to characterize the reasons why these patches appear to only be overfitting the test suites. Table 8 details the overfitting reasons for the two scenarios.
- (1)
Among the plausible patches that are generated based on IRFL identified code locations and that are not found to be correct, 6 are found to be caused by fault localization errors: these bugs are plausibly fixed by mutating irrelevantly-suspicious statements that are placed before the actual buggy statements in the fault localization output list. This phenomenon has been recently investigated in the literature as the problem of fault localization bias (Liu et al*.*, 2019b). Nevertheless, we note that patches generated based on SBFL identified code locations suffer more of fault localization bias: 15 of the 26 (= 5024) plausible patches are concerned by this issue. 2. (2)
Pattern prioritization failures may also lead to plausible patches: while a correct patch could have been generated using a specific pattern at a lower node in the AST, another pattern (leading to an only plausible patch) was first found to be matching the statement during the iterative search of matching nodes (cf. Section 3.3). 3. (3)
Finally, we note that both configurations yield plausible patches due to the lack of suitable patterns or due to a failed search for the adequate donor code (i.e., fix ingredient (Liu et al*.*, 2018a)).
Experiments with the Defects4J dataset suggest that code locations provided by IR-based fault localization lead less to overfitted patches than the code locations suggested by Spectrum-based fault localization: cf. ”Localization error” column in Table 8.
5.3. RQ3: [Patch Ordering]
While the previous experiment focused on patch generation, our final experiment assesses the complete pipeline of iFixR as it was imagined for meeting the constraints that developers can face in practice: future test cases, i.e., those which encode the functionality requirements that are not met by the buggy programs, may not be available at the time the bug is reported. We thus discard the future test cases of the Defects4J dataset and generate patches that must be recommended to developers. The evaluation protocol thus consists in assessing to what extent correct/plausible patches are placed in the top of the recommendation list.
5.3.1. Overall performance
Table 9 details the performance of the patch recommendation by iFixR: we present the number of bugs for which a correct/plausible patch is generated and presented among the top- of the list of recommended patches. In the absence of future test cases to drive the patch validation process, we use heuristics (cf. Section 4.2) to re-prioritize the patch candidates towards ensuring that patches which are recommended first will eventually be correct (or at least plausible when relevant test cases are implemented). We present results both for the case where we do not re-prioritize and the case where we re-prioritize.
Recall that, given that the re-organized benchmark separately includes the future test cases, we can leverage them to systematize the assessment of patch plausibility. The correctness (also referred to as correctness (Qi et al*.*, 2015)) of patches, however, is still decided manually by comparing against the actual bug fix provided by developers and available in the benchmark. Overall, we note that iFixR performance is promising as it manages, for 13 bugs, to present a plausible patch among its top-5 recommended patches per bug. Among those plausible patches, 8 are eventually found to be correct.
5.3.2. Comparison with the state-of-the-art test-based APR systems
To objectively position the performance of iFixR (which does not require future test cases to localize bugs, generate patches and present a sorted recommendation list of patches), we count the number of bugs for which iFixR can propose a correct/plausible patch. We consider three scenarios with iFixR:
- (1)
[] - developers will be provided with only top 5 recommended patches which have been validated only with regression tests: in this case, iFixR outperforms about half of the state-of-the-art in terms of numbers bugs fixed with both plausible or correct patches. 2. (2)
[] - developers are presented with all (i.e., not only top-5) generated patches validated with regression tests: in this case, only four (out of sixteen) state-of-the-art APR techniques outperform iFixR. 3. (3)
[] - developers are presented with all generated patches which have been validated with augmented test suites (i.e., optimistically with future test cases): with this configuration, iFixR outperforms all state-of-the-art, except SimFix (Jiang et al*.*, 2018) which uses sophisticated techniques to improve the fault localization accuracy and search for fix ingredients. It should be noted that in this case, our prioritization strategy is not applied to the generated patches. represents the reference performance for our experiment which assesses the prioritization.
Table 10 provides the comparison matrix. Information on state-of-the-art results are excerpted from their respective publications.
iFixR* offers a reasonable performance in patch recommendation when we consider the number of Defects4J bugs that are successfully patched among the top-5 (in a scenario where we assume not having relevant test cases to validate the patch candidates). Performance results are even comparable to many state-of-the-art test-based APR tools in the literature.*
5.3.3. Properties of iFixR’s patches
In Table 11, we characterize the correct and plausible patches recommended by . Overall, update and insert changes have been successful; most patches affect a single statement, and impact precisely an expression entity within a statement.
5.3.4. Diversity of iFixR’s fixed bugs
Finally, in Table 12 we dissect the nature of the bugs for which is able to recommend a correct or a plausible patch. Priority information about the bug report is collected from the issue tracking systems, while the root cause is inferred by analyzing the bug reports and fixes.
Overall, we note that 9 out of the 13 bugs have been marked as Major issues. 12 different bug types (i.e., root causes) are addressed. In contrast, R2Fix (Liu et al*.*, 2013) only focused on 3 simple bug types.
6. Discussion
This study presents the conclusions of our investigation into the feasibility of generating patches automatically from bug reports. We set strong constraints on the absence of test cases, which are used in test-based APR to approximate what the program is actually supposed to do and when the repair is completed (Weimer et al*., 2009). Our experiments on the widely-used Defects4J bugs eventually show that patch generation without bug-triggering test cases is promising.*
Manually looking at the details of failures and success in generating patches with iFixR, several insights can be drawn:
Test cases can be buggy:* During manual analysis of results, we noted that iFixR actually fails to generate correct patches for three bugs (namely, Math-5, Math-59 and Math-65) because even the test cases were buggy. Figure 7 illustrates the example of bug Math-5 where its patch also updated the relevant test case. This example supports our endeavor, given that users would find and report bugs for which the appropriate test cases were never properly written.*
Bug reports deserve more interest:* With iFixR, we have shown that bug reports could be handled automatically for a variety of bugs. This is an opportunity for issue trackers to add a recommendation layer to the bug triaging process by integrating patch generation techniques. There are, however, several directions to further investigation, among which: (1) help users write proper bug reports; and (2) re-investigate IRFL techniques at a finer-grained level that is suitable for APR. *
Prioritization techniques must be investigated:* In the absence of complete test suites for validating every single patch candidate, a recommendation system must ensure that patches presented first to the developers are the most likely to be plausible and even correct. There are thus two directions of research that are promising: (1) ensure that fix patterns are properly prioritized to generate good patches and be able to early-stop for not exploding the search space; and (2) ensure that candidate patches are effectively re-prioritized. These investigations must start with a thorough dissection of plausible patches for a deep understanding of plausibility factors.*
More sophisticated approaches to triaging and selecting fix ingredients are necessary:* In its current form, iFixR implements a naïve approach to patch generation, ensuring that the performance is tractable. However, the literature already includes novel APR techniques that implement strategies for selecting donor code and filters patterns. Integrating such techniques into iFixR may lead to performance improvement.*
More comprehensive benchmarks are needed:* Due to bug linking challenges, our experiments were only performed on half of the Defects4J benchmark. To drive strong research in patch generation for user-reported bugs, the community must build larger and reliable benchmarks, potentially even linking several artifacts of continuous integration (i.e, build logs, past execution traces, etc.). In the future, we plan to investigate the dataset of Bugs.jar (Saha et al., 2018)**.*
Automatic test generation techniques could be used as a supplement:* Our study tries to cope radically with the incompleteness of test suites. In the future, however, we could investigate the use of automatic test generation techniques to supplement the regression test cases during patch validation.*
7. Threats to Validity
Threats to external validity:* The bug reports used in this study may be of low quality (i.e., wrong links for corresponding bugs). We reduced this threat by focusing only on bugs from the Lang and Math projects, which kept a single issue tracking system. We also manually verified the links between the bug reports and the Defects4J bugs. Table 13 characterizes the bug reports of our dataset following the criteria enumerated by Zimmermann et al. (Zimmermann et al., 2010)** in their study of “what makes a good bug report”. Notably, as illustrated by the distribution of comments in Figure 8, we note that the bug reports have been actively discussed before being resolved. This suggests that they are not trivial cases (cf. (Hooimeijer and Weimer, 2007) on measuring bug report significance).*
Another threat to external validity relates to the diversity of the fix patterns used in this study. iFixR currently may not implement a reasonable number of relevant fix patterns. We minimize this threat by surveying the literature and considering patterns from several pattern-based APR.
Threats to internal validity:* Our implementation of fine-grained IRFL carries some threats: during the search of buggy statements, we considered top-50 suspicious buggy files from the file-level IRFL tool, to limit the search space. Different threshold values may lead to different results. We also considered only 5 statement types as more bug-prone. This second threat is minimized by the empirical evidence provided by Liu et al. (Liu et al., 2018c)**.*
Additionally, another internal threat is in our patch generation steps: iFixR only searches for donor code from the local code files, which contain the buggy statement. The adequate fix ingredient may however be located elsewhere.
Threats to construct validity:* In this study, we assumed that patch construction and test case creation are two separated tasks for developers. This may not be the case in practice. The threat is however mitigated given that, in any case, we have shown that the test cases are often unavailable when the bug is reported.*
8. Related Work
Fault Localization.* As stated in a recent study (Liu et al., 2019b), fault localization is a critical task affecting the effectiveness of automated program repair. Several techniques have been proposed (Parnin and Orso, 2011; Wang et al., 2015; Wong et al., 2016)** and they use different information such as spectrum (Abreu et al., 2009a), text (Wen et al., 2016), slice (Mao et al., 2014), and statistics (Liblit et al., 2005). The first two types of techniques are widely studies in the community. SBFL techniques (Abreu et al., 2009b; Jones and Harrold, 2005)** are widely adopted in APR pipelines since they identify bug positions at a fine-grained level (i.e., statements). However, they have limitations on localizing buggy locations since it highly relies on the test suite (Liu et al., 2019b). Information retrieval based fault localization (IRFL) (Lee et al., 2018) leverages textual information in a bug report. It is mainly used to help developers narrow down suspected buggy files in the absence of relevant test cases. For the purpose of our study, we have proposed an algorithm for further localizing the faulty code entities at the statement level.*
Patch Generation.* Patch generation is another key process of APR pipeline, which is, in other words, a task searching for another shape of a program (i.e., a patch) in the space of all possible programs (Le Goues et al., 2012a; Long and Rinard, 2016a). To improve repair performance, many APR systems have been explored to address the search space problem by using different information and approaches: stochastic mutation (Weimer et al., 2009; Le Goues et al., 2012b), synthesis (Long and Rinard, 2015; Xuan et al., 2017; Xiong et al., 2017), pattern (Kim et al., 2013; Le et al., 2016b; Saha et al., 2017; Long et al., 2017; Durieux et al., 2017; Le et al., 2017; Liu and Zhong, 2018; Hua et al., 2018; Jiang et al., 2018; Liu et al., 2019c), contract (Wei et al., 2010; Chen et al., 2017), symbolic execution (Nguyen et al., 2013), learning (Long and Rinard, 2016b; Gupta et al., 2017; Rolim et al., 2017; Soto and Le Goues, 2018; Bhatia et al., 2018; White et al., 2019), and donor code searching (Mechtaev et al., 2015; Ke et al., 2015). In this paper, patch generation is implemented with fix patterns presented in the literature since it may make the generated patches more robust (Schulte et al., 2014).*
Patch Validation.* The ultimate goal of APR systems is to automatically generate a correct patch that can actually resolve the program defects rather than satisfying minimal functional constraints. At the beginning, patch correctness is evaluated by passing all test cases (Weimer et al., 2009; Kim et al., 2013; Le et al., 2016b). However, these patches could be overfitting (Qi et al., 2015; Le et al., 2018)** and even worse than the bug (Smith et al., 2015). Since then, APR systems are evaluated with the precision of generating correct patches (Xiong et al., 2017; Wen et al., 2018; Jiang et al., 2018; Liu et al., 2019c). Recently, researchers explore automated frameworks that can identify patch correctness for APR systems automatically (Xiong et al., 2018; Le et al., 2019)**. In this paper, our approach validates generated patches with regression test suites since fail-inducing test cases are readily available for most of bugs as described in Section 2.
9. Conclusion
In this study, we have investigated the feasibility of automating patch generation from bug reports. To that end, we implemented iFixR, an APR pipeline variant adapted to the constraints of test cases unavailability when users report bugs. The proposed system revisits the fundamental steps, notably fault localization, patch generation and patch validation, which are all tightly-dependent to the positive test cases (Weimer et al., 2009)* in a test-based APR system.*
Without making any assumptions on the availability of test cases, we demonstrate, after re-organizing the Defects4J benchmark, that iFixR can generate and recommend priority correct (and more plausible) patches for a diverse set of user-reported bugs. The repair performance of iFixR is even found to be comparable to that of the majority of test-based APR systems on the Defects4J dataset.
We open source iFixR’s code and release all data of this study to facilitate replication and encourage further research in this direction which is promising for practical adoption in the software development community:
https://github.com/SerVal-DTF/iFixR**
Acknowledgements.
This work is supported by the Fonds National de la Recherche (FNR), Luxembourg, through RECOMMEND 15/IS/10449467 and FIXPATTERN C15/IS/9964569. *
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2d AN (2019) 2019. D&C. https://github.com/d-and-c/d-and-c .
- 3Abreu et al . (2007) Rui Abreu, Arjan JC Van Gemund, and Peter Zoeteweij. 2007. On the accuracy of spectrum-based fault localization. In Proceedings of TAICPART-MUTATION . IEEE, 89–98.
- 4Abreu et al . (2009 b) Rui Abreu, Peter Zoeteweij, Rob Golsteijn, and Arjan JC Van Gemund. 2009 b. A practical evaluation of spectrum-based fault localization. JSS 82, 11 (2009), 1780–1792.
- 5Abreu et al . (2009 a) Rui Abreu, Peter Zoeteweij, and Arjan JC Van Gemund. 2009 a. Spectrum-based multiple fault localization. In Proceedings of the 24th ASE . IEEE, 88–99.
- 6Anvik et al . (2006) John Anvik, Lyndon Hiew, and Gail C Murphy. 2006. Who should fix this bug?. In Proceedings of the 28th ICSE . ACM, 361–370.
- 7Beck (2003) Kent Beck. 2003. Test-driven development: by example . Addison-Wesley Professional.
- 8Beller et al . (2015) Moritz Beller, Georgios Gousios, Annibale Panichella, and Andy Zaidman. 2015. When, how, and why developers (do not) test in their ID Es. In Proceedings of the 10th FSE . ACM, 179–190.
