TL;DR
BERTphone introduces a phonetically-aware Transformer encoder trained on speech data, improving speaker and language recognition accuracy by leveraging dual training objectives and outperforming previous methods.
Contribution
It presents a novel pretraining approach for speech representations using combined acoustic and phonetic objectives, enhancing downstream speaker and language recognition tasks.
Findings
Achieved state-of-the-art $C_{avg}$ of 6.16 on LRE07 language recognition.
Reduced speaker EER by 18% using BERTphone vectors compared to MFCCs.
Outperformed previous phonetic pretraining methods on the same datasets.
Abstract
We introduce BERTphone, a Transformer encoder trained on large speech corpora that outputs phonetically-aware contextual representation vectors that can be used for both speaker and language recognition. This is accomplished by training on two objectives: the first, inspired by adapting BERT to the continuous domain, involves masking spans of input frames and reconstructing the whole sequence for acoustic representation learning; the second, inspired by the success of bottleneck features from ASR, is a sequence-level CTC loss applied to phoneme labels for phonetic representation learning. We pretrain two BERTphone models (one on Fisher and one on TED-LIUM) and use them as feature extractors into x-vector-style DNNs for both tasks. We attain a state-of-the-art of 6.16 on the challenging LRE07 3sec closed-set language recognition task. On Fisher and VoxCeleb speaker…
Click any figure to enlarge with its caption.
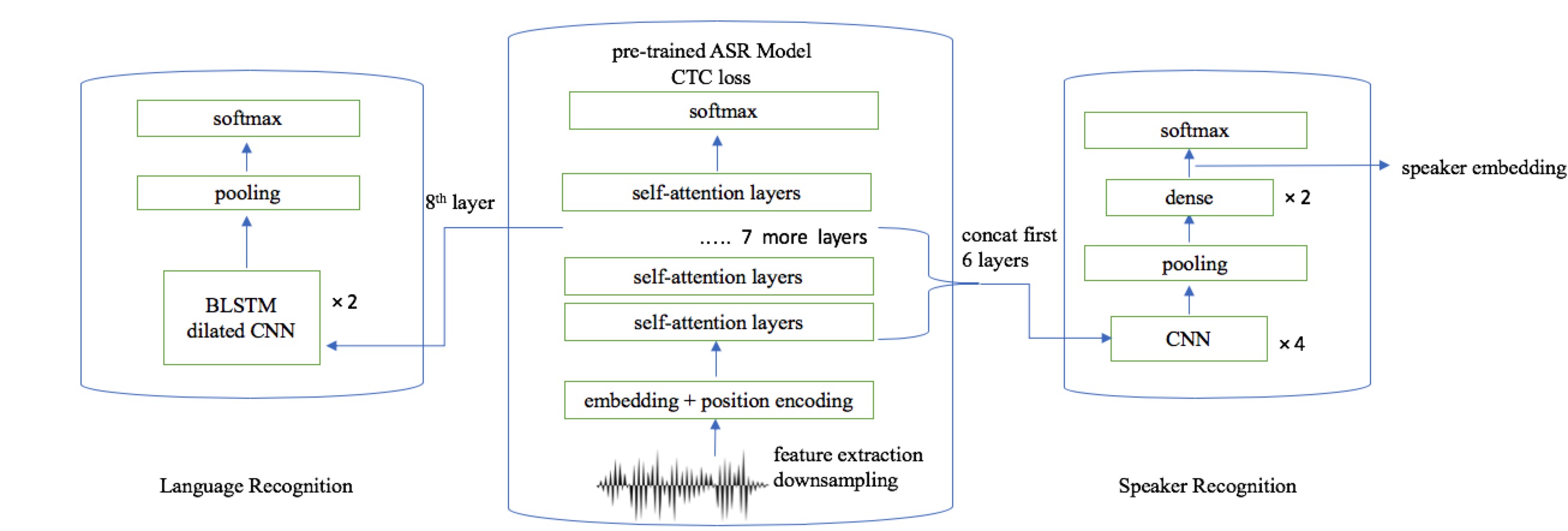 Figure 1
Figure 1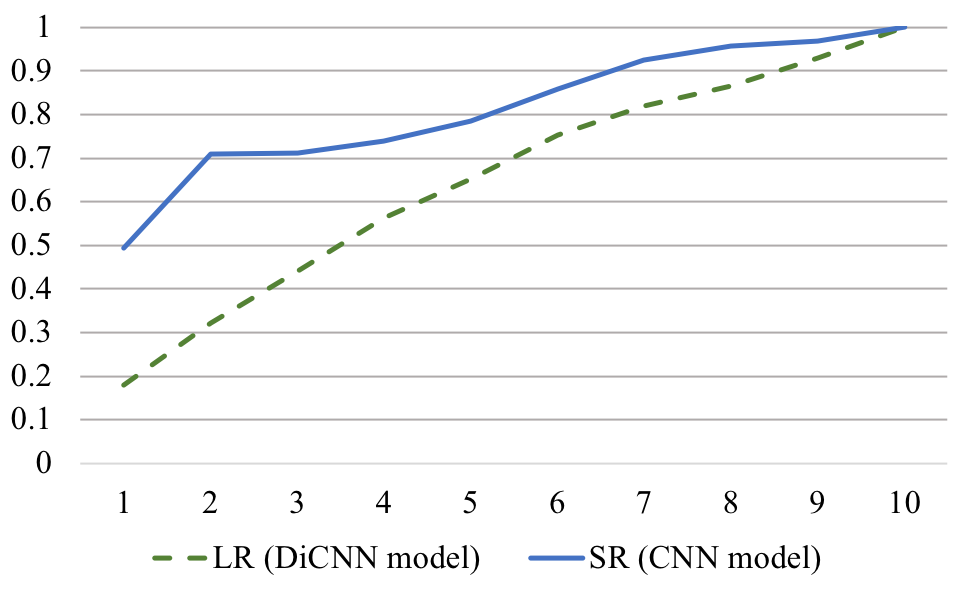 Figure 2
Figure 2| System | (Fisher ) Fisher | (TED-LIUM ) VoxCeleb | ||||
|---|---|---|---|---|---|---|
| EER | minDCF08 | minDCF10 | EER | minDCF0.01 | minDCF0.001 | |
| i-vector | 2.10 | 0.093 | 0.334 | 5.24 | 0.493 | 0.616 |
| x-vector | 1.73 | 0.086 | 0.363 | 3.13 | 0.326 | 0.500 |
| x-vector + phonetic vec. + multi-tasking [15] | 1.39 | 0.073 | 0.308 | - | - | - |
| x-vector + adv. loss + multi-tasking [14] | - | - | - | 3.17 | 0.336 | - |
| x-vector + SAP model on MFCCs | 1.50 | 0.079 | 0.316 | 3.06 | 0.322 | 0.514 |
| x-vector + SAP model on BERTphone | 1.23 | 0.067 | 0.268 | 2.51 | 0.300 | 0.439 |
| System | 3sec | 10sec | 30sec | Total | ||||
| EER% | EER% | EER% | EER% | |||||
| CNN SAP [31] | 8.59 | 9.89 | 2.49 | 4.27 | 1.09 | 2.38 | – | – |
| CNN-BLSTM SAP [33] | 9.22 | 9.50 | 2.54 | 3.48 | 0.97 | 1.77 | – | – |
| CNN-LDE [34] | 8.25 | 7.75 | 2.61 | 2.31 | 1.13 | 0.96 | – | – |
| i-vector DNN [35] | 19.67 | – | 7.84 | – | 3.31 | – | 10.27 | – |
| DNN tandem features [34] | 9.85 | 7.96 | 3.16 | 1.95 | 0.97 | 0.51 | – | – |
| DNN phoneme posterior features [34] | 8.00 | 6.90 | 2.20 | 1.43 | 0.61 | 0.32 | – | – |
| x-vector + SAP model on MFCCs | 19.42 | 13.21 | 12.74 | 8.25 | 10.03 | 6.53 | 14.06 | 9.42 |
| x-vector + SAP model on BERTphone | 6.16 | 4.63 | 2.03 | 1.21 | 1.17 | 0.79 | 3.12 | 2.19 |
| Features | PER | LR EER (3sec) | SR EER |
|---|---|---|---|
| BERTphone, = 0.0 | 11.5 | 4.63 | 5.23 |
| BERTphone, = 0.2 | 13.1 | 5.19 | 1.23 |
| BERTphone, = 0.5 | 13.9 | 5.42 | 1.27 |
| BERTphone, = 0.8 | 14.4 | 6.07 | 1.23 |
| BERTphone, = 1.0 | – | 14.97 | 1.50 |
| MFCC | – | 13.21 | 1.50 |
| Pretraining alphabet | LR EER (3sec) | SR EER |
|---|---|---|
| characters | 6.44 | 1.36 |
| phonemes (no stress) | 5.19 | 1.23 |
| phonemes (with stress) | 5.33 | 1.26 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
BERTphone: Phonetically-aware Encoder Representations for Utterance-level Speaker and Language Recognition
Abstract
We introduce BERTphone, a Transformer encoder trained on large speech corpora that outputs phonetically-aware contextual representation vectors that can be used for both speaker and language recognition. This is accomplished by training on two objectives: the first, inspired by adapting BERT to the continuous domain, involves masking spans of input frames and reconstructing the whole sequence for acoustic representation learning; the second, inspired by the success of bottleneck features from ASR, is a sequence-level CTC loss applied to phoneme labels for phonetic representation learning. We pretrain two BERTphone models (one on Fisher and one on TED-LIUM) and use them as feature extractors into x-vector-style DNNs for both tasks. We attain a state-of-the-art of 6.16 on the challenging LRE07 3sec closed-set language recognition task. On Fisher and VoxCeleb speaker recognition tasks, we see an 18% relative reduction in speaker EER when training on BERTphone vectors instead of MFCCs. In general, BERTphone outperforms previous phonetic pretraining approaches on the same data. We release our code and models at https://github.com/awslabs/speech-representations.
1 Introduction
Motivated by improvements from pretraining bidirectional contextual representations like BERT [1] for language understanding tasks, we propose BERTphone, a pretraining approach that gives versatile representations for speech processing tasks. It is a deep Transformer encoder [2] that turns an utterance into a frame-wise vector sequence capturing both acoustic and phonetic information. Notably, BERTphone can be used as a fixed feature extractor on which task-specific models for speaker, language, and speech recognition can be trained.
BERT is a deep neural network trained on text under a masked language modeling (MLM) objective, where subword tokens are masked then predicted via classification. In contrast, speech features are continuous, which suggests their reconstruction as a possible generative analogue. However, acoustic frames are highly correlated over time, which models may exploit during training [3]. More generally, a contrastive loss may be better at inducing high-level latent knowledge [4]. For example, phonetic understanding in spoken language recognition is often incorporated via intermediate “bottleneck” representations from neural networks trained to classify context-dependent phonemes [5].
Hence, BERTphone uses two objectives to pretrain on large amounts of speech data, which we describe inSection 3. First, to induce higher-level acoustic representations, we propose masking contiguous spans of acoustic frames then reconstructing all frames independently under an penalty. Second, to induce and implicitly align phonetic information to each frame, we propose applying connectionist temporal classification (CTC) [6], a sequence loss computed against each utterance’s unaligned context-independent phoneme labels.
After pretraining, we use the final layer of BERTphone as a fixed featurizer for a self-attentional x-vector model (Section 4) that is trained for either (text-independent) speaker recognition (SR) [7] or language recognition (LR) [8]. In Sections 5 and 6, we pretrain two BERTphone models (Fisher, TED-LIUM) then train classifiers for each of SR and LR; altogether, we consistently improve on end-to-end systems and other phonetic pre-training methods. Finally, in Section 7 we explore different weightings of both losses, train over BERTphone’s layers, and try graphemes as an alternate supervision for CTC. BERTphone gives competitive phoneme error rates, suggesting downstream use for end-to-end automatic speech recognition (ASR) as well.
2 Related work
2.1 Phonetic information for SR and LR
Over the past decade, the speech processing community has adopted deep neural networks (DNNs) for ASR, in both hybrid (HMM-DNN) [9] and end-to-end configurations [6, 10]. Past works have explored the “indirect method” of using the hybrid system’s DNN as a frame-level feature extractor for SR and LR [11]. As the DNN is already trained on large speech corpora, it is thought to have captured higher-level phonetic understanding that is useful for LR [12], and to a lesser extent for SR [13, 14]. This is often done with bottleneck features [5] (more generally, intermediate frame-wise features from a DNN), though DNN posteriors have also been used as sufficient statistics for i-vector systems [13]. However, since SR can require higher-level acoustic information (speaker traits) that are less relevant for ASR, the DNN’s knowledge may be insufficient. This has led to original speech features being presented in tandem with DNN features in SR systems [11]. Another approach is to multitask the frame-level DNN with SR directly [15].
In contrast, we train an end-to-end ASR system as our feature extractor (removing the need for forced alignment) to capture phonetic knowledge. We only use the final layer for both tasks. To enable this, instead of multitasking with SR or presenting early layers in tandem, we use a self-supervised reconstruction task to induce the desired acoustic knowledge.
2.2 Deep acoustic representations
Recent works have improved the effectiveness of DNNs in ASR by pretraining on large amounts of unlabeled speech. These have involved recurrent neural networks with self-supervised objectives that are either contrastive (classifying a future audio sample from negative examples) or reconstructive (recreating future audio frames or wave samples). A contrastive loss was used by CPC [4] for phone classification and SR, and wav2vec [16] for ASR. Full reconstruction was used for autoencoding by [17], and future frame reconstruction was used in autoregressive predictive coding (APC) [3] for phone classification and SR.
Concurrent to our work, a number of preprints have also proposed pretraining speech representations bidirectionally (with recurrent networks or Transformer encoders), with either a contrastive [18, 19] or reconstructive [20, 21, 22] objective. None of these explore the benefits of weak or multi-task supervision, which we use to enable frozen, multi-purpose representations. These works also do not evaluate LR or large-scale out-of-corpus SR (VoxCeleb), which are the focus of our work.
3 BERTphone pretraining
3.1 Architecture
Our pretraining scheme is depicted in Figure 1. We use a deep Transformer encoder [2], which consists of an embedding layer followed by a stack of self-attention layers, as implemented by BERT [1]. To simplify our analyses, we do not add convolutional layers or 2D attention layers before the embedding layer, though other self-attentional speech models have found these helpful [23].
Let denote a sequence of input features. The embedding layer is applied, after which a learned matrix of position embeddings (size ) are added. A self-attention layer consists of two sublayers applied in sequence. The first sublayer performs multi-head self-attention, which computes sets of queries , keys , and values by left-multiplying inputs with learned weights . The output of the -th attention head is:
[TABLE]
where the softmax is applied row-wise. Heads are concatenated to give -dimensional features where . The second sublayer learns a position-wise feed-forward network, which at position computes
[TABLE]
where for some inner dimension , and GELU is the non-linearity used in lieu of ReLU by BERT. Each sublayer has a residual connection and layer normalization, e.g., .
3.2 Training criteria
We train on the sum of two losses in our framework: reconstruction under masking, and connectionist temporal classification (CTC) [6]. Inputs to our network are cepstral mean-normalized MFCCs of speech utterances. We stack every 3 frames to reduce the memory cost of long sequences [24].
The first loss is our proposed bidirectional predictive coding and denoising task. At 5% of the positions, we mask a span of 3 stacked frames (representing 9 frames or 100ms of audio). These are replaced with zero vectors (recall inputs are mean-normalized), a method proposed in the supervised setting by SpecAugment [25]. In this way we mask 15% of tokens, similar to BERT’s pretraining scheme [1]. However, we follow SpanBERT [26] in masking spans of inputs instead, to induce higher-level representations by increasing the difficulty of the task (as speech frames are highly correlated over time). We also follow RoBERTa [27] and generate new masking patterns for each batch. Finally, instead of reconstructing only masked positions, we reconstruct everywhere to induce acoustic information at all positions and more explicitly train BERTphone as a type of denoising autoencoder [17]:
[TABLE]
where are outputs of the Transformer encoder (our “BERTphone vectors”). follows Eq. 2 but here taking ReLU, , and matching ’s dimension.
The second loss is supervised, to induce phonetic understanding and leverage our use of labeled speech corpora. To support end-to-end pretraining (i.e., no force-alignment), we propose the use of sequence-level CTC loss. Let be the output sequence of tokens . Recall that CTC is a maximum likelihood objective , where likelihood is given by summing over probabilities of all -length symbol sequences (over the original label alphabet augmented with a special blank token) that collapse to after merging repetitions and removing blanks (the operation represented by ):
[TABLE]
We see that position-wise tokens in the “path” are treated as conditionally independent from one another. The probabilities are given by taking and applying a linear projection then softmax.
The combined loss is
[TABLE]
where empirically rescales (which is averaged over frames) to be proportionate with (a sequence-level loss), and where is a hyperparameter.
4 Task-specific model
Although our pretraining is BERT-like, our method of application is closer to ELMo [28] representations in NLP, and to bottleneck and tandem features in SR and LR: we keep BERTphone frozen. Furthermore, we only use the final layer’s output, to see whether our multitask setup has captured a balance of acoustic and phonetic information. Instead, we treat BERTphone vectors as features (similar to wav2vec [16] or DeCoAR [22]) and train a segment-level DNN classifier on them.
4.1 Architecture
Our classifier (Figure 2) is based on the DNN used to extracting utterance-level x-vectors for speaker and language recognition [7, 8]. We re-implement the x-vector architecture in MXNet with two substitutions: The first 5 time-delay neural network (TDNN) layers are replaced with 5 layers of 1D convolutions (CNN) with corresponding kernel sizes (2,2,3,1,1) and channel counts (512, …, 512, 5123). Then, instead of extracting mean and standard deviation on the frame-wise vectors, we perform multi-head self-attentive pooling (SAP) [29]. By assigning relative importance to each time step, SAP focuses on frames relevant to the utterance-level decision. SAP improves duration robustness for speaker verification [30] and is used in state-of-the-art end-to-end LR models [31]. The output of a single head is a 512-dim. vector:
[TABLE]
This is analogous to the self-attention layer (Eq. 1), with is the head’s query weight vector and is a shared linear transformation that gives keys. We take 5 heads and get a combined 2560-dim. vector, similar to the x-vector system. The rest proceeds in the same way: two dense layers of size 512, then a linear projection and softmax. Batch norm and ReLU are applied between all layers except after SAP.
4.2 Training criterion
We train x-vector + SAP models on BERTphone for each of LR and SR using cross-entropy loss. For closed-set LR, we use the softmax layer directly at inference time, since the LR task has fixed language categories. For SR, we use probabilistic linear discriminant analysis (PLDA) [32] to compare pairs of speaker embeddings.
5 Experimental setup
We use Kaldi [36] for data preparation. Our BERT and x-vector + SAP model implementations are based on MXNet’s GluonNLP toolkit [37]. We release our code and models at https://github.com/awslabs/speech-representations.
5.1 BERTphone pretraining
We use 40-dimensional mean-normalized MFCCs (window size of 25ms, hop length of 10ms) as inputs (before stacking every 3 frames). Our BERTphone parameters, learning schedule, and training details are consistent with the BERT base described in [1], with 12 self-attention layers, 768 hidden dimensions, , and 12 heads. The main difference is while BERT trains on contiguous excerpts of text, we take our variable-length speech utterances and load them in batches of 80, spread over multiple GPUs. Our warmup is over the first 3,000 batches, to a maximum learning rate of 5e-5. We train for around 30 epochs.
Since the VoxCeleb dataset for SR is sampled at 16kHz while others are sampled at 8kHz (and to match previous configurations for phonetic pretraining), we train two rate-specific BERTphone models:
- •
Fisher English (8kHz). A corpus of telephone conversations [38], via the train split of Kaldi’s s5 recipe.
- •
TED-LIUM (16kHz). A corpus of English TED talks [39], via the train split of Kaldi’s s5_r3 recipe.
To give phoneme labels for CTC on both datasets, we use the CMUdict lexicon. We omit lexical stresses to give an alphabet of 39 non-silence classes.
5.2 Speaker recognition (SR)
To validate the joint usability of our representations, we take Fisher BERTphone’s representations for the text-independent Fisher SR task described in [15], using the same training and evaluation sets111https://github.com/mycrazycracy/Speaker_embedding_with_phonetic_information. This selects 172 hours of data from 5,000 speakers for training, and takes a disjoint set of 1,000 speakers for evaluation. Each person is enrolled using 10 segments (about 30sec in total) and evaluated on three 3sec segments.
To evaluate the success of BERTphone on large scale and out-of-corpus SR, we take TED-LIUM BERTphone for the text-independent VoxCeleb task [40]. We use Kaldi’s voxceleb/v2 recipe. The training set includes VoxCeleb1 development set and all of VoxCeleb2. The VoxCeleb1 test set is used as the evaluation set. The number of speakers in the training set is 7,146, and the number of utterances is 2,081,192 including augmentation [7].
We perform stochastic gradient descent with batch size 128, momentum 0.9, weight decay 1e-4, and a learning rate of 0.01, which is decayed by 10 when validation loss plateaus.
5.3 Language recognition (LR)
We take Fisher BERTphone’s representations for the closed-set general LR task of the 2007 NIST LR Evaluation (LRE07), where the objective is to identify an utterance’s language from a set of 14 languages. We use the train split of the lre07/v2 recipe, which includes LRE07’s training data along with CALLFRIEND, LRE96/03/05/09, and SRE08, analogous to past work [31, 34, 35]. The utterances are split into 4sec segments with 50% overlap, similar to [41]. Every epoch, 8,000 to 12,000 segments are randomly selected per language and distributed over batches to mitigate class imbalance. We use the same optimization as in SR, though since no validation set is available we decay the learning rate when training loss plateaus, doing this twice.
At test time, VAD was applied to reduce the length of the 6,474 closed-set test utterances. These are then split into non-overlapping segments of 4sec; however, the self-attention pooling layer (Section 4) occurs over frame features from all segments to give a single, utterance-level language prediction.
6 Results22footnotemark: 2
33footnotetext: In a preprint (https://arxiv.org/abs/1907.00457v1), we included results that sometimes outperformed the ones here. This was an early version of BERTphone () that required various internal layers and architectures for each task. In contrast, our method here uses the output layer and the same architecture for both tasks.
6.1 Speaker recognition
Table 1 shows our model’s task performance in terms of equal error rate (EER) and minimum detection cost (minDCF) versus other embedding plus phonetic information approaches. In the Fisher to Fisher case, BERTphone even improves over the shared features and multitasking approach, where the phonetic extractor is learned jointly between ASR and SR [15]. On the large-scale, out-of-corpus VoxCeleb SR task, training on TED-LIUM BERTphone gives 18% relative reduction in EER over training directly on MFCCs. Our model also improves on recent work that uses the same pretraining set [14] via multi-tasking and adversarial training, although their x-vector baseline is weaker.
6.2 Language recognition
Table 2 shows the performance of our x-vector + SAP model trained on MFCCs and on BERTphone vectors, on the LRE07 closed-set task. Performance is reported as average detection cost and equal error rate (EER%). We get significant improvements over both end-to-end and phonetically-aware systems from the past two years. We achieve state-of-the-art on the 3sec and 10sec conditions despite having only trained on 4sec segments, which is a testament to the effectiveness of self-attention in prioritizing relevant frames. Though we underperform pretrained systems at 30sec, we still improve on all end-to-end methods.
7 Analysis
7.1 Reconstruction versus CTC loss
In Table 3 we interpolate between (CTC only) and (reconstruction only). LR and SR performance is equivalent or slightly degrades when BERTphone is only trained to reconstruct. For LR, we find that CTC-only did best; any reconstruction resulted in degradation, presumably as it degraded the quality of phonetic information encoded (though all models with remain state-of-the-art). For SR, the model does best when some CTC loss is introduced, in line with previous work on the relevance of phonetic information to SR. As expected, using vectors from a CTC-only model actively degrades SR performance. In practice, one might balance these concerns and take, e.g., .
7.2 Intermediate BERTphone representations
While utterance-level SR and LR are both classification problems on speech, one would expect different features to be discriminative for each task. Instead of multi-tasking to induce a balance of features in the last layer, one could instead learn to take a linear combination of features across layers. Inspired by ELMo [28], we train the x-vector + SAP model to instead use a global, softmax-normalized set of learned weights to pool representations over the layers.
[TABLE]
Since each is layer-normalized, we interpret the weights without rescaling.
In Figure 3, we see that given this flexibility, LR uses representations largely from later layers, peaking at layer 10. This is consistent with LR primarily using phonetic information. We speculate that layer 11 and 12 begin to specialize in preparation for the CTC objective (so that conditional dependence between positions are captured before the output layer). In contrast, SR uses more of the middle layers, with modes at layer 6, 9, and 12. This suggests a healthy balance of acoustic and phonetic information being leveraged. In all, this matches one’s intuition that LR uses higher-level features (e.g., a language’s preferred phonetic sequences) while SR uses primarily lower-level features (qualities like pitch and vocal range), plus possible phonetic preferences (given our text-independent setting).
Finally, we note that these models did not perform any better than using the last layer. We speculate that a weighted summation on fixed vectors is rather unnatural and requires an unfrozen BERTphone to perform well.
7.3 Choice of pretraining alphabet
We evaluate how the choice of label set for CTC affects downstream performance. We pretrain two additional models (Fisher BERTphone, = 0.2) with other label sets: phonemes with lexical stress (primary and secondary) using CMUdict, and characters (uncased letters, digits, space, punctuation). We train task-specific models atop these systems as before; results are in Table 4.
As expected, performance improves when going from characters to context-independent phonemes, the latter being more conditionally-independent (the CTC assumption) and whose prediction more explicitly encodes phonetic information. The character-based model remains competitive, which is not too surprising as character CTC is known to still learn phonetic representations internally [42]. We see equal or slight degradation when using phonemes with lexical stresses indicated.
We note that all three models have token error rates between 10% to 13% (upon greedy decoding via CTC), corresponding with their alphabet size. Hence, with WFST-based decoding using CMUdict and a language model, BERTphone could be easily adapted to give a competitive end-to-end ASR model that looks similar to a self-attention + CTC system (SAN-CTC) [24].
8 Conclusion
We introduced BERTphone, a self-attentive, phonetically-aware, acoustic contextual representations which can be used with small task-specific models to jointly improve performance on multiple speech tasks, namely language and speaker recognition. Future work can explore the additional gains from unfreezing BERTphone as done in the original BERT work, although this removes the multi-functional property of our representations. In addition to tuning , one could also try using intermediate layers to improve performance.
One can also evaluate the use of BERTphone for speech recognition pretraining by adding further layers and implementing CTC decoding. Finally, note that the loss can be used by itself on unlabeled audio, suggesting the possibility of training on larger, unlabeled audio corpora.
9 Acknowledgements
We thank Davis Liang and Sundararajan Srinivasan for helpful feedback regarding this work.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in NAACL-HLT (1) , 2019, pp. 4171–4186.
- 2[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” in NIPS , 2017, pp. 5998–6008.
- 3[3] Yu-An Chung, Wei-Ning Hsu, Hao Tang, and James Glass, “An Unsupervised Autoregressive Model for Speech Representation Learning,” in INTERSPEECH , 2019, pp. 146–150.
- 4[4] Aäron van den Oord, Yazhe Li, and Oriol Vinyals, “Representation learning with contrastive predictive coding,” Co RR , vol. abs/1807.03748, 2018.
- 5[5] Pavel Matejka, Le Zhang, Tim Ng, Ondrej Glembek, Jeff Z. Ma, Bing Zhang, and Sri Harish Mallidi, “Neural network bottleneck features for language identification,” in Odyssey , 2014.
- 6[6] Alex Graves, Santiago Fernández, Faustino J. Gomez, and Jürgen Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in ICML , 2006, pp. 369–376.
- 7[7] David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur, “X-vectors: Robust DNN embeddings for speaker recognition,” in ICASSP , 2018, pp. 5329–5333.
- 8[8] David Snyder, Daniel Garcia-Romero, Alan Mc Cree, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur, “Spoken language recognition using x-vectors,” in Odyssey , 2018, pp. 105–111.
