On-chip learning in a conventional silicon MOSFET based Analog Hardware Neural Network
Nilabjo Dey, Janak Sharda, Utkarsh Saxena, Divya Kaushik, Utkarsh, Singh, Debanjan Bhowmik

TL;DR
This paper demonstrates on-chip learning in a silicon MOSFET-based analog neural network using SPICE simulations, offering a more fabrication-friendly and energy-efficient alternative to NVM device-based systems, with competitive performance on standard datasets.
Contribution
It introduces a novel on-chip learning approach using conventional silicon MOSFETs as synapses, avoiding complex NVM fabrication and improving energy efficiency.
Findings
Achieved high accuracy on Fisher's Iris dataset.
Demonstrated comparable speed and energy efficiency to NVM-based systems.
Validated transistor synapse model against experimental data.
Abstract
On-chip learning in a crossbar array based analog hardware Neural Network (NN) has been shown to have major advantages in terms of speed and energy compared to training NN on a traditional computer. However analog hardware NN proposals and implementations thus far have mostly involved Non Volatile Memory (NVM) devices like Resistive Random Access Memory (RRAM), Phase Change Memory (PCM), spintronic devices or floating gate transistors as synapses. Fabricating systems based on RRAM, PCM or spintronic devices need in-house laboratory facilities and cannot be done through merchant foundries, unlike conventional silicon based CMOS chips. Floating gate transistors need large voltage pulses for weight update, making on-chip learning in such systems energy inefficient. This paper proposes and implements through SPICE simulations on-chip learning in analog hardware NN using only conventional…
Click any figure to enlarge with its caption.
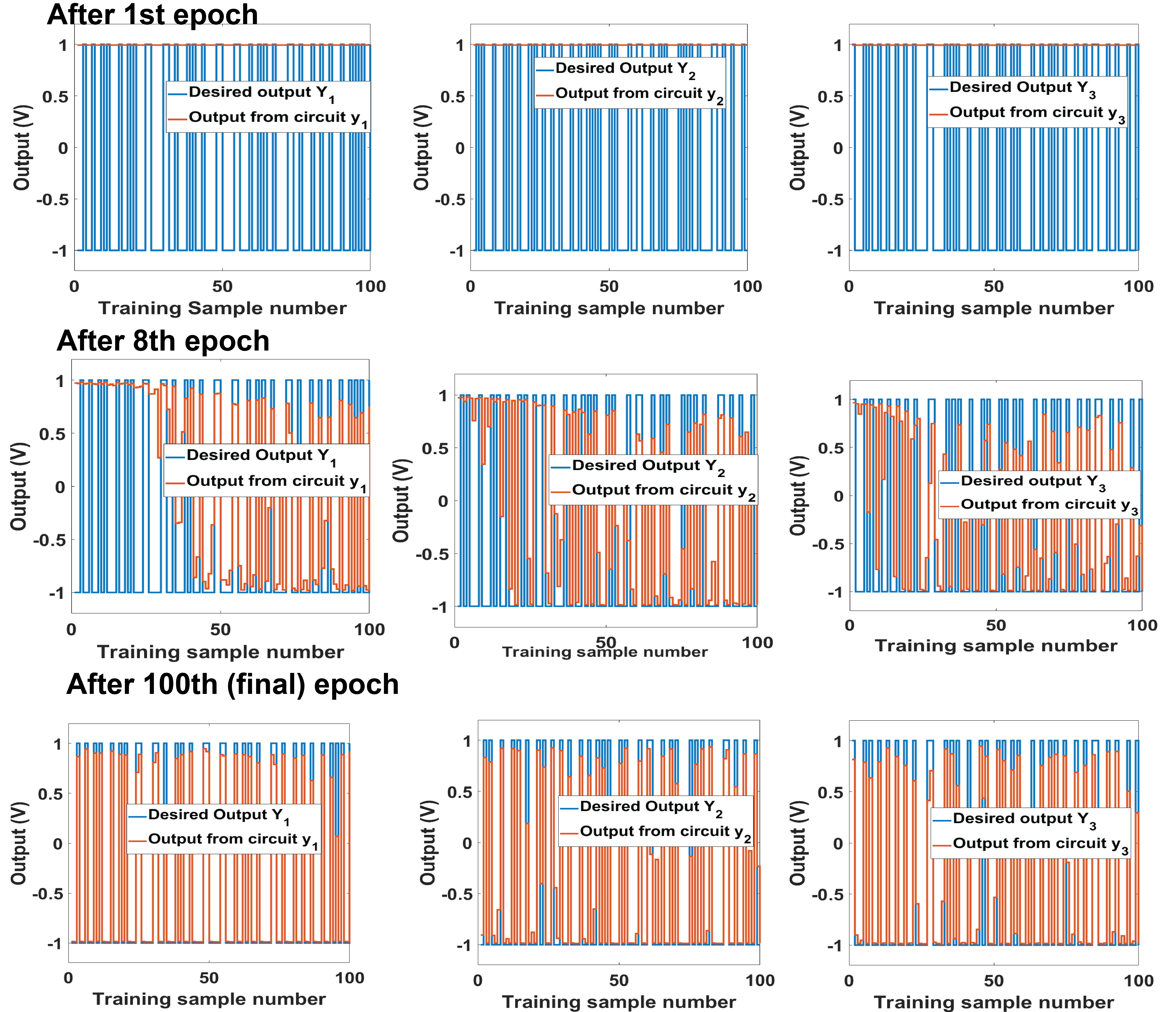 Figure 9
Figure 9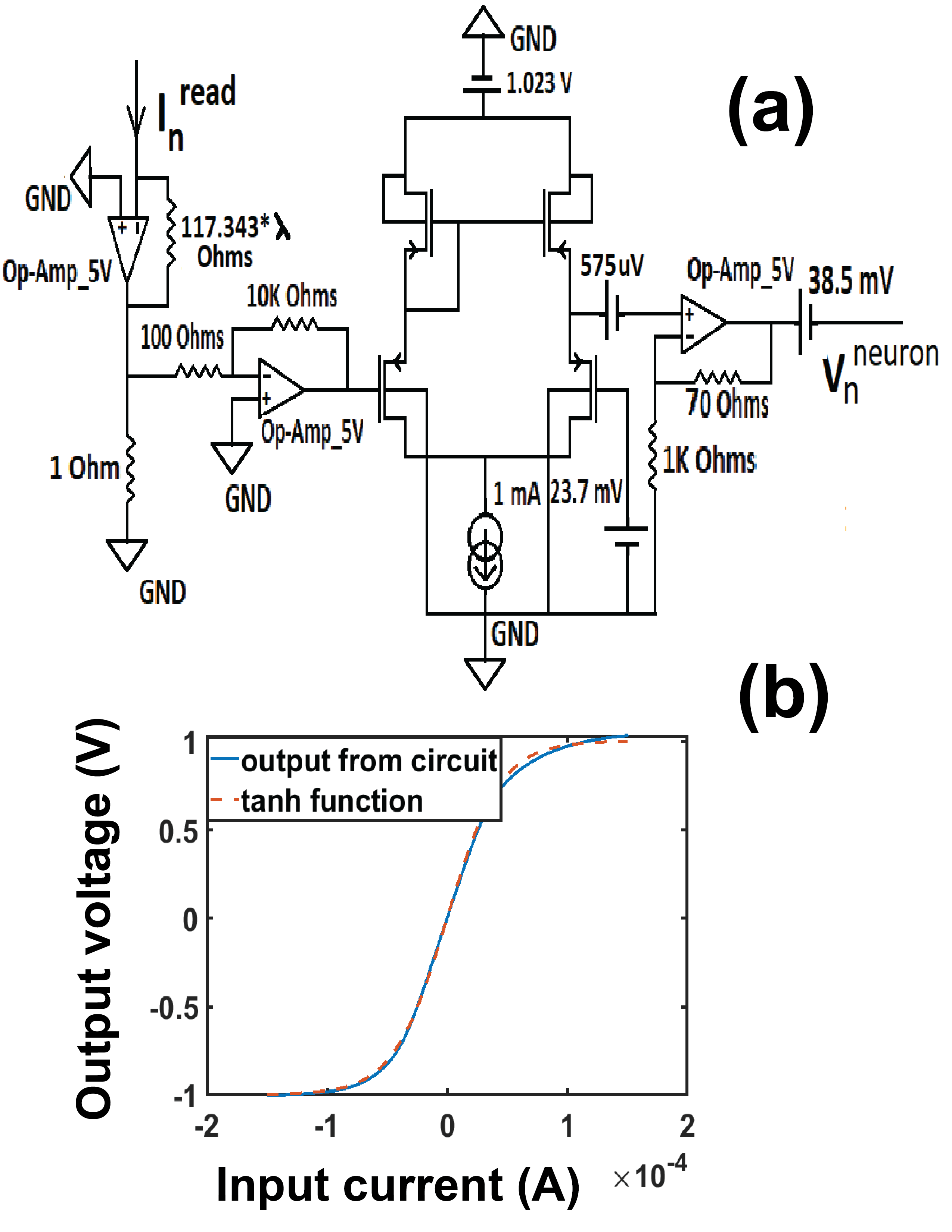 Figure 4
Figure 4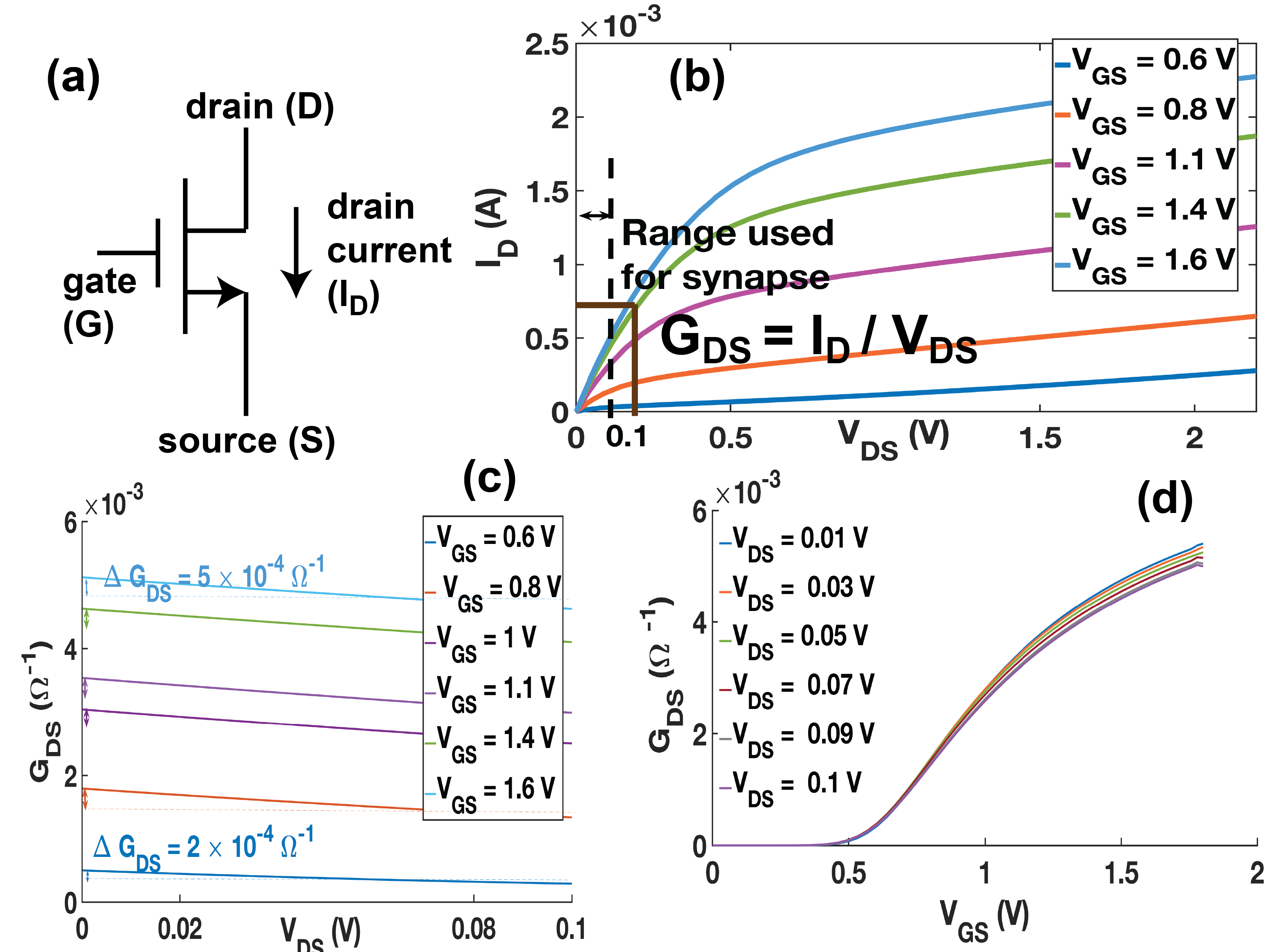 Figure 1
Figure 1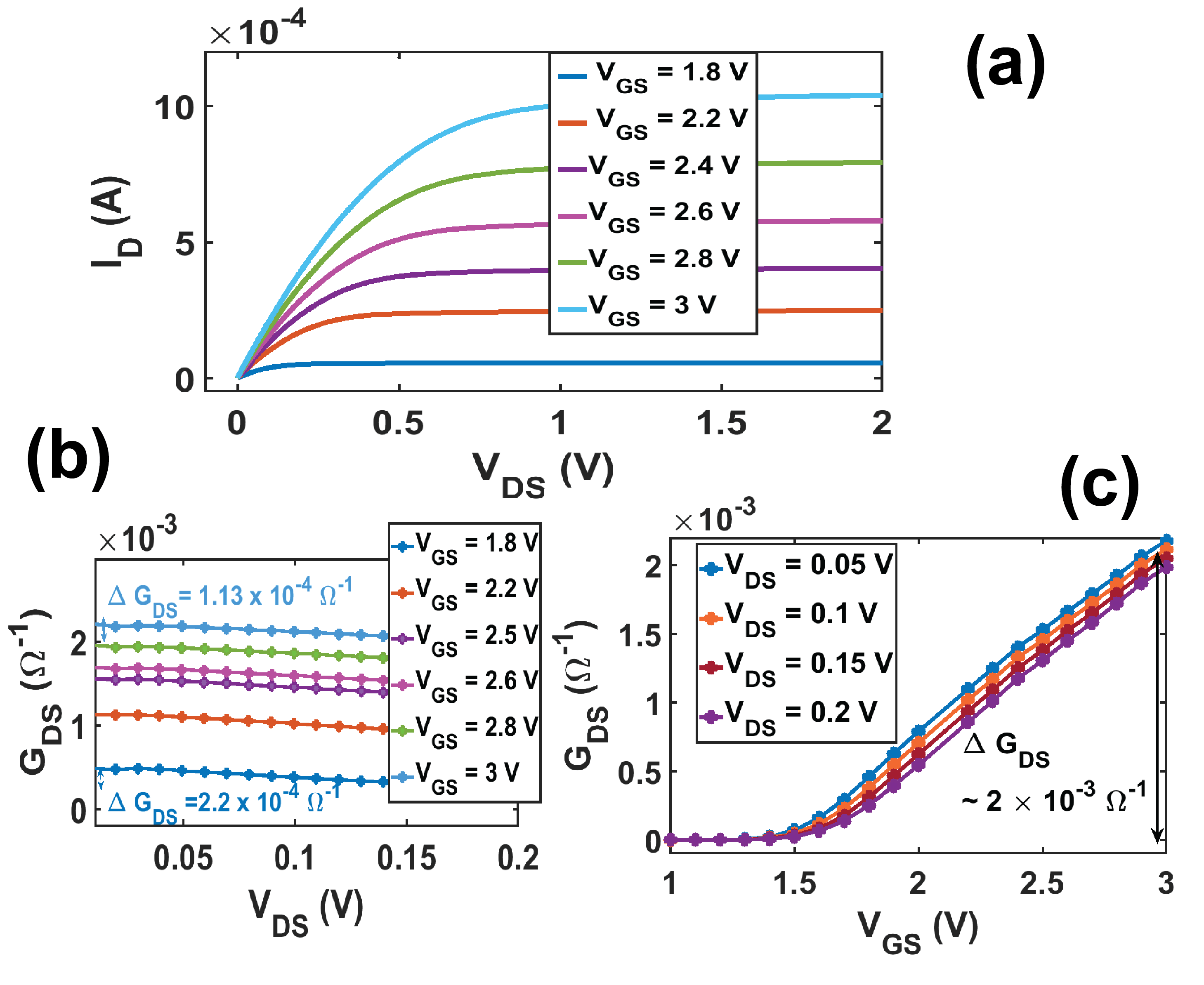 Figure 2
Figure 2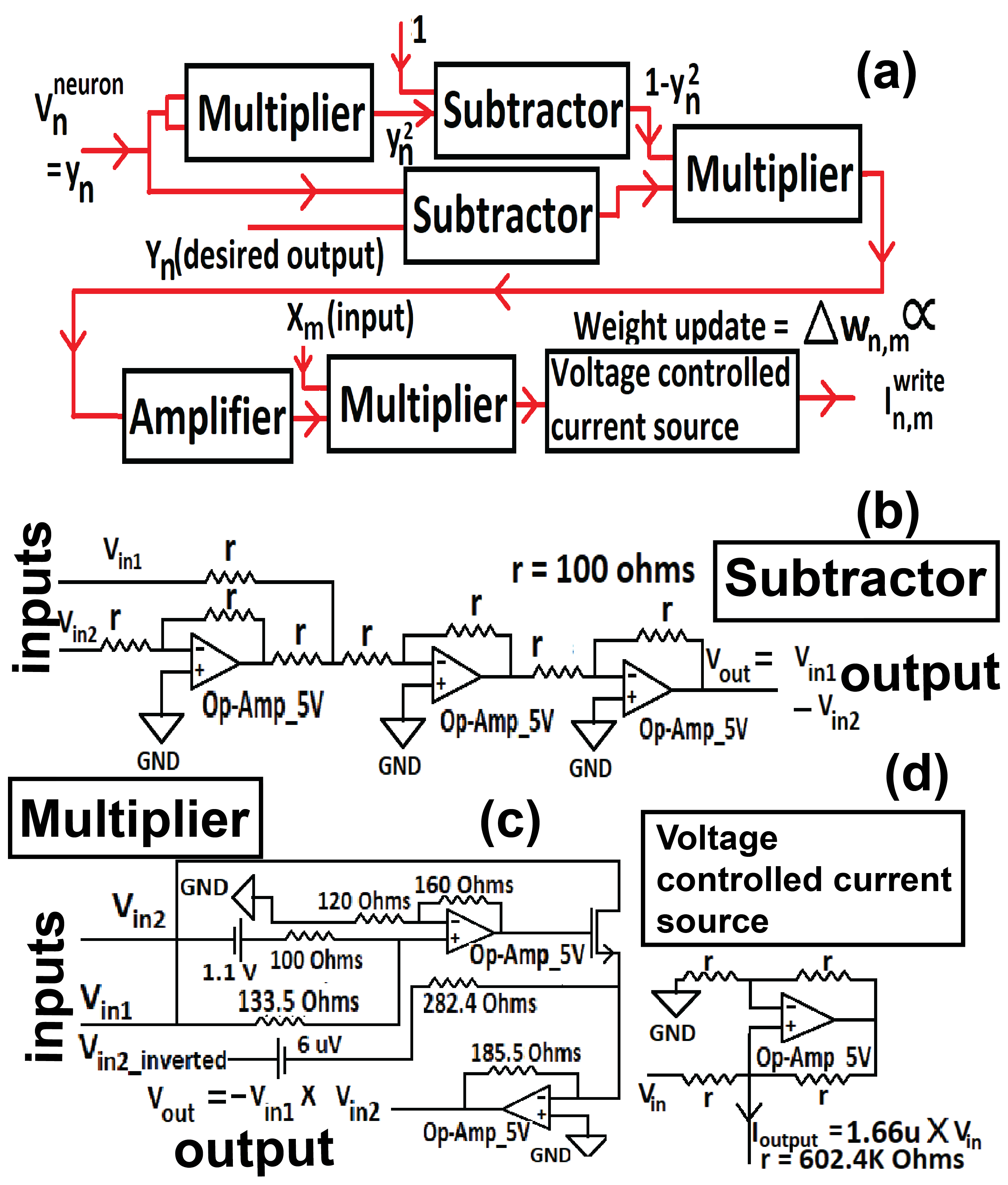 Figure 4
Figure 4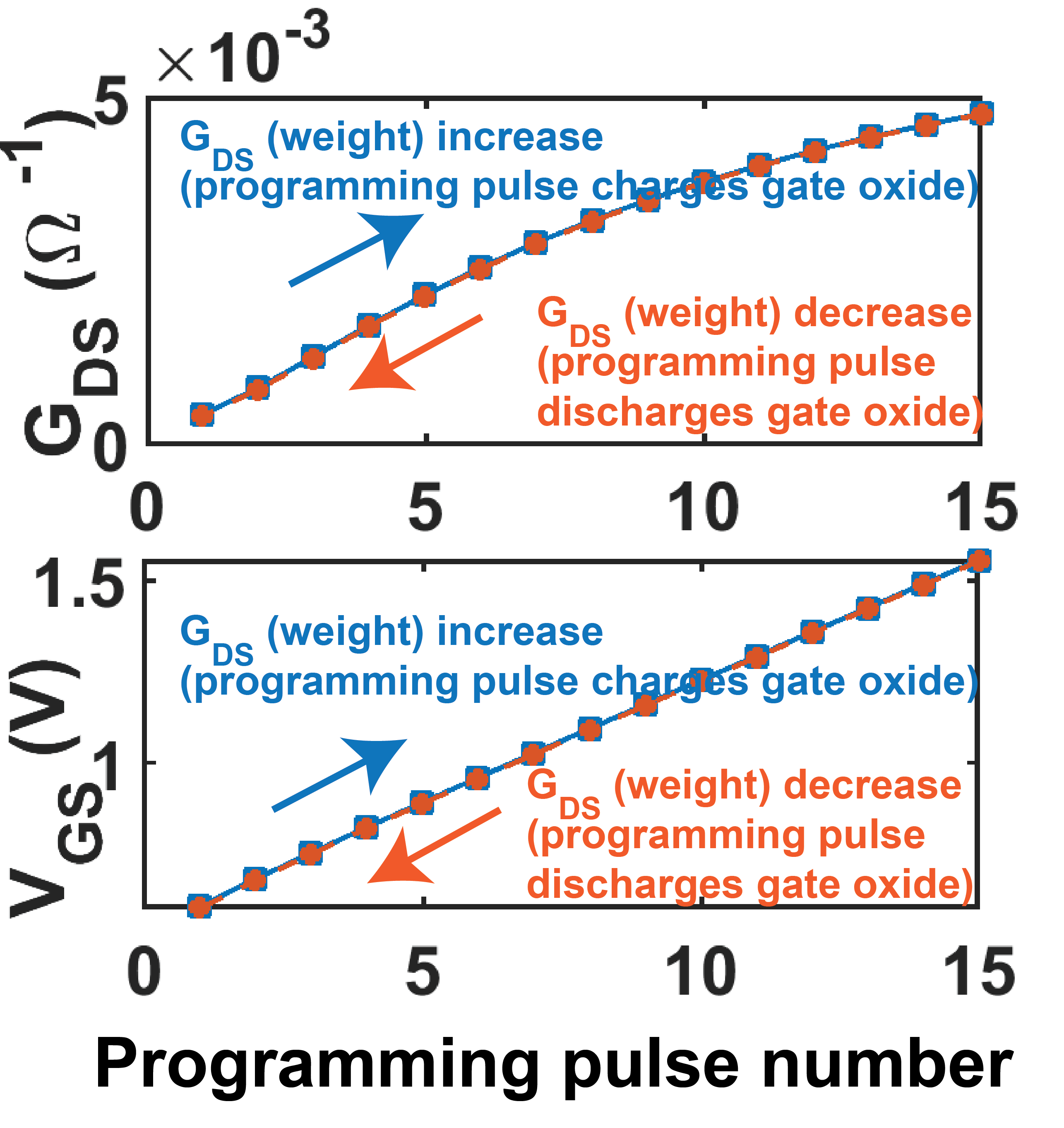 Figure 5
Figure 5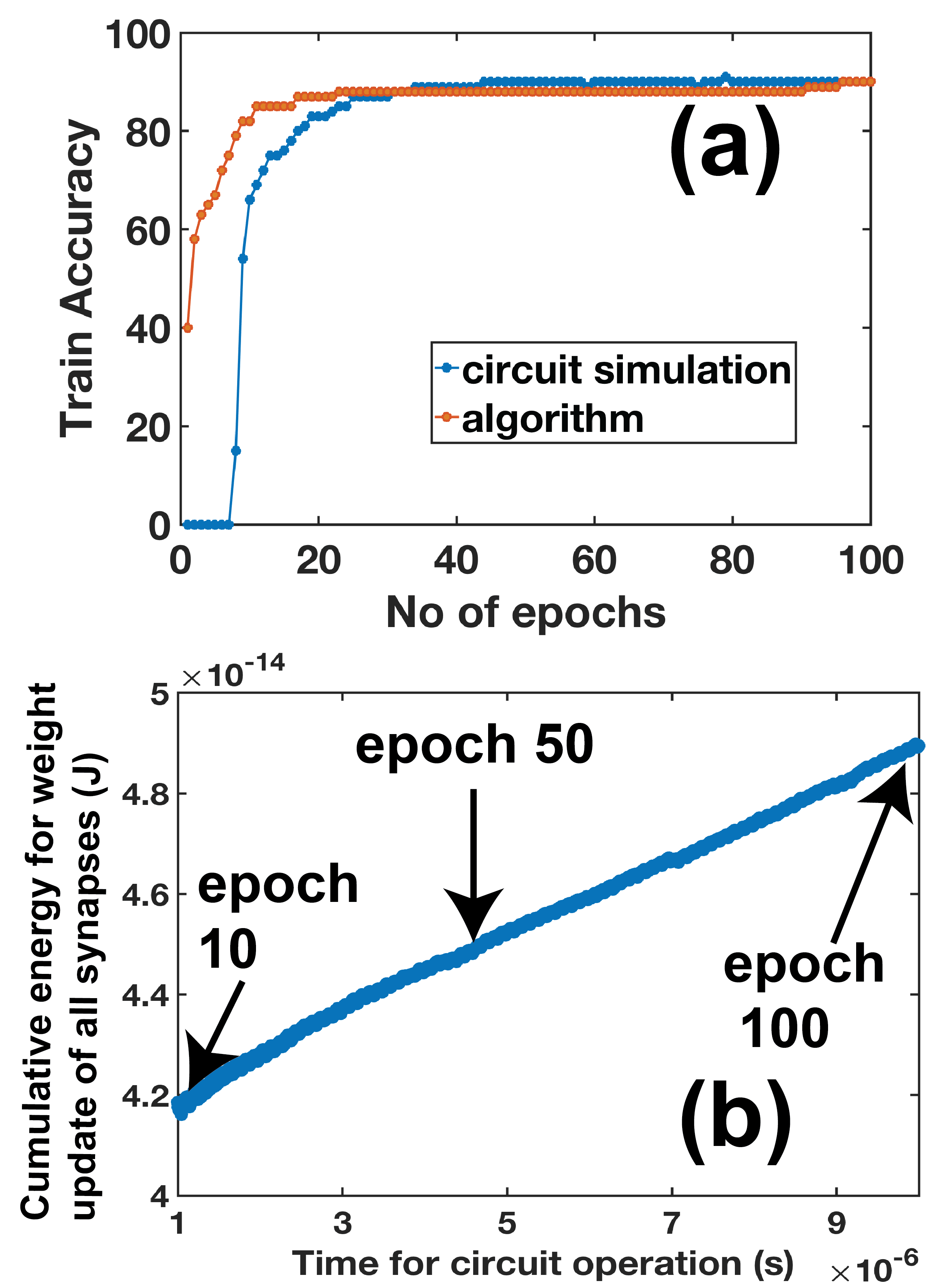 Figure 6
Figure 6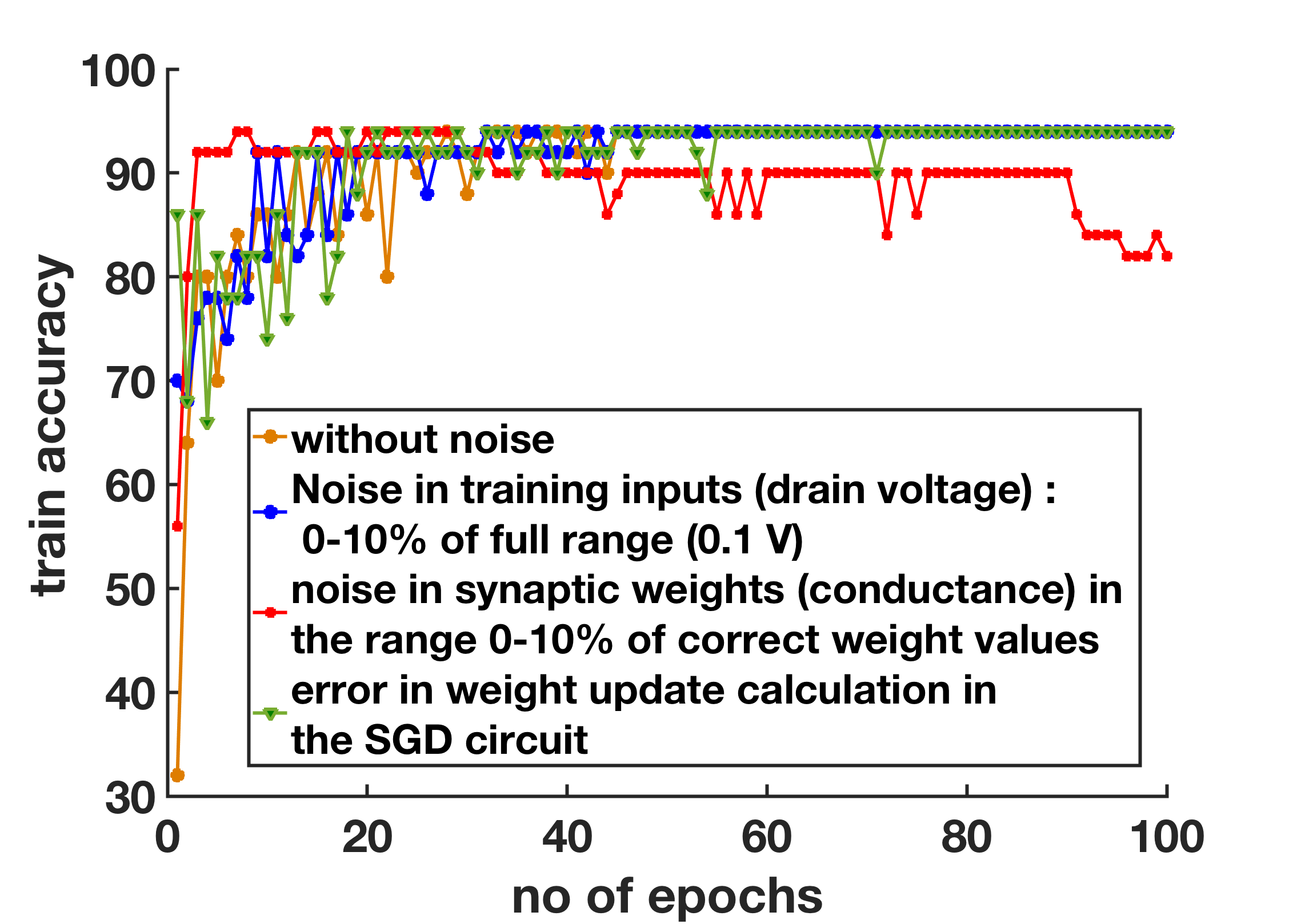 Figure 7
Figure 7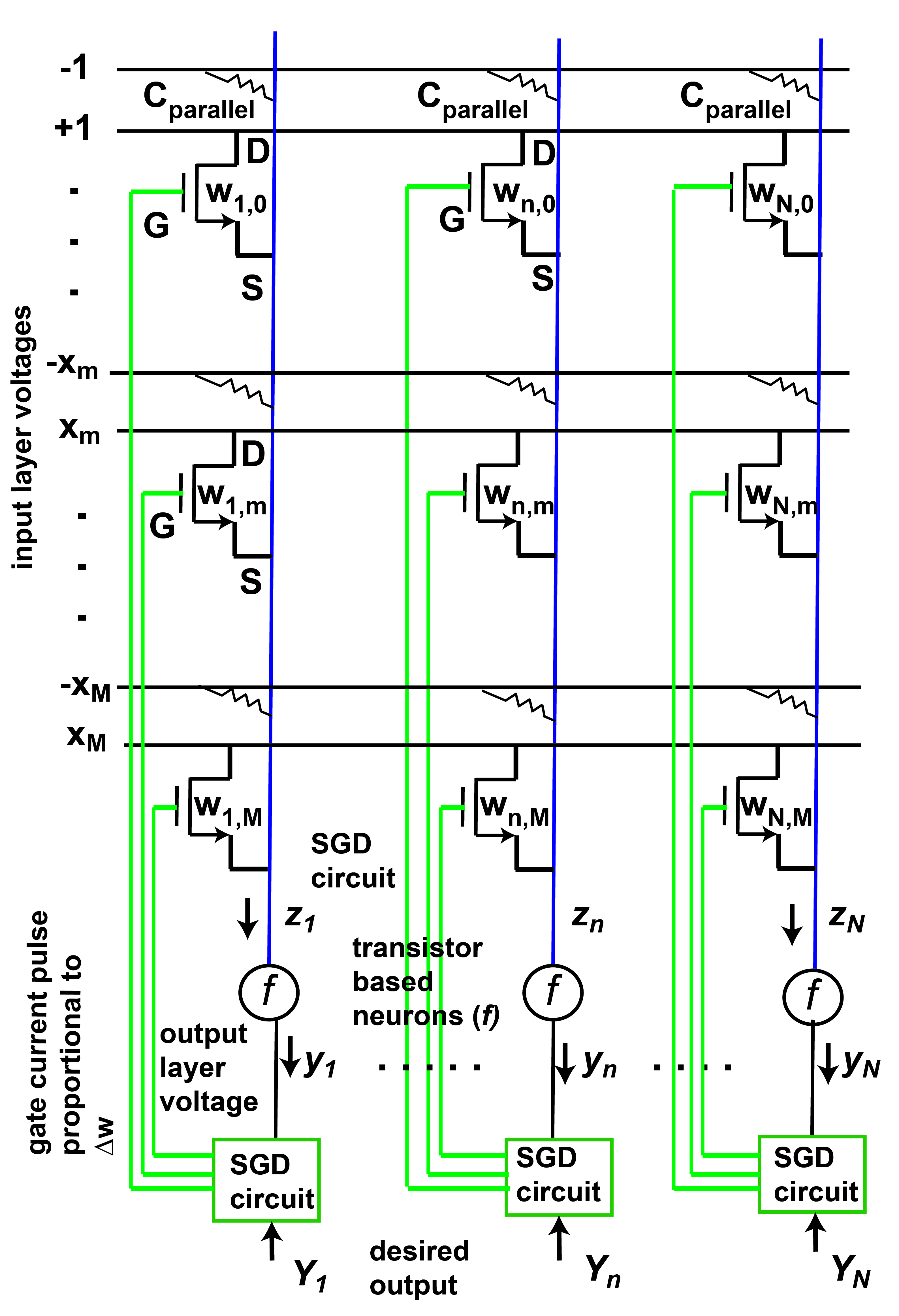 Figure 3
Figure 3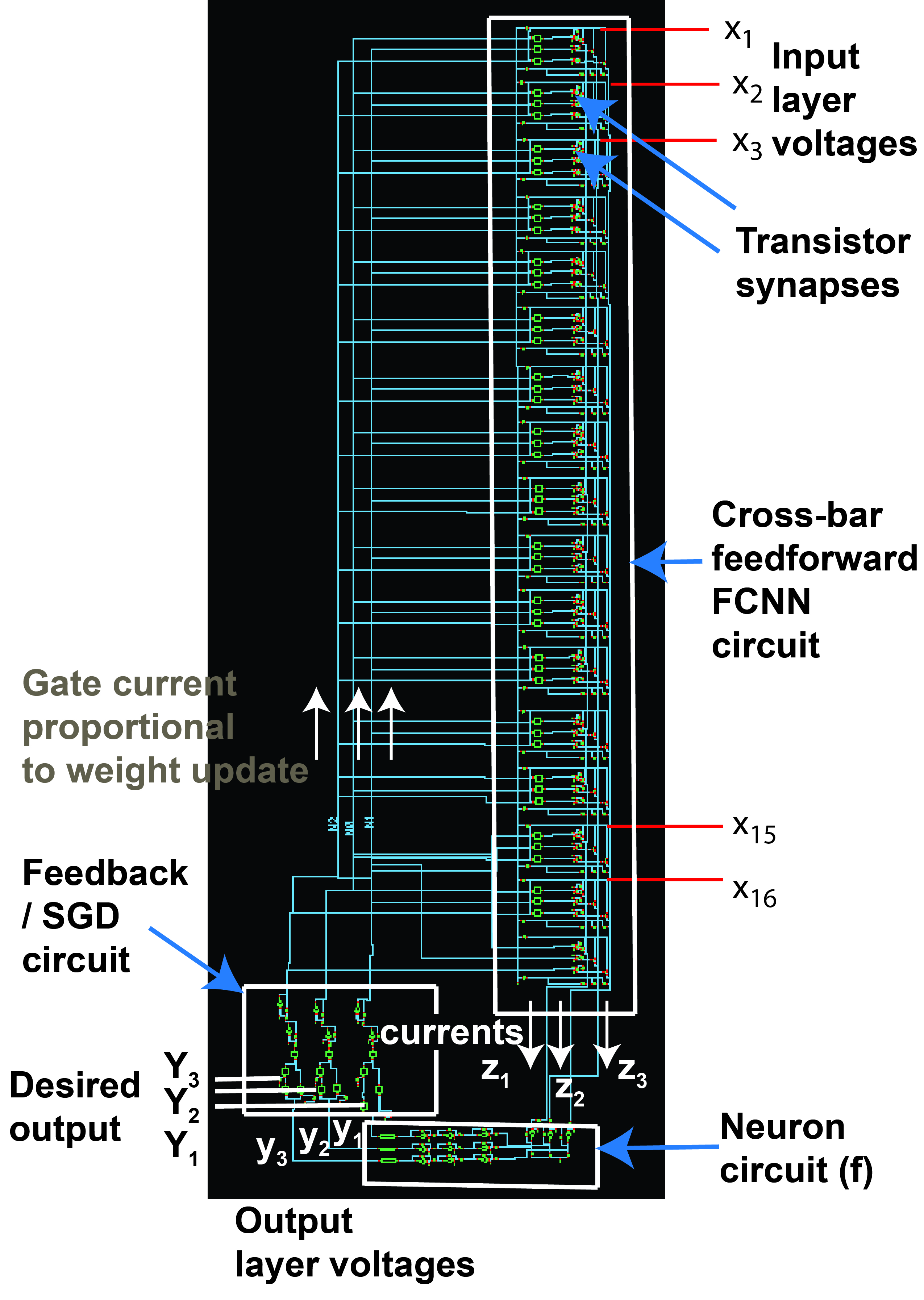 Figure 6
Figure 6| Type of synapse | Time per sample | Total time | Total energy consumed |
| per epoch | for learning | in synapses while learning | |
| Transistor (this work) | 1 ns | 10 s | 50 fJ |
| Domain wall based | 3 ns | 30 s | 9 fJ |
| spintronic device | |||
| Oxide based | between 200 ns (each pulse | variable | 1 J |
| RRAM device | for conductance increase) | ||
| and 6 s (“Reset” pulse) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
On-chip learning in a conventional silicon MOSFET
based Analog Hardware Neural Network
Nilabjo Dey*∗,1*, Janak Sharda*∗,1*, Utkarsh Saxena1,
Divya Kaushik1, Utkarsh Singh2 and Debanjan Bhowmik1
*∗*These authors contributed equally to the work.
1Department of Electrical Engineering,
Indian Institute of Technology Delhi, New Delhi 110016, India,
2Department of Electronics and Communications Engg.,
Delhi Technological University, New Delhi 110042, India
Email: [email protected]
Abstract
On-chip learning in a crossbar array based analog hardware Neural Network (NN) has been shown to have major advantages in terms of speed and energy compared to training NN on a traditional computer. However analog hardware NN proposals and implementations thus far have mostly involved Non Volatile Memory (NVM) devices like Resistive Random Access Memory (RRAM), Phase Change Memory (PCM), spintronic devices or floating gate transistors as synapses. Fabricating systems based on RRAM, PCM or spintronic devices need in-house laboratory facilities and cannot be done through merchant foundries, unlike conventional silicon based CMOS chips. Floating gate transistors need large voltage pulses for weight update, making on-chip learning in such systems energy inefficient. This paper proposes and implements through SPICE simulations on-chip learning in analog hardware NN using only conventional silicon based MOSFETs (without any floating gate) as synapses. We first model the synaptic characteristic of our single transistor synapse using SPICE circuit simulator and benchmark it against experimentally obtained current-voltage characteristics of a transistor. Next we design a Fully Connected Neural Network (FCNN) crossbar array using such transistor synapses. We also design analog peripheral circuits for neuron and synaptic weight update calculation, needed for on-chip learning, again using conventional transistors. Simulating the entire system on SPICE circuit simulator, we obtain high training and test accuracy on the standard Fisher’s Iris dataset, widely used in machine learning. We also account for device variability and noise in the circuit, and show that our circuit still trains on the given dataset. We also compare the speed and energy performance of our transistor based implementation of analog hardware NN with some previous implementations of NN with NVM devices and show comparable performance with respect to on-chip learning. Easy method of fabrication makes hardware NN using our proposed conventional silicon MOSFET really attractive for future implementations.
1 Introduction
Neural network (NN) algorithms are being widely used by the machine learning and data sciences community currently to solve several data classification and regression tasks [1]. However implementing NN on a traditional computer built on von Neumann architecture (memory and computing physically separated) involves continuous transfer of information between the memory and computing units. This von Neumann bottleneck leads to lower performance in terms of speed and energy consumption [2, 3, 4, 5, 6, 7]. Hence researchers have come up with specialized hardware NN implementations to get rid of the von Neumann bottleneck [8, 9, 10, 11]. Among these implementations, analog hardware NN uses a crossbar array of synaptic devices to perform computing at the location of the data itself [5, 6, 12]. The fact that such crossbar array enables execution of Vector Matrix Multiplication (VMM), inherent in a FCNN algorithm, in a parallel fashion makes it suitable both for forward inference [5] or on-chip learning (training in hardware). In fact, on-chip learning in such crossbar array has been considered to be faster and more energy efficient than conventional training of NN on GPU [12].
A synaptic device in a crossbar array based analog hardware NN must have several conductance states that can be controlled electrically to store and update the weight values of the NN. Several Non Volatile Memory (NVM) devices like floating gate transistors, chalcogenide based Phase Change Memory (PCM) devices, oxide based Resistive Random Access Memory (RRAM) devices and spintronic devices have been proposed and used as synaptic devices in previous implementations of analog hardware NN [5, 6, 7, 13, 14, 15, 16, 17, 18, 19]. However, these NVM devices have several issues associated with them with respect to achieving on-chip learning in crossbar arrays made of them. Floating gate transistor synapses need high voltage pulses for weight update and have low endurance [19, 20, 21, 22, 23, 24]. Memristive oxide based Resistive Random Access Memory (RRAM) devices and Phase Change Memory (PCM) devices [16, 17, 18] exhibit an asymmetric/uni-polar and non-linear dependence between conductance (and weight) update and programming pulses, which affects the accuracy during on-chip learning of crossbar arrays that use such devices [5, 25, 26, 27]. Moreover, for fabricating RRAM, PCM or spintronic device based hardware NN systems [5, 7, 28], dedicated in-house fabrication facilities are needed since they involve novel materials. The system cannot be designed in-house and then fabricated elsewhere e.g. in commercial merchant foundries, unlike silicon based conventional CMOS circuits and systems.
Instead if conventional Metal Oxide Semiconductor Field Effect Transistors (MOSFETs) with silicon (Si) as semiconducting material and SiO2 as gate oxide could be used as synaptic elements and analog values of weight could be stored in them, unlike what’s done in an SRAM cell where digital bits are stored, then fabrication of analog hardware NN will be much easier. In this paper, we propose such a conventional MOSFET as a three terminal synaptic element in analog hardware NN. In Section 2, we show through SPICE simulations at 65 nm technology node on Cadence Virtuoso circuit simulator that the conductance between drain and source of the transistor (first and second terminal) can be controlled between several analog values, which represent the weight values, by changing the voltage applied at the gate of the transistor (third terminal) (Fig. 1). We benchmark our data against experimentally measured data on a n-MOSFET present inside a commercially available chip (Fig. 2) Gate voltage can be changed by applying current pulses at the gate and charging/ discharging the gate oxide, as we show in our simulations (Fig. 3). Conductance (weight) vs programming gate current pulse plot is found to be fairly linear and symmetric for positive and negative weight update for our proposed transistor synapse (Fig. 3), unlike PCM and RRAM based synaptic devices in which non-linearity and asymmetry/ unidirectionality in conductance response degrades the overall neural network performance [5, 25, 26, 27].
In Section 3 we design a Fully Connected Neural Network (FCNN) circuit in crossbar topology using such synaptic transistors at 65 nm technology node that carries out the input Vector- weight Matrix Multiplication (VMM), characteristic of FCNN (Fig. 4). We design, using transistor and transistor based op-amps, analog neuron circuit (Figure 5) and Stochastic Gradient Descent (SGD) algorithm [1] based synaptic weight update calculation circuit (Figure 6). This weight update circuit sends current pulses to the gates of the synaptic transistors. These gate current pulses update the weight values of the FCNN (Fig. 3, 4).
In Section 4, using SPICE simulations of the whole system on Cadence Virtuso circuit simulator, we demonstrate on-chip learning in our proposed hardware (Fig. 7) on the Fisher’s Iris dataset- a popular machine learning dataset (Fig. 9) [29]. In Section 5, we next compare the speed and energy performance of our transistor synapse based analog NN against analog implementations of the same through previously proposed NVM devices with respect to on-chip learning on the exact same dataset [17, 25, 30, 49, 31]. Speed and energy consumption are almost equal for our proposed transistor synapse and spintronic (domain wall based) synapse (Table I). Compared to RRAM synapse, speed for transistor synapse is much higher. Also energy is several orders lower (Table I), again because of the asymmetric nature of conductance response of RRAM synapse as opposed to the synaptic nature of the same in transistor synapse. In Section 6, we argue that our proposed transistor synapse based FCNN circuit trains itself even in the presence of synaptic device variability and noise in input voltages.
Thus we show that Si MOSFET synapse can be considered as an attractive candidate for implementation of hardware analog NN. To the best of our knowledge, this is the first proposal and demonstration through simulations of on-chip learning on analog hardware NN using only conventional Si MOSFETs as synapses. It is to be noted that [19, 20, 21, 22] propose synaptic behaviour of MOSFET by using a floating gate. However weight modulation in floating gate synapse is much slower because electrons have to be injected inside the gate through a tunneling mechanism for a change of weight. Also, the voltages needed for such weight update are very large [23].Number of times charge can be injected into/ ejected out of the floating gate is also limited, leading to low endurance [24]. Since weight has to be frequently updated for on-chip learning, floating gate transistor hence doesn’t make for a good synapse. On the other hand, our synaptic MOSFET is conventional, doesn’t have a floating gate and hence doesn’t suffer from those disadvantages.
It is also to be noted that earlier reports of conventional silicon transistor based synapse use multiple transistors to store each bit of the weight value stored in the synapse [32, 33]. On the other hand, analog values of weight are stored in a single transistor in our proposed synapse as different conductance states.
Also, in this paper, we demonstrate the capability of our transistor synapse in a non-spiking network, trained “on-chip” through the much developed Stochastic Gradient Descent (SGD) algorithm benchmarked on several machine learning datasets, as opposed to spiking network which mostly uses Spike Time Dependent Plasticity (STDP) enabled training algorithm [25, 34, 35, 36, 38, 39]. Convergence properties and highly accurate training results have not been demonstrated on large datasets in STDP enabled spiking network algorithms to the extent they have been in SGD based non-spiking network algorithms [36, 37].
2 Characterization of a single conventional MOSFET as a synaptic device
Fig. 1(a) shows schematic of a Si-SiO2 based n-MOSFET we propose as synapse in this paper. We simulate it at the 65 nm technology node through SPICE simulations on Cadence Virtuoso using the United Microelectronics Corporation (UMC) library. Drain current () vs drain to source voltage () characteristic is linear for a certain range of (0 - 0.1 V in this case) for gate to source voltage in between 0.6 V and 1.6 V (Fig. 1(b)). This behavior is expected for conventional MOSFET [40] and matches qualitatively with - characteristic we experimentally measure on a single n-MOSFET present inside the commercially available CD4007 inverter chip and accessible through package terminals (Fig. 2(a)). We operate between 0 and 0.1 V, and between 0.6 and 1.6 V for functioning as synapse throughout this paper.
For any combination of and , ratio of to determines drain to source conductance (), which is a function of both and () (Fig. 1(b)). We observe that for a fixed , change in () is in the order of when varies in the full range we have selected (0 - 0.1 V) (Fig. 1(c)). However, for a fixed when varies in full range (0.6 - 1.6 V), change in is , which is one order higher than change in due to full sweep of . Thus can just be approximated as a function of and not (and in extension ) in the selected range of operation.
Hence we can write
[TABLE]
Experimentally measured data on transistor in CD4007 chip qualitatively matches with this observation (Fig. 2(b),(c)). For a quantitative match, the specifications of the simulated and experimentally measured transistors need to match which has not been the case in this work. When our simulated transistor is used as synapse in input nodes output nodes crossbar array based analog hardware FCNN as shown in Fig. 4(a), input vector- weight matrix multiplication, or VMM operation, takes place as a part of the feedforward computation both for the training phase and testing/ inference phase [5]. During this process, the input vector corresponding to a training sample acts as drain voltages on the transistor synapses as shown in Fig. 4(a). The sources of all the transistor synapses are maintained at 0 V using op-amps at the input stage of the neuron circuits we design (Fig. 5). Thus for a transistor synapse connecting input node with output node , its is proportional to input . If its conductance represents its weight then from equation (1) its drain current turns out to be proportional to . Even when and hence changes during the VMM operation in both training and testing phase of the hardware, as long as stays in the chosen range of 0 and 0.1 V this relation holds true. In any case, since we show training through SPICE simulations of the entire hardware in this paper, any effect of higher order term of drain voltage on the current is taken into account in our analysis and final accuracy results.
Conductance () and hence synaptic weight update is carried out by applying current pulses at the gate of the MOSFET synapse and charging/ discharging the gate oxide. Fig. 3 shows that when pulses of the same current magnitude (132 nA) and same duration (1 ns) with polarity such that gate oxide charges up, gate voltage and hence increases linearly with pulse number (blue plot). Similarly starting from the highest , programming pulses of opposite polarity but of same magnitude and duration discharge the oxide and decreases (orange plot). This linear and symmertrical/bipolar nature of weight update with programming pulse number is not the case in RRAM and PCM based synaptic devices, making implementation of on-chip learning in crossbar arrays made of such synapses quite challenging [5, 25, 26]. Even when a pair of such RRAM or PCM devices is used as a single synapse as has been done before, frequent RESET pulses, which are of long time duration and consume a lot of energy, are still needed to carry out the weight update scheme [18, 25].
The weight update process for our proposed transistor synapse is repeated for every training sample in each epoch to obtain high training accuracy after a certain number of epochs and thus achieve on-chip learning, as we show next.
3 Design of crossbar Fully Connected Neural Network (FCNN) circuit and feedback circuit to train it
Analog crossbar array of our proposed synaptic transistors is designed in Cadence Virtuoso SPICE circuit simulator next to implement a Fully Connected Neural Network (Fig. 4) [1, 41]. If the input layer has nodes and output layer has nodes then for an input vector at the input layer the output vector at the output layer is given by where:
[TABLE]
and
[TABLE]
where is the weight of the synapse connecting input node with output node , is the tanh activation function and is a parameter in the function. As discussed in the previous section, to implement the weight matrix- input vector multiplication of equation (3) in hardware, we map the weight to the conductance between drain and source of MOSFET synapse (). Minimum value of weight corresponds to minimum conductance value and maximum value of weight corresponds to maximum conductance value within the chosen gate voltage range where conductance is almost linearly proportional to gate voltage (Fig. 2(c)). Voltage proportional to input at node () is applied at the drain () of transistor synapse connecting input node with output node (Fig. 4), in the form of a 1ns long pulse corresponding to one training sample. corresponding to maximum value of is 0.1 V. varies little with when is below 0.1 V as seen in our simulations (Fig. 2(b)).
Since weight takes both positive and negative values while conductance is only positive, a resistance is added in parallel to a transistor synapse and voltage proportional to negative of is applied to it (Fig. 4). Thus current proportional to flows between drain and source of the transistor. Currents of all transistors connected to output node add up following Kirchoff’s Current law generating current proportional to in equation (3).
Current proportional to next enters a transistor based analog neuron circuit that executes tanh activation function () of equation (2) [42, 43]. Thus output voltage of neuron circuit corresponds to at output node n (Fig. 5). We design this neuron circuit using a set of pre-amplifiers composed of transistor based op-amps and a transistor based differential amplifier circuit, again on Cadence Virtuoso simulator (Fig. 5(a)). Output voltage vs input current plot (Fig. 5(b)) for the neuron circuit shows desired tanh behavior of equation (1). Hyperparameter () in the function (equation 2) can be adjusted by changing a resistance in the neuron circuit as shown in Fig. 5(a)).
Next this voltage is applied to a transistor based feedback circuit, also analog just like the neuron circuit. This circuit present at every output node updates the weights and trains the network in hardware, or rather accomplishes on-chip learning via Stochastic Gradient Descent (SGD) calculation as discussed below (Fig. 6).
For almost every vector in the input set for which the training is done (training set) the output must match the desired output: , corresponding to the known label/ class that input vector belongs to. In order to do that, the weight matrix need to be updated adopting the Stochastic Gradient Descent (SGD) method through several iterations over the training set.
The error generated at output node is given by:
[TABLE]
Weight of the synapse connecting output node with input node () is updated between iteration and as follows:
[TABLE]
and weight of the bias synapse for output node is updated as follows:
[TABLE]
where is the learning rate and each iteration corresponds to each training sample inside each epoch. Learning rate and the hyperparameter can be adjusted in hardware, by changing the gain of an opamp, using a variable resistor in the “amplifier” block of the SGD calculation circuit (Fig. 6(a)). The SGD circuit has been designed by us on Cadence Virtuoso using transistor and op-amp (made of transistors) based subtractor and multiplier blocks as shown in Fig. 6(b,c,d). The SGD circuit computes the weight update () [49]. Building a subtractor block from op-amp is a standard process in analog electronics [44]. The multiplication operation is carried out with a single transistor making use of the fact that is proportional to times [37].
Since weight of each transistor synapse is proportional to the applied gate to source voltage () (Fig. 1(b)), in order to update the weight at each synapse, from equation (4) and (5) the gate voltage has to be updated as follows:
[TABLE]
The weight update is calculated () by the SGD calculation circuit and generated in the form of a 1 ns long voltage pulse since input voltage pulse is 1ns long, corresponding to a training sample. A voltage controlled current source, working based on the principle of Howland current pump [45], is designed at the output stage. It converts the voltage pulse to 1 ns long programming current pulse. Magnitude of current is proportional to (Fig. 6(a),(d)). The current pulse is applied at the gate of the transistor such that change in gate voltage is proportional to the integral of gate current over time, as shown in the previous section, and is equal to the weight update of equation (6). Such weight update carried out over all transistor synapses over all training samples through several repetitions/ epochs results in on-chip learning of the designed FCNN.
4 Accuracy, energy and speed analysis for on chip learning on Fisher’s Iris dataset
We next do SPICE simulations of the transistor synapse based crossbar FCNN circuit (Fig. 4), neuron circuit (Fig. 5) and SGD based feedback/ weight update circuit (Fig. 6) we design, wired all together as shown in Fig. 4. The corresponding schematic of Fig. 4 on the SPICE simulator (Cadence Virtuoso) is shown in Fig. 7. We carry out on-chip learning for the circuit, following the method described in the previous section, on the Fisher’s Iris dataset- a standard dataset in the machine learning community [29].
There are 16 input nodes in our FCNN circuit (Fig. 7) corresponding to 16 inputs: 4 features of flowers passed through 4 sensors each. [48]: , , , There are 3 output nodes corresponding to 3 possible classes of flowers. For flower of type A, desired output . For flower of type B, desired output . For flower of type C, desired output . The available dataset has total 150 samples, almost equally distributed among types A,B and C. 100 samples are used here for training in each epoch and 50 separate samples are used for final testing to determine test accuracy.
Each sample is trained for 1 ns. Our transistor synapses can be operated at higher speed but magnitude of gate currents for weight updates and hence total energy for training will also go up. So we choose this speed of 1 ns per training sample in an epoch.Training accuracy vs epoch plot is shown in Fig. 8 (a). Accuracy number is obtained by comparing the voltage waveforms at the output nodes, i.e. at the output stage of the neuron circuits (), with the desired waveforms (), from the SPICE simulation of our full neural network circuit shown in Fig. 7 . For every sample, if the output at each of the three nodes is within 40 percent of the desired output then we consider it a success. For about the first five epochs the accuracy is 0. This is because all three output nodes are at 1,1,1 V for all samples. Hence the output is wrong for all the samples. Output for 2nd epoch for example is shown in Fig. 9(a). Around 10th epoch the output nodes start giving correct output and hence accuracy suddenly increases (Fig. 8(a)). Output waveform for 10th epoch is shown in Fig. 9(b). Beyond the 10th epoch, outputs at all nodes gradually start following the desired outputs. Thus accuracy increases with epoch as shown in Fig. 8(a). Output waveform for 100th epoch shows that all output nodes give the same output as desired for 90 samples. Thus after 100 epochs, or 100 x 100 iterations or 10 s, the accuracy(both train and test) (on 100 train samples) is 90 percent which is very similar to algorithm implemented in python code. Thus we have been able to achieve successful on-chip learning of our transistor synapse based analog FCNN circuit in SPICE simulations.
From Fig. 8, by 50th epoch or 5 s, train(and test) accuracy reaches 90 percent(b) and net energy consumed in the synapses is as low as 45 fJ. Energy consumed in 100 epochs is 50 fJ. It is to be noted that energy consumed in analog peripheral circuits is ignored in this calculation. Those circuits can be further optimized to enable ultra low energy on-chip learning on our proposed transistor synapses based analog hardware NN.
5 Comparision of performance of proposed MOSFET synapse with other kinds of synaptic devices
Next we compare the energy and speed performance of on-chip learning on our proposed MOSFET synapse based FCNNN with that on FCNN designed using some other kinds of synaptic devices that have been proposed and implemented elsewhere - spin orbit torque driven domain wall based synapses (spintronic synapses) [7, 49, 50] and memristive oxide based RRAM synapses [51, 52]. For fair comparison between the different synaptic devices, neural networks with the same architecture and number of nodes needs to be designed with different types of devices as synapses and they have to be trained on the same dataset using the same algorithm. Hence we simulate the same 16 input node x 3 output node FCNN circuit of Fig. 7 with transistor synapses, domain wall synapses and RRAM based synapses. We use the same rule for weight update (Fig. 6) to train these three FCNN circuits. Time for training each sample in each epoch (each iteration) during on-chip learning, total time for the learning and energy consumed in the process are listed in Table 1 for the three FCNN circuits. The energy listed includes only energy consumed in the synapses for weight update during on-chip learning.
Our domain wall synapse model is micromagnetic in nature and is calibrated against experiments of current driven domain wall motion in Pt/Co/MgO devices [53, 54]. More details on our method for on-chip learning in domain wall synapse based FCNN circuit can be found in [49]. Time for learning is comparable between transistor synapse FCNN and domain wall synapse FCNN circuit. Energy consumed is approximately 5 times higher for transistor synapses compared to domain wall synapses (Table I). However our transistor synapses are much easier to fabricate because they involve conventional silicon MOSFET, which is not the case with domain wall synapses which needs magnetic materials sputtered under specific conditions so that they exhibit perpendicular magnetic anisotropy and high Dzyoloshinski Moriya interaction [28, 53, 54].
Speed and energy performance of our designed transistor synapses based NN is also compared with similar NN designed using HfOx based RRAM synapse (Verilog model from [51] used in our simulation) with respect to on-chip learning on the same Fisher’s Iris dataset in Table I. Though two RRAM devices are used per synapse in our simulation to address the asymmetry issue in conductance response [18, 25, 52], several long duration (6 s) “Reset” pulses are still needed for successful weight update [25]. Hence a lot of energy is consumed for RRAM based NN compared to our transistor synapse based NN which doesn’t have that issue, as explained earlier [25]. Also, since “Reset” pulse may or may not be needed for a particular synapse while training the NN on each sample in each epoch, the net time for training varies in the case of RRAM based NN in our weight update scheme. But time for training RRAM synapse based NN is certainly longer than our proposed transistor synapse based NN since even one “Reset” pulse is about a s long while any pulse to increase or decrease weight in our transistor synapse is just 1 ns long, owing to its linear, bipolar synaptic characteristic (Fig. 3). Also, fabricating a RRAM based device requires in-house facilities and cannot be fabricated as easily as our proposed transistor synapse.
.
6 Device variability, noise in circuit voltages and retention of weights
Since there can be device level variations among the different transistor synapses, their weights can vary from the values calculated by the weight update circuit. Considering noise in the range of 0-10 percent for all the synaptic weights, train accuracy still turns out to be almost the same as ideal transistor synapses from our calculation (Fig. 10). This agrees with the observation in PCM synapse based FCNN, trained on-chip by similar gradient descent algorithm, that accuracy does not depend much on device stochasticity [25]. Similarly, we observe that noise in the training inputs through the drain voltages (Fig. 4) or error in weight update calculation up to 10 percent in the designed peripheral circuit does not affect the overall training accuracy much (Fig. 10).
Though linear synaptic characteristic and easy, well developed method of fabrication are the two main advantages of our proposed transistor synapse compared to RRAM, PCM or spintronic synapses, unlike those Non Volatile Memory (NVM) based synapses, our proposed transistor based synapses do not retain their weights for a very long time. Our SPICE simulations show that once on-chip learning is achieved in the designed transistor synapse based NN circuit (Fig. 4) and training inputs are stopped from being fed, the synaptic weights decay in about 1 ms. This is because the weight is proportional to the conductance, which is in turn proportional to the gate voltage. As the gate oxide capacitance of the synapse discharges, gate voltage drops and hence the correct weight value is lost with time. However, the retention time is times higher than time for training each sample in an epoch (1 ns). For that retention factor, on-chip learning can still be achieved as argued in [46, 47] and seen in our simulations (Fig. 8). However this means that our proposed transistor synapse based NN is not suitable for applications where the training is done in a traditional computer and only testing/ inference is done in hardware (off-chip learning). On the other hand, in applications where training and testing both need to be done in hardware, our proposed system provides an easily fabricable platform for training in hardware (on-chip learning) as opposed to PCM or RRAM synapse based NN ([5]) and does not need high voltage for weight update like floating gate synapse based NN. For testing/inference after a certain time duration from training, the proposed solution is to store the final weights after training in a floating gate synapse based NN for testing purposes, where this needs to be done only once and thereby the endurance and energy consumption issues in writing weight values on floating gate synapses do not become major bottleneck [23, 24].
7 Conclusion
Thus in this paper we have proposed a new functionality of conventional Si-SiO2 based MOSFET as synaptic device in analog hardware NN. No floating gate is present in the synapse unlike previous proposals. Through SPICE simulations we demonstrate successful on-chip learning on Fisher’s Iris dataset and compare its energy and speed performance with other implemenations of analog hardware FCNN with previously proposed spintronic and oxide based RRAM synapses. Easy means of fabrication through established silicon based merchant foundries and linear, bipolar synaptic characteristics make our MOSFET synapse a potential candidate for implementation of analog hardware NN in the near future.
Acknowledgment
The authors would like to thank Rajinder Singh Deol and Madhusudan Singh for help with the experimental measurement, and Apoorv Dankar, Anand Kumar Verma, Shouri Chatterjee and Ankesh Jain for help with the simulations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Y. Le Cun et al. , Nature, vol. 521, pp 436-444, 2015.
- 2[2] J. Misra and I. Saha, Neurocomputing, vol. 74, pp. 239-255, 2010.
- 3[3] C. D. Schuman et al. , arxiv. 1705.06963 v 1.
- 4[4] K. Boahen, Computing in Science & Engineering, vol. 19, no. 2, 2017.
- 5[5] H. Tsai et al. , J. Phys. D: Appl. Phys. vol. 51, no. 283001, 2018.
- 6[6] A. Sebastian et al. , J. Appl. Phys. vol. 124, no. 111101, 2018.
- 7[7] A. Sengupta et al. , IEEE Transactions on Circuits and Systems- I, vol. 63, no. 12, 2016.
- 8[8] P. A. Merolla et al. , Science vol. 345, no. 6197, pp. 668-697, 2014.