TL;DR
This paper introduces efficient approximate methods to compute the disconnected Gaussian covariance matrix for large-scale structure data, enabling accurate cosmological inference while significantly reducing computational costs.
Contribution
It presents scalable algorithms for estimating the Gaussian covariance matrix of power spectra on curved and flat skies, improving computational efficiency for large datasets.
Findings
Methods achieve $O( obreak \, \ell_{\rm max}^3)$ scaling
Accurate recovery of cosmological parameters using approximate covariance
Limitations on reliability at the largest scales and for B modes
Abstract
The disconnected part of the power spectrum covariance matrix (also known as the "Gaussian" covariance) is the dominant contribution on large scales for galaxy clustering and weak lensing datasets. The presence of a complicated sky mask causes non-trivial correlations between different Fourier/harmonic modes, which must be accurately characterized in order to obtain reliable cosmological constraints. This is particularly relevant for galaxy survey data. Unfortunately, an exact calculation of these correlations involves operations that become computationally impractical very quickly. We present an implementation of approximate methods to estimate the Gaussian covariance matrix of power spectra involving spin-0 and spin-2 flat- and curved-sky fields, expanding on existing algorithms. These methods achieve an scaling, which makes the computation…
Click any figure to enlarge with its caption.
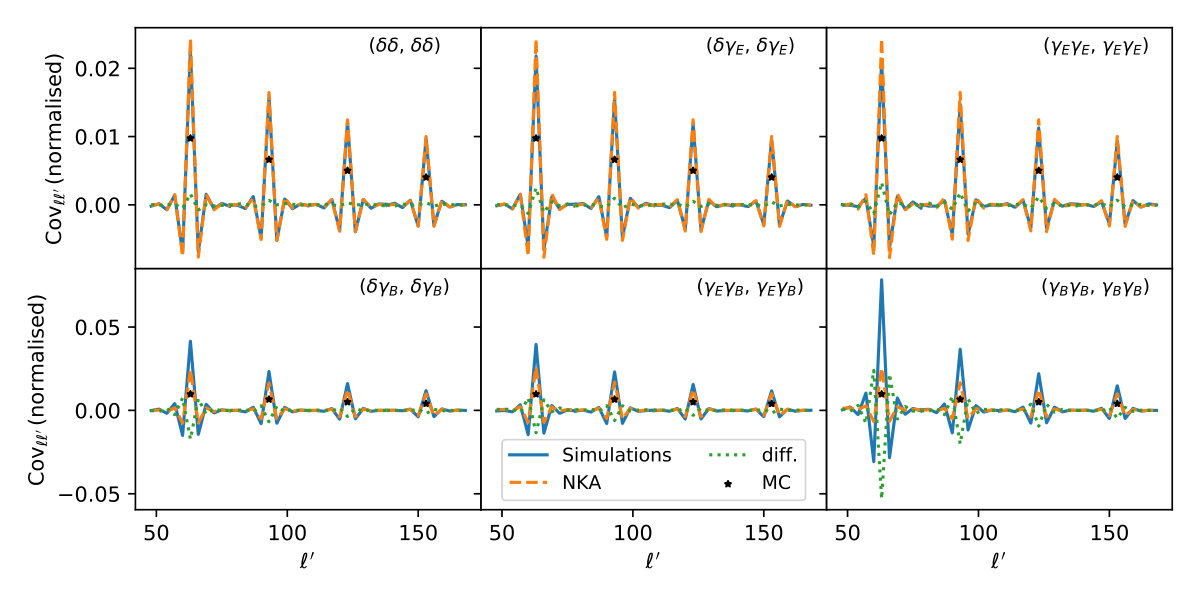 Figure 1
Figure 1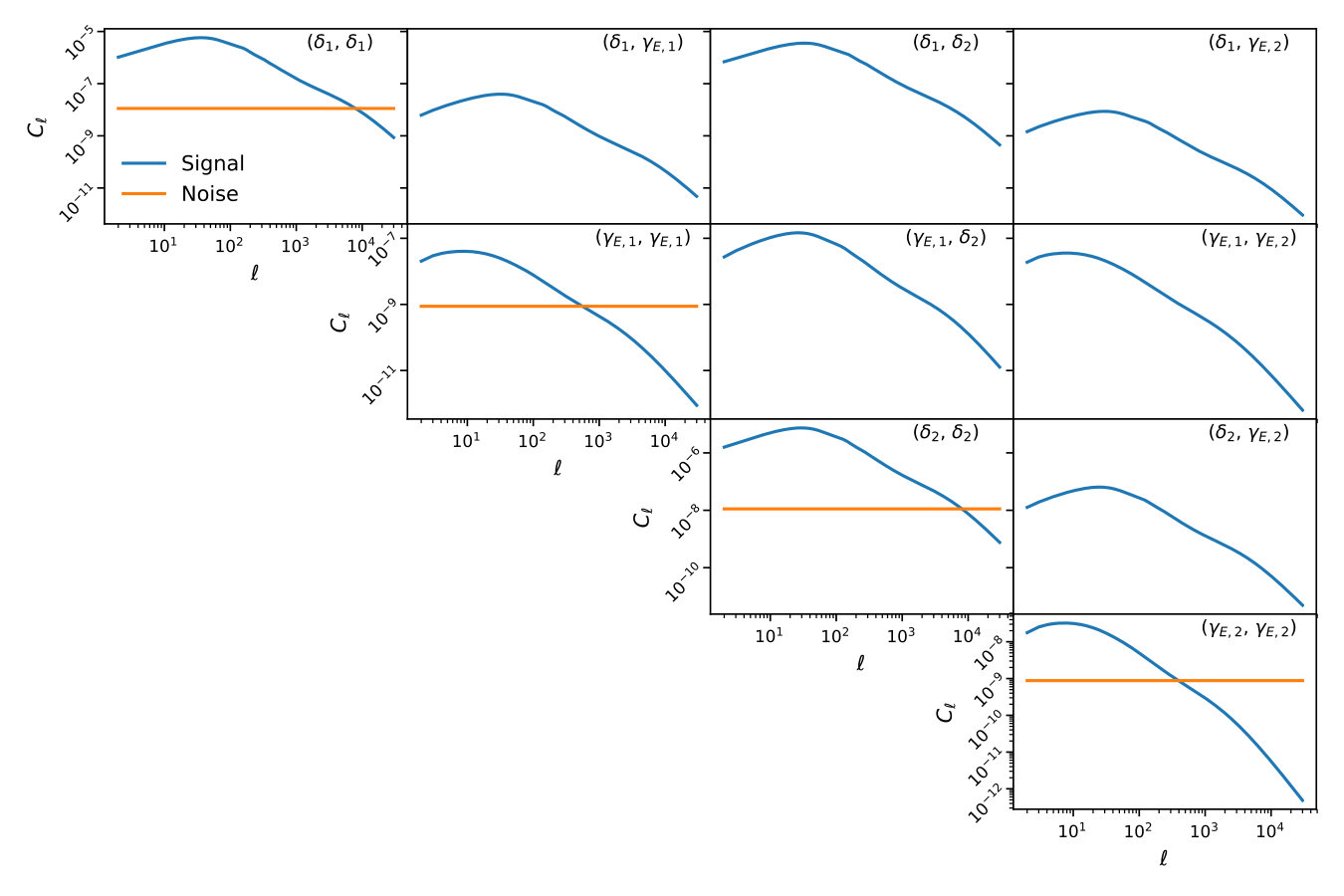 Figure 2
Figure 2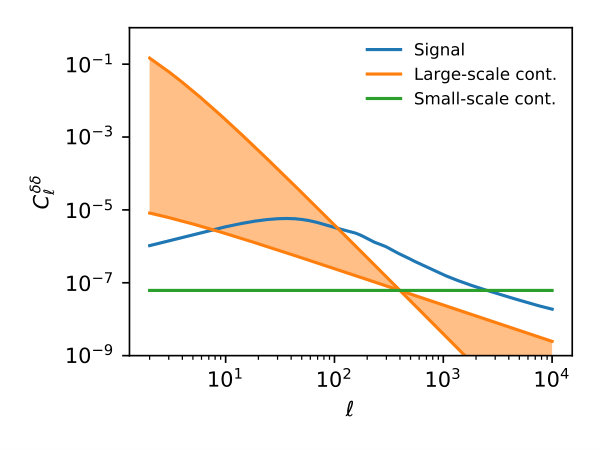 Figure 3
Figure 3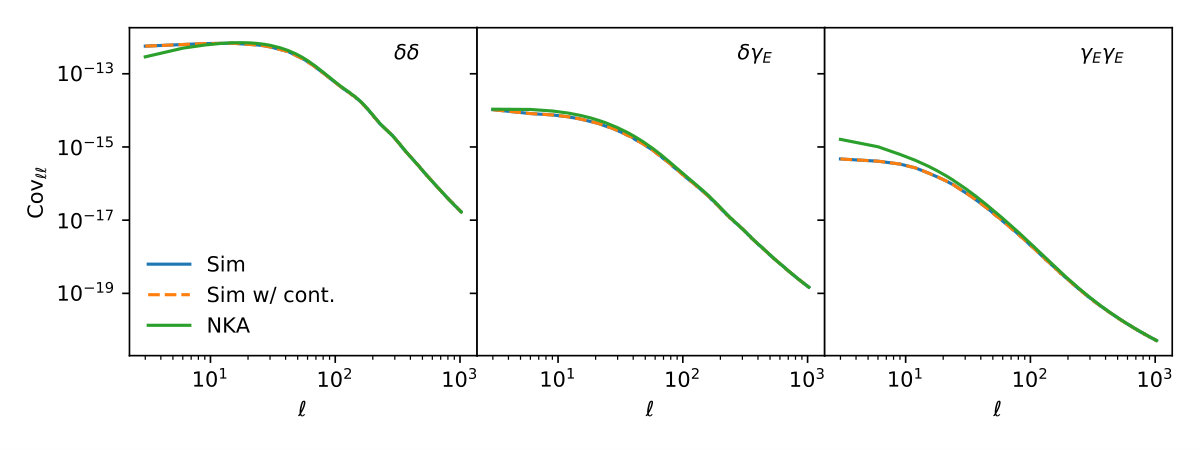 Figure 4
Figure 4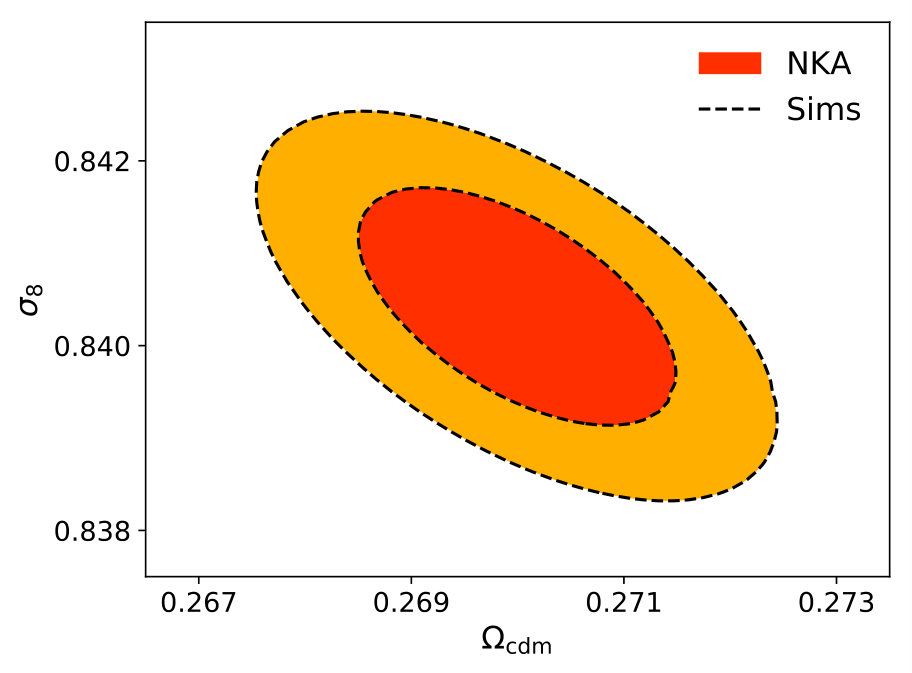 Figure 5
Figure 5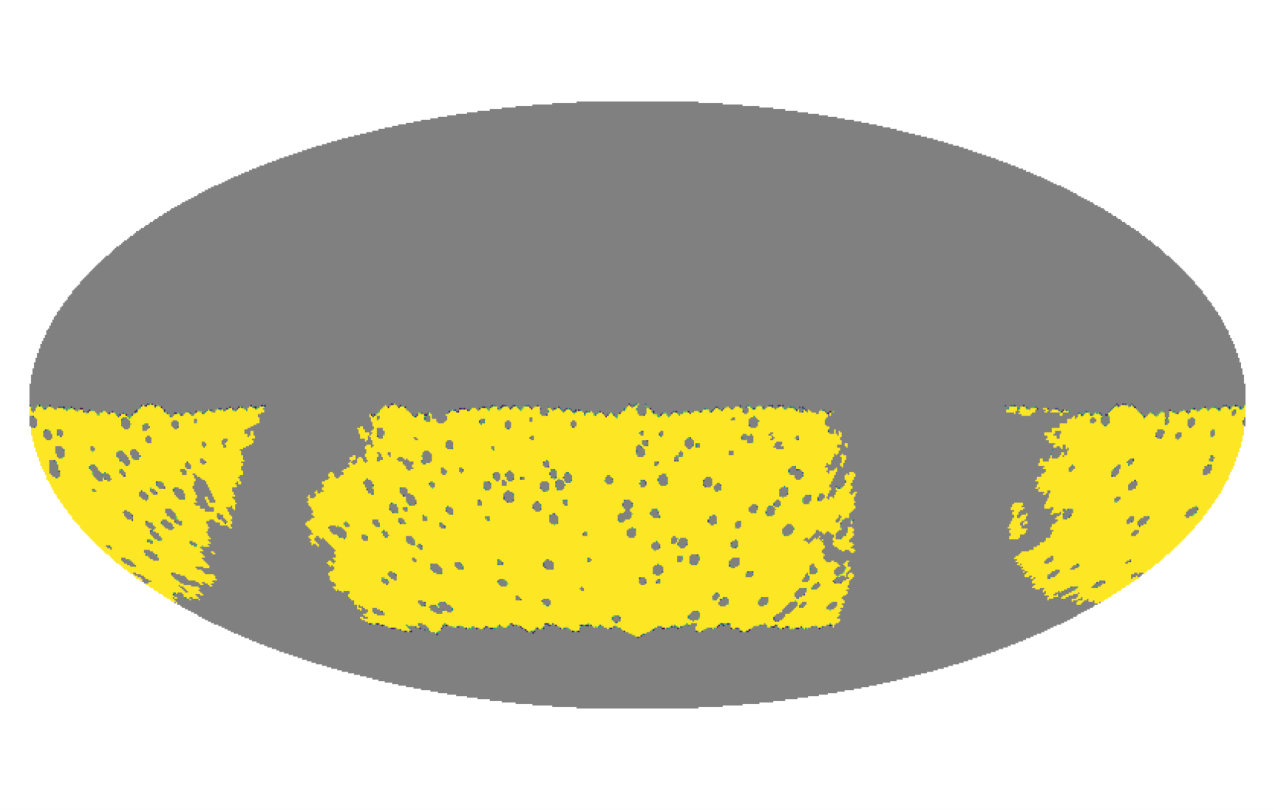 Figure 6
Figure 6 Figure 7
Figure 7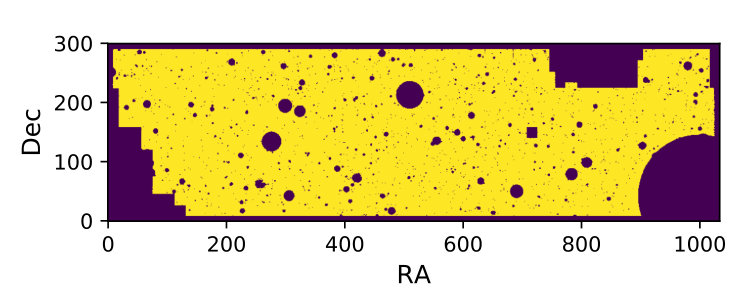 Figure 8
Figure 8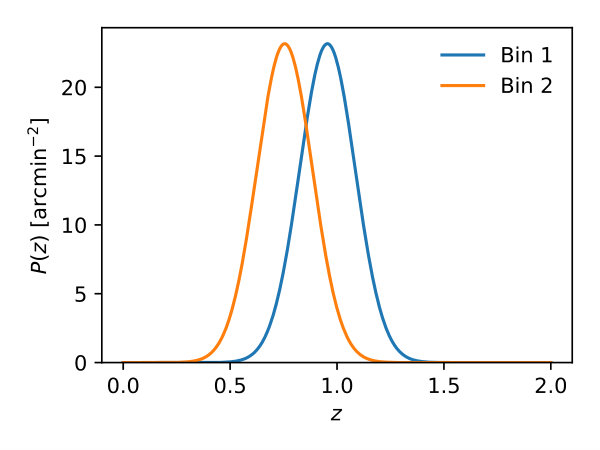 Figure 9
Figure 9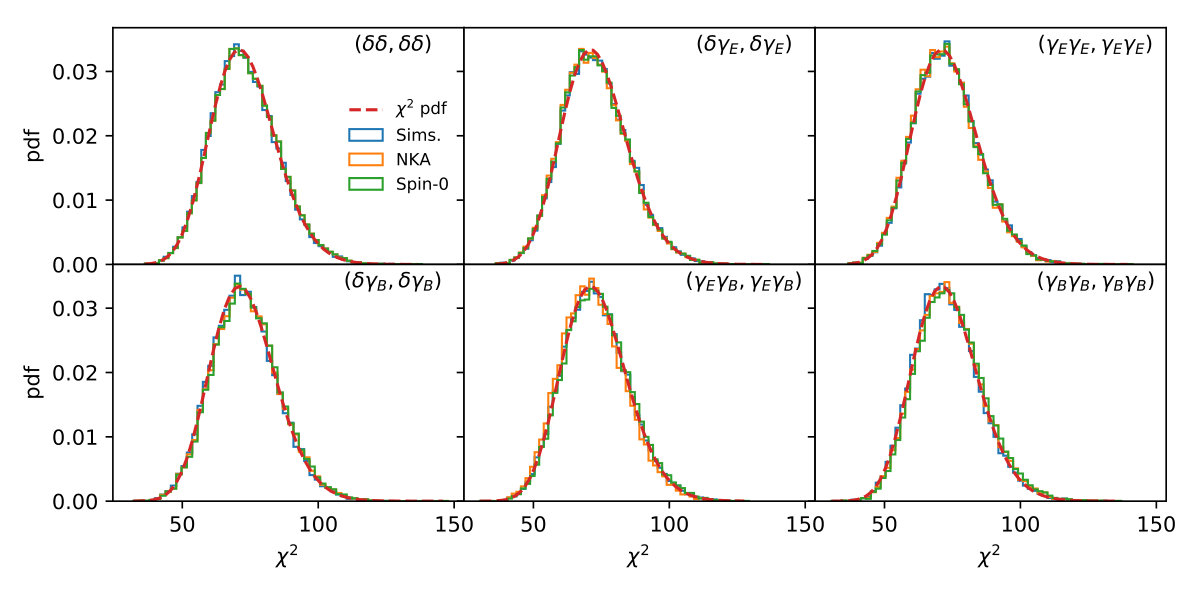 Figure 10
Figure 10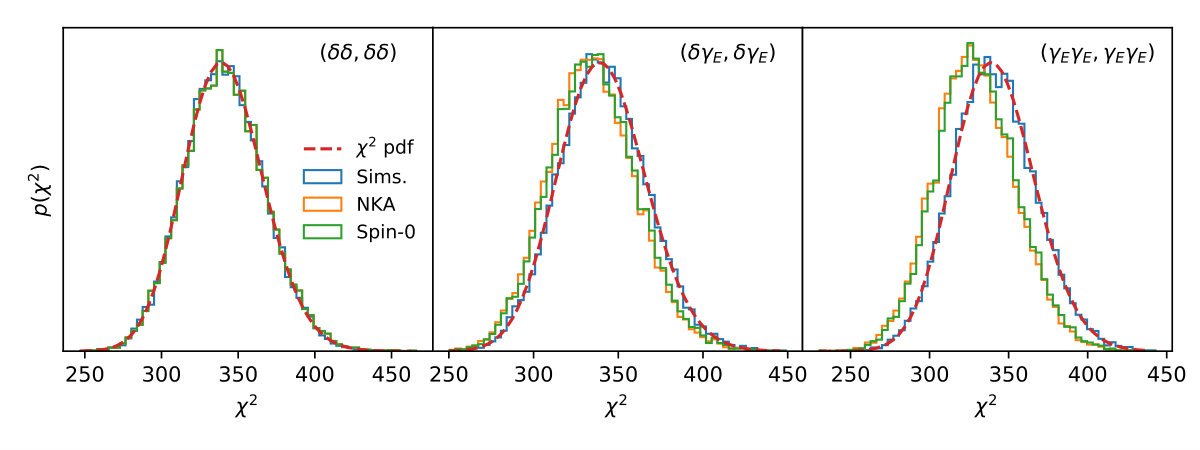 Figure 11
Figure 11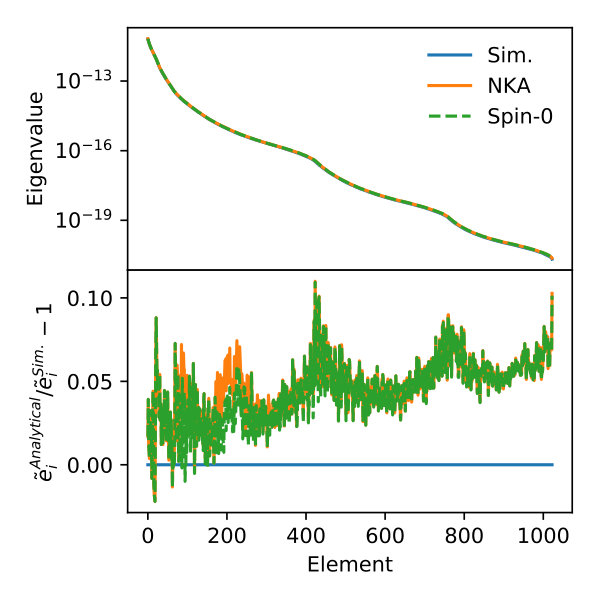 Figure 12
Figure 12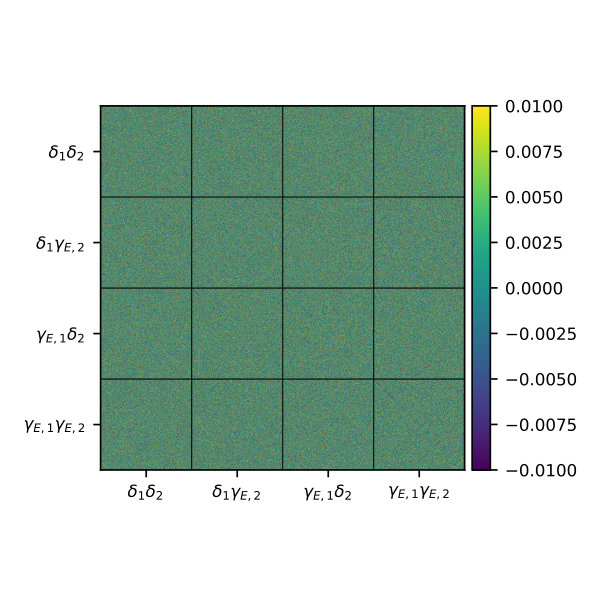 Figure 13
Figure 13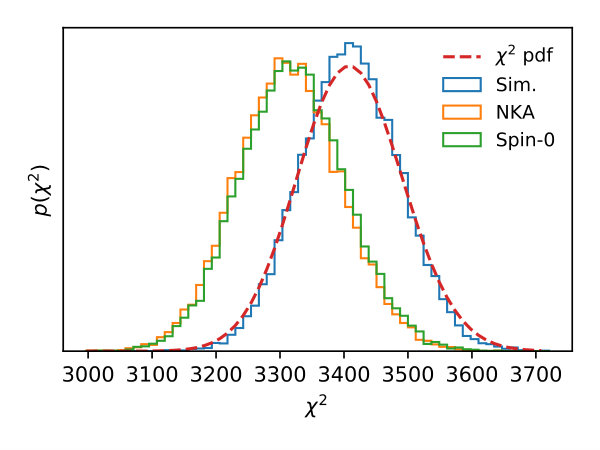 Figure 14
Figure 14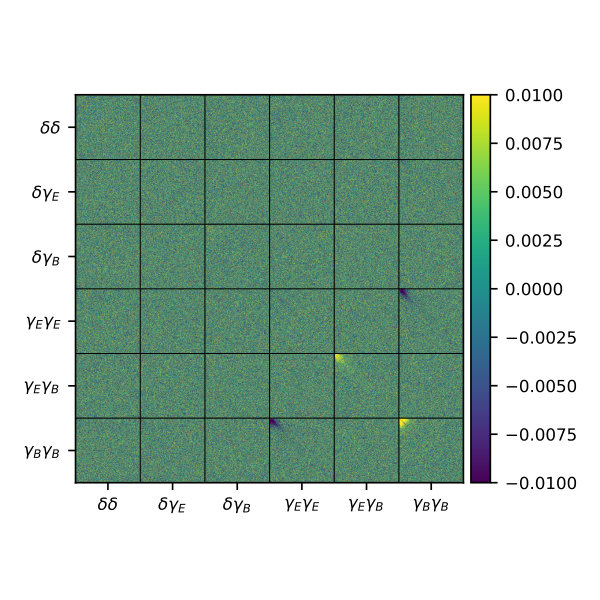 Figure 15
Figure 15| Symbol | Curved sky | Flat sky (continuum discretized) |
|---|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Disconnected pseudo- covariances for projected large-scale structure data
Carlos García-García
David Alonso
Emilio Bellini
Abstract
The disconnected part of the power spectrum covariance matrix (also known as the “Gaussian” covariance) is the dominant contribution on large scales for galaxy clustering and weak lensing datasets. The presence of a complicated sky mask causes non-trivial correlations between different Fourier/harmonic modes, which must be accurately characterized in order to obtain reliable cosmological constraints. This is particularly relevant for galaxy survey data. Unfortunately, an exact calculation of these correlations involves operations that become computationally impractical very quickly. We present an implementation of approximate methods to estimate the Gaussian covariance matrix of power spectra involving spin-0 and spin-2 flat- and curved-sky fields, expanding on existing algorithms developed in the context of CMB analyses. These methods achieve an scaling, which makes the computation of the covariance matrix as fast as the computation of the power spectrum itself. We quantify the accuracy of these methods on large-scale structure and weak lensing data, making use of a large number of Gaussian but otherwise realistic simulations. We show that, using the approximate covariance matrix, we are able to recover the true posterior distribution of cosmological parameters to high accuracy. We also quantify the shortcomings of these methods, which become unreliable on the very largest scales, as well as for covariance matrix elements involving cosmic shear modes. The algorithms presented here are implemented in the public code NaMaster https://github.com/LSSTDESC/NaMaster.
1 Introduction
The two-point correlation of different fields projected on the celestial sphere is one of the most common observables used in the analysis of large datasets in astrophysics, from studies of the Cosmic Microwave Background [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] to large-scale structure and weak lensing surveys [12, 13, 14, 15, 16, 17, 18, 19, 20]. Using these two-point functions, one achieves a high level of data compression (with respect to the size of the raw datasets – time-ordered data, images or catalogs). They can also be directly used to constrain cosmological and astrophysical parameters assuming that one can model their likelihood. This is usually done by assuming that the two-point functions are Gaussianly distributed, which is often a good approximation due to the central limit theorem [21, 22]. In this case, the only obstacle that remains is being able to estimate the covariance matrix of a set of two-point correlators. Since the form of this covariance directly affects the posterior parameter uncertainties, a precise determination of it is of paramount importance. In large-scale structure experiments, this has often been resolved by making use of one’s own data through resampling techniques [23, 24, 25, 26, 27], or by generating a large number of mock realizations [28, 29, 30]. With the advent of the larger current and future surveys, the increasing size of the data vector and of the volume to be simulated has made this solution impractical, and fully analytical and hybrid estimators are now being used.
The problem of producing accurate analytical estimates of the covariance matrix for large-scale structure data has seen significant progress in the last few years [31, 32, 33, 34, 35, 36]. As described in [37], the covariance matrix recieves three main contributions:
- •
Gaussian covariance: this is the contribution to the covariance from the disconnected part of the trispectrum of the different fields involved (also called the “disconnected” covariance). In simpler terms, this is the covariance matrix one would obtain if all fields involved were Gaussianly distributed.
- •
Connected non-Gaussian covariance: this is the contribution from the connected trispectrum (which would vanish if all fields were Gaussianly distributed).
- •
Super-sample covariance: this is the additional coupling between different scales induced by density fluctuations on scales larger than the volume mapped. This term also vanishes for Gaussian fields.
On most scales relevant for cosmological studies, the Gaussian contribution dominates the error budget, although the connected and super-sample terms cannot be neglected [37]. The Gaussian contribution is trivial to compute for fields observed over the full sky:
[TABLE]
where is the angular power spectrum between two maps and on multipole . Unfortunately, the presence of a sky mask in general induces non-trivial couplings between different s, which must be accurately estimated in order to produce unbiased evaluations of the parameter likelihood [38].
In this paper, we will present and generalize methods developed in the context of CMB experiments to account for the impact of survey geometry on the Gaussian part of the power spectrum covariance matrix [39, 40, 41, 42, 43, 44, 45, 46]111See also [47] for a similar application to the problem of 3D power spectrum covariances., and will study in detail the performance of these methods for large-scale structure and weak lensing datasets. We have also implemented these approximations in the public code NaMaster222https://github.com/LSSTDESC/NaMaster [48], making the computation of accurate Gaussian covariance matrices significantly simpler for the community.
The paper is structured as follows: Section 2 presents the methods and approximations used to calculate accurate covariances. In Section 3 we test the methods against Gaussian simulations and study their performance as well as their impact on the final cosmological parameter estimation. We then summarize our results and conclude in Section 4. Appendix A presents the performance of these methods in the flat-sky approximation, and we provide technical details of the software implementation in Appendix B.
2 Analytical Gaussian covariances
2.1 Preliminaries
We will deal with spin-0 and spin-2 fields defined on a 2-dimensional space. In two dimensions, spin- fields in general have two components 333E.g. for CMB polarization, a spin-2 field, these components are the Stokes parameters , while for cosmic shear the two components are usually labeled .. Forming a complex number from these components, , spin- fields transform, under a coordinate rotation with angle , as . Thus, spin-0 fields are invariant under rotations, and are usually expressed as real-valued fields with a single component.
Given a field , with 1 (spin-0) or 2 components (spin-2), defined on the coordinates , we define its generalized Fourier coefficients as
[TABLE]
where the operator denotes an integral or sum over all values of the coordinates , and are a set of orthogonal functions. We will also assume that the are a complete set of basis functions, in which case:
[TABLE]
where denotes an integral over all possible generalized Fourier coefficients , and and are generalized delta functions, defined through their action on functions of or :
[TABLE]
For a spin- quantity, can be written in terms of two spin-raising and spin-lowering operators, and , and a set of scalar orthogonal functions as:
[TABLE]
where is a normalization factor defined in Table 1.
Finally, we will assume that all fields are Gaussian stochastic fields that are additionally statistically isotropic. As a consequence of the latter, different generalized Fourier modes are uncorrelated:
[TABLE]
where is a volume factor (see below) and is the power spectrum. Defined this way, the power spectrum is a matrix, with elements
[TABLE]
where is the -th element of field . It will often be useful in what follows to think of as a 1-dimensional vector that we will denote by . To do so, we simply map the two indices into a single number , such that .
All the functions and operators above can be specialized to fields defined on the sphere or the 2D plane (flat sky approximation) as described in Table 1.
2.2 The pseudo- method
This section provides a very brief introduction to the pseudo- power spectrum estimator. Further details can be found in e.g. [10, 40, 48]. In any practical situation we do not have access to maps of a given field over the full sky, but rather to a weighted or masked version of them
[TABLE]
where is commonly called the “mask”. Due to the convolution theorem, the generalized Fourier coefficients of the masked field will be a convolution of the mask and true field coefficients:
[TABLE]
where we have defined the mode-coupling coefficients in the second line.
Correlating the generalized Fourier coefficients of two masked fields therefore yields a mode-coupled version of their true underlying power spectrum:
[TABLE]
The pseudo- estimator then proceeds in two steps:
We first bin different modes into sets of them called bandpowers (typically bands of similar or annuli of flat-sky Fourier modes spanning a range of radii). Let us denote a given bandpower by its index . We must note that it is more appropriate to use bandpower-averaged spectra when the underlying spectrum does not vary much within each bin. When this is not the case, it is often useful to apply -weights (such as ). The large-scale structure spectra discussed here are sufficiently flat that the binning used is appropriate. The binned pseudo-power spectrum is:
[TABLE]
where the bandpower weights are normalized such that . 2. 2.
Then, the correlation between bandpowers induced by the mode-coupling coefficients is partially reversed by multiplying by the so-called binned “mode-coupling matrix” , giving the final estimator
[TABLE]
The main advantage of the pseudo- estimator is that the mode-coupling matrix is directly related to the coupling coefficients , and can be computed analytically making use of methods that scale like (see e.g. [10]).
For completeness, the mode-coupling matrices for flat-sky and curved-sky fields are given by [48]:
- •
Curved sky. After averaging over the harmonic number , the mode-coupling matrices are:
[TABLE]
with
[TABLE]
where
[TABLE]
Here the 2-by-3 matrix-like quantities are the Wigner 3- symbols, and
[TABLE]
- •
Flat sky. In this case the averaging over the Fourier-space azimuth happens while binning into bandpowers, and therefore the unbinned mode-coupling matrix is defined before binning. Assuming flat bandpowers, such that , where is the number of Fourier-space modes in the -th bandpower:
[TABLE]
with
[TABLE]
where
[TABLE]
and is the relative angle between and .
Before we move on to covariances, it is worth considering the case of unmasked field (i.e everywhere). In this case , and therefore different modes are uncorrelated (as should have been obvious). In a non-ideal case where the mask is still sufficiently well behaved (i.e. masks without too much small-scale structure), we can still expect the coupling coefficients to be sharply peaked around .
2.3 Covariance matrices
So far we have not assumed anything about the statistics of the fields, other than the fact that they are isotropic (Eq. 2.7). This section presents a method to estimate the disconnected part of the power spectrum covariance for the pseudo- estimator.
Let and be the vector indices corresponding to the pairs of field indices and , respectively, and let us start by considering the covariance
[TABLE]
The covariance of the binned bandpowers can then be computed as
[TABLE]
which can then be used to estimate the covariance of the mode-decoupled bandpowers multiplying it by the inverse mode-coupling matrix twice. I.e., schematically:
[TABLE]
where we have suppressed all indices for simplicity. The problem of estimating the pseudo- covariance therefore reduces to estimating .
We now make use of Wick’s theorem, which states that, for Gaussian fields, . In this case, the expression for reads:
[TABLE]
where we implicitly sum over repeated indices (e.g. ), and the second term is equivalent to the first one after swapping the roles of fields and . Without any further approximations, for each pair , we would need to perform two 2-dimensional integrals, and therefore the calculation would scale like , quickly becoming unfeasible.
Under the assumption that the coupling coefficients are sharply peaked around , we can simplify the expression above approximating the power spectra as constants within the support of the coupling coefficients [39]. Explicitly, we approximate
[TABLE]
In this case, the expression for simplifies to
[TABLE]
where we have defined the covariance coupling coefficients
[TABLE]
In order to compute these coefficients, let us start by defining the quantities
[TABLE]
where is the spin of field , and
[TABLE]
Now, in what follows, we will be concerned with the auto- and cross-correlations of spin-0 and spin-2 fields. Thus, to simplify the notation, we will enumerate the different types of coupling coefficients that exist for a spin-0 field with a single component that we will call , in analogy to the projected galaxy overensity, and for a spin-2 field, , with and components, and , in analogy to the cosmic shear field. With this setup, all the possible non-zero can be expressed in terms of the as follows:
[TABLE]
Thus, in principle, we only need to compute 7 different types of terms (, , and ). In order to simplify these expressions further, we follow [42, 45] and neglect all gradients of the masks444It is worth noting that it is possible in principle to avoid this approximation, as demonstrated in [41]., which allows us to relate the different through the following set of identities:
[TABLE]
where we have made repeated use of integration by parts.
Using these identities together with the completeness relation of the basis functions, it is possible to simplify the expressions for the :
[TABLE]
where we have defined
[TABLE]
Thus, the only surviving non-zero coupling coefficients are
[TABLE]
We have reduced the problem of computing the covariance in Eq. 2.52 to the problem of computing the coupling coefficients 2.54 entering Eq. 2.53, and we have now shown that there are only 3 independent coefficients, given by Eq. 2.67. In order to simplify the calculation further, it is now useful to inspect these results for the specific case of fields defined on the sphere.
2.3.1 Covariances for curved skies
As described in Section 2.2, in the curved-sky estimator it is common to first average over the harmonic number as part of the bandpower binning operation. Let us, therefore, define
[TABLE]
The covariance of these objects, under the approximation in Eq. 2.53, can be computed as:
[TABLE]
where we have defined the symbols
[TABLE]
These quantities involve terms of the form:
[TABLE]
Making use of the completeness relation for the Wigner 3-j symbols, it is possible to show, that these can be written as:
[TABLE]
where the are defined in Eq. 2.23. Thus, computationally speaking, the problem of computing covariance matrices reduces to that of computing the same coupling coefficients needed for the computation of the pseudo- power spectra themselves, except now they involve product of two masks, rather than the masks alone. Using the same notation as in Eq. 2.57, the only non-zero coefficients are:
[TABLE]
where stand for either or , and where we have suppressed all redundant indices (including ). Any pseudo- covariance element can then be found by replacing these results in Eq. 2.73. Some explicit examples for common terms can be found in Appendix A.3.3 of [45].
2.3.2 Covariances for flat skies
Similar results hold in the case of flat skies. As mentioned in Section 2.2, in this case averaging over the Fourier-space azimuth happens while binning into bandpowers. Under the assumption that the underlying power spectra are roughly constant within each bandpower, in this case, the covariance matrix of the bandpowers defined in Eq. 2.12 takes the form:
[TABLE]
where the coefficients are related to the mode-coupling coefficients defined in Eq. 2.43, in the same way that the curved-sky coefficients were related to the :
[TABLE]
and, as before,
[TABLE]
2.4 Approximate covariances
When presenting our results in Section 3, we will compare the true covariance matrix, estimated from a large number of Gaussian simulations, with the analytical covariance estimated under different approximations. In descending order of complexity, these are:
The narrow-kernel approximation (labeled NKA here), described in the previous sections. This approximation assumes that the support of the harmonic-space masks (represented by the mode-coupling coefficients in e.g. Eq. 2.14) is small compared to the variation of the true power spectrum with . Additionally, it neglects all derivatives of the sky mask when accounting for the spin nature of the fields involved. 2. 2.
The spin-0 approximation corresponds to a simplified version of the NKA in which the spin nature of all fields involved is completely ignored, and all fields, including the - and -mode components of a spin-2 field, are treated as spin-0 quantities. 3. 3.
The mode-counting approximation (labeled MC here), commonly known as the Knox formula [49], which applies the result found for full-sky observations (Eq. 1.1) to masked fields, corrected by an overall factor that accounts to the loss of modes due to the sky mask. In this case, the covariance is simply given by:
[TABLE]
where is the mean multipole in the -th bandpower, is the number of multipoles assigned to it, and is the available sky fraction.
3 Results
3.1 Simulations
In order to quantitatively study the performance of the analytical approximations for the power spectrum covariance matrix introduced in Section 2, we generate a large number of Gaussian simulations including a number of realistic observational effects.
Each simulation is a set of maps corresponding to a number of spin-0 and spin-2 fields that are drawn as Gaussian random fields following a set of input power spectra that include all relevant cross-correlations between different fields. We generate simulations for two types of fields modeled after the two main large-scale structure observables of photometric redshift surveys:
- •
Spin-0 fields, corresponding to maps of the overdensity of galaxies within a given redshift bin projected on the sphere. In keeping with the notation introduced in Section 2.3, we will label these fields as , where the index denotes the redshift bin.
- •
Spin-2 fields, corresponding to maps of the cosmic shear measured from the projected shapes of galaxies in a given redshift bin. We will label these fields where, again, the index denotes the redshift bin.
The cross-correlation between two of these fields can be written as:
[TABLE]
where and are the power spectra of the cosmological signal and noise respectively. We model the signal part for and as:
[TABLE]
where is the comoving radial distance, is the corresponding redshift in the lightcone, is the matter power spectrum. The window functions are given by [50]555See [51] and references therein for details about these calculations.:
[TABLE]
where is the expansion rate in units where the speed of light is , , is the linear galaxy bias, is the normalized redshift distribution of galaxies within the redshift bin, and
[TABLE]
We assume zero signal for the shear -modes.
The noise power spectrum is diagonal (i.e. zero between different fields and redshift bins), and is given by:
[TABLE]
where is the mean number density of galaxies in units of sterad*-2* (see below), and is the intrinsic shape scatter per ellipticity component.
We consider the case of auto- and cross-correlations between all fields in two redshift bins, with redshift distributions modeled as Gaussians with width centered around redshifts and , with number densities . The corresponding redshift distributions are shown in Figure 1. For simplicity we use a constant bias . For these specifications, we generate signal power spectra using the Core Cosmology Library (CCL [51]) for cosmological parameters . The resulting non-zero signal and noise power spectra are shown in Figure 2.
After generating a set of Gaussian maps, we mask them making use of a realistic sky mask. This mask has three main components: a cut in declination based on the expected sky coverage of LSST [52], a more conservative Galactic cut using the dust reddening data from [53] and a set of 100 randomly positioned holes with a radius of 1 degree. To explore the case of cross-correlations between fields with different masks, we generated two masks for the two redshift bins above, consisting of two different sets of random holes. These masks are shown in Figure 3.
We have also explored the impact of the presence of sky contaminants on the estimate of the covariance matrix. As described in [48], the presence of a small contamination from observational systematics in the data can be accounted for through a technique known as mode deprojection [54, 55, 56]. In this method, the contamination is modeled as a linear contribution at the map level from contaminants with a known template. Mode deprojection then consists on projecting the data onto the subspace of modes that are perpendicular to those templates, effectively removing all modes from the map that “look like” any of the contaminants. This removal of modes has been shown to provide unbiased estimates of the power spectrum, however it could potentially affect the power spectrum uncertainties due to the loss of statistical power. To study this effect, we have also generated contaminant maps of two types:
- •
Large-scale contaminants: Gaussian random maps with a red spectrum of the form , where is a random number chosen within the range .
- •
Small-scale contaminants: Gaussian random maps with a flat spectrum
In both cases, we fixed the amplitude of the contaminant power spectrum such that it would yield a contamination in the data power spectrum at . For spin-2 fields, we assumed the same power spectrum for and modes, with no cross-correlation between them. The resulting contaminant power spectra are shown in Figure 4. When exploring the effects of mode deprojection, we generated 100 contaminant maps of both types and added them to each simulated realization. We then deprojected the full set of 100 contaminant templates from the simulated maps and computed the corresponding unbiased power spectra. Note that, in what follows, our fiducial results do not include the effects of mode deprojection. These are discussed separately.
For our fiducial results, we generated a set of 20,000 random simulations. This number was chosen in order to recover the covariance matrix for all possible auto- and cross-correlations with sufficient accuracy. All simulations were generated as HEALPix666http://healpix.sourceforge.net [57] maps with resolution . We then used NaMaster to compute all possible power spectra for each simulation using narrow bandpowers of width from to . Finally, we used the power spectra from the simulations to estimate the sample covariance matrix
[TABLE]
where is the vector of all possible power spectra for the -th realization, and is the mean of this vector over all realizations. The comparison of this sample covariance with the analytical approximations described above is presented in the next sections.
3.2 Qualitative comparison
As a first step, we visually compare the main properties of the sample covariance matrix estimated from the simulations and the NKA, Spin-0 and MC approximations described in the previous section. Figure 5 shows four rows of the covariance matrix of different auto- and cross-correlations. The rows correspond to bandpowers centered on multipoles and . The upper panels show results for the non-zero power spectra (-, - and -), with the solid blue, dashed orange and dotted green lines showing results for the sample covariance matrix, the analytical covariance using the NKA approximation and their difference, respectively. For comparison, the black stars show the diagonal covariance matrix elements predicted by the MC approximation (Eq. 2.93). We find an excellent agreement between the simulated and analytical covariances, with very small deviations in the amplitude of the diagonal and first few off-diagonal elements.
The bottom panel in Figure 5 shows the same rows of the covariance matrix for power spectra involving -modes (and therefore with zero signal expectation value). In this case we find significant differences, at the level of , on the covariance matrix elements, with the analyticial prediction underestimating the error bars overall. This is expected and can be understood as follows: the presence of a sky mask mixes and modes. Although this mixing can be accounted for at the level of the power spectrum through the pseudo- estimator, the leaked modes contribute to the variance. This is particularly significant for power spectra involving -modes, since the -mode amplitude is significantly larger, especially at , as can be seen in Fig. 2. Thus, if the effects of - mixing caused by the sky mask are not accurately accounted for in the estimation of the covariance matrix for power spectra involving -mode maps, we can expect a misestimation of the contribution to the covariance from the leaked modes that would underpredict the uncertainties. This is not a problem for power spectra involving only modes, since the only modes that leak into them are those associated with noise, and they have the same amplitude as the noise modes move into the -mode map.
This is further illustrated by Figure 6. The figure shows, for the case of a single redshift bin, the difference between the correlation matrices associated with the sample covariance matrix and the NKA estimate777The correlation matrix is defined as . While the differences between both matrices are small for all elements involving and , all terms involving -modes show a significant disagreement, particularly the -, - and - boxes.
We thus conclude that while the NKA estimator is able to recover the covariance matrix for the non-zero power spectrum elements (i.e. those involving and ) with high accuracy, a more sophisticated approach would be needed in order to obtain a precise estimate of the uncertainties for components involving -modes. This is not a major concern, since -mode power spectra are predominantly used as null tests, while cosmological parameter constraints are driven by the analysis of and . For completeness, Figure 7 shows the difference between the correlation matrices for the sample covariance and the NKA estimator for all non-zero cross-correlations between different bins in the case of two redshift bins with different small-scale masks, where we find a similarly good agreement.
3.3 Quantitative comparison
In order to quantify the validity of our analytical approximations, we need to compare the NKA covariance with the sample covariance estimated from the simulations. However, comparing two matrices is not as straightforward as comparing their elements one by one. The covariance between far-away bandpowers is expected to be very close to zero, and therefore a direct comparison of those elements would easily yield large relative differences simply due to the statistical noise in the sample covariance matrix. We will therefore quantify the differences between the different covariances making use of scalar quantities formed from them. The impact of the analytical approximations on the final parameter constraints will then be described in detail in Section 3.4.
As a first test to quantify the differences between covariance matrices, we compute the relative difference between their eigenvalues. This is shown in Figure 8 for a data vector combining all auto- and cross-correlations between and for a single redshift bin. The eigenvalues of both matrices are roughly similar, with relative differences of about . The figure also shows the eigenvalues of the covariance matrix estimated using the Spin-0 approximation, which achieves a similar level of precision (even marginally higher in some cases).
Another scalar quantity that can be used to compare different covariances is the . For a given random data vector with mean and covariance matrix , this is given by
[TABLE]
We compute this quantity for a data vector composed of different auto- and cross-correlations for each of the 20,000 Gaussian simulations, with given by the mean over all simulations and different choices of covariance matrix. Figure 9 shows the distribution of values for the three non-zero power spectra in the case of a single bin: -, - and -. The histograms show the distribution for the sample covariance matrix (blue), and the analytical NKA and Spin-0 estimators (orange and green, respectively). We additionally plot the theoretical distribution under the assumption that the underlying data vector is Gaussianly distributed (red dashed lines). In the simplest case of purely spin-0 quantities (leftmost panel), we find an excellent agreement between the different distributions. In the cases involving the spin-2 fields, we see noticeable differences between the distributions found with the sample covariance and the approximate ones. These differences are small, corresponding to less of a and shift in the mean for the - and - cases, respectively, and a negligible variation in the width of the distributions. We therefore expect these differents to have a negligible effect on the posterior parameter distributions, as we show explicitly in Section 3.4. The fact that these differences appear only for power spectra involving spin-2 quantities indicate that the NKA and spin-0 methods are imperfect at describing the additional mode coupling caused in the presence of a mask for higher-spin fields. This is rather obvious in the case of the spin-0 approximation but, interestingly, we find that the NKA and Spin-0 predictions yield results that are almost indistinguishable from each other. We therefore conclude that the additional approximation made in the NKA method for spin-2 fields – neglecting the spatial derivatives of the mask – is effectively equivalent to ignoring the spin nature of the fields involved. Note, however, that this is not the case for -modes, where the NKA estimator outperforms the spin-0 approximation by up to one order of magnitude, even though its accuracy is very poor (as we described in the previous section). For completeness, Figure 10 shows the distribution of values for a data vector composed of all possible auto- and cross-correlations of and for the case of two redshift bins, where similar conclusions hold.
We have also explored the impact of contaminant deprojection on the different covariance matrix estimates. The loss of modes due to deprojection can potentially increase the variance of the power spectrum estimates, affecting the accuracy with which an analytical estimator would be able to recover the covariance. Figure 11 shows the diagonal of the covariance matrix for the -, - and - power spectra. Each panel displays the diagonal for the sample covariance matrix estimated from simulations without contaminants or contaminant deprojection (blue line), the sample covariance from simulations with contaminants and contaminant deprojection (dashed orange line) and for the NKA covariance (green line). We see that the power spectrum uncertainties are almost indistinguishable with or without deprojection, and that those relative differences are much smaller than the differences between the sample covariance and the NKA estimator. We therefore conclude that, except in the case where a very large set of contaminant maps are deprojected (comparable with the number of unmasked pixels in the map), the analytical approximation to the covariance matrix should be as accurate as in the absence of contaminants (i.e. accurate enough).
Figure 11 serves also to illustrate another important point. In all our tests we find that the largest differences between the sample and NKA covariances occur on large scales. For - correlations, the effect is limited to the first few multipoles (), while for - we are only able to recover the sample covariance errors within for . This is the main source of the small mismatch observed in Figure 9. Note, however, that most of the cosmological information is obtained from the higher multipoles, due to their higher statistical weight, and, as we will show in the next section, the effect on the final parameter constraints is negligible. If accurate covariance matrix elements are needed on these large scales for cosmic shear, they can be estimated alternatively making use of fast, low resolution simulations (e.g. HEALPix maps), or computed exactly as in Ref. [42, 45].
3.4 Impact on parameter estimation
Ultimately, the most important test to judge the accuracy of the analytical covariance matrix estimators implemented here is to study their impact on the posterior distribution of cosmological parameters derived from power spectrum measurements. Assuming flat priors and a fiducial Gaussian likelihood approximation [21], in which the covariance matrix is computed only once for the fiducial model, the posterior distribution for parameters is simply given by:
[TABLE]
where is a vector of power spectrum measurements, is their covariance matrix, and is their theoretical prediction for parameters . It is worth noting that this Gaussian likelihood is not accurate on large scales, where the small number of modes invalidates the application of the central limit theorem. Even in this regime, the likelihood can be approximated through the method described in [21], which still requires an accurate estimate of the power spectrum covariance.
We explore for the two parameters , for a data vector composed of all possible auto- and cross-correlations between and in the case of two redshift bins described in Section 3.1. In this simple two-dimensional scenario, we simply sample the distribution in a regular grid of 100 by 100 points for each parameter. We construct a data vector from the theoretical prediction for the experimental setup described in Section 3.1, and produce theoretical predictions for it at each grid point using CCL. Note that, when evaluating the posterior for the sample covariance matrix, one needs to correct for the finite number of simulations used to construct the covariance. In most situations this can be done simply by rescaling the inverse covariance matrix by a factor given by [58]
[TABLE]
where is the number of samples used to estimate the covariance, and is the number of data points.
The 68% and 95% confidence level contours associated with the posterior distributions for the sample covariance and the NKA estimator are shown in Figure 12. We find that both distributions agree with each other remarkably well, and that the errors for each parameter agree for both covariances up to . Note that, since we have not included any statistical noise in the data vector , the relative difference in the means of both distributions is zero by construction (since Eq. 3.8 is bounded from below by zero). When adding Gaussian statistical noise compatible with the sample covariance matrix, we observe small differences (smaller than 0.3) in the best fit parameters found with both covariance matrices. These differences, however, are not systematic, and we have verified that averaging over several noise realizations does not yield biased best-fit parameters.
We therefore conclude that the analytical approximations for the power spectrum covariance matrix explored here are able to reproduce the true posterior distribution of cosmological parameters to very high accuracy.
4 Discussion
Estimating accurate covariance matrices for projected two-point correlators is an ubiquitous problem in modern cosmology [59, 60, 61], but it is particularly relevant for large-scale structure datasets. This problem is further complicated in this case, in comparison with e.g. CMB experiments, by two factors: the fact that the fields involved are non-Gaussian at some level and the arguably higher complexity of the sky masks used in optical datasets. The main impact of survey geometry is the statistical coupling it induces between different Fourier/harmonic modes, which must be accurately characterized in order to obtain reliable estimates of the posterior distribution for cosmological parameters. In this paper we have focused on the impact of survey geometry on the dominant Gaussian (i.e. disconnected) part of the covariance matrix.
We have described and generalized existing analytical approaches to estimate the covariance matrix for pseudo- power spectrum estimators [39, 40, 45], and implemented them in the public code NaMaster [48], making it straightforward to fully account for the effects of survey geometry on the data uncertainties. With these approximations, computationally speaking, the problem of estimating a covariance matrix is as complex as that of computing the power spectrum itself, and scales with the number of pixels in the map as . We leave for future work the study of the impact of extra complications, as position-dependent noise, on their performance.
The main finding of this paper is the excellent performance of the analytical methods described in Section 2.3. We have shown that the NKA estimator (see Section 2.4) is able to recover the covariance matrix for all power spectra with non-zero signal expectation value (i.e. those involving the galaxy overdensity or the -mode shear ), as well as the posterior distribution for cosmological parameters, to a high degree of accuracy.
More in detail, we have also found that the impact of contaminant deprojection on the covariance matrix, through the corresponding loss of modes, is negligible unless a very large number of contaminant templates are removed. This simplifies the procedure to estimate covariance matrices for galaxy clustering data, which are particularly sensitive to a large number of astrophysical and observational systematics. Additionally, we have found that, although the NKA estimator is accurate enough, it is not able to perfectly capture the additional effects of mode coupling that are present for spin-2 fields, and that a simpler approach treating the shear modes as a spin-0 object is able to reach similar levels of accuracy. Due to the imperfect treatment of the mixing caused by the sky mask in the NKA estimator, we also find that the predicted covariance matrix for any power spectra involving modes differs significantly from the true sample covariance, and, therefore, this approach cannot be used to reliably estimate the uncertainties of -mode power spectra. Likewise, we find that the NKA estimator yields inaccurate estimates of the power spectrum uncertainties on the largest scales (). Although these modes carry a substantially smaller statistical weight, if more accurate covariances are needed on these large scales, they can be easily computed making use of fast low-resolution simulations or exactly following Refs. [42, 45].
In spite of these shortcomings, we find that the approximations described in this paper are able to provide estimates of the power spectrum covariance matrix that are sufficiently accurate for current and future tomographic large-scale structure cosmological datasets. The main advantage of this approach is the computational cost, which is comparable to that of estimating the power spectrum in the first place, and which scales with pixel resolution in a similar way. This is, therefore, significantly less time-consuming than generating large numbers of mock datasets (even simple Gaussian or log-normal realizations), and more reliable than the traditional jackknife resampling techniques. The method, in all its generality, is currently implemented in the public code NaMaster. Future extensions to this work will focus on improving the estimator for power spectra involving modes, and incorporating the impact of -mode purification [62, 63, 64].
Acknowledgments
We thank Thibaut Louis, Eva-Maria Mueller, Francisco Javier Sánchez and Anže Slosar for useful comments and discussion. CGG is supported the Spanish grant BES-2016-077038, partially funded by the ESF and by AYA2015-67854-P from the Ministry of Industry, Science and Innovation of Spain and the FEDER funds. He was partially supported by a Balzan Fellowship while in Oxford. He would like to thank New College and the Department of Physics at Oxford for their hospitality. DA acknowledges support from STFC through an Ernest Rutherford Fellowship, grant reference ST/P004474/1. EB acknowledges support from the Beecroft Trust. Some of the results in this paper have been derived using the HEALPix [57] package.
Appendix A Flat sky
We have repeated the analysis described in Section 3 on flat-sky realizations, making use of the flat-sky implementation of NaMaster. We generate Gaussian realizations of the galaxy overdensity and shear maps making use of flat-sky extensions of the methods described in Section 3.1. In this case we use a high-resolution mask constructed from the bright-object mask distributed with the first data release of the HSC collaboration [65] for the VVDS field, which is shown in Figure 13.
We find similar levels of accuracy in the NKA and spin-0 estimators compared to the curved-sky case. The higher resolution and smaller area of these simulations allow us to focus on the small-scale galaxy clustering and lensing power spectra, covering the range of multipoles in constant bandpowers of width . On these small scales, the shear power spectrum is more dominated by noise (e.g. see Fig. 2), and therefore there is roughly the same power in and modes. This reduces the sensitivity of the method to an inaccurate treatment of leakage, and the agreement between the sample covariance matrix and the NKA estimator improves significantly. This can be seen in Figure 14, which shows the distributions for all possible power spectra (including those including modes) in the case of a single redshift bin. In all cases we find a good agreement between the distributions derived from all covariance matrix estimates (sample covariance, NKA and spin-0 in blue, orange and green respectively), which also accurately follow the expected distribution for the corresponding number of degrees of freedom (red dashed line).
Appendix B Software implementation
In addition to the code functionality described in Section 3 of [48], we have now included the capability to estimate Gaussian covariance matrices using the NKA method. This functionality is structured around a python class called NmtCovarianceWorkspace. These objects are used to compute and store the covariance mode-coupling coefficients in Eqs. 2.76 and 2.90. They are initialized from two pairs of fields corresponding to the two power spectra for which the covariance is required. Once initialized, these coefficients can be reused for any other set of fields with the same combination of sky masks. NaMaster then provides routines to estimate covariance matrix elements making use of the coupling coefficients stored in a NmtCovarianceWorkspace object and best-guess power spectra for the fields involved using Eqs. 2.73 and 2.84. Further details about the implementation and practical examples can be found in https://namaster.readthedocs.io/en/latest/sample_covariance.html.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. M. Gorski, On Determining the spectrum of primordial inhomogeneity from the Cobe DMR sky maps. 1. Method , Astrophys. J. 430 (1994) L 85 [ astro-ph/9403066 ]. · doi ↗
- 2[2] K. M. Gorski, G. Hinshaw, a. Banday, C. L. Bennett, E. L. Wright, a. Kogut et al., On determining the spectrum of primordial inhomogeneity from the COBE dmr sky maps. 2. Results of two year data analysis , Astrophys. J. 430 (1994) L 89 [ astro-ph/9403067 ]. · doi ↗
- 3[3] J. R. Bond, Signal-to-Noise Eigenmode Analysis of the Two-Year COBE Maps , Physical Review Letters 74 (1995) 4369 [ astro-ph/9407044 ]. · doi ↗
- 4[4] K. M. Gorski, A. J. Banday, C. L. Bennett, G. Hinshaw, A. Kogut, G. F. Smoot et al., Power spectrum of primordial inhomogeneity determined from the four year COBE DMR sky maps , Astrophys. J. 464 (1996) L 11 [ astro-ph/9601063 ]. · doi ↗
- 5[5] K. M. Górski, Cosmic microwave background anisotropy in the COBE DMR 4-year sky maps , in Microwave background anisotropies. Proceedings, 31st Rencontres de Moriond, 16th Moriond Astrophysics Meeting, Les Arcs, France, March 16-23, 1996 , pp. 77–84, 1997, astro-ph/9701191 .
- 6[6] M. Tegmark, How to measure CMB power spectra without losing information , Phys. Rev. D 55 (1997) 5895 [ astro-ph/9611174 ]. · doi ↗
- 7[7] J. R. Bond, A. H. Jaffe and L. Knox, Estimating the power spectrum of the cosmic microwave background , Phys. Rev. D 57 (1998) 2117 [ astro-ph/9708203 ]. · doi ↗
- 8[8] B. D. Wandelt, E. Hivon and K. M. Gorski, The pseudo- C ℓ subscript 𝐶 ℓ C_{\ell} method: cosmic microwave background anisotropy power spectrum statistics for high precision cosmology , Phys. Rev. D 64 (2001) 083003 [ astro-ph/0008111 ]. · doi ↗
