TL;DR
This paper introduces a neural network architecture for nested NER that merges tokens into nested structures and labels them independently, achieving state-of-the-art results on ACE 2005 with improved F1 scores.
Contribution
The novel merge and label neural network architecture effectively handles nested NER structures and outperforms previous methods on benchmark datasets.
Findings
Achieves 74.6 F1 on ACE 2005
Improves to 82.4 F1 with BERT embeddings
Maintains performance on flat NER tasks
Abstract
Named entity recognition (NER) is one of the best studied tasks in natural language processing. However, most approaches are not capable of handling nested structures which are common in many applications. In this paper we introduce a novel neural network architecture that first merges tokens and/or entities into entities forming nested structures, and then labels each of them independently. Unlike previous work, our merge and label approach predicts real-valued instead of discrete segmentation structures, which allow it to combine word and nested entity embeddings while maintaining differentiability. %which smoothly groups entities into single vectors across multiple levels. We evaluate our approach using the ACE 2005 Corpus, where it achieves state-of-the-art F1 of 74.6, further improved with contextual embeddings (BERT) to 82.4, an overall improvement of close to 8 F1 points over…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6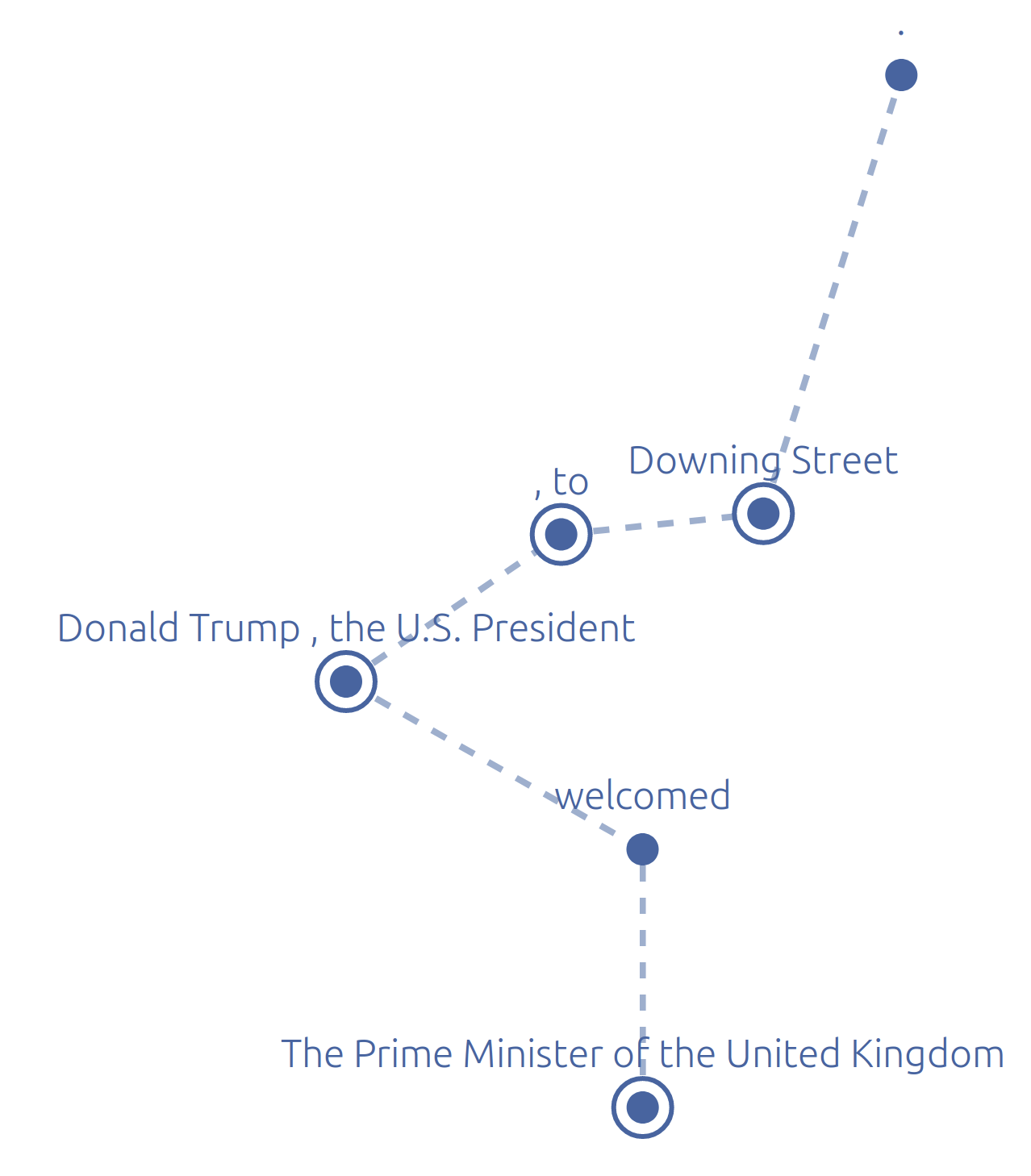 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10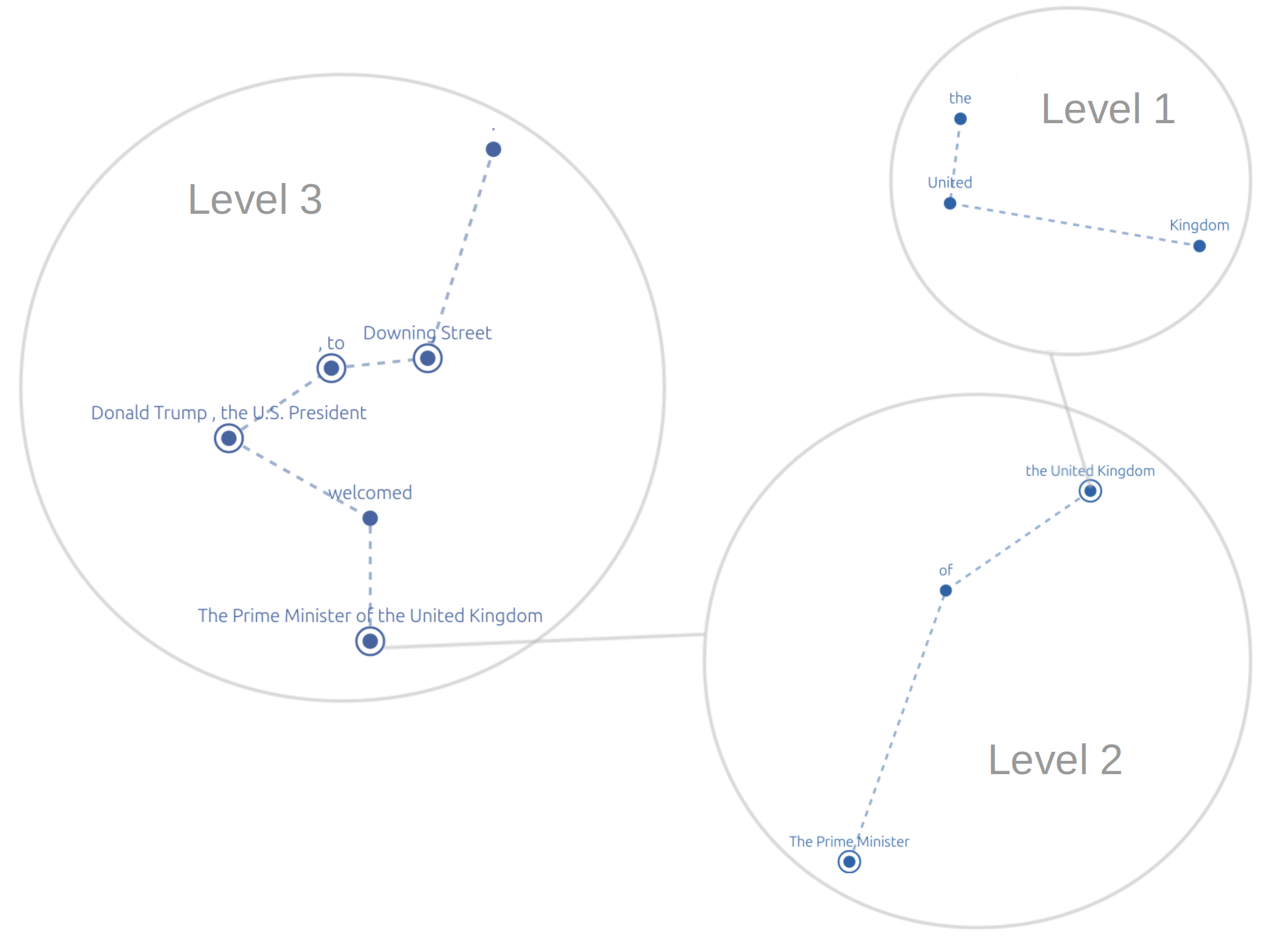 Figure 11
Figure 11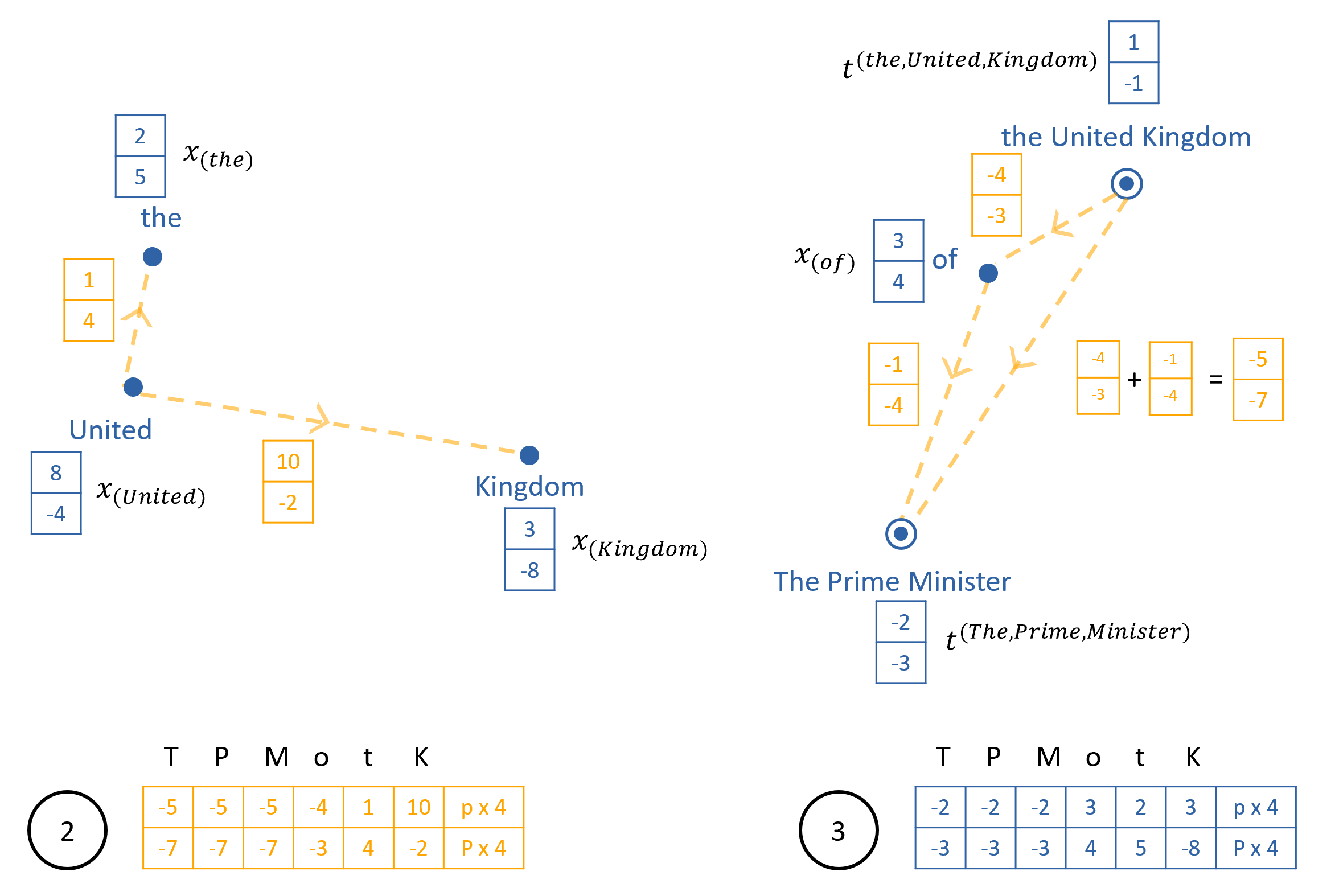 Figure 12
Figure 12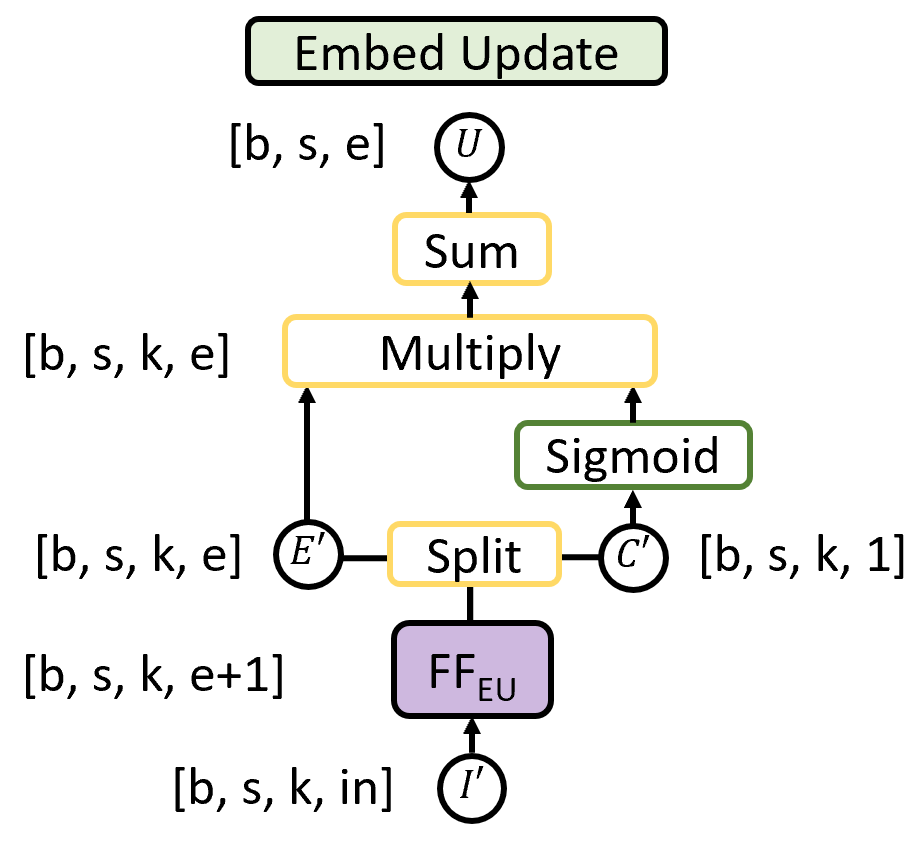 Figure 13
Figure 13 Figure 14
Figure 14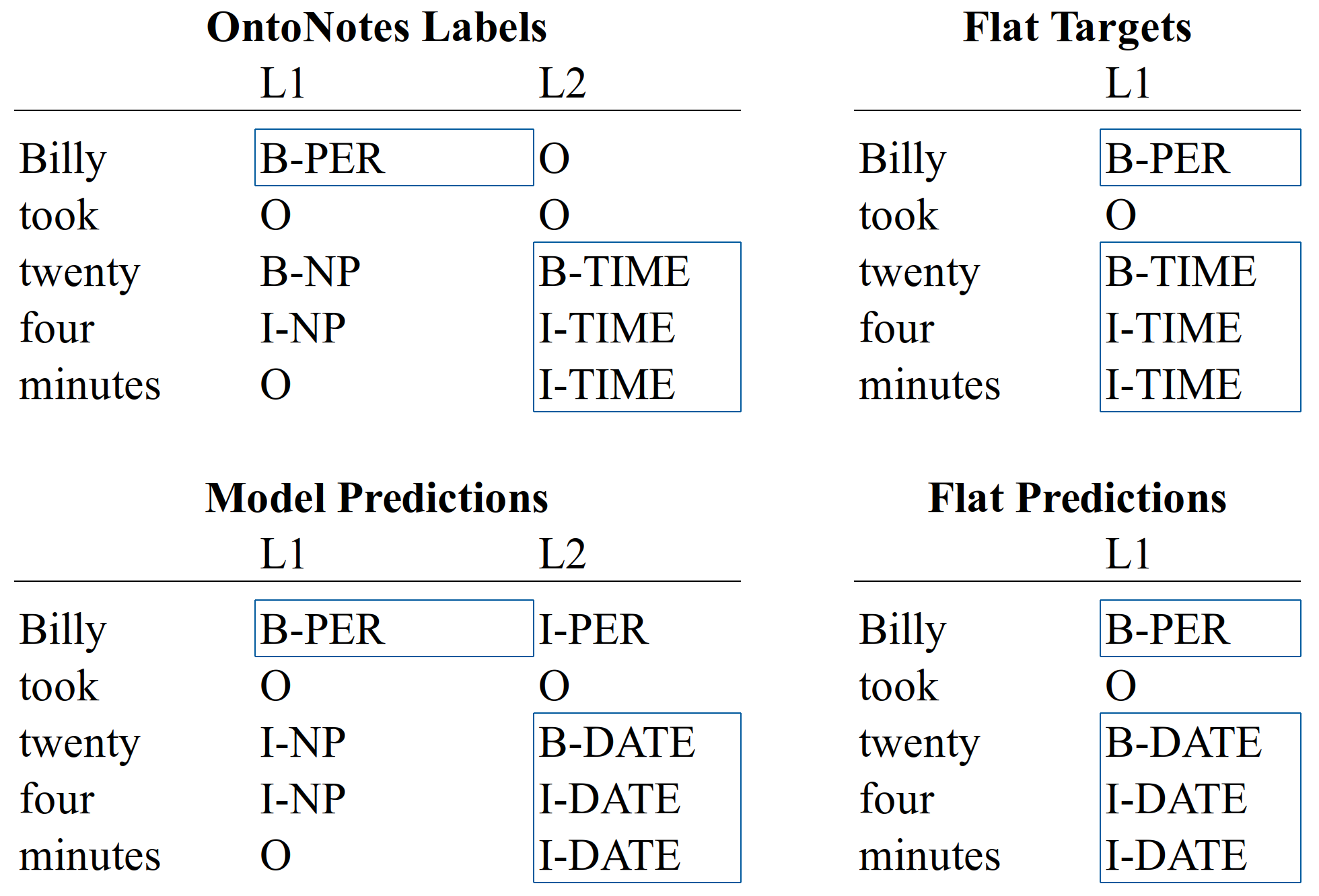 Figure 15
Figure 15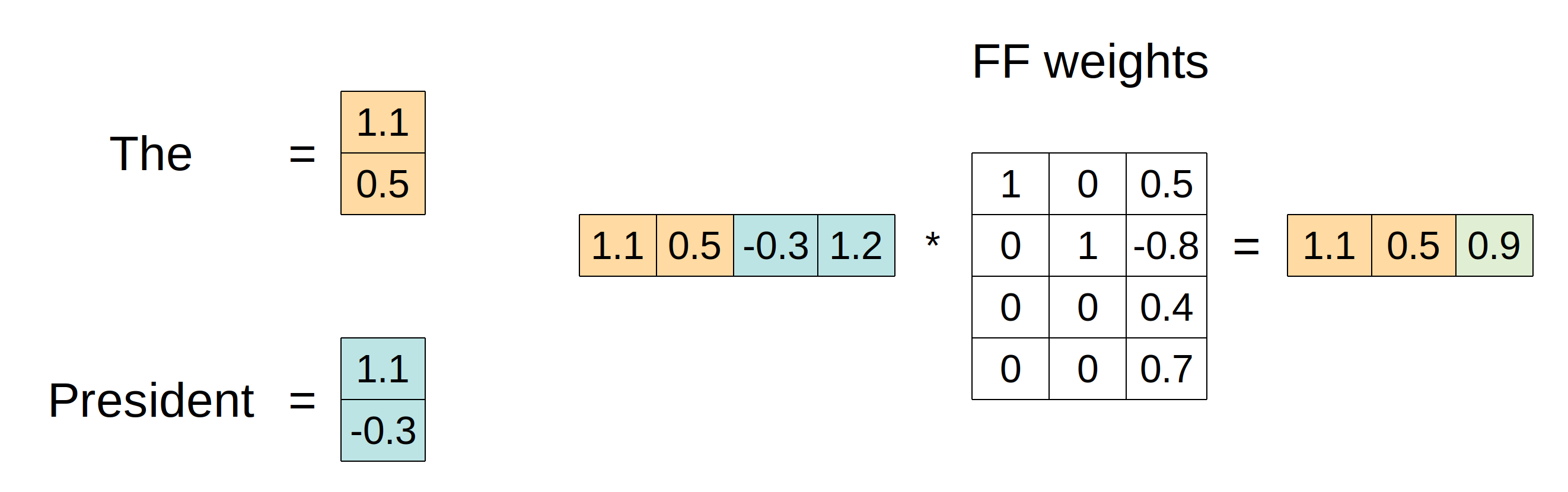 Figure 16
Figure 16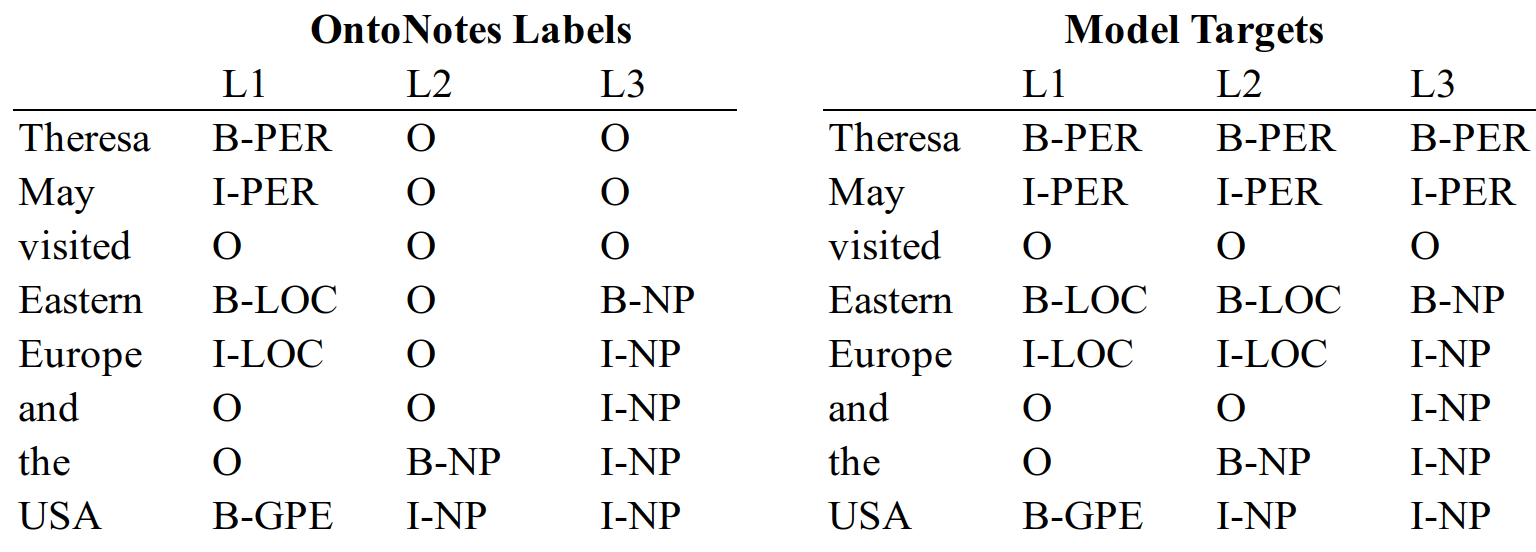 Figure 17
Figure 17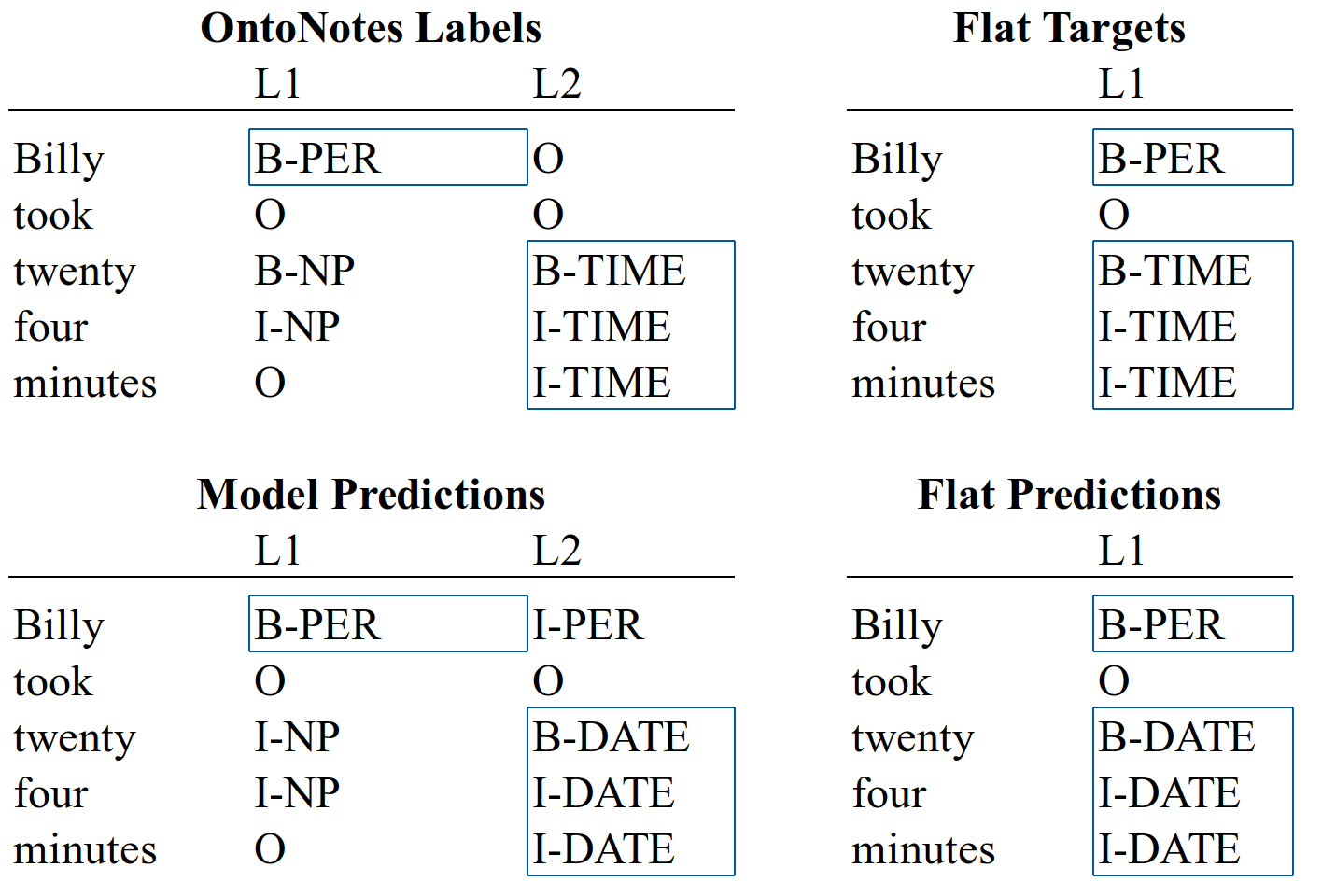 Figure 18
Figure 18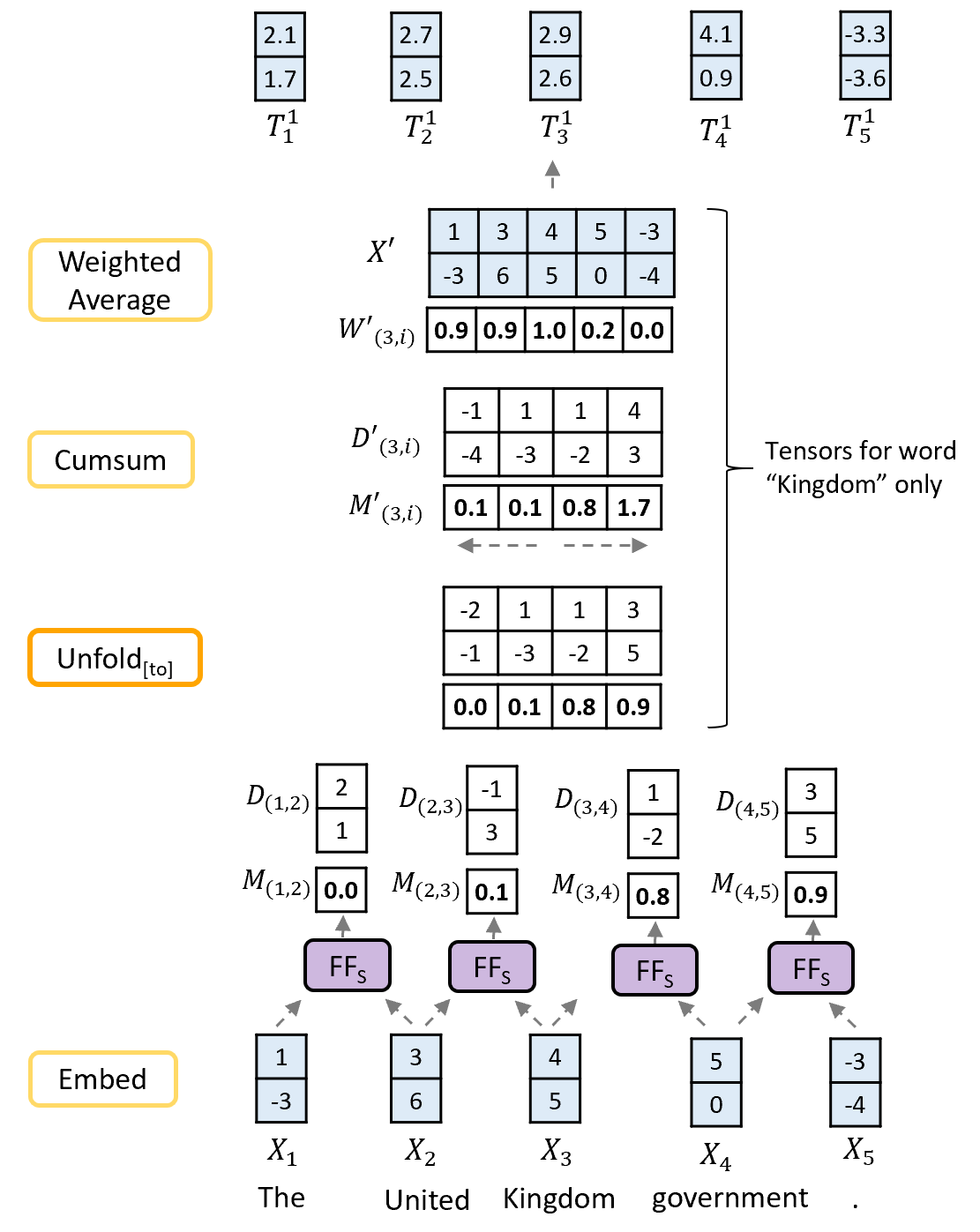 Figure 19
Figure 19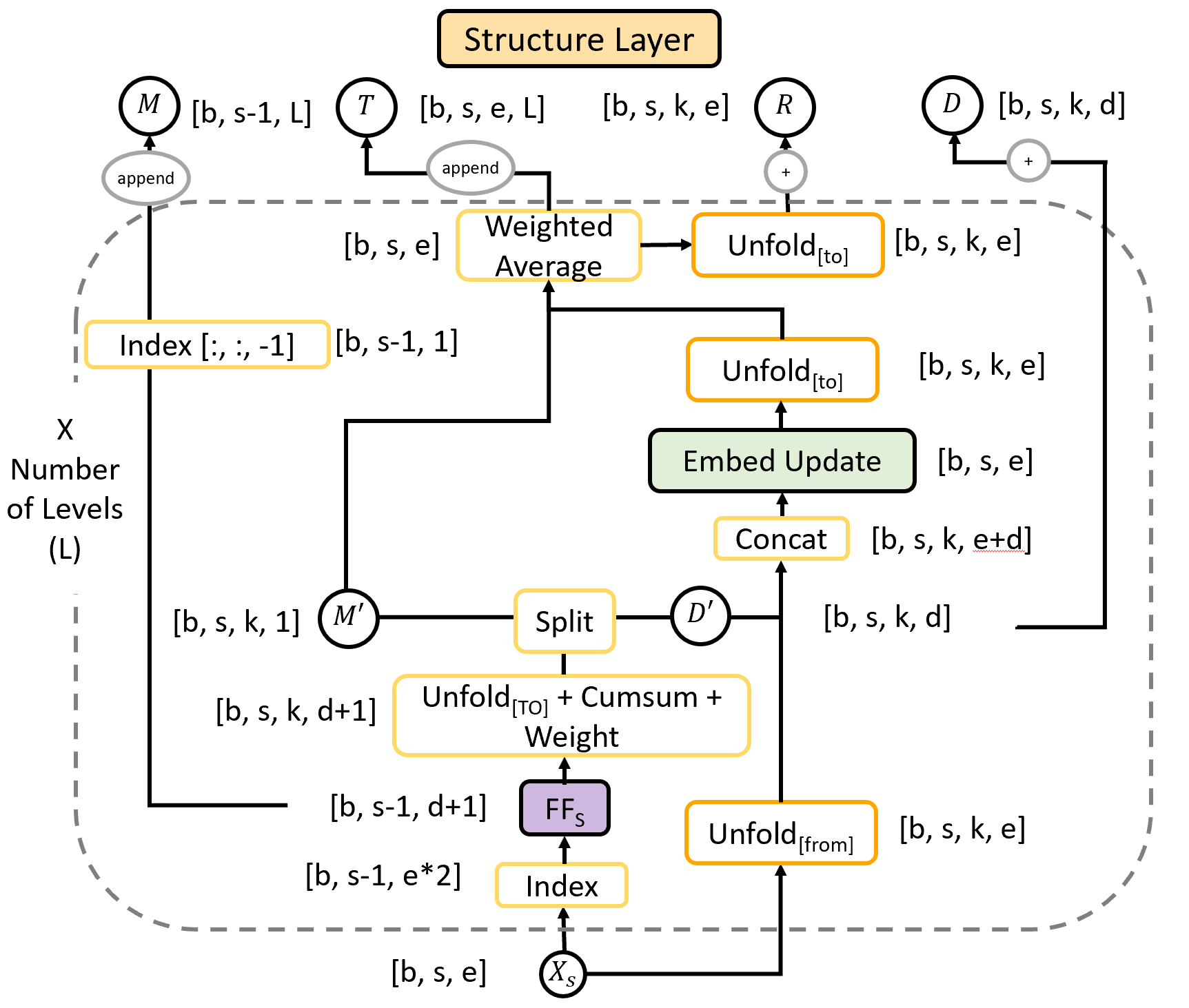 Figure 20
Figure 20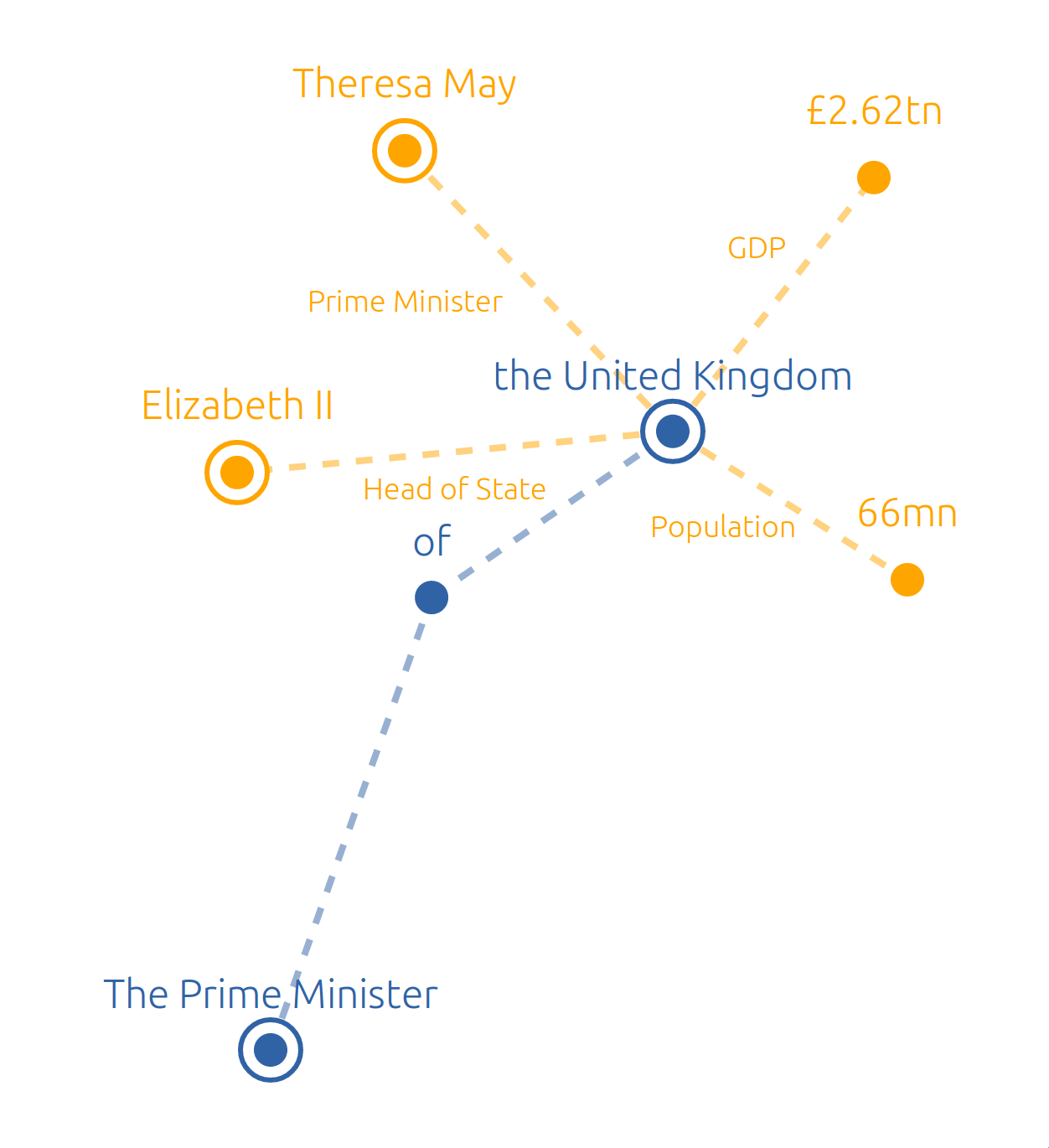 Figure 21
Figure 21 Figure 22
Figure 22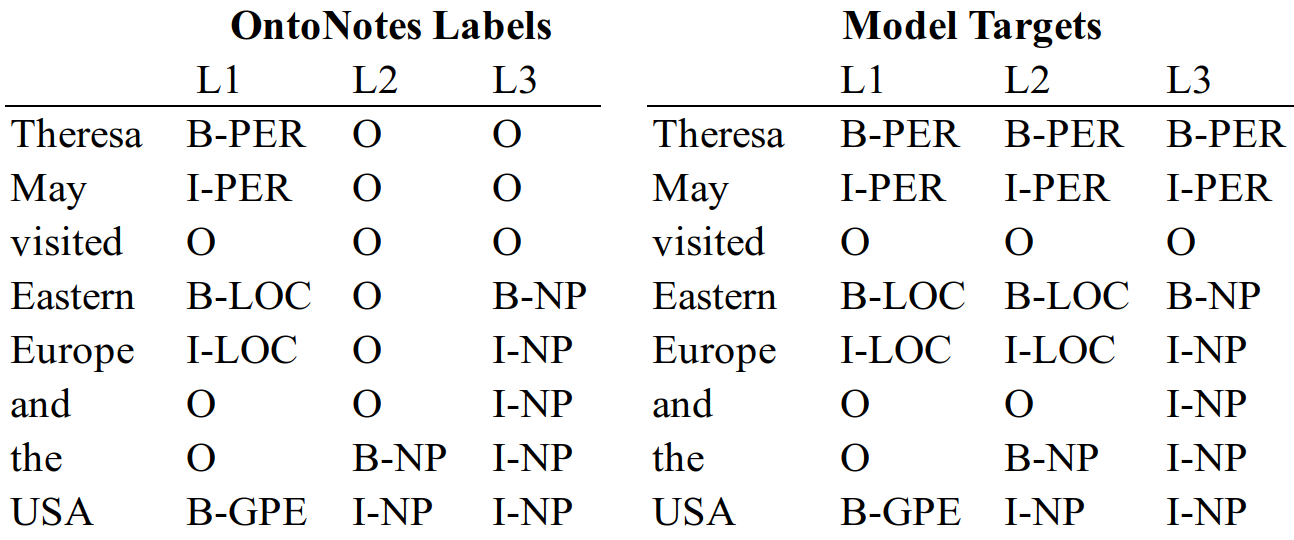 Figure 23
Figure 23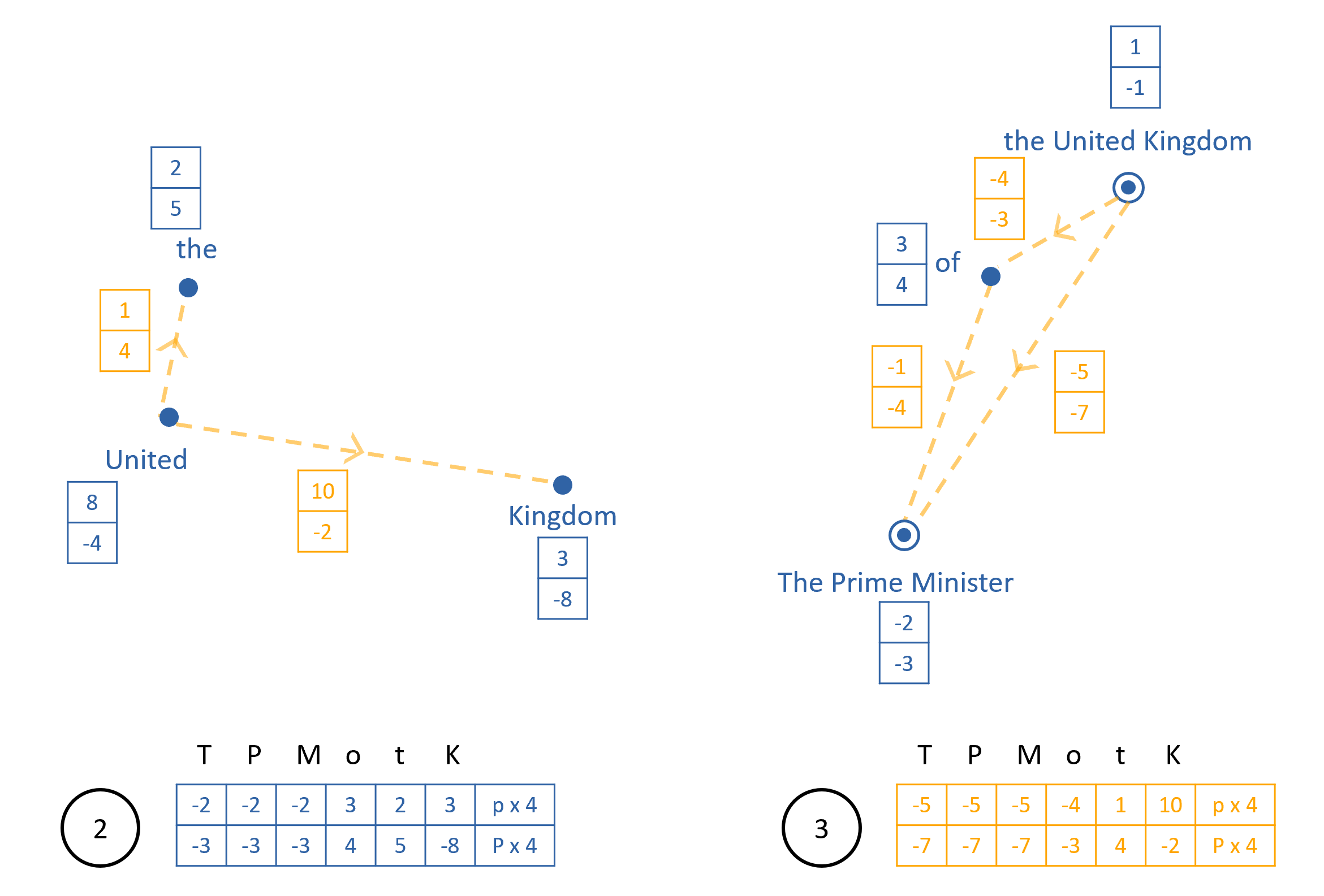 Figure 24
Figure 24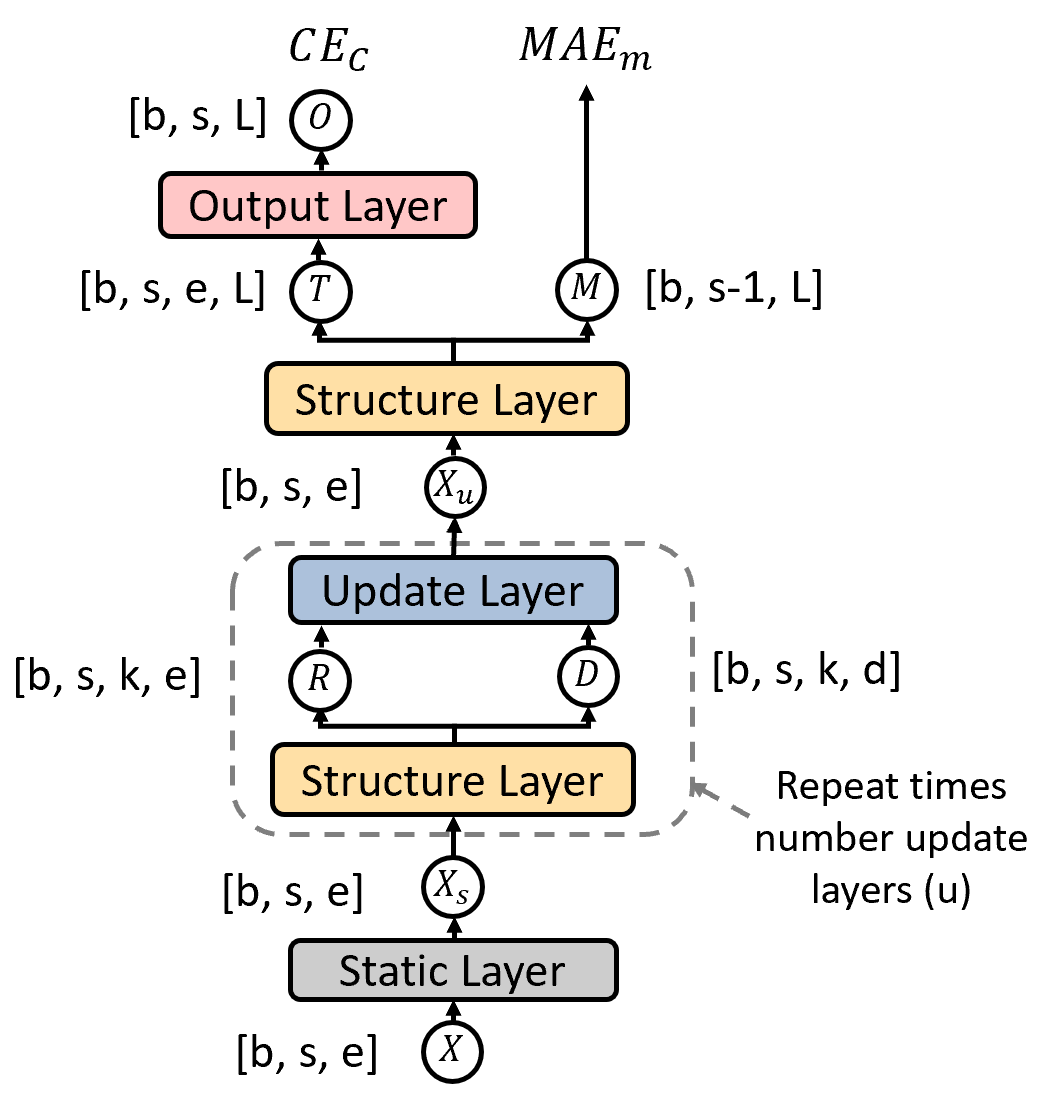 Figure 25
Figure 25 Figure 26
Figure 26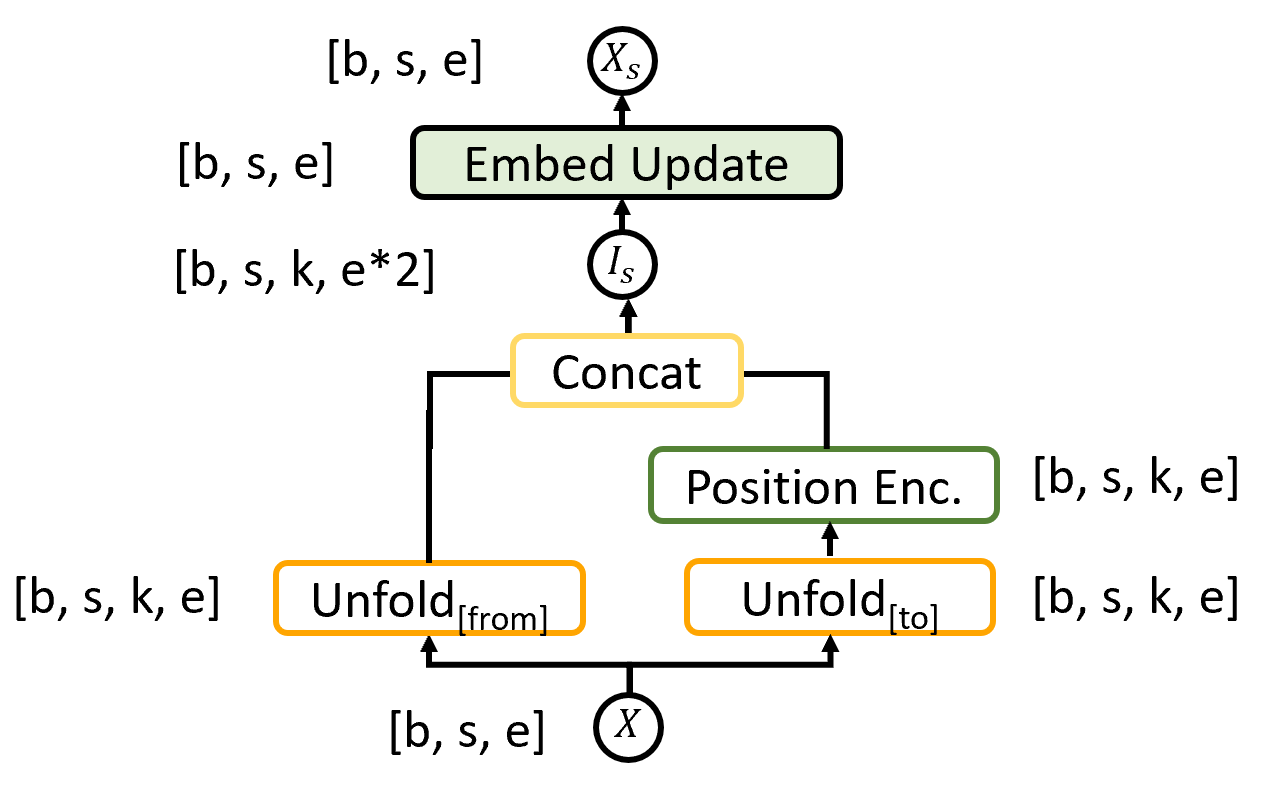 Figure 27
Figure 27 Figure 28
Figure 28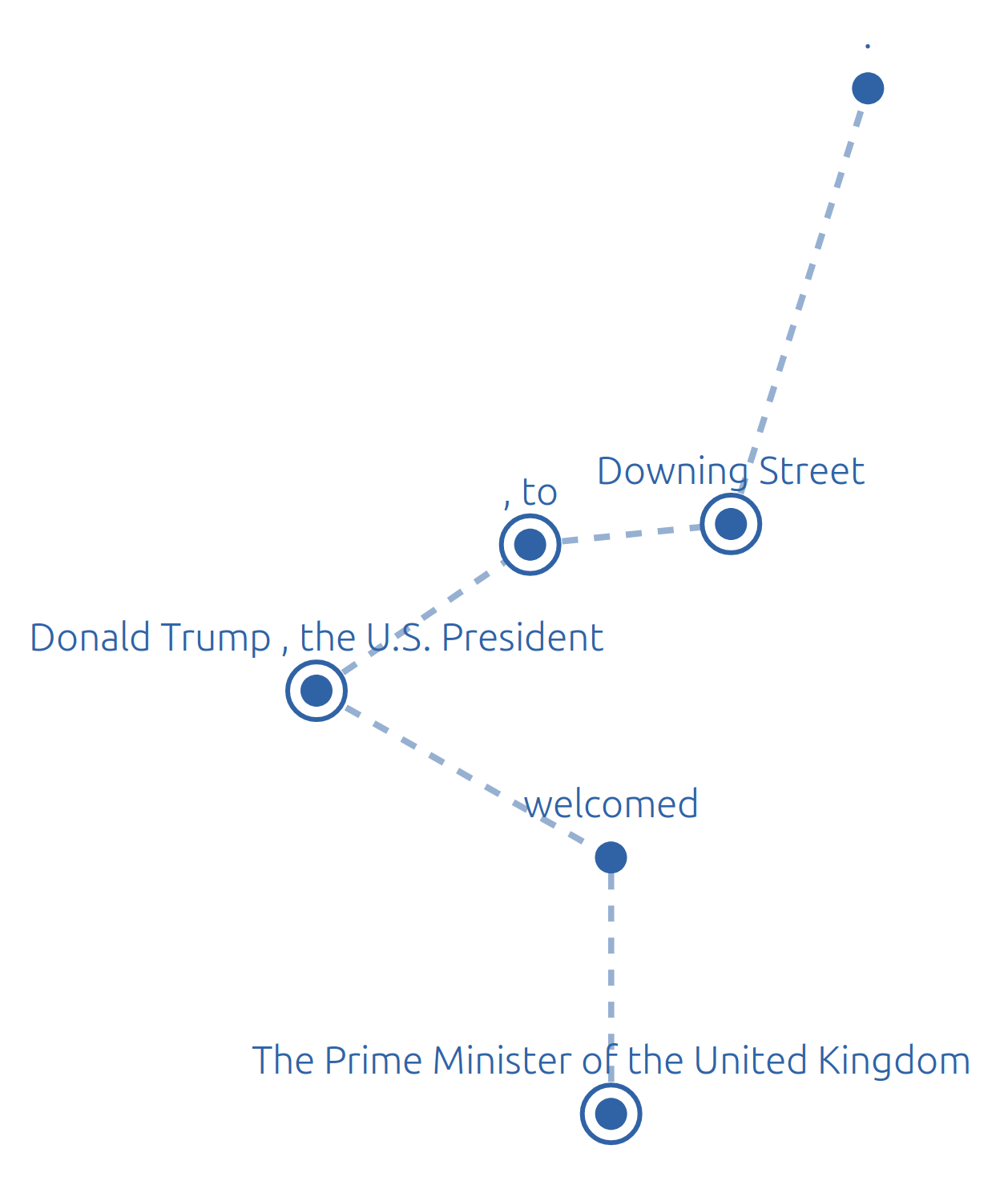 Figure 29
Figure 29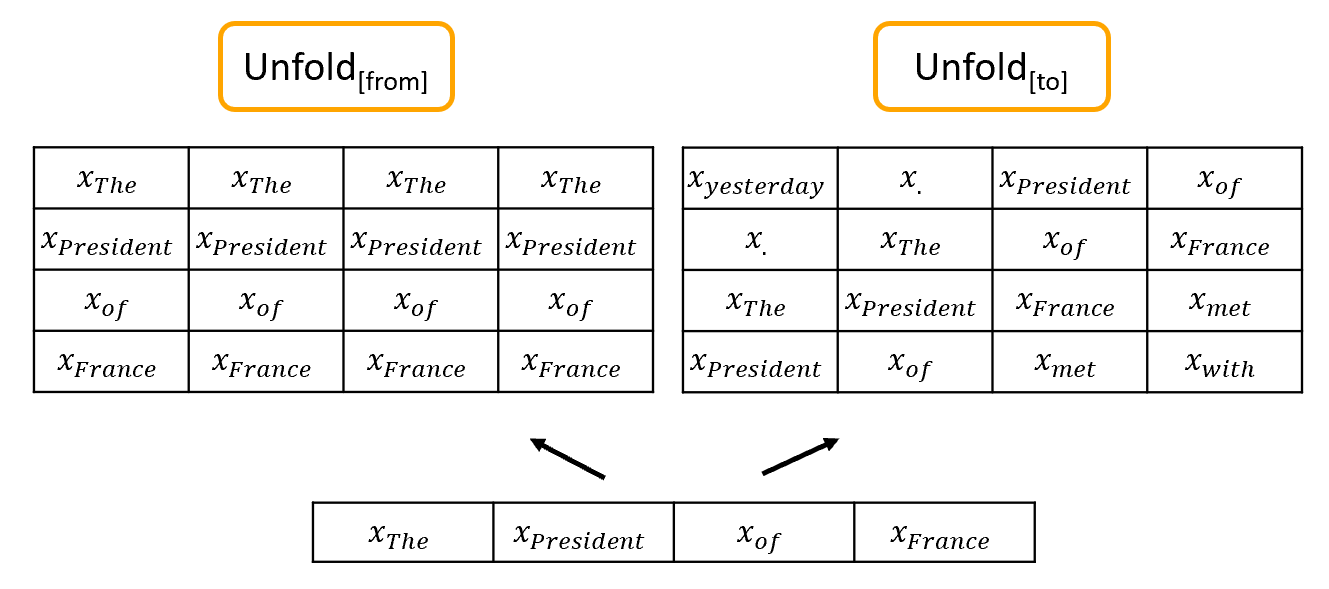 Figure 30
Figure 30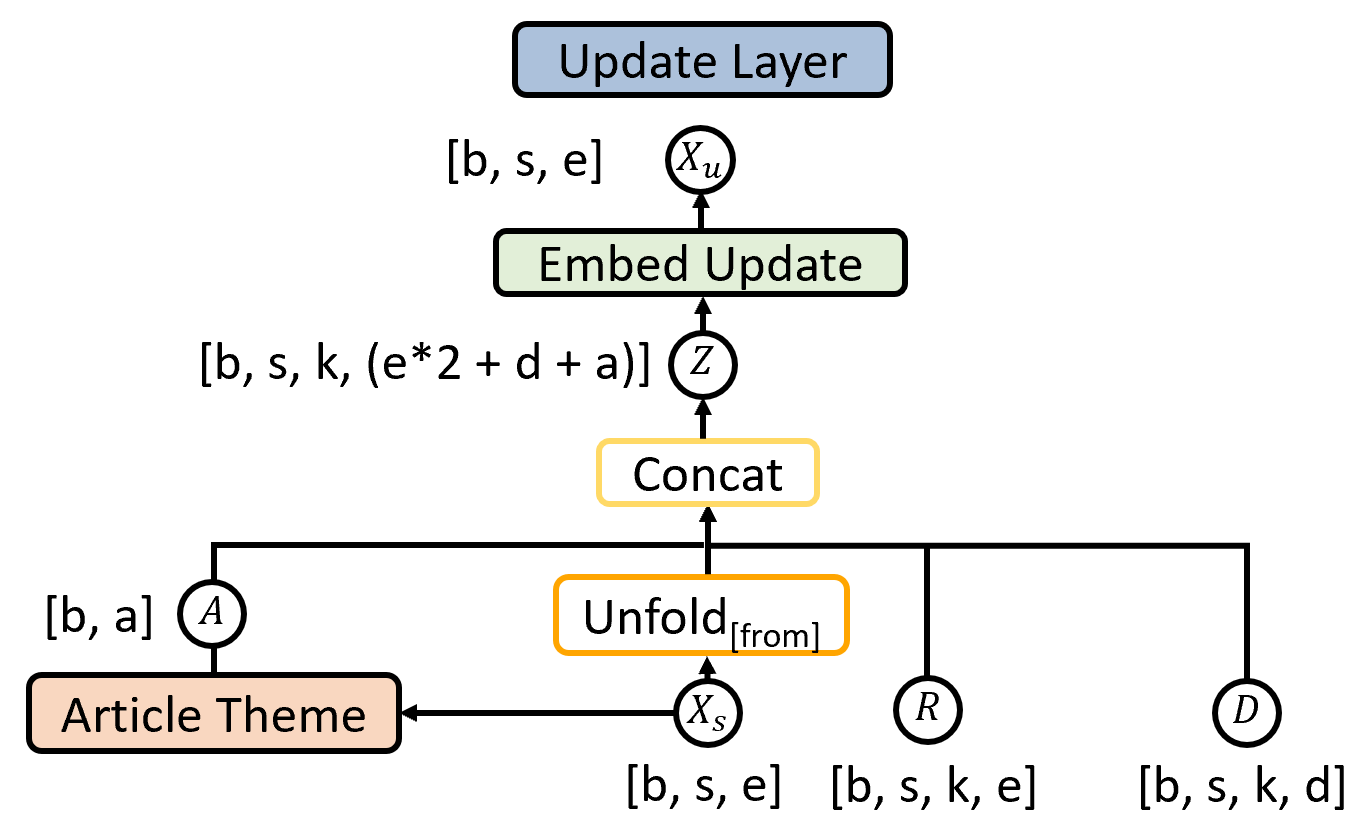 Figure 31
Figure 31| Model | Pr. | Rec. | F1 |
| Multigraph + MS Muis and Lu (2017) | 69.1 | 58.1 | 63.1 |
| RNN + hyp Katiyar and Cardie (2018) | 70.6 | 70.4 | 70.5 |
| BiLSTM-CRF stacked Ju et al. (2018) | 74.2 | 70.3 | 72.2 |
| LSTM + forest [POS] Wang et al. (2018) | 74.5 | 71.5 | 73.0 |
| Segm. hyp [POS] Wang and Lu (2018) | 76.8 | 72.3 | 74.5 |
| Merge and Label | 75.1 | 74.1 | 74.6 |
| LM embeddings | |||
| Merge and Label [ELMO] | 79.7 | 78.0 | 78.9 |
| Merge and Label [BERT] | 82.7 | 82.1 | 82.4 |
| LM + OntoNotes | |||
| DyGIE Luan et al. (2019) | 82.9 |
| Model | F1 |
|---|---|
| BiLSTM-CRF Chiu and Nichols (2016) | 86.28 |
| ID-CNN Strubell et al. (2017) | 86.84 |
| BiLSTM-CRF Strubell et al. (2017) | 86.99 |
| Merge and Label | 87.59 |
| LM embeddings or extra data | |
| BiLSTM-CRF lex Ghaddar and Langlais (2018) | 87.95 |
| BiLSTM-CRF with CVT Clark et al. (2018) | 88.81 |
| Merge and Label [BERT] | 89.20 |
| BiLSTM-CRF Flair Akbik et al. (2018) | 89.71 |
| the United Kingdom | Arab Foreign Ministers | Israeli Prime Minister Ehud Barak |
|---|---|---|
| the United States | Palestinian leaders | Italian President Francesco Cossiga |
| the Tanzania United Republic | Yemeni authorities | French Foreign Minister Hubert Vedrine |
| the Soviet Union | Palestinian security officials | Palestinian leader Yasser Arafat |
| the United Arab Emirates | Israeli officials | Iraqi leader Saddam Hussein |
| the Hungary Republic | Canadian auto workers | Likud opposition leader Ariel Sharon |
| Myanmar | Palestinian sources | UN Secretary General Kofi Annan |
| Shanghai | many Jewish voters | Russian President Vladimir Putin |
| China | Lebanese Christian lawmakers | Syrian Foreign Minister Faruq al - Shara |
| Syria | Israeli and Palestinian negotiators | PLO leader Arafat |
| the Kyrgystan Republic | A Canadian bank | Libyan leader Muammar Gaddafi |
| ACE05 | OntoNotes | |
|---|---|---|
| Static Layer | ||
| with | 74.6 | 87.59 |
| without | 73.1 | 85.22 |
| Embed Combination | ||
| Linear | 70.2 | 83.96 |
| Embed Update | 74.6 | 87.59 |
| Article Embedding | ||
| with | 74.5 | 87.59 |
| without | 74.6 | 85.60 |
| Sentence boundaries | ||
| with | 70.8 | 86.30 |
| without | 74.6 | 87.59 |
| the president | the People’s Bank of China | |
|---|---|---|
| the chairman | the SEC | |
| Vice Minister | the Ministry of Foreign Affairs | |
| Chairman | the People’s Association of Taiwan | |
| Deputy Chairman | the TBAD Women’s Division | |
| Chairman | the KMT | |
| Vice President | the Military Commission of the CCP | |
| vice-chairman | the CCP | |
| Associate Justices | the Supreme Court of the United States | |
| Chief Editor | Taiwan’s contemporary monthly | |
| General Secretary | the Communist Party of China |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Merge and Label: A novel neural network architecture for nested NER
Joseph Fisher
Department of Economics
University of Cambridge
\AndAndreas Vlachos
Dept. of Computer Science and Technology
University of Cambridge
Abstract
Named entity recognition (NER) is one of the best studied tasks in natural language processing. However, most approaches are not capable of handling nested structures which are common in many applications. In this paper we introduce a novel neural network architecture that first merges tokens and/or entities into entities forming nested structures, and then labels each of them independently. Unlike previous work, our merge and label approach predicts real-valued instead of discrete segmentation structures, which allow it to combine word and nested entity embeddings while maintaining differentiability. We evaluate our approach using the ACE 2005 Corpus, where it achieves state-of-the-art F1 of 74.6, further improved with contextual embeddings (BERT) to 82.4, an overall improvement of close to 8 F1 points over previous approaches trained on the same data. Additionally we compare it against BiLSTM-CRFs, the dominant approach for flat NER structures, demonstrating that its ability to predict nested structures does not impact performance in simpler cases.111Code available at https://github.com/fishjh2/merge_label
1 Introduction
The task of nested named entity recognition (NER) focuses on recognizing and classifying entities that can be nested within each other, such as “United Kingdom” and “The Prime Minister of the United Kingdom” in Figure 1. Such entity structures, while very commonly occurring, cannot be handled by the predominant variant of NER models (McCallum and Li, 2003; Lample et al., 2016), which can only tag non-overlapping entities.
A number of approaches have been proposed for nested NER. Lu and Roth (2015) introduced a hypergraph representation which can represent overlapping mentions, which was further improved by Muis and Lu (2017), by assigning tags between each pair of consecutive words, preventing the model from learning spurious structures (overlapping entity structures which are gramatically impossible). More recently, Katiyar and Cardie (2018) built on this approach, adapting an LSTM Hochreiter and Schmidhuber (1997) to learn the hypergraph directly, and Wang and Lu (2018) introduced a segmental hypergraph approach, which is able to incorporate a larger number of span based features, by encoding each span with an LSTM.
Our approach decomposes nested NER into two stages. First tokens are merged into entities (Level 1 in Figure 1), which are merged with other tokens or entities in higher levels. These merges are encoded as real-valued decisions, which enables a parameterized combination of word embeddings into entity embeddings at different levels. These entity embeddings are used to label the entities identified. The model itself consists of feedforward neural network layers and is fully differentiable, thus it is straightforward to train with backpropagation.
Unlike methods such as Katiyar and Cardie (2018), it does not predict entity segmentation at each layer as discrete 0-1 labels, thus allowing the model to flexibly aggregate information across layers. Furthermore inference is greedy, without attempting to score all possible entity spans as in Wang and Lu (2018), which results in faster decoding (decoding requires simply a single forward pass of the network).
To test our approach on nested NER, we evaluate it on the ACE 2005 corpus (LDC2006T06) where it achieves a state-of-the-art F1 score of 74.6. This is further improved with contextual embeddings (Devlin et al., 2018) to 82.4, an overall improvement of close to 8 F1 points against the previous best approach trained on the same data, Wang and Lu (2018). Our approach is also 60 times faster than its closest competitor. Additionally, we compare it against BiLSTM-CRFsHuang et al. (2015), the dominant flat NER paradigm, on Ontonotes (LDC2013T19) and demonstrate that its ability to predict nested structures does not impact performance in flat NER tasks as it achieves comparable results to the state of the art on this dataset.
2 Network Architecture
2.1 Overview
The model decomposes nested NER into two stages. Firstly, it identifies the boundaries of the named entities at all levels of nesting; the tensor M in Figure 2, which is composed of real values between 0 and 1 (these real values are used to infer discrete split/merge decisions at test time, giving the nested structure of entities shown in Figure 1). We refer to this as predicting the “structure” of the NER output for the sentence. Secondly, given this structure, it produces embeddings for each entity, by combining the embeddings of smaller entities/tokens from previous levels (i.e. there will be an embedding for each rectangle in Figure 1). These entity embeddings are used to label the entities identified.
An overview of the architecture used to predict the structure and labels is shown in Figure 2. The dimensions of each tensor are shown in square brackets in the figure. The input tensor, , holds the word embeddings of dimension , for every word in the input of sequence length, . The first dimension, , is the batch size. The Static Layer updates the token embeddings using contextual information, giving tensor of the same dimension, .
Next, for repetitions, we go through a series of building the structure using the Structure Layer, and then use this structure to continue updating the individual token embeddings using the Update Layer, giving an output .
The updated token embeddings are passed through the Structure Layer one last time, to give the final entity embeddings, and structure, . A feedforward Output Layer then gives the predictions of the label of each entity.
The structure is represented by the tensor , of dimensions . holds, for every pair of adjacent words ( given input length ) and every output level ( levels), a value between 0 and 1. A value close to 0 denotes that the two (adjacent) tokens/entities from the previous level are likely to be merged on this level to form an entity; nested entities emerge when entities from lower levels are used. Note that for each individual application of the Structure Layer, we are building multiple levels (L) of nested entities. That is, within each Structure Layer there is a loop of length L. By building the structure before the Update Layer, the updates to the token embeddings can utilize information about which entities each token is in, as well as neighbouring entities, as opposed to just using information about neighbouring tokens.
2.2 Preliminaries
Before analysing each of the main layers of the network, we introduce two building blocks, which are used multiple times throughout the architecture. The first one is the Unfold operators. Given that we process whole news articles in one batch (often giving a sequence_length (s) of 500 or greater) we do not allow each token in the sequence to consider every other token. Instead, we define a kernel of size k around each token, similar to convolutional neural networks (Kim, 2014), allowing it to consider the k/2 prior tokens and the k/2 following tokens.
The unfold operators create kernels transforming tensors holding the word embeddings of shape [b, s, e] to shape [b, s, k, e]. unfold[from] simply tiles the embedding of each token k times, and unfold[to] generates the k/2 token embeddings either side, as shown in Figure 3, for a kernel size of 4. The first row of the unfold[to] tensor holds the two tokens before and the two tokens after the word “The”, the second row the two before and after “President” etc. As we process whole articles, the unfold operators allow tokens to consider tokens from previous/following sentences.
The second building block is the Embed Update layer, shown in Figure 4. This layer is used to update embeddings within the model, and as such, can be thought of as equivalent in function to the residual update mechanism in Transformer Vaswani et al. (2017). It is used in each of the Static Layer, Update Layer and Structure Layer from the main network architecture in Figure 2.
It takes an input of size , formed using the unfold ops described above, where the last dimension varies depending on the point in the architecture at which the layer is used. It passes this input through the feedforward NN , giving an output of dimension (the network broadcasts over the last three dimensions of the input tensor). The output is split into two. Firstly, a tensor of shape , which holds, for each word in the sequence, k predictions of an updated word vector based on the k/2 words either side. Secondly, a weighting tensor of shape , which is scaled between 0 and 1 using the sigmoid function, and denotes how “confident” each of the predictions is about its update to the word embedding. This works similar to an attention mechanism, allowing each token to focus on updates from the most relevant neighbouring tokens.222The difference being that the weightings are generated using a sigmoid rather than a softmax layer, allowing the attention values to be close to one for multiple tokens. The output, is then a weighted average of :
[TABLE]
where denotes summing across the second dimension of size . therefore has dimensions and contains the updated embedding for each word.
During training we initialize the weights of the network using the identity function. As a result, the default behaviour of prior to training is to pass on the word embedding unchanged, which is then updated during via backpropagation. An example of the effect of the identity initialization is provided in the supplementary materials.
2.3 Static Layer
The static layer is a simple preliminary layer to update the embeddings for each word based on contextual information, and as such, is very similar to a Transformer Vaswani et al. (2017) layer. Following the unfold ops, a positional encoding of dimension (we use a learned encoding) is added, giving tensor :
[TABLE]
is then passed through the Embed Update layer. In our experiments, we use a single static layer. There is no merging of embeddings into entities in the static layer.
2.4 Structure Layer
The Structure Layer is responsible for three tasks. Firstly, deciding which token embeddings should be merged at each level, expressed as real values between 0 and 1, and denoted . Secondly, given these merge values , deciding how the separate token embeddings should be combined in order to give the embeddings for each entity, . Finally, for each token and entity, providing directional vectors to the tokens either side, which are used to update each token embedding in the Update Layer based on its context. Intuitively, the directional vectors can be thought of as encoding relations between entities - such as the relation between an organization and its leader, or that between a country and its capital city (see Section 6.2 for an analysis of these relation embeddings).
Figure 6 shows a minimal example of the calculation of , and , with word embedding and directional vector dimensions , and kernel size, . We pass the embeddings () of each pair of adjacent words through a feedforward NN to give directions [b, s-1, d] and merge values [b, s-1, 1] between each pair. If predicts to be close to 0, this indicates that tokens 1 and 2 are part of the same entity on this level. The unfold[to] op gives, for each word (we show only the unfolded tensors for the word “Kingdom” in Figure 6 for simplicity), and for pairs of words up to k/2 either side.
By taking both the left and right cumulative sum (cumsum) of the resulting two tensors from the center out (see grey dashed arrows in Figure 6 for direction of the two cumsum ops), we get directional vectors and merge values from the word “Kingdom” to the words before and after it in the phrase, and for . Note that we take the inverse of vectors and prior to the cumsum, as we are interested in the directions from the token “Kingdom” backwards to the tokens “United” and “The”. The values are converted to weights of dimension [b, s, k, 1] using the formula 333We use the notation to denote the unfolded version of tensor , i.e. , with the max operation ensuring the model puts a weight of zero on tokens in separate entities (see the reduction of the value of 1.7 in in Figure 6 to a weighting of 0.0). The weights are normalized to sum to 1, and multiplied with the unfolded token embeddings to give the entity embeddings , of dimension [b, s, e]
[TABLE]
Consequently, the embeddings at the end of level 1 for the words “The”, “United” and “Kingdom” (, and respectively) are all now close to equal, and all have been formed from a weighted average of the three separate token embeddings. If and were precisely zero, and was precisely 1.0, then all three would be identical. In addition, on higher levels, the directions from other words to each of these three tokens will also be identical. In other words, the use of “directions”444We use the term “directions” as we inverse the vectors to get the reverse direction, and cumsum them to get directions between tokens multiple steps away. allows the network to represent entities as a single embedding in a fully differentiable fashion, whilst keeping the sequence length constant.
Figure 6 shows just a single level from within the Structure Layer. The embeddings are then passed onto the next level, allowing progressively larger entities to be formed by combining smaller entities from the previous levels.
The full architecture of the Structure Layer is shown in Figure 7. The main difference to Figure 6 is the additional use of Embed Update Layer, to decide how individual token/entity embeddings are combined together into a single entity. The reason for this is that if we are joining the words “The”, “United” and “Kingdom” into a single entity, it makes sense that the joint vector should be based largely on the embeddings of “United” and “Kingdom”, as “The” should add little information. The embeddings are unfolded (using the unfold[from] op) to shape and concatenated with the directions between words, , to give the tensor of shape . This is passed through the Embed Update layer, giving, for each word, a weighted and updated embedding, ready to be combined into a single entity (for unimportant words like “The”, this embedding will have been reduced to close to zero). We use this tensor in place of tensor in Figure 6, and multiply with the weights to give the new entity embeddings, .
There are four separate outputs from the Structure Layer. The first, denoted by
, is the entity embeddings from each of the levels concatenated together, giving a tensor of size [b, s, e, L]. The second output,
, is a weighted average of the embeddings from different layers, of shape . This will be used in the place of the unfold[to] tensor described above as an input the the Update Layer. It holds, for each token in the sequence, embeddings of entities up to tokens either side.
The third output,
, will also be used by the Update Layer. It holds the directions of each token/entity to the tokens/entities either side. It is formed using the cumsum op, as shown in Figure 6. Finally, the fourth output,
, stores the merge values for every level. It is used in the loss function, to directly incentivize the correct merge decisions at the correct levels.
2.5 Update Layer
The Update Layer is responsible for updating the individual word vectors, using the contextual information derived from outputs
R
and
D
of the Structure Layer. It concatenates the two outputs together, along with the output of the unfold[from] op, , and with an article theme embedding tensor, giving tensor of dimension [b, s, k, (e*2 + d + a)]. The article theme embedding is formed by passing every word in the article through a feedforward NN, and taking a weighted average of the outputs, giving a tensor of dimension . This is then tiled555Tiling refers to simply repeating the tensor across both the sequence length and kernel size dimensions to dimension , giving tensor . allows the network to adjust its contextual understanding of each token based on whether the article is on finance, sports, etc. is then passed through an Embed Update layer, giving an output of shape .
[TABLE]
We therefore update each word vector using four pieces of information. The original word embedding, a direction to a different token/entity, the embedding of that different token/entity, and the article theme.
The use of directional vectors in the Update Layer can be thought of as an alternative to the positional encodings in Transformer Vaswani et al. (2017). That is, instead of updating each token embedding using neighbouring tokens embeddings with a positional encoding, we update using neighbouring token embeddings, and the directions to those tokens.
3 Implementation Details
3.1 Data Preprocessing
3.1.1 ACE 2005
ACE 2005 is a corpus of around 180K tokens, with 7 distinct entity labels. The corpus labels include nested entities, allowing us to compare our model to the nested NER literature. The dataset is not pre-tokenized, so we carry out sentence and word tokenization using NLTK.
3.1.2 OntoNotes
OntoNotes v5.0 is the largest corpus available for NER, comprised of around 1.3M tokens, and 19 different entity labels. Although the labelling of the entities is not nested in OntoNotes, the corpus also includes labels for all noun phrases, which we train the network to identify concurrently. For training, we copy entities which are not contained within a larger nested entity onto higher levels, as shown in Figure 9.
3.1.3 Labelling
For both datasets, during training, we replace all “B-” labels with their corresponding “I-” label. At evaluation, all predictions which are the first word in a merged entity have the “B-” added back on. As the trained model’s merging weights, , can take any value between 0 and 1, we have to set a cutoff at eval time when deciding which words are in the same entity. We perform a grid search over cutoff values using the dev set, with a value of 0.75 proving optimal.
3.2 Loss function
The model is trained to predict the correct merge decisions, held in the tensor of dimension [b, s-1, L] and the correct class labels given these decisions, . The merge decisions are trained directly using the mean absolute error (MAE):
[TABLE]
This is then weighted by a scalar , and added to the usual Cross Entropy (CE) loss from the predictions of the classes, , giving a final loss function of the form:
[TABLE]
In experiments we set the weight on the merge loss, to 0.5.
3.3 Evaluation
Following previous literature, for both the ACE and OntoNotes datasets, we use a strict F1 measure, where an entity is only considered correct if both the label and the span are correct.
3.3.1 ACE 2005
For the ACE corpus, the default metric in the literature Wang et al. (2018); Ju et al. (2018); Wang and Lu (2018) does not include sequential ordering of nested entities (as many architectures do not have a concept of ordered nested outputs). As a result, an entity is considered correct if it is present in the target labels, regardless of which layer the model predicts it on.
3.3.2 OntoNotes
NER models evaluated on OntoNotes are trained to label the 19 entities, and not noun phrases (NP). To provide as fair as possible a comparison, we consequently flatten all labelled entities into a single column. As 96.5% of labelled entities in OntoNotes do not contain a NP nested inside, this applies to only 3.5% of the dataset.
The method used to flatten the targets is shown in Figure 10. The OntoNotes labels include a named entity (TIME), in the second column, with the NP “twenty-four” minutes nested inside. Consequently, we take the model’s prediction from the second column as our prediction for this entity. This provides a fair comparison to existing NER models, as all entities are included, and if anything, disadvantages our model, as it not only has to predict the correct entity, but do so on the correct level. That said, the NP labels provide additional information during training, which may give our model an advantage over flat NER models, which do not have access to these labels.
3.4 Training and HyperParameters
We performed a small amount of hyperparameter tuning across dropout, learning rate, distance embedding size , and number of update layers . We set dropout at 0.1, the learning rate to 0.0005, to 200, and to 3. For full hyperparameter details see the supplementary materials. The number of levels, , is set to 3, with a kernel size of 10 on the first level, 20 on the second, and 30 on the third (we increase the kernel size gradually for computational efficiency as first level entities are extremely unlikely to be composed of more than 10 tokens, whereas higher level nested entities may be larger). Training took around 10 hours for OntoNotes, and around 6 hours for ACE 2005, on an Nvidia 1080 Ti.
For experiments without language model (LM) embeddings, we used pretrained Glove embeddings Pennington et al. (2014) of dimension 300. Following Strubell et al. (2017), we added a “CAP features” embedding of dimension 20, denoting if each word started with a capital letter, was all capital letters, or had no capital letters. For the experiments with LM embeddings, we used the implementations of the BERT Devlin et al. (2018) and ELMO Peters et al. (2018) models from the Flair Akbik et al. (2018) project666https://github.com/zalandoresearch/flair/. We do not finetune the BERT and ELMO models, but take their embeddings as given.
4 Results
4.1 ACE 2005
On the ACE 2005 corpus, we begin our analysis of our model’s performance by comparing to models which do not use the POS tags as additional features, and which use non-contextual word embeddings. These are shown in the top section of Table 1. The previous state-of-the-art F1 of 72.2 was set by Ju et al. (2018), using a series of stacked BiLSTM layers, with CRF decoders on top of each of them. Our model improves this result with an F1 of 74.6 (avg. over 5 runs with std. dev. of 0.4). This also brings the performance into line with Wang et al. (2018) and Wang and Lu (2018), which concatenate embeddings of POS tags with word embeddings as an additional input feature.
Given the recent success on many tasks using contextual word embeddings, we also evaluate performance using the output of pre-trained BERT Devlin et al. (2018) and ELMO Peters et al. (2018) models as input embeddings. This leads to a significant jump in performance to 78.9 with ELMO, and 82.4 with BERT (both avg. over 5 runs with 0.4 and 0.3 std. dev. respectively), an overall increase of 8 F1 points from the previous state-of-the-art. Finally, we report the concurrently published result of Luan et al. (2019), in which they use ELMO embeddings, and additional labelled data (used to train the coreference part of their model and the entity boundaries) from the larger OntoNotes dataset.
A secondary advantage of our architecture relative to those models which require construction of a hypergraph or CRF layer is its decoding speed, as decoding requires only a single forward pass of the network. As such it achieves a speed of 9468 words per second (w/s) on an Nvidia 1080 Ti GPU, relative to a reported speed of 157 w/s for the closest competitor model of Wang and Lu (2018), a sixty fold advantage.
4.2 OntoNotes
As mentioned previously, given the caveats that our model is trained to label all NPs as well as entities, and must also predict the correct layer of an entity, the results in Table 2 should be seen as indicative comparisons only. Using non-contextual embeddings, our model achieves a test F1 of 87.59. To our knowledge, this is the first time that a nested NER architecture has performed comparably to BiLSTM-CRFs Huang et al. (2015) (which have dominated the named entity literature for the last few years) on a flat NER task.
Given the larger size of the OntoNotes dataset, we report results from a single iteration, as opposed to the average of 5 runs as in the case of ACE05.
We also see a performance boost from using BERT embeddings, pushing the F1 up to 89.20. This falls slightly short of the state-of-the-art on this dataset, achieved using character-based Flair Akbik et al. (2018) contextual embeddings.
5 Ablations
To better understand the results, we conducted a small ablation study. The affect of including the Static Layer in the architecture is consistent across both datasets, yielding an improvement of around 2 F1 points; the updating of the token embeddings based on context seems to allow better merge decisions for each pair of tokens. Next, we look at the method used to update entity embeddings prior to combination into larger entities in the Structure Layer. In the described architecture, we use the Embed Update mechanism (see Figure 7), allowing embeddings to be changed dependent on which other embeddings they are about to be combined with. We see that this yields a significant improvement on both tasks of around 4 F1 points, relative to passing each embedding through a linear layer.
The inclusion of an “article theme” embedding, used in the Update Layer, has little effect on the ACE05 data. but gives a notable improvement for OntoNotes. Given that the distribution of types of articles is similar for both datasets, we suggest this is due to the larger size of the OntoNotes set allowing the model to learn an informative article theme embedding without overfitting.
Next, we investigate the impact of allowing the model to attend to tokens in neighbouring sentences (we use a set kernel size of 30, allowing each token to consider up to 15 tokens prior and 15 after, regardless of sentence boundaries). Ignoring sentence boundaries boosts the results on ACE05 by around 4 F1 points, whilst having a smaller affect on OntoNotes. We hypothesize that this is due to the ACE05 task requiring the labelling of pronominal entities, such as “he” and “it”, which is not required for OntoNotes. The coreference needed to correctly label their type is likely to require context beyond the sentence.
6 Discussion
6.1 Entity Embeddings
As our architecture merges multi-word entities, it not only outputs vectors of each word, but also for all entities - the tensor . To demonstrate this, Table 3 shows the ten closest entity vectors in the OntoNotes test data to the phrases “the United Kingdom”, “Arab Foreign Ministers” and “Israeli Prime Minister Ehud Barak”.777Note that we exclude from the 10 nearest neighbours identical entities from higher levels. I.e. if “the United Kingdom” is kept as a three token entity, and not merged into a larger entity on higher levels, we do not report the same phrase from all levels in the nearest neighbours.
Given that the OntoNotes NER task considers countries and cities as GPE (Geo-Political Entities), the nearest neighbours in the left hand column are expected. The nearest neighbours of “Arab Foreign Ministers” and “Israeli Prime Minister Ehud Barak” are more interesting, as there is no label for groups of people or jobs for the task.888The phrase “Israeli Prime Minister Ehud Barak” would have “Israeli” labelled as NORP, and “Ehud Barak” labelled as PERSON in the OntoNotes corpus. Despite this, the model produces good embedding-based representations of these complex higher level entities.
6.2 Directional Embeddings
The representation of the relationship between each pair of words/entities as a vector is primarily a mechanism used by the model to update the word/entity vectors. However, the resulting vectors, corresponding to output
D
of the Structure Layer, may also provide useful information for downstream tasks such as knowledge base population.
To demonstrate the directional embeddings, Table 5 shows the ten closest matches for the direction between “the president” and “the People’s Bank of China”. The network has clearly picked up on the relationship of an employee to an organisation.
Table 5 also provides further examples of the network merging and providing intuitive embeddings for multi-word entities.
7 Conclusion
We have presented a novel neural network architecture for smoothly merging token embeddings in a sentence into entity embeddings, across multiple levels. The architecture performs strongly on the task of nested NER, setting a new state-of-the-art F1 score by close to 8 F1 points, and is also competitive at flat NER. Despite being trained only for NER, the architecture provides intuitive embeddings for a variety of multi-word entities, a step which we suggest could prove useful for a variety of downstream tasks, including entity linking and coreference resolution.
Acknowledgments
Andreas Vlachos is supported by the EPSRC grant eNeMILP (EP/R021643/1).
Appendix A Supplemental Material
A.1 HyperParameters
In addition to the hyperparameters recorded in the main paper, there are a large number of additional hyperparameters which we kept constant throughout experiments. The feedforward NN in the Static Layer, , has two hidden layers each of dimension 200. The NN in the Embed Update layer, has two hidden layers, each of dimension 320. The output NN has one hidden layer of dimension 200. Aside from , which is initialized using the identity function as described in Supplementary section A.2, all parameters of networks are initialized from the uniform distribution between -0.1 and 0.1. The article theme size, a, is set to 50. All network layers use the SELU activation function of Klambauer et al. (2017). The kernel size for the Static Layer is set to 6, allowing each token to attend the 3 tokens either side.
On the OntoNotes Corpus, we train for 60 epochs, and half the learning rate every 12 epochs. On ACE 2005, we train for 150 epochs, and half the learning rate every 30 epochs. We train with a maximum batch dimension of 900 tokens. Articles longer than length 900 are split and processed in separate batches. We train using the Adam Optimizer, and, in addition to the dropout of 0.1, we apply a dropout to the Glove/LM embeddings of 0.2.
A.2 Identity initialization
Figure 11 gives a minimum working example of identity initialization of . The embedding for “The” is [1.1, 0.5], and that for “President” is [1.1, -0.3]. Through the unfold ops, we’ll end up with the two embeddings concatenated together. Figure 11 shows as having just one layer with no activation function to demonstrate the effect of the identity initialization. The first two dimensions of the output are the embedding for “The” with no changes. The final output (in light green) is the weighting.
In reality, the zeros in the weights tensor are initialized to very small random numbers (we use a uniform initialization between -0.01 and 0.01), so that during training learns to update the embedding for “The” using the information that it is one step before the word “President”.
A.3 Formation of outputs
R
and
D
in Structure Layer
Outputs
R
and
D
of the Structure Layer have dimensions [b,s, k, e] and [b, s, k, d] respectively. These outputs are a weighted average of the directional and embedding outputs from the L levels of the structure layer. We use the weights, , (see Figure 6) to form the weighted average:
[TABLE]
In the case of the weighted average for the embedding tensor, , we use the weights from the next level.
[TABLE]
As a result, when updating, each token “sees” information from tokens/entities on other levels dependent on whether or not they are in the same entity. For the intuition behind this, we use the example phrase “The United Kingdom government” from Figure 6. The model should output merge values which group the tokens “The United Kingdom” on the first level, and then group all the tokens on the second level. If this is the case, then for the token “United”, and will hold the embedding of/directions to the tokens “The” and “Kingdom” in their disaggregated (unmerged) form. However, for the token “government”, and will hold embeddings of/ directions to the combined entity “the United Kingdom” in each of the three slots for “The”, “United” and “Kingdom”. Because “government” is not in the same entity as “The United Kingdom” on the first level, it “sees” the aggregated embedding of this entity.
Intuitively, this allows the token “government” to update in the model based on the information that it has a country one step to the left of it, as opposed to having three separate tokens, one, two and three steps to the left respectively. Note that as with the entity merging, there are no hard decisions during training, with this effect based on the real valued merge tensor , to allow differentiability.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Akbik et al. (2018) Alan Akbik, Duncan Blythe, and Roland Vollgraf. 2018. Contextual string embeddings for sequence labeling . In Proceedings of the 27th International Conference on Computational Linguistics , pages 1638–1649. Association for Computational Linguistics.
- 2Chiu and Nichols (2016) Jason P. C. Chiu and Eric Nichols. 2016. Named entity recognition with bidirectional lstm-cnns. Transactions of the Association for Computational Linguistics , 4:357–370.
- 3Clark et al. (2018) Kevin Clark, Minh-Thang Luong, Christopher D. Manning, and Quoc V. Le. 2018. Semi-supervised sequence modeling with cross-view training . EMNLP .
- 4Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: pre-training of deep bidirectional transformers for language understanding. Co RR , abs/1810.04805.
- 5Ghaddar and Langlais (2018) Abbas Ghaddar and Philippe Langlais. 2018. Robust lexical features for improved neural network named-entity recognition . Co RR , abs/1806.03489.
- 6Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory . Neural Comput. , 9(8):1735–1780. · doi ↗
- 7Huang et al. (2015) Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidirectional LSTM-CRF models for sequence tagging . Co RR , abs/1508.01991.
- 8Ju et al. (2018) Meizhi Ju, Makoto Miwa, and Sophia Ananiadou. 2018. A neural layered model for nested named entity recognition . In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages 1446–1459. Association for Computational Linguistics.
