TL;DR
This paper introduces a pose-based domain adaptation method for multi-person part segmentation that leverages synthetic data and real skeletons to reduce the need for manual labeling, achieving competitive results.
Contribution
The novel approach uses skeleton representations to bridge synthetic and real domains, enabling effective training without human-annotated labels.
Findings
Achieves comparable performance to state-of-the-art methods without human labels.
Outperforms supervised methods when real part labels are available.
Demonstrates generalization to novel keypoints detection.
Abstract
Supervised deep learning with pixel-wise training labels has great successes on multi-person part segmentation. However, data labeling at pixel-level is very expensive. To solve the problem, people have been exploring to use synthetic data to avoid the data labeling. Although it is easy to generate labels for synthetic data, the results are much worse compared to those using real data and manual labeling. The degradation of the performance is mainly due to the domain gap, i.e., the discrepancy of the pixel value statistics between real and synthetic data. In this paper, we observe that real and synthetic humans both have a skeleton (pose) representation. We found that the skeletons can effectively bridge the synthetic and real domains during the training. Our proposed approach takes advantage of the rich and realistic variations of the real data and the easily obtainable labels of the…
Click any figure to enlarge with its caption.
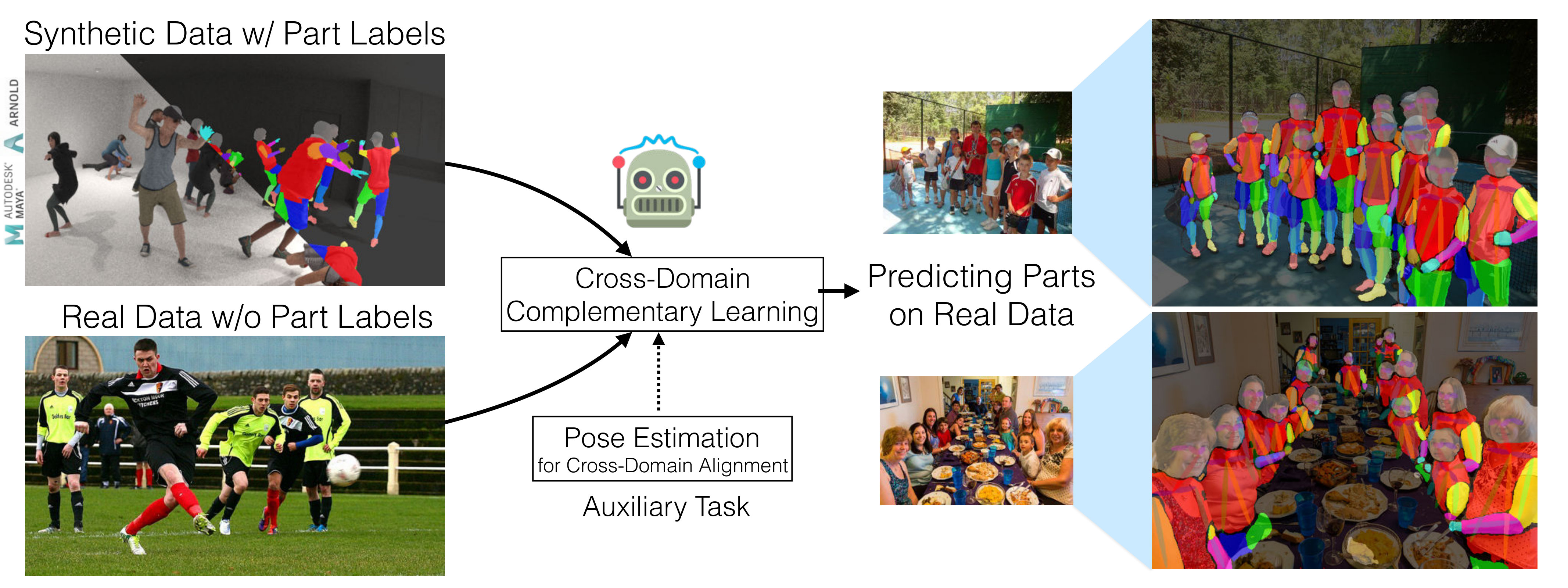 Figure 1
Figure 1 Figure 10
Figure 10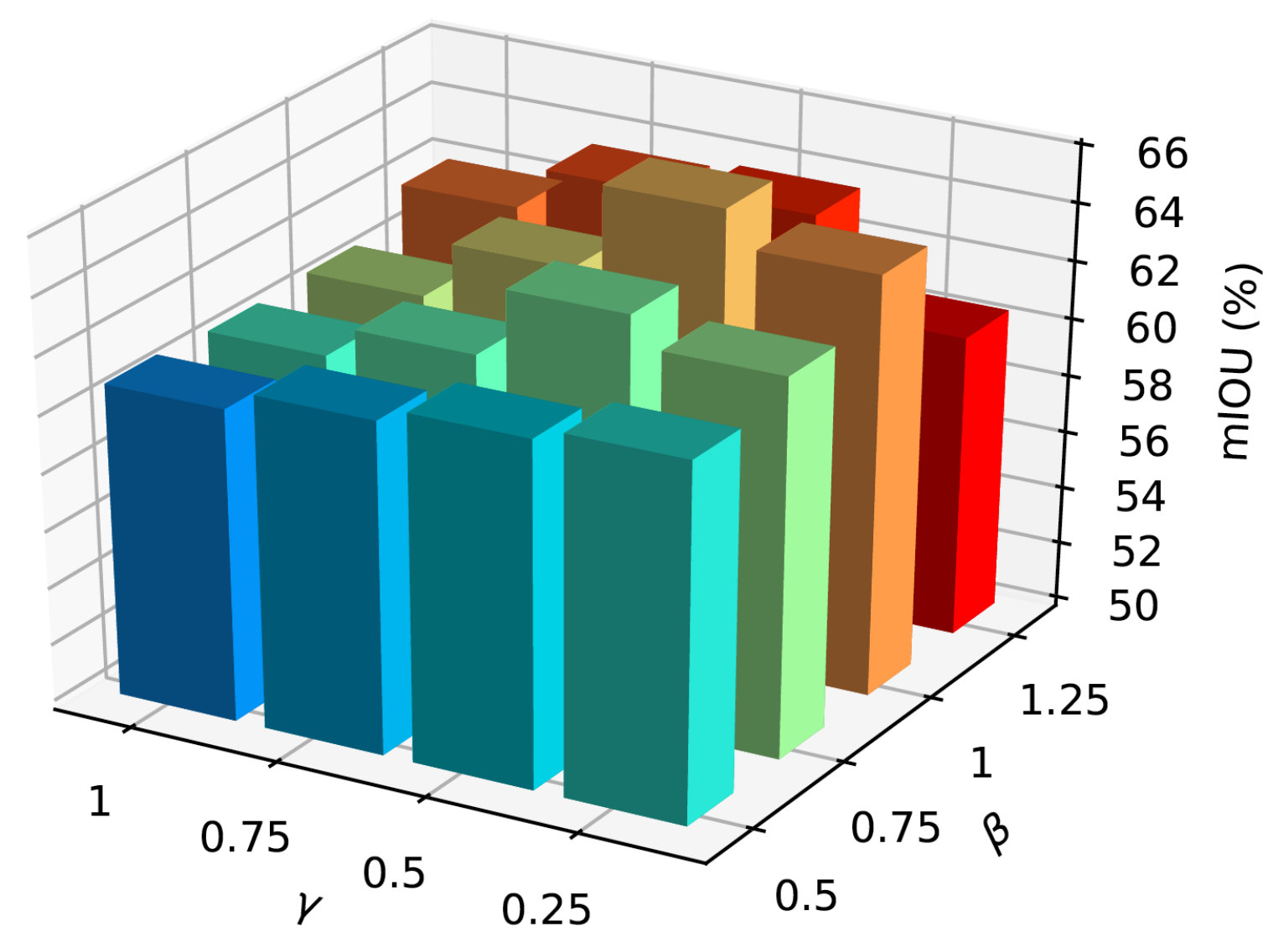 Figure 11
Figure 11 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12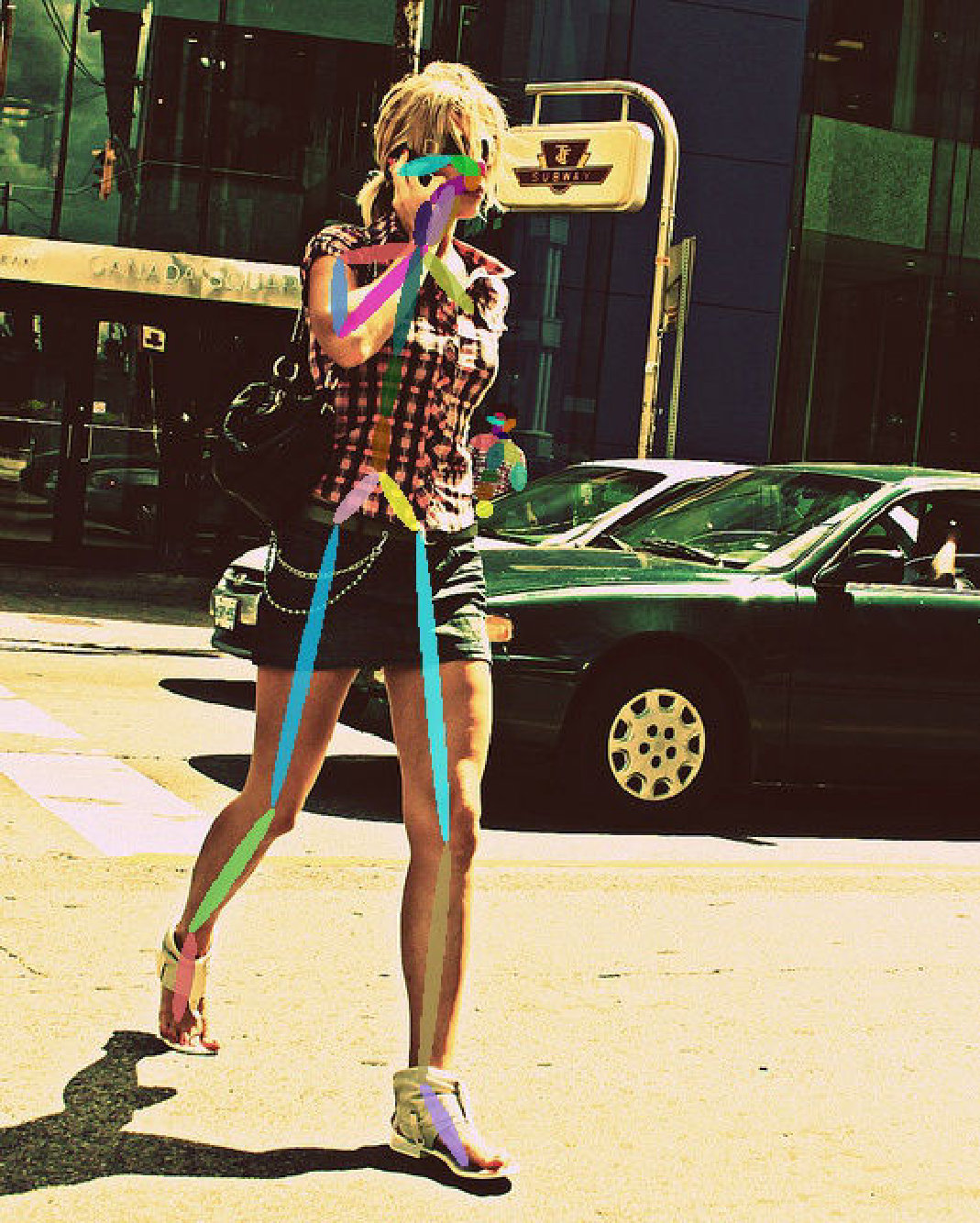 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12 Figure 12
Figure 12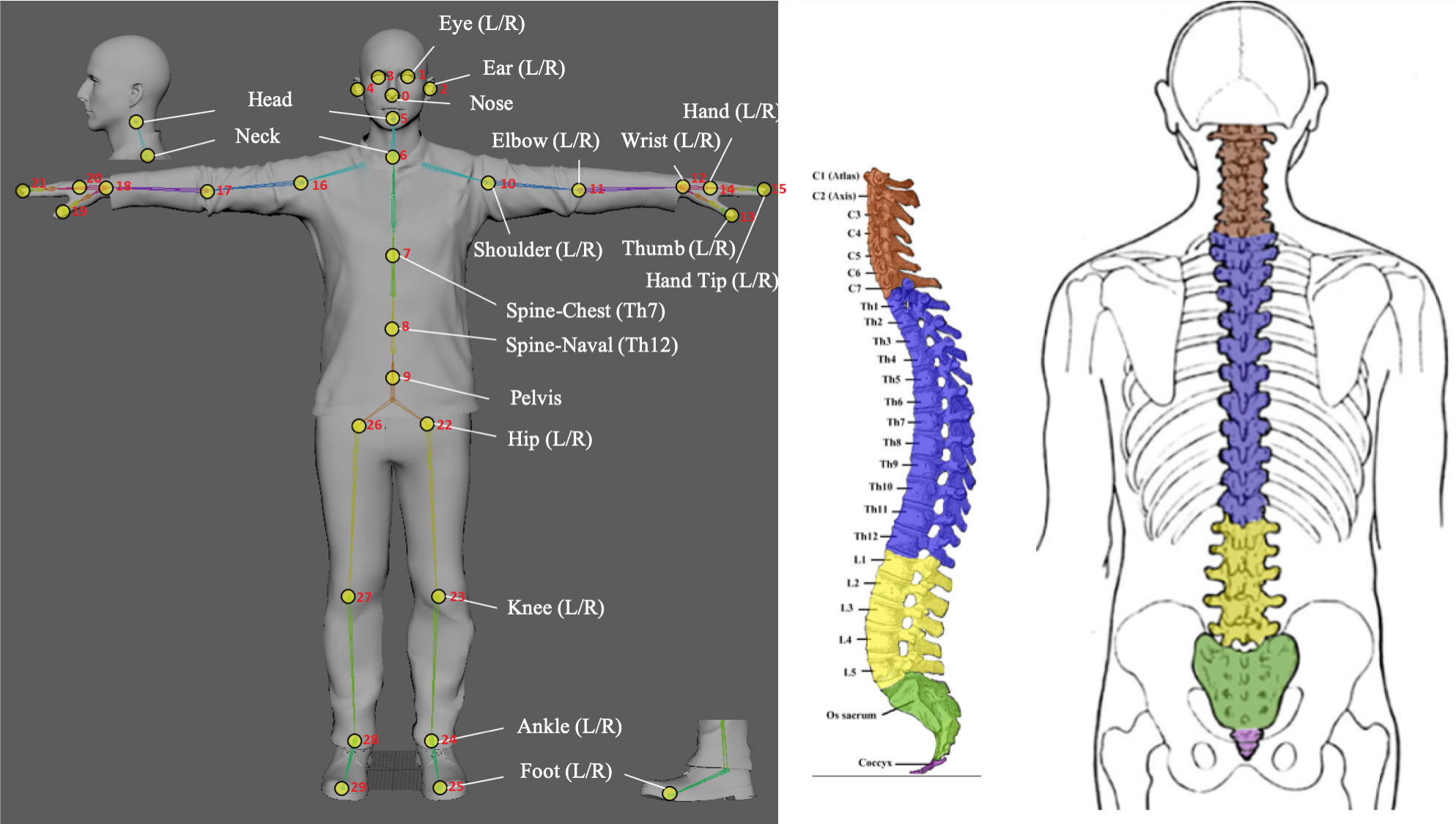 Figure 13
Figure 13 Figure 14
Figure 14 Figure 14
Figure 14 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15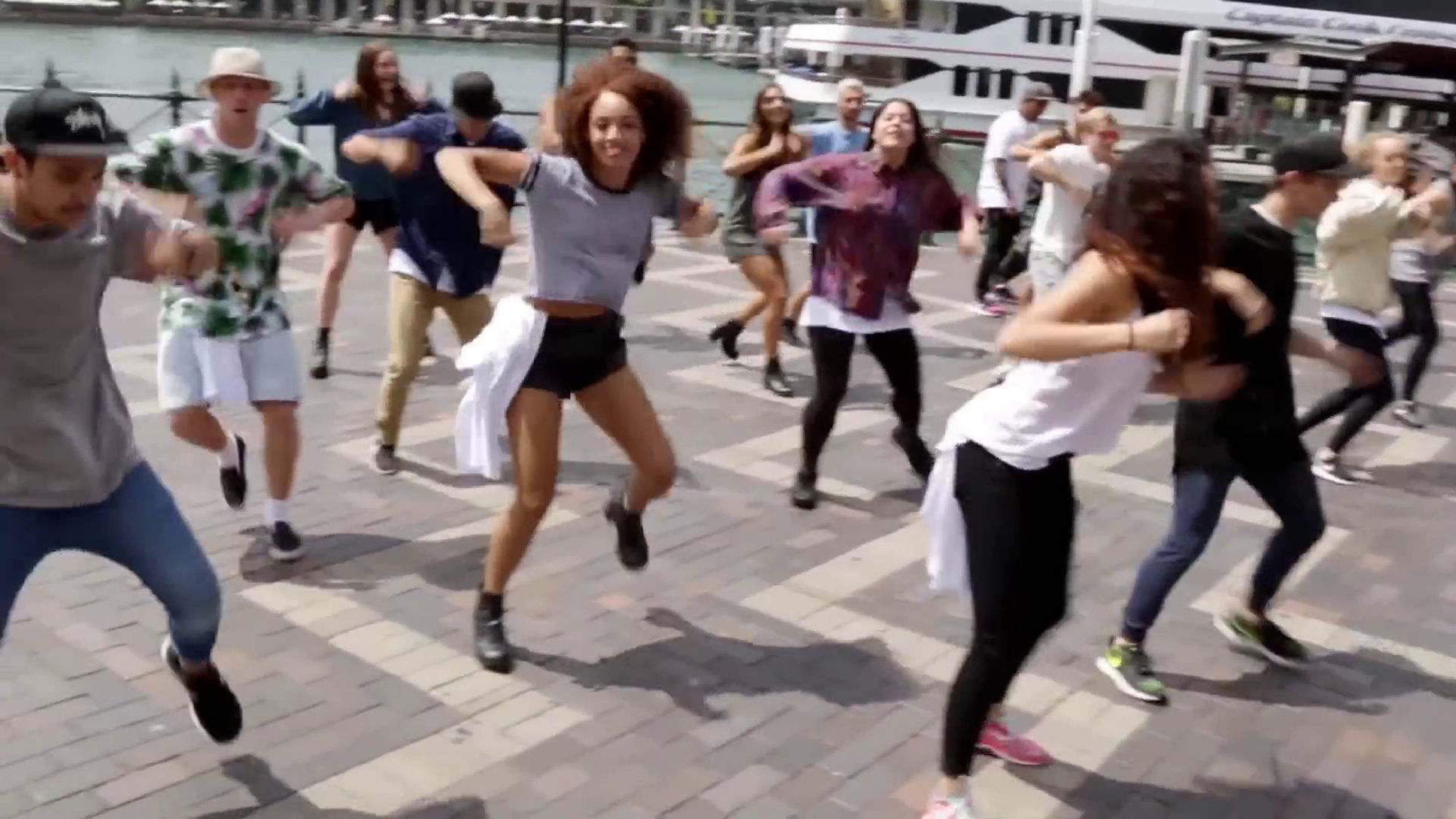 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15 Figure 15
Figure 15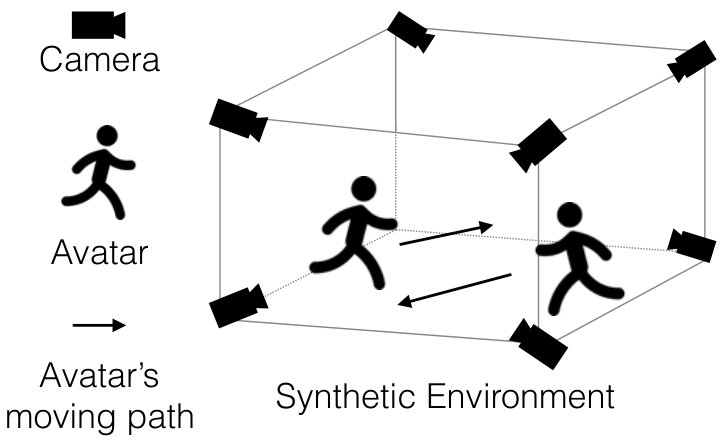 Figure 2
Figure 2 Figure 3
Figure 3| Method | Real Seg. GT | Syn Seg. GT | Head | Torso | U-arms | L-arms | U-legs | L-legs | Bkg | Avg |
| DeepLab-LFOV [1] | ✓ | ✗ | ||||||||
| HAZN [4] | ✓ | ✗ | ||||||||
| Attention [3] | ✓ | ✗ | ||||||||
| LG-LSTM [67] | ✓ | ✗ | ||||||||
| LIP [51] | ✓ | ✗ | ||||||||
| Graph LSTM [68] | ✓ | ✗ | ||||||||
| DeepLab v2 [2] | ✓ | ✗ | - | - | - | - | - | - | - | |
| WSHP [56] | ✓+ | ✗ | ||||||||
| CDCL | ✗ | ✓ | 75.53 | 66.26 | 63.28 | 57.14 | 47.75 | 51.45 | 93.72 | 65.02 |
| CDCL+Pascal | ✓ | ✓ | 86.39 | 74.70 | 68.32 | 65.98 | 59.86 | 58.70 | 95.79 | 72.82 |
| Method | Real Seg. GT | Syn Seg. GT | Head | Torso | U-arms | L-arms | U-legs | L-legs | Bkg | Avg |
| WSHP [56] | ✓+ | ✗ | ||||||||
| CDCL | ✗ | ✓ | ||||||||
| CDCL+Pascal | ✓ | ✓ | ||||||||
| CDCL+COCO | ✓ | ✓ | 73.15 | 68.74 | 63.79 | 67.66 | 63.39 | 60.62 | 93.55 | 70.13 |
| Method | Pascal-Person-Parts | COCO-DensePose |
|---|---|---|
| SYN | ||
| ADV | ||
| CDCL | 65.02 | 60.45 |
| Method | Syn. | Syn. | Real | Pascal | COCO |
|---|---|---|---|---|---|
| Parts | Poses | Poses | mIOU | mIOU | |
| SYN | ✓ | ✓ | ✗ | ||
| NO-SP | ✓ | ✗ | ✓ | ||
| CDCL | ✓ | ✓ | ✓ | 65.02 | 60.45 |
| Method | Pascal-Person-Parts | COCO-DensePose |
|---|---|---|
| CDCL | ||
| Fully-supervised |
| Original | No Background | Gray-scale | Binary Mask | |
|---|---|---|---|---|
| Pascal-Person-Parts | ||||
| COCO-DensePose |
| Number of Human Models | 1 | 5 | 10 | 15 | 20 |
|---|---|---|---|---|---|
| Pascal-Person-Parts | |||||
| COCO-DensePose |
| Number of Backgrounds | 1 | 100 | 1000 |
|---|---|---|---|
| Pascal-Person-Parts | |||
| COCO-DensePose |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Cross-Domain Complementary Learning Using Pose for Multi-Person Part Segmentation
Kevin Lin, , Lijuan Wang, , Kun Luo, Yinpeng Chen, , Zicheng Liu, , Ming-Ting Sun Manuscript received Sep. 30, 2019; revised Feb. 1, 2020 and Apr. 7, 2020; accepted May 3, 2020.K. Lin and M.-T. Sun are with the Department of Electrical and Computer Engineering, University of Washington, Seattle, WA, 98195. E-mail: {kvlin, mts}@uw.eduL. Wang, K. Luo, Y. Chen, and Z. Liu are with Microsoft Azure+AI, Redmond, WA, 98052. E-mail: {lijuanw, kun.luo, yiche, zliu}@microsoft.com
Abstract
Supervised deep learning with pixel-wise training labels has great successes on multi-person part segmentation. However, data labeling at pixel-level is very expensive. To solve the problem, people have been exploring to use synthetic data to avoid the data labeling. Although it is easy to generate labels for synthetic data, the results are much worse compared to those using real data and manual labeling. The degradation of the performance is mainly due to the domain gap, i.e., the discrepancy of the pixel value statistics between real and synthetic data. In this paper, we observe that real and synthetic humans both have a skeleton (pose) representation. We found that the skeletons can effectively bridge the synthetic and real domains during the training. Our proposed approach takes advantage of the rich and realistic variations of the real data and the easily obtainable labels of the synthetic data to learn multi-person part segmentation on real images without any human-annotated labels. Through experiments, we show that without any human labeling, our method performs comparably to several state-of-the-art approaches which require human labeling on Pascal-Person-Parts and COCO-DensePose datasets. On the other hand, if part labels are also available in the real-images during training, our method outperforms the supervised state-of-the-art methods by a large margin. We further demonstrate the generalizability of our method on predicting novel keypoints in real images where no real data labels are available for the novel keypoints detection. Code and pre-trained models are available at https://github.com/kevinlin311tw/CDCL-human-part-segmentation.
Index Terms:
Human parsing, learning from synthetic data, human pose estimation, domain adaptation.
††publicationid: pubid:
Copyright © 2020 IEEE. Personal use is permitted. However, permission to use this material for any other purposes
must be obtained from the IEEE by sending an email to [email protected].
I Introduction
Human body part segmentation [1, 2, 3, 4] aims at partitioning persons in the image to multiple semantically consistent regions (e.g., head, arms, legs), which is important to many human-centric analysis applications [5, 6, 7, 8]. Supervised training with deep Convolutional Neural Networks (CNNs) significantly improves the performance of various visual recognition tasks including the human body part segmentation [6, 2, 9, 10, 11]. However, it requires large amount of training data. Data labeling, especially at pixel level, is labor intensive and the acquisition of such annotations in large scale is prohibitively expensive.
A promising solution to address this problem is to take advantage of the graphics simulator to generate synthetic images with ground truths automatically [12, 13, 14]. For example, previous study [15] proposed to learn single-person part segmentation by directly training the neural networks using synthetic images. However, their method usually produces false alarms in the real-world background, and it does not work well for real-world images consisting of multiple person with interactions and occlusions. Also, recent studies [16, 17, 18] show that the discrepancy of the pixel value statistics between real and synthetic data, so called the domain gap, makes it challenging to transfer knowledge from synthetic domain to real domain. In addition to the pixel value statistics, the discrepancy of the content distributions (e.g., the background scenes and objects) between the two domains makes knowledge transfer even more difficult.
To address the discrepancies of the content distributions and the pixel value statistics between the two domains, recent studies [19, 20, 21] proposed to train the neural networks using adversarial training for matching the feature distributions of the real and synthetic data. They proposed to train a discriminator for distinguishing the real and synthetic images, and a generator for extracting the domain-invariant features that can fool the discriminator. However, the adversarial training may not converge due to the fact that it is difficult to maintain a balanced training between the generator and the discriminator. Previous approaches also suffer from the issue of mode collapse, where the generator may only capture a part of the real data distribution. Thus, the performances of previous approaches are much worse than the supervised training on real data with pixel-wise manual labeling.
In this paper, we observe that real and synthetic humans both have a skeleton (pose) representation and show that the skeletons can effectively bridge the synthetic and real domains during the training. With our proposed approach, we can take advantage of the complementary nature of the real and synthetic data, i.e., rich and realistic variations of the real data and the easily obtainable labels of the synthetic data, effectively. Our technique learns multi-person part segmentation on real images without any human-annotated labels and achieves performance comparable to several state-of-the-art approaches which require human labeling. On the other hand, if part labels are also available in the real-images during training, our method outperforms the supervised state-of-the-art methods by a large margin. As shown in Figure 1, we have part segmentation labels from synthetic data, but do not have part segmentation labels from real data. It should be noted that our synthetic images have an extremely simple background with white walls, while the real images have complex backgrounds with a variety of non-human objects. Given such discrepancies between the two domains, we observe that real and synthetic humans both have a common skeleton representation. By learning the skeleton representation of the real and synthetic humans, our proposed model learns a shared feature space for both real and synthetic domains. Different from previous works that try to minimize the discrepancy of the pixel value statistics between the domains, we propose to perform human pose estimation to extract skeletons from the real and synthetic images, and minimize the discrepancy of the feature spaces between the two domains by learning the domain-invariant human skeleton representation. The automatically extracted skeletons capture the structural body information and can effectively bridge the real and synthetic data domains, so that both real and synthetic data can be used in the training effectively without needing the expensive manual human part labeling for the real images.
It is worth noting that the learning of human pose estimation requires training labels. However, the pose labels are readily available on several public large-scale datasets like COCO Keypoint dataset [22] and are easy to obtain than part segmentation labels. Thus, the proposed method has the advantage of saving labeling efforts in practice.
We also show that our method can be generalized to predict a new set of keypoints for real images. For example, to predict keypoints on hands and feet, we just need to generate synthetic images with hands and feet labels, and the knowledge will transfer from the synthetic domain to the real domain using our proposed approach.
In summary, the main contributions of this paper include:
- •
We discover that human pose is very effective to bridge the real and synthetic domains for human-centric analysis applications.
- •
We introduce an effective framework, called cross-domain complementary learning with pose, to leverage information in both real and the synthetic images for multi-person part segmentation.
- •
Through experiments, we show that without any human-annotated part segmentation label, our method performs comparably with several state-of-the-art approaches which require human labeling on Pascal-PersonParts and COCO-DensePose datasets. On the other hand, if parts labels are also available in real images during training, our method outperforms the supervised state-of-the-art methods by a large margin.
- •
We show that our method can be generalized to predict new keypoints such as those on hands and feet in real images without human labeling.
II Related Work
II-A Synthetic data for computer vision tasks
There has been a long-standing history of exploring the use of 3D synthetic data for computer vision problems [23, 24, 25]. Recent studies use 3D CAD models for visual recognition tasks, such as 3D model repository [26, 27], object recognition [28, 29, 17], human analysis applications [7, 12, 15, 18], and semantic segmentation for urban scenes [14]. Among the literature, Varol et al. [15] proposed to render a single-person avatar on top of a static background image, and generate ground truths for training deep CNNs. However their method only works for the well-controlled environment and the single-person scenario in an image. This is because it is difficult and expensive to render photorealistic images with rich coverage of avatars, background scenes, and objects.
In this work, we address a more challenging and general scenario, where multiple people with interactions and occlusions are considered. Different from training the deep CNNs using synthetic data only [15], we propose to leverage the complementary natural of the real and synthetic data with human pose estimation. In the experiments, we show that our method, which learns to bridge the reality gap, performs more favorably against those proposed in previous studies [15]. In addition, as demonstrated in the experiments, our technique reduces the requirement on the photorealism of the synthetic data generation.
II-B Domain adaptation
Domain adaptation is a special case of transfer learning [30] that aims to learn a single task from a source domain, so that it performs well on a target domain. Many approaches have been proposed to address the visual dataset bias [31] for domain adaptation, including active learning with human-in-the-loop [18], training deep CNNs with reverse gradient [32], learning with auxiliary tasks to reduce domain variations [33, 34], and matching feature distributions of two domains by adversarial training [35, 36, 37, 38, 39, 40, 19, 20, 21]. In particular, Chen et al. [37] proposed an image-level adaptation approach which tries to make the appearance of synthetic images similar to real images. One key assumption of [37] is that the content distribution of the synthetic data is similar to the content distribution of the real data. It is not suitable to our research problem because all of our synthetic images have an extremely simple background (empty room with white walls) while real images have complex backgrounds with a variety of objects. The discriminators can easily distinguish our synthetic images from real images thus making the adversarial learning scheme ineffective. Instead of image-level adaptation, Ren and Lee [19] proposed a feature-level adaptation approach to learn image classifiers and object detectors using synthetic images with adversarial training. A recent study [41] proposed to learn human pose estimation with synthetic data using adversarial teacher-student network. Tsai et al. [36] further proposed to enhance the adversarial learning with patch-level alignment. However, existing domain adaptation approaches do not work as well as the fully supervised training approaches. Instead of adversarial training, our approach uses an auxiliary task of human pose estimation to bridge synthetic and real domains, which is shown to be more effective from our experiments.
II-C Multi-task learning
Prior works [42, 43, 44, 45, 30, 46, 47] have shown that multi-task learning is effective for many vision problems. Given multiple different tasks, where a subset of these tasks are related, multi-task learning aims to improve the learning of the original task by using knowledge from all or some of the other tasks [48, 49]. However, many previous studies assume that, for all the tasks, the labeled data have to be available for training [30]. Different from the previous works, our method learns without human-annotated segmentation labels in a cross-domain scenario, and learns to bridge the domain gap between real and synthetic data.
II-D Supervised and semi-supervised part segmentation
Recent studies [50, 51, 52, 53, 54, 55] proposed to jointly train human part segmentation and human pose estimation for improving the performance of part segmentation. However, the successes of the previous studies are mainly attributed to the supervised training with the pixel-wised manual labeling. Different from the fully supervised approaches, we propose to remove the manual labeling requirement by learning with synthetic data. On the other hand, Fang et al. [56] proposed a semi-supervised approach that aims to augment training samples by transferring the human-labeled part segmentation from an existing dataset to another unlabeled dataset. Our method differs from theirs in that our method does not require any human-labeled part segmentation dataset at all.
Bearman et al. [57] proposed a point-level supervision which is related to our work. The key insight of their method is to use the foreground masks (called objectness prior in [57]) to help find the foregrounds. Their method is effective for extracting the foreground regions, but it remains challenging to find the boundaries between different foreground objects such as the object parts in our problem. For example, when a person’s arm is in front of the torso, the arm region is overlapped with the torso region making it difficult to find the boundary of the arm. Instead of relying on objectness prior, we leverage synthetic data to learn the boundaries between different parts.
III Synthetic Data
It is a common belief that high-quality synthetic data should be created as similar as possible to the real-world scenarios. For example, in generating single-person synthetic data [15], the authors composed their synthetically generated human images with a variety of real world background images. An advantage of our technique is that we reduce the requirement on the photorealism of the synthetic data generation. In particular, we use a simple empty room as the background for all of our synthetic data. The reason why our technique works well even with such a simple synthetic background is that our technique learns about the background from the real data.
We have 3D human models with different body shapes and clothing. These avatars are randomly placed at different positions in the virtual room, and they are animated to perform a variety of actions such as walking, jumping, crawling, etc. To create realistic human motions, we retarget the motion capture data from CMU MoCap database [58] to the avatars. We use a ray-tracing based rendering engine [59, 60] to render the scene.
Multiple virtual cameras are set up at different positions in the environment to capture the scene from a variety of viewpoints. Figure 2 shows the layout of our simulation environment. The virtual camera model we used is a pinhole camera with a degree FoV. The exposure of the camera is 1/30-th of a second. The focal length is mm.
Figure 3 shows the examples of our synthetic data and the ground truths. Our graphics simulator generates different types of per-pixel ground truth labels for the animations. Following the common definitions of body parts and human pose [6, 22], we generate categories of body part ground truth labels, and types of keypoint ground truth labels. It is worth noting that the labels for the synthetic data can be freely extended depending on user preferences, and are more flexible than those in the conventional real datasets. For example, as shown in Section V-F, we generate a new set of keypoints including hands and feet from synthetic data thus allowing our model to predict new keypoints.
Another advantage of the graphics simulation is that we can easily generate large amount of data. In this work, we generate a total of frames and their corresponding ground truths for model training.
IV Method
Given a set of synthetic data with human part segmentation labels, we would like to learn a function that performs human part segmentation on real world data. If we directly train a neural network with synthetic data labels, it does not generalize well to real data due to the reality gap. Unlike existing methods [19] that try to transform the synthetic data to real data domain to make them look similar to each other, we use a complementary learning strategy that effectively leverages the rich variation of the real data and the part segmentation labels of the synthetic data. To make sure the synthetic data and real data are aligned in a common latent space, we use an auxiliary task, pose estimation, to bridge the two domains. In summary, our training data consist of part segmentation labels and pose labels from synthetic data, and pose labels from real data. We learn a part segmentation function without any part segmentation labels from real data.
IV-A Learning objective
Given a real dataset with pose labels , a synthetic dataset with pose labels , and a synthetic dataset with part segmentation labels , we formulate the cross-domain complementary learning (CDCL) as the following optimization problem:
[TABLE]
where is the loss function for pose estimation, and is the loss function for part segmentation. The first two terms together form the objective function for learning the auxiliary task of pose estimation from both real and synthetic data. The third term learns part segmentation from synthetic data. Note that , , are the hyperparameters for balancing the losses among the three terms.
Human pose estimation aims at detecting human skeletons in a given image. Previous study [61] proposed to detect the joint locations (i.e. keypoints) and the associations between the joints (i.e. Part Affinity Fields). After that, human skeletons are reconstructed with a greedy algorithm. Following the common definition of pose labels [61, 22], we use the annotations of keypoints and Part Affinity Fields (PAFs) [61] for learning pose estimation. In particular, let , where is the total number of real images, denotes a real RGB image, denotes a real keypoint ground truth, which has different maps, one per keypoint, denotes a real part affinity ground truth, which has affinity vector fields. Also, we have a synthetic dataset with pose labels , where is the total number of images in the synthetic data. Furthermore, we have a synthetic dataset with part segmentation labels , where is the synthetic body part segmentation ground truth and is the total number of body part categories. Note that it is convenient to assume and share the same set of images. In this work, we use COCO Keypoint dataset [22] as .
In the following, we omit the subscript r and s and use to represent either real or synthetic data. The loss function we use for learning pose estimation is where and are the Euclidean loss functions minimizing the differences between the predictions and the ground truths, and they are defined below:
[TABLE]
[TABLE]
where and denote the predicted keypoint confidence map and the predicted part affinity field, respectively, and and denote the ground truths. is a binary mask, where if the ground truth is missing at the location of the image. The mask is used to avoid penalizing the correct predictions as discussed in [61].
The loss function of learning part segmentation is denoted as , which is defined as the categorical cross entropy loss for classifying pixels to different human parts, that is:
[TABLE]
where denotes the predicted body part maps, denotes the synthetic part segmentation ground truths.
In summary, the overall objective function is
[TABLE]
IV-B Network architecture
Figure 4 illustrates the proposed network. Our network takes an image of arbitrary size as input, and predicts three different outputs including (1) a set of body part segmentation maps , (2) a set of confidence keypoint maps , and (3) a set of Part Affinity Fields (PAFs) [61]. For clarity, we describe our network in two components: backbone and head networks.
IV-B1 Backbone network
In this paper, all the results are obtained by using ResNet101 [62] with pyramid connections [63, 64] as our backbone network. We denote the output feature maps of the residual blocks in ResNet as for , , , , and , respectively. Following [64], we normalize the size of the feature maps to a fixed size as the input of the subsequent convolution layers. We denote as our backbone network, and the output of our backbone is , where is an input image.
IV-B2 Head network
We detect multi-person body parts and human poses in a bottom-up strategy, which is in spirit similar to OpenPose [61]. Our network predicts three target outputs in parallel, which are , , and . Each head network is a fully convolutional network consisting of convolution layers with filters. Note that this is different from prior studies [61, 65] that have a cascaded multi-stage head architecture. Our head networks do not have such a cascaded design, and can be seen as a single-stage network compared to prior works. Finally, we denote the three head networks as , , and , respectively. The body part segmentation maps are computed by , where is the output of our backbone. The confidence keypoint maps are computed by , and the Part Affinity Fields [61] are computed by .
IV-C Training
We initialized the backbone network using the pre-trained weights on ImageNet [9]. The head networks are randomly initialized. During training, we randomly pick an equal number of real and synthetic images to form a mini-batch, and feed it to the network. Then, we compute the loss using Eq(5), and update the network parameters via Adam optimizer with an initial learning rate . The training batch size is set to . Following the literature [55], we set , , to balance pose estimation loss and part segmentation loss. We refer the readers to Sec.V-E7 for further details on the hyperparameter analysis.
IV-D Inference
During testing, we only predict the part segmentation. Our model predicts body part score maps and one background score map. Following DeepLab [2], we run multi-scale inference and perform max-pooling to obtain the final part score maps. The part segmentation is derived by using the argmax value from the final part score maps. Given a fixed image size x, the average inference processing time is about 16 frames per second using a PC with a single Titan XP GPU.
V Experiments
We train our model with COCO Keypoint dataset [22] and our synthetic dataset. We then evaluated the performance of the resulting model on two public benchmarks, the Pascal-Person-Parts [66], and the COCO-DensePose [6].
V-A Evaluation benchmarks
Pascal-Person-Parts [66] is a challenging dataset for multi-person body part segmentation. It consists of training and test images, where the human body is split into different parts including head, torso, upper and lower arms, as well as upper and lower legs.
COCO-DensePose [6] is a manually annotated dataset with the body part annotations. We evaluate multi-person body part segmentation on its body part annotations. The dataset contains training images, and the minival has validation images.
V-B Main results
We compare our technique with several state-of-the-art supervised approaches, including HAZN [4], Attention [3], LG-LSTM [67], LIP [51], Graph LSTM [68], DeepLab [2, 1], and WSHP [56]. Note that all these approaches use Pascal-Person-Parts dataset including the part segmentation labels as the training data while our network does not need to use any of the data from Pascal-Person-Parts at all. Following the settings of Pascal-Person-Parts [66], we predict body parts and measure the prediction results using the mean Intersection of Union (mIOU) [69].
Table I shows the performance comparison with different state-of-the-art methods, and Figure 5 visualizes our prediction results. Without the segmentation training data provided by Pascal-Person-Parts, the proposed method CDCL achieves mIOU, which is comparable to or better than several state-of-the-art supervised approaches, such as DeepLab v2 [2] and Graph LSTM [68]. It is worth noting that the proposed CDCL has better or similar performance compared to the other fully supervised methods, except for the head region. The main reason is that the head definition in our synthetic dataset does not match the head definition in Pascal-Person-Parts dataset. In our synthetic dataset, the head definition consistently includes the head and the neck. But in Pascal-Person-Parts, some of the ground truth head regions do not include the neck.
We further compare our method with the state-of-the-art approach [56] on COCO-DensePose. For a fair comparison, we follow the body part settings of WSHP [56], and measure mIOU for the 6 different body parts and background. As shown on the second row CDCL of Table II, our result is slightly better than WSHP [56] which used real segmentation training data from both Pascal-Person-Parts and AIC [70].
V-C Adding real data with part segmentation labels
To obtain the performance upper bound of our technique, we evaluate our method when real data with part segmentation labels are used during training. As shown in Figure 6, we share the parameters of all the modules and train the network using real and synthetic datasets. The bottom row CDCL+Pascal of Table I shows the result on Pascal-Person-Parts where Pascal-Person-Parts training data is used. Our method outperforms WSHP by a large margin.
The same model is evaluated on the COCO-DensePose test data and the result is shown on the third row CDCL+Pascal of Table II. Again it outperforms WSHP by a large margin.
If we use COCO-DensePose training data instead, and evaluate on COCO-DensePose test data, we obtain an additional gain and the result is shown on the fourth row CDCL+COCO of Table II.
V-D Comparison with adversarial learning
Recent studies [19, 20, 39] used adversarial training to align the feature spaces of the synthetic and real images. Thus, we compare the performance of our method with the adversarial training strategy. Since the model presented in [19] cannot be directly used for part segmentation, we implemented our own network similar to [19]. Our network has a backbone (ResNet101) and two head networks, one for the part segmentation head and the other for the discriminator.
Table III shows the performance comparison on two datasets. We can see that adversarial training (ADV) achieves better performance than that of training with synthetic data only without adversarial training (SYN), but it does not perform as well as our complementary learning technique.
V-E Ablation study
V-E1 Synthetic pose labels
Since our approach uses both synthetic poses and real poses, one interesting question is whether the synthetic pose is useful. To answer this question, we have trained our network without the synthetic poses (i.e. with synthetic parts and real poses). This configuration is denoted as NO-SP, and the results on Pascal-Person-Parts and COCO-DensePose are shown in Table IV. For completeness, we also show the results of SYN (synthetic parts + synthetic poses), and CDCL (synthetic parts + synthetic poses + real poses). We can see that NO-SP outperforms SYN by a large margin thanks to the knowledge learned from the real data, and adding synthetic poses further boosts the performance. Figure 7 shows a qualitative comparison of the three configurations. SYN has trouble handling the background, NO-SP performs much better, and CDCL further improves upon NO-SP.
V-E2 Fully supervised baseline
We study a fully supervised baseline by removing the synthetic training data, and train a model using real part segmentation labels only. This configuration is denoted as Fully-supervised, and the results are shown in Table V. We see that CDCL performs comparably to Fully-supervised because CDCL effectively reduces the domain gap.
V-E3 Feature space visualization
We visualize the features of two different models (SYN and CDCL) from the real and synthetic images using the t-SNE visualization technique [71]. In Figure 8, the left column shows the features extracted with the model SYN (trained with synthetic data only), and the right column are from the model CDCL. The first row shows the features extracted at the left elbow position, and the second row shows the features extracted at the right knee position. In each plot, the red dots indicate the real data while the purple dots indicate the synthetic data. We can see that the red and purple dots in the right column are aligned very well, but they do not align well in the left column. This indicates that our complementary learning technique is effective at aligning the feature space of the real data with that of the synthetic data.
V-E4 Synthetic training data analysis
Since our method learns part segmentation from synthetic data, one may wonder what elements of the synthetic data are essential to be rendered. To answer the question, we ablate our synthetic training data by gradually removing the background, colors, and the human texture, and train our model with these configurations, respectively. Figure 9 shows the examples of different configurations of the synthetic training data, and Table VI shows the performance comparison on Pascal-Person-Parts and COCO-DensePose datasets. Firstly, we observe that removing the background from the synthetic data causes only a small drop on the segmentation performance. This is an indication that our framework is learning the background from the real data. Secondly, after we further remove the color of the synthetic data (Gray-scale), we again only see a small drop on the performance. Finally, when we degrade our synthetic data to the extreme by just using binary masks, our framework still works reasonably well. These studies indicate that our framework mainly requires the pose variations in the foreground data and the rendering quality is not as critical compared to the conventional approach of directly training from synthetic data.
V-E5 Influence of the synthetic human geometry
Since our synthetic humans each have their own geometry of body shape and clothing, we study the influence of the model geometry by training with different number of synthetic human models. Table VII shows such results on Pascal-Person-Parts and COCO-DensePose datasets. We see that as we increase the number of synthetic human models for training, it improves the performance for part segmentation. However, the impact becomes less prominent if we use more than synthetic human models for training.
V-E6 Compositing synthetic humans with different backgrounds
Since our synthetic dataset uses a single background of empty room, one may wonder what if we use more variety of backgrounds for training. Because it is time consuming to create a large variety of synthetic 3D background models, we composite the synthetic humans with a variety of real-world scenery images. We randomly select scenery images from the Holidays dataset [72] for data generation. Figure 10 shows a few examples of the composited images and Table VIII shows the results on Pascal-Person-Parts and COCO-DensePose datasets when we composite synthetic humans with different number of backgrounds. We can see that increasing the number of backgrounds improves the performance of part segmentation, but it does not work as well as using a simple background such as an empty room or a blank background. This is probably because the synthetic humans are not placed in realistic positions in the scene and there are lighting inconsistency between the synthetic humans and background.
V-E7 Influence of different losses
We study the influence of the three terms in our learning objective (in Eq.(1)). The first two terms learn pose estimation from real and synthetic data, respectively. The third term learns part segmentation from synthetic data. We study the influence of the three terms by fixing the first weight and iterating different combinations of and . The reason we set is that we can rewrite Eq.(1) as L=\alpha\Bigl{(}L_{pose}(D_{r}^{pose})+\frac{\beta}{\alpha}L_{pose}(D_{s}^{pose})+\frac{\gamma}{\alpha}L_{part}(D_{s}^{part})\Bigr{)}. Thus, we can omit the scaling factor by setting and vary and . As shown in Figure 11, our method performs more favorably when . Our method achieves the best performance when , , are set to , and , respectively. This indicates that the first two terms are equally important. We also observed that part segmentation loss is greater than pose estimation loss, thus the losses are better balanced when is smaller than . It is worth noting that the hyperparameters (i.e., , , ) are used to control the quality of the learning process. Our design principle of the hyperparameters is to ensure the three losses should have a similar scale, so that the three loss terms can be balanced and contribute to the learning process.
V-F Novel keypoint detection
Since our approach can easily create arbitrary annotations on synthetic data and transfer the knowledge to real domain, our method is highly scalable and flexible to users needs. For example, suppose we want to predict a new set of keypoints including hands and feet, it would be difficult to re-label the entire COCO dataset. With our technique, we can simply generate new labels on the synthetic data. We have performed an experiment to demonstrate this capability.
We create novel keypoints for each avatar in the graphics simulator, and use the proposed method to learn the new set of keypoints. Figure 13 shows the definition of the novel keypoints. To enable our existing network to learn such a new task, we add two additional head networks in our framework to learn the newly created keypoints and their Part Affinity Fields, resulting in a total of head networks in our network architecture. Figure 12 shows the qualitative results of our novel keypoint detection. With small modifications of the existing network, our method learns the novel skeleton representations from the synthetic data and transfers the knowledge to the real domain. It eliminates the needs of ground truth labeling of the additional joints on the real data.
VI Qualitative comparison
Recent study [15] proposed to estimate body part segmentation by learning with synthetic data, which is closely related to our method. Since MPII dataset [74] does not have part segmentation labels for quantitative evaluation, Varol et al. [15] showed qualitative results on selected images from MPII. Given a test image, Varol et al. [15] used additional preprocessing to normalize the input. From their results on MPII dataset with multiple people, it appears that they cropped each image centered at a specific person before feeding to their network. In contrast, our method does not require such preprocessing. Furthermore, our method produces better results as shown in Figure 14. For each example, we show the original image from MPII dataset [74], our part segmentation result on the original image, the cropped version which was used as the network input in [15], and the part segmentation result of [15].
We further conduct qualitative comparison with the adversarial training approach on a challenging video [73]. We compare our method with the adversarial network models presented in Sec V-D, and Figure 15 shows the results. We can see that our method performs consistently better than the previous baseline approaches on the tested frames. The results validate the effectiveness of the proposed approach.
VII Conclusion
We presented a cross-domain complementary learning framework for multi-person part segmentation. Without using any real data part segmentation labels, our method is able to achieve a comparable or better performance than several state-of-the-art techniques that use real part segmentation data for training. We further demonstrated that our technique can also be used to learn novel keypoint detection from synthetic data.
Acknowledgment
We would like to thank Alvin Chia, Jon Hanzelka, and Pedro Urbina for their help with the synthetic data generation. We would like to thank Jamie Shotton for his support.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Semantic image segmentation with deep convolutional nets and fully connected crfs,” in Proc. ICLR , 2015.
- 2[2] ——, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,” IEEE Trans. Pattern Anal. Mach. Intell. , vol. 40, no. 4, pp. 834–848, 2018.
- 3[3] L.-C. Chen, Y. Yang, J. Wang, W. Xu, and A. L. Yuille, “Attention to scale: Scale-aware semantic image segmentation,” in Proc. CVPR , 2016.
- 4[4] F. Xia, P. Wang, L.-C. Chen, and A. L. Yuille, “Zoom better to see clearer: Human and object parsing with hierarchical auto-zoom net,” in Proc. ECCV , 2016.
- 5[5] C. Gu, C. Sun, D. Ross, C. Vondrick, C. Pantofaru, Y. Li, S. Vijayanarasimhan, G. Toderici, S. Ricco, R. Sukthankar et al. , “Ava: A video dataset of spatio-temporally localized atomic visual actions,” in Proc. CVPR , 2018.
- 6[6] R. A. Güler, N. Neverova, and I. Kokkinos, “Densepose: Dense human pose estimation in the wild,” in Proc. CVPR , 2018.
- 7[7] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, “Human 3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments,” IEEE Trans. Pattern Anal. Mach. Intell. , vol. 36, no. 7, pp. 1325–1339, 2014.
- 8[8] R. Tong, D. Xie, and M. Tang, “Upper body human detection and segmentation in low contrast video,” IEEE Trans. Circuits Syst. Video Technol. , vol. 23, no. 9, pp. 1502–1509, 2013.
