Unsupervised predictive coding models may explain visual brain representation
Marcio Fonseca

TL;DR
This study investigates whether unsupervised predictive coding models, specifically PredNet, can better predict visual brain activity than supervised models, showing promising results with fMRI and MEG data.
Contribution
The paper demonstrates that unsupervised predictive coding models trained on video prediction outperform supervised image classifiers in predicting brain activity.
Findings
Unsupervised models achieved 16.67% on fMRI data.
Unsupervised models achieved 27.67% on MEG data.
Predictive coding models may better explain visual brain representations.
Abstract
Deep predictive coding networks are neuroscience-inspired unsupervised learning models that learn to predict future sensory states. We build upon the PredNet implementation by Lotter, Kreiman, and Cox (2016) to investigate if predictive coding representations are useful to predict brain activity in the visual cortex. We use representational similarity analysis (RSA) to compare PredNet representations to functional magnetic resonance imaging (fMRI) and magnetoencephalography (MEG) data from the Algonauts Project. In contrast to previous findings in the literature (Khaligh-Razavi &Kriegeskorte, 2014), we report empirical data suggesting that unsupervised models trained to predict frames of videos may outperform supervised image classification baselines. Our best submission achieves an average noise normalized score of 16.67% and 27.67% on the fMRI and MEG tracks of the Algonauts Challenge.
Click any figure to enlarge with its caption.
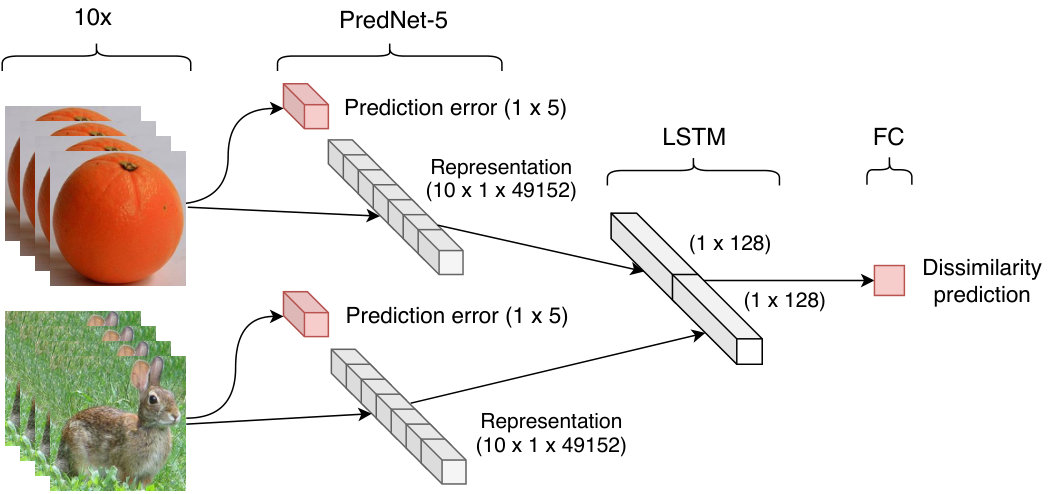 Figure 1
Figure 1| Noise Normalized (%) | |||||
| fMRI | MEG | ||||
| Model Name | Pre-training | EVC | IT | Early | Late |
| AlexNet (conv3) | ImageNet | 17.85 | 7.14 | 5.29 | 13.31 |
| AlexNet (conv4) | ImageNet | 13.98 | 10.66 | 2.72 | 16.68 |
| PredNet-4 (layer 4) | random weights | 5.25 | 1.09 | 2.33 | 3.81 |
| PredNet-4 (layer 4) | KITTI (1h) | 39.90 | 13.13 | 29.52 | 20.16 |
| PredNet-4 (layer 4) | KITTI + Moments (4h) | 47.03 | 15.27 | 32.22 | 16.78 |
| PredNet-5 (layer 3) | Moments (6h) | 51.48 | 14.52 | 40.35 | 22.89 |
| Noise Normalized (%) | |||||
| fMRI | MEG | ||||
| Model Name | Pre-training | EVC | IT | Early | Late |
| AlexNet (baseline) | ImageNet | 6.58 | 8.22 | 5.82 | 22.93 |
| PredNet-4 (layer 4) | KITTI (1h) | 10.55 | 8.55 | 3.66 | 2.41 |
| PredNet-4 (layer 4) | KITTI+Moments (4h) | 17.40 | 5.77 | 21.19 | 17.15 |
| PredNet-5 (layer 3) | Moments (6h) | 17.00 | 9.82 | 14.83 | 6.97 |
| PredNet-IT (layers 3, 4) | Moments (6h) | 17.41 | 15.93 | 27.39 | 1.95 |
| PredNet-IT+AlexNet | Moments (6h)+ImageNet | 4.01 | 6.67 | 0.83 | 27.90 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVisual Attention and Saliency Detection · Face Recognition and Perception · Image Processing Techniques and Applications
Unsupervised predictive coding models may explain visual brain representation
Marcio Fonseca
Directorate of Technology and Innovation
Chamber of Deputies
Brasília, BR 70160-900
Abstract
Deep predictive coding networks are neuroscience-inspired unsupervised learning models that learn to predict future sensory states. We build upon the PredNet implementation by Lotter \BOthers. (\APACyear2016) to investigate if predictive coding representations are useful to predict brain activity in the visual cortex. We use representational similarity analysis (RSA) to compare PredNet representations to functional magnetic resonance imaging (fMRI) and magnetoencephalography (MEG) data from the Algonauts Project (Cichy \BOthers., \APACyear2019). In contrast to previous findings in the literature (Khaligh-Razavi \BBA Kriegeskorte, \APACyear2014), we report empirical data suggesting that unsupervised models trained to predict frames of videos may outperform supervised image classification baselines in terms of correlation to spatial (fMRI) data. Our best submission achieves an average noise normalized correlation score of and on the fMRI and MEG tracks of the Algonauts Challenge.
1 Introduction
Currently, convolutional neural networks trained on image recognition tasks are the best performing models to account for brain activity during visual object recognition (Schrimpf \BOthers., \APACyear2018). The performance of such supervised models on recent benchmarks led to the idea that supervised learning may be a requirement to explain visual cortex activity, especially in higher cortical areas (Khaligh-Razavi \BBA Kriegeskorte, \APACyear2014). In this work, we report experimental data suggesting that predictive coding models trained on unlabelled video data may outperform supervised baselines, yielding internal representations with higher of correlation to representation dissimilarity matrices (RDM) (Kriegeskorte \BOthers., \APACyear2008) obtained from human fMRI and MEG data.††Code can be found at: https://github.com/thefonseca/algonauts
This report summarizes our three main contributions. First, we find that a predictive coding model trained on videos captured with a car-mounted camera (Lotter \BOthers., \APACyear2016) outperforms AlexNet (Krizhevsky \BOthers., \APACyear2012) in terms of correlation to RDMs from human data. Moreover, as we further train the model on additional videos from the Moments in Time dataset (Monfort \BOthers., \APACyear2018), the model internal representations become more similar to brain activity. Second, we propose an end-to-end method to fine-tune predictive coding representations using joint supervision from frame prediction errors and IT dissimilarity scores. Our PredNet-IT model improves the noise normalized correlation to human IT from to on the Algonauts Challenge test set (Cichy \BOthers., \APACyear2019). Lastly, we show that concatenating representations of PredNet-IT, and AlexNet improve our best MEG late interval correlation score from to , which suggests these models capture complementary information relevant to visual recognition.
2 Methods
Predictive coding networks
We build on the PredNet implementation by Lotter \BOthers. (\APACyear2016), which was shown to perform well on unsupervised learning tasks using video data. Inspired by the predictive coding theory (Friston \BBA Kiebel, \APACyear2009), their model relies on the idea that to predict the next video frame, a model needs to capture latent structure that explains the image sequences. The PredNet architecture consists of recurrent convolutional layers (Xingjian \BOthers., \APACyear2015) that propagate bottom-up prediction errors which are used by the upper-level layers to generate new predictions. For implementation details, please refer to the PredNet architecture description by Lotter \BOthers. (\APACyear2016).
Unsupervised training
We evaluate predictive coding models trained on different quantities of unlabelled videos. The main idea is that the more data we use to train the model, the more "common sense" it should get about how events unfold in the world and, as a consequence, it should be better at disentangling latent explanatory factors. Using as starting point a PredNet pre-trained on the KITTI dataset (Geiger \BOthers., \APACyear2013), we further train the model with unlabelled videos from the Moments in Time dataset (Monfort \BOthers., \APACyear2018), a large-scale activity recognition dataset. Additionally, we report correlation scores for a PredNet with random weights and a version trained from scratch using just videos from the Moments in Time dataset.
The predictive coding model is trained in an unsupervised way to predict the next frames using a top-down generative model. The errors between predictions and the actual frames are propagated bottom-up to update the prior for new predictions. In terms of architecture, we follow the same hyperparameter settings used in the original PredNet implementation proposed by Lotter \BOthers. (\APACyear2016), with four modules (PredNet-4) consisting of convolutional layers with , , , and filters and input frames with dimensions . We also train a larger 5-layer model (PredNet-5) with , , , , and filters and input frames with a higher resolution of pixels. The videos are subsampled at ten frames per second, and the network input is a sequence of ten frames for which the model generates ten frame predictions.
Feature extraction
Each layer and timestep of the PredNet model has representation units , which are extracted as features to be compared to brain data. No further preprocessing or dimensionality reduction is performed. Since the Algonauts datasets consists of images and not videos, we repeat each image ten times to make the input compatible with the PredNet architecture.
Extracted features are then transformed to representational dissimilarity matrices (RDM) as described by Kriegeskorte \BOthers. (\APACyear2008). RDM serves as a common space to compare representations of different models and capture the dissimilarity (1 minus Pearson correlation) of internal representations generated for each pair of images in the dataset. To create RDMs from features, we use the Python implementation from the development kit provided by Cichy \BOthers. (\APACyear2019).
Evaluation
The resulting RDMs for all model variants are compared to the RDMs from different brain regions, namely fMRI data from the early visual cortex (EVC) and the inferior temporal cortex (IT), and also MEG data for early and late stages of visual processing. The similarity of RDMs is computed in terms of Spearman’s correlation, as defined by Kriegeskorte \BOthers. (\APACyear2008) and implemented in the provided Python development kit. Evaluation is performed exclusively on the 92-images training set from the Algonauts Challenge, and the results are used to inform the choice of representations for submissions to the fMRI and MEG challenge tracks (78-images dataset).
Fine-tuning representations
Previous research suggests IT representation exhibits categorical clustering of concepts such as faces/non-faces and animate/inanimate entities (Khaligh-Razavi \BBA Kriegeskorte, \APACyear2014). Instead of assuming particular kinds of categories, we build a model to learn concept information implicitly from dissimilarity values. Specifically, to train our PredNet-IT model (Figure 1), we sample 5,000 (training) and 500 (validation) image pairs from the 118-images training set and minimize a loss function combining the mean absolute frame prediction error and the mean absolute error between predicted and ground truth dissimilarity given by the target IT RDM as follows:
[TABLE]
where both and weights are set to . To infer dissimilarity scores, we apply an LSTM layer on top of the PredNet-5 (layer 5) representation. The resulting vectors are concatenated and passed to a fully connected layer that outputs the predicted scalar dissimilarity value.
3 Results and Discussion
Acquiring "common sense" improves correlation with brain data
The noise normalized correlation scores on the 92-images training set (Table 1) shows that learning about how events unfold over time improves correlation scores. Notably, AlexNet (conv3 and conv4 layers) is outperformed by a PredNet pre-trained on 1 hour of videos from the KITTI dataset for both fMRI and MEG. Correlation to brain representation continues to improve as we train the PredNet-4 and PredNet-5 with up to 6 hours of videos from the Moments in Time dataset.
Fine-tuning improves correlation to IT
Fine-tuning PredNet-5 with RDM supervision improves correlation to both fMRI and MEG data (except for late interval). Interestingly, fine-tuned PredNet-IT exhibits higher correlation to EVC and IT at layers 4 and 5, respectively as opposed to layer 3 in PredNet-5. Furthermore, there is a stronger concentration of high correlation scores for features from early recurrent timesteps, with different patterns for each layer. The best scores on the test set are (layer 3, timestep 6), (layer 4, timestep 10), (layer 4, timestep 8), and (layer 4, timestep 8) for EVC, IT, early and late intervals respectively (Table 2).
Unsupervised and supervised models capture complementary information
The PredNet-IT model outperforms other supervised and unsupervised models across all data categories except late interval (MEG) (Table 2). To investigate the hypothesis that PredNet-IT captures complementary information, we generate new representations by merely concatenating PredNet-IT (layer 4, timestep 8) and AlexNet (conv4) activations. This combined representation results in a correlation score of for late interval, which is better than the AlexNet baseline () and all PredNet models. Further research is needed to check if this complementary information relates to "categorical clusters" similar to IT as found by Khaligh-Razavi \BBA Kriegeskorte (\APACyear2014).
Final remarks and future directions
Our results suggest that not only supervised but also unsupervised models may explain visual brain data. While our results are still far from the noise ceilings, there is still much room for improvement by scaling the model architecture and training data (AlexNet has almost ten times more parameters than the PredNet-4 model). An interesting future investigation could combine features from different layers to assess if predictive coding models can fully explain higher cortical areas and exhibit visuo-semantic representations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cichy \B Others . ( \APA Cyear 2019) \APA Cinsertmetastar cichy 2019 algonauts {APA Crefauthors} Cichy, R \BPBI M., Roig, G., Andonian, A., Dwivedi, K., Lahner, B., Lascelles, A. \BDBL Oliva, A. \APA Cref Year Month Day 2019. \BBOQ \APA Crefatitle The Algonauts Project: A Platform for Communication between the Sciences of Biological and Artificial Intelligence The algonauts project: A platform for communication between the sciences of biological and artificial intelligence. \BBCQ \APA Cjou
- 2Friston \BBA Kiebel ( \APA Cyear 2009) \APA Cinsertmetastar friston 2009 predictive {APA Crefauthors} Friston, K. \BCBT \BBA Kiebel, S. \APA Cref Year Month Day 2009. \BBOQ \APA Crefatitle Predictive coding under the free-energy principle Predictive coding under the free-energy principle. \BBCQ \APA Cjournal Vol Num Pages Philosophical Transactions of the Royal Society B: Biological Sciences 36415211211–1221. \Print Back Refs \Current Bib
- 3Geiger \B Others . ( \APA Cyear 2013) \APA Cinsertmetastar geiger 2013 vision {APA Crefauthors} Geiger, A., Lenz, P., Stiller, C. \BCBL \BBA Urtasun, R. \APA Cref Year Month Day 2013. \BBOQ \APA Crefatitle Vision meets robotics: The KITTI dataset Vision meets robotics: The kitti dataset. \BBCQ \APA Cjournal Vol Num Pages The International Journal of Robotics Research 32111231–1237. \Print Back Refs \Current Bib
- 4Khaligh-Razavi \BBA Kriegeskorte ( \APA Cyear 2014) \APA Cinsertmetastar khaligh 2014 deep {APA Crefauthors} Khaligh-Razavi, S \BHBI M. \BCBT \BBA Kriegeskorte, N. \APA Cref Year Month Day 2014. \BBOQ \APA Crefatitle Deep supervised, but not unsupervised, models may explain IT cortical representation Deep supervised, but not unsupervised, models may explain it cortical representation. \BBCQ \APA Cjournal Vol Num Pages P Lo S computational biology 1011 e 1003915. \Print Back Refs \Current Bib
- 5Kriegeskorte \B Others . ( \APA Cyear 2008) \APA Cinsertmetastar kriegeskorte 2008 {APA Crefauthors} Kriegeskorte, N., Mur, M. \BCBL \BBA Bandettini, P. \APA Cref Year Month Day 2008. \BBOQ \APA Crefatitle Representational similarity analysis - connecting the branches of systems neuroscience Representational similarity analysis - connecting the branches of systems neuroscience. \BBCQ \APA Cjournal Vol Num Pages Frontiers in Systems Neuroscience 24. {APA Cref URL} https://www.frontiersi
- 6Krizhevsky \B Others . ( \APA Cyear 2012) \APA Cinsertmetastar krizhevsky 2012 imagenet {APA Crefauthors} Krizhevsky, A., Sutskever, I. \BCBL \BBA Hinton, G \BPBI E. \APA Cref Year Month Day 2012. \BBOQ \APA Crefatitle Imagenet classification with deep convolutional neural networks Imagenet classification with deep convolutional neural networks. \BBCQ \B In \APA Crefbtitle Advances in neural information processing systems Advances in neural information processing systems ( \BPGS 1097–
- 7Lotter \B Others . ( \APA Cyear 2016) \APA Cinsertmetastar lotter 2016 deep {APA Crefauthors} Lotter, W., Kreiman, G. \BCBL \BBA Cox, D. \APA Cref Year Month Day 2016. \BBOQ \APA Crefatitle Deep predictive coding networks for video prediction and unsupervised learning Deep predictive coding networks for video prediction and unsupervised learning. \BBCQ \APA Cjournal Vol Num Pages ar Xiv preprint ar Xiv:1605.08104. \Print Back Refs \Current Bib
- 8Monfort \B Others . ( \APA Cyear 2018) \APA Cinsertmetastar monfort 2018 moments {APA Crefauthors} Monfort, M., Zhou, B., Bargal, S \BPBI A., Andonian, A., Yan, T., Ramakrishnan, K. \BDBL others \APA Cref Year Month Day 2018. \BBOQ \APA Crefatitle Moments in Time Dataset: one million videos for event understanding Moments in time dataset: one million videos for event understanding. \BBCQ \APA Cjournal Vol Num Pages ar Xiv preprint ar Xiv:1801.03150. \Print Back Refs \Current Bib